Particle diffusometry (PD) is a technique of measuring the diffusion coefficient of a fluid sample by seeding it with tracer particles and observing their motion under a microscope. In microfluidic set-ups, the observed particles are often defocused and their motion is affected by factors such as fluid flow, which leads to high errors for conventional and deep learning-based PD (DPD) algorithms. This work improves the performance of DPD models by updating their architecture, avoiding temporal averaging in the input, and exploring the impact of various choices during training. These models provide state-of-the-art performance for generalised datasets regardless of particle shapes, concentration, flow or image noise and are called DPD-v2. These models provide a mean absolute error of 0.09 $\mu$m2s−1 for Gaussian particles and 0.07
$\mu$m2s−1 for Gaussian particles and 0.07 $\mu$m2s−1 for defocused particles, which is 2x–4x lower errors as compared with the two following best methods. The performance of DPD-v2 models increases with crop size and the use of multiple stacks of images. The outputs of the DPD-v2 models were compared against the outputs from conventional algorithms on Gaussianised experimental no flow datasets, which provided < 0.5
$\mu$m2s−1 for defocused particles, which is 2x–4x lower errors as compared with the two following best methods. The performance of DPD-v2 models increases with crop size and the use of multiple stacks of images. The outputs of the DPD-v2 models were compared against the outputs from conventional algorithms on Gaussianised experimental no flow datasets, which provided < 0.5 $\mu$m2s−1 mean absolute difference. Hence, the DPD-v2 models can be used in real-world scenarios.
$\mu$m2s−1 mean absolute difference. Hence, the DPD-v2 models can be used in real-world scenarios.
Among various deep learning-based SLAM systems, many exhibit low accuracy and inadequate generalization on non-training datasets. The deficiency in generalization ability can result in significant errors within SLAM systems during real-world applications, particularly in environments that diverge markedly from those represented in the training set. This paper presents a methodology to enhance the generalization capabilities of deep learning SLAM systems. It leverages their superior performance in feature extraction and introduces Exponential Moving Average (EMA) and Bayes online learning to improve generalization and localization accuracy in varied scenarios. Experimental validation, utilizing Absolute Trajectory Error (ATE) metrics on the dataset, has been conducted. The results demonstrate that this method effectively reduces errors by  $20\%$ on the EuRoC dataset and by
$20\%$ on the EuRoC dataset and by  $35\%$ on the TUM dataset, respectively.
$35\%$ on the TUM dataset, respectively.
Applications of deep learning to physical simulations such as Computational Fluid Dynamics have recently experienced a surge in interest, and their viability has been demonstrated in different domains. However, due to the highly complex, turbulent, and three-dimensional flows, they have not yet been proven usable for turbomachinery applications. Multistage axial compressors for gas turbine applications represent a remarkably challenging case, due to the high-dimensionality of the regression of the flow field from geometrical and operational variables. This paper demonstrates the development and application of a deep learning framework for predictions of the flow field and aerodynamic performance of multistage axial compressors. A physics-based dimensionality reduction approach unlocks the potential for flow-field predictions, as it re-formulates the regression problem from an unstructured to a structured one, as well as reducing the number of degrees of freedom. Compared to traditional “black-box” surrogate models, it provides explainability to the predictions of the overall performance by identifying the corresponding aerodynamic drivers. The model is applied to manufacturing and build variations, as the associated performance scatter is known to have a significant impact on 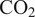 $ \mathrm{C}{\mathrm{O}}_2 $ emissions, which poses a challenge of great industrial and environmental relevance. The proposed architecture is proven to achieve an accuracy comparable to that of the CFD benchmark, in real-time, for an industrially relevant application. The deployed model is readily integrated within the manufacturing and build process of gas turbines, thus providing the opportunity to analytically assess the impact on performance with actionable and explainable data.
$ \mathrm{C}{\mathrm{O}}_2 $ emissions, which poses a challenge of great industrial and environmental relevance. The proposed architecture is proven to achieve an accuracy comparable to that of the CFD benchmark, in real-time, for an industrially relevant application. The deployed model is readily integrated within the manufacturing and build process of gas turbines, thus providing the opportunity to analytically assess the impact on performance with actionable and explainable data.

