We use cookies to distinguish you from other users and to provide you with a better experience on our websites. Close this message to accept cookies or find out how to manage your cookie settings.
This journal utilises an Online Peer Review Service (OPRS) for submissions. By clicking "Continue" you will be taken to our partner site
https://mc.manuscriptcentral.com/astro.
Please be aware that your Cambridge account is not valid for this OPRS and registration is required. We strongly advise you to read all "Author instructions" in the "Journal information" area prior to submitting.
To save this undefined to your undefined account, please select one or more formats and confirm that you agree to abide by our usage policies. If this is the first time you used this feature, you will be asked to authorise Cambridge Core to connect with your undefined account.
Find out more about saving content to .
To send this article to your Kindle, first ensure [email protected] is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about sending to your Kindle.
Find out more about saving to your Kindle.
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
We present new software to cross-match low-frequency radio catalogues: the Positional Update and Matching Algorithm. The Positional Update and Matching Algorithm combines a positional Bayesian probabilistic approach with spectral matching criteria, allowing for confusing sources in the matching process. We go on to create a radio sky model using Positional Update and Matching Algorithm based on the Murchison Widefield Array Commissioning Survey, and are able to automatically cross-match ~ 98.5% of sources. Using the characteristics of this sky model, we create simple simulated mock catalogues on which to test the Positional Update and Matching Algorithm, and find that Positional Update and Matching Algorithm can reliably find the correct spectral indices of sources, along with being able to recover ionospheric offsets. Finally, we use this sky model to calibrate and remove foreground sources from simulated interferometric data, generated using OSKAR (the Oxford University visibility generator). We demonstrate that there is a substantial improvement in foreground source removal when using higher frequency and higher resolution source positions, even when correcting positions by an average of 0.3 arcmin given a synthesised beam-width of ~ 2.3 arcmin.
Most major discoveries in astronomy are unplanned, and result from surveying the Universe in a new way, rather than by testing a hypothesis or conducting an investigation with planned outcomes. For example, of the ten greatest discoveries made by the Hubble Space Telescope, only one was listed in its key science goals. So a telescope that merely achieves its stated science goals is not achieving its potential scientific productivity.
Several next-generation astronomical survey telescopes are currently being designed and constructed that will significantly expand the volume of observational parameter space, and should in principle discover unexpected new phenomena and new types of object. However, the complexity of the telescopes and the large data volumes mean that these discoveries are unlikely to be found by chance. Therefore, it is necessary to plan explicitly for unexpected discoveries in the design and construction. Two types of discovery are recognised: unexpected objects and unexpected phenomena.
This paper argues that next-generation astronomical surveys require an explicit process for detecting the unexpected, and proposes an implementation of this process. This implementation addresses both types of discovery, and relies heavily on machine-learning techniques, and also on theory-based simulations that encapsulate our current understanding of the Universe.
We introduce pinta, a pipeline for reducing the upgraded Giant Metre-wave Radio Telescope (uGMRT) raw pulsar timing data, developed for the Indian Pulsar Timing Array experiment. We provide a detailed description of the workflow and usage of pinta, as well as its computational performance and RFI mitigation characteristics. We also discuss a novel and independent determination of the relative time offsets between the different back-end modes of uGMRT and the interpretation of the uGMRT observation frequency settings and their agreement with results obtained from engineering tests. Further, we demonstrate the capability of pinta to generate data products which can produce high-precision TOAs using PSR J1909
$-$
3744 as an example. These results are crucial for performing precision pulsar timing with the uGMRT.
Faraday complexity describes whether a spectropolarimetric observation has simple or complex magnetic structure. Quickly determining the Faraday complexity of a spectropolarimetric observation is important for processing large, polarised radio surveys. Finding simple sources lets us build rotation measure grids, and finding complex sources lets us follow these sources up with slower analysis techniques or further observations. We introduce five features that can be used to train simple, interpretable machine learning classifiers for estimating Faraday complexity. We train logistic regression and extreme gradient boosted tree classifiers on simulated polarised spectra using our features, analyse their behaviour, and demonstrate our features are effective for both simulated and real data. This is the first application of machine learning methods to real spectropolarimetry data. With 95% accuracy on simulated ASKAP data and 90% accuracy on simulated ATCA data, our method performs comparably to state-of-the-art convolutional neural networks while being simpler and easier to interpret. Logistic regression trained with our features behaves sensibly on real data and its outputs are useful for sorting polarised sources by apparent Faraday complexity.
We present an overview of the SkyMapper optical follow-up programme for gravitational-wave event triggers from the LIGO/Virgo observatories, which aims at identifying early GW170817-like kilonovae out to
$\sim200\,\mathrm{Mpc}$
distance. We describe our robotic facility for rapid transient follow-up, which can target most of the sky at
$\delta<+10\deg $
to a depth of
$i_\mathrm{AB}\approx 20\,\mathrm{mag}$
. We have implemented a new software pipeline to receive LIGO/Virgo alerts, schedule observations and examine the incoming real-time data stream for transient candidates. We adopt a real-bogus classifier using ensemble-based machine learning techniques, attaining high completeness (
$\sim98\%$
) and purity (
$\sim91\%$
) over our whole magnitude range. Applying further filtering to remove common image artefacts and known sources of transients, such as asteroids and variable stars, reduces the number of candidates by a factor of more than 10. We demonstrate the system performance with data obtained for GW190425, a binary neutron star merger detected during the LIGO/Virgo O3 observing campaign. In time for the LIGO/Virgo O4 run, we will have deeper reference images allowing transient detection to
$i_\mathrm{AB}\approx 21\,\mathrm{mag}$
.
We have adapted the Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST) Science Pipelines to process data from the Gravitational-wave Optical Transient Observer (GOTO) prototype. In this paper, we describe how we used the LSST Science Pipelines to conduct forced photometry measurements on nightly GOTO data. By comparing the photometry measurements of sources taken on multiple nights, we find that the precision of our photometry is typically better than 20 mmag for sources brighter than 16 mag. We also compare our photometry measurements against colour-corrected Panoramic Survey Telescope and Rapid Response System photometry and find that the two agree to within 10 mmag (1
$\sigma$
) for bright (i.e.,
$\sim 14{\rm th} \mathrm{mag}$
) sources to 200 mmag for faint (i.e.,
$\sim 18{\rm th} \mathrm{mag}$
) sources. Additionally, we compare our results to those obtained by GOTO’s own in-house pipeline, gotophoto, and obtain similar results. Based on repeatability measurements, we measure a
$5\sigma$
L-band survey depth of between 19 and 20 magnitudes, depending on observing conditions. We assess, using repeated observations of non-varying standard Sloan Digital Sky Survey stars, the accuracy of our uncertainties, which we find are typically overestimated by roughly a factor of two for bright sources (i.e.,
$< 15{\rm th} \mathrm{mag}$
), but slightly underestimated (by roughly a factor of 1.25) for fainter sources (
$> 17{\rm th} \mathrm{mag}$
). Finally, we present lightcurves for a selection of variable sources and compare them to those obtained with the Zwicky Transient Factory and GAIA. Despite the LSST Software Pipelines still undergoing active development, our results show that they are already delivering robust forced photometry measurements from GOTO data.
To make a power spectrum (PS) detection of the 21-cm signal from the Epoch of Reionisation (EoR), one must avoid/subtract bright foreground sources. Sources such as Fornax A present a modelling challenge due to spatial structures spanning from arc seconds up to a degree. We compare modelling with multi-scale (MS) CLEAN components to ‘shapelets’, an alternative set of basis functions. We introduce a new image-based shapelet modelling package, SHAMFI. We also introduce a new CUDA simulation code (WODEN) to generate point source, Gaussian, and shapelet components into visibilities. We test performance by modelling a simulation of Fornax A, peeling the model from simulated visibilities, and producing a residual PS. We find the shapelet method consistently subtracts large-angular-scale emission well, even when the angular resolution of the data is changed. We find that when increasing the angular resolution of the data, the MS CLEAN model worsens at large angular scales. When testing on real Murchison Widefield Array data, the expected improvement is not seen in real data because of the other dominating systematics still present. Through further simulation, we find the expected differences to be lower than obtainable through current processing pipelines. We conclude shapelets are worthwhile for subtracting extended galaxies, and may prove essential for an EoR detection in the future, once other systematics have been addressed.
The Epoch of Reionisation (EoR) is the period within which the neutral universe transitioned to an ionised one. This period remains unobserved using low-frequency radio interferometers, which target the 21 cm signal of neutral hydrogen emitted in this era. The Murchison Widefield Array (MWA) radio telescope was built with the detection of this signal as one of its major science goals. One of the most significant challenges towards a successful detection is that of calibration, especially in the presence of the Earth’s ionosphere. By introducing refractive source shifts, distorting source shapes, and scintillating flux densities, the ionosphere is a major nuisance in low-frequency radio astronomy. We introduce sivio, a software tool developed for simulating observations of the MWA through different ionospheric conditions, which is estimated using thin screen approximation models and propagated into the visibilities. This enables us to directly assess the impact of the ionosphere on observed EoR data and the resulting power spectra. We show that the simulated data captures the dispersive behaviour of ionospheric effects. We show that the spatial structure of the simulated ionospheric media is accurately reconstructed either from the resultant source positional offsets or from parameters evaluated during the data calibration procedure. In turn, this will inform on the best strategies of identifying and efficiently eliminating ionospheric contamination in EoR data moving into the Square Kilometre Array era.
In optical and infrared long-baseline interferometry, data often display significant correlated errors because of uncertain multiplicative factors such as the instrumental transfer function or the pixel-to-visibility matrix. In the context of model fitting, this situation often leads to a significant bias in the model parameters. In the most severe cases, this can can result in a fit lying outside of the range of measurement values. This is known in nuclear physics as Peelle’s Pertinent Puzzle. I show how this arises in the context of interferometry and determine that the relative bias is of the order of the square root of the correlated component of the relative uncertainty times the number of measurements. It impacts preferentially large datasets, such as those obtained in medium to high spectral resolution. I then give a conceptually simple and computationally cheap way to avoid the issue: model the data without covariances, estimate the covariance matrix by error propagation using the modelled data instead of the actual data, and perform the model fitting using the covariance matrix. I also show that a more imprecise but also unbiased result can be obtained from ignoring correlations in the model fitting.
The ability to quickly detect transient sources in optical images and trigger multi-wavelength follow up is key for the discovery of fast transients. These include events rare and difficult to detect such as kilonovae, supernova shock breakout, and ‘orphan’ Gamma-ray Burst afterglows. We present the Mary pipeline, a (mostly) automated tool to discover transients during high-cadenced observations with the Dark Energy Camera at Cerro Tololo Inter-American Observatory (CTIO). The observations are part of the ‘Deeper Wider Faster’ programme, a multi-facility, multi-wavelength programme designed to discover fast transients, including counterparts to Fast Radio Bursts and gravitational waves. Our tests of the Mary pipeline on Dark Energy Camera images return a false positive rate of ~2.2% and a missed fraction of ~3.4% obtained in less than 2 min, which proves the pipeline to be suitable for rapid and high-quality transient searches. The pipeline can be adapted to search for transients in data obtained with imagers other than Dark Energy Camera.
The Evolutionary Map of the Universe (EMU) is a proposed radio continuum surveyof the Southern Hemisphere up to declination + 30°, with the AustralianSquare Kilometre Array Pathfinder (ASKAP). EMU will use an automated sourceidentification and measurement approach that is demonstrably optimal, tomaximise the reliability and robustness of the resulting radio sourcecatalogues. As a step toward this goal we conducted a “DataChallenge” to test a variety of source finders on simulated images. Theaim is to quantify the accuracy and limitations of existing automated sourcefinding and measurement approaches. The Challenge initiators also tested thecurrent ASKAPsoft source-finding tool to establish how it could benefit fromincorporating successful features of the other tools. As expected, most findersshow completeness around 100% at ≈ 10σ dropping to about 10% by≈ 5σ. Reliability is typically close to 100% at ≈10σ, with performance to lower sensitivities varying between finders. Allfinders show the expected trade-off, where a high completeness at lowsignal-to-noise gives a corresponding reduction in reliability, and vice versa.We conclude with a series of recommendations for improving the performance ofthe ASKAPsoft source-finding tool.
Galactic electron density distribution models are crucial tools for estimating the impact of the ionised interstellar medium on the impulsive signals from radio pulsars and fast radio bursts. The two prevailing Galactic electron density models (GEDMs) are YMW16 (Yao et al. 2017, ApJ, 835, 29) and NE2001 (Cordes & Lazio 2002, arXiv e-prints, pp astro–ph/0207156). Here, we introduce a software package PyGEDM which provides a unified application programming interface for these models and the YT20 (Yamasaki & Totani 2020, ApJ, 888, 105) model of the Galactic halo. We use PyGEDM to compute all-sky maps of Galactic dispersion measure (DM) for YMW16 and NE2001 and compare the large-scale differences between the two. In general, YMW16 predicts higher DM values towards the Galactic anticentre. YMW16 predicts higher DMs at low Galactic latitudes, but NE2001 predicts higher DMs in most other directions. We identify lines of sight for which the models are most discrepant, using pulsars with independent distance measurements. YMW16 performs better on average than NE2001, but both models show significant outliers. We suggest that future campaigns to determine pulsar distances should focus on targets where the models show large discrepancies, so future models can use those measurements to better estimate distances along those line of sight. We also suggest that the Galactic halo should be considered as a component in future GEDMs, to avoid overestimating the Galactic DM contribution for extragalactic sources such as FRBs.
In this paper, we introduce Nicil: Non-Ideal magnetohydrodynamics Coefficients and Ionisation Library. Nicil is a stand-alone Fortran90 module that calculates the ionisation values and the coefficients of the non-ideal magnetohydrodynamics terms of Ohmic resistivity, the Hall effect, and ambipolar diffusion. The module is fully parameterised such that the user can decide which processes to include and decide upon the values of the free parameters, making this a versatile and customisable code. The module includes both cosmic ray and thermal ionisation; the former includes two ion species and three species of dust grains (positively charged, negatively charged, and neutral), and the latter includes five elements which can be doubly ionised. We demonstrate tests of the module, and then describe how to implement it into an existing numerical code.
We present a detailed discussion of the implementation strategies for a recently developed w-stacking w-projection hybrid algorithm used to reconstruct wide-field interferometric images. In particular, we discuss the methodology used to deploy the algorithm efficiently on a supercomputer via use of a Message Passing Interface (MPI) k-means clustering technique to achieve efficient construction and application of non-coplanar effects. Additionally, we show that the use of conjugate symmetry can increase the w-stacking efficiency, decrease the time required to construction, and apply w-projection kernels for large data sets. We then demonstrate this implementation by imaging an interferometric observation of Fornax A from the Murchison Widefield Array (MWA). We perform an exact non-coplanar wide-field correction for 126.6 million visibilities using 50 nodes of a computing cluster. The w-projection kernel construction takes only 15 min prior to reconstruction, demonstrating that the implementation is both fast and efficient.
The Binary Population and Spectral Synthesis suite of binary stellar evolution models and synthetic stellar populations provides a framework for the physically motivated analysis of both the integrated light from distant stellar populations and the detailed properties of those nearby. We present a new version 2.1 data release of these models, detailing the methodology by which Binary Population and Spectral Synthesis incorporates binary mass transfer and its effect on stellar evolution pathways, as well as the construction of simple stellar populations. We demonstrate key tests of the latest Binary Population and Spectral Synthesis model suite demonstrating its ability to reproduce the colours and derived properties of resolved stellar populations, including well-constrained eclipsing binaries. We consider observational constraints on the ratio of massive star types and the distribution of stellar remnant masses. We describe the identification of supernova progenitors in our models, and demonstrate a good agreement to the properties of observed progenitors. We also test our models against photometric and spectroscopic observations of unresolved stellar populations, both in the local and distant Universe, finding that binary models provide a self-consistent explanation for observed galaxy properties across a broad redshift range. Finally, we carefully describe the limitations of our models, and areas where we expect to see significant improvement in future versions.
Next-generation spectro-polarimetric broadband surveys will probe cosmic magnetic fields in unprecedented detail, using the magneto-optical effect known as Faraday rotation. However, non-parametric methods such as RMCLEAN can introduce non-observable linearly polarised flux into a fitted model at negative wavelengths squared. This leads to Faraday rotation structures that are consistent with the observed data, but would be impossible or difficult to measure. We construct a convex non-parametric QU-fitting algorithm to constrain the flux at negative wavelengths squared to be zero. This allows the algorithm to recover structures that are limited in complexity to the observable region in wavelength squared. We verify this approach on simulated broadband data sets where we show that it has a lower root mean square error and that it can change the scientific conclusions for real observations. We advise using this prior in next-generation broadband surveys that aim to uncover complex Faraday depth structures. We provide a public Python implementation of the algorithm at https://github.com/Luke-Pratley/Faraday-Dreams.
I introduce Profiler, a user-friendly program designed to analyse the radial surface brightness profiles of galaxies. With an intuitive graphical user interface, Profiler can accurately model galaxies of a broad range of morphological types, with various parametric functions routinely employed in the field (Sérsic, core-Sérsic, exponential, Gaussian, Moffat, and Ferrers). In addition to these, Profiler can employ the broken exponential model for disc truncations or anti–truncations, and two special cases of the edge-on disc model: along the disc's major or minor axis. The convolution of (circular or elliptical) models with the point spread function is performed in 2D, and offers a choice between Gaussian, Moffat or a user-provided profile for the point spread function. Profiler is optimised to work with galaxy light profiles obtained from isophotal measurements, which allow for radial gradients in the geometric parameters of the isophotes, and are thus often better at capturing the total light than 2D image-fitting programs. Additionally, the 1D approach is generally less computationally expensive and more stable. I demonstrate Profiler's features by decomposing three case-study galaxies: the cored elliptical galaxy NGC 3348, the nucleated dwarf Seyfert I galaxy Pox 52, and NGC 2549, a double-barred galaxy with an edge-on, truncated disc.
We present a software package for single-dish data processing of spacecraft signals observed with VLBI-equipped radio telescopes. The Spacecraft Doppler tracking (SDtracker) software allows one to obtain topocentric frequency detections with a sub-Hz precision and reconstructed and residual phases of the carrier signal of any spacecraft or landing vehicle at any location in the Solar System. These data products are estimated using the ground-based telescope’s highly stable oscillator as a reference, without requiring an a priori model of the spacecraft dynamics nor the downlink transmission carrier frequency. The software has been extensively validated in multiple observing campaigns of various deep space missions and is compatible with the raw sample data acquired by any standard VLBI radio telescope worldwide. In this paper, we report the numerical methodology of SDtracker, the technical operations for deployment and usage, and a summary of use cases and scientific results produced since its initial release.
 $-$
3744 as an example. These results are crucial for performing precision pulsar timing with the uGMRT.
$-$
3744 as an example. These results are crucial for performing precision pulsar timing with the uGMRT.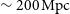 $\sim200\,\mathrm{Mpc}$
distance. We describe our robotic facility for rapid transient follow-up, which can target most of the sky at
$\sim200\,\mathrm{Mpc}$
distance. We describe our robotic facility for rapid transient follow-up, which can target most of the sky at 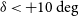 $\delta<+10\deg $
to a depth of
$\delta<+10\deg $
to a depth of 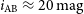 $i_\mathrm{AB}\approx 20\,\mathrm{mag}$
. We have implemented a new software pipeline to receive LIGO/Virgo alerts, schedule observations and examine the incoming real-time data stream for transient candidates. We adopt a real-bogus classifier using ensemble-based machine learning techniques, attaining high completeness (
$i_\mathrm{AB}\approx 20\,\mathrm{mag}$
. We have implemented a new software pipeline to receive LIGO/Virgo alerts, schedule observations and examine the incoming real-time data stream for transient candidates. We adopt a real-bogus classifier using ensemble-based machine learning techniques, attaining high completeness (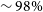 $\sim98\%$
) and purity (
$\sim98\%$
) and purity (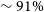 $\sim91\%$
) over our whole magnitude range. Applying further filtering to remove common image artefacts and known sources of transients, such as asteroids and variable stars, reduces the number of candidates by a factor of more than 10. We demonstrate the system performance with data obtained for GW190425, a binary neutron star merger detected during the LIGO/Virgo O3 observing campaign. In time for the LIGO/Virgo O4 run, we will have deeper reference images allowing transient detection to
$\sim91\%$
) over our whole magnitude range. Applying further filtering to remove common image artefacts and known sources of transients, such as asteroids and variable stars, reduces the number of candidates by a factor of more than 10. We demonstrate the system performance with data obtained for GW190425, a binary neutron star merger detected during the LIGO/Virgo O3 observing campaign. In time for the LIGO/Virgo O4 run, we will have deeper reference images allowing transient detection to 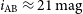 $i_\mathrm{AB}\approx 21\,\mathrm{mag}$
.
$i_\mathrm{AB}\approx 21\,\mathrm{mag}$
. $\sigma$
) for bright (i.e.,
$\sigma$
) for bright (i.e., 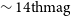 $\sim 14{\rm th} \mathrm{mag}$
) sources to 200 mmag for faint (i.e.,
$\sim 14{\rm th} \mathrm{mag}$
) sources to 200 mmag for faint (i.e., 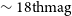 $\sim 18{\rm th} \mathrm{mag}$
) sources. Additionally, we compare our results to those obtained by GOTO’s own in-house pipeline, gotophoto, and obtain similar results. Based on repeatability measurements, we measure a
$\sim 18{\rm th} \mathrm{mag}$
) sources. Additionally, we compare our results to those obtained by GOTO’s own in-house pipeline, gotophoto, and obtain similar results. Based on repeatability measurements, we measure a 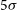 $5\sigma$
L-band survey depth of between 19 and 20 magnitudes, depending on observing conditions. We assess, using repeated observations of non-varying standard Sloan Digital Sky Survey stars, the accuracy of our uncertainties, which we find are typically overestimated by roughly a factor of two for bright sources (i.e.,
$5\sigma$
L-band survey depth of between 19 and 20 magnitudes, depending on observing conditions. We assess, using repeated observations of non-varying standard Sloan Digital Sky Survey stars, the accuracy of our uncertainties, which we find are typically overestimated by roughly a factor of two for bright sources (i.e., 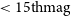 $< 15{\rm th} \mathrm{mag}$
), but slightly underestimated (by roughly a factor of 1.25) for fainter sources (
$< 15{\rm th} \mathrm{mag}$
), but slightly underestimated (by roughly a factor of 1.25) for fainter sources (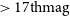 $> 17{\rm th} \mathrm{mag}$
). Finally, we present lightcurves for a selection of variable sources and compare them to those obtained with the Zwicky Transient Factory and GAIA. Despite the LSST Software Pipelines still undergoing active development, our results show that they are already delivering robust forced photometry measurements from GOTO data.
$> 17{\rm th} \mathrm{mag}$
). Finally, we present lightcurves for a selection of variable sources and compare them to those obtained with the Zwicky Transient Factory and GAIA. Despite the LSST Software Pipelines still undergoing active development, our results show that they are already delivering robust forced photometry measurements from GOTO data.