This journal utilises an Online Peer Review Service (OPRS) for submissions. By clicking "Continue" you will be taken to our partner site https://mc.manuscriptcentral.com/nws. Please be aware that your Cambridge account is not valid for this OPRS and registration is required. We strongly advise you to read all "Author instructions" in the "Journal information" area prior to submitting.
We introduce the exponentially preferential recursive tree and study some properties related to the degree profile of nodes in the tree. The definition of the tree involves a radix 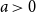 $a\gt 0$. In a tree of size
$a\gt 0$. In a tree of size  $n$ (nodes), the nodes are labeled with the numbers
$n$ (nodes), the nodes are labeled with the numbers 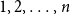 $1,2, \ldots ,n$. The node labeled
$1,2, \ldots ,n$. The node labeled 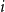 $i$ attracts the future entrant
$i$ attracts the future entrant 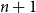 $n+1$ with probability proportional to
$n+1$ with probability proportional to 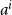 $a^i$.
$a^i$.
We dedicate an early section for algorithms to generate and visualize the trees in different regimes. We study the asymptotic distribution of the outdegree of node 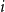 $i$, as
$i$, as 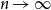 $n\to \infty$, and find three regimes according to whether
$n\to \infty$, and find three regimes according to whether 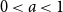 $0 \lt a \lt 1$ (subcritical regime),
$0 \lt a \lt 1$ (subcritical regime), 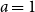 $a=1$ (critical regime), or
$a=1$ (critical regime), or 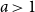 $a\gt 1$ (supercritical regime). Within any regime, there are also phases depending on a delicate interplay between
$a\gt 1$ (supercritical regime). Within any regime, there are also phases depending on a delicate interplay between 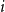 $i$ and
$i$ and  $n$, ramifying the asymptotic distribution within the regime into “early,” “intermediate” and “late” phases. In certain phases of certain regimes, we find asymptotic Gaussian laws. In certain phases of some other regimes, small oscillations in the asymototic laws are detected by the Poisson approximation techniques.
$n$, ramifying the asymptotic distribution within the regime into “early,” “intermediate” and “late” phases. In certain phases of certain regimes, we find asymptotic Gaussian laws. In certain phases of some other regimes, small oscillations in the asymototic laws are detected by the Poisson approximation techniques.
