



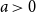

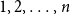
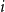
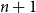
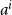
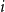
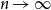
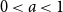
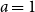
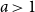
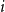

1. Scope
The recursive tree is a classic hierarchical structure. Several models of randomness are used in a variety of applications. Dozens of research papers have been devoted to the uniform model alone, many of them are surveyed in Smythe and Mahmoud (Reference Smythe and Mahmoud1995). Today, the uniform recursive tree is a standard entry in books on random structures (Drmota, Reference Drmota2009; Hofri and Mahmoud, Reference Hofri and Mahmoud2018; Frieze and Karoński, Reference Frieze and Karoński2016). The uniform recursive tree is used as a model in many applications. Some of the classic applications are in pyramid schemes (Gastwirth and Bhattacharya, Reference Gastwirth and Bhattacharya1984) and Philology (Najock and Heyde, Reference Najock and Heyde1982).
Driven by other applications, interest was developed into nonuniform models, wherein the attachment of new nodes is done preferentially according to some criterion. The earliest of these preferential models is a probability scheme in which nodes of higher outdegrees are favored (Szymański, Reference Szymański1987). Other preferential ideas are based on node fitness (Dereich and Ortgiese, Reference Dereich and Ortgiese2014), old age of nodes (Hofri and Mahmoud, Reference Hofri and Mahmoud2018), node Youthfulness (Lyon and Mahmoud, Reference Lyon and Mahmoud2020), and power-weights on the nodes (Lyon and Mahmoud, Reference Lyon and Mahmoud2022).
1.1 A proposed preferential model
In the present investigation, we propose a new preferential model parameterized by a real positive radix, which we call
 $a$
. In this exponential model, the affinity of a node is the radix raised to the node label. A precise definition is given in Subsection 1.3.
$a$
. In this exponential model, the affinity of a node is the radix raised to the node label. A precise definition is given in Subsection 1.3.
For instance, if the radix is less than 1, nodes that appear first (older in the tree) have an attraction power that is larger than newer nodes. One sees such a phenomenon in the growth of networks, where older nodes have a bigger chance of growth than younger ones. For instance, in a graph representing the growth of technology companies, nodes representing giants like Microsoft© and Apple© have a higher chance of attracting new subscribers than a node representing a small start-up company.
We assume that the reader is familiar with the jargon of trees, such as “node,” “vertex,” “edge,” “root,” “ancestors,” “descendants,” “children,” “parents,” “recruiting,” “affinity,” etc.
1.2 The building algorithm
A recursive tree is grown by an attachment algorithm that operates in the following way. Initially (at time
 $n=0$
), there is a node labeled 1. At each subsequent epoch
$n=0$
), there is a node labeled 1. At each subsequent epoch
 $n\ge 1$
of discrete time, a node labeled
$n\ge 1$
of discrete time, a node labeled
 $n+1$
joins the tree by choosing one of the existing nodes as a parent and attaching itself to it via a new edge. The parent selection is determined according to some probability model on the set
$n+1$
joins the tree by choosing one of the existing nodes as a parent and attaching itself to it via a new edge. The parent selection is determined according to some probability model on the set
 $\{1, \ldots , n\}$
. Note that the labels on any root-to-leaf path are in an increasing sequence. For this reason, some authors call these structures “increasing trees” (Bergeron et al., Reference Bergeron, Flajolet and Salvy1992).
$\{1, \ldots , n\}$
. Note that the labels on any root-to-leaf path are in an increasing sequence. For this reason, some authors call these structures “increasing trees” (Bergeron et al., Reference Bergeron, Flajolet and Salvy1992).
These trees have been studied under several probability models, notably including the natural uniform model and preferential models based on favoring certain nodes according to some criterion. The first preferential criterion in the literature is to select a node with probability proportional to 1 plus its outdegree (Szymański, Reference Szymański1987; Mahmoud et al., Reference Mahmoud, Smythe and Szymański1993). This model gained popularity, as it offers scalability properties and power laws that are met in certain trees in nature (Barabási and Albert, Reference Barabási and Albert1999). For over a decade, the terminology “preferential attachment” stood solely for preference by node outdegrees.
More recently, authors broke away from this narrower definition of “preference” to tree models with other types of preference (Hofri and Mahmoud, Reference Hofri and Mahmoud2018; Lyon and Mahmoud, Reference Lyon and Mahmoud2020; Lyon and Mahmoud, Reference Lyon and Mahmoud2022).
1.3 Exponentially preferential trees
In this investigation, we consider a new exponentially preferential attachment algorithm, wherein node
 $i$
at time
$i$
at time
 $n-1$
recruits with probability proportional to
$n-1$
recruits with probability proportional to
 $a^i$
, for some positive constant
$a^i$
, for some positive constant
 $a$
. Specifically, if we define
$a$
. Specifically, if we define
 $A_{n,i}$
as the event that node
$A_{n,i}$
as the event that node
 $i$
recruits (the node labeled
$i$
recruits (the node labeled
 $n+1$
) when the tree has
$n+1$
) when the tree has
 $n$
nodes in it (that is, when the tree is of age
$n$
nodes in it (that is, when the tree is of age
 $n-1$
), we would have
$n-1$
), we would have
 \begin{equation} \mathbb {P} (A_{n,i}) = \frac {a^i} {\sum _{j =1}^n a^j} = \begin{cases} \displaystyle {\frac 1 n}, &\mbox {if \ } a = 1; \\ \\ \displaystyle {\frac {(a-1)\, a^{i-1}} {a^n-1}, } &\mbox {otherwise}. \end{cases} \end{equation}
\begin{equation} \mathbb {P} (A_{n,i}) = \frac {a^i} {\sum _{j =1}^n a^j} = \begin{cases} \displaystyle {\frac 1 n}, &\mbox {if \ } a = 1; \\ \\ \displaystyle {\frac {(a-1)\, a^{i-1}} {a^n-1}, } &\mbox {otherwise}. \end{cases} \end{equation}
In the sequel, we observe a trichotomy of the positive real line into three regimes for
 $a$
, and in each regime we have a different behavior. We call the regime
$a$
, and in each regime we have a different behavior. We call the regime
 $0 \lt a \lt 1$
subcritical, the regime
$0 \lt a \lt 1$
subcritical, the regime
 $a = 1$
critical, and the regime
$a = 1$
critical, and the regime
 $a \gt 1$
supercritical.
$a \gt 1$
supercritical.
We call a tree grown according to this distribution for the choice of parent an exponentially preferential tree with radix
 $a$
. Since this is the only kind we study in this manuscript, we refer to it simply as the “tree” most of the time. When
$a$
. Since this is the only kind we study in this manuscript, we refer to it simply as the “tree” most of the time. When
 $a=1$
, we have the special case of uniform recruiting, which is extensively studied (Bergeron et al., Reference Bergeron, Flajolet and Salvy1992; Drmota, Reference Drmota2009; Hofri and Mahmoud, Reference Hofri and Mahmoud2018; Frieze and Karoński, Reference Frieze and Karoński2016; Smythe and Mahmoud, Reference Smythe and Mahmoud1995).
$a=1$
, we have the special case of uniform recruiting, which is extensively studied (Bergeron et al., Reference Bergeron, Flajolet and Salvy1992; Drmota, Reference Drmota2009; Hofri and Mahmoud, Reference Hofri and Mahmoud2018; Frieze and Karoński, Reference Frieze and Karoński2016; Smythe and Mahmoud, Reference Smythe and Mahmoud1995).
Figure 1 displays the six exponentially preferential trees of size 4 with radix
 $a=1/2$
. The numbers above the trees are their probabilities. Note the high probability assigned to the bushiest tree at the far right. In the uniform model, this tree only has probability
$a=1/2$
. The numbers above the trees are their probabilities. Note the high probability assigned to the bushiest tree at the far right. In the uniform model, this tree only has probability
 $1/6$
. To discern the these probabilities, we illustrate the computation for one tree. We choose the fourth one from the left (with probability
$1/6$
. To discern the these probabilities, we illustrate the computation for one tree. We choose the fourth one from the left (with probability
 $4/21$
), as it has multiple nodes recruiting and a node (the root) recruiting twice. Initially, we have a root node labeled with 1. With probability 1, this root node recruits the node labeled with 2. So, the tree
$4/21$
), as it has multiple nodes recruiting and a node (the root) recruiting twice. Initially, we have a root node labeled with 1. With probability 1, this root node recruits the node labeled with 2. So, the tree
appears with probability 1. The nodes 1 and 2 are now in a competition to attract node 3, with probabilities
 $\frac {(1/2)^1} {(1/2)^1+ (1/2)^2} = 2/3$
and
$\frac {(1/2)^1} {(1/2)^1+ (1/2)^2} = 2/3$
and
 $\frac {(1/2)^2} {(1/2)^1+ (1/2)^2} = 1/3$
. The tree
$\frac {(1/2)^2} {(1/2)^1+ (1/2)^2} = 1/3$
. The tree

emerges with probability
 $1\times 2/3$
. The nodes labeled with 1, 2, and 3 are now in competition to attract the node labeled with 4, with respective probabilities,
$1\times 2/3$
. The nodes labeled with 1, 2, and 3 are now in competition to attract the node labeled with 4, with respective probabilities,
 $\frac {(1/2)^1} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 4/7$
,
$\frac {(1/2)^1} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 4/7$
,
 $\frac {(1/2)^2} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 2/7$
, and
$\frac {(1/2)^2} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 2/7$
, and
 $\frac {(1/2)^3} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 1/7$
. Whence, if the node labeled with 2 is the one that recruits, we get the third tree on the right in Figure 1 with probability
$\frac {(1/2)^3} {(1/2)^1+ (1/2)^2+ (1/2)^3} = 1/7$
. Whence, if the node labeled with 2 is the one that recruits, we get the third tree on the right in Figure 1 with probability
 $1\times 2/3\times 2/7 = 4/21.$
.
$1\times 2/3\times 2/7 = 4/21.$
.
This example illustrates the dynamic nature of the attraction probability at node
 $i$
. While
$i$
. While
 $a^i$
is a fixed number, the scaling used is changing with time.
$a^i$
is a fixed number, the scaling used is changing with time.

Figure 1. The exponentially preferential attachment recursive trees of size 4 with radix
 $a=1/2$
and their probabilities.
$a=1/2$
and their probabilities.
2. Generation and visualization
Before we present any theoretical results, it may help the reader grasp the gist of the varied behavior of the random exponentially preferential trees in the three regimes with diagrams.
To produce images, we first need a generating algorithm to provide the data. We present one such algorithm that sequentially cranks out the edges that join the tree. The edges appear in the form
 $(n+1,r)$
, where
$(n+1,r)$
, where
 $r$
is the recruiter, when the tree size is
$r$
is the recruiter, when the tree size is
 $n$
. For instance, the pair
$n$
. For instance, the pair
 $(78,50)$
stands for an edge joining the vertex labeled 78 to a tree of size
$(78,50)$
stands for an edge joining the vertex labeled 78 to a tree of size
 $77$
, in which node 50 is the recruiter.
$77$
, in which node 50 is the recruiter.
As an illustration of the action of the algorithm, we trace through the evolution of the third tree on the right in figure 1. The algorithm builds the tree edge by edge, first constructing the edge (2,1), then adding the edge (3,2) and finally completing the description of this tree by adding the edge (4,2) to the list of edges.
Once the tree description is obtained in the form of a list of edges, we can visualize the tree by a drawing obtained with the aid of a tree-graphing package.
The algorithm assumes it can access the function
 \begin{equation*}F (s,i) \gets \sum _{r =1}^i \frac {(a-1)\, a^{r-1}} {a^s -1} = \frac {a^i -1}{a^s-1},\end{equation*}
\begin{equation*}F (s,i) \gets \sum _{r =1}^i \frac {(a-1)\, a^{r-1}} {a^s -1} = \frac {a^i -1}{a^s-1},\end{equation*}
which accumulates the probabilities
 $\mathbb {P}(A_{s,1}) +\cdots + \mathbb {P}(A_{s,i})$
for the purpose of generating the recruiting index. With
$\mathbb {P}(A_{s,1}) +\cdots + \mathbb {P}(A_{s,i})$
for the purpose of generating the recruiting index. With
 $F(s,i)$
having a closed form, it can be evaluated in
$F(s,i)$
having a closed form, it can be evaluated in
 $O(1)$
time.
$O(1)$
time.
The building algorithm assumes the existence of the primitive function random, which generates a random number uniformly distributed over the interval
 $(0,1)$
.
$(0,1)$
.
The core of the algorithm repeats the calculation of an index when the tree is of size “ size,” for
 $size = 1, \ldots , n-1$
. At each size between 1 and
$size = 1, \ldots , n-1$
. At each size between 1 and
 $n-1$
, a random variable
$n-1$
, a random variable
 $U$
distributed uniformly between 0 and 1 is generated. If the value of
$U$
distributed uniformly between 0 and 1 is generated. If the value of
 $U$
falls between
$U$
falls between
 $F( size,r-1)$
and
$F( size,r-1)$
and
 $F (size,r)$
, we take the recruiter to be
$F (size,r)$
, we take the recruiter to be
 $r$
. This recruiter is receiving the node
$r$
. This recruiter is receiving the node
 $size+1$
, and we store the pair (edge)
$size+1$
, and we store the pair (edge)
 $(size+1,r)$
in the array
$(size+1,r)$
in the array
 $R$
of recruiters. At the end of the execution of the algorithm, the array
$R$
of recruiters. At the end of the execution of the algorithm, the array
 $R$
holds a complete description of a tree of size
$R$
holds a complete description of a tree of size
 $n$
.
$n$
.
Here is a possible version in pseudo code:
for size from 1 to
 $n-1$
do
$n-1$
do
 $U \gets$
random
$U \gets$
random
 $r \gets 1$
$r \gets 1$
while
 $U \gt F(size,r)$
and
$U \gt F(size,r)$
and
 $r \lt size$
do
$r \lt size$
do
 $r \gets r+1$
$r \gets r+1$
 $R[size] \gets (size+1,r)$
$R[size] \gets (size+1,r)$
The inner while loop may run an order of
 $size$
in the worst case, and the outer
$size$
in the worst case, and the outer
 $\bf for$
loop is driving
$\bf for$
loop is driving
 $size$
through
$size$
through
 $n-1$
iterations. The overall execution performs in
$n-1$
iterations. The overall execution performs in
 $O(n^2)$
time. By this algorithm, we obtained three trees of size
$O(n^2)$
time. By this algorithm, we obtained three trees of size
 $n=100$
each, under the settings
$n=100$
each, under the settings
 $a=1/2$
,
$a=1/2$
,
 $a=1$
,
$a=1$
,
 $a=2$
, respectively. The data (edges) were then fed into the tree-drawing package “Pyvis,” which produced the three images in Figure 2. The root of each tree is shown as a red star. The figure shows a random tree in the subcritical regime with radix
$a=2$
, respectively. The data (edges) were then fed into the tree-drawing package “Pyvis,” which produced the three images in Figure 2. The root of each tree is shown as a red star. The figure shows a random tree in the subcritical regime with radix
 $a=1/2$
(top left), a random uniform (standard) recursive tree, with radix
$a=1/2$
(top left), a random uniform (standard) recursive tree, with radix
 $a=1$
(top right), and a random tree in the supercritical regime with radix
$a=1$
(top right), and a random tree in the supercritical regime with radix
 $a=2$
(bottom).
$a=2$
(bottom).

Figure 2. Randomly generated trees of size 100: subcritical (top left) with radix
 $1/2$
, uniform (top right) with radix
$1/2$
, uniform (top right) with radix
 $a=1$
, supercritical (bottom) with radix 2.
$a=1$
, supercritical (bottom) with radix 2.
In Figure 2, we chose a drawing style to fill the space, rather than one going down vertically (as in the more traditional vertical drawing as in Figure 1). The vertical drawing would use the space sparsely.
The reader will notice right away that in the subcritical tree (the one at the top left in Figure 2), the nodes cluster near the root, making it a shrubby structure. In the uniform tree (the one at the top right in Figure 2), the nodes are all over the place, whereas in the supercritical tree (the one at the bottom in Figure 2), many nodes drag the tree toward higher altitudes, making it a tall and scrawny tree with short branches sprouting out of a main thin trunk.
2.1 Notation
The indicator of event
 $\mathcal{E}$
is
$\mathcal{E}$
is
 $\mathbb {I}_{\mathcal{E}}$
. The following presentation involves
$\mathbb {I}_{\mathcal{E}}$
. The following presentation involves
 $H_p^{(r)} = \sum _{k=1}^p 1/k^r$
, the
$H_p^{(r)} = \sum _{k=1}^p 1/k^r$
, the
 $p$
th harmonic number of order
$p$
th harmonic number of order
 $r$
.Footnote
1
The harmonic numbers of the first two orders have well-known asymptotic equivalents (as
$r$
.Footnote
1
The harmonic numbers of the first two orders have well-known asymptotic equivalents (as
 $n\to \infty )$
:Footnote
2
$n\to \infty )$
:Footnote
2
 \begin{align} H_n &= \ln n + \gamma + O\Big ( \frac 1 n\Big ); \end{align}
\begin{align} H_n &= \ln n + \gamma + O\Big ( \frac 1 n\Big ); \end{align}
 \begin{align} H_n^{(2)} &= \frac {\pi ^2} 6 + O\Big ( \frac 1 n\Big ).\\[9pt]\nonumber \end{align}
\begin{align} H_n^{(2)} &= \frac {\pi ^2} 6 + O\Big ( \frac 1 n\Big ).\\[9pt]\nonumber \end{align}
Ceils and floors appear in the calculations. The floor of a real number
 $x$
can be represented by removing the floor and compensating for the fractional part of
$x$
can be represented by removing the floor and compensating for the fractional part of
 $x$
, sometimes denoted by
$x$
, sometimes denoted by
 $\{x\}$
. That is, we have
$\{x\}$
. That is, we have
 \begin{equation*}\lfloor x\rfloor = x - \{ x\}.\end{equation*}
\begin{equation*}\lfloor x\rfloor = x - \{ x\}.\end{equation*}
For
 $i\ge 1$
, and
$i\ge 1$
, and
 $a\gt 1$
, in the sequel, we use the numbers
$a\gt 1$
, in the sequel, we use the numbers
 \begin{align*} c_i^{(1)}(a) &= \sum _{k=i}^\infty \frac 1 {a^k-1},\\ c_i^{(2)}(a) &= \sum _{k=i}^\infty \frac 1 {(a^k-1)^2}. \end{align*}
\begin{align*} c_i^{(1)}(a) &= \sum _{k=i}^\infty \frac 1 {a^k-1},\\ c_i^{(2)}(a) &= \sum _{k=i}^\infty \frac 1 {(a^k-1)^2}. \end{align*}
We denote the normally distributed random variable with mean
 $\mu$
and variance
$\mu$
and variance
 $\sigma ^2\gt 0$
by
$\sigma ^2\gt 0$
by
 $\mathcal {N}(\mu ,\sigma ^2)$
and denote the Poisson random variable with parameter
$\mathcal {N}(\mu ,\sigma ^2)$
and denote the Poisson random variable with parameter
 $\lambda \gt 0$
by
$\lambda \gt 0$
by
 $\textrm { Poi}\left (\lambda \right )$
. The notation
$\textrm { Poi}\left (\lambda \right )$
. The notation
 ${\mathcal L} (X)$
stands for the law (probability distribution) of a random variable
${\mathcal L} (X)$
stands for the law (probability distribution) of a random variable
 $X$
.
$X$
.
The total variation distance (
 $d_{TV}$
) between the laws of the nonnegative integer-valued random variables
$d_{TV}$
) between the laws of the nonnegative integer-valued random variables
 $X$
and
$X$
and
 $Y$
is defined as
$Y$
is defined as
 \begin{equation*}d_{TV}\big ({\mathcal L} (X), {\mathcal L} (Y)\big )= \frac 1 2 \sum _{j=0}^\infty \big |\mathbb {P}(X=j) - \mathbb {P}(Y=j) \big |.\end{equation*}
\begin{equation*}d_{TV}\big ({\mathcal L} (X), {\mathcal L} (Y)\big )= \frac 1 2 \sum _{j=0}^\infty \big |\mathbb {P}(X=j) - \mathbb {P}(Y=j) \big |.\end{equation*}
As some authors do, we simplify the notation of the total variation distance to
 $d_{TV}(X, Y)$
, but it should be understood that it is the distance between the laws of these variables.
$d_{TV}(X, Y)$
, but it should be understood that it is the distance between the laws of these variables.
The following theorem by Barbour and Holst (Barbour and Hall, Reference Barbour and Hall1984) is beneficial in obtaining Poisson approximations for node degrees.
Theorem 2.1. Let
 $X_1, \ldots , X_n$
be independent Bernoulli random variables, such that
$X_1, \ldots , X_n$
be independent Bernoulli random variables, such that
 $\mathbb {P}(X_k = 1) = p_k$
, for
$\mathbb {P}(X_k = 1) = p_k$
, for
 $i=1, \ldots , n$
, and let
$i=1, \ldots , n$
, and let
 $S_n = \sum _{k=1}^n X_k$
be the sum of these variables. Define
$S_n = \sum _{k=1}^n X_k$
be the sum of these variables. Define
 \begin{equation*}\lambda _{n,1} = \sum _{k=1}^n \mathbb {E}[X_k] = \sum _{k=1}^n p_k, \qquad and\qquad \lambda _{n,2} =\sum _{k=1}^n p_k^2.\end{equation*}
\begin{equation*}\lambda _{n,1} = \sum _{k=1}^n \mathbb {E}[X_k] = \sum _{k=1}^n p_k, \qquad and\qquad \lambda _{n,2} =\sum _{k=1}^n p_k^2.\end{equation*}
We have
 \begin{equation*}d_{TV}\big (S_n, \textrm { Poi}\left (\lambda _{n,1}\right ) \big ) \le (1 - e^{-\lambda _{n,1}}) \, \frac {\lambda _{n,2}} {\lambda _{n,1}}. \end{equation*}
\begin{equation*}d_{TV}\big (S_n, \textrm { Poi}\left (\lambda _{n,1}\right ) \big ) \le (1 - e^{-\lambda _{n,1}}) \, \frac {\lambda _{n,2}} {\lambda _{n,1}}. \end{equation*}
The theorem is one of several versions fitting in the machinery of Poisson approximation (and the more general framework of Chen−Stein methods) (Barbour et al., Reference Barbour, Holst and Janson1992).
3. Node outdegrees
Let
 $\Delta _{n,i}$
be the outdegree of node
$\Delta _{n,i}$
be the outdegree of node
 $i$
in a tree of size
$i$
in a tree of size
 $n$
. It is related to the degree of node
$n$
. It is related to the degree of node
 $i$
. Except for the root, any node degree is 1 plus its outdegree. As the root is the only node that does not have a parent, its degree is the same as its outdegree.
$i$
. Except for the root, any node degree is 1 plus its outdegree. As the root is the only node that does not have a parent, its degree is the same as its outdegree.
Remark 3.1. In a tree of size
 $n$
, the sum of the outdegrees is
$n$
, the sum of the outdegrees is
 $n-1$
.
$n-1$
.
The outdegree of node
 $i$
increases, when it recruits, and we have the representation
$i$
increases, when it recruits, and we have the representation
 \begin{equation} \Delta _{n,i} = \sum _{k=i}^{n-1} \mathbb {I}_{A_{k,i}}. \end{equation}
\begin{equation} \Delta _{n,i} = \sum _{k=i}^{n-1} \mathbb {I}_{A_{k,i}}. \end{equation}
3.1 Mean
Take expectations of (4). We then get, for
 $n\ge 2$
, a mean value for the
$n\ge 2$
, a mean value for the
 $i$
th degree in the form
$i$
th degree in the form
 \begin{equation} \mathbb {E}[\Delta _{n,i}] = \sum _{k=i}^{n-1} \mathbb {P}(\mathbb {I}_{A_{k,i}} =1) = \begin{cases}\displaystyle {\sum _{k=i}^{n-1} \frac 1 k}, &\mbox {if \ } a=1; \\ \\ \displaystyle {\sum _{k=i}^{n-1} \frac {(a-1)\, a^{i-1}} {a^k-1}}, &\mbox {otherwise}. \end{cases} \end{equation}
\begin{equation} \mathbb {E}[\Delta _{n,i}] = \sum _{k=i}^{n-1} \mathbb {P}(\mathbb {I}_{A_{k,i}} =1) = \begin{cases}\displaystyle {\sum _{k=i}^{n-1} \frac 1 k}, &\mbox {if \ } a=1; \\ \\ \displaystyle {\sum _{k=i}^{n-1} \frac {(a-1)\, a^{i-1}} {a^k-1}}, &\mbox {otherwise}. \end{cases} \end{equation}
Proposition 3.1. Let
 $\Delta _{n,i}$
be the outdegree of node
$\Delta _{n,i}$
be the outdegree of node
 $i$
in an exponentially preferential tree of size
$i$
in an exponentially preferential tree of size
 $n$
and radix
$n$
and radix
 $0 \lt a \lt 1$
. As
$0 \lt a \lt 1$
. As
 $n\to \infty$
, we have
$n\to \infty$
, we have
 \begin{equation*}\mathbb {E}[\Delta _{n,i}] = \begin{cases} (1-a)\, a^{i-1} \, (n-i) + O(a^i), & if \ a\lt 1;\\ \ln n -\ln i + O\big (\frac 1 i\big ), & if \ a=1. \end{cases}\end{equation*}
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = \begin{cases} (1-a)\, a^{i-1} \, (n-i) + O(a^i), & if \ a\lt 1;\\ \ln n -\ln i + O\big (\frac 1 i\big ), & if \ a=1. \end{cases}\end{equation*}
Otherwise,
 $a$
is greater than 1, and the case is ramified according to the relationship between
$a$
is greater than 1, and the case is ramified according to the relationship between
 $i$
and
$i$
and
 $n$
. As
$n$
. As
 $n\to \infty$
, we have the phases:
$n\to \infty$
, we have the phases:
 \begin{equation*}\mathbb {E}[\Delta _{n,i}] = \begin{cases} (a-1) \, a^{i-1} c_i^{(1)} (a) + O\big ( \frac 1 {a^{n-i}}\big ), & i\ fixed; \\ 1 - \frac 1 {a^{n-i}} + O\big (\frac 1 {a^i}\big ), &n\ge i \to \infty . \end{cases}\end{equation*}
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = \begin{cases} (a-1) \, a^{i-1} c_i^{(1)} (a) + O\big ( \frac 1 {a^{n-i}}\big ), & i\ fixed; \\ 1 - \frac 1 {a^{n-i}} + O\big (\frac 1 {a^i}\big ), &n\ge i \to \infty . \end{cases}\end{equation*}
Proof. We need to cover three different regimes:
-
• The subcritical regime (
 $0 \lt a \lt 1$
): Start with the lower display in (5) in the formA Taylor series expansion of the summand yields:
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = (1-a)\, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {1- a^k}.\end{equation*}
\begin{align*} \mathbb {E}[\Delta _{n,i}] &= (1-a)\, a^{i-1} \sum _{k=i}^{n-1} \big (1 + O(a^k)\big ) \\ & =(1-a)\, a^{i-1} \Big ( n-i+ O\Big (\sum _{k=i}^{n-1} a^k\Big )\Big ) \\ & =(1-a)\, a^{i-1}( n-i)+ O(a^i). \end{align*}
$0 \lt a \lt 1$
): Start with the lower display in (5) in the formA Taylor series expansion of the summand yields:
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = (1-a)\, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {1- a^k}.\end{equation*}
\begin{align*} \mathbb {E}[\Delta _{n,i}] &= (1-a)\, a^{i-1} \sum _{k=i}^{n-1} \big (1 + O(a^k)\big ) \\ & =(1-a)\, a^{i-1} \Big ( n-i+ O\Big (\sum _{k=i}^{n-1} a^k\Big )\Big ) \\ & =(1-a)\, a^{i-1}( n-i)+ O(a^i). \end{align*}
-
• The critical regime (
$a=1$
): Here we use the upper display in (5), yieldingUsing the asymptotic equivalent in (2), as both
\begin{equation*}\mathbb {E}[\Delta _{n,i}] =\sum _{k=i}^{n-1}\frac 1 k = H_{n - 1} - H_{i - 1}.\end{equation*}
$n$
and
$i$
approach
$\infty$
, we geta known result (Javanian and Asl, Reference Javanian and Asl2003; Mahmoud, Reference Mahmoud2019).
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = \ln n -\ln i + O\Big (\frac 1 i\Big ),\end{equation*}
-
• The supercritical regime
$a \gt 1$
: Again, we start with the lower display in (5). We have two phases in the lives of the various nodes:










-
(i) The index
$i$
is a constant. In this phase, we have
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = (a-1) \, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {a^k-1} = (a-1) \, a^{i-1} \, c_i^{(1)}(a) + O\Big (\frac 1 {a^{n-i}}\Big ).\end{equation*}
-
(ii) The index
$i$
is increasing with
$n$
. We can approximate the series in the lower display in (5) with a geometric series. To this end, we quantify the absolute error
${\mathcal E}_{n,i}$
from the boundFrom a Taylor series expansion of the summand, we get
\begin{equation*}{\mathcal E}_{n,i} \,:\!= \Bigg |\sum _{k=i}^{n-1} \frac 1 {a^k-1} - \sum _{k=i}^{n-1} \frac 1 {a^k}\Bigg | = \sum _{k=i}^{n-1} \frac 1 {a^k-1} - \sum _{k=i}^{n-1} \frac 1 {a^k} = \sum _{k=i}^{n-1} \frac 1 {a^k(a^k-1)} .\end{equation*}
In this phase, we have
\begin{align*} {\mathcal E}_{n,i} &\,:\!= \sum _{k=i}^{n-1} \frac 1 {a^{2k}} \Big (1 + O\Big (\frac 1 {a^k}\Big )\Big ) \\ &= \frac 1 {a^{2i}}\Big ( \frac {1 - 1/a^{2(n-i)}} {1 - 1/a^2}\Big ) + O\Big (\sum _{k=i}^{n-1} \frac 1 {a^{3k}}\Big )\\ &= \frac 1 {a^{2(i-1)}}\Big ( \frac {1 - 1/a^{2(n-i)}} {a^2 - 1}\Big ) + O\Big ( \frac 1 {a^{3(i-1)}}\Big ( \frac {(1 - 1/a^{3(n-i})} {a^3 - 1}\Big ) \Big )\\ &= O\Big (\frac 1 {a^{2i}}\Big ). \end{align*}
\begin{align*} \mathbb {E}[\Delta _{n,i}] &= (a-1) \, a^{i-1}\Big (\Big ( \sum _{k=i}^{n-1} \frac 1 {a^k}\Big ) + {\mathcal E}_{n,i}\Big ) \\ &= (a-1) \, a^{i-1}\Big (\Big (\sum _{k=i}^{n-1} \frac 1 {a^k}\Big ) + O\Big (\frac 1 {a^{2i}}\Big )\Big )\\ &= (a-1) \, a^{i-1}\, \frac {1 - (1/a)^{n-i}} {a^i(1 - 1/a)} + O\Big (\frac 1 {a^i}\Big )\\ &= 1 -\frac 1 {a^{n-i}} + O\Big (\frac 1 {a^i}\Big ). \end{align*}








3.2 Variance
In (4), the indicators
 $\mathbb {I}_{A_{n, i}}$
, for
$\mathbb {I}_{A_{n, i}}$
, for
 $n\ge 1$
, are independent. It follows that
$n\ge 1$
, are independent. It follows that
 \begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = {\mathbb {V}\textrm {ar}}\Big [\sum _{k=i}^{n-1} \mathbb {I}_{A_{k,i}} \Big ] = \sum _{k=i}^{n-1} {\mathbb {V}\textrm {ar}}[\mathbb {I}_{A_{k,i}}].\end{equation*}
\begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = {\mathbb {V}\textrm {ar}}\Big [\sum _{k=i}^{n-1} \mathbb {I}_{A_{k,i}} \Big ] = \sum _{k=i}^{n-1} {\mathbb {V}\textrm {ar}}[\mathbb {I}_{A_{k,i}}].\end{equation*}
That is, we have
 \begin{equation} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = (a-1)\, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {a^k-1} - (a-1)^2 \, {a^{2i-2}} \sum _{k=i}^{n-1} \Big (\frac 1 {a^k-1}\Big )^2. \end{equation}
\begin{equation} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = (a-1)\, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {a^k-1} - (a-1)^2 \, {a^{2i-2}} \sum _{k=i}^{n-1} \Big (\frac 1 {a^k-1}\Big )^2. \end{equation}
This combinatorial form is reducible in the uniform case (
 $a=1$
), where we get
$a=1$
), where we get
 \begin{equation} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \sum _{k=i}^{n-1} \frac 1 k \Big (1- \frac 1 k\big ) = H_{n-1} - H_{i-1} - \bigl (H_{n-1}^{(2)} - H_{i-1}^{(2)} \bigr ). \end{equation}
\begin{equation} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \sum _{k=i}^{n-1} \frac 1 k \Big (1- \frac 1 k\big ) = H_{n-1} - H_{i-1} - \bigl (H_{n-1}^{(2)} - H_{i-1}^{(2)} \bigr ). \end{equation}
Again we have an asymptotic trichotomy.
Proposition 3.2. Let
 $\Delta _{n,i}$
be the outegree of node
$\Delta _{n,i}$
be the outegree of node
 $i$
in an exponential preferential tree of size
$i$
in an exponential preferential tree of size
 $n$
and radix
$n$
and radix
 $0\lt a \lt 1$
. We then have
$0\lt a \lt 1$
. We then have
 \begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \begin{cases} (1-a)\, a^{i-1}\big (1 - (1-a)\, a^{i-1} \big )(n-i)+ O(a^i), & if \ a\lt 1; \\ \ln n -\ln i + O(\frac 1 i), & if \ a=1. \end{cases}\end{equation*}
\begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \begin{cases} (1-a)\, a^{i-1}\big (1 - (1-a)\, a^{i-1} \big )(n-i)+ O(a^i), & if \ a\lt 1; \\ \ln n -\ln i + O(\frac 1 i), & if \ a=1. \end{cases}\end{equation*}
Otherwise,
 $a$
is greater than 1, and the case is ramified according to the relationship between
$a$
is greater than 1, and the case is ramified according to the relationship between
 $i$
and
$i$
and
 $n$
. As
$n$
. As
 $n\to \infty$
, we have the phases:
$n\to \infty$
, we have the phases:
 \begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \begin{cases} (a-1) \, a^{i-1} c_i ^{(1)}(a) \\ \quad \quad {} - (a-1)^2 \, a^{2i-2} c_i ^{(2)}(a) + O\big ( \frac 1 {a^{n-i}}\big ), & i\ fixed; \\ \frac 2 {a+1} -\frac 1 {a^{n-i}} +\frac {a-1} {(a+1)a^{2n-2i}} + O\big (\frac 1 {a^i}\big ),& n\ge i \to \infty . \end{cases}\end{equation*}
\begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = \begin{cases} (a-1) \, a^{i-1} c_i ^{(1)}(a) \\ \quad \quad {} - (a-1)^2 \, a^{2i-2} c_i ^{(2)}(a) + O\big ( \frac 1 {a^{n-i}}\big ), & i\ fixed; \\ \frac 2 {a+1} -\frac 1 {a^{n-i}} +\frac {a-1} {(a+1)a^{2n-2i}} + O\big (\frac 1 {a^i}\big ),& n\ge i \to \infty . \end{cases}\end{equation*}
Proof. We need to cover three different regimes:
-
• The subcritical regime (
$0 \lt a \lt 1$
): We first write the exact variance in (6) in the formAs we did in the proof of the mean, a Taylor series expansion for each series yields
\begin{equation*}{\mathbb {V}\textrm {ar}}[\Delta _{n,i}] = (1-a)\, a^{i-1} \sum _{k=i}^{n-1} \frac 1 {1-a^k} - (1-a)^2 \, {a^{2i-2}} \sum _{k=i}^{n-1} \Big (\frac 1 {1-a^k}\Big )^2.\end{equation*}
\begin{align*} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] & =\big ((1-a)\, a^{i-1}( n-i)+ O(a^i)\big )\\ & \qquad \qquad {} - \big ((1-a)^2\, a^{2i-2}( n-i) + O(a^{2i})\big )\\ & = (1-a)\, a^{i-1}\big (1 - (1-a)\, a^{i-1} \big )(n-i)+ O(a^{i}). \end{align*}
-
• The critical regime (
$a=1$
): Asymptotically, as both
$n$
and
$i\le n$
approach
$\infty$
, from (7) and the asymptotics in (2)–(3), we geta known result (Javanian and Asl, Reference Javanian and Asl2003; Mahmoud, Reference Mahmoud2019).
\begin{align*} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] &= \Big (\Big (\ln n + \gamma + O\Big (\frac 1 n\Big )\Big ) - \big (\ln i + \gamma + O\Big (\frac 1 i\Big )\Big )\\ & \qquad {} - \Big (\Big (\frac {\pi ^2} 6 + O\Big (\frac 1 n\Big )\Big ) - \Big (\frac {\pi ^2} 6 + O\Big (\frac 1 i\Big )\Big )\Big )\\ &= \ln n - \ln i + O\Big (\frac 1 i\Big ), \end{align*}
-
• The supercritical regime (
$a\gt 1$
): In (6), we have phases:-
(i) The index
$i$
is a constant. In this case, we have
\begin{align*} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] &= \Big ((a-1) \, a^{i-1} \, c_i^{(1)}(a) + O\Big (\frac 1 {a^{n-i}}\Big )\Big ) \\ & \qquad {} - \Big ((a-1)^2 \, a^{2i-2} \, c_i^{(2)}(a) + O\Big (\frac 1 {a^{{2n-2i}}}\Big )\Big ) \\ &= (a-1) \, a^{i-1} \, c_i^{(1)}(a) - (a-1)^2 \, a^{2i-2} \, c_i^{(2)}(a) + O\Big (\frac 1 {a^{n-i}}\Big ). \end{align*}
-
(ii) The index
$i$
is increasing with
$n$
. We resort again to the approximation of the two sums by geometric series. In this phase, we have
\begin{align*} {\mathbb {V}\textrm {ar}}[\Delta _{n,i}] &= (a-1) \, a^{i-1}\Big (\Big ( \sum _{k=i}^{n-1} \frac 1 {a^k}\Big ) + O\Big (\frac 1 {a^{2i}}\Big )\Big ) \\ &\qquad \qquad {}- (a-1)^2 \, a^{2i-2} \Big ( \sum _{k=i}^{n-1} \frac 1 {a^{2k}}\Big ) + O\Big (\frac 1 {a^{4i}}\Big )\Big )\\ &= (a-1) \, a^{i-1}\, \frac {1 - (1/a)^{n-i}} {a^i(1 - 1/a)}\\ &\qquad \qquad {}- (a-1)^2 \, a^{2i-2}\, \frac {1 - (1/a^2)^{n-i}} {a^{2i} (1 - 1/a^2)} + O\Big (\frac 1 {a^i}\Big )\\ &= \Big (1 -\frac 1 {a^{n-i}}\Big ) - \frac {a-1}{a+1}\Big (1 -\frac 1 {a^{2n-2i}}\Big ) + O\Big (\frac 1 {a^i}\Big )\\ &= \frac 2 {a+1} -\frac 1 {a^{n-i}} +\frac {a-1} {(a+1)a^{2n-2i}} + O\Big (\frac 1 {a^i}\Big ). \end{align*}
-














Corollary 3.1. In the subcritical regime (
 $0 \lt a \lt 1$
), when
$0 \lt a \lt 1$
), when
 $(n-i)a^i\to \infty$
, we have
$(n-i)a^i\to \infty$
, we have
 \begin{equation*}\frac {\Delta _{n,i}} {(n-i)\, a^i}\overset {\mathbb P}{\longrightarrow } \frac {1-a} a,\end{equation*}
\begin{equation*}\frac {\Delta _{n,i}} {(n-i)\, a^i}\overset {\mathbb P}{\longrightarrow } \frac {1-a} a,\end{equation*}
and in the critical regime (
 $a=1$
), when
$a=1$
), when
 $n/i\to \infty$
, we have
$n/i\to \infty$
, we have
 \begin{equation*}\frac {\Delta _{n,i}} {\ln (n/i)}\overset {\mathbb P}{\longrightarrow } 1,\end{equation*}
\begin{equation*}\frac {\Delta _{n,i}} {\ln (n/i)}\overset {\mathbb P}{\longrightarrow } 1,\end{equation*}
3.3 Distributions
In view of the trichotomy, we observed in the mean and variance, it should be anticipated that the asymptotic distribution of the outdegree would have three regimes, too, according as where
 $a$
is on the real line.
$a$
is on the real line.
Theorem 3.1. Let
 $\Delta _{n,i}$
be the outegree of node
$\Delta _{n,i}$
be the outegree of node
 $i$
in an exponentially preferential tree of size
$i$
in an exponentially preferential tree of size
 $n$
and radix
$n$
and radix
 $a \gt 0$
. We then have:
$a \gt 0$
. We then have:
-
(i) Let
$g(n)$
be a positive integer-valued function increasing to infinity, such that
$g(n) = o(\ln n)$
. In the subcritical regime (
$0 \lt a\lt 1$
), we have phases:
-
(a) In the early phase (
$1\le i\le \lfloor \log _{\frac 1 a}n\rfloor - g(n)$
),Footnote
3
as
$n\to \infty$
, we haveFootnote
4
\begin{equation*}\frac {\Delta _{n,i} - \frac {1-a}a \, a^i \, n} {\sqrt {a^i \, n}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} \Big (0, \frac {1-a} a \Big ).\end{equation*}
-
(b) In the intermediate phase (
$i= \lfloor \log _{\frac 1 a} n\rfloor +c$
, and
$c \in \mathbb Z$
), we have
\begin{equation*}d_{TV}\left (\Delta _{n,i}, \textrm { Poi}\left (\frac {1-a} a \, a^{c - {\{\log _{\frac 1 a} n}\}}\right )\right ) \to 0.\end{equation*}
-
(c) Let
$h(n)$
be a positive integer-valued function increasing to infinity, that grows faster than a constant, but remains at most
$n - \lfloor \log _{\frac 1 a} n\rfloor$
. In the late phase (
$i= \lfloor \log _{\frac 1 a} n \rfloor + h(n)$
), we have
\begin{equation*}\Delta _{n,i} \overset {\mathbb P}{\longrightarrow } 0.\end{equation*}
-
-
(ii) In the critical regime (
$a=1$
), we have phases:
-
(a) In the early phase
$n/i\to \infty$
, we have
\begin{equation*}\frac {\Delta _{n,i} - \ln (n/i)} {\sqrt {\ln (n/i)}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} (0, 1).\end{equation*}
-
(b) In the intermediate phase
$i\sim cn$
(and
$c \in (0,1)$
), we have
\begin{equation*}\Delta _{n,i} \overset {\mathbb P}{\longrightarrow } \textrm { Poi}\left (\ln \frac 1 c\right ).\end{equation*}
-
(c) In the late phase
$i\sim n$
, we have
\begin{equation*}\Delta _{n,i} \overset {\mathbb P}{\longrightarrow } 0.\end{equation*}
-
-
(iii) In the supercritical regime (
$a\gt 1$
), we have phases:
-
(a) In the early phase (
$i$
fixed), as
$n\to \infty$
, we have
and, for
\begin{equation*}\Delta _{n,i} \overset {a.s.}{\longrightarrow } \Delta _i^*, \end{equation*}
$k\ge 1$
, the limiting random variable has the distribution
\begin{align*} \mathbb {P}(\Delta _i^* =k) &= (a-1)^k a^{(i-1) k}\lim _{n\to \infty }\Big (\Big (\prod _{\ell =i}^{n-1} \frac {1}{a^\ell -1} \Big ) \sum _{i \le j_1 \lt j_2\lt \cdots \lt j_k \le n-1} \\ & \qquad \qquad \qquad \times {} \prod _{{i \le m \le n-1}\atop {m \not \in {\{j_1, \ldots , j_k}\}}} \Big ((a^m -1) - (a-1)a^{i-1} \Big )\Big ). \end{align*}
-
(b) Let
$b(n)$
be a function growing to infinity, in such a way that
$n-b(n)$
also grows to infinity. In the intermediate phase (
$1\le i = n - b(n)$
), we have
Footnote
5
\begin{align*} &\mathbb {P}(\Delta _{n,n-b(n)} =k) = (a-1)^k a^{(n-b(n)-1) k} \Big (\prod _{\ell =i}^{n-1} \frac {1}{a^\ell -1} \Big ) \\ &\quad {}\times \sum _{n-b(n) \le j_1 \lt j_2\lt \cdots \lt j_k\le n-1} \prod _{{i\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \big ((a^m -1) - (a-1)a^{n -b(n)-1} \big ). \end{align*}
-
(c) In the late phase (
$1\le i = n - c$
, with
$c \in \mathbb N$
), we have
$\Delta _{n, n-c} \overset {a.s.}{\longrightarrow } \Delta _c^\star$
,and
$\Delta _c^\star$
has the distribution
\begin{equation*}\mathbb {P}(\Delta _c^\star =k) = \frac {(a-1)^k}{a^{c(c+1)/2}} \sum _{1 \le r_1 \lt r_2\lt \cdots \lt r_k\le c} {} \prod _{{1 \le s\le c} \atop {s \not \in {\{r_1, \ldots , r_k}\}}} (a^s - a+1).\end{equation*}
-




































Proof. We need to cover three different regimes:
-
(i) The subcritical regime: Within the regime
$0\lt a\lt 1$
, we recognize phases:-
(a) The early phase (
$1\le i= \big \lfloor \log _{\frac 1 a} n\big \rfloor - g(n)$
): LetFrom the calculation of the variance in this regime (cf. Proposition3.2), we have
\begin{equation*}s_{n,i}^2 = {\mathbb {V}\textrm {ar}} [\Delta _{n,i}] = \sum _{k=i}^{n-1} {\mathbb {V}\textrm {ar}}[\mathbb {I}_{A_{k,i}}].\end{equation*}
$s_{n,i}^2 \sim (1-a)\, a^{i-1}(n-i)$
, as
$a^i(n-i) \to \infty$
. The case is amenable to normality via Lindeberg’s central limit theorem, if
$n-i \to \infty$
, in which case we have a sum of a large number of independent indicators (Bernoulli random variables).
For
$i$
to be in this phase, we must have
$\log _{\frac 1 a} (a^i\, (n-i)) \to \infty$
, as
$n \to \infty$
. That is to say,must increase to
\begin{equation*}-i + \log _{\frac 1 a} \Big (n\Big (1-\frac i n\Big )\Big ) = -i + \log _{\frac 1 a} n + \log _{\frac 1 a}\Big (1-\frac i n\Big ) = \big (\log _{\frac 1 a} n\big ) -i + O(i/n)\end{equation*}
$\infty$
. If
$\lfloor \log _{\frac 1 a} n\rfloor - i \to \infty$
, such an asymptotic relation holds, when
$i$
increases up to
$\lfloor \log _{\frac 1 a} n\rfloor - g(n)$
, for any positive integer function
$g(n)$
that is
$o(\ln n)$
. Fix
$\varepsilon \gt 0$
, and define Lindeberg’s quantitywhere
\begin{equation*}L_{n,i} (\varepsilon ) = \frac 1 {s_{n,i}^2} \sum _{k=i}^{n-1} \int _{\big |\,\mathbb {I}_{A_{k,i}} - \mathbb {E}[\mathbb {I}_{A_{k,i}}]\, \big | \gt \varepsilon s_{n,i}} \mathbb {I}_{A_{k,i}}^2 \, d\mathbb P,\end{equation*}
$\mathbb P$
is the underlying probability measure. The indicators are Bernoulli random variables bounded by 1. Hence, we havewhereas
\begin{equation*}\big |\,\mathbb {I}_{A_{k,i}} - \mathbb {E}[\mathbb {I}_{A_{k,i}}]\, \big | \le \mathbb {I}_{A_{k,i}} + \mathbb {E}[\mathbb {I}_{A_{k,i}}] \le 2,\end{equation*}
$\varepsilon s_{n,i}$
grows to infinity, no matter how small
$\varepsilon$
is, or what the value of
$i$
is within the specified phase. In other words, the sets in the integration are all empty for large enough
$n$
(greater than some
$n_0 = n_0(\varepsilon ,i)$
). We can now read the Lindeberg quantity asWe have verified that, within the phase
\begin{equation*}L_{n,i} (\varepsilon ) = \frac 1 {s_{n,i}^2} \sum _{k=i}^n \int _\phi \mathbb {I}_{A_{k,}i}^2 \, d\mathbb P=0.\end{equation*}
$i= \lfloor \log _{\frac 1 a} n\rfloor - g(n)$
, the quantity
$L_{n,i} (\varepsilon )\to 0$
, for all
$\varepsilon \gt 0$
. Thus, we have the Gaussian lawToward simpler appearance, we use Slutsky’s theorem (Karr, Reference Karr1993), pp. 146–147 to remove some factors:
\begin{equation*}\frac {\Delta _{n,i} - (1-a)\, a^{i-1} \, (n-i) + O(a^i)} {\sqrt {(1-a)\,a^{i-1}\big (1 - (1-a)\, a^{i-1} \big )(n-i) + O(a^i)}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} (0, 1).\end{equation*}
\begin{equation*}\frac {\Delta _{n,i} - \frac {1-a} a\, a^i \, n} {\sqrt {a^i n}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} \Big (0, \frac {1-a} a\, \Big ).\end{equation*}
-
(b) The intermediate phase (
$i = \big \lfloor \log _{\frac 1 a} n\big \rfloor + c$
):Let
$i = \big \lfloor \log _{\frac 1 a} n\big \rfloor + c = \log _{\frac 1 a} n-r_n+c$
, where
$r_n = \{\log _{\frac 1 a} n\}\in [0,\,1)$
, and
$c \in {\mathbb Z}$
. In this phase, we haveIn the notation of Theorem2.1, we have
\begin{equation*}a^i (n-i) = a^{\log _{\frac 1 a} n -r_n + c}(n-\log _{\frac 1 a} n +r_n- c) \sim \frac {a^{c-r_n}} n \times n=a^{c-r_n}.\end{equation*}
and
\begin{equation*}\lambda _{n,1} = \sum _{k=i}^n \mathbb {P}(\mathbb {I}_{A_{k,i}}=1) = \sum _{k=i}^n \frac {(1-a) a^{i-1}} {1-a^k}\sim (1-a) a^{i-1} (n-i) \sim \frac {1-a} a \,a^{c-r_n}, \end{equation*}
By that theorem, we conclude
\begin{align*} \lambda _{n,2} &= \sum _{k=i}^{n-1} \mathbb {P}^2(\mathbb {I}_{A_{k,i}}=1)\\ &= \sum _{k=i}^{n-i} \frac {(1-a)^2 a^{2i-2}} {(1-a^k)^2}\\ &\sim (1-a)^2 a^{2i-2} \big (n-i + O(a^{i})\big )\\ &\sim \Big (\frac {1-a} a\Big )^2 a^{2(\log _{\frac 1 a} n - r_n + c)} \times n\\ &\sim \Big (\frac {1-a} a\Big )^2\frac {a^{2c-2r_n}} {n^2} \times n\\ &\to 0. \end{align*}
\begin{equation*}d_{TV}\left (\Delta _{n,i}, \textrm { Poi}\left (\frac {1-a} a \, a^{c-r_n}\right )\right )\to 0.\end{equation*}
-
(c) The late phase (
$i = \lfloor \log _{\frac 1 a} n\rfloor +h(n) \le n$
, with
$h(n) \to \infty$
): In this late phase,
${\mathbb {V}\textrm {ar}}[\Delta _{n,i}] \sim (1-a) a^{i-1}(n-i) \to 0$
. As is well known, convergence of the variance of a sequence of random variables to 0 implies that the sequence converges weakly to a constant, a consequence of Chebyshev’s inequality. The limiting constant must be the constant obtained from the
$L_1$
converges
$\Delta _{n,i} \overset {\mathcal L}{\longrightarrow } 0$
.
-
-
(ii) The critical regime: In this uniform attachment case, the distribution as stated is known. We refer the reader to two different proofs in Javanian and Asl (Reference Javanian and Asl2003); Mahmoud (Reference Mahmoud2019).
-
(iii) The supercritical regime: In this regime we, work from the exact distribution to produce local limit theorems in the different phases. For
$\Delta _{n,i}$
to be equal to
$k$
, node
$i$
must recruit
$k$
times and fail to recruit
$n-i-k$
times. We can partition the event
$\Delta _{n,i} =k$
into disjoint sets according to the the size of the tree at the times of recruiting. Suppose the
$k$
successes in recruiting occur when the tree sizes are
$i \le j_1 \lt j_2 \lt \ldots j_k \le n-1$
. The probability of this event isUsing the probabilities in the lower display in (1), we obtain
\begin{equation*}\Big (\prod _{\ell \in {\{j_1, \ldots , j_k}\}} \mathbb {P}(\mathbb {I}_{A_{\ell ,i}} =1) \Big ) \Big (\prod _{{i\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \mathbb {P}(\mathbb {I}_{A_{m,i}} =0) \Big ).\end{equation*}
(8)
\begin{align} \mathbb {P}(\Delta _{n,i} =k) &= \sum _{i \le j_1 \lt j_2\lt \cdots j_k\le n-1}\Big (\prod _{\ell \in {\{j_1, \ldots , j_k}\}} \mathbb {P}(\mathbb {I}_{A_{\ell ,i}} =1) \Big )\nonumber \\ & \qquad \qquad \qquad \qquad \qquad \times {} \Big (\prod _{{i\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \mathbb {P}(\mathbb {I}_{A_{m,i}} =0) \Big ) \nonumber \\ &= \sum _{i \le j_1 \lt j_2\lt \cdots \lt j_k\le n-1} \Big (\prod _{\ell \in {\{j_1, \ldots , j_k}\}} \frac {(a-1)a^{i-1}}{a^\ell -1} \Big ) \nonumber \\ & \qquad \qquad \qquad \qquad \qquad \times {} \prod _{{i\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \Big (1 - \frac {(a-1)a^{i-1}}{a^m -1} \Big ) \end{align}
(9)According to Kolmogorov’s criterion (Theorem 22.3 in Billingsley (Reference Billingsley2012)), for independent zero-mean random variables
\begin{align} &= (a-1)^k a^{(i-1) k} \Big (\prod _{\ell =i}^{n-1} \frac {1}{a^\ell -1} \Big ) \sum _{i \le j_1 \lt j_2\lt \cdots \lt j_k\le n-1} \nonumber \\ & \qquad \qquad \qquad \times {} \prod _{{i\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \Big ((a^m -1) - (a-1)a^{i-1} \Big ). \end{align}
$X_1, X_2,$
$ X_3, \ldots$
, when
$\sum _{k=1}^\infty {\mathbb {V}\textrm {ar}}[X_k] \lt \infty$
, the sum
$\sum _{k=1}^n X_k$
converges almost surely to a limit.
In the supercritical regime, when
$n-i \to \infty$
, we haveIn view of Kolmogorov’s criterion, when
\begin{equation*}\sum _{k=i}^n {\mathbb {V}\textrm {ar}}\big [\mathbb {I}_{A_{k,i}} - \mathbb {E}[\mathbb {I}_{A_{k,i}}]\big ] \le \sum _{{{k=1}}}^\infty \frac {(a-1)\, a^{i-1}} {a^k-1}\Big (1 - \frac {(a-1)\, a^{i-1}} {a^k-1}\Big ) \lt \infty .\end{equation*}
$n-i = g(n) \to \infty$
,converges to a limit.
\begin{equation*}\Delta _{n,i} - \mathbb {E}[\Delta _{n,i}]= \sum _{k=i}^n \mathbb {I}_{A_{k,i}} - \sum _{k=i}^n \mathbb {E}[\mathbb {I}_{A_{k,i}}]\end{equation*}
Having shown that in the supercritical phase we have
$\sum _{k=i}^n \mathbb {E}[\mathbb {I}_{A_{k,i}}] = \mathbb {E}[\Delta _{n,i}]$
is convergent (cf. Proposition3.1), we see right away that, if
$n-i\to \infty$
, we would have
$\Delta _{n,i} = \sum _{k=i}^n \mathbb {I}_{A_{k,i}}$
converging to a limit.-
(a) The early phase (
$i$
fixed): Certainly, in this phase
$n-i\to \infty$
, as
$n\to \infty$
. By Kolmogorov’s criterion,
$\Delta _{n,i}$
converges to a limit, which we call
$\Delta _i^\star$
. We can determine the distribution of
$\Delta _i^\star \,:\!= \lim _{n\to \infty } \Delta _{n,i}$
by the following argument.Since
$\Delta _{n,i}$
converges almost surly, it also converges in distribution. The limit of the latter probabilities exists (and must be the distribution of the almost-sure limit, too). Indeed,
$\Delta _{n,i}$
converges almost surely to a limit
$\Delta _i^*$
with a distribution determined as the limit of the probabilities in (9). -
(b) The intermediate phase (
$i$
grows faster than a constant, but slower than
$n-c$
, for any
$c\in \mathbb N$
). In this phase,
$i$
is
$n - d(n)$
, for an integer-valued function
$d(n)\to \infty$
, in such a way that
$n-d(n)$
also tends to infinity. In this case, for any fixed
$k$
, (8) takes the form:Footnote
6
\begin{align*} \mathbb {P}(\Delta _{n,n-d(n)} =k) &= \sum _{n-d(n)\le j_1 \lt j_2\lt \cdots \lt j_k\le n-1} \Big (\prod _{\ell \in {\{j_1, \ldots , j_k}\}} \frac {(a-1)a^{n-d(n)-1}}{a^\ell -1} \Big ) \\ & \qquad \qquad \qquad \times {} \prod _{{n-d(n)\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \Big (1 - \frac {(a-1)a^{n-d(n)-1}}{a^m-1} \Big ) \\ &=\frac {(a-1)^k a^{k(n-d(n)-1)}} {\prod _{r=n-d(n)}^{n-1}(a^r-1)} \sum _{n-d(n)\le j_1 \lt j_2\lt \cdots \lt j_k\le n-1}\\ & \qquad \qquad \qquad {} \times \prod _{{n-d(n)\le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \big (a^m-1 - (a-1) a^{n-d(n)-1}\big ). \end{align*}
-
(c) The late phase (
$1 \le i = n - c$
, and
$c \in \mathbb N$
): Starting with the probabilities in the form (8), we write an asymptotic equivalent.Note that while the indices in the sum are large numbers there, is only a finite number of them (
$c$
of them to be exact). It is therefore legitimate to take the asymptotic terms individually:
\begin{align*} \mathbb {P}(\Delta _{n,n-c} =k) &\sim \sum _{n-c \le j_1 \lt j_2\lt \cdots \lt j_k \le n-1} \Big (\prod _{\ell \in {\{j_1, \ldots , j_k}\}} \frac {a-1}{a^{\ell -(n-c)+1} } \Big ) \\ & \qquad \qquad \qquad \qquad \times {} \prod _{{n-c \le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} \Big (1 - \frac {a-1} {a^{m-(n-c)+1}} \Big )\\ &\sim \frac {(a-1)^k}{\prod _{r=n-c}^{n-1} a^{r-(n-c)+1}} \\ & \qquad \times \sum _{n-c \le j_1 \lt j_2\lt \cdots \lt j_k\lt n-1} {} \prod _{{n-c \le m\le n-1} \atop {m \not \in {\{j_1, \ldots , j_k}\}}} (a^{m-(n-c)+1} - a+1)\\ &\to \frac {(a-1)^k}{a a^2 \ldots a^c} \sum _{1 \le r_1 \lt r_2\lt \cdots \lt r_k\le c} {} \prod _{{1 \le s \le c} \atop {s \not \in {\{r_1, \ldots , r_k}\}}} (a^s - a+1). \end{align*}
-
























































































3.4 Illustrative examples
In any of the three regimes of
 $a$
, there is an intriguing interplay between
$a$
, there is an intriguing interplay between
 $n$
and
$n$
and
 $i$
. We only discuss interpretations and examples from the subcritical and supercritical regimes, since the critical phase is well studied, and illustrative examples of it can be found elsewhere. We refer a reader interested in a discussion of the critical regime to Javanian and Asl (Reference Javanian and Asl2003); Mahmoud (Reference Mahmoud2019).
$i$
. We only discuss interpretations and examples from the subcritical and supercritical regimes, since the critical phase is well studied, and illustrative examples of it can be found elsewhere. We refer a reader interested in a discussion of the critical regime to Javanian and Asl (Reference Javanian and Asl2003); Mahmoud (Reference Mahmoud2019).
3.5 The subcritical regime
When
 $a\lt 1$
, the term
$a\lt 1$
, the term
 $a^{i-1}$
in
$a^{i-1}$
in
 $\mathbb {E}[\Delta _{n,i}]$
decreases exponentially fast in
$\mathbb {E}[\Delta _{n,i}]$
decreases exponentially fast in
 $i$
. Take
$i$
. Take
 $a = 1/2$
, for instance. With this radix, for
$a = 1/2$
, for instance. With this radix, for
 $i$
in the subcritical phase, we have the convergence
$i$
in the subcritical phase, we have the convergence
 \begin{equation*}\frac {\Delta _{n,i} - \frac n {2^i}} {\sqrt {\frac n {2^i}}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} (0, 1).\end{equation*}
\begin{equation*}\frac {\Delta _{n,i} - \frac n {2^i}} {\sqrt {\frac n {2^i}}} \ \overset {\mathcal L}{\longrightarrow } \, \mathcal {N} (0, 1).\end{equation*}
A Gaussian law holds so long as
 $i$
is well below
$i$
is well below
 $\lfloor \log _{\frac 1 a} n \rfloor$
(differing by an increasing function from that critical level). When
$\lfloor \log _{\frac 1 a} n \rfloor$
(differing by an increasing function from that critical level). When
 $i$
approaches the critical phase, Poisson approximations kick in to replace the normal distribution. When
$i$
approaches the critical phase, Poisson approximations kick in to replace the normal distribution. When
 $i$
is tied to
$i$
is tied to
 $\lfloor \log _{\frac 1 a} n\rfloor$
by a constant, it is related to
$\lfloor \log _{\frac 1 a} n\rfloor$
by a constant, it is related to
 $\log _{\frac 1 a} n$
via corrections obtained by removing the floors. These corrections are oscillating functions in
$\log _{\frac 1 a} n$
via corrections obtained by removing the floors. These corrections are oscillating functions in
 $n$
and are uniformly dense on the real line (Kuipers and Niederreiter, Reference Kuipers and Niederreiter1974). So, there is not really convergence to a Poisson limit, but rather approximations to a family of Poisson distributions, with parameters lying in the range
$n$
and are uniformly dense on the real line (Kuipers and Niederreiter, Reference Kuipers and Niederreiter1974). So, there is not really convergence to a Poisson limit, but rather approximations to a family of Poisson distributions, with parameters lying in the range
 $[\frac 1 {2^c}, \frac 2 {2^c})$
.
$[\frac 1 {2^c}, \frac 2 {2^c})$
.
Table 1 shows the behavior in the subcritical regime for
 $a=1/2$
and some selected phases. Note the fourth and fifth entries (from the top) which lie in the intermediate phase, where there is no limit per se, but rather good approximations by various Poisson distributions. For instance, in the phase
$a=1/2$
and some selected phases. Note the fourth and fifth entries (from the top) which lie in the intermediate phase, where there is no limit per se, but rather good approximations by various Poisson distributions. For instance, in the phase
 $i = \lceil \log _2 n \rceil -5$
,
$i = \lceil \log _2 n \rceil -5$
,
 $\textrm { Poi}\left (18.4136\right )$
is a good approximation for the distribution of
$\textrm { Poi}\left (18.4136\right )$
is a good approximation for the distribution of
 $\Delta _{20000, 10}$
at
$\Delta _{20000, 10}$
at
 $n=20000$
,
$n=20000$
,
 $\textrm { Poi}\left (18.4182\right )$
is a good approximation for the distribution of
$\textrm { Poi}\left (18.4182\right )$
is a good approximation for the distribution of
 $\Delta _{20001, 10}$
at
$\Delta _{20001, 10}$
at
 $n=20001$
, and
$n=20001$
, and
 $\textrm { Poi}\left (18.4228\right )$
is a good approximation for the distribution of
$\textrm { Poi}\left (18.4228\right )$
is a good approximation for the distribution of
 $\Delta _{20002, 10}$
at
$\Delta _{20002, 10}$
at
 $n=20002$
.
$n=20002$
.
Table 1. The asymptotic mean, variance, and distribution of the outdegree of an exponentially preferential tree with radix
 $1/2$
in some selected phases
$1/2$
in some selected phases

For the last two entries in Table 1, the variance is diminishing at a fast rate, and the sum of the variances converges. By Kolmogorov’s theorem, we have an almost-sure convergence in both cases.
3.6 The supercritical regime
As an instance, take
 $a = 2$
. Over an extended period of time, the average root outdegree converges:
$a = 2$
. Over an extended period of time, the average root outdegree converges:
 $\mathbb {E}[\Delta _{n,1}] \to \ c_1^{(1)} (2) \approx 1.607$
. Table 2 shows the asymptotic outdegree for the first 12 entries in the tree, approximated to three decimal places.
$\mathbb {E}[\Delta _{n,1}] \to \ c_1^{(1)} (2) \approx 1.607$
. Table 2 shows the asymptotic outdegree for the first 12 entries in the tree, approximated to three decimal places.
Table 2. The limiting value of the outdegree of the first few entries in an exponentially preferential tree with radix 2

A late entry in the tree, such as
 $i = n-\lfloor n^{1/4} \rfloor$
, has an average outdegree
$i = n-\lfloor n^{1/4} \rfloor$
, has an average outdegree
 \begin{equation*} \mathbb {E}[\Delta _{n,i}] =1 + O\Big (\frac 1 {2^{{n^{1/4}}}}\Big )\end{equation*}
\begin{equation*} \mathbb {E}[\Delta _{n,i}] =1 + O\Big (\frac 1 {2^{{n^{1/4}}}}\Big )\end{equation*}
A much later entrant, such as a node with with the index
 $n-4$
has an average outdegree
$n-4$
has an average outdegree
 \begin{equation*}\mathbb {E}[\Delta _{n,i}] = 1 - \frac 1 {2^4} + O\Big (\frac 1 {{2}^n}\Big ) = \frac {15} {16} + O\Big (\frac 1 {{2}^n}\Big ) .\end{equation*}
\begin{equation*}\mathbb {E}[\Delta _{n,i}] = 1 - \frac 1 {2^4} + O\Big (\frac 1 {{2}^n}\Big ) = \frac {15} {16} + O\Big (\frac 1 {{2}^n}\Big ) .\end{equation*}
We discern a “thinning” occurring in the tree. At a node with a high index
 $i$
, the subtree of descendants is tapered almost into a path.
$i$
, the subtree of descendants is tapered almost into a path.
At
 $a=2$
, cancellations occur in the formula in the expression in Theorem3.1 (iiia), greatly simplifying the calculation for the root outdegree (also its degree, the case
$a=2$
, cancellations occur in the formula in the expression in Theorem3.1 (iiia), greatly simplifying the calculation for the root outdegree (also its degree, the case
 $i=1$
) and giving transparency into the limiting distribution:
$i=1$
) and giving transparency into the limiting distribution:
 \begin{align*} \mathbb {P}(\Delta _{n,1}= k) &\to \mathbb {P}(\Delta _i^*=k) \\ & = \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \le j_1 \lt j_2\lt \cdots j_k\le n-1} \prod _{m \not \in {\{j_1, \ldots , j_k}\}} (2^m - 2)\Big ). \end{align*}
\begin{align*} \mathbb {P}(\Delta _{n,1}= k) &\to \mathbb {P}(\Delta _i^*=k) \\ & = \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \le j_1 \lt j_2\lt \cdots j_k\le n-1} \prod _{m \not \in {\{j_1, \ldots , j_k}\}} (2^m - 2)\Big ). \end{align*}
Note that if
 $j_1 \not = 1$
, the product retains
$j_1 \not = 1$
, the product retains
 $m=1$
as one of its indices and
$m=1$
as one of its indices and
 $2^m-2 = 0$
for this value of
$2^m-2 = 0$
for this value of
 $m$
, annihilating the entire part of the expression with
$m$
, annihilating the entire part of the expression with
 $j_1 =1$
in the sum, simplifying it further to
$j_1 =1$
in the sum, simplifying it further to
 \begin{align*} \mathbb {P}(\Delta _1^*=k) &= \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \prod _{m \not \in {\{1,j_2, \ldots , j_k}\}} 2(2^{m-1} - 1)\Big )\\ &= \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \frac {2^{n-k-1}\prod _{m=2}^{n-1} (2^{m-1} - 1)} {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}\Big )\\ &= \lim _{n \to \infty } \Big ( \frac {2^{n-k-1}}{2^{n-1} -1} \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \frac 1 {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}\Big )\\ &= \frac 1 {2^k} \sum _{1 \lt j_2\lt \cdots \lt j_k\le \infty } \ \frac 1 {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}. \end{align*}
\begin{align*} \mathbb {P}(\Delta _1^*=k) &= \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \prod _{m \not \in {\{1,j_2, \ldots , j_k}\}} 2(2^{m-1} - 1)\Big )\\ &= \lim _{n \to \infty } \Big (\Big (\prod _{\ell =1}^{n-1} \frac {1}{2^\ell -1} \Big ) \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \frac {2^{n-k-1}\prod _{m=2}^{n-1} (2^{m-1} - 1)} {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}\Big )\\ &= \lim _{n \to \infty } \Big ( \frac {2^{n-k-1}}{2^{n-1} -1} \sum _{1 \lt j_2\lt \cdots \lt j_k\le n-1} \ \frac 1 {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}\Big )\\ &= \frac 1 {2^k} \sum _{1 \lt j_2\lt \cdots \lt j_k\le \infty } \ \frac 1 {(2^{j_2-1}-1)\cdots (2^{j_k-1}-1)}. \end{align*}
The first few values in the sequence
 $\mathbb {P}(\Delta _1^* = k)$
areFootnote
7
$\mathbb {P}(\Delta _1^* = k)$
areFootnote
7
 \begin{align*} \mathbb {P}(\Delta _1^* = 1) &= \frac 1 2;\\ \mathbb {P}(\Delta _1^* = 2) &= \frac 1 4 \sum _{\ell =2}^\infty \frac 1 {2^\ell -1} \approx 0.1516737881\ldots \\ \mathbb {P}(\Delta _1^* = 3) &= \frac 1 8 \sum _{\ell =2}^\infty \sum _{m=\ell +1}^\infty \frac 1 {(2^\ell -1)(2^m-1)} \approx 0.01442126698\ldots . \end{align*}
\begin{align*} \mathbb {P}(\Delta _1^* = 1) &= \frac 1 2;\\ \mathbb {P}(\Delta _1^* = 2) &= \frac 1 4 \sum _{\ell =2}^\infty \frac 1 {2^\ell -1} \approx 0.1516737881\ldots \\ \mathbb {P}(\Delta _1^* = 3) &= \frac 1 8 \sum _{\ell =2}^\infty \sum _{m=\ell +1}^\infty \frac 1 {(2^\ell -1)(2^m-1)} \approx 0.01442126698\ldots . \end{align*}
The first three values alone contain about 0.6661 of the mass of the limiting distribution. The root comes early and stays the longest in the tree. So, it has repeated chances for recruiting. However, the probabilities are very quickly diminished by the appearance of nodes of higher indices, with higher chances of recruiting. While the limit distribution of the root outdegree (which is also the degree) is supported on
 $\mathbb N$
, there is a high probability of remaining small (confined to the values 1,2,3).
$\mathbb N$
, there is a high probability of remaining small (confined to the values 1,2,3).
The probability formula in the intermediate phase of the supercritical regime is unwieldy (Theorem3.1 (iiib)), yet it can be used to tell us something about the asymptotic structure of the tree. With
 $a=2$
and
$a=2$
and
 $i = n- \lfloor \ln n\rfloor$
, we can compute the probability of the intermediate node
$i = n- \lfloor \ln n\rfloor$
, we can compute the probability of the intermediate node
 $i$
in the following way. Here,
$i$
in the following way. Here,
 $b(n)$
is
$b(n)$
is
 $\lfloor \ln n\rfloor$
. For
$\lfloor \ln n\rfloor$
. For
 $k= 0$
, the set
$k= 0$
, the set
 $\{j_1, \ldots , j_0\}$
is empty, and the only product that stands is the one on the full set
$\{j_1, \ldots , j_0\}$
is empty, and the only product that stands is the one on the full set
 $\{n-h(n), \ldots , n-1\}$
. We have
$\{n-h(n), \ldots , n-1\}$
. We have
 \begin{align*} \mathbb {P}(\Delta _{n,n- \lfloor \ln n\rfloor } =0) &=\frac 1 {\prod _{r=n-\lfloor \ln n\rfloor }^{n-1}(2^r-1)} \prod _{m = n-\lfloor \ln n\rfloor }^{n-1} \big (2^m-1 - 2^{n-\lfloor \ln n\rfloor -1}\big ). \end{align*}
\begin{align*} \mathbb {P}(\Delta _{n,n- \lfloor \ln n\rfloor } =0) &=\frac 1 {\prod _{r=n-\lfloor \ln n\rfloor }^{n-1}(2^r-1)} \prod _{m = n-\lfloor \ln n\rfloor }^{n-1} \big (2^m-1 - 2^{n-\lfloor \ln n\rfloor -1}\big ). \end{align*}
At
 $n=1000$
, this probability is about
$n=1000$
, this probability is about
 $0.2933$
.
$0.2933$
.
The very late nodes have the lion’s share. Consider
 $a=2$
, and the tree when the size is some large
$a=2$
, and the tree when the size is some large
 $n$
. The outdegree of node
$n$
. The outdegree of node
 $n$
is 0, as it has not recruited yet (which is consistent with zero mean and zero variance as given by the exact and asymptotic formulas). Being of the second to highest index in the tree, node
$n$
is 0, as it has not recruited yet (which is consistent with zero mean and zero variance as given by the exact and asymptotic formulas). Being of the second to highest index in the tree, node
 $n-1$
, has a chance of recruiting node
$n-1$
, has a chance of recruiting node
 $n$
and has a chance of missing. The probability of node
$n$
and has a chance of missing. The probability of node
 $n-1$
recruiting node
$n-1$
recruiting node
 $n$
is
$n$
is
 $2^{n-1}(2-1)/ (2^n-1) \to 1/2$
. Thus, the outdegree of the penultimate node is asymptotically distributed like a Bernoulli(1/2) random variable.
$2^{n-1}(2-1)/ (2^n-1) \to 1/2$
. Thus, the outdegree of the penultimate node is asymptotically distributed like a Bernoulli(1/2) random variable.
Node
 $n-2$
has two chances at recruiting by time
$n-2$
has two chances at recruiting by time
 $n$
and has an asymptotic distribution on
$n$
and has an asymptotic distribution on
 $\{0,1,2\}$
with mean
$\{0,1,2\}$
with mean
 $1/4$
, and so on. According to Theorem3.1 (iiic), we have
$1/4$
, and so on. According to Theorem3.1 (iiic), we have
 \begin{equation*}\mathbb {P}(\Delta _{n, n-2}^\star =k) \to \mathbb {P}(\Delta _2^\star =k) \to \frac 1{2^3} \sum _{1 \le r_1 \lt r_2\lt \cdots \lt r_k\le 2} {} \prod _{{1 \le s\le 2} \atop {s \not \in {\{r_1, \ldots , r_k}\}}} (2^s - 1), \end{equation*}
\begin{equation*}\mathbb {P}(\Delta _{n, n-2}^\star =k) \to \mathbb {P}(\Delta _2^\star =k) \to \frac 1{2^3} \sum _{1 \le r_1 \lt r_2\lt \cdots \lt r_k\le 2} {} \prod _{{1 \le s\le 2} \atop {s \not \in {\{r_1, \ldots , r_k}\}}} (2^s - 1), \end{equation*}
for
 $k=0,1,2$
. For
$k=0,1,2$
. For
 $k=0$
, the set
$k=0$
, the set
 $ r_1 , r_2, \ldots ,r_0$
is empty, and we compute
$ r_1 , r_2, \ldots ,r_0$
is empty, and we compute
 \begin{equation*}\mathbb {P}(\Delta _2^\star =0) \to \frac 1 8 \prod _{{1 \le s\le 2}\atop {s\not \in \phi }} (2^s - 1) = \frac {1 \times 3} 8 = \frac 3 8.\end{equation*}
\begin{equation*}\mathbb {P}(\Delta _2^\star =0) \to \frac 1 8 \prod _{{1 \le s\le 2}\atop {s\not \in \phi }} (2^s - 1) = \frac {1 \times 3} 8 = \frac 3 8.\end{equation*}
Further, we have
 \begin{equation*}\mathbb {P}(\Delta _2^\star =1) \to \frac 1 8 \sum _{1 \le k_1 \le 2} \prod _{{1 \le s\le 2}\atop {s\not \in \{k_1\}}} (2^s - 1) = \frac {3 +1} 8= \frac 4 8.\end{equation*}
\begin{equation*}\mathbb {P}(\Delta _2^\star =1) \to \frac 1 8 \sum _{1 \le k_1 \le 2} \prod _{{1 \le s\le 2}\atop {s\not \in \{k_1\}}} (2^s - 1) = \frac {3 +1} 8= \frac 4 8.\end{equation*}
We can find
 $\mathbb {P}(\Delta _2^\star =2)$
from
$\mathbb {P}(\Delta _2^\star =2)$
from
 $1 - \mathbb {P}(\Delta _2^\star =0) -\mathbb {P}(\Delta _2^\star =1) = 1/8$
. In summary, we have
$1 - \mathbb {P}(\Delta _2^\star =0) -\mathbb {P}(\Delta _2^\star =1) = 1/8$
. In summary, we have
 \begin{equation*}\Delta _2^\star = \begin{cases} 0, &\mbox {with probability\ } 3/8;\\ 1, &\mbox {with probability\ } 4/8;\\ 2, &\mbox {with probability\ } 1/8. \end{cases}\end{equation*}
\begin{equation*}\Delta _2^\star = \begin{cases} 0, &\mbox {with probability\ } 3/8;\\ 1, &\mbox {with probability\ } 4/8;\\ 2, &\mbox {with probability\ } 1/8. \end{cases}\end{equation*}
Remark 3.2. We discussed phases, where the growth of
 $i$
is systematically increasing toward
$i$
is systematically increasing toward
 $n$
. However, there is no limit to how bizarre the sequence
$n$
. However, there is no limit to how bizarre the sequence
 $i=i(n)$
can be. For example,
$i=i(n)$
can be. For example,
 $i(n)$
might be a sequence alternating between two (or more values), such as the sequence
$i(n)$
might be a sequence alternating between two (or more values), such as the sequence
 $i(n) = 5 +(-1)^n$
, in which case the degree of node
$i(n) = 5 +(-1)^n$
, in which case the degree of node
 $i$
does not converge to a limit. Or,
$i$
does not converge to a limit. Or,
 $i(n)$
might alternate between low and high values, such as
$i(n)$
might alternate between low and high values, such as
 \begin{equation*}i(n) = \begin{cases} 1& n, \ even;\\ \lfloor \ln n + 0.76884 \rfloor ,& n \ odd. \end{cases} \end{equation*}
\begin{equation*}i(n) = \begin{cases} 1& n, \ even;\\ \lfloor \ln n + 0.76884 \rfloor ,& n \ odd. \end{cases} \end{equation*}
Even worse,
 $i(n)$
may not have any structure at all. We reckon that such sequences are not interesting and do not appear in practice.
$i(n)$
may not have any structure at all. We reckon that such sequences are not interesting and do not appear in practice.
4. Concluding remarks
We discussed an exponentially preferential model of recursive trees, wherein node
 $i$
recruits with probability proportional to
$i$
recruits with probability proportional to
 $a^i$
. The proportionality constant is time dependent, which captures the reality of dynamic change in networks. The radix
$a^i$
. The proportionality constant is time dependent, which captures the reality of dynamic change in networks. The radix
 $a$
governs the behavior of the tree. The case
$a$
governs the behavior of the tree. The case
 $a=1$
is critical and corresponds to the standard well-studied uniform model of random recursive trees. This criticality creates three regimes, the subcritical (
$a=1$
is critical and corresponds to the standard well-studied uniform model of random recursive trees. This criticality creates three regimes, the subcritical (
 $0\lt a\lt 1$
), the critical (
$0\lt a\lt 1$
), the critical (
 $a=1$
), and the supercritical (
$a=1$
), and the supercritical (
 $a\gt 1$
). Each regime has its own early, intermediate, and late phases. They are not the same. For instance, the early phase in the subcritical regime extends to
$a\gt 1$
). Each regime has its own early, intermediate, and late phases. They are not the same. For instance, the early phase in the subcritical regime extends to
 $O(\ln n)$
, whereas in the critical regime, the early phase stops at
$O(\ln n)$
, whereas in the critical regime, the early phase stops at
 $n/i \to \infty$
and in the supercritical regime the early phase is restricted to fixed
$n/i \to \infty$
and in the supercritical regime the early phase is restricted to fixed
 $i$
.
$i$
.
Gaussian behavior appears only in the early phases of the subcritical and critical regimes. Other behavior is detected, too. For instance, Poisson approximations are the appropriate asymptotic behavior in the intermediate phases of both the subcritical and critical regimes, with oscillations in the case of the subcritical regime.
Consistently, in the late phase of all three regimes (noting they start differently),
 $\Delta _{n,i}$
converges to a constant, with constant being 0 in the subcritical and critical regimes, while it is a positive constant in the supercritical regime. The intuition behind these constants is that in the subcritical and critical regimes, the nodes in the early and intermediate phases gobble up the largest share of recruits, but in the supercritical regime, the highest labeled nodes in the late stage are the most attractive.
$\Delta _{n,i}$
converges to a constant, with constant being 0 in the subcritical and critical regimes, while it is a positive constant in the supercritical regime. The intuition behind these constants is that in the subcritical and critical regimes, the nodes in the early and intermediate phases gobble up the largest share of recruits, but in the supercritical regime, the highest labeled nodes in the late stage are the most attractive.
The dependence on the radix
 $a$
hosts a broad range of applicability. For example, with
$a$
hosts a broad range of applicability. For example, with
 $a=1$
alone, the entire class of uniform recursive trees comes in with its plethora of known applications. The range
$a=1$
alone, the entire class of uniform recursive trees comes in with its plethora of known applications. The range
 $0\lt a \lt 1$
corresponds to applications where early nodes are the most attractive, such as the growth of companies and subsidiary branches, where the headquarters and its closest branches acquire influence and wealth over time. The case
$0\lt a \lt 1$
corresponds to applications where early nodes are the most attractive, such as the growth of companies and subsidiary branches, where the headquarters and its closest branches acquire influence and wealth over time. The case
 $a\gt 1$
corresponds to applications where late nodes are the most attractive, such as some social networks in which newcomers are the most anxious to expand their circles.
$a\gt 1$
corresponds to applications where late nodes are the most attractive, such as some social networks in which newcomers are the most anxious to expand their circles.
Future research may extend to deal with other tree properties, such as the maximal degree, the depth of nodes, and the total path length (among many others). We may also consider other weights and generalizations.
Supplementary material
The supplementary material for this article can be found at https://dx.doi.org/10.1017/nws.2025.3.



















 Open access
Open access