Gaussian graphical models are useful tools for conditional independence structure inference of multivariate random variables. Unfortunately, Bayesian inference of latent graph structures is challenging due to exponential growth of 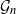 $\mathcal{G}_n$, the set of all graphs in n vertices. One approach that has been proposed to tackle this problem is to limit search to subsets of
$\mathcal{G}_n$, the set of all graphs in n vertices. One approach that has been proposed to tackle this problem is to limit search to subsets of 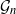 $\mathcal{G}_n$. In this paper we study subsets that are vector subspaces with the cycle space
$\mathcal{G}_n$. In this paper we study subsets that are vector subspaces with the cycle space 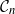 $\mathcal{C}_n$ as the main example. We propose a novel prior on
$\mathcal{C}_n$ as the main example. We propose a novel prior on 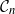 $\mathcal{C}_n$ based on linear combinations of cycle basis elements and present its theoretical properties. Using this prior, we implement a Markov chain Monte Carlo algorithm, and show that (i) posterior edge inclusion estimates computed with our technique are comparable to estimates from the standard technique despite searching a smaller graph space, and (ii) the vector space perspective enables straightforward implementation of MCMC algorithms.
$\mathcal{C}_n$ based on linear combinations of cycle basis elements and present its theoretical properties. Using this prior, we implement a Markov chain Monte Carlo algorithm, and show that (i) posterior edge inclusion estimates computed with our technique are comparable to estimates from the standard technique despite searching a smaller graph space, and (ii) the vector space perspective enables straightforward implementation of MCMC algorithms.
In set theory without the Axiom of Choice (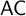 $\mathsf {AC}$
), we investigate the open problem of the deductive strength of statements which concern the existence of almost disjoint and maximal almost disjoint (MAD) families of infinite-dimensional subspaces of a given infinite-dimensional vector space, as well as the extension of almost disjoint families in infinite-dimensional vector spaces to MAD families.
$\mathsf {AC}$
), we investigate the open problem of the deductive strength of statements which concern the existence of almost disjoint and maximal almost disjoint (MAD) families of infinite-dimensional subspaces of a given infinite-dimensional vector space, as well as the extension of almost disjoint families in infinite-dimensional vector spaces to MAD families.

