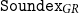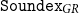1 results
SoundexGR: An algorithm for phonetic matching for the Greek language
-
- Journal:
- Natural Language Engineering / Volume 29 / Issue 5 / September 2023
- Published online by Cambridge University Press:
- 04 February 2022, pp. 1305-1340
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Text usually suffers from typos which can negatively affect various Information Retrieval and Natural Language Processing tasks. Although there is a wide variety of choices for tackling this issue in the English language, this is not the case for other languages. For the Greek language, most of the existing phonetic algorithms provide rather insufficient support. For this reason, in this paper, we introduce an algorithm for phonetic matching designed for the Greek language: we start from the original Soundex and we redesign and extend it for accommodating the Greek language’s phonetic rules, ending up to a family of algorithms, that we call
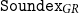 ${\tt Soundex}_{GR}$. Then, we report various experimental results showcasing how the algorithm behaves in different scenarios, and we provide comparative results for various parameters of the algorithm for revealing the trade-off between precision and recall in datasets with different kinds of errors. We also provide comparative results with matching using stemming, full phonemic transcription, and edit distance, that demonstrate that
${\tt Soundex}_{GR}$. Then, we report various experimental results showcasing how the algorithm behaves in different scenarios, and we provide comparative results for various parameters of the algorithm for revealing the trade-off between precision and recall in datasets with different kinds of errors. We also provide comparative results with matching using stemming, full phonemic transcription, and edit distance, that demonstrate that 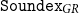 ${\tt Soundex}_{GR}$ performs better (indicatively, it achieves F-Score over 95% in collections of similar-sounded words). The simplicity, efficiency, and effectiveness of the proposed algorithm make it applicable and adaptable to a wide range of tasks.
${\tt Soundex}_{GR}$ performs better (indicatively, it achieves F-Score over 95% in collections of similar-sounded words). The simplicity, efficiency, and effectiveness of the proposed algorithm make it applicable and adaptable to a wide range of tasks.