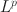 Losses and Related Inference Problems
Losses and Related Inference Problems
Researchers have widely used exploratory factor analysis (EFA) to learn the latent structure underlying multivariate data. Rotation and regularised estimation are two classes of methods in EFA that they often use to find interpretable loading matrices. In this paper, we propose a new family of oblique rotations based on component-wise \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}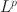 loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}
loss functions \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(0 < p\le 1)$$\end{document}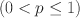 that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}
that is closely related to an \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$L^p$$\end{document}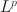 regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
regularised estimator. We develop model selection and post-selection inference procedures based on the proposed rotation method. When the true loading matrix is sparse, the proposed method tends to outperform traditional rotation and regularised estimation methods in terms of statistical accuracy and computational cost. Since the proposed loss functions are nonsmooth, we develop an iteratively reweighted gradient projection algorithm for solving the optimisation problem. We also develop theoretical results that establish the statistical consistency of the estimation, model selection, and post-selection inference. We evaluate the proposed method and compare it with regularised estimation and traditional rotation methods via simulation studies. We further illustrate it using an application to the Big Five personality assessment.
Model selection from a set of candidate models plays an important role in many structural equation modelling applications. However, traditional model selection methods introduce extra randomness that is not accounted for by post-model selection inference. In the current study, we propose a model averaging technique within the frequentist statistical framework. Instead of selecting an optimal model, the contributions of all candidate models are acknowledged. Valid confidence intervals and a \documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$\chi ^2$$\end{document} test statistic are proposed. A simulation study shows that the proposed method is able to produce a robust mean-squared error, a better coverage probability, and a better goodness-of-fit test compared to model selection. It is an interesting compromise between model selection and the full model.
test statistic are proposed. A simulation study shows that the proposed method is able to produce a robust mean-squared error, a better coverage probability, and a better goodness-of-fit test compared to model selection. It is an interesting compromise between model selection and the full model.

