The canonical income process, including autoregressive, transitory, and fixed effect components, is routinely used in macro and labor economics. We provide a guide for its estimation using quasidifferences, cataloging biases in the estimated parameters for various 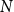 $N$,
$N$, 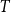 $T$, initial conditions, and weighting schemes. Using Danish administrative data on male earnings, estimation in quasidifferences yields divergent estimates of the autoregressive parameter for different weighting schemes, which conforms to our simulation results when the variance of transitory shocks is higher than that of persistent shocks, true persistence is high, and the persistent component’s variance in the first sample year is nonzero. We further apply quasidifferences to the data from a calibrated lifecycle model and find significant biases in the persistence of shocks and their insurance. Estimation of the income process using quasidifferences is reliable only when the variance of persistent shocks is higher than that of transitory shocks and the moments are equally weighted.
$T$, initial conditions, and weighting schemes. Using Danish administrative data on male earnings, estimation in quasidifferences yields divergent estimates of the autoregressive parameter for different weighting schemes, which conforms to our simulation results when the variance of transitory shocks is higher than that of persistent shocks, true persistence is high, and the persistent component’s variance in the first sample year is nonzero. We further apply quasidifferences to the data from a calibrated lifecycle model and find significant biases in the persistence of shocks and their insurance. Estimation of the income process using quasidifferences is reliable only when the variance of persistent shocks is higher than that of transitory shocks and the moments are equally weighted.

