
62 results
Mediation Analysis in Bayesian Extended Redundancy Analysis with Mixed Outcome Variables
-
- Journal:
- Psychometrika / Volume 90 / Issue 1 / March 2025
- Published online by Cambridge University Press:
- 03 January 2025, pp. 251-279
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
The Crosswise Model for Surveys on Sensitive Topics: A General Framework for Item Selection and Statistical Analysis
-
- Journal:
- Psychometrika / Volume 89 / Issue 3 / September 2024
- Published online by Cambridge University Press:
- 01 January 2025, pp. 1007-1033
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
Estimating Correlations with Missing Data, a Bayesian Approach
-
- Journal:
- Psychometrika / Volume 60 / Issue 3 / September 1995
- Published online by Cambridge University Press:
- 01 January 2025, pp. 341-354
-
- Article
- Export citation
A Hierarchical Model for Accuracy and Choice on Standardized Tests
-
- Journal:
- Psychometrika / Volume 82 / Issue 3 / September 2017
- Published online by Cambridge University Press:
- 01 January 2025, pp. 820-845
-
- Article
- Export citation
A Restricted Four-Parameter IRT Model: The Dyad Four-Parameter Normal Ogive (Dyad-4PNO) Model
-
- Journal:
- Psychometrika / Volume 85 / Issue 3 / September 2020
- Published online by Cambridge University Press:
- 01 January 2025, pp. 575-599
-
- Article
- Export citation
On the Use of Heterogeneous Thresholds Ordinal Regression Models to Account for Individual Differences in Response Style
-
- Journal:
- Psychometrika / Volume 68 / Issue 4 / December 2003
- Published online by Cambridge University Press:
- 01 January 2025, pp. 563-583
-
- Article
- Export citation
Bayesian Estimation of the DINA Q matrix
-
- Journal:
- Psychometrika / Volume 83 / Issue 1 / March 2018
- Published online by Cambridge University Press:
- 01 January 2025, pp. 89-108
-
- Article
- Export citation
Bayesian Item Selection Criteria for Adaptive Testing
-
- Journal:
- Psychometrika / Volume 63 / Issue 2 / June 1998
- Published online by Cambridge University Press:
- 01 January 2025, pp. 201-216
-
- Article
- Export citation
Hierarchical Bayesian Modeling for Test Theory Without an Answer Key
-
- Journal:
- Psychometrika / Volume 80 / Issue 2 / June 2015
- Published online by Cambridge University Press:
- 01 January 2025, pp. 341-364
-
- Article
- Export citation

Machine Learning for Archaeological Applications in R
-
- Published online:
- 10 December 2024
- Print publication:
- 16 January 2025
-
- Element
- Export citation
Data-driven optimization of a gas turbine combustor: A Bayesian approach addressing NOx emissions, lean extinction limits, and thermoacoustic stability
-
- Journal:
- Data-Centric Engineering / Volume 5 / 2024
- Published online by Cambridge University Press:
- 18 November 2024, e32
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

Bayesian Social Science Statistics
- From the Very Beginning
-
- Published online:
- 24 October 2024
- Print publication:
- 24 October 2024
-
- Element
- Export citation

Knowledge Discovery from Archaeological Materials
-
- Published online:
- 20 September 2024
- Print publication:
- 17 October 2024
-
- Element
- Export citation
Calculation of astrophysical reaction rate and uncertainty for T(d,n)4He using Bayesian statistical approach
-
- Journal:
- Publications of the Astronomical Society of Australia / Volume 41 / 2024
- Published online by Cambridge University Press:
- 13 March 2024, e019
-
- Article
-
- You have access
- HTML
- Export citation
BAYESIAN SPATIOTEMPORAL MODELS FOR INFECTIOUS DISEASES IN RELATION TO HEALTH INEQUALITY
- Part of
-
- Journal:
- Bulletin of the Australian Mathematical Society / Volume 108 / Issue 3 / December 2023
- Published online by Cambridge University Press:
- 31 August 2023, pp. 516-517
- Print publication:
- December 2023
-
- Article
-
- You have access
- HTML
- Export citation
On a wider class of prior distributions for graphical models
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 08 June 2023, pp. 230-243
- Print publication:
- March 2024
-
- Article
-
- You have access
- HTML
- Export citation
-
Gaussian graphical models are useful tools for conditional independence structure inference of multivariate random variables. Unfortunately, Bayesian inference of latent graph structures is challenging due to exponential growth of
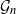 $\mathcal{G}_n$, the set of all graphs in n vertices. One approach that has been proposed to tackle this problem is to limit search to subsets of
$\mathcal{G}_n$, the set of all graphs in n vertices. One approach that has been proposed to tackle this problem is to limit search to subsets of 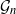 $\mathcal{G}_n$. In this paper we study subsets that are vector subspaces with the cycle space
$\mathcal{G}_n$. In this paper we study subsets that are vector subspaces with the cycle space 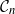 $\mathcal{C}_n$ as the main example. We propose a novel prior on
$\mathcal{C}_n$ as the main example. We propose a novel prior on 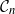 $\mathcal{C}_n$ based on linear combinations of cycle basis elements and present its theoretical properties. Using this prior, we implement a Markov chain Monte Carlo algorithm, and show that (i) posterior edge inclusion estimates computed with our technique are comparable to estimates from the standard technique despite searching a smaller graph space, and (ii) the vector space perspective enables straightforward implementation of MCMC algorithms.
$\mathcal{C}_n$ based on linear combinations of cycle basis elements and present its theoretical properties. Using this prior, we implement a Markov chain Monte Carlo algorithm, and show that (i) posterior edge inclusion estimates computed with our technique are comparable to estimates from the standard technique despite searching a smaller graph space, and (ii) the vector space perspective enables straightforward implementation of MCMC algorithms.
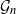
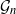
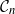
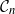
Exact convergence analysis for metropolis–hastings independence samplers in Wasserstein distances
- Part of
-
- Journal:
- Journal of Applied Probability / Volume 61 / Issue 1 / March 2024
- Published online by Cambridge University Press:
- 05 June 2023, pp. 33-54
- Print publication:
- March 2024
-
- Article
-
- You have access
- HTML
- Export citation
A data-driven method for automated data superposition with applications in soft matter science
-
- Journal:
- Data-Centric Engineering / Volume 4 / 2023
- Published online by Cambridge University Press:
- 25 May 2023, e13
-
- Article
-
- You have access
- Open access
- HTML
- Export citation

A Course in Cosmology
- From Theory to Practice
-
- Published online:
- 31 March 2023
- Print publication:
- 09 March 2023
-
- Textbook
- Export citation
10 - Statistical Methods in Cosmology and Astrophysics
- from Part III - The Later Universe
-
- Book:
- A Course in Cosmology
- Published online:
- 31 March 2023
- Print publication:
- 09 March 2023, pp 229-266
-
- Chapter
- Export citation
