


PART 1: NEW RESULTS ABOUT CIVILIZATIONS IN EVO-SETI THEORY
Introduction
Two mathematical papers were published by this author in 2013 and 2014, respectively:
-
(1) ‘SETI, Evolution and Human History Merged into a Mathematical Model’, International Journal of Astrobiology, vol. 12, issue (3), pp. 218–245 (2013) (this will be called (Maccone Reference Maccone2013) in the sequel of the current paper) and
-
(2) ‘Evolution and Mass Extinctions as Lognormal Stochastic Processes’, International Journal of Astrobiology, vol. 13, issue (4), p. 290–309 (2014) (this will be called (Maccone Reference Maccone2014) in the sequel of the current paper).
They provide the mathematical formulation of the ‘Evo-SETI Theory’, standing for ‘a unified mathematical Theory of Evolution and SETI’.
Hoverer, the calculations required to prove all Evo-SETI results are lengthy, and this circumstance may unfortunately ‘scare’ potential readers that would love to understand Evo-SETI, but do not want to face all the calculations. To get around this obstacle, the three Appendixes at the end of this paper are a printout of all the analytical calculations that this author conducted by the Maxima symbolic manipulator, especially to prove the Peak-Locus Theorem described in Section ‘Peak-Locus Theorem’. It is interesting to point out that the Macsyma symbolic manipulator or ‘computer algebra code’ (of which Maxima is a large subset) was created by NASA at the Artificial Intelligence Laboratory of MIT in the 1960s to check the equations of Celestial Mechanics that had been worked out by hand by a host of mathematicians in the previous 250 years (1700–1950). Actually, those equations might have contained errors that could have jeopardized the Moon landings of the Apollo Program, and so NASA needed to check them by computers, and Macsyma (nowadays Maxima) did a wonderful job. Today, everyone may download Maxima for free from the website http://maxima.sourceforge.net/. The Appendixes of this paper are written in Maxima language and the conventions apply of denoting the input instructions by (%i [equation number]) and the output results by (%o[equation number]), as we shall see in a moment.
In conclusion, in order to allow non-mathematically trained readers to appreciate this unified vision of how life developed on Earth over the last 3.5 billion years, a ‘not-too mathematical’ summary of the content of these two papers is now provided, also enabling readers to grasp the wide spectrum of Evo-SETI applications.
A simple proof of the b-lognormal's pdf
This paper is based on the notion of a b-lognormal, just as are (Maccone Reference Maccone2013, Reference Maccone2014). To let this paper be self-contained in this regard, we now provide an easy proof of the b-lognormal equation as a probability density function (pdf). Just start from the well-known Gaussian or normal pdf
 $${\rm Gaussian\_or\_normal}\left( {x\,;{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{{\rm e}^{ - (x - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} {\rm \sigma}}}. $$
$${\rm Gaussian\_or\_normal}\left( {x\,;{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{{\rm e}^{ - (x - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} {\rm \sigma}}}. $$
This pdf has two parameters:
-
(1) μ turns out to be the mean value of the Gaussian and the abscissa of its peak. Since the independent variable x may take up any value between −∞ and +∞, i.e. it is a real variable, so μ must be real too.
-
(2) σ turns out to be the standard deviation of the Gaussian and so it must be a positive variable.
-
(3) Since the Gaussian is a pdf, it must fulfil the normalization condition
 $$\int_{ - \infty} ^\infty {\displaystyle{{{\rm e}^{ - (x - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} {\rm \sigma}}}} \,{\rm d}x = 1$$
$$\int_{ - \infty} ^\infty {\displaystyle{{{\rm e}^{ - (x - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} {\rm \sigma}}}} \,{\rm d}x = 1$$
and this is the equation we need in order to ‘discover’ the b-lognormal. Just perform in the integral (2) the substitution x = lnt (where ln is the natural log). Then (2) is turned into the new integral
 $$\int_0^\infty {\displaystyle{{{\rm e}^{ - (\ln t - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} t}}} \,{\rm d}t = 1.$$
$$\int_0^\infty {\displaystyle{{{\rm e}^{ - (\ln t - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} t}}} \,{\rm d}t = 1.$$
But this (3) may be regarded as the normalization condition of another random variable, ranging ‘just’ between zero and +∞, and this new random variable we call ‘lognormal’ since it ‘looks like’ a normal one except that x is now replaced by ln t and t now also appears at the denominator of the fraction. In other words, the lognormal pdf is
 $$\left\{ {\matrix{ {{\rm lognormal}\left( {t\,;{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{{\rm e}^{ - (\ln (t) - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} \cdot t}},} \hfill \cr {{\rm holding}\;{\rm for}\;0 \le t \lt \infty, - \infty \lt {\rm \mu} \lt \infty, {\rm \sigma} \ge 0.} \hfill \cr}} \right.$$
$$\left\{ {\matrix{ {{\rm lognormal}\left( {t\,;{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{{\rm e}^{ - (\ln (t) - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} \cdot t}},} \hfill \cr {{\rm holding}\;{\rm for}\;0 \le t \lt \infty, - \infty \lt {\rm \mu} \lt \infty, {\rm \sigma} \ge 0.} \hfill \cr}} \right.$$
Just one more step is required to jump from the ‘ordinary lognormal’ (4) (i.e. the lognormal starting at t = 0) to the b-lognormal, that is the lognormal starting at any positive instant b > 0 (‘b’ stands for ‘birth’). Since this simply is a shifting along the time axis from 0 to the new time origin b > 0, in mathematical terms it means that we have to replace t by (t − b) everywhere in the pdf (4). Thus, the b-lognormal pdf must have the equation
 $$\left\{ {\matrix{ {b{\rm \_\hskip1pt lognormal}\left( {t\,;{\rm \mu}, {\rm \sigma}, b} \right) = \displaystyle{{{\rm e}^{ - (\ln (t - b) - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} \cdot (t - b)}}} \cr {{\rm holding}\;{\rm for}\;t \ge b\;{\rm and}\;{\rm up}\;{\rm to}\;t = \infty.} \cr}} \right.$$
$$\left\{ {\matrix{ {b{\rm \_\hskip1pt lognormal}\left( {t\,;{\rm \mu}, {\rm \sigma}, b} \right) = \displaystyle{{{\rm e}^{ - (\ln (t - b) - {\rm \mu} )^2 /\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} \cdot (t - b)}}} \cr {{\rm holding}\;{\rm for}\;t \ge b\;{\rm and}\;{\rm up}\;{\rm to}\;t = \infty.} \cr}} \right.$$
The b-lognormal (5) is called ‘three-parameter lognormal’ by statisticians, but we prefer to call it b-lognormal to stress its biological meaning described in the next section.
Defining ‘life’ in the Evo-SETI Theory
The first novelty brought by our Evo-SETI Theory is our definition of life as a ‘finite b-lognormal in time’, extending from the time of birth (b) to the time of death (d) of the living creature, let it be a cell, an animal, a human, a civilization of humans or even an Extra-Terrestrial (ET) civilization. Figure 1 shows what we call a ‘finite b-lognormal’.

Fig. 1. ‘Life’ in the Evo-SETI Theory is a ‘finite b-lognormal’ made up by a lognormal pdf between birth b and senility (descending inflexion point) s, plus the straight tangent line at s leading to death d.
On the horizontal axis is the time t ranging between b and d. But the curve on the vertical axis is actually made up by two curves:
-
(1) Between b and the ‘senility’ time s (i.e. the descending inflexion point of the curve) on the vertical axis are the positive numerical values taken up by the pdf (5), that we prefer to call ‘infinite b-lognormal’ to distinguish it from the ‘finite b-lognormal’ shown in Fig. 1.
-
(2) Between s and d the curve is just a straight line having the same tangent at s as the b-lognormal (5). We are not going to derive its equation since that would take too long, but its meaning is obvious: since nobody lives for an infinite amount of time, it was necessary to ‘cut’ the infinite b-lognormal (5) at the junction point s and continue it with a simple straight line finally intercepting the time axis at the death instant d. As easy as that.
History formulae
Having so defined ‘life’ as a finite b-lognormal, this author was able to show that, given one's birth b, death d and (somewhere in between) one's senility s, then the two parameters μ (a real number) and σ (a positive number) of the b-lognormal (5) are given by the two equations
 $$\left\{ {\matrix{ {{\rm \sigma} = \displaystyle{{d - s} \over {\sqrt {d - b} \sqrt {s - b}}},} \cr {{\rm \mu} = \ln \left( {s - b} \right) + \displaystyle{{(d - s)(b + d - 2s)} \over {(d - b)(s - b)}}.} \cr}} \right.$$
$$\left\{ {\matrix{ {{\rm \sigma} = \displaystyle{{d - s} \over {\sqrt {d - b} \sqrt {s - b}}},} \cr {{\rm \mu} = \ln \left( {s - b} \right) + \displaystyle{{(d - s)(b + d - 2s)} \over {(d - b)(s - b)}}.} \cr}} \right.$$
These were called ‘History Formulae’ by this author for their use in Mathematical History, as shown in the next section. The mathematical proof of (6) is found in (Maccone Reference Maccone2013, p. 227–231) and follows directly from the definition of s (as descending inflexion point) and d (as interception between the descending tangent straight line at s and the time axis). In previous versions of his Evo-SETI Theory, the author gave an apparently different version of the History Formulae (6) reading
 $$\left\{ {\matrix{ {{\rm \sigma} = \displaystyle{{d - s} \over {\sqrt {d - b} \,\sqrt {s - b}}},} \cr {{\rm \mu} = \ln \left( {s - b} \right) + \displaystyle{{2s^2 - (3d + b)s + d^2 + b\,d} \over {(d - b)s - b\;d + b^2}}.} \cr}} \right.$$
$$\left\{ {\matrix{ {{\rm \sigma} = \displaystyle{{d - s} \over {\sqrt {d - b} \,\sqrt {s - b}}},} \cr {{\rm \mu} = \ln \left( {s - b} \right) + \displaystyle{{2s^2 - (3d + b)s + d^2 + b\,d} \over {(d - b)s - b\;d + b^2}}.} \cr}} \right.$$
This simply was because he had not yet factorized the fraction of the second equation (with apologies).
Death formula
One more interesting result discovered by this author, and firstly published by him in 2012 (Maccone Reference Maccone2012, Chapter 6, equation (6.30), p. 163) is the following ‘Death Formula’ (its proof is obtained by inserting the History Formulae (6) into the equation for the peak abscissa, p = b + eμ−σ 2 ):
 $$d = \displaystyle{{s + b \cdot \ln ((\,p - b)/(s - b))} \over {\ln (( {\,p - b)/(s - b} )) + 1}}.$$
$$d = \displaystyle{{s + b \cdot \ln ((\,p - b)/(s - b))} \over {\ln (( {\,p - b)/(s - b} )) + 1}}.$$
This formula allows one to compute the death time d if the birth time b, the peak time p and the senility time s are known. The difficulty is that, while b and p are usually well known, s is not so, thus jeopardizing the practical usefulness of the Death Formula (8).
Birth–Peak–Death (BPD) theorem
This difficulty of estimating s for any b-lognormal led the author to discover the following BPD theorem that he only obtained on April 4, 2015, and presented here for the first time.
Ask the question: can a given b-lognormal be entirely characterized by the knowledge of its birth, peak and death only? Yes is the answer, but no exact formula exists yielding s in terms of (b, p, d) only.
Proof. Start from the exact Death Formula (8) and expand it into a Taylor series with respect to s around p and, say, to order 2. The result given by Maxima is
 $$d = p + 2\left( {s - p} \right) - \displaystyle{{3(s - p)^2} \over {2(b - p)}} + \cdots. $$
$$d = p + 2\left( {s - p} \right) - \displaystyle{{3(s - p)^2} \over {2(b - p)}} + \cdots. $$
Equation (9) is quadratic equation in s that, once solved for s, yields the second-order approximation for s in terms of (b, p, d)
 $$s = \displaystyle{{\sqrt 2 \sqrt { - p^2 + (3d - b)p - 3bd + 2b^2} + p + 2b} \over 3}.$$
$$s = \displaystyle{{\sqrt 2 \sqrt { - p^2 + (3d - b)p - 3bd + 2b^2} + p + 2b} \over 3}.$$
In the practice, equation (10) is a ‘reasonable’ numeric approximation yielding s as a function of (b, p, d), and is certainly much better that the corresponding first-order approximation given by the linear equation
 $$d = p + 2\left( {s - p} \right) + \cdots $$
$$d = p + 2\left( {s - p} \right) + \cdots $$
whose solution simply is
 $$s = \displaystyle{{\,p + d} \over 2},$$
$$s = \displaystyle{{\,p + d} \over 2},$$
i.e., s (to first approximation) simply is the middle point between p and d, as geometrically obvious.
However, if one really wants a better approximation than the quadratic one (10), it is possible to expand the Death Formula (8) into a Taylor series with respect to s around p to third order, finding
 $$d = p + 2\left( {s - p} \right) + \displaystyle{{3(s - p)^2} \over {2(\hskip1ptp - b)}} + \displaystyle{{5(s - p)^3} \over {6(\hskip1ptp-b)^2}} + \cdots $$
$$d = p + 2\left( {s - p} \right) + \displaystyle{{3(s - p)^2} \over {2(\hskip1ptp - b)}} + \displaystyle{{5(s - p)^3} \over {6(\hskip1ptp-b)^2}} + \cdots $$
Equation (13) is a cubic (i.e. third-degree polynomial) in s that may be solved for s by virtue of the well-known Cardan (Girolamo Cardano 1501–1576) formulae that we will not repeat here since they are exact but too lengthy to be reproduced in this paper.
As a matter of fact, it might even be possible to expand the Death Formula (8) to fourth order in s around p that would lead to the fourth-degree algebraic equation (a quartic) in s
 $$\eqalign{d = & \,p + 2\left( {s - p} \right) + \displaystyle{{3(s - p)^2} \over {2(\hskip1pt p - b)}} + \displaystyle{{5(s - p)^3} \over {6(\hskip1ptp-b)^2}} \cr & \quad\!\! + \displaystyle{{(s - p)^4} \over {2(\hskip1pt p-b)^3}} + \cdots} $$
$$\eqalign{d = & \,p + 2\left( {s - p} \right) + \displaystyle{{3(s - p)^2} \over {2(\hskip1pt p - b)}} + \displaystyle{{5(s - p)^3} \over {6(\hskip1ptp-b)^2}} \cr & \quad\!\! + \displaystyle{{(s - p)^4} \over {2(\hskip1pt p-b)^3}} + \cdots} $$
and then solve equation (14) for s by virtue of the exact four formulae of Lodovico Ferrari (1522–1565) (he was Cardan's pupil) that are huge and occupy a whole page each one. However, this game may not go on forever: the fifth-degree algebraic equation is not solvable by virtue of radicals and so we must stop with degree 4.
Then there is the problem of finding which one, out of the three (Cardan) or four (Ferrari) roots numerically is ‘the right one’. This author thus wrote a Maxima code given here as #1 Appendix to this paper where he solved several cases of finding s from (b, p, d) related to the important Fig. 2 of this paper.
In other words, the inputs to Table 1 of this paper were (b, p, d) and not (b, s, d), as the author had always done previously, for instance in deriving the whole of Chapter 7 of (Maccone Reference Maccone2012) back in 2012. This improvement is remarkable since it allowed a fine-tuning of Table 1 with respect to all similar previous material. In other words still, ‘it is easier to assign birth, peak and death rather than birth, senility and death’. That's why the Theorem described in this section was called BPD Theorem.
Table 1. Birth, peak, decline and death times of nine Historic Western Civilizations (3100 BC - 2035 AD), plus the relevant peak heights. They are shown in Fig. 2 as nine b-lognormal pdfs.

The reader is invited to ponder over Appendix 1 as the key to all further, future developments in Mathematical History.
Mathematical history of nine key civilizations since 3100 BC
The author called (6) the ‘History Formulae’ since in (Maccone Reference Maccone2013, p. 231–235), equations (6), with the numerical values provided there, allowed him to draw the b-lognormals of eight leading civilizations in Western History: Greece, Rome, Renaissance Italy, and the Portuguese, Spanish, French, British and American (USA) Empires.
Please notice that:
-
(1) The data in Table 1 and the resulting b-lognormals in Fig. 2 are experimental results, meaning that we just took what described in History textbooks (with a lot of words) and translated that into the simple b-lognormals shown in Fig. 2. In other words, a new branch of knowledge was forged: we love to call it ‘Mathematical History’. More about this in future papers.
-
(2) The envelope of all the above b-lognormals ‘looks like’ a simple exponential curve. In Fig. 2, two such exponential envelopes were drawn: the one going from the peak of Ancient Greece (the Pericles age in Athens, cradle of Democracy) to the peak of the British Empire (Victorian age, the age of Darwin and Maxwell) and to the peak of the USA Empire (Moon landings in 1969–1972). This notion of b-lognormal envelope will later be precisely quantified in our ‘Peak-Locus Theorem’.
-
(3) It is now high time to introduce a ‘measure of evolution’ namely a function of the three parameters μ, σ and b accounting for the fact that ‘the experimental Fig. 2 clearly shows that, the more the time elapses, the more highly peaked, and narrower and narrower, the b-lognormals are’. In (Maccone Reference Maccone2013, p. 238–243), this author showed that the requested measure of evolution is the (Shannon) entropy, namely the entropy of each infinite b-lognormal that fortunately has the simple equation
(15) $$H_{{\rm infinite\_\,}b{\rm - lognormal}} \left( {{\rm \mu}, {\rm \sigma}} \right) = \ln \left( {\sqrt {{\rm 2\pi}} {\rm \sigma}} \right) + {\rm \mu} + \displaystyle{1 \over 2}.$$
$$H_{{\rm infinite\_\,}b{\rm - lognormal}} \left( {{\rm \mu}, {\rm \sigma}} \right) = \ln \left( {\sqrt {{\rm 2\pi}} {\rm \sigma}} \right) + {\rm \mu} + \displaystyle{1 \over 2}.$$


Fig. 2. The b-lognormals of nine Historic Western Civilizations computed thanks to the History Formulae (6) with the three numeric inputs for b, p and d of each Civilization given by the corresponding line in Table 1. The corresponding s is derived from b, p and d by virtue of the second-order approximation (10) provided by the solution of the quadratic equation in the BPD theorem.
The proof of this result was given in (Maccone Reference Maccone2013, p. 238–239). If measured in bits, as customary in Shannon's Information Theory, equation (15) becomes
 $$H_{{\rm infinite\_}\hskip1pt b{\rm - lognormal\_in\_bits}} \left( {{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{\ln (\sqrt {{\rm 2\pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}.$$
$$H_{{\rm infinite\_}\hskip1pt b{\rm - lognormal\_in\_bits}} \left( {{\rm \mu}, {\rm \sigma}} \right) = \displaystyle{{\ln (\sqrt {{\rm 2\pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}.$$
This is the b-lognormal entropy definition that was used in (Maccone Reference Maccone2013, Reference Maccone2014) and we are going to use in this paper also. In reality, Shannon's entropy is a measure of the disorganization of an assigned pdf f X (x), rather than a measure of its organization. To change it into a measure of organization, we should just drop the minus sign appearing in front of the Shannon definition of entropy for any assigned pdf f X (x):
 $$H = - \int_{ - \infty} ^\infty {\,f_X \left( x \right) \cdot \ln} f_X \left( x \right)\;{\rm d}x$$
$$H = - \int_{ - \infty} ^\infty {\,f_X \left( x \right) \cdot \ln} f_X \left( x \right)\;{\rm d}x$$
We will do so to measure Evolution of life on Earth over the last 3.5 billion years.
The final goal of all these mathematical studies is of course to ‘prepare’ the future of Humankind in SETI, when we will have to face other Alien Civilizations whose past may be the future for us.
b-Scalene (triangular) probability density
Having recognized that BPD (and not birth–senility–death) are the three fundamental instants in the lifetime of any living creature, we are tempted to introduce a new pdf called b-scalene, or, more completely, b-scalene triangular pdf.
The idea is easy:
-
(1) The horizontal axis is the time axis, denoted by t.
-
(2) The vertical axis is denoted by y.
-
(3) The b-scalene pdf starts at the instant b ‘birth’.
-
(4) The b-scalene pdf ends at the instant d ‘death’.
-
(5) Somewhere in between is located the pdf peak, having the coordinates (p, P).
-
(6) The pdf between (b, 0) and (p, P) is a straight line, hereafter called ‘first b-scalene’ (line).
-
(7) The pdf between (p, P) and (d, 0) is a straight line, hereafter called ‘second b-scalene’ (line).
Let us now work out the equations of the b-scalene. First of all its normalization condition implies that the sum of the areas of the two triangles equals 1:
 $$\displaystyle{{(\,p - b)P} \over 2} + \displaystyle{{(d - p)P} \over 2} = 1.$$
$$\displaystyle{{(\,p - b)P} \over 2} + \displaystyle{{(d - p)P} \over 2} = 1.$$
Solving equation (18) for P we get
 $$P = \displaystyle{2 \over {d - b}}.$$
$$P = \displaystyle{2 \over {d - b}}.$$
Then, the equations of the two straight lines making up the b-scalene pdf are found to be, respectively:
 $$y = \displaystyle{{2(t - b)} \over {(d - b)(\,p - b)}},\quad {\rm for}\quad b \le t \le p$$
$$y = \displaystyle{{2(t - b)} \over {(d - b)(\,p - b)}},\quad {\rm for}\quad b \le t \le p$$
and
 $$y = \displaystyle{{2(t - d)} \over {(d - b)(\,p - d)}},\quad {\rm for}\quad p \le t \le d.$$
$$y = \displaystyle{{2(t - d)} \over {(d - b)(\,p - d)}},\quad {\rm for}\quad p \le t \le d.$$
Proof. The proofs of equations (20) and (21), as well as of all subsequent formulae about the b-scalene, are given in #2 Appendix to the present paper. We will simply refer to them with the numbers of the resulting equations in the Maxima code. Thus, equation (20) corresponds to (%o15) and equation (21) to (%o20). Also, it is possible to compute all moments (i.e. the kth moment) of the b-scalene immediately. In fact, Maxima yields ((%o27) and (%o28))
 $$\left\langle {b\_\!\_{\rm scalene}^k} \right\rangle = \displaystyle{{2[(d - b)p^{k + 2} + (b^{k + 2} \!-\! d^{k + 2} )p + bd^{k + 2} - b^{k + 2} d]} \over {(d - b)(k + 1)(k + 2)(\,p - b)(\,p - d)}}.$$
$$\left\langle {b\_\!\_{\rm scalene}^k} \right\rangle = \displaystyle{{2[(d - b)p^{k + 2} + (b^{k + 2} \!-\! d^{k + 2} )p + bd^{k + 2} - b^{k + 2} d]} \over {(d - b)(k + 1)(k + 2)(\,p - b)(\,p - d)}}.$$
Setting k = 0 into equation (22) yields of course the normalization condition (%o29)
 $$\left\langle {b\_{\rm scalene}^0} \right\rangle = 1.$$
$$\left\langle {b\_{\rm scalene}^0} \right\rangle = 1.$$
Setting k = 1 into equation (22) yields the mean value (%o30)
 $$\left\langle {b\_{\rm scalene}} \right\rangle = \displaystyle{{b + p + d} \over 3}.$$
$$\left\langle {b\_{\rm scalene}} \right\rangle = \displaystyle{{b + p + d} \over 3}.$$
Setting k = 2 into equation (22) yields the mean value of the square (%o32)
 $$\left\langle {b\_{\rm scalene}^2} \right\rangle = \displaystyle{{b^2 + p^2 + d^2 + b\,p + d\,p + b\,d} \over 6}.$$
$$\left\langle {b\_{\rm scalene}^2} \right\rangle = \displaystyle{{b^2 + p^2 + d^2 + b\,p + d\,p + b\,d} \over 6}.$$
Then, subtracting the square of equation (24) into (25), one gets the b-scalene variance (%o34)
 $${\rm \sigma} _{{\rm b\_\,scalene}}^2 = \displaystyle{{(d - b)^2} \over {24}}.$$
$${\rm \sigma} _{{\rm b\_\,scalene}}^2 = \displaystyle{{(d - b)^2} \over {24}}.$$
The square root of equation (26) is the b-scalene standard deviation (%o36)
 $${\rm \sigma} _{{\rm b\_scalene}} = \displaystyle{{d - b} \over {2^{3 \over 2}} \sqrt 3}. $$
$${\rm \sigma} _{{\rm b\_scalene}} = \displaystyle{{d - b} \over {2^{3 \over 2}} \sqrt 3}. $$
We could go on to find more descriptive statistical properties of the b-scalene, but we prefer to stop at this point. Much more important, in fact, is to compute the Shannon Entropy of the b-scalene. Equations (%i37) through (%o41) show that the Shannon Entropy of the b-scalene is given by
 $$\eqalign{&{\rm b} {\rm \_scalene\_Shannon\_ENTROPY\_in\_bits} \cr & \quad = \displaystyle{{1 + \ln ((d - b)^2 /4)} \over {2\ln 2}}.}$$
$$\eqalign{&{\rm b} {\rm \_scalene\_Shannon\_ENTROPY\_in\_bits} \cr & \quad = \displaystyle{{1 + \ln ((d - b)^2 /4)} \over {2\ln 2}}.}$$
This is a simple and important result. Since p does not appear in equation (28), the Shannon Entropy of the b-scalene is actually independent of where its peak is!
Also, one is tempted to make a comparison between the Entropy of the b-scalene and the Entropy of the UNIFORM distribution over the same interval (d − b) This will be done in the next section.
Uniform distribution between birth and death
In the Evo-SETI Theory, the meaning of a uniform distribution over the time interval (d − b) simply is ‘we know nothing about that living being except when he/she/it was born (at instant b) and when he/she/it died (at instant d)’. No idea even about when the ‘peak’ p of his/her/its activity occurred. Thus, the uniform distribution is the minimal amount of information about the lifetime of someone that one might possibly have.
The pdf of the uniform distribution over the time interval (d − b) is obviously given by the constant in time (%o43)
 $$f_{{\rm uniform\_}b{\rm \_}d} \left( t \right) = \displaystyle{1 \over {d - b}},\quad {\rm for}\quad b \le t \le d.$$
$$f_{{\rm uniform\_}b{\rm \_}d} \left( t \right) = \displaystyle{1 \over {d - b}},\quad {\rm for}\quad b \le t \le d.$$
It is immediately possible to compute all moments of the uniform distribution (%o44)
 $$\int_b^d {\displaystyle{{t^k} \over {d - b}}\;{\rm d}t} = \displaystyle{{d^{k + 1} - b^{k + 1}} \over {(d - b)(k + 1)}}.$$
$$\int_b^d {\displaystyle{{t^k} \over {d - b}}\;{\rm d}t} = \displaystyle{{d^{k + 1} - b^{k + 1}} \over {(d - b)(k + 1)}}.$$
The normalization condition of equation (30) is obviously found upon letting k = 0.
The mean value is found by letting k = 1 into equation (30), (%o53), and is just the middle point between birth and death
 $$\left\langle {{\rm uniform\_}b{\rm \_}d} \right\rangle = \displaystyle{{b + d} \over 2}.$$
$$\left\langle {{\rm uniform\_}b{\rm \_}d} \right\rangle = \displaystyle{{b + d} \over 2}.$$
The mean value of the square is found by letting k = 2 into equation (30) and reads (%o54)
 $$\left\langle {{\rm uniform\_}b{\rm \_}d^2} \right\rangle = \displaystyle{{b^2 + b\,d + d^2} \over 3}.$$
$$\left\langle {{\rm uniform\_}b{\rm \_}d^2} \right\rangle = \displaystyle{{b^2 + b\,d + d^2} \over 3}.$$
Subtracting the square of equation (31) into (32), we get the uniform distribution variance (%o58)
 $${\rm \sigma} _{{\rm uniform\_}b{\rm \_}d}^2 = \displaystyle{{(d - b)^2} \over {12}}.$$
$${\rm \sigma} _{{\rm uniform\_}b{\rm \_}d}^2 = \displaystyle{{(d - b)^2} \over {12}}.$$
Finally, the uniform distribution standard deviation is the square root of (33) (%o59)
 $${\rm \sigma} _{{\rm uniform\_in\_}b{\rm \_}d} = \displaystyle{{d - b} \over {2\sqrt 3}}. $$
$${\rm \sigma} _{{\rm uniform\_in\_}b{\rm \_}d} = \displaystyle{{d - b} \over {2\sqrt 3}}. $$
We stop the derivation of the descriptive statistics of the uniform distribution at this point, since it is easy to find all other formulae in textbooks. Rather, we prefer to concentrate on the Shannon Entropy of the uniform distribution, that upon inserting the pdf (29) into the entropy definition (17), yields (%o62)
 $${\rm Uniform\_distribution\_ENTROPY\_in\_bits} = \displaystyle{{\ln (d - b)} \over {\ln 2}}.$$
$${\rm Uniform\_distribution\_ENTROPY\_in\_bits} = \displaystyle{{\ln (d - b)} \over {\ln 2}}.$$
Entropy difference between uniform and b-scalene distributions
We are now in a position to find out the ‘Entropy Difference’ between the uniform and the b-scalene distributions.
Subtracting equation (28) into (35) one gets (%o71)
 $$\eqalign{&\displaystyle{{\ln (d - b)} \over {\ln 2}} - \displaystyle{{1 + \ln ((d - b)^2 /4)} \over {2\ln 2}} \cr & = \displaystyle{{\ln (d - b)} \over {\ln 2}} - \displaystyle{1 \over {2\ln 2}} - \displaystyle{{2[\ln (d - b) - \ln 2]} \over {2\ln 2}} \cr & = 1 - \displaystyle{1 \over {2\ln 2}} = 0.27865247955552.} $$
$$\eqalign{&\displaystyle{{\ln (d - b)} \over {\ln 2}} - \displaystyle{{1 + \ln ((d - b)^2 /4)} \over {2\ln 2}} \cr & = \displaystyle{{\ln (d - b)} \over {\ln 2}} - \displaystyle{1 \over {2\ln 2}} - \displaystyle{{2[\ln (d - b) - \ln 2]} \over {2\ln 2}} \cr & = 1 - \displaystyle{1 \over {2\ln 2}} = 0.27865247955552.} $$
One may say that in passing from just knowing birth and death to knowing birth, peak and death, one has reduced the uncertainty by 0.27865247955552 bits, or, if you prefer, the Shannon Entropy has been reduced by an amount of 0.27865247955552 bits. Again in a colourful language, if you just know that Napoleon was born in 1769 and died in 1821, and then add that the peak occurred in 1812 (or at any other date), than you have added 0.27865247955552 bits of information about his life.
Readers might now wish to ponder over statements like the last one about Napoleon in order build up a Mathematical Theory of History, simply called Mathematical History.
We stop here now, but some young talent might wish to develop these ideas much more in depth, disregarding all criticism and just being bold, bold, bold,….
‘Equivalence’ between uniform and b-lognormal distributions
One more ‘crazy idea’ suggested by the Evo-SETI Theory is the ‘equivalence’ between uniform and lognormal distributions, as described in #2 Appendix.
The starting point is to equate the two mean values and the two standard deviations of these two distributions and then… see what comes out!
So, just equate the two mean values first, i.e. just equate equation (31) and the well-known mean value formula for the lognormal distribution (see Table 2, fourth line) (%o2)
 $$\displaystyle{{b + d} \over 2} = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}}. $$
$$\displaystyle{{b + d} \over 2} = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}}. $$
Table 2. Summary of the properties of the b-lognormal distribution that applies to the random variable C = History in time of a certain Civilization. This set of results we like to call ‘E-Pluribus-Unum Theorem’ of the Evo-SETI Theory.

Similarly, we equate the uniform standard deviation (34) and the lognormal standard deviation (see Table 2, sixth line) and get (%o3)
 $$\displaystyle{{d - b} \over {2\sqrt 3}} = {\rm e}^{{\rm (\sigma} ^{\rm 2} {\rm /2) + \mu}} \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}. $$
$$\displaystyle{{d - b} \over {2\sqrt 3}} = {\rm e}^{{\rm (\sigma} ^{\rm 2} {\rm /2) + \mu}} \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}. $$
A glance to equations (37) and (38) shows that we may eliminate μ upon dividing equation (38) by (37), and that yields the resolving equation in σ (%o4)
 $$\displaystyle{{d - b} \over {\sqrt 3 (b + d)}} = \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}. $$
$$\displaystyle{{d - b} \over {\sqrt 3 (b + d)}} = \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}. $$
After a few steps, equation (39) may be solved for the exponential, yielding (%05)
 $${\rm e}^{{\rm \sigma} ^2} = \displaystyle{{4(b^2 + bd + d^2 )} \over {3(b + d)^2}} $$
$${\rm e}^{{\rm \sigma} ^2} = \displaystyle{{4(b^2 + bd + d^2 )} \over {3(b + d)^2}} $$
and finally, taking logs
 $${\rm \sigma} ^2 = \ln \left[ {\displaystyle{{4(b^2 + b\,d + d^2 )} \over {3(b + d)^2}}} \right].$$
$${\rm \sigma} ^2 = \ln \left[ {\displaystyle{{4(b^2 + b\,d + d^2 )} \over {3(b + d)^2}}} \right].$$
Taking the square root, equation (41) becomes
 $${\rm \sigma} = \sqrt {\ln \left[ {\displaystyle{{4(b^2 + bd + d^2)} \over {3(b + d)^2}}} \right]}. $$
$${\rm \sigma} = \sqrt {\ln \left[ {\displaystyle{{4(b^2 + bd + d^2)} \over {3(b + d)^2}}} \right]}. $$
Then, inserting equation (41) into (38) and solving the resulting equation for μ, one finds for μ (%o10)
 $${\rm \mu} = \ln \left[ {\displaystyle{{\sqrt 3 (b + d)^2} \over {4\sqrt {b^2 + b\,d + d^2}}}} \right].$$
$${\rm \mu} = \ln \left[ {\displaystyle{{\sqrt 3 (b + d)^2} \over {4\sqrt {b^2 + b\,d + d^2}}}} \right].$$
In conclusion, we have proven that, if we are given just the birth and death times of the life of anyone, this uniform distribution between birth and death may be converted into the ‘equivalent’ lognormal distribution starting at the same birth instant and having the two parameters μ and σ given by, respectively
 $$\left\{ {\matrix{ {{\rm \mu} = \ln \left[ {\displaystyle{{\sqrt 3 (b + d)^2} \over {4\sqrt {b^2 + bd + d^2}}}} \right],} \cr {{\rm \sigma} = \sqrt {\ln \left[ {\displaystyle{{4(b^2 + b\,d + d^2 )} \over {3(b + d)^2}}} \right]}.} \cr}} \right.$$
$$\left\{ {\matrix{ {{\rm \mu} = \ln \left[ {\displaystyle{{\sqrt 3 (b + d)^2} \over {4\sqrt {b^2 + bd + d^2}}}} \right],} \cr {{\rm \sigma} = \sqrt {\ln \left[ {\displaystyle{{4(b^2 + b\,d + d^2 )} \over {3(b + d)^2}}} \right]}.} \cr}} \right.$$
One may also invert the system of two simultaneous equations (44). In fact, multiplying equation (37) by 2 and equation (38) by
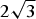 $2\sqrt 3 $
and then summing, b disappears and one is left with the d expression (%o13)
$2\sqrt 3 $
and then summing, b disappears and one is left with the d expression (%o13)
 $$d = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 + \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).$$
$$d = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 + \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).$$
Similarly, multiplying equation (37) by 2 and equation (38) by
 $2\sqrt 3 $
and then subtracting, d disappears and one is left with the b expression (%o14)
$2\sqrt 3 $
and then subtracting, d disappears and one is left with the b expression (%o14)
 $$b = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 - \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).$$
$$b = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 - \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).$$
In conclusion, the inverse formulae of equation (44) are
 $$\left\{ {\matrix{ {b = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 - \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right)} \cr {d = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 + \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).} \cr}} \right.$$
$$\left\{ {\matrix{ {b = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 - \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right)} \cr {d = {\rm e}^{({\rm \sigma} ^2 /2) + {\rm \mu}} \left( {1 + \sqrt 3 \sqrt {{\rm e}^{{\rm \sigma} ^2 - 1}}} \right).} \cr}} \right.$$
Let us now find how much the Shannon Entropy changes when we replace the lognormal distribution to the uniform distribution between birth and death. We already know that the uniform distribution entropy is the largest possible entropy, and is given by equation (35). Then, we only need to know that the lognormal entropy is given by the expression (%o16) (for the proof, see, for instance, (Maccone Reference Maccone2012), Chapter 30, p. 685–687)
 $${\rm lognormal\_entropy\_in\_bits} = \displaystyle{{\ln (\sqrt {2{\rm \pi} \,} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}$$
$${\rm lognormal\_entropy\_in\_bits} = \displaystyle{{\ln (\sqrt {2{\rm \pi} \,} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}$$
Inserting equations (44) into (48) a complicated expression would be found (%o17) that we will not re-write here. Also the uniform entropy (35) may be rewritten in terms of μ and σ by inserting equation (44) into it, and the result is (%o20). At this point we may subtract the lognormal entropy to the uniform entropy and so find out how much information we ‘arbitrarily inject into the system’ if we replace the uniform pdf by the lognormal pdf. The result is given by (%o22) and reads
 $$\eqalign{&{\rm uniform\_pdf\_ENTROPY - lognormal\_pdf\_ENTROPY} \cr {\rm =} & \displaystyle{{\ln \left[ {12({\rm e}^{{\rm \sigma} ^2} - 1)} \right] + 2{\rm \mu} + {\rm \sigma} ^2} \over {2\ln 2}} - \displaystyle{{\ln (\sqrt {{\rm 2\pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}} \cr = & \displaystyle{{\ln \left[ {6({\rm e}^{{\rm \sigma} ^2} - 1)/{\rm \pi} \,{\rm \sigma} ^2} \right] + {\rm \sigma} ^2 + 1.} \over {2\ln 2}}.} $$
$$\eqalign{&{\rm uniform\_pdf\_ENTROPY - lognormal\_pdf\_ENTROPY} \cr {\rm =} & \displaystyle{{\ln \left[ {12({\rm e}^{{\rm \sigma} ^2} - 1)} \right] + 2{\rm \mu} + {\rm \sigma} ^2} \over {2\ln 2}} - \displaystyle{{\ln (\sqrt {{\rm 2\pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}} \cr = & \displaystyle{{\ln \left[ {6({\rm e}^{{\rm \sigma} ^2} - 1)/{\rm \pi} \,{\rm \sigma} ^2} \right] + {\rm \sigma} ^2 + 1.} \over {2\ln 2}}.} $$
Notice that, rather unexpectedly, equation (49) is independent of μ. Numerically, we may get an idea about equation (49) in the limit case when σ → 0, then finding
 $$\mathop {\lim} \limits_{\sigma \to 0} \displaystyle{{\ln \left[ {6({\rm e}^{{\rm \sigma} ^2} - 1)/{\rm \pi} \,{\rm \sigma} ^2} \right] + {\rm \sigma} ^2 + 1} \over {2\ln 2}} = \displaystyle{{\ln (6/{\rm \pi} ) + 1} \over {2\ln 2}} = - 0.254\;{\rm bits}.$$
$$\mathop {\lim} \limits_{\sigma \to 0} \displaystyle{{\ln \left[ {6({\rm e}^{{\rm \sigma} ^2} - 1)/{\rm \pi} \,{\rm \sigma} ^2} \right] + {\rm \sigma} ^2 + 1} \over {2\ln 2}} = \displaystyle{{\ln (6/{\rm \pi} ) + 1} \over {2\ln 2}} = - 0.254\;{\rm bits}.$$
Not too a big numeric error, apparently.
b-lognormal of a civilization's history as CLT of the lives of its citizens
This and the following sections of Part 1 are most important since they face mathematically the finding of the b-lognormal of a certain Civilization in time, like any of the Civilizations shown in Fig. 2. We claim that the b-lognormal of a Civilization History is obtained by applying the CLT of Statistics to the lifetimes of the millions of Citizens that make and made up for that Civilization in time.
Though this statement may appear rather obvious, the mathematics is not so, and we are going to explain it from scratch right now.
Then:
-
(1) Denote by C the random variable (in time) yielding the History of that Civilization in time. In the end, the pdf of C will prove to be a b-lognormal and we will derive this fact as a consequence of the CLT of Statistics.
-
(2) Denote by C i the random variable (in time) denoting the lifetime of the ith Citizen belonging to that Civilization. We do not care about the actual pdf of the random variable C i : it could be just uniform between birth and death (in this case, C i is the lifetime of a totally anonymous guy, as the vast majority of Humans are, and certainly cells are too, and so forth for other applications). Or, on the contrary, it could be a b-scalene, as in the example about Napoleon, born 1769, died 1821, with peak in 1812, or this pdf could be anything else: no problem since the CLT allows for arbitrary input pdfs.
-
(3) Denote by N the total number of individuals that made up and are making up and will make up for the History of that Civilization over its total existence in time, let this time be years or centuries or millions or even billions of years (for ET Civilizations, we suppose!). In general, this positive integer number N is going to be very large: thousands or millions or even billions, like that fact that Humans nowadays number about 7.3 billion people. In the practice, we may well suppose that N approaches infinity, i.e. N → ∞, which is precisely the mathematical condition requested to apply the CLT of Statistics, as we shall see in a moment.
-
(4) Then consider the statistical equation
 $$C = \prod\limits_{i = 1}^N {{C_i}} .$$
$$C = \prod\limits_{i = 1}^N {{C_i}} .$$
This we shall call ‘the Statistical Equation of each Civilization’ (abbreviated SEC).
What is the meaning of this equation?
Well, if we suppose that all the random variables C i are ‘statistically independent of each other’, then equation (51) is the ‘Law of Compound Probability’, well known even to beginners in statistical courses. And the lifespans of Citizens C i almost certainly are independent of each other in time: dead guys may hardly influence the life of alive guys!
-
(5) Now take the logs of equation (51). The product is converted into a sum and the new form of our SEC is
(52)
$$\ln C = \sum\limits_{i = 1}^N {\ln C_i}. $$
-
(6) To this equation (52) we now apply the CLT. In loose terms, the CLT states that ‘if you have a sum of a number of independent random variables, and let the number of terms in the sum approach infinity, then, regardless of the actual probability distribution of each term in the sum, the overall sum approaches the normal (i.e. Gaussian) distribution’.
-
(7) And the mean value of this Gaussian equals the sum of the mean values of the ln C i , while the variance equals the sum of the variances of the ln C i . In equations, one has
(53)
$$\ln C = {\rm normally\_distributed\_random\_variable}$$


with mean value given by
 $${\rm \mu} = \left\langle {\ln C} \right\rangle = \sum\limits_{i = 1}^N {\left\langle {\ln C_i} \right\rangle} $$
$${\rm \mu} = \left\langle {\ln C} \right\rangle = \sum\limits_{i = 1}^N {\left\langle {\ln C_i} \right\rangle} $$
and variance given by
 $${\rm \sigma }_{\ln C}^2 = \sum\limits_{i = 1}^N {{\rm \sigma }_{\ln {C_i}}^2 } .$$
$${\rm \sigma }_{\ln C}^2 = \sum\limits_{i = 1}^N {{\rm \sigma }_{\ln {C_i}}^2 } .$$
-
(8) Let us now ‘invert’ equation (53), namely solve it for C. To do so, we must recall an important theorem that is proved in probability courses, but, unfortunately, does not seem to have a specific name. It is the transformation law (so we shall call it, see for instance (Papoulis & Pillai Reference Papoulis and Pillai2002, p. 130–131)) allowing us to compute the pdf of a certain new random variable Y that is a known function Y = g(X) of another random variable X having a known pdf. In other words, if the pdf f X (x) of a certain random variable X is known, then the pdf f Y (y) of the new random variable Y, related to X by the functional relationship
(56)can be calculated according to the following rules:
$$Y = g\left( X \right)$$
-
(a) First, invert the corresponding non-probabilistic equation y = g(x) and denote by x i (y) the various real roots resulting from this inversion.
-
(b) Second, take notice whether these real roots may be either finitely- or infinitely-many, according to the nature of the function y = g(x).
-
(c) Third, the pdf of Y is then given by the (finite or infinite) sum
(57)
$$f_Y \left( y \right) = \sum\limits_i {\displaystyle{{\,f_X (x_i (y))} \over {\left \vert {g^{\prime}(x_i (y))} \right \vert}}}, $$


where the summation extends to all roots x i (y) and |g′(x i (y))| is the absolute value of the first derivative of g(x) where the ith root x i (y) has been replaced instead of x.
Going now back to (53), in order to invert it, i.e. in order to find the pdf of C, we must apply the general transformation law (57) to the particular transformation
 $$y = g(x) = {\rm e}^x. $$
$$y = g(x) = {\rm e}^x. $$
That, upon inversion, yields the single root
 $$x_1 \left( y \right) = x\left( y \right) = \ln y.$$
$$x_1 \left( y \right) = x\left( y \right) = \ln y.$$
On the other hand, differentiating equation (58) one gets
 $$g^{\prime}\left( x \right) = {\rm e}^x $$
$$g^{\prime}\left( x \right) = {\rm e}^x $$
and
 $$g^{\prime}\left( {x_1 \left( y \right)} \right) = {\rm e}^{\ln y} = y,$$
$$g^{\prime}\left( {x_1 \left( y \right)} \right) = {\rm e}^{\ln y} = y,$$
where equation (60) was already used in the last step. So, the general transformation law (57) finally yields just the lognormal pdf in y for the random variable C, the time History of that Civilization:
 $$\eqalign{\,f_C \left( y \right) = & \sum\limits_i {\displaystyle{{\,f_x (x_i (y))} \over {\left \vert {g^{\prime}(x_i (y)} \right \vert}}} = \displaystyle{1 \over {\left \vert y \right \vert}} f_Y \left( {\ln \left( y \right)} \right) \cr & \quad = \displaystyle{1 \over {\sqrt {2{\rm \pi}} \,{\rm \sigma} y}}{\rm e}^{ - (\ln (y) - {\rm \mu} )^2 /\left(2\,{\rm \sigma} ^2\right)}, \quad {\rm for}\quad y \gt 0.} $$
$$\eqalign{\,f_C \left( y \right) = & \sum\limits_i {\displaystyle{{\,f_x (x_i (y))} \over {\left \vert {g^{\prime}(x_i (y)} \right \vert}}} = \displaystyle{1 \over {\left \vert y \right \vert}} f_Y \left( {\ln \left( y \right)} \right) \cr & \quad = \displaystyle{1 \over {\sqrt {2{\rm \pi}} \,{\rm \sigma} y}}{\rm e}^{ - (\ln (y) - {\rm \mu} )^2 /\left(2\,{\rm \sigma} ^2\right)}, \quad {\rm for}\quad y \gt 0.} $$
with μ given by equation (54) and σ given by equation (55). This is a very important result to understand the History of Civilizations mathematically: we now see why, for instance, all Civilizations shown in Fig. 2 are b-lognormals in their Historic development!
The pdf (62) actually is a b-lognormal, rather than just an ordinary lognormal starting at zero. In fact, the instant b at with it starts may not be smaller than the birth instant of the first (Historically!) individual of the population. Thus, the true b-lognormal pdf of the C Civilization is
 $$f_C \left( t \right) = \displaystyle{{{\rm e}^{ - [\ln \left( {t - b} \right) - {\rm \mu} ^2 ]/\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} \,{\rm \sigma} \;(t - b)}}\quad {\rm with}\quad t \ge b = \min b_i. $$
$$f_C \left( t \right) = \displaystyle{{{\rm e}^{ - [\ln \left( {t - b} \right) - {\rm \mu} ^2 ]/\left(2{\rm \sigma} ^2\right)}} \over {\sqrt {{\rm 2\pi}} \,{\rm \sigma} \;(t - b)}}\quad {\rm with}\quad t \ge b = \min b_i. $$
The very important special case of C i uniform random variables: E-Pluribus-Unum Theorem
This author has discovered new, important and rather simple equations for the particular case where the input variables C i are uniformly distributed between birth and death, namely, the pdf of each C i is
 $$f_{C_i} \left( t \right) = \displaystyle{1 \over {d_i - b_i}}, \quad {\rm for}\quad b_i \le t \le d_i. $$
$$f_{C_i} \left( t \right) = \displaystyle{1 \over {d_i - b_i}}, \quad {\rm for}\quad b_i \le t \le d_i. $$
In equation (64) b i is the instant when he/she/it was born, and d i is the instant when he/she/it died. We may not know them at all: just think of the millions of Unknown Soldiers died in World War One and in all wars (billions?). But that will not prevent us from doing the mathematics of equation (64).
Our primary goal now is to find the pdf of the random variable Y i = ln C i as requested by equation (52). To this end, we must apply again the transformation law (57), this time applied to the transformation
 $$y = g\left( x \right) = \ln \left( x \right).$$
$$y = g\left( x \right) = \ln \left( x \right).$$
Upon inversion, equation (65) yields the single root
 $$x_1 \left( y \right) = x\left( y \right) = {\rm e}^y. $$
$$x_1 \left( y \right) = x\left( y \right) = {\rm e}^y. $$
On the other hand, differentiating equation (65) yields
 $$g^{\prime}\left( x \right) = \displaystyle{1 \over x}$$
$$g^{\prime}\left( x \right) = \displaystyle{1 \over x}$$
and
 $$g^{\prime}\left( {x_1 \left( y \right)} \right) = \displaystyle{1 \over {x_1 (y)}} = \displaystyle{1 \over {{\rm e}^y}}, $$
$$g^{\prime}\left( {x_1 \left( y \right)} \right) = \displaystyle{1 \over {x_1 (y)}} = \displaystyle{1 \over {{\rm e}^y}}, $$
where equation (66) was already used in the last step. Then, by virtue of the uniform pdf (64), the general transformation law (57) finally yields
 $$\eqalign{\,f_{Y_i} \left( y \right) = & \sum\limits_i {\displaystyle{{\,f_x (x_i (y))} \over {\left \vert {g^{\prime}(x_i (y))} \right \vert}}} = \displaystyle{1 \over {d_i - b_i}} \cdot \displaystyle{1 \over {\left \vert {1/{\rm e}^y} \right \vert}} \cr & = \displaystyle{{{\rm e}^y} \over {d_i - b_i}}.} $$
$$\eqalign{\,f_{Y_i} \left( y \right) = & \sum\limits_i {\displaystyle{{\,f_x (x_i (y))} \over {\left \vert {g^{\prime}(x_i (y))} \right \vert}}} = \displaystyle{1 \over {d_i - b_i}} \cdot \displaystyle{1 \over {\left \vert {1/{\rm e}^y} \right \vert}} \cr & = \displaystyle{{{\rm e}^y} \over {d_i - b_i}}.} $$
In other words, the requested pdf of Y i = ln C i is
 $$f_{Y_i} \left( y \right) = \displaystyle{{{\rm e}^y} \over {d_i - b_i}}, \quad {\rm for}\quad \ln b_i \le y \le \ln d_i. $$
$$f_{Y_i} \left( y \right) = \displaystyle{{{\rm e}^y} \over {d_i - b_i}}, \quad {\rm for}\quad \ln b_i \le y \le \ln d_i. $$
These are the probability density functions of the natural logs of all the uniformly distributed C i random variables. Namely, in the colourful language of the applications of the Evo-SETI Theory, equation ( 70 ) is the pdf of all UNKNOWN FORMS OF LIFE, about which we only known when each of them was born and when it died.
Let us now check that the pdf (70) fulfils indeed its normalization condition
 $$\eqalign{&\int_{\ln b_i} ^{\ln d_i}{{\,f_{{Y_i}}}\left( y \right){\rm d}y} = \int_{\ln b_i} ^{\ln d_i}{\displaystyle{{{{\rm e}^y}} \over {{d_i} - {b_i}}}} dy \cr & = \displaystyle{{{{\rm e}^{\ln {d_i}}} - {{\rm e}^{\ln {b_i}}}} \over {{d_i} - {b_i}}} = \displaystyle{{{d_i} - {b_i}} \over {{d_i} - {b_i}}} = 1.} $$
$$\eqalign{&\int_{\ln b_i} ^{\ln d_i}{{\,f_{{Y_i}}}\left( y \right){\rm d}y} = \int_{\ln b_i} ^{\ln d_i}{\displaystyle{{{{\rm e}^y}} \over {{d_i} - {b_i}}}} dy \cr & = \displaystyle{{{{\rm e}^{\ln {d_i}}} - {{\rm e}^{\ln {b_i}}}} \over {{d_i} - {b_i}}} = \displaystyle{{{d_i} - {b_i}} \over {{d_i} - {b_i}}} = 1.} $$
Next we want to find the mean value and standard deviation of each Y i , since they play a crucial role for future developments. The mean value of the pdf (70) is given by either of the following alternative forms:
 $$\eqalign{\left\langle {Y_i} \right\rangle = & \int_{\ln (b_i )}^{\ln (d_i )} {y \cdot f_{Y_i} \left( y \right){\rm d}y} = \int_{\ln (b_i )}^{\ln (d_i )} {\displaystyle{{y \cdot {\rm e}^y} \over {d_i - b_i}} {\rm d}y} \cr & = \displaystyle{{d_i [\ln (d_i ) - 1] - b_i [\ln (b_i ) - 1]} \over {d_i - b_i}} \cr & = \displaystyle{{d_i \,\ln (d_i ) - b_i \,\ln (b_i )} \over {d_i - b_i}} - 1 \cr & = \displaystyle{{\ln [(d_i )^{d_i} /(b_i )^{b_i} ]} \over {d_i - b_i}} - 1 \cr & = \ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right] - 1.} $$
$$\eqalign{\left\langle {Y_i} \right\rangle = & \int_{\ln (b_i )}^{\ln (d_i )} {y \cdot f_{Y_i} \left( y \right){\rm d}y} = \int_{\ln (b_i )}^{\ln (d_i )} {\displaystyle{{y \cdot {\rm e}^y} \over {d_i - b_i}} {\rm d}y} \cr & = \displaystyle{{d_i [\ln (d_i ) - 1] - b_i [\ln (b_i ) - 1]} \over {d_i - b_i}} \cr & = \displaystyle{{d_i \,\ln (d_i ) - b_i \,\ln (b_i )} \over {d_i - b_i}} - 1 \cr & = \displaystyle{{\ln [(d_i )^{d_i} /(b_i )^{b_i} ]} \over {d_i - b_i}} - 1 \cr & = \ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right] - 1.} $$
This is thus the mean value of the natural log of all the uniformly distributed random variables C i (just to use a few of the above equivalent forms). Thus, the whole Civilization is a b-lognormal with the following parameters:
 $$\eqalign{{\rm \mu} = \sum\limits_{i = 1}^N {\left\langle {Y_i} \right\rangle} = & \sum\limits_{i = 1}^N {\left( {\displaystyle{{d_i \,\ln (d_i ) - b_i \,\ln (b_i )} \over {d_i - b_i}} - 1} \right)} \cr = & \sum\limits_{i = 1}^N {\left( {\ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right] - 1} \right)} \cr = & \sum\limits_{i = 1}^N {\ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right]} - N \cr = & \ln \left[ {\prod\limits_{i = 1}^N {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}}} \right] - N.} $$
$$\eqalign{{\rm \mu} = \sum\limits_{i = 1}^N {\left\langle {Y_i} \right\rangle} = & \sum\limits_{i = 1}^N {\left( {\displaystyle{{d_i \,\ln (d_i ) - b_i \,\ln (b_i )} \over {d_i - b_i}} - 1} \right)} \cr = & \sum\limits_{i = 1}^N {\left( {\ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right] - 1} \right)} \cr = & \sum\limits_{i = 1}^N {\ln \left[ {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}} \right]} - N \cr = & \ln \left[ {\prod\limits_{i = 1}^N {\displaystyle{{(d_i )^{d_i /\left(d_i - b_i\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}}} \right] - N.} $$
The last form of μ shows that the exponential of μ is
 $${\rm e}^{\rm \mu} = {\rm e}^{ - N} \prod\limits_{i = 1}^N {\displaystyle{{(d_i )^{d_i /\left(d_i - b\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}}. $$
$${\rm e}^{\rm \mu} = {\rm e}^{ - N} \prod\limits_{i = 1}^N {\displaystyle{{(d_i )^{d_i /\left(d_i - b\right)}} \over {(b_i )^{b_i /\left(d_i - b_i\right)}}}}. $$
In order to find the variance also, we must first compute the mean value of the square of Y i , that is
 $$\eqalign{\left\langle {Y_i ^2} \right\rangle = & \int_{\ln \left( {b_i} \right)}^{\ln \left( {d_i} \right)} {y^2 \cdot f_{Y_i} \left( y \right){\rm d}y} = \int_{\ln \left( {b_i} \right)}^{\ln \left( {d_i} \right)} {\displaystyle{{y^2 \cdot {\rm e}^y} \over {d_i - b_i}} {\rm d}y} \cr = & \displaystyle{{d_i \left[ {\ln ^2 \left( {d_i} \right) - 2\ln \left( {d_i} \right) + 2} \right] - b_i \left[ {\ln ^2 \left( {b_i} \right) - 2\ln \left( {b_i} \right) + 2} \right]} \over {d_i - b_i}}.} $$
$$\eqalign{\left\langle {Y_i ^2} \right\rangle = & \int_{\ln \left( {b_i} \right)}^{\ln \left( {d_i} \right)} {y^2 \cdot f_{Y_i} \left( y \right){\rm d}y} = \int_{\ln \left( {b_i} \right)}^{\ln \left( {d_i} \right)} {\displaystyle{{y^2 \cdot {\rm e}^y} \over {d_i - b_i}} {\rm d}y} \cr = & \displaystyle{{d_i \left[ {\ln ^2 \left( {d_i} \right) - 2\ln \left( {d_i} \right) + 2} \right] - b_i \left[ {\ln ^2 \left( {b_i} \right) - 2\ln \left( {b_i} \right) + 2} \right]} \over {d_i - b_i}}.} $$
The variance of Y i = ln(C i ) is now given by equation (75) minus the square of equation (73), that, using the first form of equation (73) and after a few reductions, yields:
 $$\eqalign{{\rm \sigma}_{Y_i}^{2} = {\rm \sigma}_{\ln (C_i )}^2 = & 1 - \displaystyle{{b_{i} d_{i} \left[{\ln (d_i /b_i})\right]^2} \over {(d_i - b_i)^2}} \cr & = 1 - \left[{\ln \left\{{\left({\displaystyle{{d_i}\over{b_i}}}\right)^{\displaystyle{{\sqrt{b_i\,d_i}}\over{d_i - b_i}}}}\right\}}\right]^2.} $$
$$\eqalign{{\rm \sigma}_{Y_i}^{2} = {\rm \sigma}_{\ln (C_i )}^2 = & 1 - \displaystyle{{b_{i} d_{i} \left[{\ln (d_i /b_i})\right]^2} \over {(d_i - b_i)^2}} \cr & = 1 - \left[{\ln \left\{{\left({\displaystyle{{d_i}\over{b_i}}}\right)^{\displaystyle{{\sqrt{b_i\,d_i}}\over{d_i - b_i}}}}\right\}}\right]^2.} $$
Whence, using the first form of equation (76) and taking the square root, yields the standard deviation of Y i
 $${\rm \sigma} _{Y_i} = {\rm \sigma} _{\ln (D_i )} = \sqrt {1 - \displaystyle{{b_i \,d_i [\ln (d_i ) - \ln (b_i )]^2} \over {(d_i - b_i )^2}}}. $$
$${\rm \sigma} _{Y_i} = {\rm \sigma} _{\ln (D_i )} = \sqrt {1 - \displaystyle{{b_i \,d_i [\ln (d_i ) - \ln (b_i )]^2} \over {(d_i - b_i )^2}}}. $$
Like the μ given by equation (73), equation (76) also may be rewritten in a few alternative forms. For instance
 $$\eqalign{{\rm \sigma}_Y^2 & = \sum\limits_{i = 1}^N{{\rm \sigma}_{Y_i}^2} = \sum\limits_{i = 1}^N {{\rm \sigma}_{\ln ({C_i})}^2} \cr & = \sum\limits_{i = 1}^N {\left({1 - \displaystyle{{b_i \,d_i [\ln (d_i /b_i) ]^2} \over {(d_i - b_i )^2}}}\right)} \cr & = N - \sum\limits_{i = 1}^N {\left[{\ln \left\{{\left({\displaystyle{{d_i}\over{b_i}}}\right)^{\displaystyle{{\sqrt{b_i \,d_i}}\over{d_i - b_i}}}}\right\}}\right]^2}.}$$
$$\eqalign{{\rm \sigma}_Y^2 & = \sum\limits_{i = 1}^N{{\rm \sigma}_{Y_i}^2} = \sum\limits_{i = 1}^N {{\rm \sigma}_{\ln ({C_i})}^2} \cr & = \sum\limits_{i = 1}^N {\left({1 - \displaystyle{{b_i \,d_i [\ln (d_i /b_i) ]^2} \over {(d_i - b_i )^2}}}\right)} \cr & = N - \sum\limits_{i = 1}^N {\left[{\ln \left\{{\left({\displaystyle{{d_i}\over{b_i}}}\right)^{\displaystyle{{\sqrt{b_i \,d_i}}\over{d_i - b_i}}}}\right\}}\right]^2}.}$$
We stop at this point, for we feel we have really proven a new theorem, yielding the b-lognormal in time of the History of any Civilization. This new theorem deserves a new name. We propose to call it by the Latin name of ‘E-Pluribus-Unum’ Theorem.
Indeed, ‘E-Pluribus-Unum’ stands for ‘Out of Many, just One’, and this was the official motto of the USA from 1782 to 1956, when replaced by ‘In God we trust’ (probably in opposition to atheists views then supported by the Soviet Union). In this author's view, ‘E-Pluribus-Unum’ adapts well to what we have described mathematically in the first part of this paper about Civilizations in Evo-SETI Theory.
PART 2: NEW RESULTS ABOUT MOLECULAR CLOCK IN EVO-SETI THEORY
Darwinian evolution as a Geometric Brownian Motion (GBM)
In (Maccone Reference Maccone2013, p. 220–227), this author ‘dared’ to re-define Darwinian Evolution as ‘just one particular realization of the stochastic process called GBM in the increasing number of Species living on Earth over the last 3.5 billion years’.
Now, the GBM mean value is the simple exponential function of the time
 $$m_{{\rm GBM}} \left( t \right) = A\;{\rm e}^{Bt} $$
$$m_{{\rm GBM}} \left( t \right) = A\;{\rm e}^{Bt} $$
with A and B being the positive constants. Thus, A equals m GBM(0), the number of Species living on Earth right now, and
 $$m_{{\rm GBM}} \left( {ts} \right) = 1$$
$$m_{{\rm GBM}} \left( {ts} \right) = 1$$
represents the first ‘living Species’ (call it RNA ?) that started life on Earth at the ‘initial instant’ ts (‘time of start’). In (Maccone Reference Maccone2013, Reference Maccone2014) we assumed that life started on Earth 3.5 billion years ago, that is
 $$ts = - 3.5 \times 10^9 \;{\rm years}$$
$$ts = - 3.5 \times 10^9 \;{\rm years}$$
and that the number of Species living on Earth nowadays is 50 million
 $$A = 50 \times 10^6. $$
$$A = 50 \times 10^6. $$
Consequently, the two constants A and B in equation (79) may be exactly determined as follows:
 $$\left\{ {\matrix{ {A = 50 \times 10^6} \hfill \cr {B = - \displaystyle{{\ln (A)} \over {ts}} = 1.605 \times 10^{ - 16} \;{\rm s}^{ - 1}.} \hfill \cr}} \right.$$
$$\left\{ {\matrix{ {A = 50 \times 10^6} \hfill \cr {B = - \displaystyle{{\ln (A)} \over {ts}} = 1.605 \times 10^{ - 16} \;{\rm s}^{ - 1}.} \hfill \cr}} \right.$$
Please note that these two numbers are to be regarded as experimental constants (valid for Earth only), just like the acceleration of gravity g = 9.8 m s−2, the solar constant, and other Earthly constants.
Also, some paleontologists claim that life on Earth started earlier, say 3.8 billion years ago. In this case, equations (83) is to be replaced by the slightly different
 $$\left\{ {\matrix{ {A = 50 \times 10^6} \hfill \cr {B = - \displaystyle{{\ln (A)} \over {ts}} = 1.478 \times 10^{ - 16} \;{\rm s}^{ - 1}.} \hfill \cr}} \right.$$
$$\left\{ {\matrix{ {A = 50 \times 10^6} \hfill \cr {B = - \displaystyle{{\ln (A)} \over {ts}} = 1.478 \times 10^{ - 16} \;{\rm s}^{ - 1}.} \hfill \cr}} \right.$$
but B did not change much, and so we will keep equations (83) as the right values as it was done in (Maccone Reference Maccone2013, Reference Maccone2014).
Figure 3 shows two realizations of GBM revealing ‘at a glance’ the exponential increasing mean value of this lognormal stochastic process (see (Maccone Reference Maccone2013, p. 222–223) for more details, and (Maccone Reference Maccone2014, p. 291–294) for a full mathematical treatment).

Fig. 3. Two realizations (i.e. actual instances) of Geometric Brownian Motion taken from the GBM Wikipedia site http://en.wikipedia.org/wiki/Geometric_Brownian_motion . Please keep in mind that the name ‘Brownian Motion’ is incorrect and misleading: in fact, physicists and mathematicians mean by ‘Brownian Motion’ a stochastic process whose pdf is Gaussian, i.e. normal. But this is not the case with GBM, whose pdf is lognormal instead. This incorrect denomination seems to go back to the Wall Street financial users of the GBM.
Assuming GBM as the ‘curve’ (a fluctuating one!) representing the increasing number of Species over the last 3.5 billion years has several advantages:
-
(1) It puts on a firm mathematical ground the intuitive notion of a ‘Malthusian’ exponential growth.
-
(2) It allows for Mass Extinctions to have occurred in the past history of life on Earth, as indeed it was the case. Mass Extinctions in the Evo-SETI Theory are just times when the number of living Species ‘decreased very much’ from its exponential mean value, for instance going down by 70% just 250 million years ago, but not going down to zero, otherwise we would not be living now. In (Maccone Reference Maccone2014) this author did more modelling about Mass Extinctions.
-
(3) After what we just said, the two curves called ‘upper’ and ‘lower standard deviation curve’ are clearly playing a major role in Evo-SETI Theory. They represent the average departure of the actual number of living Species from their exponential mean value, as shown in Figure 4. In (Maccone Reference Maccone2014, p. 292–293), the author proved that the upper (plus sign) and lower (minus sign) standard deviation curves of GBM (above and below the mean value exponential (79), respectively), are given by the equations
(85)
$$\eqalign{& {\rm upper}\_\&\_{\rm lower}\_{\rm std}\_{\rm curves}\_{\rm of}\_{\rm GBM}(t) \cr & \quad = m_{\rm GBM}(t) \cdot \left[{1 \pm \sqrt{{\rm e}^{{\rm \sigma}_{\rm GBM}2(t - ts)}- 1}}\right].}$$


Fig. 4. Darwinian evolution as the increasing number of living Species on Earth between 3.5 billion years ago and now. The red solid curve is the mean value of the GBM stochastic process, given by equation (79), while the blue dot–dot curves above and below the mean value are the two standard deviation upper and lower curves, given by equation (105). The ‘Cambrian Explosion’ of life that started around 542 million years ago, approximately marks in the above plot ‘the epoch of departure from the time axis for all the three curves, after which they start climbing up more and more’. Notice also that the starting value of living Species 3.5 billion years ago is ONE by definition, but it ‘looks like’ zero in this plot since the vertical scale (which is the true scale here, not a log scale) does not show it. Notice finally that nowadays (i.e. at time t = 0) the two standard deviation curves have exactly the same distance from the middle mean value curve, i.e. 30 million living Species above or below the mean value of 50 million Species. These are assumed values that we used just to exemplify the GBM mathematics: biologists might assume other numeric values.
The new constant σGBM appearing in equation (85) (not to be confused with the simple σ of the b-lognormal (5)) is provided by the final conditions affecting the GBM at the final instant of its motion, namely zero (=now) in our conventions. Denoting by A the current number of Species on Earth, as we did in equations (79) and (82), and by δA the standard deviation around A nowadays (for instance, we assumed A to be equal to 50 million but we might add an uncertainty of, say, ±10 million Species around that value), then the σGBM in equation (85) is given by
 $${\rm \sigma} _{{\rm GBM}} = \displaystyle{{\sqrt {{\rm ln}[1 + ({\rm \delta} A/A)^2] }} \over {\sqrt {- ts}}}. $$
$${\rm \sigma} _{{\rm GBM}} = \displaystyle{{\sqrt {{\rm ln}[1 + ({\rm \delta} A/A)^2] }} \over {\sqrt {- ts}}}. $$
A leap forward: for any assigned mean value m L (t) we construct its lognormal stochastic process
A profound message was contained in (Maccone Reference Maccone2014) for all future applications of lognormal stochastic processes (both GBM and other than GBM): for any assigned at will mean value function of the time m L (t), namely for any trend, we are able to find the equations of the lognormal process that has exactly that mean value, i.e. that trend !
This author was so amazed by this discovery (that he made between September 2013 and January 2014) that he could not give a complete account of it when he published (Maccone Reference Maccone2014) available in Open Access since October 2014. Thus, the present new paper is a completion of (Maccone Reference Maccone2014), but also is a leap forward in another unexpected direction: the proof that the Molecular Clock, well-known to geneticists for more than 50 years, may be derived mathematically as a consequence of the Evo-SETI Theory.
Completing (Maccone Reference Maccone2014): letting M L (t) there be replaced everywhere by m L (t), the assigned trend
In (Maccone Reference Maccone2014) this author started by considering the general lognormal process L(t) whose pdf is the lognormal
 $$\eqalign{& L\left( t \right)\_{\rm pdf}\left( {n\,;M_L \left( t \right),{\rm \sigma} _L, t} \right) = \displaystyle{{{\rm e}^{ - \left[ {\ln (n) - M_L (t)} \right]^2 /\left(2{\rm \sigma} _L^2 (t - ts)\right)}} \over {\sqrt {2\pi}\, {\rm \sigma} _L \sqrt {t - ts}\, n}}{\rm} \cr & {\rm with} \left\{ {\matrix{ {n \ge 0,} \cr {t \ge ts,} \cr}} \right.\;\;{\rm and}\left\{ {\matrix{ {\sigma _L \ge 0,} \hfill \cr {M_L \left( t \right) = \hbox{arbitrary function of}\;t.} \hfill \cr}} \right.} $$
$$\eqalign{& L\left( t \right)\_{\rm pdf}\left( {n\,;M_L \left( t \right),{\rm \sigma} _L, t} \right) = \displaystyle{{{\rm e}^{ - \left[ {\ln (n) - M_L (t)} \right]^2 /\left(2{\rm \sigma} _L^2 (t - ts)\right)}} \over {\sqrt {2\pi}\, {\rm \sigma} _L \sqrt {t - ts}\, n}}{\rm} \cr & {\rm with} \left\{ {\matrix{ {n \ge 0,} \cr {t \ge ts,} \cr}} \right.\;\;{\rm and}\left\{ {\matrix{ {\sigma _L \ge 0,} \hfill \cr {M_L \left( t \right) = \hbox{arbitrary function of}\;t.} \hfill \cr}} \right.} $$
Equation (87) also is the starting point of all subsequent calculations in the #3 Appendix, where it has the number (%o6). Notice that the positive parameter σ L in the pdf (87) is denoted sL in the #3 Appendix, simply because Maxima did not allow us to denote it σ L for Maxima-language reasons too long to explain! Also, m L (t) is more simply denoted m(t) in the #3 Appendix, and M L (t) is more simply denoted M(t).
The mean value, i.e. the trend, of the process L(t) is an arbitrary (and continuous) function of the time denoted by m L (t) in the sequel. In equations, that is, one has, by definition
 $$m_L (t) = \left\langle {L\left( t \right)} \right\rangle. $$
$$m_L (t) = \left\langle {L\left( t \right)} \right\rangle. $$
In other words, we analytically compute the following integral, yielding the mean value of the pdf (87), getting (for the proof, see (%o5) and (%o6) in the #3 Appendix)
 $$\eqalign{m_L(t)& \equiv \int_0^\infty {n \cdot \displaystyle{{{\rm e}^{ - [\ln (n) - M_L (t)]^2 /(2{\rm \sigma}_L^2 (t - ts))}} \over {\sqrt {2\pi}\, {\rm \sigma}_L \sqrt{t - ts}\,n}}\;} {\rm d}n \cr & = {\rm e}^{M_L (t)} {\rm e}^{({\rm \sigma}_L^2/2)(t - ts)}.}$$
$$\eqalign{m_L(t)& \equiv \int_0^\infty {n \cdot \displaystyle{{{\rm e}^{ - [\ln (n) - M_L (t)]^2 /(2{\rm \sigma}_L^2 (t - ts))}} \over {\sqrt {2\pi}\, {\rm \sigma}_L \sqrt{t - ts}\,n}}\;} {\rm d}n \cr & = {\rm e}^{M_L (t)} {\rm e}^{({\rm \sigma}_L^2/2)(t - ts)}.}$$
This is (%o8) in the #3 Appendix, and from now on, we will drop the usual sentence ‘in the #3 Appendix’ and just report the #3 Appendix equation numbers corresponding to the equation numbers in this paper.
We have thus discovered the following crucial mean value formula, holding good for the general lognormal process L(t) inasmuch as the function M L (t) is arbitrary, and so is the trend m L (t) (%o9)
 $$m_L \left( t \right) = {\rm e}^{M_L (t)} \,{\rm e}^{({\rm \sigma} _L^2 /2)(t - ts)}. $$
$$m_L \left( t \right) = {\rm e}^{M_L (t)} \,{\rm e}^{({\rm \sigma} _L^2 /2)(t - ts)}. $$
This was done by the author in (Maccone Reference Maccone2014) already, p. 292, equation (3). But at that time this author failed to invert (90), i.e. to solve it for M L (t), with the result (%o10):
 $$M_L \left( t \right) = \ln \left[ {m_L \left( t \right)} \right] - \displaystyle{{{\rm \sigma} _L^2} \over 2}\;\left( {t - ts} \right).$$
$$M_L \left( t \right) = \ln \left[ {m_L \left( t \right)} \right] - \displaystyle{{{\rm \sigma} _L^2} \over 2}\;\left( {t - ts} \right).$$
Equation (91) shows that it is always possible to get rid of M L (t) by substituting equation (91) into any equation containing M L (t) and appearing in (Maccone Reference Maccone2014). In other words, one may re-express all results of Maccone Reference Maccone2014) in terms of the trend function m L (t) only , justifying the idea ‘you give me the trend m L (t) and I'll give you all the equations of the lognormal process L(t) for which m(t) is the trend’.
An immediate consequence of (91) is found by letting t = ts ((%o11) and (%o12)):
 $$M_L \left( {ts} \right) = \ln \left[ {m_L \left( {ts} \right)} \right],\quad {\rm i}{\rm. e}{\rm.} \quad m_L \left( {ts} \right) = {\rm e}^{M_L (ts)}. $$
$$M_L \left( {ts} \right) = \ln \left[ {m_L \left( {ts} \right)} \right],\quad {\rm i}{\rm. e}{\rm.} \quad m_L \left( {ts} \right) = {\rm e}^{M_L (ts)}. $$
For instance, equation (8) on p. 292 of (Maccone Reference Maccone2014) yields the σ L in terms of both the initial input data (ts, Ns) and final input data (te, Ne, δNe):
 $${\rm \sigma} _L = \displaystyle{{\sqrt {\ln [{\rm e}^{2M_L (ts)} + ({\rm \delta} Ne)^2 (Ns/Ne)^2 ] - 2M_L (ts)}} \over {\sqrt {te - ts}}} $$
$${\rm \sigma} _L = \displaystyle{{\sqrt {\ln [{\rm e}^{2M_L (ts)} + ({\rm \delta} Ne)^2 (Ns/Ne)^2 ] - 2M_L (ts)}} \over {\sqrt {te - ts}}} $$
Well, this equation simplifies dramatically once equation (92) and the initial condition (equation (5) on p. 292 of Maccone (Reference Maccone2014)) (%o13)
 $$m_L \left( {ts} \right) = Ns$$
$$m_L \left( {ts} \right) = Ns$$
are taken into account. In fact, a few steps starting from equation (93) show that, by virtue of equations (92) and (94), it reduces to (%o31)
 $${\rm \sigma} _L = \displaystyle{{\sqrt {{\rm ln}[1 + ({\rm \delta} Ne/Ne)^2 ]}} \over {\sqrt {te - ts}}} $$
$${\rm \sigma} _L = \displaystyle{{\sqrt {{\rm ln}[1 + ({\rm \delta} Ne/Ne)^2 ]}} \over {\sqrt {te - ts}}} $$
Of course, the corresponding GBM special case of equation (95) is (86), obtained by letting (te = 0, Ne = A) into equation (95).
Also, equation (95) may be formally rewritten as follows:
 $${\rm \sigma} _L^2 = \displaystyle{{\rm ln}\big[ {1 + ({\rm \delta} Ne/Ne)^2 \big]} \over {(te - ts)}} = \ln \left\{ {\left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{1/(te - ts)}} \right\}.$$
$${\rm \sigma} _L^2 = \displaystyle{{\rm ln}\big[ {1 + ({\rm \delta} Ne/Ne)^2 \big]} \over {(te - ts)}} = \ln \left\{ {\left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{1/(te - ts)}} \right\}.$$
Taking the exponential of equation (96), one thus gets a yet unpublished equation that we shall use in a moment
 $${\rm e}^{{\rm \sigma} _L^2 (t - ts)} = \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{(t - ts)/(te - ts)}. $$
$${\rm e}^{{\rm \sigma} _L^2 (t - ts)} = \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{(t - ts)/(te - ts)}. $$
Going back to the general lognormal process L(t), in (Maccone Reference Maccone2014), Tables 1–3, we also proved that the moment of order k (with k = 0, 1, 2, …) of the L(t) process is given by
 $$\left\langle {\left[ {L\left( t \right)} \right]^k} \right\rangle = \left[ {m_L \left( t \right)} \right]^k {\rm e}^{k(k - 1){\rm \sigma} _L^2 (t - ts)/2} $$
$$\left\langle {\left[ {L\left( t \right)} \right]^k} \right\rangle = \left[ {m_L \left( t \right)} \right]^k {\rm e}^{k(k - 1){\rm \sigma} _L^2 (t - ts)/2} $$
Table 3. Summary of the most important mathematical properties of the lognormal stochastic process L(t).

The mathematical proof of this key result by virtue Maxima is given in the #3 Appendix, equations (%i16) through (%o21).
A new discovery, presented in this paper for the first time, is that, by virtue of equation (97), equation (98) may be directly rewritten in terms of the boundary conditions (ts, te, Ne, δNe):
 $$\left\langle {\left[ {L\left( t \right)} \right]^k} \right\rangle = \left[ {m_L \left( t \right)} \right]^k \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{k(k - 1)\,(t - ts)/(2\,(te - ts))}. $$
$$\left\langle {\left[ {L\left( t \right)} \right]^k} \right\rangle = \left[ {m_L \left( t \right)} \right]^k \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{k(k - 1)\,(t - ts)/(2\,(te - ts))}. $$
For k = 0, both equations (98) and (99) yield the normalization condition of L(t):
 $$\left\langle {\left[ {L\left( t \right)} \right]^0} \right\rangle = 1.$$
$$\left\langle {\left[ {L\left( t \right)} \right]^0} \right\rangle = 1.$$
For k = 1 both equations (98) and (99) yield the mean value again
 $$\left\langle {\left[ {L\left( t \right)} \right]^1} \right\rangle = \left\langle {L\left( t \right)} \right\rangle = m_L \left( t \right).$$
$$\left\langle {\left[ {L\left( t \right)} \right]^1} \right\rangle = \left\langle {L\left( t \right)} \right\rangle = m_L \left( t \right).$$
But for k = 2 (the mean value of the square of L(t)) the novelties start. In fact, equation (99) yields
 $$\left\langle {\left[ {L\left( t \right)} \right]^2} \right\rangle = \left[ {m_L \left( t \right)} \right]^2 \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{(t - ts)/(te - ts)}. $$
$$\left\langle {\left[ {L\left( t \right)} \right]^2} \right\rangle = \left[ {m_L \left( t \right)} \right]^2 \left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{(t - ts)/(te - ts)}. $$
Since the variance of L(t) is given by the mean value of its square minus the square of its mean value, subtracting the square of equation (101) into (102) yields
 $$\hbox{Variance of}\, L(t) =[{m_L(t)}]^2 \left\{{\left[{1 +{ \left({\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)}^2}\right]^{(t - ts)/(te - ts)} - 1}\right\}.$$
$$\hbox{Variance of}\, L(t) =[{m_L(t)}]^2 \left\{{\left[{1 +{ \left({\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)}^2}\right]^{(t - ts)/(te - ts)} - 1}\right\}.$$
The square root of equation (103) is of course the standard deviation of L(t):
 $$\eqalign{{\rm Standard}\_{\rm Deviation}\_{\rm of}\_\,&L(t) = \cr & m_L (t) \cdot \sqrt {\left[{1 + {\left({\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)^2}}\right]^{(t - ts)/(te - ts)}- 1}.}$$
$$\eqalign{{\rm Standard}\_{\rm Deviation}\_{\rm of}\_\,&L(t) = \cr & m_L (t) \cdot \sqrt {\left[{1 + {\left({\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)^2}}\right]^{(t - ts)/(te - ts)}- 1}.}$$
This is a quite important formula for all future applications of our general lognormal process L(t) to the Evo-SETI Theory.
Even more important for all future graphical representations of the general lognormal process L(t) is the formula yielding the upper (plus sign) and lower (minus sign) standard deviation curves as two functions of t. It follows immediately from the mean value m L (t) plus or minus the standard deviation (104):
 $$\eqalign{& {\rm Two}\_{\rm Standard}\_{\rm Deviation}\_{\rm CURVES}\_{\rm of}\_ L(t) \cr & \quad = m_L (t) \cdot \left\{{1 \pm \sqrt {\left[{1 + {\left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)^2}}\right]^{(t - ts)/(te - ts)} - 1}}\right\}.}$$
$$\eqalign{& {\rm Two}\_{\rm Standard}\_{\rm Deviation}\_{\rm CURVES}\_{\rm of}\_ L(t) \cr & \quad = m_L (t) \cdot \left\{{1 \pm \sqrt {\left[{1 + {\left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}}\right)^2}}\right]^{(t - ts)/(te - ts)} - 1}}\right\}.}$$
Just to check that our results are correct, from (105) one may immediately verify that:
-
(1) Letting t = ts in (105) yields m L (ts) as the value of both curves. But this is the same value as the mean value at t = ts also. Thus, at t = ts the process L(t) starts with probability one, since all three curves are at the just the same point.
-
(2) Letting t = te in (105) yields
(106)where m L (te) = Ne was used in the last step. This result is correct inasmuch as the two curves intercept the vertical line at t = te exactly at those two ordinates.
$$\eqalign{& {\rm Two\_Standard\_Deviation\_CURVES\_at\_}te \cr & \quad = m_L \left( {te} \right) \cdot \left\{ {1 \pm \displaystyle{{\delta Ne} \over {Ne}}} \right\} = Ne \pm {\rm \delta} Ne}$$
-
(3) Letting δNe = 0 in (105) makes the two curves coincide with the mean value m L (t), and that is correct.
-
(4) As a matter of terminology, we add that the factor
(107)is called ‘coefficient of variation’ by statisticians since it is the ratio between the standard deviation and the mean value for all time values of the L(t) process, and in particular at the end time t = te, when it equals δNe/Ne.
$$\sqrt {{\rm e}^{{\rm \sigma} _L^{\rm 2} (t - ts)} - 1} = \sqrt {\left[ {1 + \left( {\displaystyle{{{\rm \delta} Ne} \over {Ne}}} \right)^2} \right]^{(t - ts)/(te - ts)} - 1} $$
-
(5) Finally, we have summarized the content of this important set of mathematical results in Table 3.


Peak-Locus Theorem
The Peak-Locus Theorem is a new mathematical discovery of ours playing a central role in the Evo-SETI theory. In its most general formulation, it holds good for any lognormal process L(t) and any arbitrary mean value m L (t), as we show in this section.
In words, and utilizing the simple example of the Peak-Locus Theorem applied to GBMs, the Peak-Locus Theorem states what shown in the Fig. 5: the family of all b-lognormals ‘trapped’ between the time axis and the growing exponential of the GBMs (where all the b-lognormal peaks lie) can be exactly (i.e. without any numerical approximation) described by three equations yielding the three parameters μ(p), σ(p) and b(p) as three functions of the peak abscissa, p, only.

Fig. 5. GBM exponential as the geometric LOCUS OF THE PEAKS of b-lognormals. Each b-lognormal is a lognormal starting at a time (b = birth time) larger than zero and represents a different SPECIES that originated at time b of Evolution. That is CLADISTICS in our Evo-SETI Model. It is evident that, the more the generic ‘Running b-lognormal’ moves to the right, its peak becomes higher and higher and narrower and narrower, since the area under the b-lognormal always equals 1 (normalization condition). Then, the (Shannon) ENTROPY of the running b-lognormal is the DEGREE OF EVOLUTION reached by the corresponding SPECIES (or living being, or civilization, or ET civilization) in the course of Evolution.
In equations, the Peak-Locus Theorem states that the family of b-lognormals having each its peak exactly located on the mean value curve (88), is given by the following three equations, specifying the parameters μ(p), σ(p) and b(p), appearing in the b-lognormal (5) as three functions of the single ‘independent variable’ p, i.e. the abscissa (i.e. the time) of the b-lognormal's peak:
 $$\left\{ \eqalign{{\rm \mu} \left( p \right) = & \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {4{\rm \pi} [m_L (\,p)]^2}} - p\displaystyle{{{\rm \sigma} _L^2} \over 2} \cr {\rm \sigma} \left( p \right) = & \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right) \cdot p}} \over {\sqrt {2{\rm \pi}} m_L (\,p)}} \cr b\left( p \right) = & \,p - {\rm e}^{{\rm \mu} (\,p) - [{\rm \sigma} (\,p)]^2}.} \right.$$
$$\left\{ \eqalign{{\rm \mu} \left( p \right) = & \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {4{\rm \pi} [m_L (\,p)]^2}} - p\displaystyle{{{\rm \sigma} _L^2} \over 2} \cr {\rm \sigma} \left( p \right) = & \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right) \cdot p}} \over {\sqrt {2{\rm \pi}} m_L (\,p)}} \cr b\left( p \right) = & \,p - {\rm e}^{{\rm \mu} (\,p) - [{\rm \sigma} (\,p)]^2}.} \right.$$
This general form of the Peak-Locus Theorem is proven in the Appendix by equations (%i66) through (%o82). The remarkable point about all this seems to be the exact separability of all the equations involved in the derivation of equations (108), a fact that was unexpected to this author when he discovered it around December 2013. And the consequences of this new result are in the applications:
-
(1) For instance in the ‘parabola model’ for Mass Extinctions that was studied in Section 10 of (Maccone Reference Maccone2014).
-
(2) For instance to the Markov–Korotayev Cubic that was studied in Section 12 of (Maccone Reference Maccone2014; Markov & Korotayev Reference Markov and Korotayev2007, Reference Markov and Korotayev2008).
-
(3) And finally in the many stochastic processes having each a Cubic mean value that are just the natural extension into statistics of the deterministic Cubics studied by this author in Chapter 10 of his book ‘Mathematical SETI’ (Maccone Reference Maccone2012). But the study of the Entropy of all these Cubic Lognormal Processes has to be differed to a future research paper.
Notice now that, in the particular case of the GBMs having mean value eμGBM (t−ts) with μGBM = B, and starting at ts = 0 with N 0 = Ns = Ne = A, the Peak-Locus Theorem (108) boils down to the simpler set of equations
 $$\left\{ \eqalign{&{\rm \mu} \left( p \right) = \displaystyle{1 \over {4{\rm \pi} A^2}} - B\,p \cr &{\rm \sigma} = \displaystyle{1 \over {\sqrt {2{\rm \pi}} A}} \cr & b\left( p \right) = p - {\rm e}^{{\rm \mu} (\,p) - {\rm \sigma} ^2} .} \right.$$
$$\left\{ \eqalign{&{\rm \mu} \left( p \right) = \displaystyle{1 \over {4{\rm \pi} A^2}} - B\,p \cr &{\rm \sigma} = \displaystyle{1 \over {\sqrt {2{\rm \pi}} A}} \cr & b\left( p \right) = p - {\rm e}^{{\rm \mu} (\,p) - {\rm \sigma} ^2} .} \right.$$
In this simpler form, the Peak-Locus Theorem was already published by the author in Maccone (Reference Maccone2012), while its most general form (108) is now proven in detail.
Proof. Let us firstly call ‘Running b-lognormal’ (abbreviated ‘RbL’) the generic b-lognormal of the family, starting at b, having peak at p and having the variable parameters μ(p) and σ(p). Then the starting equation of the Peak-Locus Theorem (108) is the #3 Appendix equation (%o73) expressing the fact that the peak of the RbL equals the mean value (90), where, however, the old independent variable t must be replaced by the new independent variable p of the RbL, that is
 $$\displaystyle{{{\rm e}^{{\rm \sigma} ^{\rm 2} {\rm /2 - \mu}}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} }} = {\rm e}^{M_L (\,p)} {\rm e}^{\left({\rm \sigma} _L^2 /2\right)(\,p - ts)}. $$
$$\displaystyle{{{\rm e}^{{\rm \sigma} ^{\rm 2} {\rm /2 - \mu}}} \over {\sqrt {2{\rm \pi}} {\rm \sigma} }} = {\rm e}^{M_L (\,p)} {\rm e}^{\left({\rm \sigma} _L^2 /2\right)(\,p - ts)}. $$
This equation may ‘surprisingly’ be separated into the following two simultaneous equations (%o74)
 $$\left\{ {\matrix{ {{\rm e}^{{\rm (\sigma} ^{\rm 2} {\rm /2)} - {\rm \mu}} = {\rm e}^{{\rm (\sigma} _L^2 /2)p}} \cr {\displaystyle{1 \over {\sqrt {2{\rm \pi}} {\rm \sigma}}} = {\rm e}^{M_L (\,p)} {\rm e}^{ - ({\rm \sigma} _L^2 /2)ts}.} \cr}} \right.$$
$$\left\{ {\matrix{ {{\rm e}^{{\rm (\sigma} ^{\rm 2} {\rm /2)} - {\rm \mu}} = {\rm e}^{{\rm (\sigma} _L^2 /2)p}} \cr {\displaystyle{1 \over {\sqrt {2{\rm \pi}} {\rm \sigma}}} = {\rm e}^{M_L (\,p)} {\rm e}^{ - ({\rm \sigma} _L^2 /2)ts}.} \cr}} \right.$$
There are two advantages brought in by this separation of variables: in the upper equation (111) the exponentials ‘disappear’ yielding (%o79)
 $$\displaystyle{{{\rm \sigma} ^2} \over 2} - {\rm \mu} = \displaystyle{{{\rm \sigma} _L^2} \over 2}\;p$$
$$\displaystyle{{{\rm \sigma} ^2} \over 2} - {\rm \mu} = \displaystyle{{{\rm \sigma} _L^2} \over 2}\;p$$
while the lower equation (111) is in σ only, and thus it may be solved for σ immediately (%o76)
 $${\rm \sigma} = \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right)ts} {\rm e}^{ - M_L (\,p)}} \over {\sqrt {2{\rm \pi}}}}. $$
$${\rm \sigma} = \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right)ts} {\rm e}^{ - M_L (\,p)}} \over {\sqrt {2{\rm \pi}}}}. $$
We may now get rid of M(p) in equation (113) by replacing it by virtue of (91), getting, after a few steps and rewriting p instead of t, (%o78)
 $${\rm \sigma} = \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right)p}} \over {\sqrt {2{\rm \pi}} \;m_L (\hskip1pt p)}}.$$
$${\rm \sigma} = \displaystyle{{{\rm e}^{\left({\rm \sigma} _L^2 /2\right)p}} \over {\sqrt {2{\rm \pi}} \;m_L (\hskip1pt p)}}.$$
which is just the middle equation (108).
Finally, equation (112) may be solved for μ (%o79).
 $${\rm \mu} = \displaystyle{{\sigma ^2} \over 2} - \displaystyle{{\sigma _L^2} \over 2}\;p$$
$${\rm \mu} = \displaystyle{{\sigma ^2} \over 2} - \displaystyle{{\sigma _L^2} \over 2}\;p$$
so that, inserting equation (114) into (115), the final expression of μ is found also (%o80)
 $${\rm \mu} = \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 p}} \over {4{\rm \pi} [m_L(\hskip1ptp)]^2}} - \displaystyle{{{\rm \sigma \hskip0.75pt} _L^2} \over 2}p.$$
$${\rm \mu} = \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 p}} \over {4{\rm \pi} [m_L(\hskip1ptp)]^2}} - \displaystyle{{{\rm \sigma \hskip0.75pt} _L^2} \over 2}p.$$
Our general Peak-Locus Theorem (108) has thus been proven completely.
tsGBM and GBM sub-cases of the Peak-Locus Theorem
The general Peak-Locus Theorem proved in the previous section includes, as sub-cases, many particular forms of the arbitrary mean-value function m L (t). In particular, we now want to consider two of them:
-
(1) The tsGBM, i.e. the GBM starting at any given time ts, like the origin of life on Earth, that started at ts = −3.5 billion years ago.
-
(2) The ‘ordinary’ GBM, used in the Mathematics of Finances, starting at ts = 0. Clearly, the ordinary GBM is, in its turn, a sub-subcase of the tsGBM.
Then, the tsGBM is characterized by the equation
 $$m_{{\rm tsGBM}} \left( p \right) = m_{{\rm tsGBM}} \left( {ts} \right){\rm e}^{B(\,p - ts)} $$
$$m_{{\rm tsGBM}} \left( p \right) = m_{{\rm tsGBM}} \left( {ts} \right){\rm e}^{B(\,p - ts)} $$
having set in agreement with equations (79) and (90), (%o84)
 $$B = \displaystyle{{{\rm \sigma} _{{\rm tsGBM}}^2} \over 2}.$$
$$B = \displaystyle{{{\rm \sigma} _{{\rm tsGBM}}^2} \over 2}.$$
One may determine the numeric constant B in terms of both the initial and final conditions of the tsGBM by replacing into equation (117) p by te (the end-time, i.e. the time of the final condition) and then solving equation (117) for B (%o88)
 $$B = \displaystyle{{\ln (m_{{\rm tsGBM}} (te)/m_{{\rm tsGBM}} (ts))} \over {te - ts}}.$$
$$B = \displaystyle{{\ln (m_{{\rm tsGBM}} (te)/m_{{\rm tsGBM}} (ts))} \over {te - ts}}.$$
In the Evo-SETI Theory we assume ts to be the time of the ‘beginning of life’, when there was only one living Species (the first one, probably RNA, at 3.5 billion year ago on Earth, but we do not know at what time on exoplanets) and so we have
 $$m_{{\rm tsGBM}} \left( {ts} \right) = 1.$$
$$m_{{\rm tsGBM}} \left( {ts} \right) = 1.$$
Then equation (117) reduces to
 $$m_{{\rm tsGBM}} \left( p \right) = {\rm e}^{B(\,p - ts)} $$
$$m_{{\rm tsGBM}} \left( p \right) = {\rm e}^{B(\,p - ts)} $$
and equation (119) reduces to
 $$B = \displaystyle{{\ln (m_{{\rm tsGBM}} (te))} \over {te - ts}}.$$
$$B = \displaystyle{{\ln (m_{{\rm tsGBM}} (te))} \over {te - ts}}.$$
As we already did in the section ‘Death Formula’, we assume the number of living Species on Earth nowadays (i.e. at te = 0) to be equal to 50 million, namely m(te) = 50 million. Then equation (122) reduces to equation (83), as it must be.
Finally, the ordinary GBM subcase of tsGBM and sub-subcase of L(t) is characterized by equation (118) and by
 $$m_{{\rm GBM}} \left( t \right) = A{\rm e}^{Bt}. $$
$$m_{{\rm GBM}} \left( t \right) = A{\rm e}^{Bt}. $$
Then, inserting both equations (118) and (123) into the general Peak-Locus Theorem (108), the latter yields equation (109) as shown by (%o95). This is the ‘old’ Peak-Locus Theorem, firstly discovered by this author in late 2011 and already published by him in Chapter 8 of his 2012 book ‘Mathematical SETI’ of 2012, p. 218–219.
For more applications of the Peak-Locus Theorem to polynomial mean values, see Maccone (Reference Maccone2014) (p. 294–308).
Shannon entropy of the running b-lognormal
The Shannon Entropy of the Running b-lognormal is the key to measure the ‘disorganization’ of what that running b-lognormal represents, let it be a Species (in Evolution) or a Civilization (in Human History) or even an Alien Civilization (in SETI).
As it is well known, the Shannon Entropy (17) (measured in bits) of the Running b-lognormal having its peak at time p and the three parameters μ, σ, b is given by (%o96) (for the proof of this key mathematical result, please see Chapter 30 of the author's book ‘Mathematical SETI’, p. 685–687, the idea behind the proof is to expand the log of the Shannon Entropy of the b-lognormal, so that the calculation is split into three integrals, each of which may actually be computed exactly):
 $$H = \displaystyle{{\ln (\sqrt {2{\rm \pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}.$$
$$H = \displaystyle{{\ln (\sqrt {2{\rm \pi}} {\rm \sigma} ) + {\rm \mu} + 1/2} \over {\ln 2}}.$$
Having so said, the next obvious step is to insert the μ and σ given by the Peak-Locus Theorem (108) into (124). After a few steps, we thus obtain the Shannon Entropy of the Running b-lognormal (see (%o97) and (%o98)):
 $$\eqalign{H\left( {\,p,m_L \left( p \right)} \right) & = \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {4\,{\rm \pi} \ln 2 \cdot [m_L (\,p)]^2}} - \displaystyle{{\ln (m_L (\,p))} \over {\ln 2}} \cr & + \displaystyle{1 \over {2\ln 2}}.}$$
$$\eqalign{H\left( {\,p,m_L \left( p \right)} \right) & = \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {4\,{\rm \pi} \ln 2 \cdot [m_L (\,p)]^2}} - \displaystyle{{\ln (m_L (\,p))} \over {\ln 2}} \cr & + \displaystyle{1 \over {2\ln 2}}.}$$
This is the fundamental Shannon Entropy H of the Running b-lognormal for any given mean value m L (t). Notice that H is a function of the peak abscissa p in two ways:
-
(1) Directly, as in the term
${\rm e}^{{\rm \sigma} _L^2\cdot p} $
, and -
(2) Through the assigned mean value m L (p).
Introducing our… Evo-Entropy(p) measuring how much a life form has evolved
The Shannon Entropy was introduced by Claude Shannon (1916–2001) in 1948 in his seminal work about Information Theory, dealing of course with telecommunications, channel capacities and computers. But… we need something else to measure ‘how evolved’ a life form is: we need a positive function of the time starting at zero at the time ts of the origin of life on a certain planet, and then increasing (rather than decreasing).
This new function is easily found: it is just the Shannon Entropy (17) WITHOUT THE MINUS SIGN IN FRONT OF IT (so as to make it an increasing function, rather than a decreasing function) and WITH THE NUMERIC VALUE −H(ts) SUBTRACTED, so as it starts at zero at the initial instant ts.
This new function of p we call EVO-ENTROPY (Evolution Entropy) and its mathematical definition is thus simply (see (%o101) and (%o102)):
 $$\eqalign{{\rm EvoEntropy} & \left( {\,p,m_L \left({p}\right)}\right) \cr & = - H\left({\,p,m_L \left({p}\right)}\right) + H \left({ts,m_L \left({ts}\right)}\right).}$$
$$\eqalign{{\rm EvoEntropy} & \left( {\,p,m_L \left({p}\right)}\right) \cr & = - H\left({\,p,m_L \left({p}\right)}\right) + H \left({ts,m_L \left({ts}\right)}\right).}$$
In some previous papers by this author about Evo-SETI Theory, the Evo-Entropy (126) was called ‘Evo-Index’ (Index of Evolution) or with other similar names, but we now prefer to call it Evo-Entropy to make it clear that it is just the Shannon Entropy with the sign reversed and with value zero at the origin of life.
Next we compute the actual expression of Evo-Entropy as a function of the only variable p, the Running b-lognormal peak. To this end, we must first get the expression of (125) at the initial time ts. It is (%o99)
 $$\eqalign{H\left( {ts,m_L \left( {ts} \right)} \right) & = \displaystyle{{{\rm e}^{\,p \cdot ts}} \over {4{\rm \pi} \ln 2 \cdot [m_L (ts)]^2}} - \displaystyle{{\ln (m_L (ts))} \over {\ln 2}} \cr & + \displaystyle{1 \over {2\ln 2}}.}$$
$$\eqalign{H\left( {ts,m_L \left( {ts} \right)} \right) & = \displaystyle{{{\rm e}^{\,p \cdot ts}} \over {4{\rm \pi} \ln 2 \cdot [m_L (ts)]^2}} - \displaystyle{{\ln (m_L (ts))} \over {\ln 2}} \cr & + \displaystyle{1 \over {2\ln 2}}.}$$
Subtracting equation (127) into (125) with the minus sign reversed, we get the for the final (126) form of our Evo-Entropy (%o100)
 $$\eqalign{{\rm EvoEntropy}\left( {\,p,m_L \left( p \right)} \right) & = \displaystyle{1 \over {4{\rm \pi} \ln 2}}\left\{ {\displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot ts}} \over {[m_L (ts)]^2}} - \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {[m_L (\,p)]^2}}} \right\} \cr & + \displaystyle{{\ln (m_L (\,p)/m_L (ts))} \over {\ln 2}}.}$$
$$\eqalign{{\rm EvoEntropy}\left( {\,p,m_L \left( p \right)} \right) & = \displaystyle{1 \over {4{\rm \pi} \ln 2}}\left\{ {\displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot ts}} \over {[m_L (ts)]^2}} - \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {[m_L (\,p)]^2}}} \right\} \cr & + \displaystyle{{\ln (m_L (\,p)/m_L (ts))} \over {\ln 2}}.}$$
The Evo-Entropy (128) is thus made up by two terms:
-
(1) The term
(129)we shall call the NON-LINEAR PART of the Evo-Entropy (128), while
$$\displaystyle{1 \over {4\,{\rm \pi} \ln 2}}\left\{ {\displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot ts}} \over {[m_L (ts)]^2}} - \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {[m_L (\,p)]^2}}} \right\}$$
-
(2) The term
(130)
$$\displaystyle{{\ln (m_L (\,p)/m_L (ts))} \over {\ln 2}}$$


we shall call the LINEAR PART of the Evo-Entropy (128), as we explain in the next section.
The Evo-Entropy(p) of tsGBM increases exactly linearly in time
Consider again the tsGBM defined by equation (117) with (118). If we insert equation (117) into the EvoEntropy (128), then two dramatic simplifications occur:
-
(1) The non-linear term (129) vanishes, inasmuch as it reduces to
(131)
$$\displaystyle{1 \over {4\,{\rm \pi} \ln 2[m_L (ts)]^2}} \left\{ {{\rm e}^{{\rm \sigma} _L^2 \cdot ts} - \displaystyle{{{\rm e}^{{\rm \sigma} _L^2 \cdot p}} \over {{\rm e}^{{\rm \sigma} _L^2 \cdot p} \cdot {\rm e}^{ - {\rm \sigma} _L^2 \cdot ts}}}} \right\} = 0.$$
-
(2) The linear term (130) simplifies, yielding (%o104)
(132)
$$\eqalign{\displaystyle{{\ln (m_L (\,p)/m_L (ts))} \over {\ln 2}} & = \displaystyle{{\ln (m_L (ts){\rm e}^{B(\,p - ts)} /m_L (ts))} \over {\ln 2}} \cr & = \displaystyle{B \over {\ln 2}}\left( {\,p - ts} \right).}$$


In other words, the Evo-Entropy of tsGBM simply is the LINEAR function of the Running b-lognormal peak p
 $${\rm EvoEntropy}_{{\rm tsGBM}} \left( p \right) = \displaystyle{B \over {\ln 2}}\left( {\,p - ts} \right).$$
$${\rm EvoEntropy}_{{\rm tsGBM}} \left( p \right) = \displaystyle{B \over {\ln 2}}\left( {\,p - ts} \right).$$
This is a great result! And it was already envisioned back in 2012 in Chapter 30 of the author's book ‘Mathematical SETI’ when he found that the Evo-Entropy difference between two Civilizations ‘with quite different levels of technological development’ (like the Aztecs and the Spaniards in 1519) is given by the equation
 $${\rm EvoEntropy}_{{\rm tsGBM}} \left( {\,p_2 - p_1} \right) = \displaystyle{B \over {\ln 2}}\left( {\,p_2 - p_1} \right).$$
$${\rm EvoEntropy}_{{\rm tsGBM}} \left( {\,p_2 - p_1} \right) = \displaystyle{B \over {\ln 2}}\left( {\,p_2 - p_1} \right).$$
(see equation (30.29) on p. 693 of that book, where the old minus sign in front of the Shannon Entropy still ruled because this author had not yet ‘dared’ to get rid of it, as he did now in the new definition (126) of EvoEntropy.
But what is the graph of this famous linear increase of Evo-Entropy ? It is given by Fig. 6.
So, we have discovered that the tsGBM Entropy in our Evo-SETI model and the Molecular Clock (see Nei (Reference Nei2013) and Nei & Kumar (Reference Nei and Kumar2000)) are the same linear time function, apart for multiplicative constants (depending on the adopted units, such as bits, seconds, etc.). This conclusion appears to be of key importance to understand ‘where a newly discovered exoplanet stands on its way to develop LIFE’.

Fig. 6. EvoEntropy (in bits per individual) of the latest species appeared on Earth during the last 3.5 billion years. This shows that a Man (i.e. the leading Species nowadays) is 25.575 bits more evolved than the first form of life (call it RNA?) 3.5 billion years ago.
Conclusions
More and more exoplanets are now being discovered by astronomers either by observations from the ground or by virtue of space missions, like ‘CoRot’, ‘Kepler’, ‘Gaia’ and other future space missions.
As a consequence, a recent estimate sets at 40 billion the number of Earth-sized planets orbiting in the habitable zones of Sun-like stars and red dwarf stars within the Milky Way Galaxy.
With such huge numbers of ‘possible Earths’ in sight, Astrobiology and SETI are becoming research fields more and more attractive to a number of scientists.
Mathematically innovative papers like this one, revealing an unsuspected relationship between the Molecular Clock and the Entropy of b-lognormals in Evo-SETI Theory, should thus be welcome.
Acknowledgements
The author is grateful to the Reviewers for accepting this paper just as he had submitted it, without asking for any change that would have required more time. Equally, the author is grateful to Dr. Rocco Mancinelli, Editor in Chief of the International Journal of Astrobiology (IJA), for allowing him to add to each of his IJA published papers one or more pdf files with all the relevant calculations done by Maxima, a rather unusual feature in the scientific literature. Finally, the full cooperation of Ms. Amanda Johns, Ms. Corinna Connolly McCorristine and the Typesetters is gratefully acknowledged.
Supplementary material
To view supplementary material for this article, please visit http://dx.doi.org/10.1017/S1473550415000506.











 Open access
Open access