



Introduction
Multiword expressions (MWEs, e.g., collocations, kick a ball; idioms, kick the bucket; phrasal verbs, turn down) are essential in developing second language (L2) vocabulary mastery (Schmitt, Reference Schmitt1998), proficiency (Howarth, Reference Howarth1998), and fluency (Wray, Reference Wray2002). They help language speakers effectively and efficiently communicate in real time. The knowledge of MWEs is multifaceted; it goes beyond being able to recognize an MWE and explain its meaning. A key benefit of MWE mastery is speakers’ ability to process these expressions fluently, in real-time language use (Siyanova-Chanturia & Van Lancker Sidtis, Reference Siyanova-Chanturia, Van Lancker Sidtis, Siyanova-Chanturia and Pellicer-Sánchez2019).
Learning MWEs is challenging for L2 learners, especially if their exposure to the target language is limited. Therefore, investigating the relative effectiveness of different approaches to learning MWE is a worthwhile second language acquisition (SLA) research topic. Strong and Boers (Reference Strong and Boers2019a, Reference Strong and Boers2019b), for instance, found that retrieval practice (i.e., opportunities for explicit retrieval of previously studied information from memory, as a learning event) is an effective approach to learning one type of L2 MWEs—phrasal verbs. This finding supports the theoretical claim that successfully retrieving recently encoded information from memory benefits its retention (known as the testing or retrieval effect; Roediger & Karpicke, Reference Roediger and Karpicke2006). This advantage of retrieval over restudying reported in learning and retention research (Roediger & Karpicke, Reference Roediger and Karpicke2011) may be understood as a function of processing difficulty (i.e., the greater the effort at encoding, the greater the retention; Bjork, Reference Bjork, Metcalfe and Shimamura1994), and/or levels of processing during retrieval, with deeper processing (such as semantically rich processing) resulting in better knowledge retention than shallow processing (Craik & Lockhart, Reference Craik and Lockhart1972; Craik and Tulving, Reference Craik and Tulving1975; Hintzman, Reference Hintzman and Bower1976).
Furthermore, retrieval schedules (i.e., retrieval episodes distributed consecutively, massed, or further apart, spaced) affect learning and retention. Optimal retrieval difficulty (i.e., desirable difficulties) can maximize knowledge retention and transfer (Bjork, Reference Bjork, Metcalfe and Shimamura1994; Schmidt & Bjork, Reference Schmidt and Bjork1992; for a recent discussion in the L2 field, see Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019a, Reference Suzuki, Nakata and Dekeyser2019b). The testing/retrieval effect is predicted to be greater when retrieval is more effortful and requires deeper processing (see Roediger & Karpicke, Reference Roediger and Karpicke2011, for a review), for example, when retrieval involves meaning elaboration and retrieval episodes are spaced rather than massed (e.g., Balota et al., Reference Balota, Duchek, Sergent-Marshall and Roediger2006; Karpicke & Roediger, Reference Karpicke and Roediger2007). When retrieval episodes are accompanied by feedback, the feedback information is likely to receive more attention and be processed deeper in the spaced than the massed condition because it is perceived as less familiar.
Measures of MWE knowledge and processing
When evaluating MWE instructional and learning approaches, we need to look into what it means to “know” an MWE. As argued above, one of the main advantages of MWE mastery is the ease and automaticity of real-time language processing and use (Siyanova-Chanturia & Van Lancker Sidtis, Reference Siyanova-Chanturia, Van Lancker Sidtis, Siyanova-Chanturia and Pellicer-Sánchez2019). Therefore, besides commonly used offline posttests of form and meaning recall, SLA researchers can also use online (real-time) processing measures to test the fluency and automaticity of MWE processing under time pressure (Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Toomer & Elgort, Reference Toomer and Elgort2019). Notably, the effect of levels of processing may vary for explicit and implicit knowledge and processing measures (Hamann, Reference Hamann1990; Newell & Andrews, Reference Newell and Andrews2004; Roediger et al., Reference Roediger, Weldon and Challis1989), suggesting that different levels of processing associated with massed and spaced retrieval schedules may not hold the same benefits for the development of and access to different types of knowledge (Ullman & Lovelett, Reference Ullman and Lovelett2018).
Explicit knowledge is conscious knowledge about something, such as facts, meanings, and experiences (e.g., the expression “shake hands” signifies “agreement”); it can be gained very quickly from a single learning episode. This knowledge can be automatized via repeated exposure and use (e.g., readers are likely to judge “shake hands” as a more acceptable phrase than “shake hair” under time pressure). Implicit knowledge, on the other hand, is gained gradually through repeated exposure, practice, and experience, often without explicit awareness (e.g., the word “hands” may be recognized and processed faster in reading if it follows its collocate “shake” than semantically unrelated/noncollocate “swing”); it is thus particularly important in fluent comprehension and production (Isbell & Rogers, Reference Isbell, Rogers, Winke and Brunfaut2021; Suzuki & DeKeyser, Reference Suzuki and DeKeyser2017).
L2 vocabulary learning studies suggest that spaced practice (including spaced retrieval practice) tends to be more effective than massed practice in acquiring explicit knowledge of MWEs (for intentional learning of L2 collocations, for example, see Macis et al., Reference Macis, Sonbul and Alharbi2021, and Yamagata et al., Reference Yamagata, Nakata and Rogers2023); however, this may not necessarily be the case for the development of implicit knowledge (e.g., in their contextual word learning study, Nakata & Elgort, Reference Nakata and Elgort2021, did not observe the spacing effect in the semantic priming task used as a proxy for tacit knowledge). Therefore, more research is needed to examine how spacing (i.e., the distribution of repetitions over time) affects the development of different types of MWE knowledge and access to this knowledge in real-time processing. Perhaps combining different learning and memory enhancement techniques (namely, spacing and retrieval) may facilitate not only the development of explicit and automatized explicit knowledge of MWEs but also their implicit knowledge and real-time processing.
In the present study, therefore, we investigate whether the spacing effect in retrieval practice of L2 collocations (defined here as the distribution of retrieval episodes over trials) is observed in the outcome measures representing different types of collocational knowledge. Although L2 collocation learning research has begun to examine the development of implicit knowledge (operationalized as collocational priming in lexical decisions; Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Toomer & Elgort, Reference Toomer and Elgort2019), these studies have not tested whether retrieval spacing affects the acquisition of implicit knowledge.
In grammar research (e.g., Suzuki, Reference Suzuki2017), implicit knowledge has been distinguished from automatized explicit knowledge. The latter is commonly measured using a timed sentence grammaticality judgment task. The knowledge measured is considered explicit because the task instructions raise awareness of the linguistic knowledge being measured; the knowledge is considered automatized explicit because it is accessed under time pressure. In L2 collocational processing research, a parallel task is a timed acceptability judgment task, in which participants judge whether a word combination is acceptable or not in a target language under time pressure (e.g., Öksüz et al., Reference Öksüz, Brezina and Rebuschat2021; Wolter & Yamashita, Reference Wolter and Yamashita2018; Yamashita & Jiang, Reference Yamashita and Jiang2010). Recently, this task has been used to measure the acquisition of automatized explicit knowledge of L2 MWEs (Jeong & DeKeyser, Reference Jeong and DeKeyser2023; Northbrook et al., Reference Northbrook, Allen and Conklin2022).
Measuring the development of different aspects of knowledge helps us gain a more nuanced understanding of the effects of instructional techniques and learning approaches (Schmitt, Reference Schmitt2022). Although retrieval practice appears to be effective in gaining explicit knowledge of L2 MWEs (Strong & Boers, Reference Strong and Boers2019a, Reference Strong and Boers2019b), further studies are needed to optimize the use of this practice format for developing different knowledge types. Specifically, our study goes beyond traditional posttests of explicit knowledge but also investigates how massed and spaced retrieval schedules affect the development of automatized explicit and implicit knowledge of L2 collocations.
Retrieval practice and L2 MWE learning
Research evaluating MWE exercises in published English as foreign language textbooks found certain trial-and-error practice exercises problematic. In these practice exercises, learners first complete cloze or multiple-choice tasks with MWEs they need to learn and then receive corrective feedback. Learners whose responses are incorrect risk encoding undesirable associations (e.g., encoding, *talk volumes instead of speak volumes; Boers et al., Reference Boers, Dang and Strong2017). The corrective feedback in such exercises may not be sufficient to reverse these erroneous associations (Stengers & Boers, Reference Stengers and Boers2015; Strong & Boers, Reference Strong and Boers2019b). On the other hand, tasks that necessitate retrieval practice following initial learning (also common in L2 textbooks) do not cause such problems, presumably because learners are exposed to intact MWEs first, which allows them to form memory traces for the correct word combinations. The advantage of retrieval practice over trial-and-error exercises in deliberate L2 MWE learning was observed in immediate and delayed posttests (Strong & Boers, Reference Strong and Boers2019a, Reference Strong and Boers2019b).
Strong and Boers (Reference Strong and Boers2019b) operationalized trial-and-error practice as gap-fill tasks (e.g., hang ____—spend time with friends) followed by corrective feedback; the retrieval practice was operationalized as a form-meaning association procedure, where gap-fill tasks with corrective feedback were preceded by intact MWE presentation. The researchers argued that in deliberate learning and practice of L2 MWEs, learning procedures that result in fewer erroneous associations between the component words of MWEs lead to more accurate knowledge. These studies show that presenting intact L2 MWEs to learners upfront affords the creation of stronger associations between the component words of the MWEs, and retrieving these correct associations from memory improves short- and long-term knowledge retention (Karpicke & Roediger, Reference Karpicke and Roediger2007).
However, the benefits of retrieval practice were observed by Strong and Boers in a study with L2 phrasal verbs, and it is unclear whether these findings are generalizable to other MWE types, as different MWEs present different challenges to L2 learners. English phrasal verbs that usually comprise high-frequency words are challenging due to their semantic opaqueness and polysemy (Garnier & Schmitt, Reference Garnier and Schmitt2015), while the main difficulties in learning L2 (English) verb collocations are associated with the choice of verbs, due to the interference from learners’ knowledge of corresponding first language (L1) collocations (Laufer & Waldman, Reference Laufer and Waldman2011; Nesselhauf, Reference Nesselhauf2003). Further research is needed, therefore, to test whether retrieval practice benefits the learning and acquisition of L2 verb collocates (Boers et al., Reference Boers, Demecheleer, Coxhead and Webb2014; Szudarski & Carter, Reference Szudarski and Carter2016; Tsai, Reference Tsai2020; Webb & Kagimoto, Reference Webb and Kagimoto2009).
Spacing and L2 MWE learning
Most L2 vocabulary spacing studies examined the learning of single words (e.g., Nakata & Suzuki, Reference Nakata and Suzuki2019); so far, the spacing effect in MWE learning has been addressed in only a handful of studies. In a classroom study with Iranian junior high school students, Farvardin (Reference Farvardin2019) observed the spacing effect in intentional learning of L2 English collocations (assessed with near-immediate and 2-week/4-week delayed posttests of form recognition and meaning recall).
Macis et al. (Reference Macis, Sonbul and Alharbi2021) investigated the effect of spacing in incidental and intentional learning of L2 collocations. In a between-participants design, two groups of Arabic speakers learned 25 English adjective-noun collocations incidentally (through reading) or intentionally (memorizing and studying target collocations embedded in concordance lines). Two spacing schedules of a whole learning event (study plus retrieval) were used; in the massed condition, five collocations were repeated five times per session; in the spaced condition, each of the 25 collocations was presented once per session. The spacing effect was observed on a 3-week delayed cued form-recall posttest in the intentional learning group.
In Yamagata et al. (Reference Yamagata, Nakata and Rogers2023), Japanese high school students engaged in the form-focused practice of English verb-noun collocations in a classroom setting. The collocations were practiced seven times per session, following three distribution schedules over 3 weeks (three sessions each week): node-massed (i.e., massed repetitions of the same nodes each day, e.g., Week 1, run a fever/story/finger), collocation-massed (i.e., massed repetitions of collocations of different nodes each day and spaced repetitions of collocations of the same nodes across 3 weeks, e.g., Week 1, run a fever; Week 2, run a story; Week 3, run a finger), and collocation-spaced (i.e., massed repetition of the same nodes each day and spaced repetitions of individual collocations of the same node across 3 weeks, e.g., Week 1/2/3, run a fever/story/finger). Their learning treatment included retrieval attempts of a given target verb (e.g., run) in/out of context, the target collocation in context, and other learning procedures (i.e., presentation, translation, and quizzes). The collocation-spaced schedule group (i.e., the condition requiring spaced retrieval of individual collocations) outperformed the massed groups in near-immediate and delayed collocation/verb gap-filling posttests. This finding seems to align with the advantage of spaced retrieval over massed retrieval found in L2 single-word learning studies (Karatas et al., Reference Karatas, Özemir, Lovelett, Demir, Erkol and Veríssimo2021; Koval, Reference Koval2022). However, like Macis et al. (Reference Macis, Sonbul and Alharbi2021), Yamagata and colleagues (Reference Yamagata, Nakata and Rogers2023) focused on the distribution of the complete learning event, including study and retrieval, possibly conflating the effects of study spacing and retrieval spacing. Importantly, both studies only tested offline explicit knowledge of collocations. In summary, little is known about the effects of retrieval schedules on the acquisition of different aspects of L2 collocational knowledge.
Present study
We investigate the effect of retrieval schedules on the acquisition of implicit, automatized explicit, and explicit knowledge of L2 collocations. Following the findings of Strong and Boers (Reference Strong and Boers2019b), study participants first studied collocations using flashcards and decontextualized form-meaning matching tests (i.e., familiarization stage), after which they engaged in either consecutive (massed) or distributed (spaced) retrieval practice (i.e., retrieval stage). Near-immediate and announced 1-week delayed posttests were administered to capture the initial learning and retention of collocational knowledge, respectively (Soderstrom & Bjork, Reference Soderstrom and Bjork2015). The participants’ explicit knowledge of the target L2 collocations was measured using a form recall task (Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Toomer & Elgort, Reference Toomer and Elgort2019), their automatized explicit knowledge was measured using an online acceptability judgment task (Jeong & DeKeyser, Reference Jeong and DeKeyser2023; Northbrook et al., Reference Northbrook, Allen and Conklin2022), and their implicit knowledge was measured using a primed lexical decision task (Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Toomer & Elgort, Reference Toomer and Elgort2019). The following research questions guided the study:
-
1. Does retrieval schedule affect the acquisition of explicit knowledge of L2 collocations? If yes, how?
-
2. Does retrieval schedule affect the acquisition of automatized explicit knowledge of L2 collocations? If yes, how?
-
3. Does retrieval schedule affect the acquisition of implicit knowledge of L2 collocations? If yes, how?
Methods
Participants
Twenty-nine undergraduate students (28 women), English majors, from an intact class participated in the study. Each participant received 50 CNY and a small gift. Their age ranged from 18 to 21 years (M = 19.31; SD = .66). All participants have learned English through formal education, with Mandarin Chinese as a medium of instruction. The mean starting age of learning English was 9.07 years (SD = 2.39), and the mean length (in years) of learning was 10.24 (SD = 2.28). None of the participants had visited an English-speaking country. Their English vocabulary knowledge was estimated with LexTALE (Lemhöfer & Broersma, Reference Lemhöfer and Broersma2012), and the mean score was 52.93% (SD = 8.83%), which suggests an intermediate proficiency level.
Materials
Collocations
The collocations used in our study (see Appendix S1) were either adjacent (e.g., lend weight) or nonadjacent with a determiner (e.g., a, an, the) between the verb and the noun (e.g., attend a clinic). They were developed using the Academic Subcorpus of the British National Corpus (BNC Consortium, 2007), or the BNC-AC. The chosen collocations met the set thresholds (collocational frequency >10, t-scores >2, and MI >3) based on the enTenTen20 corpus (English Web Corpus 2020; Jakubíček et al., Reference Jakubíček, Kilgarriff, Kovář, Rychlỳ and Suchomel2013), and the constituent words in the collocations were four to eight letters long. The first author, a native Chinese speaker with advanced English proficiency, selected a pool of potential incongruent collocations based on the intuitive judgment of L1-L2 incongruency. These collocations were randomly listed in two translation tests and given to 15 native Chinese speakers with high English proficiency (graduate students in teaching English to speakers of other languages and applied linguistics). They were instructed to translate the English words into as many Chinese translations as possible. The most translated words were identified as dominant translation equivalents. In addition, the English-Chinese version of Oxford Collocations Dictionary (McIntosh, Reference McIntosh2015) was consulted for the Chinese translation of these English collocations. Further, the collocation renderings were compared against their word-for-word renderings to confirm that these collocations were incongruent. The selected English collocations were administered to 30 English learners from the same population as that used in this study in a productive L1-to-L2 translation test (e.g., Laufer & Girsai, Reference Laufer and Girsai2008; Webb & Kagimoto, Reference Webb and Kagimoto2011). Based on the translation test results, collocations were divided into two groups: target collocation (score <10% accuracy) and baseline familiar collocations (score >80% accuracy).
Other stimuli
In the two online posttests (acceptability judgment and primed lexical decision), the stimuli included target collocations, familiar collocations, and their matched controls (i.e., nonce phrases consisting of a noncollocate and the target word of a given collocation, e.g., serve-notice versus compete-notice), collocational and nonce-collocation fillers, and nonwords. The stimuli other than the target and familiar collocations were developed as follows. First, potential collocational fillers were selected from the BNC-AC and then searched in the enTenTen20 corpus to obtain lexical frequencies. The final collocational fillers had an enTenTen20-based MI and t-score higher than three and two, respectively. Second, other words in the nonce collocations (controls or fillers) were randomly selected from the 3,000-word families in English based on the BNC / Corpus of Contemporary American English word list (Nation, Reference Nation2012). The potential nonce collocations were only kept if the component words did not commonly co-occur in the corpus (MI <3, t-score <2). Third, the nonword stimuli were created using the Wuggy software (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010). The final stimuli were checked to contain no duplicate words, and the items were four to eight letters long.
Counterbalanced item lists were developed for the two online posttests. Each list included 18 target collocations, 18 nonce-collocation controls, 11 familiar collocations, and 11 nonce-collocation controls). In addition, the acceptability judgment lists included 18 nonce-collocation fillers and 18 collocational fillers (e.g., cause-trouble); the lists used in the primed lexical decision posttest contained 39 nonce-collocation fillers (e.g., draft-shame) and 97 word-nonword pairsFootnote 1 (e.g., handle-notave). Appendix S2 presents sample test lists of both tasks.
Final stimuli
The learning targets (target collocations) were 36 unfamiliar incongruent English verb-noun collocations (e.g., attend a clinic, lend weight). In addition, 22 familiar English collocations (e.g., spend a holiday, keep track) were selected to establish the baseline for the online processing of L2 collocations. The familiar collocations were divided into two sets. One set (i.e., studied familiar collocation) was included in the familiarization stage (see below) and the posttests but not in the retrieval practice. The second set (i.e., unstudied familiar collocation) was only included in the posttests (but not in the learning treatment or the retrieval practice) and provided a baseline for two posttests (i.e., collocation priming and online acceptability judgments). This design allowed us to check whether exposure recency was a factor at the posttest stage.
Flashcards
Flashcards (each containing a collocation, its definition, and an example sentence, all in English) were developed for the learning treatment. The English definitions were from online dictionaries (Cambridge, Collins, Merriam-Webster, Oxford, etc). The sentential materials were based on the enTenTen20 corpus (Jakubíček et al., Reference Jakubíček, Kilgarriff, Kovář, Rychlỳ and Suchomel2013); the original concordances were minimally revised so that (a) they were meaningful and complete and (b) proper nouns (e.g., names) that may introduce comprehension difficulty were substituted or paraphrased (e.g., using pronouns and general terms). The sentences were further checked and minimally revised by a native speaker of English to ensure naturalness. The AntWordProfiler program (Anthony, Reference Anthony2014) was used to assess the lexical profiling of the English definitions and example sentences. The definitions were, on average, 8.67 words long (SD = 2.97); 97.46% and 99.49% lexical coverage were reached, respectively, with the first 3,000 and 5,000 most frequent word families of English. The example sentences were, on average, 14.5 words long (SD = 1.58); 95.9% and 99.01% lexical coverage were reached, respectively, with the first 3,000 and 5,000 most frequent word families. This was considered sufficient for the participants to understand the definitions and examples in the flashcards.
Learning treatment
The learning treatment consisted of familiarization and retrieval stages. In the familiarization stage, the participants studied target collocations and familiar collocations (hereafter “studied”) using flashcards and decontextualized form-meaning matching tests. The flashcards ensured that each learning event was focused and discrete. Presenting intact collocations in the familiarization task provides an opportunity for the initial (baseline) encoding of the collocations’ form-meaning mapping. This prior exposure is necessary for subsequent retrieval (Van den Broek et al., Reference Van den Broek, Takashima, Segers and Verhoeven2018) and for the development of automatized explicit knowledge, as proposed by skill acquisition theory (McLaughlin, Reference McLaughlin1987; Suzuki & DeKeyser, Reference Suzuki and DeKeyser2017). Furthermore, it can reduce the risk of forming erroneous lexical associations during retrieval (Boers et al., Reference Boers, Dang and Strong2017; Strong & Boers, Reference Strong and Boers2019b). The matching test was used to motivate the participants to genuinely study the form-meaning associations of the collocations. In the retrieval stage, the participants engaged in retrieval practice of the learning targets (but not the familiar collocations) and received corrective feedback.Footnote 2
Familiarization stage
The familiarization stage of the learning treatment included the flashcard procedure (i.e., 47 collocations: 36 target collocations and 11 studied familiar collocation) and the form-meaning matching test. The flashcards were first presented one by one in sets of five or seven (Figure 1-a). Participants were instructed to study the association between each collocation and its definition and read the example sentence, presented on the same screen. A flashcard remained on the screen until participants pressed the space key. The flashcard activity was followed by a matching test on these five- or seven-pair sets (Figure 1-b). The participants were given as much time as needed to match the collocations and their definitions presented in separate columns and type in their responses. Regardless of the correctness of the response, a feedback screen (showing the test items, participants’ responses, and correct answers, see Figure 1-c) was presented for a maximum of 100 s in the 5-pair sets and 140 s in the 7-pair sets (i.e., approximately 20 s per pair). The participants were instructed to check the answers; they could press the space key to terminate this display as soon as they finished reviewing the answers.

Figure 1. The familiarization stage procedure (1-a: a flashcard display; 1-b: a matching test display; 1-c: a feedback display).
Note: In Figure 1-c, the black and red box content display the responses and the correct answers, respectively.
The purpose of the familiarization stage was to enable the participants to establish initial form-meaning associations for all target collocations before practicing their retrieval (Boers et al., Reference Boers, Dang and Strong2017). Because some of the target collocations may have been partially familiar to some participants before the experiment, we allowed participants to complete the familiarization procedure at their own pace. For the purposes of retrieval practice, it was more important to confirm that all participants were at a similar level of accuracy in the form-meaning matching test—a proxy for similar levels of familiarity with the collocations prior to practicing their retrieval. The corrective feedback aimed to further reduce any differences in the participants’ initial encoding of the target collocations. The results of the familiarization stage confirmed that the participants could correctly match, on average, 95% of the target items (SD = 6%), and no participant did worse than 70% on this task. A practice session with five collocational flashcards and a five-pair matching test was conducted before the respective stages of the familiarization procedure.
Retrieval stage
There were 72 trials in the retrieval stage of the learning treatment, namely, three retrieval episodes of 24 (of 36) target collocations. In a counterbalanced design, the target collocations were assigned to one of two retrieval conditions (i.e., R3_Massed or R3_Spaced, n = 12 each) or a baseline nonretrieval (R0) condition (n = 12). In the R3_Massed condition, the collocation was retrieved in three consecutive retrieval trials; in the R3_Spaced condition, the three retrieval trials for the same collocation were separated by 12 intervening retrieval trials of other collocations; in the R0 condition, the collocations were not included in the retrieval stage. Two practice trials (not including any familiar or target collocations) were presented before the retrieval stage.
For each trial, the screen displayed the following: (a) a collocation, in which the verb was replaced with an underlined space (e.g., ____ notice), (b) a definition, and (c) an input box, all displayed until a response was entered and submitted. The participants were instructed to fill in the missing verb for the collocations from the familiarization stage. After each retrieval, corrective feedback was presented for 10 s (i.e., allotting enough time to check the accuracy of their response briefly); participants could terminate the feedback in a self-paced manner. Different feedback screens were presented for correct and incorrect responses: for correct responses, the target collocation was presented in green with a tick next to it (Figure 2-b1); for incorrect responses, the participant’s response was presented in red with a cross next to it, and the target collocation was presented below in green with a tick (Figure 2-b2). Thus, the correct collocation was always present in the feedback.
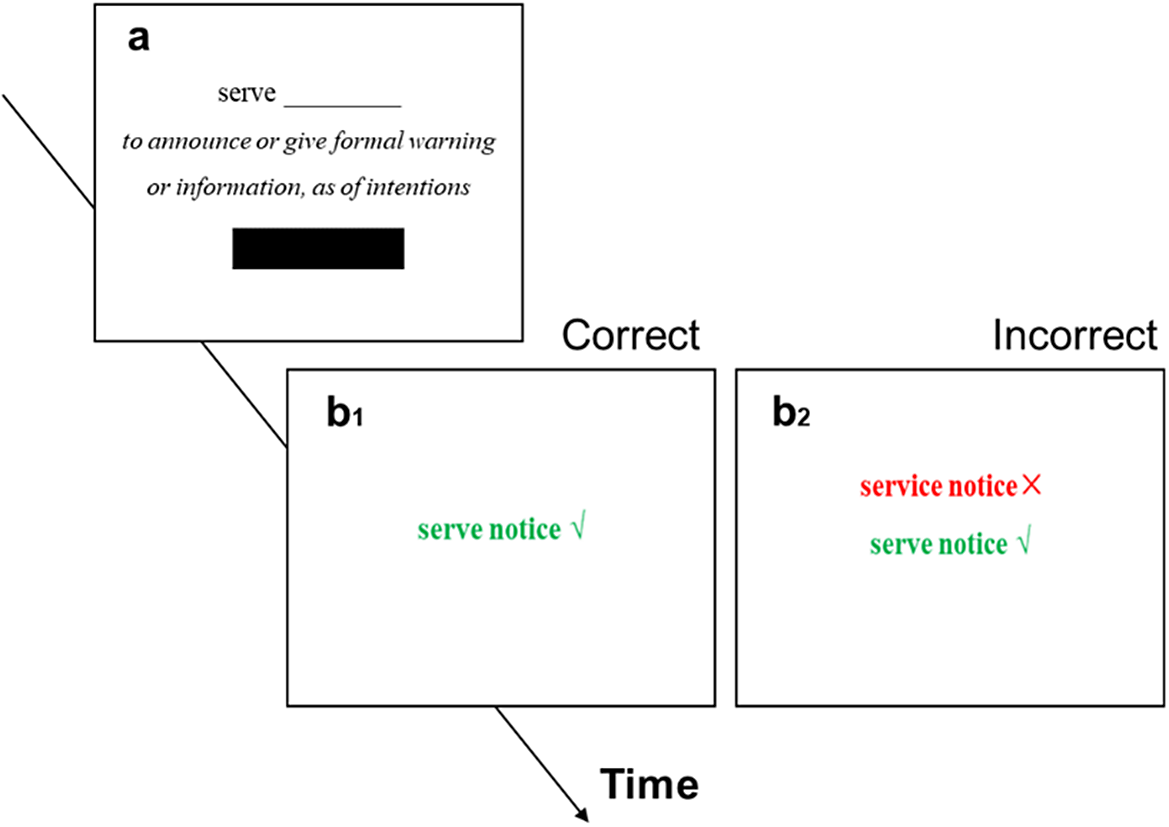
Figure 2. The retrieval practice procedure (2-a: a retrieval display; 2-b1: a correct response display; 2-b2: an incorrect response display).
Measures and posttests
Form recall
The form recall task measured participants’ explicit knowledge of the 36 target collocations (Sonbul & Schmitt, Reference Sonbul and Schmitt2013). We adopted the decontextualized format from Tsai (Reference Tsai2020). The participants had to type the missing verb of the target collocations for which the initial letter was shown (e.g., s____ notice) to restrict responses to the target words as much as possible. The definition was also displayed. The participants were instructed to fill in the gap using the collocations from the learning treatment.
Acceptability judgment task
An English acceptability judgment task was used to measure the automatized explicit knowledge of L2 collocations (Jeong & DeKeyser, Reference Jeong and DeKeyser2023; Northbrook et al., Reference Northbrook, Allen and Conklin2022). The participants were instructed to decide whether a presented word sequence is an acceptable expression in English (Yamashita & Jiang, Reference Yamashita and Jiang2010, p. 657). In each trial, participants first saw a series of 12 asterisks in the middle of the screen, presented for 800 ms, followed by a 66-ms blank screen (Figure 3) and then a collocation or nonce-collocation phrase (e.g., serve notice; compete notice), which remained on the screen until response (or for the maximum of 4,000 ms). The task included ten practice trials (not including any two-word pairs from the experimental trials of the two online tasks) and 94 experimental trials (for details, see section, Materials, Other stimuli), in random order.

Figure 3. Experiment procedure of the acceptability judgment task.
Primed lexical decision task
An English primed lexical decision task was used to measure the implicit knowledge of L2 collocations (Sonbul & Schmitt, Reference Sonbul and Schmitt2013). In this task, participants are presented with prime-target sequences and instructed to decide whether the target is an English word. The participants first saw a fixation (+) in the middle of the screen for 2,000 ms, followed by a 150-ms presentation of the prime, either the verb from the collocation or its substitution verb from the nonce collocation (e.g., serve/compete). The prime was immediately followed by the target (e.g., notice), which remained on the screen until a response was submitted (Figure 4). It included ten practice trials and 194 experimental trials (for details, see section, Materials, Other stimuli), in a random order. The determiner of the nonadjacent collocations was not included in the stimuli of this task. The presence of implicit knowledge is operationalized as collocation priming, namely, faster responses to the target (the terminal noun of the collocations, e.g., notice) preceded by its collocate verb prime (e.g., serve) compared with responses to the target preceded by a noncollocate verb prime (e.g., compete). The short prime duration and interstimulus interval were used to reduce participants’ ability to develop and deploy explicit task strategies and facilitate the deployment of implicit knowledge. Because participants made lexical decisions only on the target (the last word of the collocation) and not on the prime, they were less likely to engage their explicit knowledge of the collocations. Thus, the collocation priming effect was hypothesized to primarily measure implicit knowledge of the collocations.
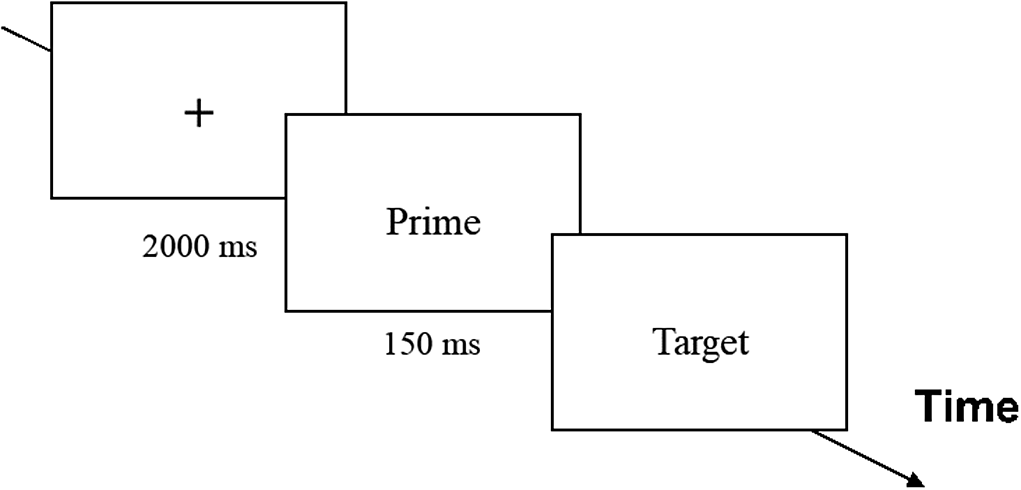
Figure 4. Experiment procedure of the primed lexical decision task.
Self-reported knowledge tasks
In a self-reported prior knowledge task (administered before the learning treatment), participants indicated whether the target collocations were known to them. In a self-reported additional exposure task (administered after the delayed posttests to account for any exposure to the target collocations between the near-immediate and delayed posttests), participants reported whether they had encountered the target collocations during the interval. Both were yes/no tasks administered as an online questionnaire.
Procedure
A day before the experiment, the participants completed LexTALE. The main study was conducted in a language lab, on an individual basis. It consisted of two parts, 1.5–2 hr in total. The first part began with the self-reported prior knowledge task, the learning treatment (familiarization stage followed by retrieval practice), the language background questionnaire (in Chinese, about 2–3 min long), and the near-immediate posttests (primed lexical decision, acceptability judgment, and form recall, in that order; the order of the tests was chosen to minimize the test-retest effect, with least explicit measures administered first). In the second part (1 week later), the participants returned for the announced delayed posttests and the additional self-reported exposure task. The posttests were completed in the same order in the near-immediate and delayed sessions; however, in the delayed primed lexical decision and acceptability judgment posttests, participants received alternative stimuli lists: if a participant saw an intact collocation in the immediate posttest, that participant saw a corresponding nonce collocation in the delayed posttest and vice versa. This design was used to counteract the potential test-retest effect.
Data analysis
We preprocessed the data as follows. For the primed lexical decision, data of erroneous responses (18.67%) were excluded. Following Jiang (Reference Jiang2012), we also excluded the extreme outliers with standardized residuals above 3 SDs and those with a response latency below 200 ms (9.63%). For the acceptability judgment, we excluded erroneous responses (36.06%) and responses with a response latency shorter than 450 ms (12.19%). The response times (RTs) were inverse-transformed (i.e., –1,000/RT) to reduce skewness in the distribution. The form recall responses were scored as 1 (correct) or 0 (incorrect) by the first author; spelling mistakes that did not interfere with the recognition of the intended answer were scored as correct responses. (e.g., *assump, assume; 31 of 2088 responses, 1.48%) (e.g., Toomer & Elgort, Reference Toomer and Elgort2019; Yamagata et al., Reference Yamagata, Nakata and Rogers2023).
The data analysis consisted of a preliminary analysis and a primary analysis. The preliminary analysis examined the effect of Exposure in the familiarization stage on the subsequent online processing of the familiar collocations (studied familiar collocation/unstudied familiar collocation), for a more nuanced interpretation of the primary analysis findings. The primary analysis focused on the effect of Treatment (R0/R3_Massed/R3_Spaced). We fitted linear mixed-effects models to the RT data in the analysis of primed lexical decisions and acceptability judgments and generalized linear mixed-effects models to the binary response data in the analyses of form recall, using the lme4 R package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015). All initial models contained by-participants and by-items random intercepts, and random slopes for Test_time. The final models contained a random-effect structure supported by data (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017). The alpha level was .05 in all analyses. The effect sizes (odds ratio [OR]; Cohen’s d [d]) were interpreted following the general guidelines in Chen et al. (Reference Chen, Cohen and Chen2010) (small OR = 1.68, medium OR = 3.47, large OR = 6.71) and Cohen (Reference Cohen1988) (small d = .2; medium d = .5; large d = .8).
We began by fitting the most complex model and conducted backward stepwise model selection. The initial model of form recall included the following primary interest predictors: Treatment (R0/R3_Massed/R3_Spaced), Test_timeFootnote 3 (near-immediate/delayed posttest), and the Treatment × Test_time interaction. In the preliminary analyses for the acceptability judgment and primed lexical decision, the initial models included Exposure (nonce-collocation control/studied familiar collocation/unstudied familiar collocation), Test_time, and the Exposure × Test_time interaction. In the primary analyses, the initial models included Treatment (nonce-collocation control/R0/R3_Massed/R3_Spaced), Test_time, and the Treatment × Test_time interaction. The interactions were included because the effects of Treatment may differ for the near-immediate and delayed posttest (as shown in previous spacing and retrieval vocabulary learning studies). Post hoc analyses with the Tukey test were performed for significant interactions using the R package emmeans (Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2018).
The following covariates were also included in all the initial models: participants’ L2 lexical proficiency (centered LexTALE scores) and whether the target included a determiner (absent/present). Furthermore, the initial models in the primary analyses included self-reported prior knowledge (yes/no) and additional exposure (yes/no) responses, as covariates. A back-stepping model simplification procedure resulted in the final models that contained the primary interest predictors; covariates and interactions were only kept when they improved the model fit. Additionally, we trimmed model residuals to 2.5 SDs after fitting the final RT models (Baayen et al., Reference Baayen, Davidson and Bates2008).
Results
Table 1 presents the descriptive statistics for the three near-immediate and delayed posttests by Treatment condition and Collocation type.
Table 1. Descriptive results of the near-immediate and delayed posttests

Note: The values are the mean accuracies for the form recall and response times (in milliseconds) for the acceptability judgment and primed lexical decision, with SDs in parentheses.
Results of form recall
The form recall data of the target collocations showed reasonable reliability (near-immediate posttest: α = .874; delayed posttest: α = .792), according to the guidelines in Plonsky and Derrick (Reference Plonsky and Derrick2016). The results (Table 2) showed significant effects of Treatment, Test_time, centered LexTALE scores, and self-reported additional exposure. When collapsed across the immediate and delayed posttests, the participants were more accurate in recalling target collocations in both the R3_Massed condition (OR = 3.39 [medium effect]) and the R3_Spaced condition (OR = 4.22 [medium effect]) than in the R0 condition. Although the R3_Spaced condition resulted in slightly higher mean accuracy than the R3_Massed condition (Table 1), the post hoc comparison results revealed that the difference was not statistically significant (R3_Massed versus R3_Spaced; b = –.21, OR = .81, p = .305 [small effect]). In all treatment conditions, the participants recalled the target collocations more accurately at the immediate posttest than at the delayed posttest (OR = .17 [small effect]). In addition, the higher accuracy of form recall was associated with higher LexTALE scores (OR = 1.11 [small effect]) and self-reported additional exposures (OR = 2.64 [small effect]). The findings of form recall can be summarized as follows:
R3_Spaced = R3_Massed > R0
Table 2. Accuracy rates of form recall (target collocations): Fixed effects
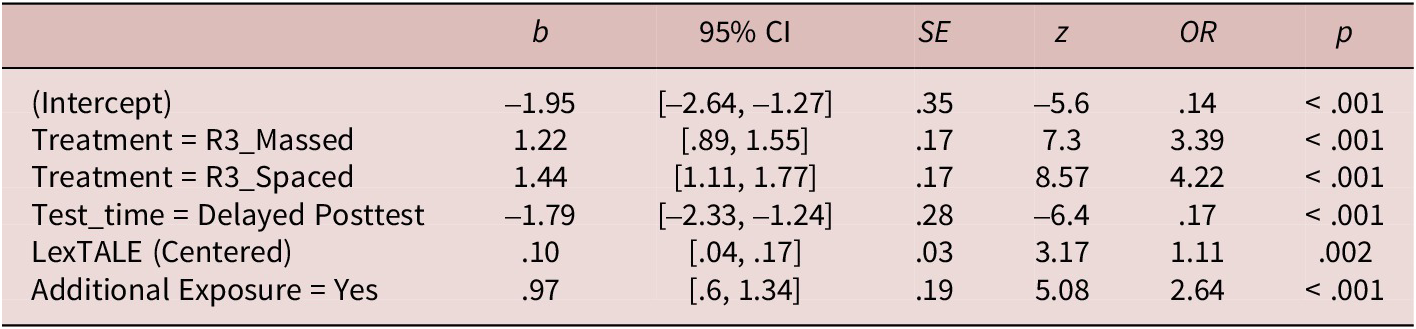
Note: CI = confidence interval; Reference level: Treatment = R0; Test_time = near-immediate posttest; Additional exposure = no. Model formula: FR.accuracy ~ Treatment + Test_time + LexTALE_centered + Additional_exposure + (Test_time+1|Participant) + (LexTALE_centered +1|Target).
Results of acceptability judgments
Preliminary analysis
We tested whether the collocation processing advantage (i.e., faster processing of collocations compared with matched nonce-collocation controls) was observed for the familiar collocations. Results (see Table 3) showed this effect for both the unstudied familiar collocations (d = .76 [medium effect]) and the studied familiar collocations (d = 1.09 [large effect]), suggesting that the participants had automatized explicit knowledge of familiar L2 collocations that could be detected regardless of the exposure recency.
Table 3. Response times of acceptability judgments (familiar collocations): Fixed effects

Note: CI = confidence interval; Reference level: Exposure = nonce-collocation control; Test_time = near-immediate posttest. Model formula: inverseRT ~ Exposure + Test_time + (Test_time +1|Participant) + (1|Target).
Primary analysis
The Treatment × Test_time interaction was significant in the final model (see Table 4). The post hoc results on the Treatment × Test_time interaction are presented in Table 5. At the near-immediate posttest, the target collocations (R0: d = .64; R3_Spaced: d = .76 [medium effect]; R3_Massed: d = .84 [large effect]) were judged faster than the nonce-collocation controls in all treatment conditions. The collocational advantage reported in the nonretrieval R0 condition suggested that any gain of automatized explicit knowledge observed for the target collocations in the retrieval practice treatment would likely be due to the cumulative effect of familiarization plus retrieval practice rather than the retrieval practice alone. However, at the delayed posttest, the collocation processing advantage was observed only in the R3_Spaced condition (d = .37 [small effect]). Additionally, the determiner presence had a significant effect (d = .2 [small effect]) on the judgment times. The findings of the acceptability judgment posttest (i.e., the difference in RTs between the nonce collocations and target collocations) can be summarized as follows (note: PA = processing advantage):
Near-immediate posttest: R3_Spaced = R3_Massed = R0
Delayed posttest: R3_Spaced (PA) > R3_Massed (no PA) = R0
Table 4. Response times of acceptability judgments (target collocations): Fixed effects
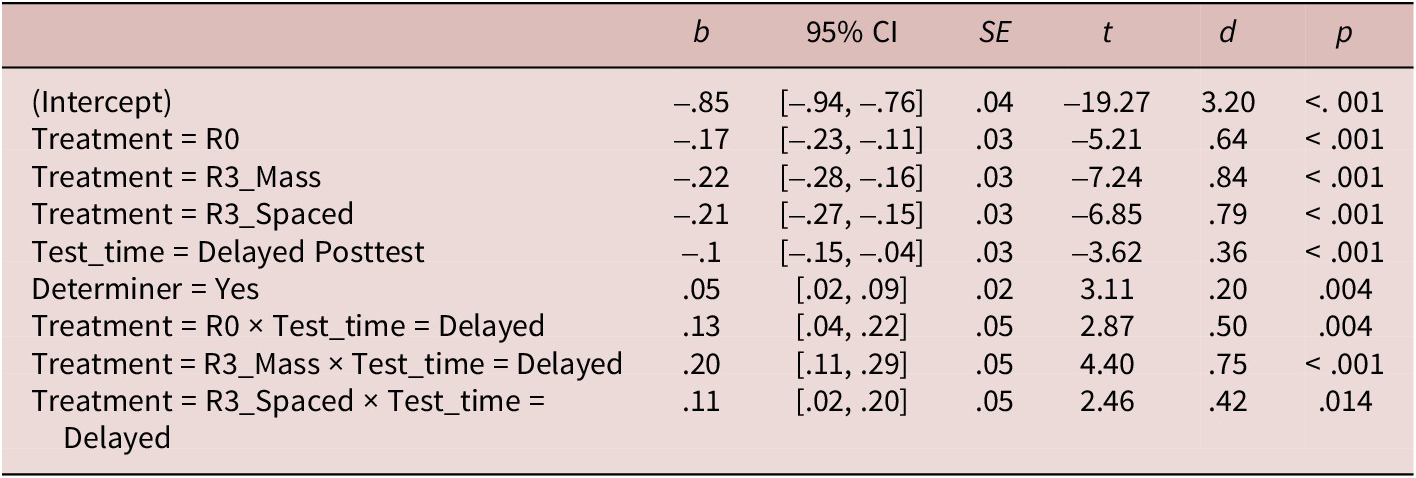
Note: CI = confidence interval; Reference level: Treatment = nonce-collocation control; Test_time = near-immediate posttest; Determiner = no determiner. Model formula: inverseRT ~ Treatment * Test_time + Determiner + (1|Participant) + (1|Target).
Table 5. Post hoc comparisons of the response times for the Treatment × Test_Time interaction in the analysis of acceptability judgments (target collocations)
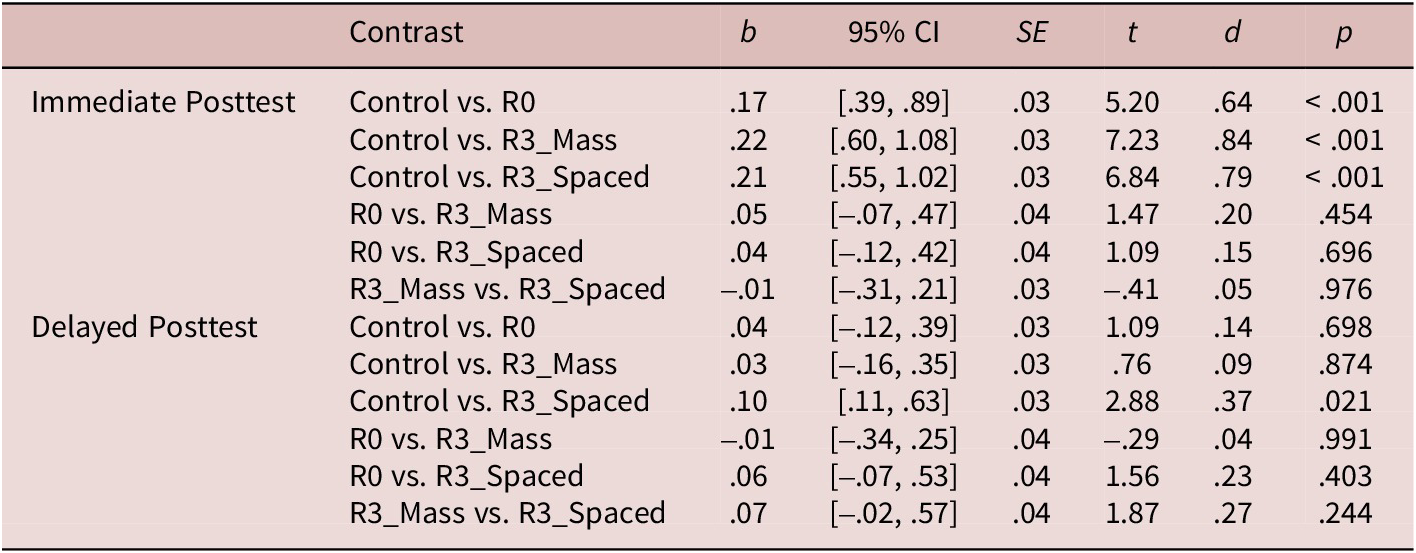
Note: CI = confidence interval; Control = nonce-collocation controls.
Table 6. Response times of primed lexical decisions (familiar collocations): Fixed effects

Note: CI = confidence interval; Reference level: Exposure = nonce-collocation control; Test_time = near-immediate posttest. Model formula: inverseRT ~ Exposure + Test_time + (Test_time + 1|Participant) + (1|Target).
Results of primed lexical decisions
Preliminary analysis
In this analysis (see Table 6), we tested whether collocation priming (i.e., faster processing of the terminal word in the collocations than in the matched nonce controls) was observed for the familiar collocations. The familiar collocations showed no priming in the unstudied condition (p = .648) or the studied condition (p = .09). This suggests that any gains in implicit knowledge of the target collocations in the primary analysis would likely reflect the effect of retrieval practice. The results showed a significant effect of Test_time (d = .66 [medium effect]): the participants judged the stimuli (both the familiar collocations and their controls) faster at the delayed posttest than they did at the near-immediate posttest. However, this speed-up did not result in priming (as indicated by the absence of significant Exposure × Posttest interactions).
Primary analysis
The Treatment × Test_time interaction was not a significant predictor of RT in this analysis and was not included in the final model (Table 7).
Table 7. Response times of primed lexical decisions (target collocations): Fixed effects
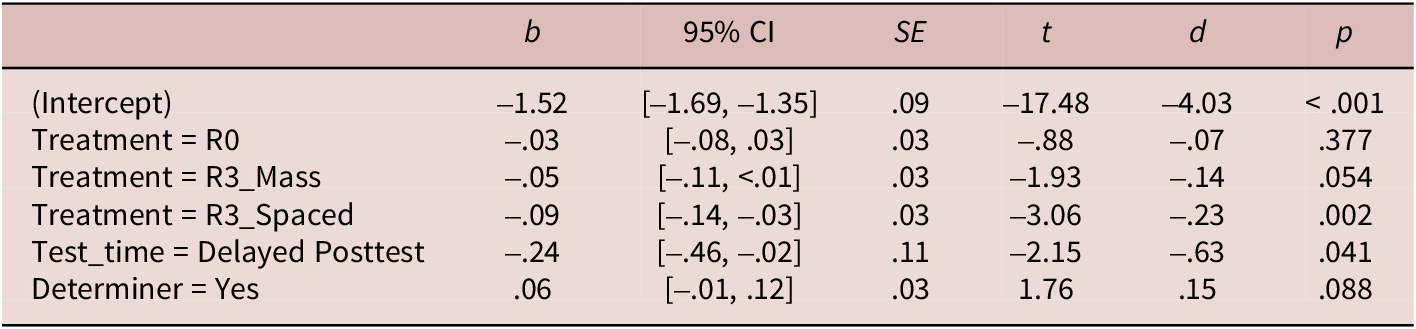
Note: CI = confidence interval; Reference level: Treatment = nonce-collocation control; Test_time = near-immediate posttest; Determiner = no determiner. Model formula: inverseRT ~ Treatment + Test_time + Determiner + (Test_time +1|Participant) + (1|Target).
The post hoc comparisons of RTs for the levels of the learning condition and experimental condition (Table 8) showed that, after applying the Tukey adjustment, there was significant collocation priming in the R3_Spaced condition (p < .05, d = .23 [small effect]) but not in the R3_Massed condition (p = .218, d = .14 [small effect]), when collapsed across the posttests. As in the preliminary analysis, Test_time had a significant fixed effect (d = .63 [medium effect]), with faster responses on the delayed posttest. The findings of the primed lexical decision task (i.e., the difference in RTs between the nonce collocations and target collocations) can be summarized as follows:
R3_Spaced (significant priming) > R3_Massed (nonsignificant priming) > R0 (no priming)
Table 8. Post hoc comparisons of the response times for the levels of Treatment in the analysis of primed lexical decisions (target collocations)
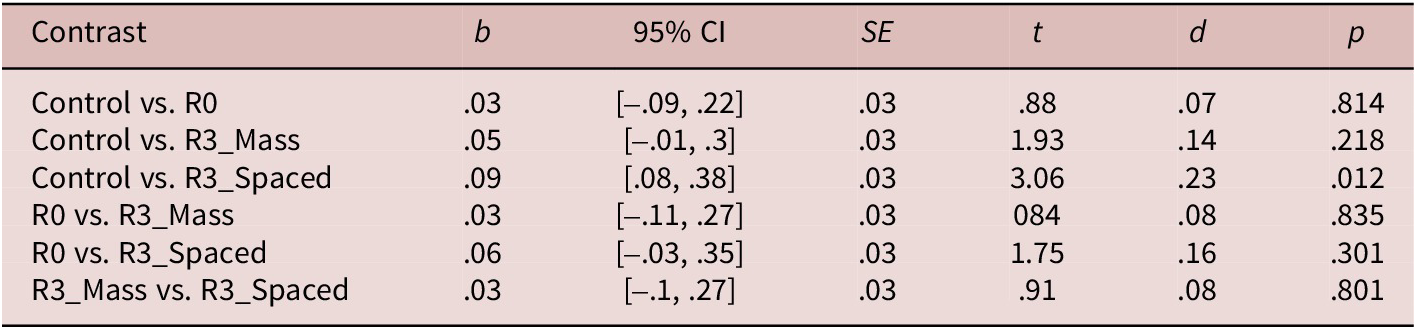
Note: CI = confidence interval; Control = nonce-collocation controls.
Discussion
The present study investigated the effect of retrieval schedules on the acquisition of implicit, automatized explicit, and explicit knowledge of L2 collocations. We found that retrieval schedules differentially affected the development of the three aspects of knowledge tested: (a) spaced and massed retrieval were equally beneficial for the acquisition of both the offline explicit knowledge (in the near-immediate and delayed posttests of form recall) and the initial automatized explicit knowledge (in the near-immediate posttest of acceptability judgment) and (b) spaced retrieval was more beneficial than massed retrieval for the retention of the automatized explicit knowledge (in the delayed posttest) and the acquisition of implicit collocation knowledge (in the near-immediate and delayed posttest of primed lexical decision). In other words, we observed the spacing effect in the retention of the automatized explicit knowledge and in the development of implicit collocational knowledge.
Surprisingly, the results of form recall showed that the massed and spaced retrieval were equally effective in promoting the acquisition of explicit knowledge, with both conditions yielding better results than the non-retrieval baseline condition. Numerically, spaced retrieval (near-immediate, 46%; delayed, 23%) led to slightly higher accuracy than massed retrieval (near-immediate, 44%; delayed, 20%), although there was no statistically significant difference between the two retrieval schedules. This finding is not aligned with the predicted spacing advantage in intentional MWE learning (Macis et al., Reference Macis, Sonbul and Alharbi2021; Yamagata et al., Reference Yamagata, Nakata and Rogers2023). The absence of the spacing effect in our study may be due to the measure of explicit knowledge, i.e., decontextualized form recall, which does not necessarily require access to meaning. It is possible that massed (consecutive) retrieval practice was particularly beneficial in creating a salient representation of the whole form of the collocations. The significant benefits of spaced and massed retrieval for explicit knowledge in our study may have also resulted from transfer-appropriate processing (Lightbown, Reference Lightbown and Han2007; Morris et al., Reference Morris, Bransford and Franks1977), as an overlap in the practice and test formats could have boosted response accuracy in the posttests. The transfer-appropriate processing effect, thus, may have offset the spacing effect (Van den Broek et al., Reference Van den Broek, Takashima, Segers and Verhoeven2018; Veltre et al., Reference Veltre, Cho and Neely2015).
An important new finding of our study concerns the acquisition of automatized explicit knowledge. We observed learning benefits for massed and spaced retrieval in the near-immediate posttest (i.e., initial learning). However, after 1 week, only spaced (but not massed) retrieval retained a processing advantage of the target collocations over the controls, indicating that the retention of the automatized explicit collocational knowledge exhibits the spacing effect. This finding also suggests that automatization of explicit knowledge of L2 collocations is not an all-or-nothing process, reflecting gradual performance improvement that may not be retained (Suzuki & DeKeyser, Reference Suzuki and DeKeyser2017). This finding is consistent with the previous finding that longer gaps between episodes tend to result in longer retention than shorter gaps. Still, shorter gaps may be either more beneficial (Cepeda et al., Reference Cepeda, Vul, Rohrer, Wixted and Pashler2008) or equally effective (Kim & Webb, Reference Kim and Webb2022) compared with longer gaps, when tested at short retention intervals. It is also consistent with the prediction that more processing required in spaced retrieval (with feedback) is likely to benefit knowledge retention (Hintzman, Reference Hintzman and Bower1976). Thus, any advantage of spaced retrieval may be more pronounced for long-term knowledge retention than initial learning, as predicted by the desirable difficulties account (Bjork, Reference Bjork, Metcalfe and Shimamura1994; Schmidt & Bjork, Reference Schmidt and Bjork1992).
We also observed an advantage of spaced over massed retrieval for the development of implicit knowledge. A statistically significant collocation priming effect was recorded in the spaced retrieval condition, and the effect size of priming was larger in the spaced practice condition (d = .25) than in the massed practice condition (d = .16). Similar to Toomer and Elgort (Reference Toomer and Elgort2019), who reported a small effect size (d = .15) for the collocation priming (in incidental learning), the priming effect sizes in our study were small. Suzuki and DeKeyser (Reference Suzuki and DeKeyser2017) argue that the effects of spacing may be mediated by practice complexity and conditions that involve different cognitive processes. In our study, the retrieval practice was decontextualized, and only three retrieval opportunities were provided, which may have resulted in relatively weak implicit associations between the components of the target collocations. Perhaps a higher number of retrieval opportunities in context could lead to more robust implicit L2 collocational knowledge (Toomer & Elgort, Reference Toomer and Elgort2019).
Our study shows that three instances of retrieval practice (after the familiarization stage) were sufficient for L2 learners to gain implicit knowledge of collocations (operationalized as collocation priming) in the spaced practice condition; in the massed practice condition, the implicit knowledge was still fragile (adjusted p = .14). Sonbul and Schmitt (Reference Sonbul and Schmitt2013) did not find collocation priming in the decontextualized learning condition after three repetitions. This discord may be due to the differences in the two studies’ learning procedures. In Sonbul and Schmitt’s study, participants saw the target L2 collocations flashed on the screen in the decontextualized condition three times, for a total of 10 s, without meaning explanations or opportunities for retrieval. This learning treatment was probably insufficient for developing implicit collocational knowledge. In our study, the familiarization stage (where intact collocations were presented with their meanings and examples of use) likely resulted in the establishment of form-meaning mappings and whole phrase representations, strengthened by the subsequent form-focused retrieval practice and feedback; this practice procedure could have promoted the development of implicit associations between the component words of the target collocations. The finding that collocation priming was not statistically significant in the massed retrieval condition suggests that not all types of deliberate retrieval practice are equally effective for the development of implicit collocational knowledge. Our findings add to the limited research on the development of implicit knowledge of L2 collocations (Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Toomer & Elgort, Reference Toomer and Elgort2019), suggesting that spaced retrieval combined with deliberate learning may benefit this knowledge type.
Finally, we discuss the findings for the familiar L2 collocations. We did not observe collocation priming for familiar collocations (either studied or unstudied). However, we did find a collocation advantage for both studied and unstudied familiar collocations in the acceptability judgment task. This suggests that (a) Chinese learners of English who participated in our study did not have observable implicit knowledge even of the L2 collocations that were considered known, but (b) their explicit knowledge of the familiar collocations was automatized. Our results show that, by engaging in spaced retrieval practice (with corrective feedback) after the familiarization stage, Chinese learners of English were able to develop not only automatized explicit knowledge but also implicit knowledge of L2 collocations.
Limitations
Several limitations to this study need to be acknowledged. First, the length of the first session might have introduced an element of fatigue among the participants. This could be mitigated in future studies by administering the tasks over more sessions and more days. We also acknowledge that the interval between the near-immediate and delayed posttests was relatively short (i.e., 1 week). Some previous studies used longer intervals, such as 2 weeks (e.g., Obermeier & Elgort, Reference Obermeier and Elgort2020; Sonbul & Schmitt, Reference Sonbul and Schmitt2013), 3 weeks (e.g., Macis et al., Reference Macis, Sonbul and Alharbi2021), and even 4 weeks (e.g., Farvardin, Reference Farvardin2019). Longer intervals could be used in future studies to examine the effect of retrieval schedules on the longer-term retention of L2 collocational knowledge. Further, because the order in which the target collocations were presented in retrieval practice was kept the same, the delay between retrieval practice and near-immediate posttests was different for the target collocations; in future studies, it may be useful to randomize the order of the retrieval practice. Finally, the Vocabulary Levels Test (Webb et al., Reference Webb, Sasao and Ballance2017) might provide a finer measure of the participants’ lexical proficiency than LexTALE.
Conclusions
The present study investigated the effects of retrieval schedules on the acquisition of explicit, automatized explicit, and implicit knowledge of L2 collocations. The results show that the effects of spacing vary by the type of collocational knowledge. Our findings corroborate the effectiveness of retrieval practice as a useful exercise for learning L2 MWEs (Strong & Boers, Reference Strong and Boers2019a, Reference Strong and Boers2019b). In addition, we found that spaced retrieval is more beneficial in learning L2 collocations than massed retrieval, adding to the existing evidence on the advantages of spaced retrieval practice on L2 single-word learning (e.g., Karatas et al., Reference Karatas, Özemir, Lovelett, Demir, Erkol and Veríssimo2021) and further highlighting the relevance of the desirable difficulty framework of practice in the L2 field (Suzuki et al., Reference Suzuki, Nakata and Dekeyser2019a, Reference Suzuki, Nakata and Dekeyser2019b).
Our results show that the distinction between implicit knowledge and automatized explicit knowledge (Suzuki, Reference Suzuki2017) is relevant in the study of L2 collocational knowledge. Our findings also show that retrieval schedules may differentially affect the development of offline and automatized explicit knowledge of L2 collocations. We, therefore, recommend instructional approaches that involve an initial presentation of intact collocations (such as the familiarization stage in our study) followed by multiple (ideally, more than three) spaced retrieval opportunities (with corrective feedback).
Importantly, the present study is only an initial step in researching the effect of retrieval schedules on the development of implicit and explicit knowledge of L2 collocations. Further research into the combined effects of retrieval schedules and frequency of retrieval episodes is theoretically and pedagogically interesting, because it can help us chart the time course of the acquisition of different aspects of L2 collocational knowledge and develop more robust instructional approaches.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/S0272263124000184.
Acknowledgments
We would like to express our sincere gratitude to the editors of Studies in Second Language Acquisition and the anonymous reviewers for their valuable suggestions and constructive comments on earlier versions of this article. This work was partially funded by Shaoguan University scientific research funds (404-9900064604).














