



A growing number of studies have explored neighbourhood factors that are correlated with childhood obesity and dietary behaviours, providing conflicting evidence base, which may be due to methodological heterogeneity(Reference Titis, Procter and Walasek1,Reference Wilkins, Morris and Radley2) or complex nature of the relationship in question, meaning multiple variables must be considered(Reference Schuurman, Peters and Oliver3). Focussing on children is relevant for modelling future obesity rates(Reference Freedman, Kettel Khan and Serdula4), as obese children tend to become obese adults(Reference Magarey, Daniels and Boulton5); it is also likely that prevalence of obesity in children mirrors current prevalence in adults, as obese adults tend to have obese children(Reference Llewellyn, Simmonds and Owen6). Given the likely long-term health effects children may experience due to poor nutrition(Reference Llewellyn, Simmonds and Owen6), this research responds to the call for more UK studies among children to inform public health policy and intervention design(Reference Cetateanu and Jones7), including rural context(Reference McGrath Davis, James and Curtis8).
Obesity results from positive energy imbalance and is a consequence of numerous factors, from genes, diet, levels of physical activity and the surrounding environment to social and cultural factors; e.g. it is thought to be associated with population density(Reference Chalkias, Papadopoulos and Kalogeropoulos9), race(Reference Williams, Ge and Petroski10), unemployment level(Reference Oddo, Nicholas and Bleich11), household income level(Reference Evans, Jones-Rounds and Belojevic12,Reference Rogers, Eagle and Sheetz13) and educational level(Reference Chalkias, Papadopoulos and Kalogeropoulos9). Community-level environmental factors may be related with obesity rates by influencing dietary choices of individuals and promoting physical activity; for example, retail food environments (RFE) likely contribute to rising levels of obesity(Reference Story, Kaphingst and Robinson-O’Brien14), as they set the context within which people acquire food by providing opportunities and constraints that are related with food buying decisions(Reference Lartey, Hemrich and Amoroso15). Consequently, ongoing obesity crisis may be driven by qualities of the environment that promote both excess energy consumption and inadequate energy expenditure(Reference Mitchell, Catenacci and Wyatt16); which may become particularly important in very restricted environments (e.g. areas of extreme poverty, rural and isolated communities, etc.)(Reference Lytle17).
A limited number of studies consider the relationship between RFE and social inequalities in diet or differences in obesity prevalence across geographical areas(Reference Titis, Procter and Walasek1). Geographical variation is important because urban and rural areas may face different barriers to eating a healthy diet, including disproportionate distribution of food sources that facilitate healthy food choices(Reference Corfe18). For example, Cummins et al.(Reference Cummins, Smith and Taylor19) found associations between neighbourhood deprivation and food accessibility varied by environmental setting(Reference Smith, Cummins and Taylor20); others have found that rural residents have lower food access(Reference Larson, Story and Nelson21) or restrictive food choices(Reference Corfe18). A recent report from the UK states that about three quarters (76 %) of food deserts, FD – generally referring to low-income areas with poor geographic accessibility to a grocery store(Reference Wrigley22) – in England and Wales are in urban areas, with the remaining 24 % located in relatively over-represented rural areas(Reference Corfe18). Indeed, there exists robust evidence of a positive association between living in a FD and higher childhood BMI, particularly among children in urban areas(Reference Thomsen, Nayga and Alviola23). FD have been universally attributed to economic drivers of poor diet, such as food affordability and food prices including regional variations, but their presence remains debatable in the UK(Reference MacDonald, Ellaway and Ball24).
This study builds upon existing work by providing a systematic analysis of which factors shape childhood BMI and under which conditions. Notably, the goal of the study is not to identify causal effects; rather, the goal is to provide a more nuanced picture of how supermarket distance and other socio-economic characteristics of locations are associated with childhood obesity. In addition to healthy food proximity and income inequality that other studies have also focussed on, this article considers associations of population density and rurality with obesity (i.e. urban v rural status of locations). Density and rurality have been chosen primarily because they have been shown on numerous occasions to relate to obesity in some settings but there is limited evidence for the UK. We therefore hypothesise that the relationship between supermarket distance and obesity is different in less populated areas than in more populated areas because the latter constitute an obesogenic environment. Moreover, population density is a strong predictor of proximity to the nearest supermarket(Reference Wilde, Llobrera and ver Ploeg25), and we would expect to see interaction between distance and density since the greater number of people living in an area should stimulate demand for food; this in turn facilitates opening of new food outlets that would translate into decreased spatial accessibility of outlets altogether, including distances to closest outlets. In addition, we also consider how rurality may interact with income in predicting obesity, as for example affluent rural areas may present less obesity-prone features compared to deprived urban areas, regardless of proximity to supermarkets.
Data and methods
The analysis we present explores the association between children obesity rates and a set of covariates capturing physical access and economic access to food in England, using well-suited, publicly available data by the Consumer Data Research Centre (CDRC)(26) and the National Child Measurement Programme (NCMP)(27). The unit of analysis is the Middle Super Output Area (MSOA) level, which is a geographical unit, the NCMP data are available at translating to average populations of 7000 and an average size of 21 km2. Our dataset includes 6772 observations, of which 5581 and 1191 are for urban and rural areas, respectively. In the next sections, we describe the data in more detail. Geographical indicators collated at the MSOA level are widely used predictors in modelling of childhood obesity(Reference Wilding, Ziauddeen and Smith28,Reference Ziauddeen, Wilding and Roderick29) to inform interventions related to healthy nutrition practices, including preventive programmes and improving geographic access to food, as well as physical activity promotion(30,Reference Sallis, Porter and Tan31) . While some research has moved to individual-level data to understand household features affecting obesity, this article focuses on how aggregated locations’ characteristics correlate with obesity rates regardless of households’ characteristic. Hence, MSOA level is suitable for investigating FD, which are indicators of food access poverty for entire areas. More importantly, aggregate-level data may provide easier recommendations for UK public health policies, which are already based on the same data.
Dependent variable
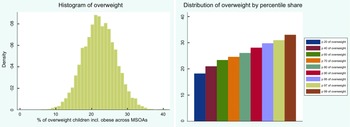
Childhood overweight data by the NCMP constituted our dependent variable measured in continuous BMI units that have been averaged across three consecutive years 2013/14, 2014/15 and 2015/16 and aggregated to 2011 MSOA level; consequently, the prevalence of overweight/obesity is in the MSOA levels rather than individual levels. Before the programme starts each school year, local authorities write to parents and carers of all children eligible for measurement to inform them of the programme. Local authorities are asked to collect data on Reception (aged 4–5) and Year 6 (aged 10–11) children’s height and weight from all state-maintained schools within their area, which then is used to produce individual-level longitudinal indicators of childhood BMI. Heights and weights are used to calculate a BMI percentile by dividing weight (in kilograms) by the square of height (in metres); children are classified as overweight (including obese) if their BMI is on or above the 85th centile of the British 1990 growth reference (UK90) according to age and sex(27). The measurement process is overseen by trained healthcare professionals. Suppression and disclosure controls (numerator greater than five and a denominator of at least 50) are implemented to ensure anonymity(27). Due to suppression, there was no data available for children in 19 out of 6791 MSOAs in England, giving the sample size of 6772. Figure 1 shows histogram of the variable (left panel), including distribution by percentile share (right panel).

Fig. 1 Distribution of overweight children including histogram and percentile shares
Independent variables
Supermarket distance, being our main independent variable, was operationalised as distance in km by car travel route from postcode centroid to the nearest outlet as calculated in 2018 by Daras et al.(Reference Daras, Green and Davies32). Measurement data are produced for lower super output areas, LSOA for England and Wales, and Data Zones (DZ) for Scotland. Data on roughly half a million retail businesses throughout Great Britain were provided by the Local Data Company (LDC) via the CDRC. The LDC dataset, which is regularly updated through validation via LDC field workers, includes the location of business and a hierarchical classification of the type of retail business (39 categories and 370 subcategories). The data is publicly available via CDRC(26).
In addition, several socio-economic factors were collated for the purpose of this study; details on these variables and their datasets are given in Table 1, which also reports the type of measurement (e.g. distance in km), level of analysis and years covered. Finally, we also used the 2011 Rural-Urban Classification (RUC), which constituted our dummy variable for rurality. RUC is an official statistic by Office for National Statistics (ONS) used to distinguish rural and urban areas; the Classification defines areas as rural if they are outside settlements with more than 10 000 resident population. We argue that density and rurality variables measure different factors and should not be treated interchangeably. Urban units are classified as such in the UK data based on a 10 000 resident population threshold that does not capture population density and may be related to the size of the unit. Rural locations, on the other hand, have less than 10 000 inhabitants, regardless of whether the distribution is concentrated or sparse. This is further confirmed by the summary statistics showing that density in urban areas has a much higher sd than density in rural areas. This suggests an important variation in density within urban areas. The average density in urban areas is approximately 50, which corresponds to the maximum density recorded in rural areas.
Table 1 Independent variables used in the study

CDRC = Consumer Data Research Centre, ONS = Office for National Statistics, MSOA = middle super output area, LSOA = lower super output area.
* This dataset provides 2011 estimates that classify usual residents in England and Wales by ethnic group. The ethnic group classification used is the standard 18-category classification corresponding to the tick box response options on the census questionnaire.
† This dataset provides 2011 estimates that classify usual residents aged 16 and over in England and Wales by their highest level of qualification. This information identifies educational achievement across the population to help government resource allocation and policy making, especially in relation to disadvantaged population groups and educationally deprived areas.
‡ This dataset provides 2011 estimates that classify usual residents aged 16–74 in England and Wales by economic activity. The census concept of economic activity is compatible with the standard for economic status defined by the International Labour Organisation (ILO). It is one of a number of definitions used internationally to produce accurate and comparable statistics on employment, unemployment and economic status.
*–‡The estimates are as at census day 27 March 2011.
Preparation and statistical description of the variables
Scatterplot matrices, Cook’s distance (any point over 4/n -where n is the total number of data points) and LOWESS (locally weighted scatterplot smoothing) tool were used to help identify outliers; the latter also allows to help diagnose non-linearities. As a result, Isles of Scilly was identified as an outlier and removed from the analysis, which resulted in 6771 observations for England and 5580 observations for urban areas; there were no outliers detected for rural areas (n 1191). Next, correlation matrix using Pearson’s coefficients was used to check the collinearity between independent variables (see Table 2); this was further extended by examining the variance inflation factors (VIF) for the regression models. Finally, after comparing a histogram of the sample data to a normal probability curve followed by examination of the QQ plot to test normality of variables, distance data were transformed using a log-10 transformation due to the strong positive skew in the distribution. With large enough sample sizes (> 30 or 40), however, the violation of the normality assumption should not cause major problems, meaning parametric procedures can be used even when the data are not normally distributed(Reference Ghasemi and Zahediasl33).
Table 2 Correlation matrix between all the variables used in the study
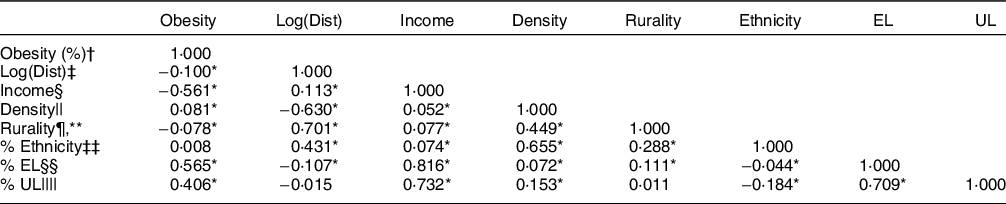
UL = unemployment level, EL = education level, MSOA = middle super output area.
* P < 0·01.
† Proportion of overweight children (incl. obese) for MSOA 2013–16 (averaged) and collapsed to MSOA level.
‡ Road distance from postcode centroid to the nearest supermarket, the variable was log-transformed.
§ Total annual household income.
|| Number of persons per hectare.
¶ Urban–rural classification (0-urban, 1-rural).
** Point-biserial correlation between the dummies and the other continuous variables.
‡‡ Proportion of households from the ethnic minority groups.
§§ Proportion of households with no qualification.
|||| Proportion of households with adults not in employment.
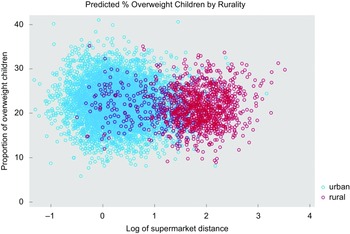
Table 3 shows the statistical descriptions for the variables used in the study. On average, nearly one-fifth (22 %) of children in the MSOA were overweight (M = 22·19, sd = 4·60), with a quarter of MSOAs (25 %) contained one in five children that were overweight. Children were more obese in urban areas (M = 22·36) when compared with rural areas (M = 21·41); unequal variance (independent) t test confirmed that there is a significant difference between the means of two populations (t(1877·71) = 6·9130, two-tailed P-value < 0·01). Percentiles for all the variables used in the analysis by urban/rural setting, including base (England), are given in online supplementary material S1. Visual examination confirmed that urban areas (M = 1·58) have better spatial accessibility to supermarkets than rural areas (M = 6·73) (see Fig. 2).
Table 3 Statistical description for the variables in the study
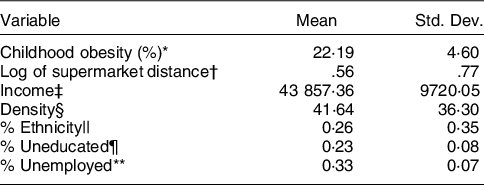
Std. Dev. = standard deviation.
* Proportion of overweight children incl. obese, 2013–16 (averaged) and collapsed to MSOA level.
† Road distance in kilometres, the variable was log-transformed.
‡ Total annual household income in pound sterling £.
§ Number of persons per hectare.
|| Proportion of households from the ethnic minority groups.
¶ Proportion of households with no qualification.
** Proportion of households with adults not in employment.
Fig. 2 Scatterplot of overweight and log of supermarket distance by urban/rural areas
Modelling approach
Both main associations of income, density and rurality, and their interactions with distance were modelled using the ordinary least squares (OLS) method. Distance, income, density and rurality were used initially to set a baseline that represents the starting point of the work; once their relationship with obesity was established in terms of basic models, additional relevant covariates (i.e. ethnicity, education, employment) were included to minimise omitted-variable bias (OVB). For density and continuous income, adjusted prediction was set at various constant values with other variables set at its mean, including: (a) mean-1sd, mean and mean + 1sd; and (b) means of income quintiles. In addition, association with rurality were examined in a separate analysis, using the urban–rural dummy variable (0 for urban, 1 for rural areas) for the following: (a) below and above-average income groups, including further split by rurality, e.g. below average income in urban areas; and (b) continuous income converted into categories based on quintiles and split into rural and urban status, e.g. non-first income quintile for urban areas.
The relation for England was analysed first, followed by comparison between rural and urban areas. The data were first examined visually, and then the Likelihood Ratio Test (LRT) was used to compare the models in a systematic manner. First, the model with only distance as predictor was compared against models including one extra predictor at a time, i.e. income, density and rurality. A model that was significantly different from this initial model became a new benchmark against which models with the remaining predictors were compared one at a time. The resulting main model was then used as a final benchmark for comparisons with corresponding nested models including interaction terms. This statistical approach was appropriate as we were interested in nested model comparisons tested via chi-square difference tests comparing changes in model fit associated with the addition or removal of the parameters. After fitting the final models, regression diagnostics were used to evaluate assumptions for linear regression (see online supplementary material S2). All analyses were conducted using Stata 16.
Results
We report similar results for England and urban areas, which is not surprising given that in 2011, 81·5 per cent (45·7 million) of the usually resident population of England and Wales lived in urban areas and 18·5 per cent (10·3 million) lived in rural areas(34). We therefore jointly present results for England and urban areas, followed by discussing results for rural areas. For England and urban areas, the final model includes distance-density interaction and income, ethnicity, education and unemployment covariates; for rural areas, the final model includes distance-income interaction and ethnicity, education and unemployment covariates. Initial visual analysis showed that income-deprived areas, both urban and rural, exhibit higher rates of obesity than affluent areas, with income-deprived urban areas showing a stronger positive relation between distance and obesity than similar rural areas (see online Supplementary material S3).
Results for England/urban areas
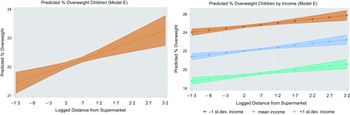
Table 4 provides the summary of the OLS results for modelling main associations for England. Models A–D contain the distance predictor (our main independent variable) with one additional independent variable added one at a time; this showed that distance alone (Model A) has no large correlation (adj. Rq = 0·01, P < 0·001), whereas adding income to the model containing distance (Model B), helps explaining 32 % of the remaining variability in the dependent variable (adj. Rq = 0·316, P < 0·001). More importantly, it is only when we include population density (Model E) that distance from supermarkets reports a positive coefficient in line with existing research, suggesting that distance is associated with higher proportions of obesity among children (adj. Rq = 0·328, P < 0·001). This is also depicted in Fig. 3 (left panel), which shows how the proportion of overweight children increases as the distance from supermarkets grows. This seems to be true across all levels of income (Fig. 3, right panel). The LRT analysis also showed that the full specification model (Model F) including both density and rurality was not significantly different from the model including distance, income and density only (Model E). Results for urban areas are given in online Supplementary material S4. Presenting results in this consecutive manner allows for alleviating multicollinearity concerns (e.g. significance or signs flipping), as well as may indicate limitations of other studies in terms of OVB or misspecified models, hence estimating the effect of distance inaccurately. A summary of OLS results for Model E is given in Table 5 for England (column i) and urban areas (column ii); the results for fitting the interaction models are given in columns iii and column iv for England and urban areas, respectively.
Table 4 The associations between childhood obesity (%) and the main variables of interest (distance, income, density and rurality) in a sample of 6771 MSOA in England

MSOA = Middle Super Output Area.
Commentary. Adding density in model E resulted in coefficient flipping for supermarket distance, which then showed a positive association with overweight in line with previous research; all the covariates are significant.
Robust standard errors in parenthesis.
* P < 0·10,
**P < 0·05,
*** P < 0·01.
† Proportion of overweight children (incl. obese), 2013–16 (averaged) and collapsed to MSOA level.
‡ Road distance from postcode centroid to the nearest supermarket, the variable was log-transformed.
§ Total annual household income.
|| Number of persons per hectare.
¶ Urban–rural classification (0-urban, 1-rural).

Fig. 3 Predicted proportion of overweight children by distance and income (Model E)
Table 5 The associations between childhood obesity (%) and other variables of interest based on model E including distance-density interaction in a sample of 6771/5580 MSOA in England/urban areas

MSOA = middle super output area.
Robust standard errors in parenthesis.
*P < 0·10,
** P < 0·05,
*** P < 0·01.
† Proportion of overweight children (incl. obese), 2013–16 (averaged) and collapsed to MSOA level.
‡ Road distance from postcode centroid to the nearest supermarket, the variable was log-transformed.
§ Number of persons per hectare.
|| Interaction between distance and density.
¶ Total annual household income.
†† Proportion of households from the ethnic minority groups.
‡‡ Proportion of households with no qualification.
§§ Proportion of households with adults not in employment.
|||| We do not report VIF for the interaction models as adding a term that is mathematically correlated to X1 and X2 automatically increases multicollinearity.
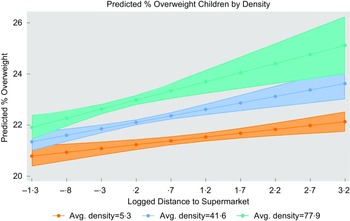
Figure 4 shows the interaction between distance and density set at low (mean –1sd), mean and high (mean + 1sd) values. The relationship between distance and obesity is stronger for densely populated areas (as given by steeper green and blue lines). The results support our hypothesis that the relationship between distance and obesity would depend on the degree of density.

Fig. 4 Adjusted predictions for the interaction effect distance-–density (England)
Results for rural areas
Table 6 provides the summary of the OLS results for modelling main associations for rural areas (column i to iv). Both income and density are significant predictors on their own, however, when both predictors are included in the model, only income remains statistically significant (P < 0·01, column iv). As given by the LRT analysis, modelling distance–income interaction (column vi) resulted in significantly different results from the corresponding main model including distance and income (column v). Results show that one sd increase in income (£7150·28) would result in 1·9 % percentage points decrease in overweight children. Figure 5 shows interactions for income set at low (mean –1sd), mean and high (mean + 1sd) values; the relationship between distance and obesity is slightly stronger for lower levels of income (as given by steeper blue and orange lines).
Table 6 The associations between childhood obesity (%) and the main variables of interest (distance, income, density), including results for the main rural model with distance-income interaction and additional covariates (Model F), in a sample of 1191 MSOA in rural areas in England

MSOA = middle super output area.
Commentary. Adding density in Model D resulted in coefficient flipping for income, which then reported a positive association with overweight being contrary to previous evidence. Model F is the final model for rural areas, which includes distance–income interaction and additional socio-economic covariates (ethnicity, education, employment).
Robust standard errors in parenthesis.
* P < 0·10,
** P < 0·05,
*** P < 0·01.
† Proportion of overweight children (incl. obese), 2013–16 (averaged) and collapsed to MSOA level.
‡Road distance from postcode centroid to the nearest supermarket, the variable was log-transformed.
§ Total annual household income.
|| Interaction between distance and income.
¶ Number of persons per hectare.
†† Proportion of households from the ethnic minority groups.
‡‡ Proportion of households with no qualification.
§§ Proportion of households with adults not in employment.
|||| We do not report VIF for the interaction model as adding a term that is mathematically correlated to X1 and X2 automatically increases multicollinearity.

Fig. 5 Adjusted predictions for the interaction effect distance–income (rural areas)
When comparing marginal effects of income set at means of income quintiles between urban and rural areas, both settings show similar rates of obesity and a clear social gradient of childhood overweight; the predicted level of overweight is 1·9 % lower when moving to a higher income quintile for urban areas, and 1·24 % lower for rural areas. Moreover, the difference in childhood overweight between 1st and 5th quintile is 7·59 % for urban and 4·95 % for rural areas; this shows that income poverty is stronger correlated with obesity rates in urban areas than in rural areas. The data are available in online supplementary material S5.
Analysis of residuals showed a minor heteroscedasticity, especially for urban areas (see online supplementary material S2), hence we used Huber-White estimator for obtaining heteroskedasticity-consistent standard errors; this should alleviate concerns of heteroscedasticity, which otherwise would violate the Gauss Markov assumptions that are necessary to render OLS the best linear unbiased estimator. Heteroscedasticity is usually mainly due to the presence of outlier in the data; however, it may also be caused due to omission of variables from the model. We therefore used the link test to examine models’ specification, being based on the idea that if a regression(-like) equation is properly specified, no additional independent variables should be significant above chance; this indeed showed that adding more variables would improve models’ estimates. It may also be that spatial variation in obesity found previously(Reference Sun, Hu and Huang35) may affect the result, meaning using spatial models is recommended. In follow-up research, we will examine spatial dependencies and plan to include additional covariates to compare the results.
Models with rurality variable
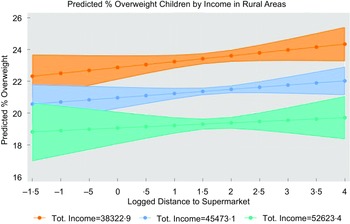
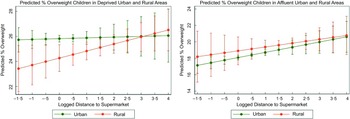
Additionally, a separate group of models with the rurality variable (dummy), including distance interactions with income and rurality, was used for exploratory purposes to better enunciate differences between urban and rural areas. Several models were fitted including the covariates used previously for consistency with earlier analysis. Income was measured as both continuous and dummy variables, the latter including below and above-average categories which were further split by rurality; additionally, analysis was carried out for deprived and affluent areas based on quintiles split by rurality and operationalised as first and fifth income quintiles, respectively. This analysis showed children tend to be more obese in deprived urban and affluent rural areas, but results are inconclusive (see Fig. 6); modelling predictions for deprived areas also showed that impact of distance on overweight can be conditional on lower level of income (Fig. 6, left panel). The model specifications and data are available in online supplementary material S6.

Fig. 6 Predicted proportion of overweight children in deprived and affluent areas by rurality (urban/rural)
Discussion
This study explored the relationship between supermarket proximity and obesity prevalence in school children in England, contributing to the growing UK literature on the role of RFE in influencing childhood obesity and extending existing studies by looking at the potential associations of distance with income and density both in the national scale and across urban and rural areas in England. Income has been shown to be a primary determinant of obesity, whereas distance played a marginal role; density remained important for urban areas, but not for rural areas, for which income was the only significant predictor. Locations that have both high density and are far from supermarkets had the highest levels of overweight children. Both urban and rural settings showed a positive relation between distance and obesity for different income groups, exhibiting a clear socio-economic gradient. Children in urban areas were slightly more obese, but this was not true for children in affluent areas; urban areas also showed a relatively stronger correlation between distance on obesity, and for deprived areas, this was conditional on lower level of income.
Direct and conditional role of distance and density
We show that both density and distance had direct but also conditional associations with childhood obesity, compounding each other and being associated with higher proportion of overweight children. Moreover, population density seemed to be important only for urban areas, for which density-based measures could better capture the relation in question due to differences in service provisions (e.g. more options in urban areas including unhealthy foods which translates to shorter distances). On the other hand, proximity could be an appropriate measure for rural areas because distances from a person’s residence to nearest food outlet found there are further apart relative to distances in urban areas(Reference Rhone and ver Ploeg36), meaning ‘proximity metrics may give a reasonable measure of food access in rural areas, but they may under-estimate food access in urban areas’(Reference Wilkins, Morris and Radley37). Drawing on the suggestion that different measures may be capturing different aspects of neighbourhoods(Reference Wilkins, Morris and Radley2), further research is needed to compare measures in different geographical settings in the UK.
Income had a stronger correlation with obesity in rural areas
Low income has a positive effect on childhood obesity, which is a well-known argument and thus the direct effect of income was merely our baseline hypothesis. We further show that income and education were the only two significant predictors of rural obesity, the former which may be attributed to additional geographical barriers in accessing supermarkets in rural areas(Reference Smith, Cummins and Taylor20), (e.g. food requires additional economic resources for using public transport or buying fuel). Our analysis also clearly picks up a socio-economic gradient of obesity, as shown by previous research(Reference Stamatakis, Wardle and Cole38). We show that higher income predicted smaller obesity rates in children regardless of setting, meaning that wealth is somehow universally protective against limited exposure to healthy RFE.
Obesogenic environments present heightened risks in urban areas
Obesity rates vary considerably between urban and rural areas both in the UK and globally due to differences in geographical profiles, with the dominant paradigm attributing a higher prevalence of obesity to be persistent in urban area. A vast body of evidence relates urbanisation to rising obesity due to food options in urban areas being typically more varied and accessible than in rural areas(Reference Bleich, Cutler and Murray39). On the other hand, children residing in rural households are more likely to consume healthier diets than those in urban households(Reference Morris and Northstone40) because of ‘traditional’ eating (based upon core foods such as bread, potatoes, vegetables)(Reference Barker, McClean and Thompson41), including higher fruit and vegetable intake(Reference Levin, Kirby and Currie42,Reference Morgan, Armstrong and Huppert43) , and typically have higher levels of physical activity because of the focus on agricultural work(Reference Popkin and Gordon-Larsen44). Higher rates of obesity in urban areas could also be explained by the increased availability of unhealthy food options in urban areas(45), transforming urban neighbourhoods into so-called food swamps. Urban dwellers may also exhibit less-traditional eating habits, such as eating away from home, that are promoted by increasing wealth(Reference Sproesser, Ruby and Arbit46). Our results confirm that children in urban areas tended to be slightly more obese than children in rural areas; this, however, was not true for children in affluent rural areas, which tended to be more obese than their counterparts in affluent urban areas. This shows that differences between the two affluent populations mainly relate to factors associated with rurality and not income, which may be due to various barriers to healthier living, some of which are unique to rural status (e.g. lack of weight loss resources in rural communities, lack of exercise facilities and lack of low fat or low-calorie options in grocery stores)(Reference Davis, James and Curtis47).
Obesity is likely dependent on the combination of deprivation and geography
Our results support previous evidence that residents of deprived neighbourhoods in rural and remote areas have poorer spatial accessibility to grocery stores(Reference Smith, Cummins and Taylor20). We also show a slightly stronger association between distance and overweight in urban areas being conditional on lower level of income, which adds further weight to the suggestion that FD may exist in urban areas in the UK. On the other hand, deprived rural areas exhibited a weaker relation and thus lower obesity rates than similar urban areas; this could be due to deprived rural areas having different typologies of food retailers, hence the closest one for rural households tend to be different from the closest one for urban households. Similarly, typologies of food retailers could vary between deprived and affluent areas in both settings. Our results for rural areas remain highly unpredictable, thus requiring further examination of urban–rural conditioning and trends in the UK context.
Strengths and limitations
In this paper, we used high-quality, openly available data. The LDC dataset is regularly validated via field work, therefore is likely more accurate compared to other administrative sources. Similarly, the NCMP programme is recognised internationally as a world-class source of public health intelligence and holds UK National Statistics status. Regardless of these advantages, we recognise that the applicability of the reported associations may be limited by the cross-sectional nature of the data and the time lag between the distance and obesity data, which, however, could not be avoided due to issues with data availability. Nevertheless, the data are well-suited for our purposes to facilitate the formulation of policies targeting public health issues based on risk factors.
We used the most recent data that was available, and supermarket distance data as of 2018 became our reference dataset to which we tried to temporarily match other variables. To alleviate concerns regarding temporal misalignment between the supermarket data and other variables, we notice that supermarkets growth has stagnated since 2016; for example, supermarket numbers growth for Sainsbury, which is the second largest supermarket in the UK, had slowed down in the previous years(48). Similarly, Tesco had the biggest increase in store numbers in 2014 with 246 more stores compared to the previous financial year; in comparison, 2016–2020 saw only a minor growth in store numbers(48). The urban–rural status as of 2011 is also less likely to significantly change over time.
For operationalising food access, we used data on supermarket proximity, following the gold standard in FDs research. However, exposure to unhealthy food may have a stronger relationship with obesity. Therefore, consideration for additional food outlets, including both healthy and unhealthy foods, would likely increase validity of the results. We also did not cover other factors, such as affordability or quality of healthy food items, which may explain some of our results. Moreover, future research should consider additional measures (e.g. density-based) and determinants of obesity, the latter which likely confound the results. Adding these variables to the analysis, however, is problematic due to data constraints, as data may be unavailable at geographical scales required for analysis or held by commercial organisations. Using a fixed-effects model with temporal variation could help mitigate the effect of unaccounted variables that likely confound the result. It is also possible that spatial models are better suited to study links between obesity and RFE, which we plan to examine in future research. Due to these limitations, our preliminary results need to be taken with a degree of caution.
Conclusion
This research focussed on the rural–urban divide in the context of food access and income poverty, showing that the two settings may experience various barriers to healthy eating choices. Our results open discussion into targeting the spatial context of how food proximity and household wealth correlates with childhood obesity in England, as being an important area of food access research largely unaccounted for so far in the UK. The results have potential value for policymaking in regard to planning and targeting of services for vulnerable groups, including the populations of young children in deprived urban and affluent rural areas; such targeting is necessary because of the different ways the environmental and social determinants of health impact on these populations. In general, research around the importance of environmental interventions in ‘real-world’ settings are lacking and further work must be done to consider multiple and time-varying dimensions of food access.
Acknowledgements
Acknowledgements: NA. Authorship: E.T.: Conception and design of the work; acquisition, analysis, and interpretation of data. J.D.S.: Analysis, and interpretation of data; drafting and revising. R.P.: Drafting and revising. All authors gave their final approval for the version to be published and agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. Ethics of human subject participation: NA.
Financial support:
Elzbieta Titis is supported by a PhD studentship from the Engineering and Physical Sciences Research Council (EPSRC) Centre for Doctoral Training in Urban Science (EP/L016400/1).
Conflict of interest:
Authors declare no conflict of interest.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S1368980023000952








 Open access
Open access