



Policy Significance Statement
The research explores machine learning techniques in Nigerian classrooms, creating predictive models to identify underperforming students. This aids universities globally in supporting struggling students, optimizing educational costs, and fostering inclusive development. Leveraging the synthetic minority oversampling and edited nearest neighbors (SMOTE–ENN) for imbalanced data, Boruta for feature selection, and genetic algorithms to enhance efficiency. Beyond technical advancements, the research translates findings into real-world impact via a Streamlit and Heroku web app. This empowers universities worldwide to customize models, view real-time results, and make informed, data-driven decisions. Ultimately, this work empowers stakeholders to utilize data science for equitable and impactful education in African smart cities, fostering sustainable development.
1. Introduction
In the vibrant landscape of African smart cities, education stands as a cornerstone for fostering sustainable development and unlocking the future potential of its youngest citizens. Accurately predicting student performance becomes crucial in this context, allowing for early intervention, improved learning outcomes, and ultimately, equitable access to quality education, aligning with the core principles of the sustainable development goal. However, this task faces unique challenges in the African context. Educational data often exhibit unpredictability, noise, and imbalanced class distributions, presenting significant hurdles for traditional prediction models (Ghorbani and Ghousi, Reference Ghorbani and Ghousi2020). These models can easily falter, favoring the majority class and leading to misleading outcomes (Fernández et al., Reference Fernández, García and Herrera2011; Phua and Batcha, Reference Phua and Batcha2020). This is where machine learning (ML) emerges as a powerful tool for informed decision-making and improved learning experiences, empowering both educators and policymakers. One key application of ML lies in predicting student academic performance (Shaukat et al., Reference Shaukat, Nawaz, Aslam, Zaheer and Shaukat2016; Reference Shaukat, Nawaz, Aslam, Zaheer and Shaukat2017). However, imbalanced datasets, a common issue in education, hinder the effectiveness of such models. Furthermore, the complexity of this issue deepens when we consider the vast dimensions of educational datasets (Sammut and Webb, Reference Sammut and Webb2011; Yin et al., Reference Yin, Ge, Xiao, Wang and Quan2013) and their inherent class imbalances (Friedman, Reference Friedman1997; Zhang and Hu, Reference Zhang and Hu2014). Predicting student performance under such conditions becomes an intricate task. Moreover, if the data are cluttered with irrelevant features, it hampers ML models, resulting in suboptimal performance and heightened computational costs (Arif, Reference Arif2020). In such scenarios, it becomes imperative to weed out insignificant attributes from the data, paving the way for more efficient and cost-effective ML processes. Feature selection methods, a suite of techniques designed to identify and retain only the most valuable features within a dataset, emerge as a solution to this challenge (Chandrashekar and Sahin, Reference Chandrashekar and Sahin2014). These methods fall into three distinct categories: filtering, wrapping, and embedding. Filtering algorithms select a subset of features based on criteria such as correlation or information entropy, offering a rank-ordered set of the most relevant attributes (Spolaôr et al., Reference Spolaôr, Cherman, Monard and Lee2013). Wrapper procedures employ ML techniques to evaluate the quality of feature subsets. Embedded approaches, on the other hand, directly enhance ML algorithms’ accuracy for predicting student performance. Feature selection has proven its worth in a multitude of applications, from gene array analysis to intrusion detection and text mining (Bharti and Singh, Reference Bharti and Singh2014). In the context of predicting student achievement, researchers harness these techniques to create more effective subsets of characteristics (Dhar and Jodder, Reference Dhar and Jodder2020; Sobnath et al., Reference Sobnath, Kaduk, Rehman and Isiaq2020). Among these strategies, genetic algorithms shine as a popular tool to optimize feature selection for enhanced predictive accuracy (Turabieh, Reference Turabieh2019; Yousafzai et al., Reference Yousafzai, Hayat and Afzal2020). At the heart of this endeavor is the deployment of dependable classification models. Education, as a sector, can harness the full potential of ML by translating these models into real-world decisions as swiftly as possible. This empowers universities and stakeholders to harness data science for equitable and impactful education in African smart cities.
1.1. Research questions
Question 1: How can hybrid sampling techniques be used to address imbalances in the data, ensuring all student groups are fairly represented and providing more reliable predictions?
Question 2: How effective are wrapper-based feature selection methods in identifying key factors impacting student performance, allowing efficient resource allocation, and reducing computational costs?
Question 3: Which of the two feature selection algorithms experimented with, the Boruta and the genetic algorithms, is better for feature selection in student performance models using the Friedman test as a statistical validity check?
Question 4: To what extent can these suggested models be deployed to improve their real-world accessibility? How to deploy models in the form of web applications to empower universities within and outside Africa To personalize models and view real-time results, optimizing student support through data-driven insights, and to offer accessible tools for policymakers to design effective and legitimate education policies aligned with the SDG, informed by accurate predictions and data analysis?
1.2. Objective
This study aims to leverage ML to enhance the prediction of student performance and optimize educational decision-making by:
-
• Mitigating class imbalance biases within student data to ensure fair and accurate representation of all student groups.
-
• Employing wrapper-based feature selection methods to identify the most critical factors influencing student academic outcomes.
-
• Validating the efficacy of different feature selection techniques using the Friedman test to determine the most statistically significant approach.
-
• Deploying the resulting ensemble model as an interactive web application accessible to universities both within and outside Africa. This application will empower institutions to personalize student support strategies and enable policymakers to design data-driven and SDG-aligned education policies informed by accurate predictions.
1.3. Organization of the paper
The remainder of this work is organized as follows: The related works are introduced in Section 2. In Section 3, we discuss the research methodology, and in Section 4, we present the experimental results and a discussion of the performance of different crafted strategies and the deployment methods. Section 5 is dedicated to our conclusions, while Section 6 offers insights into limitations and suggestions for future work.
2. Related work
This part reviews the pertinent literature and current state of the art techniques in the area of ML, specifically addressing student performance classification, the class imbalance problem, and the features dimensionality reduction problem. ML model deployment.
2.1. Student performance classification with ensemble model
Enhancing prediction accuracy poses a challenging endeavor. Because of ensemble modeling, which includes well-known algorithms like arcing (Breiman, Reference Breiman1998), boosting (Freund and Schapire, Reference Freund and Schapire1997), bagging (Breiman, Reference Breiman1996), and random forests (Breiman, Reference Breiman2001), this target is within reach. They may be divided into two broad categories: homogeneous and heterogeneous. In contrast to homogeneous approaches, which mix algorithms of a similar sort, heterogeneous approaches integrate algorithms of varying types, such as classification trees, support vector machines, and neural networks. Stacking is by far the most common (Wolpert, Reference Wolpert1992).
Student performance predictions were enhanced by using the ensemble technique, as described in his study (Almasri et al., Reference Almasri, Celebi and Alkhawaldeh2019). According to the findings, the application of ensemble approaches. It helps improve the model’s accuracy, which achieves 98.5%. The suggested method, based on bagging and boosting ensemble-based techniques, achieved an accuracy of over 80%, validating its efficacy (Amrieh et al., Reference Amrieh, Hamtini and Aljarah2016). By combining many categorization methods into a single model, Ajibade et al. (Reference Ajibade, Ahmad and Shamsuddin2020) were able to double the accuracy of their predictions based on student data.
In their study (Onan et al., Reference Onan, Korukoğlu and Bulut2016), they evaluated five statistical keyword extraction methods in scientific text document classification, finding that the most-frequent-based method, when combined with the bagging ensemble of Random Forest, achieves the highest predictive performance, thereby enhancing text classification scalability. Onan (Reference Onan2019) also introduces a two-stage framework, combining an improved word embedding scheme and an enhanced clustering ensemble approach to extract significant topics from scientific literature. This innovation leads to improvements in predictive performance and clustering results. In their research (Onan et al., Reference Onan, Korukoğlu and Bulut2017), they further present a hybrid ensemble pruning scheme that significantly enhances sentiment classification in text documents, outperforming existing ensemble methods and pruning algorithms.
2.2. Class imbalance problem
Real-world datasets often exhibit imbalanced class distributions, impacting ML models that perform best with roughly equal class examples (Longadge and Dongre, Reference Longadge and Dongre2013). Imbalances lead to biased classifiers favoring dominant groups, resulting in inconsistent results (Kotsiantis et al., Reference Kotsiantis, Kanellopoulos and Pintelas2006). Various strategies address imbalanced data using over-sampling (Yap et al., Reference Yap, Abd Rani, Abd Rahman, Fong, Khairudin and Abdullah2013), under-sampling (Liu et al., Reference Liu, Wu and Zhou2008), and hybrid-sampling (Galar et al., Reference Galar, Fernandez, Barrenechea, Bustince and Herrera2011) methods. Oversampling techniques like random over-sampler (Li et al., Reference Li, Li, Chang and Sun2013), synthetic minority oversampling (SMOTE; Chawla et al., Reference Chawla, Bowyer, Hall and Kegelmeyer2002), borderline SMOTE (Han et al., Reference Han, Wang and Mao2005), and Support Vector Machine (SVM)-SMOTE (Tang et al., Reference Tang, Zhang, Chawla and Krasser2008) counteract imbalances. Common undersampling methods, such as edited nearest neighbors (ENN) and TOMEK-links (Guan et al., Reference Guan, Yuan, Lee and Lee2009), reduce overrepresented classes. Hybrid methods, like SMOTE–ENN and SMOTE–TOMEK (Batista et al., Reference Batista, Prati and Monard2004), combine oversampling and undersampling strategies.
In their study (Chaudhury et al., Reference Chaudhury, Mishra, Tripathy and Kishore2016), they examine the influence of data preprocessing on classification algorithms using a dataset of student performance with unequal classroom distribution. Undersampling and oversampling methods are used with support vector machines, decision trees, and Naive Bayes classification algorithms, respectively, to rectify the issue of imbalanced class distribution. For example, SMOTE, an oversampling-type method (Chaudhury et al., Reference Chaudhury, Mishra, Tripathy and Kishore2016), performs better in experiments. Using the open-source Weka program, Salal et al. (Reference Salal, Abdullaev and Kumar2019) evaluate the performance of several categorization methods on a dataset of student performance. Experiments showed that certain factors have a greater impact on student performance during the data preprocessing stage, whereas classification algorithm accuracy improves following this step (Mangina and Psyrra, Reference Mangina and Psyrra2021). In their research (Sahlaoui et al., Reference Sahlaoui, Alaoui, Nayyar, Agoujil and Jaber2021), they applied a kernel shape value to the problem of categorizing students’ academic achievements. They contributed by suggesting a three-layer architecture built on top of the XGBoost concept and SMOTE technologies. As a result, the model’s efficiency and interpretability will increase while the load of an imbalanced dataset is reduced. This cutting-edge approach improves classifiers’ predicting accuracy and interpretability by using their strengths through boosting, kernel shape value, and SMOTE procedures. To improve their student performance prediction approach, Costa et al. (Reference Costa, Fonseca, Santana, de Araújo and Rego2017) used a data preprocessing and fine-tuning strategy. Superior results may be achieved using the proposed approach with an SVM classifier. Dimensional reduction in the form of the Information Gain method and data balancing using the SMOTE algorithm constitute part of the preprocessing technique. In addition, the grid search technique is utilized to find the hyper-parameter’s optimal values for the SVM algorithm.
In his study, Onan (Reference Onan2023) presents Genetic Algorithm-based Global Trajectory Reconstruction (GTR-GA), an approach that combines graph-based neural networks and genetic algorithms to create diverse, high-quality augmented text data, addressing data scarcity in natural language processing and enhancing downstream performance. Onan et al. (Reference Onan2019) also tackle class imbalance in ML with a consensus clustering-based undersampling approach, enhancing predictive performance across various imbalanced classification benchmarks by incorporating diverse clustering and classification methods.
2.3. Features dimensionality reduction problem
Optimizing ML involves crucial feature selection to enhance accuracy and understand variables influencing students’ academic success. This process strategically selects a subset of input features (Bhat, Reference Bhat2019), categorized into filtering, wrapping, and embedded methods. Filtering methods, like information gain and the chi-square test, offer computational efficiency. Wrapping approaches delegate feature selection to the classifier, incurring higher costs for heightened accuracy (Paddalwar et al., Reference Paddalwar, Mane and Ragha2022). Embedded selection integrates the process, extracting significant features during each training iteration. Well-recognized embedded approaches, including random forest, decision tree, and LASSO feature selection (Butvinik, Reference Butvinik2021), collectively optimize model performance.
Success in mortality prediction was shown by subsequent studies (Moreno García et al., Reference Moreno García, González Robledo, Martín González, Sánchez Hernández and Sánchez Barba2014; Liu et al., Reference Liu, Chen, Fang, Li, Yang, Zhan, Tong and Fang2018), which addressed dimensionality reduction and unbalanced class issues. Leppänen et al. (Reference Leppänen, Leinonen, Ihantola and Hellas2017) use linear regression, decision trees, and Naïve Bayes techniques to estimate the student performance on two separate student datasets. The feature selection method improves the accuracy values of the classification algorithms for both datasets, as shown by the experimental findings (Leppänen et al., Reference Leppänen, Leinonen, Ihantola and Hellas2017). In his study (Ünal, Reference Ünal2020), he used a decision tree-based feature selection technique to assess the efficacy of several classification algorithms on the student dataset. As stated by Ünal (Reference Ünal2020), the best accuracy values are obtained using the random forest technique. In his research (Zaffar et al., Reference Zaffar, Hashmani, Savita, Rizvi and Rehman2020), he used three different student performance datasets to determine the impact of the quick correlation-based filtering strategy on the performance of the support vector machine classifier. The feature selection technique enhances the student academic performance prediction model, as concluded by experimental data (Zaffar et al., Reference Zaffar, Hashmani, Savita, Rizvi and Rehman2020). In order to construct a performance prediction model for students, researchers employ filter-based or wrapper-based feature selection techniques. The vast majority of studies use correlation-based filtering techniques (Dhar and Jodder, Reference Dhar and Jodder2020; Sobnath et al., Reference Sobnath, Kaduk, Rehman and Isiaq2020), which evaluate the degree to which a trait is associated with a subject’s performance. Filtering techniques based on information gained evaluate each characteristic and the student’s performance to determine which one is more informative (Amrieh et al., Reference Amrieh, Hamtini and Aljarah2016; Garcia and Skrita, Reference Garcia and Skrita2019). Wrapper approaches based on gene algorithms have been utilized to tackle global optimization issues, and gene-based algorithms are widely employed in this context. To simulate biological evolution’s natural selection process, Wutzl et al. (Reference Wutzl, Leibnitz, Rattay, Kronbichler, Murata and Golaszewski2019) used a genetic-based algorithm (GA), and they iteratively fine-tuned the feature selection approach by analyzing past prediction outcomes. Similar to natural evolution, Yousafzai et al. (Reference Yousafzai, Hayat and Afzal2020) and Turabieh (Reference Turabieh2019) employed a binary GA to constantly improve feature selection via the application of the three operations of selection, crossover, and mutation on the Feature Selection Scheme. Begum and Padmannavar (Reference Begum and Padmannavar2022), in their research, have checked whether the database features are enough to develop successful models for forecasting student performance and analyze genetic algorithm-based feature selection to guarantee redundancy management and appropriate training in supervised classification. In his research, Anand et al. (Reference Anand, Sehgal, Anand and Kaushik2021) use academic data to demonstrate an FS strategy using the Boruta algorithm. This research makes an effort to enhance the classifier performance of MAIT’s undergraduate students.
In his study (Onan, Reference Onan2022), he introduces a state-of-the-art bidirectional convolutional recurrent neural network for sentiment analysis, effectively processing sequences, reducing feature dimensionality, and emphasizing essential features. Additionally, Onan and Korukoğlu (Reference Onan and Korukoğlu2017) propose an ensemble feature selection method using a genetic algorithm that aggregates feature lists from various methods, significantly improving efficiency and classification accuracy in sentiment analysis. In the context of text genre analysis, Onan (Reference Onan2018) developed an ensemble classification scheme with a high average predictive performance of 94.43%. This approach combines the random subspace ensemble of a random forest with multiple feature types to achieve outstanding results. Furthermore, Kou et al. (Reference Kou, Xu, Peng, Shen, Chen, Chang and Kou2021) introduce a novel bankruptcy prediction model for small and medium-sized enterprises (SMEs) using transactional data. This model incorporates a two-stage feature-selection method, reducing the number of features while preserving classification performance. Finally, in their study (Kou et al., Reference Kou, Yang, Peng, Xiao, Chen and Alsaadi2020), they employed multiple criteria decision-making (MCDM) methods to comprehensively evaluate feature selection techniques in the domain of text classification with small sample datasets, offering valuable recommendations to enhance this area of research.
2.4. Machine learning model deployment
Model deployment is the crucial final phase of a ML project, enabling live use of business insights. Integration into web or mobile applications using cloud services facilitates swift identification of at-risk students by teachers for timely intervention (Prakash, Reference Prakash2021). Understanding both frontend (HTML, CSS, and JavaScript) and backend frameworks (Linux administration, networking, and security) is crucial for web program creation (Kim, Reference Kim2021). Flask, an open-source Python framework, suits modern web applications, while Django, more advanced, requires additional mastery time. TensorFlow.js excels at storing web-compatible models but has limitations in handling complex ML implementations (Vadapalli, Reference Vadapalli2020; Buvaneshwaran, Reference Buvaneshwaran2022). Streamlit, an open-source platform, empowers data scientists and MLOps developers to craft engaging interfaces for datasets. As a Python-based frontend framework, Streamlit facilitates swift development of ML web applications without extensive frontend development knowledge (Kimnaruk, Reference Kimnaruk2022). Serving as a free model deployment solution, Streamlit streamlines the process, allowing rapid implementation without expertise in front-end development or other programming languages (Flynn, Reference Flynn2021; Thetechwriters, 2021). Unlike Flask and Express, Streamlit seamlessly integrates these functions (Kimnaruk, Reference Kimnaruk2022). While deploying Streamlit applications on cloud services like Amazon, GCD, or Azure may seem daunting (Sharm, Reference Sharm2020), Heroku offers a user-friendly alternative. This free online app hosting service simplifies and accelerates hosting cloud-based apps in any language. Operating as a Platform as a Service (PaaS), Heroku facilitates deploying and starting an app in under 5 min, with system management handled by Heroku, freeing developers from the complexities of setting up their server infrastructure (Melo, Reference Melo2023).
In his study (Dempere Guillermo, Reference Dempere Guillermo2018), he has built a full-featured mentoring platform that is integrated with the results of ML algorithms, and this effort is focused on the deployment of the student performance model. The authors create a Mentor Academic Guidance Support Platform based on predictive data-driven dashboards. The “APPA” mobile app developed by the researcher makes use of the benefits offered by the React-Native platform in order to provide answers to problems associated with predicting students’ performance (Moharekar and Pol, Reference Moharekar and Pol2021).
2.5. Research contribution and significance
While previous studies have explored feature selection to enhance student performance models, this research explores the use of ML techniques within the unique environment of Nigerian classrooms, focusing on developing predictive models to identify underperforming students. This empowers universities both within and outside Africa to proactively support struggling students, optimize educational costs, and promote inclusive development. We move beyond previous studies by tackling the intricacies of predicting student performance in demanding scenarios, particularly within small and imbalanced datasets. We do this by leveraging a unique combination of techniques: SMOTE–ENN resampling methods address imbalances in the data, ensuring all student groups are fairly represented, and feature selection through Boruta and the genetic Algorithm: To identify and utilize only the most relevant factors impacting academic achievement, reducing model complexity and enhancing generalizability. This approach significantly boosts prediction accuracy, offering valuable insights for universities within and outside Africa. Our research transcends technical advancements by translating these findings into real-world impact through an accessible web application built with Streamlit and Heroku. This empowers universities within and outside Africa to customize model settings and view real-time results, fostering informed decision-making based on data-driven insights and predictions. Moreover, this research demonstrates how data science can inform policy by improving situation analysis through a deeper understanding of factors impacting student performance, enhancing predictions for timely interventions and resource allocation, and supporting public service design for effective and legitimate education policies. Ultimately, this research empowers stakeholders to harness data science for equitable and impactful education in African smart cities, paving the way for a future where data empower education, fosters sustainable development, and unlocks the potential of every student in African smart cities.
3. Research methodology
In this section, we describe our proposed approach, explaining the workflow adopted in this research. We detail the various approaches to testing the dataset, including the sampling methods, wrapper-based feature selection algorithms, and learning classifiers utilized. Additionally, we discuss the criteria used to evaluate these techniques during the learning and training process.
3.1. Proposed system
To assess the efficacy of ML in predicting Nigerian classroom outcomes, this study adopts a multi-step methodology. First, data preprocessing will address potential class imbalances using the SMOTE–ENN hybrid sampling method. Next, wrapper-based feature selection techniques, Boruta and the genetic algorithm, will be employed to identify the most relevant features and potentially enhance model performance through dimensionality reduction. Finally, model development and evaluation will involve employing a diverse range of ML classifiers with varying theoretical foundations. The selection of the optimal model will be based on established metrics like accuracy, precision, recall, F1-score, and area under the curve (AUC). Tenfold stratified cross-validation will ensure robust evaluation, and hyper-parameter tuning will further refine the chosen model’s performance. The workflow for this investigation is elucidated in Figure 1.

Figure 1. Global ensemble-based system for the classification of students’ academic performance.
3.2. Data preprocessing
3.2.1. Dataset information
Accessing educational data sources for educational data mining (EDM) research can pose challenges. To overcome this, we utilized a publicly available dataset from Nigerian educational institutions (https://www.kaggle.com/c/datasciencenigeria/data). This dataset comprises 650 students, each characterized by 23 different elements. The study focuses on the final grade point average (GPA) as the outcome variable, categorizing students into poor, medium, and good based on their grade-point average. Table 1 summarizes the dataset, including various psychological, individual, and contextual variables such as student attendance, travel time to school, reading time, educational assistance, health, and parental education level. These elements collectively contribute to understanding and analyzing factors influencing student performance, addressing the multi-categorization challenge posed by the study.
Table 1. Explanation of the Nigeria dataset variables used to forecast student outcomes

3.2.2. Data sampling
Real-world datasets often exhibit class imbalances, impacting model performance data (Longadge and Dongre, Reference Longadge and Dongre2013) and yielding unpredictable results (Kotsiantis et al., Reference Kotsiantis, Kanellopoulos and Pintelas2006). This study addresses this by applying SMOTE–ENN, a hybrid sampling method that combines SMOTE (generating synthetic minority class data) and ENN for data cleaning. This approach aims to create a more balanced class distribution within the Nigerian student performance dataset, which is heavily skewed toward the low-performance class (73.8%). The remaining classes are underrepresented, with medium performance at 15.1% and high performance at 11.1%, as depicted in Figure 2.

Figure 2. Distribution of student performance in relation to the different classes.
Utilizing SMOTE–ENN aims to mitigate this imbalance and ensure the model is trained on a more representative distribution of student performance outcomes, as shown in Figure 3.

Figure 3. Schematic flow of SMOTE–ENN.
3.2.3. Feature selection
Feature selection refers to the procedure of picking out and keeping just the most relevant features of a model (Bhat, Reference Bhat2019). In this study, we employ two wrapper-based feature selection methods, namely Boruta and the genetic algorithm, with the aim of enhancing the precision of predicted student performance. This section delves into the detailed explanation of these feature selection techniques, shedding light on their way of optimizing model performance by strategically choosing the most influential features. However, before applying these techniques, it’s crucial to assess potential redundancy within the features themselves. We assessed feature redundancy using Pearson correlation to identify highly correlated features. The analysis revealed no strong correlations, as depicted in Figure 4’s heatmap, suggesting a minimal risk of multicollinearity. This allows us to proceed with wrapper-based feature selection methods (Boruta and genetic algorithm) without additional preprocessing for redundancy.
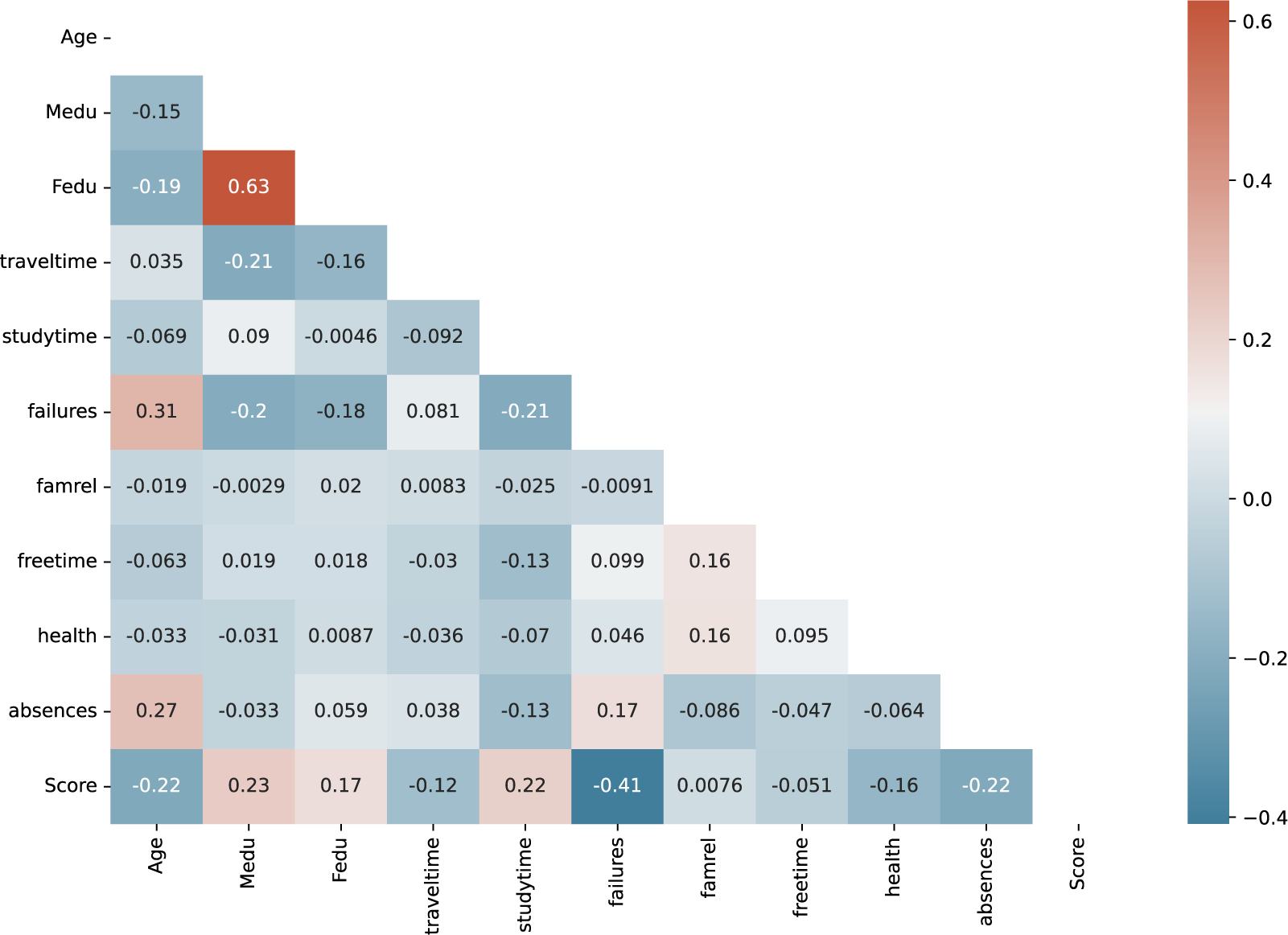
Figure 4. Correlation heatmap for student performance data.
• Genetic algorithm
A genetic algorithm is a method for resolving optimization issues by utilizing processes like mutation, crossover, and selection (kindsonthegenius, 2018), as shown in Figure 5.

Figure 5. The features selection process using genetic algorithm.
Starting with a large population, it uses heuristics (Algorithm 1) to narrow it down until only the best candidates remain. The process begins with a group of people, or the population, whose characteristics are determined by factors called genes. An individual’s fitness level is measured by a score based on the fitness function, where higher scores indicate more fitness. As a way to decide which member of the current generation will be used to produce the next, “selection” is a concept worth considering. In order to create a new generation, two people are chosen to act as “parents.” Crossover is a technique used to create hybrid offspring by combining the genetic information of both parents. In a process known as mutation, the order of genes on a chromosome is changed, resulting in a whole new chromosome. When termination requirements are met, the algorithm stops and a new generation of offspring emerges that is not significantly different from the preceding one.
Algorithm 1 Genetic algorithm
Begin
Generate the initial population
Compute Fitness
REPEAT
Perform Selection
Perform Crossover
Perform Mutation
Compute Fitness
UNTIL Population converges
END
• Boruta algorithm
The Boruta algorithm is a ML technique for choosing which features to employ. Specifically, it works by duplicating the features in the original dataset into a new one, which are then referred to as shadow features (Ruto, Reference Ruto2022) as shown in Figure 6.

Figure 6. The features selection process using Boruta algorithm.
After including these characteristics, the resulting feature space has double the dimension of the original dataset. The method next creates a classifier (Random Forest Classifier) on the expanded feature space and uses a statistical test called the [Z-Score] to rank the features in order of relevance. A feature is regarded as important and retained if its value is greater than the maximum importance of its shadow characteristics; otherwise, it is discarded. This continues until either a certain number of iterations has been reached or all features have been validated or abandoned.
3.3. Classifiers and learning algorithms
The classifiers tested in the experiments are the following:
Random Forest: Conceived by Breiman in the 2000s, operates as an ensemble method utilizing a myriad of diverse decision trees to enhance prediction and classification (Wang et al., Reference Wang, Tian, Zheng, Yang, Ren, Li, Han and Zhang2021). The strength of Random Forest lies in its incorporation of randomness during both tree construction and feature selection (Altman and Krzywinski, Reference Altman and Krzywinski2017). This intentional diversity equips the model to adeptly handle intricate challenges, resulting in consistent success across various studies (Bock et al., Reference Bock, Rossner, Wissen, Remm, Langanke, Lang, Klug, Blaschke and Vrščaj2005).
Balanced Bagging Classifier: A counterpart to Scikit-Learn’s bagging method, adeptly handles imbalanced data. By skillfully sampling smaller portions from the majority class, this classifier ensures fair and representative results (imbalanced-learn.org).
Easy Ensemble Classifier: A formidable solution for imbalanced data, employs a unique approach. It systematically creates a more balanced dataset by carefully shrinking the dominant class. This strategy enables training a classifier on a more even distribution, resulting in fairer predictions for all (Liu et al., Reference Liu, Wu and Zhou2008).
Xgboost : A leader in gradient boosting, continually evolves and adapts. Introduced by Chen and Guestrin (Reference Chen and Guestrin2016) and built upon J. H. Friedman (Reference Friedman2001) is foundational work, it demonstrates exceptional performance in various classification and regression challenges (Hongshan et al., Reference Zhao, Yan, Wang and Yin2019).
AdaBoost : An ensemble learning method, envisions individual learners uniting to form a formidable entity. In this iterative process, less effective learners gain more weight and are retrained, culminating in a robust and accurate final model (Kavish, Reference Kavish2022).
LightGBM: Elevates tree-based methods, pushing the boundaries of gradient boosting. Outperforming XGBoost (Sahlaoui et al., Reference Sahlaoui, Alaoui, Nayyar, Agoujil and Jaber2021), it adopts a leaf-wise growth strategy, constructing a tree one leaf at a time. With its versatility in handling continuous and categorical features, LightGBM proves invaluable for data scientists. Its popularity is reinforced by support for parallel processing and GPU training, enhancing efficiency with large datasets.
CatBoost : Excels in handling categorical data, utilizing ordered boosting for superior prediction accuracy in this domain (Kavish, Reference Kavish2022). Its meticulous approach involves carefully ordering and analyzing categories, uncovering hidden patterns for more precise predictions.
3.4. Metrics of performance or evaluation methods
3.4.1. Metrics used in the experiment
To compare and determine the best model, it is necessary to evaluate the performance of the classifiers. There are many ways to measure and verify ML algorithms. This research uses five different criteria to compare the different tactics. These metrics are F1, precision, recall, accuracy, and AUC. They are widely regarded as the best metrics to gauge performance in unbalanced situations:
 $$ {F}_1=2.\frac{Precision. Recall}{Precision+ Recall}, $$
$$ {F}_1=2.\frac{Precision. Recall}{Precision+ Recall}, $$
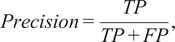 $$ Precision=\frac{TP}{TP+ FP}, $$
$$ Precision=\frac{TP}{TP+ FP}, $$
 $$ Recall=\frac{TP}{TP+ FN}, $$
$$ Recall=\frac{TP}{TP+ FN}, $$
 $$ Accuracy=\frac{TP+ TN}{TP+ TN+ FP+ FN}, $$
$$ Accuracy=\frac{TP+ TN}{TP+ TN+ FP+ FN}, $$
 $$ AUC=\frac{1+{TP}_{rate}-{FP}_{rate}}{2}. $$
$$ AUC=\frac{1+{TP}_{rate}-{FP}_{rate}}{2}. $$
Moreover, the statistical assessment approach allows for stronger analysis and comparison.
3.4.2. Statistical analysis
To evaluate the effectiveness of the proposed methods, this study will utilize established statistical techniques. The Shapiro–Wilk test will assess data normality (Brownlee, Reference Brownlee2018; Jäntschi and Bolboacă, Reference Jäntschi and Bolboacă2018), followed by either ANOVA (for normally distributed data; Fisher, Reference Fisher1959) or the Friedman test (for non-normal data; Kaur and Kaur, Reference Kaur and Kaur2018) to identify significant differences in performance metrics (accuracy, precision, recall) across the four experimental approaches: SMOTE–ENN with Boruta, SMOTE–ENN with genetic algorithm, and the baseline strategy with various classifiers. Post-hoc analysis (if applicable) will pinpoint specific method differences. Additionally, rankings based on performance metrics will be generated to identify the most effective approach (Friedman, Reference Friedman1940).
4. Experiments and result analysis
In this section, we delve into a comprehensive examination of the gathered findings. Initially, we provide a detailed elucidation of the specific hyper-parameter settings for each of the ML models and the key parameter settings for each feature selection method employed in this work. Subsequently, we discuss the actual implementation and deployment of the model. We outline the experimental process used to assess the accuracy of the proposed models for predicting student performance, comparing various ML techniques through training and cross-validation score analysis. We track accuracy, precision, recall, and AUC values for model comparison. Our aim is to evaluate the performance gains achieved by employing tailored strategies on the Nigerian dataset, utilizing ensemble techniques, hybrid data sampling methods, such as SMOTE–ENN, combined with wrapper-based feature selection techniques, particularly incorporating Boruta and genetic algorithms, and comparing them against baseline strategies. Additionally, we investigate the feasibility of deploying ensemble techniques using Streamlit on the front end and Heroku on the back end.
4.1. The performance of the different classifiers
4.1.1. Hyper-parameters setting
In this study, all evaluations were performed using LightGBM, XGBoost, AdaBoost, CatBoost, Random Forest, Easy Ensemble, and Balanced Bagging. Table 2 shows the specific hyper-parameter settings for each of the ML models used in this work.
Table 2. Machine learning models with their specific hyper-parameters settings

In addition, the key parameter settings for each feature selection method employed in this work are listed in Table 3.
Table 3. Hyper-parameters used in Boruta and genetic algorithm

List of hyper-parameters used in Boruta and genetic algorithm
With these settings, optimal outcomes are achieved, and the replicability and reproducibility of our study are enhanced. To achieve this, this study employs GeneticSelectionCV, a feature selection technique within scikit-learn that utilizes a genetic algorithm to optimize the feature subset for a ML model. Notably, GeneticSelectionCV incorporates cross-validation during the selection process, mitigating the risk of overfitting. BorutaPy, another feature selection library, is implemented to identify relevant features from a potentially large pool. This approach aims to improve model performance and reduce the risk of overfitting by discarding irrelevant features. Scikit-learn provides a comprehensive suite of ML algorithms, including ensemble methods like Random Forest, AdaBoost, and Gradient Boosting. These ensemble methods leverage the power of multiple models to achieve superior performance compared to individual models.
4.1.2. The results of classifiers performance with and without SMOTE–ENN
In Table 4, we observe that the classifiers’ performance on the imbalanced dataset demonstrates the challenges in predicting student performance. CatBoost exhibits the highest accuracy at 85%, but even this leading classifier falls short of achieving impressive accuracy. Notably, all classifiers show precision results below 70%, indicating the overall difficulty in correctly classifying student performance. This is further substantiated by F1-scores, which reveal that predictive classifiers struggle with a few classes, with CatBoost achieving an F1-score of 59%, reflecting suboptimal classifier performance.
Table 4. The results of classifiers performance with and without SMOTE–ENN
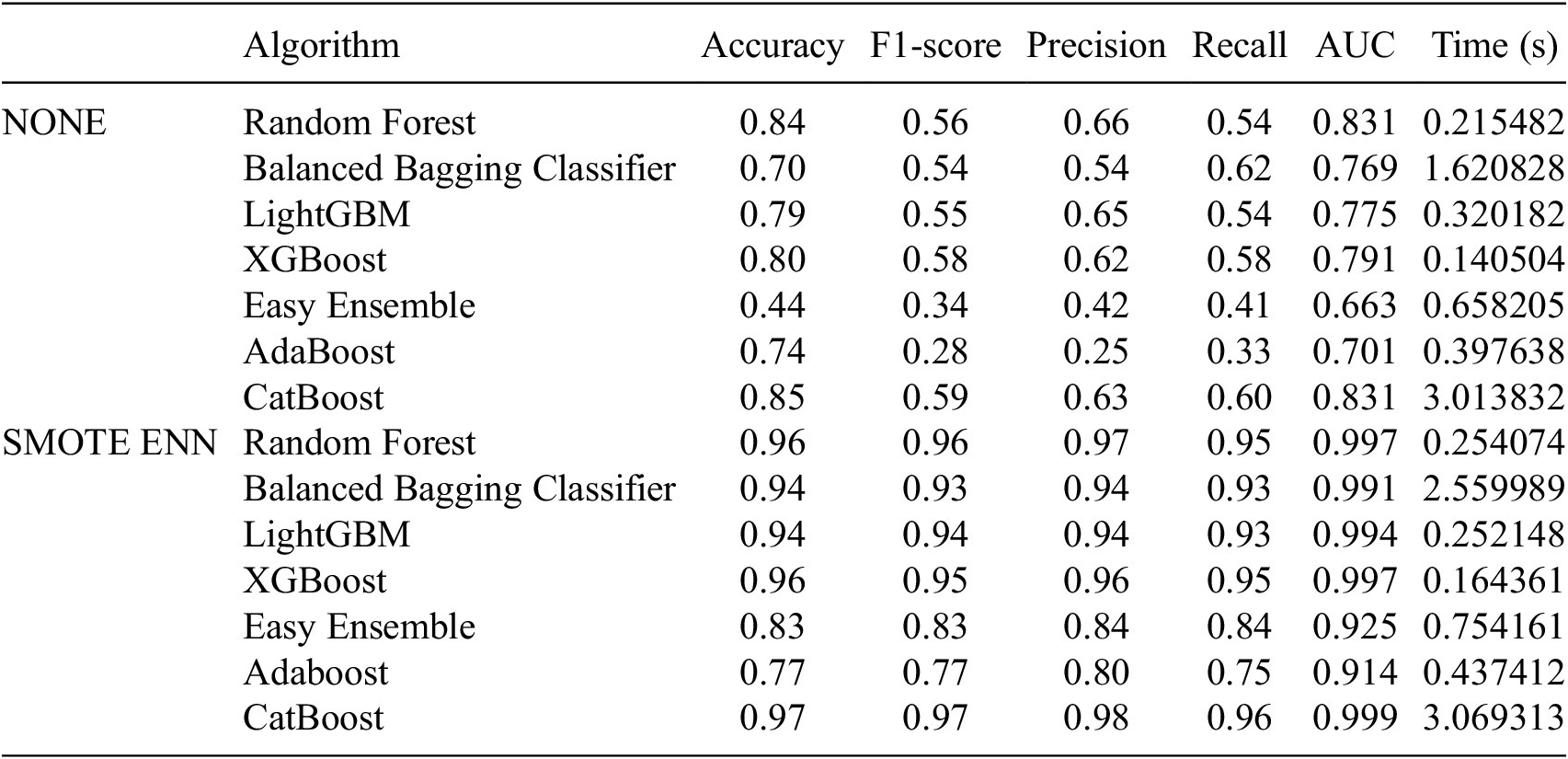
Table 4 also highlights the impact of addressing class imbalances using SMOTE–ENN. With this resampling technique, CatBoost significantly improves its accuracy to 97%, demonstrating its efficacy on balanced data. However, despite the improvement in accuracy, certain classes continue to pose challenges, emphasizing the need to address the issue of imbalanced data. Furthermore, the table shows varying execution times for the classifiers, highlighting the trade-off between classifier accuracy and the time required to execute them.
4.1.3. The results of classifiers after applying the Boruta feature selection method
In our examination of feature selection in Tables 5 and 6, Boruta adeptly identifies 75% of features as pivotal, showcasing its proficiency in pinpointing pertinent student attributes. Noteworthy is its sustained impact on classifier AUC, consistently maintaining a high value of 99%, validating its reliability in forecasting student outcomes. This unwavering stability underscores Boruta’s effectiveness in systematically choosing essential predictors for tailored interventions in education, offering valuable perspectives for both practitioners and policymakers in the field.
Table 5. Selected features by Boruta and genetic algorithm

Table 6. The results of classifiers performance using SMOTE–ENN + Boruta and SMOTE–ENN + genetic algorithm

4.1.4. The result of classifiers after applying genetic algorithms and the feature selection method
When applying the genetic algorithm, we discover that attributes such as study time, parents’ education, and school absence significantly impact student performance. The results in Table 6 highlight that both Boruta and genetic algorithms lead to improvements in classifier performance, with AUC values indicating high prediction model performance with a value of 99%. Importantly, the genetic algorithm retains less than 50% of the student attributes, contributing to efficient model building. These numerical findings underscore the utility of feature selection methods in enhancing the precision of the prediction models while reducing the computational and time costs associated with feature-rich datasets. The choice of genetic algorithm for feature selection stands out due to its ability to swiftly construct accurate models. In essence, these results provide empirical validation of the strategies employed in our study, substantiating their effectiveness in addressing the challenges of predicting student performance. In conclusion, this discussion underscores the importance of addressing class imbalance and applying feature selection methods in the context of predicting student performance. These techniques not only enhance model accuracy but also contribute to computational efficiency. The choice of classifier also plays a significant role in the overall performance. By combining these strategies, we aim to provide educational institutions and policymakers with valuable insights into enhancing academic achievements.
4.2. The result of statistical analysis
Based on the Shapiro–Wilk normality test results, the data for the Nigeria dataset do not follow a normal distribution (p < 0.05), as displayed in Table 7. Consequently, parametric statistical tests like ANOVA are not suitable for analyzing these results. Therefore, a non-parametric test, specifically the Friedman test, is the more appropriate choice for this dataset to assess statistically significant differences in precision-recall, F1, and AUC metrics across the various classifiers and feature selection and sampling techniques.
Table 7. Shapiro test

Friedman test for Nigerian dataset
Table 8 demonstrates that the
 $ p $
values of the data for the Friedman test are greater than 0.05 (a = 0.05) for the Nigeria dataset. This indicates that the null hypothesis has been accepted. This suggests that the experimental procedures are not statistically significantly different. This implies that all three approaches could potentially yield comparable impacts on the academic performance of Nigerian students; however, additional research is imperative to confirm these findings.
$ p $
values of the data for the Friedman test are greater than 0.05 (a = 0.05) for the Nigeria dataset. This indicates that the null hypothesis has been accepted. This suggests that the experimental procedures are not statistically significantly different. This implies that all three approaches could potentially yield comparable impacts on the academic performance of Nigerian students; however, additional research is imperative to confirm these findings.
Table 8. Friedman test

4.3. Deployment results
Streamlit, a user-centric web application development framework, plays a crucial role in disseminating the developed model’s capabilities to a wider audience. This platform streamlines the deployment process by consolidating both front-end and back-end functionalities within a single environment. Unlike frameworks like Flask or Express, Streamlit eliminates the need for separate development of user interfaces and server-side logic, facilitating a more rapid and efficient deployment (Sharma, Reference Sharma2020). The deployed application leverages Streamlit’s intuitive interface to provide users with a user-friendly experience for interacting with the model. This interface incorporates several input fields, allowing users to enter relevant data points that influence student performance, as identified by the model. Once the user submits this input, the application seamlessly integrates with the trained model, performing real-time predictions on the user’s academic standing as depicted in Figure 7.

Figure 7. Web-based student performance model application.
The results are then presented in a clear and concise manner, enabling users to understand their predicted performance outcomes (favorable or unfavorable). Furthermore, the interactive nature of the application empowers users to explore various “what-if” scenarios. By modifying the input values, users can observe how different factors might influence their academic performance. This dynamic feedback empowers users to gain valuable insights and potentially make informed decisions to optimize their academic trajectory. In essence, Streamlit facilitates the deployment of a user-friendly and interactive web application that leverages the predictive capabilities of the developed model. This application provides a valuable tool for students to gain insights into their academic standing and explore strategies for potential improvement.
4.4. Discussion
This study explores the use of ML techniques within the unique environment of Nigerian classrooms, focusing on developing predictive models to identify underperforming students. This empowers universities both within and outside Africa to proactively support struggling students, optimize educational costs, and promote inclusive development. We move beyond previous studies by tackling the intricacies of predicting student performance in demanding scenarios, particularly within small and imbalanced datasets. The dataset’s limited size and imbalanced class distribution posed significant obstacles. With only three categories in the dataset, capturing meaningful trends was particularly difficult. Typically, larger datasets are required to effectively handle multi-classification problems. To tackle class imbalance, we applied SMOTE–ENN techniques to oversample data on student performance. This approach not only mitigates bias but also reduces computational costs. Balancing class distribution is crucial for ensuring accurate predictions across all categories. To address the challenges of irrelevant features, feature selection became a critical aspect of our research. We needed to ensure the efficiency of our ML models by eliminating redundant or minimally informative predictions. Our choice of feature selection methods included the genetic algorithm and Boruta, aiming to leverage the strengths of both approaches. Genetic algorithms have proven effective in various domains, while Boruta is a robust technique for identifying relevant features. Two classifiers, XGBoost and LightGBM, emerged as strong performers in our experiments. These algorithms demonstrated their ability to handle the challenges posed by the small dataset and class imbalance. It’s worth noting that the choice of classifier has a substantial impact on predictive accuracy. Our analysis highlighted attributes such as study time, parents’ education, school support, the number of school absences, health, and participation in extra-paid classes as significant factors influencing students’ academic achievements. Understanding the importance of these attributes is invaluable for educational institutions. Incorporating modern deployment tools, such as Streamlit and Heroku, further facilitates the practical application of our research. Streamlit simplified the development of ML applications, allowing more time for model improvement, while Heroku streamlined system management for quicker and simpler app development. Our research transcends technical advancements by translating these findings into real-world impact through an accessible web application built with Streamlit and Heroku. This empowers universities within and outside Africa to customize model settings and view real-time results, fostering informed decision-making based on data-driven insights and predictions. Moreover, this research demonstrates how data science can inform policy by improving situation analysis through a deeper understanding of factors impacting student performance, enhancing predictions for timely interventions and resource allocation, and supporting public service design for effective and legitimate education policies. Ultimately, this research empowers stakeholders to harness data science for equitable and impactful education in African smart cities, paving the way for a future where data empower education, fosters sustainable development, and unlocks the potential of every student in African smart cities.
5. Conclusion
This research explores the use of ML techniques within the unique environment of Nigerian classrooms, focusing on developing predictive models to identify underperforming students. This empowers universities both within and outside Africa to proactively support struggling students, optimize educational costs, and promote inclusive development. This study harnessed the power of ML to predict student performance and employed feature selection techniques to expedite the resolution of this critical issue. The results from our experimentation underscore the viability of the genetic algorithm and Boruta feature selection methods when coupled with SMOTE–ENN and CatBoost classifiers. Notably, this approach proved effective in reducing the number of features by over 50% while significantly expediting the model-building process. The genetic algorithm stood out by offering the swiftest training times, demonstrating its applicability to extensive and complex training datasets. Feature selection emerges as a pivotal aspect of ML and prediction, as it serves to enhance prediction accuracy across various student classifiers while simultaneously reducing processing costs. This study identified a range of factors, including study time, mother’s and father’s education levels, school support, school absences, health status, and participation in extra-paid classes, as significant contributors to students’ academic achievements. These attributes, when integrated into the model, significantly enhance prediction accuracy and interpretability. Classifier analysis demonstrated that robust classifiers like CatBoost and Random Forest deliver promising results across all performance indicators. However, it’s essential to acknowledge the higher maintenance costs associated with these classifiers compared to XGBoost and LightGBM. The findings equip software developers and researchers with insights into the selection of sampling and feature selection strategies, enabling them to optimize performance under various scenarios and evaluation criteria. Moreover, the utilization of modern technologies like Streamlit and Heroku for web deployment underscores the importance of user-friendly ML applications and efficient model building. This aspect not only enhances the accessibility of ML models but also supports the continuous improvement of predictive outcomes. Our research transcends technical advancements by translating these findings into real-world impact through an accessible web application built with Streamlit and Heroku. This empowers universities within and outside Africa to customize model settings and view real-time results, fostering informed decision-making based on data-driven insights and predictions. Moreover, this research demonstrates how data science can inform policy by improving situation analysis through a deeper understanding of factors impacting student performance, enhancing predictions for timely interventions and resource allocation, and supporting public service design for effective and legitimate education policies. Ultimately, this research empowers stakeholders to harness data science for equitable and impactful education in African smart cities, paving the way for a future where data empower education, fosters sustainable development, and unlocks the potential of every student in African smart cities.
6. Limitations and future work
This study has certain limitations. The use of publicly available datasets rather than a custom student data collection and the relatively small dataset comprising less than a thousand records pose constraints on the scope of the study. Future research should aim to leverage larger, more feature-rich datasets, harness cutting-edge big data technologies, and explore deep learning techniques to further enhance model performance. The challenge of feature selection for academic performance prediction will be an area of focused investigation. Future efforts will involve amassing substantial datasets and conducting comprehensive experiments to evaluate the efficacy of different feature selection algorithms and assess their adaptability to various contexts. Furthermore, exploring the synergy between feature selection techniques and classification algorithms to enhance prediction performance will be a priority. The study’s forward-looking approach extends to the exploration of individualized course recommendation systems and the development of a web application for deploying recommender system models. With an eye on mobile app development, we aim to address challenges associated with the individualized course recommender system. In conclusion, this study presents a robust methodology that effectively addresses the challenge of student performance prediction in the education sector. While acknowledging its limitations, the study offers valuable insights and paves the way for broader applications and extensive research expansion.
Data availability statement
The authors declare that all the data being used in the design and production cum layout of the manuscript are declared in the manuscript.
Author contribution
Conceptualization: E.A.A.A., S.A.; Formal analysis: H.S.; Methodology: H.S.; Software: H.S.; Supervision: E.A.A.A., S.A.; Validation: E.A.A.A., S.A.; Visualization: H.S.; Writing—original draft: H.S.; Writing—review and editing: H.A., S.C.K.T., B.A.
Funding statement
The authors received no specific funding for this study.
Competing interest
The authors declare that they have no competing interests to report regarding the present study.
















 Open access
Open access
Comments
No Comments have been published for this article.