



1. Introduction
Gibbs point processes are a tool for modelling a variety of phenomena that can be described as distributions of random spatial events [Reference Baddeley, Gregori, Mateu, Stoica and Stoyan4, Reference Møller and Waagepetersen26]. Such phenomena include the location of stars in the universe, a sample of cells under the microscope, or the location of pores and cracks in the ground (see [Reference Møller and Waagepetersen25, Reference Van Lieshout31] for more on applications of Gibbs point processes). In statistical physics, such point processes are frequently used as stochastic models for gases or liquids of interacting particles [Reference Ruelle28].
A Gibbs point process on a finite-volume region
 $\Lambda$
is parameterized by a fugacity
$\Lambda$
is parameterized by a fugacity
 $\lambda$
and a pair potential
$\lambda$
and a pair potential
 $\phi$
expressing the interactions between pairs of points. Every point configuration in the region is assigned a weight according to the pair interactions
$\phi$
expressing the interactions between pairs of points. Every point configuration in the region is assigned a weight according to the pair interactions
 $\phi$
between all pairs of points in the configuration. One can then think of a Gibbs point process as a Poisson point process of intensity
$\phi$
between all pairs of points in the configuration. One can then think of a Gibbs point process as a Poisson point process of intensity
 $\lambda$
, where the density of each configuration is scaled proportionally to its weight. The density is normalized by the partition function, which is the integral of the weights over the configuration space [see Section 4.1 for a formal definition of the model]. The most famous example of such a process is the hard-sphere model, a model of a random packing of equal-sized spheres with radius
$\lambda$
, where the density of each configuration is scaled proportionally to its weight. The density is normalized by the partition function, which is the integral of the weights over the configuration space [see Section 4.1 for a formal definition of the model]. The most famous example of such a process is the hard-sphere model, a model of a random packing of equal-sized spheres with radius
 $r$
. The pair potential in the hard-sphere model defines hard-core interactions, that is configurations where two points closer than some distance
$r$
. The pair potential in the hard-sphere model defines hard-core interactions, that is configurations where two points closer than some distance
 $2r$
have weight zero, while all other configurations have weight one. In this article, we consider Gibbs point processes with repulsive potentials, that is, pair potentials in which adding a point to a configuration does not increase its weight. The hard-sphere model, for example, does have a repulsive pair potential, however, we do not restrict ourselves to hard-core potentials and allow for soft-core interactions.
$2r$
have weight zero, while all other configurations have weight one. In this article, we consider Gibbs point processes with repulsive potentials, that is, pair potentials in which adding a point to a configuration does not increase its weight. The hard-sphere model, for example, does have a repulsive pair potential, however, we do not restrict ourselves to hard-core potentials and allow for soft-core interactions.
The two most fundamental algorithmic tasks considered on Gibbs point processes are to sample from the model and to compute its partition function, which are closely related. Understanding for which potentials and fugacities these two tasks are tractable is an ambitious endeavour. Towards this goal, there has been a plethora of algorithmic results on Gibbs point processes spanning several decades. Notably, the Markov chain Monte Carlo method was developed for sampling an instance of the hard-sphere model [Reference Metropolis, Rosenbluth, Rosenbluth, Teller and Teller22]. Since then, a variety of exact and approximate sampling algorithms for such point processes have been proposed in the literature, and their efficiency has been studied extensively both without [Reference Garcia13, Reference Häggström, Van Lieshout and Møller16] and with rigorous running time guarantees [Reference Anand, Göbel, Pappik and Perkins1, Reference Guo and Jerrum15, Reference Huber18, Reference Michelen and Perkins23, Reference Møller24]. The key objective of rigorous works is to identify a parameter regime for their respective model for which a randomized algorithm for sampling and approximating the partition function exists with running time polynomial in the volume of the region. In addition, deterministic algorithms for approximating the partition function have also appeared in the literature [Reference Friedrich, Göbel, Katzmann, Krejca and Pappik11, Reference Jenssen, Michelen and Ravichandran20] with running time quasi-polynomial in the volume of the region.
This recent flurry of algorithmic results on Gibbs point processes can be attributed to progress in understanding the computational properties of discrete spin systems, such as the hard-core model. Within these works, two main approaches can be identified for transferring insights from discrete spin systems to Gibbs point processes. The first one, which includes results such as [Reference Anand, Göbel, Pappik and Perkins1, Reference Helmuth, Perkins and Petti17, Reference Michelen and Perkins23], considers properties proven to hold in discrete spin systems and translates them to the continuous setting of Gibbs point processes. More precisely, these works consider the notion of strong spatial mixing, which has been strongly connected to algorithmic properties of discrete spin systems [Reference Feng, Guo and Yin9, Reference Sinclair, Srivastava, Štefankovič and Yin29, Reference Weitz33], and translate it to an analogous notion for Gibbs point processes to obtain algorithmic results. A common pattern in these works is that once the parameter regime for which strong spatial mixing holds is established, one needs to prove from scratch that this implies efficient algorithms for Gibbs point processes. In addition, the definition of strong spatial mixing for Gibbs points processes assumes that the pair interactions of two particles is always of bounded range, that is if two particles are placed at distance greater than some constant
 $r \in{\unicode{x211D}}_{\ge 0}$
, they do not interact with each other.
$r \in{\unicode{x211D}}_{\ge 0}$
, they do not interact with each other.
The second approach, used in [Reference Friedrich, Göbel, Katzmann, Krejca and Pappik11, Reference Friedrich, Göbel, Krejca and Pappik12], is to discretize the model, that is reduce it to an instance of the hard-core model and then solve the respective algorithmic problem for the hard-core model. In this case, the algorithmic arsenal developed over the years for the hard-core model is now readily available for the instances resulting from this reduction. The main downside of these approaches is that they only apply to the hard-sphere model, a special case of bounded-range repulsive interactions.
1.1. Our contributions
We introduce a natural approach for reducing repulsive point processes to the hard-core model. Given an instance
 $(\Lambda, \lambda, \phi )$
of such a point process, we generate a random graph by sampling sufficiently many points independently and uniformly at random in
$(\Lambda, \lambda, \phi )$
of such a point process, we generate a random graph by sampling sufficiently many points independently and uniformly at random in
 $\Lambda$
. Each point represents a vertex in the graph, and we connect each pair of vertices by an edge with a probability that depends on
$\Lambda$
. Each point represents a vertex in the graph, and we connect each pair of vertices by an edge with a probability that depends on
 $\phi$
. We show that both computational problems considered can be reduced to studying the hard-core model on graphs generated by this model for an appropriately scaled vertex activity.
$\phi$
. We show that both computational problems considered can be reduced to studying the hard-core model on graphs generated by this model for an appropriately scaled vertex activity.
Our first step towards this result is to show that the partition function of the hard-core model on these graphs concentrates around the partition function of the Gibbs point process. Using existing algorithms for the hard-core model as a black box, our result immediately yields randomized approximation algorithms for the partition function of the point process in running time polynomial in the volume of
 $\Lambda$
. Furthermore, we show that sampling an independent set from the generated hard-core model and returning the positions of its vertices in
$\Lambda$
. Furthermore, we show that sampling an independent set from the generated hard-core model and returning the positions of its vertices in
 $\Lambda$
results in an approximate sampler from the distribution of the Gibbs point process. Our approach, in contrast to all previous algorithmic work in the literature, does not require the pair potential
$\Lambda$
results in an approximate sampler from the distribution of the Gibbs point process. Our approach, in contrast to all previous algorithmic work in the literature, does not require the pair potential
 $\phi$
of the point process to be of bounded range. This includes various models of interest in statistical physics, such as the (hard-core) Yukawa model [Reference El Azhar, Baus, Ryckaert and Meijer8, Reference Rowlinson27], the Gaussian overlap model [Reference Berne and Pechukas5], the generalized exponential model [Reference Bacher, Schrøder and Dyre3], and the Yoshida–Kamakura model [Reference Yoshida and Kamakura34].
$\phi$
of the point process to be of bounded range. This includes various models of interest in statistical physics, such as the (hard-core) Yukawa model [Reference El Azhar, Baus, Ryckaert and Meijer8, Reference Rowlinson27], the Gaussian overlap model [Reference Berne and Pechukas5], the generalized exponential model [Reference Bacher, Schrøder and Dyre3], and the Yoshida–Kamakura model [Reference Yoshida and Kamakura34].
2. Notation
We write
 $\mathbb{N}$
for the non-negative integers (including
$\mathbb{N}$
for the non-negative integers (including
 $0$
) and
$0$
) and
 ${\mathbb{N}}_{\ge 1}$
for the positive integers. Moreover, for
${\mathbb{N}}_{\ge 1}$
for the positive integers. Moreover, for
 $n \in{\mathbb{N}}$
, we denote
$n \in{\mathbb{N}}$
, we denote
 $[n] ={\mathbb{N}}_{\ge 1} \cap [0, n]$
(note that
$[n] ={\mathbb{N}}_{\ge 1} \cap [0, n]$
(note that
 $[0] = \emptyset$
). For a set
$[0] = \emptyset$
). For a set
 $S$
and
$S$
and
 $k \in{\mathbb{N}}$
, we write
$k \in{\mathbb{N}}$
, we write
 $\binom{S}{k} \,:\!=\, \{S^{\prime} \subseteq S \mid 3 = k\}$
for the subsets of
$\binom{S}{k} \,:\!=\, \{S^{\prime} \subseteq S \mid 3 = k\}$
for the subsets of
 $S$
of size
$S$
of size
 $k$
. Throughout the paper, we let
$k$
. Throughout the paper, we let
 $G=(V, E)$
denote undirected graphs with vertex set
$G=(V, E)$
denote undirected graphs with vertex set
 $V$
and edge set
$V$
and edge set
 $E \subseteq \binom{V}{2}$
. Moreover, for
$E \subseteq \binom{V}{2}$
. Moreover, for
 $n \in{\mathbb{N}}$
we write
$n \in{\mathbb{N}}$
we write
 $\mathcal{G}_{n}$
for the set of undirected graphs with vertex set
$\mathcal{G}_{n}$
for the set of undirected graphs with vertex set
 $[n]$
.
$[n]$
.
3. Concentration of the hard-core partition functions on random graphs
Before we discuss our results on Gibbs point processes, we first derive our main tool, which is a concentration result for the hard-core partition function on random graphs generated based on a graphon. We start by introducing the necessary notation and terminology.
3.1. Hard-core model
For a graph
 $G$
we write
$G$
we write
 $\mathcal{I}(G) \subseteq{{2^{{V}}}}$
for its independent sets. That is,
$\mathcal{I}(G) \subseteq{{2^{{V}}}}$
for its independent sets. That is,
 $S \in \mathcal{I}(G)$
if and only if no two vertices in
$S \in \mathcal{I}(G)$
if and only if no two vertices in
 $S$
are adjacent in
$S$
are adjacent in
 $G$
. The hard-core partition function on
$G$
. The hard-core partition function on
 $G$
at vertex activity
$G$
at vertex activity
 ${z} \in{\unicode{x211D}}_{\ge 0}$
is defined as
${z} \in{\unicode{x211D}}_{\ge 0}$
is defined as
 \begin{equation*} Z_G(z) \,:\!=\, \sum _{S \in \mathcal {I}(G)} {z}^{\left \vert {S} \right \vert } . \end{equation*}
\begin{equation*} Z_G(z) \,:\!=\, \sum _{S \in \mathcal {I}(G)} {z}^{\left \vert {S} \right \vert } . \end{equation*}
The hard-core model on
 $G$
at activity
$G$
at activity
 $z$
is a probability distribution on
$z$
is a probability distribution on
 ${2^{{V}}}$
with support
${2^{{V}}}$
with support
 $\mathcal{I}(G)$
that is defined by
$\mathcal{I}(G)$
that is defined by
 \begin{equation*} \mu _{{G}, {z}} (S) \,:\!=\, \frac {{z}^{\left \vert {S} \right \vert }}{Z_G(z)}. \end{equation*}
\begin{equation*} \mu _{{G}, {z}} (S) \,:\!=\, \frac {{z}^{\left \vert {S} \right \vert }}{Z_G(z)}. \end{equation*}
for every
 $S \in \mathcal{I}(G)$
.
$S \in \mathcal{I}(G)$
.
3.2. Graphons and random graphs
We will show that the hard-core partition
 $Z_G(z)$
of sufficiently large random graphs generated from a graphon concentrates around its expectation. Here, we refer to graphons in a very general sense, as defined in [Reference Lovász21, Chapter
$Z_G(z)$
of sufficiently large random graphs generated from a graphon concentrates around its expectation. Here, we refer to graphons in a very general sense, as defined in [Reference Lovász21, Chapter
 $13$
]. That is, for a probability space
$13$
]. That is, for a probability space
 $\mathcal{X} = ({X},{\mathcal{A}},{\xi })$
, a graphon is a symmetric function
$\mathcal{X} = ({X},{\mathcal{A}},{\xi })$
, a graphon is a symmetric function
 ${W}\colon{X}^2 \to [0, 1]$
that is measurable with respect to the product algebra
${W}\colon{X}^2 \to [0, 1]$
that is measurable with respect to the product algebra
 ${\mathcal{A}}^2 ={\mathcal{A}}{\otimes }{\mathcal{A}}$
. Note that, even though we call the function
${\mathcal{A}}^2 ={\mathcal{A}}{\otimes }{\mathcal{A}}$
. Note that, even though we call the function
 $W$
the graphon, we mean implicitly that a graphon is a tuple of an underlying probability space and a suitable function
$W$
the graphon, we mean implicitly that a graphon is a tuple of an underlying probability space and a suitable function
 $W$
.
$W$
.
A graphon
 $W$
naturally defines a family of random-graph models, sometimes called
$W$
naturally defines a family of random-graph models, sometimes called
 $W$
-random graphs (see [Reference Lovász21, Chapter
$W$
-random graphs (see [Reference Lovász21, Chapter
 $11$
]). For every
$11$
]). For every
 $n \in{\mathbb{N}}_{\ge 1}$
, we denote by
$n \in{\mathbb{N}}_{\ge 1}$
, we denote by
 $\mathbb{G}_{W,n}$
a distribution on
$\mathbb{G}_{W,n}$
a distribution on
 $\mathcal{G}_{n}$
that is induced by the following procedure for generating a random graph:
$\mathcal{G}_{n}$
that is induced by the following procedure for generating a random graph:
-
1. Draw a tuple
 $(x_1, \dots x_n) \in{X}^n$
according to the product distribution
${\xi }^n$
.
$(x_1, \dots x_n) \in{X}^n$
according to the product distribution
${\xi }^n$
. -
2. For all
$i, j \in [n], i \neq j$
, add the edge
$\{i, j\}$
independently with probability
${W}(x_i,x_j)$
.





Formally, this gives a probability distribution
 $\mathbb{G}_{W,n}$
on
$\mathbb{G}_{W,n}$
on
 $\mathcal{G}_{n}$
with
$\mathcal{G}_{n}$
with
 \begin{equation*} \mathbb {G}_{W,n}(G) = \int _{{X}^n} \left (\prod _{\{i, j\} \in E} {W}(x_i, x_j)\right ) \cdot \left (\prod _{\{i, j\} \in \binom {[n]}{2} \setminus E} \left (1 - {W}(x_i,x_j)\right )\right ) {\xi }^{n}({\textrm {d}}{\textbf {x}}). \end{equation*}
\begin{equation*} \mathbb {G}_{W,n}(G) = \int _{{X}^n} \left (\prod _{\{i, j\} \in E} {W}(x_i, x_j)\right ) \cdot \left (\prod _{\{i, j\} \in \binom {[n]}{2} \setminus E} \left (1 - {W}(x_i,x_j)\right )\right ) {\xi }^{n}({\textrm {d}}{\textbf {x}}). \end{equation*}
for all
 ${G} \in{\mathcal{G}_{n}}$
, where
${G} \in{\mathcal{G}_{n}}$
, where
 $\textbf{x} = (x_i)_{i \in [n]}$
inside the integral. Observe that
$\textbf{x} = (x_i)_{i \in [n]}$
inside the integral. Observe that
 $\mathbb{G}_{W,n}$
encompasses classical random-graph models, such as Erdős–Rényi random graphs and geometric random graphs.
$\mathbb{G}_{W,n}$
encompasses classical random-graph models, such as Erdős–Rényi random graphs and geometric random graphs.
3.3 Efron–Stein inequality
For proving our concentration result, we use the Efron–Stein inequality. For
 $N \in{\mathbb{N}}_{\ge 1}$
let
$N \in{\mathbb{N}}_{\ge 1}$
let
 $\{\left ({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i}\right )\}_{i \in [N]}$
be a collection of probability spaces and let
$\{\left ({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i}\right )\}_{i \in [N]}$
be a collection of probability spaces and let
 $f\,:\,{\Omega } \to{\unicode{x211D}}$
be a measurable function on the product space
$f\,:\,{\Omega } \to{\unicode{x211D}}$
be a measurable function on the product space
 $({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i})$
. For each
$({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i})$
. For each
 $i \in [N]$
define a function
$i \in [N]$
define a function
 ${\Delta }_{i}^{(f)}\,:\,\Omega \times \Omega _i \to{\unicode{x211D}}_{\ge 0}$
, where, for every
${\Delta }_{i}^{(f)}\,:\,\Omega \times \Omega _i \to{\unicode{x211D}}_{\ge 0}$
, where, for every
 $\textbf{x} = (x_1, \dots, x_{N}) \in{\Omega }$
and
$\textbf{x} = (x_1, \dots, x_{N}) \in{\Omega }$
and
 $y_i \in{\Omega }_i$
, the value
$y_i \in{\Omega }_i$
, the value
 $\Delta _{i}^{(f)}(\textbf{x}, y_i)$
is defined as the squared difference in
$\Delta _{i}^{(f)}(\textbf{x}, y_i)$
is defined as the squared difference in
 $f$
that is caused by replacing
$f$
that is caused by replacing
 $x_i$
in
$x_i$
in
 $\textbf{x}$
with
$\textbf{x}$
with
 $y_i$
. Formally, this is
$y_i$
. Formally, this is
 $\Delta _{i}^{(f)}(\textbf{x},y_i) = (f(\textbf{x}) - f(\textbf{y}))^2$
where
$\Delta _{i}^{(f)}(\textbf{x},y_i) = (f(\textbf{x}) - f(\textbf{y}))^2$
where
 $\textbf{y} = (x_1, \dots, x_{i-1}, y_i, x_{i+1}, \dots, x_{N})$
. The Efron–Stein inequality bounds the variance of
$\textbf{y} = (x_1, \dots, x_{i-1}, y_i, x_{i+1}, \dots, x_{N})$
. The Efron–Stein inequality bounds the variance of
 $f$
under
$f$
under
 $\mu$
based on the local squared deviations
$\mu$
based on the local squared deviations
 $\Delta _{i}^{(f)}(\textbf{x},y_i)$
.
$\Delta _{i}^{(f)}(\textbf{x},y_i)$
.
Theorem 3.1 (Efron – Stein inequalitye [Reference Efron and Stein7]). Let
 $\{({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i})\}_{i \in [N]}$
be probability spaces with product space
$\{({\Omega }_i,{\mathcal{F}}_i,{\mu }_{i})\}_{i \in [N]}$
be probability spaces with product space
 $({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])$
. For every
$({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])$
. For every
 $\mathcal{F}$
-measurable function
$\mathcal{F}$
-measurable function
 $f\,:\,{\Omega } \to{\unicode{x211D}}$
it holds that
$f\,:\,{\Omega } \to{\unicode{x211D}}$
it holds that
 \begin{equation*} \mathrm{Var}_{\mu }[f] \le \frac {1}{2} \sum \nolimits _{i \in [N]} \mathbb {E}_{\mu \times \mu _{i}}[\Delta _{i}^{(f)}] . \end{equation*}
\begin{equation*} \mathrm{Var}_{\mu }[f] \le \frac {1}{2} \sum \nolimits _{i \in [N]} \mathbb {E}_{\mu \times \mu _{i}}[\Delta _{i}^{(f)}] . \end{equation*}
Remark 3.1. The Efron–Stein inequality is usually stated for functions of independent real-valued random variables. However, it extends to functions on products of arbitrary probability spaces.
3.4. Proof of concentration
We start by deriving the following simple corollary of Theorem 3.1.
Corollary 3.1 (Corollary of the Efron – Stein inequality). Let
 $\{({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])\}_{i \in [N]}$
be probability spaces with product space
$\{({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])\}_{i \in [N]}$
be probability spaces with product space
 $({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])$
, and let
$({\Omega },{\mathcal{F}}, \mu ) = \bigotimes _{i \in [N]} ({\Omega }_i,{\mathcal{F}}_i,{\mu }_i])$
, and let
 $f\colon{\Omega } \to{\unicode{x211D}}$
be an
$f\colon{\Omega } \to{\unicode{x211D}}$
be an
 $\mathcal{F}$
-measurable function. Assume that there are
$\mathcal{F}$
-measurable function. Assume that there are
 $c_i \in{\unicode{x211D}}_{\ge 0}$
for
$c_i \in{\unicode{x211D}}_{\ge 0}$
for
 $i \in [N]$
such that
$i \in [N]$
such that
 $C \,:\!=\, \sum _{i \in [N]} c_i^2 \lt 2$
and, for all
$C \,:\!=\, \sum _{i \in [N]} c_i^2 \lt 2$
and, for all
 $\textbf{x} = (x_j)_{j \in [N]} \in{\Omega }$
and
$\textbf{x} = (x_j)_{j \in [N]} \in{\Omega }$
and
 $\textbf{y} = (y_j)_{j \in [N]} \in{\Omega }$
that disagree only at position
$\textbf{y} = (y_j)_{j \in [N]} \in{\Omega }$
that disagree only at position
 $i$
, it holds that
$i$
, it holds that
 \begin{equation*} {\left \vert f(\textbf {x}) - f(\textbf {y}) \right \vert } \le c_i \cdot \min \{{\left \vert f(\textbf {x}) \right \vert }, {\left \vert f(\textbf {y}) \right \vert }\} . \end{equation*}
\begin{equation*} {\left \vert f(\textbf {x}) - f(\textbf {y}) \right \vert } \le c_i \cdot \min \{{\left \vert f(\textbf {x}) \right \vert }, {\left \vert f(\textbf {y}) \right \vert }\} . \end{equation*}
Then, for all
 ${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
, it holds that
${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
, it holds that
 \begin{equation*} {\mathbb {P}}{\left [{\left \vert f - \mathbb {E}_\mu [f] \right \vert } \ge {\varepsilon } \mathbb {E}_\mu [f]\right ]} \le \left (\frac {2}{2 - C} - 1\right ) \frac {1}{{\varepsilon }^2} . \end{equation*}
\begin{equation*} {\mathbb {P}}{\left [{\left \vert f - \mathbb {E}_\mu [f] \right \vert } \ge {\varepsilon } \mathbb {E}_\mu [f]\right ]} \le \left (\frac {2}{2 - C} - 1\right ) \frac {1}{{\varepsilon }^2} . \end{equation*}
Proof. First, we observe that
 ${\left \vert f(\textbf{x}) - f(\textbf{y}) \right \vert } \le c_i \min \{{\left \vert f(\textbf{x}) \right \vert },{\left \vert f(\textbf{y}) \right \vert }\} \le c_i{\left \vert f(\textbf{x}) \right \vert }$
implies
${\left \vert f(\textbf{x}) - f(\textbf{y}) \right \vert } \le c_i \min \{{\left \vert f(\textbf{x}) \right \vert },{\left \vert f(\textbf{y}) \right \vert }\} \le c_i{\left \vert f(\textbf{x}) \right \vert }$
implies
 $\mathbb{E}_{\mu \times{\mu _{i}}}\left [\Delta _{i}^{(f)}\right ] \le c_i^2 \mathbb{E}_\mu \left [f^2\right ]$
for all
$\mathbb{E}_{\mu \times{\mu _{i}}}\left [\Delta _{i}^{(f)}\right ] \le c_i^2 \mathbb{E}_\mu \left [f^2\right ]$
for all
 $i \in [N]$
. Thus, by Theorem3.1, we have
$i \in [N]$
. Thus, by Theorem3.1, we have
 $\mathrm{Var}_\mu [f] \le \frac{C}{2} \mathbb{E}_\mu \left [f^2\right ]$
. Now, recall that by definition
$\mathrm{Var}_\mu [f] \le \frac{C}{2} \mathbb{E}_\mu \left [f^2\right ]$
. Now, recall that by definition
 $ \mathrm{Var}_\mu [f] = \mathbb{E}_\mu \left [f^2\right ] - \mathbb{E}_\mu [f]^2$
, which implies
$ \mathrm{Var}_\mu [f] = \mathbb{E}_\mu \left [f^2\right ] - \mathbb{E}_\mu [f]^2$
, which implies
 $\mathbb{E}_\mu \left [f^2\right ] - \mathbb{E}_\mu [f]^2 \le \frac{C}{2} \mathbb{E}_\mu \left [f^2\right ]$
. Rearranging for
$\mathbb{E}_\mu \left [f^2\right ] - \mathbb{E}_\mu [f]^2 \le \frac{C}{2} \mathbb{E}_\mu \left [f^2\right ]$
. Rearranging for
 $\mathbb{E}_{\mu }[f^2]$
and using the fact that
$\mathbb{E}_{\mu }[f^2]$
and using the fact that
 $\frac{C}{2} \lt 1$
yields
$\frac{C}{2} \lt 1$
yields
 $\mathbb{E}_{\mu }[f^2] \le \frac{2}{2 - C} \mathbb{E}_{\mu }[f]^2$
. Substituting this back into the definition of the variance, we obtain
$\mathbb{E}_{\mu }[f^2] \le \frac{2}{2 - C} \mathbb{E}_{\mu }[f]^2$
. Substituting this back into the definition of the variance, we obtain
 \begin{equation*} \mathrm {Var}_\mu [f] \le \left (\frac {2}{2 - C} - 1\right ) \mathbb {E}_{\mu } \left [f\right ]^2 . \end{equation*}
\begin{equation*} \mathrm {Var}_\mu [f] \le \left (\frac {2}{2 - C} - 1\right ) \mathbb {E}_{\mu } \left [f\right ]^2 . \end{equation*}
The claim follows immediately by applying Chebyshev’s inequality.
Remark 3.2. Usually, we want to characterize concentration asymptotically in
 $N$
. In this setting, Corollary 3.1 tells us that, if
$N$
. In this setting, Corollary 3.1 tells us that, if
 $c_i \in{\mathrm{O}}\left (N^{-\frac{1 + \alpha }{2}}\right )$
for all
$c_i \in{\mathrm{O}}\left (N^{-\frac{1 + \alpha }{2}}\right )$
for all
 $i \in [N]$
and some
$i \in [N]$
and some
 $\alpha \gt 0$
, then, for all
$\alpha \gt 0$
, then, for all
 ${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
and
${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
and
 ${\delta } \in (0, 1]$
such that
${\delta } \in (0, 1]$
such that
 ${\varepsilon }^2{\delta } \lt 1$
, it is sufficient to choose
${\varepsilon }^2{\delta } \lt 1$
, it is sufficient to choose
 $N \in{\Theta }\left ({\delta }^{-\frac{1}{\alpha }}{\varepsilon }^{-\frac{2}{\alpha }}\right )$
to ensure
$N \in{\Theta }\left ({\delta }^{-\frac{1}{\alpha }}{\varepsilon }^{-\frac{2}{\alpha }}\right )$
to ensure
 \begin{equation*} {\mathbb {P}}{\left [{\left \vert f - \mathbb {E}_\mu [f] \right \vert } \ge {\varepsilon } \mathbb {E}_\mu [f]\right ]} \le {\delta }. \end{equation*}
\begin{equation*} {\mathbb {P}}{\left [{\left \vert f - \mathbb {E}_\mu [f] \right \vert } \ge {\varepsilon } \mathbb {E}_\mu [f]\right ]} \le {\delta }. \end{equation*}
To apply Corollary3.1 to the hard-core partition functions on random graphs from
 $\mathbb{G}_{W,n}$
, we will need to bound how much the partition function changes when applying small modifications to the structure of a graph. More specifically, we want to get a bound on the relative change of the partition function, given that we
$\mathbb{G}_{W,n}$
, we will need to bound how much the partition function changes when applying small modifications to the structure of a graph. More specifically, we want to get a bound on the relative change of the partition function, given that we
-
• add or remove a single edge, or
-
• add or remove a set of edges that are all incident to the same vertex.
The following two lemmas provide such bounds.
Lemma 3.1.
Let
 ${G} = ({V},{E})$
be a graph and, for some
${G} = ({V},{E})$
be a graph and, for some
 $e \in{E}$
, let
$e \in{E}$
, let
 ${G}^{\prime} = ({V},{E} \setminus \{e\})$
. For all
${G}^{\prime} = ({V},{E} \setminus \{e\})$
. For all
 ${z} \in{\unicode{x211D}}_{\ge 0}$
it holds that
${z} \in{\unicode{x211D}}_{\ge 0}$
it holds that
 \begin{equation*} Z_G(z) \le {Z}_{{G}^{\prime}} (z) \le \left (1 + {z}^2\right ) Z_G(z). \end{equation*}
\begin{equation*} Z_G(z) \le {Z}_{{G}^{\prime}} (z) \le \left (1 + {z}^2\right ) Z_G(z). \end{equation*}
Proof. The lower bound follows immediately from observing that
 $\mathcal{I}(G) \subseteqq{\mathcal{I}\left ({G}^{\prime}\right )}$
. For the upper bound, observe that
$\mathcal{I}(G) \subseteqq{\mathcal{I}\left ({G}^{\prime}\right )}$
. For the upper bound, observe that
 \begin{equation*} {Z}_{{G}^{\prime}} (z) - Z_G(z) = \sum _{\substack {S \in {\mathcal {I}\left ({G}^{\prime}\right )}:\\ e \subseteq S}} {z}^{\left \vert {S} \right \vert } \le {z}^2 \sum _{\substack {S^{\prime} \in {\mathcal {I}\left ({G}^{\prime}\right )}:\\ S^{\prime} \cap e = \emptyset }} {z}^{\left \vert {S^{\prime}} \right \vert } \le {z}^2 Z_G(z), \end{equation*}
\begin{equation*} {Z}_{{G}^{\prime}} (z) - Z_G(z) = \sum _{\substack {S \in {\mathcal {I}\left ({G}^{\prime}\right )}:\\ e \subseteq S}} {z}^{\left \vert {S} \right \vert } \le {z}^2 \sum _{\substack {S^{\prime} \in {\mathcal {I}\left ({G}^{\prime}\right )}:\\ S^{\prime} \cap e = \emptyset }} {z}^{\left \vert {S^{\prime}} \right \vert } \le {z}^2 Z_G(z), \end{equation*}
Lemma 3.2.
Let
 ${G} = ({V},{E}),{G}^{\prime} = ({V},{E}^{\prime})$
be two graphs on a common vertex set
${G} = ({V},{E}),{G}^{\prime} = ({V},{E}^{\prime})$
be two graphs on a common vertex set
 $V$
and assume there is some vertex
$V$
and assume there is some vertex
 $v \in{V}$
such that
$v \in{V}$
such that
 $v \in e$
for all edges
$v \in e$
for all edges
 $e$
in the symmetric difference of
$e$
in the symmetric difference of
 $E$
and
$E$
and
 ${E}^{\prime}$
. For all
${E}^{\prime}$
. For all
 ${z} \in{\unicode{x211D}}_{\ge 0}$
it holds that
${z} \in{\unicode{x211D}}_{\ge 0}$
it holds that
 \begin{equation*} {\left \vert Z_G(z) - {Z}_{{G}^{\prime}} (z) \right \vert } \le {z} \min \{Z_G(z), {Z}_{{G}^{\prime}} (z)\} . \end{equation*}
\begin{equation*} {\left \vert Z_G(z) - {Z}_{{G}^{\prime}} (z) \right \vert } \le {z} \min \{Z_G(z), {Z}_{{G}^{\prime}} (z)\} . \end{equation*}
Proof. Let
 $F = ({E} \cup{E}^{\prime}) \setminus \{\{v, w\} \mid w \neq v\}$
where
$F = ({E} \cup{E}^{\prime}) \setminus \{\{v, w\} \mid w \neq v\}$
where
 $v$
is as given by the claim. Let
$v$
is as given by the claim. Let
 $F^{\prime} = F \cup \{\{v, w\} \mid w \neq v\}$
, and set
$F^{\prime} = F \cup \{\{v, w\} \mid w \neq v\}$
, and set
 $H = ({V}, F)$
and
$H = ({V}, F)$
and
 $H^{\prime} = ({V}, F^{\prime})$
. Note that for every
$H^{\prime} = ({V}, F^{\prime})$
. Note that for every
 $S \in{\mathcal{I}\left (H^{\prime}\right )}$
with
$S \in{\mathcal{I}\left (H^{\prime}\right )}$
with
 $v \notin S$
we have
$v \notin S$
we have
 $S \in{\mathcal{I}\left (H\right )}$
and
$S \in{\mathcal{I}\left (H\right )}$
and
 $S \cup \{v\} \in{\mathcal{I}\left (H\right )}$
. Thus, we get
$S \cup \{v\} \in{\mathcal{I}\left (H\right )}$
. Thus, we get
 \begin{align*}{Z}_{H} (z) \le (1 +{z}) \sum _{\substack{S \in{\mathcal{I}\left (H^{\prime}\right )}:\\ v \notin S}}{z}^{\left \vert{S} \right \vert } \le (1 +{z}){Z}_{H^{\prime}} (z) . \end{align*}
\begin{align*}{Z}_{H} (z) \le (1 +{z}) \sum _{\substack{S \in{\mathcal{I}\left (H^{\prime}\right )}:\\ v \notin S}}{z}^{\left \vert{S} \right \vert } \le (1 +{z}){Z}_{H^{\prime}} (z) . \end{align*}
Further, we have
 $F \subseteq{E},{E}^{\prime} \subseteq F^{\prime}$
and, by Lemma3.1, we know that the hard-core partition function is non-decreasing under removing edges from the graph. Applying the triangle inequality we get
$F \subseteq{E},{E}^{\prime} \subseteq F^{\prime}$
and, by Lemma3.1, we know that the hard-core partition function is non-decreasing under removing edges from the graph. Applying the triangle inequality we get
 \begin{equation*} \left \vert Z_G(z) - {Z}_{{G}^{\prime}} (z) \right \vert \le {Z}_{H} (z) - {Z}_{H^{\prime}} (z) \le {z} {Z}_{H^{\prime}} (z) \le {z} \min \{Z_G(z), {Z}_{{G}^{\prime}} (z)\} . \end{equation*}
\begin{equation*} \left \vert Z_G(z) - {Z}_{{G}^{\prime}} (z) \right \vert \le {Z}_{H} (z) - {Z}_{H^{\prime}} (z) \le {z} {Z}_{H^{\prime}} (z) \le {z} \min \{Z_G(z), {Z}_{{G}^{\prime}} (z)\} . \end{equation*}
Based on Lemmas3.1 and 3.2, we use Corollary3.1 to prove the following statement.
Theorem 3.2.
Let
 $W$
be a graphon on the probability space
$W$
be a graphon on the probability space
 $\mathcal{X} = ({X},{\mathcal{A}},{\xi })$
. Let
$\mathcal{X} = ({X},{\mathcal{A}},{\xi })$
. Let
 $({z}_n)_{n \ge 1}$
be such that
$({z}_n)_{n \ge 1}$
be such that
 ${z}_n \le{{z}_0} n^{-\frac{1 + \alpha }{2}}$
for some
${z}_n \le{{z}_0} n^{-\frac{1 + \alpha }{2}}$
for some
 ${{z}_0} \in{\unicode{x211D}}_{\ge 0}$
and
${{z}_0} \in{\unicode{x211D}}_{\ge 0}$
and
 $\alpha \in{\unicode{x211D}}_{\gt 0}$
. For all
$\alpha \in{\unicode{x211D}}_{\gt 0}$
. For all
 ${\varepsilon } \in (0, 1]$
,
${\varepsilon } \in (0, 1]$
,
 ${\delta } \in (0, 1]$
,
${\delta } \in (0, 1]$
,
 $n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }}$
, and
$n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }}$
, and
 ${G} \sim \mathbb{G}_{W,n}$
, it holds that
${G} \sim \mathbb{G}_{W,n}$
, it holds that
 \begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G({z}_{n})\right ]\right \vert \ge \varepsilon \mathbb {E}\left [Z_G({z}_{n})\right ]\right ] \le \delta . \end{equation*}
\begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G({z}_{n})\right ]\right \vert \ge \varepsilon \mathbb {E}\left [Z_G({z}_{n})\right ]\right ] \le \delta . \end{equation*}
Proof. We aim for applying Corollary3.1 to prove our claim. To this end, for each
 $n \in{\mathbb{N}}_{\ge 1}$
we need to write the partition function
$n \in{\mathbb{N}}_{\ge 1}$
we need to write the partition function
 $Z_G({z}_n)$
for
$Z_G({z}_n)$
for
 ${G} \sim \mathbb{G}_{W,n}$
as a function on a product of probability spaces (i.e., a function of independent random variables). At first, an obvious choice seems to be
${G} \sim \mathbb{G}_{W,n}$
as a function on a product of probability spaces (i.e., a function of independent random variables). At first, an obvious choice seems to be
 $\mathcal{X}^{n}$
together with
$\mathcal{X}^{n}$
together with
 $\binom{n}{2}$
additional binary random variables, one for each potential edge
$\binom{n}{2}$
additional binary random variables, one for each potential edge
 $\{i, j\} \in \binom{[n]}{2}$
. However, note that the edges might not necessarily be independent, meaning that the resulting product distribution would not resemble
$\{i, j\} \in \binom{[n]}{2}$
. However, note that the edges might not necessarily be independent, meaning that the resulting product distribution would not resemble
 $\mathbb{G}_{W,n}$
. Instead, let
$\mathbb{G}_{W,n}$
. Instead, let
 ${\mathcal{Y}} = ([0, 1],{\mathcal{B}} ([0, 1]),{u})$
, where
${\mathcal{Y}} = ([0, 1],{\mathcal{B}} ([0, 1]),{u})$
, where
 $\mathcal{B} ([0, 1])$
is the Borel algebra restricted to
$\mathcal{B} ([0, 1])$
is the Borel algebra restricted to
 $[0, 1]$
and
$[0, 1]$
and
 $u$
is the uniform distribution on that interval. We consider the probability space
$u$
is the uniform distribution on that interval. We consider the probability space
 $\mathcal{X}^{n}{\otimes }{\mathcal{Y}}^{\binom{n}{2}}$
.
$\mathcal{X}^{n}{\otimes }{\mathcal{Y}}^{\binom{n}{2}}$
.
For
 $\textbf{x} \in{X}^{n}$
and
$\textbf{x} \in{X}^{n}$
and
 $\textbf{y} \in [0, 1]^{\binom{n}{2}}$
let
$\textbf{y} \in [0, 1]^{\binom{n}{2}}$
let
 $\textbf{x} \circ \textbf{y} \in{X}^{n} \times [0, 1]^{\binom{n}{2}}$
denote the concatenation of
$\textbf{x} \circ \textbf{y} \in{X}^{n} \times [0, 1]^{\binom{n}{2}}$
denote the concatenation of
 $\textbf{x}$
and
$\textbf{x}$
and
 $\textbf{y}$
. We construct a measurable function
$\textbf{y}$
. We construct a measurable function
 $g:{X}^n \times [0, 1]^{\binom{n}{2}} \to{\mathcal{G}_{n}}$
by mapping every
$g:{X}^n \times [0, 1]^{\binom{n}{2}} \to{\mathcal{G}_{n}}$
by mapping every
 $\textbf{z} = \textbf{x} \circ \textbf{y} \in{X}^n \times [0, 1]^{\binom{n}{2}}$
with
$\textbf{z} = \textbf{x} \circ \textbf{y} \in{X}^n \times [0, 1]^{\binom{n}{2}}$
with
 $\textbf{x} = (x_i)_{i \in [n]} \in{X}^n$
and
$\textbf{x} = (x_i)_{i \in [n]} \in{X}^n$
and
 $\textbf{y} = (y_{i, j})_{1 \le i \lt j \le n} \in [0, 1]^{\binom{n}{2}}$
to
$\textbf{y} = (y_{i, j})_{1 \le i \lt j \le n} \in [0, 1]^{\binom{n}{2}}$
to
 $g(\textbf{z}) = ([n],{E})$
such that, for all
$g(\textbf{z}) = ([n],{E})$
such that, for all
 $i\lt j$
, it holds that
$i\lt j$
, it holds that
 $\{i, j\} \in{E}$
if and only if
$\{i, j\} \in{E}$
if and only if
 ${W}(x_i,x_j) \ge y_{i, j}$
. Simple calculations show that, for
${W}(x_i,x_j) \ge y_{i, j}$
. Simple calculations show that, for
 $\textbf{z} \sim{\xi }^n \times u^{\binom{n}{2}}$
, it holds that
$\textbf{z} \sim{\xi }^n \times u^{\binom{n}{2}}$
, it holds that
 $g(z) \sim \mathbb{G}_{W,n}$
. Now, let
$g(z) \sim \mathbb{G}_{W,n}$
. Now, let
 $f\,:\,{X}^n \times [0, 1]^{\binom{n}{2}} \to{\unicode{x211D}}$
with
$f\,:\,{X}^n \times [0, 1]^{\binom{n}{2}} \to{\unicode{x211D}}$
with
 $\textbf{z} \mapsto{Z}_{g(z)} ({z}_n)$
. In order to apply Corollary3.1, we need to bound the relative change of
$\textbf{z} \mapsto{Z}_{g(z)} ({z}_n)$
. In order to apply Corollary3.1, we need to bound the relative change of
 $f(\textbf{z})$
if we change one component of
$f(\textbf{z})$
if we change one component of
 $\textbf{z}$
. Let
$\textbf{z}$
. Let
 $ \textbf{x}^{\boldsymbol{\prime}} = (x_1, \cdots, x_{i-1}, x_{i}^{\prime}, x_{i+1}, \dots, x_{n}) \in{X}^n$
for any
$ \textbf{x}^{\boldsymbol{\prime}} = (x_1, \cdots, x_{i-1}, x_{i}^{\prime}, x_{i+1}, \dots, x_{n}) \in{X}^n$
for any
 $i \in [n]$
. Then
$i \in [n]$
. Then
 $g(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf{y})$
can only differ from
$g(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf{y})$
can only differ from
 $g(\textbf{z})$
on edges that are incident to vertex
$g(\textbf{z})$
on edges that are incident to vertex
 $i$
. Thus, by Lemma3.2, it holds that
$i$
. Thus, by Lemma3.2, it holds that
 \begin{equation*} {\left \vert f(\textbf {z}) - f(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf {y}) \right \vert } \le {z}_n \min \{f(\textbf {z}), f(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf{y})\}. \end{equation*}
\begin{equation*} {\left \vert f(\textbf {z}) - f(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf {y}) \right \vert } \le {z}_n \min \{f(\textbf {z}), f(\textbf{x}^{\boldsymbol{\prime}} \circ \textbf{y})\}. \end{equation*}
Now, let
 $\textbf{y}^{\boldsymbol{\prime}} = (y_{i, j}^{\prime} )_{1 \le i \lt j \le n} \in [0, 1]^{\binom{n}{2}}$
such that
$\textbf{y}^{\boldsymbol{\prime}} = (y_{i, j}^{\prime} )_{1 \le i \lt j \le n} \in [0, 1]^{\binom{n}{2}}$
such that
 $y_{i, j}^{\prime} = y_{i, j}$
except for one pair
$y_{i, j}^{\prime} = y_{i, j}$
except for one pair
 $1 \le i \lt j \le n$
. Note that
$1 \le i \lt j \le n$
. Note that
 $g(\textbf{z})$
and
$g(\textbf{z})$
and
 $g(\textbf{x} \circ \textbf{y}^{\boldsymbol{\prime}})$
differ by at most one edge. By Lemma3.1, we have
$g(\textbf{x} \circ \textbf{y}^{\boldsymbol{\prime}})$
differ by at most one edge. By Lemma3.1, we have
 \begin{equation*} {\left \vert f(\textbf {z}) - f(\textbf {x} \circ \textbf{y}^{\boldsymbol{\prime}}) \right \vert } \le {z}_n^2 \min \{f(\textbf {z}), f(\textbf {x} \circ \textbf{y}^{\boldsymbol{\prime}})\} . \end{equation*}
\begin{equation*} {\left \vert f(\textbf {z}) - f(\textbf {x} \circ \textbf{y}^{\boldsymbol{\prime}}) \right \vert } \le {z}_n^2 \min \{f(\textbf {z}), f(\textbf {x} \circ \textbf{y}^{\boldsymbol{\prime}})\} . \end{equation*}
For
 ${\varepsilon } \le 1$
and
${\varepsilon } \le 1$
and
 ${\delta } \le 1$
it holds that
${\delta } \le 1$
it holds that
 $n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }} \gt{{z}_0}^{\frac{2}{\alpha }}$
. Hence, for
$n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }} \gt{{z}_0}^{\frac{2}{\alpha }}$
. Hence, for
 ${z}_n \le{{z}_0} n^{-\frac{1 + \alpha }{2}}$
, it holds that
${z}_n \le{{z}_0} n^{-\frac{1 + \alpha }{2}}$
, it holds that
 \begin{equation*} C \,:\!=\, n {z}_n^2 + \binom {n}{2} {z}_n^4 \le {{z}_0}^2 n^{-\alpha } + {{z}_0}^4 n^{-2 \alpha } \le 2 {{z}_0}^2 n^{-\alpha } \lt 2 . \end{equation*}
\begin{equation*} C \,:\!=\, n {z}_n^2 + \binom {n}{2} {z}_n^4 \le {{z}_0}^2 n^{-\alpha } + {{z}_0}^4 n^{-2 \alpha } \le 2 {{z}_0}^2 n^{-\alpha } \lt 2 . \end{equation*}
By Corollary3.1 we obtain
 \begin{equation*} \mathbb {P}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G({z}_n)\right ]\right \vert \ge {\varepsilon } \mathbb {E}\left [Z_G({z}_{n})\right ]\right ] \le \left (\frac {1}{1 - {{z}_0}^2 n^{-\alpha }} - 1\right ) \frac {1}{{\varepsilon }^2} = \frac {{{z}_0}^2}{\left (n^{\alpha } - {{z}_0}^2\right ) {\varepsilon }^2} . \end{equation*}
\begin{equation*} \mathbb {P}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G({z}_n)\right ]\right \vert \ge {\varepsilon } \mathbb {E}\left [Z_G({z}_{n})\right ]\right ] \le \left (\frac {1}{1 - {{z}_0}^2 n^{-\alpha }} - 1\right ) \frac {1}{{\varepsilon }^2} = \frac {{{z}_0}^2}{\left (n^{\alpha } - {{z}_0}^2\right ) {\varepsilon }^2} . \end{equation*}
Using again that
 $n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }}$
we get
$n \ge \left (2{{z}_0}^2{\varepsilon }^{-2}{\delta }^{-1}\right )^{\frac{1}{\alpha }}$
we get
 \begin{equation*} \mathbb {P}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G ({z}_{n})\right ]\right \vert \ge {\varepsilon } \mathbb {E}\left [Z_G ({z}_{n})\right ]\right ] \le \delta, \end{equation*}
\begin{equation*} \mathbb {P}\left [\left \vert Z_G({z}_{n}) - \mathbb {E}\left [Z_G ({z}_{n})\right ]\right \vert \ge {\varepsilon } \mathbb {E}\left [Z_G ({z}_{n})\right ]\right ] \le \delta, \end{equation*}
which concludes the proof.
4. Approximating the partition function of Gibbs point processes
We now turn towards the main goal of this paper, which is applying Theorem3.2 to approximate repulsive Gibbs point processes using the hard-core model on random graphs. To this end, we start by formally defining the class of point processes that we are interested in.
4.1. Gibbs point processes
Let
 $({\mathbb{X}}, d)$
be a complete, separable metric space and let
$({\mathbb{X}}, d)$
be a complete, separable metric space and let
 ${\mathcal{B}} ={\mathcal{B}} (\mathbb{X})$
be the Borel algebra of that space. Let
${\mathcal{B}} ={\mathcal{B}} (\mathbb{X})$
be the Borel algebra of that space. Let
 $\nu$
be a locally finite reference measure on
$\nu$
be a locally finite reference measure on
 $\left ({\mathbb{X}}, \mathcal{B}\right )$
such that all bounded measurable sets have finite measure. Denote by
$\left ({\mathbb{X}}, \mathcal{B}\right )$
such that all bounded measurable sets have finite measure. Denote by
 $\mathcal{N}$
the set of all locally finite counting measures on
$\mathcal{N}$
the set of all locally finite counting measures on
 $\left ({\mathbb{X}},{\mathcal{B}}\right )$
. Formally, this is the set of all measures
$\left ({\mathbb{X}},{\mathcal{B}}\right )$
. Formally, this is the set of all measures
 $\eta$
on
$\eta$
on
 $({\mathbb{X}},{\mathcal{B}})$
with values in
$({\mathbb{X}},{\mathcal{B}})$
with values in
 ${\mathbb{N}} \cup \{\infty \}$
such that
${\mathbb{N}} \cup \{\infty \}$
such that
 ${\nu } (A) \lt \infty$
implies
${\nu } (A) \lt \infty$
implies
 $\eta [A] \lt \infty$
for all
$\eta [A] \lt \infty$
for all
 $A \in \mathcal{B}$
. For each
$A \in \mathcal{B}$
. For each
 $A \in \mathcal{B}$
, define a map
$A \in \mathcal{B}$
, define a map
 $N_{A}\,:\,\mathcal{N} \to{\mathbb{N}} \cup \{\infty \}$
with
$N_{A}\,:\,\mathcal{N} \to{\mathbb{N}} \cup \{\infty \}$
with
 $\eta \mapsto \eta [A]$
and let
$\eta \mapsto \eta [A]$
and let
 $\mathcal{R}$
be the sigma algebra on
$\mathcal{R}$
be the sigma algebra on
 $\mathcal{N}$
that is generated by the set of those maps
$\mathcal{N}$
that is generated by the set of those maps
 $\{N_{A}\mid A \in \mathcal{B}\}$
. A point process on
$\{N_{A}\mid A \in \mathcal{B}\}$
. A point process on
 $\mathbb{X}$
is now a measurable map from some probability space to the measurable space
$\mathbb{X}$
is now a measurable map from some probability space to the measurable space
 $(\mathcal{N},{\mathcal{R}})$
. With some abuse of terminology, we call any probability distribution on
$(\mathcal{N},{\mathcal{R}})$
. With some abuse of terminology, we call any probability distribution on
 $(\mathcal{N},{\mathcal{R}})$
a point process. Moreover, a point process is called simple if
$(\mathcal{N},{\mathcal{R}})$
a point process. Moreover, a point process is called simple if
 $N_{x}(\eta ) \le 1$
with probability
$N_{x}(\eta ) \le 1$
with probability
 $1$
, where we write
$1$
, where we write
 $N_{x}$
for
$N_{x}$
for
 $N_{\{x\}}$
.
$N_{\{x\}}$
.
Note that every counting measure
 $\eta \in \mathcal{N}$
is associated with a multiset of points in
$\eta \in \mathcal{N}$
is associated with a multiset of points in
 $\mathbb{X}$
. To see this, define
$\mathbb{X}$
. To see this, define
 $X_(\eta ) = \{x \in{\mathbb{X}} \mid N_{x} (\eta ) \gt 0\}$
. Then
$X_(\eta ) = \{x \in{\mathbb{X}} \mid N_{x} (\eta ) \gt 0\}$
. Then
 $\eta$
can be expressed as a weighted sum of Dirac measures
$\eta$
can be expressed as a weighted sum of Dirac measures
 \begin{equation*} \eta = \sum _{x \in X_(\eta )} N_{x} (\eta ) \delta _{x} . \end{equation*}
\begin{equation*} \eta = \sum _{x \in X_(\eta )} N_{x} (\eta ) \delta _{x} . \end{equation*}
In this sense,
 $\eta$
is associated with a multiset of points
$\eta$
is associated with a multiset of points
 $x \in X_(\eta )$
, each occurring with finite multiplicity
$x \in X_(\eta )$
, each occurring with finite multiplicity
 $N_{x} (\eta )$
. We may use such a point configuration interchangeably with its corresponding counting measure.
$N_{x} (\eta )$
. We may use such a point configuration interchangeably with its corresponding counting measure.
An important example for point processes are Poisson point processes. A Poisson point process with intensity
 ${\kappa } \in{\unicode{x211D}}_{\ge 0}$
on
${\kappa } \in{\unicode{x211D}}_{\ge 0}$
on
 $({\mathbb{X}}, d)$
is uniquely defined by the following properties
$({\mathbb{X}}, d)$
is uniquely defined by the following properties
-
• for all bounded measurable
$A \subseteq{\mathbb{X}}$
it holds that
$N_{A}$
is Poisson distributed with intensity
${\kappa }{\nu } (A)$
and -
• for all
$m \in{\mathbb{N}}_{\ge 2}$
and disjoint measurable
$A_1, \dots, A_m \subseteq{\mathbb{X}}$
it holds that
$N_{A_1}, \dots, N_{A_m}$
are independent.






Generally speaking, a Gibbs point process is a point process that is absolutely continuous with respect to a Poisson point process. For a bounded measurable
 $\Lambda \subseteq{\mathbb{X}}$
let
$\Lambda \subseteq{\mathbb{X}}$
let
 $\mathcal{N}(\Lambda )$
denote the set of locally finite counting measures
$\mathcal{N}(\Lambda )$
denote the set of locally finite counting measures
 $\eta \in \mathcal{N}$
that satisfy
$\eta \in \mathcal{N}$
that satisfy
 $N_{A}(\eta ) = 0$
for all measurable
$N_{A}(\eta ) = 0$
for all measurable
 $A \subseteq{\mathbb{X}} \setminus \Lambda$
. In this work we are interested in Gibbs point processes
$A \subseteq{\mathbb{X}} \setminus \Lambda$
. In this work we are interested in Gibbs point processes
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
on bounded measurable regions
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
on bounded measurable regions
 $\Lambda \subseteq{\mathbb{X}}$
that are parameterized by a fugacity parameter
$\Lambda \subseteq{\mathbb{X}}$
that are parameterized by a fugacity parameter
 $\lambda \in{\unicode{x211D}}_{\ge 0}$
and non-negative, symmetric, measurable potential function
$\lambda \in{\unicode{x211D}}_{\ge 0}$
and non-negative, symmetric, measurable potential function
 $\phi\,:\,{\mathbb{X}}^2 \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
. Formally, such a process
$\phi\,:\,{\mathbb{X}}^2 \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
. Formally, such a process
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is defined by having a density with respect to a Poisson point process with intensity
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is defined by having a density with respect to a Poisson point process with intensity
 $\lambda$
of the form
$\lambda$
of the form
 \begin{equation*} \frac {{\text {d}} P_{\Lambda }^{(\lambda, \phi )}}{{\text {d}} \text {d}Q_\lambda } (\eta ) = \frac {\unicode {x1D7D9}_{\eta \in \mathcal {N}_\Lambda } {\text {e}^{-H(\eta )}} \text {e}^{\lambda \,v(\Lambda )}}{\Xi _{\Lambda }(\lambda, \phi )} \end{equation*}
\begin{equation*} \frac {{\text {d}} P_{\Lambda }^{(\lambda, \phi )}}{{\text {d}} \text {d}Q_\lambda } (\eta ) = \frac {\unicode {x1D7D9}_{\eta \in \mathcal {N}_\Lambda } {\text {e}^{-H(\eta )}} \text {e}^{\lambda \,v(\Lambda )}}{\Xi _{\Lambda }(\lambda, \phi )} \end{equation*}
where
 $H\,:\,\mathcal{N} \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
is the Hamiltonian defined by
$H\,:\,\mathcal{N} \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
is the Hamiltonian defined by
 \begin{equation*} H (\eta ) = \sum _{\{x, y\} \in \binom {X_{\eta }}{2}} N_{x} (\eta ) N_{y} (\eta ) \phi (x,y) + \sum _{x \in {X_\eta }} \frac {N_{x} (\eta ) \left (N_{x}(\eta )-1\right )}{2} \phi (x,x). \end{equation*}
\begin{equation*} H (\eta ) = \sum _{\{x, y\} \in \binom {X_{\eta }}{2}} N_{x} (\eta ) N_{y} (\eta ) \phi (x,y) + \sum _{x \in {X_\eta }} \frac {N_{x} (\eta ) \left (N_{x}(\eta )-1\right )}{2} \phi (x,x). \end{equation*}
The normalizing constant
 $\Xi _{\Lambda } (\lambda, \phi )$
is usually called the (grand-canonical) partition function and can be written explicitly as
$\Xi _{\Lambda } (\lambda, \phi )$
is usually called the (grand-canonical) partition function and can be written explicitly as
 \begin{align*} \Xi _{\Lambda } (\lambda, \phi ) & = 1 + \sum _{{k} \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \mathrm{e}^{- H}\left (\delta _{x_1}+ \dots + \delta _{x_{k}}\right ){\nu }^{k} (\text{d}\textbf{x}) \\ & = 1 + \sum _{{k} \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[k]}{2}} \mathrm{e}^{- \phi (x_i,x_j)}{\nu }^{k} (\text{d}\textbf{x}) . \end{align*}
\begin{align*} \Xi _{\Lambda } (\lambda, \phi ) & = 1 + \sum _{{k} \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \mathrm{e}^{- H}\left (\delta _{x_1}+ \dots + \delta _{x_{k}}\right ){\nu }^{k} (\text{d}\textbf{x}) \\ & = 1 + \sum _{{k} \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[k]}{2}} \mathrm{e}^{- \phi (x_i,x_j)}{\nu }^{k} (\text{d}\textbf{x}) . \end{align*}
For a more detailed overview on the theory of Gibbs point processes, see [Reference Jansen19].
4.2. Concentration of the partition function
The rest of this paper will use the following assumptions:
 $(\mathbb{X}, d)$
is a complete, separable metric space with Borel algebra
$(\mathbb{X}, d)$
is a complete, separable metric space with Borel algebra
 $\mathcal{B} = \mathcal{B}(\mathbb{X})$
, and
$\mathcal{B} = \mathcal{B}(\mathbb{X})$
, and
 $\nu$
is a locally-finite reference measure on
$\nu$
is a locally-finite reference measure on
 $(\mathbb{X}, \mathcal{B})$
. Moreover,
$(\mathbb{X}, \mathcal{B})$
. Moreover,
 $\Lambda \subseteq{\mathbb{X}}$
is bounded and measurable,
$\Lambda \subseteq{\mathbb{X}}$
is bounded and measurable,
 $\lambda \in{\unicode{x211D}}_{\ge 0}$
, and
$\lambda \in{\unicode{x211D}}_{\ge 0}$
, and
 $\phi\,\colon\,{\mathbb{X}}^2 \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
is a symmetric repulsive potential.
$\phi\,\colon\,{\mathbb{X}}^2 \to{\unicode{x211D}}_{\ge 0} \cup \{\infty \}$
is a symmetric repulsive potential.
Under the assumptions above, we introduce the following way of obtaining a graphon from a Gibbs point process.
Definition 4.1.
The graphon associated with a repulsive Gibbs point process, denoted by
 ${W}_{\phi }$
, is defined as follows: We consider the probability space
${W}_{\phi }$
, is defined as follows: We consider the probability space
 $(\Lambda, \mathcal{B}_{\Lambda },{u}_{\Lambda })$
, where
$(\Lambda, \mathcal{B}_{\Lambda },{u}_{\Lambda })$
, where
 $\mathcal{B}_{\Lambda }$
is the trace of
$\mathcal{B}_{\Lambda }$
is the trace of
 $\Lambda$
in
$\Lambda$
in
 $\mathcal{B}$
and
$\mathcal{B}$
and
 $u_{\Lambda }$
is the probability measure on
$u_{\Lambda }$
is the probability measure on
 $(\Lambda, \mathcal{B}_{\Lambda })$
that is defined via the constant density
$(\Lambda, \mathcal{B}_{\Lambda })$
that is defined via the constant density
 $\frac{1}{\nu (\Lambda )}$
with respect to
$\frac{1}{\nu (\Lambda )}$
with respect to
 $\nu$
restricted to
$\nu$
restricted to
 $\Lambda$
. We define
$\Lambda$
. We define
 $W_{\phi }\,:\,\Lambda ^2 \to [0, 1]$
via
$W_{\phi }\,:\,\Lambda ^2 \to [0, 1]$
via
 $W_{\phi } (x,y) \,:\!=\, 1 - \mathrm{e}^{- \phi (x,y)}$
for
$W_{\phi } (x,y) \,:\!=\, 1 - \mathrm{e}^{- \phi (x,y)}$
for
 $x, y \in \Lambda$
.
$x, y \in \Lambda$
.
We are particularly interested in the random graph model
 $\mathbb{G}_{W_{\phi },n}$
. Note that, given
$\mathbb{G}_{W_{\phi },n}$
. Note that, given
 $n \in{\mathbb{N}}$
, a random graph from
$n \in{\mathbb{N}}$
, a random graph from
 $n\in \mathbb{N}$
can be generated by the following procedure:
$n\in \mathbb{N}$
can be generated by the following procedure:
-
1. Draw
$x_1, \dots, x_n$
independently from
${u}_{\Lambda }$
. -
2. Output a random graph on vertex set
$[n]$
, where
$i \neq j$
share an edge independently with probability
$W_{\phi } (x_i,x_j) = 1 - \mathrm{e}^{- \phi (x_i,x_j)}$
.





Our goal is to reduce the problem of approximate sampling from
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
to approximate sampling from
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
to approximate sampling from
 $\mu _{G, z}$
and, similarly, to reduce the problem of approximating
$\mu _{G, z}$
and, similarly, to reduce the problem of approximating
 $\Xi _{\Lambda } (\lambda, \phi )$
to approximating
$\Xi _{\Lambda } (\lambda, \phi )$
to approximating
 $Z_{G(z)}$
for a random graph
$Z_{G(z)}$
for a random graph
 $G \sim \mathbb{G}_{W_{\phi },n}$
at an appropriate vertex activity
$G \sim \mathbb{G}_{W_{\phi },n}$
at an appropriate vertex activity
 $z$
. To this end, our first step it to derive the following concentration result.
$z$
. To this end, our first step it to derive the following concentration result.
Theorem 4.1.
Let
 $W_{\phi }$
be as in Definition 4.1
and let
$W_{\phi }$
be as in Definition 4.1
and let
 ${z}_{n} = \lambda \frac{\nu (\Lambda )}{n}$
for
${z}_{n} = \lambda \frac{\nu (\Lambda )}{n}$
for
 $n \in{\mathbb{N}}_{\ge 1}$
. For all
$n \in{\mathbb{N}}_{\ge 1}$
. For all
 $\varepsilon \in (0, 1]$
,
$\varepsilon \in (0, 1]$
,
 ${\delta } \in (0, 1]$
and
${\delta } \in (0, 1]$
and
 $n \ge 4{\varepsilon }^{-2}{\delta }^{-1} \max \left \{\mathrm{e}^{6} \lambda ^2 \nu (\Lambda )^2, \ln \left (4{\varepsilon }^{-1}\right )^2\right \}$
, it holds that, for
$n \ge 4{\varepsilon }^{-2}{\delta }^{-1} \max \left \{\mathrm{e}^{6} \lambda ^2 \nu (\Lambda )^2, \ln \left (4{\varepsilon }^{-1}\right )^2\right \}$
, it holds that, for
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
,
${G} \sim \mathbb{G}_{W_{\phi },n}$
,
 \begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z_n}) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge \varepsilon \Xi _{\Lambda } (\lambda, \phi ) \right ] \le \delta . \end{equation*}
\begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z_n}) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge \varepsilon \Xi _{\Lambda } (\lambda, \phi ) \right ] \le \delta . \end{equation*}
To prove Theorem4.1, we start by relating the expected hard-core partition function with the partition function of the Gibbs point process.
Lemma 4.1.
Let
 $W_{\phi }$
be as in Definition 4.1
and let
$W_{\phi }$
be as in Definition 4.1
and let
 ${z}_n = \lambda \frac{\nu (\Lambda )}{n}$
for
${z}_n = \lambda \frac{\nu (\Lambda )}{n}$
for
 $n \in{\mathbb{N}}_{\ge 1}$
. For all
$n \in{\mathbb{N}}_{\ge 1}$
. For all
 ${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
and
${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
and
 $n \ge 2{\varepsilon }^{-1} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (2{\varepsilon }^{-1}\right )^2\right \}$
it holds that, for
$n \ge 2{\varepsilon }^{-1} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (2{\varepsilon }^{-1}\right )^2\right \}$
it holds that, for
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
,
${G} \sim \mathbb{G}_{W_{\phi },n}$
,
 \begin{equation*} \left (1 - {\varepsilon }\right ) \Xi _{\Lambda } (\lambda, \phi ) \le {\mathbb {E}}\left [Z_G({z}_n)\right ] \le \Xi _{\Lambda } (\lambda, \phi ). \end{equation*}
\begin{equation*} \left (1 - {\varepsilon }\right ) \Xi _{\Lambda } (\lambda, \phi ) \le {\mathbb {E}}\left [Z_G({z}_n)\right ] \le \Xi _{\Lambda } (\lambda, \phi ). \end{equation*}
Proof. We start by rewriting the hard-core partition function as
 \begin{equation*} Z_G({z}_n) = 1 + \sum _{{k} = 1}^{n} \lambda ^{k} \frac {\nu (\Lambda )^{k}}{n^{k}} \sum _{S \in \binom {[n]}{{k}}} \unicode {x1D7D9}_{S \in \mathcal {I}(G)} . \end{equation*}
\begin{equation*} Z_G({z}_n) = 1 + \sum _{{k} = 1}^{n} \lambda ^{k} \frac {\nu (\Lambda )^{k}}{n^{k}} \sum _{S \in \binom {[n]}{{k}}} \unicode {x1D7D9}_{S \in \mathcal {I}(G)} . \end{equation*}
Thus, by linearity of expectation we have
 \begin{align*}{\mathbb{E}}[{Z_G({z}_n)}] = 1 + \sum _{{k} = 1}^{n} \lambda ^{{k}} \frac{\nu (\Lambda )^{k}}{n^{{k}}} \sum _{S \in \binom{[n]}{{k}}}{\mathbb{P}}[S \in \mathcal{I}(G)]. \end{align*}
\begin{align*}{\mathbb{E}}[{Z_G({z}_n)}] = 1 + \sum _{{k} = 1}^{n} \lambda ^{{k}} \frac{\nu (\Lambda )^{k}}{n^{{k}}} \sum _{S \in \binom{[n]}{{k}}}{\mathbb{P}}[S \in \mathcal{I}(G)]. \end{align*}
By the definition of
 $W_{\phi }$
we observe that for all
$W_{\phi }$
we observe that for all
 $S \in \binom{[n]}{{k}}$
with
$S \in \binom{[n]}{{k}}$
with
 $\left \vert{S} \right \vert ={k}$
$\left \vert{S} \right \vert ={k}$
 \begin{align*}{\mathbb{P}}[S \in \mathcal{I}(G)] & = \int _{\Lambda ^{n}} \prod _{\{i, j\} \in \binom{S}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ & = \frac{\nu (\Lambda )^{n -{k}}}{\nu (\Lambda )^{n}} \int _{\Lambda ^{k}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) \\ & = \frac{1}{\nu (\Lambda )^{k}} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}), \end{align*}
\begin{align*}{\mathbb{P}}[S \in \mathcal{I}(G)] & = \int _{\Lambda ^{n}} \prod _{\{i, j\} \in \binom{S}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ & = \frac{\nu (\Lambda )^{n -{k}}}{\nu (\Lambda )^{n}} \int _{\Lambda ^{k}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) \\ & = \frac{1}{\nu (\Lambda )^{k}} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}), \end{align*}
where the second equality uses that, by symmetry, the value of the integral does not depend on the particular choice of
 $S$
. We obtain
$S$
. We obtain
 \begin{align*}{\mathbb{E}}[Z_G({z}_n)] = 1 + \sum _{{k} = 1}^{n} \lambda ^{{k}} \frac{\binom{n}{{k}}}{n^{{k}}} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) . \end{align*}
\begin{align*}{\mathbb{E}}[Z_G({z}_n)] = 1 + \sum _{{k} = 1}^{n} \lambda ^{{k}} \frac{\binom{n}{{k}}}{n^{{k}}} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) . \end{align*}
Writing
 $\binom{n}{k} / n^k = \frac{1}{k!} \prod _{i = 0}^{k-1} (1 - i/n)$
we immediately obtain the upper bound
$\binom{n}{k} / n^k = \frac{1}{k!} \prod _{i = 0}^{k-1} (1 - i/n)$
we immediately obtain the upper bound
 \begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \le \Xi _{\Lambda } (\lambda, \phi ) . \end{equation*}
\begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \le \Xi _{\Lambda } (\lambda, \phi ) . \end{equation*}
For the lower bound, we set
 \begin{equation*} S_{m} = 1 + \sum _{{k} = 1}^{m} \frac {\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom {[{k}]}{2}} {\mathrm {e}}^{-\phi (x_i,x_j)} {\nu }^{{k}} (\text {d}\textbf {x}). \end{equation*}
\begin{equation*} S_{m} = 1 + \sum _{{k} = 1}^{m} \frac {\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom {[{k}]}{2}} {\mathrm {e}}^{-\phi (x_i,x_j)} {\nu }^{{k}} (\text {d}\textbf {x}). \end{equation*}
for any
 $1 \le m \le n$
and observe that
$1 \le m \le n$
and observe that
 \begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \ge \left (1 - \frac {m}{n}\right )^{m} S_{m} . \end{equation*}
\begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \ge \left (1 - \frac {m}{n}\right )^{m} S_{m} . \end{equation*}
In particular, for
 $n \ge 2{\varepsilon }^{-1} m^2$
, Bernoulli’s inequality yields
$n \ge 2{\varepsilon }^{-1} m^2$
, Bernoulli’s inequality yields
 ${\mathbb{E}}[Z_G({z}_n)]\ge \left (1 - \frac{{\varepsilon }}{2}\right ) S_{m}$
. Moreover, using that
${\mathbb{E}}[Z_G({z}_n)]\ge \left (1 - \frac{{\varepsilon }}{2}\right ) S_{m}$
. Moreover, using that
 $\phi$
is non-negative, we note that
$\phi$
is non-negative, we note that
 \begin{align*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} = \sum _{{k} = m+1}^{\infty } \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) \le \sum _{{k} = m+1}^{\infty } \frac{\lambda ^{{k}}\nu (\Lambda )^{k}}{{k}!} . \end{align*}
\begin{align*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} = \sum _{{k} = m+1}^{\infty } \frac{\lambda ^{{k}}}{{k}!} \int _{\Lambda ^{{k}}} \prod _{\{i, j\} \in \binom{[{k}]}{2}}{\mathrm{e}}^{-\phi (x_i,x_j)}{\nu }^{{k}} (\text{d}\textbf{x}) \le \sum _{{k} = m+1}^{\infty } \frac{\lambda ^{{k}}\nu (\Lambda )^{k}}{{k}!} . \end{align*}
Using Lagrange’s remainder formula, we obtain
 \begin{equation*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} \le \frac {{\mathrm {e}}^{\lambda \nu (\Lambda )}}{(m+1)!} \left (\lambda \nu (\Lambda )\right )^{m+1} . \end{equation*}
\begin{equation*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} \le \frac {{\mathrm {e}}^{\lambda \nu (\Lambda )}}{(m+1)!} \left (\lambda \nu (\Lambda )\right )^{m+1} . \end{equation*}
Choosing
 $m \ge \max \left \{{\mathrm{e}}^3 \lambda \nu (\Lambda ), \ln \left (2{\varepsilon }^{-1}\right )\right \}$
and using the fact that
$m \ge \max \left \{{\mathrm{e}}^3 \lambda \nu (\Lambda ), \ln \left (2{\varepsilon }^{-1}\right )\right \}$
and using the fact that
 $(m+1)! \gt{\left (\frac{m+1}{\mathrm{e}}\right )}^{m+1}$
yields
$(m+1)! \gt{\left (\frac{m+1}{\mathrm{e}}\right )}^{m+1}$
yields
 \begin{equation*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} \le \left (\frac {{\mathrm {e}}^{2} \lambda \nu (\Lambda )}{m+1}\right )^{m+1} \le {\mathrm {e}}^{-(m+1)} \le \frac {\varepsilon }{2}, \end{equation*}
\begin{equation*} \Xi _{\Lambda } (\lambda, \phi ) - S_{m} \le \left (\frac {{\mathrm {e}}^{2} \lambda \nu (\Lambda )}{m+1}\right )^{m+1} \le {\mathrm {e}}^{-(m+1)} \le \frac {\varepsilon }{2}, \end{equation*}
and, as
 $\Xi _{\Lambda } (\lambda, \phi ) \ge 1$
, we get
$\Xi _{\Lambda } (\lambda, \phi ) \ge 1$
, we get
 $S_{m} \ge \left ( 1 - \frac{{\varepsilon }}{2}\right ) \Xi _{\Lambda } (\lambda, \phi )$
. Hence, for
$S_{m} \ge \left ( 1 - \frac{{\varepsilon }}{2}\right ) \Xi _{\Lambda } (\lambda, \phi )$
. Hence, for
 $n \ge 2{\varepsilon }^{-1} m^2 = 2{\varepsilon }^{-1} \max $
$n \ge 2{\varepsilon }^{-1} m^2 = 2{\varepsilon }^{-1} \max $
 $\left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2,\ln \left (2{\varepsilon }^{-1}\right )^2\right \}$
, we obtain
$\left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2,\ln \left (2{\varepsilon }^{-1}\right )^2\right \}$
, we obtain
 \begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \ge \left (1 - \frac {{\varepsilon }}{2}\right ) S_m \ge \left (1 - \frac {{\varepsilon }}{2}\right )^2 \Xi _{\Lambda } (\lambda, \phi ) \ge \left (1 - {\varepsilon }\right ) \Xi _{\Lambda } (\lambda, \phi ), \end{equation*}
\begin{equation*} {\mathbb {E}}[Z_G({z}_n)] \ge \left (1 - \frac {{\varepsilon }}{2}\right ) S_m \ge \left (1 - \frac {{\varepsilon }}{2}\right )^2 \Xi _{\Lambda } (\lambda, \phi ) \ge \left (1 - {\varepsilon }\right ) \Xi _{\Lambda } (\lambda, \phi ), \end{equation*}
which proves the claim.
Proof of Theorem
4.1. By setting
 $\alpha = 1$
and
$\alpha = 1$
and
 ${{z}_0} = \lambda \nu (\Lambda )$
and using the fact that
${{z}_0} = \lambda \nu (\Lambda )$
and using the fact that
 \begin{equation*} n \ge 4 {\varepsilon }^{-2} {\delta }^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln {\left (4 {\varepsilon }^{-1}\right )}^2\right \} \ge {\left (2 {{z}_0}^2 \left (\frac {{\varepsilon }}{2}\right )^{-2} {\delta }^{-1}\right )}^{\frac {1}{\alpha }}, \end{equation*}
\begin{equation*} n \ge 4 {\varepsilon }^{-2} {\delta }^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln {\left (4 {\varepsilon }^{-1}\right )}^2\right \} \ge {\left (2 {{z}_0}^2 \left (\frac {{\varepsilon }}{2}\right )^{-2} {\delta }^{-1}\right )}^{\frac {1}{\alpha }}, \end{equation*}
Theorem 3.2 yields
 \begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_n) - {\mathbb {E}}[Z_G({z}_n)]\right \vert \ge \frac {{\varepsilon }}{2} {\mathbb {E}}[Z_G({z}_n)]\right ] \le \delta . \end{equation*}
\begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_n) - {\mathbb {E}}[Z_G({z}_n)]\right \vert \ge \frac {{\varepsilon }}{2} {\mathbb {E}}[Z_G({z}_n)]\right ] \le \delta . \end{equation*}
Furthermore, by Lemma4.1 we know that for
 \begin{equation*} n \ge 4 {\varepsilon }^{-2} {\delta }^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln \left (4 {\varepsilon }^{-1}\right )^2\right \} \ge 2 \left (\frac {{\varepsilon }}{2}\right )^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln \left ( 2 \left (\frac {{\varepsilon }}{2}\right )^{-1}\right )^2\right \}. \end{equation*}
\begin{equation*} n \ge 4 {\varepsilon }^{-2} {\delta }^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln \left (4 {\varepsilon }^{-1}\right )^2\right \} \ge 2 \left (\frac {{\varepsilon }}{2}\right )^{-1} \max \left \{{\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2, \ln \left ( 2 \left (\frac {{\varepsilon }}{2}\right )^{-1}\right )^2\right \}. \end{equation*}
it holds that
 \begin{equation*} \left (1 - \frac {{\varepsilon }}{2}\right ) \Xi _{\Lambda } (\lambda, \phi ) \le {\mathbb {E}}[Z_G({z}_n)] \le \Xi _{\Lambda } (\lambda, \phi ). \end{equation*}
\begin{equation*} \left (1 - \frac {{\varepsilon }}{2}\right ) \Xi _{\Lambda } (\lambda, \phi ) \le {\mathbb {E}}[Z_G({z}_n)] \le \Xi _{\Lambda } (\lambda, \phi ). \end{equation*}
Combining both, we obtain
 \begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge {\varepsilon } {\Xi _{\Lambda } (\lambda, \phi )}\right ]\le \delta, \end{equation*}
\begin{equation*} {\mathbb {P}}\left [\left \vert Z_G({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge {\varepsilon } {\Xi _{\Lambda } (\lambda, \phi )}\right ]\le \delta, \end{equation*}
which proves the claim.
4.3. Approximation algorithm for the partition function
One of the main applications of Theorem4.1 is that it yields a rather simple randomized procedure for approximating
 $\Xi _{\Lambda } (\lambda, \phi )$
. That is, we will use Theorem4.1 to
$\Xi _{\Lambda } (\lambda, \phi )$
. That is, we will use Theorem4.1 to
 $\varepsilon$
-approximate
$\varepsilon$
-approximate
 $\Xi _{\Lambda } (\lambda, \phi )$
: compute some value
$\Xi _{\Lambda } (\lambda, \phi )$
: compute some value
 $x \in{\unicode{x211D}}$
such that
$x \in{\unicode{x211D}}$
such that
 $(1-{\varepsilon })\Xi _{\Lambda } (\lambda, \phi ) \le x \le (1+{\varepsilon })\Xi _{\Lambda } (\lambda, \phi )$
. More specifically, we will obtain a randomized
$(1-{\varepsilon })\Xi _{\Lambda } (\lambda, \phi ) \le x \le (1+{\varepsilon })\Xi _{\Lambda } (\lambda, \phi )$
. More specifically, we will obtain a randomized
 $\varepsilon$
-approximation algorithm, i.e. an algorithm that outputs an
$\varepsilon$
-approximation algorithm, i.e. an algorithm that outputs an
 $\varepsilon$
-approximation of
$\varepsilon$
-approximation of
 $\Xi _{\Lambda } (\lambda, \phi )$
with probability at least
$\Xi _{\Lambda } (\lambda, \phi )$
with probability at least
 $\frac{2}{3}$
.Footnote 1
$\frac{2}{3}$
.Footnote 1
The rough idea of the approximation algorithm is as follows:
-
1. For
$n \in{\mathbb{N}}$
sufficiently large, sample
${G} \sim \mathbb{G}_{W_{\phi },n}$
where
$W_{\phi }$
is as in Definition4.1. -
2. Approximate
$Z_G({z}_n)$
for
${z}_n = \lambda \frac{\nu (\Lambda )}{n}$
and use the result as an approximation for
$\Xi _{\Lambda } (\lambda, \phi )$
.






We are especially interested in obtaining an algorithm that is asymptotically efficient in the volume
 $\nu (\Lambda )$
, as this gives a natural way to parameterize the algorithmic problem. More specifically, we want to characterize the regime of the fugacity
$\nu (\Lambda )$
, as this gives a natural way to parameterize the algorithmic problem. More specifically, we want to characterize the regime of the fugacity
 $\lambda$
in terms of the potential
$\lambda$
in terms of the potential
 $\phi$
for which we can get a randomized
$\phi$
for which we can get a randomized
 $\varepsilon$
-approximation of
$\varepsilon$
-approximation of
 $\Xi _{\Lambda } (\lambda, \phi )$
in time polynomial in
$\Xi _{\Lambda } (\lambda, \phi )$
in time polynomial in
 $\nu (\Lambda )$
and
$\nu (\Lambda )$
and
 $\frac{1}{{\varepsilon }}$
. We characterize this fugacity regime in terms of the temperedness constant
$\frac{1}{{\varepsilon }}$
. We characterize this fugacity regime in terms of the temperedness constant
 \begin{equation*} C_{\phi } = \text {ess sup}_{x_1 \in {\mathbb {X}}} \int _{{\mathbb {X}}} {\left \vert 1 - {\mathrm {e}}^{-\phi (x_1, x_2)} \right \vert } {\nu } (\text {d} x_2), \end{equation*}
\begin{equation*} C_{\phi } = \text {ess sup}_{x_1 \in {\mathbb {X}}} \int _{{\mathbb {X}}} {\left \vert 1 - {\mathrm {e}}^{-\phi (x_1, x_2)} \right \vert } {\nu } (\text {d} x_2), \end{equation*}
where
 $\text{ess sup}$
denotes the essential supremum (i.e., an upper bound that holds almost everywhere). We obtain the following result.
$\text{ess sup}$
denotes the essential supremum (i.e., an upper bound that holds almost everywhere). We obtain the following result.
Theorem 4.2.
Assume for
 $n \in{\mathbb{N}}$
there is a sampler for
$n \in{\mathbb{N}}$
there is a sampler for
 $\mathbb{G}_{W_{\phi },n}$
with running time
$\mathbb{G}_{W_{\phi },n}$
with running time
 ${t}_{\Lambda, \phi }\left (n\right )$
.
${t}_{\Lambda, \phi }\left (n\right )$
.
If
 $\lambda \lt \frac{\mathrm{e}}{C_{\phi }}$
, then, for all
$\lambda \lt \frac{\mathrm{e}}{C_{\phi }}$
, then, for all
 ${\varepsilon } \in (0, 1]$
, there is a randomized
${\varepsilon } \in (0, 1]$
, there is a randomized
 $\varepsilon$
-approximation algorithm for
$\varepsilon$
-approximation algorithm for
 $\Xi _{\Lambda } (\lambda, \phi )$
with running time in
$\Xi _{\Lambda } (\lambda, \phi )$
with running time in
 ${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right ) +{t}_{\Lambda, \phi }\left ({\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-2}}\right )\right )$
.
${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right ) +{t}_{\Lambda, \phi }\left ({\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-2}}\right )\right )$
.
To prove Theorem4.2 we need two ingredients. First, we need to bound how large
 $n$
needs to be chosen to ensure that
$n$
needs to be chosen to ensure that
 $Z_G({z}_n)$
is close to
$Z_G({z}_n)$
is close to
 $\Xi _{\Lambda } (\lambda, \phi )$
with high probability. Second, we need to ensure that
$\Xi _{\Lambda } (\lambda, \phi )$
with high probability. Second, we need to ensure that
 $Z_G({z}_n)$
can be approximated in time polynomial in
$Z_G({z}_n)$
can be approximated in time polynomial in
 $\nu (\Lambda )$
. To tackle the first part, we use Theorem4.1. For the second part, we will use some well known results on approximating the hard-core partition function.
$\nu (\Lambda )$
. To tackle the first part, we use Theorem4.1. For the second part, we will use some well known results on approximating the hard-core partition function.
Theorem 4.3 [(Reference Štefankovič, Vempala and Vigoda30, Corollary
 $8.4$
] and [Reference Anari, Jain, Koehler, Pham and Vuong2, Theorem
$8.4$
] and [Reference Anari, Jain, Koehler, Pham and Vuong2, Theorem
 $1$
)]. Let
$1$
)]. Let
 ${G} = ({V},{E})$
be an undirected graph with maximum vertex degree bounded by
${G} = ({V},{E})$
be an undirected graph with maximum vertex degree bounded by
 ${d_{G}} \in{\mathbb{N}}_{\ge 2}$
and let
${d_{G}} \in{\mathbb{N}}_{\ge 2}$
and let
 ${z} \in{\unicode{x211D}}_{\ge 0}$
with
${z} \in{\unicode{x211D}}_{\ge 0}$
with
 \begin{equation*} {z} \lt {z}_{\text {c}}\left (d_{{G}}\right ) = \frac {\left ({d_{G}} - 1\right )^{{d_{G}} - 1}}{\left ({d_{G}} - 2\right )^{{d_{G}}}}. \end{equation*}
\begin{equation*} {z} \lt {z}_{\text {c}}\left (d_{{G}}\right ) = \frac {\left ({d_{G}} - 1\right )^{{d_{G}} - 1}}{\left ({d_{G}} - 2\right )^{{d_{G}}}}. \end{equation*}
Then, for all
 ${\varepsilon } \in (0, 1]$
, there is a randomized
${\varepsilon } \in (0, 1]$
, there is a randomized
 $\varepsilon$
-approximation algorithm for the hard-core partition function
$\varepsilon$
-approximation algorithm for the hard-core partition function
 $Z_G(z)$
with running time
$Z_G(z)$
with running time
 ${\widetilde{\mathrm{O}}}\left (\left |{V}\right |^2{\varepsilon }^{-2}\right )$
.
${\widetilde{\mathrm{O}}}\left (\left |{V}\right |^2{\varepsilon }^{-2}\right )$
.
Remark 4.1. In [Reference Štefankovič, Vempala and Vigoda30] the result above is only stated for
 ${z} \lt \frac{2}{{d_{G}}}$
as an older mixing time result for Glauber dynamics from [Reference Vigoda32] is used. Combining their approach with the more recent mixing time bound in [Reference Anari, Jain, Koehler, Pham and Vuong2] gives the desired bound of
${z} \lt \frac{2}{{d_{G}}}$
as an older mixing time result for Glauber dynamics from [Reference Vigoda32] is used. Combining their approach with the more recent mixing time bound in [Reference Anari, Jain, Koehler, Pham and Vuong2] gives the desired bound of
 ${z} \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
.
${z} \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
.
Thus, arguing that
 $Z_G$
for
$Z_G$
for
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
can be approximated in time
${G} \sim \mathbb{G}_{W_{\phi },n}$
can be approximated in time
 ${\mathrm{poly}}\left ({n}\right )$
boils down to obtaining a probabilistic upper bound on
${\mathrm{poly}}\left ({n}\right )$
boils down to obtaining a probabilistic upper bound on
 $d_{G}$
. We use the following simple lemma.
$d_{G}$
. We use the following simple lemma.
Lemma 4.2.
Assume
 $C_{\phi } \gt 0$
. For
$C_{\phi } \gt 0$
. For
 $\alpha \in{\unicode{x211D}}_{\gt 0}$
,
$\alpha \in{\unicode{x211D}}_{\gt 0}$
,
 ${q} \in (0, 1]$
,
${q} \in (0, 1]$
,
 $n \ge 3 \max \left \{{\alpha }^{-1},{\alpha }^{-2}\right \} \ln \left ({q}^{-1}\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1$
and
$n \ge 3 \max \left \{{\alpha }^{-1},{\alpha }^{-2}\right \} \ln \left ({q}^{-1}\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1$
and
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
it holds that
${G} \sim \mathbb{G}_{W_{\phi },n}$
it holds that
 \begin{equation*} {\mathbb {P}}\left [{d_{G}} \ge (1 + {\alpha }) \frac {n-1}{\nu (\Lambda )} C_{\phi }\right ]\le {q} n. \end{equation*}
\begin{equation*} {\mathbb {P}}\left [{d_{G}} \ge (1 + {\alpha }) \frac {n-1}{\nu (\Lambda )} C_{\phi }\right ]\le {q} n. \end{equation*}
Proof. By union bound, it is sufficient to argue that, for each
 $i \in [n]$
it holds that
$i \in [n]$
it holds that
 \begin{equation*} {\mathbb {P}}\left [{d_{G}}(i) \ge (1 + {\alpha }) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ]\le {q}, \end{equation*}
\begin{equation*} {\mathbb {P}}\left [{d_{G}}(i) \ge (1 + {\alpha }) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ]\le {q}, \end{equation*}
where
 ${d_{G}}[i]$
denotes the degree of vertex
${d_{G}}[i]$
denotes the degree of vertex
 $i \in [n]$
in
$i \in [n]$
in
 $G$
. Now, observe that the random variables
$G$
. Now, observe that the random variables
 ${d_{G}}[i]$
for
${d_{G}}[i]$
for
 $i \in [n]$
are identically distributed. Thus, we can focus on
$i \in [n]$
are identically distributed. Thus, we can focus on
 ${d_{G}}[n]$
for ease of notation. By definition, it holds for
${d_{G}}[n]$
for ease of notation. By definition, it holds for
 $k \in [n-1] \cup \{0\}$
that
$k \in [n-1] \cup \{0\}$
that
 \begin{align*}{\mathbb{P}}\left [{d_{G}}(n) = k\right ] & = \sum _{S \in \binom{[n-1]}{k}} \int _{\Lambda ^{n}} \left (\prod _{i \in S} W_{\phi } ({x}_n, x_i) \right ) \cdot \left (\prod _{i \in [n-1] \setminus S} (1 - W_{\phi } (x_n, x_i))\right ){u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ & = \int _{\Lambda } \binom{n-1}{k} \left (\int _{\Lambda } W_{\phi } (x_1,x_2),{u}_{\Lambda } (\textrm{d}x_2)\right )^{k} \\ & \quad \left (1 - \int _{\Lambda } W_{\phi } (x_1, x_2) \,{u}_{\Lambda } (\textrm{d}x_2)\right )^{n-1-k} \,{u}_{\Lambda } (\textrm{d}x_1) . \end{align*}
\begin{align*}{\mathbb{P}}\left [{d_{G}}(n) = k\right ] & = \sum _{S \in \binom{[n-1]}{k}} \int _{\Lambda ^{n}} \left (\prod _{i \in S} W_{\phi } ({x}_n, x_i) \right ) \cdot \left (\prod _{i \in [n-1] \setminus S} (1 - W_{\phi } (x_n, x_i))\right ){u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ & = \int _{\Lambda } \binom{n-1}{k} \left (\int _{\Lambda } W_{\phi } (x_1,x_2),{u}_{\Lambda } (\textrm{d}x_2)\right )^{k} \\ & \quad \left (1 - \int _{\Lambda } W_{\phi } (x_1, x_2) \,{u}_{\Lambda } (\textrm{d}x_2)\right )^{n-1-k} \,{u}_{\Lambda } (\textrm{d}x_1) . \end{align*}
For every
 $x_1 \in \Lambda$
, let
$x_1 \in \Lambda$
, let
 $B_{x_1}$
be a binomial random variable with
$B_{x_1}$
be a binomial random variable with
 $n-1$
trials and with success probability
$n-1$
trials and with success probability
 $\int _{\Lambda } W_{\phi } (x_1,x_2)\,{u}_{\Lambda } (\textrm{d}x_2)$
. We obtain
$\int _{\Lambda } W_{\phi } (x_1,x_2)\,{u}_{\Lambda } (\textrm{d}x_2)$
. We obtain
 \begin{equation*} {\mathbb {P}}[d_{G}(n) = k] = \int _{\Lambda } \mathbb {P}[B_{x_1} = k] \, {u}_{\Lambda } (\textrm {d}x_1). \end{equation*}
\begin{equation*} {\mathbb {P}}[d_{G}(n) = k] = \int _{\Lambda } \mathbb {P}[B_{x_1} = k] \, {u}_{\Lambda } (\textrm {d}x_1). \end{equation*}
Next, let
 $B$
be a binomial random variable with
$B$
be a binomial random variable with
 $n-1$
trials and success probability
$n-1$
trials and success probability
 $\frac{C_{\phi }}{\nu (\Lambda )}$
. Observe that, by the definition of
$\frac{C_{\phi }}{\nu (\Lambda )}$
. Observe that, by the definition of
 $C_{\phi }$
, it holds for
$C_{\phi }$
, it holds for
 $\nu$
-almost all
$\nu$
-almost all
 $x_1 \in \Lambda$
that
$x_1 \in \Lambda$
that
 $\int _{\Lambda } W_{\phi } (x_1, x_2)\,{u}_{\Lambda } (\textrm{d}x_2) \le \frac{C_{\phi }}{\nu (\Lambda )}$
. Thus, we have that
$\int _{\Lambda } W_{\phi } (x_1, x_2)\,{u}_{\Lambda } (\textrm{d}x_2) \le \frac{C_{\phi }}{\nu (\Lambda )}$
. Thus, we have that
 $B$
stochastically dominates
$B$
stochastically dominates
 $B_{x_1}$
for
$B_{x_1}$
for
 ${u}_{\Lambda }$
almost all
${u}_{\Lambda }$
almost all
 $x_1 \in \Lambda$
. Consequently, we obtain
$x_1 \in \Lambda$
. Consequently, we obtain
 \begin{equation*} {\mathbb {P}}[{d_{G}}(n) \ge a] \le \int _{\Lambda } {\mathbb {P}}[B \ge a]\,{u}_{\Lambda } (\textrm {d}x_1) = {\mathbb {P}}[B \ge a]. \end{equation*}
\begin{equation*} {\mathbb {P}}[{d_{G}}(n) \ge a] \le \int _{\Lambda } {\mathbb {P}}[B \ge a]\,{u}_{\Lambda } (\textrm {d}x_1) = {\mathbb {P}}[B \ge a]. \end{equation*}
Observing that
 ${\mathbb{E}}(B)= \frac{n-1}{\nu (\Lambda )} C_{\phi }$
and applying Chernoff bound yields
${\mathbb{E}}(B)= \frac{n-1}{\nu (\Lambda )} C_{\phi }$
and applying Chernoff bound yields
 \begin{align*}{\mathbb{P}}\left [{d_{G}}(n) \ge (1 +{\alpha }) \frac{n-1}{\nu (\Lambda )}C_{\phi }\right ] \le{\mathrm{e}}^{- \frac{\min \left \{{\alpha },{\alpha }^{2}\right \} C_{\phi } (n-1)}{3{\nu (\Lambda )}}} . \end{align*}
\begin{align*}{\mathbb{P}}\left [{d_{G}}(n) \ge (1 +{\alpha }) \frac{n-1}{\nu (\Lambda )}C_{\phi }\right ] \le{\mathrm{e}}^{- \frac{\min \left \{{\alpha },{\alpha }^{2}\right \} C_{\phi } (n-1)}{3{\nu (\Lambda )}}} . \end{align*}
Setting
 $n \ge 3 \max \left \{{\alpha }^{-1},{\alpha }^{-2}\right \} \ln \left ({q}^{-1}\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1$
we have
$n \ge 3 \max \left \{{\alpha }^{-1},{\alpha }^{-2}\right \} \ln \left ({q}^{-1}\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1$
we have
 ${\mathbb{P}}\left [{d_{G}}(n) \ge (1 +{\alpha }) \frac{n-1}{\nu (\Lambda )}C_{\phi }\right ] \le q$
, which proves the claim.
${\mathbb{P}}\left [{d_{G}}(n) \ge (1 +{\alpha }) \frac{n-1}{\nu (\Lambda )}C_{\phi }\right ] \le q$
, which proves the claim.
Combining Theorem4.1, Lemma4.2, and Theorem4.3, we prove our main algorithmic result for approximating the partition function of repuslive Gibbs point processes.
Proof of Theorem 4.2. We start by giving a more precise outline of the algorithmic idea. To this end, we define
 \begin{equation*} N = \max \left \{\substack {324 {\varepsilon }^{-2} \max \left \{ {\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2,\, \ln \left (4 {\varepsilon }^{-1}\right )^2 \right \}, \\ 24 \max \left \{\frac {1}{\mathrm {e}- \lambda C_{\phi }}, \frac {\lambda C_{\phi } }{\left (\mathrm {e}-\lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \ln {\left (24 \max \left \{\frac {1}{\mathrm {e}- \lambda C_{\phi }}, \frac {\lambda C_{\phi }}{\left (\mathrm {e}- \lambda C_{\phi }\right )^{2}}\right \} \lambda \nu (\Lambda )\right )}^2 }\right \}. \end{equation*}
\begin{equation*} N = \max \left \{\substack {324 {\varepsilon }^{-2} \max \left \{ {\mathrm {e}}^6 \lambda ^2 {\nu } (\Lambda )^2,\, \ln \left (4 {\varepsilon }^{-1}\right )^2 \right \}, \\ 24 \max \left \{\frac {1}{\mathrm {e}- \lambda C_{\phi }}, \frac {\lambda C_{\phi } }{\left (\mathrm {e}-\lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \ln {\left (24 \max \left \{\frac {1}{\mathrm {e}- \lambda C_{\phi }}, \frac {\lambda C_{\phi }}{\left (\mathrm {e}- \lambda C_{\phi }\right )^{2}}\right \} \lambda \nu (\Lambda )\right )}^2 }\right \}. \end{equation*}
We now use the following procedure to approximate
 $\Xi _{\Lambda } (\lambda, \phi )$
:
$\Xi _{\Lambda } (\lambda, \phi )$
:
-
1. Choose some integer
$n \ge N$
and draw a graph
${G} \sim \mathbb{G}_{W_{\phi },n}$
for
$W_{\phi }$
as in Definition4.1. -
2. If
${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, return an arbitrary value. -
3. Else, use the algorithm from Theorem4.3 to
$\frac{\varepsilon }{3}$
-approximate
$Z_G({z}_n)$
for
${z}_n = \lambda \frac{\nu (\Lambda )}{n}$
with an error probability of at most
$\frac{1}{9}$
and return the result.








We proceed by arguing that this procedure yields an
 $\varepsilon$
-approximation of
$\varepsilon$
-approximation of
 $\Xi _{\Lambda } (\lambda, \phi )$
in time
$\Xi _{\Lambda } (\lambda, \phi )$
in time
 ${\mathrm{poly}}\left (\nu (\Lambda ){\varepsilon }^{-1}\right )$
. We start by bounding the probability that the computed value is not an
${\mathrm{poly}}\left (\nu (\Lambda ){\varepsilon }^{-1}\right )$
. We start by bounding the probability that the computed value is not an
 $\varepsilon$
-approximation.
$\varepsilon$
-approximation.
First, we assume that, whenever
 ${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, the algorithm returns no
${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, the algorithm returns no
 $\varepsilon$
-approximation in step 2. Let
$\varepsilon$
-approximation in step 2. Let
 $A$
be the event that this happens. Second, let
$A$
be the event that this happens. Second, let
 $B$
denote the event that the hard-core partition function
$B$
denote the event that the hard-core partition function
 $Z_G({z}_n)$
of
$Z_G({z}_n)$
of
 $G$
as in step 1 is not an
$G$
as in step 1 is not an
 $\frac{{\varepsilon }}{3}$
-approximation of
$\frac{{\varepsilon }}{3}$
-approximation of
 $\Xi _{\Lambda } (\lambda, \phi )$
. Finally, let
$\Xi _{\Lambda } (\lambda, \phi )$
. Finally, let
 $C$
denote the event we do not manage to compute an
$C$
denote the event we do not manage to compute an
 $\frac{{\varepsilon }}{3}$
-approximation of
$\frac{{\varepsilon }}{3}$
-approximation of
 $Z_G({z}_n)$
in step 3. Note that the probability that the above procedure does not output an
$Z_G({z}_n)$
in step 3. Note that the probability that the above procedure does not output an
 $\varepsilon$
-approximation for
$\varepsilon$
-approximation for
 $\Xi _{\Lambda } (\lambda, \phi )$
is upper bounded by
$\Xi _{\Lambda } (\lambda, \phi )$
is upper bounded by
 \begin{equation*} {\mathbb {P}}\left [A \cup (B \cap {\overline {A}}) \cup (C \cap {\overline {B}} \cap {\overline {A}})\right ] \le {\mathbb {P}}[A] + {\mathbb {P}}(B) + {\mathbb {P}}[C \overline {A}] . \end{equation*}
\begin{equation*} {\mathbb {P}}\left [A \cup (B \cap {\overline {A}}) \cup (C \cap {\overline {B}} \cap {\overline {A}})\right ] \le {\mathbb {P}}[A] + {\mathbb {P}}(B) + {\mathbb {P}}[C \overline {A}] . \end{equation*}
We proceed with bounding each of these probabilities separately.
To bound
 ${\mathbb{P}}[A]$
, let
${\mathbb{P}}[A]$
, let
 $x = 24 \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi } }{\left (\mathrm{e}- \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda )$
. As we are interested in asymptotic behavior in terms of
$x = 24 \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi } }{\left (\mathrm{e}- \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda )$
. As we are interested in asymptotic behavior in terms of
 $\nu (\Lambda )$
, we may assume that
$\nu (\Lambda )$
, we may assume that
 $\nu (\Lambda )$
is sufficiently large to ensure
$\nu (\Lambda )$
is sufficiently large to ensure
 $x \ge 5$
. Note that for this, we have to exclude the case
$x \ge 5$
. Note that for this, we have to exclude the case
 $\lambda = 0$
, which trivially yields
$\lambda = 0$
, which trivially yields
 $\Xi _{\Lambda } (\lambda, \phi ) = 1$
. Now, observe that for
$\Xi _{\Lambda } (\lambda, \phi ) = 1$
. Now, observe that for
 $x \ge 5$
it holds that
$x \ge 5$
it holds that
 $x \ln (x)^2 \ge x \ln \left (x \ln (x)^2\right )$
. Next, observe that
$x \ln (x)^2 \ge x \ln \left (x \ln (x)^2\right )$
. Next, observe that
 $n \ge x \ln (x)^2$
. Thus, we have
$n \ge x \ln (x)^2$
. Thus, we have
 $n \ge x \ln (n)$
. Furthermore, by
$n \ge x \ln (n)$
. Furthermore, by
 $n \ge 5 \ln (5)^2 \ge{\mathrm{e}} \ge 2$
, we have
$n \ge 5 \ln (5)^2 \ge{\mathrm{e}} \ge 2$
, we have
 \begin{align*} n - 1 & \ge 12 \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e}- \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \ln (n) \\ & = 3 \left (\ln \left (9\right ) \ln (n) + \ln (n)\right ) \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \\ & \ge 3 \ln \left (9n\right ) \max \left \{\frac{1}{\left (\mathrm{e} - \lambda C_{\phi }\right )}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) . \end{align*}
\begin{align*} n - 1 & \ge 12 \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e}- \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \ln (n) \\ & = 3 \left (\ln \left (9\right ) \ln (n) + \ln (n)\right ) \max \left \{\frac{1}{\mathrm{e}- \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) \\ & \ge 3 \ln \left (9n\right ) \max \left \{\frac{1}{\left (\mathrm{e} - \lambda C_{\phi }\right )}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )^{2}}\right \} \lambda \nu (\Lambda ) . \end{align*}
Thus, we obtain
 \begin{equation*} n \ge 3 \max \left \{\frac {\lambda C_{\phi }}{\mathrm {e} - \lambda C_{\phi }}, \left (\frac {\lambda C_{\phi } }{\mathrm {e} - \lambda C_{\phi }}\right )^{2}\right \} \ln \left (9n\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1 \end{equation*}
\begin{equation*} n \ge 3 \max \left \{\frac {\lambda C_{\phi }}{\mathrm {e} - \lambda C_{\phi }}, \left (\frac {\lambda C_{\phi } }{\mathrm {e} - \lambda C_{\phi }}\right )^{2}\right \} \ln \left (9n\right ) C_{\phi }^{-1} \nu (\Lambda ) + 1 \end{equation*}
and by Lemma4.2
 \begin{equation*} {\mathbb {P}}\left [d_{G} \ge \frac {\mathrm {en}}{\lambda {\nu (\Lambda )}}\right ] \le {\mathbb {P}}\left [d_{G} \ge \left (1 + \frac {\mathrm {e} - \lambda C_{\phi }}{\lambda C_{\phi }}\right ) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ] \le \frac {1}{9} . \end{equation*}
\begin{equation*} {\mathbb {P}}\left [d_{G} \ge \frac {\mathrm {en}}{\lambda {\nu (\Lambda )}}\right ] \le {\mathbb {P}}\left [d_{G} \ge \left (1 + \frac {\mathrm {e} - \lambda C_{\phi }}{\lambda C_{\phi }}\right ) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ] \le \frac {1}{9} . \end{equation*}
To bound
 ${\mathbb{P}}(B)$
, note that for
${\mathbb{P}}(B)$
, note that for
 $n \ge 324{\varepsilon }^{-2} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2,\, \ln \left (4{\varepsilon }^{-1}\right )^2 \right \}$
Theorem4.1 yields
$n \ge 324{\varepsilon }^{-2} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2,\, \ln \left (4{\varepsilon }^{-1}\right )^2 \right \}$
Theorem4.1 yields
 \begin{equation*} {\mathbb {P}}(B) = {\mathbb {P}}\left [\left \vert Z_G({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge \frac {\varepsilon }{3} \Xi _{\Lambda } (\lambda, \phi ) \right ] \le \frac {1}{9} . \end{equation*}
\begin{equation*} {\mathbb {P}}(B) = {\mathbb {P}}\left [\left \vert Z_G({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert \ge \frac {\varepsilon }{3} \Xi _{\Lambda } (\lambda, \phi ) \right ] \le \frac {1}{9} . \end{equation*}
Finally, note that, by Theorem4.3, we can obtain an
 $\frac{{\varepsilon }}{3}$
-approximation of
$\frac{{\varepsilon }}{3}$
-approximation of
 $Z_G({z}_n)$
with error probability at most
$Z_G({z}_n)$
with error probability at most
 $\frac{1}{9}$
in time
$\frac{1}{9}$
in time
 ${\widetilde{\mathrm{O}}}\left ({n^2{\varepsilon }^{-2}}\right )$
as long as
${\widetilde{\mathrm{O}}}\left ({n^2{\varepsilon }^{-2}}\right )$
as long as
 ${z}_n \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
, meaning that
${z}_n \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
, meaning that
 ${\mathbb{P}}[C|\overline{A}] \le \frac{1}{9}$
.
${\mathbb{P}}[C|\overline{A}] \le \frac{1}{9}$
.
We obtain that the error probability is bounded by
 $\frac{1}{3}$
. To finish the proof, we need to argue that our algorithm has the desired running time. To this end, note that
$\frac{1}{3}$
. To finish the proof, we need to argue that our algorithm has the desired running time. To this end, note that
 $N \in{\mathrm{O}}\left (\nu (\Lambda )^{2}{\varepsilon }^{-2}\right )$
. Thus, we can also choose
$N \in{\mathrm{O}}\left (\nu (\Lambda )^{2}{\varepsilon }^{-2}\right )$
. Thus, we can also choose
 $n \in{\mathrm{O}}(\nu (\Lambda )^{2}{\varepsilon }^{-2})$
. By assumption, step 1 can be computed in time
$n \in{\mathrm{O}}(\nu (\Lambda )^{2}{\varepsilon }^{-2})$
. By assumption, step 1 can be computed in time
 ${{t}_{\Lambda, \phi }\left (n\right )} ={t}_{\Lambda, \phi }\left ({\mathrm{O}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-2}\right )\right )$
. Furthermore, step 2 can be computed in time
${{t}_{\Lambda, \phi }\left (n\right )} ={t}_{\Lambda, \phi }\left ({\mathrm{O}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-2}\right )\right )$
. Furthermore, step 2 can be computed in time
 ${\widetilde{\mathrm{O}}}\left (n^2{\nu (\Lambda )^{-1}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^3{\varepsilon }^{-4}}\right )$
and, by Theorem4.3, step 3 runs in time
${\widetilde{\mathrm{O}}}\left (n^2{\nu (\Lambda )^{-1}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^3{\varepsilon }^{-4}}\right )$
and, by Theorem4.3, step 3 runs in time
 ${\widetilde{\mathrm{O}}}\left ({n^2{\varepsilon }^{-2}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right )$
for
${\widetilde{\mathrm{O}}}\left ({n^2{\varepsilon }^{-2}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right )$
for
 ${z}_n \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
. Consequently, the overall running time is in
${z}_n \lt{{z}_{\text{c}}\left ({d_{G}}\right )}$
. Consequently, the overall running time is in
 ${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right ) +{t}_{\Lambda, \phi }\left ({\mathrm{O}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-2}}\right )\right )$
.
${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^{4}{\varepsilon }^{-6}}\right ) +{t}_{\Lambda, \phi }\left ({\mathrm{O}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-2}}\right )\right )$
.
5. Sampling from Gibbs point processes
In this section, we propose an approximate sampling algorithm for the Gibbs measure of a repulsive Gibbs point process. To this end, consider the setting of Section 4.2. Formally, the problem of
 $\varepsilon$
-approximate sampling from
$\varepsilon$
-approximate sampling from
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is defined as producing a random point configuration with a distribution that has a total variation distance of at most
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is defined as producing a random point configuration with a distribution that has a total variation distance of at most
 $\varepsilon$
to
$\varepsilon$
to
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. As for approximating the partition function, we consider an
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. As for approximating the partition function, we consider an
 $\varepsilon$
-approximate sampler efficient if the running time is polynomial in the volume
$\varepsilon$
-approximate sampler efficient if the running time is polynomial in the volume
 $\nu (\Lambda )$
and in
$\nu (\Lambda )$
and in
 ${\varepsilon }^{-1}$
.
${\varepsilon }^{-1}$
.
With respect to sampling from
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
, it is less obvious how Theorem4.1 can be utilized. However, under mild assumptions, we obtain an approximate sampler, given in Algorithm 1.
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
, it is less obvious how Theorem4.1 can be utilized. However, under mild assumptions, we obtain an approximate sampler, given in Algorithm 1.
Algorithm 1: Approximate sampling algorithm for a repulsive point process
 $(\Lambda, \lambda, \phi )$
.
$(\Lambda, \lambda, \phi )$
.

Our main theorem in this section is as follows.
Theorem 5.1. Assume we can sample from the uniform distribution
 ${u}_{\Lambda }$
in time
${u}_{\Lambda }$
in time
 ${t}_{\Lambda }$
and, for every
${t}_{\Lambda }$
and, for every
 $x, y \in \Lambda$
, evaluate
$x, y \in \Lambda$
, evaluate
 $\phi (x,y)$
in time
$\phi (x,y)$
in time
 ${t}_{\phi }$
. If the Gibbs point process
${t}_{\phi }$
. If the Gibbs point process
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple and
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple and
 $ \lambda \lt \frac{\mathrm{e}}{C_{\phi }}$
then, for every
$ \lambda \lt \frac{\mathrm{e}}{C_{\phi }}$
then, for every
 ${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
, Algorithm 1
samples
${\varepsilon } \in{\unicode{x211D}}_{\gt 0}$
, Algorithm 1
samples
 $\varepsilon$
-approximately from
$\varepsilon$
-approximately from
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
and has running time
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
and has running time
 ${\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-4} +{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }} +{\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
.
${\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-4} +{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }} +{\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
.
Algorithm 2: Modified sampling process.

To prove Theorem 5.1, we start by analyzing a simplified algorithm, given in Algorithm 2. The main difference between Algorithm 1 and Algorithm2 is that the latter one does not check if the maximum degree of the sampled graph
 $G$
is bounded and that is assumes access to a perfect sampler for
$G$
is bounded and that is assumes access to a perfect sampler for
 $\mu _{{G},{z}_n}$
. It is not clear if such a perfect sampler for the hard-core Gibbs distribution can be realized in polynomial time, especially for arbitrary vertex degrees. Therefore, Algorithm 2 is not suitable for algorithmic applications. However, the main purpose of Algorithm 2 is that the distribution of point multisets that it outputs are much easier to analyse. We use this, together with a coupling argument, to bound the total variation distance between the output of Algorithm 1 and
$\mu _{{G},{z}_n}$
. It is not clear if such a perfect sampler for the hard-core Gibbs distribution can be realized in polynomial time, especially for arbitrary vertex degrees. Therefore, Algorithm 2 is not suitable for algorithmic applications. However, the main purpose of Algorithm 2 is that the distribution of point multisets that it outputs are much easier to analyse. We use this, together with a coupling argument, to bound the total variation distance between the output of Algorithm 1 and
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. Once this is done, it remains to show that Algorithm 1 satisfies the running time requirements, given in Theorem5.1.
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. Once this is done, it remains to show that Algorithm 1 satisfies the running time requirements, given in Theorem5.1.
To analyse the output distribution of Algorithm 2, we start by considering the resulting distribution of multisets of points (or counting measures respectively) when conditioning on the event that the hard-core partition function
 ${Z}_{{G}} ({z}_n)$
of the drawn graph
${Z}_{{G}} ({z}_n)$
of the drawn graph
 $G$
is close to the partition function of the continuous process
$G$
is close to the partition function of the continuous process
 $\Xi _{\Lambda } (\lambda, \phi )$
. More specifically, for any given
$\Xi _{\Lambda } (\lambda, \phi )$
. More specifically, for any given
 $n$
and
$n$
and
 $\alpha \in{\unicode{x211D}}_{\ge 0}$
, let
$\alpha \in{\unicode{x211D}}_{\ge 0}$
, let
 ${A^{\left (n\right )}_{\alpha }} = \{H \in{\mathcal{G}_{n}} \mid{\left \vert{Z}_{H} ({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert } \le \alpha \Xi _{\Lambda } (\lambda, \phi )\}$
. We derive an explicit density for the output of Algorithm 2 with respect to a Poisson point process under the condition that
${A^{\left (n\right )}_{\alpha }} = \{H \in{\mathcal{G}_{n}} \mid{\left \vert{Z}_{H} ({z}_n) - \Xi _{\Lambda } (\lambda, \phi ) \right \vert } \le \alpha \Xi _{\Lambda } (\lambda, \phi )\}$
. We derive an explicit density for the output of Algorithm 2 with respect to a Poisson point process under the condition that
 ${G} \in{A^{\left (n\right )}_{\alpha }}$
for some sufficiently small
${G} \in{A^{\left (n\right )}_{\alpha }}$
for some sufficiently small
 $\alpha$
. To this end, we use the following characterization of simple point processes via so called void probabilities.
$\alpha$
. To this end, we use the following characterization of simple point processes via so called void probabilities.
Theorem 5.2 (Rényi–Mönch, see [Reference Daley and Vere-Jones6, Theorem 9.2.XII]). Let
 $P$
and
$P$
and
 $Q$
be simple point process on
$Q$
be simple point process on
 $({\mathbb{X}},{d})$
. If, for
$({\mathbb{X}},{d})$
. If, for
 $\eta _P \sim P$
and
$\eta _P \sim P$
and
 $\eta _Q \sim Q$
and for all bounded
$\eta _Q \sim Q$
and for all bounded
 $B \in \mathcal{B}$
, it holds that
$B \in \mathcal{B}$
, it holds that
 \begin{equation*} \mathbb {P}\left [\eta _{P}(B) = 0\right ] = {\mathbb {P}}\left [\eta _{Q}(B)= 0\right ],\end{equation*}
\begin{equation*} \mathbb {P}\left [\eta _{P}(B) = 0\right ] = {\mathbb {P}}\left [\eta _{Q}(B)= 0\right ],\end{equation*}
then
 $P = Q$
.
$P = Q$
.
Theorem5.2 greatly simplifies proving that a given candidate function actually is a valid density for the point process in question, as it implies that it is sufficient to check if it yields the correct void probabilities.
Lemma 5.1.
For
 ${\varepsilon } \in (0, 1]$
let
${\varepsilon } \in (0, 1]$
let
 $\widehat{P_{{\varepsilon }}}$
be the point process produced by Algorithm 2
conditioned on
$\widehat{P_{{\varepsilon }}}$
be the point process produced by Algorithm 2
conditioned on
 ${G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
, and let
${G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
, and let
 $Q_{\lambda }$
denote a Poisson point process with intensity
$Q_{\lambda }$
denote a Poisson point process with intensity
 $\lambda$
. If the Gibbs point process
$\lambda$
. If the Gibbs point process
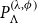 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple, then
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple, then
 $\widehat{P_{{\varepsilon }}}$
has a density with respect to
$\widehat{P_{{\varepsilon }}}$
has a density with respect to
 $Q_{\lambda }$
of the form
$Q_{\lambda }$
of the form
 \begin{align*}{g_{{\varepsilon }} (\eta ) = \unicode{x1D7D9}_\eta (\Lambda ) \le n} \cdot \unicode{x1D7D9}_\eta \in \mathcal{N}(\Lambda ) \cdot \mathbb{P}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac{i}{n} \right ){\mathrm{e}}^{-{H (\eta )}} \Psi ^{\left (\eta (\Lambda )\right )}_{n} \left (\varphi (\eta )\right ){\mathrm{e}}^{\lambda{\nu (\Lambda )}}, \end{align*}
\begin{align*}{g_{{\varepsilon }} (\eta ) = \unicode{x1D7D9}_\eta (\Lambda ) \le n} \cdot \unicode{x1D7D9}_\eta \in \mathcal{N}(\Lambda ) \cdot \mathbb{P}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac{i}{n} \right ){\mathrm{e}}^{-{H (\eta )}} \Psi ^{\left (\eta (\Lambda )\right )}_{n} \left (\varphi (\eta )\right ){\mathrm{e}}^{\lambda{\nu (\Lambda )}}, \end{align*}
where
 $\varphi$
maps every finite counting measure
$\varphi$
maps every finite counting measure
 $\eta$
to an arbitrary but fixed tuple
$\eta$
to an arbitrary but fixed tuple
 $(x_1, \dots, x_{\eta ({\mathbb{X}})})$
such that
$(x_1, \dots, x_{\eta ({\mathbb{X}})})$
such that
 $\eta = \sum _{i = 1}^{\eta ({\mathbb{X}})} \delta _{x_i}$
and
$\eta = \sum _{i = 1}^{\eta ({\mathbb{X}})} \delta _{x_i}$
and
 \begin{align*} \Psi ^{(k)}_{n} (\textbf{x}) = \sum _{\substack{H \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}(H)}}} \frac{1}{{Z}_{H} ({z}_n)} \int _{\Lambda ^{n - k}} &\left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda }({\text{d}} \textbf{y}) \end{align*}
\begin{align*} \Psi ^{(k)}_{n} (\textbf{x}) = \sum _{\substack{H \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}(H)}}} \frac{1}{{Z}_{H} ({z}_n)} \int _{\Lambda ^{n - k}} &\left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda }({\text{d}} \textbf{y}) \end{align*}
for all
 $\textbf{x} = (x_1, \dots, x_k) \in \Lambda ^{k}$
.
$\textbf{x} = (x_1, \dots, x_k) \in \Lambda ^{k}$
.
Proof. First, observe that in Algorithm 2 it holds that
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
for
${G} \sim \mathbb{G}_{W_{\phi },n}$
for
 $W_{\phi }$
as in Definition4.1. As
$W_{\phi }$
as in Definition4.1. As
 $n \ge 4 \frac{12^3}{{\varepsilon }^{3}} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (4 \frac{12}{{\varepsilon }}\right )^2\right \}$
, Theorem4.1 implies that
$n \ge 4 \frac{12^3}{{\varepsilon }^{3}} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (4 \frac{12}{{\varepsilon }}\right )^2\right \}$
, Theorem4.1 implies that
 ${\mathbb{P}}\left [{{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}}\right ]\ge 1 - \frac{{\varepsilon }}{12} \gt 0$
. Therefore, conditioning on the event
${\mathbb{P}}\left [{{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}}\right ]\ge 1 - \frac{{\varepsilon }}{12} \gt 0$
. Therefore, conditioning on the event
 ${G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
is well defined.
${G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
is well defined.
Next, note that, for all
 $x \in \Lambda$
it holds that
$x \in \Lambda$
it holds that
 \begin{equation*} {\mathbb {P}}\left [\eta (\{x\}) \ge 2\right ] \ge \frac {{\mathrm {e}}^{-\phi (x, x)} \lambda ^2 {\nu }\left (\{x\}\right )^2}{\Xi _{\Lambda } (\lambda, \phi )} \ge \frac {{\mathrm {e}}^{-\phi (x, x)} \lambda ^2 {\nu } (\{x\})^2}{\mathrm {e}^{\lambda {\nu (\Lambda )}}} \end{equation*}
\begin{equation*} {\mathbb {P}}\left [\eta (\{x\}) \ge 2\right ] \ge \frac {{\mathrm {e}}^{-\phi (x, x)} \lambda ^2 {\nu }\left (\{x\}\right )^2}{\Xi _{\Lambda } (\lambda, \phi )} \ge \frac {{\mathrm {e}}^{-\phi (x, x)} \lambda ^2 {\nu } (\{x\})^2}{\mathrm {e}^{\lambda {\nu (\Lambda )}}} \end{equation*}
for
 $\eta \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
. Thus, if
$\eta \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
. Thus, if
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple (i.e.,
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple (i.e.,
 ${\mathbb{P}}\left [\eta (\{x\}) \ge 2\right ]= 0$
for all
${\mathbb{P}}\left [\eta (\{x\}) \ge 2\right ]= 0$
for all
 $x \in \Lambda$
), it holds that
$x \in \Lambda$
), it holds that
 $\lambda = 0$
or, for all
$\lambda = 0$
or, for all
 $x \in \Lambda$
,
$x \in \Lambda$
,
 ${\nu } (\{x\}) = 0$
or
${\nu } (\{x\}) = 0$
or
 $\phi (x, x) = \infty$
. This implies that the output of Algorithm 2 is simple as well, and consequently
$\phi (x, x) = \infty$
. This implies that the output of Algorithm 2 is simple as well, and consequently
 $\widehat{P_{{\varepsilon }}}$
is a simple point process.
$\widehat{P_{{\varepsilon }}}$
is a simple point process.
Knowing that
 $\widehat{P_{{\varepsilon }}}$
is simple, Theorem5.2 implies that, in order to verify that
$\widehat{P_{{\varepsilon }}}$
is simple, Theorem5.2 implies that, in order to verify that
 $g_{{\varepsilon }}$
is indeed a density for
$g_{{\varepsilon }}$
is indeed a density for
 $\widehat{P_{{\varepsilon }}}$
, it suffices to prove that it yields the correct void probabilities. Formally, this means showing that for all bounded
$\widehat{P_{{\varepsilon }}}$
, it suffices to prove that it yields the correct void probabilities. Formally, this means showing that for all bounded
 $B \in \mathcal{B}$
it holds that
$B \in \mathcal{B}$
it holds that
 \begin{equation*} {\mathbb {P}}\left [{Y} \cap B = \emptyset |{G} \in {A^{(n)}_{\frac {{\varepsilon }}{12}}}\right ] = \int _{\mathcal {N}} \unicode {x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ) {Q_{\lambda }}({\text {d}} \eta ) \end{equation*}
\begin{equation*} {\mathbb {P}}\left [{Y} \cap B = \emptyset |{G} \in {A^{(n)}_{\frac {{\varepsilon }}{12}}}\right ] = \int _{\mathcal {N}} \unicode {x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ) {Q_{\lambda }}({\text {d}} \eta ) \end{equation*}
for
 $Y$
and
$Y$
and
 $G$
as in Algorithm 2.
$G$
as in Algorithm 2.
To prove this, we first write
 \begin{align*} & \int _{\mathcal{N}} \unicode{x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) \\ & \quad = \int _{\mathcal{N}(\Lambda )} \unicode{x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) \\ & \quad = {\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \cdot \left ({g_{{\varepsilon }}(\textbf{0}) + \sum _{k \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^k}{k!} \int _{\Lambda ^k} \unicode{x1D7D9}_\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i} \right )}{\nu }^{k} (\text{d}\textbf{x})\right ), \end{align*}
\begin{align*} & \int _{\mathcal{N}} \unicode{x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) \\ & \quad = \int _{\mathcal{N}(\Lambda )} \unicode{x1D7D9}_\eta (B) = 0 \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) \\ & \quad = {\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \cdot \left ({g_{{\varepsilon }}(\textbf{0}) + \sum _{k \in{\mathbb{N}}_{\ge 1}} \frac{\lambda ^k}{k!} \int _{\Lambda ^k} \unicode{x1D7D9}_\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i} \right )}{\nu }^{k} (\text{d}\textbf{x})\right ), \end{align*}
where
 $\textbf{0}$
denotes the constant
$\textbf{0}$
denotes the constant
 $0$
measure on
$0$
measure on
 $\mathbb{X}$
. Note that
$\mathbb{X}$
. Note that
 \begin{align*} &{\mathrm{e}}^{-\lambda{\nu (\Lambda )}} g_{{\varepsilon }} (\textbf{0})\\ &={\mathbb{P}}\left [{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ]^{-1} \cdot \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \frac{1}{{Z}_{H} ({z}_n)} \int _{\Lambda ^{n}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n}_{\Lambda } (\text{d} \textbf{y}) \\ &={\mathbb{P}}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \cdot \sum _{H \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = \emptyset |{G} = H\right ] \mathbb{P}\left [{G} = H\right ]\\ &= \frac{\mathbb{P}\left [{S^{\prime} = \emptyset \wedge{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}}\right ]}{\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{\varepsilon }{12}}}\right ]} \\ &= \mathbb{P}\left [S^{\prime} = \emptyset | G \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ] \end{align*}
\begin{align*} &{\mathrm{e}}^{-\lambda{\nu (\Lambda )}} g_{{\varepsilon }} (\textbf{0})\\ &={\mathbb{P}}\left [{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ]^{-1} \cdot \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \frac{1}{{Z}_{H} ({z}_n)} \int _{\Lambda ^{n}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n}_{\Lambda } (\text{d} \textbf{y}) \\ &={\mathbb{P}}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \cdot \sum _{H \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = \emptyset |{G} = H\right ] \mathbb{P}\left [{G} = H\right ]\\ &= \frac{\mathbb{P}\left [{S^{\prime} = \emptyset \wedge{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}}\right ]}{\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{\varepsilon }{12}}}\right ]} \\ &= \mathbb{P}\left [S^{\prime} = \emptyset | G \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ] \end{align*}
for
 $S^{\prime}$
as in Algorithm 2. We proceed with a case distinction based on
$S^{\prime}$
as in Algorithm 2. We proceed with a case distinction based on
 $k$
. For every
$k$
. For every
 $k \gt n$
and
$k \gt n$
and
 $(x_1, \dots, x_k) \in \Lambda ^k$
we have
$(x_1, \dots, x_k) \in \Lambda ^k$
we have
 $g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_k}\right ) = 0$
. Therefore, we get
$g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_k}\right ) = 0$
. Therefore, we get
 \begin{equation*} \int _{\Lambda ^k} \unicode {x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot {g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i} \right )} {\nu }^{k} (\text {d}\textbf {x}) = 0 \end{equation*}
\begin{equation*} \int _{\Lambda ^k} \unicode {x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot {g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i} \right )} {\nu }^{k} (\text {d}\textbf {x}) = 0 \end{equation*}
for all
 $k \gt n$
. Now, consider
$k \gt n$
. Now, consider
 $k \in [n]$
and observe that for all
$k \in [n]$
and observe that for all
 $\textbf{x} = (x_1, \dots, x_k) \in \Lambda ^k$
we have
$\textbf{x} = (x_1, \dots, x_k) \in \Lambda ^k$
we have
 \begin{equation*} \Psi ^{(k)}_{n} \left (\varphi \left (\sum _{i \in [k]} \delta _{x_i} \right )\right ) = \Psi ^{(k)}_{n} (\textbf {x}) \end{equation*}
\begin{equation*} \Psi ^{(k)}_{n} \left (\varphi \left (\sum _{i \in [k]} \delta _{x_i} \right )\right ) = \Psi ^{(k)}_{n} (\textbf {x}) \end{equation*}
by symmetry. Moreover, it holds that
 \begin{equation*} \frac {\lambda ^{k}}{k!} \left (\prod _{i=0}^{k - 1} 1 - \frac {i}{n} \right ) = \binom {n}{k} \frac {{z}_n^k}{\nu (\Lambda )^k} . \end{equation*}
\begin{equation*} \frac {\lambda ^{k}}{k!} \left (\prod _{i=0}^{k - 1} 1 - \frac {i}{n} \right ) = \binom {n}{k} \frac {{z}_n^k}{\nu (\Lambda )^k} . \end{equation*}
Therefore, we have
 \begin{align*}{\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \frac{\lambda ^{k}}{k!} &\int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i}\right )}{\nu }^{k} (\text{d}\textbf{x}) \\ &={\mathbb{P}}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \binom{n}{k}{z}_n^k \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left (\prod _{{i, j} \in \binom{[k]}{2}}{\mathrm{e}}^{- \phi (x_i,x_j)} \right ) \Psi ^{(k)}_{n} (\textbf{x}){u}^{k}_{\Lambda } (\text{d}\textbf{x}) . \end{align*}
\begin{align*}{\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \frac{\lambda ^{k}}{k!} &\int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i}\right )}{\nu }^{k} (\text{d}\textbf{x}) \\ &={\mathbb{P}}\left [{G} \in A^{(n)}_{\frac{{\varepsilon }}{12}}\right ]^{-1} \binom{n}{k}{z}_n^k \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left (\prod _{{i, j} \in \binom{[k]}{2}}{\mathrm{e}}^{- \phi (x_i,x_j)} \right ) \Psi ^{(k)}_{n} (\textbf{x}){u}^{k}_{\Lambda } (\text{d}\textbf{x}) . \end{align*}
Next, note that
 \begin{align*} &{z}_n^k \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left (\prod _{{i, j} \in \binom{[k]}{2}}{\mathrm{e}}^{- \phi (x_i,x_j)} \right ) \Psi ^{\left (k\right )}_{n} (\textbf{x}){u}^{k}_{\Lambda } (\text{d}\textbf{x}) \\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \unicode{x1D7D9}_[k] \in{\mathcal{I}\left (H\right )} \frac{{z}_n^k}{{Z}_{H} ({z}_n)} \int _{\Lambda ^n} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,x_j)}\right )\\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,x_j)}\right ){u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}}{\mathbb{P}}\left [S^{\prime} = [k]|{G} = H\right ]{\mathbb{P}}\left [{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ] \end{align*}
\begin{align*} &{z}_n^k \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left (\prod _{{i, j} \in \binom{[k]}{2}}{\mathrm{e}}^{- \phi (x_i,x_j)} \right ) \Psi ^{\left (k\right )}_{n} (\textbf{x}){u}^{k}_{\Lambda } (\text{d}\textbf{x}) \\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \unicode{x1D7D9}_[k] \in{\mathcal{I}\left (H\right )} \frac{{z}_n^k}{{Z}_{H} ({z}_n)} \int _{\Lambda ^n} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot \left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,x_j)}\right )\\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n]}{2}: \\\{i, j\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,x_j)}\right ){u}^{n}_{\Lambda } (\text{d}\textbf{x}) \\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}}{\mathbb{P}}\left [S^{\prime} = [k]|{G} = H\right ]{\mathbb{P}}\left [{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ] \end{align*}
for
 ${X}_1, \dots, {X}_n$
as in Algorithm 2. Furthermore, because the event
${X}_1, \dots, {X}_n$
as in Algorithm 2. Furthermore, because the event
 $S^{\prime} = [k]$
is independent of
$S^{\prime} = [k]$
is independent of
 ${X}_1, \dots, {X}_n$
given
${X}_1, \dots, {X}_n$
given
 $G$
, it holds that
$G$
, it holds that
 \begin{align*} & \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = [k]|{G} = H\right ] \mathbb{P}\left [{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]\\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = [k] \wedge{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]\\ &={\mathbb{P}}\left [S^{\prime} = [k] \wedge{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ] \end{align*}
\begin{align*} & \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = [k]|{G} = H\right ] \mathbb{P}\left [{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]\\ &= \sum _{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \mathbb{P}\left [S^{\prime} = [k] \wedge{G} = H \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]\\ &={\mathbb{P}}\left [S^{\prime} = [k] \wedge{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ] \end{align*}
and
 \begin{align*} & {\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \frac{\lambda ^{k}}{k!} \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i}\right )}{\nu }^{k} (\text{d}\textbf{x}) \\ & \quad= \binom{n}{k} \frac{{\mathbb{P}}\left [S^{\prime} = [k] \wedge{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}} \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]}{\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ]} \end{align*}
\begin{align*} & {\mathrm{e}}^{-\lambda{\nu (\Lambda )}} \frac{\lambda ^{k}}{k!} \int _{\Lambda ^k} \unicode{x1D7D9}_{\forall i \in [k]: x_i \notin B} \cdot{g_{{\varepsilon }} \left (\sum _{i \in [k]} \delta _{x_i}\right )}{\nu }^{k} (\text{d}\textbf{x}) \\ & \quad= \binom{n}{k} \frac{{\mathbb{P}}\left [S^{\prime} = [k] \wedge{G} \in{A^{(n)}_{\frac{{\varepsilon }}{12}}} \wedge \forall i \in [k]\,:\,{X}_i \notin B\right ]}{\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ]} \end{align*}
 \begin{align*} & = \binom{n}{k}{\mathbb{P}}\left [S^{\prime} = [k] \wedge \forall i \in [k]\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ & = \sum _{{V}^{\prime} \in \binom{[n]}{k}} \mathbb{P}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ], \end{align*}
\begin{align*} & = \binom{n}{k}{\mathbb{P}}\left [S^{\prime} = [k] \wedge \forall i \in [k]\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ & = \sum _{{V}^{\prime} \in \binom{[n]}{k}} \mathbb{P}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ], \end{align*}
where the last equality is due to symmetry. Combining everything yields
 \begin{align*} \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (B) = 0} \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) &={\mathbb{P}}\left [S^{\prime} = \emptyset |{G}\in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ]\\ &\quad + \sum _{k=1}^{n} \sum _{{V}^{\prime} \in \binom{[n]}{k}}{\mathbb{P}}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &= \sum _{{V}^{\prime} \in{{2^{[n]}}}}{\mathbb{P}}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &={\mathbb{P}}\left [\forall i \in S^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &={\mathbb{P}}\left [{Y} \cap B = \emptyset |{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ], \end{align*}
\begin{align*} \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (B) = 0} \cdot g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}} \eta ) &={\mathbb{P}}\left [S^{\prime} = \emptyset |{G}\in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ]\\ &\quad + \sum _{k=1}^{n} \sum _{{V}^{\prime} \in \binom{[n]}{k}}{\mathbb{P}}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &= \sum _{{V}^{\prime} \in{{2^{[n]}}}}{\mathbb{P}}\left [S^{\prime} ={V}^{\prime} \wedge \forall i \in{V}^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &={\mathbb{P}}\left [\forall i \in S^{\prime}\,:\,{X}_i \notin B|{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \\ &={\mathbb{P}}\left [{Y} \cap B = \emptyset |{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ], \end{align*}
which concludes the proof.
We proceed by upper and lower bounding the density
 $g_{{\varepsilon }} (\eta )$
in terms of the density of
$g_{{\varepsilon }} (\eta )$
in terms of the density of
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. To this end, we use the following basic facts about the partition function of the hard-core model.
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. To this end, we use the following basic facts about the partition function of the hard-core model.
Observation 5.1 (see [Reference Friedrich, Göbel, Katzmann, Krejca and Pappik11]). For every undirected graph
 ${G} = ({V},{E})$
the following holds:
${G} = ({V},{E})$
the following holds:
-
1. For all
${z}_1,{z}_2 \in{\unicode{x211D}}_{\ge 0}$
\begin{equation*} Z_G[{z}_1] \le Z_G[{z}_1 + {z}_2] \le {\mathrm {e}}^{{z}_2 |{V}|} Z_G[{z}_1] . \end{equation*}
-
2. For all
${z} \in{\unicode{x211D}}_{\ge 0}$
and
$U \subseteq{V}$
where
\begin{equation*} {Z}_{{G} - U} (z) \le Z_G(z) \le {\mathrm {e}}^{{z} |U|}{Z}_{{G} - U} (z), \end{equation*}
${G} - U$
denotes the subgraph of
$G$
that is induced by
${V} \setminus U$
.








Using Observation5.1 we derive the following bounds.
Lemma 5.2.
Consider the setting of Lemma
5.1
and let
 $f$
denote the density of
$f$
denote the density of
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
 $Q_{\lambda }$
. For
$Q_{\lambda }$
. For
 $n$
as in Algorithm 2
and all
$n$
as in Algorithm 2
and all
 $\eta \in \mathcal{N}$
with
$\eta \in \mathcal{N}$
with
 $\eta (\Lambda ) \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
it holds that
$\eta (\Lambda ) \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
it holds that
 \begin{equation*} \left (1 - \frac {{\varepsilon }}{4}\right ) f(\eta ) \le g_{{\varepsilon }} (\eta ) \le \left (1 + \frac {{\varepsilon }}{4}\right ) f(\eta ) . \end{equation*}
\begin{equation*} \left (1 - \frac {{\varepsilon }}{4}\right ) f(\eta ) \le g_{{\varepsilon }} (\eta ) \le \left (1 + \frac {{\varepsilon }}{4}\right ) f(\eta ) . \end{equation*}
Proof. First, recall that, when
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple, its density with respect to
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is simple, its density with respect to
 $Q_{\lambda }$
can be expressed as
$Q_{\lambda }$
can be expressed as
 \begin{equation*} f(\eta ) = \unicode {x1D7D9}_{\eta \in \mathcal {N}(\Lambda )} \cdot \frac {{\mathrm {e}}^{- {H (\eta )}}}{\Xi _{\Lambda } (\lambda, \phi )} {\mathrm {e}}^{\lambda {\nu (\Lambda )}} \end{equation*}
\begin{equation*} f(\eta ) = \unicode {x1D7D9}_{\eta \in \mathcal {N}(\Lambda )} \cdot \frac {{\mathrm {e}}^{- {H (\eta )}}}{\Xi _{\Lambda } (\lambda, \phi )} {\mathrm {e}}^{\lambda {\nu (\Lambda )}} \end{equation*}
for every
 $\eta \in \mathcal{N}$
. Therefore, we have
$\eta \in \mathcal{N}$
. Therefore, we have
 \begin{equation*} g_{{\varepsilon }} (\eta ) = \unicode {x1D7D9}_{\eta (\Lambda ) \le n} \cdot {\mathbb {P}}\left [{G} \in {A^{\left (n\right )}_{\frac {{\varepsilon }}{12}}}\right ]^-1 \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \Psi ^{\left (\eta (\Lambda )\right )}_{n} \left (\varphi (\eta )\right ) \Xi _{\Lambda } (\lambda, \phi ) f(\eta ) . \end{equation*}
\begin{equation*} g_{{\varepsilon }} (\eta ) = \unicode {x1D7D9}_{\eta (\Lambda ) \le n} \cdot {\mathbb {P}}\left [{G} \in {A^{\left (n\right )}_{\frac {{\varepsilon }}{12}}}\right ]^-1 \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \Psi ^{\left (\eta (\Lambda )\right )}_{n} \left (\varphi (\eta )\right ) \Xi _{\Lambda } (\lambda, \phi ) f(\eta ) . \end{equation*}
As we focus on
 $\eta$
with
$\eta$
with
 $\eta (\Lambda ) \le \sqrt{\frac{{\varepsilon } n}{12}} \le n$
, we omit the indicator
$\eta (\Lambda ) \le \sqrt{\frac{{\varepsilon } n}{12}} \le n$
, we omit the indicator
 $\unicode{x1D7D9}_\eta (\Lambda ) \le n$
from now on.
$\unicode{x1D7D9}_\eta (\Lambda ) \le n$
from now on.
We proceed by deriving an upper bound on
 $g_{{\varepsilon }} (\eta )$
for
$g_{{\varepsilon }} (\eta )$
for
 $\eta \in \mathcal{N}$
with
$\eta \in \mathcal{N}$
with
 $\eta (\Lambda ) \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
. To this end, note that
$\eta (\Lambda ) \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
. To this end, note that
 \begin{equation*} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \le 1. \end{equation*}
\begin{equation*} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \le 1. \end{equation*}
Moreover, for
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
for
${G} \sim \mathbb{G}_{W_{\phi },n}$
for
 $W_{\phi }$
as in Definition4.1 and
$W_{\phi }$
as in Definition4.1 and
 $n \ge 4 \frac{12^3}{{\varepsilon }^{3}} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (4 \frac{12}{{\varepsilon }}\right )^2\right \}$
Theorem4.1 yields
$n \ge 4 \frac{12^3}{{\varepsilon }^{3}} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (4 \frac{12}{{\varepsilon }}\right )^2\right \}$
Theorem4.1 yields
 ${\mathbb{P}}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
. Finally, observe that for all
${\mathbb{P}}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
. Finally, observe that for all
 $\textbf{x} \in \Lambda ^{k}$
for
$\textbf{x} \in \Lambda ^{k}$
for
 $k \le n$
we have
$k \le n$
we have
 \begin{align*} \Psi ^{\left (k\right )}_{n} (\textbf{x}) &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\cdot \left (\prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\!\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &= \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \int _{\Lambda ^{n - k}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \int _{\Lambda ^{n - k}} 1\,{u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} . \end{align*}
\begin{align*} \Psi ^{\left (k\right )}_{n} (\textbf{x}) &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\cdot \left (\prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\!\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &= \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \int _{\Lambda ^{n - k}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \int _{\Lambda ^{n - k}} 1\,{u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &\le \frac{1}{\left (1 - \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} . \end{align*}
Given that
 ${\varepsilon } \le 1$
we get
${\varepsilon } \le 1$
we get
 \begin{equation*} g_{{\varepsilon }} (\eta ) \le \left (1 - \frac {{\varepsilon }}{12}\right )^{-2} f(\eta ) \le \left (1 + \frac {{\varepsilon }}{11}\right )^{2} f(\eta ) \le \left (1 + \frac {{\varepsilon }}{4}\right ) f(\eta ), \end{equation*}
\begin{equation*} g_{{\varepsilon }} (\eta ) \le \left (1 - \frac {{\varepsilon }}{12}\right )^{-2} f(\eta ) \le \left (1 + \frac {{\varepsilon }}{11}\right )^{2} f(\eta ) \le \left (1 + \frac {{\varepsilon }}{4}\right ) f(\eta ), \end{equation*}
which proves the upper bound.
For the lower bound, note that
 \begin{equation*} {\mathbb {P}}\left [{G} \in {A^{\left (n\right )}_{\frac {{\varepsilon }}{12}}}\right ]^{-1} \ge 1 \end{equation*}
\begin{equation*} {\mathbb {P}}\left [{G} \in {A^{\left (n\right )}_{\frac {{\varepsilon }}{12}}}\right ]^{-1} \ge 1 \end{equation*}
and for
 $\eta (\Lambda ) \le \sqrt{\frac{{\varepsilon } n}{12}}$
$\eta (\Lambda ) \le \sqrt{\frac{{\varepsilon } n}{12}}$
 \begin{equation*} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \ge \left (1 - \frac {\eta (\Lambda )}{n}\right )^{\eta (\Lambda )} \ge 1 - \frac {\eta (\Lambda )^2}{n} \ge 1 - \frac {{\varepsilon }}{12}. \end{equation*}
\begin{equation*} \left (\prod _{i=0}^{\eta (\Lambda ) - 1} 1 - \frac {i}{n} \right ) \ge \left (1 - \frac {\eta (\Lambda )}{n}\right )^{\eta (\Lambda )} \ge 1 - \frac {\eta (\Lambda )^2}{n} \ge 1 - \frac {{\varepsilon }}{12}. \end{equation*}
We proceed by lower bounding
 $\Psi ^{\left (k\right )}_{n} (\textbf{x})$
. First, observe that
$\Psi ^{\left (k\right )}_{n} (\textbf{x})$
. First, observe that
 \begin{align*} \Psi ^{\left (k\right )}_{n} (\textbf{x}) &\ge \frac{1}{\left (1 + \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &= \frac{1}{\left (1 + \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{\mathcal{G}_{n}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \unicode{x1D7D9}_H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}). \end{align*}
\begin{align*} \Psi ^{\left (k\right )}_{n} (\textbf{x}) &\ge \frac{1}{\left (1 + \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ &= \frac{1}{\left (1 + \frac{{\varepsilon }}{12}\right ){\Xi _{\Lambda } (\lambda, \phi )}} \sum _{\substack{H \in{\mathcal{G}_{n}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \unicode{x1D7D9}_H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\\ &\cdot \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right )\! \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}). \end{align*}
Next, for each graph
 $H \in{\mathcal{G}_{n}}$
, let
$H \in{\mathcal{G}_{n}}$
, let
 $H^{\prime} = ([n-k], E^{\prime})$
denote the subgraph that results from
$H^{\prime} = ([n-k], E^{\prime})$
denote the subgraph that results from
 $H - [k]$
after relabelling each vertex in
$H - [k]$
after relabelling each vertex in
 $i \in [n] \setminus [k]$
to
$i \in [n] \setminus [k]$
to
 $i - k \in [n-k]$
(note that this relabelling is formally required for
$i - k \in [n-k]$
(note that this relabelling is formally required for
 $H^{\prime} \in{\mathcal{G}_{n-k}}$
). By Observation5.1 and the fact that
$H^{\prime} \in{\mathcal{G}_{n-k}}$
). By Observation5.1 and the fact that
 ${z}_n \le{z}_{n-k}$
and
${z}_n \le{z}_{n-k}$
and
 ${Z}_{H^{\prime}} (z) ={Z}_{H - [k]} (z)$
for all
${Z}_{H^{\prime}} (z) ={Z}_{H - [k]} (z)$
for all
 ${z} \in{\unicode{x211D}}_{\ge 0}$
we have
${z} \in{\unicode{x211D}}_{\ge 0}$
we have
 \begin{equation*} {Z}_{H} ({z}_n) \le {\mathrm {e}}^{{z}_n k}{Z}_{H^{\prime}} ({z}_n) \le {\mathrm {e}}^{\frac {k}{n} \lambda \nu (\Lambda )} {Z}_{H^{\prime}} ({z}_{n-k}) . \end{equation*}
\begin{equation*} {Z}_{H} ({z}_n) \le {\mathrm {e}}^{{z}_n k}{Z}_{H^{\prime}} ({z}_n) \le {\mathrm {e}}^{\frac {k}{n} \lambda \nu (\Lambda )} {Z}_{H^{\prime}} ({z}_{n-k}) . \end{equation*}
On the other hand, note that
 \begin{align*}{z}_{n - k} = \frac{\lambda{\nu (\Lambda )}}{n - k} &= \frac{n}{n(n - k)} \lambda \nu (\Lambda ) = \left (\frac{n - k}{n(n - k)} + \frac{k}{n(n-k)}\right ) \lambda \nu (\Lambda ) \\ &= \left (\frac{1}{n} + \frac{k}{n(n-k)}\right ) \lambda \nu (\Lambda ) ={z}_n + \frac{k}{n(n-k)} \lambda \nu (\Lambda ). \end{align*}
\begin{align*}{z}_{n - k} = \frac{\lambda{\nu (\Lambda )}}{n - k} &= \frac{n}{n(n - k)} \lambda \nu (\Lambda ) = \left (\frac{n - k}{n(n - k)} + \frac{k}{n(n-k)}\right ) \lambda \nu (\Lambda ) \\ &= \left (\frac{1}{n} + \frac{k}{n(n-k)}\right ) \lambda \nu (\Lambda ) ={z}_n + \frac{k}{n(n-k)} \lambda \nu (\Lambda ). \end{align*}
Therefore, Observation5.1 yields
 \begin{equation*} {Z}_{H} ({z}_{n-k}) \le {\mathrm {e}}^{\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H} ({z}_n) \end{equation*}
\begin{equation*} {Z}_{H} ({z}_{n-k}) \le {\mathrm {e}}^{\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H} ({z}_n) \end{equation*}
and
 \begin{equation*} {Z}_{H} ({z}_n) \ge {\mathrm {e}}^{-\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H} ({z}_{n-k}) \ge {\mathrm {e}}^{-\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H^{\prime}} ({z}_{n-k}). \end{equation*}
\begin{equation*} {Z}_{H} ({z}_n) \ge {\mathrm {e}}^{-\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H} ({z}_{n-k}) \ge {\mathrm {e}}^{-\frac {k}{n-k} \lambda \nu (\Lambda )} {Z}_{H^{\prime}} ({z}_{n-k}). \end{equation*}
Thus, for
 $k \le \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n$
we have
$k \le \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n$
we have
 \begin{equation*} {\mathrm {e}}^{-\frac {{\varepsilon }}{40}} {Z}_{H^{\prime}} ({z}_{n-k}) \le {Z}_{H} ({z}_n) \le {\mathrm {e}}^{\frac {{\varepsilon }}{40}}{Z}_{H^{\prime}} ({z}_{n-k}) . \end{equation*}
\begin{equation*} {\mathrm {e}}^{-\frac {{\varepsilon }}{40}} {Z}_{H^{\prime}} ({z}_{n-k}) \le {Z}_{H} ({z}_n) \le {\mathrm {e}}^{\frac {{\varepsilon }}{40}}{Z}_{H^{\prime}} ({z}_{n-k}) . \end{equation*}
As
 ${\mathrm{e}}^{-\frac{{\varepsilon }}{40}}\left (1 - \frac{{\varepsilon }}{18}\right ) \ge \left (1 - \frac{{\varepsilon }}{12}\right )$
and
${\mathrm{e}}^{-\frac{{\varepsilon }}{40}}\left (1 - \frac{{\varepsilon }}{18}\right ) \ge \left (1 - \frac{{\varepsilon }}{12}\right )$
and
 ${\mathrm{e}}^{\frac{{\varepsilon }}{40}}\left (1 + \frac{{\varepsilon }}{18}\right ) \le \left (1 + \frac{{\varepsilon }}{12}\right )$
for all
${\mathrm{e}}^{\frac{{\varepsilon }}{40}}\left (1 + \frac{{\varepsilon }}{18}\right ) \le \left (1 + \frac{{\varepsilon }}{12}\right )$
for all
 ${\varepsilon } \in [0, 1]$
, this means that
${\varepsilon } \in [0, 1]$
, this means that
 $H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}$
is a sufficient condition for
$H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}$
is a sufficient condition for
 $H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
and
$H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
and
 \begin{align*} &\sum _{\substack{H \in{\mathcal{G}_{n}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \unicode{x1D7D9}_{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ & \ge \sum _{H^{\prime} \in{\mathcal{G}_{n-k}}} \unicode{x1D7D9}_{H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i,j\} \in{E}_{H^{\prime}}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i, j\} \notin{E}_{H^{\prime}}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \\ & \sum _{F \subseteq [k]\times [n-k]} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\(i, j) \in F}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\(i, j) \notin F}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y})\\ & = \sum _{H^{\prime} \in{\mathcal{G}_{n-k}}} \unicode{x1D7D9}_{H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i,j\} \in{E}_{H^{\prime}}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i, j\} \notin{E}_{H^{\prime}}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } = ({\text{d}} \textbf{y}) \\ & = \mathbb{P}\left [{G}^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}} \right ] \end{align*}
\begin{align*} &\sum _{\substack{H \in{\mathcal{G}_{n}}:\\ [k] \in{\mathcal{I}\left (H\right )}}} \unicode{x1D7D9}_{H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\\{i, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \\ &\left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \in{E}_{H}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i + k, j + k\} \notin{E}_{H}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y}) \\ & \ge \sum _{H^{\prime} \in{\mathcal{G}_{n-k}}} \unicode{x1D7D9}_{H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i,j\} \in{E}_{H^{\prime}}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i, j\} \notin{E}_{H^{\prime}}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \\ & \sum _{F \subseteq [k]\times [n-k]} \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\(i, j) \in F}} 1 -{\mathrm{e}}^{-\phi (x_i,y_j)}\right ) \left ( \prod _{\substack{(i, j) \in [k] \times [n - k]: \\(i, j) \notin F}}{\mathrm{e}}^{-\phi (x_i,y_j)}\right ){u}^{n - k}_{\Lambda } ({\text{d}} \textbf{y})\\ & = \sum _{H^{\prime} \in{\mathcal{G}_{n-k}}} \unicode{x1D7D9}_{H^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}} \int _{\Lambda ^{n - k}} \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i,j\} \in{E}_{H^{\prime}}}} 1 -{\mathrm{e}}^{-\phi (y_i,y_j)}\right ) \left ( \prod _{\substack{\{i, j\} \in \binom{[n - k]}{2}: \\\{i, j\} \notin{E}_{H^{\prime}}}}{\mathrm{e}}^{-\phi (y_i,y_j)}\right ){u}^{n - k}_{\Lambda } = ({\text{d}} \textbf{y}) \\ & = \mathbb{P}\left [{G}^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}} \right ] \end{align*}
for
 ${G}^{\prime} \sim \mathbb{G}_{W_{\phi },n-k}$
. Next, observe that
${G}^{\prime} \sim \mathbb{G}_{W_{\phi },n-k}$
. Next, observe that
 $n \ge 1$
we have
$n \ge 1$
we have
 $k \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda \nu (\Lambda ) +{\varepsilon }} n\right \} \le \frac{n}{2}$
and
$k \le \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda \nu (\Lambda ) +{\varepsilon }} n\right \} \le \frac{n}{2}$
and
 $n - k \ge \frac{n}{2}$
. Therefore, for
$n - k \ge \frac{n}{2}$
. Therefore, for
 $n \ge 8 \frac{18^2 \cdot 12}{{\varepsilon }^3} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (\frac{4 \cdot 18}{{\varepsilon }}\right )^2\right \}$
Theorem4.1 yields
$n \ge 8 \frac{18^2 \cdot 12}{{\varepsilon }^3} \max \left \{{\mathrm{e}}^6 \lambda ^2{\nu } (\Lambda )^2, \ln \left (\frac{4 \cdot 18}{{\varepsilon }}\right )^2\right \}$
Theorem4.1 yields
 $\mathbb{P}\left [{G}^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
for
$\mathbb{P}\left [{G}^{\prime} \in{A^{\left (n-k\right )}_{\frac{{\varepsilon }}{18}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
for
 ${G}^{\prime} \sim \mathbb{G}_{W_{\phi },n-k}$
. Consequently, we have
${G}^{\prime} \sim \mathbb{G}_{W_{\phi },n-k}$
. Consequently, we have
 \begin{equation*} \Psi ^{\left (k\right )}_{n} (\textbf {x}) \ge \frac {1 - \frac {{\varepsilon }}{12}}{1 + \frac {{\varepsilon }}{12}} \cdot \frac {1}{\Xi _{\Lambda } (\lambda, \phi )} \end{equation*}
\begin{equation*} \Psi ^{\left (k\right )}_{n} (\textbf {x}) \ge \frac {1 - \frac {{\varepsilon }}{12}}{1 + \frac {{\varepsilon }}{12}} \cdot \frac {1}{\Xi _{\Lambda } (\lambda, \phi )} \end{equation*}
and
 \begin{equation*} g_{{\varepsilon }} (\eta ) \ge \left (1 - \frac {{\varepsilon }}{12}\right )^{2} \left (1 + \frac {{\varepsilon }}{12}\right )^{-1} f(\eta ) \ge \left (1 - \frac {{\varepsilon }}{12}\right )^{3} f(\eta ) \ge \left (1 - \frac {{\varepsilon }}{4}\right ) f(\eta ), \end{equation*}
\begin{equation*} g_{{\varepsilon }} (\eta ) \ge \left (1 - \frac {{\varepsilon }}{12}\right )^{2} \left (1 + \frac {{\varepsilon }}{12}\right )^{-1} f(\eta ) \ge \left (1 - \frac {{\varepsilon }}{12}\right )^{3} f(\eta ) \ge \left (1 - \frac {{\varepsilon }}{4}\right ) f(\eta ), \end{equation*}
which concludes the proof.
We proceed by using Lemmas5.1 and 5.2 to bound the total variation distance between
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
and the output distribution of Algorithm 2. However, as Lemma5.2 only provides information for point sets that are sufficiently small compared to
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
and the output distribution of Algorithm 2. However, as Lemma5.2 only provides information for point sets that are sufficiently small compared to
 $n$
, we need a different way to deal with large point configurations. To this end, the following two results are useful. The first lemma is a domination result for the size of independent sets, drawn from a hard-core model.
$n$
, we need a different way to deal with large point configurations. To this end, the following two results are useful. The first lemma is a domination result for the size of independent sets, drawn from a hard-core model.
Lemma 5.3.
Let
 ${G} \in{\mathcal{G}_{n}}$
for some
${G} \in{\mathcal{G}_{n}}$
for some
 $n \in{\mathbb{N}}$
and let
$n \in{\mathbb{N}}$
and let
 ${z} \in{\unicode{x211D}}_{\ge 0}$
. For
${z} \in{\unicode{x211D}}_{\ge 0}$
. For
 $S \sim \mu _{{G},{z}}$
it holds that
$S \sim \mu _{{G},{z}}$
it holds that
 $|{S}|$
is stochastically dominated by a binomial random variable with
$|{S}|$
is stochastically dominated by a binomial random variable with
 $n$
trials and success probability
$n$
trials and success probability
 $\frac{{z}}{1 +{z}}$
.
$\frac{{z}}{1 +{z}}$
.
Proof. We use a coupling argument to prove this statement. Consider the following procedure for sampling a set
 $S_n \subseteq [n]$
:
$S_n \subseteq [n]$
:
-
1. Start with
$S_0 = \emptyset$
. -
2. For each
$i \in [n]$
, set
$S_i = S_{i-1} \cup \{i\}$
with probability
$\mathbb{P}\left [i \in S|S_{i - 1} \subseteq S\right ]$
and
$S_i = S_{i-1}$
otherwise.





Note that
 $S_n$
has law
$S_n$
has law
 $\sigma \sim \mu _{{G},{z}}$
. Due to the definition of this process, it suffices to consider sequences
$\sigma \sim \mu _{{G},{z}}$
. Due to the definition of this process, it suffices to consider sequences
 $(S_i)_{i \in [n] \cup \{0\}}$
such that the event
$(S_i)_{i \in [n] \cup \{0\}}$
such that the event
 $S_i \subseteq S$
has non-zero probability for all
$S_i \subseteq S$
has non-zero probability for all
 $i$
. Further, note that for all
$i$
. Further, note that for all
 $i \in [n]$
$i \in [n]$
 \begin{equation*} \mathbb {P}\left [i \in S|S_{i-1} \subseteq S\right ] \le \frac {{z}}{1 + {z}} \end{equation*}
\begin{equation*} \mathbb {P}\left [i \in S|S_{i-1} \subseteq S\right ] \le \frac {{z}}{1 + {z}} \end{equation*}
Now, we consider a modified process
 $(S^{\prime}_i)_{i \in [n] \cup \{0\}}$
with
$(S^{\prime}_i)_{i \in [n] \cup \{0\}}$
with
 $S^{\prime}_0 = \emptyset$
and
$S^{\prime}_0 = \emptyset$
and
 $S^{\prime}_i = S^{\prime}_{i-1} \cup \{i\}$
with probability
$S^{\prime}_i = S^{\prime}_{i-1} \cup \{i\}$
with probability
 $\frac{{z}}{1 +{z}}$
. Observe that
$\frac{{z}}{1 +{z}}$
. Observe that
 $(S_i)_{i \in [n] \cup \{0\}}$
and
$(S_i)_{i \in [n] \cup \{0\}}$
and
 $(S^{\prime}_i)_{i \in [n] \cup \{0\}}$
can be coupled in such a way that
$(S^{\prime}_i)_{i \in [n] \cup \{0\}}$
can be coupled in such a way that
 $S_i \subseteq S^{\prime}_i$
whenever
$S_i \subseteq S^{\prime}_i$
whenever
 $S_{i-1} \subseteq S^{\prime}_{i-1}$
for all
$S_{i-1} \subseteq S^{\prime}_{i-1}$
for all
 $i \in [n]$
. As initially
$i \in [n]$
. As initially
 $S_0 = S^{\prime}_0$
, the same coupling yields
$S_0 = S^{\prime}_0$
, the same coupling yields
 $S_n \subseteq S^{\prime}_n$
. Finally, observing that
$S_n \subseteq S^{\prime}_n$
. Finally, observing that
 $\left |S^{\prime}_n\right |$
follows a binomial distribution with
$\left |S^{\prime}_n\right |$
follows a binomial distribution with
 $n$
trials and success probability
$n$
trials and success probability
 $\frac{{z}}{1 +{z}}$
concludes the proof.
$\frac{{z}}{1 +{z}}$
concludes the proof.
The second lemma is the analog of Lemma5.3 for repulsive point processes. However, proving it is slightly more technically involved. We start by introducing some additional notation and terminology. For two counting measures
 $\eta _1, \eta _2 \in \mathcal{N}$
, we write
$\eta _1, \eta _2 \in \mathcal{N}$
, we write
 $\eta _1 \le \eta _2$
if
$\eta _1 \le \eta _2$
if
 $\eta _1(B) \le \eta _2(B)$
for every
$\eta _1(B) \le \eta _2(B)$
for every
 $B \in \mathcal{B}$
. A measurable function
$B \in \mathcal{B}$
. A measurable function
 $h: \mathcal{N} \to{\unicode{x211D}}$
is called increasing if
$h: \mathcal{N} \to{\unicode{x211D}}$
is called increasing if
 $h(\eta _1) \le h(\eta _2)$
for all
$h(\eta _1) \le h(\eta _2)$
for all
 $\eta _1 \le \eta _2$
. Moreover, for some
$\eta _1 \le \eta _2$
. Moreover, for some
 ${\kappa } \in{\unicode{x211D}}_{\ge 0}$
, let
${\kappa } \in{\unicode{x211D}}_{\ge 0}$
, let
 $Q_\kappa$
denote the Poisson point process with intensity
$Q_\kappa$
denote the Poisson point process with intensity
 $\kappa$
and let
$\kappa$
and let
 $P$
be a point process that has a density
$P$
be a point process that has a density
 $f_{{P}}$
with respect to
$f_{{P}}$
with respect to
 $Q_\kappa$
. A function
$Q_\kappa$
. A function
 $\zeta\,:\,\mathcal{N} \times{\mathbb{X}} \to{\unicode{x211D}}_{\ge 0}$
is called a Papangelou intensity for
$\zeta\,:\,\mathcal{N} \times{\mathbb{X}} \to{\unicode{x211D}}_{\ge 0}$
is called a Papangelou intensity for
 $P$
(w.r.t.
$P$
(w.r.t.
 $Q_\kappa$
) if, for all
$Q_\kappa$
) if, for all
 $\eta \in \mathcal{N}$
and
$\eta \in \mathcal{N}$
and
 $x \in{\mathbb{X}}$
, it holds that
$x \in{\mathbb{X}}$
, it holds that
 \begin{equation*} f_{{P}}\left (\eta + \delta _{x}\right ) = \zeta \left (\eta, x\right ) f_{{P}}(\eta ) . \end{equation*}
\begin{equation*} f_{{P}}\left (\eta + \delta _{x}\right ) = \zeta \left (\eta, x\right ) f_{{P}}(\eta ) . \end{equation*}
The domination lemma we are aiming for is implied by the following result.
Theorem 5.3 [(Reference Georgii and Küneth14, Theorem
 $1.1$
)]. Let
$1.1$
)]. Let
 $Q_\kappa$
be a Poisson point process of intensity
$Q_\kappa$
be a Poisson point process of intensity
 ${\kappa } \in{\unicode{x211D}}_{\ge 0}$
and let
${\kappa } \in{\unicode{x211D}}_{\ge 0}$
and let
 ${P}_1,{P}_2$
be point processes that are absolutely continuous with respect to
${P}_1,{P}_2$
be point processes that are absolutely continuous with respect to
 $Q_\kappa$
. Assume
$Q_\kappa$
. Assume
 ${P}_1$
and
${P}_1$
and
 ${P}_2$
have Papangelou intensities
${P}_2$
have Papangelou intensities
 $\zeta_{1}$
and
$\zeta_{1}$
and
 $\zeta_{2}$
. If, for all
$\zeta_{2}$
. If, for all
 $x \in{\mathbb{X}}$
and
$x \in{\mathbb{X}}$
and
 $\eta _1, \eta _2 \in \mathcal{N}$
with
$\eta _1, \eta _2 \in \mathcal{N}$
with
 $\eta _1 \le \eta _2$
,
$\eta _1 \le \eta _2$
,
 $\zeta_{1}(\eta _{1}, x) \le \zeta_{2} (\eta _{2}, x)$
, then, for all increasing
$\zeta_{1}(\eta _{1}, x) \le \zeta_{2} (\eta _{2}, x)$
, then, for all increasing
 $h\,:\,\mathcal{N} \to{\unicode{x211D}}$
, it holds that
$h\,:\,\mathcal{N} \to{\unicode{x211D}}$
, it holds that
 \begin{equation*} \int _{\mathcal {N}} h(\eta ) {P}_1({\text {d}} \eta ) \le \int _{\mathcal {N}} h(\eta ) {P}_2({\text {d}} \eta ). \end{equation*}
\begin{equation*} \int _{\mathcal {N}} h(\eta ) {P}_1({\text {d}} \eta ) \le \int _{\mathcal {N}} h(\eta ) {P}_2({\text {d}} \eta ). \end{equation*}
With that, we show the following simple domination result.
Lemma 5.4.
For
 $\eta \sim{P}_{\Lambda }^{\left (\lambda, \phi \right )}$
it holds that
$\eta \sim{P}_{\Lambda }^{\left (\lambda, \phi \right )}$
it holds that
 $\eta (\Lambda )$
is dominated by a Poisson random variable with parameter
$\eta (\Lambda )$
is dominated by a Poisson random variable with parameter
 $\lambda \nu (\Lambda )$
.
$\lambda \nu (\Lambda )$
.
Proof. Let
 $Q_{\lambda }$
denote a Poisson point process with intensity
$Q_{\lambda }$
denote a Poisson point process with intensity
 $\lambda$
. Note that
$\lambda$
. Note that
 \begin{equation*} f_1(\eta ) = \unicode {x1D7D9}_\eta \in \mathcal {N}(\Lambda ) \cdot \frac {1}{\Xi _{\Lambda } (\lambda, \phi )} \left (\prod _{\{x, y\} \in \binom {X_(\eta )}{2}} {\mathrm {e}}^{- N_{x} (\eta ) {N_{y} (\eta ) \phi (x,y)}}\right ) \left (\prod _{x \in X_(\eta )} {\mathrm {e}}^{- \frac {N_{x} (\eta ) (N_{x} (\eta )-1)}{2} \phi (x, x)}\right ) {\mathrm {e}}^{\lambda {\nu (\Lambda )}} \end{equation*}
\begin{equation*} f_1(\eta ) = \unicode {x1D7D9}_\eta \in \mathcal {N}(\Lambda ) \cdot \frac {1}{\Xi _{\Lambda } (\lambda, \phi )} \left (\prod _{\{x, y\} \in \binom {X_(\eta )}{2}} {\mathrm {e}}^{- N_{x} (\eta ) {N_{y} (\eta ) \phi (x,y)}}\right ) \left (\prod _{x \in X_(\eta )} {\mathrm {e}}^{- \frac {N_{x} (\eta ) (N_{x} (\eta )-1)}{2} \phi (x, x)}\right ) {\mathrm {e}}^{\lambda {\nu (\Lambda )}} \end{equation*}
is a density for
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
 $Q_{\lambda }$
. Therefore,
$Q_{\lambda }$
. Therefore,
 \begin{equation*} \zeta _{1}, (\eta, x) = \unicode {x1D7D9}_{x \in \Lambda } \prod _{y \in X_(\eta )} {\mathrm {e}}^{- {N_{y} (\eta ) \phi (x,y)}} \end{equation*}
\begin{equation*} \zeta _{1}, (\eta, x) = \unicode {x1D7D9}_{x \in \Lambda } \prod _{y \in X_(\eta )} {\mathrm {e}}^{- {N_{y} (\eta ) \phi (x,y)}} \end{equation*}
is a Papangelou intensity for
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. Moreover, let
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. Moreover, let
 $P$
denote the point process defined by the density
$P$
denote the point process defined by the density
 $f_2(\eta ) = \unicode{x1D7D9}_\eta \in \mathcal{N}(\Lambda )$
and observe that
$f_2(\eta ) = \unicode{x1D7D9}_\eta \in \mathcal{N}(\Lambda )$
and observe that
 $\zeta _{2}(\eta, x) = \unicode{x1D7D9}_x \in \Lambda$
is a Papangelou intensity for
$\zeta _{2}(\eta, x) = \unicode{x1D7D9}_x \in \Lambda$
is a Papangelou intensity for
 $P$
.
$P$
.
For all
 $k \in{\mathbb{N}}$
, let
$k \in{\mathbb{N}}$
, let
 $h_k(\eta ) = \unicode{x1D7D9}_{\eta (\Lambda ) \ge k}$
and observe that
$h_k(\eta ) = \unicode{x1D7D9}_{\eta (\Lambda ) \ge k}$
and observe that
 $h_k$
is increasing. Further, note that, for all
$h_k$
is increasing. Further, note that, for all
 $x \in{\mathbb{X}}$
and
$x \in{\mathbb{X}}$
and
 $\eta _1, \eta _2 \in \mathcal{N}$
, it holds that
$\eta _1, \eta _2 \in \mathcal{N}$
, it holds that
 \begin{equation*} \zeta _{1}, (\eta, x) = \unicode {x1D7D9}_{x \in \Lambda } \prod _{y \in X_{\eta _1}} {\mathrm {e}}^{- {N_{y} (\eta _1) \phi (x,y)} \le \unicode {x1D7D9}_x \in \Lambda } = \zeta _{1}, (\eta _2,x) . \end{equation*}
\begin{equation*} \zeta _{1}, (\eta, x) = \unicode {x1D7D9}_{x \in \Lambda } \prod _{y \in X_{\eta _1}} {\mathrm {e}}^{- {N_{y} (\eta _1) \phi (x,y)} \le \unicode {x1D7D9}_x \in \Lambda } = \zeta _{1}, (\eta _2,x) . \end{equation*}
By Theorem5.3, this implies that for all
 $k \in{\mathbb{N}}$
$k \in{\mathbb{N}}$
 \begin{equation*} \int _{\mathcal {N}} h_k(\eta ) {{P}_{\Lambda }^{\left (\lambda, \phi \right )}}({\text {d}} \eta ) \le \int _{\mathcal {N}} h_k(\eta ) {P}({\text {d}} \eta ). \end{equation*}
\begin{equation*} \int _{\mathcal {N}} h_k(\eta ) {{P}_{\Lambda }^{\left (\lambda, \phi \right )}}({\text {d}} \eta ) \le \int _{\mathcal {N}} h_k(\eta ) {P}({\text {d}} \eta ). \end{equation*}
Consequently, for
 $\eta \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
and
$\eta \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
and
 $\xi \sim{P}$
and for all
$\xi \sim{P}$
and for all
 $k \in{\mathbb{N}}$
, it holds that
$k \in{\mathbb{N}}$
, it holds that
 \begin{equation*} \mathbb {P}\left [\eta (\Lambda ) \ge k\right ] \le \mathbb {P}\left [\xi (\Lambda ) \ge k\right ]\end{equation*}
\begin{equation*} \mathbb {P}\left [\eta (\Lambda ) \ge k\right ] \le \mathbb {P}\left [\xi (\Lambda ) \ge k\right ]\end{equation*}
and observing that
 $\xi (\Lambda )$
follows a Poisson distribution with parameter
$\xi (\Lambda )$
follows a Poisson distribution with parameter
 $\lambda \nu (\Lambda )$
concludes the proof.
$\lambda \nu (\Lambda )$
concludes the proof.
We now bound the total variation distance between the output of Algorithm 2 and
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
.
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
.
Lemma 5.5.
For every given
 ${\varepsilon } \in (0, 1]$
, Algorithm 2
is an
${\varepsilon } \in (0, 1]$
, Algorithm 2
is an
 $\frac{{\varepsilon }}{2}$
-approximate sampler from
$\frac{{\varepsilon }}{2}$
-approximate sampler from
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
.
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
.
Proof. We start by bounding the total variation distance between
 ${d_{\text{tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}},{\widehat{P_{{\varepsilon }}}}\right )$
for
${d_{\text{tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}},{\widehat{P_{{\varepsilon }}}}\right )$
for
 $\widehat{P_{{\varepsilon }}}$
as in Lemma5.1. The statement then follows from a coupling argument. Let
$\widehat{P_{{\varepsilon }}}$
as in Lemma5.1. The statement then follows from a coupling argument. Let
 $Q_{\lambda }$
denote a Poisson point process of intensity
$Q_{\lambda }$
denote a Poisson point process of intensity
 $\lambda$
. Let
$\lambda$
. Let
 $g_{\varepsilon }$
be the density of
$g_{\varepsilon }$
be the density of
 $\widehat{P_{{\varepsilon }}}$
with respect to
$\widehat{P_{{\varepsilon }}}$
with respect to
 $Q_{\lambda }$
as given in Lemma5.1 and let
$Q_{\lambda }$
as given in Lemma5.1 and let
 $f$
denote the density of
$f$
denote the density of
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
with respect to
 $Q_{\lambda }$
. Moreover, set
$Q_{\lambda }$
. Moreover, set
 $m = \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
. Note that the total variation distance can be expressed as
$m = \min \left \{\sqrt{\frac{{\varepsilon } n}{12}}, \frac{{\varepsilon }}{40 \lambda{\nu (\Lambda ) +{\varepsilon }}} n\right \}$
. Note that the total variation distance can be expressed as
 \begin{align*}{d_{\text{tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}},{\widehat{P_{{\varepsilon }}}}\right ) &= \int _{\mathcal{N}}{\left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert }{Q_{\lambda }}({\text{d}} \eta ) \\ &= \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \le m}{\left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert }{Q_{\lambda }}({\text{d}} \eta ) + \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert{Q_{\lambda }}({\text{d}} \eta ) . \end{align*}
\begin{align*}{d_{\text{tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}},{\widehat{P_{{\varepsilon }}}}\right ) &= \int _{\mathcal{N}}{\left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert }{Q_{\lambda }}({\text{d}} \eta ) \\ &= \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \le m}{\left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert }{Q_{\lambda }}({\text{d}} \eta ) + \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert{Q_{\lambda }}({\text{d}} \eta ) . \end{align*}
By Lemma5.2, we get
 \begin{equation*} \int _{\mathcal {N}} \unicode {x1D7D9}_{\eta (\Lambda ) \le m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert {Q_{\lambda }}({\text {d}} \eta ) \le \frac {{\varepsilon }}{4} \int _{\mathcal {N}} \unicode {x1D7D9}_{\eta (\Lambda ) \le m} f(\eta ) {Q_{\lambda }}({\text {d}} \eta ) \le \frac {{\varepsilon }}{4} . \end{equation*}
\begin{equation*} \int _{\mathcal {N}} \unicode {x1D7D9}_{\eta (\Lambda ) \le m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert {Q_{\lambda }}({\text {d}} \eta ) \le \frac {{\varepsilon }}{4} \int _{\mathcal {N}} \unicode {x1D7D9}_{\eta (\Lambda ) \le m} f(\eta ) {Q_{\lambda }}({\text {d}} \eta ) \le \frac {{\varepsilon }}{4} . \end{equation*}
Further, it holds that
 \begin{align*} \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert{Q_{\lambda }}({\text{d}} \eta ) &\le \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} f(\eta ){Q_{\lambda }}({\text{d}} \eta ) + \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}}\ \eta ) \\ &= \mathbb{P}\left [\xi (\Lambda ) \gt m\right ] + \mathbb{P}\left [|{Y}| \gt m| G \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \end{align*}
\begin{align*} \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} \left \vert f(\eta ) - g_{{\varepsilon }} (\eta ) \right \vert{Q_{\lambda }}({\text{d}} \eta ) &\le \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} f(\eta ){Q_{\lambda }}({\text{d}} \eta ) + \int _{\mathcal{N}} \unicode{x1D7D9}_{\eta (\Lambda ) \gt m} g_{{\varepsilon }} (\eta ){Q_{\lambda }}({\text{d}}\ \eta ) \\ &= \mathbb{P}\left [\xi (\Lambda ) \gt m\right ] + \mathbb{P}\left [|{Y}| \gt m| G \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \end{align*}
for
 $\xi \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
, and
$\xi \sim{{P}_{\Lambda }^{\left (\lambda, \phi \right )}}$
, and
 $G$
and
$G$
and
 $Y$
as in Algorithm 2.
$Y$
as in Algorithm 2.
We proceed by bounding each of these probability separately. Note that, by our choice of
 $n$
it holds that
$n$
it holds that
 $m \ge \frac{12}{{\varepsilon }} \lambda \nu (\Lambda )$
. By Lemma5.4, we have
$m \ge \frac{12}{{\varepsilon }} \lambda \nu (\Lambda )$
. By Lemma5.4, we have
 $\mathbb{E}[\xi (\Lambda )] \le \lambda \nu (\Lambda )$
. Thus, Markov’s inequality yields
$\mathbb{E}[\xi (\Lambda )] \le \lambda \nu (\Lambda )$
. Thus, Markov’s inequality yields
 $\mathbb{P}\left [\xi (\Lambda ) \gt m\right ]\le \frac{{\varepsilon }}{12}$
. Moreover, note that
$\mathbb{P}\left [\xi (\Lambda ) \gt m\right ]\le \frac{{\varepsilon }}{12}$
. Moreover, note that
 $|{Y}| = |S^{\prime}|$
for
$|{Y}| = |S^{\prime}|$
for
 $S^{\prime}$
as in Algorithm 2. As
$S^{\prime}$
as in Algorithm 2. As
 $S^{\prime} \sim \mu _{H,{zn}}$
for some
$S^{\prime} \sim \mu _{H,{zn}}$
for some
 $H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \subseteq{\mathcal{G}_{n}}$
and Lemma5.3 applies to all such graphs, we get
$H \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}} \subseteq{\mathcal{G}_{n}}$
and Lemma5.3 applies to all such graphs, we get
 \begin{equation*} \mathbb {E}\left [|{Y}||G \in {A^{(n)}_{\frac {{\varepsilon }}{12}}}\right ] \le \frac {{z}_n}{1+{z}_n} n \le {z}_{n} n = \lambda \nu (\Lambda ) . \end{equation*}
\begin{equation*} \mathbb {E}\left [|{Y}||G \in {A^{(n)}_{\frac {{\varepsilon }}{12}}}\right ] \le \frac {{z}_n}{1+{z}_n} n \le {z}_{n} n = \lambda \nu (\Lambda ) . \end{equation*}
Again, applying Markov’s inequality gives
 $\mathbb{P}\left [|{Y}| \gt m|G \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ] \le \frac{{\varepsilon }}{12}$
. Consequently, we have
$\mathbb{P}\left [|{Y}| \gt m|G \in{A^{(n)}_{\frac{{\varepsilon }}{12}}}\right ] \le \frac{{\varepsilon }}{12}$
. Consequently, we have
 \begin{equation*} {d_{\text {tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}}, {\widehat {P_{{\varepsilon }}}}\right ) \le \frac {{\varepsilon }}{4} + \frac {{\varepsilon }}{6} = \frac {5}{12} {\varepsilon } . \end{equation*}
\begin{equation*} {d_{\text {tv}}}\left ({{P}_{\Lambda }^{\left (\lambda, \phi \right )}}, {\widehat {P_{{\varepsilon }}}}\right ) \le \frac {{\varepsilon }}{4} + \frac {{\varepsilon }}{6} = \frac {5}{12} {\varepsilon } . \end{equation*}
To finish the proof, we now relate the output of Algorithm 2 with
 $\widehat{P_{{\varepsilon }}}$
by using a coupling argument. To this end, note that Algorithm 2 can be used to sample from
$\widehat{P_{{\varepsilon }}}$
by using a coupling argument. To this end, note that Algorithm 2 can be used to sample from
 $\widehat{P_{{\varepsilon }}}$
by simply restarting the sampler whenever
$\widehat{P_{{\varepsilon }}}$
by simply restarting the sampler whenever
 ${G} \notin{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
. For our choice of
${G} \notin{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}$
. For our choice of
 $n$
we know that with a probability of
$n$
we know that with a probability of
 $\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
only a single run of Algorithm 2 is required. By this coupling, the total variation distance between the output of Algorithm 2 and
$\mathbb{P}\left [{G} \in{A^{\left (n\right )}_{\frac{{\varepsilon }}{12}}}\right ] \ge 1 - \frac{{\varepsilon }}{12}$
only a single run of Algorithm 2 is required. By this coupling, the total variation distance between the output of Algorithm 2 and
 $\widehat{P_{{\varepsilon }}}$
is at most
$\widehat{P_{{\varepsilon }}}$
is at most
 $\frac{{\varepsilon }}{12}$
. Finally, applying triangle inequality shows that the total variation distance between the output of Algorithm 2 and
$\frac{{\varepsilon }}{12}$
. Finally, applying triangle inequality shows that the total variation distance between the output of Algorithm 2 and
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is bounded by
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
is bounded by
 $\frac{5}{12}{\varepsilon } + \frac{{\varepsilon }}{12} = \frac{{\varepsilon }}{2}$
, which concludes the proof.
$\frac{5}{12}{\varepsilon } + \frac{{\varepsilon }}{12} = \frac{{\varepsilon }}{2}$
, which concludes the proof.
Using Lemma5.5, we are able to prove that Algorithm 1 is an
 $\varepsilon$
-approximate sampler for
$\varepsilon$
-approximate sampler for
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. In order to argue that Algorithm 1 also satisfies the running time requirements, given in Theorem5.1, we require an efficient approximate sampler from the hard-core distribution
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. In order to argue that Algorithm 1 also satisfies the running time requirements, given in Theorem5.1, we require an efficient approximate sampler from the hard-core distribution
 $\mu _{{G},{z}_n}$
. To this end, we use the following known result.
$\mu _{{G},{z}_n}$
. To this end, we use the following known result.
Theorem 5.4 [Reference Anari, Jain, Koehler, Pham and Vuong(2, Theorem
 $5$
)]. Let
$5$
)]. Let
 ${G} = ({V},{E})$
be an undirected graph with maximum vertex degree bounded by
${G} = ({V},{E})$
be an undirected graph with maximum vertex degree bounded by
 ${d_{G}} \in{\mathbb{N}}_{\ge 2}$
and let
${d_{G}} \in{\mathbb{N}}_{\ge 2}$
and let
 ${z} \in{\unicode{x211D}}_{\ge 0}$
with
${z} \in{\unicode{x211D}}_{\ge 0}$
with
 \begin{equation*} {z} \lt {{z}_{\text {c}}\left ({d_{G}}\right )} = \frac {\left ({d_{G}} - 1\right )^{{d_{G}} - 1}}{\left ({d_{G}} - 2\right )^{{d_{G}}}}. \end{equation*}
\begin{equation*} {z} \lt {{z}_{\text {c}}\left ({d_{G}}\right )} = \frac {\left ({d_{G}} - 1\right )^{{d_{G}} - 1}}{\left ({d_{G}} - 2\right )^{{d_{G}}}}. \end{equation*}
Then, for all
 ${\varepsilon } \in (0, 1]$
, there is an
${\varepsilon } \in (0, 1]$
, there is an
 $\varepsilon$
-approximate sampler for the hard-core Gibbs distribution
$\varepsilon$
-approximate sampler for the hard-core Gibbs distribution
 $\mu _{{G},{z}}$
with an expected running time of
$\mu _{{G},{z}}$
with an expected running time of
 ${\mathrm{O}}\left (|{V}| \ln \left (\frac{|{V}|}{{\varepsilon }}\right )\right )$
.
${\mathrm{O}}\left (|{V}| \ln \left (\frac{|{V}|}{{\varepsilon }}\right )\right )$
.
Proof of Theorem
5.1. We start by arguing that Algorithm 1 is an
 $\varepsilon$
-approximate sampler for
$\varepsilon$
-approximate sampler for
 ${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. To this end, we show that the total variation distance between the output distributions of Algorithm 1 and Algorithm 2 is bounded by
${P}_{\Lambda }^{\left (\lambda, \phi \right )}$
. To this end, we show that the total variation distance between the output distributions of Algorithm 1 and Algorithm 2 is bounded by
 $\frac{{\varepsilon }}{2}$
. Using the triangle inequality and Lemma5.5 then yields the desired result. To bound the total variation distance between the Algorithm 1 and Algorithm 2 by
$\frac{{\varepsilon }}{2}$
. Using the triangle inequality and Lemma5.5 then yields the desired result. To bound the total variation distance between the Algorithm 1 and Algorithm 2 by
 $\frac{{\varepsilon }}{2}$
, it suffices to construct a coupling of both algorithms such that their output coincides with a probability of at least
$\frac{{\varepsilon }}{2}$
, it suffices to construct a coupling of both algorithms such that their output coincides with a probability of at least
 $1 - \frac{{\varepsilon }}{2}$
. This is, we want to find a coupling of both algorithms such that
$1 - \frac{{\varepsilon }}{2}$
. This is, we want to find a coupling of both algorithms such that
 ${X} \neq{Y}$
with probability at most
${X} \neq{Y}$
with probability at most
 $\frac{{\varepsilon }}{2}$
, where
$\frac{{\varepsilon }}{2}$
, where
 $X$
and
$X$
and
 $Y$
are as in Algorithm 1 and Algorithm 2.
$Y$
are as in Algorithm 1 and Algorithm 2.
To construct such a coupling, we start by letting both algorithms draw the same points
 ${X}_1, \dots, {X}_n$
and construct the same graph
${X}_1, \dots, {X}_n$
and construct the same graph
 $G$
. If
$G$
. If
 ${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, then we may just assume
${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, then we may just assume
 ${X} \neq{Y}$
. Otherwise, if
${X} \neq{Y}$
. Otherwise, if
 ${d_{G}} \lt \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, then
${d_{G}} \lt \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
, then
 $S = S^{\prime}$
is a sufficient condition for
$S = S^{\prime}$
is a sufficient condition for
 ${X} ={Y}$
. As
${X} ={Y}$
. As
 $S^{\prime}$
is drawn from
$S^{\prime}$
is drawn from
 $\mu _{{G},{z}_n}$
and
$\mu _{{G},{z}_n}$
and
 $S$
is drawn from an
$S$
is drawn from an
 $\frac{{\varepsilon }}{4}$
approximation of that distribution, they can be coupled in such a way that
$\frac{{\varepsilon }}{4}$
approximation of that distribution, they can be coupled in such a way that
 $\mathbb{P}\left [S^{\prime} \neq S\right ] \le \frac{{\varepsilon }}{4}$
. Using this coupling of Algorithm 1 and Algorithm 2, we have
$\mathbb{P}\left [S^{\prime} \neq S\right ] \le \frac{{\varepsilon }}{4}$
. Using this coupling of Algorithm 1 and Algorithm 2, we have
 \begin{equation*} \mathbb {P}\left [{X} \neq {Y}\right ] \le \mathbb {P}\left [{d_{G}} \ge \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] + \frac {{\varepsilon }}{4} \cdot {\mathbb {P}}\left [{d_{G}} \lt \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] \le \mathbb {P}\left [{d_{G}} \ge \frac {{\mathrm {en}}}{\lambda {\nu (\Lambda )}}\right ] + \frac {{\varepsilon }}{4} . \end{equation*}
\begin{equation*} \mathbb {P}\left [{X} \neq {Y}\right ] \le \mathbb {P}\left [{d_{G}} \ge \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] + \frac {{\varepsilon }}{4} \cdot {\mathbb {P}}\left [{d_{G}} \lt \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] \le \mathbb {P}\left [{d_{G}} \ge \frac {{\mathrm {en}}}{\lambda {\nu (\Lambda )}}\right ] + \frac {{\varepsilon }}{4} . \end{equation*}
Therefore, it remains to prove that
 ${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
with probability at most
${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
with probability at most
 $\frac{\varepsilon }{4}$
, where
$\frac{\varepsilon }{4}$
, where
 ${G} \sim \mathbb{G}_{W_{\phi },n}$
for
${G} \sim \mathbb{G}_{W_{\phi },n}$
for
 $W_{\phi }$
as in Definition4.1. We follow a similar arguments as in the proof of Theorem4.2. Note that, for our choice of
$W_{\phi }$
as in Definition4.1. We follow a similar arguments as in the proof of Theorem4.2. Note that, for our choice of
 $n$
, there exists
$n$
, there exists
 $x \ge 3 \ln \left (\frac{4{\mathrm{e}}}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda{C_{\phi }}}{\left (\mathrm{e} - \lambda C_{\phi }\right )^{2}}\right \} \lambda \nu (\Lambda )$
such that
$x \ge 3 \ln \left (\frac{4{\mathrm{e}}}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda{C_{\phi }}}{\left (\mathrm{e} - \lambda C_{\phi }\right )^{2}}\right \} \lambda \nu (\Lambda )$
such that
 $n = 2 x \ln (x)^2$
. Moreover, we have
$n = 2 x \ln (x)^2$
. Moreover, we have
 $n \ge \mathrm{e} \ge 2$
and, for
$n \ge \mathrm{e} \ge 2$
and, for
 $\nu (\Lambda )$
(consequently
$\nu (\Lambda )$
(consequently
 $x$
) sufficiently large, it holds that
$x$
) sufficiently large, it holds that
 $2 x \ln (x)^2 \ge 2 x \ln \left (2 x \ln (x)^2\right ) = 2 x \ln (n)$
. Therefore, we have
$2 x \ln (x)^2 \ge 2 x \ln \left (2 x \ln (x)^2\right ) = 2 x \ln (n)$
. Therefore, we have
 \begin{align*} n - 1 &\ge \frac{n}{2} \\ &\ge 3 \ln \left (\frac{4{\mathrm{e}}}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )}^{2}\right \} \lambda \nu (\Lambda ) \ln (n) \\ &\ge 3 \ln \left (\frac{4n}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )}^{2}\right \} \lambda \nu (\Lambda ) \end{align*}
\begin{align*} n - 1 &\ge \frac{n}{2} \\ &\ge 3 \ln \left (\frac{4{\mathrm{e}}}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )}^{2}\right \} \lambda \nu (\Lambda ) \ln (n) \\ &\ge 3 \ln \left (\frac{4n}{{\varepsilon }}\right ) \max \left \{\frac{1}{\mathrm{e} - \lambda C_{\phi }}, \frac{\lambda C_{\phi }}{\left (\mathrm{e} - \lambda C_{\phi } \right )}^{2}\right \} \lambda \nu (\Lambda ) \end{align*}
and by Lemma4.2
 \begin{equation*} \mathbb {P}\left [{d_{G}} \ge \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] \le \mathbb {P}\left [{d_{G}} \ge \left (1 + \frac {\mathrm {e} - \lambda C_{\phi }}{\lambda C_{\phi }}\right ) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ] \le \frac {{\varepsilon }}{4} . \end{equation*}
\begin{equation*} \mathbb {P}\left [{d_{G}} \ge \frac {\mathrm {en}}{\lambda \nu (\Lambda )}\right ] \le \mathbb {P}\left [{d_{G}} \ge \left (1 + \frac {\mathrm {e} - \lambda C_{\phi }}{\lambda C_{\phi }}\right ) \frac {n-1}{\nu (\Lambda )}C_{\phi }\right ] \le \frac {{\varepsilon }}{4} . \end{equation*}
To prove Theorem 5.1, it remains to show that Algorithm 1 satisfies the given running time requirements. To this end, note that, for all
 $\lambda \lt \frac{{\mathrm{e}}}{C_{\phi }}$
, it holds that
$\lambda \lt \frac{{\mathrm{e}}}{C_{\phi }}$
, it holds that
 $n \in{\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-3}\right )$
. Therefore, sampling
$n \in{\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-3}\right )$
. Therefore, sampling
 ${X}_1, \dots, {X}_n$
requires a running time of
${X}_1, \dots, {X}_n$
requires a running time of
 ${\widetilde{\mathrm{O}}}\left ({n{{t}_{\Lambda }}}\right ) ={\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }}}\right )$
. Moreover, the graph can be constructed in time
${\widetilde{\mathrm{O}}}\left ({n{{t}_{\Lambda }}}\right ) ={\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }}}\right )$
. Moreover, the graph can be constructed in time
 ${\widetilde{\mathrm{O}}}\left ({n^2{{t}_{\phi }}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
and
${\widetilde{\mathrm{O}}}\left ({n^2{{t}_{\phi }}}\right ) ={\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
and
 ${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
can be checked in
${d_{G}} \ge \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
can be checked in
 $\mathrm{O}(1)$
if we keep track of
$\mathrm{O}(1)$
if we keep track of
 $d_{G}$
while constructing the graph. Finally, for
$d_{G}$
while constructing the graph. Finally, for
 ${d_{G}} \lt \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
it holds that
${d_{G}} \lt \frac{\mathrm{en}}{\lambda \nu (\Lambda )}$
it holds that
 \begin{equation*} {z}_n = \frac {\lambda \nu (\Lambda )}{n} \lt \frac {{\mathrm {e}}}{{d_{G}}} \lt {{z}_{\text {c}}\left ({d_{G}}\right )}. \end{equation*}
\begin{equation*} {z}_n = \frac {\lambda \nu (\Lambda )}{n} \lt \frac {{\mathrm {e}}}{{d_{G}}} \lt {{z}_{\text {c}}\left ({d_{G}}\right )}. \end{equation*}
Thus, Theorem5.4 guarantees the existence of an
 $\frac{{\varepsilon }}{8}$
-approximate sampler from
$\frac{{\varepsilon }}{8}$
-approximate sampler from
 $\mu _{{G},{z}_n}$
with an expected running time in
$\mu _{{G},{z}_n}$
with an expected running time in
 ${\mathrm{O}}\left ({n \ln \left (\frac{n}{{\varepsilon }}\right )}\right ) ={\mathrm{O}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-3} \ln \left (\frac{\nu (\Lambda )}{{\varepsilon }}\right )}\right )$
. Note that, by Markov’s inequality, the probability that this sampler takes more than
${\mathrm{O}}\left ({n \ln \left (\frac{n}{{\varepsilon }}\right )}\right ) ={\mathrm{O}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-3} \ln \left (\frac{\nu (\Lambda )}{{\varepsilon }}\right )}\right )$
. Note that, by Markov’s inequality, the probability that this sampler takes more than
 $\frac{8}{{\varepsilon }}$
times its expected running time is bounded by
$\frac{8}{{\varepsilon }}$
times its expected running time is bounded by
 $\frac{{\varepsilon }}{8}$
. Therefore, if we run the sampler from Theorem5.4 with an error bound of
$\frac{{\varepsilon }}{8}$
. Therefore, if we run the sampler from Theorem5.4 with an error bound of
 $\frac{{\varepsilon }}{8}$
and, whenever the algorithm takes more than
$\frac{{\varepsilon }}{8}$
and, whenever the algorithm takes more than
 $\frac{8}{{\varepsilon }}$
times its expected running time, stop it and return an arbitrary spin configuration, this results in an
$\frac{8}{{\varepsilon }}$
times its expected running time, stop it and return an arbitrary spin configuration, this results in an
 $\frac{{\varepsilon }}{4}$
-approximate sampler with a guaranteed running time in
$\frac{{\varepsilon }}{4}$
-approximate sampler with a guaranteed running time in
 ${\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-4}}\right )$
. Consequently, Algorithm 1 runs in time
${\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2{\varepsilon }^{-4}}\right )$
. Consequently, Algorithm 1 runs in time
 ${\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-4} +{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }} +{\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
, which concludes the proof.
${\widetilde{\mathrm{O}}}\left ({\nu } (\Lambda )^2{\varepsilon }^{-4} +{\nu } (\Lambda )^2{\varepsilon }^{-3}{{t}_{\Lambda }} +{\nu (\Lambda )^4{\varepsilon }^{-6}{{t}_{\phi }}}\right )$
, which concludes the proof.
6. Discussion and outlook
The most commonly studied setting for algorithms for Gibbs point processes is when
 $\Lambda = [0, \ell ]^d$
is a box of side length
$\Lambda = [0, \ell ]^d$
is a box of side length
 $\ell$
in
$\ell$
in
 $d$
-dimensional Euclidean space. Usually, the following computational assumptions are made:
$d$
-dimensional Euclidean space. Usually, the following computational assumptions are made:
-
• We can perform arithmetic operations and comparison with arbitrary floating-point precision.
-
• We have oracle access to a uniform sampler for the continuous interval
$[0, 1]$
. -
• We have oracle access to
${\mathrm{e}}^{- \phi (x,y)}$
for any
$x, y \in{\unicode{x211D}}^d$
.



In this setting, Theorem4.2 and Theorem5.1 provide an approximation algorithm for the partition function and an approximate sampling algorithm with running time
 ${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^4}\right )$
up to a fugacity of
${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )^4}\right )$
up to a fugacity of
 $\lambda \lt \mathrm{e}/C_{\phi }$
and for arbitrary repulsive potentials
$\lambda \lt \mathrm{e}/C_{\phi }$
and for arbitrary repulsive potentials
 $\phi$
.
$\phi$
.
Recently, Michelen and Perkins [Reference Michelen and Perkins23] provide a
 ${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )}\right )$
approximate sampler and a
${\widetilde{\mathrm{O}}}\left ({\nu (\Lambda )}\right )$
approximate sampler and a
 ${\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2}\right )$
approximation for the partition function in the setting of bounded-range potentials up to a slightly better fugacity threshold of
${\widetilde{\mathrm{O}}}\left ({{\nu } (\Lambda )^2}\right )$
approximation for the partition function in the setting of bounded-range potentials up to a slightly better fugacity threshold of
 $\mathrm{e}/\Delta _{\phi }$
, where
$\mathrm{e}/\Delta _{\phi }$
, where
 $\Delta _{\phi }$
is called the potential-weighted connective constant. This result is obtained by directly applying a Markov chain Monte-Carlo algorithm on the continuous problem, which is efficient as long as the Gibbs point process satisfies a property called strong spatial mixing. The strong spatial mixing assumption restricts their approach to bounded-range potentials. This raises the question if there are efficient approximation algorithms for repulsive Gibbs point processes without bounded-range assumption for every
$\Delta _{\phi }$
is called the potential-weighted connective constant. This result is obtained by directly applying a Markov chain Monte-Carlo algorithm on the continuous problem, which is efficient as long as the Gibbs point process satisfies a property called strong spatial mixing. The strong spatial mixing assumption restricts their approach to bounded-range potentials. This raises the question if there are efficient approximation algorithms for repulsive Gibbs point processes without bounded-range assumption for every
 $\lambda \lt{\mathrm{e}/\Delta _{\phi }}$
. As a first step towards this, we argue in an extended version of this paper [Reference Friedrich, Göbel, Katzmann, Krejca and Pappik10] that a bound for the connective constant of our discretization can be obtained in terms of
$\lambda \lt{\mathrm{e}/\Delta _{\phi }}$
. As a first step towards this, we argue in an extended version of this paper [Reference Friedrich, Göbel, Katzmann, Krejca and Pappik10] that a bound for the connective constant of our discretization can be obtained in terms of
 $\Delta _{\phi }$
. However, while this is known to imply some notion of spatial mixing for the discrete hard-core model [Reference Sinclair, Srivastava, Štefankovič and Yin29], it is not clear if it suffices for a polynomial-time approximation.
$\Delta _{\phi }$
. However, while this is known to imply some notion of spatial mixing for the discrete hard-core model [Reference Sinclair, Srivastava, Štefankovič and Yin29], it is not clear if it suffices for a polynomial-time approximation.
Moreover, Jenssen, Michelen and Ravichandran [Reference Jenssen, Michelen and Ravichandran20] recently obtained a deterministic quasi-polynomial time approximation algorithm for the partition function of repulsive Gibbs point processes with sufficiently smooth bounded-range potentials up to
 $\lambda \lt{\mathrm{e}/\Delta _{\phi }}$
. Their result is based on using a discretization to approximate the coefficients of a suitable expansion of the logarithm of the partition function. To perform the involved enumeration task efficiently, they require the potential to have bounded range. It would be interesting to see if such a quasi-polynomial deterministic approximation can be obtained without bounded-range assumptions. In particular, we wonder if a derandomized version of our discretization under similar smoothness assumptions on the potential as in [Reference Jenssen, Michelen and Ravichandran20] could give such a result.
$\lambda \lt{\mathrm{e}/\Delta _{\phi }}$
. Their result is based on using a discretization to approximate the coefficients of a suitable expansion of the logarithm of the partition function. To perform the involved enumeration task efficiently, they require the potential to have bounded range. It would be interesting to see if such a quasi-polynomial deterministic approximation can be obtained without bounded-range assumptions. In particular, we wonder if a derandomized version of our discretization under similar smoothness assumptions on the potential as in [Reference Jenssen, Michelen and Ravichandran20] could give such a result.
Acknowledgements
Andreas Göbel was funded by the project PAGES (project No. 467516565) of the German Research Foundation (DFG). Marcus Pappik was funded by the HPI Research School on Data Science and Engineering.
Competing interests
The authors declare no competing interests.








 Open access
Open access