


1. Introduction
Artificial intelligence (AI) has been a story of booms and busts, yet by any traditional measure of success, the last few years have been marked by exceptional progress. Much of this progress has come from recent advances in “deep learning,” characterized by learning large neural network-style models with multiple layers of representation (see Glossary in Table 1). These models have achieved remarkable gains in many domains spanning object recognition, speech recognition, and control (LeCun et al. Reference LeCun, Bengio and Hinton2015; Schmidhuber Reference Schmidhuber2015). In object recognition, Krizhevsky et al. (Reference Krizhevsky, Sutskever, Hinton, Pereira, Burges, Bottou and Weinberger2012) trained a deep convolutional neural network (ConvNet [LeCun et al. Reference LeCun, Boser, Denker, Henderson, Howard, Hubbard and Jackel1989]) that nearly halved the previous state-of-the-art error rate on the most challenging benchmark to date. In the years since, ConvNets continue to dominate, recently approaching human-level performance on some object recognition benchmarks (He et al. Reference He, Zhang, Ren and Sun2016; Russakovsky et al. Reference Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg and Fei-Fei2015; Szegedy et al. Reference Szegedy, Liu, Jia, Sermanet, Reed, Anguelov, Erhan, Vanhoucke and Rabinovich2014). In automatic speech recognition, hidden Markov models (HMMs) have been the leading approach since the late 1980s (Juang & Rabiner Reference Juang and Rabiner1990), yet this framework has been chipped away piece by piece and replaced with deep learning components (Hinton et al. Reference Hinton, Deng, Yu, Dahl, Mohamed, Jaitly, Senior, Vanhoucke, Nguyen, Sainath and Kingsbury2012). Now, the leading approaches to speech recognition are fully neural network systems (Graves et al. Reference Graves, Mohamed and Hinton2013; Hannun et al. Reference Hannun, Case, Casper, Catanzaro, Diamos, Elsen, Prenger, Satheesh, Shubho, Coates and Ng2014). Ideas from deep learning have also been applied to learning complex control problems. Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015) combined ideas from deep learning and reinforcement learning to make a “deep reinforcement learning” algorithm that learns to play large classes of simple video games from just frames of pixels and the game score, achieving human- or superhuman-level performance on many of them (see also Guo et al. Reference Guo, Singh, Lee, Lewis, Wang, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014; Schaul et al. Reference Schaul, Quan, Antonoglou and Silver2016; Stadie et al. Reference Stadie, Levine and Abbeel2016).
Table 1. Glossary

These accomplishments have helped neural networks regain their status as a leading paradigm in machine learning, much as they were in the late 1980s and early 1990s. The recent success of neural networks has captured attention beyond academia. In industry, companies such as Google and Facebook have active research divisions exploring these technologies, and object and speech recognition systems based on deep learning have been deployed in core products on smart phones and the web. The media have also covered many of the recent achievements of neural networks, often expressing the view that neural networks have achieved this recent success by virtue of their brain-like computation and, therefore, their ability to emulate human learning and human cognition.
In this article, we view this excitement as an opportunity to examine what it means for a machine to learn or think like a person. We first review some of the criteria previously offered by cognitive scientists, developmental psychologists, and artificial intelligence (AI) researchers. Second, we articulate what we view as the essential ingredients for building a machine that learns or thinks like a person, synthesizing theoretical ideas and experimental data from research in cognitive science. Third, we consider contemporary AI (and deep learning in particular) in the light of these ingredients, finding that deep learning models have yet to incorporate many of them, and so may be solving some problems in different ways than people do. We end by discussing what we view as the most plausible paths toward building machines that learn and think like people. This includes prospects for integrating deep learning with the core cognitive ingredients we identify, inspired in part by recent work fusing neural networks with lower-level building blocks from classic psychology and computer science (attention, working memory, stacks, queues) that have traditionally been seen as incompatible.
Beyond the specific ingredients in our proposal, we draw a broader distinction between two different computational approaches to intelligence. The statistical pattern recognition approach treats prediction as primary, usually in the context of a specific classification, regression, or control task. In this view, learning is about discovering features that have high-value states in common – a shared label in a classification setting or a shared value in a reinforcement learning setting – across a large, diverse set of training data.
The alternative approach treats models of the world as primary, where learning is the process of model building. Cognition is about using these models to understand the world, to explain what we see, to imagine what could have happened that didn't, or what could be true that isn't, and then planning actions to make it so. The difference between pattern recognition and model building, between prediction and explanation, is central to our view of human intelligence. Just as scientists seek to explain nature, not simply predict it, we see human thought as fundamentally a model building activity. We elaborate this key point with numerous examples below. We also discuss how pattern recognition, even if it is not the core of intelligence, can nonetheless support model building, through “model-free” algorithms that learn through experience how to make essential inferences more computationally efficient.
Before proceeding, we provide a few caveats about the goals of this article, and a brief overview of the key ideas.
1.1. What this article is not
For nearly as long as there have been neural networks, there have been critiques of neural networks (Crick Reference Crick1989; Fodor & Pylyshyn Reference Fodor and Pylyshyn1988; Marcus Reference Marcus1998, Reference Marcus2001; Minsky & Papert Reference Minsky and Papert1969; Pinker & Prince Reference Pinker and Prince1988). Although we are critical of neural networks in this article, our goal is to build on their successes rather than dwell on their shortcomings. We see a role for neural networks in developing more human-like learning machines: They have been applied in compelling ways to many types of machine learning problems, demonstrating the power of gradient-based learning and deep hierarchies of latent variables. Neural networks also have a rich history as computational models of cognition (McClelland et al. Reference McClelland and Rumelhart1986; Rumelhart et al. Reference Rumelhart and McClelland1986b). It is a history we describe in more detail in the next section. At a more fundamental level, any computational model of learning must ultimately be grounded in the brain's biological neural networks.
We also believe that future generations of neural networks will look very different from the current state-of-the-art neural networks. They may be endowed with intuitive physics, theory of mind, causal reasoning, and other capacities we describe in the sections that follow. More structure and inductive biases could be built into the networks or learned from previous experience with related tasks, leading to more human-like patterns of learning and development. Networks may learn to effectively search for and discover new mental models or intuitive theories, and these improved models will, in turn, enable subsequent learning, allowing systems that learn-to-learn – using previous knowledge to make richer inferences from very small amounts of training data.
It is also important to draw a distinction between AI that purports to emulate or draw inspiration from aspects of human cognition and AI that does not. This article focuses on the former. The latter is a perfectly reasonable and useful approach to developing AI algorithms: avoiding cognitive or neural inspiration as well as claims of cognitive or neural plausibility. Indeed, this is how many researchers have proceeded, and this article has little pertinence to work conducted under this research strategy.Footnote 1 On the other hand, we believe that reverse engineering human intelligence can usefully inform AI and machine learning (and has already done so), especially for the types of domains and tasks that people excel at. Despite recent computational achievements, people are better than machines at solving a range of difficult computational problems, including concept learning, scene understanding, language acquisition, language understanding, speech recognition, and so on. Other human cognitive abilities remain difficult to understand computationally, including creativity, common sense, and general-purpose reasoning. As long as natural intelligence remains the best example of intelligence, we believe that the project of reverse engineering the human solutions to difficult computational problems will continue to inform and advance AI.
Finally, whereas we focus on neural network approaches to AI, we do not wish to give the impression that these are the only contributors to recent advances in AI. On the contrary, some of the most exciting recent progress has been in new forms of probabilistic machine learning (Ghahramani Reference Ghahramani2015). For example, researchers have developed automated statistical reasoning techniques (Lloyd et al. Reference Lloyd, Duvenaud, Grosse, Tenenbaum and Ghahramani2014), automated techniques for model building and selection (Grosse et al. Reference Grosse, Salakhutdinov, Freeman, Tenenbaum, de Freitas and Murphy2012), and probabilistic programming languages (e.g., Gelman et al. Reference Gelman, Lee and Guo2015; Goodman et al. Reference Goodman, Mansinghka, Roy, Bonawitz and Tenenbaum2008; Mansinghka et al. Reference Mansinghka, Selsam and Perov2014). We believe that these approaches will play important roles in future AI systems, and they are at least as compatible with the ideas from cognitive science we discuss here. However, a full discussion of those connections is beyond the scope of the current article.
1.2. Overview of the key ideas
The central goal of this article is to propose a set of core ingredients for building more human-like learning and thinking machines. We elaborate on each of these ingredients and topics in Section 4, but here we briefly overview the key ideas.
The first set of ingredients focuses on developmental “start-up software,” or cognitive capabilities present early in development. There are several reasons for this focus on development. If an ingredient is present early in development, it is certainly active and available well before a child or adult would attempt to learn the types of tasks discussed in this paper. This is true regardless of whether the early-present ingredient is itself learned from experience or innately present. Also, the earlier an ingredient is present, the more likely it is to be foundational to later development and learning.
We focus on two pieces of developmental start-up software (see Wellman & Gelman [Reference Wellman and Gelman1992] for a review of both). First is intuitive physics (sect. 4.1.1): Infants have primitive object concepts that allow them to track objects over time and to discount physically implausible trajectories. For example, infants know that objects will persist over time and that they are solid and coherent. Equipped with these general principles, people can learn more quickly and make more accurate predictions. Although a task may be new, physics still works the same way. A second type of software present in early development is intuitive psychology (sect. 4.1.2): Infants understand that other people have mental states like goals and beliefs, and this understanding strongly constrains their learning and predictions. A child watching an expert play a new video game can infer that the avatar has agency and is trying to seek reward while avoiding punishment. This inference immediately constrains other inferences, allowing the child to infer what objects are good and what objects are bad. These types of inferences further accelerate the learning of new tasks.
Our second set of ingredients focus on learning. Although there are many perspectives on learning, we see model building as the hallmark of human-level learning, or explaining observed data through the construction of causal models of the world (sect. 4.2.2). From this perspective, the early-present capacities for intuitive physics and psychology are also causal models of the world. A primary job of learning is to extend and enrich these models and to build analogous causally structured theories of other domains.
Compared with state-of-the-art algorithms in machine learning, human learning is distinguished by its richness and its efficiency. Children come with the ability and the desire to uncover the underlying causes of sparsely observed events and to use that knowledge to go far beyond the paucity of the data. It might seem paradoxical that people are capable of learning these richly structured models from very limited amounts of experience. We suggest that compositionality and learning-to-learn are ingredients that make this type of rapid model learning possible (sects. 4.2.1 and 4.2.3, respectively).
A final set of ingredients concerns how the rich models our minds build are put into action, in real time (sect. 4.3). It is remarkable how fast we are to perceive and to act. People can comprehend a novel scene in a fraction of a second, or a novel utterance in little more than the time it takes to say it and hear it. An important motivation for using neural networks in machine vision and speech systems is to respond as quickly as the brain does. Although neural networks are usually aiming at pattern recognition rather than model building, we discuss ways in which these “model-free” methods can accelerate slow model-based inferences in perception and cognition (sect. 4.3.1) (see Glossary in Table 1). By learning to recognize patterns in these inferences, the outputs of inference can be predicted without having to go through costly intermediate steps. Integrating neural networks that “learn to do inference” with rich model building learning mechanisms offers a promising way to explain how human minds can understand the world so well and so quickly.
We also discuss the integration of model-based and model-free methods in reinforcement learning (sect. 4.3.2.), an area that has seen rapid recent progress. Once a causal model of a task has been learned, humans can use the model to plan action sequences that maximize future reward. When rewards are used as the metric for successs in model building, this is known as model-based reinforcement learning. However, planning in complex models is cumbersome and slow, making the speed-accuracy trade-off unfavorable for real-time control. By contrast, model-free reinforcement learning algorithms, such as current instantiations of deep reinforcement learning, support fast control, but at the cost of inflexibility and possibly accuracy. We review evidence that humans combine model-based and model-free learning algorithms both competitively and cooperatively and that these interactions are supervised by metacognitive processes. The sophistication of human-like reinforcement learning has yet to be realized in AI systems, but this is an area where crosstalk between cognitive and engineering approaches is especially promising.
2. Cognitive and neural inspiration in artificial intelligence
The questions of whether and how AI should relate to human cognitive psychology are older than the terms artificial intelligence and cognitive psychology. Alan Turing suspected that it was easier to build and educate a child-machine than try to fully capture adult human cognition (Turing Reference Turing1950). Turing pictured the child's mind as a notebook with “rather little mechanism and lots of blank sheets,” and the mind of a child-machine as filling in the notebook by responding to rewards and punishments, similar to reinforcement learning. This view on representation and learning echoes behaviorism, a dominant psychological tradition in Turing's time. It also echoes the strong empiricism of modern connectionist models – the idea that we can learn almost everything we know from the statistical patterns of sensory inputs.
Cognitive science repudiated the oversimplified behaviorist view and came to play a central role in early AI research (Boden Reference Boden2006). Newell and Simon (Reference Newell and Simon1961) developed their “General Problem Solver” as both an AI algorithm and a model of human problem solving, which they subsequently tested experimentally (Newell & Simon Reference Newell and Simon1972). AI pioneers in other areas of research explicitly referenced human cognition and even published papers in cognitive psychology journals (e.g., Bobrow & Winograd Reference Bobrow and Winograd1977; Hayes-Roth & Hayes-Roth Reference Hayes-Roth and Hayes-Roth1979; Winograd Reference Winograd1972). For example, Schank (Reference Schank1972), writing in the journal Cognitive Psychology, declared that “We hope to be able to build a program that can learn, as a child does, how to do what we have described in this paper instead of being spoon-fed the tremendous information necessary” (p. 629).
A similar sentiment was expressed by Minsky (Reference Minsky1974): “I draw no boundary between a theory of human thinking and a scheme for making an intelligent machine; no purpose would be served by separating these today since neither domain has theories good enough to explain—or to produce—enough mental capacity” (p. 6).
Much of this research assumed that human knowledge representation is symbolic and that reasoning, language, planning and vision could be understood in terms of symbolic operations. Parallel to these developments, a radically different approach was being explored based on neuron-like “sub-symbolic” computations (e.g., Fukushima Reference Fukushima1980; Grossberg Reference Grossberg1976; Rosenblatt Reference Rosenblatt1958). The representations and algorithms used by this approach were more directly inspired by neuroscience than by cognitive psychology, although ultimately it would flower into an influential school of thought about the nature of cognition: parallel distributed processing (PDP) (McClelland et al. Reference McClelland and Rumelhart1986; Rumelhart et al. Reference Rumelhart and McClelland1986b). As its name suggests, PDP emphasizes parallel computation by combining simple units to collectively implement sophisticated computations. The knowledge learned by these neural networks is thus distributed across the collection of units rather than localized as in most symbolic data structures. The resurgence of recent interest in neural networks, more commonly referred to as “deep learning,” shares the same representational commitments and often even the same learning algorithms as the earlier PDP models. “Deep” refers to the fact that more powerful models can be built by composing many layers of representation (see LeCun et al. [Reference LeCun, Bengio and Hinton2015] and Schmidhuber [Reference Schmidhuber2015] for recent reviews), still very much in the PDP style while utilizing recent advances in hardware and computing capabilities, as well as massive data sets, to learn deeper models.
It is also important to clarify that the PDP perspective is compatible with “model building” in addition to “pattern recognition.” Some of the original work done under the banner of PDP (Rumelhart et al. Reference Rumelhart and McClelland1986b) is closer to model building than pattern recognition, whereas the recent large-scale discriminative deep learning systems more purely exemplify pattern recognition (see Bottou [Reference Bottou2014] for a related discussion). But, as discussed, there is also a question of the nature of the learned representations within the model – their form, compositionality, and transferability – and the developmental start-up software that was used to get there. We focus on these issues in this article.
Neural network models and the PDP approach offer a view of the mind (and intelligence more broadly) that is sub-symbolic and often populated with minimal constraints and inductive biases to guide learning. Proponents of this approach maintain that many classic types of structured knowledge, such as graphs, grammars, rules, objects, structural descriptions, and programs, can be useful yet misleading metaphors for characterizing thought. These structures are more epiphenomenal than real, emergent properties of more fundamental sub-symbolic cognitive processes (McClelland et al. Reference McClelland, Botvinick, Noelle, Plaut, Rogers, Seidenberg and Smith2010). Compared with other paradigms for studying cognition, this position on the nature of representation is often accompanied by a relatively “blank slate” vision of initial knowledge and representation, much like Turing's blank notebook.
When attempting to understand a particular cognitive ability or phenomenon within this paradigm, a common scientific strategy is to train a relatively generic neural network to perform the task, adding additional ingredients only when necessary. This approach has shown that neural networks can behave as if they learned explicitly structured knowledge, such as a rule for producing the past tense of words (Rumelhart & McClelland Reference Rumelhart, McClelland, Rumelhart and McClelland1986), rules for solving simple balance beam physics problems (McClelland Reference McClelland1988), or a tree to represent types of living things (plants and animals) and their distribution of properties (Rogers & McClelland Reference Rogers and McClelland2004). Training large-scale relatively generic networks is also the best current approach for object recognition (He et al. Reference He, Zhang, Ren and Sun2016; Krizhevsky et al. Reference Krizhevsky, Sutskever, Hinton, Pereira, Burges, Bottou and Weinberger2012; Russakovsky et al. Reference Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg and Fei-Fei2015; Szegedy et al. Reference Szegedy, Liu, Jia, Sermanet, Reed, Anguelov, Erhan, Vanhoucke and Rabinovich2014), where the high-level feature representations of these convolutional nets have also been used to predict patterns of neural response in human and macaque IT cortex (Khaligh-Razavi & Kriegeskorte Reference Khaligh-Razavi and Kriegeskorte2014; Kriegeskorte Reference Kriegeskorte2015; Yamins et al. Reference Yamins, Hong, Cadieu, Solomon, Seibert and DiCarlo2014), as well as human typicality ratings (Lake et al. Reference Lake, Zaremba, Fergus and Gureckis2015b) and similarity ratings (Peterson et al. Reference Peterson, Abbott, Griffiths, Papafragou, Grodner, Mirman and Trueswell2016) for images of common objects. Moreover, researchers have trained generic networks to perform structured and even strategic tasks, such as the recent work on using a Deep Q-learning Network (DQN) to play simple video games (Mnih et al. Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015) (see Glossary in Table 1). If neural networks have such broad application in machine vision, language, and control, and if they can be trained to emulate the rule-like and structured behaviors that characterize cognition, do we need more to develop truly human-like learning and thinking machines? How far can relatively generic neural networks bring us toward this goal?
3. Challenges for building more human-like machines
Although cognitive science has not yet converged on a single account of the mind or intelligence, the claim that a mind is a collection of general-purpose neural networks with few initial constraints is rather extreme in contemporary cognitive science. A different picture has emerged that highlights the importance of early inductive biases, including core concepts such as number, space, agency, and objects, as well as powerful learning algorithms that rely on prior knowledge to extract knowledge from small amounts of training data. This knowledge is often richly organized and theory-like in structure, capable of the graded inferences and productive capacities characteristic of human thought.
Here we present two challenge problems for machine learning and AI: learning simple visual concepts (Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a) and learning to play the Atari game Frostbite (Mnih et al. Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015). We also use the problems as running examples to illustrate the importance of core cognitive ingredients in the sections that follow.
3.1. The Characters Challenge
The first challenge concerns handwritten character recognition, a classic problem for comparing different types of machine learning algorithms. Hofstadter (Reference Hofstadter1985) argued that the problem of recognizing characters in all of the ways people do – both handwritten and printed – contains most, if not all, of the fundamental challenges of AI. Whether or not this statement is correct, it highlights the surprising complexity that underlies even “simple” human-level concepts like letters. More practically, handwritten character recognition is a real problem that children and adults must learn to solve, with practical applications ranging from reading envelope addresses or checks in an automated teller machine (ATM). Handwritten character recognition is also simpler than more general forms of object recognition; the object of interest is two-dimensional, separated from the background, and usually unoccluded. Compared with how people learn and see other types of objects, it seems possible, in the near term, to build algorithms that can see most of the structure in characters that people can see.
The standard benchmark is the Mixed National Institute of Standards and Technology (MNIST) data set for digit recognition, which involves classifying images of digits into the categories ‘0’ to ‘9’ (LeCun et al. Reference LeCun, Bottou, Bengio and Haffner1998). The training set provides 6,000 images per class for a total of 60,000 training images. With a large amount of training data available, many algorithms achieve respectable performance, including K-nearest neighbors (5% test error), support vector machines (about 1% test error), and convolutional neural networks (below 1% test error [LeCun et al. Reference LeCun, Bottou, Bengio and Haffner1998]). The best results achieved using deep convolutional nets are very close to human-level performance at an error rate of 0.2% (Ciresan et al. Reference Ciresan, Meier and Schmidhuber2012). Similarly, recent results applying convolutional nets to the far more challenging ImageNet object recognition benchmark have shown that human-level performance is within reach on that data set as well (Russakovsky et al. Reference Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg and Fei-Fei2015).
Although humans and neural networks may perform equally well on the MNIST digit recognition task and other large-scale image classification tasks, it does not mean that they learn and think in the same way. There are at least two important differences: people learn from fewer examples and they learn richer representations, a comparison true for both learning handwritten characters and for learning more general classes of objects (Fig. 1). People can learn to recognize a new handwritten character from a single example (Fig. 1A-i), allowing them to discriminate between novel instances drawn by other people and similar looking non-instances (Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a; Miller et al. Reference Miller, Matsakis and Viola2000). Moreover, people learn more than how to do pattern recognition: they learn a concept, that is, a model of the class that allows their acquired knowledge to be flexibly applied in new ways. In addition to recognizing new examples, people can also generate new examples (Fig. 1A-ii), parse a character into its most important parts and relations (Fig. 1A-iii) (Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2012), and generate new characters given a small set of related characters (Fig. 1A-iv). These additional abilities come for free along with the acquisition of the underlying concept.

Figure 1. The Characters Challenge: Human-level learning of novel handwritten characters (A), with the same abilities also illustrated for a novel two-wheeled vehicle (B). A single example of a new visual concept (red box) can be enough information to support the (i) classification of new examples, (ii) generation of new examples, (iii) parsing an object into parts and relations, and (iv) generation of new concepts from related concepts. Adapted from Lake et al. (Reference Lake, Salakhutdinov and Tenenbaum2015a).
Even for these simple visual concepts, people are still better and more sophisticated learners than the best algorithms for character recognition. People learn a lot more from a lot less, and capturing these human-level learning abilities in machines is the Characters Challenge. We recently reported progress on this challenge using probabilistic program induction (Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a) (see Glossary in Table 1), yet aspects of the full human cognitive ability remain out of reach. Although both people and models represent characters as a sequence of pen strokes and relations, people have a far richer repertoire of structural relations between strokes. Furthermore, people can efficiently integrate across multiple examples of a character to infer which have optional elements, such as the horizontal cross-bar in ‘7's, combining different variants of the same character into a single coherent representation. Additional progress may come by combining deep learning and probabilistic program induction to tackle even richer versions of the Characters Challenge.
3.2. The Frostbite Challenge
The second challenge concerns the Atari game Frostbite (Fig. 2), which was one of the control problems tackled by the DQN of Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015). The DQN was a significant advance in reinforcement learning, showing that a single algorithm can learn to play a wide variety of complex tasks. The network was trained to play 49 classic Atari games, proposed as a test domain for reinforcement learning (Bellemare et al. Reference Bellemare, Naddaf, Veness and Bowling2013), impressively achieving human-level performance or above on 29 of the games. It did, however, have particular trouble with Frostbite and other games that required temporally extended planning strategies.
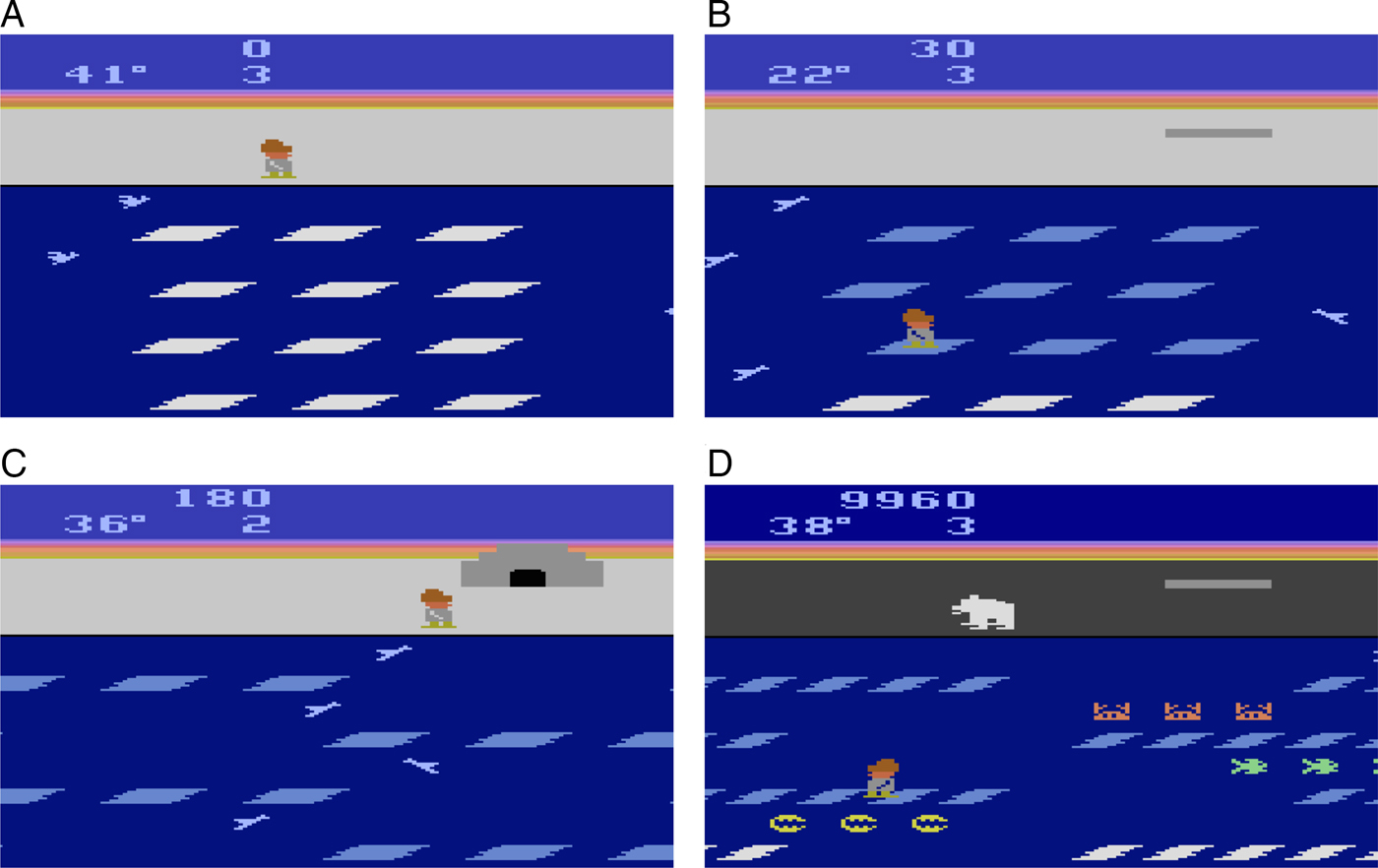
Figure 2. Screenshots of Frostbite, a 1983 video game designed for the Atari game console. (A) The start of a level in Frostbite. The agent must construct an igloo by hopping between ice floes and avoiding obstacles such as birds. The floes are in constant motion (either left or right), making multi-step planning essential to success. (B) The agent receives pieces of the igloo (top right) by jumping on the active ice floes (white), which then deactivates them (blue). (C) At the end of a level, the agent must safely reach the completed igloo. (D) Later levels include additional rewards (fish) and deadly obstacles (crabs, clams, and bears).
In Frostbite, players control an agent (Frostbite Bailey) tasked with constructing an igloo within a time limit. The igloo is built piece by piece as the agent jumps on ice floes in water (Fig. 2A–C). The challenge is that the ice floes are in constant motion (moving either left or right), and ice floes only contribute to the construction of the igloo if they are visited in an active state (white, rather than blue). The agent may also earn extra points by gathering fish while avoiding a number of fatal hazards (falling in the water, snow geese, polar bears, etc.). Success in this game requires a temporally extended plan to ensure the agent can accomplish a sub-goal (such as reaching an ice floe) and then safely proceed to the next sub-goal. Ultimately, once all of the pieces of the igloo are in place, the agent must proceed to the igloo and complete the level before time expires (Fig. 2C).
The DQN learns to play Frostbite and other Atari games by combining a powerful pattern recognizer (a deep convolutional neural network) and a simple model-free reinforcement learning algorithm (Q-learning [Watkins & Dayan Reference Watkins and Dayan1992]). These components allow the network to map sensory inputs (frames of pixels) onto a policy over a small set of actions, and both the mapping and the policy are trained to optimize long-term cumulative reward (the game score). The network embodies the strongly empiricist approach characteristic of most connectionist models: very little is built into the network apart from the assumptions about image structure inherent in convolutional networks, so the network has to essentially learn a visual and conceptual system from scratch for each new game. In Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015), the network architecture and hyper-parameters were fixed, but the network was trained anew for each game, meaning the visual system and the policy are highly specialized for the games it was trained on. More recent work has shown how these game-specific networks can share visual features (Rusu et al. Reference Rusu, Rabinowitz, Desjardins, Soyer, Kirkpatrick, Kavukcuoglu, Pascanu and Hadsell2016) or be used to train a multitask network (Parisotto et al. Reference Parisotto, Ba and Salakhutdinov2016), achieving modest benefits of transfer when learning to play new games.
Although it is interesting that the DQN learns to play games at human-level performance while assuming very little prior knowledge, the DQN may be learning to play Frostbite and other games in a very different way than people do. One way to examine the differences is by considering the amount of experience required for learning. In Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015), the DQN was compared with a professional gamer who received approximately 2 hours of practice on each of the 49 Atari games (although he or she likely had prior experience with some of the games). The DQN was trained on 200 million frames from each of the games, which equates to approximately 924 hours of game time (about 38 days), or almost 500 times as much experience as the human received.Footnote 2 Additionally, the DQN incorporates experience replay, where each of these frames is replayed approximately eight more times on average over the course of learning.
With the full 924 hours of unique experience and additional replay, the DQN achieved less than 10% of human-level performance during a controlled test session (see DQN in Fig. 3). More recent variants of the DQN perform better, and can even outperform the human tester (Schaul et al. Reference Schaul, Quan, Antonoglou and Silver2016; Stadie et al. Reference Stadie, Levine and Abbeel2016; van Hasselt et al. Reference van Hasselt, Guez and Silver2016; Wang et al. Reference Wang, Schaul, Hessel, Hasselt, Lanctot and de Freitas2016), reaching 83% of the professional gamer's score by incorporating smarter experience replay (Schaul et al. Reference Schaul, Quan, Antonoglou and Silver2016), and 172% by using smarter replay and more efficient parameter sharing (Wang et al. Reference Wang, Schaul, Hessel, Hasselt, Lanctot and de Freitas2016) (see DQN+ and DQN++ in Fig. 3).Footnote 3 But they require a lot of experience to reach this level. The learning curve for the model of Wang et al. (Reference Wang, Schaul, Hessel, Hasselt, Lanctot and de Freitas2016) shows performance is approximately 44% after 200 hours, 8% after 100 hours, and less than 2% after 5 hours (which is close to random play, approximately 1.5%). The differences between the human and machine learning curves suggest that they may be learning different kinds of knowledge, using different learning mechanisms, or both.
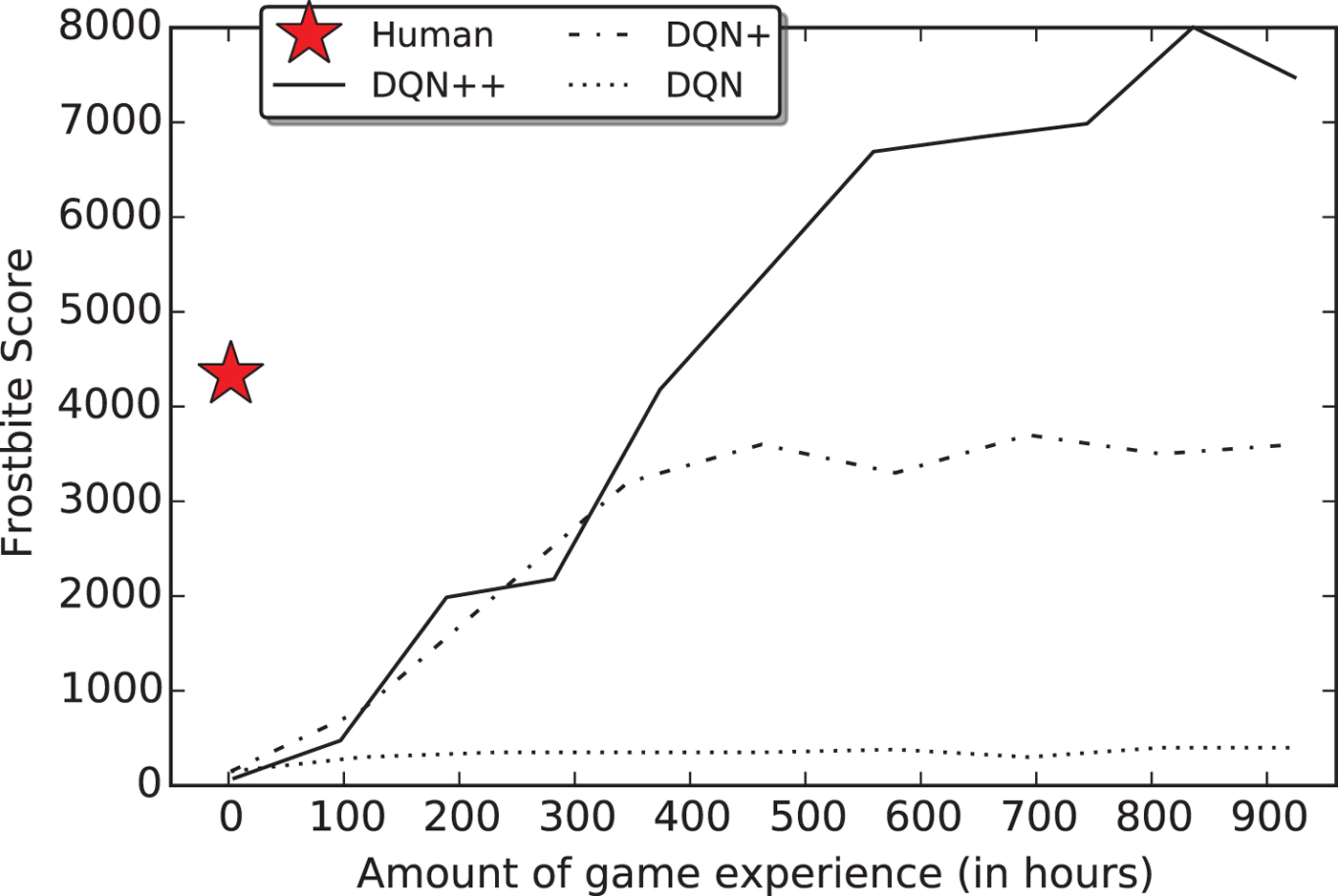
Figure 3. Comparing learning speed for people versus Deep Q-Networks (DQNs). Performance on the Atari 2600 game Frostbite is plotted as a function of game experience (in hours at a frame rate of 60 fps), which does not include additional experience replay. Learning curves and scores are shown from different networks: DQN (Mnih et al. Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015), DQN+ (Schaul et al. Reference Schaul, Quan, Antonoglou and Silver2016), and DQN++ (Wang et al. Reference Wang, Schaul, Hessel, Hasselt, Lanctot and de Freitas2016). Random play achieves a score of 65.2.
The contrast becomes even more dramatic if we look at the very earliest stages of learning. Although both the original DQN and these more recent variants require multiple hours of experience to perform reliably better than random play, even non-professional humans can grasp the basics of the game after just a few minutes of play. We speculate that people do this by inferring a general schema to describe the goals of the game and the object types and their interactions, using the kinds of intuitive theories, model-building abilities and model-based planning mechanisms we describe below. Although novice players may make some mistakes, such as inferring that fish are harmful rather than helpful, they can learn to play better than chance within a few minutes. If humans are able to first watch an expert playing for a few minutes, they can learn even faster. In informal experiments with two of the authors playing Frostbite on a Javascript emulator (http://www.virtualatari.org/soft.php?soft=Frostbite), after watching videos of expert play on YouTube for just 2 minutes, we found that we were able to reach scores comparable to or better than the human expert reported in Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015) after at most 15 to 20 minutes of total practice.Footnote 4
There are other behavioral signatures that suggest fundamental differences in representation and learning between people and the DQN. For example, the game of Frostbite provides incremental rewards for reaching each active ice floe, providing the DQN with the relevant sub-goals for completing the larger task of building an igloo. Without these sub-goals, the DQN would have to take random actions until it accidentally builds an igloo and is rewarded for completing the entire level. In contrast, people likely do not rely on incremental scoring in the same way when figuring out how to play a new game. In Frostbite, it is possible to figure out the higher-level goal of building an igloo without incremental feedback; similarly, sparse feedback is a source of difficulty in other Atari 2600 games such as Montezuma's Revenge, in which people substantially outperform current DQN approaches.
The learned DQN network is also rather inflexible to changes in its inputs and goals. Changing the color or appearance of objects or changing the goals of the network would have devastating consequences on performance if the network is not retrained. Although any specific model is necessarily simplified and should not be held to the standard of general human intelligence, the contrast between DQN and human flexibility is striking nonetheless. For example, imagine you are tasked with playing Frostbite with any one of these new goals:
-
1. Get the lowest possible score.
-
2. Get closest to 100, or 300, or 1,000, or 3,000, or any level, without going over.
-
3. Beat your friend, who's playing next to you, but just barely, not by too much, so as not to embarrass them.
-
4. Go as long as you can without dying.
-
5. Die as quickly as you can.
-
6. Pass each level at the last possible minute, right before the temperature timer hits zero and you die (i.e., come as close as you can to dying from frostbite without actually dying).
-
7. Get to the furthest unexplored level without regard for your score.
-
8. See if you can discover secret Easter eggs.
-
9. Get as many fish as you can.
-
10. Touch all of the individual ice floes on screen once and only once.
-
11. Teach your friend how to play as efficiently as possible.
This range of goals highlights an essential component of human intelligence: people can learn models and use them for arbitrary new tasks and goals. Although neural networks can learn multiple mappings or tasks with the same set of stimuli – adapting their outputs depending on a specified goal – these models require substantial training or reconfiguration to add new tasks (e.g., Collins & Frank Reference Collins and Frank2013; Eliasmith et al. Reference Eliasmith, Stewart, Choo, Bekolay, DeWolf and Rasmussen2012; Rougier et al. Reference Rougier, Noelle, Braver, Cohen and O'Reilly2005). In contrast, people require little or no retraining or reconfiguration, adding new tasks and goals to their repertoire with relative ease.
The Frostbite example is a particularly telling contrast when compared with human play. Even the best deep networks learn gradually over many thousands of game episodes, take a long time to reach good performance, and are locked into particular input and goal patterns. Humans, after playing just a small number of games over a span of minutes, can understand the game and its goals well enough to perform better than deep networks do after almost a thousand hours of experience. Even more impressively, people understand enough to invent or accept new goals, generalize over changes to the input, and explain the game to others. Why are people different? What core ingredients of human intelligence might the DQN and other modern machine learning methods be missing?
One might object that both the Frostbite and Characters challenges draw an unfair comparison between the speed of human learning and neural network learning. We discuss this objection in detail in Section 5, but we feel it is important to anticipate it here as well. To paraphrase one reviewer of an earlier draft of this article, “It is not that DQN and people are solving the same task differently. They may be better seen as solving different tasks. Human learners – unlike DQN and many other deep learning systems – approach new problems armed with extensive prior experience. The human is encountering one in a years-long string of problems, with rich overlapping structure. Humans as a result often have important domain-specific knowledge for these tasks, even before they ‘begin.’ The DQN is starting completely from scratch.”
We agree, and indeed this is another way of putting our point here. Human learners fundamentally take on different learning tasks than today's neural networks, and if we want to build machines that learn and think like people, our machines need to confront the kinds of tasks that human learners do, not shy away from them. People never start completely from scratch, or even close to “from scratch,” and that is the secret to their success. The challenge of building models of human learning and thinking then becomes: How do we bring to bear rich prior knowledge to learn new tasks and solve new problems so quickly? What form does that prior knowledge take, and how is it constructed, from some combination of inbuilt capacities and previous experience? The core ingredients we propose in the next section offer one route to meeting this challenge.
4. Core ingredients of human intelligence
In the Introduction, we laid out what we see as core ingredients of intelligence. Here we consider the ingredients in detail and contrast them with the current state of neural network modeling. Although these are hardly the only ingredients needed for human-like learning and thought (see our discussion of language in sect. 5), they are key building blocks, which are not present in most current learning-based AI systems – certainly not all present together – and for which additional attention may prove especially fruitful. We believe that integrating them will produce significantly more powerful and more human-like learning and thinking abilities than we currently see in AI systems.
Before considering each ingredient in detail, it is important to clarify that by “core ingredient” we do not necessarily mean an ingredient that is innately specified by genetics or must be “built in” to any learning algorithm. We intend our discussion to be agnostic with regards to the origins of the key ingredients. By the time a child or an adult is picking up a new character or learning how to play Frostbite, he or she is armed with extensive real-world experience that deep learning systems do not benefit from – experience that would be hard to emulate in any general sense. Certainly, the core ingredients are enriched by this experience, and some may even be a product of the experience itself. Whether learned, built in, or enriched, the key claim is that these ingredients play an active and important role in producing human-like learning and thought, in ways contemporary machine learning has yet to capture.
4.1. Developmental start-up software
Early in development, humans have a foundational understanding of several core domains (Spelke Reference Spelke, Gentner and Goldin-Meadow2003; Spelke & Kinzler Reference Spelke and Kinzler2007). These domains include number (numerical and set operations), space (geometry and navigation), physics (inanimate objects and mechanics), and psychology (agents and groups). These core domains cleave cognition at its conceptual joints, and each domain is organized by a set of entities and abstract principles relating the entities to each other. The underlying cognitive representations can be understood as “intuitive theories,” with a causal structure resembling a scientific theory (Carey Reference Carey2004; Reference Carey2009; Gopnik et al. Reference Gopnik, Glymour, Sobel, Schulz, Kushnir and Danks2004; Gopnik & Meltzo Reference Gopnik and Meltzoff1999; Gweon et al. Reference Gweon, Tenenbaum and Schulz2010; Schulz Reference Schulz2012b; Wellman & Gelman Reference Wellman and Gelman1992; Reference Wellman, Gelman, Damon and Damon1998). The “child as scientist” proposal further views the process of learning itself as also scientist-like, with recent experiments showing that children seek out new data to distinguish between hypotheses, isolate variables, test causal hypotheses, make use of the data-generating process in drawing conclusions, and learn selectively from others (Cook et al. Reference Cook, Goodman and Schulz2011; Gweon et al. Reference Gweon, Tenenbaum and Schulz2010; Schulz et al. Reference Schulz, Gopnik and Glymour2007; Stahl & Feigenson Reference Stahl and Feigenson2015; Tsividis et al. Reference Tsividis, Gershman, Tenenbaum and Schulz2013). We address the nature of learning mechanisms in Section 4.2.
Each core domain has been the target of a great deal of study and analysis, and together the domains are thought to be shared cross-culturally and partly with non-human animals. All of these domains may be important augmentations to current machine learning, though below, we focus in particular on the early understanding of objects and agents.
4.1.1. Intuitive physics
Young children have a rich knowledge of intuitive physics. Whether learned or innate, important physical concepts are present at ages far earlier than when a child or adult learns to play Frostbite, suggesting these resources may be used for solving this and many everyday physics-related tasks.
At the age of 2 months, and possibly earlier, human infants expect inanimate objects to follow principles of persistence, continuity, cohesion, and solidity. Young infants believe objects should move along smooth paths, not wink in and out of existence, not inter-penetrate and not act at a distance (Spelke Reference Spelke1990; Spelke et al. Reference Spelke, Gutheil and Van de Walle1995). These expectations guide object segmentation in early infancy, emerging before appearance-based cues such as color, texture, and perceptual goodness (Spelke Reference Spelke1990).
These expectations also go on to guide later learning. At around 6 months, infants have already developed different expectations for rigid bodies, soft bodies, and liquids (Rips & Hespos Reference Rips and Hespos2015). Liquids, for example, are expected to go through barriers, while solid objects cannot (Hespos et al. Reference Hespos, Ferry and Rips2009). By their first birthday, infants have gone through several transitions of comprehending basic physical concepts such as inertia, support, containment, and collisions (Baillargeon Reference Baillargeon2004; Baillargeon et al. Reference Baillargeon, Li, Ng, Yuan, Woodward and Neeham2009; Hespos & Baillargeon Reference Hespos and Baillargeon2008).
There is no single agreed-upon computational account of these early physical principles and concepts, and previous suggestions have ranged from decision trees (Baillargeon et al. Reference Baillargeon, Li, Ng, Yuan, Woodward and Neeham2009), to cues, to lists of rules (Siegler & Chen Reference Siegler and Chen1998). A promising recent approach sees intuitive physical reasoning as similar to inference over a physics software engine, the kind of simulators that power modern-day animations and games (Bates et al. Reference Bates, Yildirim, Tenenbaum and Battaglia2015; Battaglia et al. Reference Battaglia, Hamrick and Tenenbaum2013; Gerstenberg et al. Reference Gerstenberg, Goodman, Lagnado, Tenenbaum, Noelle, Dale, Warlaumont, Yoshimi, Matlock, Jennings and Maglio2015; Sanborn et al. Reference Sanborn, Mansingkha and Griffiths2013). According to this hypothesis, people reconstruct a perceptual scene using internal representations of the objects and their physically relevant properties (such as mass, elasticity, and surface friction) and forces acting on objects (such as gravity, friction, or collision impulses). Relative to physical ground truth, the intuitive physical state representation is approximate and probabilistic, and oversimplified and incomplete in many ways. Still, it is rich enough to support mental simulations that can predict how objects will move in the immediate future, either on their own or in responses to forces we might apply.
This “intuitive physics engine” approach enables flexible adaptation to a wide range of everyday scenarios and judgments in a way that goes beyond perceptual cues. For example, (Fig. 4), a physics-engine reconstruction of a tower of wooden blocks from the game Jenga can be used to predict whether (and how) a tower will fall, finding close quantitative fits to how adults make these predictions (Battaglia et al. Reference Battaglia, Hamrick and Tenenbaum2013), as well as simpler kinds of physical predictions that have been studied in infants (Téglás et al. Reference Téglás, Vul, Girotto, Gonzalez, Tenenbaum and Bonatti2011). Simulation-based models can also capture how people make hypothetical or counterfactual predictions: What would happen if certain blocks were taken away, more blocks were added, or the table supporting the tower was jostled? What if certain blocks were glued together, or attached to the table surface? What if the blocks were made of different materials (Styrofoam, lead, ice)? What if the blocks of one color were much heavier than those of other colors? Each of these physical judgments may require new features or new training for a pattern recognition account to work at the same level as the model-based simulator.
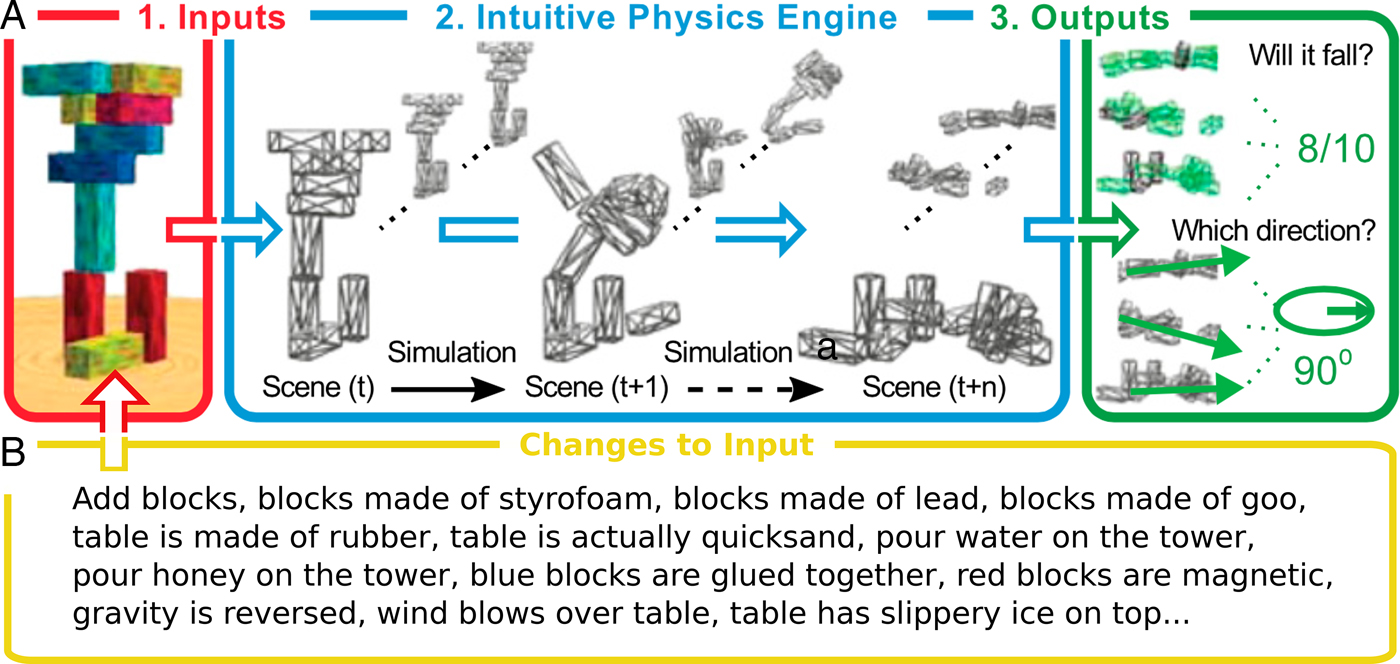
Figure 4. The intuitive physics-engine approach to scene understanding, illustrated through tower stability. (A) The engine takes in inputs through perception, language, memory, and other faculties. It then constructs a physical scene with objects, physical properties, and forces; simulates the scene's development over time; and hands the output to other reasoning systems. (B) Many possible “tweaks” to the input can result in very different scenes, requiring the potential discovery, training, and evaluation of new features for each tweak. Adapted from Battaglia et al. (Reference Battaglia, Hamrick and Tenenbaum2013).
What are the prospects for embedding or acquiring this kind of intuitive physics in deep learning systems? Connectionist models in psychology have previously been applied to physical reasoning tasks such as balance-beam rules (McClelland Reference McClelland1988; Shultz Reference Shultz2003) or rules relating to distance, velocity, and time in motion (Buckingham & Shultz Reference Buckingham and Shultz2000). However, these networks do not attempt to work with complex scenes as input, or a wide range of scenarios and judgments as in Figure 4. A recent paper from Facebook AI researchers (Lerer et al. Reference Lerer, Gross and Fergus2016) represents an exciting step in this direction. Lerer et al. (Reference Lerer, Gross and Fergus2016) trained a deep convolutional network-based system (PhysNet) to predict the stability of block towers from simulated images similar to those in Figure 4A, but with much simpler configurations of two, three, or four cubical blocks stacked vertically. Impressively, PhysNet generalized to simple real images of block towers, matching human performance on these images, meanwhile exceeding human performance on synthetic images. Human and PhysNet confidence were also correlated across towers, although not as strongly as for the approximate probabilistic simulation models and experiments of Battaglia et al. (Reference Battaglia, Hamrick and Tenenbaum2013). One limitation is that PhysNet currently requires extensive training – between 100,000 and 200,000 scenes – to learn judgments for just a single task (will the tower fall?) on a narrow range of scenes (towers with two to four cubes). It has been shown to generalize, but also only in limited ways (e.g., from towers of two and three cubes to towers of four cubes). In contrast, people require far less experience to perform any particular task, and can generalize to many novel judgments and complex scenes with no new training required (although they receive large amounts of physics experience through interacting with the world more generally). Could deep learning systems such as PhysNet capture this flexibility, without explicitly simulating the causal interactions between objects in three dimensions? We are not sure, but we hope this is a challenge they will take on.
Alternatively, instead of trying to make predictions without simulating physics, could neural networks be trained to emulate a general-purpose physics simulator, given the right type and quantity of training data, such as the raw input experienced by a child? This is an active and intriguing area of research, but it too faces significant challenges. For networks trained on object classification, deeper layers often become sensitive to successively higher-level features, from edges to textures to shape-parts to full objects (Yosinski et al. Reference Yosinski, Clune, Bengio, Lipson, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014; Zeiler & Fergus Reference Zeiler, Fergus, Fleet, Pajdla, Schiele and Tuytelaars2014). For deep networks trained on physics-related data, it remains to be seen whether higher layers will encode objects, general physical properties, forces, and approximately Newtonian dynamics. A generic network trained on dynamic pixel data might learn an implicit representation of these concepts, but would it generalize broadly beyond training contexts as people's more explicit physical concepts do? Consider, for example, a network that learns to predict the trajectories of several balls bouncing in a box (Kodratoff & Michalski Reference Kodratoff and Michalski2014). If this network has actually learned something like Newtonian mechanics, then it should be able to generalize to interestingly different scenarios – at a minimum different numbers of differently shaped objects, bouncing in boxes of different shapes and sizes and orientations with respect to gravity, not to mention more severe generalization tests such as all of the tower tasks discussed above, which also fall under the Newtonian domain. Neural network researchers have yet to take on this challenge, but we hope they will. Whether such models can be learned with the kind (and quantity) of data available to human infants is not clear, as we discuss further in Section 5.
It may be difficult to integrate object and physics-based primitives into deep neural networks, but the payoff in terms of learning speed and performance could be great for many tasks. Consider the case of learning to play Frostbite. Although it can be difficult to discern exactly how a network learns to solve a particular task, the DQN probably does not parse a Frostbite screenshot in terms of stable objects or sprites moving according to the rules of intuitive physics (Fig. 2). But incorporating a physics-engine–based representation could help DQNs learn to play games such as Frostbite in a faster and more general way, whether the physics knowledge is captured implicitly in a neural network or more explicitly in a simulator. Beyond reducing the amount of training data, and potentially improving the level of performance reached by the DQN, it could eliminate the need to retrain a Frostbite network if the objects (e.g., birds, ice floes, and fish) are slightly altered in their behavior, reward structure, or appearance. When a new object type such as a bear is introduced, as in the later levels of Frostbite (Fig. 2D), a network endowed with intuitive physics would also have an easier time adding this object type to its knowledge (the challenge of adding new objects was also discussed in Marcus [Reference Marcus1998; Reference Marcus2001]). In this way, the integration of intuitive physics and deep learning could be an important step toward more human-like learning algorithms.
4.1.2. Intuitive psychology
Intuitive psychology is another early-emerging ability with an important influence on human learning and thought. Pre-verbal infants distinguish animate agents from inanimate objects. This distinction is partially based on innate or early-present detectors for low-level cues, such as the presence of eyes, motion initiated from rest, and biological motion (Johnson et al. Reference Johnson, Slaughter and Carey1998; Premack & Premack Reference Premack and Premack1997; Schlottmann et al. Reference Schlottmann, Ray, Mitchell and Demetriou2006; Tremoulet & Feldman Reference Tremoulet and Feldman2000). Such cues are often sufficient but not necessary for the detection of agency.
Beyond these low-level cues, infants also expect agents to act contingently and reciprocally, to have goals, and to take efficient actions toward those goals subject to constraints (Csibra Reference Csibra2008; Csibra et al. Reference Csibra, Biro, Koos and Gergely2003; Spelke & Kinzler Reference Spelke and Kinzler2007). These goals can be socially directed; at around 3 months of age, infants begin to discriminate antisocial agents that hurt or hinder others from neutral agents (Hamlin Reference Hamlin2013; Hamlin et al. Reference Hamlin, Wynn and Bloom2010), and they later distinguish between anti-social, neutral, and pro-social agents (Hamlin et al. Reference Hamlin, Wynn and Bloom2007; Reference Hamlin, Ullman, Tenenbaum, Goodman and Baker2013).
It is generally agreed that infants expect agents to act in a goal-directed, efficient, and socially sensitive fashion (Spelke & Kinzler Reference Spelke and Kinzler2007). What is less agreed on is the computational architecture that supports this reasoning and whether it includes any reference to mental states and explicit goals.
One possibility is that intuitive psychology is simply cues “all the way down” (Schlottmann et al. Reference Schlottmann, Cole, Watts and White2013; Scholl & Gao Reference Scholl, Gao, Rutherford and Kuhlmeier2013), though this would require more and more cues as the scenarios become more complex. Consider, for example, a scenario in which an agent A is moving toward a box, and an agent B moves in a way that blocks A from reaching the box. Infants and adults are likely to interpret B's behavior as “hindering” (Hamlin Reference Hamlin2013). This inference could be captured by a cue that states, “If an agent's expected trajectory is prevented from completion, the blocking agent is given some negative association.”
Although the cue is easily calculated, the scenario is also easily changed to necessitate a different type of cue. Suppose A was already negatively associated (a “bad guy”); acting negatively toward A could then be seen as good (Hamlin Reference Hamlin2013). Or suppose something harmful was in the box, which A did not know about. Now B would be seen as helping, protecting, or defending A. Suppose A knew there was something bad in the box and wanted it anyway. B could be seen as acting paternalistically. A cue-based account would be twisted into gnarled combinations such as, “If an expected trajectory is prevented from completion, the blocking agent is given some negative association, unless that trajectory leads to a negative outcome or the blocking agent is previously associated as positive, or the blocked agent is previously associated as negative, or….”
One alternative to a cue-based account is to use generative models of action choice, as in the Bayesian inverse planning, or Bayesian theory of mind (ToM), models of Baker et al. (Reference Baker, Saxe and Tenenbaum2009) or the naive utility calculus models of Jara-Ettinger et al. (Reference Jara-Ettinger, Gweon, Tenenbaum and Schulz2015) (see also Jern and Kemp [Reference Jern and Kemp2015] and Tauber and Steyvers [Reference Tauber and Steyvers2011] and a related alternative based on predictive coding from Kilner et al. [Reference Kilner, Friston and Frith2007]). These models formalize explicitly mentalistic concepts such as “goal,” “agent,” “planning,” “cost,” “efficiency,” and “belief,” used to describe core psychological reasoning in infancy. They assume adults and children treat agents as approximately rational planners who choose the most efficient means to their goals. Planning computations may be formalized as solutions to Markov decision processes (MDPs) or partially observable Markov decision processes (POMDPs), taking as input utility and belief functions defined over an agent's state-space and the agent's state-action transition functions, and returning a series of actions the agent should perform to most efficiently fulfill their goals (or maximize their utility). By simulating these planning processes, people can predict what agents might do next, or use inverse reasoning from observing a series of actions to infer the utilities and beliefs of agents in a scene. This is directly analogous to how simulation engines can be used for intuitive physics, to predict what will happen next in a scene or to infer objects’ dynamical properties from how they move. It yields similarly flexible reasoning abilities: Utilities and beliefs can be adjusted to take into account how agents might act for a wide range of novel goals and situations. Importantly, unlike in intuitive physics, simulation-based reasoning in intuitive psychology can be nested recursively to understand social interactions. We can think about agents thinking about other agents.
As in the case of intuitive physics, the success that generic deep networks will have in capturing intuitive psychological reasoning will depend in part on the representations humans use. Although deep networks have not yet been applied to scenarios involving theory of mind and intuitive psychology, they could probably learn visual cues, heuristics and summary statistics of a scene that happens to involve agents.Footnote 5 If that is all that underlies human psychological reasoning, a data-driven deep learning approach can likely find success in this domain.
However, it seems to us that any full formal account of intuitive psychological reasoning needs to include representations of agency, goals, efficiency, and reciprocal relations. As with objects and forces, it is unclear whether a complete representation of these concepts (agents, goals, etc.) could emerge from deep neural networks trained in a purely predictive capacity. Similar to the intuitive physics domain, it is possible that with a tremendous number of training trajectories in a variety of scenarios, deep learning techniques could approximate the reasoning found in infancy even without learning anything about goal-directed or socially directed behavior more generally. But this is also unlikely to resemble how humans learn, understand, and apply intuitive psychology unless the concepts are genuine. In the same way that altering the setting of a scene or the target of inference in a physics-related task may be difficult to generalize without an understanding of objects, altering the setting of an agent or their goals and beliefs is difficult to reason about without understanding intuitive psychology.
In introducing the Frostbite challenge, we discussed how people can learn to play the game extremely quickly by watching an experienced player for just a few minutes and then playing a few rounds themselves. Intuitive psychology provides a basis for efficient learning from others, especially in teaching settings with the goal of communicating knowledge efficiently (Shafto et al. Reference Shafto, Goodman and Griffiths2014). In the case of watching an expert play Frostbite, whether or not there is an explicit goal to teach, intuitive psychology lets us infer the beliefs, desires, and intentions of the experienced player. For example, we can learn that the birds are to be avoided from seeing how the experienced player appears to avoid them. We do not need to experience a single example of encountering a bird, and watching Frostbite Bailey die because of the bird, to infer that birds are probably dangerous. It is enough to see that the experienced player's avoidance behavior is best explained as acting under that belief.
Similarly, consider how a sidekick agent (increasingly popular in video games) is expected to help a player achieve his or her goals. This agent can be useful in different ways in different circumstances, such as getting items, clearing paths, fighting, defending, healing, and providing information, all under the general notion of being helpful (Macindoe Reference Macindoe2013). An explicit agent representation can predict how such an agent will be helpful in new circumstances, whereas a bottom-up pixel-based representation is likely to struggle.
There are several ways that intuitive psychology could be incorporated into contemporary deep learning systems. Although it could be built in, intuitive psychology may arise in other ways. Connectionists have argued that innate constraints in the form of hard-wired cortical circuits are unlikely (Elman Reference Elman2005; Elman et al. Reference Elman, Bates, Johnson, Karmiloff-Smith, Parisi and Plunkett1996), but a simple inductive bias, for example, the tendency to notice things that move other things, can bootstrap reasoning about more abstract concepts of agency (Ullman et al. Reference Ullman, Harari and Dorfman2012a).Footnote 6 Similarly, a great deal of goal-directed and socially directed actions can also be boiled down to a simple utility calculus (e.g., Jara-Ettinger et al. Reference Jara-Ettinger, Gweon, Tenenbaum and Schulz2015), in a way that could be shared with other cognitive abilities. Although the origins of intuitive psychology are still a matter of debate, it is clear that these abilities are early emerging and play an important role in human learning and thought, as exemplified in the Frostbite challenge and when learning to play novel video games more broadly.
4.2. Learning as rapid model building
Since their inception, neural networks models have stressed the importance of learning. There are many learning algorithms for neural networks, including the perceptron algorithm (Rosenblatt Reference Rosenblatt1958), Hebbian learning (Hebb Reference Hebb1949), the BCM rule (Bienenstock et al. Reference Bienenstock, Cooper and Munro1982), backpropagation (Rumelhart et al. Reference Rumelhart, Hinton and Williams1986a), the wake-sleep algorithm (Hinton et al. Reference Hinton, Dayan, Frey and Neal1995), and contrastive divergence (Hinton Reference Hinton2002). Whether the goal is supervised or unsupervised learning, these algorithms implement learning as a process of gradual adjustment of connection strengths. For supervised learning, the updates are usually aimed at improving the algorithm's pattern recognition capabilities. For unsupervised learning, the updates work toward gradually matching the statistics of the model's internal patterns with the statistics of the input data.
In recent years, machine learning has found particular success using backpropagation and large data sets to solve difficult pattern recognition problems (see Glossary in Table 1). Although these algorithms have reached human-level performance on several challenging benchmarks, they are still far from matching human-level learning in other ways. Deep neural networks often need more data than people do to solve the same types of problems, whether it is learning to recognize a new type of object or learning to play a new game. When learning the meanings of words in their native language, children make meaningful generalizations from very sparse data (Carey & Bartlett Reference Carey and Bartlett1978; Landau et al. Reference Landau, Smith and Jones1988; Markman Reference Markman1989; Smith et al. Reference Smith, Jones, Landau, Gershkoff-Stowe and Samuelson2002; Xu & Tenenbaum Reference Xu and Tenenbaum2007; although see Horst & Samuelson Reference Horst and Samuelson2008 regarding memory limitations). Children may only need to see a few examples of the concepts hairbrush, pineapple, and lightsaber, before they largely “get it,” grasping the boundary of the infinite set that defines each concept from the infinite set of all possible objects. Children are far more practiced than adults at learning new concepts, learning roughly 9 or 10 new words each day, after beginning to speak through the end of high school (Bloom Reference Bloom2000; Carey Reference Carey, Bresnan, Miller and Halle1978). Yet the ability for rapid “one-shot” learning does not disappear in adulthood. An adult may need to see a single image or movie of a novel two-wheeled vehicle to infer the boundary between this concept and others, allowing him or her to discriminate new examples of that concept from similar-looking objects of a different type (Fig. 1B-i).
Contrasting with the efficiency of human learning, neural networks, by virtue of their generality as highly flexible function approximators, are notoriously data hungry (the bias/variance dilemma [Geman et al. Reference Geman, Bienenstock and Doursat1992]). Benchmark tasks such as the ImageNet data set for object recognition provide hundreds or thousands of examples per class (Krizhevsky et al. Reference Krizhevsky, Sutskever, Hinton, Pereira, Burges, Bottou and Weinberger2012; Russakovsky et al. Reference Russakovsky, Deng, Su, Krause, Satheesh, Ma, Huang, Karpathy, Khosla, Bernstein, Berg and Fei-Fei2015): 1,000 hairbrushes, 1,000 pineapples, and so on. In the context of learning new, handwritten characters or learning to play Frostbite, the MNIST benchmark includes 6,000 examples of each handwritten digit (LeCun et al. Reference LeCun, Bottou, Bengio and Haffner1998), and the DQN of Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015) played each Atari video game for approximately 924 hours of unique training experience (Fig. 3). In both cases, the algorithms are clearly using information less efficiently than a person learning to perform the same tasks.
It is also important to mention that there are many classes of concepts that people learn more slowly. Concepts that are learned in school are usually far more challenging and more difficult to acquire, including mathematical functions, logarithms, derivatives, integrals, atoms, electrons, gravity, DNA, and evolution. There are also domains for which machine learners outperform human learners, such as combing through financial or weather data. But for the vast majority of cognitively natural concepts – the types of things that children learn as the meanings of words – people are still far better learners than machines. This is the type of learning we focus on in this section, which is more suitable for the enterprise of reverse engineering and articulating additional principles that make human learning successful. It also opens the possibility of building these ingredients into the next generation of machine learning and AI algorithms, with potential for making progress on learning concepts that are both easy and difficult for humans to acquire.
Even with just a few examples, people can learn remarkably rich conceptual models. One indicator of richness is the variety of functions that these models support (Markman & Ross Reference Markman and Ross2003; Solomon et al. Reference Solomon, Medin and Lynch1999). Beyond classification, concepts support prediction (Murphy & Ross Reference Murphy and Ross1994; Rips Reference Rips1975), action (Barsalou Reference Barsalou1983), communication (Markman & Makin Reference Markman and Makin1998), imagination (Jern & Kemp Reference Jern and Kemp2013; Ward Reference Ward1994), explanation (Lombrozo Reference Lombrozo2009; Williams & Lombrozo Reference Williams and Lombrozo2010), and composition (Murphy Reference Murphy1988; Osherson & Smith Reference Osherson and Smith1981). These abilities are not independent; rather they hang together and interact (Solomon et al. Reference Solomon, Medin and Lynch1999), coming for free with the acquisition of the underlying concept. Returning to the previous example of a novel two-wheeled vehicle, a person can sketch a range of new instances (Fig. 1B-ii), parse the concept into its most important components (Fig. 1B-iii), or even create a new complex concept through the combination of familiar concepts (Fig. 1B-iv). Likewise, as discussed in the context of Frostbite, a learner who has acquired the basics of the game could flexibly apply his or her knowledge to an infinite set of Frostbite variants (sect. 3.2). The acquired knowledge supports reconfiguration to new tasks and new demands, such as modifying the goals of the game to survive, while acquiring as few points as possible, or to efficiently teach the rules to a friend.
This richness and flexibility suggest that learning as model building is a better metaphor than learning as pattern recognition. Furthermore, the human capacity for one-shot learning suggests that these models are built upon rich domain knowledge rather than starting from a blank slate (Mikolov et al. Reference Mikolov, Joulin and Baroni2016; Mitchell et al. Reference Mitchell, Keller and Kedar-Cabelli1986). In contrast, much of the recent progress in deep learning has been on pattern recognition problems, including object recognition, speech recognition, and (model-free) video game learning, that use large data sets and little domain knowledge.
There has been recent work on other types of tasks, including learning generative models of images (Denton et al. Reference Denton, Chintala, Szlam, Fergus, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Gregor et al. Reference Gregor, Danihelka, Graves, Rezende and Wierstra2015), caption generation (Karpathy & Fei-Fei Reference Karpathy and Fei-Fei2017; Vinyals et al. Reference Vinyals, Toshev, Bengio and Erhan2014; Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015), question answering (Sukhbaatar et al. Reference Sukhbaatar, Szlam, Weston, Fergus, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Weston et al. Reference Weston, Chopra and Bordes2015b), and learning simple algorithms (Graves et al. Reference Graves, Wayne and Danihelka2014; Grefenstette et al. Reference Grefenstette, Hermann, Suleyman, Blunsom, Cortes, Lawrence, Lee, Sugiyama and Garnett2015). We discuss question answering and learning simple algorithms in Section 6.1. Yet, at least for image and caption generation, these tasks have been mostly studied in the big data setting that is at odds with the impressive human ability to generalize from small data sets (although see Rezende et al. [Reference Rezende, Mohamed, Danihelka, Gregor and Wierstra2016] for a deep learning approach to the Character Challenge). And it has been difficult to learn neural network–style representations that effortlessly generalize new tasks that they were not trained on (see Davis & Marcus Reference Davis and Marcus2015; Marcus Reference Marcus1998; Reference Marcus2001). What additional ingredients may be needed to rapidly learn more powerful and more general-purpose representations?
A relevant case study is from our own work on the Characters Challenge (sect. 3.1; Lake Reference Lake2014; Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a). People and various machine learning approaches were compared on their ability to learn new handwritten characters from the world's alphabets. In addition to evaluating several types of deep learning models, we developed an algorithm using Bayesian program learning (BPL) that represents concepts as simple stochastic programs: structured procedures that generate new examples of a concept when executed (Fig. 5A). These programs allow the model to express causal knowledge about how the raw data are formed, and the probabilistic semantics allow the model to handle noise and perform creative tasks. Structure sharing across concepts is accomplished by the compositional re-use of stochastic primitives that can combine in new ways to create new concepts.

Figure 5. A causal, compositional model of handwritten characters. (A) New types are generated compositionally by choosing primitive actions (color coded) from a library (i), combining these sub-parts (ii) to make parts (iii), and combining parts with relations to define simple programs (iv). These programs can create different tokens of a concept (v) that are rendered as binary images (vi). (B) Probabilistic inference allows the model to generate new examples from just one example of a new concept; shown here in a visual Turing test. An example image of a new concept is shown above each pair of grids. One grid was generated by nine people and the other is nine samples from the BPL model. Which grid in each pair (A or B) was generated by the machine? Answers by row: 1,2;1,1. Adapted from Lake et al. (Reference Lake, Salakhutdinov and Tenenbaum2015a).
Note that we are overloading the word model to refer to the BPL framework as a whole (which is a generative model), as well as the individual probabilistic models (or concepts) that it infers from images to represent novel handwritten characters. There is a hierarchy of models: a higher-level program that generates different types of concepts, which are themselves programs that can be run to generate tokens of a concept. Here, describing learning as “rapid model building” refers to the fact that BPL constructs generative models (lower-level programs) that produce tokens of a concept (Fig. 5B).
Learning models of this form allows BPL to perform a challenging one-shot classification task at human-level performance (Fig. 1A-i) and to outperform current deep learning models such as convolutional networks (Koch et al. Reference Koch, Zemel and Salakhutdinov2015).Footnote 7 The representations that BPL learns also enable it to generalize in other, more creative, human-like ways, as evaluated using “visual Turing tests” (e.g., Fig. 5B). These tasks include generating new examples (Figs. 1A-ii and 5B), parsing objects into their essential components (Fig. 1A-iii), and generating new concepts in the style of a particular alphabet (Fig. 1A-iv). The following sections discuss the three main ingredients – compositionality, causality, and learning-to-learn – that were important to the success of this framework and, we believe, are important to understanding human learning as rapid model building more broadly. Although these ingredients fit naturally within a BPL or a probabilistic program induction framework, they could also be integrated into deep learning models and other types of machine learning algorithms, prospects we discuss in more detail below.
4.2.1. Compositionality
Compositionality is the classic idea that new representations can be constructed through the combination of primitive elements. In computer programming, primitive functions can be combined to create new functions, and these new functions can be further combined to create even more complex functions. This function hierarchy provides an efficient description of higher-level functions, such as a hierarchy of parts for describing complex objects or scenes (Bienenstock et al. Reference Bienenstock, Geman, Potter, Mozer, Jordan and Petsche1997). Compositionality is also at the core of productivity: an infinite number of representations can be constructed from a finite set of primitives, just as the mind can think an infinite number of thoughts, utter or understand an infinite number of sentences, or learn new concepts from a seemingly infinite space of possibilities (Fodor Reference Fodor1975; Fodor & Pylyshyn Reference Fodor and Pylyshyn1988; Marcus Reference Marcus2001; Piantadosi Reference Piantadosi2011).
Compositionality has been broadly influential in both AI and cognitive science, especially as it pertains to theories of object recognition, conceptual representation, and language. Here, we focus on compositional representations of object concepts for illustration. Structural description models represent visual concepts as compositions of parts and relations, which provides a strong inductive bias for constructing models of new concepts (Biederman Reference Biederman1987; Hummel & Biederman Reference Hummel and Biederman1992; Marr & Nishihara Reference Marr and Nishihara1978; van den Hengel et al. Reference van den Hengel, Russell, Dick, Bastian, Pooley, Fleming and Agapitol2015; Winston Reference Winston1975). For instance, the novel two-wheeled vehicle in Figure 1B might be represented as two wheels connected by a platform, which provides the base for a post, which holds the handlebars, and so on. Parts can themselves be composed of sub-parts, forming a “partonomy” of part-whole relationships (Miller & Johnson-Laird Reference Miller and Johnson-Laird1976; Tversky & Hemenway Reference Tversky and Hemenway1984). In the novel vehicle example, the parts and relations can be shared and re-used from existing related concepts, such as cars, scooters, motorcycles, and unicycles. Because the parts and relations are themselves a product of previous learning, their facilitation of the construction of new models is also an example of learning-to-learn, another ingredient that is covered below. Although compositionality and learning-to-learn fit naturally together, there are also forms of compositionality that rely less on previous learning, such as the bottom-up, parts-based representation of Hoffman and Richards (Reference Hoffman and Richards1984).
Learning models of novel handwritten characters can be operationalized in a similar way. Handwritten characters are inherently compositional, where the parts are pen strokes, and relations describe how these strokes connect to each other. Lake et al. (Reference Lake, Salakhutdinov and Tenenbaum2015a) modeled these parts using an additional layer of compositionality, where parts are complex movements created from simpler sub-part movements. New characters can be constructed by combining parts, sub-parts, and relations in novel ways (Fig. 5). Compositionality is also central to the construction of other types of symbolic concepts beyond characters, where new spoken words can be created through a novel combination of phonemes (Lake et al. Reference Lake, Lee, Glass and Tenenbaum2014), or a new gesture or dance move can be created through a combination of more primitive body movements.
An efficient representation for Frostbite should be similarly compositional and productive. A scene from the game is a composition of various object types, including birds, fish, ice floes, igloos, and so on (Fig. 2). Representing this compositional structure explicitly is both more economical and better for generalization, as noted in previous work on object-oriented reinforcement learning (Diuk et al. Reference Diuk, Cohen and Littman2008). Many repetitions of the same objects are present at different locations in the scene, and therefore, representing each as an identical instance of the same object with the same properties is important for efficient representation and quick learning of the game. Further, new levels may contain different numbers and combinations of objects, where a compositional representation of objects – using intuitive physics and intuitive psychology as glue – would aid in making these crucial generalizations (Fig. 2D).
Deep neural networks have at least a limited notion of compositionality. Networks trained for object recognition encode part-like features in their deeper layers (Zeiler & Fergus Reference Zeiler, Fergus, Fleet, Pajdla, Schiele and Tuytelaars2014), whereby the presentation of new types of objects can activate novel combinations of feature detectors. Similarly, a DQN trained to play Frostbite may learn to represent multiple replications of the same object with the same features, facilitated by the invariance properties of a convolutional neural network architecture. Recent work has shown how this type of compositionality can be made more explicit, where neural networks can be used for efficient inference in more structured generative models (both neural networks and three-dimensional scene models) that explicitly represent the number of objects in a scene (Eslami et al. Reference Eslami, Heess, Weber, Tassa, Kavukcuoglu, Hinton, Lee, Sugiyama, Luxburg, Guyon and Garnett2016). Beyond the compositionality inherent in parts, objects, and scenes, compositionality can also be important at the level of goals and sub-goals. Recent work on hierarchical DQNs shows that by providing explicit object representations to a DQN, and then defining sub-goals based on reaching those objects, DQNs can learn to play games with sparse rewards (such as Montezuma's Revenge) by combining these sub-goals together to achieve larger goals (Kulkarni et al. Reference Kulkarni, Narasimhan, Saeedi and Tenenbaum2016).
We look forward to seeing these new ideas continue to develop, potentially providing even richer notions of compositionality in deep neural networks that lead to faster and more flexible learning. To capture the full extent of the mind's compositionality, a model must include explicit representations of objects, identity, and relations, all while maintaining a notion of “coherence” when understanding novel configurations. Coherence is related to our next principle, causality, which is discussed in the section that follows.
4.2.2. Causality
In concept learning and scene understanding, causal models represent hypothetical real-world processes that produce the perceptual observations. In control and reinforcement learning, causal models represent the structure of the environment, such as modeling state-to-state transitions or action/state-to-state transitions.
Concept learning and vision models that use causality are usually generative (as opposed to discriminative; see Glossary in Table 1), but not every generative model is also causal. Although a generative model describes a process for generating data, or at least assigns a probability distribution over possible data points, this generative process may not resemble how the data are produced in the real world. Causality refers to the subclass of generative models that resemble, at an abstract level, how the data are actually generated. Although generative neural networks such as Deep Belief Networks (Hinton et al. Reference Hinton, Osindero and Teh2006) or variational auto-encoders (Gregor et al. Reference Gregor, Besse, Rezende, Danihelka, Wierstra, Lee, Sugiyama, Luxburg, Guyon and Garnett2016; Kingma et al. Reference Kingma, Rezende, Mohamed, Welling, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014) may generate compelling handwritten digits, they mark one end of the “causality spectrum,” because the steps of the generative process bear little resemblance to steps in the actual process of writing. In contrast, the generative model for characters using BPL does resemble the steps of writing, although even more causally faithful models are possible.
Causality has been influential in theories of perception. “Analysis-by-synthesis” theories of perception maintain that sensory data can be more richly represented by modeling the process that generated it (Bever & Poeppel Reference Bever and Poeppel2010; Eden Reference Eden1962; Halle & Stevens Reference Halle and Stevens1962; Neisser Reference Neisser1966). Relating data to their causal source provides strong priors for perception and learning, as well as a richer basis for generalizing in new ways and to new tasks. The canonical examples of this approach are speech and visual perception. For example, Liberman et al. (Reference Liberman, Cooper, Shankweiler and Studdert-Kennedy1967) argued that the richness of speech perception is best explained by inverting the production plan, at the level of vocal tract movements, to explain the large amounts of acoustic variability and the blending of cues across adjacent phonemes. As discussed, causality does not have to be a literal inversion of the actual generative mechanisms, as proposed in the motor theory of speech. For the BPL of learning handwritten characters, causality is operationalized by treating concepts as motor programs, or abstract causal descriptions of how to produce examples of the concept, rather than concrete configurations of specific muscles (Fig. 5A). Causality is an important factor in the model's success in classifying and generating new examples after seeing just a single example of a new concept (Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a) (Fig. 5B).
Causal knowledge has also been shown to influence how people learn new concepts; providing a learner with different types of causal knowledge changes how he or she learns and generalizes. For example, the structure of the causal network underlying the features of a category influences how people categorize new examples (Rehder Reference Rehder2003; Rehder & Hastie Reference Rehder and Hastie2001). Similarly, as related to the Characters Challenge, the way people learn to write a novel handwritten character influences later perception and categorization (Freyd Reference Freyd1983; Reference Freyd1987).
To explain the role of causality in learning, conceptual representations have been likened to intuitive theories or explanations, providing the glue that lets core features stick, whereas other equally applicable features wash away (Murphy & Medin Reference Murphy and Medin1985). Borrowing examples from Murphy and Medin (Reference Murphy and Medin1985), the feature “flammable” is more closely attached to wood than money because of the underlying causal roles of the concepts, even though the feature is equally applicable to both. These causal roles derive from the functions of objects. Causality can also glue some features together by relating them to a deeper underlying cause, explaining why some features such as “can fly,” “has wings,” and “has feathers” co-occur across objects, whereas others do not.
Beyond concept learning, people also understand scenes by building causal models. Human-level scene understanding involves composing a story that explains the perceptual observations, drawing upon and integrating the ingredients of intuitive physics, intuitive psychology, and compositionality. Perception without these ingredients, and absent the causal glue that binds them, can lead to revealing errors. Consider image captions generated by a deep neural network (Fig. 6) (Karpathy & Fei-Fei Reference Karpathy and Fei-Fei2017). In many cases, the network gets the key objects in a scene correct, but fails to understand the physical forces at work, the mental states of the people, or the causal relationships between the objects. In other words, it does not build the right causal model of the data.

Figure 6. Perceiving scenes without intuitive physics, intuitive psychology, compositionality, and causality. Image captions are generated by a deep neural network (Karpathy & Fei-Fei Reference Karpathy and Fei-Fei2017) using code from github.com/karpathy/neuraltalk2. Image credits: Gabriel Villena Fernández (left), TVBS Taiwan/Agence France-Presse (middle), and AP Photo/Dave Martin (right). Similar examples using images from Reuters news can be found at twitter.com/interesting_jpg.
There have been steps toward deep neural networks and related approaches that learn causal models. Lopez-Paz et al. (Reference Lopez-Paz, Muandet, Scholköpf and Tolstikhin2015) introduced a discriminative, data-driven framework for distinguishing the direction of causality from examples. Although it outperforms existing methods on various causal prediction tasks, it is unclear how to apply the approach to inferring rich hierarchies of latent causal variables, as needed for the Frostbite Challenge and especially the Characters Challenge. Graves (Reference Graves2014) learned a generative model of cursive handwriting using a recurrent neural network trained on handwriting data. Although it synthesizes impressive examples of handwriting in various styles, it requires a large training corpus and has not been applied to other tasks. The DRAW network performs both recognition and generation of handwritten digits using recurrent neural networks with a window of attention, producing a limited circular area of the image at each time step (Gregor et al. Reference Gregor, Danihelka, Graves, Rezende and Wierstra2015). A more recent variant of DRAW was applied to generating examples of a novel character from just a single training example (Rezende et al. Reference Rezende, Mohamed, Danihelka, Gregor and Wierstra2016). The model demonstrates an impressive ability to make plausible generalizations that go beyond the training examples, yet it generalizes too broadly in other cases, in ways that are not especially human-like. It is not clear that it could yet pass any of the “visual Turing tests” in Lake et al. (Reference Lake, Salakhutdinov and Tenenbaum2015a) (Fig. 5B), although we hope DRAW-style networks will continue to be extended and enriched, and could be made to pass these tests.
Incorporating causality may greatly improve these deep learning models; they were trained without access to causal data about how characters are actually produced, and without any incentive to learn the true causal process. An attentional window is only a crude approximation of the true causal process of drawing with a pen, and in Rezende et al. (Reference Rezende, Mohamed, Danihelka, Gregor and Wierstra2016) the attentional window is not pen-like at all, although a more accurate pen model could be incorporated. We anticipate that these sequential generative neural networks could make sharper one-shot inferences, with the goal of tackling the full Characters Challenge by incorporating additional causal, compositional, and hierarchical structure (and by continuing to use learning-to-learn, described next), potentially leading to a more computationally efficient and neurally grounded variant of the BPL model of handwritten characters (Fig. 5).
A causal model of Frostbite would have to be more complex, gluing together object representations and explaining their interactions with intuitive physics and intuitive psychology, much like the game engine that generates the game dynamics and, ultimately, the frames of pixel images. Inference is the process of inverting this causal generative model, explaining the raw pixels as objects and their interactions, such as the agent stepping on an ice floe to deactivate it or a crab pushing the agent into the water (Fig. 2). Deep neural networks could play a role in two ways: by serving as a bottom-up proposer to make probabilistic inference more tractable in a structured generative model (sect. 4.3.1) or by serving as the causal generative model if imbued with the right set of ingredients.
4.2.3. Learning-to-learn
When humans or machines make inferences that go far beyond the data, strong prior knowledge (or inductive biases or constraints) must be making up the difference (Geman et al. Reference Geman, Bienenstock and Doursat1992; Griffiths et al. Reference Griffiths, Chater, Kemp, Perfors and Tenenbaum2010; Tenenbaum et al. Reference Tenenbaum, Kemp, Griffiths and Goodman2011). One way people acquire this prior knowledge is through “learning-to-learn,” a term introduced by Harlow (Reference Harlow1949) and closely related to the machine learning notions of “transfer learning,” “multitask learning,” and “representation learning.” These terms refer to ways that learning a new task or a new concept can be accelerated through previous or parallel learning of other related tasks or other related concepts. The strong priors, constraints, or inductive bias needed to learn a particular task quickly are often shared to some extent with other related tasks. A range of mechanisms have been developed to adapt the learner's inductive bias as they learn specific tasks and then apply these inductive biases to new tasks.
In hierarchical Bayesian modeling (Gelman et al. Reference Gelman, Carlin, Stern and Rubin2004), a general prior on concepts is shared by multiple specific concepts, and the prior itself is learned over the course of learning the specific concepts (Salakhutdinov et al. Reference Salakhutdinov, Tenenbaum and Torralba2012; Reference Salakhutdinov, Tenenbaum and Torralba2013). These models have been used to explain the dynamics of human learning-to-learn in many areas of cognition, including word learning, causal learning, and learning intuitive theories of physical and social domains (Tenenbaum et al. Reference Tenenbaum, Kemp, Griffiths and Goodman2011). In machine vision, for deep convolutional networks or other discriminative methods that form the core of recent recognition systems, learning-to-learn can occur through the sharing of features between the models learned for old objects or old tasks and the models learned for new objects or new tasks (Anselmi et al. Reference Anselmi, Leibo, Rosasco, Mutch, Tacchetti and Poggio2016; Baxter Reference Baxter2000; Bottou Reference Bottou2014; Lopez-Paz et al. Reference Lopez-Paz, Bottou, Scholköpf and Vapnik2016; Rusu et al. Reference Rusu, Rabinowitz, Desjardins, Soyer, Kirkpatrick, Kavukcuoglu, Pascanu and Hadsell2016; Salakhutdinov et al. Reference Salakhutdinov, Torralba and Tenenbaum2011; Srivastava & Salakhutdinov, Reference Srivastava, Salakhutdinov, Burges, Bottou, Welling, Ghagramani and Weinberger2013; Torralba et al. Reference Torralba, Murphy and Freeman2007; Zeiler & Fergus Reference Zeiler, Fergus, Fleet, Pajdla, Schiele and Tuytelaars2014). Neural networks can also learn-to-learn by optimizing hyper-parameters, including the form of their weight update rule (Andrychowicz et al. Reference Andrychowicz, Denil, Gomez, Hoffman, Pfau, Schaul, Shillingford, de Freitas, Lee, Sugiyama, Luxburg, Guyon and Garnett2016), over a set of related tasks.
Although transfer learning and multitask learning are already important themes across AI, and in deep learning in particular, they have not yet led to systems that learn new tasks as rapidly and flexibly as humans do. Capturing more human-like learning-to-learn dynamics in deep networks and other machine learning approaches could facilitate much stronger transfer to new tasks and new problems. To gain the full benefit that humans get from learning-to-learn, however, AI systems might first need to adopt the more compositional (or more language-like, see sect. 5) and causal forms of representations that we have argued for above.
We can see this potential in both of our challenge problems. In the Characters Challenge as presented in Lake et al. (Reference Lake, Salakhutdinov and Tenenbaum2015a), all viable models use “pre-training” on many character concepts in a background set of alphabets to tune the representations they use to learn new character concepts in a test set of alphabets. But to perform well, current neural network approaches require much more pre-training than do people or our Bayesian program learning approach. Humans typically learn only one or a few alphabets, and even with related drawing experience, this likely amounts to the equivalent of a few hundred character-like visual concepts at most. For BPL, pre-training with characters in only five alphabets (for around 150 character types in total) is sufficient to perform human-level one-shot classification and generation of new examples. With this level of pre-training, current neural networks perform much worse on classification and have not even attempted generation; they are still far from solving the Characters Challenge.Footnote 8
We cannot be sure how people get to the knowledge they have in this domain, but we do understand how this works in BPL, and we think people might be similar. BPL transfers readily to new concepts because it learns about object parts, sub-parts, and relations, capturing learning about what each concept is like and what concepts are like in general. It is crucial that learning-to-learn occurs at multiple levels of the hierarchical generative process. Previously learned primitive actions and larger generative pieces can be re-used and re-combined to define new generative models for new characters (Fig. 5A). Further transfer occurs by learning about the typical levels of variability within a typical generative model. This provides knowledge about how far and in what ways to generalize when we have seen only one example of a new character, which on its own could not possibly carry any information about variance. BPL could also benefit from deeper forms of learning-to-learn than it currently does. Some of the important structure it exploits to generalize well is built in to the prior and not learned from the background pre-training, whereas people might learn this knowledge, and ultimately, a human-like machine learning system should as well.
Analogous learning-to-learn occurs for humans in learning many new object models, in vision and cognition: Consider the novel two-wheeled vehicle in Figure 1B, where learning-to-learn can operate through the transfer of previously learned parts and relations (sub-concepts such as wheels, motors, handle bars, attached, powered by) that reconfigure compositionally to create a model of the new concept. If deep neural networks could adopt similarly compositional, hierarchical, and causal representations, we expect they could benefit more from learning-to-learn.
In the Frostbite Challenge, and in video games more generally, there is a similar interdependence between the form of the representation and the effectiveness of learning-to-learn. People seem to transfer knowledge at multiple levels, from low-level perception to high-level strategy, exploiting compositionality at all levels. Most basically, they immediately parse the game environment into objects, types of objects, and causal relations between them. People also understand that video games like these have goals, which often involve approaching or avoiding objects based on their type. Whether the person is a child or a seasoned gamer, it seems obvious that interacting with the birds and fish will change the game state in some way, either good or bad, because video games typically yield costs or rewards for these types of interactions (e.g., dying or points). These types of hypotheses can be quite specific and rely on prior knowledge: When the polar bear first appears and tracks the agent's location during advanced levels (Fig. 2D), an attentive learner is sure to avoid it. Depending on the level, ice floes can be spaced far apart (Fig. 2A–C) or close together (Fig. 2D), suggesting the agent may be able to cross some gaps, but not others. In this way, general world knowledge and previous video games may help inform exploration and generalization in new scenarios, helping people learn maximally from a single mistake or avoid mistakes altogether.
Deep reinforcement learning systems for playing Atari games have had some impressive successes in transfer learning, but they still have not come close to learning to play new games as quickly as humans can. For example, Parisotto et al. (Reference Parisotto, Ba and Salakhutdinov2016) present the “actor-mimic” algorithm that first learns 13 Atari games by watching an expert network play and trying to mimic the expert network action selection and/or internal states (for about 4 million frames of experience each, or 18.5 hours per game). This algorithm can then learn new games faster than a randomly initialized DQN: Scores that might have taken 4 or 5 million frames of learning to reach might now be reached after 1 or 2 million frames of practice. But anecdotally, we find that humans can still reach these scores with a few minutes of practice, requiring far less experience than the DQNs.
In sum, the interaction between representation and previous experience may be key to building machines that learn as fast as people. A deep learning system trained on many video games may not, by itself, be enough to learn new games as quickly as people. Yet, if such a system aims to learn compositionally structured causal models of each game – built on a foundation of intuitive physics and psychology – it could transfer knowledge more efficiently and thereby learn new games much more quickly.
4.3. Thinking Fast
The previous section focused on learning rich models from sparse data and proposed ingredients for achieving these human-like learning abilities. These cognitive abilities are even more striking when considering the speed of perception and thought: the amount of time required to understand a scene, think a thought, or choose an action. In general, richer and more structured models require more complex and slower inference algorithms, similar to how complex models require more data, making the speed of perception and thought all the more remarkable.
The combination of rich models with efficient inference suggests another way psychology and neuroscience may usefully inform AI. It also suggests an additional way to build on the successes of deep learning, where efficient inference and scalable learning are important strengths of the approach. This section discusses possible paths toward resolving the conflict between fast inference and structured representations, including Helmholtz machine–style approximate inference in generative models (Dayan et al. Reference Dayan, Hinton, Neal and Zemel1995; Hinton et al. Reference Hinton, Dayan, Frey and Neal1995) and cooperation between model-free and model-based reinforcement learning systems.
4.3.1. Approximate inference in structured models
Hierarhical Bayesian models operating over probabilistic programs (Goodman et al. Reference Goodman, Mansinghka, Roy, Bonawitz and Tenenbaum2008; Lake et al. Reference Lake, Salakhutdinov and Tenenbaum2015a; Tenenbaum et al. Reference Tenenbaum, Kemp, Griffiths and Goodman2011) are equipped to deal with theory-like structures and rich causal representations of the world, yet there are formidable algorithmic challenges for efficient inference. Computing a probability distribution over an entire space of programs is usually intractable, and often even finding a single high-probability program poses an intractable search problem. In contrast, whereas representing intuitive theories and structured causal models is less natural in deep neural networks, recent progress has demonstrated the remarkable effectiveness of gradient-based learning in high-dimensional parameter spaces. A complete account of learning and inference must explain how the brain does so much with limited computational resources (Gershman et al. Reference Gershman, Horvitz and Tenenbaum2015; Vul et al. Reference Vul, Goodman, Griffiths and Tenenbaum2014).
Popular algorithms for approximate inference in probabilistic machine learning have been proposed as psychological models (see Griffiths et al. [Reference Griffiths, Vul and Sanborn2012] for a review). Most prominently, it has been proposed that humans can approximate Bayesian inference using Monte Carlo methods, which stochastically sample the space of possible hypotheses and evaluate these samples according to their consistency with the data and prior knowledge (Bonawitz et al. Reference Bonawitz, Denison, Griffiths and Gopnik2014; Gershman et al. Reference Gershman, Vul and Tenenbaum2012; Ullman et al. Reference Ullman, Goodman and Tenenbaum2012b; Vul et al. Reference Vul, Goodman, Griffiths and Tenenbaum2014). Monte Carlo sampling has been invoked to explain behavioral phenomena ranging from children's response variability (Bonawitz et al. Reference Bonawitz, Denison, Griffiths and Gopnik2014), to garden-path effects in sentence processing (Levy et al. Reference Levy, Reali and Griffiths2009) and perceptual multistability (Gershman et al. Reference Gershman, Vul and Tenenbaum2012; Moreno-Bote et al. Reference Moreno-Bote, Knill and Pouget2011). Moreover, we are beginning to understand how such methods could be implemented in neural circuits (Buesing et al. Reference Buesing, Bill, Nessler and Maass2011; Huang & Rao Reference Huang, Rao, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014; Pecevski et al. Reference Pecevski, Buesing and Maass2011).Footnote 9
Although Monte Carlo methods are powerful and come with asymptotic guarantees, it is challenging to make them work on complex problems like program induction and theory learning. When the hypothesis space is vast, and only a few hypotheses are consistent with the data, how can good models be discovered without exhaustive search? In at least some domains, people may not have an especially clever solution to this problem, instead grappling with the full combinatorial complexity of theory learning (Ullman et al. Reference Ullman, Goodman and Tenenbaum2012b). Discovering new theories can be slow and arduous, as testified by the long time scale of cognitive development, and learning in a saltatory fashion (rather than through gradual adaptation) is characteristic of aspects of human intelligence, including discovery and insight during development (Schulz Reference Schulz2012b), problem-solving (Sternberg & Davidson Reference Sternberg and Davidson1995), and epoch-making discoveries in scientific research (Langley et al. Reference Langley, Bradshaw, Simon and Zytkow1987). Discovering new theories can also occur much more quickly. A person learning the rules of Frostbite will probably undergo a loosely ordered sequence of “Aha!” moments: He or she will learn that jumping on ice floes causes them to change color, that changing the color of ice floes causes an igloo to be constructed piece-by-piece, that birds make him or her lose points, that fish make him or her gain points, that he or she can change the direction of ice floes at the cost of one igloo piece, and so on. These little fragments of a “Frostbite theory” are assembled to form a causal understanding of the game relatively quickly, in what seems more like a guided process than arbitrary proposals in a Monte Carlo inference scheme. Similarly, as described in the Characters Challenge, people can quickly infer motor programs to draw a new character in a similarly guided processes.
For domains where program or theory learning occurs quickly, it is possible that people employ inductive biases not only to evaluate hypotheses, but also to guide hypothesis selection. Schulz (Reference Schulz2012b) has suggested that abstract structural properties of problems contain information about the abstract forms of their solutions. Even without knowing the answer to the question, “Where is the deepest point in the Pacific Ocean?” one still knows that the answer must be a location on a map. The answer “20 inches” to the question, “What year was Lincoln born?” can be invalidated a priori, even without knowing the correct answer. In recent experiments, Tsividis et al. (Reference Tsividis, Tenenbaum and Schulz2015) found that children can use high-level abstract features of a domain to guide hypothesis selection, by reasoning about distributional properties like the ratio of seeds to flowers, and dynamical properties like periodic or monotonic relationships between causes and effects (see also Magid et al. Reference Magid, Sheskin and Schulz2015).
How might efficient mappings from questions to a plausible subset of answers be learned? Recent work in AI, spanning both deep learning and graphical models, has attempted to tackle this challenge by “amortizing” probabilistic inference computations into an efficient feed-forward mapping (Eslami et al. Reference Eslami, Tarlow, Kohli, Winn, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014; Heess et al. Reference Heess, Tarlow, Winn, Pereira, Burges, Bottou and Weinberger2013; Mnih & Gregor, Reference Mnih and Gregor2014; Stuhlmüller et al. Reference Stuhlmüller, Taylor, Goodman, Burges, Bottou, Welling, Ghagramani and Weinberger2013). We can also think of this as “learning to do inference,” which is independent from the ideas of learning as model building discussed in the previous section. These feed-forward mappings can be learned in various ways, for example, using paired generative/recognition networks (Dayan et al. Reference Dayan, Hinton, Neal and Zemel1995; Hinton et al. Reference Hinton, Dayan, Frey and Neal1995) and variational optimization (Gregor et al. Reference Gregor, Danihelka, Graves, Rezende and Wierstra2015; Mnih & Gregor Reference Mnih and Gregor2014; Rezende et al. Reference Rezende, Mohamed and Wierstra2014), or nearest-neighbor density estimation (Kulkarni et al. Reference Kulkarni, Kohli, Tenenbaum and Mansinghka2015a; Stuhlmüller et al. Reference Stuhlmüller, Taylor, Goodman, Burges, Bottou, Welling, Ghagramani and Weinberger2013). One implication of amortization is that solutions to different problems will become correlated because of the sharing of amortized computations. Some evidence for inferential correlations in humans was reported by Gershman and Goodman (Reference Gershman and Goodman2014). This trend is an avenue of potential integration of deep learning models with probabilistic models and probabilistic programming: Training neural networks to help perform probabilistic inference in a generative model or a probabilistic program (Eslami et al. Reference Eslami, Heess, Weber, Tassa, Kavukcuoglu, Hinton, Lee, Sugiyama, Luxburg, Guyon and Garnett2016; Kulkarni et al. Reference Kulkarni, Whitney, Kohli and Tenenbaum2015b; Yildirim et al. Reference Yildirim, Kulkarni, Freiwald and Tenenbaum2015). Another avenue for potential integration is through differentiable programming (Dalrymple Reference Dalrymple2016), by ensuring that the program-like hypotheses are differentiable and thus learnable via gradient descent – a possibility discussed in the concluding section (Section 6.1).
4.3.2. Model-based and model-free reinforcement learning
The DQN introduced by Mnih et al. (Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015) used a simple form of model-free reinforcement learning in a deep neural network that allows for fast selection of actions. There is indeed substantial evidence that the brain uses similar model-free learning algorithms in simple associative learning or discrimination learning tasks (see Niv Reference Niv2009, for a review). In particular, the phasic firing of midbrain dopaminergic neurons is qualitatively (Schultz et al. Reference Schultz, Dayan and Montague1997) and quantitatively (Bayer & Glimcher Reference Bayer and Glimcher2005) consistent with the reward prediction error that drives updating of model-free value estimates.
Model-free learning is not, however, the whole story. Considerable evidence suggests that the brain also has a model-based learning system, responsible for building a “cognitive map” of the environment and using it to plan action sequences for more complex tasks (Daw et al. Reference Daw, Niv and Dayan2005; Dolan & Dayan Reference Dolan and Dayan2013). Model-based planning is an essential ingredient of human intelligence, enabling flexible adaptation to new tasks and goals; it is where all of the rich model-building abilities discussed in the previous sections earn their value as guides to action. As we argued in our discussion of Frostbite, one can design numerous variants of this simple video game that are identical except for the reward function; that is, governed by an identical environment model of state-action–dependent transitions. We conjecture that a competent Frostbite player can easily shift behavior appropriately, with little or no additional learning, and it is hard to imagine a way of doing that other than having a model-based planning approach in which the environment model can be modularly combined with arbitrary new reward functions and then deployed immediately for planning. One boundary condition on this flexibility is the fact that the skills become “habitized” with routine application, possibly reflecting a shift from model-based to model-free control. This shift may arise from a rational arbitration between learning systems to balance the trade-off between flexibility and speed (Daw et al. Reference Daw, Niv and Dayan2005; Keramati et al. Reference Keramati, Dezfouli and Piray2011).
Similarly to how probabilistic computations can be amortized for efficiency (see previous section), plans can be amortized into cached values by allowing the model-based system to simulate training data for the model-free system (Sutton Reference Sutton1990). This process might occur offline (e.g., in dreaming or quiet wakefulness), suggesting a form of consolidation in reinforcement learning (Gershman et al. Reference Gershman, Markman and Otto2014). Consistent with the idea of cooperation between learning systems, a recent experiment demonstrated that model-based behavior becomes automatic over the course of training (Economides et al. Reference Economides, Kurth-Nelson, Lübbert, Guitart-Masip and Dolan2015). Thus, a marriage of flexibility and efficiency might be achievable if we use the human reinforcement learning systems as guidance.
Intrinsic motivation also plays an important role in human learning and behavior (Berlyne Reference Berlyne1966; Harlow Reference Harlow1950; Ryan & Deci Reference Ryan and Deci2007). Although much of the previous discussion assumes the standard view of behavior as seeking to maximize reward and minimize punishment, all externally provided rewards are reinterpreted according to the “internal value” of the agent, which may depend on the current goal and mental state. There may also be an intrinsic drive to reduce uncertainty and construct models of the environment (Edelman Reference Edelman2015; Schmidhuber Reference Schmidhuber2015), closely related to learning-to-learn and multitask learning. Deep reinforcement learning is only just starting to address intrinsically motivated learning (Kulkarni et al. Reference Kulkarni, Narasimhan, Saeedi and Tenenbaum2016; Mohamed & Rezende Reference Mohamed, Rezende, Cortes, Lawrence, Lee, Sugiyama and Garnett2015).
5. Responses to common questions
In disussing the arguments in this article with colleagues, three lines of questioning or critiques have frequently arisen. We think it is helpful to address these points directly, to maximize the potential for moving forward together.
5.1. Comparing the learning speeds of humans and neural networks on specific tasks is not meaningful, because humans have extensive prior experience
It may seem unfair to compare neural networks and humans on the amount of training experience required to perform a task, such as learning to play new Atari games or learning new handwritten characters, when humans have had extensive prior experience that these networks have not benefited from. People have had many hours playing other games, and experience reading or writing many other handwritten characters, not to mention experience in a variety of more loosely related tasks. If neural networks were “pre-trained” on the same experience, the argument goes, then they might generalize similarly to humans when exposed to novel tasks.
This has been the rationale behind multitask learning or transfer learning, a strategy with a long history that has shown some promising results recently with deep networks (e.g., Donahue et al. Reference Donahue, Jia, Vinyals, Hoffman, Zhang, Tzeng and Darrell2014; Luong et al. Reference Luong, Le, Sutskever, Vinyals and Kaiser2015; Parisotto et al. Reference Parisotto, Ba and Salakhutdinov2016). Furthermore, some deep learning advocates argue the human brain effectively benefits from even more experience through evolution. If deep learning researchers see themselves as trying to capture the equivalent of humans' collective evolutionary experience, this would be equivalent to a truly immense “pre-training” phase.
We agree that humans have a much richer starting point than neural networks when learning most new tasks, including learning a new concept or learning to play a new video game. That is the point of the “developmental start-up software” and other building blocks that we argued are key to creating this richer starting point. We are less committed to a particular story regarding the origins of the ingredients, including the relative roles of genetically programmed and experience-driven developmental mechanisms in building these components in early infancy. Either way, we see them as fundamental building blocks for facilitating rapid learning from sparse data.
Learning-to-learn across multiple tasks is conceivably one route to acquiring these ingredients, but simply training conventional neural networks on many related tasks may not be sufficient to generalize in human-like ways for novel tasks. As we argued in Section 4.2.3, successful learning-to-learn – or, at least, human-level transfer learning – is enabled by having models with the right representational structure, including the other building blocks discussed in this article. Learning-to-learn is a powerful ingredient, but it can be more powerful when operating over compositional representations that capture the underlying causal structure of the environment, while also building on intuitive physics and psychology.
Finally, we recognize that some researchers still hold out hope that if only they can just get big enough training data sets, sufficiently rich tasks, and enough computing power – far beyond what has been tried out so far – then deep learning methods might be sufficient to learn representations equivalent to what evolution and learning provide humans. We can sympathize with that hope, and believe it deserves further exploration, although we are not sure it is a realistic one. We understand in principle how evolution could build a brain with the cognitive ingredients we discuss here. Stochastic hill climbing is slow. It may require massively parallel exploration, over millions of years with innumerable dead ends, but it can build complex structures with complex functions if we are willing to wait long enough. In contrast, trying to build these representations from scratch using backpropagation, Deep Q-learning, or any stochastic gradient-descent weight update rule in a fixed network architecture, may be unfeasible regardless of how much training data are available. To build these representations from scratch might require exploring fundamental structural variations in the network's architecture, which gradient-based learning in weight space is not prepared to do. Although deep learning researchers do explore many such architectural variations, and have been devising increasingly clever and powerful ones recently, it is the researchers who are driving and directing this process. Exploration and creative innovation in the space of network architectures have not yet been made algorithmic. Perhaps they could, using genetic programming methods (Koza Reference Koza1992) or other structure-search algorithms (Yamins et al. Reference Yamins, Hong, Cadieu, Solomon, Seibert and DiCarlo2014). We think this would be a fascinating and promising direction to explore, but we may have to acquire more patience than machine-learning researchers typically express with their algorithms: the dynamics of structure search may look much more like the slow random hill climbing of evolution than the smooth, methodical progress of stochastic gradient descent. An alternative strategy is to build in appropriate infant-like knowledge representations and core ingredients as the starting point for our learning-based AI systems, or to build learning systems with strong inductive biases that guide them in this direction.
Regardless of which way an AI developer chooses to go, our main points are orthogonal to this objection. There are a set of core cognitive ingredients for human-like learning and thought. Deep learning models could incorporate these ingredients through some combination of additional structure and perhaps additional learning mechanisms, but for the most part have yet to do so. Any approach to human-like AI, whether based on deep learning or not, is likely to gain from incorporating these ingredients.
5.2. Biological plausibility suggests theories of intelligence should start with neural networks
We have focused on how cognitive science can motivate and guide efforts to engineer human-like AI, in contrast to some advocates of deep neural networks who cite neuroscience for inspiration. Our approach is guided by a pragmatic view that the clearest path to a computational formalization of human intelligence comes from understanding the “software” before the “hardware.” In the case of this article, we proposed key ingredients of this software in previous sections.
Nonetheless, a cognitive approach to intelligence should not ignore what we know about the brain. Neuroscience can provide valuable inspirations for both cognitive models and AI researchers: The centrality of neural networks and model-free reinforcement learning in our proposals for “thinking fast” (sect. 4.3) are prime exemplars. Neuroscience can also, in principle, impose constraints on cognitive accounts, at both the cellular and systems levels. If deep learning embodies brain-like computational mechanisms and those mechanisms are incompatible with some cognitive theory, then this is an argument against that cognitive theory and in favor of deep learning. Unfortunately, what we “know” about the brain is not all that clear-cut. Many seemingly well-accepted ideas regarding neural computation are in fact biologically dubious, or uncertain at best, and therefore should not disqualify cognitive ingredients that pose challenges for implementation within that approach.
For example, most neural networks use some form of gradient-based (e.g., backpropagation) or Hebbian learning. It has long been argued, however, that backpropagation is not biologically plausible. As Crick (Reference Crick1989) famously pointed out, backpropagation seems to require that information be transmitted backward along the axon, which does not fit with realistic models of neuronal function (although recent models circumvent this problem in various ways [Liao et al. Reference Liao, Leibo and Poggio2015; Lillicrap et al. Reference Lillicrap, Cownden, Tweed and Akerman2014; Scellier & Bengio Reference Scellier and Bengio2016]). This has not prevented backpropagation from being put to good use in connectionist models of cognition or in building deep neural networks for AI. Neural network researchers must regard it as a very good thing, in this case, that concerns of biological plausibility did not hold back research on this particular algorithmic approach to learning.Footnote 10 We strongly agree: Although neuroscientists have not found any mechanisms for implementing backpropagation in the brain, neither have they produced definitive evidence against it. The existing data simply offer little constraint either way, and backpropagation has been of obviously great value in engineering today's best pattern recognition systems.
Hebbian learning is another case in point. In the form of long-term potentiation (LTP) and spike-timing dependent plasticity (STDP), Hebbian learning mechanisms are often cited as biologically supported (Bi & Poo Reference Bi and Poo2001). However, the cognitive significance of any biologically grounded form of Hebbian learning is unclear. Gallistel and Matzel (Reference Gallistel and Matzel2013) have persuasively argued that the critical interstimulus interval for LTP is orders of magnitude smaller than the intervals that are behaviorally relevant in most forms of learning. In fact, experiments that simultaneously manipulate the interstimulus and intertrial intervals demonstrate that no critical interval exists. Behavior can persist for weeks or months, whereas LTP decays to baseline over the course of days (Power et al. Reference Power, Thompson, Moyer and Disterhoft1997). Learned behavior is rapidly re-acquired after extinction (Bouton Reference Bouton2004), whereas no such facilitation is observed for LTP (Jonge & Racine Reference Jonge and Racine1985). Most relevantly for our focus, it would be especially challenging to try to implement the ingredients described in this article using purely Hebbian mechanisms.
Claims of biological plausibility or implausibility usually rest on rather stylized assumptions about the brain that are wrong in many of their details. Moreover, these claims usually pertain to the cellular and synaptic levels, with few connections made to systems-level neuroscience and subcortical brain organization (Edelman Reference Edelman2015). Understanding which details matter and which do not requires a computational theory (Marr Reference Marr1982). Moreover, in the absence of strong constraints from neuroscience, we can turn the biological argument around: Perhaps a hypothetical biological mechanism should be viewed with skepticism if it is cognitively implausible. In the long run, we are optimistic that neuroscience will eventually place more constraints on theories of intelligence. For now, we believe cognitive plausibility offers a surer foundation.
5.3. Language is essential for human intelligence. Why is it not more prominent here?
We have said little in this article about people's ability to communicate and think in natural language, a distinctively human cognitive capacity where machine capabilities strikingly lag. Certainly one could argue that language should be included on any short list of key ingredients in human intelligence: For example, Mikolov et al. (Reference Mikolov, Joulin and Baroni2016) featured language prominently in their recent paper sketching challenge problems and a road map for AI. Moreover, whereas natural language processing is an active area of research in deep learning (e.g., Bahdanau et al. Reference Bahdanau, Cho and Bengio2015; Mikolov et al. Reference Mikolov, Sutskever, Chen, Burges, Bottou, Welling, Ghagramani and Weinberger2013; Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015), it is widely recognized that neural networks are far from implementing human language abilities. The question is, how do we develop machines with a richer capacity for language?
We believe that understanding language and its role in intelligence goes hand-in-hand with understanding the building blocks discussed in this article. It is also true that language builds on the core abilities for intuitive physics, intuitive psychology, and rapid learning with compositional, causal models that we focus on. These capacities are in place before children master language, and they provide the building blocks for linguistic meaning and language acquisition (Carey Reference Carey2009; Jackendoff Reference Jackendoff2003; Kemp Reference Kemp2007; O'Donnell Reference O'Donnell2015; Pinker Reference Pinker2007; Xu & Tenenbaum Reference Xu and Tenenbaum2007). We hope that by better understanding these earlier ingredients and how to implement and integrate them computationally, we will be better positioned to understand linguistic meaning and acquisition in computational terms and to explore other ingredients that make human language possible.
What else might we need to add to these core ingredients to get language? Many researchers have speculated about key features of human cognition that give rise to language and other uniquely human modes of thought: Is it recursion, or some new kind of recursive structure building ability (Berwick & Chomsky Reference Berwick and Chomsky2016; Hauser et al. Reference Hauser, Chomsky and Fitch2002)? Is it the ability to re-use symbols by name (Deacon Reference Deacon1998)? Is it the ability to understand others intentionally and build shared intentionality (Bloom Reference Bloom2000; Frank et al. Reference Frank, Goodman and Tenenbaum2009; Tomasello Reference Tomasello2010)? Is it some new version of these things, or is it just more of the aspects of these capacities that are already present in infants? These are important questions for future work with the potential to expand the list of key ingredients; we did not intend our list to be complete.
Finally, we should keep in mind all of the ways that acquiring language extends and enriches the ingredients of cognition that we focus on in this article. The intuitive physics and psychology of infants are likely limited to reasoning about objects and agents in their immediate spatial and temporal vicinity and to their simplest properties and states. But with language, older children become able to reason about a much wider range of physical and psychological situations (Carey Reference Carey2009). Language also facilitates more powerful learning-to-learn and compositionality (Mikolov et al. Reference Mikolov, Joulin and Baroni2016), allowing people to learn more quickly and flexibly by representing new concepts and thoughts in relation to existing concepts (Lupyan & Bergen Reference Lupyan and Bergen2016; Lupyan & Clark Reference Lupyan and Clark2015). Ultimately, the full project of building machines that learn and think like humans must have language at its core.
6. Looking forward
In the last few decades, AI and machine learning have made remarkable progress: Computer programs beat chess masters; AI systems beat Jeopardy champions; apps recognize photos of your friends; machines rival humans on large-scale object recognition; smart phones recognize (and, to a limited extent, understand) speech. The coming years promise still more exciting AI applications, in areas as varied as self-driving cars, medicine, genetics, drug design, and robotics. As a field, AI should be proud of these accomplishments, which have helped move research from academic journals into systems that improve our daily lives.
We should also be mindful of what AI has and has not achieved. Although the pace of progress has been impressive, natural intelligence is still by far the best example of intelligence. Machine performance may rival or exceed human performance on particular tasks, and algorithms may take inspiration from neuroscience or aspects of psychology, but it does not follow that the algorithm learns or thinks like a person. This is a higher bar worth reaching for, potentially leading to more powerful algorithms, while also helping unlock the mysteries of the human mind.
When comparing people with the current best algorithms in AI and machine learning, people learn from fewer data and generalize in richer and more flexible ways. Even for relatively simple concepts such as handwritten characters, people need to see just one or a few examples of a new concept before being able to recognize new examples, generate new examples, and generate new concepts based on related ones (Fig. 1A). So far, these abilities elude even the best deep neural networks for character recognition (Ciresan et al. Reference Ciresan, Meier and Schmidhuber2012), which are trained on many examples of each concept and do not flexibly generalize to new tasks. We suggest that the comparative power and flexibility of people's inferences come from the causal and compositional nature of their representations.
We believe that deep learning and other learning paradigms can move closer to human-like learning and thought if they incorporate psychological ingredients, including those outlined in this article. Before closing, we discuss some recent trends that we see as some of the most promising developments in deep learning – trends we hope will continue and lead to more important advances.
6.1. Promising directions in deep learning
There has been recent interest in integrating psychological ingredients with deep neural networks, especially selective attention (Bahdanau et al. Reference Bahdanau, Cho and Bengio2015; Mnih et al. Reference Mnih, Heess, Graves, Kavukcuoglu, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014; Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015), augmented working memory (Graves et al. Reference Graves, Wayne and Danihelka2014; Reference Graves, Wayne, Reynolds, Harley, Danihelka, Grabska-Barwińska, Colmenarejo, Grefenstette, Ramalho, Agapiou, Badia, Hermann, Zwols, Ostrovski, Cain, King, Summerfield, Blunsom, Kayukcuoglu and Hassabis2016; Grefenstette et al. Reference Grefenstette, Hermann, Suleyman, Blunsom, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Sukhbaatar et al. Reference Sukhbaatar, Szlam, Weston, Fergus, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Weston et al. Reference Weston, Chopra and Bordes2015b), and experience replay (McClelland et al. Reference McClelland, McNaughton and O'Reilly1995; Mnih et al. Reference Mnih, Kavukcuoglu, Silver, Rusu, Veness, Bellemare, Graves, Riedmiller, Fidjeland, Ostrovski, Petersen, Beattie, Sadik, Antonoglous, King, Kumaran, Wierstra and Hassabis2015). These ingredients are lower-level than the key cognitive ingredients discussed in this article. yet they suggest a promising trend of using insights from cognitive psychology to improve deep learning, one that may be even furthered by incorporating higher-level cognitive ingredients.
Paralleling the human perceptual apparatus, selective attention forces deep learning models to process raw, perceptual data as a series of high-resolution “foveal glimpses” rather than all at once. Somewhat surprisingly, the incorporation of attention has led to substantial performance gains in a variety of domains, including in machine translation (Bahdanau et al. Reference Bahdanau, Cho and Bengio2015), object recognition (Mnih et al. Reference Mnih, Heess, Graves, Kavukcuoglu, Ghahramani, Welling, Cortes, Lawrence and Weinberger2014), and image caption generation (Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015). Attention may help these models in several ways. It helps to coordinate complex, often sequential, outputs by attending to only specific aspects of the input, allowing the model to focus on smaller sub-tasks rather than solving an entire problem in one shot. For example, during caption generation, the attentional window has been shown to track the objects as they are mentioned in the caption, where the network may focus on a boy and then a Frisbee when producing a caption like, “A boy throws a Frisbee” (Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015). Attention also allows larger models to be trained without requiring every model parameter to affect every output or action. In generative neural network models, attention has been used to concentrate on generating particular regions of the image rather than the whole image at once (Gregor et al. Reference Gregor, Danihelka, Graves, Rezende and Wierstra2015). This could be a stepping stone toward building more causal generative models in neural networks, such as a neural version of the Bayesian program learning model that could be applied to tackling the Characters Challenge (sect. 3.1).
Researchers are also developing neural networks with “working memories” that augment the shorter-term memory provided by unit activation and the longer-term memory provided by the connection weights (Graves et al. Reference Graves, Wayne and Danihelka2014; Reference Graves, Wayne, Reynolds, Harley, Danihelka, Grabska-Barwińska, Colmenarejo, Grefenstette, Ramalho, Agapiou, Badia, Hermann, Zwols, Ostrovski, Cain, King, Summerfield, Blunsom, Kayukcuoglu and Hassabis2016; Grefenstette et al. Reference Grefenstette, Hermann, Suleyman, Blunsom, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Reed & Freitas Reference Reed and de Freitas2016; Sukhbaatar et al. Reference Sukhbaatar, Szlam, Weston, Fergus, Cortes, Lawrence, Lee, Sugiyama and Garnett2015; Weston et al. Reference Weston, Chopra and Bordes2015b). These developments are also part of a broader trend toward “differentiable programming,” the incorporation of classic data structures, such as random access memory, stacks, and queues, into gradient-based learning systems (Dalrymple Reference Dalrymple2016). For example, the neural Turing machine (NTM) (Graves et al. Reference Graves, Wayne and Danihelka2014) and its successor the differentiable neural computer (DNC) (Graves et al. Reference Graves, Wayne, Reynolds, Harley, Danihelka, Grabska-Barwińska, Colmenarejo, Grefenstette, Ramalho, Agapiou, Badia, Hermann, Zwols, Ostrovski, Cain, King, Summerfield, Blunsom, Kayukcuoglu and Hassabis2016) are neural networks augmented with a random access external memory with read and write operations that maintain end-to-end differentiability. The NTM has been trained to perform sequence-to-sequence prediction tasks such as sequence copying and sorting, and the DNC has been applied to solving block puzzles and finding paths between nodes in a graph after memorizing the graph. Additionally, neural programmer-interpreters learn to represent and execute algorithms such as addition and sorting from fewer examples, by observing input-output pairs (like the NTM and DNC), as well as execution traces (Reed & Freitas Reference Reed and de Freitas2016). Each model seems to learn genuine programs from examples, albeit in a representation more like assembly language than a high-level programming language.
Although this new generation of neural networks has yet to tackle the types of challenge problems introduced in this article, differentiable programming suggests the intriguing possibility of combining the best of program induction and deep learning. The types of structured representations and model building ingredients discussed in this article – objects, forces, agents, causality, and compositionality – help explain important facets of human learning and thinking, yet they also bring challenges for performing efficient inference (sect. 4.3.1). Deep learning systems have not yet shown they can work with these representations, but they have demonstrated the surprising effectiveness of gradient descent in large models with high-dimensional parameter spaces. A synthesis of these approaches, able to perform efficient inference over programs that richly model the causal structure an infant sees in the world, would be a major step forward in building human-like AI.
Another example of combining pattern recognition and model-based search comes from recent AI research into the game Go. Go is considerably more difficult for AI than chess, and it was only recently that a computer program – AlphaGo – first beat a world-class player (Chouard Reference Chouard2016) by using a combination of deep convolutional neural networks (ConvNets) and Monte-Carlo Tree Search (Silver et al. Reference Silver, Huang, Maddison, Guez, Sifre, Driessche, Schrittwieser, Antonoglou, Panneershelvam, Lanctot, Dieleman, Grewe, Nham, Kalchbrenner, Sutskever, Lillicrap, Leach, Kavukcuoglu, Graepel and Hassabis2016). Each of these components has made gains against artificial and real Go players (Gelly & Silver Reference Gelly and Silver2008; Reference Gelly and Silver2011; Silver et al. Reference Silver, Huang, Maddison, Guez, Sifre, Driessche, Schrittwieser, Antonoglou, Panneershelvam, Lanctot, Dieleman, Grewe, Nham, Kalchbrenner, Sutskever, Lillicrap, Leach, Kavukcuoglu, Graepel and Hassabis2016; Tian & Zhu Reference Tian and Zhu2016), and the notion of combining pattern recognition and model-based search goes back decades in Go and other games. Showing that these approaches can be integrated to beat a human Go champion is an important AI accomplishment (see Fig. 7). Just as important, however, are the new questions and directions they open up for the long-term project of building genuinely human-like AI.
Figure 7. An AI system for playing Go, combining a deep convolutional network (ConvNet) and model-based search through Monte-Carlo Tree Search (MCTS). (A) The ConvNet on its own can be used to predict the next k moves given the current board. (B) A search tree with the current board state as its root and the current “win/total” statistics at each node. A new MCTS rollout selects moves along the tree according to the MCTS policy (red arrows) until it reaches a new leaf (red circle), where the next move is chosen by the ConvNet. From there, play proceeds until the game's end according to a pre-defined default policy based on the Pachi program (Baudiš & Gailly Reference Baudiš, Gailly, van den Herik and Plast2012), itself based on MCTS. (C) The end-game result of the new leaf is used to update the search tree. Adapted from Tian and Zhu (Reference Tian and Zhu2016) with permission.
One worthy goal would be to build an AI system that beats a world-class player with the amount and kind of training human champions receive, rather than overpowering them with Google-scale computational resources. AlphaGo is initially trained on 28.4 million positions and moves from 160,000 unique games played by human experts; it then improves through reinforcement learning, playing 30 million more games against itself. Between the publication of Silver et al. (Reference Silver, Huang, Maddison, Guez, Sifre, Driessche, Schrittwieser, Antonoglou, Panneershelvam, Lanctot, Dieleman, Grewe, Nham, Kalchbrenner, Sutskever, Lillicrap, Leach, Kavukcuoglu, Graepel and Hassabis2016) and facing world champion Lee Sedol, AlphaGo was iteratively retrained several times in this way. The basic system always learned from 30 million games, but it played against successively stronger versions of itself, effectively learning from 100 million or more games altogether (D. Silver, personal communication, 2017). In contrast, Lee has probably played around 50,000 games in his entire life. Looking at numbers like these, it is impressive that Lee can even compete with AlphaGo. What would it take to build a professional-level Go AI that learns from only 50,000 games? Perhaps a system that combines the advances of AlphaGo with some of the complementary ingredients for intelligence we argue for here would be a route to that end.
Artificial intelligence could also gain much by trying to match the learning speed and flexibility of normal human Go players. People take a long time to master the game of Go, but as with the Frostbite and Characters challenges (sects. 3.1 and 3.2), humans can quickly learn the basics of the game through a combination of explicit instruction, watching others, and experience. Playing just a few games teaches a human enough to beat someone who has just learned the rules but never played before. Could AlphaGo model these earliest stages of real human learning curves? Human Go players can also adapt what they have learned to innumerable game variants. The Wikipedia page “Go variants” describes versions such as playing on bigger or smaller board sizes (ranging from 9 × 9 to 38 × 38, not just the usual 19 × 19 board), or playing on boards of different shapes and connectivity structures (rectangles, triangles, hexagons, even a map of the English city Milton Keynes). The board can be a torus, a mobius strip, a cube, or a diamond lattice in three dimensions. Holes can be cut in the board, in regular or irregular ways. The rules can be adapted to what is known as First Capture Go (the first player to capture a stone wins), NoGo (the player who avoids capturing any enemy stones longer wins), or Time Is Money Go (players begin with a fixed amount of time and at the end of the game, the number of seconds remaining on each player's clock is added to his or her score). Players may receive bonuses for creating certain stone patterns or capturing territory near certain landmarks. There could be four or more players, competing individually or in teams. In each of these variants, effective play needs to change from the basic game, but a skilled player can adapt, and does not simply have to relearn the game from scratch. Could AlphaGo quickly adapt to new variants of Go? Although techniques for handling variable-sized inputs in ConvNets may help in playing on different board sizes (Sermanet et al. Reference Sermanet, Eigen, Zhang, Mathieu, Fergus and LeCun2014), the value functions and policies that AlphaGo learns seem unlikely to generalize as flexibly and automatically as people. Many of the variants described above would require significant reprogramming and retraining, directed by the smart humans who programmed AlphaGo, not the system itself. As impressive as AlphaGo is in beating the world's best players at the standard game – and it is extremely impressive – the fact that it cannot even conceive of these variants, let alone adapt to them autonomously, is a sign that it does not understand the game as humans do. Human players can understand these variants and adapt to them because they explicitly represent Go as a game, with a goal to beat an adversary who is playing to achieve the same goal he or she is, governed by rules about how stones can be placed on a board and how board positions are scored. Humans represent their strategies as a response to these constraints, such that if the game changes, they can begin to adjust their strategies accordingly.
In sum, Go presents compelling challenges for AI beyond matching world-class human performance, in trying to match human levels of understanding and generalization, based on the same kinds and amounts of data, explicit instructions, and opportunities for social learning afforded to people. In learning to play Go as quickly and as flexibly as they do, people are drawing on most of the cognitive ingredients this article has laid out. They are learning-to-learn with compositional knowledge. They are using their core intuitive psychology and aspects of their intuitive physics (spatial and object representations). And like AlphaGo, they are also integrating model-free pattern recognition with model-based search. We believe that Go AI systems could be built to do all of these things, potentially better capturing how humans learn and understand the game. We believe it would be richly rewarding for AI and cognitive science to pursue this challenge together and that such systems could be a compelling testbed for the principles this article suggests, as well as building on all of the progress to date that AlphaGo represents.
6.2. Future applications to practical AI problems
In this article, we suggested some ingredients for building computational models with more human-like learning and thought. These principles were explained in the context of the Characters and Frostbite Challenges, with special emphasis on reducing the amount of training data required and facilitating transfer to novel yet related tasks. We also see ways these ingredients can spur progress on core AI problems with practical applications. Here we offer some speculative thoughts on these applications.
-
1. Scene understanding. Deep learning is moving beyond object recognition and toward scene understanding, as evidenced by a flurry of recent work focused on generating natural language captions for images (Karpathy & Fei-Fei Reference Karpathy and Fei-Fei2017; Vinyals et al. Reference Vinyals, Toshev, Bengio and Erhan2014; Xu et al. Reference Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel and Bengio2015). Yet current algorithms are still better at recognizing objects than understanding scenes, often getting the key objects right but their causal relationships wrong (Fig. 6). We see compositionality, causality, intuitive physics, and intuitive psychology as playing an increasingly important role in reaching true scene understanding. For example, picture a cluttered garage workshop with screw drivers and hammers hanging from the wall, wood pieces and tools stacked precariously on a work desk, and shelving and boxes framing the scene. For an autonomous agent to effectively navigate and perform tasks in this environment, the agent would need intuitive physics to properly reason about stability and support. A holistic model of the scene would require the composition of individual object models, glued together by relations. Finally, causality helps infuse the recognition of existing tools or the learning of new ones with an understanding of their use, helping to connect different object models in the proper way (e.g., hammering a nail into a wall, or using a saw horse to support a beam being cut by a saw). If the scene includes people acting or interacting, it will be nearly impossible to understand their actions without thinking about their thoughts and especially their goals and intentions toward the other objects and agents they believe are present.
-
2. Autonomous agents and intelligent devices. Robots and personal assistants such as cell phones cannot be pre-trained on all possible concepts they may encounter. Like a child learning the meaning of new words, an intelligent and adaptive system should be able to learn new concepts from a small number of examples, as they are encountered naturally in the environment. Common concept types include new spoken words (names like “Ban Ki-Moon” and “Kofi Annan”), new gestures (a secret handshake and a “fist bump”), and new activities, and a human-like system would be able to learn both to recognize and to produce new instances from a small number of examples. As with handwritten characters, a system may be able to quickly learn new concepts by constructing them from pre-existing primitive actions, informed by knowledge of the underlying causal process and learning-to-learn.
-
3. Autonomous driving. Perfect autonomous driving requires intuitive psychology. Beyond detecting and avoiding pedestrians, autonomous cars could more accurately predict pedestrian behavior by inferring mental states, including their beliefs (e.g., Do they think it is safe to cross the street? Are they paying attention?) and desires (e.g., Where do they want to go? Do they want to cross? Are they retrieving a ball lost in the street?). Similarly, other drivers on the road have similarly complex mental states underlying their behavior (e.g., Does he or she want to change lanes? Pass another car? Is he or she swerving to avoid a hidden hazard? Is he or she distracted?). This type of psychological reasoning, along with other types of model-based causal and physical reasoning, are likely to be especially valuable in challenging and novel driving circumstances for which there are few relevant training data (e.g., navigating unusual construction zones, natural disasters).
-
4. Creative design. Creativity is often thought to be a pinnacle of human intelligence. Chefs design new dishes, musicians write new songs, architects design new buildings, and entrepreneurs start new businesses. Although we are still far from developing AI systems that can tackle these types of tasks, we see compositionality and causality as central to this goal. Many commonplace acts of creativity are combinatorial, meaning they are unexpected combinations of familiar concepts or ideas (Boden Reference Boden1998; Ward Reference Ward1994). As illustrated in Figure 1-iv, novel vehicles can be created as a combination of parts from existing vehicles, and similarly, novel characters can be constructed from the parts of stylistically similar characters, or familiar characters can be re-conceptualized in novel styles (Rehling Reference Rehling2001). In each case, the free combination of parts is not enough on its own: Although compositionality and learning-to-learn can provide the parts for new ideas, causality provides the glue that gives them coherence and purpose.
6.3. Toward more human-like learning and thinking machines
Since the birth of AI in the 1950s, people have wanted to build machines that learn and think like people. We hope researchers in AI, machine learning, and cognitive science will accept our challenge problems as a testbed for progress. Rather than just building systems that recognize handwritten characters and play Frostbite or Go as the end result of an asymptotic process, we suggest that deep learning and other computational paradigms should aim to tackle these tasks using as few training data as people need, and also to evaluate models on a range of human-like generalizations beyond the one task on which the model was trained. We hope that the ingredients outlined in this article will prove useful for working toward this goal: seeing objects and agents rather than features, building causal models and not just recognizing patterns, recombining representations without needing to retrain, and learning-to-learn rather than starting from scratch.
ACKNOWLEDGMENTS
We are grateful to Peter Battaglia, Matt Botvinick, Y-Lan Boureau, Shimon Edelman, Nando de Freitas, Anatole Gershman, George Kachergis, Leslie Kaelbling, Andrej Karpathy, George Konidaris, Tejas Kulkarni, Tammy Kwan, Michael Littman, Gary Marcus, Kevin Murphy, Steven Pinker, Pat Shafto, David Sontag, Pedro Tsividis, and four anonymous reviewers for helpful comments on early versions of this article. Tom Schaul and Matteo Hessel were very helpful in answering questions regarding the DQN learning curves and Frostbite scoring. This work was supported by The Center for Minds, Brains and Machines (CBMM), under National Science Foundation (NSF) Science and Technology Centers (NTS) Award CCF-1231216, and the Moore–Sloan Data Science Environment at New York University.









Target article
Building machines that learn and think like people
Related commentaries (27)
Autonomous development and learning in artificial intelligence and robotics: Scaling up deep learning to human-like learning
Avoiding frostbite: It helps to learn from others
Back to the future: The return of cognitive functionalism
Benefits of embodiment
Building brains that communicate like machines
Building machines that adapt and compute like brains
Building machines that learn and think for themselves
Building on prior knowledge without building it in
Causal generative models are just a start
Children begin with the same start-up software, but their software updates are cultural
Crossmodal lifelong learning in hybrid neural embodied architectures
Deep-learning networks and the functional architecture of executive control
Digging deeper on “deep” learning: A computational ecology approach
Evidence from machines that learn and think like people
Human-like machines: Transparency and comprehensibility
Intelligent machines and human minds
Social-motor experience and perception-action learning bring efficiency to machines
The architecture challenge: Future artificial-intelligence systems will require sophisticated architectures, and knowledge of the brain might guide their construction
The argument for single-purpose robots
The fork in the road
The humanness of artificial non-normative personalities
The importance of motivation and emotion for explaining human cognition
Theories or fragments?
Thinking like animals or thinking like colleagues?
Understand the cogs to understand cognition
What can the brain teach us about building artificial intelligence?
Will human-like machines make human-like mistakes?
Author response
Ingredients of intelligence: From classic debates to an engineering roadmap