



A growing body of literature has investigated the effect of spelling on processing of first (L1) and second language (L2) speech (e.g., Frauenfelder et al., Reference Frauenfelder, Segui and Dijkstra1990; Morais et al., Reference Morais, Cary, Alegria and Bertelson1979; Seidenberg & Tanenhaus, Reference Seidenberg and Tanenhaus1979; Zou et al., Reference Zou, Desroches, Liu, Xia and Shu2012) (See Hayes-Harb and Barrios (Reference Hayes-Harb and Barrios2021) for an overview of L2 studies). The processing of spoken words is affected by inconsistencies between pronunciation and spelling (e.g., Ziegler et al., Reference Ziegler, Ferrand and Montant2004). Work by Ziegler et al. (Reference Ziegler, Petrova and Ferrand2008) found that auditory lexical decisions are faster and more accurate for consistent words whose rhyme can be spelled in only one way (e.g., /-ʌk/ in luck) than for inconsistent words whose rhyme can be spelled in multiple ways (e.g., /-ip/ in leap or keep). A consistent relationship between pronunciation and spelling has been reported as a possible cause of unreduced pronunciations being easier to process than reduced counterparts, despite reduced pronunciations occurring more frequently (Ranbom & Connine, Reference Ranbom and Connine2007). The present study examines the extent to which orthography affects the processing of reduced pronunciations. More specifically, how pronunciation-to-spelling consistency interacts with reduced pronunciations for L1 and L2 listeners of Japanese, a non-alphabetic language.
Orthographic consistency effect in spoken word recognition
Considerable evidence for orthographic effects in spoken word processing has been provided by studies on pronunciation and spelling consistency. In particular, pronunciation-to-spelling (i.e., phonology-to-orthography) consistency has been shown to affect the ease of spoken word processing. Research has shown slower response times and higher error rates for inconsistent words than consistent words in French (Ziegler & Ferrand, Reference Ziegler and Ferrand1998) and English (Ziegler et al., Reference Ziegler, Petrova and Ferrand2008) in auditory lexical decision. Furthermore, Ziegler et al. (Reference Ziegler, Ferrand and Montant2004) revealed an effect of spelling probability within a consistency effect. They found the slowest response times and the highest error rates for inconsistent non-dominant spelling words, followed by the inconsistent dominant spelling words, and the fastest responses and lowest error rates for consistent words. They also compared the relative effect of consistency across three tasks: auditory lexical decision, rhyme detection, and auditory naming, and found that the effect is strongest in the auditory lexical decision task, the second strongest in the rhyme detection task, and the smallest (or null) in the auditory naming task. Similar results were also reported for Portuguese (Ventura et al., Reference Ventura, Morais, Pattamadilok and Kolinsky2004) and Thai (Pattamadilok et al., Reference Pattamadilok, Kolinsky, Luksaneeyanawin and Morais2008).
While it has been argued that the emergence of consistency effects is dependent on a meta-phonological or meta-linguistic analysis required to complete a given task, the effect has been demonstrated in a semantic and non-(meta)linguistic task as well. Peereman et al. (Reference Peereman, Dufour and Burt2009) employed a semantic and gender categorization task and measured response latencies and accuracy. Their results indicated that there is a consistency effect for both tasks. Similarly, Pattamadilok et al. (Reference Pattamadilok, Perre, Dufau and Ziegler2009) examined semantic categorization during event-related potentials (ERPs) and a Go-NoGo task. The ERPs revealed the time-locked consistency effects, where early inconsistent words show an early effect and late inconsistent words display a late effect of inconsistency. Additionally, Perre et al. (Reference Perre, Bertrand and Ziegler2011) demonstrated the consistency effect during ERPs using a Go-NoGo non-(meta)linguistic task, where participants pressed a button for white noise and they did not press the button for French words. Although participants did not have to make a linguistic decision on the French words, the consistency effect emerged.
Work by Perre et al. (Reference Perre, Pattamadilok, Montant and Ziegler2009), also employed ERPs, but they used standardized low-resolution electromagnetic tomography (sLORETA) to determine the possible underlying cortical generators of the consistency effect. Using sLORETA, they directly examined the mechanism by which orthography affects spoken word processing. Their predictions were based on two accounts hypothesizing the nature of the consistency effect: (1) orthographic information is co-activated with phonological information and (2) orthographic information “contaminates” phonological representations during development. The first account predicts that orthographic information is co-activated with phonological information online. Autonomous orthographic and phonological representations are bidirectionally linked, and these two involuntarily interact with each other (Dijkstra et al., Reference Dijkstra, Van Heuven and Grainger1998; Stone et al., Reference Stone, Vanhoy and Van Orden1997). This online view is in line with the feedback loop in interactive-activation models in the resonance theory framework (McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Stone & Van Orden, Reference Stone and Van Orden1994), where activation of one representation “feeds forward” to another representation and then the activated representation “feeds back” to the original representation to alter the activation level. According to this view, learning to read/write builds strong and permanent associations between phonological and orthographic representations. Accordingly, Perre et al., (Reference Perre, Pattamadilok, Montant and Ziegler2009) postulated activation in brain regions that are responsible for both phonological and orthographic information processing (See Cohen et al. (Reference Cohen, Jobert, Le Bihan and Dehaene2004); Dehaene et al. (Reference Dehaene, Naccache, Cohen, Bihan, Mangin, Poline and Rivière2001); Perre et al., (Reference Perre, Pattamadilok, Montant and Ziegler2009) for detailed discussion of cortical systems for the processing of phonological and orthographic information). The second account predicts that orthographic information “contaminates” phonology during the development of reading/writing skills, thus alternating the nature of the phonological representations (Muneaux & Ziegler, Reference Muneaux and Ziegler2004; Ziegler & Goswami, Reference Ziegler and Goswami2005). According to this restructuring view, orthographic information is utilized to restructure phonological representations of lexical representations. That is, orthographically consistent words build better specified and finer-grained phonological representations than inconsistent words do in the course of learning to read and write. Accordingly, in contrast to the online view, an orthographic consistency effect emerges because of the qualitative difference between the phonological representations of consistent and inconsistent words. This account follows the conceptualization of the phonological restructuring model (Metsala, Reference Metsala1997; Metsala & Walley, Reference Metsala, Walley, Metsala and Ehri1998), where children recognize words in a more holistic way than adults do, but as children’s vocabulary size grows, restructuring of lexical representations progresses, resulting in lexical representations becoming more segmental for successful recognition of spoken words.
Since these two accounts are not mutually exclusive, it is possible to find evidence supporting both accounts simultaneously, which would become the third account. For this account, Perre et al., (Reference Perre, Pattamadilok, Montant and Ziegler2009) postulated activation in brain regions that are responsible for both phonological and orthographic information processing, as well as differences in activation of brain regions that are responsible for phonological processing between consistent and inconsistent words simultaneously. While Perre et al., (Reference Perre, Pattamadilok, Montant and Ziegler2009), as well as Pattamadilok et al. (Reference Pattamadilok, Knierim, Duncan and Devlin2010), found evidence for the phonological restructuring account, Chen et al. (Reference Chen, Chao, Chang, Hsu and Lee2016) also employed sLORETA and found evidence supporting the third account in Mandarin, possibly suggesting script-specific (alphabetic vs. logographic) processing for orthographic consistency effects.
Orthographic consistency effect and logographic scripts
Languages that utilize logographic scripts, such as Mandarin and Japanese, also show the consistency effect. In such languages however, the pronunciation and spelling mappings are not straightforward because, in the Japanese writing system for example, logographic characters do not reliably correspond to sub-lexical phonological units (Fushimi et al., Reference Fushimi, Ijuin, Patterson and Tatsumi1999; Wydell, Reference Wydell1998; Wydell et al., Reference Wydell, Patterson and Humphreys1993). However, logographs can be decomposed into smaller sub-characters, one of which is the phonetic radical that often provides a clue to the pronunciation of the whole character. The phonetic radicals have been utilized to define the pronunciation and orthographic consistency for Mandarin. Using ERPs and sLORETA, Chen et al. (Reference Chen, Chao, Chang, Hsu and Lee2016) investigated the effect of orthography by measuring homophone density and orthographic consistency. The ERP measures revealed both effects of the orthographic consistency and homophone density, and the sLORETA indicated activation of both in the phonological and the orthographic processing regions. Similar results were found in Chao et al. (Reference Chao, Chen, Zevin and Lee2021) where they employed event-related functional magnetic resonance imaging and functional connectivity analysis.
While a number of studies investigated the effect of orthography-to-phonology (O-P) consistency in Japanese (Fushimi et al., Reference Fushimi, Ijuin, Patterson and Tatsumi1999; Hino et al., Reference Hino, Miyamura and Lupker2011; Saito et al., Reference Saito, Masuda and Kawakami1998; Wydell et al., Reference Wydell, Butterworth and Patterson1995; Wydell et al., Reference Wydell, Patterson and Humphreys1993), research on the effect of phonology-to-orthography (P-O) consistency is limited. One of the experiments in Hino et al. (Reference Hino, Kusunose and Lupker2017) investigated the P-O consistency effect in Japanese using the P-O consistency index. Hino et al. (Reference Hino, Miyamura and Lupker2011) calculated the index based on the frequency of phonological and orthographic neighbors of target words, which is in line with the approach taken by Fushimi et al. (Reference Fushimi, Ijuin, Patterson and Tatsumi1999) that follows the procedures employed in Jared et al. (Reference Jared, McRae and Seidenberg1990). Hino et al. (Reference Hino, Kusunose and Lupker2017) selected 48 Japanese logographic words based on the index, 24 high- and 24 low-consistency words, and conducted an auditory lexical decision task. They found that response latencies for low-consistency words are longer than for high-consistency words.
Orthographic consistency effect and reduced pronunciation
Mitterer and Reinisch (Reference Mitterer and Reinisch2015) extended the investigation of the orthographic effect to reduced pronunciations by looking at conversational spontaneous speech. They compared the processing cost of deletion of the orthographically uncoded segment /ʔ/ and orthographically coded segment /h/ in German and Maltese. Their hypothesis was that, if orthographic coding plays a role in the processing of spoken words, the deletion of orthographically uncoded segments should have a smaller impact on processing than the deletion of orthographically coded segments. They conducted a visual world eye-tracking experiment and pronunciation judgment task. Stimuli for the eye-tracking experiment were recorded as casually pronounced words and presented to participants with a carrier sentence containing discourse markers (e.g., like) and contractions (you’ve). The results indicated that the processing cost caused by the reduction of orthographically coded and uncoded segments does not differ, suggesting that orthographic coding does not affect processing. For the pronunciation judgment task, stimuli were recorded as carefully pronounced words and presented to participants with a short carrier phrase without discourse markers or contractions. In contrast to the findings in the eye-tracking experiment, the researchers found the effect of orthographic coding of segments in reduction.
As a result, Mitterer and Reinisch (Reference Mitterer and Reinisch2015) concluded that orthography does not play an important role in processing conversational-style speech. This result is in line with research arguing that careful speech can induce participants to use orthographic information to perform tasks, enhancing task effects (Bates & Liu, Reference Bates and Liu1996; Cutler et al., Reference Cutler, Treiman and van Ooijen2010; McQueen, Reference McQueen1996; Titone, Reference Titone1996). Mitterer and Reinisch (Reference Mitterer and Reinisch2015) also noted a few issues to be addressed in future work. One of the relevant issues is to further describe how task type and speech style interact to activate orthography, as the contrast between their two experiments confounds speech styles (casual vs. careful) with task types (explicit vs. implicit): They found an effect of orthography with the pronunciation judgment task (explicit task) using careful speech, but not with the visual world paradigm (implicit task) using casual speech.
In casual and spontaneous speech, reduction is ubiquitous and phonetic realization varies substantially. Segments and/or syllables can be realized with varying degrees of shortening, deletion, and/or incomplete articulation compared to a dictionary entry for the word’s pronunciation (Ernestus & Warner, Reference Ernestus and Warner2011; Greenberg, Reference Greenberg1999; Warner & Tucker, Reference Warner and Tucker2011). For example, in English, yesterday may be realized as [jɛʃeɪ] (Tucker, Reference Tucker2007) and in Japanese, sukoshi hanashite “speak a little bit” as [sɯkoʃɑnɑʃite] (Arai, Reference Arai1999).
The important question for our research is how such variant pronunciations are realized. Although these reduced pronunciations occur more frequently than unreduced dictionary entry pronunciations, a number of studies found that these reduced forms are recognized less efficiently than their unreduced counterparts (e.g., Arai et al., Reference Arai, Warner and Greenberg2007; Brouwer et al., Reference Brouwer, Mitterer and Huettig2013; Connine & Pinnow, Reference Connine and Pinnow2006; Ernestus et al., Reference Ernestus, Baayen and Schreuder2002; Janse et al., Reference Janse, Nooteboom and Quené2007; van de Ven et al., Reference van de Ven, Tucker and Ernestus2011). For example, Tucker (Reference Tucker2011) found that the comprehension of words with reduced word-medial [ɾ] and /g/ had slower response latencies than words with unreduced counterparts. Similar results were found in Ranbom and Connine (Reference Ranbom and Connine2007), where the more frequent pronunciation of reduced variant [ɾ] elicits slower response latencies than the less frequent pronunciation of careful spelling-like variant /nt/. While Pitt (Reference Pitt2009) argues that the reason that /nt/ is easier to recognize than [ɾ] may be because /nt/ is perceptually more distinct than [ɾ], Ranbom and Connine (Reference Ranbom and Connine2007) and others argue that the reason that unreduced forms are easier to process than reduced counterparts could be due to the orthographic form of the words, specifically the consistent relationship between the unreduced pronunciation and its orthographic form (Charoy & Samuel, Reference Charoy and Samuel2019; Racine et al., Reference Racine, Bürki and Spinelli2014; Viebahn et al., Reference Viebahn, McQueen, Ernestus, Frauenfelder and Bürki2018). Crucially, these spontaneous speech studies suggest that the surface form (i.e., phonetic realization) of words could be substantially inconsistent with its spelling, meaning that the inconsistency between the way yesterday is pronounced and spelled should be greater for the reduced pronunciation [jɛʃeɪ] than for the unreduced one /jɛstɚdeɪ/, and the inconsistency could affect perception of spoken words.
The present study
Previous research has demonstrated effects of orthography in spoken word processing in both alphabetic and logographic languages in both L1 and L2 listeners. In the present study, we extend this research by investigating the effect of P-O consistency for reduced and unreduced pronunciations in L1 and L2 listeners of a logographic language. More precisely, we compare L1 and L2 Japanese listeners to probe whether they use orthographic information differently when processing reduced and unreduced pronunciations. For L1 listeners, phonological representations are acquired prior to orthography, but L2 learners are likely to acquire phonological and orthographic information simultaneously or the acquisition of orthographic representation may even precede that of phonological representations. A number of studies have shown that orthographic effects appear in L2 word recognition with logographic languages (Mitsugi, Reference Mitsugi2018; Qu et al., Reference Qu, Cui and Damian2018) and knowledge of spelling-pronunciation correspondences in L1 impacts the perception and learning of L2 sounds (Bassetti, Reference Bassetti2006; Escudero et al., Reference Escudero, Hayes-harb and Mitterer2008; Escudero & Wanrooij, Reference Escudero and Wanrooij2010; Han et al., Reference Han, Kim and Choi2020; Hayes-Harb et al., Reference Hayes-Harb, Brown and Smith2018; Hayes-Harb et al., Reference Hayes-Harb, Nicol and Barker2010; Showalter & Hayes-Harb, Reference Showalter and Hayes-Harb2015). The research focusing on these topics along with the methodology discussed below is unique to the present study as far as we know.
The present study employs pupillometry, the measurement of pupil dilation (Kahneman & Beatty, Reference Kahneman and Beatty1966), to investigate P-O consistency effects between reduced and unreduced pronunciations. This methodology has been applied to a variety of psycholinguistic studies (e.g., Geller et al., Reference Geller, Still and Morris2016; Guasch et al., Reference Guasch, Ferré and Haro2017; Haro et al., Reference Haro, Guasch, Vallès and Ferré2017; Kuchinke et al., Reference Kuchinke, Vo, Hofmann and Jacobs2007; Lõo et al., Reference Lõo, van Rij, Järvikivi and Baayen2016) as it offers a reliable measure of cognitive effort, attention, and affect imposed by different variables in speech processing (Laeng et al., Reference Laeng, Sirois and Gredebäck2012). The activities within the locus coeruleus are correlated with two modes of pupillary responses: tonic and phasic (Aston-Jones et al., Reference Aston-Jones, Rajkowski and Cohen1999). While the tonic (or baseline) response is slow-changing and related to the state of arousal or vigilance, the phasic pupillary response is time-locked to task-related events and stimuli (Laeng et al., Reference Laeng, Sirois and Gredebäck2012; Papesh & Goldinger, Reference Papesh, Goldinger, Gendolla, Tops and Koole2015). The phasic response has been employed in a variety of speech perception and processing studies coupled with various types of tasks, with greater pupil dilation indexing greater cognitive effort: delayed naming (Goldinger et al., Reference Goldinger, Azuma, Abramson and Jain1997; Papesh & Goldinger, Reference Papesh and Goldinger2012; Porretta & Tucker, Reference Porretta and Tucker2019), speech reception threshold test (Kramer et al., Reference Kramer, Lorens, Coninx, Zekveld, Piotrowska and Skarzynski2013; Zekveld et al., Reference Zekveld, Heslenfeld, Johnsrude, Versfeld and Kramer2014; Zekveld et al., Reference Zekveld, Kramer and Festen2010), spoken language comprehension (Hubert Lyall & Järvikivi, Reference Hubert Lyall and Järvikivi2021), and listening to words or syllables (Hochmann & Papeo, Reference Hochmann and Papeo2014; Tamási et al., Reference Tamási, McKean, Gafos, Fritzsche and Höhle2017) (See Schmidtke (Reference Schmidtke2018) for an overview of pupillometry studies in a wide range of linguistic research).
For our experiments, pupillometry is particularly beneficial because (1) pupillary response reflects the extent to which our variables of interest impact the amount of cognitive effort in the absence of voluntary processes (Papesh & Goldinger, Reference Papesh, Goldinger, Gendolla, Tops and Koole2015), (2) pupillary response is physiological and automatic; therefore, cognitive effort estimated by pupil dilation can minimize the influences from task-specific strategies (Goldinger & Papesh, Reference Goldinger and Papesh2012), and (3) pupillary dilation has been reported to reveal differences in cognitive effort even when behavioral measures exhibit equivalent performance (Karatekin et al., Reference Karatekin, Couperus and Marcus2004).
Following previous studies (Papesh & Goldinger, Reference Papesh and Goldinger2012; Pattamadilok et al., Reference Pattamadilok, Perre, Dufau and Ziegler2009), we use Go-NoGo and delayed naming tasks. These tasks allow us to design our experiments in such a way that (1) target trials are free of artifacts resulting from motor movements invoked by responses that possibly influence pupil dilation (Haro et al., Reference Haro, Guasch, Vallès and Ferré2017), (2) the Go-NoGo task does not require the extraction of word meaning or the explicit analysis of phonological structure or lexical status, meaning that participants do not need to make linguistically derived decisions on the target items (Pattamadilok et al., Reference Pattamadilok, Perre, Dufau and Ziegler2009), and (3) the delayed naming task allows us to examine decision-free P-O consistency effects, as naming occurs after lexical access is complete (Papesh & Goldinger, Reference Papesh and Goldinger2012). If P-O consistency effects occur solely during the perception and/or decision stages, the effects should disappear during the speech planning stage; however, if postlexical access processes are P-O consistency-sensitive, the differences should persist, meaning that P-O consistency modulates the cognitive effort required for speech planning. Additionally, since the delayed naming task requires more active involvement (listen and repeat target words) than the Go-NoGo task (passively listen to target words), we expect overall pupillary responses to be greater for the delayed naming task than for the Go-NoGo task.
If the orthographic effect does not play a role in the processing of reduced speech, as Mitterer and Reinisch (Reference Mitterer and Reinisch2015) propose, we should observe the P-O consistency effect in unreduced forms but not in reduced forms, meaning that inconsistent words will induce greater pupil dilation than consistent ones for unreduced words, but there will be no difference in pupil dilation between the two types of words for reduced words. Alternatively, there may be a consistency effect for both types of words, but it might influence the two types differently (e.g., the difference could be manifested by the degree and/or time course of the effect indicated by the degree and the time course of pupil dilation), suggesting that the phonetic realization of words matters for the effect (i.e., it could mean either reduction creates an additional sound-to-spelling mismatch or the consistency effect does not affect reduced forms as much as it does unreduced forms). Furthermore, the consistency effect could influence L1 and L2 listeners differently. If L2 learners have a strong orthographic component in their lexical knowledge due to the early learning of orthography, as the orthographic bias hypothesis states in Veivo et al. (Reference Veivo, Järvikivi, Porretta and Hyönä2016), L2 learners might show a stronger P-O consistency effect, meaning that the differences in the degree of pupil dilation between consistent and inconsistent words might be greater for L2 listeners than L1 listeners. Moreover, the consistency effect could be modulated by their proficiency. If phonological and orthographic representations in L2 learners, especially for low proficiency learners, do not interact efficiently because these representations are not yet fully established, as suggested by Veivo and Järvikivi (Reference Veivo and Järvikivi2013), we should only observe a consistency effect with high proficiency learners, meaning that inconsistent words will induce greater pupil dilation than consistent ones for advanced learners, but for beginners, there will be small or no difference between inconsistent and consistent words in pupil dilation.
Method
Participants
We recruited sixty-four participants at Nagoya University in Japan, thirty-eight of whom were native speakers of Japanese (female, n = 16) ranging in age from 18 to 25 years old (M = 19.7, SD = 1.69) and twenty-six of whom were native speakers of English (female, n = 16) who speak Japanese as a second language1, ranging in age from 19 to 34 years old (M = 23.2, SD = 4.61). All participants reported normal or corrected-to-normal vision and hearing, and performed both the Go-NoGo and delayed naming task. For each speaker group, the task presentation order was split so that half of them performed the Go-NoGo task first and the other half did the delayed naming task first. Four L1 participants and three L2 participants were excluded from our data in both tasks due to their excessive blinks and artifacts.2
Materials
We chose 226 four-mora and two-logograph words. We used the Balanced Corpus of Contemporary Written Japanese (BCCWJ) (Maekawa et al., Reference Maekawa, Yamazaki, Ogiso, Maruyama, Ogura, Kashino, Koiso, Yamaguchi, Tanaka and Den2014) to collect lexical information and calculate the P-O consistency index for each target word according to the criteria in Hino et al. (Reference Hino, Kusunose and Lupker2017, Reference Hino, Miyamura and Lupker2011). We selected BCCWJ because it is one of the largest Japanese datasets. Also, it is composed of more recent data and has a wider range of genres than the database used in Hino et al. (Reference Hino, Kusunose and Lupker2017, Reference Hino, Miyamura and Lupker2011). All of the target words contain a word-medial nasal or voiced stop (with a few words containing both of the consonants) because previous research demonstrated that both types of consonants show various forms of reduction in Japanese (Vance, Reference Vance2008). For example, in the case of a word-medial voiced stop, articulation of the word-medial voiced stop in /dɑigɑkɯ/ “university” is approximated due to the lack of full oral closure and realized as [dɑiɣɑkɯ], and in the extreme case, the consonant is deleted and the realization of the word becomes [dɑiɑkɯ] (Arai, Reference Arai1999).
Our stimuli were recorded in both reduced and unreduced forms by a female native Japanese speaker. We instructed the speaker to produce the words clearly (careful speech) for unreduced forms and casually (spontaneous speech) for reduced forms. The speaker produced multiple tokens of both forms, and we selected the most natural sounding tokens. We then normalized the amplitude of the words for presentation purposes. Table 1 illustrates the acoustic properties of both reduced and unreduced forms. The intensity difference was defined as the difference between the minimum intensity of the target segment to the averaged maximum intensity of surrounding segments (Mukai & Tucker, Reference Mukai and Tucker2017; Warner & Tucker, Reference Warner and Tucker2011). Overall, reduced forms have shorter duration, faster articulation rate, lower mean pitch, and smaller intensity difference. Importantly, the difference between the two forms in our study is represented in such a way that a target segment is produced as reduced or unreduced, as discussed in Tucker (Reference Tucker2011) and Mukai (Reference Mukai2020), rather than the absence or presence of the segment. Previous studies on the effect of orthography in processing of reduced speech treated reduction as phonological phenomena (Mitterer & Reinisch, Reference Mitterer and Reinisch2015), such as the absence or presence of a word-medial schwa in French (Bürki et al., Reference Bürki, Spinelli and Gaskell2012; Bürki et al., Reference Bürki, Viebahn, Racine, Mabut and Spinelli2018). While this is true for some cases, many reduction processes appear to be gradient (Bürki et al., Reference Bürki, Fougeron, Gendrot and Frauenfelder2011; Ernestus & Warner, Reference Ernestus and Warner2011; Warner & Tucker, Reference Warner and Tucker2011).
Table 1. Mean acoustic values of stimuli in reduced and unreduced forms
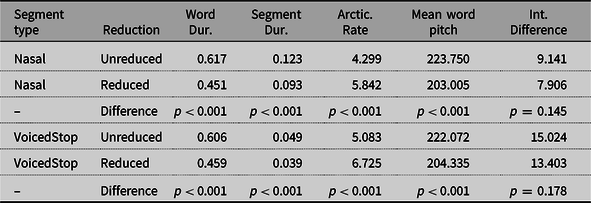
Note. Both word and segment durations are represented in seconds. Articulation rate was measured by the number of vowels per second. P-values indicate the probability that the difference between the two forms was significantly different from 0.
We created four lists for each task and each list contained 150 items (5 practice words, 113 target words (reduced or unreduced forms), and 32 non-target items (i.e., pure tones for the Go-NoGo task and filler Japanese words for the delayed naming task, which were recorded together with target words). As in Perre et al. (Reference Perre, Bertrand and Ziegler2011), we employed a 500-ms-long pure tone as non-target items for the Go-NoGo task and set the ratio between the target and non-target trials as 70% and 30%. The same 500-ms-long pure tone was used in the delayed naming task as well. The target words were counterbalanced across both pronunciation and task, so that none of the participants heard the same word twice within the entire experiment.
Apparatus and procedure
We designed and controlled the experiment using SR Research Experiment Builder software. Participants’ right eye was tracked using an EyeLink II head-mounted eye tracker (SR Research, Canada) in the pupil-only mode with a sampling rate of 250 Hz. Prior to the beginning of each experiment, we calibrated the system using a 9-point calibration procedure. We utilized Etymotic Research insert ER1 earphones to present auditory stimuli and a 1024 × 768 resolution computer screen to present a fixation cross. Participants sat on a chair in a quiet room at a distance of approximately 60 cm from the computer screen. Luminance of the room was kept constant throughout the experiment. For the delayed naming task, we used a head-mounted Countryman E6 microphone and Korg portable digital recorder to record participants’ naming responses.
In the Go-NoGo task, participants looked at a fixation cross presented at the center of the screen on a gray background for 1500 ms and heard either a pure tone or Japanese word as they continued looking at the fixation cross. They responded to the pure tone by pressing a button on a Microsoft Side Winder game-pad or they did not respond to the Japanese word (passively listening). The fixation cross disappeared after the button press triggered by the pure tone or 2000 ms after the onset of the Japanese word. To allow pupil dilation to return to baseline, a blank screen on a gray background remained for 4000 ms after the disappearance of the fixation cross (Papesh & Goldinger, Reference Papesh and Goldinger2012).
In the delayed naming task, participants looked at a fixation cross presented at the center of the screen on a gray background for 1500 ms and heard a Japanese word as they continued looking at the fixation cross. They then waited 1000 ms and heard a 500 ms-long pure tone. They then repeated what they had heard. The fixation cross disappeared 2000 ms after the onset of the Japanese word. A blank screen on a gray background remained for 4000 ms after the disappearance of the fixation cross for the pupil to settle back to baseline. In each session of both tasks, the practice items were provided at the beginning of sessions to familiarize the participants with the task. We calibrated the eye tracker before each session and after participants took a brief break (every 29 trials). We also ran drift correction at the onset of every trial. The target and non-target items were randomly assigned to each trial by the software. Each task lasted approximately 45 minutes. Before the experiment, L2-speaking participants answered a Language Experience and Proficiency Questionnaire (LEAP-Q) (Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007) to provide their demographic information and Japanese language experience and proficiency. LEAP-Q has been utilized in a wide range of psycholinguistic research, and it has been shown that self-reported proficiency in LEAP-Q correlates with behavioral performance data, particularly for L2 speakers, suggesting that self-reported proficiency reflects approximations of overall language skill (see Kaushanskaya et al. (Reference Kaushanskaya, Blumenfeld and Marian2019) for an overview of LEAP-Q).
Preprocessing pupil size data
We performed data preprocessing in the statistical environment R, version 3.4.4 (R Development Core Team, 2018). After visually inspecting the range of pre- and post-marked blinks, we cleaned the data by removing 50 samples (100 ms time window) before and after the blinks. We then linearly interpolated the removed data points for each trial. When initial and/or final samples in a trial were eye blinks or their artifacts, these samples were replaced with the nearest value to complete the interpolation. We then downsampled the interpolated data to 50Hz and smoothed it using a five-point weighted moving-average smoothing function. The same interpolation and smoothing procedures were also applied to the gaze location data to use the data as a control variable. Relevant pupillary variables were computed on a trial-by-trial basis in the time window from the onset of stimulus to 2000 ms after onset for the Go-NoGo task and from the onset of stimuli to 2500 ms after onset for the delayed naming task.
Data were cleaned and checked visually on a trial-by-trial basis to detect unexpected deviations (Winn et al., Reference Winn, Wendt, Koelewijn and Kuchinsky2018). The trials that contained excessive blinks and their artifacts (more than 30% of the trial) were excluded. Based on the first author’s visual inspection of trials, additional trials were excluded (1) when the peak latency was shorter than 400 ms and (2) when the peak dilation was smaller than 0 or bigger than 400 in order to remove large outliers. In total, we excluded 19.7% of the data in the Go-NoGo task and 20.7% of data in the delayed naming task for L1 participants and 23% of data in the Go-NoGo task and 13.7% of data in the delayed naming task for L2 participants.3
Statistical considerations
We applied Generalized Additive Mixed Modeling (GAMM) (Hastie & Tibshirani, Reference Hastie and Tibshirani1990) to our pupil dilation data for three reasons. First, GAMM allows us to model non-linear relationships, as well as linear relationships, between dependent and independent variables (Sóskuthy, Reference Sóskuthy2017; van Rij et al., Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019; van Rij et al., Reference van Rij, Vaci, Wurm, Feldman, Pirrelli, Plag and Dressler2020; Wieling et al., Reference Wieling, Tomaschek, Arnold, Tiede, Bröker, Thiele, Wood and Baayen2016). This was important as we expected pupil size to fluctuate over time (van Rij et al., Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019). Second, GAMM can model two or more dimensional non-linear interactions of continuous variables. Third, GAMM allowed us to control for serial dependency in time series data, namely, autocorrelation (see Baayen et al. (Reference Baayen, Vasishth, Bates and Kliegl2017) and Wood (Reference Wood2017) for an overview of autocorrelation in GAMM). Because of this functionality, GAMM has been utilized not only to model pupillometric data (Lõo et al., Reference Lõo, van Rij, Järvikivi and Baayen2016; Mukai et al., Reference Mukai, Järvikivi, Tucker and Dmyterko2018; Porretta & Tucker, Reference Porretta and Tucker2019; van Rij et al., Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019), but a variety of non-linear time series data, such as electromagnetic articulography data, the position of tongue and lips during speech (Wieling et al., Reference Wieling, Tomaschek, Arnold, Tiede, Bröker, Thiele, Wood and Baayen2016), formant trajectory data, the time course of formant frequencies in speech (Sóskuthy, Reference Sóskuthy2017), visual world eye-tracking data (Porretta et al., Reference Porretta, Tucker and Järvikivi2016; Veivo et al., Reference Veivo, Järvikivi, Porretta and Hyönä2016), and event-related potential data (Kryuchkova et al., Reference Kryuchkova, Tucker, Wurm and Baayen2012; Meulman et al., Reference Meulman, Wieling, Sprenger, Stowe and Schmid2015; Porretta et al., Reference Porretta, Tremblay and Bolger2017). We performed model fitting and comparisons in the statistical environment R, version 3.4.4 (R Development Core Team, 2018) using the package mgcv (Wood, Reference Wood2017), version 1.8-23 and itsadug (van Rij et al., Reference van Rij, Wieling, Baayen and van Rijn2017), version 2.3. We followed the procedure of fitting and evaluating models illustrated in Sóskuthy (Reference Sóskuthy2017); van Rij et al. (Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019); Wieling (Reference Wieling2018); Wieling et al., (Reference Wieling, Tomaschek, Arnold, Tiede, Bröker, Thiele, Wood and Baayen2016). We employed a backward selection procedure for fixed effects and a forward fitting procedure for random effects to fit the optimal model (Matuschek et al., Reference Matuschek, Kliegl, Vasishth, Baayen and Bates2017). We evaluated the contribution of input variables by χ 2 test of fREML scores using the compareML function. We compared the fREML score of the full model to the score of the model without one of the input variables and kept the input variables that were justified by the comparison (p<.05). Inclusion of interactions was also assessed by the fREML score comparison.
Variables of interest
Our dependent variable was Baseline Normalized Pupil Dilation (in the standard arbitrary unit delivered by the eye-tracking system). We calculated the baseline pupil size for each trial by averaging the pupil size in the time window from 200 ms preceding the onset of stimulus to the onset of stimulus and performed standard baseline subtraction for each trial to quantify the degree of pupil dilation. We employed a subtractive baseline correction (absolute difference) rather than divisive baseline correction (proportional difference) because percentage measures are inflated when baseline pupil size is small (Beatty & Lucero-Wagoner, Reference Beatty, Lucero-Wagoner, Cacioppo, Tassinary and Berntson2000; Mathôt et al., Reference Mathôt, Fabius, Heusden and der Stigchel2018; Reilly et al., Reference Reilly, Kelly, Kim, Jett and Zuckerman2019). Our independent variables were Language, P-O Consistency Index, Reduction, and Time.
Language is a binary category, and it represents whether the participant uses Japanese as an L1 or L2. The P-O consistency index was calculated according to the criteria in Hino et al. (Reference Hino, Kusunose and Lupker2017, Reference Hino, Miyamura and Lupker2011). The index ranges from 0 to 1, with 0 indicating low consistency and 1 indicating high consistency. Reduction is a binary category, and it represents whether the participant heard a reduced or unreduced stimulus. To investigate the interaction between Language and Reduction, a new factor with four levels was created and named “LangaugeReduction” (L1.Unreduced, L2.Unreduced, L1.Reduced, and L2.Reduced) (see van Rij et al. (Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019); Wieling (Reference Wieling2018); Wieling et al. (Reference Wieling, Tomaschek, Arnold, Tiede, Bröker, Thiele, Wood and Baayen2016), for an overview of how to analyze interactions in GAMM). We were also interested in the time course of processing; therefore, Time (in milliseconds) was included as a covariate.
Additionally, we included control variables: Baseline Pupil Size (same unit as Pupil Dilation), Pupil Gaze Coordinate X and Y (x- and y-axis eye gaze position on the screen in pixels), Trial Index (from 6 to 150), Word Duration (in milliseconds), Target Segment (whether the stimulus contains a word-medial voiced stop or nasal), Target Word Frequency (log-transformed), Number of Phonological Neighbors of Target Word (log-transformed), and Number of Homophones of Target Word (Z-transformed). For the Go-NoGo task, Participant’s Mean Reaction Time (in milliseconds) was also included.
The baseline pupil size was included to account for the extent to which the pupil can dilate (i.e., a larger baseline size limits the extent of dilation). Pupil Gaze Coordinates account for the possible change in pupil size caused by different gaze locations on the screen (Wang, Reference Wang, Schulte-Mecklenbeck, Kühberger and Ranyard2011). Trial index was included to control for an effect of trial order and the fatigue of the pupil responses (McLaughlin et al., Reference McLaughlin, Zink, Gaunt, Reilly, Sommers, Engen and Peelle2022). Target Segment, Word Duration, Logged Target Word Frequency, Logged Number of Phonological Neighbors of Target Word, and Standardized Number of Homophones of Target Word were included to account for the differences in the lexical items (Kuchinke et al., Reference Kuchinke, Vo, Hofmann and Jacobs2007; Porretta & Tucker, Reference Porretta and Tucker2019). The correlation between Logged Target Word Frequency and P-O Consistency Index was weak (r = 0.27) but Logged Number of Phonological Neighbors was negatively correlated with P-O Consistency Index (r = −0.66). That is, high consistency words tend to have a small number of phonological neighbors. Therefore, P-O Consistency Index and Logged Number of Phonological Neighbors were not included in the same model. The mean reaction time for non-target items in each participant (i.e., a button press for a pure tone) was included to account for the degree to which participants were attentive to the stimuli, as the fast (more attentive) and slow reaction time (less attentive) participants could show different patterns of effects of independent variables. That is, less attentive participants may not make any effort, which could be indicated by overall weak pupillary responses, thereby diminishing the effects.
Data, stimulus lists, analysis codes, and supplementary materials of the experiments are available on the Open Science Framework at https://osf.io/je3t4/.
Results
In the sections that follow, we first present the statistical analysis and result of each task for both speaker groups together, with a focus on a difference between L1 and L2 listeners. We then discuss the analysis and result of each task for each speaker group separately.
Go-NoGo task
We inspected the aggregated raw pupil dilation data prior to fitting models. Figure 1 illustrates the grand average of pupil dilation (y-axis) over time (x-axis) for reduced and unreduced word forms from −1500 ms to 2000 ms in the Go-NoGo task for L1 (left panel) and L2 (right panel) listeners. For L1 listeners, the trend of pupil dilation over time appears to be comparable between the two forms, but the reduced form demonstrates greater peak dilation and slower peak latency. For L2 listeners, both forms appear to demonstrate a similar trend to that of L1 listeners, but the difference between the two forms appears to be smaller. In addition, the overall dilation appears to be slightly greater for L1 than for L2 listeners.4
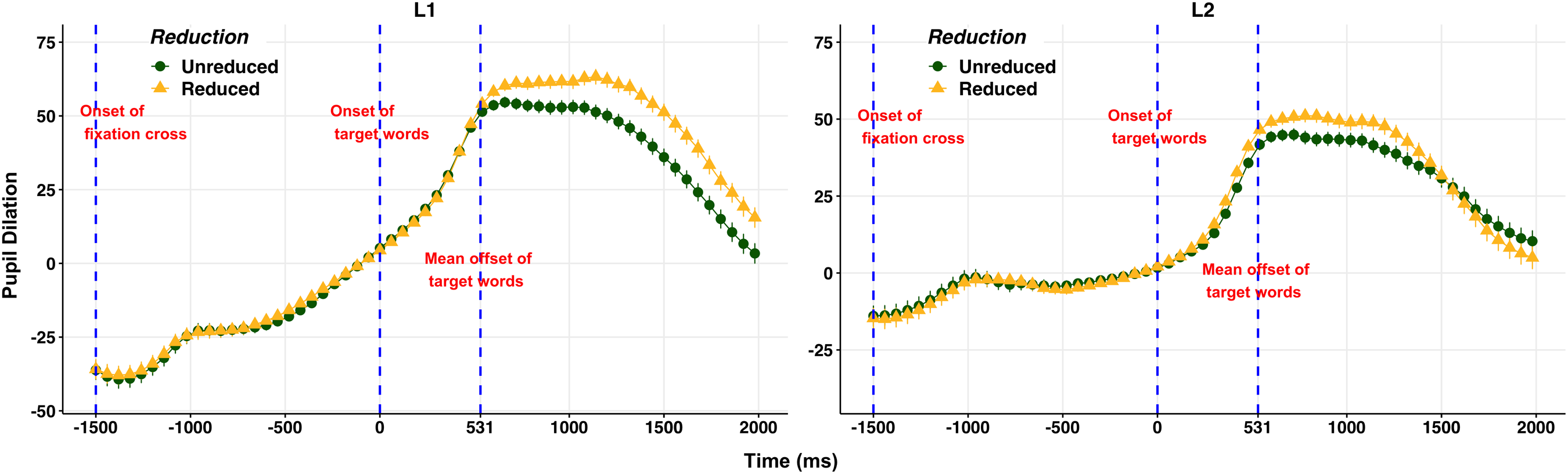
Figure 1. The grand average of pupillary dilation (y-axis) over time (x-axis) for reduced and unreduced word forms in the Go-NoGo task for L1 (left panel) and L2 (right panel) listeners. The vertical dotted line at -1500 ms indicates the onset of the fixation cross, the line at 0 ms indicates the onset of stimuli and the line at 531 ms indicates the mean offset of stimuli.
We chose the time window from 200 ms to 2000 ms post-stimulus onset for our analyses, as reliable effects emerge slowly in pupillary response 200 to 300 ms after a relevant cognitive event (Beatty, Reference Beatty1982). Pupil Dilation (dependent variable) was fitted as a function of P-O Consistency Index, LanguageReduction, and Time (independent variables). A three-way interaction was included between Time, P-O Consistency Index, and LanguageReduction. We used a tensor product smooth interaction (te-constructor) in order to model multi-dimensional non-linear interaction effects, allowing us to examine an effect of LanguageReduction, P-O Consistency Index and Time, as well as effects of interaction among those variables (See Sóskuthy (Reference Sóskuthy2017); van Rij et al. (Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019, Reference van Rij, Vaci, Wurm, Feldman, Pirrelli, Plag and Dressler2020); Wieling et al. (Reference Wieling, Tomaschek, Arnold, Tiede, Bröker, Thiele, Wood and Baayen2016) for an overview of a smooth function and tensor product smooth interaction). Also, Pupil Gaze Coordinate X and Y (control variables) were included as a two-way interaction to capture the possible change in pupil size caused by different gaze locations on the screen (Wang, Reference Wang, Schulte-Mecklenbeck, Kühberger and Ranyard2011).
For fixed effects, Target Segment, Logged Target Word Frequency, Z-transformed Number of Homophones, and Participant’s Mean Reaction Time were removed from the model during the model fitting and evaluating procedures, as they did not significantly improve the fit of the model (the variables that remained in the model are illustrated in Table 2). Word Duration and Baseline Pupil Size were refitted without a smooth function because their effects were linear and they can be included in the parametric coefficients. For random effects, we included two factor smooths: “ParIDConsis” (unique combination of Participant ID and P-O Consistency Index) for Time and “ItemReduc” (unique combination of Item (i.e., word) and Reduction) for Time. That is, we fitted separate factor smooths for each participant at each P-O Consistency Index to reflect participant-specific trends in the effect of P-O consistency over time, as well as for each item at each word form to take into account item-specific trends in the effect of reduction over time (See Wieling (Reference Wieling2018) for an overview of random effects structures). After verifying the number of basis functions for the independent variables and interactions using the gam.check function (Please see Sóskuthy (Reference Sóskuthy2017) for an overview of basis functions), we included an AR-1 correlation parameter at the value of 0.980 in the model to address autocorrelation and also fitted the model with the scaled-t family in order for residuals to be normally distributed (Meulman et al., Reference Meulman, Wieling, Sprenger, Stowe and Schmid2015; van Rij et al., Reference van Rij, Hendriks, van Rijn, Baayen and Wood2019; Wieling, Reference Wieling2018).
Table 2. The summary of the model for L1 and L2 listeners in Go-NoGo task, showing the parametric coefficients and approximate significance of smooth terms in the model: estimated degrees of freedom (edf), reference degrees of freedom (Ref.df), F- and p-values for smooth terms
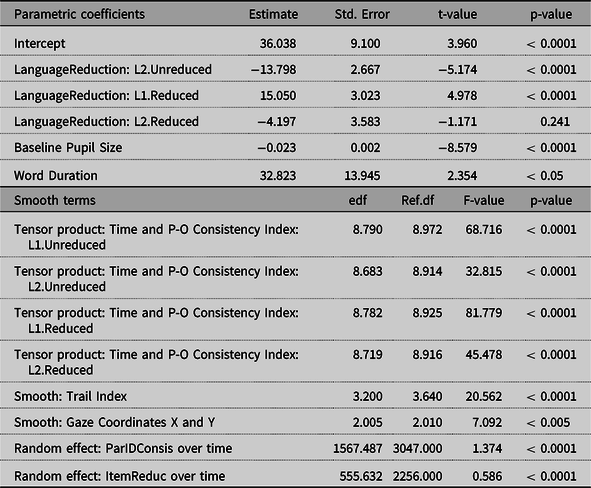
Table 2 summarizes our final model, showing the parametric coefficients and approximate significance of smooth terms in the model: estimated degrees of freedom (edf), reference degrees of freedom (Ref.df), F- and p-values for smooth terms. The parametric coefficients indicate that (1) the overall pupil dilation is smaller for L2.Unreduced than for L1.Unreduced (t = −5.174, p < 0.0001), and (2) the overall pupil dilation is greater for L1.Reduced than for L1.Unreduced (t = 4.978, p < 0.0001). In addition, (3) the overall pupil dilation is smaller for larger baseline pupil sizes (t = −8.579, p < 0.0001), and (4) the overall pupil dilation becomes greater as word duration increases (t = 2.354, p < 0.05). The smooth terms reveal the significance of non-linear patterns associated with all the independent variables. We further discuss the summary of the final model along with visualization of the results.
The contour plots in Figure 2 illustrate the interaction between the effect of Time (x-axis) and P-O Consistency Index (y-axis) by both Language and Reduction: L1.Unreduced (left top panel), L1.Reduced (right top panel), L2.Unreduced (bottom left panel), and L2.Reduced (bottom right panel). Shades of colors indicate the degree of pupil dilation: yellow: large dilation, green: medium dilation, blue: small dilation, and white: smaller than 0. The contour lines represent the pupil dilation values predicted by the model and their boundaries. These plots demonstrate that (1) dilation peaks around 800 to 1000 ms for both word forms and for both listener groups. However, for L2 listeners the peaks come a little earlier for the low-consistency index than for the high consistency index. (2) Reduced forms elicit overall larger dilation and greater peak dilation than their unreduced counterparts for both groups, and (3) similar to Figure 1, the overall dilation is greater for L1 listeners than for L2 listeners. (4) All word forms and listener groups exhibit a gradient effect of P-O consistency. (5) There is greater pupil dilation as P-O consistency index decreases for L1.Reduced, while the others demonstrate that dilation becomes greater as P-O consistency index increases. That is, while inconsistent words induce greater dilation for L1.Reduced, consistent words elicit greater dilation for the others. The trend of the effect for L1.Reduced is in line with the results reported by Hino et al. (Reference Hino, Kusunose and Lupker2017), but the trend of the effect for the others conflicts with the previous findings.
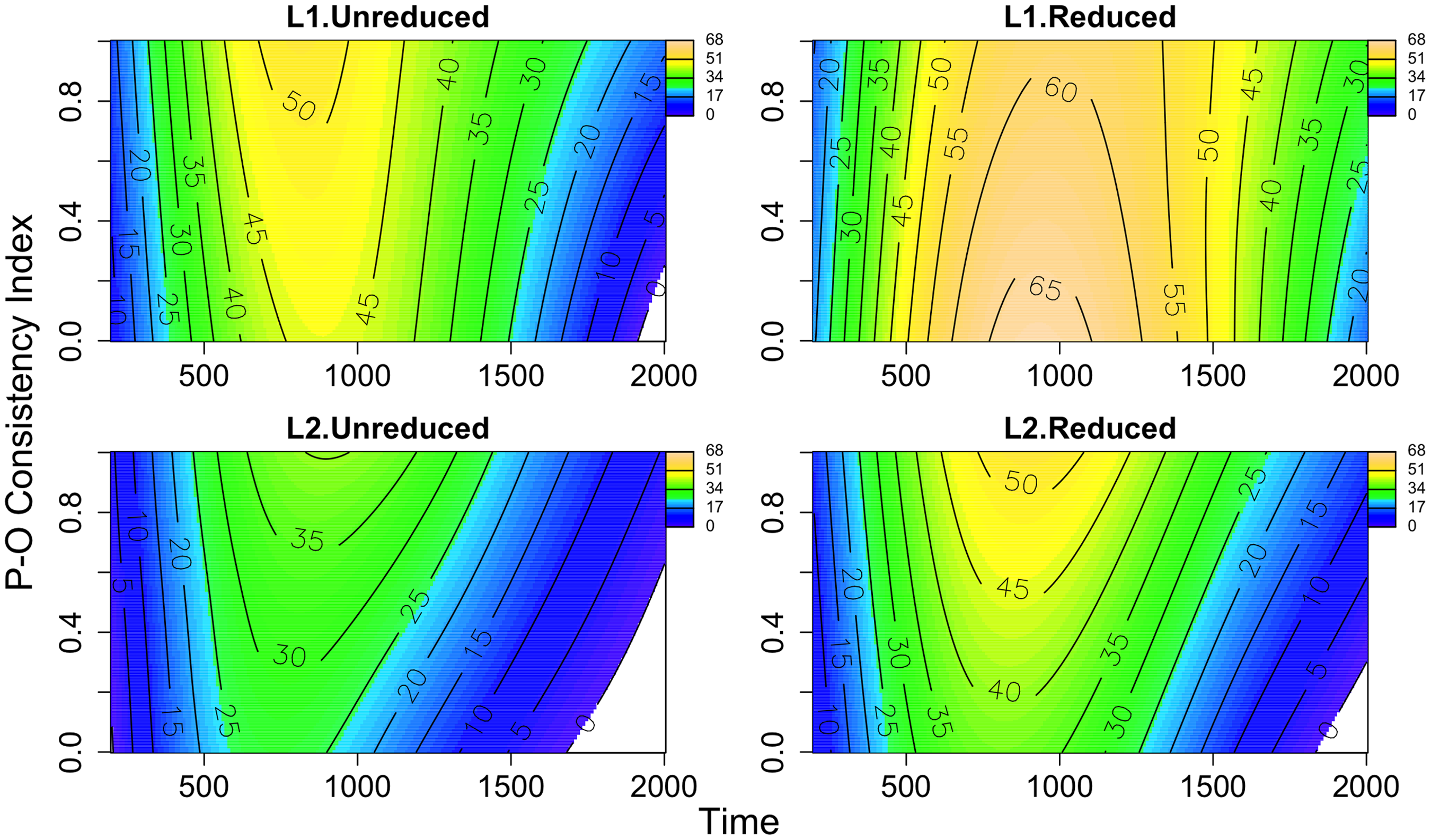
Figure 2. Contour plots of the interaction between the effect of Time (x-axis) and P-O Consistency Index (y-axis) by both Language and Reduction: L1.Unreduced (left top panel), L1.Reduced (right top panel), L2.Unreduced (bottom left panel), and L2.Reduced (bottom right panel). Shades of colours indicate the degree of pupil dilation: yellow: large dilation, green: medium dilation, blue: small dilation, and white: smaller than 0. The contour lines represent the pupil dilation values predicted by the model and their boundaries.
To further examine these aspects of the three-way interaction, we followed the procedure illustrated in Wieling (Reference Wieling2018) and formally evaluated the difference between L1 and L2 listeners using binary difference smooths. We first decomposed the tensor product smooth interaction of P-O Consistency Index, LanguageReduction, and Time into separate parts using a ti constructor: the effect of Time by Reduction, the effect of P-O Consistency Index by Reduction, and the effect of the interaction between Time and P-O Consistency Index by Reduction. We then re-specified the model with a newly created binary variable representing if a given word is heard by L1 or L2 listeners (see Wieling (Reference Wieling2018) for an overview of binary difference smooths and a ti constructor). The results demonstrate that the time course of dilation between L1 and L2 listeners differs for both reduced (edf = 2.985, F = 4.721, p < 0.005) and unreduced forms (edf = 2.731, F = 3.968, p < 0.01). Also, the trend of the P-O consistency effect between L1 and L2 listeners differs for both reduced (edf = 2.605, F = 12.355, p < 0.0001) and unreduced forms (edf = 2.005, F = 11.318, p < 0.0001). These results are in line with the description of the effects of (2) and (3) above. The trend of the interaction between Time and P-O consistency between L1 and L2 listeners does not differ for either forms (Reduced: edf = 1.943, F = 1.863, p = 0.20831; Unreduced: edf = 1.590, F = 0.945, p = 0.31864).
In sum, reduced forms elicit greater dilation than their unreduced counterparts for both L1 and L2 listeners, but the overall dilation appears to be greater for L1 listeners than for L2 listeners. The time course of dilation and the trend of the effect of consistency differ between the two listener groups for all the word forms.
Delayed naming task
Figure 3 displays the grand average of pupil dilation (y-axis) over time (x-axis) for reduced and unreduced word forms from −1500 ms to 2500 ms in the delayed naming task for L1 (left panel) and L2 (right panel) listeners. For both listener groups and for both word forms, pupil dilation increases as time progresses. Similar to the Go-NoGo task, for L1 listeners, the trend of pupil dilation over time appears to be comparable between the two forms, but reduced forms demonstrate greater peak dilation. The mean error rate for naming responses was lower than 1%. For L2 listeners, although the reduced form demonstrates a slightly greater dilation over time after 1000 ms, the difference between the two forms appears to be smaller than that of L1 listeners. Additionally, the dilation appears to be steeper and greater for L2 than for L1 listeners. The mean error rate for naming responses was 6.43 % (SD = 5.25).
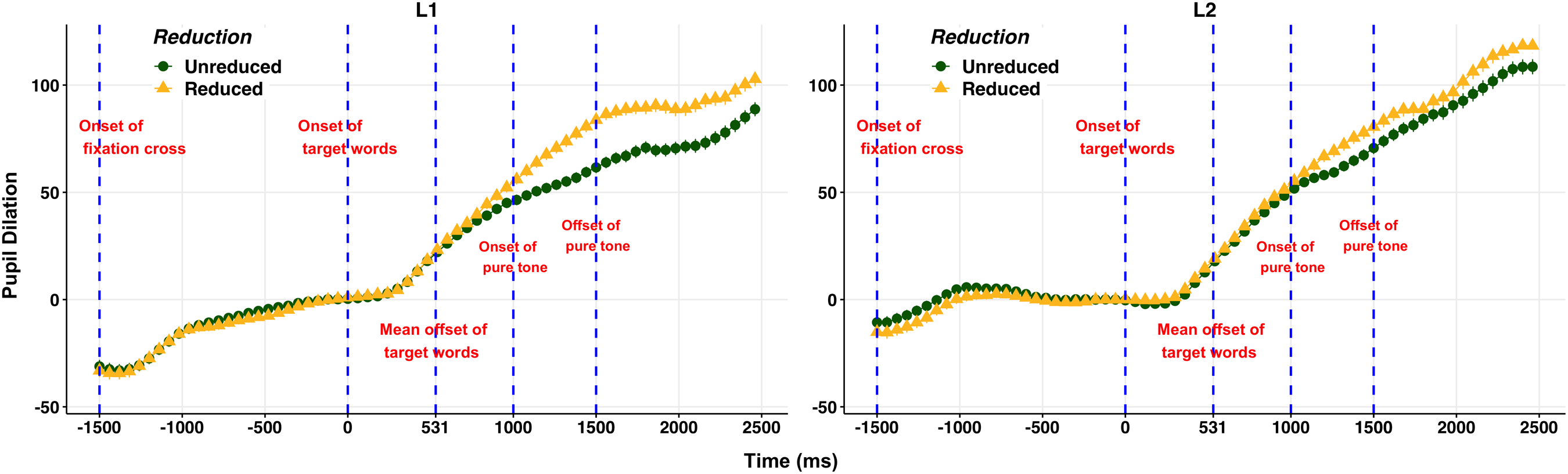
Figure 3. The grand average of pupillary dilation (y-axis) over time (x-axis) for reduced and unreduced word forms in the delayed naming task for L1 (left panel) and L2 (right panel) listeners. The vertical dot line at -1500 ms indicates the onset of the fixation cross, the line at 0 ms indicates the onset of stimuli, the line at 531 ms indicates the mean offset of stimuli, the line at 1000 ms indicates the onset of pure tone, and the line at 1500 ms displays the offset of pure tone.
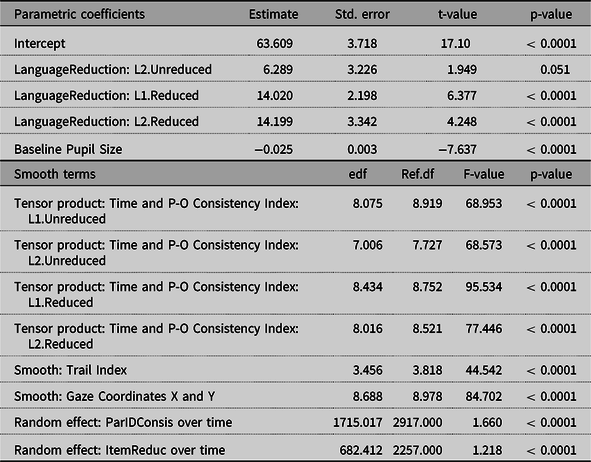
We chose the time window from 200 ms to 2500 ms post-stimulus onset for this analysis. We used the same variables and procedures as earlier, but we did not include the Participant’s Mean Reaction Time variable, as we did not measure the speed of naming for this task. For fixed effects, Target Segment, Logged Target Word Frequency, Word Duration, and Z-transformed Number of Homophones were removed from the model during the model fitting and evaluating procedures, as they did not significantly improve the fit of the model (the variables that remained in the model are illustrated in Table 3). Baseline Pupil Size was refitted without a smooth function because the effect was linear. As in the Go-NoGo task, two factor smooths were included for random effects: ParIDConsis (unique combination of Participant ID and P-O Consistency Index) for Time and ItemReduc (unique combination of Item (i.e., word) and Reduction) for Time. We also included an AR-1 correlation parameter at the value of 0.985 and fitted the model with the scaled-t family. The summary of our final model is described in Table 3. The parametric coefficients indicate that (1) the overall pupil dilation is greater for L1.Reduced (t = 6.377, p < 0.0001) and L2.Reduced (t = 4.248, p < 0.0001) than for L1.Unreduced. In addition, (2) the overall pupil dilation is smaller for larger baseline pupil sizes (t = −7.637, p < 0.0001). Similarly, the smooth terms reveal the significance of non-linear patterns associated with all the independent variables.
Table 3. The summary of the model for L1 and L2 listeners in delayed naming task, showing the parametric coefficients and approximate significance of smooth terms in the model: estimated degrees of freedom (edf), reference degrees of freedom (Ref.df), F- and p-values for smooth terms
As in the Go-NoGo task, Figure 4 demonstrates the interaction between the effect of Time and P-O Consistency Index by both Language and Reduction: L1.Unreduced (left top panel), L1.Reduced (right top panel), L2.Unreduced (bottom left panel), and L2.Reduced (bottom right panel). As indicated by the shades of colors and pupil dilation values of lines on the contour plots, we observe that: (1) for both word forms and both listener groups, the pupil dilates more greatly over time as we saw in Figure 3, and (2) reduced forms induce greater dilation than unreduced counterparts for both listener groups. (3) The consistency effect is larger for reduced forms than for unreduced counterparts for both listener groups, but (4) the direction of the effect of P-O consistency for reduced forms differs between L1 and L2 listeners. While pupil dilation becomes steeper and greater as P-O consistency index decreases for L1 listeners, L2 listeners demonstrate that dilation becomes steeper and greater as P-O consistency index increases. That is, while inconsistent words induce greater dilation for L1 listeners, consistent words elicit greater dilation for L2 listeners. As in the findings in the Go-NoGo task, the trend of the effect for L1 listeners is in line with the result of Hino et al. (Reference Hino, Kusunose and Lupker2017), but the trend of the effect for L2 listeners conflicts with the previous findings.
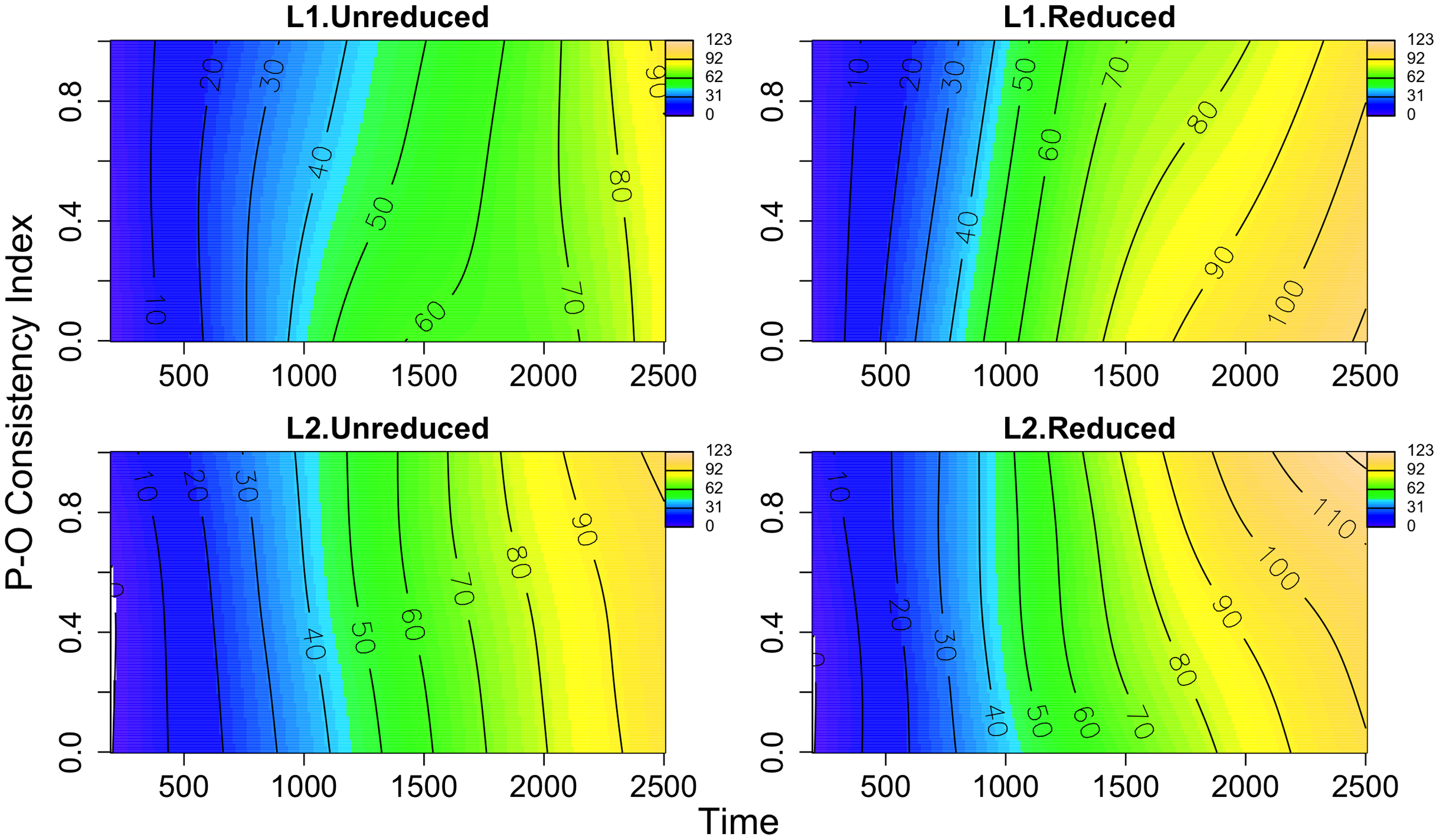
Figure 4. Contour plots of the interaction between the effect of Time (x-axis) and P-O Consistency Index (y-axis) by both Language and Reduction: L1.Unreduced (left top panel), L1.Reduced (right top panel), L2.Unreduced (bottom left panel), and L2.Reduced (bottom right panel). Shades of colours indicate the degree of pupil dilation: yellow: large dilation, green: medium dilation, blue: small dilation, and white: smaller than 0. The contour lines represent the pupil dilation values predicted by the model and their boundaries.
As in the Go-NoGo task, we further examined these aspects of the three-way interaction by formally evaluating the difference between L1 and L2 listeners using binary difference smooths. The results demonstrate that only the trend of the P-O consistency effect between L1 and L2 listeners for reduced forms differs (edf = 2.013, F = 3.150, p < 0.05), which is in line with the discussion of (4). In short, for both listener groups, reduced forms appear to induce a greater dilation than unreduced counterparts, and the consistency effect is stronger for reduced forms than for unreduced forms. In addition, the effect of consistency differs between the two listener groups for reduced forms.
Overall, reduction and P-O consistency affect L1 and L2 listeners differently in both tasks. Further analyses were conducted focusing on the comparison between unreduced and reduced forms for L1 and L2 listeners separately, as well as their interaction with proficiency for L2 listeners. A full analysis and results of the L1 listeners, which mirror those reported in the previous section, are included in the supplementary material. A full analysis and results of the L2 listeners are also included in the supplementary material. The results of the L2 proficiency analysis are briefly discussed in the general discussion section, but it is important to note that the number of participants per group for the L2 proficiency analysis is small. Therefore, we need to be careful not to overly interpret the results.
Of particular interest is the interaction between the effect of orthography and the processing cost of reduced and unreduced forms. Previous research suggests that the processing advantage of unreduced forms could be due to a consistent relationship between an unreduced pronunciation and its orthographic form (Connine & Pinnow, Reference Connine and Pinnow2006; Racine et al., Reference Racine, Bürki and Spinelli2014; Ranbom & Connine, Reference Ranbom and Connine2007). However, our findings suggest that P-O consistency plays an important role in the processing of reduced forms as well. For example, Figure 5 illustrates differences in pupil dilation between the two forms over both Time (x-axis) and P-O consistency index (y-axis) in the Go-NoGo (left panel) and delayed naming task (right panel) for L1 listeners. The difference was calculated by subtracting the pupil dilation value of unreduced forms from that of reduced forms. Similar to the earlier plots, shades of colors indicate the degree of difference in pupil dilation between the two forms: yellow: large difference, green: medium difference, blue: small difference, and white: smaller than 0. The contour lines represent the difference values in pupil dilation between the two forms and their boundaries. As shown by these plots, the difference in the processing cost between the two forms becomes smaller as the P-O consistency index increases, suggesting that the additional processing cost incurred by reduced forms is attenuated by the consistent P-O relationship. Consequently, the processing advantage of unreduced forms is greater for inconsistent words than for consistent ones. For example, in the Go-NoGo task, pupil dilation peaks approximately at 800 ms for unreduced forms and at 1000 ms for reduced forms (as shown in Figure 2). Within the time window (around 900 ms), the difference value is 30 at the lowest P-O consistency index but the value becomes half at the highest consistency index (left panel in Figure 5).
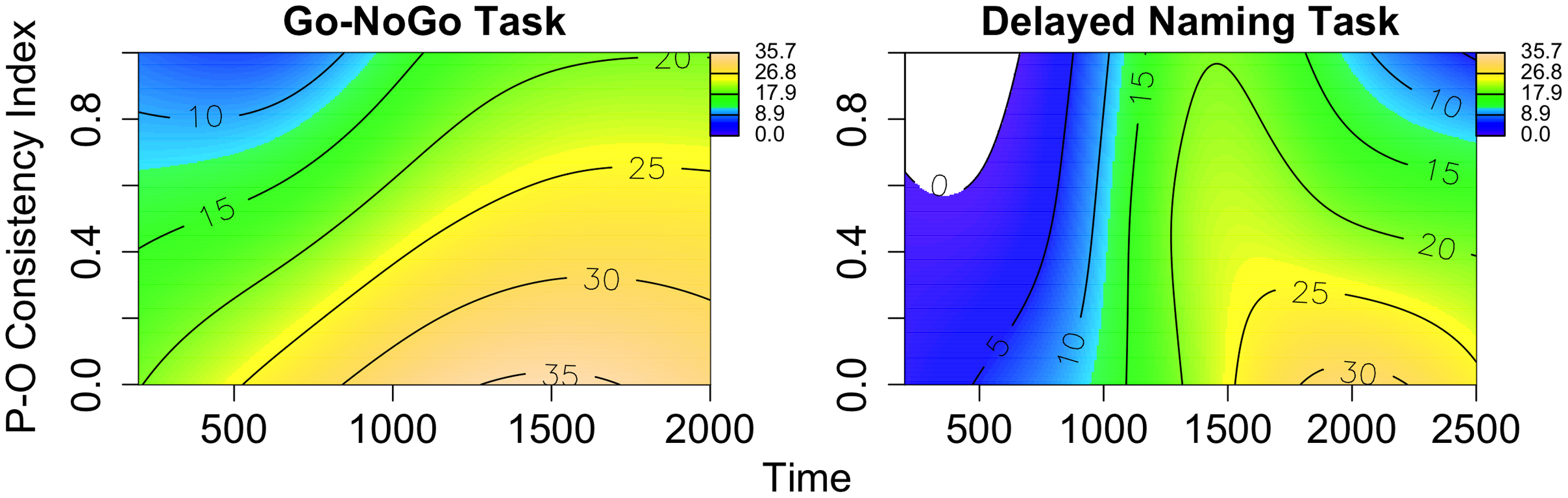
Figure 5. These contour plots demonstrate the difference in pupil dilation between reduced and unreduced forms over Time (x-axis) and P-O consistency Index (y-axis) in the Go-NoGo task (left panel) and delayed naming task (right panel) for L1 listeners (the difference was calculated by subtracting the pupil dilation value of unreduced forms from that of reduced forms). Shades of colours indicate the degree of difference in pupil dilation between the two forms: yellow: large difference, green: medium difference, blue: small difference, and white: smaller than 0. The contour lines represent the difference values in pupil dilation between the two forms and their boundaries.
If the processing advantage of unreduced forms were due to a consistent relationship between an unreduced pronunciation and its orthographic form, as previous research suggested (Connine & Pinnow, Reference Connine and Pinnow2006; Racine et al., Reference Racine, Bürki and Spinelli2014; Ranbom & Connine, Reference Ranbom and Connine2007), we would not expect to observe the processing advantage for P-O inconsistent words. However, our findings suggest an advantage for unreduced forms for both consistent and inconsistent words in both tasks, suggesting that it is unlikely that consistency is the sole driving factor of the advantage. Instead, our result reveals a facilitatory effect for P-O consistent words in reduced forms, where the orthographic information that is consistent with its phonological form (phonology-to-orthography consistency) appears to reinforce the correct phonological representations. Our findings are in line with the notion raised by Mitterer and Reinisch (Reference Mitterer and Reinisch2015) where the P-O consistency effect should be re-conceptualized as facilitatory for consistent words instead of inhibitory for inconsistent words.
L2 advanced learners also demonstrate a similar pattern of the facilitatory effect for P-O consistent words in reduced forms, particularly in the Go-NoGo task (See the supplementary materials). However, the effect is not as pronounced as what has been found in L1 listeners. This could be due to either the qualitative difference between L1 and L2 listener’s orthographic and phonological information in their lexical representations (Veivo & Järvikivi, Reference Veivo and Järvikivi2013) or the proficiency difference between L1 and L2 listeners (i.e., L2 advanced listeners are not as proficient as L1 listeners).
General discussion
The present study investigated how the P-O consistency effect interacts with reduced pronunciations for L1 and L2 Japanese listeners. Go-NoGo and delayed naming tasks were employed, in combination with pupillometry, to compare the consistency effect between reduced and unreduced word forms over time. In particular, our study investigated whether the argument made by Mitterer and Reinisch (Reference Mitterer and Reinisch2015), that orthography does not play an important role in the perception of conversational reduced speech, holds for Japanese (a logographic language) with L1 and L2 listeners. Our predictions were that (1) if the orthographic effect does not play an important role in the processing of reduced speech, we should observe an interaction between the effect of reduction and P-O consistency, indicating that P-O consistency affects reduced and unreduced pronunciations differently, and (2) the consistency effect would influence L1 and L2 listeners differently and the effect would be modulated by their proficiency for L2 listeners. We found that: (1) reduced forms elicit larger dilation than unreduced counterparts. (2) The P-O consistency effect emerges in both tasks, and the effect influences reduced and unreduced pronunciations for both L1 and L2 listeners differently, and (3) it is likely to be the case that the consistency effect varies depending on L2 proficiency (See the supplementary materials). Additionally, (4) there is a facilitatory effect for P-O consistent words instead of an inhibitory effect for P-O inconsistent words in reduced forms. These results are discussed in terms of their implications for how listeners process reduced speech and the role of the orthographic form in speech processing.
Orthographic consistency and reduced pronunciation
As in previous research (e.g., Brouwer et al., Reference Brouwer, Mitterer and Huettig2013; Ernestus et al., Reference Ernestus, Baayen and Schreuder2002; Janse et al., Reference Janse, Nooteboom and Quené2007; Tucker, Reference Tucker2011; van de Ven et al., Reference van de Ven, Tucker and Ernestus2011), we observed that unreduced forms are easier to process than their reduced counterparts in both tasks as evidenced by an overall smaller pupil dilation for unreduced forms. The difference between the two forms, however, appears to be smaller for L2 listeners. This is likely because some words are difficult to comprehend, particularly for basic and intermediate learners, regardless of word forms (reduced or not) due to the lack of lexical exposure. Importantly, we found a facilitatory effect for P-O consistent words in reduced forms, where the orthographic information that is consistent with its phonological form (phonology-to-orthography consistency) appears to be capitalized on to reinforce the correct phonological representations.
Crucially, this result is highly relevant to the discussion of the hypothesis that orthography plays a role in the processing of reduced speech. Our results demonstrate that acoustically reduced words require additional cognitive effort for processing, but orthography facilitates the processing and attenuates the additional processing cost, particularly for words that have a consistent P-O relationship. This result could extend the discussion of why Viebahn et al. (Reference Viebahn, McQueen, Ernestus, Frauenfelder and Bürki2018) did not find an effect of orthography in the processing of reduced pronunciation variants. In their study, the orthographic effect was measured by the presence or absence of orthographic <e> corresponding to the reduced pronunciation of /ə/ in novel French words. The researchers hypothesized that reduced pronunciations (without /ə/) that are spelled without <e> would be recognized faster than reduced pronunciations that are spelled with <e> because of the mismatch between the absence of /ə/ and the presence of <e>. They speculated that they did not find the orthographic effect because they did not consider the degree of spelling-to-pronunciation consistency between <e> and /ə/. Since <e> can be pronounced in multiple ways in French (e.g., /ə/, /ɛ/, /e/, or silent), the presence of <e> was not a reliable cue for the presence of /ə/. Accordingly, they predicted that they would find an effect of orthography if they examined an orthography that was highly consistent with its pronunciation.
While Viebahn et al. (Reference Viebahn, McQueen, Ernestus, Frauenfelder and Bürki2018) discussed their result from the spelling-to-pronunciation consistency point of view, we could further their discussion from the pronunciation-to-spelling consistency perspective. When stimuli are presented auditorily, phonological information is accessed before its orthographic information comes in (Rastle et al., Reference Rastle, McCormick, Bayliss and Davis2011). It is, therefore, likely that consistency of phonology-to-orthography plays a more immediate and direct role than that of orthography-to-phonology (Ziegler et al., Reference Ziegler, Petrova and Ferrand2008). According to our results, the strong effect of orthography appears in the context of high P-O consistency for reduced pronunciations, meaning that in Viebahn et al. (Reference Viebahn, McQueen, Ernestus, Frauenfelder and Bürki2018), /ə/ should have a highly consistent P-O relationship with <e> to show the orthographic effect. However, since /ə/ is inconsistent with its orthographic form in French, they did not find an effect of orthography.
It is also possible to extend the discussion of our results from the phonological restructuring view. According to our findings, the degree of additional processing costs incurred by reduced pronunciations would be dependent on orthographic realizations. Specifically, how consistent the orthographic realization is with its phonological form (pronunciation-to-spelling consistency) modulates the extent to which the reduced pronunciation induces additional processing effort. In other words, the more consistent the orthographic realization is, the more restructuring it gives to its phonological representation. It then creates better specified and finer-grained phonological representations, which give a facilitatory effect when reduced consistent words are processed. This view is compatible with the discussion of the processing advantage of /nt/ (i.e., unreduced form) over the nasal flap [ɾ] (i.e., reduced form) in English (Ranbom & Connine, Reference Ranbom and Connine2007). Their hypothesis is that the [nt] processing advantage is due to orthographic forms that are consistent with their phonological form. From a frequency-based perspective, along with auditory input of the [nt] pronunciations, written input of <nt> orthography (that are consistent with its pronunciation of [nt]) may boost its frequency distribution. A nasal flap, however, does not receive the orthographic boost, as the [ɾ] pronunciation and <nt> orthography are not consistent, meaning that its frequency distribution is based on the auditory domain solely. From the phonological restructuring view, we could argue that the orthographic form of [nt] is consistent with its phonological form. Therefore, it builds a finer phonological representation, which facilitates processing. An orthographic realization of nasal flap, however, is null, meaning that no phonological restructuring occurs that could build better specified phonological representations and facilitate its processing.
It is important to note that in our L1 results, the direction of the P-O consistency effect for unreduced forms in the Go-NoGo task was opposite to what has been found in previous studies—consistent words were more difficult to process than inconsistent words. This consistency effect in the reverse direction could be due to the relative time course of the effect and the task demands. According to Rastle et al. (Reference Rastle, McCormick, Bayliss and Davis2011), phonological representations are activated before the orthographic information comes in when the stimulus is a spoken word. When a given task demands less cognitive resources for its execution (e.g., comprehension of clearly articulated unreduced spoken words), the phonological activation can drive and complete the process before the orthographic information comes into effect. However, when the task requires a great amount of cognitive effort (e.g., comprehension of acoustically reduced spoken words), additional processing time is needed. The extra cognitive effort and time provide an opportunity for orthographic information to be utilized to reinforce the correct phonological representation. In other words, the type of information that comes into play varies depending on task demands (Cutler et al., Reference Cutler, Treiman and van Ooijen2010; Norris et al., Reference Norris, McQueen and Cutler2000), and orthographic information may be assigned less weight than phonological information as a processing cue because it is accessed indirectly, requiring an additional step (i.e., orthographic information is accessed via phonological representation). As a result, orthographic information does not play an important role when the processing effort is low. Accordingly, we could assume that the observed effect for unreduced forms in the Go-NoGo task is phonological because of its processing ease. The observed effect could be due to phonological neighbors. Ziegler et al. (Reference Ziegler, Petrova and Ferrand2008) indicate that P-O consistency is naturally confounded with other lexical variables. We found that our low P-O consistent words tend to have a higher number of phonological neighbors. Cross-linguistic studies show that while an inhibitory effect of phonological neighborhood density has been found in English and French (i.e., high phonological neighborhood density leads to slower reaction time (e.g., Luce & Pisoni, Reference Luce and Pisoni1998; Sommers, Reference Sommers1996; Vitevitch & Luce, Reference Vitevitch and Luce1999; Ziegler & Muneaux, Reference Ziegler and Muneaux2007; Ziegler et al., Reference Ziegler, Muneaux and Grainger2003) and larger pupillary response (McLaughlin et al., Reference McLaughlin, Zink, Gaunt, Spehar, Van Engen, Sommers and Peelle2022), a facilitatory effect has also been found in other languages such as Spanish and Russian (e.g., Arutiunian & Lopukhina, Reference Arutiunian and Lopukhina2020; Vitevitch & Rodríguez, Reference Vitevitch and Rodríguez2005).
For Japanese, work by Yoneyama (Reference Yoneyama2002) shows that high phonological neighborhood density facilitates the recognition of Japanese words. In line with Yoneyama’s result, the facilitatory effect of high phonological neighborhood density might have completed the process of unreduced words before the inhibitory effect of low P-O consistency would come into effect in the Go-NoGo task. This discussion also applies to the result of L2 listeners (See the supplementary materials). Additionally, the reason that we did not observe the reverse direction of consistency effect for unreduced forms in the delayed naming task could be because the overall cognitive demands were greater for the delayed naming task than for the Go-NoGo task.
Furthermore, as for the delayed naming task, our L1 findings appear to indicate a modest effect of P-O consistency. Our results are in line with the findings of previous studies, and they shed light on the interaction between the effect of the time course and reduction. The modest consistency effect emerges around 1200 to 1500 ms in unreduced forms, and the consistency effect appears to be stronger and it arises from 1500 to 2500 ms in reduced forms. Even when we consider the slowness of pupillary response (200 to 300 ms after a target cognitive event (Beatty, Reference Beatty1982)), the effect arises after the onset of the naming signal (shown by Figure 3), suggesting that the effect is likely involved in postlexical access stages (i.e., speech planning and production) rather than the perception stage. As a result, similar to the analysis of Bürki et al. (Reference Bürki, Spinelli and Gaskell2012), in future work we should analyze participant’s productions and compare it to our experimental stimuli to investigate how participants adjust their production of words as they hear either reduced or unreduced word forms, and how such adjustments interact with the P-O consistency of words.
It is also noteworthy that our L2 listeners are native speakers of English, meaning that the orthographic system between their L1 (English) and L2 (Japanese) differs substantially (alphabetic vs. logographic). According to the psycholinguistic grain size theory (Ziegler & Goswami, Reference Ziegler and Goswami2005), there is a different degree of phonological awareness for a different grain size of unit. For English, a rhyme is a salient unit of mapping between phonology and orthography; however for Japanese, a mapping between phonology and orthography is at the logographic character and syllable levels. We need to be careful not to overly interpret our result because it is possible that the substantially different levels of mapping processes could mean that even for advanced learners, they may not be able to access and utilize the information of P-O consistency during spoken word processing.
Orthographic consistency, reduced pronunciation, and task type
One of the issues raised by Mitterer and Reinisch (Reference Mitterer and Reinisch2015) is the relationship between speech type and task. As indicated by a number of studies (e.g., Cutler et al., Reference Cutler, Treiman and van Ooijen2010; Ranbom & Connine, Reference Ranbom and Connine2007; Viebahn & Luce, Reference Viebahn and Luce2020), an effect of orthography (e.g., P-O consistency) and speech style (e.g., reduced or unreduced word forms) appears to interact with a type of task that participants perform. Mitterer and Reinisch (Reference Mitterer and Reinisch2015) noted that the contrast between the two experiments in their study confounds speech type with task. That is, they found an orthographic effect with an explicit task (pronunciation judgment task) with careful speech (unreduced forms with limited contextual information) but they did not find the effect with an implicit task (visual world paradigm) with casual speech (reduced forms with conversational speech context), suggesting that further research is needed to investigate the effect in an implicit task with careful speech and in an explicit task with casual speech. Our results suggest that it is unlikely that orthography plays an important role in the comprehension of careful speech (unreduced forms in isolation) in an implicit task (delayed naming and Go-NoGo task). Additionally, in contrast to the results of Mitterer and Reinisch (Reference Mitterer and Reinisch2015), our findings indicate that the effect of P-O consistency emerges in implicit tasks (both in the Go-NoGo task and delayed naming task) with casual speech (reduced forms in isolation). This contrasting result could be because of the difference in the degree of “conversational likeness.” While reduced forms were presented with informal sentences including discourse markers and contractions in Mitterer and Reinisch (Reference Mitterer and Reinisch2015), stimuli were presented in isolation in our study. Mitterer and Reinisch (Reference Mitterer and Reinisch2015) discussed possibilities that presentation of stimuli in isolation could facilitate the activation of orthography. This notion is in line with our earlier discussion of the relative time course of orthographic effects and task demands. When contextual information is provided together with stimuli (e.g., sentence or discourse), linguistic cues in the contextual information can drive and complete the processing, but when no contextual information is provided (e.g., stimuli in isolation), additional cognitive effort and processing time is required, and it provides an opportunity for low weighted processing cues, such as orthography, to come into effect. Our results further provide evidence for the role of contextual information (with what information stimuli are presented) in the processing of reduced speech and its relationship with its orthographic form.
Methodological considerations for orthographic consistency and reduced pronunciation effect
Importantly, P-O consistency has been treated as a binary variable (consistent vs. inconsistent words) although research (Jared et al., Reference Jared, McRae and Seidenberg1990; Ziegler et al., Reference Ziegler, Ferrand and Montant2004) indicates that the degree of (in)consistency is crucial. Work by Ziegler et al. (Reference Ziegler, Jacobs and Stone1996); Ziegler et al. (Reference Ziegler, Stone and Jacobs1997) and Berndt et al. (Reference Berndt, Reggia and Mitchum1987) demonstrate a statistical analysis of bidirectional inconsistency between spelling and pronunciation in monosyllabic French and English words. In addition to the categorization of P-O and O-P consistent words, they also provide prior and conditional probabilities. As a result, the conditional probabilities are connected to Jared et al.’s notion of a “friend word” and an “enemy word” and how the size of consistency effect is related to the summed frequency of these friend and enemy words. Work by Hino et al. (Reference Hino, Kusunose and Lupker2017, Reference Hino, Miyamura and Lupker2011) and our study adapted this notion to compute the consistency. Our research is one of the few studies that follows Ziegler et al. (Reference Ziegler, Jacobs and Stone1996, Reference Ziegler, Stone and Jacobs1997) and employed a P-O consistency scale to examine how the degree of the consistency interacts with the amount of additional processing effort induced by reduced pronunciations during spoken word processing.
Additionally, our results extend the discussion in Viebahn and Luce (Reference Viebahn and Luce2020) and shed light on the role of methodology. The researchers demonstrated that the processing difficulty of reduced pronunciations, which was found in a lexical decision task, disappeared in a shadowing task. They argue that meta-linguistic decision-making processes in lexical decisions amplify the effect of processing difficulty for reduced pronunciations. We however found a reduction effect in both delayed naming and Go-NoGo tasks. Although our tasks do not require linguistically motivated decision-making for target words, we found the effect. This contrasting result could be due to the measures employed. While we measured pupil dilation, they measured accuracy rates and response latencies. As Goldinger and Papesh (Reference Goldinger and Papesh2012) reported, pupillary responses can be used to examine lexical processes and reveal differences in cognitive effort even when behavioral measures exhibit equivalent performance.
Conclusion
Drawing on the pupillometry technique, the current study suggests that orthographic realization matters in the processing of reduced pronunciations for L1 and L2 advanced listeners. Specifically, how consistent the orthographic realization is with its phonological form (phonology-to-orthography consistency) modulates the extent to which the reduced pronunciation induces additional processing costs.
Replication package
The supplementary materials, data, stimulus lists, and analysis code for this study are available at https://osf.io/je3t4/.
Acknowledgements
This research was supported in part by a Social Sciences and Humanities Research Council (SSHRC) Partnership Grant, “Words in the World,” 895-2016-1008. The authors would like to thank the editor, three anonymous reviewers, Dr. Koji Miwa, and the Graduate School of Humanities at Nagoya University for assistance with data collection, and Dr. Matthew C. Kelley for assisting with the P-O consistency script.
Competing interest
We declare that we have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.









 Open access
Open access