We consider sets 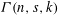 ${\it\Gamma}(n,s,k)$ of narrow clauses expressing that no definition of a size
${\it\Gamma}(n,s,k)$ of narrow clauses expressing that no definition of a size  $s$ circuit with
$s$ circuit with  $n$ inputs is refutable in resolution R in
$n$ inputs is refutable in resolution R in 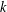 $k$ steps. We show that every CNF with a short refutation in extended R, ER, can be easily reduced to an instance of
$k$ steps. We show that every CNF with a short refutation in extended R, ER, can be easily reduced to an instance of 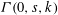 ${\it\Gamma}(0,s,k)$ (with
${\it\Gamma}(0,s,k)$ (with 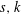 $s,k$ depending on the size of the ER-refutation) and, in particular, that
$s,k$ depending on the size of the ER-refutation) and, in particular, that 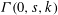 ${\it\Gamma}(0,s,k)$ when interpreted as a relativized NP search problem is complete among all such problems provably total in bounded arithmetic theory
${\it\Gamma}(0,s,k)$ when interpreted as a relativized NP search problem is complete among all such problems provably total in bounded arithmetic theory 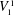 $V_{1}^{1}$ . We use the ideas of implicit proofs from Krajíček [J. Symbolic Logic, 69 (2) (2004), 387–397; J. Symbolic Logic, 70 (2) (2005), 619–630] to define from
$V_{1}^{1}$ . We use the ideas of implicit proofs from Krajíček [J. Symbolic Logic, 69 (2) (2004), 387–397; J. Symbolic Logic, 70 (2) (2005), 619–630] to define from 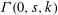 ${\it\Gamma}(0,s,k)$ a nonrelativized NP search problem
${\it\Gamma}(0,s,k)$ a nonrelativized NP search problem 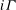 $i{\it\Gamma}$ and we show that it is complete among all such problems provably total in bounded arithmetic theory
$i{\it\Gamma}$ and we show that it is complete among all such problems provably total in bounded arithmetic theory 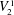 $V_{2}^{1}$ . The reductions are definable in theory
$V_{2}^{1}$ . The reductions are definable in theory 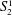 $S_{2}^{1}$ . We indicate how similar results can be proved for some other propositional proof systems and bounded arithmetic theories and how the construction can be used to define specific random unsatisfiable formulas, and we formulate two open problems about them.
$S_{2}^{1}$ . We indicate how similar results can be proved for some other propositional proof systems and bounded arithmetic theories and how the construction can be used to define specific random unsatisfiable formulas, and we formulate two open problems about them.
Recent inapproximability results of Sly (2010), together with an approximation algorithm presented by Weitz (2006), establish a beautiful picture of the computational complexity of approximating the partition function of the hard-core model. Let λc(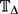 $\mathbb{T}_{\Delta}$) denote the critical activity for the hard-model on the infinite Δ-regular tree. Weitz presented an FPTAS for the partition function when λ < λc($\mathbb{T}_{\Delta}$) for graphs with constant maximum degree Δ. In contrast, Sly showed that for all Δ ⩾ 3, there exists εΔ > 0 such that (unless RP = NP) there is no FPRAS for approximating the partition function on graphs of maximum degree Δ for activities λ satisfying λc($\mathbb{T}_{\Delta}$) < λ < λc($\mathbb{T}_{\Delta}$) + εΔ.
$\mathbb{T}_{\Delta}$) denote the critical activity for the hard-model on the infinite Δ-regular tree. Weitz presented an FPTAS for the partition function when λ < λc($\mathbb{T}_{\Delta}$) for graphs with constant maximum degree Δ. In contrast, Sly showed that for all Δ ⩾ 3, there exists εΔ > 0 such that (unless RP = NP) there is no FPRAS for approximating the partition function on graphs of maximum degree Δ for activities λ satisfying λc($\mathbb{T}_{\Delta}$) < λ < λc($\mathbb{T}_{\Delta}$) + εΔ.
We prove that a similar phenomenon holds for the antiferromagnetic Ising model. Sinclair, Srivastava and Thurley (2014) extended Weitz's approach to the antiferromagnetic Ising model, yielding an FPTAS for the partition function for all graphs of constant maximum degree Δ when the parameters of the model lie in the uniqueness region of the infinite Δ-regular tree. We prove the complementary result for the antiferromagnetic Ising model without external field, namely, that unless RP = NP, for all Δ ⩾ 3, there is no FPRAS for approximating the partition function on graphs of maximum degree Δ when the inverse temperature lies in the non-uniqueness region of the infinite tree $\mathbb{T}_{\Delta}$. Our proof works by relating certain second moment calculations for random Δ-regular bipartite graphs to the tree recursions used to establish the critical points on the infinite tree.
Suppose that X1, X2, . . . are independent identically distributed Bernoulli random variables with mean p. A Bernoulli factory for a function f takes as input X1, X2, . . . and outputs a random variable that is Bernoulli with mean f(p). A fast algorithm is a function that only depends on the values of X1, . . ., XT, where T is a stopping time with small mean. When f(p) is a real analytic function the problem reduces to being able to draw from linear functions Cp for a constant C > 1. Also it is necessary that Cp ⩽ 1 − ε for known ε > 0. Previous methods for this problem required extensive modification of the algorithm for every value of C and ε. These methods did not have explicit bounds on 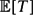 $\mathbb{E}[T]$ as a function of C and ε. This paper presents the first Bernoulli factory for f(p) = Cp with bounds on $\mathbb{E}[T]$ as a function of the input parameters. In fact, supp∈[0,(1−ε)/C]$\mathbb{E}[T]$ ≤ 9.5ε−1C. In addition, this method is very simple to implement. Furthermore, a lower bound on the average running time of any Cp Bernoulli factory is shown. For ε ⩽ 1/2, supp∈[0,(1−ε)/C]$\mathbb{E}[T]$≥0.004Cε−1, so the new method is optimal up to a constant in the running time.
$\mathbb{E}[T]$ as a function of C and ε. This paper presents the first Bernoulli factory for f(p) = Cp with bounds on $\mathbb{E}[T]$ as a function of the input parameters. In fact, supp∈[0,(1−ε)/C]$\mathbb{E}[T]$ ≤ 9.5ε−1C. In addition, this method is very simple to implement. Furthermore, a lower bound on the average running time of any Cp Bernoulli factory is shown. For ε ⩽ 1/2, supp∈[0,(1−ε)/C]$\mathbb{E}[T]$≥0.004Cε−1, so the new method is optimal up to a constant in the running time.
The aim of the discrete logarithm problem with auxiliary inputs is to solve for  ${\it\alpha}$, given the elements
${\it\alpha}$, given the elements 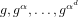 $g,g^{{\it\alpha}},\ldots ,g^{{\it\alpha}^{d}}$ of a cyclic group
$g,g^{{\it\alpha}},\ldots ,g^{{\it\alpha}^{d}}$ of a cyclic group 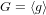 $G=\langle g\rangle$, of prime order
$G=\langle g\rangle$, of prime order  $p$. The best-known algorithm, proposed by Cheon in 2006, solves for
$p$. The best-known algorithm, proposed by Cheon in 2006, solves for  ${\it\alpha}$ in the case where
${\it\alpha}$ in the case where 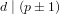 $d\mid (p\pm 1)$, with a running time of
$d\mid (p\pm 1)$, with a running time of 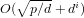 $O(\sqrt{p/d}+d^{i})$ group exponentiations (
$O(\sqrt{p/d}+d^{i})$ group exponentiations (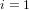 $i=1$ or
$i=1$ or 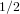 $1/2$ depending on the sign). There have been several attempts to generalize this algorithm to the case of
$1/2$ depending on the sign). There have been several attempts to generalize this algorithm to the case of 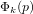 ${\rm\Phi}_{k}(p)$ where
${\rm\Phi}_{k}(p)$ where 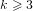 $k\geqslant 3$. However, it has been shown by Kim, Cheon and Lee that a better complexity cannot be achieved than that of the usual square root algorithms.
$k\geqslant 3$. However, it has been shown by Kim, Cheon and Lee that a better complexity cannot be achieved than that of the usual square root algorithms.
We propose a new algorithm for solving the DLPwAI. We show that this algorithm has a running time of 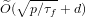 $\widetilde{O}(\sqrt{p/{\it\tau}_{f}}+d)$ group exponentiations, where
$\widetilde{O}(\sqrt{p/{\it\tau}_{f}}+d)$ group exponentiations, where 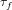 ${\it\tau}_{f}$ is the number of absolutely irreducible factors of
${\it\tau}_{f}$ is the number of absolutely irreducible factors of 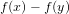 $f(x)-f(y)$. We note that this number is always smaller than
$f(x)-f(y)$. We note that this number is always smaller than 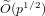 $\widetilde{O}(p^{1/2})$.
$\widetilde{O}(p^{1/2})$.
In addition, we present an analysis of a non-uniform birthday problem.
A prime sieve is an algorithm that finds the primes up to a bound  $n$. We say that a prime sieve is incremental, if it can quickly determine if
$n$. We say that a prime sieve is incremental, if it can quickly determine if 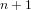 $n+1$ is prime after having found all primes up to
$n+1$ is prime after having found all primes up to  $n$. We say a sieve is compact if it uses roughly
$n$. We say a sieve is compact if it uses roughly 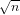 $\sqrt{n}$ space or less. In this paper, we present two new results.
$\sqrt{n}$ space or less. In this paper, we present two new results.
We describe the rolling sieve, a practical, incremental prime sieve that takes We also show how to modify the sieve of Atkin and Bernstein from 2004 to obtain a sieve that is simultaneously sublinear, compact, and incremental.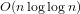 $O(n\log \log n)$ time and
$O(n\log \log n)$ time and 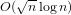 $O(\sqrt{n}\log n)$ bits of space.
$O(\sqrt{n}\log n)$ bits of space.
The second result solves an open problem given by Paul Pritchard in 1994.
We consider ‘unconstrained’ random k-XORSAT, which is a uniformly random system of m linear non-homogeneous equations in 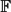 $\mathbb{F}$2 over n variables, each equation containing k ⩾ 3 variables, and also consider a ‘constrained’ model where every variable appears in at least two equations. Dubois and Mandler proved that m/n = 1 is a sharp threshold for satisfiability of constrained 3-XORSAT, and analysed the 2-core of a random 3-uniform hypergraph to extend this result to find the threshold for unconstrained 3-XORSAT.
$\mathbb{F}$2 over n variables, each equation containing k ⩾ 3 variables, and also consider a ‘constrained’ model where every variable appears in at least two equations. Dubois and Mandler proved that m/n = 1 is a sharp threshold for satisfiability of constrained 3-XORSAT, and analysed the 2-core of a random 3-uniform hypergraph to extend this result to find the threshold for unconstrained 3-XORSAT.
We show that m/n = 1 remains a sharp threshold for satisfiability of constrained k-XORSAT for every k ⩾ 3, and we use standard results on the 2-core of a random k-uniform hypergraph to extend this result to find the threshold for unconstrained k-XORSAT. For constrained k-XORSAT we narrow the phase transition window, showing that m − n → −∞ implies almost-sure satisfiability, while m − n → +∞ implies almost-sure unsatisfiability.
We develop a theory of complexity for numerical computations that takes into account the condition of the input data and allows for roundoff in the computations. We follow the lines of the theory developed by Blum, Shub and Smale for computations over 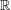 $\mathbb{R}$ (which in turn followed those of the classical, discrete, complexity theory as laid down by Cook, Karp, and Levin, among others). In particular, we focus on complexity classes of decision problems and, paramount among them, on appropriate versions of the classes
$\mathbb{R}$ (which in turn followed those of the classical, discrete, complexity theory as laid down by Cook, Karp, and Levin, among others). In particular, we focus on complexity classes of decision problems and, paramount among them, on appropriate versions of the classes 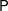 $\mathsf{P}$,
$\mathsf{P}$, 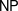 $\mathsf{NP}$, and
$\mathsf{NP}$, and 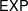 $\mathsf{EXP}$ of polynomial, nondeterministic polynomial, and exponential time, respectively. We prove some basic relationships between these complexity classes, and provide natural NP-complete problems.
$\mathsf{EXP}$ of polynomial, nondeterministic polynomial, and exponential time, respectively. We prove some basic relationships between these complexity classes, and provide natural NP-complete problems.
This paper revisits the solution of the word problem for  ${\it\omega}$-terms interpreted over finite aperiodic semigroups, obtained by J. McCammond. The original proof of correctness of McCammond’s algorithm, based on normal forms for such terms, uses McCammond’s solution of the word problem for certain Burnside semigroups. In this paper, we establish a new, simpler, correctness proof of McCammond’s algorithm, based on properties of certain regular languages associated with the normal forms. This method leads to new applications.
${\it\omega}$-terms interpreted over finite aperiodic semigroups, obtained by J. McCammond. The original proof of correctness of McCammond’s algorithm, based on normal forms for such terms, uses McCammond’s solution of the word problem for certain Burnside semigroups. In this paper, we establish a new, simpler, correctness proof of McCammond’s algorithm, based on properties of certain regular languages associated with the normal forms. This method leads to new applications.
Non-degenerate monoids of skew type are considered. This is a class of monoids S defined by n generators and 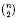 quadratic relations of certain type, which includes the class of monoids yielding set-theoretic solutions of the quantum Yang–Baxter equation, also called binomial monoids (or monoids of I-type with square-free defining relations). It is shown that under any degree-lexicographic order on the associated free monoid FMn. of rank n the set of normal forms of elements of S is a regular language in FMn. As one of the key ingredients of the proof, it is shown that an identity of the form xN yN = yN xN holds in S. The latter is derived via an investigation of the structure of S viewed as a semigroup of matrices over a field. It also follows that the semigroup algebra K[S] is a finite module over a finitely generated commutative subalgebra of the form K[A] for a submonoid A of S.
quadratic relations of certain type, which includes the class of monoids yielding set-theoretic solutions of the quantum Yang–Baxter equation, also called binomial monoids (or monoids of I-type with square-free defining relations). It is shown that under any degree-lexicographic order on the associated free monoid FMn. of rank n the set of normal forms of elements of S is a regular language in FMn. As one of the key ingredients of the proof, it is shown that an identity of the form xN yN = yN xN holds in S. The latter is derived via an investigation of the structure of S viewed as a semigroup of matrices over a field. It also follows that the semigroup algebra K[S] is a finite module over a finitely generated commutative subalgebra of the form K[A] for a submonoid A of S.

