
2 results
Nowcasting Euro Area Economic Activity in Real Time: The Role of Confidence Indicators
-
- Journal:
- National Institute Economic Review / Volume 210 / October 2009
- Published online by Cambridge University Press:
- 26 March 2020, pp. 90-97
- Print publication:
- October 2009
-
- Article
- Export citation
Efficient description logic reasoning in Prolog: The DLog system
-
- Journal:
- Theory and Practice of Logic Programming / Volume 9 / Issue 3 / May 2009
- Published online by Cambridge University Press:
- 01 May 2009, pp. 343-414
-
- Article
- Export citation
-
Traditional algorithms for description logic (DL) instance retrieval are inefficient for large amounts of underlying data. As DL is becoming more and more popular in areas such as the Semantic Web and information integration, it is very important to have systems which can reason efficiently over large data sets. In this paper we present an approach to transform DL axioms, formalised in the
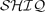 DL language, into a Prolog program under the unique name assumption. This transformation is performed with no knowledge about particular individuals: they are accessed dynamically during the normal Prolog execution of the generated program. This technique, together with the top-down Prolog execution, implies that only those pieces of data are accessed that are indeed important for answering the query. This makes it possible to store the individuals in a database instead of memory, which results in better scalability and helps in using DL ontologies directly on top of existing information sources. The transformation process consists of two steps: (1) the DL axioms are converted to first-order clauses of a restricted form, and (2) a Prolog program is generated from these clauses. Step (2), which is the focus of the present paper, actually works on more general clauses than those obtainable by applying step (1) to a knowledge base. We first present a base transformation, the output of which can be either executed using a simple interpreter or further extended to executable Prolog code. We then discuss several optimisation techniques, applicable to the output of the base transformation. Some of these techniques are specific to our approach, while others are general enough to be interesting for DL reasoner implementors not using Prolog. We give an overview of DLog, a DL reasoner in Prolog, which is an implementation of the techniques outlined above. We evaluate the performance of DLog and compare it to some widely used DL reasoners, such as RacerPro, Pellet and KAON2.
DL language, into a Prolog program under the unique name assumption. This transformation is performed with no knowledge about particular individuals: they are accessed dynamically during the normal Prolog execution of the generated program. This technique, together with the top-down Prolog execution, implies that only those pieces of data are accessed that are indeed important for answering the query. This makes it possible to store the individuals in a database instead of memory, which results in better scalability and helps in using DL ontologies directly on top of existing information sources. The transformation process consists of two steps: (1) the DL axioms are converted to first-order clauses of a restricted form, and (2) a Prolog program is generated from these clauses. Step (2), which is the focus of the present paper, actually works on more general clauses than those obtainable by applying step (1) to a knowledge base. We first present a base transformation, the output of which can be either executed using a simple interpreter or further extended to executable Prolog code. We then discuss several optimisation techniques, applicable to the output of the base transformation. Some of these techniques are specific to our approach, while others are general enough to be interesting for DL reasoner implementors not using Prolog. We give an overview of DLog, a DL reasoner in Prolog, which is an implementation of the techniques outlined above. We evaluate the performance of DLog and compare it to some widely used DL reasoners, such as RacerPro, Pellet and KAON2.
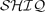 DL language, into a Prolog program under the unique name assumption. This transformation is performed with no knowledge about particular individuals: they are accessed dynamically during the normal Prolog execution of the generated program. This technique, together with the top-down Prolog execution, implies that only those pieces of data are accessed that are indeed important for answering the query. This makes it possible to store the individuals in a database instead of memory, which results in better scalability and helps in using DL ontologies directly on top of existing information sources. The transformation process consists of two steps: (1) the DL axioms are converted to first-order clauses of a restricted form, and (2) a Prolog program is generated from these clauses. Step (2), which is the focus of the present paper, actually works on more general clauses than those obtainable by applying step (1) to a
DL language, into a Prolog program under the unique name assumption. This transformation is performed with no knowledge about particular individuals: they are accessed dynamically during the normal Prolog execution of the generated program. This technique, together with the top-down Prolog execution, implies that only those pieces of data are accessed that are indeed important for answering the query. This makes it possible to store the individuals in a database instead of memory, which results in better scalability and helps in using DL ontologies directly on top of existing information sources. The transformation process consists of two steps: (1) the DL axioms are converted to first-order clauses of a restricted form, and (2) a Prolog program is generated from these clauses. Step (2), which is the focus of the present paper, actually works on more general clauses than those obtainable by applying step (1) to a 