In this article, we present a general theorem and proof for the global identification of composed CFA models. They consist of identified submodels that are related only through covariances between their respective latent factors. Composed CFA models are frequently used in the analysis of multimethod data, longitudinal data, or multidimensional psychometric data. Firstly, our theorem enables researchers to reduce the problem of identifying the composed model to the problem of identifying the submodels and verifying the conditions given by our theorem. Secondly, we show that composed CFA models are globally identified if the primary models are reduced models such as the CT-C\documentclass[12pt]{minimal}\usepackage{amsmath}\usepackage{wasysym}\usepackage{amsfonts}\usepackage{amssymb}\usepackage{amsbsy}\usepackage{mathrsfs}\usepackage{upgreek}\setlength{\oddsidemargin}{-69pt}\begin{document}$$(M-1)$$\end{document}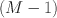 model or similar types of models. In contrast, composed CFA models that include non-reduced primary models can be globally underidentified for certain types of cross-model covariance assumptions. We discuss necessary and sufficient conditions for the global identification of arbitrary composed CFA models and provide a Python code to check the identification status for an illustrative example. The code we provide can be easily adapted to more complex models.
model or similar types of models. In contrast, composed CFA models that include non-reduced primary models can be globally underidentified for certain types of cross-model covariance assumptions. We discuss necessary and sufficient conditions for the global identification of arbitrary composed CFA models and provide a Python code to check the identification status for an illustrative example. The code we provide can be easily adapted to more complex models.

