


1 Introduction
Design creativity is the ability of an agent to address a design opportunity by developing outcomes that are both novel and useful (Sarkar & Chakrabarti Reference Sarkar and Chakrabarti2011). Concept generation is an early phase in the design process where solution principles are conceived to address design opportunities (Jensen et al. Reference Jensen, Weaver, Wood, Linsey and Wood2009; Taura & Yukari Reference Taura and Yukari2012). Concept generation is a significant phase of the design process because a successful product is likely to be an outcome of an exploration of a variety of solution principles (Pahl & Beitz Reference Pahl, Beitz and Wallace2013). Owing to the ease of making changes that are less expensive in this phase, the scope for design creativity is greater in this early phase than the downstream phases (French Reference French1985). Several guidelines, methods and tools have been proposed to foster creativity during the concept generation phase.
Providing stimuli to designers in order to identify analogies from them for generating concepts is one of the most potent and useful methods (Chakrabarti et al. Reference Chakrabarti, Sarkar, Leelavathamma and Nataraju2005; Chan et al. Reference Chan, Fu, Schunn, Cagan, Wood and Kotovsky2011). A stimulus is beneficial for concept generation by helping develop creative solutions, enhance novelty, inhibit fixation, etc. (Qian & Gero Reference Qian and Gero1996; Goel Reference Goel1997; Linsey et al. Reference Linsey, Tseng, Fu, Cagan, Wood and Schunn2010; Chan et al. Reference Chan, Fu, Schunn, Cagan, Wood and Kotovsky2011). Simultaneously, certain stimuli can also inhibit concept generation by causing bias and fixation (Jansson & Smith Reference Jansson and Smith1991). Therefore, stimuli need to be carefully chosen before using them. Several kinds of aids to foster the use of stimuli and analogies have been proposed and found to be effective at improving quantity, novelty and creativity of solutions (Chakrabarti et al. Reference Chakrabarti, Sarkar, Leelavathamma and Nataraju2005; Linsey et al. Reference Linsey, Tseng, Fu, Cagan, Wood and Schunn2010). Prior studies have found that it is easier to analogize with stimuli from near than far domains to the target domain, because stimuli from near domains have more structural similarities to the target design problem than stimuli from far domains (Christensen & Schunn Reference Christensen and Schunn2007). However, stimuli from far domains, owing to their surface dissimilarities, are the best sources for novelty and creative breakthroughs (Gentner & Markman Reference Gentner and Markman1997; Ward Reference Ward1998). Several researchers investigated the effects of stimulation from near and far analogical distances on the outcomes of ideation, for instance Wilson et al. (Reference Wilson, Nelson, Rosen and Yen2010), Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013b ) and Chan & Schunn (Reference Chan and Schunn2015). However, to date, the characterization of near and far stimuli have been inconsistent in existing studies, and so, their findings cannot be generalized across these studies.
Meanwhile, patents have been increasingly explored as sources of stimuli for engineering design (Fantoni et al. Reference Fantoni, Apreda, Orletta and Monge2013; Fu et al. Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013b , Reference Fu, Murphy, Yang, Otto, Jensen and Wood2015; Murphy et al. Reference Murphy, Fu, Otto, Yang, Jensen and Wood2014; Srinivasan et al. Reference Srinivasan, Song, Luo, Subburaj and Rajesh2017a ,Reference Srinivasan, Song, Luo, Subburaj and Rajesh b ). Patents contain technical descriptions of products and processes, which are both novel and functional, from various domains. The patent database is an enormous reservoir of design precedents. The growing patent data, as inventors continually file patent applications over time, present both opportunities and challenges for using them as design stimuli. Therefore, efficient methods and tools are required for designers to retrieve the most relevant from among millions of patents in the vast patent databases. While it is acknowledged that patents are useful for inspiration, questions persist pertaining to: from where in the complex database can designers find useful patent stimuli, and which of these patent stimuli can most effectively inspire designers to generate novel and valuable concepts. Moreover, due to a lack of uniform characterization of near and far stimuli, there is no single method to characterize stimuli as near or far, and consequently, not much work has been done to identify from where in the patent database can near and far patent stimuli be identified.
As a solution, network analysis techniques have been increasingly exploited to uncover the knowledge structure in the patent database to facilitate engineering design. For example, Fu et al. (Reference Fu, Cagan, Kotovsky and Wood2013a ) analyzed the similarities of occurrences of functional verbs between patents to construct the Bayesian networks of patents. Such a network provides information of functional similarity between individual patents, which in turn has potential for a patent recommendation system for design stimulation (Fu et al. Reference Fu, Murphy, Yang, Otto, Jensen and Wood2015). At a higher level, the patent classification and citation information have also been analyzed to measure knowledge proximity or distance between different classes of patents and construct technology network maps to approximate the total technology space (Kay et al. Reference Kay, Newman, Youtie, Porter and Rafols2014; Leydesdorff, Kushnir & Rafols Reference Leydesdorff, Kushnir and Rafols2014; Alstott et al. Reference Alstott, Triulzi, Yan and Luo2017a ; Yan & Luo Reference Yan and Luo2017). In these network maps, nodes are technology classes that represent various technology categories and contain patents related to corresponding technology categories. These nodes are connected according to the knowledge proximity between them. A structural analysis of the networks can allow one to define and identify the technology classes near or far from a given design problem in the technology space. In this study, we will utilize such a technology space network to locate the patents that designers found useful in an ideation exercise, according to the proximity between technology classes in the network. Herein, we consider a patent as useful if it is used as a stimulus for concrete concepts generated by designers.
The broad objectives of this research are: (a) to identify locations within the network of technology classes from where designers identify useful patent stimuli and (b) to study the implications of using such patent stimuli for ideation on the outcomes of ideation. Toward these broad objectives, the research in this paper examines the effects of using patents – sourced from technology classes which are located at the home field, near field and far field to a design problem – as stimuli for ideation on the outcomes, based on the data from an open concept generation exercise. The three fields in the technology space are defined based on community detection within the network of technology classes. The home field entails the technology classes that are directly relevant to the design problem, the near field comprises the technology classes that are in the same cohesive network communities as those in the home field, and the far field includes the technology classes in all the other communities in the technology network.
In the following sections, we review prior literature relevant to the theories and methods grounding our research (Section 2), introduce our data and research method (Section 3), present and discuss our findings (Sections 4 and 5).
2 Literature review
This study is theoretically motivated and grounded by the literature on design by analogy. Within the field of Design Science, the area of analogical design has been extensively researched. However, to fit the scope of this research, only those prior studies that use patents for stimulation in ideation or analyze the effect of analogical distance on the performance of ideation are reviewed here.
2.1 Patent stimuli and design by analogy
Many researchers have studied the use of patents as stimuli for design and developed tools for the search and analysis of patents. For example, several tools have been developed to search for patents to facilitate the use of TRIZ principles (Altshuller & Shapiro Reference Altshuller and Shapiro1956) in solving design problems (Mukherjea, Bamba & Kankar Reference Mukherjea, Bamba and Kankar2005; Cascini & Russo Reference Cascini and Russo2006; Souili et al. Reference Souili, Cavallucci, Rousselot and Zanni2015) developed the Biomedical Patent Semantic Web for retrieving patents based on the semantic associations between biological terms within the abstracts of biomedical patents. Particularly, a recent strand of research has focused on analyzing and using patents to aid in design by analogy.
Fu et al. (Reference Fu, Cagan, Kotovsky and Wood2013a ) developed a computational tool for automatically identifying patent stimuli at different analogical distances. They extracted verb and noun content from the technical descriptions of patents, used semantic analysis to quantify the functional and surface similarities between patents, and created function- and surface-based Bayesian networks of patents, respectively. In the networks, a design problem can be located as the starting point, and the ‘analogical distance’ between the problem and patents is defined as the length of path between them. Murphy et al. (Reference Murphy, Fu, Otto, Yang, Jensen and Wood2014) proposed a functional vector approach to systematically search and identify functional analogies from the patent database. The following steps constitute the methodology: (a) process patents to identify a vocabulary of functions, (b) define a set of functions in patents comprising primary, secondary and correspondent functions, (c) index patents using the functional set to create a vector representation of the patent database, (d) develop methods for generating query and estimate relevance of patents to a query, and (e) retrieve and display patents relevant to the query. Fu et al. (Reference Fu, Murphy, Yang, Otto, Jensen and Wood2015) empirically tested the functional vector approach of Murphy et al. (Reference Murphy, Fu, Otto, Yang, Jensen and Wood2014), to aid in the search for functional analogies from patent databases to stimulate design concepts, and found the experimental group generated solutions of higher novelty than the control group. Srinivasan et al. (Reference Srinivasan, Song, Luo, Subburaj and Rajesh2017a ) tested the efficacy of using patents as design stimuli through a concept generation experiment, and found that the average quality and novelty of the concepts generated with patent stimuli individually or in combination with other resources is higher than those generated without any stimuli.
2.2 Stimulation distance
Design by analogy leverages existing solutions from source fields to solve design problems in target fields (Gick & Holyoak Reference Gick and Holyoak1980; Weisberg Reference Weisberg2006; Linsey Reference Linsey2007). The distance between the source and target fields is referred to as the stimulation or analogical distance. The Conceptual Leap hypothesis states that stimuli from far sources, owing to their surface dissimilarities, provide the best stimulation for creative breakthroughs (Gentner & Markman Reference Gentner and Markman1997; Ward Reference Ward1998). Some anecdotal evidence exists in support of this hypothesis. However, empirical findings related to the validation of this hypothesis have not been consistent.
Chan et al. (Reference Chan, Fu, Schunn, Cagan, Wood and Kotovsky2011) observed that far-field analogies help develop concepts of higher novelty, higher variability in quality and greater solution transfer but stimulate fewer concepts than near-field analogies. Chan & Schunn (Reference Chan and Schunn2015) reasoned that the most creative solutions are more likely to be developed from near distance than far distance stimuli, owing to better perception and connection to the problem at hand. Srinivasan et al. (Reference Srinivasan, Song, Luo, Subburaj and Rajesh2017b ) observed that as analogical distance of patent stimuli from the design problem increases, novelty of concepts generated using these stimuli increases but quality of concepts decreases. However, Wilson et al. (Reference Wilson, Nelson, Rosen and Yen2010) observed no distinctions between stimuli from far sources and near sources. Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013b ) found that stimuli from near sources or ‘middle ground’ help generate solutions of higher ‘maximum novelty’ than far sources; no significant differences were seen in ‘average novelty’ between near and far sources. Fu et al. also observed that both the ‘mean quality’ and the ‘maximum quality’ of solutions generated using stimuli from near sources are higher than those generated using stimuli from far sources. Consequently, they argued stimuli from ‘middle ground’ to be more beneficial for developing creative solutions. With these findings, Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013b ) posited that comparisons of effects of analogical distance across different studies are hard owing to different metrics being used to measure distance in these studies. They also argued about the terms ‘near’ and ‘far’ as being relative and not being able to completely characterize these across different studies due to lack of a common metric to measure distance.
2.3 Network of technologies by distance or proximity
These prior studies have implied the potential value for designers to make use of the knowledge of the relative distance or proximity between technologies in the search for design stimuli from either near or far sources. For example, to use patents as design stimuli, the Bayesian network of patents of Fu et al. (Reference Fu, Cagan, Kotovsky and Wood2013a ) quantifies and visualizes the analogical distance between patents and a design problem, and thus designers can potentially use the network to identify patent stimuli from near or far distance from the design problem. However, the network of patents is only applicable for a small set of patents, whereas the total patent database contains millions of patents that may provide varied inspirations from different distances to a design problem.
According to the patent classification systems, such as the International Patent Classification (IPC) system, each patent is classified in one or multiple technology classes, which are categories of patents and represent different technology fields. This presents a structure for locating patents in the enormous database. A few recent studies have proposed methods to measure the knowledge proximity between the patent technology classes and used such proximity information to construct the network map of technology classes (Kay et al. Reference Kay, Newman, Youtie, Porter and Rafols2014; Leydesdorff et al. Reference Leydesdorff, Kushnir and Rafols2014; Yan & Luo Reference Yan and Luo2017). The network of all technology classes in the patent database can be used to approximate the total technology space (Alstott et al. Reference Alstott, Triulzi, Yan and Luo2017a ). Such a network of technology classes, given the proximity information, may serve as a framework to define the near or far field of design stimulation. In turn, such a network map will allow the designers to be better informed of the proximity (or distance) between the source field of potential patent stimuli and the target field where a design problem or opportunity is located, or be better oriented to identify patents specifically from either the near or far field from the design problem.
In particular, the key requirement to create such a network is the measure of knowledge proximity between the patent technology classes, i.e., link weight in the network. In the literature, a variety of measures of knowledge proximity have been reported. One group of measures are computed using the data of patent references. For example, Jaccard index can be adopted to calculate the number of shared references of a pair of classes normalized by the total number of all unique references of patents in either class (Jaccard Reference Jaccard1901; Small Reference Small1973) as an indicator of knowledge proximity. Alternatively, the cosine similarity index can be calculated between two vectors indicating patent references made from the patents in a pair of classes to all classes respectively (Jaffe Reference Jaffe1986; Kay et al. Reference Kay, Newman, Youtie, Porter and Rafols2014; Leydesdorff et al. Reference Leydesdorff, Kushnir and Rafols2014), i.e., class-to-class reference vectors. For a higher granularity, Yan & Luo (Reference Yan and Luo2017) extended the cosine similarity measure to class-to-patent vectors, concerning references to specific patents instead of aggregated classes. Another group of measures use the ‘co-classification’ information, i.e., how often two classes are co-assigned to individual patents, to compute knowledge proximity. For instance, the cosine similarity index can be calculated between two vectors of the occurrences of a pair of classes with all other classes in patents (Breschi, Lissoni & Malerba Reference Breschi, Lissoni and Malerba2003; Ejermo Reference Ejermo2005; Kogler, Rigby & Tucker Reference Kogler, Rigby and Tucker2013). The normalized co-classification index measures the deviation of the actual observed co-occurrences of class pairs in patents from random expectations (Teece et al. Reference Teece, Rumelt, Dosi and Winter1994; Dibiaggio, Nasiriyar & Nesta Reference Dibiaggio, Nasiriyar and Nesta2014; Yan & Luo Reference Yan and Luo2017) have reviewed and compared various knowledge proximity measures used in patent mapping. Note that, this strand of research on measuring the knowledge proximity between different patent technology classes was not previously engaged in the engineering design literature.
2.4 Summary
In brief, patents have been used as stimuli to foster ideation; however, while there exists evidence that the use of such stimuli is beneficial, the observations on the effect of analogical distance on for example, the attributes of design outcomes have not been consistent. Moreover, several metrics have been used to measure the proximity between stimuli and design problems and distinguish near- and far-field stimuli (Fu et al. Reference Fu, Cagan, Kotovsky and Wood2013a ). However, most of the prior studies are based on the textual analysis of small sets of patents selected from the patent database. No efforts, to our knowledge, have been pursued at identifying near and far fields to a design problem in the total technology space, and at searching for patent stimuli in the total patent database. The network of all technology classes may serve as a macro and consistent framework to define home, near and far fields to a target design problem or more open-ended design interest.
In the present study, we make use of the patent technology class network to classify the patents in the total patent database into home, near and far fields to a design problem. On this basis, we seek to answer the following questions:
-
(1) Where are the sources of useful patent stimuli in the technology class network: home, near or far fields?
-
(2) What are the implications of using patent stimuli from these different fields on the outcomes of ideation?
3 Method and data
This study analyzes the data, including the patent stimuli and generated concepts, from an ideation exercise. In this section, we will introduce the exercise and the methods used to analyze the patent stimuli and concepts.
3.1 Ideation exercise and data
Data from an ideation exercise of 30.007 Engineering Design and Project Engineering, a course offered at the Engineering Product Development (EPD) Pillar (https://epd.sutd.edu.sg/) of Singapore University of Technology & Design (SUTD) (https://www.sutd.edu.sg/) is used for this research. This course is mandatory for the second-year undergraduate students in the EPD Pillar and provides a holistic understanding and competency in engineering design. All the students participating in this ideation exercise had undertaken several design courses and structured design projects prior to this course. The ideation exercise was an early part of a design project, which ran throughout the course. The objective in this project was to conceive, design and develop an innovative spherical rolling robot (SRR) concept of self-defined system requirements, and fabricate a functional prototype. This objective was deliberately kept open to provide students the flexibility and room for creativity and innovation.
Before ideation, all the student designers were provided with Sphero
 $^{\text{TM}}$
, a SRR toy manufactured by the company Sphero Inc. (http://www.sphero.com/sphero), to play, analyze and understand the structure and functioning of a SRR. Sphero is propelled by a self-contained cart and installed with an on-board micro-controller unit. Users may manipulate its motion remotely via a smartphone or tablet. Sphero represents a generic design of SRRs and is also a successful commercial product in the market. The designers were also offered access to 15 prototypes of SRRs developed earlier at SUTD. The purpose of such sharing before ideation is to allow the students to rapidly learn and build up the basic design knowledge of SRRs.
$^{\text{TM}}$
, a SRR toy manufactured by the company Sphero Inc. (http://www.sphero.com/sphero), to play, analyze and understand the structure and functioning of a SRR. Sphero is propelled by a self-contained cart and installed with an on-board micro-controller unit. Users may manipulate its motion remotely via a smartphone or tablet. Sphero represents a generic design of SRRs and is also a successful commercial product in the market. The designers were also offered access to 15 prototypes of SRRs developed earlier at SUTD. The purpose of such sharing before ideation is to allow the students to rapidly learn and build up the basic design knowledge of SRRs.
The research team prepared two sets of patents for student designers to read and get inspired. The most cited US patent from each of the 121 3-digit technology classes defined in the IPC system was provided. The number of forward citations received by a patent is highly correlated to its realized value or importance (Trajtenberg Reference Trajtenberg1990; Hall, Jaffe & Trajtenberg Reference Hall, Jaffe and Trajtenberg2000). These 121 patents constituted the first set (Most Cited set). In addition, a randomly identified patent from each of the 121 3-digit IPC technology classes was also provided. These 121 random patents were identified using a random number generator and constituted the second set (Random set). The participants were provided with the title, abstract and images of the patents. If the participants found these contents relevant and inspirational for their problem, they could read the technical descriptions of the patents. Note that it was not mandatory for participants to use the provided patents as stimuli. In addition to the 242 given patents, all the participants were allowed to search and use other patents and resources (such as internet and books) for inspiration. The two sets of patents provide a basic coverage of patents from all the 121 technology classes in the total technology space, and complement the intuitive unguided search of the participants by bringing all the technology classes to the attention of the searchers.
The participants were instructed to generate functional and novel concepts, but no limit was fixed on the number of concepts they must generate. The participants were given a week to generate concepts and asked to sketch or render concepts with annotations and briefly explain how they work. At the end of the exercise, they needed to submit a report for each concept generated. Figure 1 shows an example of the submitted reports. Specifically, the participant must report which patents were used as stimuli and their justification, other resources accessed, and how stimuli were transformed into the new SRR concept (see Figure 1a), in addition to a textual description and a sketch of the generated SRR concept (Figure 1b). In the end of the concept generation exercise, 138 SRR concepts were generated using 231 patent stimuli. Among these patent stimuli, 39 patents were from the Most Cited set, 33 from the Random set, and the rest were searched and identified by the student designers on their own.

Figure 1. A concept generation report from a student designer. (a) Reported information in the concept generation report. (b) Concept sketch with annotations in the concept generation report.
In addition, a consent form seeking the approval of participation was also collected from all the participants. A pre- and a post-ideation survey were conducted to collect information relating to age, gender, academic background, nationality, and other demographic data of the participants, to understand their experience of using patents a priori and posteriori to this exercise and the effects of their use.
3.2 Evaluation of ideation outcome
From the concept generation reports from individual participants, the stimuli used to generate each concept were identified, and novelty and quality of generated concepts were assessed based on their sketches, renderings and annotations. In the literature, researchers have proposed various metrics to assess the performance of ideation, in terms of the attributes of ideation outcomes, such as quantity, quality, novelty, variety, fluency, usefulness, feasibility, and similarity (Mcadams & Wood Reference Mcadams and Wood2002; Shah et al. Reference Shah, Li, Gessmann and Schubert2003; Sarkar & Chakrabarti Reference Sarkar and Chakrabarti2011). In this research, novelty and quality were used as metrics to assess performance of ideation.
Novelty of a design outcome is a measure of unusualness or unexpectedness of the outcome in comparison to other outcomes that perform the same overall function. An expert in robotics and SRRs rated the novelty of the concepts on a 4-point scale (0–3), corresponding to no, low, medium and high novelty. This expert has extensive knowledge of prior arts in SRRs, based on which novelty of the generated concepts was evaluated. For example, the concept shown in Figure 1(b) can climb stairs by extending its arms, which had been seldom seen in prior designs. Therefore, this concept obtained a novelty score of 3.
Quality of an outcome is the degree of the fulfillment of requirements for which the outcome is developed. In the assessment of quality, three abstraction levels, namely functional, working principle, and structural levels, were considered. Quality of a concept was assessed using the formula:
 $$\begin{eqnarray}\displaystyle Q=0.5\times f+0.3\times w+0.2\times s & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle Q=0.5\times f+0.3\times w+0.2\times s & & \displaystyle\end{eqnarray}$$
where
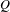 $Q$
is the overall quality of a concept,
$Q$
is the overall quality of a concept,
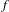 $f$
is a measure of the degree of fulfillment of the identified requirements by the functions in the concept,
$f$
is a measure of the degree of fulfillment of the identified requirements by the functions in the concept,
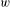 $w$
is the degree of fulfillment of the identified functions by the working principles in the concept, and
$w$
is the degree of fulfillment of the identified functions by the working principles in the concept, and
 $s$
is the degree of fulfillment of the working principles by the components and their relations in the concept. A weighting scale of 0.5, 0.3 and 0.2Footnote
1
was used corresponding to the function, working principle, and structural levels, respectively, because higher abstraction levels are the basis for building the lower abstraction levels.
$s$
is the degree of fulfillment of the working principles by the components and their relations in the concept. A weighting scale of 0.5, 0.3 and 0.2Footnote
1
was used corresponding to the function, working principle, and structural levels, respectively, because higher abstraction levels are the basis for building the lower abstraction levels.
 $f$
,
$f$
,
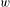 $w$
and
$w$
and
 $s$
were rated by one of the authors using a 3-point scale (0–2)Footnote
2
, corresponding to no, partial and complete fulfillment. Therefore, the overall quality of a concept also varied between 0 and 2. For example, the sketch of the design for climbing stairs (see Figure 1b) describes a full set of functions required to fulfill the stated objectives (rolling on ground and climbing stairs) including rotate two hemispheres for propelling and steering, increase grip, monitor environment with camera, and extend arms for lifting the robot. So, it received 2 points for fulfilling requirements. This concept lacks mechanism details of how to propel the robot and extend the arms, and so, it received 1 point for partially fulfilling the functions identified earlier. Due to the absence of working principles, the design also lacks information of structural features required to fulfill the missing working principles, such as the transmission system for propelling, and so, it received 1 point for the fulfillment of working principles. When these individual weightings were substituted in (1), an overall quality score of 1.5 was obtained for the concept.
$s$
were rated by one of the authors using a 3-point scale (0–2)Footnote
2
, corresponding to no, partial and complete fulfillment. Therefore, the overall quality of a concept also varied between 0 and 2. For example, the sketch of the design for climbing stairs (see Figure 1b) describes a full set of functions required to fulfill the stated objectives (rolling on ground and climbing stairs) including rotate two hemispheres for propelling and steering, increase grip, monitor environment with camera, and extend arms for lifting the robot. So, it received 2 points for fulfilling requirements. This concept lacks mechanism details of how to propel the robot and extend the arms, and so, it received 1 point for partially fulfilling the functions identified earlier. Due to the absence of working principles, the design also lacks information of structural features required to fulfill the missing working principles, such as the transmission system for propelling, and so, it received 1 point for the fulfillment of working principles. When these individual weightings were substituted in (1), an overall quality score of 1.5 was obtained for the concept.
An inter-rater reliability test was conducted using three raters for 20 concepts. After two iterative rounds of analyzing, settling, reconciling differences and reaching Cohen’s Kappa ratio of 0.86, the quality of the remaining concepts was rated based on the learning gained from the earlier iterations.
3.3 Locating patent stimuli in home, near and far fields within the patent technology network
To analyze the influence of stimulation distance of patent stimuli on ideation outcomes, we located the patents used as stimuli in the ideation exercise within the network of all technology classes. In the network, the stimulation distance of a patent to a design problem can be measured according to the knowledge proximity between the technology classes containing the patent and the technology classes that correspond to the designers’ knowledge related to the design problem, i.e., the home field. To align with the theoretical lens of near and far analogies in the literature, we further located patents in home, near and far fields, which are groups of technology classes based on the latent community structure of the technology network.
3.3.1 Construct a technology network
First, we used the entire USPTO database from 1976 to 2016 to empirically create a patent technology network that approximates the total space of all known technologies to date (Alstott et al. Reference Alstott, Triulzi, Yan and Luo2017a ; Yan & Luo Reference Yan and Luo2017). In the network, 121 3-digit IPC classes, such as node F02 that represents a class of patents for combustion engine and node G06 for computing, are used to operationalize the nodes. Each network node representing a technology class can be viewed as a category of patents. The nodes are connected to each other according to the knowledge proximity between them, as shown in Figure 2.

Figure 2. Home, near and far fields of the SRR design in the technology class network. The size of each node is proportional to the number of patents in each technology class, and the thickness of a link is proportional to the knowledge proximity between the corresponding pair of technology classes. Nodes in the home field are highlighted in green, near field in orange, and far field in blue.
If two technology classes have low knowledge proximity, i.e., design processes in two technology categories require relatively distinct design knowledge, designers specializing in one technology category may find it difficult to understand or design using knowledge and technologies from the other (Luo Reference Luo2015). On the contrary, if the design process in two technology categories requires similar knowledge pieces, designers in one category can easily understand and leverage design knowledge from the other. Prior patent data analysis has also statistically shown that inventors are more likely to succeed in filing patents in proximate categories in the technology space (Alstott et al. Reference Alstott, Triulzi, Yan and Luo2017a ,Reference Alstott, Triulzi, Yan and Luo b ). Therefore, the information of knowledge proximity among technology classes will enable one to locate patents with different distances to a design problem in the technology space.
We utilized the reference-based cosine similarity index to calculate the knowledge proximity. Specifically, the distribution of references from patents in a technology class to unique patents is represented as a vector to characterize the design knowledge base of the technology class. The references of a patented technology are the proxy of the design knowledge used in the design of the technology. Then the knowledge proximity between a pair of technology classes is calculated as the cosine of the angle between their corresponding vectors (Yan & Luo Reference Yan and Luo2017), as follows:
 $$\begin{eqnarray}\displaystyle \text{Proximity}=\text{cosin}(i,j)=\frac{\mathop{\sum }_{k}C_{ik}C_{jk}}{\sqrt{\mathop{\sum }_{k}C_{ik}^{2}}\sqrt{\mathop{\sum }_{k}C_{jk}^{2}}} & & \displaystyle\end{eqnarray}$$
$$\begin{eqnarray}\displaystyle \text{Proximity}=\text{cosin}(i,j)=\frac{\mathop{\sum }_{k}C_{ik}C_{jk}}{\sqrt{\mathop{\sum }_{k}C_{ik}^{2}}\sqrt{\mathop{\sum }_{k}C_{jk}^{2}}} & & \displaystyle\end{eqnarray}$$
where
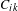 $C_{ik}$
or
$C_{ik}$
or
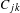 $C_{jk}$
denotes the number of citations referred from patents in technology class
$C_{jk}$
denotes the number of citations referred from patents in technology class
 $i$
or
$i$
or
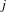 $j$
to the specific patent
$j$
to the specific patent
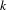 $k$
;
$k$
;
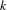 $k$
belongs to all the patents cited by patents in either technology class
$k$
belongs to all the patents cited by patents in either technology class
 $i$
or
$i$
or
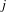 $j$
. The cosine similarity index value is in the range
$j$
. The cosine similarity index value is in the range
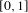 $[0,1]$
and indicates the proximity of knowledge pieces required in designing technologies in both classes. In this study, the references of more than 6 million utility patents in the USPTO database were analyzed to calculate the cosine between each pair of the 121 IPC classes for the best possible empirical approximation of knowledge proximity between them.
$[0,1]$
and indicates the proximity of knowledge pieces required in designing technologies in both classes. In this study, the references of more than 6 million utility patents in the USPTO database were analyzed to calculate the cosine between each pair of the 121 IPC classes for the best possible empirical approximation of knowledge proximity between them.
This knowledge proximity measure is theoretically motivated by the design-by-analogy literature that has primarily focused on ‘similarity’, e.g., functional, structural and surface similarity, to define and measure analogical stimulation distance (Gentner & Markman Reference Gentner and Markman1997; Ward Reference Ward1998; Christensen & Schunn Reference Christensen and Schunn2007; Fu et al. Reference Fu, Cagan, Kotovsky and Wood2013a ; Murphy et al. Reference Murphy, Fu, Otto, Yang, Jensen and Wood2014; Fu et al. Reference Fu, Murphy, Yang, Otto, Jensen and Wood2015). In contrast to these prior studies addressing the similarity between specific designs or individual patent documents, our measure is formulated for the similarity between technology classes, i.e., categories of patents. At this level, a few studies (Kay et al. Reference Kay, Newman, Youtie, Porter and Rafols2014; Leydesdorff et al. Reference Leydesdorff, Kushnir and Rafols2014) have used the cosine similarity of the vectors of patent references made from a pair of classes to other classes (i.e., class-to-class reference vectors). Our measure extends to class-to-patent vectors, concerning references to specific patents instead of aggregated classes, for a higher granularity. In addition, according to a recent study that compared 12 alternative knowledge proximity measures, our measure appears as one of the most correlated with and representative of other alternative knowledge proximity measures in the literature (Yan & Luo Reference Yan and Luo2017).
3.3.2 Detect communities in the technology network
In the technology network, some groups of nodes are more cohesively connected internally and have a higher density of links within than between them. Such dense groups of nodes are often called communities or clusters. In the network analysis and graph theory literature, various community detection algorithms have been developed to discover and analyze the latent community structures in networks (Clauset, Newman & Moore Reference Clauset, Newman and Moore2004; Newman Reference Newman2006; Blondel et al. Reference Blondel, Guillaume, Lambiotte and Lefebvre2008; Chen et al. Reference Chen, Wang, Chen and Xu2010; Browet, Absil & Van Dooren Reference Browet, Absil and Van Dooren2013; Wu et al. Reference Wu, Jin, Li and Zhang2015). Specifically, in terms of the technology network in Figure 2, communities are cohesive groups of technologies (i.e., patent classes) with high knowledge proximity between them. Technologies in the same communities possess more common knowledge than technologies in different communities, and thus it is more likely to draw analogies across technology classes in the same community.
In this paper, we employed a hierarchical agglomeration algorithm proposed by Clauset et al. (Reference Clauset, Newman and Moore2004) to detect the technology network’s latent community structure. This algorithm was chosen because it is more efficient and faster than competing algorithms and returns a uniquely determined community partition rather than heuristic results. We assessed the community groupings of technology classes resulting from the algorithm and deemed them reasonable based on our engineering knowledge. Consequently, the 121 technology classes of the technology network were clustered into 5 communities. We also compared the community detection result with those from Louvain’s greedy optimization method (Blondel et al. Reference Blondel, Guillaume, Lambiotte and Lefebvre2008) and found the results are consistent.
3.3.3 Locate ‘home field’
To locate the ‘home field’ of SRRs in the total technology space, we first need to retrieve a set of US patents that can comprehensively represent the participant designers’ knowledge base that is related to SRRs. As introduced in Section 3.1, prior to the ideation exercise, Sphero provided the students with the basic knowledge and understanding of SRRs, so we utilized the patents related to Sphero to define the students’ SRR-related knowledge base. On this basis, we searched the patents of Sphero Inc. and obtained 16 patents as of 31st August 2016.
Then we used the classification information of the retrieved patents to identify the home field in the technology network. To do this, the following two steps are carried out: (1) identify the technology classes that contain the retrieved patents and sort them in descending order of the number of retrieved patents they contain; (2) successively identify the minimum set of classes required to cover all the retrieved patents. Such a procedure is unambiguous and reproducible. Specifically, the 16 patents are classified in 8 technology classes. Among them, the 6 technology classes – ‘G05 Controlling & Regulating’, ‘A63 Sports & Amusements’, ‘B62 Land Vehicles’, ‘G06 Computing’, ‘B60 Vehicles in General’ and ‘B63 Ships’ – constitute the smallest set of top classes that cover all the 16 patents.
In addition, the technologies used in the 15 exemplar SRRs presented to the students are also well covered by the 6 technology classes. Therefore, we considered these 6 technology classes as the ‘home field’ of the SRR design in the total technology space, which are located at the center and highlighted in green in Figure 2. We also tested the robustness of the choice of technology classes to represent the home field. First, we found each of the top 3 technology classes contains more than a half of the total set of 16 patents and has a much greater coverage than the other technology classes. We tested only using the top 3 classes to define the home field. The statistical results presented in Section 4 vary slightly and do not affect the general conclusions. In addition, we also compared the patent set used in this paper with the patent set that resulted from an exhaustive patent search for SRRs and contained 153 SRR patents (Song & Luo Reference Song and Luo2017). The results show that only 1 of the top 6 technology classes differs for the two patent sets. These results show the robustness of the definition of the home field.
3.3.4 Identify ‘near field’ and ‘far field’
Based on the network partition results from the algorithm of Clauset et al. (Reference Clauset, Newman and Moore2004), the home-field classes G05, A63, B62, G06, B60 and B63 belong to 2 network communities. Then the technology classes other than these 6 in the same 2 communities were designated as the ‘near field’ of the SRR design, which are located at the inner ring and highlighted in orange in Figure 2. The near field surrounds the home field. The technology classes outside these 2 network communities were considered the ‘far field’ of the SRR design, which are located at the outer layer and highlighted in light blue in Figure 2. Thus, the technology class network, which represents the total technology space, was divided into three mega fields: home, near and far fields. On this basis, the patent stimuli used were assigned to one or multiple of the three fields in the technology space, according to their classification information. Note that a patent may belong to multiple fields if it is assigned in multiple technology classes.
In brief, the method of locating patents in home, near or far field involves three main procedures: (1) construct a network map of all technology classes in the patent database to represent the total technology space, (2) detect network communities, and (3) determine the home, near and far fields in the network. In turn, these three procedures respectively require: (1) a measure of the knowledge proximity between patent classes, (2) a community detection algorithm, and (3) a patent set representing the home of a design problem. In this sub-section, we have introduced our choices for each of the three elements. On this basis, we located the patent stimuli used in the ideation exercise in the home, near and far fields of the SRR design in the technology network, for further analysis.
4 Findings
In this section, we report the frequencies and likelihood of the participants finding patent stimuli from home, near and far fields, and the novelty and quality of the concepts generated with patent stimuli from home, near and far fields.
4.1 Where designers find patent stimuli in the technology space
Figure 4(a) shows the number of reported unique patent stimuli from home, near and far fields. The participant designers can use a patent as a stimulus for generating multiple concepts. Figure 4(b) shows the frequency of patents being used with multiple counting, i.e., it counts the use of a patent as stimulus for multiple concepts. Both the figures (Figure 4a,b) show a similar pattern: most patent stimuli used for concept generation are from the near field of the SRR design. We also calculated the likelihood for patent stimuli being identified from the various fields, as the number of patents used in a field to generate concepts divided by the total number of patents granted in the corresponding field from 1976 to 2016. As seen in Figure 4(c), patents in the home field are more likely to be used to generate concepts than those in the near and far fields, for which the likelihoods are almost the same.

Figure 3. The three procedures of our method to determine home, near and far fields.

Figure 4. Patent stimuli in each field of the technology space: (a) number of unique patents used; (b) frequency of patents being used; (c) likelihood of patents being used.
A concept can be stimulated by either a single patent or multiple patents, whose classes may fall into one or more of the home, near and far fields. Figure 5 shows the number of the concepts generated using patents from the individual fields and their combinations. In Figure 5(a), a concept stimulated by patents from multiple fields is counted multiple times, once for each field to which a patent stimulus belongs. Patents from the near and far fields help generate more concepts than patents from the home field. In order to present the results more unambiguously, we categorize a concept into only one of the individual fields or the combinations of multiple fields according to the sources of patent stimuli used by the concept. Under this setting, each concept is counted only once in one category. As shown in Figure 5(b), the highest number of the concepts is generated using patents from a combination of home, near and far fields (H, N & F), followed by the combination of near and far fields (N & F). The influence of patents from the near field either individually or in combination with other fields is prominent. As a single source, patents from the near field help generate most concepts.

Figure 5. Numbers of concepts generated using patents from individual fields and combinations of fields: (a) with patents from each field (one concept may be counted more than once); (b) with patents from combinations of the three fields (each concept is counted only once).
4.2 Implications of home-, near- and far-field stimuli on ideation outcomes
The average quality of the concepts generated using patents from the individual fields and their combinations is shown in Figure 6(a) and Figure 6(b), respectively. No significant difference in average quality across the individual fields is observed in Figure 6(a), suggesting that the three fields contribute almost identically to the quality of the concepts. When considering the combinations of the fields, we can see in Figure 6(b) that concepts stimulated with patents from the far field individually or the combination of home and far fields (H & F) have a significantly higher average quality than the rest. Such differences in concept quality are significant at 5% level in most cases based on pairwise 2-tailed t-tests, as shown in Table 1.

Figure 6. Average quality of generated concepts: (a) with patents from each field; (b) with patents from combinations of the three fields.
Figures 7(a) and figure 7(b) shows the distributions of the concepts generated using patents from the individual fields and their combinations by quality, respectively. In the figures, the low, medium and high quality categories correspond to the ranges of quality scores
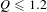 $Q\leqslant 1.2$
,
$Q\leqslant 1.2$
,
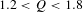 $1.2<Q<1.8$
and
$1.2<Q<1.8$
and
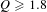 $Q\geqslant 1.8$
, respectively, according to the multimodal frequency distribution of the generated concepts by quality. As observed in Figure 7(a), patents from the home or far field stimulate a higher percentage of high quality concepts than those from the near field. In Figure 7(b), a higher percentage of the concepts stimulated by patents from: (a) the far field and (b) the combination of the home and far fields (H & F) have high quality. Interestingly, no low-quality concepts are generated using patents from the far field individually, the combination of the home and far fields (H & F) and the combination of the home and near fields (H & N).
$Q\geqslant 1.8$
, respectively, according to the multimodal frequency distribution of the generated concepts by quality. As observed in Figure 7(a), patents from the home or far field stimulate a higher percentage of high quality concepts than those from the near field. In Figure 7(b), a higher percentage of the concepts stimulated by patents from: (a) the far field and (b) the combination of the home and far fields (H & F) have high quality. Interestingly, no low-quality concepts are generated using patents from the far field individually, the combination of the home and far fields (H & F) and the combination of the home and near fields (H & N).

Figure 7. Distributions of concepts by quality: (a) with patents from each field; (b) with patents from combinations of the three fields.
Table 1.
 $t$
statistics with
$t$
statistics with
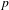 $p$
-values in parentheses for the pairwise comparison of the quality of concept sets as indicated by the row and column labels. Underlines denote significance at 5% level
$p$
-values in parentheses for the pairwise comparison of the quality of concept sets as indicated by the row and column labels. Underlines denote significance at 5% level

The average novelty of the concepts generated using patents from the individual fields and their combinations is shown in Figure 8(a) and Figure 8(b), respectively. The differences in average novelty of the concepts generated using patents from the individual fields are not statistically significant (see Figure 8a). Concepts stimulated by patents from the near field individually and all combinations containing the near field (N; H & N; N & F; H, N & F) have higher average novelty than concepts stimulated by patents from other individual fields or combinations (see Figure 8b). Specifically, the differences in average novelty are statistically significant at 5% level between concepts stimulated by patents from the combinations containing the near field (H & N; N & F; H, N & F) and those stimulated by patents from the home or far field individually or their combination (H; F; H & F), as shown in Table 2.

Figure 8. Average novelty of generated concepts: (a) with patents from each field; (b) with patents from combinations of the three fields.

Figure 9. Distributions of concepts by novelty: (a) with patents from each field; (b) with patents from combinations of the three fields.
Table 2.
 $t$
statistics with
$t$
statistics with
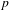 $p$
-values in parentheses for the pairwise comparison of the novelty of concept sets as indicated by the row and column labels. Underlines denote significance at 5% level
$p$
-values in parentheses for the pairwise comparison of the novelty of concept sets as indicated by the row and column labels. Underlines denote significance at 5% level

Figures 9(a) and figure 9(b) shows the distributions of the concepts generated using patents from the individual fields and their combinations by novelty, respectively. As mentioned earlier, the high, medium, low and no novelty corresponds to novelty score 3, 2, 1 and 0, respectively. As observed in Figure 9(a), patents from the near field contribute a slightly higher percentage of high novelty concepts than patents from the home and far fields. It is clear from Figure 9(b) that the concepts generated with patents from the near field individually and all combinations containing the near field (N; H & N; N & F; H, N & F) present a higher percentage of high and medium novelty. These results are consistent with the findings in Figure 8(b). The results suggest that patents from the near field play a major role in stimulating concepts of higher novelty compared to patents from the home or far field.
4.3 Summary of findings
The following are observed in the data from the open concept generation exercise and using the technology space network-based definition of home, near and far fields of patent stimuli:
-
(1) Patents from the home field are most likely to be used as stimuli for concept generation.
-
(2) The near field contributes most patent stimuli for concept generation, and the most number of concepts are generated using patents from the near field.
-
(3) The concepts generated with patent stimuli from the far field individually and the combination of the home and far fields have a higher average quality than concepts generated with patents from other individual fields or other combinations of the three fields.
-
(4) The concepts generated with patent stimuli from the near field individually and the combinations of the near field with other fields have higher average novelty than concepts generated with patent stimuli from the home field, far field or their combination.
5 Discussion
5.1 Significance of findings
In this paper, we have presented a network-based approach to divide the technology space into three fields – home field, near field and far field – with varied knowledge proximity to a design problem based on the community detection within the network of all 3-digit IPC technology classes in the patent databases. The ‘home field’ entails technology classes that contain patents that are directly relevant to a design problem, the ‘near field’ comprises technology classes that are in the same network communities as those in the ‘home field,’ and the remaining technology classes from other communities in the technology network constitute the ‘far field’. Each technology class can be further viewed as a category of patents. The data-driven definition of the home, near and far fields is motivated by the literature on design by analogy using patents as stimuli, which has used such terms as near or far analogies or stimuli, to characterize discrete stimuli or patents. Our approach provides a systemic and macro framework, which one can consistently use to position a patent in either home, near or far fields of design stimulation in the total technology space.
Based on the definitions of the home, near and far fields in the total technology space, our experiment shows that patents from the home field are more likely to be used than those from the near or far field. Since the home field is the area nearest to the defined design problem or opportunity, the result produces evidence in support of the argument that it is easier to analogize with stimuli from near domains than far domains to some extent. In the studied case, patents in the home field record technologies and processes having much more common knowledge basis with the SRR-related design knowledge of the student designers, and so the patents are much easier to be identified, understood and assimilated by them.
Results in this paper further suggest that in the given context, concepts generated using patents from the far field or the combination of the home and far fields have a higher average quality than the concepts stimulated by patents from other individual fields or combinations. This seems to contradict the findings of Fu et al. (Reference Fu, Chan, Cagan, Kotovsky, Schunn and Wood2013b ) that solutions generated using stimuli from near sources had higher quality than those generated using far sources, but support the findings of Chan et al. (Reference Chan, Fu, Schunn, Cagan, Wood and Kotovsky2011) that stimuli from far sources were more beneficial for developing solutions of higher quality. However, these studies and ours might not be comparable, primarily because the characterization of near and far is not the same. Fu et al. and Chan et al. used functional similarity to characterize the distance as near and far between individual patents and a specific design problem, while in this study knowledge base similarity between patent technology classes is used. Also, it must be noted that the context setting for this study is quite different from theirs. That is, the objective of the design problem is open and the participants are free to select patent stimuli from the given sets or search their own independently. In this case, it is understandable that where the patent stimuli are from has limited influence on feature creation. Although patents from different fields are used with different likelihoods, once they are identified and chosen as stimuli for concept generation, the designers would make effort to understand and make sense of the information provided in the patents and transform it into features in their own concepts.
The near field provides the most patent stimuli, which further stimulate the largest portion of the concepts. Concepts generated using patents from the near field have higher novelty on average than those generated without patents from the near field. On one hand, the near field is relatively nearer to the design problem than the far field, and contains design knowledge that is relatively easy to understand and make sense of. On the other hand, it is relatively more distant to the design problem than the home field, and probably provides stimuli with plenty of additional features for conceiving innovative attributes. Potentially, these attributes may contribute to novelty. In brief, it can be argued that patents from the near field are more beneficial for identifying stimuli and creating novel attributes in concepts compared to those from the other fields.
This research uses data that comprises several variables. 138 concepts were generated with 231 patents by student designers, who ideated individually in uncontrolled conditions. The student designers in this study, unlike other laboratory-based controlled ideation experiments, required more domain knowledge to accomplish the task. From among an alternative set of the concepts generated by individuals, one concept was chosen and if necessary, modified, and then prototyped and demonstrated by each team. So, the quality of the prototype depended on the concept set generated earlier. Therefore, the ideation was a fun exercise with lots of project stakes attached to it. The grades of student designers depended on their performance at every phase of the SRR development process. Some of the projects were further pursued toward entrepreneurial and co-curricular activities. So, the participants had adequate vested incentives to pursue this ideation exercise seriously. Therefore, the results of this study must be viewed taking into consideration the wide span of variables and the seriousness with which this exercise was pursued.
In addition to our experiment findings, this paper may have made a contribution to ideation methodology development, specifically regarding patent stimuli search. Although prior studies have suggested the efficacy of using patents as stimuli for concept generation, browsing through the huge patent database within a short period to identify relevant stimuli may be cumbersome. To address the problem, an efficient search-and-retrieve interface is required, through which millions of patents can be searched through using defined keywords and relevant patents can be retrieved and ranked in the order of their appropriateness to the keywords. Fu et al. (Reference Fu, Cagan, Kotovsky and Wood2013a ) and Murphy et al. (Reference Murphy, Fu, Otto, Yang, Jensen and Wood2014) have developed computational design tools to search and identify functionally relevant analogies from the US patent database. Results in this paper offer fundamental insights on designers’ natural preferences for stimuli and the influence of stimulation distance on ideation outcomes. With these findings, the introduced method in Section 3.3, which is based on a technology class network and community detection to define the home field, near field and far field, might be a first step toward a data-driven computational tool for better-guided and more-informed search of patents as design stimuli. Such a tool is expected to allow designers to locate the home field of a design problem and be informed of the fields of their search for patent stimuli, and systematically guide them through the search for patent stimuli in either home field, near field, far field or their combinations.
In fact, the method we used in this experimental research is structured and repeatable. As introduced in Section 3.3 and depicted in Figure 3, the method generally involves three main procedures: (1) construct a network map of technology classes to represent the total technology space; (2) detect network communities; and, (3) determine the home, near and far fields in the network. In practice, once the home, near and far fields have been identified in the network, a designer can search, locate and use patent stimuli within the home, near and far fields, with the guidance of the understanding of the potential effectiveness of finding useful patent stimuli from different fields and the corresponding performance implications, as suggested from our experimental findings.
Meanwhile, the procedures require three key elements in practical implementation: (a) a knowledge proximity measure for constructing the network of technology classes, (b) a computer algorithm for partitioning the technology network into a few communities, and (c) a patent set for identifying the technology classes to determine the home field. For each of the elements, there are alternative implementation choices. In this paper, we have provided one superior choice for each element for our case study, but do not limit to them. For the first two elements, in this study, alternative knowledge proximity measures and alternative community detection algorithms result in quite similar community partitions of the technology network. In a different case, one can still pick out superior choices of the measures and algorithms by comparing the resulting community partitions with the expectation based on his or her knowledge and the specific context. Moreover, the patent set used to identify the home field can also be determined using an approach according to the context. For example, to find the home field of a designer, one can search the patents granted to the designer; to find the home field of a designer who has no patents, one can search patents using keywords that describe the technical expertise of the designer; one can also combine the search approaches. In brief, our method provides a structured but flexible framework, whose elements can be operationalized and calibrated according to the specific context and situation of its application.
5.2 Limitations
The results in this research have the following limitations. First, in this research the measure used to assess the knowledge proximity between 3-digit technology classes may not be directly related to the relevance of a stimulus to a problem. Future research may explore knowledge proximity at alternative granularity levels, such as proximity between 4-digit IPC technology classes or between classes and patents. Second, the student designers received two sets of 121 patents (the most cited patent and a random patent from each of the 121 technology classes) for the ideation exercise. A patent’s description text is often lengthy and written in a tedious and non-obvious manner, so it may be difficult for the student designers to browse through all the 242 patents to assimilate the information, identify relevant stimuli from them and use these for generating concepts all within a week. That is, coverage of all the 121 technology classes in the total technology space may not be guaranteed in practice. Future research may seek approaches for communicating the technical information and design knowledge in patent documents to designers more effectively and efficiently. Also, the ideation was an after-class exercise and thus uncontrolled. For concepts generated using both patents and other resources of inspiration, the influence of other resources was not accounted for locating the stimuli in the home, near and far fields in the technology space. This discounts a significant influence of other resources on the novelty or quality of the generated concepts.
Moreover, it should be noted that our findings result from a technology-driven design process with undergraduate designers as the participants. The findings may not hold true for experienced designers or in other design situations, such as the design of market-driven products. For example, when solving a design problem, experienced designers typically have extensive knowledge of the near field as well as the home field through their own learning and experience, which allows them to build their own ‘feeling for near’. In such a situation, the experienced designers would not find patent stimuli from the home and near fields so useful as the student designers do. In addition, for the design of market-driven products, the goal is to identify users’ value-based needs and convert them into product features successfully. In such a design process, the distance of stimuli from the design problem is largely determined by users’ requirements but not the intrinsic proximity or distance between technologies. Moreover, the findings in this paper are based on the case of SRRs and may not hold true for other products, whereas the introduced method of locating patent stimuli is applicable to other contexts. This suggests a future research opportunity to apply our network-based methodology to more diverse products and contexts and potentially develop a contingency understanding on the influence of stimulation distance on ideation outcomes for different types of products.
6 Conclusions and future work
This research contributes to fundamental insights on designers’ preferences for patent stimuli and the influence of stimulation distance on the ideation outcomes, as well as a network-based methodology for better-guided search of patents as design stimuli in concept generation practices. The objectives of this research are: (a) to identify where designers identify useful patent stimuli within the technology space: home, near or far fields, and (b) to study the implications of using patent stimuli from these fields on the novelty and quality of the concepts generated. It is observed that: (a) patents from the home field are more likely to be used as stimuli, (b) the near field contributes most patent stimuli, which further stimulates the most number of the concepts, (c) concepts generated with patents from the far field and the combination of the home and far fields have higher average quality than concepts generated using patents from other individual fields or combinations of the three fields, and (d) the concepts generated with patents from the near field have higher average novelty than concepts generated without patents from the near field. The methodology based on a technology class network and community detection to define the home field, near field and far field might be a first step toward a tool for better-guided search of patents as design stimuli. Further efforts can be made to retrieve most useful patents for ideation at the field or class level.
Acknowledgments
This research is supported partly by a grant from the SUTD-MIT International Design Centre (IDG31600105), and by Singapore Ministry of Education Tier 2 Academic Research Grant (T2MOE1403).















 Open access
Open access