



1. Introduction
Slice sampling algorithms are designed for Markov chain Monte Carlo (MCMC) sampling from a distribution given by a possibly unnormalized density. They belong to the class of auxiliary-variable algorithms that define a suitable Markov chain on an extended state space. Following [Reference Edwards and Sokal6] and [Reference Wang and Swendsen41], a number of different versions have been discussed and proposed in [Reference Besag and Green4, Reference Higdon9, Reference Mira, Møller and Roberts20–Reference Murray, Adams and MacKay22, Reference Neal25, Reference Roberts and Rosenthal29, Reference Roberts and Rosenthal30, Reference Schär, Habeck and Rudolf37]. We refer to these papers for details of algorithmic design and applications in Bayesian inference and statistical physics. Here let us first focus on the appealing simple slice sampler setting, in which no further algorithmic tuning or design by the user is necessary: assume that
 $K\subseteq \mathbb{R}^d$
and let the unnormalized density be
$K\subseteq \mathbb{R}^d$
and let the unnormalized density be
 $\varrho\colon K \to (0,\infty)$
. The goal is to sample approximately with respect to the distribution
$\varrho\colon K \to (0,\infty)$
. The goal is to sample approximately with respect to the distribution
 $\pi$
determined by
$\pi$
determined by
 $\varrho$
, i.e.
$\varrho$
, i.e.
 \begin{align*}\pi(A)=\frac{\int_A \varrho(x)\,\textrm{d} x}{\int_K \varrho(x)\,\textrm{d} x},\qquad A\in\mathcal{B}(K),\end{align*}
\begin{align*}\pi(A)=\frac{\int_A \varrho(x)\,\textrm{d} x}{\int_K \varrho(x)\,\textrm{d} x},\qquad A\in\mathcal{B}(K),\end{align*}
where
 $\mathcal{B}(K)$
denotes the Borel
$\mathcal{B}(K)$
denotes the Borel
 $\sigma$
-algebra. Given the current state
$\sigma$
-algebra. Given the current state
 $X_n = x\in K$
, the simple slice sampling algorithm generates the next Markov chain instance
$X_n = x\in K$
, the simple slice sampling algorithm generates the next Markov chain instance
 $X_{n+1}$
by the following two steps:
$X_{n+1}$
by the following two steps:
-
1. Choose t uniformly at random from
 $(0,\varrho(x))$
, i.e.
$t\sim \mathcal{U}(0,\varrho(x))$
.
$(0,\varrho(x))$
, i.e.
$t\sim \mathcal{U}(0,\varrho(x))$
. -
2. Choose
$X_{t+1}$
uniformly at random from the level set of
\begin{align*} K(t)\;:\!=\; \{x \in K \mid \varrho(x) > t\}, \end{align*}
$\varrho$
determined by t.





The above-defined simple slice sampler transition mechanism is known to be reversible with respect to
 $\pi$
and possesses very robust convergence properties that have been observed empirically and established formally. For example Mira and Tierney [Reference Mira and Tierney21] proved that if
$\pi$
and possesses very robust convergence properties that have been observed empirically and established formally. For example Mira and Tierney [Reference Mira and Tierney21] proved that if
 $\varrho$
is bounded and the support of
$\varrho$
is bounded and the support of
 $\varrho$
has finite Lebesgue measure, then the simple slice sampler is uniformly ergodic. Roberts and Rosenthal in [Reference Roberts and Rosenthal29] provide criteria for geometric ergodicity. Moreover, in [Reference Roberts and Rosenthal29, Reference Roberts and Rosenthal30] the authors prove explicit estimates for the total variation distance of the distribution of
$\varrho$
has finite Lebesgue measure, then the simple slice sampler is uniformly ergodic. Roberts and Rosenthal in [Reference Roberts and Rosenthal29] provide criteria for geometric ergodicity. Moreover, in [Reference Roberts and Rosenthal29, Reference Roberts and Rosenthal30] the authors prove explicit estimates for the total variation distance of the distribution of
 $X_n$
to
$X_n$
to
 $\pi$
. In the recent work [Reference Natarovskii, Rudolf and Sprungk24], depending on the volume of the level sets, an explicit lower bound of the spectral gap of simple slice sampling is derived.
$\pi$
. In the recent work [Reference Natarovskii, Rudolf and Sprungk24], depending on the volume of the level sets, an explicit lower bound of the spectral gap of simple slice sampling is derived.
Unfortunately, the applicability of the simple slice sampler is limited. In high dimensions it is in general infeasible to sample uniformly from the level set of
 $\varrho$
, and thus the second step of the algorithm above cannot be performed. Consequently, the second step is replaced by sampling a Markov chain on the level set, which has the uniform distribution as the invariant one. Following the terminology of [Reference Roberts and Rosenthal28] we call such algorithms hybrid slice samplers. We refer to [Reference Neal26], where various procedures and designs for the Markov chain on the slice are suggested and insightful expert advice is given.
$\varrho$
, and thus the second step of the algorithm above cannot be performed. Consequently, the second step is replaced by sampling a Markov chain on the level set, which has the uniform distribution as the invariant one. Following the terminology of [Reference Roberts and Rosenthal28] we call such algorithms hybrid slice samplers. We refer to [Reference Neal26], where various procedures and designs for the Markov chain on the slice are suggested and insightful expert advice is given.
Despite being easy to implement, hybrid slice sampling in general has not been analyzed theoretically, and little is known about its convergence properties. (A notable exception is elliptical slice sampling [Reference Murray, Adams and MacKay22], which has recently been investigated in [Reference Natarovskii, Rudolf and Sprungk23], where a geometric ergodicity statement is provided.) The present paper is aimed at closing this gap by providing statements about the inheritance of convergence from the simple to the hybrid setting.
To this end we study the absolute spectral gap of hybrid slice samplers. The absolute spectral gap of a Markov operator P or a corresponding Markov chain
 $(X_n)_{n\in \mathbb{N}}$
is given by
$(X_n)_{n\in \mathbb{N}}$
is given by
 \begin{align*}\textrm{{g}ap}(P)=1-\left\Vert P \right\Vert_{L^0_{2,\pi} \to L^0_{2,\pi}}\!,\end{align*}
\begin{align*}\textrm{{g}ap}(P)=1-\left\Vert P \right\Vert_{L^0_{2,\pi} \to L^0_{2,\pi}}\!,\end{align*}
where
 $L^0_{2,\pi}$
is the space of functions
$L^0_{2,\pi}$
is the space of functions
 $f\colon K \to \mathbb{R}$
with zero mean and finite variance (i.e.
$f\colon K \to \mathbb{R}$
with zero mean and finite variance (i.e.
 $\int_K f(x) \textrm{d}\pi(x) = 0;$
$\int_K f(x) \textrm{d}\pi(x) = 0;$
 $\left\Vert f \right\Vert_{2}^2 = \int_K \left\vert f(x) \right\vert^2 \textrm{d}\pi(x)<\infty$
) and
$\left\Vert f \right\Vert_{2}^2 = \int_K \left\vert f(x) \right\vert^2 \textrm{d}\pi(x)<\infty$
) and
 $\left\Vert P \right\Vert_{L^0_{2,\pi} \to L^0_{2,\pi}}$
denotes the operator norm. We refer to [Reference Rudin32] for the functional-analytic background. From the computational point of view, the existence of the spectral gap (i.e.
$\left\Vert P \right\Vert_{L^0_{2,\pi} \to L^0_{2,\pi}}$
denotes the operator norm. We refer to [Reference Rudin32] for the functional-analytic background. From the computational point of view, the existence of the spectral gap (i.e.
 $\textrm{{g}ap}(P)>0$
) implies a number of desirable and well studied robustness properties, in particular the following:
$\textrm{{g}ap}(P)>0$
) implies a number of desirable and well studied robustness properties, in particular the following:
-
The spectral gap implies geometric ergodicity [Reference Kontoyiannis and Meyn15, Reference Roberts and Rosenthal28] and the variance bounding property [Reference Roberts and Rosenthal31].
-
For reversible Markov chains, the spectral gap implies that a CLT holds for all functions
$f \in L_{2,\pi}$
(cf. [Reference Geyer8, Reference Kipnis14]). -
Furthermore, consistent estimation of the CLT asymptotic variance is well established for geometrically ergodic chains (cf. [Reference Bednorz and Łatuszyński2, Reference Flegal and Jones7, Reference Hobert, Jones, Presnell and Rosenthal10, Reference Jones, Haran, Caffo and Neath11]).

Additionally, quantitative information on the spectral gap allows the formulation of precise non-asymptotic statements. In particular, it is well known (see e.g. [Reference Novak and Rudolf27, Lemma 2]) that if
 $\nu$
is the initial distribution of the reversible Markov chain in question, i.e.
$\nu$
is the initial distribution of the reversible Markov chain in question, i.e.
 $\nu=\mathbb{P}_{X_1},$
then
$\nu=\mathbb{P}_{X_1},$
then
 \begin{align*}\left\Vert \nu P^n - \pi \right\Vert{}_{\mbox{tv}} \leq (1-\textrm{{g}ap}(P))^n \left\Vert \frac{d\nu}{d \pi}-1 \right\Vert_{2},\end{align*}
\begin{align*}\left\Vert \nu P^n - \pi \right\Vert{}_{\mbox{tv}} \leq (1-\textrm{{g}ap}(P))^n \left\Vert \frac{d\nu}{d \pi}-1 \right\Vert_{2},\end{align*}
where
 $\nu P^n = \mathbb{P}_{X_{n+1}}$
. See [Reference Baxendale1, Section 6] for a related
$\nu P^n = \mathbb{P}_{X_{n+1}}$
. See [Reference Baxendale1, Section 6] for a related
 $L_{2,\pi}$
convergence result. Moreover, when considering the sample average, one obtains
$L_{2,\pi}$
convergence result. Moreover, when considering the sample average, one obtains
 \begin{align*}\mathbb{E} \left\vert \frac{1}{n} \sum_{j=1}^n f(X_j) - \int_K f(x) \textrm{d}\pi(x) \right\vert^2\leq \frac{2}{n\cdot \textrm{{g}ap}(P)}+ \frac{c_p\left\Vert \frac{d\nu}{d\pi}-1 \right\Vert_{\infty}}{n^2 \cdot \textrm{{g}ap}(P)},\end{align*}
\begin{align*}\mathbb{E} \left\vert \frac{1}{n} \sum_{j=1}^n f(X_j) - \int_K f(x) \textrm{d}\pi(x) \right\vert^2\leq \frac{2}{n\cdot \textrm{{g}ap}(P)}+ \frac{c_p\left\Vert \frac{d\nu}{d\pi}-1 \right\Vert_{\infty}}{n^2 \cdot \textrm{{g}ap}(P)},\end{align*}
for any
 $p>2$
and any function
$p>2$
and any function
 $f \colon K \to \mathbb{R}$
with
$f \colon K \to \mathbb{R}$
with
 $\left\Vert f \right\Vert_{p}^p= \int_K \left\vert f(x) \right\vert^p \pi(\textrm{d} x) \leq 1$
, where
$\left\Vert f \right\Vert_{p}^p= \int_K \left\vert f(x) \right\vert^p \pi(\textrm{d} x) \leq 1$
, where
 $c_p$
is an explicit constant which depends only on p. One can also take a burn-in into account; for further details see [Reference Rudolf33, Theorem 3.41]. This indicates that the spectral gap of a Markov chain is central to robustness and a crucial quantity in both asymptotic and non-asymptotic analysis of MCMC estimators.
$c_p$
is an explicit constant which depends only on p. One can also take a burn-in into account; for further details see [Reference Rudolf33, Theorem 3.41]. This indicates that the spectral gap of a Markov chain is central to robustness and a crucial quantity in both asymptotic and non-asymptotic analysis of MCMC estimators.
The route we undertake is to conclude the spectral gap of the hybrid slice sampler from the more tractable spectral gap of the simple slice sampler. So what is known about the spectral gap of the simple slice sampler? To say more on this, we require the following notation. Define
 $v_\varrho \colon [0,\infty) \to [0,\infty]$
by
$v_\varrho \colon [0,\infty) \to [0,\infty]$
by
 $v_\varrho(t)\;:\!=\; \textrm{vol}_d(K(t))$
, which for level t returns the volume of the level set. We say for
$v_\varrho(t)\;:\!=\; \textrm{vol}_d(K(t))$
, which for level t returns the volume of the level set. We say for
 $m\in\mathbb{N}$
that
$m\in\mathbb{N}$
that
 $v_\varrho \in \Lambda_m$
if
$v_\varrho \in \Lambda_m$
if
-
$v_\varrho$
is continuously differentiable and
$v'_{\!\!\varrho}(t)<0$
for any
$t\geq0$
, and
-
the mapping
$t\mapsto t v'_{\!\!\varrho}(t)/v_\varrho(t)^{1-1/m}$
is decreasing on the support of
$v_\varrho$
.





Recently, in [Reference Natarovskii, Rudolf and Sprungk24, Theorem 3.10], it has been shown that if
 $v_\varrho \in \Lambda_m$
, then
$v_\varrho \in \Lambda_m$
, then
 $\textrm{{g}ap}(U)\geq 1/$
$\textrm{{g}ap}(U)\geq 1/$
 $(m+1)$
. This provides a criterion for the existence of a spectral gap as well as a quantitative lower bound, essentially depending on whether
$(m+1)$
. This provides a criterion for the existence of a spectral gap as well as a quantitative lower bound, essentially depending on whether
 $t\mapsto t v'_{\!\!\varrho}(t)/v_\varrho(t)^{1-1/m}$
is decreasing or not.
$t\mapsto t v'_{\!\!\varrho}(t)/v_\varrho(t)^{1-1/m}$
is decreasing or not.
Now we are in a position to explain our contributions. Let H be the Markov kernel of the hybrid slice sampler determined by a family of transition kernels
 $H_t$
, where each
$H_t$
, where each
 $H_t$
is a Markov kernel with uniform limit distribution, say
$H_t$
is a Markov kernel with uniform limit distribution, say
 $U_t$
, on the level determined by t. Consider
$U_t$
, on the level determined by t. Consider
 \begin{align*}\beta_k \;:\!=\; \sup_{x\in K} \left(\int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2},\end{align*}
\begin{align*}\beta_k \;:\!=\; \sup_{x\in K} \left(\int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2},\end{align*}
and note that the quantity
 $\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2$
measures how quickly
$\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2$
measures how quickly
 $H_t$
gets close to
$H_t$
gets close to
 $U_t$
. Thus
$U_t$
. Thus
 $\beta_k$
is the supremum over expectations of a function which measures the speed of convergence of
$\beta_k$
is the supremum over expectations of a function which measures the speed of convergence of
 $H_t^k$
to
$H_t^k$
to
 $U_t$
. The main result, stated in Theorem 1, is as follows. Assume that
$U_t$
. The main result, stated in Theorem 1, is as follows. Assume that
 $\beta_k \to 0$
for increasing k and assume
$\beta_k \to 0$
for increasing k and assume
 $H_t$
induces a positive semidefinite Markov operator for every level t. Then
$H_t$
induces a positive semidefinite Markov operator for every level t. Then
 \begin{equation} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H) \leq \textrm{{g}ap}(U), \quad k\in\mathbb{N} .\end{equation}
\begin{equation} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H) \leq \textrm{{g}ap}(U), \quad k\in\mathbb{N} .\end{equation}
The first inequality implies that whenever there exists a spectral gap of the simple slice sampler and
 $\beta_k \to 0$
, then there is a spectral gap of the hybrid slice sampler. The second inequality of (1) verifies a very intuitive result, namely that the simple slice sampler is always better than the hybrid one.
$\beta_k \to 0$
, then there is a spectral gap of the hybrid slice sampler. The second inequality of (1) verifies a very intuitive result, namely that the simple slice sampler is always better than the hybrid one.
We demonstrate how to apply our main theorem in different settings. First, we consider a stepping-out shrinkage slice sampler, suggested in [Reference Neal26], in a simple bimodal 1-dimensional setting. Next we turn to the d-dimensional case and on each slice perform a single step of the hit-and-run algorithm, studied in [Reference Bélisle, Romeijn and Smith3, Reference Lovász16, Reference Smith38]. Using our main theorem we prove equivalence of the spectral gap (and hence geometric ergodicity) of this hybrid hit-and-run on the slice and the simple slice sampler. Let us also mention here that in [Reference Rudolf and Ullrich36] the hit-and-run algorithm, hybrid hit-and-run on the slice, and the simple slice sampler are compared, according to covariance ordering [Reference Mira19], to a random-walk Metropolis algorithm. Finally, we combine the stepping-out shrinkage and hit-and-run slice sampler. The resulting algorithm is practical and easily implementable in multidimensional settings. For this version we again show equivalence of the spectral gap and geometric ergodicity with the simple slice sampler for multidimensional bimodal targets.
Further note that we consider single-auxiliary-variable methods to keep the arguments simple. We believe that a similar analysis can also be done if one considers multi-auxiliary-variable methods.
The structure of the paper is as follows. In Section 2 the notation and preliminary results are provided. These include a necessary and sufficient condition for reversibility of hybrid slice sampling in Lemma 1, followed by a useful representation of slice samplers in Section 2.1, which is crucial in the proof of the main result. In Section 3 we state and prove the main result. For example, Corollary 1 provides a lower bound on the spectral gap of a hybrid slice sampler, which performs several steps with respect to
 $H_t$
on the chosen level. In Section 4 we apply our result to analyze a number of specific hybrid slice sampling algorithms in different settings that include multidimensional bimodal distributions.
$H_t$
on the chosen level. In Section 4 we apply our result to analyze a number of specific hybrid slice sampling algorithms in different settings that include multidimensional bimodal distributions.
2. Notation and basics
Recall that
 $\varrho\;:\; K \to (0, \infty)$
is an unnormalized density on
$\varrho\;:\; K \to (0, \infty)$
is an unnormalized density on
 $K \subseteq \mathbb{R}^d$
, and denote the level set of
$K \subseteq \mathbb{R}^d$
, and denote the level set of
 $\varrho$
by
$\varrho$
by
 \begin{align*}K(t)=\lbrace x\in K\mid \varrho(x)> t \rbrace.\end{align*}
\begin{align*}K(t)=\lbrace x\in K\mid \varrho(x)> t \rbrace.\end{align*}
Hence the sequence
 $(K(t))_{t\geq 0}$
of subsets of
$(K(t))_{t\geq 0}$
of subsets of
 $\mathbb{R}^d$
satisfies the following:
$\mathbb{R}^d$
satisfies the following:
-
1.
$K(0) = K$
. -
2.
$K(s) \subseteq K(t)$
for
$t<s$
. -
3.
$K(t) = \emptyset$
for
$t\geq\left\Vert \varrho \right\Vert_{\infty}$
.





Let
 $\textrm{vol}_d$
be the d-dimensional Lebesgue measure, and let
$\textrm{vol}_d$
be the d-dimensional Lebesgue measure, and let
 $(U_t)_{t\in (0,\Vert \varrho \Vert_\infty)}$
be a sequence of distributions, where
$(U_t)_{t\in (0,\Vert \varrho \Vert_\infty)}$
be a sequence of distributions, where
 $U_t$
is the uniform distribution on K(t), i.e.
$U_t$
is the uniform distribution on K(t), i.e.
 \begin{align*}U_t(A)=\frac{\textrm{vol}_d(A\cap K(t))}{\textrm{vol}_d(K(t))}, \quad A\in \mathcal{B}(K).\end{align*}
\begin{align*}U_t(A)=\frac{\textrm{vol}_d(A\cap K(t))}{\textrm{vol}_d(K(t))}, \quad A\in \mathcal{B}(K).\end{align*}
Furthermore, let
 $(H_t)_{t\in (0,\Vert \varrho \Vert_\infty)}$
be a sequence of transition kernels, where
$(H_t)_{t\in (0,\Vert \varrho \Vert_\infty)}$
be a sequence of transition kernels, where
 $H_t$
is a transition kernel on
$H_t$
is a transition kernel on
 $K(t)\subseteq \mathbb{R}^d$
. For convenience we extend the definition of the transition kernel
$K(t)\subseteq \mathbb{R}^d$
. For convenience we extend the definition of the transition kernel
 $H_{t}(\cdot,\cdot)$
on the measurable space
$H_{t}(\cdot,\cdot)$
on the measurable space
 $(K,\mathcal{B}(K))$
. We set
$(K,\mathcal{B}(K))$
. We set
 \begin{align} \bar{H}_t(x,A)& = \begin{cases}0, & x\not\in K(t),\\[5pt] H_t(x,A\cap K(t)), & x\in K(t).\end{cases}\end{align}
\begin{align} \bar{H}_t(x,A)& = \begin{cases}0, & x\not\in K(t),\\[5pt] H_t(x,A\cap K(t)), & x\in K(t).\end{cases}\end{align}
In the following we write
 $H_t$
for
$H_t$
for
 $\bar{H}_t$
and consider
$\bar{H}_t$
and consider
 $H_t$
as extension on
$H_t$
as extension on
 $(K,\mathcal{B}(K))$
. The transition kernel of the hybrid slice sampler is given by
$(K,\mathcal{B}(K))$
. The transition kernel of the hybrid slice sampler is given by
 \begin{align*}H(x,A) = \frac{1}{\varrho(x)}\int_0^{\varrho(x)} H_t(x,A)\, \textrm{d} t, \quad x\in K,\, A\in \mathcal{B}(K).\end{align*}
\begin{align*}H(x,A) = \frac{1}{\varrho(x)}\int_0^{\varrho(x)} H_t(x,A)\, \textrm{d} t, \quad x\in K,\, A\in \mathcal{B}(K).\end{align*}
If
 $H_t=U_t$
we have the simple slice sampler studied in [Reference Mira and Tierney21, Reference Natarovskii, Rudolf and Sprungk24, Reference Roberts and Rosenthal29, Reference Roberts and Rosenthal30]. The transition kernel of this important special case is given by
$H_t=U_t$
we have the simple slice sampler studied in [Reference Mira and Tierney21, Reference Natarovskii, Rudolf and Sprungk24, Reference Roberts and Rosenthal29, Reference Roberts and Rosenthal30]. The transition kernel of this important special case is given by
 \begin{align*}U(x,A) = \frac{1}{\varrho(x)}\int_0^{\varrho(x)} U_t(A)\, \textrm{d} t, \quad x\in K,\, A\in \mathcal{B}(K).\end{align*}
\begin{align*}U(x,A) = \frac{1}{\varrho(x)}\int_0^{\varrho(x)} U_t(A)\, \textrm{d} t, \quad x\in K,\, A\in \mathcal{B}(K).\end{align*}
We provide a criterion for reversibility of H with respect to
 $\pi$
. Therefore let us define the density
$\pi$
. Therefore let us define the density
 \begin{align*}\ell(s) = \frac{\textrm{vol}_d(K(s))}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(r))\,\textrm{d} r},\quad s\in(0,\Vert \varrho \Vert_\infty),\end{align*}
\begin{align*}\ell(s) = \frac{\textrm{vol}_d(K(s))}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(r))\,\textrm{d} r},\quad s\in(0,\Vert \varrho \Vert_\infty),\end{align*}
of the distribution of the level sets on
 $((0,\Vert \varrho \Vert_\infty),\mathcal{B}((0,\Vert \varrho \Vert_\infty))).$
$((0,\Vert \varrho \Vert_\infty),\mathcal{B}((0,\Vert \varrho \Vert_\infty))).$
Lemma 1. The transition kernel H is reversible with respect to
 $\pi$
if and only if
$\pi$
if and only if
 \begin{equation} \int_0^{\Vert \varrho \Vert_\infty} \int_B H_t(x,A)\, U_t(\textrm{d} x)\, \ell(t)\textrm{d} t = \int_0^{\Vert \varrho \Vert_\infty} \int_A H_t(x,B)\, U_t(\textrm{d} x)\, \ell(t)\textrm{d} t, \quad A,B \in \mathcal{B}(K). \end{equation}
\begin{equation} \int_0^{\Vert \varrho \Vert_\infty} \int_B H_t(x,A)\, U_t(\textrm{d} x)\, \ell(t)\textrm{d} t = \int_0^{\Vert \varrho \Vert_\infty} \int_A H_t(x,B)\, U_t(\textrm{d} x)\, \ell(t)\textrm{d} t, \quad A,B \in \mathcal{B}(K). \end{equation}
In particular, if
 $H_t$
is reversible with respect to
$H_t$
is reversible with respect to
 $U_t$
for almost all t (concerning
$U_t$
for almost all t (concerning
 $\ell$
), then H is reversible with respect to
$\ell$
), then H is reversible with respect to
 $\pi$
.
$\pi$
.
Equation (3) is the detailed balance condition of
 $H_t$
with respect to
$H_t$
with respect to
 $U_t$
in the average sense, i.e.
$U_t$
in the average sense, i.e.
 \begin{align*}\mathbb{E}_\ell [H_\cdot(x,\textrm{d} y) U_\cdot(\textrm{d} x)] = \mathbb{E}_\ell [H_\cdot(y,\textrm{d} x) U_\cdot(\textrm{d} y)],\quad x,y\in K.\end{align*}
\begin{align*}\mathbb{E}_\ell [H_\cdot(x,\textrm{d} y) U_\cdot(\textrm{d} x)] = \mathbb{E}_\ell [H_\cdot(y,\textrm{d} x) U_\cdot(\textrm{d} y)],\quad x,y\in K.\end{align*}
Now we prove Lemma 1.
Proof. First, note that
 \begin{align*} \int_K \varrho(x)\, \textrm{d} x & = \int_0^{\Vert \varrho \Vert_\infty} \int_K \mathbf{1}_{(0,\varrho(x))} (s) \, \textrm{d} x\, \textrm{d} s \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_K \mathbf{1}_{K(s)} (x) \, \textrm{d} x\, \textrm{d} s = \int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \, \textrm{d} s. \end{align*}
\begin{align*} \int_K \varrho(x)\, \textrm{d} x & = \int_0^{\Vert \varrho \Vert_\infty} \int_K \mathbf{1}_{(0,\varrho(x))} (s) \, \textrm{d} x\, \textrm{d} s \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_K \mathbf{1}_{K(s)} (x) \, \textrm{d} x\, \textrm{d} s = \int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \, \textrm{d} s. \end{align*}
From this we obtain for any
 $A,B\in \mathcal{B}(K)$
that
$A,B\in \mathcal{B}(K)$
that
 \begin{align*} & \int_B H(x,A)\, \pi(\textrm{d} x) = \int_B \int_0^{\varrho(x)} H_t(x,A) \frac{\textrm{d} t}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\textrm{d} s} \textrm{d} x\\[5pt] & = \int_B \int_0^{\Vert \varrho \Vert_\infty} \mathbf{1}_{K(t)}(x)H_t(x,A) \frac{\ell(t)}{\textrm{vol}_d(K(t))} \textrm{d} t\textrm{d} x = \int_0^{\Vert \varrho \Vert_{\infty}} \int_B H_t(x,A)\, U_t(\textrm{d} x)\,\ell(t) \textrm{d} t. \end{align*}
\begin{align*} & \int_B H(x,A)\, \pi(\textrm{d} x) = \int_B \int_0^{\varrho(x)} H_t(x,A) \frac{\textrm{d} t}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\textrm{d} s} \textrm{d} x\\[5pt] & = \int_B \int_0^{\Vert \varrho \Vert_\infty} \mathbf{1}_{K(t)}(x)H_t(x,A) \frac{\ell(t)}{\textrm{vol}_d(K(t))} \textrm{d} t\textrm{d} x = \int_0^{\Vert \varrho \Vert_{\infty}} \int_B H_t(x,A)\, U_t(\textrm{d} x)\,\ell(t) \textrm{d} t. \end{align*}
As an immediate consequence of the previous equation, we have the claimed equivalence of reversibility and (3). By the definition of the reversibility of
 $H_t$
according to
$H_t$
according to
 $U_t$
, we have
$U_t$
, we have
 \begin{align*} \int_B H_t(x,A)\, U_t(\textrm{d} x) = \int_A H_t(x,B)\, U_t(\textrm{d} x). \end{align*}
\begin{align*} \int_B H_t(x,A)\, U_t(\textrm{d} x) = \int_A H_t(x,B)\, U_t(\textrm{d} x). \end{align*}
This, combined with (3), leads to the reversibility of H.
We always want to have that H is reversible with respect to
 $\pi$
. Therefore we formulate the following assumption.
$\pi$
. Therefore we formulate the following assumption.
Assumption 1. Let
 $H_t$
be reversible with respect to
$H_t$
be reversible with respect to
 $U_t$
for any
$U_t$
for any
 $t\in(0,\Vert \varrho \Vert_{\infty})$
.
$t\in(0,\Vert \varrho \Vert_{\infty})$
.
Now we define Hilbert spaces of square-integrable functions and Markov operators. Let
 $L_{2,\pi}=L_2(K,\pi)$
be the space of functions
$L_{2,\pi}=L_2(K,\pi)$
be the space of functions
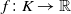 $f\colon K \to \mathbb{R}$
which satisfy
$f\colon K \to \mathbb{R}$
which satisfy
 $\left\Vert f \right\Vert_{2,\pi}^2 \;:\!=\; \langle f,f \rangle_{\pi} <\infty$
, where
$\left\Vert f \right\Vert_{2,\pi}^2 \;:\!=\; \langle f,f \rangle_{\pi} <\infty$
, where
 \begin{align*}\langle f,g \rangle_\pi \;:\!=\;\int_K f(x)\, g(x)\, \pi(\textrm{d} x)\end{align*}
\begin{align*}\langle f,g \rangle_\pi \;:\!=\;\int_K f(x)\, g(x)\, \pi(\textrm{d} x)\end{align*}
denotes the corresponding inner product of
 $f,g \in L_{2,\pi}$
. For
$f,g \in L_{2,\pi}$
. For
 $f\in L_{2,\pi}$
and
$f\in L_{2,\pi}$
and
 $t\in(0,\Vert \varrho \Vert_\infty)$
define
$t\in(0,\Vert \varrho \Vert_\infty)$
define
 \begin{equation} H_t f(x) = \int_{K(t)} f(y)\, H_t(x,\textrm{d} y), \qquad x\in K.\end{equation}
\begin{equation} H_t f(x) = \int_{K(t)} f(y)\, H_t(x,\textrm{d} y), \qquad x\in K.\end{equation}
Note that if
 $x\not \in K(t)$
, then we have
$x\not \in K(t)$
, then we have
 $H_t f(x) = 0$
by the convention on
$H_t f(x) = 0$
by the convention on
 $H_t$
; see (2). The Markov operator
$H_t$
; see (2). The Markov operator
 $H\colon L_{2,\pi}\to L_{2,\pi}$
is defined by
$H\colon L_{2,\pi}\to L_{2,\pi}$
is defined by
 \begin{align*}Hf(x)=\frac{1}{\varrho(x)}\int_0^{\varrho(x)} H_t f(x)\, \textrm{d} t,\end{align*}
\begin{align*}Hf(x)=\frac{1}{\varrho(x)}\int_0^{\varrho(x)} H_t f(x)\, \textrm{d} t,\end{align*}
and similarly
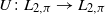 $U\colon L_{2,\pi}\to L_{2,\pi}$
is defined by
$U\colon L_{2,\pi}\to L_{2,\pi}$
is defined by
 \begin{align*}U f(x)=\frac{1}{\varrho(x)}\int_0^{\varrho(x)} U_t(f)\, \textrm{d} t,\end{align*}
\begin{align*}U f(x)=\frac{1}{\varrho(x)}\int_0^{\varrho(x)} U_t(f)\, \textrm{d} t,\end{align*}
where
 $U_t(f)=\int_{K(t)} f(x)\,U_t(\textrm{d} x)$
is a special case of (4). Furthermore, for
$U_t(f)=\int_{K(t)} f(x)\,U_t(\textrm{d} x)$
is a special case of (4). Furthermore, for
 $t \in(0,\Vert \varrho \Vert_\infty)$
let
$t \in(0,\Vert \varrho \Vert_\infty)$
let
 $L_{2,t}=L_2(K(t),U_t)$
be the space of functions
$L_{2,t}=L_2(K(t),U_t)$
be the space of functions
 $f\colon K(t) \to \mathbb{R}$
with
$f\colon K(t) \to \mathbb{R}$
with
 $\left\Vert f \right\Vert_{2,t}^2 \;:\!=\; \langle f,f \rangle_{t} <\infty$
, where
$\left\Vert f \right\Vert_{2,t}^2 \;:\!=\; \langle f,f \rangle_{t} <\infty$
, where
 \begin{align*}\langle f,g \rangle_{t} \;:\!=\; \int_{K(t)} f(x)\, g(x)\, U_t(\textrm{d} x)\end{align*}
\begin{align*}\langle f,g \rangle_{t} \;:\!=\; \int_{K(t)} f(x)\, g(x)\, U_t(\textrm{d} x)\end{align*}
denotes the corresponding inner product of
 $f,g\in L_{2,t}$
. Then
$f,g\in L_{2,t}$
. Then
 $H_t\colon L_{2,t} \to L_{2,t}$
can also be considered as a Markov operator. Define the functional
$H_t\colon L_{2,t} \to L_{2,t}$
can also be considered as a Markov operator. Define the functional
 \begin{align*}S(f) = \int_K f(x)\, \pi(\textrm{d} x),\quad f\in L_{2,\pi},\end{align*}
\begin{align*}S(f) = \int_K f(x)\, \pi(\textrm{d} x),\quad f\in L_{2,\pi},\end{align*}
as the operator
 $S\colon L_{2,\pi} \to L_{2,\pi}$
which maps functions to the constant functions given by their mean value. We say
$S\colon L_{2,\pi} \to L_{2,\pi}$
which maps functions to the constant functions given by their mean value. We say
 $f\in L_{2,\pi}^0$
if and only if
$f\in L_{2,\pi}^0$
if and only if
 $f\in L_{2,\pi}$
and
$f\in L_{2,\pi}$
and
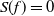 $S(f)=0$
. Now the absolute spectral gap of a Markov kernel or Markov operator
$S(f)=0$
. Now the absolute spectral gap of a Markov kernel or Markov operator
 $P \colon L_{2,\pi} \to L_{2,\pi}$
is given by
$P \colon L_{2,\pi} \to L_{2,\pi}$
is given by
 \begin{align*}\textrm{{g}ap}(P) = 1 - \left\Vert P-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} = 1- \left\Vert P \right\Vert_{L^0_{2,\pi}\to L^0_{2,\pi}} .\end{align*}
\begin{align*}\textrm{{g}ap}(P) = 1 - \left\Vert P-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} = 1- \left\Vert P \right\Vert_{L^0_{2,\pi}\to L^0_{2,\pi}} .\end{align*}
For details of the last equality we refer to [Reference Rudolf33, Lemma 3.16]. Moreover, for the equivalence of
 $\textrm{{g}ap}(P)>0$
and (almost sure) geometric ergodicity we refer to [Reference Kontoyiannis and Meyn15, Proposition 1.2]. For any
$\textrm{{g}ap}(P)>0$
and (almost sure) geometric ergodicity we refer to [Reference Kontoyiannis and Meyn15, Proposition 1.2]. For any
 $t>0$
the norm
$t>0$
the norm
 $\left\Vert f \right\Vert_{2,t}$
can also be considered for
$\left\Vert f \right\Vert_{2,t}$
can also be considered for
 $f\colon K \to \mathbb{R}$
. With this in mind we have the following relation between
$f\colon K \to \mathbb{R}$
. With this in mind we have the following relation between
 $\left\Vert f \right\Vert_{2,\pi}$
and
$\left\Vert f \right\Vert_{2,\pi}$
and
 $\left\Vert f \right\Vert_{2,t}$
.
$\left\Vert f \right\Vert_{2,t}$
.
Lemma 2. For any
 $f\colon K\to \mathbb{R}$
, with the notation defined above, we obtain
$f\colon K\to \mathbb{R}$
, with the notation defined above, we obtain
 \begin{equation} S(f) =\int_0^{\Vert \varrho \Vert_\infty} U_t(f)\, \,\ell(t)\,\textrm{d} t. \end{equation}
\begin{equation} S(f) =\int_0^{\Vert \varrho \Vert_\infty} U_t(f)\, \,\ell(t)\,\textrm{d} t. \end{equation}
In particular,
 \begin{align} \left\Vert f \right\Vert_{2,\pi}^2 & = \int_0^{\Vert \varrho \Vert_\infty} \left\Vert f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t. \end{align}
\begin{align} \left\Vert f \right\Vert_{2,\pi}^2 & = \int_0^{\Vert \varrho \Vert_\infty} \left\Vert f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t. \end{align}
Proof. The assertion of (6) is a special case of (5), since
 $S(\left\vert f \right\vert^2)=\left\Vert f \right\Vert_{2,\pi}^2$
. By
$S(\left\vert f \right\vert^2)=\left\Vert f \right\Vert_{2,\pi}^2$
. By
 $\int_K \varrho(x)\,\textrm{d} x = \int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\, \textrm{d} s$
(see the proof of Lemma 1), one obtains
$\int_K \varrho(x)\,\textrm{d} x = \int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\, \textrm{d} s$
(see the proof of Lemma 1), one obtains
 \begin{align*} S(f)& = \frac{\int_K f(x)\,\varrho(x)\,\textrm{d} x}{\int_0^{{\Vert \varrho \Vert_\infty}} \textrm{vol}_d(K(s))\, \textrm{d} s} = \int_K \int_0^{\varrho(x)} f(x) \frac{\textrm{d} t\; \textrm{d} x}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\, \textrm{d} s} \\[5pt] &= \int_0^{{\Vert \varrho \Vert_\infty}} \int_{K(t)} f(x) \, \frac{\textrm{d} x}{\textrm{vol}_d(K(t))}\,\ell(t) \textrm{d} t = \int_0^{{\Vert \varrho \Vert_\infty}} U_t(f)\,\ell(t)\, \textrm{d} t, \end{align*}
\begin{align*} S(f)& = \frac{\int_K f(x)\,\varrho(x)\,\textrm{d} x}{\int_0^{{\Vert \varrho \Vert_\infty}} \textrm{vol}_d(K(s))\, \textrm{d} s} = \int_K \int_0^{\varrho(x)} f(x) \frac{\textrm{d} t\; \textrm{d} x}{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d(K(s))\, \textrm{d} s} \\[5pt] &= \int_0^{{\Vert \varrho \Vert_\infty}} \int_{K(t)} f(x) \, \frac{\textrm{d} x}{\textrm{vol}_d(K(t))}\,\ell(t) \textrm{d} t = \int_0^{{\Vert \varrho \Vert_\infty}} U_t(f)\,\ell(t)\, \textrm{d} t, \end{align*}
which proves (5).
2.1. A useful representation
As in [Reference Rudolf and Ullrich35, Section 3.3], we derive a suitable representation of H and U. We define a
 $(d+1)$
-dimensional auxiliary state space. Let
$(d+1)$
-dimensional auxiliary state space. Let
 \begin{align*}K_\varrho=\lbrace (x,t)\in\mathbb{R}^{d+1}\mid x\in K,\, t\in(0,\varrho(x)) \rbrace\end{align*}
\begin{align*}K_\varrho=\lbrace (x,t)\in\mathbb{R}^{d+1}\mid x\in K,\, t\in(0,\varrho(x)) \rbrace\end{align*}
and let
 $\mu$
be the uniform distribution on
$\mu$
be the uniform distribution on
 $(K_\varrho,\mathcal{B}(K_\varrho))$
, i.e.
$(K_\varrho,\mathcal{B}(K_\varrho))$
, i.e.
 \begin{align*}\mu(\textrm{d}(x,t)) = \frac{\textrm{d} t\, \textrm{d} x}{\textrm{vol}_{d+1}(K_\varrho)}.\end{align*}
\begin{align*}\mu(\textrm{d}(x,t)) = \frac{\textrm{d} t\, \textrm{d} x}{\textrm{vol}_{d+1}(K_\varrho)}.\end{align*}
Note that
 $\textrm{vol}_{d+1}(K_\varrho) = \int_K \varrho(x)\, \textrm{d} x$
. By
$\textrm{vol}_{d+1}(K_\varrho) = \int_K \varrho(x)\, \textrm{d} x$
. By
 $L_{2,\mu}=L_2(K_\varrho,\mu)$
we denote the space of functions
$L_{2,\mu}=L_2(K_\varrho,\mu)$
we denote the space of functions
 $f\colon K_\varrho \to \mathbb{R}$
that satisfy
$f\colon K_\varrho \to \mathbb{R}$
that satisfy
 $\left\Vert f \right\Vert_{2,\mu}^2 \;:\!=\; \langle f,f \rangle_\mu <\infty$
, where
$\left\Vert f \right\Vert_{2,\mu}^2 \;:\!=\; \langle f,f \rangle_\mu <\infty$
, where
 \begin{align*}\langle f,g \rangle_\mu \;:\!=\; \int_{K_\varrho} f(x,s)\, g(x,s)\, \mu(\textrm{d}(x,s))\end{align*}
\begin{align*}\langle f,g \rangle_\mu \;:\!=\; \int_{K_\varrho} f(x,s)\, g(x,s)\, \mu(\textrm{d}(x,s))\end{align*}
denotes the corresponding inner product for
 $f,g\in L_{2,\mu}$
. Here, similarly to (6), we have
$f,g\in L_{2,\mu}$
. Here, similarly to (6), we have
 \begin{align*}\left\Vert f \right\Vert_{2,\mu}^2= \int_0^{\Vert \varrho \Vert_\infty} \left\Vert f(\cdot,s) \right\Vert_{2,s}^2 \ell(s)\textrm{d} s.\end{align*}
\begin{align*}\left\Vert f \right\Vert_{2,\mu}^2= \int_0^{\Vert \varrho \Vert_\infty} \left\Vert f(\cdot,s) \right\Vert_{2,s}^2 \ell(s)\textrm{d} s.\end{align*}
Let
 $T\colon L_{2,\mu} \to L_{2,\pi}$
and
$T\colon L_{2,\mu} \to L_{2,\pi}$
and
 $T^*\colon L_{2,\pi} \to L_{2,\mu}$
be given by
$T^*\colon L_{2,\pi} \to L_{2,\mu}$
be given by
 \begin{align*}Tf(x)=\frac{1}{\varrho(x)} \int_0^{\varrho(x)} f(x,s)\,\textrm{d} s,\quad\mbox{and}\quad T^*f(x,s)=f(x).\end{align*}
\begin{align*}Tf(x)=\frac{1}{\varrho(x)} \int_0^{\varrho(x)} f(x,s)\,\textrm{d} s,\quad\mbox{and}\quad T^*f(x,s)=f(x).\end{align*}
Then
 $T^*$
is the adjoint operator of T, i.e. for all
$T^*$
is the adjoint operator of T, i.e. for all
 $f\in L_{2,\pi}$
and
$f\in L_{2,\pi}$
and
 $g\in L_{2,\mu}$
we have
$g\in L_{2,\mu}$
we have
 \begin{align*}\langle f , Tg \rangle_{\pi} = \langle T^*f , g \rangle_\mu.\end{align*}
\begin{align*}\langle f , Tg \rangle_{\pi} = \langle T^*f , g \rangle_\mu.\end{align*}
Then, for
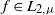 $f\in L_{2,\mu}$
, define
$f\in L_{2,\mu}$
, define
 \begin{align*}\widetilde{H}f(x,s)=\int_{K(s)} f(y,s)\,H_s(x,\textrm{d} y).\end{align*}
\begin{align*}\widetilde{H}f(x,s)=\int_{K(s)} f(y,s)\,H_s(x,\textrm{d} y).\end{align*}
By the stationarity of
 $U_s$
according to
$U_s$
according to
 $H_s$
it is easily seen that
$H_s$
it is easily seen that
 \begin{align*}\left\Vert \widetilde{H}f \right\Vert_{2,\mu}^2& = \int_K \int_0^{\varrho(x)} \left\vert \widetilde H f(x,s) \right\vert^2 \frac{\textrm{d} s\,\textrm{d} x}{\int_K \varrho(y)\textrm{d} y} = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \left\vert \widetilde H f(x,s) \right\vert^2 U_s(\textrm{d} x)\, \ell(s) \textrm{d} s \\[5pt] & \leq \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \int_{K(s)} \left\vert f(y,s) \right\vert^2 H_s(x,\textrm{d} y)\, U_s(\textrm{d} x)\, \ell(s) \textrm{d} s\\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \left\vert f(x,s) \right\vert^2 \, U_s(\textrm{d} x)\, \ell(s) \textrm{d} s= \left\Vert f \right\Vert_{2,\mu}^2.\end{align*}
\begin{align*}\left\Vert \widetilde{H}f \right\Vert_{2,\mu}^2& = \int_K \int_0^{\varrho(x)} \left\vert \widetilde H f(x,s) \right\vert^2 \frac{\textrm{d} s\,\textrm{d} x}{\int_K \varrho(y)\textrm{d} y} = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \left\vert \widetilde H f(x,s) \right\vert^2 U_s(\textrm{d} x)\, \ell(s) \textrm{d} s \\[5pt] & \leq \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \int_{K(s)} \left\vert f(y,s) \right\vert^2 H_s(x,\textrm{d} y)\, U_s(\textrm{d} x)\, \ell(s) \textrm{d} s\\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(s)} \left\vert f(x,s) \right\vert^2 \, U_s(\textrm{d} x)\, \ell(s) \textrm{d} s= \left\Vert f \right\Vert_{2,\mu}^2.\end{align*}
Furthermore, define
 \begin{align*}\widetilde{U}f(x,s)=\int_{K(s)} f(y,s)\,U_s(\textrm{d} y).\end{align*}
\begin{align*}\widetilde{U}f(x,s)=\int_{K(s)} f(y,s)\,U_s(\textrm{d} y).\end{align*}
Then
 $\widetilde{H} \colon L_{2,\mu}\to L_{2,\mu}$
,
$\widetilde{H} \colon L_{2,\mu}\to L_{2,\mu}$
,
 $\widetilde{U}\colon L_{2,\mu} \to L_{2,\mu}$
, and
$\widetilde{U}\colon L_{2,\mu} \to L_{2,\mu}$
, and
 \begin{align*}\left\Vert \widetilde{H} \right\Vert_{L_{2,\mu}\to L_{2,\mu}} = 1,\quad \quad\left\Vert \widetilde{U} \right\Vert_{L_{2,\mu}\to L_{2,\mu}}=1.\end{align*}
\begin{align*}\left\Vert \widetilde{H} \right\Vert_{L_{2,\mu}\to L_{2,\mu}} = 1,\quad \quad\left\Vert \widetilde{U} \right\Vert_{L_{2,\mu}\to L_{2,\mu}}=1.\end{align*}
By construction we have the following.
Lemma 3. Let H, U, T,
 $T^*$
,
$T^*$
,
 $\widetilde{H}$
, and
$\widetilde{H}$
, and
 $\widetilde{U}$
be as above. Then
$\widetilde{U}$
be as above. Then
 \begin{align*} H=T \widetilde{H} T^* \quad \textit{and} \quad U= T\widetilde{U}T^*. \end{align*}
\begin{align*} H=T \widetilde{H} T^* \quad \textit{and} \quad U= T\widetilde{U}T^*. \end{align*}
Here
 $TT^*\colon L_{2,\pi} \to L_{2,\pi}$
satisfies
$TT^*\colon L_{2,\pi} \to L_{2,\pi}$
satisfies
 $TT^*f(x)=f(x)$
, i.e.
$TT^*f(x)=f(x)$
, i.e.
 $TT^*$
is the identity operator, and
$TT^*$
is the identity operator, and
 $T^*T\colon L_{2,\mu} \to L_{2,\mu}$
satisfies
$T^*T\colon L_{2,\mu} \to L_{2,\mu}$
satisfies
 \begin{align*}T^*Tf(x,s) = Tf(x),\end{align*}
\begin{align*}T^*Tf(x,s) = Tf(x),\end{align*}
i.e. it returns the average of the function
 $f(x,\cdot)$
over the second variable.
$f(x,\cdot)$
over the second variable.
3. On the spectral gap of hybrid slice samplers
We start with a relation between the convergence on the slices and the convergence of
 $T\widetilde{H}^k T^*$
to
$T\widetilde{H}^k T^*$
to
 $T\widetilde{U}T^*$
for increasing k.
$T\widetilde{U}T^*$
for increasing k.
Lemma 4. Let
 $k\in\mathbb{N}$
. Then
$k\in\mathbb{N}$
. Then
 \begin{align*} & \left\Vert T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi} \to L_{2,\pi}} \leq \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
\begin{align*} & \left\Vert T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi} \to L_{2,\pi}} \leq \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
Proof. First note that
 $\left\Vert f \right\Vert_{2,\pi} < \infty$
implies
$\left\Vert f \right\Vert_{2,\pi} < \infty$
implies
 $\left\Vert f \right\Vert_{2,t}<\infty$
for
$\left\Vert f \right\Vert_{2,t}<\infty$
for
 $\ell$
-almost every t. For any
$\ell$
-almost every t. For any
 $k\in \mathbb{N}$
and
$k\in \mathbb{N}$
and
 $f\in L_{2,\pi}$
we have
$f\in L_{2,\pi}$
we have
 \begin{align*} (\widetilde{H}^k T^* f)(x,t) = (H^k_t f)(x)\quad \mbox{and} \quad (\widetilde{U}T^*f)(x,t)=U_t(f), \end{align*}
\begin{align*} (\widetilde{H}^k T^* f)(x,t) = (H^k_t f)(x)\quad \mbox{and} \quad (\widetilde{U}T^*f)(x,t)=U_t(f), \end{align*}
so that
 \begin{align*} T(\widetilde{H}^k-\widetilde{U})T^*f(x) & = \int_0^{\Vert \varrho \Vert_\infty} (H^k_t-U_t)f(x)\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t. \end{align*}
\begin{align*} T(\widetilde{H}^k-\widetilde{U})T^*f(x) & = \int_0^{\Vert \varrho \Vert_\infty} (H^k_t-U_t)f(x)\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t. \end{align*}
It follows that
 \begin{align*} & \left\Vert T(\widetilde{H}^k-\widetilde{U})T^*f \right\Vert_{2,\pi}^2 = \int_K \left\vert \int_0^{\Vert \varrho \Vert_\infty} (H^k_t-U_t)f(x)\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t \right\vert^2 \,\pi(\textrm{d} x) \\[5pt] & \leq \int_K \int_0^{\Vert \varrho \Vert_\infty} \left\vert (H^k_t-U_t)f(x) \right\vert^2\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t \, \frac{\varrho(x)}{\int_K \varrho(y) \,\textrm{d} y}\,\textrm{d} x \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \left\vert (H^k_t-U_t)f(x) \right\vert^2\, \frac{\textrm{d} x}{\textrm{vol}_d({K(t)})} \, \frac{\textrm{vol}_d(K(t)) }{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \,\textrm{d} s}\,\textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \left\Vert (H^k_t-U_t)f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t \\[5pt] & \leq \int_0^{\Vert \varrho \Vert_\infty} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \left\Vert f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \left\vert f(x) \right\vert^2 \frac{\textrm{d} x}{\textrm{vol}_d({K(t)})} \, \, \frac{\textrm{vol}_d(K(t)) }{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \,\textrm{d} s}\,\textrm{d} t \\[5pt] & = \int_K \int_0^{\varrho(x)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \frac{\textrm{d} t}{\varrho(x)} \, \left\vert f(x) \right\vert^2\, \frac{\varrho(x) }{\int_K \varrho(y) \,\textrm{d} y}\textrm{d} x \\[5pt] & \leq \left\Vert f \right\Vert_{2,\pi}^2 \; \sup_{x\in K} \int_0^{\varrho(x)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \frac{\textrm{d} t}{\varrho(x)}. \end{align*}
\begin{align*} & \left\Vert T(\widetilde{H}^k-\widetilde{U})T^*f \right\Vert_{2,\pi}^2 = \int_K \left\vert \int_0^{\Vert \varrho \Vert_\infty} (H^k_t-U_t)f(x)\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t \right\vert^2 \,\pi(\textrm{d} x) \\[5pt] & \leq \int_K \int_0^{\Vert \varrho \Vert_\infty} \left\vert (H^k_t-U_t)f(x) \right\vert^2\, \frac{\mathbf{1}_{K(t)}(x)}{\varrho(x)} \,\textrm{d} t \, \frac{\varrho(x)}{\int_K \varrho(y) \,\textrm{d} y}\,\textrm{d} x \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \left\vert (H^k_t-U_t)f(x) \right\vert^2\, \frac{\textrm{d} x}{\textrm{vol}_d({K(t)})} \, \frac{\textrm{vol}_d(K(t)) }{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \,\textrm{d} s}\,\textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \left\Vert (H^k_t-U_t)f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t \\[5pt] & \leq \int_0^{\Vert \varrho \Vert_\infty} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \left\Vert f \right\Vert_{2,t}^2 \,\ell(t)\,\textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \left\vert f(x) \right\vert^2 \frac{\textrm{d} x}{\textrm{vol}_d({K(t)})} \, \, \frac{\textrm{vol}_d(K(t)) }{\int_0^{\Vert \varrho \Vert_\infty} \textrm{vol}_d({K(s)}) \,\textrm{d} s}\,\textrm{d} t \\[5pt] & = \int_K \int_0^{\varrho(x)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \frac{\textrm{d} t}{\varrho(x)} \, \left\vert f(x) \right\vert^2\, \frac{\varrho(x) }{\int_K \varrho(y) \,\textrm{d} y}\textrm{d} x \\[5pt] & \leq \left\Vert f \right\Vert_{2,\pi}^2 \; \sup_{x\in K} \int_0^{\varrho(x)} \left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \frac{\textrm{d} t}{\varrho(x)}. \end{align*}
Remark 1. If there exists a number
 $\beta \in[0,1]$
such that
$\beta \in[0,1]$
such that
 $\left\Vert H_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}\leq \beta$
for any
$\left\Vert H_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}\leq \beta$
for any
 $t\in(0,\Vert \varrho \Vert_\infty)$
, then one obtains (as a consequence of the former lemma) that
$t\in(0,\Vert \varrho \Vert_\infty)$
, then one obtains (as a consequence of the former lemma) that
 \begin{align*} & \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} \leq \left\Vert T\widetilde{U}T^*-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} + \beta^k. \end{align*}
\begin{align*} & \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} \leq \left\Vert T\widetilde{U}T^*-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} + \beta^k. \end{align*}
Here we have employed the triangle inequality and the fact that
 $$\Vert H^k_t-U_t \Vert_{L_{2,t}\to L_{2,t}} \leq \Vert H_t-U_t \Vert_{L_{2,t}\to L_{2,t}}^k \leq \beta^k;$$
$$\Vert H^k_t-U_t \Vert_{L_{2,t}\to L_{2,t}} \leq \Vert H_t-U_t \Vert_{L_{2,t}\to L_{2,t}}^k \leq \beta^k;$$
see for example [Reference Rudolf33, Lemma 3.16].
Now a corollary follows which provides a lower bound for
 $\textrm{{g}ap}(T\widetilde{H}^k T^*)$
.
$\textrm{{g}ap}(T\widetilde{H}^k T^*)$
.
Corollary 1. Let us assume that
 $\textrm{{g}ap}(U)>0$
, i.e.
$\textrm{{g}ap}(U)>0$
, i.e.
 $\left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}<1$
, and let
$\left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}<1$
, and let
 \begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
\begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
Then
 \begin{equation} \textrm{gap}(T\widetilde{H}^kT^*) \geq \textrm{gap}(U) - \beta_k. \end{equation}
\begin{equation} \textrm{gap}(T\widetilde{H}^kT^*) \geq \textrm{gap}(U) - \beta_k. \end{equation}
Proof. It is enough to prove
 \begin{align*} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}+\beta_k. \end{align*}
\begin{align*} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}+\beta_k. \end{align*}
By
 $\widetilde{H}^k = \widetilde{U}+\widetilde{H}^k - \widetilde{U}$
and Lemma 4 we have
$\widetilde{H}^k = \widetilde{U}+\widetilde{H}^k - \widetilde{U}$
and Lemma 4 we have
 \begin{align*} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} & = \left\Vert T\widetilde{U}T^*-S+T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}\\[5pt] & \leq \left\Vert U-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} + \beta_k. \end{align*}
\begin{align*} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} & = \left\Vert T\widetilde{U}T^*-S+T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}\\[5pt] & \leq \left\Vert U-S \right\Vert_{L_{2,\pi} \to L_{2,\pi}} + \beta_k. \end{align*}
Remark 2. If one can sample with respect to
 $U_t$
for every
$U_t$
for every
 $t\geq 0$
, then
$t\geq 0$
, then
 $H_t=U_t$
, and in the estimate of Corollary 1 we obtain
$H_t=U_t$
, and in the estimate of Corollary 1 we obtain
 $\beta_k=0$
and equality in (7).
$\beta_k=0$
and equality in (7).
Now let us state the main theorem.
Theorem 1. Let us assume that for almost all t (with respect to
 $\ell$
)
$\ell$
)
 $H_t$
is positive semidefinite on
$H_t$
is positive semidefinite on
 $L_{2,t}$
, and let
$L_{2,t}$
, and let
 \begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
\begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}. \end{align*}
Further assume that
 $\lim_{k\to \infty }\beta_k = 0$
. Then
$\lim_{k\to \infty }\beta_k = 0$
. Then
 \begin{equation} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H) \leq \textrm{{g}ap}(U), \quad k\in\mathbb{N} . \end{equation}
\begin{equation} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H) \leq \textrm{{g}ap}(U), \quad k\in\mathbb{N} . \end{equation}
Several conclusions can be drawn from the theorem. First, under the assumption that
 $\lim_{k\to \infty} \beta_k = 0,$
the left-hand side of (8) implies that in the setting of the theorem, whenever the simple slice sampler has a spectral gap, so does the hybrid version. See Section 4 for examples. Second, it also provides a quantitative bound on
$\lim_{k\to \infty} \beta_k = 0,$
the left-hand side of (8) implies that in the setting of the theorem, whenever the simple slice sampler has a spectral gap, so does the hybrid version. See Section 4 for examples. Second, it also provides a quantitative bound on
 $\textrm{{g}ap}(H)$
given appropriate estimates on
$\textrm{{g}ap}(H)$
given appropriate estimates on
 $\textrm{{g}ap}(U)$
and
$\textrm{{g}ap}(U)$
and
 $\beta_k.$
Third, the right-hand side of (8) verifies the intuitive result that the simple slice sampler is better than the hybrid one (in terms of the spectral gap).
$\beta_k.$
Third, the right-hand side of (8) verifies the intuitive result that the simple slice sampler is better than the hybrid one (in terms of the spectral gap).
To prove the theorem we need some further results.
Lemma 5.
-
1. For any
$t\in(0,\Vert \varrho \Vert_{\infty})$
assume that
$H_t$
is reversible with respect to
$U_t$
. Then
$\widetilde{H}$
is self-adjoint on
$L_{2,\mu}$
. -
2. Assume that for almost all t (with respect to
$\ell$
)
$H_t$
is positive semidefinite on
$L_{2,t}$
, i.e. for all
$f\in L_{2,t}$
, it holds that
$\langle H_t f , f \rangle_t \geq 0$
. Then
$\widetilde{H}$
is positive semidefinite on
$L_{2,\mu}$
.












Proof. Note that
 $\left\Vert f \right\Vert_{2,\mu}<\infty$
implies
$\left\Vert f \right\Vert_{2,\mu}<\infty$
implies
 $\left\Vert f(\cdot,t) \right\Vert_{2,t}<\infty$
for almost all t (with respect to
$\left\Vert f(\cdot,t) \right\Vert_{2,t}<\infty$
for almost all t (with respect to
 $\ell$
).
$\ell$
).
Part 1: Let
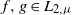 $f,g\in L_{2,\mu}$
; then we have to show that
$f,g\in L_{2,\mu}$
; then we have to show that
 \begin{align*} \langle \widetilde{H}f , g \rangle_{\mu} = \langle f , \widetilde{H}g \rangle_\mu. \end{align*}
\begin{align*} \langle \widetilde{H}f , g \rangle_{\mu} = \langle f , \widetilde{H}g \rangle_\mu. \end{align*}
Note that for
 $f,g\in L_{2,\mu}$
we have for almost all t, by the reversibility of
$f,g\in L_{2,\mu}$
we have for almost all t, by the reversibility of
 $H_t$
, that
$H_t$
, that
 \begin{align*} \langle H_t f(\cdot,t) , g(\cdot,t) \rangle_t = \langle f(\cdot,t) , H_tg(\cdot,t) \rangle_t. \end{align*}
\begin{align*} \langle H_t f(\cdot,t) , g(\cdot,t) \rangle_t = \langle f(\cdot,t) , H_tg(\cdot,t) \rangle_t. \end{align*}
Since
 \begin{align*} \langle \widetilde{H}f , g \rangle_{\mu} & = \int_{K_\varrho} \widetilde{H}f(x,t) g(x,t) \,\mu(\textrm{d}(x,t)) \\[5pt] & = \int_K \int_0^{\varrho(x)} \int_{K(t)} f(y,t)\,H_t(x,\textrm{d} y) g(x,t)\, \frac{\textrm{d} t\, \textrm{d} x}{\textrm{vol}_{d+1}(K_\varrho)} \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \int_{K(t)} f(y,t)\,H_t(x,\textrm{d} y) g(x,t)\, U_t(\textrm{d} y)\, \ell(t)\, \textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \langle H_t f(\cdot,t) , g(\cdot,t) \rangle_t \, \ell(t)\, \textrm{d} t, \end{align*}
\begin{align*} \langle \widetilde{H}f , g \rangle_{\mu} & = \int_{K_\varrho} \widetilde{H}f(x,t) g(x,t) \,\mu(\textrm{d}(x,t)) \\[5pt] & = \int_K \int_0^{\varrho(x)} \int_{K(t)} f(y,t)\,H_t(x,\textrm{d} y) g(x,t)\, \frac{\textrm{d} t\, \textrm{d} x}{\textrm{vol}_{d+1}(K_\varrho)} \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \int_{K(t)} \int_{K(t)} f(y,t)\,H_t(x,\textrm{d} y) g(x,t)\, U_t(\textrm{d} y)\, \ell(t)\, \textrm{d} t \\[5pt] & = \int_0^{\Vert \varrho \Vert_\infty} \langle H_t f(\cdot,t) , g(\cdot,t) \rangle_t \, \ell(t)\, \textrm{d} t, \end{align*}
the assertion of Part 1 holds.
Part 2. We have to prove for all
 $f\in L_{2,\mu}$
that
$f\in L_{2,\mu}$
that
 \begin{align*} \langle \widetilde{H}f , f \rangle_{\mu} = \int_{K_\varrho} \widetilde{H}f(x,t) f(x,t) \, \mu(\textrm{d}(x,t)) \geq 0. \end{align*}
\begin{align*} \langle \widetilde{H}f , f \rangle_{\mu} = \int_{K_\varrho} \widetilde{H}f(x,t) f(x,t) \, \mu(\textrm{d}(x,t)) \geq 0. \end{align*}
Note that for
 $f\in L_{2,\mu}$
we have for almost all t that
$f\in L_{2,\mu}$
we have for almost all t that
 \begin{align*} \langle H_t f(\cdot,t) , f(\cdot,t) \rangle_t\geq 0. \end{align*}
\begin{align*} \langle H_t f(\cdot,t) , f(\cdot,t) \rangle_t\geq 0. \end{align*}
By the same computation as in Part 1 we obtain that the positive semidefiniteness of
 $H_t$
carries over to
$H_t$
carries over to
 $\widetilde{H}$
.
$\widetilde{H}$
.
The statements and proofs of the following lemmas closely follow the lines of argument in [Reference Ullrich39, Reference Ullrich40] and make essential use of [Reference Ullrich40, Lemma 12 and Lemma 13]. We provide alternative proofs of the aforementioned lemmas in Appendix A.
Lemma 6. Let
 $\widetilde{H}$
be positive semidefinite on
$\widetilde{H}$
be positive semidefinite on
 $L_{2,\mu}$
. Then
$L_{2,\mu}$
. Then
 \begin{equation} \left\Vert T \widetilde{H}^{k+1} T^* -S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}},\quad k\in\mathbb{N}. \end{equation}
\begin{equation} \left\Vert T \widetilde{H}^{k+1} T^* -S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}},\quad k\in\mathbb{N}. \end{equation}
Furthermore, if
 \begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2} \end{align*}
\begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2} \end{align*}
and
 $\lim_{k\to \infty }\beta_k = 0$
, then
$\lim_{k\to \infty }\beta_k = 0$
, then
 \begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
\begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
Proof. Let
 $S_1 \colon L_{2,\mu} \to L_{2,\pi}$
and the adjoint
$S_1 \colon L_{2,\mu} \to L_{2,\pi}$
and the adjoint
 $S_1^* \colon L_{2,\pi} \to L_{2,\mu}$
be given by
$S_1^* \colon L_{2,\pi} \to L_{2,\mu}$
be given by
 \begin{align*} S_1(f) = \int_{K_\varrho} f(x,s)\, \mu(\textrm{d}(x,s)) \quad \mbox{and} \quad S_1^*(g)= \int_K g(x) \, \pi(\textrm{d} x). \end{align*}
\begin{align*} S_1(f) = \int_{K_\varrho} f(x,s)\, \mu(\textrm{d}(x,s)) \quad \mbox{and} \quad S_1^*(g)= \int_K g(x) \, \pi(\textrm{d} x). \end{align*}
Thus,
 $\langle S_1 f , g \rangle_\pi = \langle f , S_1^* g \rangle_\mu$
. Furthermore, observe that
$\langle S_1 f , g \rangle_\pi = \langle f , S_1^* g \rangle_\mu$
. Furthermore, observe that
 $S_1S_1^*=S$
. Let
$S_1S_1^*=S$
. Let
 $R=T-S_1$
and note that
$R=T-S_1$
and note that
 $RR^*=I-S$
, with identity I, and
$RR^*=I-S$
, with identity I, and
 $RR^*=(RR^*)^2$
. Since
$RR^*=(RR^*)^2$
. Since
 $RR^*\not = 0$
, and by the projection property
$RR^*\not = 0$
, and by the projection property
 $RR^*=(RR^*)^2$
, one gets
$RR^*=(RR^*)^2$
, one gets
 $\left\Vert RR^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}=1$
. We have
$\left\Vert RR^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}=1$
. We have
 \begin{align*} R \widetilde{H}^k R^* & = (T-S_1) \widetilde{H}^k (T^*-S_1^*) \\[5pt] & = T\widetilde{H}^kT^*-T\widetilde{H}^k S_1^*- S_1 \widetilde{H}^k T^*+ S_1 \widetilde{H}^k S_1^* = T\widetilde{H}^kT^*-S. \end{align*}
\begin{align*} R \widetilde{H}^k R^* & = (T-S_1) \widetilde{H}^k (T^*-S_1^*) \\[5pt] & = T\widetilde{H}^kT^*-T\widetilde{H}^k S_1^*- S_1 \widetilde{H}^k T^*+ S_1 \widetilde{H}^k S_1^* = T\widetilde{H}^kT^*-S. \end{align*}
Furthermore,
 $\left\Vert S_1 \widetilde{H} S_1^* \right\Vert_{L_{2,\mu}\to L_{2,\mu}}\leq 1$
. By Lemma 12 it follows that
$\left\Vert S_1 \widetilde{H} S_1^* \right\Vert_{L_{2,\mu}\to L_{2,\mu}}\leq 1$
. By Lemma 12 it follows that
 \begin{align*} \left\Vert R \widetilde{H}^{k+1} R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert R \widetilde{H}^{k} R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{align*}
\begin{align*} \left\Vert R \widetilde{H}^{k+1} R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert R \widetilde{H}^{k} R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{align*}
and the proof of (9) is completed.
By Lemma 4 we obtain
 $\left\Vert T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \beta_k$
, and by (9) as well as Lemma 3 we obtain
$\left\Vert T(\widetilde{H}^k-\widetilde{U})T^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \beta_k$
, and by (9) as well as Lemma 3 we obtain
 \begin{align*} \left\Vert T \widetilde{H}^{k} T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}},\quad k\in\mathbb{N}. \end{align*}
\begin{align*} \left\Vert T \widetilde{H}^{k} T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}},\quad k\in\mathbb{N}. \end{align*}
This implies by the triangle inequality that
 \begin{align*} \lim_{k\to\infty} \left\Vert T \widetilde{H}^{k} T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} = \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{align*}
\begin{align*} \lim_{k\to\infty} \left\Vert T \widetilde{H}^{k} T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} = \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{align*}
and the assertion is proven.
Lemma 7. Let
 $\widetilde{H}$
be positive semidefinite on
$\widetilde{H}$
be positive semidefinite on
 $L_{2,\mu}$
. Then
$L_{2,\mu}$
. Then
 \begin{equation} \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} \leq \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{equation}
\begin{equation} \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} \leq \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}, \end{equation}
for any
 $k\in\mathbb{N}$
.
$k\in\mathbb{N}$
.
Proof. As in the proof of Lemma 6 we use
 $R \widetilde{H}^k R^* = T\widetilde{H}^kT^*-S$
to reformulate the assertion. It remains to prove that
$R \widetilde{H}^k R^* = T\widetilde{H}^kT^*-S$
to reformulate the assertion. It remains to prove that
 \begin{align*} \left\Vert R\widetilde{H}R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} \leq \left\Vert R \widetilde{H}^k R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
\begin{align*} \left\Vert R\widetilde{H}R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} \leq \left\Vert R \widetilde{H}^k R^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
Recall that
 $RR^*$
is a projection and satisfies
$RR^*$
is a projection and satisfies
 $\left\Vert RR^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} = 1$
. By Lemma 13 the assertion is proven.
$\left\Vert RR^* \right\Vert_{L_{2,\pi}\to L_{2,\pi}} = 1$
. By Lemma 13 the assertion is proven.
Now we turn to the proof of Theorem 1.
Proof of Theorem
1. By Lemma 5 we know that
 $\widetilde{H}\colon L_{2,\mu} \to L_{2,\mu}$
is self-adjoint and positive semidefinite. By Lemma 6 we have
$\widetilde{H}\colon L_{2,\mu} \to L_{2,\mu}$
is self-adjoint and positive semidefinite. By Lemma 6 we have
 \begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
\begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}. \end{align*}
By Theorem 1 we have for any
 $k\in\mathbb{N}$
that
$k\in\mathbb{N}$
that
 \begin{equation} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}+\beta_k. \end{equation}
\begin{equation} \left\Vert T\widetilde{H}^kT^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} \leq \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}+\beta_k. \end{equation}
Then
 \begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} & \underset{11} {\geq} \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} - \beta_k \\[5pt] & \underset{10} {\geq} \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} - \beta_k\\[5pt] & \geq 1- k\,(1-\left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}) - \beta_k\\[5pt] & = 1-k\,\textrm{{g}ap}(H) - \beta_k, \end{align*}
\begin{align*} \left\Vert U-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} & \underset{11} {\geq} \left\Vert T \widetilde{H}^k T^*-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}} - \beta_k \\[5pt] & \underset{10} {\geq} \left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}^{k} - \beta_k\\[5pt] & \geq 1- k\,(1-\left\Vert H-S \right\Vert_{L_{2,\pi}\to L_{2,\pi}}) - \beta_k\\[5pt] & = 1-k\,\textrm{{g}ap}(H) - \beta_k, \end{align*}
where we applied a version of Bernoulli’s inequality, i.e.
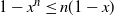 $1-x^n\leq n (1-x)$
for
$1-x^n\leq n (1-x)$
for
 $x\geq 0$
and
$x\geq 0$
and
 $n\in\mathbb{N}$
. Thus
$n\in\mathbb{N}$
. Thus
 \begin{align*} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H), \end{align*}
\begin{align*} \frac{\textrm{{g}ap}(U)-\beta_k}{k} \leq \textrm{{g}ap}(H), \end{align*}
and the proof is completed.
4. Applications
In this section we apply Theorem 1 under different assumptions with different Markov chains on the slices. We provide a criterion for geometric ergodicity of these hybrid slice samplers by showing that there is a spectral gap whenever the simple slice sampler has a spectral gap.
First we consider a class of bimodal densities in a 1-dimensional setting. We study a stepping-out shrinkage slice sampler, suggested in [Reference Neal26], which is explained in Algorithm 1.
Then we consider a hybrid slice sampler which performs a hit-and-run step on the slices in a d-dimensional setting. Here we impose very weak assumptions on the unnormalized densities. The drawback is that an implementation of this algorithm may be difficult.
Motivated by this difficulty, we study a combination of the previous sampling procedures on the slices. The resulting hit-and-run stepping-out shrinkage slice sampler is presented in Algorithm 2. Here we consider a class of bimodal densities in a d-dimensional setting.
4.1. Stepping-out and shrinkage procedure
Let
 $w>0$
be a parameter and
$w>0$
be a parameter and
 $\varrho \colon \mathbb{R} \to (0,\infty)$
be an unnormalized density. We say
$\varrho \colon \mathbb{R} \to (0,\infty)$
be an unnormalized density. We say
 $\varrho\in \mathcal{R}_{w}$
if there exist
$\varrho\in \mathcal{R}_{w}$
if there exist
 $t_1,t_2\in(0,\left\Vert \varrho \right\Vert_{\infty})$
with
$t_1,t_2\in(0,\left\Vert \varrho \right\Vert_{\infty})$
with
 $t_1\leq t_2$
such that the following hold:
$t_1\leq t_2$
such that the following hold:
-
1. For all
$t\in(0,t_1)\cup [t_2,\left\Vert \varrho \right\Vert_{\infty})$
, the level set K(t) is an interval. -
2. For all
$t\in[t_1,t_2)$
, there are disjoint intervals
$K_1(t),K_2(t)$
with strictly positive Lebesgue measure such that and for all
\begin{align*} K(t)=K_1(t)\cup K_2(t), \end{align*}
$\varepsilon>0$
it holds that
$K_i(t+\varepsilon)\subseteq K_i(t)$
for
$i=1,2$
. For convenience we set
$K_i(t) =\emptyset$
for
$t\not \in [t_1,t_2)$
.
-
3. For all
$t\in(0,\left\Vert \varrho \right\Vert_{\infty})$
we assume
$\delta_t < w$
, where
\begin{align*} \delta_t \;:\!=\; \begin{cases} \inf_{r\in K_1(t),\; s\in K_2(t)} \left\vert r-s \right\vert, & t\in [t_1,t_2), \\[5pt] 0 & \mbox{otherwise}. \end{cases} \end{align*}












The next result shows that certain bimodal densities belong to
 $\mathcal{R}_w$
.
$\mathcal{R}_w$
.
Lemma 8. Let
 $\varrho_1 \colon \mathbb{R} \to (0,\infty)$
and
$\varrho_1 \colon \mathbb{R} \to (0,\infty)$
and
 $\varrho_2 \colon \mathbb{R} \to (0,\infty)$
be unnormalized density functions. Let us assume that
$\varrho_2 \colon \mathbb{R} \to (0,\infty)$
be unnormalized density functions. Let us assume that
 $\varrho_1$
,
$\varrho_1$
,
 $\varrho_2$
are lower semicontinuous and quasi-concave, i.e. the level sets are open intervals, and
$\varrho_2$
are lower semicontinuous and quasi-concave, i.e. the level sets are open intervals, and
 \begin{align*} \inf_{r \in \arg \max \varrho_1,\, s\in \arg\max \varrho_2} \left\vert r-s \right\vert<w. \end{align*}
\begin{align*} \inf_{r \in \arg \max \varrho_1,\, s\in \arg\max \varrho_2} \left\vert r-s \right\vert<w. \end{align*}
Then
 $\varrho_{\max} \;:\!=\;\max\{\varrho_1,\varrho_2\} \in \mathcal{R}_w$
.
$\varrho_{\max} \;:\!=\;\max\{\varrho_1,\varrho_2\} \in \mathcal{R}_w$
.
Proof. For
 $t\in (0,\left\Vert \varrho_{\max} \right\Vert_{\infty})$
let
$t\in (0,\left\Vert \varrho_{\max} \right\Vert_{\infty})$
let
 $K_{\varrho_{\max}}(t)$
,
$K_{\varrho_{\max}}(t)$
,
 $K_{\varrho_1}(t)$
, and
$K_{\varrho_1}(t)$
, and
 $K_{\varrho_2}(t)$
be the level sets of
$K_{\varrho_2}(t)$
be the level sets of
 $\varrho_{\max}$
,
$\varrho_{\max}$
,
 $\varrho_1$
, and
$\varrho_1$
, and
 $\varrho_2$
of level t. Note that
$\varrho_2$
of level t. Note that
 \begin{align*} K_{\varrho_{\max}}(t) = K_{\varrho_1}(t) \cup K_{\varrho_2}(t). \end{align*}
\begin{align*} K_{\varrho_{\max}}(t) = K_{\varrho_1}(t) \cup K_{\varrho_2}(t). \end{align*}
With the choice
 \begin{align*} t_1 & = \inf \{ t\in (0,\left\Vert \varrho_{\max} \right\Vert_{\infty}) \;:\; K_{\varrho_1}(t) \cap K_{\varrho_2}(t) = \emptyset \},\\[5pt] t_2 & = \min\{ \left\Vert \varrho_1 \right\Vert_{\infty}, \left\Vert \varrho_2 \right\Vert_{\infty} \}, \end{align*}
\begin{align*} t_1 & = \inf \{ t\in (0,\left\Vert \varrho_{\max} \right\Vert_{\infty}) \;:\; K_{\varrho_1}(t) \cap K_{\varrho_2}(t) = \emptyset \},\\[5pt] t_2 & = \min\{ \left\Vert \varrho_1 \right\Vert_{\infty}, \left\Vert \varrho_2 \right\Vert_{\infty} \}, \end{align*}
we have the properties 1 and 2. Observe that
 $\arg \max \varrho_i \subseteq K_{\varrho_i}(t)$
for
$\arg \max \varrho_i \subseteq K_{\varrho_i}(t)$
for
 $i=1,2$
, which yields
$i=1,2$
, which yields
 \begin{align*} \inf_{r\in K_{\varrho_1}(t),\, s\in K_{\varrho_2}(t) } \left\vert r-s \right\vert & \leq \inf_{r\in \arg \max \varrho_1,\,s\in \arg \max \varrho_2 } \left\vert r-s \right\vert < w. \end{align*}
\begin{align*} \inf_{r\in K_{\varrho_1}(t),\, s\in K_{\varrho_2}(t) } \left\vert r-s \right\vert & \leq \inf_{r\in \arg \max \varrho_1,\,s\in \arg \max \varrho_2 } \left\vert r-s \right\vert < w. \end{align*}
In [Reference Neal26] a stepping-out and shrinkage procedure is suggested for the transitions on the level sets. The procedures are explained in Algorithm 1, where a single transition from the resulting hybrid slice sampler from x to y is presented.
Algorithm 1. A hybrid slice sampling transition of the stepping-out and shrinkage procedure from x to y, i.e. with input x and output y. The stepping-out procedure has input x (current state), t (chosen level),
 $w>0$
(step size parameter from
$w>0$
(step size parameter from
 $\mathcal{R}_w$
) and outputs an interval [L, R]. The shrinkage procedure has input [L, R] and output y:
$\mathcal{R}_w$
) and outputs an interval [L, R]. The shrinkage procedure has input [L, R] and output y:
-
1. Choose a level
$t \sim \mathcal{U}(0,\varrho(x))$
; -
2. Stepping-out with input x, t, w outputs an interval [L, R]:
-
(a) Choose
$u \sim \mathcal{U}[0,1]$
. Set
$L=x-u w$
and
$R=L+w$
; -
(b) Repeat until
$t \geq \varrho(L)$
, i.e.
$L \not \in K(t)$
: Set
$L=L-w$
; -
(c) Repeat until
$t \geq \varrho(R)$
, i.e.
$R \not \in K(t)$
: Set
$R=R+w$
;
-
-
3. Shrinkage procedure with input [L, R] outputs y:
-
(a) Set
$\bar{L}=L$
and
$\bar{R}=R$
; -
(b) Repeat:
-
i. Choose
$v\sim \mathcal{U}[0,1]$
and set
$y=\bar{L}+ v (\bar{R}-\bar{L})$
; -
ii. If
$y \in K(t)$
then return y and exit the loop; -
iii. If
$y<x$
then set
$\bar{L}=y$
, else
$\bar{R}=y$
.
-
-

















For short we write
 $\left\vert K(t) \right\vert=\textrm{vol}_1(K(t))$
, and for
$\left\vert K(t) \right\vert=\textrm{vol}_1(K(t))$
, and for
 $t\in(0,\Vert\varrho\Vert_\infty)$
we set
$t\in(0,\Vert\varrho\Vert_\infty)$
we set
 \begin{align*}\gamma_t \;:\!=\; \frac{(w-\delta_t)}{w} \frac{\left\vert K(t) \right\vert}{(\left\vert K(t) \right\vert+\delta_t)}.\end{align*}
\begin{align*}\gamma_t \;:\!=\; \frac{(w-\delta_t)}{w} \frac{\left\vert K(t) \right\vert}{(\left\vert K(t) \right\vert+\delta_t)}.\end{align*}
Now we provide useful results for applying Theorem 1.
Lemma 9. Let
 $\varrho\in \mathcal{R}_w$
with
$\varrho\in \mathcal{R}_w$
with
 $t_2> 0$
satisfying the properties 1 and 2 of the definition of
$t_2> 0$
satisfying the properties 1 and 2 of the definition of
 $\mathcal{R}_w$
. Moreover, let
$\mathcal{R}_w$
. Moreover, let
 $t\in(0,\Vert \varrho \Vert_\infty)$
.
$t\in(0,\Vert \varrho \Vert_\infty)$
.
-
1. The transition kernel
$H_t$
of the stepping-out and shrinkage slice sampler from Algorithm 1 takes the form with
\begin{align*} & H_t(x,A) = \gamma_t\, U_t(A) + (1 - \gamma_t) \left[\mathbf{1}_{K_1(t)}(x) U_{t,1}(A) + \mathbf{1}_{K_2(t)}(x) U_{t,2}(A) \right], \end{align*}
$x\in \mathbb{R}$
,
$A\in \mathcal{B}(\mathbb{R})$
, and for
\begin{align*} U_{t,i} (A) = \begin{cases} \frac{\left\vert K_i(t)\cap A \right\vert}{\left\vert K_i(t) \right\vert}, & t\in[t_1,t_2), \\[5pt] 0, & t\in (0,t_1) \cup [t_2,\Vert \varrho \Vert_\infty), \end{cases} \end{align*}
$i=1,2$
; i.e. in the case
$t\in[t_1,t_2) $
we have that
$U_{t,i}$
denotes the uniform distribution in
$K_{i}(t)$
. (For
$t\in(0,t_1)\cup [t_2,\left\Vert \varrho \right\Vert_{\infty})$
we have
$H_t = U_t$
since
$\delta_t=0$
yields
$\gamma_t=1$
.)
-
2. The transition kernel
$H_t$
is reversible and induces a positive semidefinite operator, i.e. for any
$f\in L_{2,t}$
, it holds that
$\langle H_t f , f \rangle_{t}\geq 0$
. -
3. We have
$ \left\Vert H_t-U_t \right\Vert_{L_{t,2}\to L_{t,2}} = 1 - \gamma_t $
and (12)
\begin{equation} \beta_k \leq \left(\frac{1}{t_2} \int_{0}^{t_2} \left(1 - \gamma_t \right)^{2k} \textrm{d} t\right)^{1/2}, \quad k\in\mathbb{N}. \end{equation}


















Proof.
Part 1. For
 $t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_{\infty})$
the stepping-out procedure returns an interval that contains K(t) entirely. Then, since K(t) is also an interval, the shrinkage scheme returns a sample with respect to
$t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_{\infty})$
the stepping-out procedure returns an interval that contains K(t) entirely. Then, since K(t) is also an interval, the shrinkage scheme returns a sample with respect to
 $U_t$
in K(t).
$U_t$
in K(t).
For
 $t\in [t_1,t_2)$
,
$t\in [t_1,t_2)$
,
 $i\in \{1,2\}$
, and
$i\in \{1,2\}$
, and
 $x\in K_i(t)$
, within the stepping-out procedure, with probability
$x\in K_i(t)$
, within the stepping-out procedure, with probability
 $(w-\delta_t)/w$
an interval that contains
$(w-\delta_t)/w$
an interval that contains
 $K(t)=K_1(t) \cup K_2(t)$
is returned, and with probability
$K(t)=K_1(t) \cup K_2(t)$
is returned, and with probability
 $1-(w-\delta_t)/w$
an interval that contains
$1-(w-\delta_t)/w$
an interval that contains
 $K_i(t)$
but not
$K_i(t)$
but not
 $K(t)\setminus K_i(t)$
is returned. We distinguish these cases:
$K(t)\setminus K_i(t)$
is returned. We distinguish these cases:
Case 1: K(t) contained in the stepping-out output:
Then with probability
 $\vert K(t) \vert/(\vert K(t) \vert+\delta_t)$
the shrinkage scheme returns a sample with respect to
$\vert K(t) \vert/(\vert K(t) \vert+\delta_t)$
the shrinkage scheme returns a sample with respect to
 $U_t$
, and with probability
$U_t$
, and with probability
 $1-\vert K(t) \vert/(\vert K(t) \vert+\delta_t)$
it returns a sample with respect to
$1-\vert K(t) \vert/(\vert K(t) \vert+\delta_t)$
it returns a sample with respect to
 $U_{t,i}$
.
$U_{t,i}$
.
Case 2:
 $K_i(t)$
, but not
$K_i(t)$
, but not
 $K(t) \setminus K_i(t)$
, contained in the stepping-out output:
$K(t) \setminus K_i(t)$
, contained in the stepping-out output:
Then with probability 1 the shrinkage scheme returns a sample with respect to
 $U_{t,i}$
. In total, for
$U_{t,i}$
. In total, for
 $x\in K_i(t)$
we obtain
$x\in K_i(t)$
we obtain
 \begin{align*} H_t(x,A) & = \frac{(w-\delta_t)}{w} \Big[\frac{\vert K(t)\vert}{\vert K(t) \vert + \delta_t} \; U_t(A) + \big(1-\frac{\vert K(t)\vert}{\vert K(t) \vert + \delta_t}\big)U_{t,i}(A) \Big] \\[5pt] & \qquad \qquad +\big(1-\frac{(w-\delta_t)}{w} \big) U_{t,i}(A)\\[5pt] & = \gamma_t U_t (A) + (1-\gamma_t) U_{t,i}(A), \end{align*}
\begin{align*} H_t(x,A) & = \frac{(w-\delta_t)}{w} \Big[\frac{\vert K(t)\vert}{\vert K(t) \vert + \delta_t} \; U_t(A) + \big(1-\frac{\vert K(t)\vert}{\vert K(t) \vert + \delta_t}\big)U_{t,i}(A) \Big] \\[5pt] & \qquad \qquad +\big(1-\frac{(w-\delta_t)}{w} \big) U_{t,i}(A)\\[5pt] & = \gamma_t U_t (A) + (1-\gamma_t) U_{t,i}(A), \end{align*}
where we emphasize that for
 $t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_{\infty})$
it follows that
$t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_{\infty})$
it follows that
 $\gamma_t=1$
(since
$\gamma_t=1$
(since
 $\delta_t=0$
), so that
$\delta_t=0$
), so that
 $H_t(x,A)$
coincides with
$H_t(x,A)$
coincides with
 $U_t(A)$
.
$U_t(A)$
.
Part 2. For
 $A,B\in\mathcal{B}(\mathbb{R})$
we have
$A,B\in\mathcal{B}(\mathbb{R})$
we have
 \begin{align*} & \int_A H_t(x,A) \,U_t(\textrm{d} x) = \gamma_t\, U_t(B) U_t(A)\\[5pt] &\qquad \qquad + (1-\gamma_t)\int_A\big[\mathbf{1}_{K_1(t)}(x) U_{t,1}(B)+\mathbf{1}_{K_2(t)}(x) U_{t,2}(B)\big] U_t(\textrm{d} x)\\[5pt] & = \gamma_t\, U_t(B) U_t(A) + (1-\gamma_t) \Big[ \frac{\vert K_1(t) \vert}{\vert K(t )\vert} U_{t,1}(A) U_{t,1}(B) + \frac{\vert K_2(t)\vert}{\vert K(t)\vert} U_{t,2}(A) U_{t,2}(B) \Big], \end{align*}
\begin{align*} & \int_A H_t(x,A) \,U_t(\textrm{d} x) = \gamma_t\, U_t(B) U_t(A)\\[5pt] &\qquad \qquad + (1-\gamma_t)\int_A\big[\mathbf{1}_{K_1(t)}(x) U_{t,1}(B)+\mathbf{1}_{K_2(t)}(x) U_{t,2}(B)\big] U_t(\textrm{d} x)\\[5pt] & = \gamma_t\, U_t(B) U_t(A) + (1-\gamma_t) \Big[ \frac{\vert K_1(t) \vert}{\vert K(t )\vert} U_{t,1}(A) U_{t,1}(B) + \frac{\vert K_2(t)\vert}{\vert K(t)\vert} U_{t,2}(A) U_{t,2}(B) \Big], \end{align*}
which is symmetric in A, B and therefore implies the claimed reversibility with respect to
 $U_t$
. Similarly, we have
$U_t$
. Similarly, we have
 \begin{align} \langle H_t f , f \rangle_t & = \gamma_t\; U_t(f)^2 + (1 - \gamma_t ) \left[ \frac{\left\vert K_1(t) \right\vert}{\left\vert K(t) \right\vert}\; U_{t,1}(f)^2 + \frac{\left\vert K_2(t) \right\vert}{\left\vert K(t) \right\vert}\;U_{t,2}(f)^2 \right]\geq 0, \end{align}
\begin{align} \langle H_t f , f \rangle_t & = \gamma_t\; U_t(f)^2 + (1 - \gamma_t ) \left[ \frac{\left\vert K_1(t) \right\vert}{\left\vert K(t) \right\vert}\; U_{t,1}(f)^2 + \frac{\left\vert K_2(t) \right\vert}{\left\vert K(t) \right\vert}\;U_{t,2}(f)^2 \right]\geq 0, \end{align}
where
 $U_{t,i}(f)$
denotes the integral of f with respect to
$U_{t,i}(f)$
denotes the integral of f with respect to
 $U_{t,i}$
for
$U_{t,i}$
for
 $i=1,2$
, which proves the positive semidefiniteness.
$i=1,2$
, which proves the positive semidefiniteness.
Part 3. By virtue of [Reference Rudolf33, Lemma 3.16], the reversibility (or equivalently self-adjointness) of
 $H_t$
, and [Reference Werner42, Theorem V.5.7], we have
$H_t$
, and [Reference Werner42, Theorem V.5.7], we have
 \begin{equation} \Vert H_t - U_t \Vert_{L_{2,t}\to L_{2,t}} = \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} \vert \langle H_tf,f\rangle \vert = \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} \langle H_tf,f\rangle, \end{equation}
\begin{equation} \Vert H_t - U_t \Vert_{L_{2,t}\to L_{2,t}} = \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} \vert \langle H_tf,f\rangle \vert = \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} \langle H_tf,f\rangle, \end{equation}
where the last equality follows by the positive semidefiniteness. Observe that for any
 $f\in L_{2,s}$
with
$f\in L_{2,s}$
with
 $s\in [t_1,t_2)$
we have by
$s\in [t_1,t_2)$
we have by
 $U_{s,i}(f)^2 \leq U_{s,i}(f^2)$
for
$U_{s,i}(f)^2 \leq U_{s,i}(f^2)$
for
 $i=1,2$
that
$i=1,2$
that
 \begin{align*} \frac{\left\vert K_1(s) \right\vert}{\left\vert K(s) \right\vert}\; U_{s,1}(f)^2 + \frac{\left\vert K_2(s) \right\vert}{\left\vert K(s) \right\vert}\;U_{s,2}(f)^2 \leq \frac{\left\vert K_1(s) \right\vert}{\left\vert K(s) \right\vert}\; U_{s,1}(f^2) + \frac{\left\vert K_2(s) \right\vert}{\left\vert K(s) \right\vert}\;U_{s,2}(f^2) = \Vert f \Vert_{2,s}^2. \end{align*}
\begin{align*} \frac{\left\vert K_1(s) \right\vert}{\left\vert K(s) \right\vert}\; U_{s,1}(f)^2 + \frac{\left\vert K_2(s) \right\vert}{\left\vert K(s) \right\vert}\;U_{s,2}(f)^2 \leq \frac{\left\vert K_1(s) \right\vert}{\left\vert K(s) \right\vert}\; U_{s,1}(f^2) + \frac{\left\vert K_2(s) \right\vert}{\left\vert K(s) \right\vert}\;U_{s,2}(f^2) = \Vert f \Vert_{2,s}^2. \end{align*}
Therefore, the equality in (13) yields
 \begin{equation} \Vert H_t - U_t \Vert_{L_{2,t}\to L_{2,t}} \leq \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} (1-\gamma_t) \Vert f \Vert_{2,t}^2 = 1-\gamma_t. \end{equation}
\begin{equation} \Vert H_t - U_t \Vert_{L_{2,t}\to L_{2,t}} \leq \sup_{\Vert f\Vert_{2,t} \leq 1,\, U_t(f)=0} (1-\gamma_t) \Vert f \Vert_{2,t}^2 = 1-\gamma_t. \end{equation}
For
 $t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_\infty)$
, by
$t\in (0,t_1)\cup [t_2,\Vert \varrho \Vert_\infty)$
, by
 $H_t=U_t$
and
$H_t=U_t$
and
 $1-\gamma_t=0$
we have an equality. For
$1-\gamma_t=0$
we have an equality. For
 $t\in [t_1,t_2)$
with
$t\in [t_1,t_2)$
with
 \begin{align*} h(x) = \frac{\left\vert K(t) \right\vert}{\left\vert K_1(t) \right\vert}\; \mathbf{1}_{K_1(t)}(x) - \frac{\left\vert K(t) \right\vert}{\left\vert K_2(t) \right\vert}\; \mathbf{1}_{K_2(t)}(x) \end{align*}
\begin{align*} h(x) = \frac{\left\vert K(t) \right\vert}{\left\vert K_1(t) \right\vert}\; \mathbf{1}_{K_1(t)}(x) - \frac{\left\vert K(t) \right\vert}{\left\vert K_2(t) \right\vert}\; \mathbf{1}_{K_2(t)}(x) \end{align*}
the upper bound of (15) is attained for
 $f=h/\Vert h \Vert_{2,t}$
in the supremum expression of (14).
$f=h/\Vert h \Vert_{2,t}$
in the supremum expression of (14).
We turn to the verification of (12). For
 $t\in (t_2,\left\Vert \varrho \right\Vert_{\infty}]$
we have
$t\in (t_2,\left\Vert \varrho \right\Vert_{\infty}]$
we have
 $1-\gamma_t=0$
, and for
$1-\gamma_t=0$
, and for
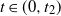 $t\in(0,t_2)$
the function
$t\in(0,t_2)$
the function
 $1-\gamma_t$
is increasing, which also yields that
$1-\gamma_t$
is increasing, which also yields that
 $t\mapsto (1-\gamma_t)^{2k}$
is increasing on
$t\mapsto (1-\gamma_t)^{2k}$
is increasing on
 $(0,t_2)$
for any
$(0,t_2)$
for any
 $k\in\mathbb{N}$
. By [Reference Rudolf33, Lemma 3.16] we obtain
$k\in\mathbb{N}$
. By [Reference Rudolf33, Lemma 3.16] we obtain
 \begin{align*} \Vert H^k_t - U_t \Vert_{L_{2,t} \to L_{2,t}} \leq (1-\gamma_t)^{k}. \end{align*}
\begin{align*} \Vert H^k_t - U_t \Vert_{L_{2,t} \to L_{2,t}} \leq (1-\gamma_t)^{k}. \end{align*}
Consequently, we have
 \begin{equation} \beta_k \leq \sup_{r\in (0,t_2)} \frac{1}{r} \int_0^r (1-\gamma_t)^{2k} \textrm{d} t. \end{equation}
\begin{equation} \beta_k \leq \sup_{r\in (0,t_2)} \frac{1}{r} \int_0^r (1-\gamma_t)^{2k} \textrm{d} t. \end{equation}
Furthermore, note that for
 $a\in(0,\infty)$
, any increasing function
$a\in(0,\infty)$
, any increasing function
 $g\colon (0,a) \to \mathbb{R}$
, and
$g\colon (0,a) \to \mathbb{R}$
, and
 $p,q\in (0,a)$
with
$p,q\in (0,a)$
with
 $p\leq q$
, it holds that
$p\leq q$
, it holds that
 \begin{equation} \frac{1}{p} \int_0^p g(t)\, \textrm{d} t \leq \frac{1}{q} \int_0^q g(t)\,\textrm{d} t. \end{equation}
\begin{equation} \frac{1}{p} \int_0^p g(t)\, \textrm{d} t \leq \frac{1}{q} \int_0^q g(t)\,\textrm{d} t. \end{equation}
The former inequality can be verified by showing that the function
 $p\mapsto G(p)$
for
$p\mapsto G(p)$
for
 $p\geq0$
with
$p\geq0$
with
 $G(p)=\frac{1}{p} \int_0^p g(t)\, \textrm{d} t$
satisfies
$G(p)=\frac{1}{p} \int_0^p g(t)\, \textrm{d} t$
satisfies
 $G'(p)\geq 0$
. Applying (17) with
$G'(p)\geq 0$
. Applying (17) with
 $g(t)=(1-\gamma_t)^{2k}$
in combination with (16) yields (12).
$g(t)=(1-\gamma_t)^{2k}$
in combination with (16) yields (12).
By Theorem 1 and the previous lemma we have the following result.
Corollary 2. For any
 $\varrho \in \mathcal{R}_w$
the stepping-out and shrinkage slice sampler has a spectral gap if and only if the simple slice sampler has a spectral gap.
$\varrho \in \mathcal{R}_w$
the stepping-out and shrinkage slice sampler has a spectral gap if and only if the simple slice sampler has a spectral gap.
Remark 3. We want to discuss two extremal situations:
-
Consider densities
$\varrho \colon \mathbb{R} \to (0,\infty)$
that are lower semicontinuous and quasi-concave, i.e. the level sets are open intervals. Loosely speaking, we assume we have unimodal densities. Then for any
$w>0$
we have
$\varrho\in\mathcal{R}_w$
(just take
$t_1=t_2$
arbitrarily) and
$\delta_t=0$
for all
$t\in(0,\Vert \varrho \Vert_\infty)$
. Hence
$H_t=U_t$
for all
$t\in(0,\Vert \varrho \Vert_\infty)$
, and Algorithm 1 provides an effective implementation of simple slice sampling. -
Assume that
$\varrho\colon \mathbb{R} \to (0,\infty)$
satisfies the properties 1 and 2 from the definition of
$\mathcal{R}_w$
for some
$w>0$
, but for any
$t\in(0,\Vert \varrho \Vert_\infty)$
we have
$\delta_t\geq w$
. In this setting our theory is not applicable and it is clear that the corresponding Markov chain does not work well, since it is not possible to get from one part of the support to the other part.













4.2. Hit-and-run slice sampler
The idea is to combine the hit-and-run algorithm with slice sampling. We ask whether a spectral gap of simple slice sampling implies a spectral gap of this combination. The hit-and-run algorithm was proposed by Smith [Reference Smith38]. It is well studied (see for example [Reference Bélisle, Romeijn and Smith3, Reference Diaconis and Freedman5, Reference Kaufman and Smith12, Reference Kiatsupaibul, Smith and Zabinsky13, Reference Lovász16, Reference Lovász and Vempala17, Reference Rudolf and Ullrich35]) and used for numerical integration (see [Reference Rudolf33, Reference Rudolf34]). We define the setting and the transition kernel of hit-and-run.
We consider a d-dimensional state space
 $K\subseteq \mathbb{R}^d$
and suppose
$K\subseteq \mathbb{R}^d$
and suppose
 $\varrho\colon K \to (0,\infty)$
is an unnormalized density. We denote the diameter of a level set by
$\varrho\colon K \to (0,\infty)$
is an unnormalized density. We denote the diameter of a level set by
 \begin{align*}\textrm{diam}(K(t))=\sup_{x,y\in K(t)} \left\vert x-y \right\vert\end{align*}
\begin{align*}\textrm{diam}(K(t))=\sup_{x,y\in K(t)} \left\vert x-y \right\vert\end{align*}
with the Euclidean norm
 $\left\vert \cdot \right\vert$
. We impose the following assumption.
$\left\vert \cdot \right\vert$
. We impose the following assumption.
Assumption 2. The limit
 $\kappa\;:\!=\;\lim_{t\downarrow 0} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d}$
exists, and there are numbers
$\kappa\;:\!=\;\lim_{t\downarrow 0} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d}$
exists, and there are numbers
 $c,\varepsilon\in (0,1]$
such that
$c,\varepsilon\in (0,1]$
such that
 \begin{equation} \inf_{t\in (0,\varepsilon)} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} = c>0. \end{equation}
\begin{equation} \inf_{t\in (0,\varepsilon)} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} = c>0. \end{equation}
Note that under Assumption 2 we always have
 $\kappa \geq c$
. If K is bounded, has positive Lebesgue measure, and satisfies
$\kappa \geq c$
. If K is bounded, has positive Lebesgue measure, and satisfies
 $\inf_{x\in K} \varrho(x)>0$
, then Assumption 2 is satisfied with
$\inf_{x\in K} \varrho(x)>0$
, then Assumption 2 is satisfied with
 $\kappa=c$
. Moreover, for instance, the density of a standard normal distribution satisfies Assumption 2 with unbounded K, where again
$\kappa=c$
. Moreover, for instance, the density of a standard normal distribution satisfies Assumption 2 with unbounded K, where again
 $c=\kappa$
. However, the following example indicates that this is not always the case.
$c=\kappa$
. However, the following example indicates that this is not always the case.
Example 1. Let
 $K=(0,1)^2$
and
$K=(0,1)^2$
and
 $\varrho(x_1,x_2)=2-x_1-x_2$
. Then for
$\varrho(x_1,x_2)=2-x_1-x_2$
. Then for
 $t\in(0,1]$
we have
$t\in(0,1]$
we have
 \begin{align*} K(t) = \{(x_1,x_2)\in (0,1)^2\colon x_2\in (0,\min\{1,2-t-x_1\})\}, \end{align*}
\begin{align*} K(t) = \{(x_1,x_2)\in (0,1)^2\colon x_2\in (0,\min\{1,2-t-x_1\})\}, \end{align*}
so that
 $\textrm{vol}_2(K(t))=1-t^2/2$
. Moreover, the fact that
$\textrm{vol}_2(K(t))=1-t^2/2$
. Moreover, the fact that
 $\{(\alpha,1-\alpha)\colon \alpha\in (0,1)\}\subseteq K(t)$
yields
$\{(\alpha,1-\alpha)\colon \alpha\in (0,1)\}\subseteq K(t)$
yields
 $\textrm{diam}(K(t))=\sqrt{2}$
, so that for
$\textrm{diam}(K(t))=\sqrt{2}$
, so that for
 $\varepsilon=1$
we have
$\varepsilon=1$
we have
 $c=1/4$
and
$c=1/4$
and
 $\kappa = 1/2$
.
$\kappa = 1/2$
.
In general, we consider Assumption 2 a weak regularity requirement, since there is no condition on the level sets and also no condition on the modality.
Let
 $S_{d-1}$
be the Euclidean unit sphere and
$S_{d-1}$
be the Euclidean unit sphere and
 $\sigma_d = \textrm{vol}_{d-1}(S_{d-1})$
. A transition from x to y by hit-and-run on the level set K(t) works as follows:
$\sigma_d = \textrm{vol}_{d-1}(S_{d-1})$
. A transition from x to y by hit-and-run on the level set K(t) works as follows:
-
1. Choose
$\theta \in S_{d-1}$
uniformly distributed. -
2. Choose y according to the uniform distribution on the line
$x+ r \theta$
intersected with K(t).


This leads to
 \begin{align*}H_t(x,A)=\int_{S_{d-1}} \int_{L_t(x,\theta)} \mathbf{1}_A(x+s\theta) \frac{\textrm{d} s}{\textrm{vol}_1(L_t(x,\theta))}\,\frac{\textrm{d} \theta}{\sigma_d}\end{align*}
\begin{align*}H_t(x,A)=\int_{S_{d-1}} \int_{L_t(x,\theta)} \mathbf{1}_A(x+s\theta) \frac{\textrm{d} s}{\textrm{vol}_1(L_t(x,\theta))}\,\frac{\textrm{d} \theta}{\sigma_d}\end{align*}
with
 \begin{align*}L_t(x,\theta) = \{ r \in \mathbb{R} \mid x+r \theta \in K(t) \}.\end{align*}
\begin{align*}L_t(x,\theta) = \{ r \in \mathbb{R} \mid x+r \theta \in K(t) \}.\end{align*}
The hit-and-run algorithm is reversible and induces a positive semidefinite operator on
 $L_{2,t}$
; see [Reference Rudolf and Ullrich35]. The following property is well known; see for example [Reference Diaconis and Freedman5].
$L_{2,t}$
; see [Reference Rudolf and Ullrich35]. The following property is well known; see for example [Reference Diaconis and Freedman5].
Proposition 1. For
 $t\in (0,\left\Vert \varrho \right\Vert_{\infty})$
,
$t\in (0,\left\Vert \varrho \right\Vert_{\infty})$
,
 $x\in K(t)$
and
$x\in K(t)$
and
 $A\in \mathcal{B}(K)$
we have
$A\in \mathcal{B}(K)$
we have
 \begin{equation} H_t(x,A) = \frac{2}{\sigma_d} \int_A \frac{\textrm{d} y}{\left\vert x-y \right\vert^{d-1} \textrm{vol}_1(L(x,\frac{x-y}{\left\vert x-y \right\vert}))} \end{equation}
\begin{equation} H_t(x,A) = \frac{2}{\sigma_d} \int_A \frac{\textrm{d} y}{\left\vert x-y \right\vert^{d-1} \textrm{vol}_1(L(x,\frac{x-y}{\left\vert x-y \right\vert}))} \end{equation}
and
 \begin{equation} \left\Vert H_t - U_t \right\Vert_{L_{2,t} \to L_{2,t}} \leq 1 - \frac{2}{\sigma_d}\, \frac{ \textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d}. \end{equation}
\begin{equation} \left\Vert H_t - U_t \right\Vert_{L_{2,t} \to L_{2,t}} \leq 1 - \frac{2}{\sigma_d}\, \frac{ \textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d}. \end{equation}
Proof. The representation of
 $H_t$
stated in (19) is well known; see for example [Reference Diaconis and Freedman5]. From this we have for any
$H_t$
stated in (19) is well known; see for example [Reference Diaconis and Freedman5]. From this we have for any
 $x\in K(t)$
that
$x\in K(t)$
that
 \begin{align*} H_t(x,A) \geq \frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \cdot \frac{\textrm{vol}_d(K(t)\cap A)}{\textrm{vol}_d(K(t))}, \end{align*}
\begin{align*} H_t(x,A) \geq \frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \cdot \frac{\textrm{vol}_d(K(t)\cap A)}{\textrm{vol}_d(K(t))}, \end{align*}
which means that the whole state space K(t) is a small set. By [Reference Meyn and Tweedie18] we have uniform ergodicity, and by [Reference Rudolf33, Proposition 3.24] we obtain (20).
Furthermore, we obtain the following helpful result.
Lemma 10. Under Assumption 2, with
 \begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}, \end{align*}
\begin{align*} \beta_k = \sup_{x\in K} \left( \int_0^{\varrho(x)}\left\Vert H^k_t-U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \,\frac{\textrm{d} t}{\varrho(x)}\right)^{1/2}, \end{align*}
we have that
 $ \lim_{k \to \infty} \beta_k = 0. $
$ \lim_{k \to \infty} \beta_k = 0. $
Proof. By (20) and [Reference Rudolf33, Lemma 3.16], in combination with reversibility (or equivalently self-adjointness) of
 $H_t$
, it holds that
$H_t$
, it holds that
 \begin{equation} \left\Vert H_t^k - U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \leq \left( 1-\frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \right)^{2k}. \end{equation}
\begin{equation} \left\Vert H_t^k - U_t \right\Vert_{L_{2,t}\to L_{2,t}}^2 \leq \left( 1-\frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \right)^{2k}. \end{equation}
Let
 $g_k\colon [0,\Vert \varrho \Vert_\infty) \to [0,1]$
be given by
$g_k\colon [0,\Vert \varrho \Vert_\infty) \to [0,1]$
be given by
 \begin{align*} g_k(t) = \begin{cases} \left( 1-\frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \right)^{2k}, & t\in(0,\Vert \varrho \Vert_\infty),\\[5pt] \left( 1-\frac{2\, \kappa}{\sigma_d} \right)^{2k}, & t=0, \end{cases} \end{align*}
\begin{align*} g_k(t) = \begin{cases} \left( 1-\frac{2}{\sigma_d} \frac{\textrm{vol}_d(K(t))}{\textrm{diam}(K(t))^d} \right)^{2k}, & t\in(0,\Vert \varrho \Vert_\infty),\\[5pt] \left( 1-\frac{2\, \kappa}{\sigma_d} \right)^{2k}, & t=0, \end{cases} \end{align*}
which is the continuous extension at zero of the upper bound of (21) with
 $\kappa\geq c\in (0,1]$
from Assumption 2. Note that
$\kappa\geq c\in (0,1]$
from Assumption 2. Note that
 $\lim_{k\to \infty} g_k(t) = 0$
for all
$\lim_{k\to \infty} g_k(t) = 0$
for all
 $t\in[0,\Vert \varrho \Vert_\infty)$
and
$t\in[0,\Vert \varrho \Vert_\infty)$
and
 $ \beta_k \leq \sup_{r\in (0,\left\Vert \varrho \right\Vert_{\infty}]}\left( \frac{1}{r} \int_0^r g_k(t)\,\textrm{d} t \right)^{1/2}. $
Considering the continuous function
$ \beta_k \leq \sup_{r\in (0,\left\Vert \varrho \right\Vert_{\infty}]}\left( \frac{1}{r} \int_0^r g_k(t)\,\textrm{d} t \right)^{1/2}. $
Considering the continuous function
 \begin{align*} h_k(r) = \begin{cases} \frac{1}{r} \int_0^r g_k(t)\textrm{d} t, & r\in (0,\Vert \varrho\Vert_\infty],\\[5pt] g_k(0), & r=0, \end{cases} \end{align*}
\begin{align*} h_k(r) = \begin{cases} \frac{1}{r} \int_0^r g_k(t)\textrm{d} t, & r\in (0,\Vert \varrho\Vert_\infty],\\[5pt] g_k(0), & r=0, \end{cases} \end{align*}
the supremum can be replaced by a maximum over
 $r\in[0,\left\Vert \varrho \right\Vert_{\infty}]$
which is attained, say for
$r\in[0,\left\Vert \varrho \right\Vert_{\infty}]$
which is attained, say for
 $r^{(k)} \in [0,\left\Vert \varrho \right\Vert_{\infty}]$
, i.e.
$r^{(k)} \in [0,\left\Vert \varrho \right\Vert_{\infty}]$
, i.e.
 $\beta_k\leq h_k(r^{(k)})^{1/2}$
. Define
$\beta_k\leq h_k(r^{(k)})^{1/2}$
. Define
 \begin{align*} (r_0^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} =0, k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}},\\[5pt] (r_1^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} \in (0,\varepsilon), k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}},\\[5pt] (r_2^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} \geq \varepsilon, k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}}. \end{align*}
\begin{align*} (r_0^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} =0, k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}},\\[5pt] (r_1^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} \in (0,\varepsilon), k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}},\\[5pt] (r_2^{(k)})_{k\in\mathbb{N}} & \;:\!=\; \{ r^{(k)} \mid r^{(k)} \geq \varepsilon, k\in\mathbb{N} \} \subseteq (r^{(k)})_{k\in\mathbb{N}}. \end{align*}
Without loss of generality we assume that
 $(r_0^{(k)})_{k\in\mathbb{N}} \not = \emptyset$
,
$(r_0^{(k)})_{k\in\mathbb{N}} \not = \emptyset$
,
 $(r_1^{(k)})_{k\in\mathbb{N}}\not = \emptyset$
and
$(r_1^{(k)})_{k\in\mathbb{N}}\not = \emptyset$
and
 $(r_2^{(k)})_{k\in\mathbb{N}}\not = \emptyset$
. Then
$(r_2^{(k)})_{k\in\mathbb{N}}\not = \emptyset$
. Then
 $\lim_{k\to \infty} h_k(r_0^{(k)})=0$
, and using Assumption 2 we have
$\lim_{k\to \infty} h_k(r_0^{(k)})=0$
, and using Assumption 2 we have
 \begin{align*} 0\leq \lim_{k\to\infty} h_k(r_1^{(k) }) \leq \lim_{k\to\infty} \sup_{s\in (0,\varepsilon)} g_k(s) \leq \lim_{k\to\infty} \left(1-\frac{2c}{\sigma_d}\right)^{2k} =0. \end{align*}
\begin{align*} 0\leq \lim_{k\to\infty} h_k(r_1^{(k) }) \leq \lim_{k\to\infty} \sup_{s\in (0,\varepsilon)} g_k(s) \leq \lim_{k\to\infty} \left(1-\frac{2c}{\sigma_d}\right)^{2k} =0. \end{align*}
Moreover, by the definition of
 $(r_2^{(k)})_{k\in\mathbb{N}}$
, note that
$(r_2^{(k)})_{k\in\mathbb{N}}$
, note that
 $1/r_2^{(k)}\cdot\mathbf{1}_{(0,r_2^{(k)})}(t) \leq \varepsilon^{-1}$
for
$1/r_2^{(k)}\cdot\mathbf{1}_{(0,r_2^{(k)})}(t) \leq \varepsilon^{-1}$
for
 $t\in(0,\infty)$
, so that
$t\in(0,\infty)$
, so that
 \begin{align*} \lim_{k\to \infty} h_k(r_1^{(k)}) & = \lim_{k\to \infty}\int_0^{\Vert \varrho \Vert_\infty} \frac{\mathbf{1}_{(0,r_1^{(k)})}(t)}{r_1^{(k)}} g_k(t) \textrm{d} t = \int_0^{\Vert \varrho \Vert_\infty} \lim_{k\to \infty} \frac{\mathbf{1}_{(0,r_1^{(k)})} (t)}{r_1^{(k)}} g_k(t) \textrm{d} t =0. \end{align*}
\begin{align*} \lim_{k\to \infty} h_k(r_1^{(k)}) & = \lim_{k\to \infty}\int_0^{\Vert \varrho \Vert_\infty} \frac{\mathbf{1}_{(0,r_1^{(k)})}(t)}{r_1^{(k)}} g_k(t) \textrm{d} t = \int_0^{\Vert \varrho \Vert_\infty} \lim_{k\to \infty} \frac{\mathbf{1}_{(0,r_1^{(k)})} (t)}{r_1^{(k)}} g_k(t) \textrm{d} t =0. \end{align*}
Consequently
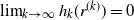 $\lim_{k\to \infty} h_k(r^{(k)})=0$
, so that
$\lim_{k\to \infty} h_k(r^{(k)})=0$
, so that
 $\lim_{k\to\infty} \beta_k \leq \lim_{k\to \infty} h_k(r^{(k)})^{1/2} =0.$
$\lim_{k\to\infty} \beta_k \leq \lim_{k\to \infty} h_k(r^{(k)})^{1/2} =0.$
By Theorem 1, this observation leads to the following result.
Corollary 3. Let
 $\varrho \colon K \to (0,\infty)$
and let Assumption 2 be satisfied. Then the hit-and-run slice sampler has an absolute spectral gap if and only if the simple slice sampler has an absolute spectral gap.
$\varrho \colon K \to (0,\infty)$
and let Assumption 2 be satisfied. Then the hit-and-run slice sampler has an absolute spectral gap if and only if the simple slice sampler has an absolute spectral gap.
We stress that we do not know whether the level sets of
 $\varrho$
are convex or star-shaped or have any additional structure. In this sense the assumptions imposed on
$\varrho$
are convex or star-shaped or have any additional structure. In this sense the assumptions imposed on
 $\varrho$
can be considered weak. This also means that it may be difficult to implement hit-and-run in this generality. In the next section we consider a combination of hit-and-run, stepping-out, and the shrinkage procedure, for which we provide a concrete implementable algorithm.
$\varrho$
can be considered weak. This also means that it may be difficult to implement hit-and-run in this generality. In the next section we consider a combination of hit-and-run, stepping-out, and the shrinkage procedure, for which we provide a concrete implementable algorithm.
4.3. Hit-and-run, stepping-out, shrinkage slice sampler
We combine hit-and-run, stepping-out, and the shrinkage procedure. Let
 $w>0$
, let
$w>0$
, let
 $K\subseteq \mathbb{R}^d$
, and assume that
$K\subseteq \mathbb{R}^d$
, and assume that
 $\varrho\colon K \to (0,\infty)$
. We say
$\varrho\colon K \to (0,\infty)$
. We say
 $\varrho\in \mathcal{R}_{d,w}$
if the following conditions are satisfied:
$\varrho\in \mathcal{R}_{d,w}$
if the following conditions are satisfied:
-
1. There are not necessarily normalized lower semicontinuous and quasi-concave densities
$\varrho_1,\varrho_2 \colon K \to (0,\infty)$
, i.e. the level sets are open and convex, with such that
\begin{align*} \inf_{y \in \arg \max \varrho_1,\,z\in \arg \max \varrho_2 } \left\vert z-y \right\vert \leq \frac{w}{2}, \end{align*}
$\varrho(x)=\max\{ \varrho_1(x), \varrho_2(x) \}$
.
-
2. The limit
$\kappa\;:\!=\;\lim_{t\downarrow 0} \frac{\textrm{vol}_d(K(t))}{\textrm{diam} (K(t))^d}$
exists, and there are numbers
$c,\varepsilon\in (0,1]$
such that
\begin{align*} \inf_{t\in(0,\varepsilon)} \frac{\textrm{vol}_d(K(t))}{\textrm{diam} (K(t))^d} = c. \end{align*}






For
 $i=1,2$
, let the level set of
$i=1,2$
, let the level set of
 $\varrho_i$
be denoted by
$\varrho_i$
be denoted by
 $K_i(t)$
for
$K_i(t)$
for
 $t\in [0,\left\Vert \varrho_i \right\Vert_{\infty})$
, and set
$t\in [0,\left\Vert \varrho_i \right\Vert_{\infty})$
, and set
 $K_i(t) = \emptyset$
for
$K_i(t) = \emptyset$
for
 $t\geq \left\Vert \varrho_i \right\Vert_{\infty}$
. Then, since
$t\geq \left\Vert \varrho_i \right\Vert_{\infty}$
. Then, since
 $\varrho=\max\{ \varrho_1, \varrho_2 \}$
, it follows that
$\varrho=\max\{ \varrho_1, \varrho_2 \}$
, it follows that
 $K(t)=K_1(t) \cup K_2(t)$
. If K is bounded and has positive Lebesgue measure, then the condition 2 is always satisfied. For
$K(t)=K_1(t) \cup K_2(t)$
. If K is bounded and has positive Lebesgue measure, then the condition 2 is always satisfied. For
 $K=\mathbb{R}^d$
one has to check the condition 2. For example,
$K=\mathbb{R}^d$
one has to check the condition 2. For example,
 $\varrho\colon \mathbb{R}^d \to (0,\infty)$
with
$\varrho\colon \mathbb{R}^d \to (0,\infty)$
with
 \begin{align*}\varrho(x) = \max\{\exp\!(\!-\!\alpha \left\vert x \right\vert^2),\exp\!(\!-\!\beta \left\vert x-x_0 \right\vert^2)\},\end{align*}
\begin{align*}\varrho(x) = \max\{\exp\!(\!-\!\alpha \left\vert x \right\vert^2),\exp\!(\!-\!\beta \left\vert x-x_0 \right\vert^2)\},\end{align*}
and
 $2\beta> \alpha$
satisfies the conditions 1 and 2 for
$2\beta> \alpha$
satisfies the conditions 1 and 2 for
 $w=2\left\vert x_0 \right\vert$
. The rough idea for a transition from x to y of the combination of the different methods on the level set K(t) is as follows. Consider a line/segment of the form
$w=2\left\vert x_0 \right\vert$
. The rough idea for a transition from x to y of the combination of the different methods on the level set K(t) is as follows. Consider a line/segment of the form
 \begin{align*}L_t(x,\theta) = \{ r\in \mathbb{R} \mid x+r\theta \in K(t) \}.\end{align*}
\begin{align*}L_t(x,\theta) = \{ r\in \mathbb{R} \mid x+r\theta \in K(t) \}.\end{align*}
Then run the stepping-out and shrinkage procedure on
 $L_t(x,\theta)$
and return y. We present in detail a single transition from x to y of the hit-and-run, stepping-out, and shrinkage slice sampler in Algorithm 2.
$L_t(x,\theta)$
and return y. We present in detail a single transition from x to y of the hit-and-run, stepping-out, and shrinkage slice sampler in Algorithm 2.
Algorithm 2. A hybrid slice sampling transition of the hit-and-run, stepping-out, and shrinkage procedure from x to y, i.e. with input x and output y. The stepping-out procedure on
 $L_t(x,\theta)$
(line of hit-and-run on level set) has inputs x,
$L_t(x,\theta)$
(line of hit-and-run on level set) has inputs x,
 $w>0$
(step size parameter from
$w>0$
(step size parameter from
 $\mathcal{R}_{d,w}$
) and outputs an interval [L, R]. The shrinkage procedure has input [L, R] and output
$\mathcal{R}_{d,w}$
) and outputs an interval [L, R]. The shrinkage procedure has input [L, R] and output
 $y=x+s\theta$
:
$y=x+s\theta$
:
-
1. Choose a level
$t \sim \mathcal{U}(0,\varrho(x))$
; -
2. Choose a direction
$\theta \in S_{d-1}$
uniformly distributed; -
3. Stepping-out on
$L_t(x,\theta)$
with
$w>0$
outputs an interval [L, R]:-
(a) Choose
$u \sim \mathcal{U}[0,1]$
. Set
$L= u w$
and
$R=L+w$
; -
(b) Repeat until
$t \geq \varrho(x+L\theta)$
, i.e.
$L \not \in L_t(x,\theta)$
: Set
$L=L-w$
; -
(c) Repeat until
$t \geq \varrho(x+R\theta)$
, i.e.
$R \not \in L_t(x,\theta)$
: Set
$R=R+w$
;
-
-
4. Shrinkage procedure with input [L, R] outputs y:
-
(a) Set
$\bar{L}=L$
and
$\bar{R}=R$
; -
(b) Repeat:
-
i. Choose
$v\sim \mathcal{U}[0,1]$
and set
$s=\bar{L}+ v (\bar{R}-\bar{L})$
; -
ii. If
$s \in L_t(x,\theta)$
return
$y=x+s\theta$
and exit the loop; -
iii. If
$s<0$
then set
$\bar{L}=s$
, else
$\bar{R}=s$
.
-
-






















Now we present the corresponding transition kernel on K(t). Since
 $\varrho \in \mathcal{R}_{d,w}$
, we can define for
$\varrho \in \mathcal{R}_{d,w}$
, we can define for
 $i=1,2$
the open intervals
$i=1,2$
the open intervals
 \begin{align*}L_{t,i}(x,\theta) = \{ s\in \mathbb{R} \mid x+s\theta \in K_i(t) \}\end{align*}
\begin{align*}L_{t,i}(x,\theta) = \{ s\in \mathbb{R} \mid x+s\theta \in K_i(t) \}\end{align*}
and have
 $L_t(x,\theta) = L_{t,1}(x,\theta) \cup L_{t,2}(x,\theta).$
Let
$L_t(x,\theta) = L_{t,1}(x,\theta) \cup L_{t,2}(x,\theta).$
Let
 \begin{align*}\delta_{t,\theta,x} = \inf_{r \in L_{t,1}(x,\theta),\;s \in L_{t,2}(x,\theta)} \left\vert r-s \right\vert,\end{align*}
\begin{align*}\delta_{t,\theta,x} = \inf_{r \in L_{t,1}(x,\theta),\;s \in L_{t,2}(x,\theta)} \left\vert r-s \right\vert,\end{align*}
and note that if
 $\delta_{t,\theta,x}>0$
then
$\delta_{t,\theta,x}>0$
then
 $L_{t,1}(x,\theta)\cap L_{t,2}(x,\theta) = \emptyset$
.
$L_{t,1}(x,\theta)\cap L_{t,2}(x,\theta) = \emptyset$
.
We also write for short
 $\left\vert L_t(x,\theta) \right\vert=\textrm{vol}_1(L_t(x,\theta))$
, and for
$\left\vert L_t(x,\theta) \right\vert=\textrm{vol}_1(L_t(x,\theta))$
, and for
 $A\in \mathcal{B}(K)$
,
$A\in \mathcal{B}(K)$
,
 $x\in K$
,
$x\in K$
,
 $\theta \in S_{d-1}$
, let
$\theta \in S_{d-1}$
, let
 $A_{x,\theta} = \{ s\in \mathbb{R}\mid x+s\theta \in A \}$
. With this notation, for
$A_{x,\theta} = \{ s\in \mathbb{R}\mid x+s\theta \in A \}$
. With this notation, for
 $t>0$
, the transition kernel
$t>0$
, the transition kernel
 $H_t$
on K(t) is given by
$H_t$
on K(t) is given by
 \begin{align*}& H_t(x,A)= \int_{S_{d-1}} \Bigg[ \gamma_t(x,\theta) \frac{\left\vert L_t(x,\theta)\cap A_{x,\theta} \right\vert}{\left\vert L_t(x,\theta) \right\vert}\\[5pt] & \qquad + (1-\gamma_t(x,\theta))\sum_{i=1}^2 \mathbf{1}_{K_i(t)}(x)\frac{\left\vert L_{t,i}(x,\theta)\cap A_{x,\theta} \right\vert}{\left\vert L_{t,i}(x,\theta) \right\vert}\Bigg] \frac{\textrm{d} \theta}{\sigma_d},\end{align*}
\begin{align*}& H_t(x,A)= \int_{S_{d-1}} \Bigg[ \gamma_t(x,\theta) \frac{\left\vert L_t(x,\theta)\cap A_{x,\theta} \right\vert}{\left\vert L_t(x,\theta) \right\vert}\\[5pt] & \qquad + (1-\gamma_t(x,\theta))\sum_{i=1}^2 \mathbf{1}_{K_i(t)}(x)\frac{\left\vert L_{t,i}(x,\theta)\cap A_{x,\theta} \right\vert}{\left\vert L_{t,i}(x,\theta) \right\vert}\Bigg] \frac{\textrm{d} \theta}{\sigma_d},\end{align*}
with
 \begin{align*}\gamma_t(x,\theta) = \frac{(w-\delta_{t,x,\theta})}{w} \cdot \frac{\left\vert L_{t}(x,\theta) \right\vert}{\left\vert L_{t}(x,\theta) \right\vert+\delta_{t,x,\theta}}.\end{align*}
\begin{align*}\gamma_t(x,\theta) = \frac{(w-\delta_{t,x,\theta})}{w} \cdot \frac{\left\vert L_{t}(x,\theta) \right\vert}{\left\vert L_{t}(x,\theta) \right\vert+\delta_{t,x,\theta}}.\end{align*}
The following result is helpful.
Lemma 11. For
 $\varrho\in \mathcal{R}_{d,w}$
and for any
$\varrho\in \mathcal{R}_{d,w}$
and for any
 $t\in (0,\left\Vert \varrho \right\Vert_{\infty})$
, the following hold:
$t\in (0,\left\Vert \varrho \right\Vert_{\infty})$
, the following hold:
-
1. The transition kernel
$H_t$
is reversible and induces a positive semidefinite operator on
$L_{2,t}$
, i.e. for
$f\in L_{2,t}$
, it holds that
$\langle H_t f , f \rangle_t \geq 0$
. -
2. We have
(22)in particular
\begin{equation} \left\Vert H_t - U_t \right\Vert_{L_{2,t} \to L_{2,t}} \leq 1-\frac{\textrm{vol}_d(K(t))}{\sigma_d\; \textrm{diam}(K(t))^d}; \end{equation}
$\lim_{k\to \infty} \beta_k = 0$
with
$\beta_k$
defined in Theorem 1.







Proof. First, note that
 $L_t(x+s\theta,\theta)=L_t(x,\theta)-s$
,
$L_t(x+s\theta,\theta)=L_t(x,\theta)-s$
,
 $\left\vert L_t(x+s\theta,\theta) \right\vert=\left\vert L_t(x,\theta) \right\vert$
, and
$\left\vert L_t(x+s\theta,\theta) \right\vert=\left\vert L_t(x,\theta) \right\vert$
, and
 $\gamma_t(x+s\theta,\theta)=\gamma_t(x,\theta)$
for any
$\gamma_t(x+s\theta,\theta)=\gamma_t(x,\theta)$
for any
 $x\in \mathbb{R}^d$
,
$x\in \mathbb{R}^d$
,
 $\theta\in S_{d-1}$
, and
$\theta\in S_{d-1}$
, and
 $s\in \mathbb{R}$
.
$s\in \mathbb{R}$
.
Part 1. The reversibility of
 $H_t$
with respect to
$H_t$
with respect to
 $U_t$
(in the setting of
$U_t$
(in the setting of
 $\varrho\in\mathcal{R}_{d,w}$
) is inherited by the reversibility of hit-and-run and the reversibility of the combination of the stepping-out and shrinkage procedure; see Lemma 9.
$\varrho\in\mathcal{R}_{d,w}$
) is inherited by the reversibility of hit-and-run and the reversibility of the combination of the stepping-out and shrinkage procedure; see Lemma 9.
We turn to the positive semidefiniteness. Let
 $C_t=\textrm{vol}_d(K(t))$
. We have
$C_t=\textrm{vol}_d(K(t))$
. We have
 \begin{align*} & \langle f , H_t f \rangle_{t} = \int_{S_{d-1}} \int_{K(t)} \gamma_t(x,\theta)f(x) \int_{L_t(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & + \sum_{i=1}^2 \int_{S_{d-1}} \int_{K_i(t)} (1-\gamma_t(x,\theta))f(x) \int_{L_{t,i}(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_{t,i}(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}. \end{align*}
\begin{align*} & \langle f , H_t f \rangle_{t} = \int_{S_{d-1}} \int_{K(t)} \gamma_t(x,\theta)f(x) \int_{L_t(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & + \sum_{i=1}^2 \int_{S_{d-1}} \int_{K_i(t)} (1-\gamma_t(x,\theta))f(x) \int_{L_{t,i}(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_{t,i}(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}. \end{align*}
We prove positivity of the first summand. The positivity of the other two summands follows by the same arguments. For
 $\theta \in S_{d-1}$
let us define the projected set
$\theta \in S_{d-1}$
let us define the projected set
 \begin{align*} P_{\theta^\bot}(K(t)) = \{ \tilde x \in \mathbb{R}^d \mid \tilde x \bot \theta, \; \exists s\in \mathbb{R}\;\, \mbox{s.t.} \;\, \tilde x + \theta s \in K(t) \}. \end{align*}
\begin{align*} P_{\theta^\bot}(K(t)) = \{ \tilde x \in \mathbb{R}^d \mid \tilde x \bot \theta, \; \exists s\in \mathbb{R}\;\, \mbox{s.t.} \;\, \tilde x + \theta s \in K(t) \}. \end{align*}
Then
 \begin{align*} & \int_{S_{d-1}} \int_{K(t)} \gamma_t(x,\theta)f(x) \int_{L_t(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))}\int_{L_t(\tilde x,\theta)} \gamma_t(\tilde x+s\theta,\theta)f(\tilde x+s \theta)\, \times \\[5pt] & \qquad\qquad \int_{L_t(\tilde x+s\theta,\theta)} f(\tilde x+(r+s)\theta) \, \frac{\textrm{d} r}{\left\vert L_t(\tilde x+s\theta,\theta) \right\vert} \frac{\textrm{d} s\, \textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))}\int_{L_t(\tilde x,\theta)} \gamma_t(\tilde x,\theta)f(\tilde x+s \theta)\, \times \\[5pt] & \qquad\qquad \int_{L_t(\tilde x,\theta)-s} f(\tilde x+(r+s)\theta) \, \frac{\textrm{d} r}{\left\vert L_t(\tilde x,\theta)-s \right\vert} \frac{\textrm{d} s\, \textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))} \frac{\gamma_t(\tilde x,\theta)}{\left\vert L_t(\tilde x,\theta) \right\vert} \left( \int_{L_t(\tilde x,\theta)} f(\tilde x+u \theta) \textrm{d} u \right)^2 \frac{\textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d} \geq 0. \end{align*}
\begin{align*} & \int_{S_{d-1}} \int_{K(t)} \gamma_t(x,\theta)f(x) \int_{L_t(x,\theta)} f(x+r\theta) \, \frac{\textrm{d} r}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))}\int_{L_t(\tilde x,\theta)} \gamma_t(\tilde x+s\theta,\theta)f(\tilde x+s \theta)\, \times \\[5pt] & \qquad\qquad \int_{L_t(\tilde x+s\theta,\theta)} f(\tilde x+(r+s)\theta) \, \frac{\textrm{d} r}{\left\vert L_t(\tilde x+s\theta,\theta) \right\vert} \frac{\textrm{d} s\, \textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))}\int_{L_t(\tilde x,\theta)} \gamma_t(\tilde x,\theta)f(\tilde x+s \theta)\, \times \\[5pt] & \qquad\qquad \int_{L_t(\tilde x,\theta)-s} f(\tilde x+(r+s)\theta) \, \frac{\textrm{d} r}{\left\vert L_t(\tilde x,\theta)-s \right\vert} \frac{\textrm{d} s\, \textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] & = \int_{S_{d-1}} \int_{P_{\theta^{\bot}}(K(t))} \frac{\gamma_t(\tilde x,\theta)}{\left\vert L_t(\tilde x,\theta) \right\vert} \left( \int_{L_t(\tilde x,\theta)} f(\tilde x+u \theta) \textrm{d} u \right)^2 \frac{\textrm{d} \tilde x}{C_t}\, \frac{\textrm{d} \theta}{\sigma_d} \geq 0. \end{align*}
This yields that
 $H_t$
is positive semidefinite.
$H_t$
is positive semidefinite.
Part 2. For any
 $x\in K(t)$
and measurable
$x\in K(t)$
and measurable
 $A\subseteq K(t)$
we have
$A\subseteq K(t)$
we have
 \begin{align*} & H_t(x,A) \geq \int_{S_{d-1}} \gamma_t(x,\theta) \int_{L_t(x,\theta)} \mathbf{1}_{A}(x+s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] &= \int_{S_{d-1}} \int_0^\infty \gamma_t(x,\theta) \mathbf{1}_{A}(x-s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & \quad + \int_{S_{d-1}} \int_0^\infty \gamma_t(x,\theta) \mathbf{1}_{A}(x+s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & = \int_{\mathbb{R}^d} \frac{\gamma_t(x,\frac{y}{\left\vert y \right\vert})}{\sigma_d\cdot \left\vert L_t(x,\frac{y}{\left\vert y \right\vert}) \right\vert} \frac{\mathbf{1}_{A}(x-y)}{\left\vert y \right\vert^{d-1}}\, \textrm{d} y + \int_{\mathbb{R}^d} \frac{\gamma_t(x,\frac{y}{\left\vert y \right\vert})}{\sigma_d\cdot \left\vert L_t(x,\frac{y}{\left\vert y \right\vert}) \right\vert} \frac{\mathbf{1}_{A}(x+y)}{\left\vert y \right\vert^{d-1}}\, \textrm{d} y\\[5pt] & = \frac{2}{\sigma_d} \int_A \frac{\gamma_t(x,\frac{x-y}{\left\vert x-y \right\vert})}{\left\vert x-y \right\vert^{d-1}\left\vert L_t(x,\frac{x-y}{\left\vert x-y \right\vert}) \right\vert}\; \textrm{d} y \geq \frac{\textrm{vol}_d(K(t))}{\sigma_d\; \textrm{diam}(K(t))^d} \cdot \frac{\textrm{vol}_d(A)}{\textrm{vol}_d(K(t))}. \end{align*}
\begin{align*} & H_t(x,A) \geq \int_{S_{d-1}} \gamma_t(x,\theta) \int_{L_t(x,\theta)} \mathbf{1}_{A}(x+s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert}\, \frac{\textrm{d} \theta}{\sigma_d}\\[5pt] &= \int_{S_{d-1}} \int_0^\infty \gamma_t(x,\theta) \mathbf{1}_{A}(x-s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & \quad + \int_{S_{d-1}} \int_0^\infty \gamma_t(x,\theta) \mathbf{1}_{A}(x+s\theta)\, \frac{\textrm{d} s}{\left\vert L_t(x,\theta) \right\vert} \frac{\textrm{d} \theta}{\sigma_d} \\[5pt] & = \int_{\mathbb{R}^d} \frac{\gamma_t(x,\frac{y}{\left\vert y \right\vert})}{\sigma_d\cdot \left\vert L_t(x,\frac{y}{\left\vert y \right\vert}) \right\vert} \frac{\mathbf{1}_{A}(x-y)}{\left\vert y \right\vert^{d-1}}\, \textrm{d} y + \int_{\mathbb{R}^d} \frac{\gamma_t(x,\frac{y}{\left\vert y \right\vert})}{\sigma_d\cdot \left\vert L_t(x,\frac{y}{\left\vert y \right\vert}) \right\vert} \frac{\mathbf{1}_{A}(x+y)}{\left\vert y \right\vert^{d-1}}\, \textrm{d} y\\[5pt] & = \frac{2}{\sigma_d} \int_A \frac{\gamma_t(x,\frac{x-y}{\left\vert x-y \right\vert})}{\left\vert x-y \right\vert^{d-1}\left\vert L_t(x,\frac{x-y}{\left\vert x-y \right\vert}) \right\vert}\; \textrm{d} y \geq \frac{\textrm{vol}_d(K(t))}{\sigma_d\; \textrm{diam}(K(t))^d} \cdot \frac{\textrm{vol}_d(A)}{\textrm{vol}_d(K(t))}. \end{align*}
Here the last inequality follows from the fact that
 $\delta_{t,x,\theta} \leq w/2$
and
$\delta_{t,x,\theta} \leq w/2$
and
 $\left\vert L_t(x,\theta) \right\vert+\delta_{t,x,\theta} \leq \textrm{diam}(K(t))$
. Thus, by [Reference Meyn and Tweedie18] we have uniform ergodicity and by [Reference Rudolf33, Proposition 3.24] we obtain (22). Finally,
$\left\vert L_t(x,\theta) \right\vert+\delta_{t,x,\theta} \leq \textrm{diam}(K(t))$
. Thus, by [Reference Meyn and Tweedie18] we have uniform ergodicity and by [Reference Rudolf33, Proposition 3.24] we obtain (22). Finally,
 $\lim_{k\to \infty}\beta_k =0$
follows by the same arguments as in Lemma 10.
$\lim_{k\to \infty}\beta_k =0$
follows by the same arguments as in Lemma 10.
By Theorem 1, this observation leads to the following result.
Corollary 4. Let
 $\varrho \in \mathcal{R}_{d,w}$
. Then the hit-and-run, stepping-out, shrinkage slice sampler has an absolute spectral gap if and only if the simple slice sampler has an absolute spectral gap.
$\varrho \in \mathcal{R}_{d,w}$
. Then the hit-and-run, stepping-out, shrinkage slice sampler has an absolute spectral gap if and only if the simple slice sampler has an absolute spectral gap.
5. Concluding remarks
We provide a general framework to prove convergence results for hybrid slice sampling via spectral gap arguments. More precisely, we state sufficient conditions for the spectral gap of an appropriately designed hybrid slice sampler to be equivalent to the spectral gap of the simple slice sampler. Since all Markov chains we are considering are reversible, this also provides a criterion for geometric ergodicity; see [Reference Roberts and Rosenthal28].
To illustrate how our analysis can be applied to specific hybrid slice sampling implementations, we analyze the hit-and-run algorithm on the slice on multidimensional targets under weak conditions, as well as the easily implementable stepping-out shrinkage hit-and-run on the slice for bimodal d-dimensional distributions. The latter analysis can in principle be extended to settings with more than two modes, at the price of further notational and computational complexity.
These examples demonstrate that the robustness of the simple slice sampler is inherited by appropriately designed hybrid versions of it in realistic computational settings, providing theoretical underpinnings for their use in applications.
Appendix A. Technical lemmas
Lemma 12. Let
 $H_1$
and
$H_1$
and
 $H_2$
be two Hilbert spaces. Furthermore, let
$H_2$
be two Hilbert spaces. Furthermore, let
 $R\colon H_2 \to H_1 $
be a bounded linear operator with adjoint
$R\colon H_2 \to H_1 $
be a bounded linear operator with adjoint
 $R^* \colon H_1 \to H_2$
, and let
$R^* \colon H_1 \to H_2$
, and let
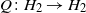 $Q\colon H_2 \to H_2$
be a bounded linear operator which is self-adjoint. Then
$Q\colon H_2 \to H_2$
be a bounded linear operator which is self-adjoint. Then
 \begin{align*} \left\Vert R Q^{k+1} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R \left\vert Q \right\vert^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} \left\Vert R Q^{k+1} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R \left\vert Q \right\vert^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Let us additionally assume that Q is positive semidefinite. Then
 \begin{align*} \left\Vert R Q ^{k+1} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R Q^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} \left\Vert R Q ^{k+1} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R Q^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Proof. Let us denote the inner products of
 $H_1$
and
$H_1$
and
 $H_2$
by
$H_2$
by
 $\langle \cdot , \cdot \rangle_1$
and
$\langle \cdot , \cdot \rangle_1$
and
 $\langle \cdot , \cdot \rangle_2$
, respectively. By the spectral theorem for the bounded and self-adjoint operator
$\langle \cdot , \cdot \rangle_2$
, respectively. By the spectral theorem for the bounded and self-adjoint operator
 $Q\colon H_2 \to H_2$
we obtain
$Q\colon H_2 \to H_2$
we obtain
 \begin{align*} \frac{ \langle Q R^* f , R^* f \rangle_{2} }{ \langle R^* f , R^* f \rangle_{2}} = \int_{\textrm{spec}(Q)} \lambda \,\textrm{d} \nu_{Q,R^*f}(\lambda), \end{align*}
\begin{align*} \frac{ \langle Q R^* f , R^* f \rangle_{2} }{ \langle R^* f , R^* f \rangle_{2}} = \int_{\textrm{spec}(Q)} \lambda \,\textrm{d} \nu_{Q,R^*f}(\lambda), \end{align*}
where
 $\textrm{spec}(Q)$
denotes the spectrum of Q and
$\textrm{spec}(Q)$
denotes the spectrum of Q and
 $\nu_{Q,R^*f}$
denotes the normalized spectral measure. Thus,
$\nu_{Q,R^*f}$
denotes the normalized spectral measure. Thus,
 \begin{align*} &\qquad \left\Vert R Q ^{k+1} R^* \right\Vert_{H_1 \to H_1} = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\left\vert \langle Q^{k+1} R^* f , R^* f \rangle_2 \right\vert }{\langle f , f \rangle_1}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \frac{\left\vert \langle Q^{k+1} R^* f , R^* f \rangle_2 \right\vert }{\langle R^* f , R^*f \rangle_2}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \left\vert \int_{\textrm{spec}(Q)} \lambda^{k+1} \,\textrm{d} \nu_{Q,R^*f}(\lambda) \right\vert\\[5pt] & \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \int_{\textrm{spec}(Q)} \left\vert \lambda \right\vert^{k} \,\textrm{d} \nu_{Q,R^*f}(\lambda)\\[5pt] & = \left\Vert Q \right\Vert_{H_2 \to H_2} \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \frac{ \langle \left\vert Q \right\vert^{k} R^* f , R^* f \rangle_2 }{\langle R^* f , R^*f \rangle_2}\\[5pt] & = \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R \left\vert Q \right\vert ^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} &\qquad \left\Vert R Q ^{k+1} R^* \right\Vert_{H_1 \to H_1} = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\left\vert \langle Q^{k+1} R^* f , R^* f \rangle_2 \right\vert }{\langle f , f \rangle_1}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \frac{\left\vert \langle Q^{k+1} R^* f , R^* f \rangle_2 \right\vert }{\langle R^* f , R^*f \rangle_2}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \left\vert \int_{\textrm{spec}(Q)} \lambda^{k+1} \,\textrm{d} \nu_{Q,R^*f}(\lambda) \right\vert\\[5pt] & \leq \left\Vert Q \right\Vert_{H_2 \to H_2} \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \int_{\textrm{spec}(Q)} \left\vert \lambda \right\vert^{k} \,\textrm{d} \nu_{Q,R^*f}(\lambda)\\[5pt] & = \left\Vert Q \right\Vert_{H_2 \to H_2} \sup_{\langle f , f \rangle_1 \not = 0} \frac{\langle R^* f , R^*f \rangle_2}{\langle f , f \rangle_1} \frac{ \langle \left\vert Q \right\vert^{k} R^* f , R^* f \rangle_2 }{\langle R^* f , R^*f \rangle_2}\\[5pt] & = \left\Vert Q \right\Vert_{H_2 \to H_2} \left\Vert R \left\vert Q \right\vert ^{k} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Here we used that the operator norm of
 $Q \colon H_2 \to H_2$
is the same as the operator norm of
$Q \colon H_2 \to H_2$
is the same as the operator norm of
 $\left\vert Q \right\vert\colon H_2 \to H_2$
. If Q is positive semidefinite, then
$\left\vert Q \right\vert\colon H_2 \to H_2$
. If Q is positive semidefinite, then
 $Q= \left\vert Q \right\vert$
.
$Q= \left\vert Q \right\vert$
.
Lemma 13. Let us assume that the conditions of Lemme 12 are satisfied. Furthermore, let
 $\left\Vert R \right\Vert_{H_2 \to H_1}^2 = \left\Vert R R^* \right\Vert_{H_1 \to H_1} \leq 1$
. Then
$\left\Vert R \right\Vert_{H_2 \to H_1}^2 = \left\Vert R R^* \right\Vert_{H_1 \to H_1} \leq 1$
. Then
 \begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1}^{k} \leq \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1}^{k} \leq \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Let us additionally assume that Q is positive semidefinite. Then
 \begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1}^{k} \leq \left\Vert R Q ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1}^{k} \leq \left\Vert R Q ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Proof. We use the same notation as in the proof of Lemma 12. Thus
 \begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1} ^k & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \frac{\left\vert \langle Q R^* f , R^* f \rangle_{2} \right\vert}{\langle R^* f , R^* f \rangle_2} \right)^ k\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \left\vert \int_{\textrm{spec}(Q)} \lambda \,\textrm{d} \nu_{Q,R^*f}(\lambda) \right\vert^ k\\[5pt] & \leq \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \int_{\textrm{spec}(Q)} \left\vert \lambda \right\vert^k \,\textrm{d} \nu_{Q,R^*f}(\lambda) \\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \frac{\langle \left\vert Q \right\vert^k R^* f , R^* f \rangle_2 }{\langle R^* f , R^* f \rangle_2}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ {k-1} \frac{\langle \left\vert Q \right\vert^k R^* f , R^* f \rangle_2 }{\langle f , f \rangle_1} \\[5pt] & \leq \left\Vert R R^* \right\Vert_{H_1 \to H_1} ^{k-1} \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
\begin{align*} \left\Vert R Q R^* \right\Vert_{H_1 \to H_1} ^k & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \frac{\left\vert \langle Q R^* f , R^* f \rangle_{2} \right\vert}{\langle R^* f , R^* f \rangle_2} \right)^ k\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \left\vert \int_{\textrm{spec}(Q)} \lambda \,\textrm{d} \nu_{Q,R^*f}(\lambda) \right\vert^ k\\[5pt] & \leq \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \int_{\textrm{spec}(Q)} \left\vert \lambda \right\vert^k \,\textrm{d} \nu_{Q,R^*f}(\lambda) \\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ k \frac{\langle \left\vert Q \right\vert^k R^* f , R^* f \rangle_2 }{\langle R^* f , R^* f \rangle_2}\\[5pt] & = \sup_{\langle f , f \rangle_1 \not = 0} \left(\frac{\langle R^* f , R^* f \rangle_2}{\langle f , f \rangle_1} \right)^ {k-1} \frac{\langle \left\vert Q \right\vert^k R^* f , R^* f \rangle_2 }{\langle f , f \rangle_1} \\[5pt] & \leq \left\Vert R R^* \right\Vert_{H_1 \to H_1} ^{k-1} \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1} \leq \left\Vert R \left\vert Q \right\vert ^{{k}} R^* \right\Vert_{H_1 \to H_1}. \end{align*}
Note that we applied Jensen’s inequality here. Furthermore, if Q is positive semidefinite, then
 $Q= \left\vert Q \right\vert$
, which finishes the proof.
$Q= \left\vert Q \right\vert$
, which finishes the proof.
Acknowledgements
We are extremely grateful for the referees’ careful reading and comments on the paper. In particular, we thank one of the referees, who pointed us to Example 1.
Funding information
K. L. was supported by the Royal Society through the Royal Society University Research Fellowship. D. R. gratefully acknowledges support from the DFG, within project 522337282.
Competing interests
There were no competing interests to declare which arose during the preparation or publication process of this article.

 Open access
Open access