



Qaqet (Glottocode qaqe1238; ISO 639-3: byx) is a Papuan (i.e. non-Austronesian) Baining language that is spoken by an estimated 15,000 people in Papua New Guinea’s East New Britain Province. Figure 1 shows a map of where Qaqet and the four other known Baining languages (Mali, Kairak (also spelt Qairaq – see map), Simbali and Ura) are spoken (see Stebbins, Evans & Terrill Reference Stebbins, Evans and Terrill2017 for an overview of Baining; for phonological descriptions, see Stanton Reference Stanton2007 on Ura, and Stebbins Reference Stebbins2011 on Mali). The wider affiliations of the Baining languages are unknown. They share typological features with other East Papuan languages (i.e. the non-Austronesian languages of Island Melanesia), but there is no historical-comparative evidence to establish genealogical relationships.Footnote 1 In terms of phonology, there are no structures shared across all of East Papuan, but Baining languages have similarities to the East Papuan language Kuot spoken on neighbouring New Ireland (i.e. the intervocalic lenition of voiceless plosives; pitch movements at the right edge of intonation units).Footnote 2 Furthermore, language contact is known to have taken place across the entire region, and Baining languages share typological features with Oceanic languages. This includes phonemic contrasts between voiceless and voiced plosives and between /r/ and /l/; as well as a number of morphosyntactic structures (e.g. a large inventory of definite and indefinite articles, AVO/SV constituent order, prepositions).

Figure 1 Map of Qaqet and surrounding Baining languages (in grey).
As shown in Figure 1, Qaqet is spoken over an area of more than 1000 square kilometers of the Gazelle Peninsula, including both the mountainous interior and the coastal regions. People live a highly mobile lifestyle and frequently move between their homes in small villages, and semi-permanent settlements in their different subsistence and cash-crop gardens. They are predominantly engaged in slash-and-burn gardening, and families usually maintain more than one garden, often at considerable distances from their home villages. Most speakers are bilingual, speaking minimally Qaqet and the national lingua franca Tok Pisin, plus sometimes additional languages. Qaqet continues to be the dominant language in the remote areas: it is spoken in all day-to-day activities, children learn it as their first language, and the use of Tok Pisin is restricted to communication with outsiders. In the more accessible regions, however, Qaqet speakers live in close contact with speakers from many different languages, and Qaqet is being replaced by Tok Pisin.
The data for this contribution were collected in the remote village of Raunsepna. Appendix A summarizes some basic metadata information. All of the speakers are engaged in subsistence farming, and all are female, except for the speaker of the North Wind and the Sun passage, who is male. Most of the speakers are born in the 1970s or 1980s, although two were born in the 1960s and one was born in the 1990s. The first six speakers contributed the data for the analyses presented here as well as some of the illustrative examples. Additional examples were produced by the other speakers included in the table.
It should be noted that in Qaqet, considerable individual variability is observed on all levels of language, including phonetics, morphosyntax and lexicon. To our present knowledge, this variability cannot be linked to any regional or social factors. Our database is such that we do not have repetitions of individual words by multiple speakers, and consequently we have recordings of words from different speakers for this Illustration. However, as already noted, all of the words are produced by female speakers, and thus at least one potential source of variability is kept constant.
Consonants

Qaqet has a relatively small phoneme inventory (16 consonant and four vowel phonemes) that includes a phonemic contrast between voiceless and voiced plosives, and a phonemic contrast between /r/ and /l/. These two features are considered characteristic features of Oceanic, not of East Papuan languages (Dunn et al. Reference Dunn, Levinson, Lindström, Reesink and Terrill2008: 743), and are thought to have arisen as the result of contact between speakers of Qaqet and speakers of Oceanic languages. The consonant table above is based on Hellwig (Reference Hellwig2019); non-transparent orthography is shown between angular brackets. Note that there are no glide phonemes.
Below, we give some near-minimal pairs to illustrate the contrasts. If a consonant can appear in both onset and coda position, we give examples of both (see section on syllable structure below). Note that voiceless plosives in onset position are rare. Although many roots start with a phonemic voiceless plosive, they are often obligatorily preceded by vowel-final morphemes, which trigger the lenition of these plosives. Lenition is a synchronic process, creating the following allophony: /p/ → [β] ∼ [w], /t/ → [r] ∼ [ɾ] ∼ [ɹ], /k/ → [ɣ] ∼ [ɰ] ∼ [ʝ] ∼ [j] ∼ [ʁ] ∼ [ʁ̞]. The realization of the allophone [ɣ] (of the phoneme /k/), just like the realization of the phoneme /ɣ/, is highly variable, as the alternative variants listed above would indicate – see Figures 3 and 4 below, with associated discussion. Note that we represent all lenited plosives as fricatives/rhotics in IPA, but their actual realization varies between fricative/rhotic and approximant realizations. Furthermore, there are exceptions to the lenition rule, and some examples in this Illustration feature voiceless plosives in intervocalic position. Exceptions include intervocalic plosives in aspectual verb stems (which originated diachronically in consonant clusters) and loanwords (for details, see Hellwig Reference Hellwig2019: 21–32). There is evidence for the phonemicization of these lenited consonants in some environments, though, and the list below therefore also contrasts voiceless plosive and lenited consonant phonemes (note that the relevant phonemic contrast is highlighted in bold in the orthographic form).

Voiceless plosives are unaspirated, and voiced plosives have strong pre-voicing, often involving prenasalization. Prenasalization of voiced stops is a widespread phenomenon across Melanesia, including in Papuan languages (Foley Reference Foley1986: 61–62; see also the typological sketches of different Papuan families in Palmer Reference Palmer2018). In our database we have 379 voiced plosive tokens, and of these, 222 (i.e. 59
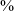 $\%$
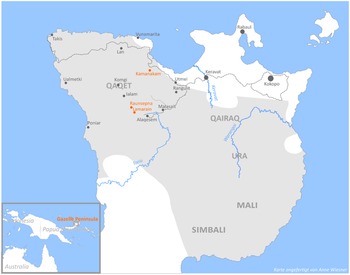
) were labelled as prenasalized [mb nd ŋɡ], and 157 were labelled as not being phonetically prenasalized. Prenasalization was marked when it was visible on the time waveform or spectrogram. Figure 2 shows two repetitions of the word gilmet /ɡilmət/ ‘split’. The first production contains a prenasalized /ɡ/, and the second token contains a non-prenasalized /ɡ/. It can be seen that the prenasalized portion (labelled N) contains greater energy in the time-waveform, and shows evidence of a clearer formant structure in the spectrogram. Note however that the non-prenasalized /ɡ/ contains very strong voicing, but that the overall token duration is shorter than the duration of the prenasalized /ɡ/.
$\%$
) were labelled as prenasalized [mb nd ŋɡ], and 157 were labelled as not being phonetically prenasalized. Prenasalization was marked when it was visible on the time waveform or spectrogram. Figure 2 shows two repetitions of the word gilmet /ɡilmət/ ‘split’. The first production contains a prenasalized /ɡ/, and the second token contains a non-prenasalized /ɡ/. It can be seen that the prenasalized portion (labelled N) contains greater energy in the time-waveform, and shows evidence of a clearer formant structure in the spectrogram. Note however that the non-prenasalized /ɡ/ contains very strong voicing, but that the overall token duration is shorter than the duration of the prenasalized /ɡ/.

Figure 2 Sample spectrogram and time-waveform of the word gilmet /ɡilmət/ ‘split’ spoken by speaker B. The first production contains a prenasalized /ɡ/, and the second token contains a non-prenasalized /ɡ/ (with the prenasalized portion labelled N, and burst/aspiration labelled H). The red line in the waveform shows f0 (range displayed: 100–300 Hz). The spectrogram shows the range to 5000 Hz.Footnote 3
Table 1a gives mean and standard deviation for closure duration for voiceless and voiced plosive tokens from six female speakers of Qaqet. The voiced plosives are separated into phonetically prenasalized and phonetically non-prenasalized (whereas the voiceless tokens are simply listed phonemically). All data in the table are non-final; in addition, the voiceless plosive data are not word-initial, since closure duration cannot be measured accurately in this position for voiceless plosives. For the voiced plosives, closure duration in initial position was measured from the onset of voicing. Table 1b gives the duration of the prenasalized portion of the phonetically prenasalized voiced plosive tokens.
Table 1 (a) Mean, standard deviation (SD) and number of tokens for closure duration for 743 plosive tokens. (b) Mean, standard deviation (SD) and number of tokens for prenasalization duration for the phonetically prenasalized voiced plosive tokens.

It can be seen that closure duration for the voiceless plosives tends to be around 100 ms. This long voiceless consonant duration may reflect historical morpho-phonological geminates. Historically, singleton plosives lenited to fricatives intervocalically, and the modern-day orthography represents this alternation by different graphemes. Thus, the remaining (apparently singleton) intervocalic plosives’ long duration may be a historical remnant. We refer the reader to Hellwig (Reference Hellwig2019: 326–334) for details of the historical evolution, as well as the full range of evidence.
The closure duration for the phonetically prenasalized voiced plosives also tends around 100 ms. Table 1b shows that around 60–70 ms of this is prenasalization. By contrast, the voiced plosives that are not prenasalized have greatly varying closure duration values, with mean values ranging from about 30 ms to 70 ms depending on place. Thus, one may conclude that an important function of the phonetic prenasalization of voiced plosives is to extend closure duration; one may further hypothesize that in this language, the very long closure durations of the voiced plosives are motivated by rhythmic considerations whereby duration of voiced plosives matches the duration of the very long voiceless plosives. The reader is referred to Tabain et al. (in press) for a more detailed phonetic study of prenasalization in Qaqet, which shows that the amount of prenasalization varies depending on place of articulation.
Table 2 shows burst/aspiration duration values (i.e. positive Voice Onset Time) for the Qaqet plosives (voiced plosive data are not separated for prenasalization in this table). Word-final tokens are excluded (these often have weak or no audible release). It can be seen that plosive burst duration is quite short, usually around 12–17 ms for all plosives except /k/, which is longer.
Table 2 Mean, standard deviation (SD) and number of tokens for burst/aspiration duration (i.e. positive Voice Onset Time) for 799 plosive tokens.


Figure 3 Source of Excitation for 799 plosive tokens. Data include any prenasalized portion of the voiced plosive. Data are time-normalized and smoothed using a Generalized Additive Model (with grey lines around each smoothed line indicating confidence intervals).
It must be noted that this very long voiced plosive closure contains very strong voicing throughout. Figure 3 shows the Strength of Excitation (SoE) for the 799 tokens presented in Table 2, as measured by VoiceSauce (Shue Reference Shue2010, Shue et al. Reference Shue, Keating, Vicenik and Yu2011, Vicenik, Lin, Keating & Shue Reference Vicenik, Lin, Keating and Shue2020) interfaced with EMU (Winkelmann, Harrington & Jänsch Reference Winkelmann, Harrington and Jänsch2017, Winkelmann et al. Reference Winkelmann, Jaensch, Cassidy and Harrington2019) and the R statistical package (R Core Team 2020). Strength of Excitation is a measure of voicing intensity calculated over a short interval of time around each individual glottal closure. Voiced plosive data include any prenasalized portion. It can be seen that SoE rapidly becomes weaker for the voiceless plosives; however, for the voiced plosives, SoE remains strong throughout closure duration. An analysis of SoE according to whether or not the voiced plosives were prenasalized (not shown here) suggests that prenasalized tokens have a greater Strength of Excitation than non-prenasalized tokens – however, even the non-prenasalized voiced plosives have consistently greater SoE values throughout token duration than the voiceless plosives. This suggests the possibility of at least some nasal leakage even in the non-prenasalized tokens, which serves to maintain strong voicing throughout consonant closure.
Qaqet also has three nominally-fricative phonemes. Alveolar /s/ is the only fricative phoneme in the language whose diachronic origin is unknown, while both /β/ and /ɣ/ originated diachronically in voiceless plosives that lenited in intervocalic position (as outlined above). Their different historical trajectories are reflected in their realizations. Whilst the alveolar sibilant /s/ is clearly always a fricative, the voiced bilabial /β/ (written <v>) is often pronounced as a glide, and the voiced ‘velar’ /ɣ/, written <q>, varies greatly between a glide and a fricative. More importantly, /ɣ/ varies greatly in place of articulation, ranging from uvular to velar to palatal. The variability is across both speakers and to a lesser extent across lexical items, but it does not appear to have a clear sociolinguistic function (however, the possibility of a morphological influence on individual speaker productions – for example, a difference in height of palatal vault – cannot be discounted). In general the variability is between velar and uvular, with a palatal (glide) realization more likely to be found in a front vowel context. We place this sound in the velar fricative cell because of its diachronic origin in the velar plosive /k/. Phonetically, however, it could more accurately be described as occupying its own space in the post-palatal continuant region of the consonant chart.
Figure 4 shows harmonic-to-noise ratio values in four frequency bands: 0–500 Hz (HNR05), 0–1500 Hz (HNR15), 0–2500 Hz (HNR25), and 0–3500 Hz (HNR35). Broadly speaking, sonorants have a higher harmonic-to-noise ratio than fricatives, and this is usually more evident in higher frequency bands where fricatives tend to have more energy (especially sibilant fricatives such as /s/). Data are plotted for the alveolar sonorants /l n/, the fricative /s/ and the fricative/glides /ɣ/ and /β/. It can be seen that in general, /ɣ/ patterns between the sonorants and the fricative /s/. More importantly, it can be seen that the variability is greater for /ɣ/ than for these various alveolars, confirming our impression that /ɣ/ varies greatly between fricative and glide. Moreover, when we plot speakers individually (not shown here), we see that some speakers tend to have /ɣ/ pattern more closely with the sonorants, and other speakers tend to have /ɣ/ pattern more closely with the fricative. A similar pattern can be seen for /β/, though to a lesser extent as compared to /ɣ/.
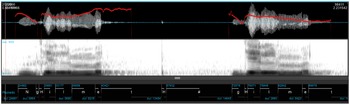
Figure 5 shows examples of /ɣ/ as produced by two different speakers from our database – one who tends towards a more consistently fricative production (speaker A), and one who tends towards a more consistently glide production (speaker B).

Figure 4 Boxplots of harmonic-to-noise ratio values in four frequency bands: 0–500 Hz (HNR05), 0–1500 Hz (HNR15), 0–2500 Hz (HNR25), and 0–3500 Hz (HNR35). Data are plotted for the alveolar sonorants /l n/, the fricative /s/ and the fricative/glides /ɣ/, written <q>; and /β/, written <v>. Data are sampled at the temporal midpoint of the consonant. Data are for 1773 tokens from six female speakers: 382 /l/; 350 /n/; 525 <q>; 373 /s/; 143 <v>.

Figure 5 Sample spectrograms and time-waveforms of the words (a) airiqim /airiɣim/ ‘scraper’ (second repetition) as spoken by speaker A, and (b) aqenaqaqa /aɣənaɣaɣa/ ‘breathlessness’ (second repetition) as spoken by speaker B. The first spectrogram contains a fricative realization of /ɣ/ (labelled <q>) and the second spectrogram contains glide productions of this same sound. The red line in the waveform shows f0 (range displayed: 100–300 Hz). The spectrogram shows the range to 5000 Hz.
Note: The formants presented in this figure, and the f0 data presented in Figure 10, were estimated using the Snack pitch and formant tool (Sjölander Reference Sjölander2014).

Figure 6 Boxplots of F1 and F2 values for the alveolar sonorants /l n/ and the fricative/glides /ɣ/, written <q>; and /β/, written <v>. Data are sampled at the temporal midpoint of the consonant. Data are for 1400 tokens from six female speakers: 382 /l/; 350 /n/; 525 <q>; 143 <v>.
Figure 6 shows F1 and F2 values for the same dataset as Figure 4 above (minus /s/), taken at the temporal midpoint of the consonant. It can once again be seen that /ɣ/ has much more variability than any of the other consonants in the plot. In general /ɣ/ also has a higher F1 than the other consonants, which may indicate a tendency towards a more uvular place of articulation. An examination of violin plots for these data (not shown here) suggested a small possibility of a bimodal distribution in F1 for /ɣ/, though in general the data were evenly spread across a wide range of values (note also that it is difficult to compare across the different manners of articulation plotted here, for instance given the very low F1 typical of nasal consonants). At the same time F2 is lower for both /ɣ/ and /β/, which may reflect the more ‘grave’ feature of velars and labials (i.e. the lower spectral centre of gravity for these sounds). However, it is clear that articulatory work is needed to clarify the place of articulation of /ɣ/ for different speakers and for different phonological environments. The most important point to note is the extreme variability in F2 for /ɣ/, indicating that the sound likely varies greatly in place of articulation. When data are plotted for each speaker individually (not shown here), the pattern remains similar, i.e. slightly higher F1 and slightly lower F2 for /ɣ/, accompanied by extreme variability compared to the other sounds. Again, it is not evident to us that there is any sociolinguistic patterning to this variation (e.g. by age or hamlet).
Qaqet also has four nasal consonant places of articulation: bilabial, alveolar, palatal and velar. However, the palatal is lexically less frequent (for instance, in our database there are only 66 tokens of /ɲ/, compared to 660 /m/, 350 /n/ and 297 /ŋ/), and it does not appear to occur before /ə/.
Finally, Qaqet has three liquid phonemes: the alveolar lateral /l/, the alveolar trill/tap /r/ and the retroflex flap /ɽ/. Figure 7 shows formant values sampled 10 ms to the left of the liquid consonant, and 10 ms to the right of the liquid consonant. It can be seen that the retroflex flap is distinguished by lower F3 and F4 to the left of the consonant; however, there appears to be greater variability for this sound compared to the F3 and F4 values to the left of the consonant for the other liquids /r/ and /l/. This is in line with our auditory impression, whereby we sometimes found it difficult to distinguish the retroflex flap from an alveolar tap. Historically, the retroflex flap may be a recent development of /r/ plus a schwa (Hellwig Reference Hellwig2019: 36–37). As may be expected, the lateral /l/ is distinguished from /r/ and /ɽ/ by its greater duration (typically around 100 ms for /l/), greater RMS energy, and a steady-state formant structure.

Figure 7 Boxplots of F1, F2, F3 and F4 values for the liquids /l r ɽ/. Data are sampled 10 ms to the left of the consonant (top row), and 10 ms to the right of the consonant (bottom row). Data are for 628 intervocalic tokens from six female speakers: 190 /l/; 174 /r/; 264 /ɽ/.
Figure 8 shows a spectrogram of the word amerlanus /aməɽanus/ ‘plate, leaf’, which contains the retroflex flap. This spectrogram shows the characteristically very brief duration of this sound, as well as its greatly reduced spectral energy when compared to adjacent vowels. It also shows the very low spectral centre-of-gravity of the preceding formant transitions (i.e. low or falling F2, F3 and F4). This example may be compared with the example of /r/ in Figure 5a above – in that example, /r/ has a considerably longer duration (albeit also a very low spectral energy), and there is evidence for perhaps three contacts between the active and passive articulators in the trilled (and somewhat fricated) production.

Figure 8 Sample spectrogram and time-waveform of the amerlanus /aməɽanus/ ‘plate, leaf’ (first repetition) as spoken by speaker A. The red line in the waveform shows f0 (range displayed: 100–300 Hz). The spectrogram shows the range to 5000 Hz.
Vowels

Qaqet has four phonemic monophthong vowels /i ə a u/Footnote 4 (represented orthographically as <i e a u>). Figure 9 presents F1 and F2 values for 3401 vowel tokens (note that 570 /a/ tokens with F1 less than 500 Hz were excluded). In addition, Qaqet has three phonemically long vowels /iː aː uː/. However these long vowels are not lexically frequent – for instance, in our database, there are 3496 tokens of /i a u/, but only 52 tokens of their long counterparts – see Table 3 below. They are realized as more peripheral in the vowel space than their short counterparts (the long vowels are not shown on Figure 9). The list below gives near minimal pairs illustrating contrasts between short vowels and between short and long vowels. We also include examples of diphthongs, but do not give minimal pairs due to their rarity in the language.

Figure 9 Formant plot of Qaqet vowels based on 3401 tokens from six female speakers (note that /a/ vowel tokens with F1 less than 500 Hz were excluded from this plot, since these tended to be mis-trackings).

Table 3 gives mean, standard deviation (SD) and number of tokens for vowel duration. It can be seen that while /i a u/ durations tend to range from about 110–150 ms, /iː aː uː/ durations tend to range from about 180–200 ms. If one pairs the mean values for vowels of the same quality (e.g. /a/ with /aː/), it can be seen that long vowels are about 1.4 –1.6 times the duration of short vowels.Footnote 6
Table 3 Mean, standard deviation (SD) and number of tokens for vowel duration for 4155 vowel tokens, as produced by six female speakers of Qaqet.

By contrast, the phonemic schwa vowel is very short, at around 50 ms. Hellwig (Reference Hellwig2019) discusses the phonemic status of this vowel and contrasts it with what is often termed an ‘epenthetic’ vowel in Papuan languages (see Blevins & Pawley Reference Blevins and Pawley2010, Hall Reference Hall2006), but that perhaps may be better characterized as an excrescent vowel – that is, a vowel that results from an open transition between two consonants. The non-phonemic schwa vowel may be considered excrescent, rather than epenthetic, since there is no sense that it is inserted to break up an illegal phonological cluster. By contrast, evidence for the existence of a phonemic schwa comes from morphophonemic alternations. Here, schwa behaves exactly like the three other vowel phonemes and, e.g. triggers the lenition of voiceless plosives. Speakers agree on the presence of the phonemic vowel when asked for an orthographic representation, but do not write the excrescent vowel, whose presence is indeed highly variable across speakers and across lexical items. In our database of six female speakers, we marked 133 instances of excrescent schwa based on a clear vowel-like formant structure between segments. Of these 133 segments, 107 were adjacent to /r/ or /ɽ/ in words such as [mraɽik] ∼ [mᵊraɽik] ‘cross’. Of the 28 remaining excrescent schwas, all were between /s/ and a nasal consonant, except for one token between /l/ and /β/. The mean duration for this excrescent schwa was 57 ms (SD 37.4), which is very comparable to the duration for phonemic schwa in Table 3 (for which there were 475 tokens). Moreover, the excrescent schwa formants overlapped almost exactly with the phonemic schwa formants in an F1–F2 vowel space. It is possible that we underestimated the number of excrescent schwas in the database, since we did not label tokens where we perceived the excrescent schwa, but where a formant structure was not immediately obvious to the human labeller (e.g. a devoiced schwa between /s/ and /n/). For examples, see section on syllable structure below.
Qaqet also has the diphthongs /ia iu ai au ui ua/. These sequences of sounds are analyzed as VV (as opposed to V+glide) due to the lack of phonemic glides in the language. The diphthongs are mostly loans from Tok Pisin, the national language of Papua New Guinea, and some of them are not lexically frequent. For instance, in our database there are 216 diphthong tokens, ranging from six tokens of /iu/ to 97 tokens of /ai/. However, there is tremendous variation in the realization of the diphthongs both across speakers and across lexical items, with many productions being monophthongal despite a longer duration (e.g. /ai/ is often realized as [ee], as in the word ailany ‘foot, leg’ given in the consonants table above). For these reasons we do not present a plot of average diphthong trajectories here, and instead suggest that further study is needed of this variability. The reader is once again referred to Hellwig (Reference Hellwig2019) for further discussion.
Syllable structure
Like many East Papuan languages, Qaqet allows for initial consonant clusters and word-final consonants. The syllable structure template can be summarized as (C)(C)V(V)(C).Footnote 7 The nucleus is either a short vowel, a long vowel or a diphthong. The syllable can end in a coda consonant, but this consonant cannot be a voiced plosive, a fricative (except /s/) or /r/. This leaves the following possibilities: voiceless plosives (/p t k/), fricative /s/, nasals (/m n ɲ ŋ/) and liquids (/ɽ l/). In the case of a simple onset, all consonants are attested. Examples of simple onsets, simple codas and nuclei have been given above (see also Hellwig Reference Hellwig2019: 47).
In addition, Qaqet has complex onsets. They usually consist of an obstruent followed by a sonorant, but there are also clusters of a nasal followed by a liquid. In the latter case, we often observe the presence of an excrescent schwa. It is likely that consonant clusters originated diachronically through the loss of a phonemic schwa vowel. It is also possible that remnants of this historical schwa remain in the open transition often observed between consonants in a cluster, as discussed above. The reader is referred to Hellwig (Reference Hellwig2019) for further discussion of the status of schwa.

Stress
Qaqet does not have lexical stress. There are no minimal pairs, and there is no evidence for the existence of metrically strong syllables as anchor points for post-lexical pitch accents.
Figure 10 shows syllable duration, mean f0 and mean RMS energy, for words varying from one to six syllables in length. Syllables boundaries were marked according to the maximum onset principle. It can be seen that there is no effect of syllable position on mean f0 (although there is generally greater variability in f0 on the final syllable of the word, most likely due to the fact that the data are taken from word-list recordings). Similarly, there is no effect of syllable position on mean RMS energy (although there may be a tendency for some initial and final syllables to have less energy).

Figure 10 Syllable duration, mean f0 and mean RMS energy, for words varying from one to six syllables in length. Data are based on 620 different lexical items. Plots show 71 word tokens of one syllable; 263 word tokens of two syllables; 397 word tokens of three syllables; 398 word tokens of four syllables; 143 word tokens of five syllables; and 21 word tokens of six syllables, giving a total of 4221 syllables in each plot.
By contrast, there is a clear effect of syllable position on duration. It can be seen that, broadly speaking, final lengthening extends over the last (two-to-)three syllables of the word. It should be noted that these plots show different types of syllables combined, and teasing out the relative contribution of vowel and consonant to this final lengthening will require more work. Preliminary results suggest that if vowel data only are plotted (rather than the entire syllable), the f0 and RMS data are the same, but the duration data shows lengthening mostly on the final syllable. This suggests differential effects of phrase-final lengthening on consonants and vowels. Hellwig (Reference Hellwig2019) notes that the (phonemic) schwa vowel does not show effects of final lengthening (an effect which is consistent with the ‘non-elastic’ nature of this vowel cross-linguistically – see Tabain Reference Tabain2016), and it is likely that the consonant is proportionately more lengthened in this case.
The following examples (containing non-schwa vowels) illustrate lengthening over the final two-to-three syllables of the word:


Preliminary analyses suggest that this final lengthening is accompanied by intonational phenomena which mark the right edge of prosodic units. Hellwig (Reference Hellwig2019: 52–63) presents a preliminary inventory of such pitch movements, including example pitch tracks, and discusses their contours and pragmatic functions: final (final fall), non-final (final rise–fall), continuation (final level + glottalization), list (final rise), content question (fall), quoted content question (initial rise + final fall), polar question (final rise–fall) and imperative ((initial rise) + final rise). An example of a list contour followed by a final fall can be seen in Figure 2 above, where the word gilmet is repeated for the recording. The other spectrogram examples in this Illustration highlight the generally flat f0 contours on the prosodic words in the language, with only microprosodic variation due to consonant.
Transcription of recorded passage ‘The Wind and the Sun’
The transcription is broadly phonemic, but including some phonetic details discussed in this paper (lenition of voiceless plosives, excrescent schwa, prenasalisation) as well as glottalisation (indicating hesitation pauses). The text also features two phenomena not discussed in this Illustration: cases of the reduction of full phonemic vowels to a very brief [ᵊ] (e.g. line 8: < nama qaqeraqa > [namᵊɣaɣəraɣa]); and cases of consonant assimilation within words: /r/ (and intervocalic /t/ → [r]) can be realized as [ɽ] if the word contains /ɽ/ (e.g. line 5: <raqurla> [ɽaɣuɽa]); line 2: <prerl> [pᵊɽəɽᵊ]). Both processes are not obligatory and vary greatly among individual speakers. Note that we represent long vowels and diphthongs in their phonemic form (e.g. line 7: <aiska> is represented as /aiska/, not [eeska]). Pause units are marked by | (minor phrase) and ‖ (major phrase). Qaqet distinguishes between non-final units (essentially exhibiting a level, global rise, or final rise–fall contour) and final units (usually, but not always, a global fall contour, plus pitch resets in the following units) (see Hellwig Reference Hellwig2019: 48–64). Non-final units are grouped together in one line.
The phonemic transcription is followed by a transcription in the practical Qaqet orthography and an English translation. The English translation attempts to follow the structure of the Qaqet original as closely as possible and is not idiomatic. On both lines, a comma indicates pauses and ..indicates hesitation pauses.

Acknowledgements
Our sincere thanks go to Rose Bonni, Betty Dangas, Martha Iaken, Clara Kimas, Gloria Kunas, Chris Mitparlingi, Lucy Rluses, Roberta Nakai, Joana Samisim, Maria Savarin, Joana Stadi, Monica Sunun, Lucy Sutit and Terry Tamiam who contributed recordings to this illustration, and to Henrike Frye who did most of the recordings. We would also like to thank Adele Gregory for her careful labelling of the phonetic database, and Richard Beare and Sam Gregory for programming assistance. This research was made possible through funding from the Australian Research Council, the Endangered Languages Documentation Programme and the Volkswagen Foundation’s Lichtenberg program. We would also like to thank two anonymous reviewers, as well as editors Marc Garellek, Matthew Gordon and Jody Kreiman, for their comments on a previous version of this Illustration.
Supplementary material
To view supplementary material for this article (including audio files to accompany the language examples), please visit https://doi.org/10.1017/S0025100321000359.
Appendix. Contributors














 Open access
Open access