


1 INTRODUCTION
In recent years, astronomical instrumentation across a range of wavelength bands has improved to the point where high-resolution, sensitive surveys of large areas of the sky are becoming much more common (e.g. Benjamin et al. Reference Benjamin2003; Johnston et al. Reference Johnston2007). The higher data rates from new instrumentation and large surveys give the opportunity to collect detailed information on very large numbers of sources and undertake more sophisticated statistical investigations of their properties. This will enable both more reliable identification of sub-groups within the broader population, and identification of rare or unusual objects. However, these new instruments also present the astronomical community with a challenge of how best to extract the maximum utility from large volumes of data.
The desire to accurately and efficiently classify astronomical sources identified in large surveys into different groups is an increasingly common one. Attempts to develop efficient criteria for targeted searches for interstellar masers, is one specific example of an application of survey source classification. A number of studies have found that star-formation regions with an associated interstellar maser differ significantly in their infrared or millimetre continuum properties from the majority of the population (e.g. Ellingsen Reference Ellingsen2005, Reference Ellingsen2006; Chen et al. Reference Chen, Ellingsen, Shen, Titmarsh and Gan2011). In developing criteria for targeting future searches, it is desirable to identify a large fraction of the population of interest while including only a small number of sources which do not yield detections. In the terminology of classification, it is important to minimise both the number of false-negatives and false-positives. A related issue is in understanding the characteristics through which the classification has been achieved. For example, if you are able to develop efficient criteria for targeting a search for interstellar masers on the basis of infrared or millimetre continuum properties, what is the physical meaning of those characteristics—do they correspond to a particular mass range, or evolutionary phase of the associated high-mass star-formation region?
Maser emission occurs naturally in a range of astrophysical environments, including the molecular gas close to newly forming stars, the envelopes of late-type stars, and close to the nuclei of some active galaxies. Masers have proven to be a reliable signpost of the very early stages of high-mass star formation (e.g. Ellingsen Reference Ellingsen2006); with recent improvements in the availability of sensitive large-area surveys at mid-infrared through millimetre wavelengths, they are increasingly being used as tools to study high-mass star formation (e.g. Titmarsh et al. Reference Titmarsh, Ellingsen, Breen, Caswell and Voronkov2013). Masers can provide information on the dynamics of the star-formation region through observations of their kinematics (e.g. Goddi, Moscadelli, & Sanna Reference Goddi, Moscadelli and Sanna2011), on the magnetic field from observations of the polarisation (e.g. Surcis et al. Reference Surcis, Vlemmings, van Langevelde and Hutawarakorn Kramer2012), and potentially the presence and absence of different transitions can provide an evolutionary timeline (e.g. Ellingsen et al. Reference Ellingsen, Voronkov, Cragg, Sobolev, Breen, Godfrey, Chapman and Baan2007; Breen et al. Reference Breen, Ellingsen, Caswell and Lewis2010). If it is possible to use classification techniques to reliably identify which regions host different types of maser transition, then an understanding of the physical properties of those regions in combination with the maser-based evolutionary timeline could provide important insights into the formation of high-mass stars.
These types of classification problems are commonly encountered in a wide range of scientific disciplines, and from the broader literature we have been able to identify a number of commonly used classification techniques. When considering different classification methods, Breiman (Reference Breiman2001b) has suggested that there is a trade off between parametric techniques that are easy to interpret but not always as accurate, and non-parametric methods that are more difficult to interpret, but deliver a higher level of accuracy. Here, we use three different classification techniques to investigate their strengths and weaknesses when applied to the specific problem of efficiently identifying target sources for searches for interstellar masers. The three methods we have chosen for our investigation are linear discriminant analysis (LDA), logistic regression, and random forests. These three methods were chosen because they have proven effective across a wide range of problem domains, they are relatively easy to implement, and they include two parametric methods (LDA and logistic regression) and one non-parametric method (random forests).
LDA uses similar calculations and techniques to principal component analysis (PCA) which is quite widely used in astronomy (e.g. Lo et al. Reference Lo2009; Einasto et al. Reference Einasto, Liivamägi, Saar, Einasto, Tempel, Tago and Martínez2011). Kobel et al. (Reference Kobel, Hirzberger, Solanki, Gandorfer and Zakharov2009) used LDA in their classification of different photospheric magnetic elements on the Sun. They found that the predictions they were able to make on the basis of LDA showed good agreement with the results from previous studies. This can in part be credited to the semi-artificial segregation between the classes of photospheric magnetic elements, as the variables chosen were those with the most significant differences in brightness values. Logistic regression has been less commonly applied in astronomy than PCA, although it has previously been used to successfully identify which star-formation regions are more likely to host different types of interstellar masers (e.g. Breen et al. Reference Breen2007; Ellingsen et al. Reference Ellingsen, Breen, Caswell and Quinn2010). Yuan et al. (Reference Yuan, Shih, Jing and Wang2010) and Song et al. (Reference Song, Tan, Jing, Wang, Yurchyshyn and Abramenko2009) have both shown that logistic regression can be an effective means of predicting solar flares. Random forests are a relatively new, non-parametric classification technique which has proven to be very effective in other fields, such as ecology. Cutler et al. (Reference Cutler, Edwards, Beard, Cutler, Hess and Lawler2007) compared the results of classifying ecological data, using the same classification methods as are used here and found that random forests had the highest accuracy. Within astronomy, random forests have been used by Bailey et al. (Reference Bailey, Aragon, Romano, Thomas, Weaver and Wong2007) to improve the reliability of finding supernovae from images, while Carliles et al. (Reference Carliles, Budavári, Heinis, Priebe and Szalay2010) used them to assign photometric redshifts. Recently, they have also been used as the basis of processes for automated rapid classification and decision making. Morgan et al. (Reference Morgan, Long, Richards, Broderick, Butler and Bloom2012) used random forests as part of a method for making time-efficient recommendations as to which gamma-ray burst events are likely to be high-redshift in order to prioritise whether a specific event deserves additional observing time. They found that by observing the top 20% of recommended events, it was possible to identify 56% of the high-redshift bursts, while using the top 40% of recommendations allows identification of 84% of high-redshift events. Mirabal et al. (Reference Mirabal, Frías-Martinez, Hassan and Frías-Martinez2012) used random forests to accurately classify whether unidentified objects detected in Gamma-rays by the Fermi satellite were likely to be Active Galactic Nuclei (AGN) or pulsars (they achieved accuracies of 97.7 and 96.5% for AGN and pulsar identification, respectively).
To better understand the strengths and limitations of these different classification techniques, both in terms of their efficiency and the degree to which the outcomes of the classification process can be related to the properties of the astronomical sources, we compared their performance on three published datasets (Breen et al. Reference Breen2007; Ellingsen et al. Reference Ellingsen, Breen, Caswell and Quinn2010; Chen et al. Reference Chen2012). For each of these three sets of data, we applied the three classification techniques to make predictions as to which infrared (or millimetre) sources are likely to also be associated with masers. In Section 2, we describe in more detail each of the classification techniques used. The properties of each of the datasets are outlined in Section 3 where we examine the results of applying the different classification techniques in each case.
2 CLASSIFICATION TECHNIQUES
In the context of the current work, our data typically consists of astronomical sources for which a range of parameters (e.g. the intensity in a particular wavelength range) have been measured, along with parameters which are related to the quality or uncertainty in the measurement and others which identify the particular astronomical object (e.g. the source number or coordinates). These parameters are all potential inputs to the different classification techniques and we refer to these as predictor variables. In the field of machine learning, these are often referred to as features, however, as that term frequently has a different meaning in astronomical literature we do not use that terminology here. For some (sometimes all) of the sources in the data set, we also have information as to whether or not that source has an associated maser emission from a specific molecular transition. Hence, we are seeking to accurately classify our astronomical sources into two classes, those with an associated interstellar maser and those without.
2.1. Linear discriminant analysis
LDA finds the linear combination of predictor variables which maximises the separation of the different classes and minimises the variation within classes (Feigelson & Babu Reference Feigelson and Babu2012). LDA can be visualised geometrically as projection from a high-dimensional space onto a line. When given a new source to classify, LDA uses this linear combination to convert the high-dimensional data to a real number, and the classification of the sample is determined by comparing this number to a threshold value. The technique is relatively simple and so is unsuitable if there are complex, non-linear interactions between the variables. LDA is a technique of dimensionality reduction similar to PCA, which is more commonly used in astronomy. Both LDA and PCA attempt to model the data with linear combinations of the predictor variables; the difference is that PCA does not use classification information in producing the model, whereas LDA does (Feigelson & Babu Reference Feigelson and Babu2012).
The assumptions of LDA are that the data follows a multivariate normal distribution for each class, classes may have different means but are assumed to have the same variance structure. This makes LDA a parametric method in the sense that it assumes a particular model of the data. Most astronomical data are not normally distributed, so transformations of the variables are usually required. For each of the three datasets we studied, LDA was applied to both the original data and to the transformed data as a comparison. Data Set 2 required an inverse function to normalise the data (each predictor variable was transformed via a
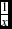 $\frac{1}{x}$
function). In the case of Data Sets 1 and 3 where the samples were naturally clustered, an inverse transformation would have destroyed the bimodality present. For this reason, a log transformation was selected as it improved the normality of the data while still being easy to interpret.
$\frac{1}{x}$
function). In the case of Data Sets 1 and 3 where the samples were naturally clustered, an inverse transformation would have destroyed the bimodality present. For this reason, a log transformation was selected as it improved the normality of the data while still being easy to interpret.
LDA models were fitted using the lda function in R (R Core Team 2013, part of the MASS package), we left the prior input parameter at its default setting which is to assume that probability of being in a particular class is equal to the relative frequency of the class in the training data.
2.2. Logistic regression
Logistic regression is a form of generalised linear modelling (GLM) that is used to predict the probability of an event occurring; in this case, whether or not an astrophysical source has an associated interstellar maser. The probability of occurrence P is calculated from
 $$\begin{equation*}
P = \frac{1}{1+e^{-z}},
\end{equation*}$$
$$\begin{equation*}
P = \frac{1}{1+e^{-z}},
\end{equation*}$$
where z = b 0 + b 1.x 1 + ⋅⋅⋅ + bn .xn , the b values are regression coefficients and the xi values are the predictor variables. P is then compared to a cut-off threshold of 0.5 (50% likelihood) to determine whether an object is predicted to have an associated maser, or not. Like LDA, logistic regression is also a parametric method.
Linear regression assumes that the response variable is normally distributed, in contrast logistic regression assumes that the response variable follows a binomial distribution (which is applicable in our case of two classes). This means that the method of least squares (used in linear regression), cannot be applied to logistic regression (Hosmer & Lemeshow Reference Hosmer and Lemeshow2000). Instead, maximum likelihood (formulated by Fisher Reference Fisher1922) is used to estimate the parameters of the model. The likelihood function is calculated using the product of contributions to the model from each of the predictor variables (Hosmer & Lemeshow Reference Hosmer and Lemeshow2000).
Logistic regression was implemented using the function glm which is part of the base R package (R Core Team 2013). To perform a logistic regression, the family option in glm is set to binomial and the link function is set to logit. It was not feasible to alter any other input parameters in the function to produce our models.
2.3. Random forests
Classification trees are a non-parametric technique of classification (in contrast to both logistic regression and LDA), which means that they do not assume an underlying model of the data (Cutler et al. Reference Cutler, Edwards, Beard, Cutler, Hess and Lawler2007; Carliles et al. Reference Carliles, Budavári, Heinis, Priebe and Szalay2010). Classification trees can be more accurate than parametric approaches when complex interactions occur between the predictor variables. This could be the expected case for maser association with infrared or millimetre sources, as well as a broad range of astronomical classification problems. Individual classification trees may not be very accurate, especially when there are more than a few predictor variables, however, a collection of trees grown independently on randomly perturbed versions of the data greatly increases the accuracy of predictions (Breiman Reference Breiman2001c; Cutler et al. Reference Cutler, Edwards, Beard, Cutler, Hess and Lawler2007). Random forests work by producing large numbers of classification trees and then determining the classification of a particular sample (in our case, an astronomical source) by allowing each of these trees to ‘vote’ and then taking the majority rule (Breiman Reference Breiman2001a). This voting system is also how the probability of a sample being classified into a certain group is calculated; by dividing the number of trees voting for a certain classification by the total number of trees.
To produce individual classification trees in a random forest, a bootstrap sample is selected for each tree. For a data set with N entries, N samples are taken. Because sampling is done with replacement, approximately two-thirds of the original data occurs at least once in each bootstrap sample (Efron & Tibshirani Reference Efron and Tibshirani1994). Hastie, Tibshirani, & Friedman (Reference Hastie, Tibshirani and Friedman2001) showed that bootstrap sampling causes the variance of the estimated class to converge to a lower limit when more trees are added to the forest, and so rarely overfit (Breiman Reference Breiman2001c). A classification tree is grown from each bootstrap sample using recursive binary partitioning. The branching points of the trees are called nodes. In standard trees, the predictor variable at each node is chosen based on the best split, which is determined by the Gini index (a measure of statistical dispersion, see Hastie et al. Reference Hastie, Tibshirani and Friedman2001, pg 271). In a random forest, the variable providing the best split is chosen from a random subset of predictor variables (Liaw & Wiener Reference Liaw and Wiener2002). The predictor variable and the subset of predictor variables from which it is chosen is independent of any other nodes’ variable choices. This approach decreases the dependence between individual trees. The splitting process continues until further subdivision no longer decreases the Gini index. The final classification given by each tree depends on the terminal node the source has been allocated to.
A nice feature of random forests is that they have an inbuilt way of estimating the classification error because of the use of bootstrapping to select slightly different data for each tree. Data not included in the bootstrap sample (approximately one-third of observations) for a particular tree are referred to as out-of-bag (oob) values. The tree grown from each bootstrap sample is used to predict the classification for each of the oob values, giving an estimate of the classification error as well as a means to compare the importance of each variable in the classification process (Breiman & Cutler Reference Breiman and Cutler2013). The importance of a variable is expressed by the difference between the probability of predicting the class correctly in shuffled oob data (the sample order is rearranged to eliminate systematic errors) compared to the unshuffled oob data (Cutler et al. Reference Cutler, Edwards, Beard, Cutler, Hess and Lawler2007).
Random forests also give a natural metric for determining the similarity of two different astronomical sources (or other groups of samples). Proximities between two sources are calculated in the random forest process. If a pair of sources end up in the same terminal node, their proximity is increased by one. Similar source pairs end up in the same terminal node more often than dissimilar ones. The proximities are then normalised (divided by the total number of trees) and the proximity of a point and itself is set to be one. The proximities are then expressed as a symmetric matrix, where the diagonal entries all have the value one. The proximity matrix can be used as input for multi-dimensional scaling (MDS), as a way of visualising the classification results (displayed in Section 3).
A potential drawback of random forests is that they cannot be used to directly test hypotheses (Cutler et al. Reference Cutler, Edwards, Beard, Cutler, Hess and Lawler2007). They also do not give a clear representation of the actual classification process. However, although the internal calculations are difficult to interpret, they produce useful properties such as relative variable importance and an estimate of the classification error without extra external calculations (Breiman & Cutler Reference Breiman and Cutler2013).
To create the random forests used in the modelling and classification, we used the R function randomForest (in the randomForest package). For an introduction to the usage and features of randomForest functions in the R environment, see Liaw & Wiener (Reference Liaw and Wiener2002). There are a number of parameters that can be varied when growing the random forest in order to optimise its classification and predictive accuracy. These include the number of trees in the forest, the number of variables randomly sampled as candidates at each split, and the maximum number of terminal nodes in the trees. The minimum size of the terminal nodes can also be varied, where a larger number leads to smaller trees which take less time to grow. Setting the node size to k means that no node with fewer than k cases will be split (Breiman & Cutler Reference Breiman and Cutler2013). A terminal node size of 1 is therefore the most accurate, but in cases with large datasets, memory constraints may require this to be higher. We found that altering these parameters did not consistently increase the sensitivity or specificity significantly, so the default values for the parameters were used: 500 trees grown in the forest, a node size of 1 (default for regression is 5), and the maximum possible number of terminal nodes. The default number of variables chosen at each split is
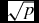 $\sqrt{p}$
for classification and p/3 for regression (rounded to the nearest integer), where p is the total number of predictor variables in the data set. Other factors that can be varied are whether or not the cases are sampled with replacement (the default, which we used, is with replacement), and the prior probability of each class occurring can also be set with the default being to assume equal class probabilities.
$\sqrt{p}$
for classification and p/3 for regression (rounded to the nearest integer), where p is the total number of predictor variables in the data set. Other factors that can be varied are whether or not the cases are sampled with replacement (the default, which we used, is with replacement), and the prior probability of each class occurring can also be set with the default being to assume equal class probabilities.
For both Data Set 2 and 3 (where predictions were done), random forests were grown using 3 000 trees rather than the default 500. Since each tree is grown independently, this is equivalent to combining the results of multiple smaller forests. 3 000 trees was chosen for both data sets because this produced the most accurate results in the cross validation. Generally, random forests is robust against over-fitting (see Breiman Reference Breiman2001c), however, in the case of Data Set 2, due to the very small training set compared to its number of predictor variables, more than 3 000 trees decreased the classification accuracy. In the case of Data Set 3, using more than 3 000 trees had no effect.
2.4. Accuracy of classification techniques
There are four possible outcomes of the classification of each astronomical source. The two desired outcomes are that the classification technique can correctly identify a source which does have an associated maser (a ‘true positive’), or it can correctly identify a source as not having a maser (a ‘true negative’). A perfect classification would have all samples with one or the other of these outcomes. There are however, two ways in which the classification scheme can give an incorrect outcome and depending on the circumstances these are not necessarily of equal importance. A ‘false positive’ outcome is where a source which does not have an associated maser is classified as being associated with one, while a ‘false negative’ occurs when a source which does have an associated maser is classified as not having one associated (see the Confusion Matrix in Table 1).
Table 1. The relationship between the four possible classification results and the calculated values of the sensitivity and the specificity.

For each classification method, we calculated both the sensitivity (known as recall in machine learning) and specificity. In this context, the sensitivity, or true positive rate (TPR), is the percentage of maser associations correctly predicted by the model, and specificity is the percentage of maser non-associations correctly predicted, or the true negative rate (TNR).
 $$\begin{equation*}
\mbox{Sensitivity (TPR)} = \frac{\mbox{True Positives}}{\mbox{True Postives + False Negatives}}
\end{equation*}$$
$$\begin{equation*}
\mbox{Sensitivity (TPR)} = \frac{\mbox{True Positives}}{\mbox{True Postives + False Negatives}}
\end{equation*}$$
 $$\begin{equation*}
\mbox{Specificity (TNR)} = \frac{\mbox{True Negatives}}{\mbox{True Negatives + False Positives}}
\end{equation*}$$
$$\begin{equation*}
\mbox{Specificity (TNR)} = \frac{\mbox{True Negatives}}{\mbox{True Negatives + False Positives}}
\end{equation*}$$
2.4.1. Predictor variable importance
Logistic regression performed using R has two techniques for determining the importance of the variables included in the model. The first is a set of p-values provided when the logistic regression is performed. The second is the in-built stepAIC function, which includes all possible predictor variables in the starting model and iteratively removes variables which do not significantly contribute to the model to yield the most parsimonious model with the greatest predictive power. To determine which variables to include in the logistic regression models, we used a combination of the stepAIC function and manual variable selection. Variables that did not increase the accuracy of the model were excluded (see Section 3).
For LDA, variable selection was done manually. We used the logistic regression’s selection as a starting point, and then included additional predictors if they improved the prediction accuracy.
Random forests includes an internal calculation of the mean decrease in accuracy for each of the variables utilised, which is a measure of how poorly the model performs when that variable is not included. Thus, the higher the value is, the more the predictor variable contributes to the accuracy of the model. Negative values decrease the accuracy and values close to zero offer little or no effect. It is worth noting that random forests is potentially robust enough to deal with all available variables and so including them all in the model does not generally decrease the accuracy significantly (Feigelson & Babu Reference Feigelson and Babu2012).
2.4.2. Cross validation
The aim of classification is to build models that will generalise well to new data. When constructing models, there is a danger in over-fitting to the training data. In order to determine the accuracy of each of the classification methods on the three data sets, we used a 10-fold cross validation technique. Using a fitted model that has been trained on a randomly chosen 90% of the data, the classification of the remaining tenth is predicted. This procedure of training and prediction is then repeated 1 000 times in order to obtain an estimate of the classification error. Repeating the cross validation ensures that a high number of the possible combinations of the data are used, reducing sampling bias associated with randomly folding the data. Repeated 10-fold cross validation of this kind is especially useful when modelling a random forest as the over-fitting associated with regression tree techniques is compensated for by the generous error estimation of the cross validation (Borra & Di Ciaccio Reference Borra and Di Ciaccio2010).
In repeated 10-fold cross validation, the results from the multiple runs are averaged. In this case, the averaged cross validation produced a mean probability of being associated with a maser for each sample. A source was classified as a maser if the probability was 50% or above. The percentage of predicted classifications were then compared to the actual classifications (maser source or non-maser source) to determine the accuracy for each model for each of the three data sets. Adjusting the cut-off threshold for maser classification from 50% was also investigated to explore the trade-off between sensitivity and specificity of the model. This is useful information to have available when it is important to obtain all the positive classifications, even when it means many false positives are given, and alternatively the model can be adjusted so that there is only a very small chance of a false positive, at the expense of false negative classifications. The receiver operating characteristic (ROC) curves (explained in Section 2.4.3), display the results of this analysis.
2.4.3. Receiver operating characteristic curves
An ROC curve plots the TPR (sensitivity) against the false positive rate (1 − specificity), effectively showing the trade-off in prediction power for accuracy in a given classification model. The diagonal line y = x represents randomly classifying the samples, with half predicted as positive and half as negative. Anywhere in the space above, this line means that the model is better than random classification, with the best possible system showing 100% sensitivity with no false predictions, resulting in a point in the top left-hand corner. ROC curves were plotted here to compare each classification method for each data set in Figures 2, 5, and 8.
3 RESULTS
3.1. Water masers associated with star-formation regions in the RCW106 giant molecular cloud
Breen et al. (Reference Breen2007) undertook a complete search for 22 GHz water masers within the giant molecular cloud RCW 106. This search detected nine 22 GHz water masers and the region searched included 73 1.2-mm dust clumps observed and characterised by Mookerjea et al. (Reference Mookerjea, Kramer, Nielbock and Nyman2004). Seven of the dust clumps were found to be associated with masers (Breen et al. Reference Breen2007). Breen et al. used a form of logistic regression called binomial GLM to investigate the properties of the astronomical sources (in this case dust clumps) with and without water masers in RCW106. They found that water masers were associated with those sources which are denser, more massive, and have higher luminosity.
There are clear differences in the values of all the predictor variables between those sources with an associated water maser and those without, as is demonstrated by the boxplots shown in Figure 1. However, it should be noted that there are varying degrees of overlap in the ranges observed for the maser associated sources and those which are not. The obvious difference in the distributions for all the predictor variables means that we might expect that they should all contribute to the classification and that the relative importance might also be similar. The variable importance ratings returned by the random forest classification are a measure of the degree to which the classification trees utilised each predictor variable. The five predictor variables available as inputs for the classification process were : peak flux density, source radius, total integrated flux density, dust mass (calculated assuming a temperature of 40 K and optically thin dust emission), and column density. Using only source radius and the total integrated flux density provided the highest accuracy for random forests, logistic regression and LDA, while LDA using the ‘normalised’ data (transformed using a log function, see Section 2.1) was able to utilise the column density too. Table 2 shows the comparison of which of the predictor variables were included in the models based on their contributions to an increase in classification accuracy. Breen et al. (Reference Breen2007) showed that their sample of water masers preferred denser, more massive and more luminous sources. Our models indicated that the radius, luminosity and in the case of LDA on the normalised data, the density were important variables in predicting whether the sources were associated with a maser or not. Our results are in agreement with Breen et al. (Reference Breen2007), except that our models were not improved by inclusion of mass as a predictor variable.

Figure 1. Boxplots comparing the variables from Data Set 1 between the sources with an associated water maser and those without. The outline in each of the boxplots represents the range between the first and third quartiles, with the median being the solid line horizontally through the box. The vertical lines outside the box extend to the minimum and maximum values, with any outliers (values separated from the quartiles by more than one and a half times the interquartile range) shown separately as dots. In this case, due to the very small number of samples being associated with a maser in this data set, the individual sample points are also plotted.
Table 2. The predictor variables that increased the classification accuracy of the various methods for Data Set 1. Random forests provides an internal calculation of the mean decrease in accuracy (the higher the value, the more important the variable), logistic regression provides p -values (the lower the value, the more significant the variable’s contribution to the model), and LDA provides no internal measurement of the importance of each variable, so it is just noted which variables were used (see Section 2.4.1).

Table 3 summarises the results we obtained from cross validation of the three different classification techniques under consideration (for details, see Section 2.4.2). Specificity values were high, due to the fact that the majority of the sources were not associated with masers, with the sensitivity values being lower in each case. For Data Set 1, random forests performed the best considering both sensitivity and specificity. Notably, there are very few false positive classifications over all the models, which is most likely due to the data being unbalanced in that the majority of the samples were not associated with masers. Another clear result is that performing LDA on the log transformed data increases the model’s sensitivity, making it comparable to logistic regression in this case. The advantage of transforming the data is also obvious in the ROC shown below in Figure 2 (for an explanation on ROC curves, see Section 2.4.3).

Figure 2. Receiver operating characteristic curves showing the results of the cross validation for Data Set 1. The diagonal line y = x represents randomly classifying the samples, with half predicted as positive and half as negative. For definitions of classification results, see Section 2.4.
Table 3. The results of cross-validating random forests, logistic regression, and LDA (without and with transformation of the predictor variables) classification and prediction for Data Set 1.

Figure 2 shows that LDA under-performs for Data Set 1, however, when LDA is applied to the transformed data it is more accurate than logistic regression. The relatively small data set causes the apparent steps in the plot and this is also evident for Data Set 2 in Figure 5. The ROC curves for Data Set 3 (Figure 8) are much smoother because there are 214 samples rather than 73, or 32. Despite the apparent steps in the ROC curves, the plot very clearly shows the most accurate classification technique for this data set (the non-parametric method of random forests) and the least accurate (the parametric method of LDA using untransformed data).
Figure 3 shows a MDS plot for the full data set. MDS plots give a visual representation of the distances between proximities identified in the random forest implementation; sources that the random forest process identifies as being similar are clustered within the MDS plot. The distance values are arbitrary, they are simply relative magnitudes, plotted here as Dimension[1] and Dimension[2]. Figure 3 shows the four correctly identified maser sources in a group at the top-left, separated from the non-maser sources. ‘Border-line’ classifications were samples with a predicted maser association between 45 and 55%, with the last correctly classified maser shown just below the others as such. The model was not sensitive enough to detect the differences in the predictor variables for the other maser-associated sources (which is why they were classified as not having an associated water maser). This is probably due to the small number of sources in this data set.

Figure 3. MDS plot of the proximity values produced by the random forest classification (Data Set 1). The values on the axes are arbitrary, the graph just compares relative magnitudes. The closer two points are on the plot, the more similar their properties as determined by the random forest classification. ‘Border-line’ classifications were samples with a predicted maser association between 45 and 55%.
3.2. The properties of water maser-associated YSOs in the LMC
Gruendl & Chu (Reference Gruendl and Chu2009) used the Spitzer Space Telescope Surveying Agents of Galaxy Evolution (SAGE) Legacy programme data (Meixner et al. Reference Meixner2006), along with other public data sets to identify high- and intermediate-mass young stellar objects (YSOs) in the Large Magellanic Cloud (LMC). Gruendl & Chu identified 855 definite YSOs in the LMC and compiled near- and mid-infrared photometric measurements for the sample. Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010) made Australia Telescope Compact Array (ATCA) observations for the 22 GHz transition of water towards all known star-formation maser sites in the LMC, resulting in a total of 13 water masers in the LMC for which positions are known to arcsecond accuracy. The fields observed for the water maser observations included a total of 32 sources from the Gruendl & Chu (Reference Gruendl and Chu2009) YSO catalogue. Of the 13 water masers, 11 are within 2 arcsec of a Gruendl & Chu YSO, meaning that from a total catalogue of 855 sources there are 11 which are known to have an associated water maser and 22 which are known not to. The 33 sources for which there is information on whether or not they have an associated water maser can be used as a training set for classification/prediction.
Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010) used the infrared data from Gruendl & Chu (Reference Gruendl and Chu2009) to construct the spectral energy distribution (SED) of each of the YSOs using the online SED-fitter of Robitaille et al. (Reference Robitaille, Whitney, Indebetouw and Wood2007) and this forms Data Set 2. For some wavelength ranges, the infrared data for the Gruendl & Chu (Reference Gruendl and Chu2009) sample is incomplete, hence there is missing data. However, the results of the SED modelling contain no missing data (although there is likely to be greater uncertainty in the fitted SED parameters for those sources which have less infrared photometric measurements contributing to the fitting process). All available information about a source is incorporated into the SED model. According to Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010), there is very little variation in the amount of information available for each SED fit, with between seven and nine infrared intensities available for each source and in the majority of cases the chi-squared values for the resulting SED fits are reasonable. Due to the large number of sources modelled, we made no attempt to remove the sources where this was not the case, with the exception of one maser-associated source with more missing data than the others (making our training sample 32 with 10 known masers, and the total data set 854).
Fifteen predictor variables were extracted from the SED fitting results; distance to the source, age, radius, mass, and temperature of the central source, envelope accretion, or infall rate, outer and inner radius of the envelope, cavity opening angle, disc mass, ambient density, inclination of source to line of sight (LoS), average integrated flux density (from the outside of the YSO to the stellar surface, along the LoS), total luminosity, and mass of the envelope. Table 4 shows which variables were used in each model and how they contributed to that model. Across the different methods, the most important predictor variables appeared to be the mass of the central source, the outer envelope radius, the inclination towards the LoS, and the mass of the envelope. In comparison, Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010) found that the majority of YSOs with an associated water maser have high luminosities, central masses, and ambient densities. They also tend to have redder infrared colours than those YSOs which are not associated with a maser. The distributions of the high-importance variables are shown in Figure 4.

Figure 4. Only the predictor variables from Data Set 2 showing noticeable differences between those YSO with and without an associated water maser are shown. Due to the very small data set, the individual sample points are also plotted. Some of the variables are on logarithmic scales to better illustrate the differences. For an explanation of boxplots, see Figure 1.
Table 4. The predictor variables that increased the classification accuracy of the various methods for Data Set 2. The value given for random forests is the mean decrease in accuracy, while logistic regression provides p -values. The most important variables in logistic regression and random forest models are shown in bold. For further explanation, see Table 2.

Unlike Data Set 1, these data include some sources where the maser association is known (32) and some where it is unknown (822). This means predictions can be made on the unknown sources. To test how well the various methods will generalise to data where maser association is unknown, a cross-validation was applied. For a full description of the technique used, see Section 2.4.2. The predictions were then compared with the actual maser association. The results are given in Table 5.
Table 5. The results of cross-validating random forests, logistic regression, and LDA classification and prediction for Data Set 2 (association of water masers with infrared YSO in the LMC) using the full sample of 32 sources with known water maser association status as the training sample. For definitions of classification results, see Section 2.4.

The SED Data Set 2 had a fairly small number of entries with known maser status (32), but a large number of possible predictor variables (15). The results for the cross validation are shown in Table 5 and in the form of ROC curves in Figure 5.

Figure 5. Receiver operating characteristic curves showing the results of the cross validation for Data Set 2. The diagonal line y = x represents randomly classifying the samples, with half predicted as positive and half as negative. For a full description of a ROC curve, see Section 2.4.3.
The cross validation results show that overall, the sensitivity values were quite poor, with LDA performed on the normalised data being the most accurate method. This was possibly due to the small data set, methods could not construct an accurate model using only 29 sources and then predicting on the remaining 3. These results can be visualised in a ROC curve shown in Figure 5, where in a number of cases the models fall below the y = x diagonal line, meaning that they perform worse that simple random classification with a 50% chance of a source being associated with a maser. Due to these poor results, we decided not to use this training data to make predictions on the remaining 822 sources with unknown maser status.
It is evident from the MDS plot in Figure 6 why the random forest model had a low sensitivity; the data is not clustered in groups to the same extent as Data Set 1 (Figure 3). The known maser sources are represented by the black and red triangles, while the blue circles and green diamonds represent the known non-maser sources. This could be due to the model’s inability to condense the 15 predictor variables (equivalent to 15 dimensions) into a two-dimensional plot, or another bi-product of the small sample size.

Figure 6. The MDS plot for the random forest model used to predict potential YSOs with an associated water maser in the LMC (Data Set 2). ‘Border-line’ predictions were samples with a predicted maser association between 45 and 55%. For details on multidimensional plots in random forest analysis, see Figure 3.
In summary, the variables that had the most influence over the various classification models were mass of the central star, the outer envelope radius, the inclination towards the LoS, and the mass of the envelope (see Table 4). The likelihood of a YSO being associated with a water maser source did not appear to depend heavily on variables such as the age of the source, mass of the disc, ambient density, or average integrated flux. Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010) applied Mann–Whitney tests to the different variables to find the difference in the medians of the distributions of those associated with masers and those not associated. Statistically significant differences were found in the data for the mass of the central star, the outer radius of the envelope, ambient density, inclination towards the LoS, and the total luminosity; results that agree with our analysis. It was previously suggested that the inclination angle is one of the most influential predictors in determining the SED for YSOs (Robitaille, et al. Reference Robitaille, Whitney, Indebetouw, Wood and Denzmore2006). As a result of the orientation of the cavity, the inclination angle dictates the contribution from the inner, hotter regions of the envelope to the SED. Hence, our classification results here agree with those from previous studies, indicating that the physical variables mentioned above are likely to dictate water maser-association with certain YSOs in the LMC.
3.3. The properties of dust continuum emission associated with class I methanol masers
The final data set we investigated (hereafter, Data Set 3) was a search for 95 GHz class I methanol masers targeted towards regions selected on the basis of both their emission at mid-infrared and millimetre wavelength ranges (Chen et al. Reference Chen2012). The mid-infrared data was taken from the Spitzer Space Telescope GLIMPSE (Galactic Legacy Infrared Mid-Plane Survey Extraordinaire) programme, which provides photometric measurements in four wavelength bands (3.6, 4.5, 5.8, and 8.0 μm; Benjamin et al. Reference Benjamin2003; Churchwell et al. Reference Churchwell2009), while the millimetre continuum data was from the Bolocam Galactic Place Survey (BGPS) (Aguirre et al. Reference Aguirre2011). The motivation for this survey was a previous search for 95 GHz class I methanol masers by Chen et al. (Reference Chen, Ellingsen, Shen, Titmarsh and Gan2011). The authors targeted infrared sources for which GLIMPSE images show extended emission with an excess in the 4.5-μm band (thought to indicate an outflow from a high-mass YSO). It was found that those GLIMPSE sources with an associated BGPS source (54 of the 62 sources which lay within the BGPS region) were much more likely to exhibit class I methanol maser emission. Chen et al. (Reference Chen, Ellingsen, Shen, Titmarsh and Gan2011) also found that the GLIMPSE sources with redder mid-infrared colours were more likely to be associated with methanol masers and the higher the mass and density of the BGPS dust clump, the stronger the class I maser emission.
Chen et al. (Reference Chen2012) used the results of Chen et al. (Reference Chen, Ellingsen, Shen, Titmarsh and Gan2011) to identify 420 sources detected in both the Spitzer GLIMPSE and BGPS catalogues as likely to have an associated class I methanol maser. They then observed a random selection of 214 of these sources and detected 95 GHz class I methanol masers towards 62 (hence 152 non-detections). For the classification process, we used only the data from the BGPS catalogue (version 1.0) which contains a total of 8 358 sources (Aguirre et al. Reference Aguirre2011). The predictor variables used in the classification models for Data Set 3 were the angular size of the major and minor axis of the dust clump, as well as its position angle, deconvolved angular radius, and 1.1-mm flux density within apertures of diameter 40, 80, and 120 arcsec and the integrated flux density. Boxplots of these variables are shown in Figure 7. As with the classification of the other two data sets, here each of the models were optimised by omitting superfluous variables, as well as those that decreased the models’ accuracy. Both logistic regression and random forests utilised all eight variables, while LDA performed better without including all of them (see Table 6).

Figure 7. The variables used in the classification and prediction of Data Set 3. Some of the variables are on logarithmic scales to better illustrate the differences. For an explanation of boxplots, see Figure 1.
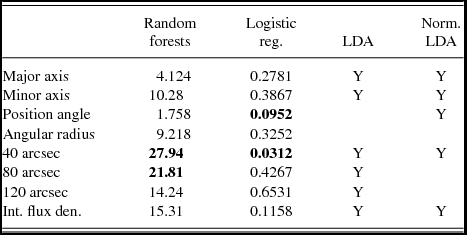
Table 6. The predictor variables that increased the classification accuracy of the various methods for Data Set 3. The value given for random forests is the mean decrease in accuracy, while logistic regression provides p-values. The most important variables in logistic regression and random forest models are shown in bold. For further explanation, see Table 2.
This data set was the primary focus of our analysis, as it has a training set with several hundred sources, including a large number of detections and there are also a large number of BGPS sources which have not been searched for class I methanol maser emission (8 144) which provide the opportunity to make testable predictions.
The variables with high importance in the random forests calculations were the flux densities (each of the 40, 80, and 120 arcsec aperture values and the integrated) and also the angular size of the minor axis. The most important variable was the flux density within 40 arcsec (the smallest angular scale measured by Bolocam). Logistic regression also found the flux density within 40 arcsec to be the most important variable with a p-value of 0.0312, with the next most significant variable being the position angle with a p-value of 0.0952, while the 80 arcsec flux had the next highest contribution. This is consistent with the results of Chen et al. (Reference Chen2012) which showed that class I masers were preferentially associated with sources with the highest beam averaged column density (which is directly proportional to the 40 arcsec flux density). There is no physical reason why the position angle of the dust clump would effect the likelihood of a dust clump having an associated class I methanol maser, but when this variable was omitted from the classification, the accuracy of the models decreased. However, while the p-value suggests that the position angle is a significant predictor variable in logistic regression, the change in accuracy was not significant compared to that of the other variables. This suggests that we can dismiss it as an artefact of the classification method, but it does serve as a reminder to view results such as this with a degree of scepticism. It is also worth noting that random forests presented it with the lowest variable importance.
Table 7 shows the results of the cross-validation of the different classification techniques used on Data Set 3 (see Section 2.4.2). Here, random forests offered the highest sensitivity, while surprisingly performing LDA on the untransformed data produced the highest specificity. This is the first instance in our studies where transforming the data set to be closer to a normal distribution decreased the performance of LDA, although the decrease was minor (2%) and likely not significant. The ROC curve in Figure 8 gives a more complete representation of the models’ capabilities, showing that random forests, logistic regression, and LDA using the transformed data performed to similar standards, while generally LDA on the untransformed data performed the worst.

Figure 8. Receiver operating characteristic curves showing the results of the cross validation for Data Set 3. The diagonal line y = x represents randomly classifying the samples, with half predicted as positive and half as negative.
Table 7. The results of cross-validating random forests, logistic regression, and LDA classification and prediction for Data Set 3 (class I methanol masers associated with GLIMPSE sources). Figure 8 shows the ROC curve for each of the models. For definitions of classification results, see Section 2.4.

Figure 9 shows the MDS plot for the random forest model generated using all the training data for Data Set 3. It is clear that the maser-associated dust clumps are generally located in the bottom-right region of the plot. Comparing this plot to the MDS plots for the other two Data Sets (Figures 3 and 6), we can see that the maser-associated sources are more clearly separated from those without a maser-association. The green squares in Figure 9 represent sources which the random forests model predicts to have an associated class I methanol maser, but for which the observations of Chen et al. (Reference Chen2012) did not detect a maser. Many of these sources lie very close on the MDS plot to others where a maser was detected and it may be that some of these non-detections have a weak class I methanol maser which was not detected by Chen et al. due to the limited sensitivity of those observations. The 95 GHz class I methanol masers are in the same transition family as the best studied class I methanol maser transition at 44 GHz. In general, the 44 GHz class I methanol masers have a peak flux density approximately a factor of 3 greater than the 95 GHz maser emission in the same source (Val’tts et al. Reference Val’tts, Ellingsen, Slysh, Kalenskii, Otrupcek and Larionov2000). These sources would be good candidates for sensitive observations in the 44 GHz transition to more robustly determine if they are associated with class I methanol masers.

Figure 9. The MDS plot for the random forest model used to predict potential millimetre dust-clumps with associated class I methanol masers (Data Set 3). ‘Border-line’ classifications were samples with a predicted maser association between 45 and 55%. For details on multidimensional plots in random forest analysis, see Figure 3.
The classification models we have developed can also be used to predict which of the BGPS sources that were not observed by Chen et al. (Reference Chen2012) are the best candidates for having an associated class I methanol maser. Since we have four different classification models, we can compare the results of each, as those sources identified by all, or most of the models would be expected to be the promising targets for further searches.
For the prediction model, as with Data Set 2, we grew a random forest using 3 000 trees (instead of the default 500, see Section 3.2). Table A1 in the Appendix lists the 739 BGPS sources which were predicted to have an associated class I methanol maser by one or more of the four classification models for the 8 144 BGPS sources which have not yet been searched. Table 8 shows that of the 8 144 potential BGPS target sources random forests predicts 632 to have an associated class I methanol maser and this is significantly more than any of the other classification models. There are 242 of the 8 144 BGPS sources which all models predict will have an associated class I methanol maser and these will be the prime targets for future searches. Table 9 shows the number of sources predicted to be masers by one or two classification methods, which should be considered if there is sufficient time to search additional targets.
Table 8. The classification results on the training data subset (where the maser presence is known), and the number of predicted masers from the 8 144 sources for which maser presence is unknown, using Data Set 3 (class I methanol masers associated with GLIMPSE sources). For definitions of classification results, see Section 2.4.

Table 9. Number of maser predictions on sources from Data Set 3 shared by two classification methods, with 242 sources predicted to be masers using all four methods.

4 DISCUSSION
We applied three different classification techniques to three different searches for interstellar masers to investigate each technique’s performance. We show the classification and prediction results of LDA performed on both the normally distributed data and the untransformed data to demonstrate the difference (see Section 2.1). In most cases, LDA performs significantly better when applied to transformed data.
All three methods of classification (both parametric and non-parametric) used on Data Set 1 returned high values for both sensitivity (correctly classifying sources associated with masers) and specificity (correctly classifying non-maser sources). The highest accuracy was achieved through the non-parametric method of random forests, which in this case classified every source correctly.
Data Set 2 had a relatively small training sample (32 sources) compared with the number of predictor variables (15), and we found here that LDA appeared to give the best results, while random forests and logistic regression performed quite poorly in correctly identifying sources associated with a maser.
For Data Set 3, which has more than 50 detections and more than 150 non-detections, the non-parametric random forests had the highest sensitivity, while the parametric method of LDA performed on the untransformed data had the lowest, but also had the highest specificity. Considering both sensitivity and specificity, logistic regression, and random forests were the most accurate methods.
Based on the predictions of Breiman (Reference Breiman2001b), our initial expectation was that given sufficient training data the complex relationship between the predictor variables and the presence or absence of a related astrophysical phenomenon would be more accurately represented by a non-parametric approach than a simple linear model. However, the training data sets were relatively small, and so made it difficult for the models to capture and convey all the information contained within the predictor variables. We find that random forests does perform relatively better for the largest data set, but in this case, it is comparable with the accuracy of the non-parametric techniques, not superior to them. It may be that in order to outperform parametric methods, the non-parametric techniques require still larger amounts of training data. However, it is more likely that for Data Set 3 all techniques approximately reach the limit of the information available within the measured parameters of the data.
There are a number of factors related specifically to the data which will lead to limitations in the accuracy of any classification model developed using it. One factor is the intrinsic measurement uncertainty for parameters such as the flux density, angular size, etc., which can influence the results directly in the sense that it is always possible that given observations with greater sensitivity additional sources would be detected. However, the absence of these weaker sources does more than simply qualifying the question that is being answered by the classification model. For example, the intensity of astrophysical masers depends in a complex and non-linear manner on the physical parameters of the environment and some of these parameters may not be represented either directly or indirectly in any of the predictor variables being used as inputs to the classification methods. A second, less obvious factor which may limit the accuracy of classification techniques is that for derived parameters there are often implicit assumptions. For example, the calculation of the mass of the dust clumps used for Data Set 1 assumes that the emission at 1.2-mm wavelength is optically thin (likely a reasonable assumption), and that the dust is at a constant temperature of 40 K for all the dust. This second assumption is necessary because we do not have any information on the specific temperature distribution of the dust, but it inevitably leads to systematic errors in the relative mass calculated for regions where the true dust temperature is on average higher (or lower) than the assumed value. Similarly, the distance to individual sources has been estimated using kinematic distance models, which on average provide a reasonable estimate, but which can lead to significant errors for individual sources. It is also highly probable that our sensitivity values obtained after cross validation of the classification techniques were poor due to the unbalanced nature of the data, in that for all three data sets, the vast majority of the samples are not associated with masers.
Breen & Ellingsen (Reference Breen and Ellingsen2011) tested the binomial generalised linear model of (Breen et al. Reference Breen2007, Data Set 1) by searching for 22 GHz water masers towards 267 dust clumps. They found a high-detection rate towards dust clumps for which the binomial GLM predicted a probability of greater than 10% for the presence of a water maser (20 of 27 sources). They also found that while the detection rate dropped for sources for which the model predicted a lower probability of having an associated water maser, a substantial fraction of water masers (approximately 70%) were detected towards sources for which the model predicted a probability of less than 1%. Breen & Ellingsen (Reference Breen and Ellingsen2011) show that unreliable distance estimates for many of the dust clumps is in part responsible for the misclassification. This is consistent with the assertion we make above that the combination of measurement and systematic uncertainties in the underlying data ultimately limit the accuracy which can be obtained with any classification technique.
When the different classification models we developed using Data Set 3 are applied to the 8 144 BGPS sources which have not been searched for class I methanol maser emission a total of 739 sources are predicted to have an associated maser by one or more of the models, with 242 sources predicted by all four models (see Section 3.3 and Appendix A). Figure 12 of Chen et al. (Reference Chen2012) plots the integrated flux density against the beam averaged H2 column density for Data Set 3 and shows that the maser associated sources are restricted to a limited range for these two predictor variables. Figure 10 shows the integrated flux density versus the beam averaged H2 column density for the 8 144 BGPS sources not observed by Chen et al. Those sources for which one or more of the classification models predict an associated class I methanol maser are indicated with a red dot, with sources which no model predicts to have an associated class I maser are indicated with a black dot. Figure 10 shows that there is a high level of agreement between the predictions of the classification models and the empirical criteria developed by Chen et al. (Reference Chen2012). In total 1 200 BGPS sources meet the criteria identified by Chen et al. (Reference Chen2012), approximately a factor of two more than identified by any of the classification models. In their calculation of the beam averaged column density, Chen et al. (Reference Chen2012) assumed a constant temperature of 20 K for the dust clumps and used the 40 arcsec flux density measurement as the intensity of the dust continuum emission. This means that the calculated beam average column density is directly proportional to the BGPS 40 arcsec flux density measurement. The relationship derived by Chen et al. (Reference Chen2012) suggested this is the most important predictor variable for the presence (or otherwise) of class I methanol maser emission towards these sources. The results presented here also support this.

Figure 10. The integrated flux density versus the beam averaged H2 column density for the 8 144 BGPS sources not searched for class I methanol masers by Chen et al. (Reference Chen2012). Sources for which one or more of the classification models predicts the presence of a class I methanol masers are represented with red dots, other sources are represented with black dots. The blue line shows the criteria developed by Chen et al. (Reference Chen2012) to identify BGPS sources likely to have an associated class I methanol maser.
Ultimately, determining the relative accuracy of these classification models, and whether they are superior to directly derived criteria [such as those of Chen et al. (Reference Chen2012)] is to test them through future observations. There are currently approximately 400 different class I methanol maser sources which have been identified throughout the Galaxy (see Chen et al. Reference Chen, Gan, Ellingsen, He, Shen and Titmarsh2013, and references therein), so a search targeted towards the candidate BGPS sources we have identified is likely to significantly increase the number of known sources.
5 CONCLUSIONS
In this paper, we present three major findings regarding the utilisation of different classification techniques on different size astronomical data sets. (1) For small data sets parametric methods (such as LDA and logistic regression perform better than random forests (a non-parametric method). (2) For larger data sets, random forests has the capability to out-perform the parametric methods trialled here. (3) In almost all cases, transforming the data to be closer to a normal distribution significantly increases the accuracy of LDA. In the case where using transformed data slightly decreased the accuracy of the model, the classification results were very similar. Since the process of transforming data is relatively easy, this is a step that should be definitely employed if LDA is utilised. This step has typically not been included when LDA has been applied to astronomical data used in past studies.
Our results suggest that where there is very limited training information parametric models which can only predict based on simple combinations of the input variables are more accurate than non-parametric methods. However, where there is more training data (such as Data Sets 1 and 3), non-parametric models can perform as well (likely better in some circumstances) than parametric techniques. Our results for Data Set 3 show that random forests is comparable in accuracy to the parametric methods, rather than exceeding them as expected (see Breiman Reference Breiman2001b).
Frequently in astrophysics relationships are sought between two or three variables in the form of correlations between them, such as the radio:far-infrared correlation for galaxies, or colour–colour selection criteria for Hii regions. In the past, this has often been because of limited numbers of predictor variables being available for large samples of data, however, this is now less of an issue. Mathematical classification techniques such as those utilised here potentially offer significant improvements over simple correlation relationships, but the most appropriate technique to apply depends heavily on the nature of the data available and the goal of the investigation (e.g. detection prediction, physical understanding of relationship between variables). Our models determined which predictor variables were important in the classification process, and for all three Data Sets our results agreed with the previous studies of Breen et al. (Reference Breen2007), Ellingsen et al. (Reference Ellingsen, Breen, Caswell and Quinn2010), and Chen et al. (Reference Chen2012), respectively.
For the specific goal of identifying millimetre dust clumps which are more likely to have an associated class I methanol maser, we find that on the basis of cross-validation tests and the predictions the models produce on the training data, both the non-parametric method of random forests, and the parametric methods of logistic regression and LDA are well suited for the task of identifying likely targets for future searches. 242 sources out of the 8 144 in Data Set 3, were predicted by all four of our techniques to have associated masers. The results of future searches for class I methanol masers towards BGPS sources will allow a direct test of each of the classification models and allow us to determine the validity of these conclusions.
ACKNOWLEDGEMENTS
EMM undertook much of this work funded through a University of Tasmania Dean’s Summer Research Scholarship. Shari Breen is the recipient of an Australian Research Council DECRA Fellowship (project number DE130101270). This research has made use of NASA’s Astrophysics Data System Abstract Service.
APPENDIX A CLASSIFICATION MODEL PREDICTIONS
Table A1 summarises the predictions for each of the classification models for class I methanol masers associated with Bolocam sources.
Table A1. Bolocam Galactic Plane sources for which one or more of the mathematical classification models predicted the presence of an associated class I methanol maser (probability of a maser > 0.5). The maser probability for each model is listed, those which exceed 0.5 are in bold type. This list contains a total of 739 sources that were predicted to be masers by at least one of the four methods (242 of which were predicted by all methods), from a total of 8 144 sources in version 1.0.1 of the Bolocam catalogue.





















