



Introduction
Though decades of psycholinguistic research have provided valuable insight into the mental storage and processing of morphologically complex words, it remains unclear how knowledge of morphological structure develops within a growing mental lexicon. A common experimental strategy that is used to probe the mental representation of morphological structure is to examine the impact of distributional, frequency-based properties of complex words on lexical processing outcomes (see reviews in Amenta & Crepaldi, Reference Amenta and Crepaldi2012 and Marelli et al., Reference Marelli, Traficante and Burani2020). For example, the effects of the frequencies of morphemes (e.g., play and -er in player) and the size of the morphological families of complex words (e.g., playful, playlist, playoff) are influential in the processing of complex words. Since these effects are used as indices of the mental storage and processing of morphological structure, by implication, observing changes in sensitivity to these frequency-based properties as a function of language experience ought to shed light on the development of morphological knowledge in a dynamic mental lexicon. The present study tests this hypothesis in a novel way by examining how within-individual gains in language experience and the distributional morpho-lexical properties of derived words influence the development of morphological knowledge in English language learner (ELL) university students.
Lexical characteristics as indices of morphological knowledge
A common factor uniting most accounts of complex word processing is that complex word processing in a first (L1) and second language (L2) is sensitive to a wealth of quantitative properties pertaining to the full forms of complex words and their morphological constituents (for L1 accounts, see Baayen & Schreuder, Reference Baayen and Schreuder1999; Caramazza et al., Reference Caramazza, Laudanna and Romani1988; Kuperman et al., Reference Kuperman, Schreuder, Bertram and Baayen2009; Libben, Reference Libben2005, Reference Libben2014; Moscoso del Prado Martín, Reference Moscoso del Prado Martín2007; for L2 accounts, see Diependaele et al., Reference Diependaele, Dunabeitia, Morris and Keuleers2011; Feldman & Kroll, Reference Feldman and Kroll2020; Libben et al., Reference Libben, Goral, Baayen, Libben, Goral and Libben2017). In particular, the effects of frequency-based properties of complex words and their constituents on measures of cognitive effort during lexical processing are often used as indices of access to the mental representations of complex words and their morphological structure (for behavioral studies, see e.g., Andrews, Reference Andrews1986; Baayen et al., Reference Baayen, Wurm and Aycock2007; Juhasz et al., Reference Juhasz, Starr, Inhoff and Placke2003; Kuperman & Van Dyke, Reference Kuperman and Van Dyke2011; Taft, Reference Taft2004; for neurophysiological studies, see e.g., Fruchter & Marantz, Reference Fruchter and Marantz2015; Leminen et al., Reference Leminen, Leminen, Kujala and Shtyrov2013; Solomyak & Marantz, Reference Solomyak and Marantz2010). This study focuses on three commonly used measures: the frequencies of complex words, their constituents, and their morphological family members.
The presence of the derived word frequency effect (often referred to as surface or whole-word frequency effect), independently of effects of morphological properties, has been interpreted as a signature of access to the whole complex word representation (e.g., Beauvillain, Reference Beauvillain1996; Fruchter & Marantz, Reference Fruchter and Marantz2015; Niswander et al., Reference Niswander, Pollatsek and Rayner2000; Taft, Reference Taft1979; for an excellent review see Lõo et al., Reference Lõo, Jarvikivi, Tomaschek, Tucker and Baayen2018a). Derived word frequency predicts acoustic durations and naming latencies of words in speech production (e.g., Caselli et al., Reference Caselli, Caselli and Cohen-Goldberg2016; Lõo et al., Reference Lõo, Jarvikivi, Tomaschek, Tucker and Baayen2018a), and reading times in visual word recognition (Baayen et al., Reference Baayen, Wurm and Aycock2007; Kuperman et al., Reference Kuperman, Schreuder, Bertram and Baayen2009). Turning to morphological effects, a common diagnostic measure of access to morphological structure is the effect of stem frequency, e.g., the standalone frequency of humor as a stem in the complex word humorous. Another diagnostic of access to morphological structure is affix productivity, defined as the number of word types that share the same suffix as the target word, e.g., the number of words that end in -ous during the processing of humorous (Baayen et al., Reference Baayen, Wurm and Aycock2007; Bertram et al., Reference Bertram, Laine and Karvinen1999; Bertram et al., Reference Bertram, Schreuder and Baayen2000; Kuperman et al., Reference Kuperman, Bertram and Baayen2010; Laudanna & Burani, Reference Laudanna, Burani and Feldman1995; Laudanna et al., Reference Laudanna, Burani and Cermele1994). In summary, the effect of derived word frequency signals access to the whole complex word representation, and the stem frequency and affix productivity on complex word processing typically serve as evidence in support of the engagement of morphological units during word recognition.
The effect of morphological family size (i.e., the number of derived and compound word types sharing a stem, e.g., joyful, joyous, joyride) are also used as diagnostics of the processing of morphological structure. Complex words that have larger morphological families tend to be processed faster than those that have smaller families (e.g., Bertram et al., Reference Bertram, Baayen and Schreuder2000; De Jong et al., Reference De Jong, Schreuder and Harald Baayen2000; Lõo et al., Reference Lõo, Jarvikivi and Baayen2018b). Family size effects are also present in L2 lexical processing (Dijkstra et al., Reference Dijkstra, Moscoso del Prado Martín, Schulpen, Schreuder and Harald Baayen2005; Mulder et al., Reference Mulder, Dijkstra, Schreuder and Baayen2014; Mulder et al., Reference Mulder, Dijkstra and Baayen2015), demonstrating that effects of morphological relations between words occur once a morphological paradigm is acquired in a non-native language. Research on L1 morphological processing also shows that the frequency distribution of words within an inflectional and derivational paradigm predicts complex word processing (for an excellent overview see Milin and Blevins, Reference Milin and Blevins2020). An important finding in this regard is that complex words with morphological families that have fewer dominant members, that is, those with a small number of highly frequent members existing in the language, are recognized faster than those with morphological families that have many dominant members, that is, those with many relatively equally frequent members (Fruchter & Marantz, Reference Fruchter and Marantz2015; Moscoso del Prado Martín et al., Reference Moscoso del Prado Martín, Kostić and Baayen2004; Schmidtke et al., Reference Schmidtke, Matsuki and Kuperman2017). Such family-based effects are argued to arise as a consequence of spreading lexical co-activation throughout a morphological family (De Jong et al., Reference De Jong, Schreuder and Harald Baayen2000).
If the previously described effects signal access to complex words and their morphemic units during complex word recognition, then what can they tell us about how morphological information is formed in a continuously developing mental lexicon? The present study addresses this question by drawing inspiration from an approach that examines the interplay between individual language experience and language statistics on morphological knowledge (Falkauskas & Kuperman, Reference Falkauskas and Kuperman2015; Ulicheva et al., Reference Ulicheva, Marelli and Rastle2020). The premise of this approach is that, while statistical patterns of language use affect language processing, individual differences in the amount of exposure to these patterns lead to individual differences in language comprehension and production (MacDonald, Reference MacDonald2013). Here, we build on prior work in a novel way by examining whether within-participant change in language experience modulates the effects of the distributional properties of complex words in written production. We reason that the within-participant changes in sensitivity to frequency-based morphological effects, should they emerge, would constitute evidence of change in morphological knowledge as a result of experience with language. In what follows, we summarize empirical research that examines the interactions between language experience and morpho-lexical knowledge, before outlining our hypotheses.
Language experience and morpho-lexical knowledge
It is widely accepted that language experience is instrumental in forming, refining, and maintaining mental representations of linguistic structure (MacDonald, Reference MacDonald2013; Perfetti, Reference Perfetti2007; Seidenberg & MacDonald, Reference Seidenberg and MacDonald1999; Stanovich & West, Reference Stanovich and West1989). A key principle of these accounts is that internalized word knowledge is shaped by the distributional properties of the input, including frequency statistics and co-occurrence patterns of words and phrases. Results from experimental morphological research on the language comprehension-production interface are broadly consistent with this idea. We highlight three strands of research in this regard, paying particular attention to the comprehension-production interface in the written modality.
First, there is substantial evidence from spelling research that monolingual children track graphotactic regularities (i.e., statistical patterns of the positioning of letters in words) from printed language input, including those specific to morphological structure, and take advantage of such regularities when developing spelling ability (Deacon et al., Reference Deacon, Conrad and Pacton2008). Deacon et al. reviewed several studies supporting this notion, including a study by Pacton et al. (Reference Pacton, Fayol and Perruchet2005), that demonstrated that children’s spelling of French-derived words is influenced by graphotactic regularities even in conditions in which it would have been possible to rely on abstract morphological rules. Deacon et al. (Reference Deacon, Conrad and Pacton2008) propose that spelling regularities are therefore acquired by attending to “the co-occurrence of letters, sounds, and meaning within words and the frequencies of pairings of words within sentences” (p. 123). This line of research suggests that the written production of complex word forms is partly a reflection of the learning of graphotactic patterns via exposure to printed language.
A second source of evidence in support of the effects of the morpho-distributional properties of complex words on written production comes from typing tasks: these tasks show that keystroke latencies to morphologically complex words are influenced by stem and whole-word frequency (e.g., Feldman et al., Reference Feldman, Dale and van Rij2019; Sahel et al., Reference Sahel, Nottbusch, Grimm and Weingarten2008). Since the frequencies of constituent morphemes and whole words have each been shown to affect production latencies, it is argued that written production draws upon knowledge of morpheme units and holistic representations. This line of research aligns with the larger body of written production work that shows that morphological structure (e.g., the presence of a morphological constituent boundary) plays a role in typing latencies (e.g., Badecker et al., Reference Badecker, Hillis and Caramazza1990; Bertram et al., Reference Bertram, Tonnessen, Stromqvist, Hyona and Niemi2015; Gagné & Spalding, Reference Gagné and Spalding2016; Orliaguet & Boë, Reference Orliaguet and Boë1993; Pynte et al., Reference Pynte, Courrieu and Frenck1991; Weingarten et al., Reference Weingarten, Nottbusch and Will2004).
Third, cross-sectional research has perhaps more directly addressed the relationship between language experience and the distributional properties of complex words. A word definition study comparing third- and sixth-grade Finnish school children (Bertram et al., Reference Bertram, Laine and Virkkala2000) showed that, for both groups, Finnish words with highly productive suffixes (e.g., laula + ja, meaning “singer”) elicited more accurate definitions than those with less productive suffixes (e.g., taru + sto, meaning “mythology”). However, for sixth-graders, the difference between less and more productive derivational morphemes was not as dramatic as for third-graders. In addition, an eye-movement study by Falkauskas and Kuperman (Reference Falkauskas and Kuperman2015) found that the facilitative effect of spacing bias in compound word recognition (e.g., ringtone vs. ring tone) was stronger among readers with greater language experience. This finding indicates that exposure to written materials serves to heighten sensitivity to the statistical regularities of complex word spelling (see also Häikiö et al., Reference Häikiö, Bertram and Hyönä2011, for a separate eye-movement study showing the effects of grade level on sensitivity to compound spelling format). More recently, Ulicheva et al. (Reference Ulicheva, Marelli and Rastle2020) conducted a series of nonword classification tasks in which participants judged whether an orthographic string resembled a noun or an adjective. They reported that suffix spellings that provide stronger cues to a lexical category were more likely to be judged as members of that category, and that participants with greater reading experience, vocabulary knowledge, and spelling ability were more sensitive to category-specific cues.
Taken together, the research summarized above strongly suggests that readers are sensitive to the distributional and semantic characteristics of morphologically complex words, and that this sensitivity is more acute among readers with greater experience with written language materials. Given these findings, it ought to be possible to demonstrate an empirical association between change in exposure to written language and change in sensitivity to that distributional information within the same group of individuals. In what follows, we hypothesize two ways in which language experience may shape morphological knowledge and outline our predictions about how these changes may affect the development of the written production of complex word forms in ELLs.
Hypothesis 1 Morpheme entrenchment
As noted earlier, the effects of stem frequency and suffix productivity are used as diagnostics of sensitivity to morphological structure during lexical processing. We therefore selected these variables in the present study to investigate experience-related changes in the strength of morphological representations during learning. The refinement of and initial reliance on morphological knowledge in language and literacy development has been demonstrated in prior work. It has been established that developing L1 readers begin to form mental representations of complex words by detecting and segmenting words into morphemes (e.g., perform and -ance in performance). This idea is also supported by the results of studies of developing readers of English (Beyersmann et al., Reference Beyersmann, Castles and Coltheart2012), French (Beyersmann et al., Reference Beyersmann, Grainger, Casalis and Ziegler2015), German (Hasenäcker et al., Reference Hasenäcker, Beyersmann and Schroeder2020), Hebrew (Schiff et al., Reference Schiff, Raveh and Fighel2012), and Italian (Burani et al., Reference Burani, Marcolini and Stella2002). Morphological knowledge is also a predictor of literacy outcomes in developing monolingual readers (see review in Goodwin & Ahn, Reference Goodwin and Ahn2013) and Chinese-speaking ELLs (Jiang & Kuo, Reference Jiang and Kuo2019; Lam et al., Reference Lam, Chen, Geva, Luo and Li2012; Zhang & Koda, Reference Zhang and Koda2012; Reference Zhang and Koda2013). Based on these results, we therefore expect ELLs to rely on knowledge of morphemes: we expect derived words with more frequent stems and more productive suffixes to be more accurately produced than derived words composed of less frequent stems and less productive suffixes. Our specific interest lies, however, in the interactions between exposure to language and stem frequency and exposure to language and suffix productivity.
How might the interaction between language exposure and frequency inform complex word learning? The word frequency effect reflects the stability and entrenchment of lexical representations: more frequent words are encountered more often, which results in stronger lexical representations (Brysbaert et al., Reference Brysbaert, Mandera and Keuleers2018). Critically, both L1 and L2 word processing studies show that the word frequency effect becomes weaker as language experience increases, such that less experienced readers, and readers with smaller vocabularies, are especially slow at processing low-frequency words (Brysbaert et al., Reference Brysbaert, Lagrou and Stevens2017; Cop et al., Reference Cop, Keuleers, Drieghe and Duyck2015; Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013; Duyck et al., Reference Duyck, Van Assche, Drieghe and Hartsuiker2007; Mainz et al., Reference Mainz, Shao, Brysbaert and Meyer2017; Monaghan et al., Reference Monaghan, Chang, Welbourne and Brysbaert2017; Whitford & Joanisse, Reference Whitford and Joanisse2018; Whitford & Titone, Reference Whitford and Titone2012). In other words, when contrasting low and high proficiency readers, the greatest differences in word processing efficiency are found for low-frequency words. The lexical entrenchment hypothesis was proposed to account for this interaction: less experienced readers “require more energy” to process low-frequency words because these individuals have had fewer opportunities to strengthen their memory representations of these lexical items (Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013, p. 846; for a similar proposal see also Kuperman & Van Dyke, Reference Kuperman and Van Dyke2013). The pattern of the lexical entrenchment effect, based on prior research, is depicted in Figure 1, and shows that greater language experience is associated with a flatter positive slope for the frequency effect.

Figure 1. Predicted pattern of language experience on lexical entrenchment based on prior research.
We investigate the entrenchment effect at the lexical and morpheme level. Indeed, Bertram et al. (Reference Bertram, Baayen and Schreuder2000) reported an entrenchment pattern for suffix productivity in a cross-sectional study of Finnish monolinguals. However, to our knowledge such a pattern has not yet been observed in ELLs, nor has the trend been observed in a within-participants longitudinal study design. Based on the predictions of the lexical entrenchment hypothesis, it is expected that continued exposure to language will lead to the greatest observable changes in the production of complex words composed of low-frequency stems or less productive affixes. Evidence for this hypothesis would be supported by observing an interaction between timepoint and suffix productivity or stem frequency, resembling the entrenchment pattern presented in Figure 1. We reason that observing the entrenchment pattern for stem frequency or suffix productivity would indicate that experience with language provides more opportunities to solidify representations of stems and suffixes embedded within derived words, with gains being especially pronounced for derived words with stems and suffixes that occur less frequently in the language.
Hypothesis 2 Morphological connectivity
Prior work has addressed the concept of relational knowledge (Tyler & Nagy, Reference Tyler and Nagy1989), a dimension of morphological knowledge that involves recognizing that multiple words share a common morpheme, that is, the knowledge that humanity, humanistic, humanize and humankind all belong to the same derivational family. While a skilled native speaker of English may know many morphologically complex words and have greater implicit awareness of the connections among common members of a morphological family, it is not clear how this relational knowledge develops in language learners. In the present study of ELLs, we examine interlexical connectivity among members of a morphological family, that is, morphological connectivity, and track the development of this knowledge over time.
We selected derivational family entropy (Moscoso del Prado Martín et al., Reference Moscoso del Prado Martín, Kostić and Baayen2004) as an index of morphological connectivity. Because derivational family entropy takes into account the relative frequencies of members of morphological families, the presence of its effect on written production would entail that ELLs tap into information within the network of a morphological family in addition to the target-derived word itself. Entropy is lower, that is, there is less uncertainty in a morphological paradigm, when the frequency of occurrence of one family member dramatically exceeds the frequencies of all other members. On the other hand, entropy is greater when the frequencies of family members are more uniformly distributed. Based on the pattern of effects of prior L1 visual word processing studies outlined earlier (e.g., Fruchter & Marantz, Reference Fruchter and Marantz2015; Moscoso del Prado Martín et al., Reference Moscoso del Prado Martín, Kostić and Baayen2004; Schmidtke et al., Reference Schmidtke, Matsuki and Kuperman2017), we expect target forms with greater derivational family entropy to elicit more production errors as a result of a relative lack of precision in morphological knowledge for these items. We predict that it will be more difficult for learners to pinpoint the correct derived word when that word belongs to a more diffuse morphological family, leading to a higher likelihood of written production error. Any effect of derivational family entropy would be evidence of sensitivity to implicit knowledge of relations among morphological families, that is, morphological connectivity.
Critically, we expect to find a weaker negative effect of derivational family entropy earlier in language development compared to later in language development. We predict the effect of entropy to be more acute later in language development as a result of continued exposure to morphologically complex words in the language. Our reasoning is based on the results of lexical processing reviewed earlier which point to an increased sensitivity to the statistical properties of morphologically complex words as a function of language experience (e.g., Falkauskas & Kuperman, Reference Falkauskas and Kuperman2015; Ulicheva et al., Reference Ulicheva, Marelli and Rastle2020). During language learning, many newly acquired complex words will belong to the same morphological family as complex words that already exist in lexical memory, thereby expanding the size of a morphological family. We predict that as morphological families expand in the lexicon, through exposure to language, so does sensitivity to relative probabilities of members within those morphological families, that is, an increase in morphological connectivity. We expect that this increase in sensitivity will be expressed as a stronger negative effect of entropy on written word production. The stronger negative effect later in language learning might be visible as a larger penalty in accuracy for high entropy words or as a larger gain in accuracy for low entropy words.
Although our hypothesis advocates a causal link between exposure to language and precision in producing the correct derived form within a morphological family, we cannot rule out an opposite effect arising from an increased ability to discriminate between members of a morphological family (Baayen et al., Reference Baayen, Milin, Durđević, Hendrix and Marelli2011) Footnote 1 . For instance, instead of observing a stronger effect of entropy as a consequence of language exposure, it is possible that the effect becomes weaker over time as learners are able to better handle diffusion in a high entropy morphological family. This would entail that the greatest gains in written production would be found for words belonging to high entropy families. It is also possible for both effects to occur simultaneously, whereby the effect of an increase in discrimination skill masks the gradual strengthening of the entropy effect as a result of language experience.
The present study
In the present study, we examined the morphological entrenchment and morphological connectivity hypotheses. These hypotheses were tested in a within-participant longitudinal study of the written production of derived words in English. The participant cohort was a sample of adult ELLs enrolled in an 8-month university-level English bridging program at a Canadian university. Participants were tested at two timepoints: at the beginning (
 ${t_1}$
) and end (
${t_1}$
) and end (
 ${t_2}$
) of the bridging program. The bridging program affords a unique opportunity to examine intra-individual change in morphological knowledge for two reasons. First, the duration of the program is fixed, which provides a controlled window of time across which we are able to examine change in sensitivity to morphological knowledge. Second, we are able to examine change in a homogeneous sample of language learners. The sample represents a population of Chinese adult ELLs who are aged 18–24 years, have L1 Cantonese or Mandarin, and are all at approximately the same level of English language proficiency.
${t_2}$
) of the bridging program. The bridging program affords a unique opportunity to examine intra-individual change in morphological knowledge for two reasons. First, the duration of the program is fixed, which provides a controlled window of time across which we are able to examine change in sensitivity to morphological knowledge. Second, we are able to examine change in a homogeneous sample of language learners. The sample represents a population of Chinese adult ELLs who are aged 18–24 years, have L1 Cantonese or Mandarin, and are all at approximately the same level of English language proficiency.
Method
Design
The design was longitudinal with two testing timepoints (
 ${t_1}$
and
${t_1}$
and
 ${t_2}$
). Data for
${t_2}$
). Data for
 ${t_1}$
were collected during the first month of the bridging program and data for
${t_1}$
were collected during the first month of the bridging program and data for
 ${t_2}$
were collected during the final month of the program.
${t_2}$
were collected during the final month of the program.
Participants
A total of 196 consenting participants (78 female, 113 male, 5 undisclosed) took part in the experiment at
 ${t_1}$
and
${t_1}$
and
 ${t_2}$
Footnote 2
. The average age of participants at
${t_2}$
Footnote 2
. The average age of participants at
 ${t_1}$
was 19.88 (SD = 2.71). Participants were recruited from the 2019–2020 (n = 167) and 2020–2021 (n = 29) academic sessions of the McMaster English Language Development program, an 8-month full-time intensive bridging program. The bridging program provides two semesters (over 21 hr per week) of English instruction designed for international students who meet the academic requirements for an undergraduate program but whose overall scores on the Academic version of the International English Language Testing System (IELTS) test do not meet the university’s English language proficiency threshold of 6.5. All participants were living in Canada for the duration of the study. Prospective students must obtain a minimum overall IELTS score of 5 to be admitted to the bridging program. IELTS is one of the officially recognized English language proficiency qualifications for Canadian Higher Education institutions and is assessed on a 9-band scale, ranging from non-user (band score 1) to expert (band score 9), with a band score of 6 equivalent to a competent user and a band score of 7 equivalent to a good user
Footnote 3
. In IELTS terms, participants would be described as “limited” to “modest” users of English upon entry to the program (median overall IELTS score = 5.5), and as “modest” to “competent” language users at program completion (i.e., approximately an IELTS score of 6.5).
${t_1}$
was 19.88 (SD = 2.71). Participants were recruited from the 2019–2020 (n = 167) and 2020–2021 (n = 29) academic sessions of the McMaster English Language Development program, an 8-month full-time intensive bridging program. The bridging program provides two semesters (over 21 hr per week) of English instruction designed for international students who meet the academic requirements for an undergraduate program but whose overall scores on the Academic version of the International English Language Testing System (IELTS) test do not meet the university’s English language proficiency threshold of 6.5. All participants were living in Canada for the duration of the study. Prospective students must obtain a minimum overall IELTS score of 5 to be admitted to the bridging program. IELTS is one of the officially recognized English language proficiency qualifications for Canadian Higher Education institutions and is assessed on a 9-band scale, ranging from non-user (band score 1) to expert (band score 9), with a band score of 6 equivalent to a competent user and a band score of 7 equivalent to a good user
Footnote 3
. In IELTS terms, participants would be described as “limited” to “modest” users of English upon entry to the program (median overall IELTS score = 5.5), and as “modest” to “competent” language users at program completion (i.e., approximately an IELTS score of 6.5).
Language instruction
The program includes both exposures to advanced academic texts and some explicit morphological instruction. Students are exposed to advanced (university-level) readings spanning multiple academic disciplines (e.g., economics, engineering, health sciences) over the entire program, and across all courses in the program (ten), through core language teaching materials that include academic content and related activities, chapters of undergraduate textbooks not intended for a second language audience, and through assignments that require the reading of journal articles (e.g., a short literature review). Early in the program, in a course (one of five courses in first term) that focuses on the development of effective reading strategies, there is some explicit morphological instruction. Students are taught to analyze multimorphemic words into constituent roots and affixes (including Latinate units), e.g., dis + mis + ive. Although students practise combining roots and affixes (e.g., by identifying additional words containing a particular morpheme, such as act in transaction and react), the focus is on morphological decomposition as a strategy for understanding unfamiliar words encountered when reading. Importantly, the selection of complex words used in teaching materials was conducted independently and without knowledge of the present experiment and its hypotheses. None of the materials in teaching were selected based on the frequency-based properties examined in the current study.
Test of morphological structure
The test of morphological structure was an adapted version of the 28-item derivation task from Carlisle (Reference Carlisle2000). For each trial of the task, participants were given a base word (e.g., teach) and an incomplete sentence (e.g., He was a good _____.). Participants were instructed to modify the base word to appropriately complete the sentence (e.g., He was a good teacher.). The position of the target word was the last word of the sentence for every item. Target form suffixes included -th (e.g., warmth); -ance (e.g., appearance); -er (e.g., washer); -ity (e.g., activity); -ion (e.g., expression); -ous (e.g., adventurous); and -able (e.g., profitable). Further details on the construction of the test are available in Carlisle (Reference Carlisle2000). Since the task was administered at two timepoints in the present study, we split the test into two lists of 14 items each (List A and List B). When possible, suffixes were split evenly across both lists. Tables A.1 and A.2 in Appendix A contain the test items for lists A and B, respectively.
Procedure
Participants were administered each test individually in English. For the 2019–2020 cohort, at
 ${t_1}$
participants produced answers using a pen and paper. At
${t_1}$
participants produced answers using a pen and paper. At
 ${t_2}$
participants were given a digital version of the test where responses were typed into a computer
Footnote 4
. All 2020–2021 participants completed the task online at both timepoints. All test items were presented on the same page/screen at both timepoints. At
${t_2}$
participants were given a digital version of the test where responses were typed into a computer
Footnote 4
. All 2020–2021 participants completed the task online at both timepoints. All test items were presented on the same page/screen at both timepoints. At
 ${t_1}$
, half of the participants were administered List A and the remaining half were administered List B. Lists were counterbalanced across testing timepoints such that those who were administered List A at
${t_1}$
, half of the participants were administered List A and the remaining half were administered List B. Lists were counterbalanced across testing timepoints such that those who were administered List A at
 ${t_1}$
were administered List B at
${t_1}$
were administered List B at
 ${t_2}$
, and vice-versa. Trials for the pen and paper version of the task at
${t_2}$
, and vice-versa. Trials for the pen and paper version of the task at
 ${t_1}$
were digitized and cross-checked by two research assistants. Participation in the study was voluntary and participants received course credit for their participation (course credit was awarded for completion of the test and was not based on performance on the task). The study was approved by the McMaster University Research Ethics Board Ethics Board (protocol 2018-0239).
${t_1}$
were digitized and cross-checked by two research assistants. Participation in the study was voluntary and participants received course credit for their participation (course credit was awarded for completion of the test and was not based on performance on the task). The study was approved by the McMaster University Research Ethics Board Ethics Board (protocol 2018-0239).
Scoring morphological production accuracy
We used the POMplexity spelling error classification system (Bahr et al., Reference Bahr, Lebby and Wilkinson2020; Bahr et al., Reference Bahr, Silliman and Berninger2020; Benson-Goldberg, Reference Benson-Goldberg2014; Quick & Erickson, Reference Quick and Erickson2018) as a framework for categorizing the accuracy of target word spellings. The POMplexity system codes spelling errors across three different linguistic categories: Phonological (P), Orthographic (O), and Morphological (M). We used the morphological POMplexity criteria described in Quick and Erickson (Reference Quick and Erickson2018) to evaluate the spelling accuracy of the responses. The responses were annotated in such a way that a spelling that was identical to the target-derived word was classed as “correct”, e.g., remarkable for the target form remarkable. A “plausible” spelling contained errors that indicate awareness of the target morpheme, but contain a grapheme transposition (e.g., reasonalbe for reasonable), omission (e.g., swimer for swimmer), addition (e.g., humanitty for humanity), or other obvious typing errors (e.g., sborption for absorption). Another type of spelling error included “homophone substitution” (e.g., appearence for appearance, gloryous for glorious and mysteries for mysterious). Spelling errors for which an incorrect suffix (correctly spelled or not) was combined with the target stem were annotated as “morpheme substitution” errors (e.g., gloryful for glorious and humanable for humanity). Spelling errors wherein an illegal orthographic sequence was produced for a suffix or a stem were classified as “nonmorpheme substitution” errors (e.g., humanalixl for humanity). Finally, responses that did not show an attempt at providing a suffix (e.g., do not know), did not include a suffix (e.g., swim for swimmer) or contained the wrong stem (e.g., master for mystery), were annotated as “omission errors”. Our research questions pertain to L2 knowledge of English derivational morphology and not knowledge of English spelling conventions. Therefore, “correct” forms, and “plausible” and “homophone substitution” errors were categorized as correct responses (1), and the remaining responses were categorized as incorrect (0). Appendix B provides a plotted tabulation of all spelling types across timepoints.
Reliability
We assessed parallel forms reliability and the internal consistency of the test of morphological structure. Parallel forms reliability was examined by comparing the differences in means in accuracy for List A and List B at each timepoint (Gulliksen, Reference Gulliksen1950). We also examined the impact of the switch from pen-and-paper to computer input partway through the testing of the 2019–2020 cohort (see Procedure); it is possible that the switch to typing artificially inflated results. If this was the case then growth between timepoints would be disproportionately larger for the 2019–2020 cohort, that is, the cohort that switched instruments between timepoints, compared to growth for the 2020–2021 cohort, that is, the cohort that typed results at both timepoints. A generalized linear mixed-effects model with an underlying binomial distribution was fitted to accuracy scores (0 = incorrect; 1 = correct). List (List A vs. List B), Timepoint (t1 vs. t2), and Cohort (2019–2020 vs. 2020–2021) were included as fixed effects, including the interactions between Timepoint and List and Timepoint and Cohort. Random intercepts were included for participants and items. The Timepoint × List interaction term was not statistically significant [
 $\hat \beta $
= 0.02; SE = 0.28; z = 0.07; p = .94], indicating that the difference in average accuracy between lists was equivalent at
$\hat \beta $
= 0.02; SE = 0.28; z = 0.07; p = .94], indicating that the difference in average accuracy between lists was equivalent at
 ${t_1}$
(List A; M = 57.43%, List B; M = 62.81%) and at
${t_1}$
(List A; M = 57.43%, List B; M = 62.81%) and at
 ${t_2}$
(List A; M = 64.58%, List B; M = 71.65%). A main effect of List was also not significant in a model that did not include a Timepoint × List interaction [
${t_2}$
(List A; M = 64.58%, List B; M = 71.65%). A main effect of List was also not significant in a model that did not include a Timepoint × List interaction [
 $\hat \beta $
= 0.41; SE = 0.45; z = 0.9; p = .37]. We therefore concluded that List A and List B produced similar results at each timepoint. In addition, the Timepoint × Cohort interaction was not statistically significant [
$\hat \beta $
= 0.41; SE = 0.45; z = 0.9; p = .37]. We therefore concluded that List A and List B produced similar results at each timepoint. In addition, the Timepoint × Cohort interaction was not statistically significant [
 $\hat \beta $
= −0.09; SE = 0.27; z = −0.33; p = .74]. This effect indicates that the amount of between-timepoint change was the same for the 2019–2020 cohort (
$\hat \beta $
= −0.09; SE = 0.27; z = −0.33; p = .74]. This effect indicates that the amount of between-timepoint change was the same for the 2019–2020 cohort (
 $\Delta $
= 7.88%) and 2020–2021 cohort (
$\Delta $
= 7.88%) and 2020–2021 cohort (
 $\Delta $
= 8.08%), even when there was a switch to typing from pen-and-paper partway between 2019–2020 testing sessions. We therefore concluded that the switch to typing did not artificially inflate responses. Cronbach’s alpha reliability coefficient was 0.76 for Form A and 0.66 for Form B.
$\Delta $
= 8.08%), even when there was a switch to typing from pen-and-paper partway between 2019–2020 testing sessions. We therefore concluded that the switch to typing did not artificially inflate responses. Cronbach’s alpha reliability coefficient was 0.76 for Form A and 0.66 for Form B.
Independent variables
Suffix productivity and stem frequency
We obtained estimates of frequency of occurrence for stem words from the 51 million-token SUBTLEX-US corpus of US film and media (Brysbaert & New, Reference Brysbaert and New2009). We refer to the frequency of the stem word as Stem frequency.
Suffix productivity is formally defined as the number of word types that share a suffix with the target word. For example, the measure takes into account the number of times -ity appears as a suffix across all unique derived word forms, such as activity, density, majority, in English. We retrieved this information from the English Lexicon Project (ELP: Balota et al., Reference Balota, Yap, Hutchison, Cortese, Kessler, Loftis and Treiman2007), which provides morphological information for 79,672 English words. We ensured that we counted all suffixes in complex words using the morphological parse provided in the MorphSp column of the ELP database. We did not include derived words containing bound stems (e.g., populous) in our suffix productivity counts. We also discounted plural and/or possessive forms of derived words, therefore ensuring that words such as swimmers and swimmer’s were not included as an extra count for swimmer. Furthermore, we manually coded a small number of derived words with the -th suffix that did not appear in the database as morphologically complex.
Derivational family entropy
We computed derivational family entropy for the target-derived words by estimating frequencies of words that also share the target’s stem form (e.g., humanistic and humanize for the target derived word humanity). Derivational entropy was defined as Shannon entropy calculated over the probability distribution p of the derived word’s morphological family (obtained by dividing the frequencies of family members by the cumulative family frequency):
 $H = - \Sigma lo{g_2}(p)*p$
.
$H = - \Sigma lo{g_2}(p)*p$
.
Additional lexical characteristics
As control variables, we included the frequency of the target word form taken from SUBTLEX-US, which we refer to as Derived word frequency. We also considered word length (measured in number of characters) and orthographic neighbourhood density. The orthographic neighborhood of a word was estimated using the average Levenshtein distance (OLD20), which is defined as the average orthographic distance from the 20 nearest orthographic neighbors. OLD20 was estimated for each target word in our stimulus list using the library vwr (Keuleers, Reference Keuleers2013) in the R statistical computing software program (Version 4.1.2; R Core Team, 2021). We used all unique words in the SUBTLEX-US corpus as the source lexicon with which to estimate orthographic neighborhood density. A series of independent two-sample Mann–Whitney U-tests were conducted to examine the differences in each lexical characteristic (critical variables and controls) across stimulus Lists A and B. All ps were > .67, indicating that stimuli lists were reasonably matched for each lexical variable. We also considered the effect of words that do not undergo a phonological shift when a suffix is added (e.g., teacher) versus those derived words whose forms do undergo such a shift (e.g., discussion). We do not discuss this measure further because it neither reached statistical significance nor improved model fit.
The distributional characteristics of all lexical predictor variables are reported in Table 1. Correlations between lexical statistics are presented in Table 2. The full list of stimuli with lexical statistics is provided in Appendix C. The materials are also hosted on the Open Science Framework at the following link: https://osf.io/8egz7/ Footnote 5 .
Table 1. Descriptive statistics for the independent variables. Reported are the range, mean, and standard deviations of the original and transformed variables after selection and trimming procedures

Table 2. Correlation matrix of lexical variables
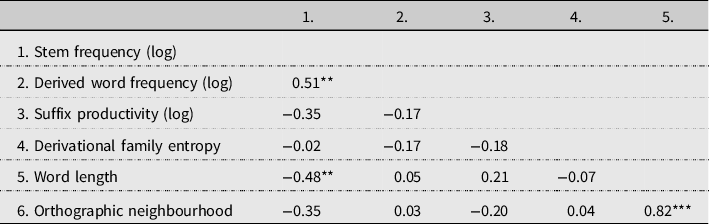
Lower triangle provides Pearson correlation coefficients.
*Correlation is significant at the .05 level.
Prior L2 experience
We also included age of initial English language instruction as a measure of prior of English language experience. The average age of initial English language instruction was 8.64 years (SD = 4.58).
Statistical considerations
Model fitting procedure
We applied an explanatory item response analysis to the longitudinal data set (De Boeck & Wilson, Reference De Boeck and Wilson2004). We fitted a generalized linear mixed-effects multiple regression model (Baayen et al., Reference Baayen, Davidson and Bates2008; Jaeger, Reference Jaeger2008; Pinheiro & Bates, Reference Pinheiro and Bates2000) to morphological production accuracy, which has a binomial underlying distribution (0 = incorrect; 1 = correct). We used restricted maximum likelihood estimations. The fixed effects structure of the model included interactions between Timepoint and each of the critical lexical variables of interest: Stem frequency, Suffix productivity, and Derivational family entropy. Any interactions that were not statistically significant were removed from the model. The removal of nonsignificant interactions did not change the direction of any of the remaining effects, nor did it change the significance of any effect at the .05 alpha level. All frequency-based measures (including suffix productivity) were log-transformed before they were entered into models. Timepoint was included in models as a factor using contrast coding (
 ${t_1}$
= −1;
${t_1}$
= −1;
 ${t_2}$
= 1). We included Derived word frequency, length (in characters) and OLD20 of the target word as control variables. All continuous independent variables were z-transformed in order to ensure the interpretable comparison of effects across variables with different scales. We also controlled for possible list counterbalancing artefacts by including a fixed effect of list order (two levels: AB and BA).
${t_2}$
= 1). We included Derived word frequency, length (in characters) and OLD20 of the target word as control variables. All continuous independent variables were z-transformed in order to ensure the interpretable comparison of effects across variables with different scales. We also controlled for possible list counterbalancing artefacts by including a fixed effect of list order (two levels: AB and BA).
We also included random intercepts for Participant with random slopes for Timepoint. By-participant random slopes for Timepoint account for individual differences in longitudinal change. A property of the structure of the data is that target words are nested under suffix type (the same suffixes are used with multiple stems). We therefore fitted a model with random intercepts for Item nested under Suffix. Using AIC values as a diagnostic of model fit (AIC values closer to negative infinity indicate greater goodness of fit), we compared the nested random effects structure to a model without random intercepts for Suffix. Chi-square goodness-of-fit tests compared AIC values across models and confirmed that the addition of random intercepts for Suffix as a nested effect with Item did not provide any gains in goodness-of-fit Footnote 6 . Therefore, the final model included (i) random intercepts for Item and (ii) random intercepts for Participant with random slopes for Timepoint.
Software
All data analysis was performed in the R statistical environment (Version 4.1.2; R Core Team, 2021). The generalized linear mixed-effects multiple regression model was fitted using the lme4 package (using the BOBYQA algorithm for optimization, Bates et al., Reference Bates, Mächler, Bolker and Walker2015). We obtained p-values for lmer model fits using the lmerTest package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017), which uses Satterthwaite’s degrees of freedom method. Contrast coding was implemented using the car package (Fox & Weisberg, Reference Fox and Weisberg2019). The significance of the fixed effects from the generalized linear-mixed effects model was estimated with Type-II Wald tests using the Anova() function also provided by the car package. Effect estimates were extracted from the model using the effects package (Fox & Weisberg, Reference Fox and Weisberg2019). All plots were generated using the ggplot2 package (Wickham, Reference Wickham2016). For the critical variables of interest, where significant interaction effects were observed with Timepoint, we examined the significance of the simple slopes of
 ${t_1}$
and
${t_1}$
and
 ${t_2}$
using the emtrends function in the emmeans package (Lenth, Reference Lenth2021). A simple slope was considered significant if the estimated 95% confidence interval contained zero.
${t_2}$
using the emtrends function in the emmeans package (Lenth, Reference Lenth2021). A simple slope was considered significant if the estimated 95% confidence interval contained zero.
Model criticism
We assessed the level of harmful collinearity in our final model in two ways. First, in the spirit of Tomaschek et al. (Reference Tomaschek, Hendrix and Baayen2018), we estimated the variance inflation factor (VIF) for each fixed effect in R using the vif() function in the car package. A VIF score of > 10 for a fixed effect indicates that its model coefficient is poorly estimated due to overfitting (Kutner et al., Reference Kutner, Nachtsheim, Neter and Li2005). VIF scores for all effects were < 6.5; critical effects of interest were all < 1.5. Second, we computed the condition number (
 $\kappa $
) using the languageR package in R (Baayen & Shafaei-Bajestan, Reference Baayen and Shafaei-Bajestan2019).
$\kappa $
) using the languageR package in R (Baayen & Shafaei-Bajestan, Reference Baayen and Shafaei-Bajestan2019).
 $\kappa $
= 5, indicating that the level of multicollinearity between all predictors is below the harmful level of 30 (Belsley et al., Reference Belsley, Kuh and Welsch2005). We are therefore satisfied that overfitting due to multicollinearity was not an issue in our model. We refitted the model after removing outliers, which were defined as data points with absolute standardized residuals exceeding 2.5 standard deviations (Baayen & Milin, Reference Baayen and Milin2010).
$\kappa $
= 5, indicating that the level of multicollinearity between all predictors is below the harmful level of 30 (Belsley et al., Reference Belsley, Kuh and Welsch2005). We are therefore satisfied that overfitting due to multicollinearity was not an issue in our model. We refitted the model after removing outliers, which were defined as data points with absolute standardized residuals exceeding 2.5 standard deviations (Baayen & Milin, Reference Baayen and Milin2010).
Statistical power
A statistical power analysis was performed for sample size estimation (see Brysbaert, Reference Brysbaert2021 for an overview of statistical power issues in bilingualism research). We conducted a power simulation study based on the fixed and random effects of the generalized mixed-effects model fitted to data from the initial study cohort (Brysbaert & Stevens, Reference Brysbaert and Stevens2018; Green & MacLeod, Reference Green and MacLeod2016). We used the simr R package (Green & MacLeod, Reference Green and MacLeod2016) to estimate the sample size required to detect effect sizes of d = .4, .2, .1 and .05 with power set to 80% and higher. We used the extend() and powerCurve() functions to perform Monte Carlo simulations for each effect size. We obtained power estimates for each main effect and interaction effect of interest for sample sizes ranging from 100 to 500 in increments of 25. We retained all the default settings of the powerCurve() function and set the analysis to conduct 100 iterations per simulation. The results indicated that a minimum of 125 participants are required to detect the smallest effect size, d = .05, with > 80% power (for the interaction between timepoint and any of the critical lexical variables). To ensure we were able to remain sufficiently overpowered, we collected additional data from a subsequent cohort of participants, setting the target sample size at 190 participants.
Results
The raw data set included 5,488 trials (
 ${t_1}$
= 2,744;
${t_1}$
= 2,744;
 ${t_2}$
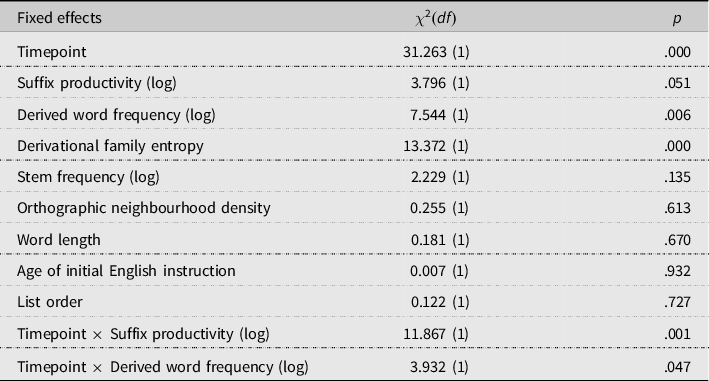
= 2,744), where a trial is defined as a participant’s response to an individual target item on the test of morphological structure. Table 3 provides descriptive statistics of the results, divided into tertiles for each lexical measure per each timepoint. Table 4 provides a summary of an analysis of variance for the final model. The fixed and random effects of the final model are provided in Appendix D.
${t_2}$
= 2,744), where a trial is defined as a participant’s response to an individual target item on the test of morphological structure. Table 3 provides descriptive statistics of the results, divided into tertiles for each lexical measure per each timepoint. Table 4 provides a summary of an analysis of variance for the final model. The fixed and random effects of the final model are provided in Appendix D.
Table 3. Mean morphological production accuracy (%) to words (SEs in parentheses) across tertiles of each critical lexical variable
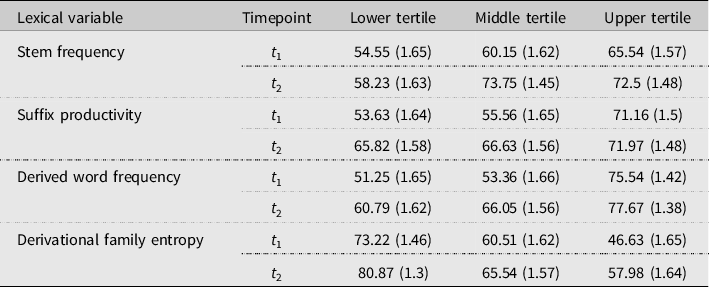
Table 4. Analysis of variance table for the fixed effects of the generalized linear mixed-effects model fitted to production accuracy
Entrenchment effects
There was a statistically significant main effect for Timepoint [
 $\hat \beta $
= 0.249; SE = 0.048; z = 5.141; p < .001], confirming that there was a reliable average within-participant increase in morphological production accuracy,
$\hat \beta $
= 0.249; SE = 0.048; z = 5.141; p < .001], confirming that there was a reliable average within-participant increase in morphological production accuracy,
 $\Delta $
= 8% (M
$\Delta $
= 8% (M
 ${t_1}$
= 60%; M
${t_1}$
= 60%; M
 ${t_2}$
= 68%). There was a statistically significant interaction between Timepoint and Suffix productivity [
${t_2}$
= 68%). There was a statistically significant interaction between Timepoint and Suffix productivity [
 $\hat \beta $
= −0.128; SE = 0.037; z = −3.445; p = .003]. There was also significant interaction between Timepoint and Derived word frequency [
$\hat \beta $
= −0.128; SE = 0.037; z = −3.445; p = .003]. There was also significant interaction between Timepoint and Derived word frequency [
 $\hat \beta $
= −0.073; SE = 0.037; z = −1.983; p = .047]. The interaction between Timepoint and Stem frequency was not significant [
$\hat \beta $
= −0.073; SE = 0.037; z = −1.983; p = .047]. The interaction between Timepoint and Stem frequency was not significant [
 $\hat \beta $
= −0.012; SE = 0.04; z = −0.334; p = .738]. This interaction was removed from the final model. There was also a nonsignificant main effect of Stem frequency [
$\hat \beta $
= −0.012; SE = 0.04; z = −0.334; p = .738]. This interaction was removed from the final model. There was also a nonsignificant main effect of Stem frequency [
 $\hat \beta $
= 0.319; SE = 0.214; z = 1.493; p = .135], which indicates that the frequency of the stem did not influence the morphological production accuracy of derived words.
$\hat \beta $
= 0.319; SE = 0.214; z = 1.493; p = .135], which indicates that the frequency of the stem did not influence the morphological production accuracy of derived words.
The significant Timepoint × Suffix productivity interaction effect is visualized in Figure 2 (panel a). Tests of the simple slopes indicated that the effect of Suffix productivity was significant at
 ${t_1}$
[
${t_1}$
[
 $\hat \beta $
= 0.550; SE = 0.221; 95% CI = 0.117 to 0.984; p < .05] but not at
$\hat \beta $
= 0.550; SE = 0.221; 95% CI = 0.117 to 0.984; p < .05] but not at
 ${t_2}$
[
${t_2}$
[
 $\hat \beta $
= 0.293; SE = 0.222; 95% CI = −0.141 to 0.117; p > .05]. The qualitative pattern of the significant interaction indicates that the greatest exposure-related gains in morphological production accuracy were for target words that contained relatively less productive suffixes. For example, target-derived words consisting of the least productive suffix, -th, underwent a predicted 23% change in morphological production accuracy, whereas targets comprising the most productive suffix, -er, saw a 2% gain in morphological production accuracy (see Table 3 for a breakdown of raw accuracy for each tertile of Suffix productivity at each timepoint). In short, the overall trend of this interaction aligns with the predicted pattern of the lexical entrenchment account (Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013, see Figure 1).
$\hat \beta $
= 0.293; SE = 0.222; 95% CI = −0.141 to 0.117; p > .05]. The qualitative pattern of the significant interaction indicates that the greatest exposure-related gains in morphological production accuracy were for target words that contained relatively less productive suffixes. For example, target-derived words consisting of the least productive suffix, -th, underwent a predicted 23% change in morphological production accuracy, whereas targets comprising the most productive suffix, -er, saw a 2% gain in morphological production accuracy (see Table 3 for a breakdown of raw accuracy for each tertile of Suffix productivity at each timepoint). In short, the overall trend of this interaction aligns with the predicted pattern of the lexical entrenchment account (Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013, see Figure 1).

Figure 2. Production accuracy effects. Panel a: partial interaction effects of timepoint by suffix productivity; panel b: partial interaction effects of timepoint by derived word frequency; panel c: partial main effects of derivational family entropy and timepoint.
The significant Timepoint × Derived word frequency interaction effect is visualized in Figure 2 (panel b). Tests of the simple slopes indicated that the effect of Derived word frequency was significant at
 ${t_1}$
[
${t_1}$
[
 $\hat \beta $
= 0.598; SE = 0.195; 95% CI = 0.217 to 0.979; p < .05] and at
$\hat \beta $
= 0.598; SE = 0.195; 95% CI = 0.217 to 0.979; p < .05] and at
 ${t_2}$
[
${t_2}$
[
 $\hat \beta $
= 0.452; SE = 0.194; 95% CI = 0.071 to 0.833; p < .05]. As indicated by the simple slopes, the effect of derived word frequency was weaker at
$\hat \beta $
= 0.452; SE = 0.194; 95% CI = 0.071 to 0.833; p < .05]. As indicated by the simple slopes, the effect of derived word frequency was weaker at
 ${t_2}$
, and the qualitative pattern of the interaction converged with the expectations of the lexical entrenchment account. There were larger gains in production accuracy for low frequency derived words compared to high-frequency derived words: there was a 20% gain in production accuracy for the least frequent derived words, and a smaller 3% gain in production accuracy for the most frequently occurring derived words. Interestingly, the size of the entrenchment effect was smaller for derived word frequency than it was for suffix productivity. Intraindividual gains in morphological production accuracy were 12 times larger for derived words containing the least productive suffixes relative to derived words containing the most productive suffixes. This change was less dramatic for derived word frequency: intraindividual gains were seven times larger for the least frequent words relative to the most frequent words. We discussed the difference between the magnitudes of the suffix productivity and derived word frequency entrenchment effects in the General discussion.
${t_2}$
, and the qualitative pattern of the interaction converged with the expectations of the lexical entrenchment account. There were larger gains in production accuracy for low frequency derived words compared to high-frequency derived words: there was a 20% gain in production accuracy for the least frequent derived words, and a smaller 3% gain in production accuracy for the most frequently occurring derived words. Interestingly, the size of the entrenchment effect was smaller for derived word frequency than it was for suffix productivity. Intraindividual gains in morphological production accuracy were 12 times larger for derived words containing the least productive suffixes relative to derived words containing the most productive suffixes. This change was less dramatic for derived word frequency: intraindividual gains were seven times larger for the least frequent words relative to the most frequent words. We discussed the difference between the magnitudes of the suffix productivity and derived word frequency entrenchment effects in the General discussion.
Connectivity effects
There was a significant main effect of Derivational family entropy [
 $\hat \beta $
= −0.554; SE = 0.151; z = −3.657; p < .001], but we did not find a significant interaction between Timepoint and Derivational family entropy [
$\hat \beta $
= −0.554; SE = 0.151; z = −3.657; p < .001], but we did not find a significant interaction between Timepoint and Derivational family entropy [
 $\hat \beta $
= −0.056; SE = 0.035; z = −1.585; p = .113]. The direction of the main effect of Derivational family entropy was negative, indicating that, at both timepoints, morphological production was less accurate for target words that belong to derivational paradigms with many relatively equally frequent members (Figure 2, panel c). The effect size for the main effect of derivational family entropy (estimated for the minimum and maximum entropy values) indicates that morphological production accuracy for target-derived words with low derivational family entropy was 85%, compared to 39% for target-derived words with the highest family entropy. Therefore, the results support the idea that participants were sensitive to the relative frequencies of members within a derivational family, but sensitivity to this source of stored morphological information did not change as a result of the language exposure captured in this study. In sum, this result supports the morphological connectivity hypothesis, indicating that ELLs draw upon distributional information about members of the target word’s morphological family during the written production of English derived words.
$\hat \beta $
= −0.056; SE = 0.035; z = −1.585; p = .113]. The direction of the main effect of Derivational family entropy was negative, indicating that, at both timepoints, morphological production was less accurate for target words that belong to derivational paradigms with many relatively equally frequent members (Figure 2, panel c). The effect size for the main effect of derivational family entropy (estimated for the minimum and maximum entropy values) indicates that morphological production accuracy for target-derived words with low derivational family entropy was 85%, compared to 39% for target-derived words with the highest family entropy. Therefore, the results support the idea that participants were sensitive to the relative frequencies of members within a derivational family, but sensitivity to this source of stored morphological information did not change as a result of the language exposure captured in this study. In sum, this result supports the morphological connectivity hypothesis, indicating that ELLs draw upon distributional information about members of the target word’s morphological family during the written production of English derived words.
In addition, we conducted a post hoc analysis to examine whether differences in the amount of prior L2 exposure may have been responsible for failing to detect changes in the effect of derivational family entropy over time. A three-way interaction between Age of initial English language instruction (as a proxy of quantity of prior L2 exposure), Derivational family entropy, and Timepoint was conducted and did not produce a significant effect [
 ${\chi ^2}$
= 0.622; p = .43]. This result indicates that the effect of morphological connectivity remained stable regardless of the amount of prior L2 exposure
Footnote 7
.
${\chi ^2}$
= 0.622; p = .43]. This result indicates that the effect of morphological connectivity remained stable regardless of the amount of prior L2 exposure
Footnote 7
.
General discussion
The current study sought to address an outstanding question about the relationship between language experience and the development of morphological knowledge: how does an individual’s exposure to the distributional patterns of language contribute to that same individual’s change in complex word knowledge? This question is critical for understanding whether exposure to language influences a learner’s ability to efficiently exploit statistically driven cues to morphological structure during production. We addressed this question by evaluating the extent of exposure-related changes in L2 learners’ sensitivity to the distributional properties of complex words as a diagnostic of the development of morphological knowledge.
Morpheme entrenchment
Critically, our study found that the extent of exposure-related change in the written production of derived words in ELLs is modulated by suffix productivity. The largest gains in complex word knowledge were found for English words with the least productive suffixes, which is consistent with the predictions of the lexical entrenchment account (Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013). In observing that the entrenchment effect operates upon suffix productivity, we argue that exposure to language specifically reinforces knowledge of the morphological elements of words. Taken together, this result builds upon past research (e.g., Bertram et al. Reference Bertram, Baayen and Schreuder2000; Cop et al., Reference Cop, Keuleers, Drieghe and Duyck2015; Whitford & Titone, Reference Whitford and Titone2012) by providing within-participant developmental evidence that the mechanism of lexical entrenchment occurs at the morpheme level, that is, morpheme entrenchment.
The results indicated that the morpheme entrenchment effect was specific only to suffixes and not stems. The interaction between stem frequency and timepoint, and the main effect of stem frequency, were not statistically significant. It may be possible to conclude from this finding that continued exposure to language leads only to changes in the production of suffixes, and that gradual entrenchment of stem units in the lexicon is absent. It is also possible, though, that the absence of any effect of stem frequency could be an artifact of the morphological production task itself. Participants were already provided with the stem and were asked to modify it to complete the sentence, which leads us to speculate that this task relies more heavily on compositional processing associated with suffix representations and not stems. To summarize, it is possible that the representations of low-frequency stems were reinforced over time, but that participants did not tap into this information given the demands of the task.
Derived word entrenchment
We found a significant interaction between derived word frequency and timepoint. The pattern of the interaction effect was consistent with the predictions of the lexical entrenchment account. For the present sample of ELLs, full forms of complex words, particularly low frequency words, were more accurately produced by the end of the bridging program. Thus, language exposure was associated with the reinforcement of the full forms of low frequency derived words in ELLs. Based on the negative and weak correlation between suffix productivity and derived word frequency (r = −.17, p > .05; see Table 2), it is not likely that the interaction between suffix productivity and timepoint could be explained by the interaction between derived word frequency and timepoint, and vice versa (see also low VIF values for these effects reported in Statistical considerations).
The test of individual slopes indicated that derived word frequency was a significant predictor of production accuracy at
 ${t_1}$
and
${t_1}$
and
 ${t_2}$
, but that suffix productivity was only a reliable predictor of accuracy at
${t_2}$
, but that suffix productivity was only a reliable predictor of accuracy at
 ${t_1}$
(see Results). The nonsignificant effect of suffix productivity at
${t_1}$
(see Results). The nonsignificant effect of suffix productivity at
 ${t_2}$
indicate that as suffix forms become more entrenched (see discussion above), derived words with suffixes that are less productive become easier to correctly produce, so much so that these derived words are no longer a problem for written word production. However, whole word frequency remains a critical predictor: low-frequency whole word forms may still negatively impact written word production accuracy relative to high frequency derived words. What might be a reason for the difference in magnitude of the entrenchment effect for suffix productivity compared to derived word frequency? Recall that the central claim of the entrenchment account is that exposure to words drives the consolidation of words in memory, and that language users have fewer opportunities to strengthen the lexical representations of low-frequency items because they are less prevalent in the language. Thus, it is possible that participants did not encounter the lowest frequency derived words as often as the least productive suffixes within the duration of the study, leading to a smaller entrenchment effect for low frequency-derived words compared to the least productive suffixes. The frequency data of our materials support this view (see Table 1): derived words, on average, occur less often than isolated suffix forms.
${t_2}$
indicate that as suffix forms become more entrenched (see discussion above), derived words with suffixes that are less productive become easier to correctly produce, so much so that these derived words are no longer a problem for written word production. However, whole word frequency remains a critical predictor: low-frequency whole word forms may still negatively impact written word production accuracy relative to high frequency derived words. What might be a reason for the difference in magnitude of the entrenchment effect for suffix productivity compared to derived word frequency? Recall that the central claim of the entrenchment account is that exposure to words drives the consolidation of words in memory, and that language users have fewer opportunities to strengthen the lexical representations of low-frequency items because they are less prevalent in the language. Thus, it is possible that participants did not encounter the lowest frequency derived words as often as the least productive suffixes within the duration of the study, leading to a smaller entrenchment effect for low frequency-derived words compared to the least productive suffixes. The frequency data of our materials support this view (see Table 1): derived words, on average, occur less often than isolated suffix forms.
Morphological connectivity
ELLs in this study were affected by the distributional properties of morphological families but did not show evidence of exposure-driven change in the strength of this effect. The effect of derivational family entropy was negative and remained stable at both timepoints. That is, at both
 ${t_1}$
and
${t_1}$
and
 ${t_2}$
, morphological production accuracy was highest for morphological families with lower derivational entropy, that is, derived words that belong to families with fewer equally dominant members. Since the measure of derivational family entropy relies on the relative frequencies of words within a given morphological paradigm, the presence of an entropy effect necessarily implies that ELLs in this study exploited lexical knowledge about morphological families during derived word production. We interpret this as a stable effect of morphological connectivity, that is, sensitivity to inter-lexical connectivity between the members of a morphological family. Previous L2 research (Mulder et al., Reference Mulder, Dijkstra, Schreuder and Baayen2014) has shown that morphological family size influences language processing. Here, we show that L2 lexical knowledge comprises both morphological family size and the relative frequencies of members of a morphological family.
${t_2}$
, morphological production accuracy was highest for morphological families with lower derivational entropy, that is, derived words that belong to families with fewer equally dominant members. Since the measure of derivational family entropy relies on the relative frequencies of words within a given morphological paradigm, the presence of an entropy effect necessarily implies that ELLs in this study exploited lexical knowledge about morphological families during derived word production. We interpret this as a stable effect of morphological connectivity, that is, sensitivity to inter-lexical connectivity between the members of a morphological family. Previous L2 research (Mulder et al., Reference Mulder, Dijkstra, Schreuder and Baayen2014) has shown that morphological family size influences language processing. Here, we show that L2 lexical knowledge comprises both morphological family size and the relative frequencies of members of a morphological family.
The main effects of timepoint and derivational family entropy indicate that instead of observing a bias toward longitudinal gains for either low or high entropy words, there was an overall improvement across the entropy continuum. As noted in Introduction, it is also a possibility that greater morphological connectivity was masked by an increase in individual discrimination ability. That is, a steeper negative effect (stemming from larger gains for low entropy words or a higher penalty for high entropy derived words) was counteracted upon by an opposite effect: an improvement in the ability to select the correct form within a derivational family. Future research should be devoted to more clearly disentangling both possibilities in ELLs.
Insights from a recent study may also shed light on why the effect of morphological connectivity remained stable across the program. In an investigation of English morphological awareness among adult ELLs registered in US universities whose L1 was either Turkish or Chinese, Wu and Juffs (Reference Wu and Juffs2021) uncovered a persistent effect of L1 morphological experience on the development of morphological awareness in English. Despite advanced proficiency in English for both groups, L1 Turkish ELLs outperformed L1 Chinese ELLs in tasks tapping into derivation and morphological relatedness, suggesting that the effects of an L1 experience with an agglutinative language such as Turkish facilitated morphological awareness in English. Moreover, the study suggests that ELLs with an L1 rich in inflection and derivation can develop more acute English morphological awareness even with an overall lower English proficiency than ELLs whose L1 is an isolating language such as Chinese. For our participants, who are also L1 Chinese ELLs, and whose English proficiency is lower than that of Wu and Juffs’ (Reference Wu and Juffs2021) learners, the L2 experience afforded by the program regarding morphological connectivity is likely insufficient to act upon the persistent influence of L1 experience with an isolating morphological system.
Taken together, the morpheme entrenchment and connectivity findings accord with prior work on L2 morphological processing (Diependaele et al., Reference Diependaele, Dunabeitia, Morris and Keuleers2011; Mulder et al., Reference Mulder, Dijkstra and Baayen2015) by showing that both L1 and L2 lexical knowledge comprises the same types of distributional information about morphological structure. Furthermore, as noted in the Introduction, the hypotheses put forward in the present study were motivated by the idea that the mental structuring of language reflects the distributional properties of the input acquired through experience (MacDonald, Reference MacDonald2013; Stanovich & West, Reference Stanovich and West1989). Our results align with this premise: even at the outset of the longitudinal study (
 ${t_1}$
) ELLs were sensitive to the distributional properties of words as encoded in the orthography.
${t_1}$
) ELLs were sensitive to the distributional properties of words as encoded in the orthography.
Relationship to prior research
Much of the existing research on L2 morphological awareness is correlational and has been conducted on bilingual children who learn English as a second language (see the meta-analysis in Ke et al., Reference Ke, Miller, Zhang and Koda2021); few studies have examined morphological awareness in adult L2 learners of English (Zhang & Koda, Reference Zhang and Koda2012). The goal of these studies is to examine whether individual variability in morphological awareness translates into interindividual differences in reading comprehension and vocabulary knowledge. The present study contributes to this body of research in the following three ways. First, our analysis focuses on the properties of the items in the morphological awareness task. We examined sources of variability of within-participant change in morphological knowledge that stem from the statistical-distributional properties of words and the morphological families they belong to. In this regard, our findings supplement existing longitudinal ELL research by Jiang and Kuo (Reference Jiang and Kuo2019) which shows how within-participant change in morphological production varies across complex words with different phonological properties and parts of speech. Second, our focus on established frequency-based markers of morphological knowledge, coupled with a longitudinal design, allowed us to link research on the development of L2 morphological knowledge to existing psycholinguistic theories of word learning and morphological processing. Third, the focus on university-level Chinese ELLs enabled us to contribute to research on bilingualism and the development of morphological knowledge from an important dimension that is less prominent in the literature: the lens of the adult learner in a learning environment (post-secondary) who needs to engage in a sophisticated manner with an additional language that is typologically distant from their L1.
Practical implications
According to a report by the Institute of International Education (Mason, Reference Mason2021), based on UNESCO data, China was the leading place of origin for international students for the
 ${11^{th}}$
consecutive year in 2020: almost one million students (993,367) from China were registered in higher education institutions outside China in 2020, the vast majority in the USA, Australia, the UK, and Canada. Our findings therefore have implications for the educational practice of Chinese ELLs, especially those enrolled in bridging programs. Bridging programs are established with the aim of “bridging” lower proficiency students into post-secondary programs. However, at present, the number of studies that quantify the extent of linguistic gains of students enrolled in bridging programs is limited. Based on our results, it would be worthwhile for developers of advanced English as a second language materials and texts to take into account the need for learners to repeatedly encounter a rich variety of low-frequency affixes. Because derived words with less productive suffixes (e.g., -th, -ence/-ance, and -ous) are challenging to correctly produce early on, students should be exposed to materials containing an overrepresentation of derived words with these morpheme characteristics. Moreover, it is worth highlighting that, as with derived word frequency, derivational family entropy was a reliable predictor of production accuracy at
${11^{th}}$
consecutive year in 2020: almost one million students (993,367) from China were registered in higher education institutions outside China in 2020, the vast majority in the USA, Australia, the UK, and Canada. Our findings therefore have implications for the educational practice of Chinese ELLs, especially those enrolled in bridging programs. Bridging programs are established with the aim of “bridging” lower proficiency students into post-secondary programs. However, at present, the number of studies that quantify the extent of linguistic gains of students enrolled in bridging programs is limited. Based on our results, it would be worthwhile for developers of advanced English as a second language materials and texts to take into account the need for learners to repeatedly encounter a rich variety of low-frequency affixes. Because derived words with less productive suffixes (e.g., -th, -ence/-ance, and -ous) are challenging to correctly produce early on, students should be exposed to materials containing an overrepresentation of derived words with these morpheme characteristics. Moreover, it is worth highlighting that, as with derived word frequency, derivational family entropy was a reliable predictor of production accuracy at
 ${t_1}$
. This indicates that interlexical connections between members of a morphological family are present for ELLs even at the outset of the bridging program. In our population, the median overall incoming IELTS score was 5.5 (range = 5 to 7), suggesting that knowledge of derivational families is already established among ELLs with “limited to modest” knowledge of English (to use IELTS terminology). Therefore, ESL curriculum developers may wish to use this information when designing materials aimed at ELLs who fall within a similar IELTS proficiency band. For example, special attention could be directed at the creation of texts and exercises containing derived words belonging to morphological families with multiple similarly frequent members.
${t_1}$
. This indicates that interlexical connections between members of a morphological family are present for ELLs even at the outset of the bridging program. In our population, the median overall incoming IELTS score was 5.5 (range = 5 to 7), suggesting that knowledge of derivational families is already established among ELLs with “limited to modest” knowledge of English (to use IELTS terminology). Therefore, ESL curriculum developers may wish to use this information when designing materials aimed at ELLs who fall within a similar IELTS proficiency band. For example, special attention could be directed at the creation of texts and exercises containing derived words belonging to morphological families with multiple similarly frequent members.
Additional work is needed to examine change in morphological knowledge as a consequence of language exposure. The current task was designed to examine morphological knowledge using written word production as an outcome measure. This task provides an indication of the accuracy of morphological knowledge, by assessing whether a correct suffix was applied to a stem. This method is limited, however, because it cannot capture cognitive processing effort during the task. Having established the viability of assessing the development of morphological knowledge in a relatively simple-to-administer production task, we can begin to investigate how language exposure determines speed of processing during written production. For example, future research could employ the same task and longitudinal design yet examine keystroke latencies as an additional measure (e.g., Feldman et al., Reference Feldman, Dale and van Rij2019; Sahel et al., Reference Sahel, Nottbusch, Grimm and Weingarten2008). Furthermore, we wish to note that during the course of the present study, all ELLs were provided with explicit morphological instruction in addition to exposure to advanced academic texts. Although we are confident that responsiveness to word frequency information would stem from exposure to language, it is also possible that part of this knowledge results from explicit instruction. A clear distinction would be achieved in a controlled randomized intervention study with two treatment groups: explicit morphological instruction versus no explicit morphological instruction.
Conclusions
Our study shows that it is possible to capture change in L2 learners’ sensitivity to morphological structure with increased language exposure across a fixed window of time. Through a written task, we discovered that written L2-derived word production is driven by (i) gains in knowledge of the distribution of suffixes; and (ii) knowledge of connections between words within a derivational morphological family. Derived word production among ELLs can be explained as a function of their learning and exploitation of the distributional properties of the morphological structure of words.
Appendix A. Test of morphological structure
Table A.1. Test of morphological structure, List A

Table A.2. Test of morphological structure, List B

Appendix B. Response type distribution
Figure B.1 provides the counts of the different spelling types broken down by timepoint. The response types are based on the POMplexity framework (Bahr et al., Reference Bahr, Lebby and Wilkinson2020) outlined in Methods. A chi-square test of association confirmed that there was a relationship between response type and Timepoint,
 ${\chi ^2}$
(5, N = 5,488) = 110.11, p < .001. This analysis indicates that there was a significant imbalance in the number of response types across timepoints. The figure shows that there were more fully correct spellings, e.g., humanity, at
${\chi ^2}$
(5, N = 5,488) = 110.11, p < .001. This analysis indicates that there was a significant imbalance in the number of response types across timepoints. The figure shows that there were more fully correct spellings, e.g., humanity, at
 ${t_2}$
compared to
${t_2}$
compared to
 ${t_1}$
. In addition, there were fewer “plausible” and “homophone” substitution errors at
${t_1}$
. In addition, there were fewer “plausible” and “homophone” substitution errors at
 ${t_2}$
relative to
${t_2}$
relative to
 ${t_1}$
, e.g., humanitiy. Finally, the largest change in error type across timepoints was found for morpheme substitution errors: cases for which an incorrect suffix was applied to the stem form, e.g., humanable.
${t_1}$
, e.g., humanitiy. Finally, the largest change in error type across timepoints was found for morpheme substitution errors: cases for which an incorrect suffix was applied to the stem form, e.g., humanable.

Figure B.1. Frequency of spellings broken down by type and timepoint.
Appendix C. List of stimuli with distributional lexical properties
Table C.1. List of stimuli with distributional lexical properties

Appendix D. Fixed and random effects of the generalized linear mixed-effects model fitted to production accuracy
Table D.1. Fixed effects of the generalized linear mixed-effects model fitted to production accuracy. Conditional
 ${R^2} = 0.46$
. SD of the residual = 0.96. N = 5,488. N after trimming = 5,478
${R^2} = 0.46$
. SD of the residual = 0.96. N = 5,488. N after trimming = 5,478

Table D.2. Random effects of the generalized linear mixed-effects model fitted to production accuracy



















 Open access
Open access