


1 Introduction
Intonation can convey linguistic information (e.g. syntactic constituency, reference resolution, illocution type), paralinguistic meaning (e.g. speakers' attitudes towards the propositions or the addressee, speakers' epistemic, bouletic, or deontic biases) and information-structural and discourse-organisational information (e.g. topic–comment, focus–background, topic change, turn-taking). However, it is to date not entirely clear how to formalise the link between the intonation contour and the meaning it contributes (for recent overviews see Prieto Reference Prieto2015 and Truckenbrodt Reference Truckenbrodt, Maienborn, Heusinger and Portner2012 and references therein). For instance, meaning has been attributed to nuclear tunes (e.g. O'Connor & Arnold Reference O'Connor and Arnold1973, Liberman & Sag Reference Liberman and Sag1974, Brazil Reference Brazil1975, Ward & Hirschberg Reference Ward and Hirschberg1985, Portes et al. Reference Portes, Beyssade, Michelas, Marandin and Champagne-Lavau2014), pitch accents (e.g. Hobbs Reference Hobbs1990, Pierrehumbert & Hirschberg Reference Pierrehumbert and Hirschberg1990, Kohler Reference Kohler1991, Steedman Reference Steedman, Lee, Gordon and Büring2007, Lommel & Michalsky Reference Lommel, Michalsky, Levkovych and Urdze2017), boundary tones (e.g. Bartels Reference Bartels1997, Gunlogson Reference Gunlogson2003), and combinations of intonation contours and further prosodic properties, such as voice quality, duration, etc. (Ogden Reference Ogden, Trouvain and Barry2007, Reference Ogden and Niebuhr2012; Niebuhr Reference Niebuhr, Bimbot, Cerisara, Fougeron, Gravier, Lamel, Pellegrino and Perrier2013; Hedberg, Sosa & Görgülü Reference Hedberg, Sosa and Görgülü2014; Petrone & Niebuhr Reference Petrone and Niebuhr2014; Ward Reference Ward2014; Ward & Gallardo Reference Ward and Gallardo2017). According to Ward & Gallardo (Reference Ward and Gallardo2017: 3), a ‘shared notion of prosodic constructions has emerged’ from the approaches which combine intonation contours and further prosodic/phonetic properties. Ward & Gallardo (Reference Ward and Gallardo2017: 3f.) characterise prosodic constructions as ‘recurring temporal patterns of prosodic activity that express specific meanings and functions and which typically involve not only pitch contours but also energy, rate, timing and articulation properties’.
In this paper, we investigate the prosodic realisation of vocatives in different pragmatic contexts to shed more light on the link between meaning and prosody. Vocatives are direct address forms which serve a number of functions, including: (i) to attract someone's attention and to open a communicative act, (ii) to maintain the contact between interlocutors and to reinforce the social relationship, and (iii) to identify the addressee by naming them explicitly (see Wood & Kroger Reference Wood and Kroger1991, Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan1999, Daniel & Spencer Reference Daniel, Spencer, Malchukov and Spencer2009, Parrott Reference Parrott2010, Borràs-Comes, Sichel-Bazin & Prieto Reference Borràs-Comes, Sichel-Bazin and Prieto2015). Since vocatives are syntactically simple and independent (Schegloff Reference Schegloff1968; Zwicky Reference Zwicky1974; Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan1999: 149; Moro Reference Moro, Quer, Schroten, Scorretti, Sleeman and Verhengd2003; Parrott Reference Parrott2010), semantically unspecific (in that they only consist of a name and do not contain any further semantic information) (Haverkate Reference Haverkate and Zonnefeld1978: 47; Pierrehumbert & Hirschberg Reference Pierrehumbert and Hirschberg1990: 293), and can themselves function as requests, reproaches, orders, insisting calls, etc. (de-la-Mota, Martín Butragueño & Prieto (Reference Prieto and Roseano2010: 341) for Mexican Spanish; Parrott Reference Parrott2010, Prieto & Roseano (Reference Prieto and Roseano2010a: 12) for Spanish in general), they are a perfect test case for investigating the prosody–pragmatics interface. In the following we will use the term vocative to refer to the use of a single proper name to call out for a person (note that also other word categories can be used in this sense, see Zwicky Reference Zwicky1974 and Wilson & Zeitlyn Reference Wilson and Zeitlyn1995 for observations on vocatively used expressions in English; see Biber et al. Reference Biber, Johansson, Leech, Conrad and Finegan1999 for an exhaustive list of categories and their position and distribution in English).
Vocatives are sensitive to pragmatic and social factors (see Zwicky Reference Zwicky1974 for English, Hualde et al. Reference Hualde, Olarrea, Escobar and Travis2010 for Spanish, Parrott Reference Parrott2010 for Russian, Hualde & Prieto Reference Hualde and Prieto2015 for Spanish). In our study, we tested how three pragmatic conditions – greeting, confirmation-seeking, reprimand – affect the intonational and prosodic realisation of vocatives in Colombian Spanish (Bogotá) and related this with the concept of prosodic constructions. We kept social factors constant. To test whether the resulting intonation contours are specific for these pragmatic contexts, we additionally analysed single-word utterances that can be uttered in these contexts (¡Hola! ‘Hello!’ and ¡Para! ‘Stop.imp’, henceforth referred to as non-vocatives). The results showed that the pragmatic condition affected the choice of intonation contours, but that there was no clear one-to-one relationship. Furthermore, the non-vocatives partly showed a different distribution of intonation contours across pragmatic conditions than the vocatives. Therefore, our data do not support a direct relation between intonation contours and pragmatic meaning. We saw, however, fine-grained phonetic differences that could be used to distinguish the contours across pragmatic conditions. Since these prosodic differences did not hold for vocatives and non-vocatives alike, there is little support for the prosodic construction view.
1.1 Prosodic realisation of vocatives and theoretical background
Neutral vocatives are often associated with the so-called ‘calling contour’: a high or rising pitch movement associated with the accented syllable and a fall to a mid-pitch level which is sustained until the end of the utterance. This contour has also been termed spoken chant, vocative chant, calling contour, stylized fall, stylized interjection, chanted call, and ‘one-step-down’ contour (for English: Pike Reference Pike1945, Liberman Reference Liberman1975 cited in Ladd Reference Ladd1978: 517, Gibbon Reference Gibbon and Gibbon1976, Ladd Reference Ladd1978, Day-O'Connell Reference Day-O'Connell2013; for Dutch: Gussenhoven Reference Gussenhoven1993; for German: Niebuhr Reference Niebuhr, Niebuhr and Skarnitzl2015). An example of such a calling contour, from a speaker of Madrilenian Spanish, is illustrated in Figure 1. The tonal annotation of the intonational contour in that figure follows the Tones and Break Indices transcription system for Spanish (Sp_ToBI; Estebas-Vilaplana & Prieto Reference Estebas-Vilaplana and Prieto2009, Reference Prieto and Roseano2010; Hualde & Prieto Reference Hualde and Prieto2015), a system we also applied in our study (see below). Following Niebuhr (Reference Niebuhr, Niebuhr and Skarnitzl2015: 42) in the use of a form-based term, we call such a rise with a subsequent drop to a mid-pitch level which is sustained until the end of the utterance a ‘one-step-down contour’, for easier reading abbreviated to step-down contour.

Figure 1 Waveform, spectrogram and f0-trace for the Madrilenian Spanish vocative ¡Marina! produced with an L+H* pitch accent followed by an !H% boundary tone, adapted from http://prosodia.upf.edu/atlasentonacion/enquestes/espanol/madrid/index-english.html, accessed 16 August 2017 (Prieto & Roseano Reference Prieto and Roseano2009–2013). Thanks to Paolo Roseano for providing the soundfile and to Wendy Elvira García for the praat-script to create the figure.
The intonation of vocatives has been investigated for different Spanish varieties, among them Colombian (Velásquez Upegui Reference Velásquez Upegui2013), Chilean (Cid & Ortiz Reference Cid and Ortiz1998, Ortiz, Fuentes & Astruc Reference Ortiz, Fuentes and Astruc2010), Mexican (de-la-Mota et al. Reference de-la-Mota, Butragueño and Prieto2010), Argentinian (Gabriel et al. Reference Gabriel, Feldhausen, Pešková, Colantoni, Lee, Arana and Labastía2010), and Peninsular Spanish (Alonso-Cortés Reference Alonso-Cortés, Demonte and Bosque1999, Estebas-Vilaplana & Prieto Reference Estebas-Vilaplana and Prieto2010, López-Bobo & Cuevas-Alonso Reference López-Bobo and Cuevas-Alonso2010). For most Spanish varieties, a step-down was reported as the default contour for vocatives; see Prieto & Roseano (Reference Prieto and Roseano2010a) and Hualde & Prieto (Reference Hualde and Prieto2015) for an overview. A step-down occurs in other Romance languages as well (e.g. Delais-Roussarie et al. Reference Delais-Roussarie, Post, Avanzi, Buthke, Cristo, Feldhausen, Jun, Martin, Meisenburg, Rialland, Sichel-Bazin and Yoo2015 for French, Gili Fivela et al. Reference Gili Fivela, Avesani, Barone, Bocci, Crocco, D'Imperio, Giordano, Marotta, Savino and Sorianello2015 for Italian). Note, however, that vocatives can also be realised with other contours, such as a rising–falling contour (e.g. Borràs-Comes et al. Reference Borràs-Comes, Sichel-Bazin and Prieto2015 for Catalan, Frota et al. Reference Frota, Cruz, Svartman, Collischonn, Fonseca, Serra, Oliveira and Vigário2015 for Brazilian Portuguese, Prieto et al. Reference Prieto, Borràs-Comes, Cabré, Crespo-Sendra, Mascaró, Roseano, Sichel-Bazin and Vanrell2015 for Catalan), a rising contour (Borràs-Comes et al. Reference Borràs-Comes, Sichel-Bazin and Prieto2015 for Catalan), a falling contour (Sichel-Bazin, Meisenburg & Prieto Reference Sichel-Bazin, Meisenburg and Prieto2015 for Occitan), or a rise-plateau-rise contour (Arvaniti, Żygis & Jaskuła Reference Arvaniti, Żygis and Jaskuła2016 for Polish). Before dealing with Colombian Spanish vocatives in greater detail, we briefly introduce the Sp_ToBI transcription system and its theoretical background. This is necessary, because the previous research on Colombian Spanish is couched in that system.
The ToBI system is based on the autosegmental–metrical (AM) theory of intonation (Ladd Reference Ladd2008 and references therein). The AM theory distinguishes between (i) phonological representations, consisting of underlying tonal targets (High (H) or low (L), and their combinations) represented on a tonal tier, and (ii) the phonetic implementation. Furthermore, there exists the diacritic ‘¡’, called upstep, to mark that a high tone has a higher peak compared to a preceding one. Two types of tonal events are assumed: pitch accents and boundary tones. The former associate with metrically strong syllables (and are marked by an asterisk, ‘*’); the latter associate with the edge of higher-level prosodic constituents of the prosodic hierarchy (Selkirk Reference Selkirk1984, Nespor & Vogel Reference Nespor and Vogel1986). The last pitch accent of an utterance together with the following boundary tone is referred to as nuclear contour. The ToBI transcription system was established at the beginning of the 1990s for American English (Silverman et al. Reference Silverman, Beckman, Pitrelli, Ostendorf, Wightman, Price, Pierrehumbert and Hirschberg1992) and subsequently applied to many languages (see Jun Reference Jun2005, Reference Jun2014), among them Spanish (Beckman et al. Reference Beckman, Días-Campos, McGory and Morgan2002, Hualde Reference Hualde2003, Sosa Reference Sosa2003, Face & Prieto Reference Face and Prieto2007, Aguilar, de-la-Mota & Prieto Reference Aguilar, de-la-Mota and Prieto2009, Estebas-Vilaplana & Prieto Reference Estebas-Vilaplana and Prieto2009, Prieto & Roseano Reference Prieto and Roseano2010b). The most recent version of the Sp_ToBI system is provided in Hualde & Prieto (Reference Hualde and Prieto2015) and reflects consideration of the dialectal variety found in Spanish. In addition to a tonal inventory of Spanish, Sp_ToBI specifies two levels above the prosodic word (ω) in the prosodic hierarchy: the intermediate phrase (ip) and the intonational phrase (IP). The corresponding boundary tones are marked by ‘-’ and ‘%’, respectively. See Face (Reference Face2014) for an overview and a critical review of Sp_ToBI.
Colombian Spanish vocatives were investigated by Velásquez Upegui (Reference Velásquez Upegui2013).Footnote 1 She collected data by several tasks, including a discourse-completion task (DCT henceforth; Blum-Kulka, House & Kasper Reference Blum-Kulka, House, Kasper, Blum-Kulka, House and Kasper1989, Prieto Reference Prieto, Bover, Lloret and Vidal-Tibbits2001, Prieto & Roseano Reference Prieto and Roseano2009–2013, Vanrell, Feldhausen & Astruc in press). The DCT is a guided questionnaire in which the researcher presents the participants a set of different situations/contexts one after the other (such as ‘You go into a grocery store and ask the shop assistant if they sell marmalade’) and then asks them to react accordingly. Thus, the participants respond by completing a turn of a dialogue (i.e. the situation) and each situation is ‘intended to elicit a particular type of utterance and pragmatic meaning’ (Prieto et al. Reference Prieto, Borràs-Comes, Cabré, Crespo-Sendra, Mascaró, Roseano, Sichel-Bazin and Vanrell2015: 15). In prosody research, the task is typically carried out orally. This solicitation method has been applied for several years in research on pragmatics and sociolinguistics and more recently on prosody (Prieto et al. Reference Prieto, Borràs-Comes, Cabré, Crespo-Sendra, Mascaró, Roseano, Sichel-Bazin and Vanrell2015: 15; Vanrell et al. in press and references therein).
Velásquez Upegui (Reference Velásquez Upegui2013) recorded four native speakers (two male, two female) in each of the four economically most important cities of Colombia with the greatest dialectal distance (Bogotá, Cali, Medellín, and Cartagena). The vocative ¡Marina! was elicited in five pragmatic conditions (neutral, reprimand, tenderness, surprise, and doubt). She reported typical contours for each variety and pragmatic condition, together with average syllable durations and pitch range in the nuclear contour. Velásquez Upegui (Reference Velásquez Upegui2013) labelled the data according to the Sp_ToBI annotation system as proposed in Estebas-Vilaplana & Prieto (Reference Estebas-Vilaplana and Prieto2009). In terms of intonational contours, Velásquez Upegui (Reference Velásquez Upegui2013: 180–191) reported similar contours across dialects, but variation in peak height, peak alignment, height of the boundary tone, pitch range, and syllable duration. Doubt was typically signalled by a rise (Bogotá: L* HH%),Footnote 2 tenderness by a high–flat contour (H* M%, but with a final fall in Bogotá: H* HL%), neutral calls by a step-down contour (Bogotá with increased pitch range: L+¡H* M%), surprise by a rise–fall (Bogotá: L+¡H* L%), and reprimand also by a rise–fall (Bogotá with a delayed peak: L+>H* M%) (Velásquez Upegui Reference Velásquez Upegui2013: 180–191). One weakness of this study was that the fictive addressee was not held constant across pragmatic conditions but instead varied in age (younger, same age, older than the speaker), social status (family member vs. non-family member), relationship to the speaker (close vs. distant), and power relation between speaker and hearer (superior vs. inferior). Since these factors have all been said to influence the prosodic realisation (Zwicky Reference Zwicky1974, Hualde et al. Reference Hualde, Olarrea, Escobar and Travis2010, Parrott Reference Parrott2010, Borràs-Comes et al. Reference Borràs-Comes, Sichel-Bazin and Prieto2015, Hualde & Prieto Reference Hualde and Prieto2015), in this data it is difficult to pin down the effect of pragmatic condition on the prosodic realisation of vocatives. Neither do we know whether these prosodic realisations are specific to vocatives or also generalise to other utterances that are appropriate in the same contexts (e.g. ¡Hola!, ¡Para!).
1.2 Outline and hypotheses
We elicited semi-spontaneous productions of Colombian Spanish vocatives and non-vocatives in three pragmatic conditions while keeping constant the status and social relationship between speaker and hearer, the formality of the interaction, and the environmental setting. The independent variables were pragmatic condition (greeting, confirmation-seeking, reprimand) and utterance-type (vocative vs. non-vocative). Pragmatic condition was manipulated within-subjects and within-items. Utterance-type was manipulated within-subjects and between-items.
Items were elicited by means of a DCT, a guided questionnaire, as mentioned above, which was also used in the work on the prosody of other Spanish varieties within the project of the Atlas interactivo de la entonación del español/Interactive Atlas of Spanish Intonation (Prieto & Roseano Reference Prieto and Roseano2009–2013, Reference Prieto and Roseano2010b; Hualde & Prieto Reference Hualde and Prieto2015). We chose to use the DCT for the advantages it confers. Although doubts about the naturalness of the productions obtained in this task have been raised, Vanrell et al. (in press) note in their critical review of the DCT that it (i) offers the possibility to easily elicit comparable (semi-)spontaneous data across speakers (and dialects), and (ii) still allows for the possibility to control both the context (such as pragmatic and politeness factors) and relevant aspects of the target sentence (such as sentence type, stress pattern, and target words). Although the DCT may be less successful with complex speech acts, we note that the speech acts evoked in the present study are relatively straightforward. This way of data collection, additionally, allowed a better comparison to the results of previous studies on Colombian Spanish (Velásquez Upegui Reference Velásquez Upegui2013), as well as on further varieties of Spanish and on other Romance languages (Prieto & Roseano Reference Prieto and Roseano2010b, Frota & Prieto Reference Frota and Prieto2015b). The contexts were constructed as similarly as possible to the ones used by Velásquez Upegui (Reference Velásquez Upegui2013), but were adapted where necessary in order to control for social factors and to be as parallel as possible across pragmatic conditions.
With reference to the previous literature, our main hypothesis was as follows:
Hypothesis
Pragmatic condition affects the intonation contour of the vocative (Velásquez Upegui Reference Velásquez Upegui2013) even when sociopragmatic and situational factors are controlled.
Given this main hypothesis, we established four sub-hypotheses (SHs) that highlight different aspects of the main hypothesis:
Sub-hypotheses
SH1 For each pragmatic condition we expected vocatives to be realised with a predominant intonation contour (i.e. produced in more than 50% of the cases): step-down contour for greeting (see Hualde et al. Reference Hualde, Olarrea, Escobar and Travis2010, Velásquez Upegui Reference Velásquez Upegui2013 on calling contour as typical for vocatives), rising contour for confirmation-seeking (Velásquez Upegui Reference Velásquez Upegui2013), and rising-falling contour for reprimand (Velásquez Upegui Reference Velásquez Upegui2013).
SH2 The step-down and the rising contour were expected to be specific for certain pragmatic conditions: the step-down contour is expected to occur predominantly in greeting vocatives (Velásquez Upegui Reference Velásquez Upegui2013) and a rising contour in confirmation-seeking vocatives (Velásquez Upegui Reference Velásquez Upegui2013).
SH3 Non-vocatives and vocatives were expected to show the same distribution of intonation contours across pragmatic conditions. That is, when a vocative with a greeting intention is produced with a step-down contour, we expected to find the same intonation contour realised on the non-vocative (i.e. ¡Hola!) elicited in the same context.
SH4 In case an intonation contour occurs in more than one pragmatic condition, we expected differences in the phonetic realisation of the contour across pragmatic condition. That is, when the rising–falling contour occurs in both the greeting and the reprimand condition, the phonetic realisation of these two contours is expected to differ (with respect to acoustic properties regarding spectral tilt, duration, alignment of tonal targets, f0-range, and slope). Further, we expected such prosodic differences to hold for vocatives and non-vocatives.
2 Experiment
2.1 Methods
2.1.1 Participants
Eight monolingual speakers of Colombian Spanish (three male, five female) aged between 23 and 33 years (average age = 27 years, SD = 3.96 years) participated for a small fee. All of them originated from Bogotá D.C., the capital of Colombia, and were studying in Germany. Even though they all studied German as a foreign language and were living in Germany at the time of the recordings (range between nine months and six-and-a-half years; see Appendix A for speaker details), they used Spanish frequently. The participants were unaware of the purpose of the study.
2.1.2 Materials
2.1.2.1 Items
We tested vocatives and non-vocatives. For the vocatives, we selected six Spanish proper names (three male, three female) with stress on the penultimate syllable. Four names were trisyllabic (e.g. Manolo – underlining signals the stressed syllable) and two bisyllabic (e.g. Nora). Two trisyllabic proper names with stress on the antepenultimate syllable (Ángela, Álvaro) served as fillers to create rhythmic variation. Table 1 shows the complete list of recorded names. Names were selected to be predominantly sonorant, to allow more accurate pitch tracking.
Table 1 Overview of the experimental vocatives.

For the non-vocatives, situation-specific lexical responses instead of proper names were selected. For the greeting and confirmation-seeking condition, we used the disyllabic word Hola ‘Hello’. For the reprimand condition, we used Para ‘Stop.imp’.
2.1.2.2 Contexts
We constructed three experimental contexts, one for each pragmatic condition (greeting, confirmation-seeking, reprimand), and seven filler contexts. The experimental contexts describe comparable situations that only differ in the speaker's purpose for the call. Sociopragmatic and situational factors, in particular the age relation between speaker and fictional addressee, social status, and physical distance were kept constant across pragmatic conditions: The scene was always placed in a shopping mall since this is a place of medium distance, neither short (same room), nor far (other side of the street). Furthermore, it offers a context in which all pragmatic conditions are likely. The addressee was always the speaker's best friend, assumed to be of the same age as the speaker. Example contexts are shown in (1)–(3); the Spanish originals are given in Appendix B. All contexts had parallel syntax and only differed in the purpose of the summons. To avoid ambiguity, the intended mood and/or epistemic state of the speaker were explicitly stated (underlined here but not further highlighted for the participants).
Example contexts
(1) Greeting (happy): You are at the shopping mall and you see your best friend who is called Camila. You are happy to see her. Call her (name) so that she turns around and you can greet her.
(2) Confirmation-seeking (uncertain): You are at the shopping mall and you see a girl that looks like your best friend who is called Camila. You wonder whether it is her. Call her (name) so that she turns around and you can confirm whether it is her or not.
(3) Reprimand (angry): You are at the shopping mall together with your best friend Camila and some other friends. Camila is telling an embarrassing secret of yours. It makes you angry and you want her to stop. Call her (name) so that she turns around and stops talking.
We constructed two types of fillers: two further calling contexts which elicited vocatives in similar pragmatic conditions but with different emotions (bored reprimand and non-emotional reprimand) and five question–answer contexts which elicited non-vocative, single-word productions of names (with the same mood/epistemic-state descriptions as the experimental contexts; see Appendix C for filler contexts).
2.1.3 Procedure
There were eight blocks: one block for each test item (six experimental names, two filler names). Each block contained (i) all three experimental contexts twice: once paired with the name and once with the respective non-vocative (¡Hola! for greeting and confirmation-seeking, ¡Para! for reprimand); (ii) the two filler calling contexts twice: once paired with the name and once with the non-vocative ¡Para!; and (iii) the five filler question–answer contexts paired with the name. Note that each call was immediately rerecorded in an insistent manner, but these data are not reported here (see Huttenlauch Reference Huttenlauch2016 for that analysis). The order of the contexts in a block was pseudo-randomised and no more than three vocatives followed each other. Vocatives and non-vocatives of the same pragmatic condition were separated by at least three other trials. There were four experimental lists, each with a different order of blocks.
The contexts were described orally to the participants in Spanish by the first author and the participants were asked to imagine the given situation and to react to it in the most natural manner, e.g. call out to their best friend either using a name or ¡Hola! or ¡Para!, respectively. Participants were randomly assigned to one of the lists and recorded using an MXL 990 condenser microphone and a Tascam HD P2 portable stereo audio recorder in a sound-attenuated cabin at the phonetics laboratory (PhonLab) of the University of Konstanz, Germany. The participants were instructed to stay close to the microphone during the recording. Recording sessions started with a short warm-up phase in order to familiarise the participants with the experimental setting and recording situation. Each context was presented once (except for three cases of obvious hesitations; in which cases items were rerecorded). The recording sessions lasted about one hour for each participant.
2.1.4 Data treatment
For each speaker, we recorded 36 experimental items: 18 vocatives (6 names × 3 contexts) and 18 non-vocatives. The 288 productions (144 vocatives and 144 non-vocatives) were first annotated with respect to intonation contour by the first author. The following four clearly distinct nuclear tunes were realised:
• Rising contour: the pitch starts at a low level and is monotonically rising until the end of the utterance; the rise typically starts either during the stressed (also called tonic) syllable or the post-tonic syllable (see Figure 2 left panel).
• Step-down contour: consists of a pitch peak that is associated with the stressed syllable and a drop to a lower pitch level (mid-level or even lower) in the post-tonic syllable, a level that is sustained until the end of the utterance. Perceptually, there is no audible pitch fall at the end of the utterance (see Figure 2 right panel).
• Low–flat contour: the pitch does not vary much during the whole utterance and basically stays at a low-level tone throughout (see Figure 3 left panel); it is impossible to make out a falling or rising movement. This contour is comparatively rare in the data.
• Rising–falling contour: the pitch rises and then falls from a pitch peak to a low level; the peak is aligned with the stressed or the post-tonic syllable. Accordingly, the rise starts during the pre-stressed or the stressed syllable; additionally, the end of the fall does not always occur at the very end of the utterance but sometimes already during the last syllable and stays low until the end (see Figure 3 right panel and Figure 4 left and right panel).

Figure 2 Vocatives ¡Camila! with a rising contour (left panel) and a step-down contour (right panel), produced by female speaker 4.

Figure 3 Vocatives ¡Camilo! with a low–flat contour (left panel) and a rising–falling contour with rising nuclear pitch accent (right panel), produced by female speakers 4 and 6.

Figure 4 Vocative ¡Camila! with a rising–falling contour with a low nuclear pitch accent (left panel) and vocative ¡Camilo! with a rising–falling contour ending with a final low stretch (right panel), produced by female speakers 7 and 8.
These contours could be reliably distinguished, as shown by a very high inter-annotator agreement of 93% (κ = .9) for a subset of 20% of the vocative productions (N = 29) that was annotated independently by the first and the last author.
For further phonetic analysis, we used Praat (Boersma & Weenink Reference Boersma and Weenink2015) and manually labelled the syllable boundaries (following the criteria in Turk, Satsuki & Sugahara Reference Turk, Satsuki, Sugahara, Sudhoff, Lenertová, Meyer, Pappert, Augurzky, Mleinek, Richter and Schließer2006) and the following f0-turning points (following the criteria in Ladd, Mennen & Schepman Reference Ladd, Mennen and Schepman1999: 2688), see Figures (2)–(4). The f0-turning points are labelled as L1, H, and L2:
• L1: local f0-minimum preceding an f0-rise, if any.
• H: f0-maximum, if any.
• L2: local f0-minimum following an f0-fall, if any.
To the two annotators, 19 of the vocatives in the greeting condition sounded more like a reprimand than a greeting. To verify this perception, these 19 greeting vocatives were presented to a native speaker of Colombian Spanish (different from the participants in the production experiment), together with eight randomly selected non-ambiguous greetings and reprimands as baseline. Her task was to indicate whether the critical productions signalled a neutral/happy greeting or an angry reprimand. Seven items were perceived as angry reprimands and therefore excluded from further analyses; the other twelve items were perceived as neutral greetings and included as greetings in the analyses reported below. Thus, 137 vocatives remained for the analyses.
For the phonetic analyses, we analysed a number of acoustic properties regarding voice quality, duration and f0 (see Table 2 for all included measurements):
• As acoustic correlate for voice quality, we used H1*-A3* as a stable mid-range spectral tilt measure and as an indication of vocal effort (see DiCanio Reference DiCanio2009 for different spectral tilt measures and their relation to glottal activity). We calculated H1*-A3* of the tonic and the post-tonic syllable, i.e. the difference in dB of the amplitude of the first harmonic and the third formant, corrected for the effect of bandwidth of the formants for each vowel (Mooshammer Reference Mooshammer2010). Higher values of H1*-A3* mean a steeper slope and thus less energy in the region of the third formant, which may be caused by less efficient vocal fold vibration.
• For durational measurements, the durations of tonic and post-tonic syllables were divided by the duration of the utterance to normalise for differences in speech rate.
• As acoustic properties for the intonational realisation we calculated the L1-alignment and the H-alignment relative to the onset of the tonic syllable and the H-alignment relative to the onset of the post-tonic syllable. These alignment measures were normalised by dividing the respective values by the duration of the tonic or post-tonic syllable, respectively (see Table 2). Furthermore, we extracted the f0-values and time points of L1, L2, and H (marked in Figures (2)–(4)) and calculated the f0-range and the steepness of the rising as well as the falling movement in semitones (st). Finally, the duration of the rising and the falling movement were normalised by dividing them by the duration of the tonic or the post-tonic syllable, respectively.
Table 2 Description and units of variables used in the phonetic analyses.

2.2 Results
2.2.1 Intonation contours
An overview of the number of contours produced in the three pragmatic conditions, separately for vocatives and non-vocatives, is shown in Table 3. We observe that choice of intonation contour is not apparently affected by word length since, for each contour, between 31% and 36% of the data stem from the bisyllabic names, the rest from the trisyllabic names.
Table 3 Distribution of contours on vocatives and non-vocatives in the three pragmatic conditions (¡Hola! was used in the non-vocatives for the greeting and confirmation-seeking conditions, and ¡Para! was used for the reprimand condition).

Sub-hypothesis SH1 dealt with the intonational realisation of vocatives in the different pragmatic conditions: greeting vocatives were predicted to be most frequently produced with a step-down, which did not hold (12 step-downs vs. 29 other contours), confirmation-seeking vocatives were predicted to be mostly rising, which is borne out by the data (45 rises vs. three other contours), and reprimand vocatives were predicted to be mostly rising–falling, which is also borne out (44 rise–falls vs. four other contours). Surprisingly, the most frequent contour in greeting vocatives was a rise–fall (24 rise–falls vs. 17 other contours). Note that the data contains also a low–flat contour that was not expected for any of the three pragmatic conditions. For the vocatives, it only occurred in the reprimand condition, but very infrequently (four occurrences). To test whether a contour was more frequent than the other contours in a given pragmatic condition, we conducted a generalised linear mixed-effects regression model (henceforth glmer) with contour as dependent variable (predicted contour coded as 1, other contours coded as 0) and participants and items as crossed random factors for each pragmatic condition. If the model failed to converge, the random effects structure was simplified. To suit the binomial nature of the dependent variable, a binomial linking function was used (see Agresti Reference Agresti2002, Baayen Reference Baayen2008, Baayen, Davidson & Bates Reference Baayen, Davidson and Bates2008, Dobson & Barnett Reference Dobson and Barnett2008, Jaeger Reference Jaeger2008). This allows us to test whether the predicted contour occurred significantly more frequently than 50% in the expected pragmatic condition. In the greeting condition, the step-down contour appeared only in 29% of the vocatives which, statistically, did not differ from 50% (p = .11), in the confirmation-seeking condition, the rising contour occurred more frequently than 50% (94%, β = 9.06, SE = 4.50, z = 2.01, p = .04), and in the reprimand condition, the rise–fall occurred more frequently than 50% (92%, β = 2.55, SE = 0.84, z = 3.05, p = .002).
Sub-hypothesis SH2 predicted that the step-down contour was specific for greeting vocatives, which was the case (12 times in greetings vs. never in other conditions – statistical testing was therefore impossible). The rising contour was predicted to be specific for confirmation-seeking vocatives, which was confirmed too (45 times in confirmation-seeking vs. five times in other conditions). For statistical analysis, the rising contour was coded as 1 in the confirmation-seeking vocatives and as 0 in all other vocative conditions. Results of a glmer with contour as dependent variable and items as random factor showed that rises occurred significantly more frequently than 50% in the confirmation-seeking condition (β = 13.02, SE = 4.65, z = 2.80, p = .005).
In sum, our vocative data suggest that step-down contours are specific for greetings (in the vocative data they only occurred in the greeting condition) even though they are not the most frequent contour in that condition. Rises are specific for confirmation-seeking purposes, but rise–falls were found in greeting and reprimand conditions and are thus unspecific for pragmatic condition.
Sub-hypothesis SH3 predicted a similar distribution of intonational contours across pragmatic conditions for both the non-vocatives and the vocatives. Table 3 above shows a rather different distribution across conditions. Most strikingly, the productions of step-down contours seemed to increase at the expense of rising contours. To quantify these differences in distribution for vocatives and non-vocatives, we calculated a multinomial regression model with contour as dependent variable (four levels) and utterance-type as fixed factor (vocative vs. non-vocative), using the mlogit-package in R (Croissant Reference Croissant2013). Results showed that the distribution of step-down and rising contours differed statistically: in non-vocatives, there were significantly more step-down contours than in vocatives (β = 1.18, SE = .37, t = 3.18, p = .001) and significantly fewer rising contours (β = 0.78, SE = .30, t = 2.57, p = .01). There were no differences in rise–falls (p = .5) and low–flat contours (p = .1). To assess the most frequent intonational realisation of non-vocatives in the different pragmatic conditions, we calculated a glmer for each pragmatic condition (as for sub-hypothesis SH1). Results showed that in the non-vocative greetings, the step-down contours were not more frequent than 50% (44%, p = .7), in the non-vocative confirmation-seeking productions, the rises were not more frequent than 50% (46%, p = .7), and only in the non-vocative reprimands, the rise–falls were more frequent than 50% (β = 3.45, SE = 1.56, z = 2.24, p = .03). Furthermore, the specificity of the step-down contour was lost in non-vocatives. The step-down contour did not occur more frequently than 50% (p = .6). Similar to the vocative data, the rise occurred more frequently in confirmation-seeking than in other conditions (β = 14.00, SE = 6.19, z = 2.26, p = .02).
The counts of the intonation contours (Table 3) showed that there is no clear one-to-one correspondence between pragmatic condition and intonation contour (some contours are used in two conditions, e.g. rise–fall, and some conditions are produced with two contours, e.g. greeting vocatives) and that vocatives differed from the non-vocatives in the distribution of their intonational contours across different pragmatic conditions.
2.2.2 Phonetic analyses
Sub-hypothesis SH4 was concerned with phonetic differences in intonation contours that were not specific for a certain pragmatic condition, in our data rising–falling vocatives and ¡Hola! with a step-down contour.
2.2.2.1 Rising–falling contour
The rising–falling contour was unspecific for vocatives, in that it occurred frequently in both greeting and reprimand conditions. To suit the exploratory character of sub-hypothesis SH4 we followed the procedure of Leemann, Kolly & Dellwo (Reference Leemann, Kolly and Dellwo2014: 62) and calculated model comparisons separately for each acoustic measurement. A glmer with pragmatic condition as dependent variable (levels: greeting and reprimand), number of syllables, vowel type, and each of the acoustic measurements as independent variable, and participants and items as random factors (e.g. glmer(condition ~ steepnessRise + nsyllable + vowel + (1| participant) + (1|item), data = data) was compared to a reduced model without the variable in question (e.g. glmer(condition ~ nsyllable + vowel + (1| participant) + (1|item), data = data). We then extracted the log-likelihood χ2-value of each model comparison and divided the likelihood-ratio χ2 for each variable by the sum of the likelihood-ratio χ2-values of all the model comparisons, times one hundred. Note that these χ2-values are very highly correlated with the models' information criterion (AIC scores, see Akaike Reference Akaike1974), in our case r = .99, p < .000001. For the vocatives realised with a rising–falling movement, the relative importance of each of the variables (relative χ2-value in %) is visualised by means of a radar chart (Figure 5); higher values (more peripheral points) indicate stronger impact.
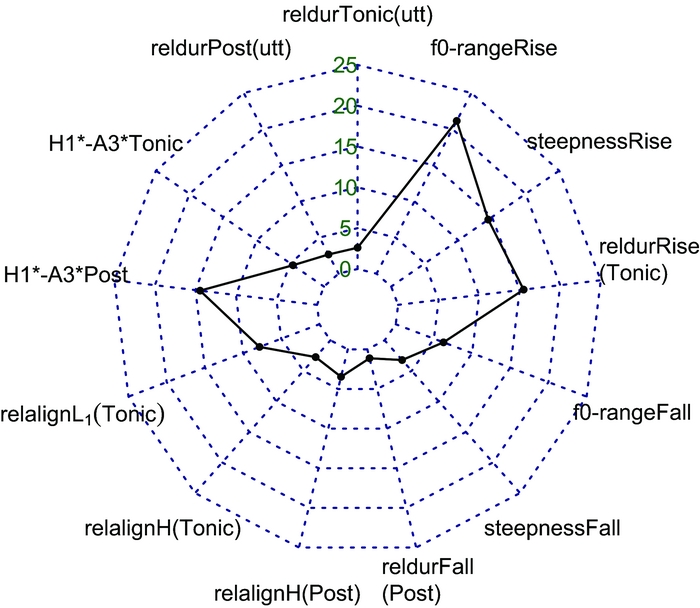
Figure 5 Relative importance of each of the variables (relative χ2-value in %) for predicting greeting vs. reprimand in rising–falling vocatives (see text for details).
As shown in Figure 5, the variables f0-rangeRise, steepnessRise, reldurRise(Tonic), and H1*-A3*Post have a strong or very strong contribution for signalling pragmatic condition (relative χ2-values > 10%). On the other hand, factors such as reldurTonic(utt), relalignH(Tonic), and H1*-A3*Tonic lend very little (< 5%). Note, however, that not all variables are independent of each other: a contribution that is attributed to one variable may in fact be caused by another variable. To sort this out, we calculated the pairwise correlation coefficients between all the variables (and their p-values) and removed those variables that had a weaker impact than a variable they correlated with. The criterion for the removal of a variable was a correlation coefficient r > |.5| and p < .05, i.e. if either of those criteria was not fulfilled, we considered the variables as uncorrelated and they were both kept. As a consequence, we only retained the variables f0-rangeRise and H1*-A3*Post. These two variables were best at explaining the variance of the model, with relative χ2-values of 21% and 14%, respectively, and they did not correlate strongly with each other (r = –.26).
Note that this procedure of finding the most relevant predictors for dissociating the two pragmatic conditions does not allow us to see the direction of the effects. For these two phonetic variables, we therefore calculated linear mixed-effects regression models, henceforth lmers (Baayen Reference Baayen2008, Baayen et al. Reference Baayen, Davidson and Bates2008, Barr et al. Reference Barr, Levy, Scheepers and Tily2013) in the R package lme4. Pragmatic condition, number of syllables, and vowel type were entered as fixed factors and participants and items as crossed random factors. The initial model included random intercepts for subjects and items; random slopes for condition were added if this improved the fit of the model (as operationalised by log-likelihood tests using the R-function anova()).
The f0-rise in greeting vocatives was 3.25 st wider than in reprimand vocatives (β = 3.25, SE = .73, t = 4.47, p = .005), and the post-tonic syllable had a steeper spectral tilt in reprimand compared to greeting vocatives (β = 10.09, SE = 3.72, t = 2.71, p = .02), suggesting less efficient vocalisation. However, there were similar tendencies but no statistical support for these being consistent for the non-vocative rising–falling contours (p = .96 for f0-range of the rise and p = .1 for spectral tilt). When combining the rising–falling vocatives and non-vocatives, there was a significant interaction between utterance-type and pragmatic condition (p = .04 for f0-rangeRise and p < .009 for H1*-A3*Post), see Figures 6 and 7 below). Hence, there are phonetic differences in rising–falling vocatives that are produced in different pragmatic conditions, but importantly these differences do not generalise to non-vocative rise–falls. Figures 6 and 7 further suggest that there are phonetic differences within a single pragmatic condition across utterance-types, i.e. the rise–falls in greeting vocatives appear to be realised with a larger f0-range of the rise than the rise–fall in greeting non-vocatives and the rise–falls in reprimand vocatives appear to have a steeper spectral tilt than reprimand non-vocatives. Statistical analysis showed that the difference in f0-range of the rise was significant (β = 2.98, SE = 1.05, t = 2.84, p = .04), while the difference in spectral tilt was not (p = .9).

Figure 6 Average f0-range of the rise in rising–falling contours across pragmatic conditions for vocatives and non-vocatives.

Figure 7 Average spectral tilt of the post-tonic syllable in rising–falling contours across pragmatic conditions for vocatives and non-vocatives.
2.2.2.2 Step-down contour
For non-vocatives, the step-down contour was unspecific in that it occurred in greeting and confirmation-seeking contexts alike. To detect relevant phonetic variables to differentiate between greeting and confirmation-seeking conditions, we performed the same procedure as above (i.e. we compared how strongly a certain acoustic variable improves the model fit, using χ2-values of model comparisons). Here, number of syllables and vowel type were not included as factors because the non-vocatives with a step-down contour were only realised on the item hola. The radar chart for ¡Hola! in Figure 8 shows the relative χ2-value (in %) of each measurement.
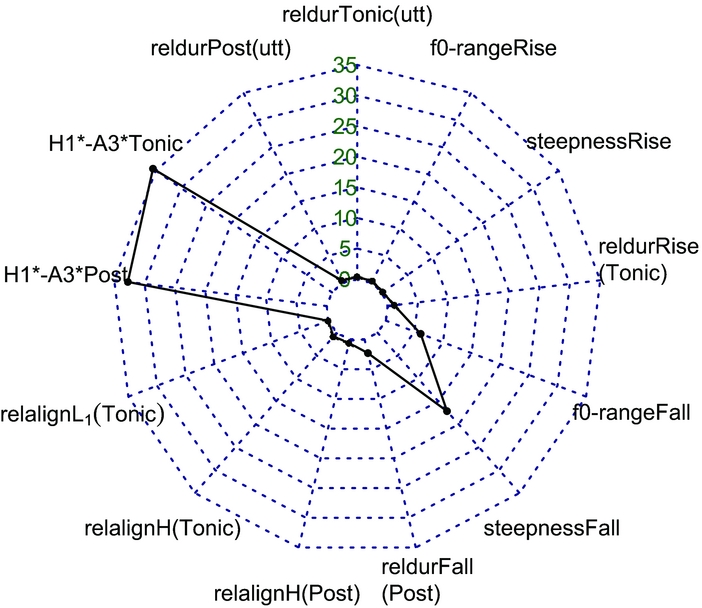
Figure 8 Relative importance of each of the variables (relative χ2-value in %) for predicting greeting vs. confirmation-seeking in the non-vocative ¡Hola! produced with a step-down contour.
As shown in Figure 8, three variables had an impact above 15% (spectral tilt of the tonic and post-tonic syllable and the steepness of the fall); all other variables had minor to no impact for differentiating pragmatic condition. We again excluded variables that were correlated (r > |0.5| and p < .05). This left two variables that were only weakly correlated: H1*-A3*Tonic and steepnessFall (r = .30). For these two variables, we calculated separate lmers to investigate the direction of the effects. Pragmatic condition was entered as fixed factor, participants and items as crossed random factors. The non-vocative ¡Hola! had a steeper fall in the confirmation-seeking condition than in the greeting condition (β = 6.52, SE = 2.03, t = 3.21, p < .01). Furthermore, confirmation-seeking ¡Hola! had a steeper spectral tilt in the tonic syllable than greeting ¡Hola!, a difference that approached significance (β = 8.16, SE = 3.31, t = 2.46, p = .06). Note that we cannot test whether these differences also hold for vocatives, since in the vocative data, there were no step-down contours in confirmation-seeking contexts.
3 Discussion
Hualde & Prieto (Reference Hualde and Prieto2015: 390) stated in their study on intonational variation in Spanish that ‘[o]ne of the important challenges that intonationalists face today is to try to pin down the pragmatic meanings associated to different pitch contour types’. Given our prosodic analysis of Colombian Spanish vocatives and non-vocative calls in three pragmatic conditions, we agree that this is a challenge. As discussed below in more detail, we found prosodic differences across conditions and thus confirmation for our main hypothesis, but a direct link from prosodic form to pragmatic condition is untenable for our data.
3.1 Predominant and specific contours for vocatives in different pragmatic conditions
Sub-hypothesis SH1 predicted a step-down contour for greeting vocatives, a rising contour for confirmation-seeking vocatives, and a rising–falling contour for reprimand vocatives. We tested whether these contours occurred more frequently than the other intonation contours in the respective pragmatic conditions. The data supported sub-hypothesis SH1 for confirmation-seeking and reprimand vocatives, since they were predominantly realised with a rise and a rise–fall, respectively, but not for greeting vocatives, since the step-down contour did not represent the most common pattern for greeting vocatives. Sub-hypothesis SH2 predicted the step-down contour to be specific for greeting vocatives and the rising contour for confirmation-seeking vocatives. This was indeed the case. Sub-hypotheses SH1 and SH2 will be discussed separately for greeting, confirmation-seeking, and reprimand vocatives.
3.1.1 Greeting vocatives
In the greeting condition, the step-down contour was specific for greeting vocatives, but it was not the most frequent contour; the rising–falling contour was numerically more frequent. The finding of more rising–falling than step-down contours is of interest, because the step-down contour had been described as typical for many Spanish varieties (e.g. Armstrong Reference Armstrong2010 for Puerto Rican; Astruc, Mora & Rew Reference Astruc, Mora and Rew2010 for Venezuelan Andean; de-la-Mota et al. Reference de-la-Mota, Butragueño and Prieto2010 for Mexican; Estebas-Vilaplana & Prieto Reference Estebas-Vilaplana and Prieto2010 for Castilian; Gabriel et al. Reference Gabriel, Feldhausen, Pešková, Colantoni, Lee, Arana and Labastía2010 for Argentinian; López-Bobo & Cuevas-Alonso Reference López-Bobo and Cuevas-Alonso2010 for Cantabrian; O'Rourke Reference O'Rourke2010 for Ecuadorian; Ortiz et al. Reference Ortiz, Fuentes and Astruc2010 for Chilean; Velásquez Upegui Reference Velásquez Upegui2013 for Colombian) and other Romance languages (see Frota & Prieto Reference Frota and Prieto2015b, Reference Frota and Prieto2015a) and non-Romance languages (Dutch: Gussenhoven Reference Gussenhoven1993; German: Niebuhr Reference Niebuhr, Niebuhr and Skarnitzl2015; English, Hungarian, and other languages: Ladd Reference Ladd2008: 116–119). Velásquez Upegui (Reference Velásquez Upegui2013) also reported a rising–falling contour for Colombian Spanish vocatives. It was the second most common pattern in her calling condition (llamada, page 180), after the step-down contour. The rising–falling contour was, however, not reported for first calls in most other Spanish varieties (see Prieto & Roseano Reference Prieto and Roseano2010b, Reference Prieto and Roseano2010a); instead, they were typically reported for insistent calls (Armstrong Reference Armstrong2010 for Puerto Rican, Astruc et al. Reference Astruc, Mora and Rew2010 for Venezuelan Andean, de-la-Mota et al. Reference de-la-Mota, Butragueño and Prieto2010 for Mexican, Estebas-Vilaplana & Prieto Reference Estebas-Vilaplana and Prieto2010 for Castilian, Gabriel et al. Reference Gabriel, Feldhausen, Pešková, Colantoni, Lee, Arana and Labastía2010 for Argentinian, López-Bobo & Cuevas-Alonso Reference López-Bobo and Cuevas-Alonso2010 for Cantabrian). The more frequent use of step-down contours in the greeting contexts in other studies compared to ours may be due to the different settings used to elicit the greetings (in a friend's house as opposed to the shopping mall). As such, contour choice may be sensitive to predictability (higher probability of seeing the friend at their home than at the shopping mall). This factor has also been noted by Ladd (Reference Ladd1978). He argued that step-down contours (‘stylized falls’, in his terminology) are used more frequently in more predictable situations, while rising–falling contours are more appropriate in situations that are not predictable. This interpretation is compatible with our data. Our results thus place Colombian Spanish in line with varieties or languages that do not (typically) display the step-down contour or that show variation in the choice of intonation contours (e.g. Dominican Spanish in Willis (Reference Willis2010: 148), Occitan in Sichel-Bazin et al. (Reference Sichel-Bazin, Meisenburg and Prieto2015: 226), Catalan in Borràs-Comes et al. (Reference Borràs-Comes, Sichel-Bazin and Prieto2015) and Prieto et al. (Reference Prieto, Borràs-Comes, Cabré, Crespo-Sendra, Mascaró, Roseano, Sichel-Bazin and Vanrell2015: 39), and Polish in Arvaniti et al. (Reference Arvaniti, Żygis and Jaskuła2016)).
The rising–falling contour also occurred in the reprimand condition and was hence not specific for greeting vocatives. Interestingly, it differed in phonetic realisation in the two conditions: greeting vocatives had a wider f0-range in the rise than the rising–falling contours of the reprimand vocatives. This may suggest a phonological difference between two types of rising–falling contours, e.g. L+¡H* L% for greeting vocatives vs. L+H* L% for reprimand vocatives. However, further experiments would be necessary to corroborate this.
Regarding the step-down contours in Velásquez Upegui (Reference Velásquez Upegui2013: 180), these seem to differ in realisation from the step-down contours in our data. She annotated the step-down in her neutral calling condition (‘vocativo de llamada’) as L+(¡)H* M%. Her figure of the calling vocative (p. 181), however, shows a plateau of more or less the same height as the peak, while we found a plateau that is lower than the peak. Future research is necessary to identify the factors that affect the height of the plateau (see Niebuhr Reference Niebuhr, Niebuhr and Skarnitzl2015 for German).
3.1.2 Confirmation-seeking vocatives
In line with sub-hypotheses SH1 and SH2, we found predominantly rising contours in confirmation-seeking vocatives and the rise was specific for confirmation-seeking vocatives. We labelled the rise by means of a low pitch accent followed by a high boundary tone (L* H%). A rising contour was also reported in the doubt condition in Velásquez Upegui (Reference Velásquez Upegui2013: 186–187). Note that the context used to elicit doubt in Velásquez Upegui (Reference Velásquez Upegui2013) and confirmation-seeking here are very similar, despite highlighting different aspects of the scenarios (doubt: you are not sure, and confirmation-seeking: you want to confirm whether it is them).
3.1.3 Reprimand vocatives
Reprimand vocatives, as expected, were predominantly realised with rising–falling contours, which we labelled by L+H* L%. The finding of a rising–falling contour in the reprimand condition is partly in line with Velásquez Upegui (Reference Velásquez Upegui2013: 182–183); however, there appeared to be differences in the phonetic realisation across studies: we often found a rising–falling contour that ended in a low boundary tone (L%). Velásquez Upegui (Reference Velásquez Upegui2013) reported contours with an incomplete fall (M%), a contour that was absent in our data.Footnote 3 The differences in the realisation of reprimand vocatives may be attributed to differences in power and age relation across studies (younger girl in Velásquez Upegui (Reference Velásquez Upegui2013) as opposed to friend of same age in our study). Another potential explanation is the different speaker characteristics in the two studies: Velásquez Upegui (Reference Velásquez Upegui2013) recorded working class speakers aged between 30 and 50 years, while our speakers were university students between 23 and 33 years. Furthermore, while her subjects were tested in Colombia, our informants were recorded in Germany. They used Spanish on a daily basis (six out of eight speakers) or at least weekly (two out of eight speakers). We do not think, though, that recording the subjects in Germany represents a severe problem. According to Grosjean (Reference Grosjean2008, Reference Grosjean and Chapelle2013), highly language dominant bilinguals, such as second language learners, do ‘more language mixing when speaking their weaker language than their stronger language’ (Grosjean Reference Grosjean2008: 63) and they do so only when ‘they make regular functional use of their second language’ (p. 63). In our study, the informants were native speakers of Colombian Spanish, speaking German only as a second language. Thus, language mode problems are not expected to influence the production of the dominant language of our speakers.
3.2 Differences between vocatives and non-vocatives
Sub-hypothesis SH3 predicted that non-vocatives show the same distribution of the intonation contours across conditions as their vocative counterparts. This was not the case: confirmation-seeking vocatives were predominantly realised with rising contours, while their non-vocative counterparts were typically realised with rising and step-down contours with a more or less balanced frequency. Moreover, the step-down contour, which was specific for greetings in vocatives, was not specific for greetings in non-vocatives. These differences in choice of intonation contour across utterance-types in the same pragmatic condition make it hard to formulate a direct link between intonation contour and pragmatic function. The fact that the same contour can express a number of different meanings also exists when going beyond vocatives. The L* H% nuclear configuration, attested for confirmation-seeking vocatives in our study, is also attested for Spanish information-seeking questions in Hualde & Prieto (Reference Hualde and Prieto2015: 389). Our greeting vocatives were realised by a step-down contour (L+H* !H%) and a rise–fall (L+¡H* L%), the latter contour is also attested for echo-questions in Hualde & Prieto (Reference Hualde and Prieto2015: 389). Finally, reprimand vocatives were realised by a low–flat contour (L* L%) and a rise–fall (L+H* L%) in our study. Both contours are also attested for statements and commands/imperatives in Hualde & Prieto (Reference Hualde and Prieto2015: 389), and for commands/imperatives in Brehm, Lausecker & Feldhausen (Reference Brehm, Lausecker, Feldhausen, Fuchs, Grice, Hermes, Lancia and Mücke2014) and Lausecker, Brehm & Feldhausen (Reference Lausecker, Brehm and Feldhausen2014). The latter two studies show that the different nuclear contours depend more on the length of the sentence (L+H* L% in short imperatives (¡Cállate! ‘Be quiet!’), and L* L% in long imperatives (¡Deja de comer! ‘Stop eating!’)) than on the fact that the utterance is a command. For the alternation of the nuclear contour depending on the number of prosodic words in a phrase in Spanish see also Torreira & Grice (this volume). Future research will have to show in which ways the contours used for vocatives in our study differ from similar intonation contours in other conditions, potentially in subtle phonetic ways.
Sub-hypothesis SH4 put the idea of prosodic constructions to the test more directly. We predicted phonetic differences when the same intonation contour was used in different pragmatic conditions. This was indeed the case. For the rising–falling contour, which was unspecific for greeting and reprimand vocatives, we found differences in the f0-range of the rise and in the spectral tilt (H1*-A3*) of the post-tonic syllable (increased f0-range and shallower spectral tilt in the greeting compared to the reprimand condition). Furthermore, the step-down contour, which occurred in greeting and confirmation-seeking non-vocatives, showed a significantly steeper f0-fall for confirmation-seeking ¡Hola! compared to greeting ¡Hola!. These phonetic differences can be considered as lending support to proposals that enrich intonation contours by phonetic detail, such as prosodic constructions. In other words, when only considering vocatives, it is possible to argue that prosodic constructions could be identified for different pragmatic conditions:
• rise–fall with an increased f0-range of the rise and shallow spectral tilt OR step-down contour signalled greeting.
• rise–fall with a shallow f0-range of the rise and a steep spectral tilt signalled reprimand.
• rising contour signalled confirmation-seeking.
However, these associations fail for non-vocative calls (¡Hola!, ¡Para!), both in terms of the specificity of the intonation contours and in terms of more fine-grained phonetic differences. For the rising–falling contours, the phonetic characteristics that differed in the vocatives did not differ in the non-vocatives. Hence, while greeting vocatives showed an increased f0-range in the rise compared to reprimand ones (¡H* vs. H*), there was no phonological difference in the non-vocatives. Moreover, there were even prosodic differences within a single pragmatic condition, depending on whether the speaker uttered a vocative or a non-vocative.
4 Conclusion
The present paper has shown that the purpose shapes the vocative, but not in a strict manner. Our results show that the intonation contours are more specific and their distribution is clearer in vocatives (which are semantically non-informative) than in non-vocatives (that have their own lexical contribution), but no contour occurs exclusively for a specific pragmatic condition. The investigation of fine-grained phonetic differences (such as steepness or f0-range of the rising or falling part of the intonation contour and spectral tilt (H1*-A3*)) between intonation contours that occurred in more than one pragmatic condition showed two things: First, ambiguous intonation contours in vocatives can be distinguished by fine-grained phonetic differences but the corresponding intonation contours realised on non-vocatives cannot. Second, phonetic differences also occur within single pragmatic conditions across vocatives and non-vocatives (e.g. larger f0-range in greeting vocatives than in greeting non-vocatives). A brief discussion of these findings in light of the recently developed concept of prosodic constructions led to the conclusion that the prosodic realisation of vocatives and non-vocatives in Bogotá Colombian Spanish cannot be easily modelled by prosodic constructions.
Acknowledgements
We gratefully acknowledge the reviewers and editors for their insightful feedback, which has helped to restructure this article into its current format. We also thank Angela James for proof-reading the paper. All shortcomings are our own.
Appendix A
Table A1 Speaker details.

Appendix B. Original (Spanish) versions of the experimental contexts
Greeting context
Estás en un centro comercial y ves a tu mejor amiga, que se llama Camila. Te alegra verla. Llámala (por su nombre) para que te voltee a ver y la puedas saludar.
‘You are at the shopping mall and you see your best friend who is called Camila. You are happy to see her. Call her (name), so that she turns around and you can greet her.’
Confirmation-seeking context
Estás en un centro comercial y ves a una chica que parece mucho a tu mejor amiga que se llama Camila. Te preguntas si es ella. Llámala (por su nombre) para que te voltee a ver y puedas confirmar si se trata de ella.
‘You are at the shopping mall and you see a girl that looks like your best friend who is called Camila. You wonder whether it is her. Call her (name), so that she turns around and you can confirm whether it is her or not.’
Reprimand context
Estás con tu mejor amiga Camila y unos amigos en un centro comercial. Camila está contando un secreto vergonzoso tuyo. Te enoja y quieres que pare. Llámala (por su nombre) para que te voltee a ver y deje de hablar.
‘You are at the shopping mall together with your best friend Camila and some other friends. Camila is telling an embarrassing secret of yours. It makes you angry and you want her to stop. Call her (name) so that she turns around and stops talking.’
Appendix C. Filler contexts
Contexts used as calling fillers
(C1) Non-emotional reprimand (deontic bias): You are at the shopping mall together with your best friend Camila and some other friends. Camila is telling an embarrassing secret of an unknown girl. You know that it is not okay to do so. Call her (name) so that she turns around and stops talking.
(C2) Bored reprimand (bored): You are at the shopping mall together with your best friend Camila and some other friends. Camila has been complaining for half an hour about the same thing. You are bored and you want her to stop. Call her (name) so that she turns around and stops talking.
Contexts used as question–answer fillers
(C3) Happy: They ask you who won the swimming championship. You are happy, because it was your best friend Camila. Answer that it was Camila (only the name).
(C4) Uncertain: You are at a party with friends. You return from the toilet and your friends ask you to guess who arrived in the meantime. You think, that it was your best friend Camila, but you are not sure. Say it.
(C5) Angry emotional: You are with some friends in front of the cinema. The movie starts in three minutes, but your best friend Camila has the tickets and did not arrive yet. She knows that you do not want to miss the beginning. You are angry that Camila is still missing. Someone asks you who is missing. Answer that it is Camila.
(C6) Non-emotional: They ask you with whom you are going in the park. You answer that you go with Camila (only the name).
(C7) Bored: They have already asked you a thousand times who won the swimming championship. You are bored because you already answered a thousand times that it was Camila. Answer that it was Camila (only the name).












