


1. Background
1.1 Using typographic enhancement to help learners notice multiword items
The past couple of decades have seen a growing interest in lexical items larger than single words, such as idioms, collocations, phrasal verbs, prepositional phrases, and various other types of expressions (Boers & Lindstromberg, Reference Boers and Lindstromberg2009; Schmitt, Reference Schmitt2004; Siyanova-Chanturia & Omidian, Reference Siyanova-Chanturia, Omidian and Webb2020; Siyanova-Chanturia & Pellicer-Sánchez, Reference Siyanova-Chanturia and Pellicer-Sánchez2019; Wood, Reference Wood2010; Wray, Reference Wray2002). It is now well recognized that knowledge of a large repertoire of multiword items (MWIs) is vital for learners' proficiency in a second language. Such knowledge has been shown crucial for learners' comprehension of second language (L2) discourse (e.g., Kremmel et al., Reference Kremmel, Brunfaut and Alderson2017; Martinez & Murphy, Reference Martinez and Murphy2011), as well as adequate production of L2 discourse (e.g., Bestgen, Reference Bestgen2017; Boers et al., Reference Boers, Eyckmans, Kappel, Stengers and Demecheleer2006; Crossley et al., Reference Crossley, Salsbury and McNamara2015; Garner, Reference Garner2022; Hou et al., Reference Hou, Loerts and Verspoor2018; Paquot, Reference Paquot2018, Reference Paquot2019; Saito, Reference Saito2020; Siyanova-Chanturia & Spina, Reference Siyanova-Chanturia and Spina2020; Stengers et al., Reference Stengers, Boers, Housen and Eyckmans2011; Tavakoli & Uchihara, Reference Tavakoli and Uchihara2020). As a result, there has been a proliferation of studies gauging the effectiveness of various “interventions” to help learners master this important, phraseological dimension of language (see Pellicer-Sánchez & Boers, Reference Pellicer-Sánchez, Boers, Siyanova-Chanturia and Pellicer-Sánchez2019, for a review). Typographic enhancement of MWIs is one of those interventions that has attracted a lot of interest in this strand of research.
Typographic enhancement (also known as textual enhancement and visual enhancement) of language features or items in texts is a simple intervention to make features or items more salient for learners (Sharwood Smith, Reference Sharwood Smith1993). Enhancement can take diverse forms such as underlining and change of font (e.g., boldface). Directing learners’ attention to certain language features or items this way is considered useful because there is a broad consensus in the literature that attention plays a vital role in L2 acquisition (Schmidt, Reference Schmidt and Robinson2001; VanPatten, Reference VanPatten1996). Early studies on the effectiveness of typographic enhancement concerned the acquisition of grammar features (see Lee & Huang, Reference Lee and Huang2008, for a meta-analysis, and Boers, Reference Boers2021, pp. 53–61, for a narrative review), but more recently researchers have turned to the lexical dimension of language as a target for typographic enhancement (e.g., Vu & Peters, Reference Vu and Peters2022a), with several studies focusing on MWIs such as collocations (i.e., word partnerships, such as conduct research; slim chance; on purpose). Directing learners’ attention to the lexical makeup of collocations is useful, especially when it differs from a counterpart in the learners’ first language (L1) (e.g., Eyckmans et al., Reference Eyckmans, Boers and Lindstromberg2016; Laufer & Girsai, Reference Laufer and Girsai2008; Peters, Reference Peters2016; Terai et al., Reference Terai, Fukuta and Tamura2023; Zhang & Graham, Reference Zhang and Graham2020). For example, the Dutch counterpart of the English make an effort is “do an effort”, and the Dutch counterpart of running water is “streaming water.” Furthermore, many collocations include components that go unnoticed because they are highly familiar words, such as high-frequency verbs (e.g., do, have, and make) and prepositions (e.g., in and on). These factors help to explain why even advanced learners produce inaccurate L2 word combinations according to analyses of learner language (e.g., Laufer & Waldman, Reference Laufer and Waldman2011; Nesselhauf, Reference Nesselhauf2003; Siyanova-Chanturia & Spina, Reference Siyanova-Chanturia and Spina2020).
1.2 Enhancing multiword items in reading texts
This article reports a replication of a study that investigated the effects of typographically enhancing MWIs in video captions. However, most research on the benefits of enhancement for the acquisition of MWIs so far has concerned reading texts (and occasionally reading while listening to a text; Jung & Lee, Reference Jung and Lee2023). Some used texts without deliberately manipulating the number of occurrences of the MWIs. In these cases, learners met most of the target MWIs only once. An example is Boers et al. (Reference Boers, Demecheleer, He, Deconinck, Stengers and Eyckmans2017), where learners read texts in which MWIs were either enhanced (underlined) or unenhanced. Overall, the participants were more likely in a post-test to recognize the MWIs that had been enhanced than those that had been unenhanced. Choi (Reference Choi2017) had learners read a text containing MWIs in either an enhanced (boldface) or unenhanced version while their eye movements were recorded. The eye-movement data confirmed that the enhancement drew the learners’ attention to the MWIs. In a two-week delayed recall test, the learners who had read the enhanced text recalled on average twice as many MWIs as the comparison group who had read the unenhanced version. Interestingly, the learners who read the enhanced version of the text were less able than the comparison group to remember segments of the text that had been left unenhanced. It is likely that they interpreted typographic enhancement as an effort on the part of the teacher/researcher to flag the important elements of a text, and so they felt less need to focus on the remainder of the text. A recent study, by Vu and Peters (Reference Vu and Peters2022b), applied enhancement in a longitudinal fashion where learners read a series of stories over nine weeks with MWIs either enhanced (underlined) or left unenhanced. A cued recall test showed a significant effect of enhancement: enhanced MWIs were, on average, recalled more than three times better than unenhanced ones.
Studies have also examined the effect of encountering enhanced MWIs multiple times (Jung et al., Reference Jung, Stainer and Tran2022; Puimège et al., Reference Puimège, Montero Perez and Peters2023; Sonbul & Schmitt, Reference Sonbul and Schmitt2013; Szudarski & Carter, Reference Szudarski and Carter2016; Toomer & Elgort, Reference Toomer and Elgort2019; Toomer et al., Reference Toomer, Elgort and Coxhead2024). Post-tests almost invariably show greater learning gains for enhanced items if they are encountered several times. It needs to be conceded, however, that embedding multiple instances of the same MWIs in texts (e.g., Webb et al., Reference Webb, Newton and Chang2013) requires considerable creativity and it risks compromising the authenticity of the texts, and so it is probably a less appealing choice for busy teachers and course designers. In the case of authentic audiovisual materials, which we turn to next, embedding extra instances of words or phrases is even less straightforward owing to technical obstacles.
1.3 Enhancing multiword items in captions
There has been a steep increase in the number of studies on the use of audiovisual input for L2 learning in general (e.g., Montero Perez, Reference Montero Perez2022; Peters, Reference Peters2019; Pujadas & Muñoz, Reference Pujadas and Muñoz2019; Teng, Reference Teng2021). A substantial number of these studies have assessed the benefits of captions for text comprehension and vocabulary acquisition (see Montero Perez, Reference Montero Perez2022, for a review), but only a few have focused on MWIs in captions, let alone with a specific interest in the use of typographic enhancement of MWIs. Puimège et al. (Reference Puimège, Montero Perez and Peters2024) examined eye movements to ascertain that typographically enhanced MWIs in captions attract more attention and are better recalled than unenhanced ones. They found that the enhancement indeed drew the learners’ attention, and that the amount of attention they gave to MWIs predicted successful recall. The latter held true also for unenhanced MWIs, however, such that the presence of enhancement per se was not a statistically significant predictor of recall according to mixed effects modelling. In Puimège et al.'s (Reference Puimège, Montero Perez and Peters2024) study, the learners watched the video once and since each MWI occurred only once, there were no repeated encounters. A way of increasing the number of encounters is to have learners watch the same materials twice. This is what was done in a study by Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021). There were six viewing conditions: watching a video once with standard captions, enhanced captions, or without captions, and watching the same video twice with standard captions, enhanced captions, or without captions. Both the standard captions and the enhanced captions benefited MWI recall more than watching the video without onscreen text, but there was no difference between the two caption conditions when participants watched the video only once. The descriptive statistics did show larger learning gains from enhanced captions when the video had been watched twice, but altogether the effect of enhancement was not statistically significant according to mixed effects modeling. Viewing the video twice instead of once was found to be a stronger predictor of learning gains.
The findings of both Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) and Puimège et al. (Reference Puimège, Montero Perez and Peters2024) suggest that, compared with its attested usefulness in reading texts, typographic enhancement of MWIs in captions has only a modest impact. A likely explanation is that viewing captioned video is more demanding as regards attention allocation than reading a text. There are more stimuli to attend to (images, sound, and captions) and (unless the video is paused) there is very little time to dwell on language items, regardless of whether they are typographically enhanced. Because authentic audiovisual materials are used in “real time” and require fast processing, learners also have less opportunity to reflect on the purpose and focus of typographic enhancement. If they see several MWIs enhanced in a text during self-paced reading, they may go back and forth between them, recognize what the enhanced items have in common (e.g., they are all word partnerships), and understand the intention of the instructor or materials designer is to direct their attention to this specific language feature. Discovering the purpose and focus of enhancement will likely take longer in the case of captioned video, because watching a captioned video in real time requires sequential processing of lines of text that disappear from the screen straightway. These factors may explain why enhancement made no difference in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) when the video was watched only once. Arguably, steps are needed to make learners aware of the purpose and focus of the intervention beforehand. It is this possibility that is explored in the approximate replication we report on below.
Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) also assessed the learners’ comprehension and recollection of the content of the video. Captions were found to support comprehension, which is in keeping with conclusions from other studies (Montero Perez et al., Reference Montero Perez, Van Den Noortgate and Desmet2013, Reference Montero Perez, Peters, Clarebout and Desmet2014), but this benefit was reduced in the caption condition with typographic enhancement. This is reminiscent of the findings of Choi (Reference Choi2017), which we mentioned earlier, and of some studies about enhancing grammar features as well (e.g., Lee & Huang, Reference Lee and Huang2008). Enhancement may focus learners’ attention on specific language features or items in the materials, but this may come at the cost of their engagement with other aspects of the input. Such a trade-off seems likely also when learners are made aware of the purpose and focus of the enhancement.
1.4 Justifications for replication
Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) and the other studies on typographic enhancement mentioned previously are situated in the realm of “incidental” learning, where participants are not informed that a test about certain language items will follow (see, Webb, Reference Webb and Webb2020, for a discussion). If a test is announced in such studies, this usually concerns content comprehension, and it is expected participants will then focus primarily on the content of the text (or video), as they would in “real” life. Of course, learners may suspect that a language-oriented test will follow a certain activity even if the test was not announced beforehand, or they may consider it likely that certain language items or patterns in course materials will be included in the end-of-term summative assessment. A study by Montero Perez et al. (Reference Montero Perez, Peters and Desmet2018) on the benefits of various types of captions (but not typographically enhanced ones) for vocabulary learning found no significant impact of test announcement on learning gains, but it was recognized that, regardless of whether or not they were forewarned of a test, many students may have considered the materials as a source for intentional language learning. An additional reason why test announcement may not make a big difference is that students may not know precisely what kind of test to expect. For example, announcing a “vocabulary test” will not help learners much to determine which specific items in the input materials are likely to be included in the test. Typographic enhancement may help them in this regard, at least if they understand its purpose. If learners know that a test about MWIs will follow, and if they then see MWIs typographically enhanced in texts or in captions, this should be an incentive for them to focus on these items.
This approximate replication study was an integral part of a project comprising two studies that were planned at the same time. The replication part was conducted shortly after the initial study at the same research site and with the same participants. A few years have passed since the initial study was published (in March 2021), allowing an evaluation of its impact so far. At the time of writing the present report (in June 2024), it had been cited 64 times according to Google Scholar. The observation that the initial study was attracting a good amount of attention served as an additional incentive to report the findings of this replication.
Following Porte and McManus (Reference Porte and McManus2019, Chapter 5), we consider the new study an approximate replication rather than a close replication, because two variables differ from the original (whereas in a close replication there should be only one). The two differences are (a) the video material and (b) the learners’ awareness of the intended language-learning outcome.
The research questions were identical to those of Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), except that this study investigated learning outcomes under what we shall (for simplicity's sake) call intentional learning as opposed to incidental learning:
1. Is there an effect of caption condition (i.e., enhanced captions, standard captions, no captions) on intentional learning of MWEs?
2. Is there an effect of caption condition (i.e., enhanced captions, standard captions, no captions) on content comprehension?
3. Is there an effect of repeated viewing on the learning of MWEs under the various caption conditions?
4. Is there an effect of repeated viewing on content comprehension under the various caption conditions?
As in the initial study, the same learner-participants, the same six viewing conditions (albeit applied to a different video), and the same types of tests were used. However, unlike the initial study, the students were made aware that the viewing activity served the purpose of MWI learning and that a test would follow with a focus on the MWIs encountered in the video.
Throughout the remainder of the article, we adhere as much as possible to the guidelines for reporting replication research outlined in McManus (Reference McManus, Gurzynski-Weiss and Kim2022) and Porte and McManus (Reference Porte and McManus2019).
2. Method
2.1 Participants
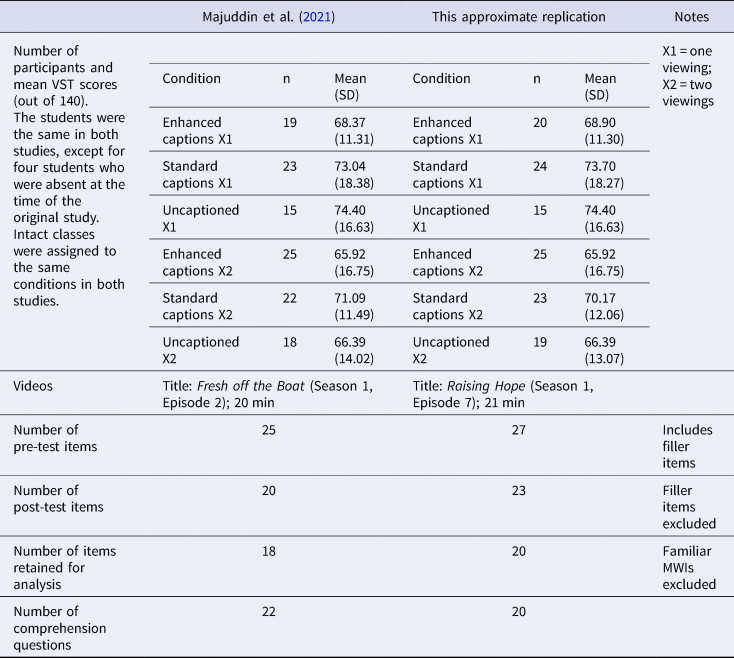
The participants were 126 students (48 males) in higher education in Malaysia, aged 17 to 22. Apart from four students, they had all previously participated in the study that is replicated here. They were first-year and second-year students in fields such as Hospitality Management and Information Technology Systems. Their L1 was Malay or Mandarin. All the participants had learned English at school for at least ten years. Their vocabulary size test (VST) (Nation & Beglar, Reference Nation and Beglar2007) scores indicated receptive familiarity with 4,000- to 9,000-word families, with a mean of 6,600. The participants were in the same six intact classes as in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), and these intact classes were assigned to one of six viewing conditions, which was the same as in the initial study. Two of the classes had the same number of participants as the original study, while the others had one more. There was no significant difference between the classes in their VST scores (Kruskal-Wallis χ2(5) = 4.57; p = 0.47). Schmitt et al.'s (Reference Schmitt, Schmitt and Clapham2001) Vocabulary Levels Test (VLT) (Version 2) was also administered. All six classes obtained a mean score of ≥ 25 out of the 30 test items belonging to the 2,000 most frequent word families and of ≥ 22 on the next frequency band (see Appendix 1).
2.2 Materials
As in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), the video used in this study was an episode from an American sitcom, but it was different from the sitcom selected for the original study. We could not re-use the same video (an episode of Fresh off the Boat) because the students had already watched it as participants in the original study. The Fresh off the Boat episode is 20-minutes long, and the story's premise centers around how a stern Asian mother uses her “tiger mother” ideals and values to deal with her family business and children. For the present study, an episode of Raising Hope was chosen (Episode 7, Season 1). Raising Hope tells the story of an American family raising a little girl they named Hope. The selected 21-minute episode is about events around the day of Thanksgiving.
A RANGE (Nation & Heatley, Reference Nation and Heatley2002) analysis of the lexical profile of the two episodes did not show substantial differences between them. The most frequent 2,000-word families provided 94.87% and 91.42% coverage (including proper nouns and marginal words) of the total running words of the script for the video in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) and the video used in the present replication study, respectively. Knowledge of the most frequent 3,000-word families provided 96.37% cumulative coverage of the initial video's script and 94.25% coverage of the video used in the present study. In the case of reading texts, 95% coverage appeared necessary for adequate text comprehension (e.g., Laufer, Reference Laufer2020; Laufer & Ravenhorst-Kalovski, Reference Laufer and Ravenhorst-Kalovski2010), but for audiovisual input such as TV, the threshold for adequate comprehension was probably lower (e.g., Durbahn et al., Reference Durbahn, Rodgers and Peters2020).
The original study had 18 target final items. In the present study, 23 MWIs were selected from the episode that were considered highly likely to be unfamiliar to the students. Each occurred once in the episode. According to the pre-test (see below), three of these were already known by over half of the students, and so these three MWIs were excluded from data analysis. The remaining 20 MWIs were (in order of appearance in the episode): unsung hero, (someone's) day in the sun, play the […] card, make the most of, invest in, bring out the big guns, whip up, spread the word, the dust has settled, in the bag, screw with, take […] lying down, step […] up, have a beef with, small potatoes, have a run-in with, rat out, hopped up, hit the streets and [be] caught up in. As in the original study, this represents a mix of MWIs, varying in formal and semantic characteristics, which is to be expected in authentic discourse. Neither the original study nor the approximate replication intended to examine the learnability of one specific type of MWIs or to compare the learnability of different types.
The format of all the test instruments in the present study was identical to that of the original study. MWI knowledge was gauged by means of form-recall tests. A sentence-based cued gap-fill format was used for the pre-test. For example: “Let's wait until the d_____ has s_____ before we decide what to do. It's best to wait until the situation has calmed down.” For each MWI, only the content words had missing letters. The function words were kept intact. The test items were run through RANGE to make sure that all the words used in the sentences belonged to the 3,000 most frequent word families in English.
The cued gap-fill format was also used in the immediate post-test, but this time within the broader verbatim contexts in which the MWIs had been encountered in the sitcom episode, so the learners could possibly make use of episodic memory to recall the expressions. For example: “Virginia [narrating]: When the d____ has s____ and the candy was gone, it was time to count up the earnings and see who was going to ride the float.”
The delayed post-test, administered two weeks later, was the same as the pre-test, except for the order of the test items (see Appendix 2 for the test items for all 20 target MWIs).
A content comprehension test was given to the students shortly after they had watched the video. The questions were created by drawing on established listening constructs as well as taxonomies of listening skills. One of the most widely accepted descriptions of listening involves the notions of top-down and bottom-up processing (e.g., Buck, Reference Buck2001). Skills such as identifying facts and other local points of information constitute the ability to perform bottom-up processing. The ability to perform top-down processing, on the other hand, is observed through global skills such as listening for gist and making inferences about contexts and speakers’ attitudes. As both types of processing are vital for successful comprehension, we created a comprehension test intended to capture both. All words used in the questions belonged to the 3,000 most frequent word families in English. An initial set of comprehension questions was trialed with three postgraduate students. They first watched the video from start to end, proceeded to answer the questions, and then commented on the difficulty and clarity of the test items. Based on this feedback, the test was revised and trialed with one L1 and one L2 English postgraduate students, both of whom answered all the test items correctly and pointed out no further issues with clarity. The final version of the test consisted of nine multiple-choice questions and 11 true/false questions (see Appendix 3).
Appendix 4 presents a side-by-side comparison of the original study and the present study regarding participant groups, materials, and instruments.
2.3 Procedures
Prior to the start of the two-study project, the participants gave their informed consent, and they took the VLT, the scores on which helped to ascertain that the lexical profiles of the materials in both studies were matched to the participants’ vocabulary knowledge. As in the original study, there was a two-week lapse between the MWI pre-test and the treatment, and between the treatment and the post-tests. The VST was also administered right after the MWI pre-test, which included the 20 target MWIs in the present study. Analogous to Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), the students were, in their intact classes, assigned to one of six viewing conditions two weeks after the MWI pre-test: viewing once with enhanced captions (n = 20), viewing once with standard captions (n = 24), viewing once without captions (n = 15), viewing twice with enhanced captions (n = 25), viewing twice with standard captions (n = 23), and viewing twice without captions (n = 19). In the enhanced-captions conditions, the target MWIs were bolded and underlined. After watching the video (either once or twice), the participants first answered the 20 content comprehension questions and then proceeded with the immediate post-test on the MWIs. Two weeks later, they took the delayed MWI test.
2.4 Analysis
Two raters independently scored the responses in the MWI recall tests. Scoring was approached the same way as in the initial study. For test items with only one word missing, a full point was awarded also when the supplied word included a minor mistake, such as using a singular form when it should have been plural. For test items with two missing words, partial credit (0.5) was awarded when one of the supplied words was correct or exhibited only a minor mistake. In three-gap responses, two of the words needed to be correct (or exhibit only a minor mistake) for partial (0.5) credit. Inter-rater agreement was high (0.96, 0.94, and 0.97 for the pretest, immediate post-test, and delayed post-test, respectively), and so the average score awarded by the two raters was used in the statistical analyses. This yielded five possible accuracy levels: 0, 0.25, 0.5, 0.75, or 1. As the pre-test data was non-normally distributed with unequal variance, this data was first transformed using Tukey Ladder of Powers before running a one-way non-parametric ANOVA (Kruskal-Wallis) test. This revealed no significant differences between the groups’ pre-test scores (Kruskal-Wallis χ2 (5) = 4.58, p = 0.47).
Two cumulative link mixed models (clmm) (Christensen, Reference Christensen2019) were built in R (R Core Team, Reference R Core Team2018) for the immediate and delayed post-test data, with performance on the pre-test at the item level included as one of the fixed effects in the statistical modelling. The following were the other fixed effects: caption condition, number of viewings (once or twice), and VST score. The latter was included given that learners with a relatively large vocabulary have an advantage in acquiring new lexical items from reading/listening/viewing activities (e.g., Elgort & Warren, Reference Elgort and Warren2014; Majuddin et al., Reference Majuddin, Siyanova-Chanturia and Boers2021; Montero Perez et al., Reference Montero Perez, Peters and Desmet2018; Montero Perez, Reference Montero Perez2020; Noreillie et al., Reference Noreillie, Kestemont, Heylen, Desmet and Peters2018; Peters & Webb, Reference Peters and Webb2018; Pujadas & Muñoz, Reference Pujadas and Muñoz2019). The VST scores were centered prior to analysis. No issues of multicollinearity were found between pre-test scores and VST scores. The model comparison procedure for the post-test data was identical to Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021).
Starting with a full model that included all the fixed effects as well as the two- and three-way interactions, each factor was incrementally removed. The full model was then compared with the reduced model using likelihood ratio tests to determine the significance level of the removed factor. The comparison returned likelihood ratio statistics with a chi-square distribution. This is reported in the form (LRT χ2 (n1) = n2, p < n3), where n1 = degrees of freedom, n2 = likelihood ratio statistic, and n3 = p-value. To correct for multiple testing, Bonferroni adjustment was applied so that the level of significance was p < 0.025 rather than p < 0.05. The emmeans function in the emmeans package was used to locate the differences between the caption conditions (Lenth, Reference Lenth2018).
As regards the content comprehension test, as in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), all responses were coded as correct or incorrect. The data were analyzed by means of the glmer function of the lme4 package (Bates et al., Reference Bates, Maechler, Bolker and Walker2015). The fixed effects included caption condition, number of viewings, and VST score. Model comparisons were performed in the same way as the clmm analyses.
We will consider findings from Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) as replicated in this approximate replication when the same factors emerge as significant predictors of the learners’ performance on the MWI post-tests and the content-comprehension test.
3. Results and discussion
3.1 Multiword item recall
Table 1 displays the scores on the cued MWI recall tests in this study and in the original study. Similar to the latter, very little learning occurred in the absence of captions. Also similar to the original study, learning was better in the captioned conditions, although (as in the original study) the learning gains diminished by the time the students took the delayed post-test. The best scores on the immediate and the delayed post-tests were obtained by the group who watched the video twice with enhanced captions. This held true only for the immediate post-test in the original study. Different from the original study is the indication that the enhanced captions brought about greater immediate learning gains than the standard captions after a single viewing of the video.
Table 1. Mean scores (first row), standard deviations (second row), and 95% confidence intervals (third row) per condition for the MWI tests
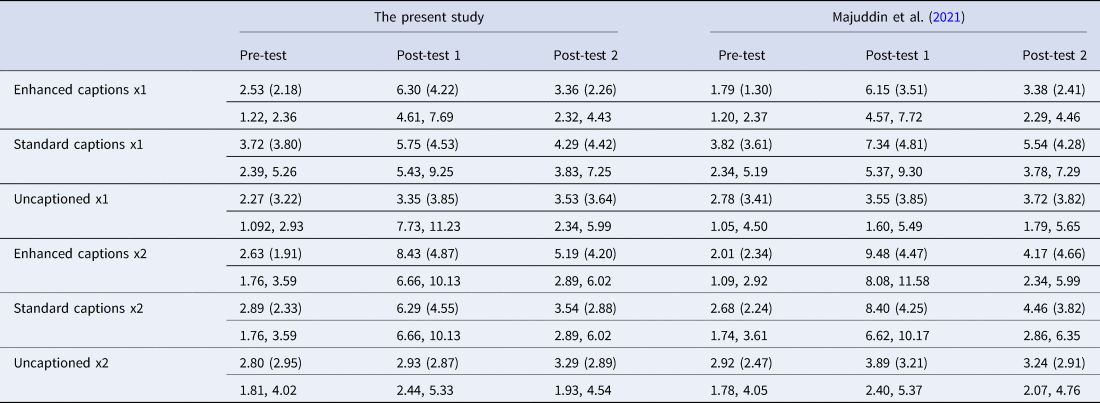
Note: The maximum scores were 20 and 18 in the present study and in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), respectively. Post-test 1 = immediate; post-test 2 = delayed.
The results of the clmm analysis revealed that caption condition, (χ2 (2) = 30.6, p < 0.001), VST score (χ2 (1) = 26.8, p < 0.001), and pre-test score (χ2 (1) = 64.6, p < 0.001) predicted participants’ immediate post-test scores. Unlike what was found in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), repeated viewing did not emerge as a significant predictor, and so that finding is not replicated here. Table 2 shows the output of the best-fit model for the immediate post-test in the present study, including the odds ratios (ORs) as indicators of effect sizes. As for the effect of caption condition, comparisons using the emmeans function in the emmeans package revealed that enhanced captions were much more likely to yield a score that is one level higher (e.g., a score of 1 instead of 0.75 for the item) compared with the uncaptioned video (p < 0.0001). The standard captions were also more likely to bring about a score that is one level higher in the immediate post-test compared with the uncaptioned video (p = 0.004), but the odds ratios indicate that the difference was not as pronounced. Importantly, the enhanced captions led to significantly better test performance than the standard captions (p = 0.01), which is different from the original study, where the advantage of enhanced captions relative to standard ones did not reach significance. Table 3 shows the model from the original study, for comparison.
Table 2. Output of best-fit model for the immediate post-test in the present study

Note: Intercept levels: caption condition = uncaptioned; number of viewings = once.
Table 3. Output of best-fit model for the immediate post-test in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021)
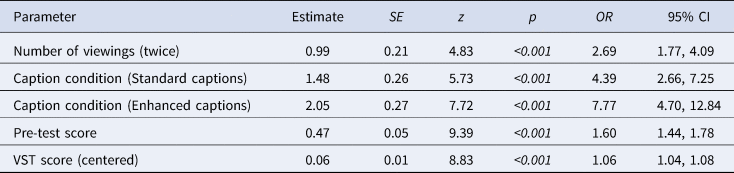
Note: Intercept levels: caption condition = uncaptioned; number of viewings = once.
As to the delayed post-test, strong predictors of successful recall were VST score (χ2 (1) = 32.3, p < 0.001) and pre-test score (χ2 (1) = 341.2, p < 0.001). Enhancement was as an additional predictor (Table 4), but standard captioning was not, which is different from the original study. Table 5 presents the model from the latter study for comparison.
Table 4. Output of best-fit model for the delayed post-test in the present study

Note: Intercept levels: caption condition = uncaptioned; viewings = once.
Table 5. Output of best-fit model for the delayed post-test in Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021)
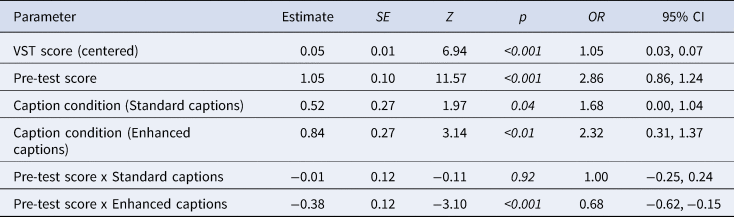
Note: Intercept levels: caption condition = uncaptioned; viewings = once.
Summing up, the results indicate that typographic enhancement had a positive impact on MWI learning in the present study, while repeated viewing did not emerge as a significant predictor. This is different from the study by Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), where repeated viewing rather than typographic enhancement made the greater impact on MWI learning; this was likely because the enhancement only began to make a difference when the students watched the video twice. In short, this finding of the initial study is not replicated here.
3.2 Content comprehension
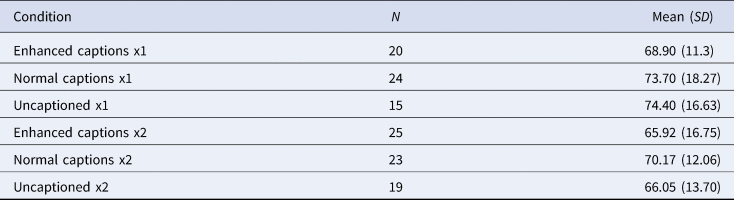
Let us now turn to the results of the content comprehension test. As expected, the mean scores were higher in the captioned conditions than in the condition without captions (see Table 6), but this advantage was less pronounced in the case of enhanced captions. This suggests that the presence of typographic enhancement partly compromised the supporting role of captions for content comprehension. In Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), there was some indication of this side effect as well, but it was confined to the condition where participants watched the video only once.
Table 6. Descriptive statistics for the content comprehension test

In the present replication, by contrast, repeated viewing did not appear to make up for the distracting effect of enhancement. It is likely that the participants’ awareness of the language-learning goal of the activity made them attend specifically to MWIs at the cost of attending to content both times they processed the material. That said, the glmer analysis of the content-comprehension data did not show a significant difference between the caption conditions, which is similar to Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021). The analysis did reveal a significant interaction between caption condition and VST score (χ2 (2) = 12.5, p < 0.01). No such interaction emerged in the original study. To examine this interaction, we broke down the VST scores into ranges from the lowest (38) to highest (112) scores. The mean VST score was close to 70, and so we used ranges with the following values: 40, 50, 60, 70, 80, 90, and 100. The probabilities of correct responses in the comprehension test were then compared for these ranges (Figure 1).

Figure 1. Content comprehension in relation to vocabulary size.
The interaction suggests that, for content comprehension, participants with a low VST score did not benefit from captions that featured typographic enhancement. By contrast, content comprehension by participants with a high VST score benefited from captions regardless of whether they featured enhancement. This finding, when compared with the original study, suggests that learners at a relatively low proficiency level found it particularly hard to process the content of the video when they were presented with enhanced captions and were aware of the intended learning outcome from the enhancement.
4. Conclusions
4.1 Summary of the findings
This approximate replication of Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021) examined the effect of the same six viewing conditions, but this time the English as a second language (ESL) learners were made aware of the MWI focus of the activity and of the type of test that would follow. Trends found in the original study were replicated, but the strength of these trends differed, so that different factors stood out as significant predictors of test performance. Most notably, whereas repeated viewing was found to be a stronger predictor of learning gains than enhancement in the original study, enhancement emerged as a stronger predictor in the present study. This is probably because enhancement already led to better immediate recall after watching the video once, whereas in the original study the benefits of enhancement for MWI learning only emerged after the repeated viewing. In addition, the present study found indications that enhanced captions can negatively affect content comprehension even when the learners watched the video twice, while in the original study this seemed confined to the condition where the students watched the video only once. The present study further detailed that this downside of enhanced captions affected mostly students with comparatively poor proficiency (going by their VST scores). These students must have found it particularly challenging to process the content of the sitcom episode while they tried to attend to the enhanced MWIs in the captions. Learners with a comparatively large vocabulary size performed well on the content comprehension test regardless of whether captions were enhanced. However, learners with a comparatively poor vocabulary knowledge, and who by that token must have found the video challenging, benefited more from standard captions. The learners’ prior vocabulary knowledge, as gauged by the VST, was a strong predictor of both MWI learning and content comprehension. This replicates Majuddin et al. (Reference Majuddin, Siyanova-Chanturia and Boers2021), and it accords with numerous previous studies (e.g., Montero Perez, Reference Montero Perez2020; Peters & Webb, Reference Peters and Webb2018; Puimège & Peters, Reference Puimège and Peters2019; Pujadas & Muñoz, Reference Pujadas and Muñoz2019).
A comparison with the findings of the original study needs to remain tentative because a different video and consequently also different target MWIs were used. For example, the average scores on the comprehension test were lower than in the previous study, which could be interpreted as evidence for a greater trade-off between a focus on the language code and a focus on content, but it is also possible that the learners simply found the sitcom episode in the original study easier to follow. The same word of caution applies to a comparison of the MWI learning gains in the two studies – it cannot be ruled out that the target MWIs in one study were more challenging to remember than in the other. While bearing all this in mind, the findings do lend indirect support for the notion that awareness of the intended vocabulary-learning outcome and the anticipation of a test on MWIs influences learners’ uptake of MWIs from enhanced captions.
4.2 Possible directions for further (replication) research
If it is true that typographic enhancement can negatively impact learners’ intake of content, then a possible procedure to remedy this is to have learners first watch a video with normal captions (to support content comprehension), and subsequently watch it again with enhanced captions (to direct attention to specific language features or items). Future studies could put this scenario to the test by comparing this procedure with a condition where participants watch the same video twice with either standard captions or enhanced captions (see Wi & Boers, Reference Wi and Boers2024, for an example, albeit not focused on enhancement). In a similar vein, more compelling evidence of the effect of test announcement could be obtained from between-participant designs where all learners are exposed to the same input materials but with presence/absence of test-announcement as the independent variable (e.g., Montero Perez et al., Reference Montero Perez, Peters and Desmet2018). In addition, triangulation with eye-movement data would be helpful to ascertain not only if typographically enhanced items attract attention (e.g., Puimège et al., Reference Puimège, Montero Perez and Peters2023) but also if the enhancement affects learners’ attention to other elements (e.g., Choi, Reference Choi2023).
Another future direction is to evaluate the effects of typographic enhancement when this intervention is integrated in a larger ensemble of instructional approaches to MWIs – and to other language items and features, for that matter (e.g., Chung & Révész, Reference Chung and Révész2024). For example, an additional way of prompting learners to attend to certain language features or items in texts is to provide explicit instruction about them beforehand (e.g., Cintrón-Valentín & García-Amaya, Reference Cintrón-Valentín and García-Amaya2021; Indrarathne & Kormos, Reference Indrarathne and Kormos2017; Pellicer-Sánchez et al., Reference Pellicer-Sánchez, Conklin and Vilkaitė-Lozdienė2020; Pujadas & Muñoz, Reference Pujadas and Muñoz2019). The research agenda should also include longitudinal interventions that regularly raise learners’ awareness of the importance of phraseology with a view to promoting autonomous engagement with MWIs in discourse (e.g., Boers et al., Reference Boers, Eyckmans, Kappel, Stengers and Demecheleer2006, Reference Boers, Bui, Deconinck, Stengers and Coxhead2023; Bui et al., Reference Bui, Boers and Coxhead2020; Jones & Haywood, Reference Jones, Haywood and Schmitt2004).
Within each of these lines of inquiry, replication research is needed to gauge the generalizability of findings and to identify factors for consideration in future applications. Replication studies are usually inspired by previously published studies that have over time attracted attention, but they can also be planned proactively as an integral feature of a multi-study project, as was the case here.
Appendix 1. Scores on the vocabulary size test (VST) and the vocabulary levels test (VLT)
VST scores (out of 140)
VLT scores (out of 30 per level)

Appendix 2. Pre-test and delayed post-test items (target MWIs)
In each of the following questions, there is one phrase with missing letters. Look at the context and fill in the blanks with the missing letters.
1. I can wh_____ up a meal in no time.
2. Teachers are the uns_____ he_____ of a great writer's success. They are often not noticed or praised for their hard work.
3. We are only in Paris for a day, so let's m_____ the m_____ of it. We should enjoy our day as much as possible.
4. We have arranged a meeting for next Thursday, so if you see anyone, do sp_____ the w_____. We have to inform everyone.
5. When the score got to 8-2, we knew the game was in the b_____. We knew we were going to be the champions.
6. Let's just wait until the d_____ has s_____ before we decide what to do. It's better to make a decision when the situation has calmed down.
7. Someone has been sc_____ with my computer, and now it doesn't work anymore.
8. The gap between the rich and the poor is wide, and the poor aren't going to t_____ it ly_____ d_____. They are going to be more violent.
9. After the recent bombing attacks, airports in major cities around the world have installed more cameras to st_____ up security.
10. I don't have anything against advertising, but I do have a b_____ with how many bad advertisements there are on TV.
11. We i_____ a lot in Tom, so we have every right to expect a lot from him. We devoted a lot of time and effort in training him to be a professional athlete.
12. He had a r_____ in with his boss. The argument caused him to lose his job.
13. My brother came home drunk so I r_____ him out to my mother. I told my mother that he had been sneaking out at night.
14. You have so much energy on your television shows, I always suspect you must be ho_____ up on energy drinks.
15. I was so c_____ up in my school work that I didn't realise what was happening with my sister.
16. The cooking competition is designed to give home cooks their d_____ in the s_____. The home cooks will finally get the attention they deserve.
17. The candidate pl_____ the race c_____, claiming that she received less attention than the Malay candidate simply because she is Chinese.
18. After failing to convince the IT department that new security passwords are needed, Mike felt it was time to br_____ out the b_____ g_____. So he called a meeting with the Head of the Company.
19. The new iPhone model is confirmed to h_____ the str_____ at the end of 2017.
20. Last week's rain was sm_____ pot_____ compared to the thunder storm we had two months ago.
Appendix 3. Content comprehension test
The following questions are about the video you have just watched. Circle the correct answer.
1. What did the high school donate to the Natesville Auxiliary (volunteer) Police?
A) Radishes
B) Whistles
C) Chocolate
2. Why did Jimmy want Hope to become the little pilgrim?
A) To boost her confidence for potty (toilet) training
B) To make her the most popular child
C) To prove that Virginia was not cheating
3. Why was young Jimmy not allowed in the pool?
A) He was being naughty
B) He did not sell any chocolate bars
C) He did not win the contest
4. Why did young Virginia fail to sell the original chocolate bars?
A) She did not try hard enough
B) Rosa's family stopped her from selling the bars
C) The original chocolate bars did not taste good
5. At first, Virginia did not want to help Hope win because
A) She wanted Rosa's grandson to win
B) She did not want to burden Maw Maw
C) She knew winning would make another child sad
6. When young Virginia just started working with Knock Knock Knock Housekeeping, young Jimmy also started his long-life affair with
A) Chocolate
B) Fire and explosives
C) Growing radishes
7. What did Maw Maw do when Burt found the horse's head in his bed?
A) She made her chocolate stronger
B) She destroyed the Flores family's chocolate bars
C) She sold her chocolate bars at a cheaper price
8. Why was Virginia angry at Sabrina?
A) Sabrina started stealing Maw Maw's Magic Brown
B) Sabrina did not help Jimmy win the contest
C) Sabrina did not sell enough Maw Maw's Magic Brown
9. What did Barney want Jimmy to do?
A) Beat his mother
B) Wear a wire
C) Confess to cheating
The following statements are about the video you have just watched. If the statement is true, circle the word True. If the statement is false, circle the word False.

Appendix 4. Side-by-side comparison of participant groups and materials
Elvenna Majuddin currently serves as a Senior Learning Adviser at Te Taiako Student Learning, Te Herenga Waka–Victoria University of Wellington, New Zealand. She earned her Ph.D. in Applied Linguistics from the same institution. Her research focuses on the learning of multi-word expressions through video watching, exploring various caption conditions and their impact on both incidental and intentional learning settings. The first study undertaken as part of her doctoral research was published in Studies in Second Language Acquisition.
Frank Boers was a language teacher and teacher trainer in his home country, Belgium (1988–2010), before he joined Te Herenga Waka–Victoria University of Wellington, New Zealand (2010–2018) to teach courses in Applied Linguistics. He is now a Professor at the Faculty of Education of Western University, Canada. He publishes mostly on matters of second language education. His latest books are Evaluating second language vocabulary and grammar instruction (2021) and (with L. Zwier) English L2 vocabulary learning and teaching (2023), both published by Routledge.
Anna Siyanova-Chanturia is Associate Professor in Applied Linguistics at Te Herenga Waka–Victoria University of Wellington, New Zealand. Anna's research interests include psychological aspects of second language acquisition, bilingualism, usage-based approaches to language acquisition, processing and use, vocabulary and multi-word expressions, as well as quantitative research methods (e.g., corpus research and eye-movement research).








 Open access
Open access