


INTRODUCTION
Tuberculosis (TB) is a communicable infectious disease that is transmitted almost exclusively by cough aerosol, and is caused by the Mycobacterium tuberculosis complex [Reference Dheda1]. As a major cause of illness and death, TB has plagued humankind worldwide for thousands of years and remains a serious public health problem, with more than 9·6 million new cases and 1·5 million related deaths occurring annually [2]. World Health Organization (WHO) reported that China was one of the six countries that have the largest number of TB cases, and China was among three countries with more than half of multidrug-resistant TB cases in 2014, second only to India [2]. In China, with the growth of population, especially the increase of migrants, many areas have experienced a resurgence of TB.
The prediction of the incidence of TB as a form of early surveillance and detection can facilitate prevention and control of TB. Epidemic forecasting models were regarded as important tools to predict the occurrence of infectious diseases and to formulate reasonable precautions. Many statistical methods have been used for forecasting infectious diseases, such as exponential smoothing, the grey model, generalized regression methods, ecomposition methods, multilevel time-series models, the Markov model, and the autoregressive integrated moving average (ARIMA) model [Reference Tabaszewski3–Reference Li7]. Of these methods, the ARIMA model is the most popular linear modelling technique for forecasting time series. This model assumes that the present data have a linear relationship with past data points and past errors of a time series. However, real-world problems show uncertainty and are often complex and nonlinear, therefore the linear approach might be not suitable for cases where independent and dependent variables are in a nonlinear relationship. To overcome the problem of nonlinearity, several nonlinear models have been proposed as alternative techniques, where the artificial neural network (ANN) has become one of the most popular and important methods. ANN models can approximate a nonlinear mapping with any degree of complexity and without prior knowledge of problem solving, which makes them attractive in forecasting tasks. However, the ANN model cannot capture both linear and nonlinear patterns of data equally well [Reference Taskaya-Temizel8]. Recently, to overcome the limitations related to the separate use of these models in real problems, hybrid methodologies (ARIMA-ANNs) that decompose a time series into its linear and nonlinear form have recently been shown to be successful for single models [Reference Aslanargun9–Reference Yu11]. All of these hybrid models improve the prediction accuracy of future values compared to the ARIMA model alone. Therefore, to predict the incidence of TB, a hybrid model incorporating ARIMA and a nonlinear autoregressive (NAR) network model was developed on the basis of annual and monthly TB incidence from January 2007 to March 2016 in Jiangsu province, China. The hybrid model will be helpful for forecasting the epidemic trend of TB and for providing references for TB public health interventions.
METHODS
Data collection
The observed monthly cases of TB were obtained from the website of the Bureau of Health, Jiangsu province, China, and population data was collected from the Jiangsu Statistics Bureau. In our study, we collected the incidence time series of TB from January 2007 to March 2016.
In this study, a hybrid model, developed by combining ARIMA and a NAR model, is utilized as a benchmark model. The forecasting of the hybrid ARIMA model will be accurately evaluated by comparison with the ARIMA model. To demonstrate the effectiveness of the proposed hybrid model, two datasets for use in training and forecasting are utilized in this study to examine the performance. Regarding the single ARIMA model, in the first part, 99 months’ data are taken into account for the January 2007–February 2015 period. These data are used in the modelling performance to construct the models. In the second part, with the help of the model constructed in the first part, the predication performance of that model is calculated using 12 months’ data for the March 2015–March 2016 period.
The ARIMA model
Box & Jenkins presented the ARIMA model in 1970 [Reference Box and Jenkins12]. It has been widely used in financial, economic, and social scientific fields. The general form of the ARIMA models is written as follows [Reference Box and Jenkins12]: ARIMA (p,d,q) × (P,D,Q) s , where p is the number of parameters in the autoregressive (AR) model, d the differencing degree, q the number of parameters in the MA model, P the number of parameters in AR seasonal model, D the seasonal differencing degree, Q the number of parameters in MA seasonal model, and s the period of seasonality. Because there was a strong seasonality trend in this study, we constructed a seasonal ARIMA (p,d,q) × (P,D,Q) s model. Prior to fitting the ARIMA model, an appropriate differencing of the series is usually performed to make the series stationary. If the series is not stationary, differencing can be used to transform it into a stationary series. The Box–Jenkins approach uses an iterative model-building strategy consisting of four steps: identification, estimation, diagnostic checking, and forecasting. Box & Jenkins proposed the use of the autocorrelation function (ACF) and the partial autocorrelation function (PACF) of the sample data as basic tools to identify the order of the ARIMA model. The conditional least squares method was applied to estimate the model parameters. The adequacy of the established model for the series is verified by employing white-noise tests to check whether the residuals are independent and normally distributed. Several ARIMA models may be identified, and the selection of an optimum model is necessary. Such selection of models has been proposed based on Akaike's Information Criterion (AIC) and Bayesian information criterion (BIC).
The NAR model
An ANN is an intelligent nonlinear mapping system built to loosely simulate the functions of the human brain and has been considered as a nonlinear regression analysis tool capable of approximating any sort of arbitrary function [Reference Adly13]. Owing to their flexibility as function approximators, ANNs are robust methods in tasks related to time-series forecasting [Reference Connor14]. Among various ANNs, the NAR network, as an architectural approach of recurrent neural networks with embedded memory, represents a powerful class of models that can symbolize arbitrary nonlinear dynamical mappings and has favourable qualities for modelling dynamical systems and forecasting nonlinear time series [Reference Benmouiza and Cheknane15]. The defining equation for the NAR model is:
 $$\hat y{\rm (}t{\rm )} = f\,{\rm (}y{\rm (}t - {\rm 1)} + y{\rm (}t - {\rm 2)} + \cdot \cdot \cdot + y(t - d){\rm ),}$$
$$\hat y{\rm (}t{\rm )} = f\,{\rm (}y{\rm (}t - {\rm 1)} + y{\rm (}t - {\rm 2)} + \cdot \cdot \cdot + y(t - d){\rm ),}$$
where f is a nonlinear function, where the future values depend only on the regressed d earlier values of the output signal.
When using a NAR network, the closed loop network is used to perform a multistep-ahead prediction. The output of the closed loop NAR network is expressed as follows:
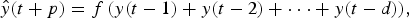 $$\hat y{\rm (}t + p{\rm )} = f\,{\rm (}y{\rm (}t - {\rm 1) }+ y{\rm (}t - {\rm 2)} + \cdot \cdot \cdot + y(t - d){\rm ),}$$
$$\hat y{\rm (}t + p{\rm )} = f\,{\rm (}y{\rm (}t - {\rm 1) }+ y{\rm (}t - {\rm 2)} + \cdot \cdot \cdot + y(t - d){\rm ),}$$
where p represents the forecast steps in the future.
The hybrid model
A time series can be considered as comprising a linear autocorrelation structure and a nonlinear component. The ARIMA model and the NAR network are methodologies that predict future values using historically observed data, and are suitable for linear and nonlinear problems, respectively. According to Zhang's [Reference Zhang16] model, we developed a hybrid model combining the ARIMA model (linear approach) and the NAR network (nonlinear approach) for our study.
It is assumed that time series are composed of a linear autocorrelation structure and a nonlinear part:
 $$y_i = L_i + N_t, $$
$$y_i = L_i + N_t, $$
where y i denotes the original monthly incidence, L i denotes the linear part, and N t denotes the nonlinear part at time t. The proposed methodology of the hybrid system consists of two steps. In the first step, an ARIMA model is used to predict future values at time t noted, as expressed by the following equation:
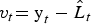 $$v_t {\rm = y}_t - \hat L_t $$
$$v_t {\rm = y}_t - \hat L_t $$
where v
t
denotes the residual at time t as obtained from the ARIMA model, and
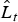 $\hat L_t $
denotes the forecast value by the ARIMA model at time t. In the second step, the NAR model is developed to model the residuals from the ARIMA model. With n input nodes, the NAR model for the residuals will be:
$\hat L_t $
denotes the forecast value by the ARIMA model at time t. In the second step, the NAR model is developed to model the residuals from the ARIMA model. With n input nodes, the NAR model for the residuals will be:
 $$v_t {\rm } = f\,(v_{t - 1}, v_{t - 2}, \cdot \cdot \cdot, v_{t - n} ) + e_t, $$
$$v_t {\rm } = f\,(v_{t - 1}, v_{t - 2}, \cdot \cdot \cdot, v_{t - n} ) + e_t, $$
where f is a nonlinear function determined by the neural network, and e t is the random error. Then, the combined forecast is given by the following formula:
 $$\hat{y}_t = \hat{L}_t + \hat{N}_t, $$
$$\hat{y}_t = \hat{L}_t + \hat{N}_t, $$
where
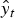 $\hat{y}_t$
represents the predicted value using the hybrid model at time t, and
$\hat{y}_t$
represents the predicted value using the hybrid model at time t, and
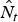 $\hat{N}_t$
is the forecast value of equation (6).
$\hat{N}_t$
is the forecast value of equation (6).
To construct the NAR model, it is generally best to start with the neural network time-series tool, one of the graphical user interfaces (GUI) in MATLAB, which can automatically generate command-line scripts in accordance with the demand of the research. This study collected the monthly incidence of TB (98 points) for eight years (February 2008–March 2016). From this, the data were split into three blocks of (1) training the network with 70% of data (February 2008–September 2013; 68 points); (2) validation with 15% of data (October 2013–December 2014; 15 points); and (3) verification with 15% of data (January 2015–March 2016; 15 points).
Forecast evaluation methods
The performance of the model is related to the similarity in the forecast values for the test data and the observed values. Three different forecast consistency measures are used for comparing the performances obtained for the ARIMA and ARIMA-NAR models: mean square error (MSE), mean absolute error (MAE), and mean absolute percentage error (MAPE). The smaller the MSE, MAE, and MAPE of the prediction model, the better its prediction accuracy. In other words, the prediction model with the smallest MSE, MAE, and MAPE can be selected as the optimum model.
 $${\rm MSE} = \displaystyle{1 \over {n}}\sum\limits_{t{\rm =} 1}^n {\mathop {\left( {y_t - \hat y_t} \right)}\nolimits^2}, $$
$${\rm MSE} = \displaystyle{1 \over {n}}\sum\limits_{t{\rm =} 1}^n {\mathop {\left( {y_t - \hat y_t} \right)}\nolimits^2}, $$
 $${\rm MAE} = \displaystyle{1 \over n}\sum\limits_{t = 1}^n {\left \vert {y_t - \hat y_t} \right \vert}, $$
$${\rm MAE} = \displaystyle{1 \over n}\sum\limits_{t = 1}^n {\left \vert {y_t - \hat y_t} \right \vert}, $$
 $${\rm MAPE} = \displaystyle{1 \over n}\sum\limits_{t = 1^{\prime}}^n {\displaystyle{{\left \vert {y_t - \hat y_t} \right \vert} \over {y_t}}}. $$
$${\rm MAPE} = \displaystyle{1 \over n}\sum\limits_{t = 1^{\prime}}^n {\displaystyle{{\left \vert {y_t - \hat y_t} \right \vert} \over {y_t}}}. $$
Data processing and analysis
The ARIMA model was constructed using the appropriate module in Stata version 12·0 (StataCorp, USA). The ARIMA-NAR modelling was implemented using the Neural Network Toolbox in MATLAB v. 8·4 (R2014b). A two-sided P value of ⩽0·05 was regarded as significant.
Ethical review
The study protocol and utilization of TB incidence data were obtained from the website of the Bureau of Health, Jiangsu province, China and no ethical issues were identified. Therefore, an ethical statement was not necessary because the data are public access data.
RESULTS
The best-fit ARIMA model
Between January 2007 and March 2016, a total of 469 029 TB cases were reported in Jiangsu province. Figure 1 shows the incidence rate of TB. The annual incidence decreased from 50·87/100 000 in 2007 to 80·36/100 000 population in 2015, with an average annual incidence rate of 66·21/100 000 population. In January, February, and March 2014, the incidence rates were 3·58, 3·64, and 4·70/100 000 population, respectively, less than three-quarters of the rates in January, February, and March 2007. Further, Figure 1 shows that the series has an obvious seasonal trend, with a higher seasonal index in March and April. The ARIMA model can be applied to analyse the time series with characteristics of seasons and tendency. The ARIMA model is fitted to a stationary time series, and seasonal data require regular and seasonal differencing to become stationary. The test time-series data were processed by taking the first-order regular difference and the first seasonal difference to remove the growth trend and seasonality characteristics (Fig. 2). Next, the series showed no trend, and the result of the unit root test was statistically significant (T = −18·604, P < 0·0001), which confirmed that the differenced data is stationary. This suggests that it would be appropriate to consider an order d = 1 and s = 12 in the fitted model given by the ARIMA (p,1,q)×(P,1,Q)12. All further statistical procedures are performed on the stationary series. Figure 3 also shows that the ACF and PACF of the new data tended to be stationary after using the one-order trend difference and one-order seasonal difference. By analysing Figure 3, a series of candidate models [ARIMA(3,1,0) × (0,1,1)12, ARIMA(3,1,0) × (0,1,0)12, ARIMA(3,1,0) × (1,1,0)12, ARIMA(2,1,0) × (0,1,1)12, ARIMA(2,1,0) × (0,1,0)12, and ARIMA(2,1,0) × (1,1,0)12] were tested. Based on the results of the goodness-of-fit test statistics, we confirmed the optimal ARIMA(3,1,0) × (0,1,1)12 model, which had the lowest AIC (127·3396) and BIC (140·2644) of the six candidate models (Table 1). The Ljung–Box test also shows that its residual was white noise with Q = 31·4463 (P = 0·8311), indicating that the fitted data series was stationary, random, and zero-related. Figure 4 shows that the ACF and PACF of the residual sequence fell within the random confidence interval. The parameter estimate results of the ARIMA model are shown in Table 2, and all the parameter estimates were significant. Therefore, we confirmed that the best model was ARIMA(3,1,0) × (0,1,1)12.

Fig. 1. The incidence/100 000 of tuberculosis from January 2007 to March 2016 in Jiangsu province, China.

Fig. 2. One-order trend difference and one-order seasonal difference of tuberculosis incidence (per 100 000 population).

Fig. 3. Autocorrelation function and partial autocorrelation function of tuberculosis incidence after the one-order trend difference and one-order seasonal difference.

Fig. 4. Autocorrelation function and partial autocorrelation function of the residual series of the ARIMA(3,1,0) × (0,1,1)12 model.
Table 1. Comparison of tested models

ARIMA, Autoregressive integrated moving average; AIC, Akaike's Information Criterion; BIC, Bayesian Information Criterion.
Table 2. Model estimation of the ARIMA(3,1,1)×(0,1,1)12 model

ARIMA, Autoregressive integrated moving average; CI, confidence interval; AR, autoregression; MA, moving average.
The hybrid model
The NAR model was selected for the prediction of TB incidence in Jiangsu province, China, because of its ability to represent nonlinear data and complex relationships. The residual series between February 2008 and March 2016 were used as the target series of the NAR model. After selecting input variables, developing the optimum NAR model requires determination of the lag, the number of neurons in the hidden layer, and the best training algorithm. Trial and error revealed that the optimum neurons in the hidden layers and the lag number were 12 and 4 based on the highest R values of training, validation, and testing data subsets of 0·9489, 0·5390, and 0·3439, respectively. The error autocorrelation function plot, which describes the relationship of the prediction errors and time, is shown in Figure 5. For a perfect prediction model, there should only be one nonzero value of the ACF, and it should occur at zero lag. This would mean that the prediction errors were completely uncorrelated with each other (white noise). In this study the correlations, except for the one at zero lag, of prediction errors fall within the 95% confidence limits around zero. Therefore, the model appears to be adequate [Reference Beale17]. Model performance and prediction comparison, between the forecast and measured TB incidence time series, is shown in Figure 6. The response of the network, outputs, and targets was observed with the help of plots where the observed (target) values were plotted with the model calculated (output) values against time. The errors obtained in the process were also plotted against time. The overall trend of TB incidence is well captured by the model, and the model has the ability to represent and mimic the targeted output. Furthermore, most of the estimation errors vs. time lay between −1 and 1. Therefore, we determined that we had chosen the appropriate model.

Fig. 5. The error autocorrelation plot.

Fig. 6. Time-series response plots of different target series of ARIMA-NAR model.
Comparison of the prediction accuracy by model
Fitting and predicting curves about the incidence values for January 2007–March 2016 forecast using the ARIMA model and ARIMA-NAR model are shown in Figure 7. It can be seen that both models are effective, but it is not obvious which model is best. To evaluate the quality of the proposed models, the MAE, MSE, and MAPE between the actual data and forecast data are chosen as the fitting and forecasting accuracy measures. As seen in Table 3, the ARIMA-NAR model's performance and forecasting for TB incidence provides more satisfactory results and better accuracy compared to the single ARIMA model. The MAE, MSE, and MAPE of the ARIMA-NAR model in the modelling stage are 0·2209 (percentage reductions, 41·84%), 0·1373 (percentage reductions, 40·59%), and 0·0406 (percentage reductions, 41·33%), lower than the ARIMA model, respectively. Regarding the forecasting stage, similar results are found.

Fig. 7. Graphical presentation of different forecasting methods.
Table 3. Comparison of the modeling and forecasting performance of ARIMA and ARIMA-NAR models

ARIMA, Autoregressive integrated moving average; NAR, nonlinear autoregressive; MAE, Mean absolute error; MSE, mean square error; MAPE, mean absolute percentage error.
In addition, the data from January to December 2016 are used as the forecasting set (Table 4). The absolute errors between actual values and predicted values fluctuate from 0·1254 to 0·3808 for the ARIMA model and 0·0021 to 0·3794 for the ARIMA-NAR model. The MAE of the ARIMA-NAR model is 0·1724, lower than the ARIMA model. Therefore the predicted values match the actual values well.
Table 4. Comparison of predicted values and actual values for the single ARIMA model and ARIMA-NAR model during April–October 2016 (per 100 000 population)

ARIMA, Autoregressive integrated moving average; NAR, nonlinear autoregressive; MAE, Mean absolute error.
DISCUSSION
In this study, we propose to take a combination approach to time-series forecasting. A hybrid model integrating ARIMA and NAR was constructed. The ARIMA-NAR hybrid model with nonlinear components has shown better performance compared to the single ARIMA model in forecasting TB incidence in Jiangsu province, China, owing to the MSE, MAE, and MAPE measures.
The TB data series from January 2007 to March 2016 in Jiangsu province showed large fluctuating trends over a 12-month cycle with strong seasonality, as shown in Figure 1. There is a sharp rise each year that generally occurs in March and April and a drop in winter. Time-series forecasting is an important area of forecasting in which past observations of the same variable are collected and analysed to develop a model describing the underlying relationship.
Research on the model forecasting incidence can detect the epidemic tendency of TB early, which can form the basis for an early warning of the disease. The prediction model can reveal the epidemic trend of TB clearly through assumptions, parameter estimation, and fitting inspection, and can provide a theoretical basis for the development of prevention strategies and measures. Time-series forecasting is an important area of forecasting in which various factors and comprehensive effects of uncertain variables are united into a time variable. A time series needs large amounts of historical data, and identifying the relationships between them is required to develop a model for forecasting future unknown values. This method has the advantages of low-cost data collection and wide practical application. The most commonly used models for time-series analysis are ARIMA models. The popularity of the ARIMA model is due to its statistical properties as well as the well-known Box–Jenkins methodology [Reference Box and Jenkins12] in the model building process. In this study, we obtained a multiplicative ARIMA model that can effectively extract the trend and seasonal components of time series, but the performances of modeling and forecasting were not satisfactory. As is well-known, TB is affected greatly by environmental and natural factors, for example, sunshine exposure, elevation, climate, and air pollution [Reference Koh18–Reference Tremblay21].
We assumed that nonlinear relationships may exist among monthly TB incidences and the ARIMA model cannot extract the full relationship efficiently. To make better predictions, an approach that uses ARIMA and ANN models together for time-series forecasts has been recommended in the present study. ANNs have a significant advantage compared to other classes of nonlinear models, in that they are universal approximators that can approximate a large class of functions with a high degree of accuracy [Reference Zhang22]. Furthermore, ANNs belong to flexible computing frameworks for modelling a broad range of nonlinear problems and can give more efficient results in forecasting problems compared to linear models. NAR, a dynamic recurrent network with feedback connections including several layers of the network, is a powerful class of models that can symbolize arbitrary nonlinear dynamical mappings and has favourable qualities for modelling dynamic systems and forecasting nonlinear time series [Reference Lin23]. In this study, the hybrid model integrated the ARIMA and NAR model, and was tested with raw seasonal data to forecast a seasonal time series. In this hybrid mechanism, the linear correlation structure of the time series is modelled by ARIMA, and then, the remaining residuals, which contain only the nonlinear part, are modelled by the NAR model. Moreover, this study compares the results obtained from the hybrid model with the forecast results from the single ARIMA model. It is found that the ARIMA-NAR hybrid model outperformed the single ARIMA mode in terms of overall proposed criteria, including MSE, MAE, and MAPE. In the present study, the MSE, MAE, and MAPE of the ARIMA-NAR model were lower than those of the single ARIMA model in the forecasting and modelling stages. The NAR model can learn to predict a simple time series given past values of the same time series. Some advantages of the NAR model with a gradient-descending learning algorithm have been reported: (1) learning is more efficient in NAR networks than in other neural networks and (2) the NAR model generalizes better and converges much faster than other networks [Reference Lin23]. Therefore, the experimental results suggested that the proposed ARIMA-NAR hybrid model, which can extract the linear and nonlinear components of TB incidence in Jiangsu province, China, is typically a reliable tool for forecasting similar problems.
CONCLUSIONS
In this paper, a new hybrid forecasting model is proposed by integrating an autoregressive integrated moving average (ARIMA) model and a nonlinear autoregressive network (NAR) for TB incidence time-series forecasting. The ARIMA and NAR models are used together, with the aim of capturing the component of the time-series data and the nonlinear component. The MSE, MAE, and MAPE were used as performance criteria to measure the goodness-of-fit of ARIMA and hybrid models. The experimental results showed that the ARIMA-NAR hybrid model is superior to the single ARIMA model in this inspection data series. It is believed that the prediction results and the comments presented in this paper will be helpful to policy makers in China for the prevention and control of TB.
ACKNOWLEDGEMENTS
We thank the Bureau of Health, Jiangsu province, China, and the Jiangsu Statistics Bureau. This study was supported by the young teachers’ startup fund for scientific research at Jiangnan University (JUSRP11569), the plan of public health research centre of Jiangnan University (JUPH201508) and the project of Wuxi science and technology supporting plan (WX0302-B010507-150016-PB).
DECLARATION OF INTEREST
None.











