


INTRODUCTION
The risk ratio or relative risk (RR) quantifies the risk in a study population (say, in those exposed to a risk factor) relative to a reference population. Naive inference assumes that the applied diagnostic procedure is perfect (its sensitivity and specificity is 100%), i.e. no misclassification occurs. Unfortunately, this assumption usually does not hold, and ignoring this may result in misleading conclusions. Our aim is to present an exact unconditional test and confidence interval for RR controlling for sensitivity and specificity of the diagnostic test.
We address the situation, in which
-
• risks are quantified by the proportion of those having the condition (disease, recovery, etc.), which is typical in cross-sectional epidemiological studies but may also occur in other study designs;
-
• two independent random samples are drawn from the two populations;
-
• there is no classification error in the group definition (i.e. in the exposure);
-
• sensitivity and specificity of the diagnostic procedure are known (rather than estimated in the same or in another study).
In this case RR is defined as the ratio of two proportions, RR = p 2/p 1, where p 2 is the proportion of diseased in the study group and p 1 is that in the reference group. Many authors use the term ‘prevalence ratio’ (PR) for this measure preserving the term ‘risk ratio’ for the incidence ratio [Reference Lee and Chia1–Reference Santos3], while others call it ‘prevalence risk ratio’ (PRR) [Reference Lui4, Reference Holmes and Opara5]. In the following text we will use the term risk ratio (RR). In cross-sectional studies and in therapeutic or vaccine trials with fixed-length follow-up this is the most natural measure to compare the groups. Guidelines for vaccine studies define vaccine efficacy as 1 − RR, where the reference group is placebo. Despite this, in many studies odds ratios (OR) are calculated just because logistic regression has become a standard analysis tool readily available in most statistical software systems, although using OR instead of RR is repeatedly criticized by statisticians [Reference Lee and Chia1, Reference Axelson, Fredriksson and Ekberg6–Reference Savu, Liu and Yasui8].
While the impact of misclassification on the results of statistical analyses has been studied since the 1950s in the biomedical as well as in the social sciences [Reference Bross9–Reference Jackson and Rothman16], no exact test or confidence interval for the true PR has been proposed. In the next section we describe the proposed procedures, then we present two applications, finally we summarize the properties of the method. R code for the procedures is available at www2.univet.hu/users/jreiczig/RR_SeSp.
METHODS
Let us denote for population i (i = 1, 2) the true prevalence by p
i
, the sensitivity by Se
i
, and the specificity by Sp
i
. Then the probability of a positive diagnosis (also called observed or apparent prevalence) in the ith population is p
ia
= p
i
·Se
i
+ (1 − p
i
)·(1 − Sp
i
). This implies that taking independent samples of sizes n
1 and n
2 from the two populations, the number of test positives x
1 and x
2 follow the binomial distribution with parameters n
1, p
1a
and n
2, p
2a
. Thus, the relative frequencies x
1/n
1 and x
2/n
2 are estimates of p
1a
and p
2a
, therefore we will denote them by
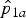 ${\hat p}_{1a}$
and
${\hat p}_{1a}$
and
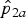 ${\hat p}_{2a}$
. What we will make use of in the following text is that the parameters p
1a
and p
2a
are in a one-to-one relationship with the true prevalences p
1 and p
2, i.e. a hypothesis about p
1 and p
2 can be mapped onto a corresponding hypothesis about p
1a
and p
2a
, and tested using their estimates
${\hat p}_{2a}$
. What we will make use of in the following text is that the parameters p
1a
and p
2a
are in a one-to-one relationship with the true prevalences p
1 and p
2, i.e. a hypothesis about p
1 and p
2 can be mapped onto a corresponding hypothesis about p
1a
and p
2a
, and tested using their estimates
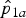 ${\hat p}_{1a}$
and
${\hat p}_{1a}$
and
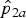 ${\hat p}_{2a}$
. The general equation, which describes the relationship between the parameters p
i
and p
ia
, and allows for Se
1≠Se
2 and/or Sp
1≠Sp
2 is
${\hat p}_{2a}$
. The general equation, which describes the relationship between the parameters p
i
and p
ia
, and allows for Se
1≠Se
2 and/or Sp
1≠Sp
2 is
 $$\eqalign{p_{2a} &= p_{1a}{\rm RR}\displaystyle{{(Se_2 + Sp_2 - 1)} \over {(Se_1 + Sp_1 - 1)}}\cr &\quad - {\rm RR} (1 - Sp_1)\displaystyle{{(Se_2 + Sp_2 - 1)} \over {(Se_1 + Sp_1 - 1)}} + (1 - Sp_2).}$$
$$\eqalign{p_{2a} &= p_{1a}{\rm RR}\displaystyle{{(Se_2 + Sp_2 - 1)} \over {(Se_1 + Sp_1 - 1)}}\cr &\quad - {\rm RR} (1 - Sp_1)\displaystyle{{(Se_2 + Sp_2 - 1)} \over {(Se_1 + Sp_1 - 1)}} + (1 - Sp_2).}$$
If Se 1 = Se 2 and Sp 1 = Sp 2, which can often be assumed in real-life applications, the equation simplifies to
 $$p_{2a} = p_{1a}{\rm RR} + \left( {1 - Sp} \right)\left( {1 - {\rm RR}} \right),$$
$$p_{2a} = p_{1a}{\rm RR} + \left( {1 - Sp} \right)\left( {1 - {\rm RR}} \right),$$
where Sp denotes the common specificity; and for a perfect diagnostic test, i.e. for Se 1 = Se 2 = Sp 1 = Sp 2 = 1, it reduces to
 $$p_{2a} = p_{1a}{\rm RR}.$$
$$p_{2a} = p_{1a}{\rm RR}.$$
Solving the equations (1)–(3) for RR, the following expressions are obtained:
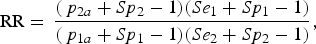 $${\rm RR} = \,\displaystyle{{(\,p_{2a} + Sp_2 - 1)(Se_1 + Sp_1 - 1)} \over {(\,p_{1a} + Sp_1 - 1)(Se_2 + Sp_2 - 1)}},$$
$${\rm RR} = \,\displaystyle{{(\,p_{2a} + Sp_2 - 1)(Se_1 + Sp_1 - 1)} \over {(\,p_{1a} + Sp_1 - 1)(Se_2 + Sp_2 - 1)}},$$
 $${\rm RR} = \left( {p_{2a} + Sp - 1} \right)/\left( {p_{1a} + Sp - 1} \right),$$
$${\rm RR} = \left( {p_{2a} + Sp - 1} \right)/\left( {p_{1a} + Sp - 1} \right),$$
 $${\rm RR} = p_{2a}/p_{1a}.$$
$${\rm RR} = p_{2a}/p_{1a}.$$
The point estimates for RR can be obtained by replacing p
1a
and p
2a
by
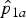 ${\hat p}_{1a}$
and
${\hat p}_{1a}$
and
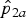 ${\hat p}_{2a}$
in equations (4)–(6). Note that the parameter space for the true prevalences (p
1, p
2) is the unit square, whereas that for (p
1a
, p
2a
) is a rectangle within the unit square, namely [1 − Sp
1, Se
1] × [1 − Sp
2, Se
2]. Note also that the estimates (
${\hat p}_{2a}$
in equations (4)–(6). Note that the parameter space for the true prevalences (p
1, p
2) is the unit square, whereas that for (p
1a
, p
2a
) is a rectangle within the unit square, namely [1 − Sp
1, Se
1] × [1 − Sp
2, Se
2]. Note also that the estimates (
 ${\hat p}_{1a}$
,
${\hat p}_{1a}$
,
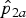 ${\hat p}_{2a}$
) form a point in the sample space (which is actually a grid of points), rather than in the parameter space. In formula
${\hat p}_{2a}$
) form a point in the sample space (which is actually a grid of points), rather than in the parameter space. In formula
 $$({\hat p}_{1a},\,{\hat p}_{2a})\, \in \,\left\{ {0, 1/n_1, 2/n_1, \ldots, 1} \right\} \times \left\{ {0, 1/n_2, 2/n_2, \ldots, 1} \right\}.$$
$$({\hat p}_{1a},\,{\hat p}_{2a})\, \in \,\left\{ {0, 1/n_1, 2/n_1, \ldots, 1} \right\} \times \left\{ {0, 1/n_2, 2/n_2, \ldots, 1} \right\}.$$
Assume now that we want to test for H 0: RR = RR0, where RR = p 2/p 1 is the true risk ratio. This H 0 is a composite hypothesis, corresponding to a line segment in the parameter space of the true prevalences p 1 and p 2, namely the set of points in the unit square satisfying the equation p 2 = p 1RR0. If we map this onto the parameter space of the observed binomials p 1a and p 2a , it will form another line segment. Its position depends on RR0 as well as on the sensitivities and specificities according to equations (1)–(3), but it is always located within the rectangle [1 − Sp 1, Se 1] × [1 − Sp 2, Se 2]. Figure 1 illustrates the position of this line segment for H 0: RR = 2 depending on the sensitivities Se 1, Se 2, and specificities Sp 1, Sp 2.

Fig. 1. Lines corresponding to the hypothesis H 0: RR = 2 in the two-dimensional space of the parameters p 1a and p 2a of the observed binomial variables. The position of the line depends on sensitivity (Se 1 and Se 2) and specificity (Sp 1 and Sp 2) of the test in the two populations.
Testing for H 0 is equivalent to testing whether the parameters p 1a and p 2a of the observed independent binomial variables are located on the line segment corresponding to H 0. As this is also a composite hypothesis, it can be tested applying the intersection-union principle [Reference Casella and Berger17], which means that a critical (or rejection) region for a composite H 0 can be obtained by constructing an appropriate critical region for each element of H 0, and taking the intersection of these regions. The steps of constructing this critical region follow the logic of Reiczigel et al. [Reference Reiczigel, Abonyi-Tóth and Singer18].
-
(1) For each simple hypothesis h 0 ∈ H 0, i.e. for each point (p 1a , p 2a ) on the line segment representing H 0, we construct a critical region (rejection region) C h0 in the sample space, consisting of those points, which have probability under h 0 less than or equal to the probability of the observed point (
 ${\hat p}_{1a}$
,
${\hat p}_{2a}$
). In formula
where P h0() denotes the probability of a point (or a set of points) in the sample space, given h 0 is true. C h0 can be considered as the two-dimensional generalization of that proposed by Sterne [Reference Sterne19] for a single binomial proportion. Let P h0(C h0) denote the probability of C h0 under h 0, and let M = max{P h0(C h0), h 0 ∈ H 0}.
$$\eqalign{C_{h0} =\,& \{ \left( {i/n_1,j/n_2} \right)\!\!:i \in \left\{ {0, \ldots, n_1} \right\},j \in \cr & \left\{ {0, \ldots, n_2} \right\},P_{h0} \left( {i/n_1,j/n_2} \right)\, \les \,P_{h0} ({\hat p}_{1a},\,{\hat p}_{2a})\},}$$
${\hat p}_{1a}$
,
${\hat p}_{2a}$
). In formula
where P h0() denotes the probability of a point (or a set of points) in the sample space, given h 0 is true. C h0 can be considered as the two-dimensional generalization of that proposed by Sterne [Reference Sterne19] for a single binomial proportion. Let P h0(C h0) denote the probability of C h0 under h 0, and let M = max{P h0(C h0), h 0 ∈ H 0}.
$$\eqalign{C_{h0} =\,& \{ \left( {i/n_1,j/n_2} \right)\!\!:i \in \left\{ {0, \ldots, n_1} \right\},j \in \cr & \left\{ {0, \ldots, n_2} \right\},P_{h0} \left( {i/n_1,j/n_2} \right)\, \les \,P_{h0} ({\hat p}_{1a},\,{\hat p}_{2a})\},}$$
-
(2) Next, for each h 0 ∈ H 0 we determine the subset S h0 of the sample space consisting of the points with the smallest probability under h 0 so that P h0(S h0)⩽M but adding any further point to S h0 would result in P h0(S h0) > M. Let C H0 denote the intersection of all these subsets, i.e.
$C_{H0}=$
$\cap _{h_0 \in H_0}S_{h0}$
. It is easy to see that C
H0 contains (
${\hat p}_{1a}$
,
${\hat p}_{2a}$
) on its boundary. -
(3) Finally, the P value is defined as the highest probability of C H0 under H 0 (i.e. for all simple hypotheses h 0 in H 0). In formula, the P value is equal to max{P h0(C H0), h 0 ∈ H 0}.
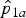


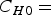
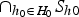
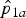
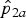
Figure 2 illustrates how the resulting critical region for H
0: RR = 2 depends on sensitivities and specificities, given the two observed prevalences are
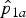 ${\hat p}_{1a}$
= 0·575 (n
1 = 40) and
${\hat p}_{1a}$
= 0·575 (n
1 = 40) and
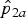 ${\hat p}_{2a}$
= 0·667 (n
2 = 36).
${\hat p}_{2a}$
= 0·667 (n
2 = 36).

Fig. 2. Critical regions in the sample space for H
0: RR = 2 with observed proportions
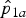 ${\hat p}_{1a}$
= 0·575 (n
1 = 40) and
${\hat p}_{1a}$
= 0·575 (n
1 = 40) and
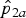 ${\hat p}_{2a}$
= 0·667 (n
2 = 36), depending on the sensitivities and specificities. Black dots form the critical region, the black square represents the observed data. The line shows the location of H
0 in the parameter space.
${\hat p}_{2a}$
= 0·667 (n
2 = 36), depending on the sensitivities and specificities. Black dots form the critical region, the black square represents the observed data. The line shows the location of H
0 in the parameter space.
Confidence intervals for the true RR can be constructed by inverting the above test. That is, lower and upper confidence limits to a given confidence level (1 − α) are defined as the smallest and largest true RR0 not rejected by the test, i.e.
 $$L = {\rm inf}\{ {{\rm RR}_0}\!\!:p_{{\rm RR}_0} \gt \alpha\} \,{\rm and}\,U = {\rm sup}\{ {{\rm RR}_0}\!\!:p_{{\rm RR}_0} \gt \alpha\}, $$
$$L = {\rm inf}\{ {{\rm RR}_0}\!\!:p_{{\rm RR}_0} \gt \alpha\} \,{\rm and}\,U = {\rm sup}\{ {{\rm RR}_0}\!\!:p_{{\rm RR}_0} \gt \alpha\}, $$
where p
RR0
denotes the P value from testing for H
0: RR = RR0. Computationally, L and U are determined by increasing RR0 in small steps and performing the test. Step size may depend on the required precision. In our implementation of the algorithm the default is a multiplicative increment with step size 0·001, i.e. RR0 is increased or decreased as RR0,next = 1·001*RR0 or 0·999*RR
0. Figure 3 illustrates the procedure for observed proportions
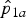 ${\hat p}_{1a}$
= 0·575 (n
1
= 40),
${\hat p}_{1a}$
= 0·575 (n
1
= 40),
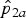 ${\hat p}_{2a}$
= 0·667 (n
2
= 36), and Se
1 = Se
2 = 0·91, Sp
1 = Sp
2 = 0·8.
${\hat p}_{2a}$
= 0·667 (n
2
= 36), and Se
1 = Se
2 = 0·91, Sp
1 = Sp
2 = 0·8.

Fig. 3. Illustration of the confidence interval construction for observed proportions
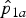 ${\hat p}_{1a}$
= 0·575 (n
1 = 40),
${\hat p}_{1a}$
= 0·575 (n
1 = 40),
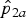 ${\hat p}_{2a}$
= 0·667 (n
2 = 36), and Se
1 = Se
2 = 0·91, Sp
1 = Sp
2 = 0·8. The confidence limits represent the smallest and largest true risk ratio (RR) not rejected by the test.
${\hat p}_{2a}$
= 0·667 (n
2 = 36), and Se
1 = Se
2 = 0·91, Sp
1 = Sp
2 = 0·8. The confidence limits represent the smallest and largest true risk ratio (RR) not rejected by the test.
One-tailed testing, i.e. H 0: RR = RR0 against H 1: RR > RR0 (or H 1: RR < RR0) is also possible, although there are different options to define this. Perhaps the simplest method is that one side of the line representing H 0 (i.e. the intersection of the critical region with that half-plane) is removed from the critical region. One-sided confidence intervals (CI) can be derived by inverting this one-sided test.
APPLICATIONS
Example 1
Everhart et al. [Reference Everhart20] studied the seroprevalence of Helicobacter pylori infection in adults in the United States. The analysis was carried out stratified by age and ethnic group. The infection status was determined by an IgG ELISA assay having 91% sensitivity and 96% specificity in all groups. For illustration we now compare the group of the youngest (20–29 years) and the oldest (⩾70 years), in which the observed seroprevalence was 16·7% and 56·9%, respectively. For these groups, the ratio of observed prevalences is 56·9/16·7 = 3·41 (95% CI 3·00–3·88), whereas the correction for sensitivity and specificity results in the true PR of 4·17 (95% CI 3·58–4·96).
Example 2
Suwancharoen et al. [Reference Suwancharoen21] conducted a serological survey of leptospirosis in livestock in Thailand using the microscopic agglutination test (MAT) to determine serostatus of the examined animals. Five animal species were included in the study: cattle, buffaloes, pigs, sheep and goats. Infection status of each species was measured by seroprevalence, and all other species were compared to cattle as the reference group by calculating the PRs (which are same as risk ratios). In this study the MAT test was assumed to be perfect, as this test is usually regarded to be the gold standard test. However, other studies found that the sensitivity of the MAT test is far below 100% [Reference Cumberland, Everard and Levett22–Reference Limmathurotsakul25]. Cumberland et al. [Reference Cumberland, Everard and Levett22] found the sensitivity to be 30% for first acute-phase specimens, 63% for second acute-phase specimens, and 76% for convalescent specimens. At the same time specificity was 99%, 98%, and 97%, respectively. Limmathurotsakul et al. [Reference Limmathurotsakul25] estimated the sensitivity of MAT by a Bayesian analysis and found it to be 49·8%. These findings indicate the need for an adjustment of the PR estimates.
If we consider the most optimistic scenario of these, i.e. Se = 76% and Sp = 97% [Reference Cumberland, Everard and Levett22], we obtain the adjusted PRs shown in Table 1. The difference between the unadjusted and adjusted PR is far from negligible, for example in case of sheep the adjusted ratio is less than half of the unadjusted one. In case of buffaloes, adjusted and unadjusted 95% CIs do not even overlap.
Table 1. Prevalence ratios reported in Suwancharoen et al. [ Reference Suwancharoen21 ] and adjusted prevalence ratios assuming sensitivity = 0·76 and specificity = 0·97 (same in all groups), as reported by Cumberland et al. [ Reference Cumberland, Everard and Levett22 ]

PR, Prevalence ratio; CI, confidence interval.
DISCUSSION
If sensitivity and/or specificity of the diagnostic test is <100%, the observed and true prevalence may differ from each other, influencing also estimation and testing of relative risk measured by the PR. We proposed an exact unconditional test and CIs for the true PR. The method can be applied even if the sensitivities and specificities differ in the two groups, for example if patients are diagnosed by different methods or some sort of differential misclassification occurs.
Taking sensitivity and specificity into account may either increase or decrease the P value compared to the one obtained without considering sensitivity and specificity. For instance, consider testing for H
0: RR = 2 with observed prevalences
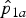 ${\hat p}_{1a}$
= 0·48 (n
1 = 50) and
${\hat p}_{1a}$
= 0·48 (n
1 = 50) and
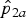 ${\hat p}_{2a}$
= 0·62 (n
2 = 50). Assuming Se
1 = Se
2 = Sp
1 = Sp
2 = 1 results in P = 0·0251, for Se
1 = Se
2 = 0·8 and Sp
1 = Sp
2 = 1 the P value increases to P = 0·0474, whereas for Se
1 = Se
2 = 0·6 and Sp
1 = Sp
2 = 1 a smaller P value of 0·0155 is obtained.
${\hat p}_{2a}$
= 0·62 (n
2 = 50). Assuming Se
1 = Se
2 = Sp
1 = Sp
2 = 1 results in P = 0·0251, for Se
1 = Se
2 = 0·8 and Sp
1 = Sp
2 = 1 the P value increases to P = 0·0474, whereas for Se
1 = Se
2 = 0·6 and Sp
1 = Sp
2 = 1 a smaller P value of 0·0155 is obtained.
It may occur that the observed data contradict the given sensitivity and specificity. Let us assume, for example, that a certain diagnostic test is known to have Se = 0·8 and Sp = 1 and using this test we observe 90 positives out of 100. This observation is very unlikely even if the true prevalence is 100%, since under these conditions the observed variable has a binomial distribution with n = 100, P = 0·8, and the probability that it is ⩾90 is as low as 0·0057. The same problem may arise if the number of positives is much less than the expected minimum assuming the given sensitivity and specificity. In such cases one should consider the possibility that sensitivity and/or specificity data are incorrect.
The proposed method can be further developed in several directions. First, one can take into account misclassification also in the group definition, i.e. in the exposure. Brenner et al. [Reference Brenner, Savitz and Gefeller26] investigated this for the incidence ratio in a cohort study. Going further, similar methods could be worked out for models with several predictors, of which the categorical ones may also be affected by misclassification. Some results are known on correcting the OR obtained from logistic regression [Reference Magder and Hughes27, Reference Cheng and Hsueh28] but similar results still lack for the PR.
There has been a long debate whether the PR or the OR is more appropriate to quantify the risk in the study group relative to the control group in a study design in which both of them can be calculated [Reference Lee and Chia1, Reference Nurminen7, Reference Pearce29, Reference Reichenheim and Coutinho30]. Savu et al. [Reference Savu, Liu and Yasui8] stated that RR or PR is more intuitively interpretable than the OR. In spite of this, many studies report OR estimates, even if the design permits calculation of RR or PR. Petersen & Deddens [Reference Petersen and Deddens31] emphasized that in cross-sectional studies, in particular when the disease is not rare, it is preferable to use PR instead of OR. Anyway, it is worth noting that our method can quite easily be adapted to testing the OR or the risk difference (RD), as the hypotheses H 0: OR = OR0 and H 0: RD = RD0 also correspond to a subset of the parameter space [0,1] × [0,1].
Another direction of potential improvement of the proposed methods is to extend them to the case when sensitivity and specificity are not taken as known but estimated from other samples, which may increase the variance of the RR estimate. This is analogous to the problem solved by Lang & Reiczigel [Reference Lang and Reiczigel32] for estimating prevalence.
ACKNOWLEDGEMENTS
This work was supported by the Hungarian National Research Fund (grant no. OTKA K108571) and by the Research Faculty Grant 2015 of the Szent István University, Faculty of Veterinary Science.
DECLARATION OF INTEREST
None.




