



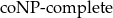
1 Introduction
Data exchange is the problem of transferring data from a source schema to a target schema, where the transfer process is usually described via so-called schema mappings: a set of logical assertions specifying how the data should be moved and restructured. Furthermore, the target schema may have its own constraints to be satisfied. Schema mappings and target constraints are usually encoded via standard database dependencies: tuple-generating dependencies (TGDs) and equality-generating dependencies (EGDs). Thus, given an instance I over the source schema
 $\mathsf{S}$
, the goal is to materialize an instance J over the target schema
$\mathsf{S}$
, the goal is to materialize an instance J over the target schema
 $\mathsf{T}$
, called solution, in such a way that I and J together satisfy the dependencies.
$\mathsf{T}$
, called solution, in such a way that I and J together satisfy the dependencies.
Since multiple solutions might exist, a precise semantics for answering queries is needed. By now, the certain answers semantics is the most accepted one. The certain answers to a query is the set of all tuples that are answers to the query in every solution of the data exchange setting (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005).Although it has been formally shown that for positive queries (e.g., conjunctive queries) the notion of solution of of (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005) is the right one to use, for more general queries such solutions become inappropriate, as they easily lead to counterintuitive results.
Example 1 Consider a data exchange setting denoted by
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S}$
is the source schema, storing product orders in a binary relation
$\mathsf{S}$
is the source schema, storing product orders in a binary relation
 $\mathsf{Ord}$
, with the first argument being the id of an order, and the second argument specifying whether the order has been paid. Moreover,
$\mathsf{Ord}$
, with the first argument being the id of an order, and the second argument specifying whether the order has been paid. Moreover,
 $\mathsf{T}$
is the target schema having unary relations
$\mathsf{T}$
is the target schema having unary relations
 $\mathsf{AllOrd}$
and
$\mathsf{AllOrd}$
and
 $\mathsf{Paid}$
, storing all orders and the paid orders, respectively. The schema mapping is described by the following source-to-target TGDs
$\mathsf{Paid}$
, storing all orders and the paid orders, respectively. The schema mapping is described by the following source-to-target TGDs
 $\Sigma_{st}$
:
$\Sigma_{st}$
:
 \[ \begin{array}{llllll} \rho_1 = & \forall x,y & \mathsf{Ord}(x,y) \rightarrow \mathsf{AllOrd}(x),\qquad \rho_2 = & \forall x & \mathsf{Ord}(x,\mathsf{yes}) \rightarrow \mathsf{Paid}(x). \end{array} \]
\[ \begin{array}{llllll} \rho_1 = & \forall x,y & \mathsf{Ord}(x,y) \rightarrow \mathsf{AllOrd}(x),\qquad \rho_2 = & \forall x & \mathsf{Ord}(x,\mathsf{yes}) \rightarrow \mathsf{Paid}(x). \end{array} \]
In this example, we assume that the set of target dependencies
 $\Sigma_t$
is empty. The above schema mapping states that all orders in the source schema must be copied to the
$\Sigma_t$
is empty. The above schema mapping states that all orders in the source schema must be copied to the
 $\mathsf{AllOrd}$
relation, and all the paid orders must be copied to the
$\mathsf{AllOrd}$
relation, and all the paid orders must be copied to the
 $\mathsf{Paid}$
relation. Assume the source instance is as follows:
$\mathsf{Paid}$
relation. Assume the source instance is as follows:
 $$I=\{\mathsf{Ord}(1,\mathsf{yes}),\mathsf{Ord}(2,\mathsf{no})\},$$
$$I=\{\mathsf{Ord}(1,\mathsf{yes}),\mathsf{Ord}(2,\mathsf{no})\},$$
and assume we want to pose the query Q over the target schema asking for all the unpaid orders. This can be written as the following first-order (FO) query:
 $$ Q(x) = \mathsf{AllOrd}(x) \wedge \neg \mathsf{Paid}(x).$$
$$ Q(x) = \mathsf{AllOrd}(x) \wedge \neg \mathsf{Paid}(x).$$
One would expect the answer to be
 $\{2\}$
, since the schema mapping above is simply copying I to the target schema, and hence
$\{2\}$
, since the schema mapping above is simply copying I to the target schema, and hence
 $J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1)\}$
should be the only candidate solution. However, under the classical notion of solution of (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005), also the instance
$J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1)\}$
should be the only candidate solution. However, under the classical notion of solution of (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005), also the instance
 $J' = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1),\mathsf{Paid}(2)\}$
is a solution (since
$J' = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1),\mathsf{Paid}(2)\}$
is a solution (since
 $I \cup J'$
satisfies the TGDs), and every order in J’ is paid. Hence, the certain answers to Q, which are computed as the intersection of the answers over all solutions, are empty.
$I \cup J'$
satisfies the TGDs), and every order in J’ is paid. Hence, the certain answers to Q, which are computed as the intersection of the answers over all solutions, are empty.
The issue above arises because the classical notion of solution is too permissive, in that it allows the existence of facts in a solution that have no support from the source (e.g.,
 $\mathsf{Paid}(2)$
in the solution J’ of Example 1 above).
$\mathsf{Paid}(2)$
in the solution J’ of Example 1 above).
Some efforts exist in the literature that provide alternative notions of solutions for which certain answers to general queries become more meaningful. Prime examples are the works of (Hernich et al. Reference Hernich, Libkin and Schweikardt2011) and (Hernich Reference Hernich2011). In both approaches, the certain answers in the example above are
 $\{2\}$
. However, the works above have their own drawbacks too. In (Hernich et al. Reference Hernich, Libkin and Schweikardt2011), so-called CWA-solutions are introduced, which are a subset of the classical solutions with some restrictions. However, these restrictions are so severe that certain answers over such solutions fail to capture certain answers over classical solutions, when focusing on positive queries. Moreover, even when focusing on more general queries, answers can still be counterintuitive, as shown in the following example.
$\{2\}$
. However, the works above have their own drawbacks too. In (Hernich et al. Reference Hernich, Libkin and Schweikardt2011), so-called CWA-solutions are introduced, which are a subset of the classical solutions with some restrictions. However, these restrictions are so severe that certain answers over such solutions fail to capture certain answers over classical solutions, when focusing on positive queries. Moreover, even when focusing on more general queries, answers can still be counterintuitive, as shown in the following example.
Example 2 Consider the data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S}$
stores employees of a company in the unary relation
$\mathsf{S}$
stores employees of a company in the unary relation
 $\mathsf{Emp}$
. For some employees, the city they live in is known, and it is stored in the binary relation
$\mathsf{Emp}$
. For some employees, the city they live in is known, and it is stored in the binary relation
 $\mathsf{KnownC}$
. The target schema
$\mathsf{KnownC}$
. The target schema
 $\mathsf{T}$
contains the binary relation
$\mathsf{T}$
contains the binary relation
 $\mathsf{EmpC}$
, storing employees and the cities they live in, and the binary relation
$\mathsf{EmpC}$
, storing employees and the cities they live in, and the binary relation
 $\mathsf{SameC}$
, storing pairs of employees living in the same city. The sets
$\mathsf{SameC}$
, storing pairs of employees living in the same city. The sets
 $\Sigma_{st} = \{\rho_1,\rho_2\}$
and
$\Sigma_{st} = \{\rho_1,\rho_2\}$
and
 $\Sigma_t = \{\rho_3,\eta\}$
are as follows (for simplicity, we omit the universal quantifiers):
$\Sigma_t = \{\rho_3,\eta\}$
are as follows (for simplicity, we omit the universal quantifiers):
 \[ \begin{array}{l} \rho_1 = \mathsf{Emp}(x) \rightarrow \exists z\, \mathsf{EmpC}(x,z), \\ \rho_2 = \mathsf{KnownC}(x,y) \rightarrow \mathsf{EmpC}(x,y), \\ \rho_3 = \mathsf{EmpC}(x,y),\ \mathsf{EmpC}(x',y) \rightarrow \mathsf{SameC}(x,x'), \\ \eta\ = \mathsf{EmpC}(x,y),\ \mathsf{EmpC}(x,z) \rightarrow y=z.\\ \end{array} \]
\[ \begin{array}{l} \rho_1 = \mathsf{Emp}(x) \rightarrow \exists z\, \mathsf{EmpC}(x,z), \\ \rho_2 = \mathsf{KnownC}(x,y) \rightarrow \mathsf{EmpC}(x,y), \\ \rho_3 = \mathsf{EmpC}(x,y),\ \mathsf{EmpC}(x',y) \rightarrow \mathsf{SameC}(x,x'), \\ \eta\ = \mathsf{EmpC}(x,y),\ \mathsf{EmpC}(x,z) \rightarrow y=z.\\ \end{array} \]
The above setting copies employees from the source to the target. The TGD
 $\rho_1$
states that every copied employee x must have some city z associated, whereas
$\rho_1$
states that every copied employee x must have some city z associated, whereas
 $\rho_2$
states that when the city y of an employee x is known, this should be copied as well. Moreover, the target schema requires that employees living in the same city should be stored in relation
$\rho_2$
states that when the city y of an employee x is known, this should be copied as well. Moreover, the target schema requires that employees living in the same city should be stored in relation
 $\mathsf{SameC}$
(
$\mathsf{SameC}$
(
 $\rho_3$
), and each employee must live in only one city (
$\rho_3$
), and each employee must live in only one city (
 $\eta$
). Assume the source instance is
$\eta$
). Assume the source instance is
 $$I = \{\mathsf{Emp}(\mathsf{john}), \mathsf{Emp}(\mathsf{mary}),\mathsf{KnownC}(\mathsf{\mathsf{john}},\mathsf{miami})\},$$
$$I = \{\mathsf{Emp}(\mathsf{john}), \mathsf{Emp}(\mathsf{mary}),\mathsf{KnownC}(\mathsf{\mathsf{john}},\mathsf{miami})\},$$
and consider the query Q that asks for all pairs of employees living in different cities. This can be written as:
 $$ Q(x,x') = \exists y \exists y'\, \mathsf{EmpC}(x,y) \wedge \mathsf{EmpC}(x',y') \wedge \neg \mathsf{SameC}(x,x').$$
$$ Q(x,x') = \exists y \exists y'\, \mathsf{EmpC}(x,y) \wedge \mathsf{EmpC}(x',y') \wedge \neg \mathsf{SameC}(x,x').$$
One would expect that the set of certain answers to Q is empty, since it is not certain that
 $\mathsf{john}$
and
$\mathsf{john}$
and
 $\mathsf{mary}$
live in different cities. However, no CWA-solution admits
$\mathsf{mary}$
live in different cities. However, no CWA-solution admits
 $\mathsf{mary}$
and
$\mathsf{mary}$
and
 $\mathsf{john}$
to live in the same city, and thus
$\mathsf{john}$
to live in the same city, and thus
 $(\mathsf{\mathsf{john}},\mathsf{mary})$
is a certain answer under the CWA-solution-based semantics.
$(\mathsf{\mathsf{john}},\mathsf{mary})$
is a certain answer under the CWA-solution-based semantics.
The approach of (Hernich Reference Hernich2011), where the notion of GCWA
 $^*$
-solution is presented, seems to be the most promising one. For positive queries, certain answers w.r.t. GCWA
$^*$
-solution is presented, seems to be the most promising one. For positive queries, certain answers w.r.t. GCWA
 $^*$
-solutions coincide with certain answers w.r.t. classical solutions. Moreover, GCWA
$^*$
-solutions coincide with certain answers w.r.t. classical solutions. Moreover, GCWA
 $^*$
-solutions solve some other limitations of CWA-solutions, like the one discussed in Example 2. However, the practical applicability of this semantics is somehow limited, since the (rather involved) construction of GCWA
$^*$
-solutions solve some other limitations of CWA-solutions, like the one discussed in Example 2. However, the practical applicability of this semantics is somehow limited, since the (rather involved) construction of GCWA
 $^*$
-solutions easily makes certain query answering undecidable, even for very simple settings with only two source-to-target TGDs, and no target dependencies.
$^*$
-solutions easily makes certain query answering undecidable, even for very simple settings with only two source-to-target TGDs, and no target dependencies.
Other semantics have been proposed in (Libkin and Sirangelo Reference Libkin and Sirangelo2011), but they are only defined for data exchange settings without target dependencies. Hence, one needs to assume that the target schema has no dependencies at all.
As a final remark, in a data exchange setting, it might be the case that the source is not always available, and thus the materialization of a single solution, over which certain answers can be computed, is a desirable requirement. This is especially true when using weakly-acyclic dependencies, which form the standard language for data exchange (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). However, none of the semantics above allow for the materialization of such a special solution, for weakly-acyclic settings.
In this paper, we propose a new notion of data exchange solution, dubbed supported solution, which allows us to deal with general queries, but at the same time is suitable for practical applications. That is, we show that certain answers under supported solutions naturally generalize certain answers under classical solutions, when focusing on positive queries. Moreover, such solutions do not make any assumption on how values associated to existential variables compare to other values, hence solving issues like the ones of Example 2.
As expected, there is a price to pay to get meaningful answers over general queries: we show that certain answering is undecidable for general settings, but it becomes
 $\text{co}\text{NP}\text{-complete}$
when we focus on weakly-acyclic dependencies.
$\text{co}\text{NP}\text{-complete}$
when we focus on weakly-acyclic dependencies.
Moreover, we show that exact answers under supported solutions for general queries in weakly-acyclic settings can be computed via an encoding into logic programming with the well-known choice construct, allowing one to use efficient off-the-shelf reasoning systems.
Finally, we also show that if one is not willing to incur the high complexity of exact certain answers for weakly-acyclic settings, then it is possible to construct a target instance in polynomial time, which is similar in spirit to a universal solution of (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005), that can be exploited for computing exact answers, for positive queries, and approximate answers, for general FO queries, in polynomial time. The latter is achieved by adapting existing approximation algorithms originally defined for querying incomplete databases.
2 Preliminaries
Basics. We consider pairwise disjoint countably infinite sets
 $\mathsf{Const}$
,
$\mathsf{Const}$
,
 $\mathsf{Var}$
, and
$\mathsf{Var}$
, and
 $\mathsf{Null}$
of constants, variables, and labeled nulls, respectively. Nulls are denoted by the symbol
$\mathsf{Null}$
of constants, variables, and labeled nulls, respectively. Nulls are denoted by the symbol
 ${\perp}$
, possibly subscripted. A term is a constant, a variable, or a null. We additionally assume the existence of a countably infinite set
${\perp}$
, possibly subscripted. A term is a constant, a variable, or a null. We additionally assume the existence of a countably infinite set
 $\mathsf{Rel}$
of relations, disjoint from the previous ones. A relation R has an arity, denoted ar(R), which is a non-negative integer. We also use
$\mathsf{Rel}$
of relations, disjoint from the previous ones. A relation R has an arity, denoted ar(R), which is a non-negative integer. We also use
 $R/n$
to say that R is a relation of arity n. A schema is a set of relations. A position is an expression of the form R[i], where R is a relation and
$R/n$
to say that R is a relation of arity n. A schema is a set of relations. A position is an expression of the form R[i], where R is a relation and
 $i \in \{1,\ldots,ar(R)\}$
.
$i \in \{1,\ldots,ar(R)\}$
.
An atom
 $\alpha$
(over a schema
$\alpha$
(over a schema
 $\mathsf{S}$
) is of the form
$\mathsf{S}$
) is of the form
 $R(\mathbf{t})$
, where R is an n-ary relation (of
$R(\mathbf{t})$
, where R is an n-ary relation (of
 $\mathsf{S}$
) and
$\mathsf{S}$
) and
 $\mathbf{t}$
is a tuple of terms of length n. We use
$\mathbf{t}$
is a tuple of terms of length n. We use
 $\mathbf{t}[i]$
to denote the i-th term in
$\mathbf{t}[i]$
to denote the i-th term in
 $\mathbf{t}$
, for
$\mathbf{t}$
, for
 $i \in \{1,\ldots,n\}$
. An atom without variables is a fact. An instance I (over a schema
$i \in \{1,\ldots,n\}$
. An atom without variables is a fact. An instance I (over a schema
 $\mathsf{S}$
) is a finite set of facts (over
$\mathsf{S}$
) is a finite set of facts (over
 $\mathsf{S}$
). A database D is an instance without nulls. For a set of atoms A,
$\mathsf{S}$
). A database D is an instance without nulls. For a set of atoms A,
 $\mathsf{dom}(A)$
is the set of all terms in A, whereas
$\mathsf{dom}(A)$
is the set of all terms in A, whereas
 $\mathsf{var}(A)$
is the set
$\mathsf{var}(A)$
is the set
 $\mathsf{dom}(A) \cap \mathsf{Var}$
. A homomorphism from a set of atoms A to a set of atoms B is a function
$\mathsf{dom}(A) \cap \mathsf{Var}$
. A homomorphism from a set of atoms A to a set of atoms B is a function
 $h : \mathsf{dom}(A) \rightarrow \mathsf{dom}(B)$
that is the identity on
$h : \mathsf{dom}(A) \rightarrow \mathsf{dom}(B)$
that is the identity on
 $\mathsf{Const}$
, and such that for each atom
$\mathsf{Const}$
, and such that for each atom
 $R(\mathbf{t}) = R(t_1,\ldots,t_n) \in A$
,
$R(\mathbf{t}) = R(t_1,\ldots,t_n) \in A$
,
 $R(h(\mathbf{t}))=R(h(t_1),\ldots,h(t_n)) \in B$
.
$R(h(\mathbf{t}))=R(h(t_1),\ldots,h(t_n)) \in B$
.
Dependencies. A TGD
 $\rho$
(over a schema
$\rho$
(over a schema
 $\mathsf{S}$
) is a FO formula of the form
$\mathsf{S}$
) is a FO formula of the form
 $\forall {\textbf {x}},{\textbf {y}}\, \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, where
$\forall {\textbf {x}},{\textbf {y}}\, \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, where
 ${\textbf {x}},{\textbf {y}},{\textbf {z}}$
are disjoint tuples of variables, and
${\textbf {x}},{\textbf {y}},{\textbf {z}}$
are disjoint tuples of variables, and
 $\varphi$
and
$\varphi$
and
 $\psi$
are conjunctions of atoms (over
$\psi$
are conjunctions of atoms (over
 $\mathsf{S}$
) without nulls, and over the variables in
$\mathsf{S}$
) without nulls, and over the variables in
 ${\textbf {x}},{\textbf {y}}$
and
${\textbf {x}},{\textbf {y}}$
and
 ${\textbf {y}},{\textbf {z}}$
, respectively. The body of
${\textbf {y}},{\textbf {z}}$
, respectively. The body of
 $\rho$
, denoted
$\rho$
, denoted
 $\mathsf{body}(\rho)$
, is
$\mathsf{body}(\rho)$
, is
 $\varphi({\textbf {x}},{\textbf {y}})$
, whereas the head of
$\varphi({\textbf {x}},{\textbf {y}})$
, whereas the head of
 $\rho$
, denoted
$\rho$
, denoted
 $\mathsf{head}(\rho)$
, is
$\mathsf{head}(\rho)$
, is
 $\psi({\textbf {y}},{\textbf {z}})$
. We use
$\psi({\textbf {y}},{\textbf {z}})$
. We use
 $\mathsf{exvar}(\rho)$
to denote the tuple
$\mathsf{exvar}(\rho)$
to denote the tuple
 ${\textbf {z}}$
and
${\textbf {z}}$
and
 $\mathsf{fr}(\rho)$
to denote the tuple
$\mathsf{fr}(\rho)$
to denote the tuple
 ${\textbf {y}}$
, also called the frontier of
${\textbf {y}}$
, also called the frontier of
 $\rho$
. An EGD
$\rho$
. An EGD
 $\eta$
(over a schema
$\eta$
(over a schema
 $\mathsf{S}$
) is a FO formula of the form
$\mathsf{S}$
) is a FO formula of the form
 $\forall {\textbf {x}}\, \varphi({\textbf {x}}) \rightarrow x=y$
, where
$\forall {\textbf {x}}\, \varphi({\textbf {x}}) \rightarrow x=y$
, where
 ${\textbf {x}}$
is a tuple of variables,
${\textbf {x}}$
is a tuple of variables,
 $\varphi$
a conjunction of atoms (over
$\varphi$
a conjunction of atoms (over
 $\mathsf{S}$
) without nulls, and over
$\mathsf{S}$
) without nulls, and over
 ${\textbf {x}}$
, and
${\textbf {x}}$
, and
 $x,y \in {\textbf {x}}$
. The body of
$x,y \in {\textbf {x}}$
. The body of
 $\eta$
, denoted
$\eta$
, denoted
 $\mathsf{body}(\eta)$
, is
$\mathsf{body}(\eta)$
, is
 $\varphi({\textbf {x}})$
, and the head of
$\varphi({\textbf {x}})$
, and the head of
 $\eta$
, denoted
$\eta$
, denoted
 $\mathsf{head}(\eta)$
, is the equality
$\mathsf{head}(\eta)$
, is the equality
 $x=y$
. For clarity, we will omit the universal quantifiers in front of dependencies and replace the conjunction symbol
$x=y$
. For clarity, we will omit the universal quantifiers in front of dependencies and replace the conjunction symbol
 $\wedge$
with a comma. Moreover, with a slight abuse of notation, we sometimes treat a conjunction of atoms as the set of its atoms. Consider an instance I. We say that I satisfies a TGD
$\wedge$
with a comma. Moreover, with a slight abuse of notation, we sometimes treat a conjunction of atoms as the set of its atoms. Consider an instance I. We say that I satisfies a TGD
 $\rho$
if for every homomorphism h from
$\rho$
if for every homomorphism h from
 $\mathsf{body}(\rho)$
to I, there is an extension h’ of h such that h’ is a homomorphism from
$\mathsf{body}(\rho)$
to I, there is an extension h’ of h such that h’ is a homomorphism from
 $\mathsf{head}(\rho)$
to I. We say that I satisfies an EGD
$\mathsf{head}(\rho)$
to I. We say that I satisfies an EGD
 $\eta = \varphi({\textbf {x}}) \rightarrow x=y$
, if for every homomorphism h from
$\eta = \varphi({\textbf {x}}) \rightarrow x=y$
, if for every homomorphism h from
 $\mathsf{body}(\eta)$
to I,
$\mathsf{body}(\eta)$
to I,
 $h(x)=h(y)$
. I satisfies a set of TGDs and EGDs
$h(x)=h(y)$
. I satisfies a set of TGDs and EGDs
 $\Sigma$
if I satisfies every TGD and EGD in
$\Sigma$
if I satisfies every TGD and EGD in
 $\Sigma$
.
$\Sigma$
.
Queries. A query
 $Q(\mathbf{x})$
, with free variables
$Q(\mathbf{x})$
, with free variables
 $\mathbf{x}$
, is a FO formula
$\mathbf{x}$
, is a FO formula
 $\varphi({\textbf {x}})$
with free variables
$\varphi({\textbf {x}})$
with free variables
 ${\textbf {x}}$
. The arity of
${\textbf {x}}$
. The arity of
 $Q(\mathbf{x})$
, denoted ar(Q), is the number
$Q(\mathbf{x})$
, denoted ar(Q), is the number
 $|\mathbf{x}|$
. The output of
$|\mathbf{x}|$
. The output of
 $Q(\mathbf{x})$
over an instance I, denoted Q(I), is the set
$Q(\mathbf{x})$
over an instance I, denoted Q(I), is the set
 $\{\mathbf{t} \in \mathsf{dom}(I)^{|\mathbf{x}|} \mid I \models \varphi(\mathbf{t})\}$
, where
$\{\mathbf{t} \in \mathsf{dom}(I)^{|\mathbf{x}|} \mid I \models \varphi(\mathbf{t})\}$
, where
 $\models$
is FO entailment.
Footnote 1
A query is Boolean if it has arity 0, in which case its output over an instance is either the empty set or the empty tuple
$\models$
is FO entailment.
Footnote 1
A query is Boolean if it has arity 0, in which case its output over an instance is either the empty set or the empty tuple
 $\langle \rangle$
. A conjunctive query (CQ) is a query of the form
$\langle \rangle$
. A conjunctive query (CQ) is a query of the form
 $Q(\mathbf{x}) = \exists \mathbf{y}\, \varphi(\mathbf{x},\mathbf{y})$
, where
$Q(\mathbf{x}) = \exists \mathbf{y}\, \varphi(\mathbf{x},\mathbf{y})$
, where
 $\varphi(\mathbf{x},\mathbf{y})$
is a conjunction of atoms over
$\varphi(\mathbf{x},\mathbf{y})$
is a conjunction of atoms over
 $\mathbf{x}$
and
$\mathbf{x}$
and
 $\mathbf{y}$
. A union of conjunctive queries (UCQs) is a query of the form
$\mathbf{y}$
. A union of conjunctive queries (UCQs) is a query of the form
 $Q(\mathbf{x}) = \bigvee^n_{i=1} Q_i(\mathbf{x})$
, where each
$Q(\mathbf{x}) = \bigvee^n_{i=1} Q_i(\mathbf{x})$
, where each
 $Q_i({\textbf {x}})$
is a CQ. We refer to UCQs also as positive queries.
$Q_i({\textbf {x}})$
is a CQ. We refer to UCQs also as positive queries.
Data Exchange Settings. A data exchange setting (or simply setting) is a tuple of the form
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S},\mathsf{T}$
are disjoint schemas, called source and target schema, respectively;
$\mathsf{S},\mathsf{T}$
are disjoint schemas, called source and target schema, respectively;
 $\Sigma_{st}$
is a finite set of TGDs, called the source-to-target TGDs of
$\Sigma_{st}$
is a finite set of TGDs, called the source-to-target TGDs of
 $\mathcal{S}$
, such that for each TGD
$\mathcal{S}$
, such that for each TGD
 $\rho \in \Sigma_{st}$
,
$\rho \in \Sigma_{st}$
,
 $\mathsf{body}(\rho)$
is over
$\mathsf{body}(\rho)$
is over
 $\mathsf{S}$
and
$\mathsf{S}$
and
 $\mathsf{head}(\rho)$
is over
$\mathsf{head}(\rho)$
is over
 $\mathsf{T}$
;
$\mathsf{T}$
;
 $\Sigma_t$
is a finite set of TGDs and EGDs over
$\Sigma_t$
is a finite set of TGDs and EGDs over
 $\mathsf{T}$
, called the target dependencies of
$\mathsf{T}$
, called the target dependencies of
 $\mathcal{S}$
. We say
$\mathcal{S}$
. We say
 $\mathcal{S}$
is TGD-only if
$\mathcal{S}$
is TGD-only if
 $\Sigma_t$
contains only TGDs.
$\Sigma_t$
contains only TGDs.
A source (resp., target) instance of
 $\mathcal{S}$
is an instance I over
$\mathcal{S}$
is an instance I over
 $\mathsf{S}$
(resp.,
$\mathsf{S}$
(resp.,
 $\mathsf{T}$
). We assume that source instances are databases, that is, they do not contain nulls. Given a source instance I of
$\mathsf{T}$
). We assume that source instances are databases, that is, they do not contain nulls. Given a source instance I of
 $\mathcal{S}$
, a solution of I w.r.t.
$\mathcal{S}$
, a solution of I w.r.t.
 $\mathcal{S}$
is a target instance J of
$\mathcal{S}$
is a target instance J of
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $I \cup J$
satisfies
$I \cup J$
satisfies
 $\Sigma_{st}$
and J satisfies
$\Sigma_{st}$
and J satisfies
 $\Sigma_t$
(Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). We use
$\Sigma_t$
(Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). We use
 $\mathsf{sol}(I,\mathcal{S})$
to denote the set of all solutions of I w.r.t.
$\mathsf{sol}(I,\mathcal{S})$
to denote the set of all solutions of I w.r.t.
 $\mathcal{S}$
.
$\mathcal{S}$
.
Given a data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
 $\mathcal{S}$
and a query Q over
$\mathcal{S}$
and a query Q over
 $\mathsf{T}$
, the certain answers to Q over I w.r.t.
$\mathsf{T}$
, the certain answers to Q over I w.r.t.
 $\mathcal{S}$
is the set
$\mathcal{S}$
is the set
 $\mathsf{cert}_{\mathcal{S}}(I,Q) = \bigcap_{J \in \mathsf{sol}(I,\mathcal{S})} Q(J)$
.
$\mathsf{cert}_{\mathcal{S}}(I,Q) = \bigcap_{J \in \mathsf{sol}(I,\mathcal{S})} Q(J)$
.
To distinguish between the notion of solution (resp., certain answers) above and the one defined in Section 3, we will refer to the former as classical.
A universal solution of I w.r.t.
 $\mathcal{S}$
is a solution
$\mathcal{S}$
is a solution
 $J \in \mathsf{sol}(I,\mathcal{S})$
such that, for every
$J \in \mathsf{sol}(I,\mathcal{S})$
such that, for every
 $J' \in \mathsf{sol}(I,\mathcal{S})$
, there is a homomorphism from J to J’ (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). Letting
$J' \in \mathsf{sol}(I,\mathcal{S})$
, there is a homomorphism from J to J’ (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). Letting
 $Q(J)_{\downarrow} = Q(J) \cap \mathsf{Const}^{|{\textbf {x}}|}$
, for any instance J and query
$Q(J)_{\downarrow} = Q(J) \cap \mathsf{Const}^{|{\textbf {x}}|}$
, for any instance J and query
 $Q({\textbf {x}})$
, the following result from (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005) is well-known:
$Q({\textbf {x}})$
, the following result from (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005) is well-known:
Consider a data exchange setting
 $\mathcal{S}$
, a source instance I of
$\mathcal{S}$
, a source instance I of
 $\mathcal{S,}$
and a positive query Q. If J is a universal solution of I w.r.t.
$\mathcal{S,}$
and a positive query Q. If J is a universal solution of I w.r.t.
 $\mathcal{S}$
, then
$\mathcal{S}$
, then
 $ \mathsf{cert}_{\mathcal{S}}(I,Q) = Q(J)_{\downarrow}$
.
$ \mathsf{cert}_{\mathcal{S}}(I,Q) = Q(J)_{\downarrow}$
.
3 Semantics for general queries
The goal of this section is to introduce a new notion of solution for data exchange that we call supported. As already discussed, the main issue we want to solve w.r.t. classical solutions is that such solutions are too permissive, that is, they allow for the presence of facts that are not a certain consequence of the source instance and the dependencies. Consider again Example 1. The (classical) solution J’ in Example 1 is not supported, since from the source instance I and the dependencies, we cannot conclude that the fact
 $\mathsf{Paid}(2)$
should occur in the target. On the other hand, the solution
$\mathsf{Paid}(2)$
should occur in the target. On the other hand, the solution
 $J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1)\}$
is supported: it contains precisely the facts supported by I and the dependencies, and no more than that. Similarly, considering Example 2, the instance
$J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2),\mathsf{Paid}(1)\}$
is supported: it contains precisely the facts supported by I and the dependencies, and no more than that. Similarly, considering Example 2, the instance
 $J = \{\mathsf{EmpC}(\mathsf{john},\mathsf{miami})$
,
$J = \{\mathsf{EmpC}(\mathsf{john},\mathsf{miami})$
,
 $\mathsf{EmpC}(\mathsf{mary},\mathsf{chicago})$
,
$\mathsf{EmpC}(\mathsf{mary},\mathsf{chicago})$
,
 $\mathsf{SameC}(\mathsf{john},\mathsf{mary})\}$
is a solution, but it is not supported, since from the source and the dependencies we cannot certainly conclude that
$\mathsf{SameC}(\mathsf{john},\mathsf{mary})\}$
is a solution, but it is not supported, since from the source and the dependencies we cannot certainly conclude that
 $\mathsf{john}$
and
$\mathsf{john}$
and
 $\mathsf{mary}$
live in the same city. We now formalize the above intuitions.
$\mathsf{mary}$
live in the same city. We now formalize the above intuitions.
Consider a TGD
 $\rho$
and a mapping h from the variables of
$\rho$
and a mapping h from the variables of
 $\rho$
to
$\rho$
to
 $\mathsf{Const}$
. We say that a TGD
$\mathsf{Const}$
. We say that a TGD
 $\rho'$
is a ground version of
$\rho'$
is a ground version of
 $\rho$
(via h) if
$\rho$
(via h) if
 $\rho' = h(\mathsf{body}(\rho)) \rightarrow h(\mathsf{head}(\rho))$
.
$\rho' = h(\mathsf{body}(\rho)) \rightarrow h(\mathsf{head}(\rho))$
.
Definition 1 (ex-choice)
An ex-choice is a function
 $\gamma$
, that given as input a TGD
$\gamma$
, that given as input a TGD
 $\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
and a tuple
$\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
and a tuple
 $\mathbf{t} \in \mathsf{Const}^{|{\textbf {y}}|}$
, returns a set
$\mathbf{t} \in \mathsf{Const}^{|{\textbf {y}}|}$
, returns a set
 $\gamma(\rho,\mathbf{t})$
of pairs of the form (z,c), one for each existential variable
$\gamma(\rho,\mathbf{t})$
of pairs of the form (z,c), one for each existential variable
 $z \in \mathsf{exvar}(\rho)$
, where c is a constant of
$z \in \mathsf{exvar}(\rho)$
, where c is a constant of
 $\mathsf{Const}$
. Note that if
$\mathsf{Const}$
. Note that if
 $\rho$
does not contain existential variables,
$\rho$
does not contain existential variables,
 $\gamma(\rho,\mathbf{t})$
is the empty set.
$\gamma(\rho,\mathbf{t})$
is the empty set.
Intuitively, given a TGD, an ex-choice specifies a valuation for the existential variables of the TGD which depends on a given valuation of its frontier variables.
We now define when a ground version of a TGD indeed assigns existential variables according to an ex-choice.
Definition 2 (Coherence)
Consider a TGD
 $\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, an ex-choice
$\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, an ex-choice
 $\gamma$
and a ground version
$\gamma$
and a ground version
 $\rho'$
of
$\rho'$
of
 $\rho$
via some mapping h. We say that
$\rho$
via some mapping h. We say that
 $\rho'$
is coherent with
$\rho'$
is coherent with
 $\gamma$
if for each existential variable
$\gamma$
if for each existential variable
 $z \in \mathsf{exvar}(\rho)$
,
$z \in \mathsf{exvar}(\rho)$
,
 $(z,h(z)) \in \gamma(\rho,h({\textbf {y}}))$
. For a set
$(z,h(z)) \in \gamma(\rho,h({\textbf {y}}))$
. For a set
 $\Sigma$
of TGDs and EGDs, and an ex-choice
$\Sigma$
of TGDs and EGDs, and an ex-choice
 $\gamma$
,
$\gamma$
,
 $\Sigma^\gamma$
denotes the set of dependencies obtained from
$\Sigma^\gamma$
denotes the set of dependencies obtained from
 $\Sigma$
by replacing each TGD
$\Sigma$
by replacing each TGD
 $\rho$
in
$\rho$
in
 $\Sigma$
with all ground versions of
$\Sigma$
with all ground versions of
 $\rho$
that are coherent with
$\rho$
that are coherent with
 $\gamma$
. Note that the set
$\gamma$
. Note that the set
 $\Sigma^\gamma$
can be infinite. We are now ready to present our notion of solution.
$\Sigma^\gamma$
can be infinite. We are now ready to present our notion of solution.
Definition 3 (Supported Solution)
Consider a setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
 $\mathcal{S}$
. A target instance J of
$\mathcal{S}$
. A target instance J of
 $\mathcal{S}$
is a supported solution of I w.r.t.
$\mathcal{S}$
is a supported solution of I w.r.t.
 $\mathcal{S}$
if there exists an ex-choice
$\mathcal{S}$
if there exists an ex-choice
 $\gamma$
such that
$\gamma$
such that
 $I \cup J$
satisfies
$I \cup J$
satisfies
 $\Sigma_{st}^\gamma$
and J satisfies
$\Sigma_{st}^\gamma$
and J satisfies
 $\Sigma_t^\gamma$
, and there is no other target instance
$\Sigma_t^\gamma$
, and there is no other target instance
 $J' \subsetneq J$
of
$J' \subsetneq J$
of
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $I \cup J'$
satisfies
$I \cup J'$
satisfies
 $\Sigma_{st}^\gamma$
and J’ satisfies
$\Sigma_{st}^\gamma$
and J’ satisfies
 $\Sigma_t^\gamma$
.
$\Sigma_t^\gamma$
.
Note that a supported solution contains no nulls. We use
 $\mathsf{ssol}(I,\mathcal{S})$
to denote the set of all supported solutions of I w.r.t.
$\mathsf{ssol}(I,\mathcal{S})$
to denote the set of all supported solutions of I w.r.t.
 $\mathcal{S}$
.
$\mathcal{S}$
.
Example 3 Consider the data exchange setting
 $\mathcal{S}$
and the source instance I of Example 2. The target instance
$\mathcal{S}$
and the source instance I of Example 2. The target instance
 $J = \{\mathsf{EmpC}(\mathsf{john},\mathsf{miami}),\mathsf{EmpC}(\mathsf{mary},\mathsf{chicago})\}$
is a supported solution of I w.r.t.
$J = \{\mathsf{EmpC}(\mathsf{john},\mathsf{miami}),\mathsf{EmpC}(\mathsf{mary},\mathsf{chicago})\}$
is a supported solution of I w.r.t.
 $\mathcal{S}$
. Indeed, consider the ex-choice
$\mathcal{S}$
. Indeed, consider the ex-choice
 $\gamma$
such that
$\gamma$
such that
 $\gamma(\rho_1,\mathsf{john}) = \{ (z,\mathsf{miami})\}$
, and
$\gamma(\rho_1,\mathsf{john}) = \{ (z,\mathsf{miami})\}$
, and
 $\gamma(\rho_1,\mathsf{mary}) = \{(z,\mathsf{chicago})\}$
. Then,
$\gamma(\rho_1,\mathsf{mary}) = \{(z,\mathsf{chicago})\}$
. Then,
 $\Sigma_{st}^\gamma$
is
$\Sigma_{st}^\gamma$
is
 \[ \begin{array}{ll} \{\mathsf{KnownC}(\alpha,\beta) \rightarrow \mathsf{EmpC}(\alpha,\beta) \mid \alpha,\beta \in \mathsf{Const}\} \cup \\ \{\mathsf{Emp}(\alpha) \rightarrow \mathsf{EmpC}(\alpha,\beta) \mid \alpha \in \mathsf{Const} \wedge (z,\beta) \in \gamma(\rho_1,\alpha)\}, \end{array} \]
\[ \begin{array}{ll} \{\mathsf{KnownC}(\alpha,\beta) \rightarrow \mathsf{EmpC}(\alpha,\beta) \mid \alpha,\beta \in \mathsf{Const}\} \cup \\ \{\mathsf{Emp}(\alpha) \rightarrow \mathsf{EmpC}(\alpha,\beta) \mid \alpha \in \mathsf{Const} \wedge (z,\beta) \in \gamma(\rho_1,\alpha)\}, \end{array} \]
whereas
 $\Sigma_t^\gamma$
is the set containing the EGD
$\Sigma_t^\gamma$
is the set containing the EGD
 $\eta$
of Example 2, and the set of TGDs
$\eta$
of Example 2, and the set of TGDs
 \[ \begin{array}{l} \{\mathsf{EmpC}(\alpha,\beta),\mathsf{EmpC}(\alpha',\beta) \rightarrow \mathsf{SameC}(\alpha,\alpha') \mid \alpha,\alpha',\beta \in \mathsf{Const}\}. \end{array} \]
\[ \begin{array}{l} \{\mathsf{EmpC}(\alpha,\beta),\mathsf{EmpC}(\alpha',\beta) \rightarrow \mathsf{SameC}(\alpha,\alpha') \mid \alpha,\alpha',\beta \in \mathsf{Const}\}. \end{array} \]
Clearly,
 $I \cup J$
satisfies
$I \cup J$
satisfies
 $\Sigma_{st}^\gamma$
, and J satisfies
$\Sigma_{st}^\gamma$
, and J satisfies
 $\Sigma_t^\gamma$
, and any other strict subset J’ of J is such that
$\Sigma_t^\gamma$
, and any other strict subset J’ of J is such that
 $I \cup J'$
does not satisfy
$I \cup J'$
does not satisfy
 $\Sigma_{st}^\gamma$
. Another supported solution is
$\Sigma_{st}^\gamma$
. Another supported solution is
 $\{\mathsf{EmpC}(\mathsf{john},\mathsf{miami})$
,
$\{\mathsf{EmpC}(\mathsf{john},\mathsf{miami})$
,
 $\mathsf{EmpC}(\mathsf{mary},\mathsf{miami})$
,
$\mathsf{EmpC}(\mathsf{mary},\mathsf{miami})$
,
 $\mathsf{SameC}(\mathsf{john},\mathsf{mary})\}$
.
$\mathsf{SameC}(\mathsf{john},\mathsf{mary})\}$
.
With the notion of supported solution in place, it is now straightforward to define the supported certain answers.
Definition 4 (Supported Certain Answers)
Consider a data exchange setting
 $\mathcal{S}$
, a source instance I of
$\mathcal{S}$
, a source instance I of
 $\mathcal{S,}$
and a query Q over
$\mathcal{S,}$
and a query Q over
 $\mathsf{T}$
. The supported certain answers to Q over I w.r.t.
$\mathsf{T}$
. The supported certain answers to Q over I w.r.t.
 $\mathcal{S}$
is the set of tuples
$\mathcal{S}$
is the set of tuples
 $\mathsf{scert}_{\mathcal{S}}(I,Q) = \bigcap_{J \in \mathsf{ssol}(I,\mathcal{S})} Q(J)$
.
$\mathsf{scert}_{\mathcal{S}}(I,Q) = \bigcap_{J \in \mathsf{ssol}(I,\mathcal{S})} Q(J)$
.
Example 4 Consider the data exchange setting
 $\mathcal{S}$
, the source instance I, and the query Q of Example 1. It is not difficult to see that the only supported solution of I w.r.t.
$\mathcal{S}$
, the source instance I, and the query Q of Example 1. It is not difficult to see that the only supported solution of I w.r.t.
 $\mathcal{S}$
is the instance
$\mathcal{S}$
is the instance
 $$J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2), \mathsf{Paid}(1)\}.$$
$$J = \{\mathsf{AllOrd}(1),\mathsf{AllOrd}(2), \mathsf{Paid}(1)\}.$$
Thus, the supported certain answers to Q over I w.r.t.
 $\mathcal{S}$
are
$\mathcal{S}$
are
 $ \mathsf{scert}_{\mathcal{S}}(I,Q) = Q(J) = \{2\}$
. Consider now the data exchange setting
$ \mathsf{scert}_{\mathcal{S}}(I,Q) = Q(J) = \{2\}$
. Consider now the data exchange setting
 $\mathcal{S}$
, the source instance I, and the query Q of Example 2. Then, one can verify that
$\mathcal{S}$
, the source instance I, and the query Q of Example 2. Then, one can verify that
 $\mathsf{scert}_{\mathcal{S}}(I,Q) = \emptyset$
.
$\mathsf{scert}_{\mathcal{S}}(I,Q) = \emptyset$
.
We now start establishing some important results regarding supported solutions and supported certain answers. The following theorem states that supported solutions are a refined subset of the classical ones, but whether a supported solution exists is still tightly related to the existence of a classical one.
Theorem 2 Consider a data exchange setting
 $\mathcal{S}$
. For every source instance I of
$\mathcal{S}$
. For every source instance I of
 $\mathcal{S}$
, it holds that:
$\mathcal{S}$
, it holds that:
-
1.
 $\mathsf{ssol}(I,\mathcal{S}) \subseteq \mathsf{sol}(I,\mathcal{S})$
, and
$\mathsf{ssol}(I,\mathcal{S}) \subseteq \mathsf{sol}(I,\mathcal{S})$
, and -
2.
$\mathsf{ssol}(I,\mathcal{S}) = \emptyset$
iff
$\mathsf{sol}(I,\mathcal{S}) = \emptyset$
.



Proof.
Item 1 follows by definition. For proving Item 2, it suffices to show that
 $\mathsf{sol}(I,\mathcal{S}) \neq \emptyset$
implies
$\mathsf{sol}(I,\mathcal{S}) \neq \emptyset$
implies
 $\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Let
$\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Let
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and consider a solution
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and consider a solution
 $J \in \mathsf{sol}(I,\mathcal{S})$
. We construct from J a supported solution
$J \in \mathsf{sol}(I,\mathcal{S})$
. We construct from J a supported solution
 $\hat{J}$
in
$\hat{J}$
in
 $\mathsf{ssol}(I,\mathcal{S})$
. Let J’ be one of the minimal subsets of J such that J’ is still a solution of
$\mathsf{ssol}(I,\mathcal{S})$
. Let J’ be one of the minimal subsets of J such that J’ is still a solution of
 $\mathsf{sol}(I,\mathcal{S})$
. Moreover, let
$\mathsf{sol}(I,\mathcal{S})$
. Moreover, let
 $\hat{J}$
be the instance obtained from J’, where each null
$\hat{J}$
be the instance obtained from J’, where each null
 $\perp$
in J’ is replaced with a new constant
$\perp$
in J’ is replaced with a new constant
 $c_\perp$
not occurring in
$c_\perp$
not occurring in
 $\Sigma_{st} \cup \Sigma_t$
and J’. Since
$\Sigma_{st} \cup \Sigma_t$
and J’. Since
 $\hat{J}$
and J’ are the same instance, up to null renaming, we conclude that
$\hat{J}$
and J’ are the same instance, up to null renaming, we conclude that
 $\hat{J}$
is also a solution in
$\hat{J}$
is also a solution in
 $\mathsf{sol}(I,\mathcal{S})$
. To see that
$\mathsf{sol}(I,\mathcal{S})$
. To see that
 $\hat{J}$
is a supported solution, consider the following ex-choice
$\hat{J}$
is a supported solution, consider the following ex-choice
 $\gamma$
. For every TGD
$\gamma$
. For every TGD
 $\rho \in \Sigma_{st} \cup \Sigma_t$
, and every tuple
$\rho \in \Sigma_{st} \cup \Sigma_t$
, and every tuple
 $\mathbf{t}$
of constants such that there exists a homomorphism h from
$\mathbf{t}$
of constants such that there exists a homomorphism h from
 $\mathsf{body}(\rho)$
to
$\mathsf{body}(\rho)$
to
 $\hat{J}$
, and
$\hat{J}$
, and
 $\mathbf{t} = h(\mathsf{fr}(\rho))$
, let
$\mathbf{t} = h(\mathsf{fr}(\rho))$
, let
 $\gamma(\rho,\mathbf{t}) = \{(z,h(z)) \mid z \in \mathsf{exvar}(\rho)\}$
. By construction of
$\gamma(\rho,\mathbf{t}) = \{(z,h(z)) \mid z \in \mathsf{exvar}(\rho)\}$
. By construction of
 $\gamma$
,
$\gamma$
,
 $I \cup \hat{J}$
satisfies
$I \cup \hat{J}$
satisfies
 $\Sigma_{st}^\gamma$
, and
$\Sigma_{st}^\gamma$
, and
 $\hat{J}$
satisfies
$\hat{J}$
satisfies
 $\Sigma_t^{\gamma}$
. Since
$\Sigma_t^{\gamma}$
. Since
 $\hat{J}$
is minimal, that is, for every
$\hat{J}$
is minimal, that is, for every
 $J'' \subsetneq \hat{J}$
,
$J'' \subsetneq \hat{J}$
,
 $J'' \not \in \mathsf{sol}(I,\mathcal{S})$
, from Item 1 of this claim, every
$J'' \not \in \mathsf{sol}(I,\mathcal{S})$
, from Item 1 of this claim, every
 $J'' \subsetneq J$
is such that
$J'' \subsetneq J$
is such that
 $J'' \not \in \mathsf{ssol}(I,\mathcal{S})$
, that is, either
$J'' \not \in \mathsf{ssol}(I,\mathcal{S})$
, that is, either
 $I \cup J''$
does not satisfy
$I \cup J''$
does not satisfy
 $\Sigma_{st}^\gamma$
or J” does not satisfy
$\Sigma_{st}^\gamma$
or J” does not satisfy
 $\Sigma_t^\gamma$
. Thus,
$\Sigma_t^\gamma$
. Thus,
 $\hat{J}$
is a supported solution of
$\hat{J}$
is a supported solution of
 $\mathsf{ssol}(I,\mathcal{S})$
, and the claim follows.
$\mathsf{ssol}(I,\mathcal{S})$
, and the claim follows.
Regarding certain answers, we show that supported solutions indeed enjoy an important property: supported certain answers and classical certain answers coincide, when focusing on positive queries. Note that this does not necessarily follow from Theorem 2.
Theorem 3 Consider a setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a positive query Q over
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a positive query Q over
 $\mathsf{T}$
. For every source instance I of
$\mathsf{T}$
. For every source instance I of
 $\mathcal{S}$
,
$\mathcal{S}$
,
 $\mathsf{scert}_{\mathcal{S}}(I,Q) = \mathsf{cert}_{\mathcal{S}}(I,Q)$
.
$\mathsf{scert}_{\mathcal{S}}(I,Q) = \mathsf{cert}_{\mathcal{S}}(I,Q)$
.
Proof. The fact that
 $\mathsf{cert}_{\mathcal{S}}(I,Q) \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
, follows from Item 1 of Theorem 2. To prove that
$\mathsf{cert}_{\mathcal{S}}(I,Q) \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
, follows from Item 1 of Theorem 2. To prove that
 $\mathsf{scert}_{\mathcal{S}}(I,Q) \subseteq \mathsf{cert}_{\mathcal{S}}(I,Q)$
, assume
$\mathsf{scert}_{\mathcal{S}}(I,Q) \subseteq \mathsf{cert}_{\mathcal{S}}(I,Q)$
, assume
 $\mathbf{t} \not \in \mathsf{cert}_{\mathcal{S}}(I,Q)$
, which means that there exists a solution J of I w.r.t.
$\mathbf{t} \not \in \mathsf{cert}_{\mathcal{S}}(I,Q)$
, which means that there exists a solution J of I w.r.t.
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $\mathbf{t} \not \in Q(J)$
. Since Q is positive, and hence monotone,
$\mathbf{t} \not \in Q(J)$
. Since Q is positive, and hence monotone,
 $\mathbf{t} \not \in Q(J)$
iff
$\mathbf{t} \not \in Q(J)$
iff
 $\mathbf{t} \not \in Q(J')$
, where J’ is one of the minimal subsets of J such that J’ is still a solution of I w.r.t.
$\mathbf{t} \not \in Q(J')$
, where J’ is one of the minimal subsets of J such that J’ is still a solution of I w.r.t.
 $\mathcal{S}$
. Let
$\mathcal{S}$
. Let
 $\hat{J}$
be the instance obtained from J’, where each null
$\hat{J}$
be the instance obtained from J’, where each null
 $\perp$
in J’ is replaced with a new constant
$\perp$
in J’ is replaced with a new constant
 $c_\perp$
not occurring in
$c_\perp$
not occurring in
 $\mathbf{t}$
, Q,
$\mathbf{t}$
, Q,
 $\Sigma_{st} \cup \Sigma_t$
, and J’. With a similar discussion to the one given in the proof of Theorem 2, we conclude that
$\Sigma_{st} \cup \Sigma_t$
, and J’. With a similar discussion to the one given in the proof of Theorem 2, we conclude that
 $\hat{J}$
is a supported solution of I w.r.t.
$\hat{J}$
is a supported solution of I w.r.t.
 $\mathcal{S}$
. Since Q is positive, and since
$\mathcal{S}$
. Since Q is positive, and since
 $\mathbf{t}$
and Q do not contain any of the constants introduced in J’, we conclude that
$\mathbf{t}$
and Q do not contain any of the constants introduced in J’, we conclude that
 $\mathbf{t} \not \in Q(\hat{J})$
, which implies that
$\mathbf{t} \not \in Q(\hat{J})$
, which implies that
 $\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I,Q)$
, and the claim follows.
$\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I,Q)$
, and the claim follows.
From the above, we conclude that for positive queries, certain query answering can be performed as done in the classical setting, and thus all important results from that setting, like query answering via universal solutions, carry over.
Corollary 1 Consider a setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a positive query Q over
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a positive query Q over
 $\mathsf{T}$
. If J is a (classical) universal solution of I w.r.t.
$\mathsf{T}$
. If J is a (classical) universal solution of I w.r.t.
 $\mathcal{S}$
, then
$\mathcal{S}$
, then
 $ \mathsf{scert}_{\mathcal{S}}(I,Q) = Q(J)_{\downarrow}$
.
$ \mathsf{scert}_{\mathcal{S}}(I,Q) = Q(J)_{\downarrow}$
.
Proof. It follows from Theorems 1 and 3.
We now move to the complexity analysis of the two most important data exchange tasks: deciding whether a supported solution exists, and computing the supported certain answers to a query.
4 Complexity
In data exchange, it is usually assumed that a setting
 $\mathcal{S}$
does not change over time, and a given query Q is much smaller than a given source instance. Thus, for understanding the complexity of a data exchange problem, it is customary to assume that
$\mathcal{S}$
does not change over time, and a given query Q is much smaller than a given source instance. Thus, for understanding the complexity of a data exchange problem, it is customary to assume that
 $\mathcal{S}$
and Q are fixed, and only I is considered in the complexity analysis, that is, we consider the data complexity of the problem. Hence, the problems we are going to discuss will always be parametrized via a setting
$\mathcal{S}$
and Q are fixed, and only I is considered in the complexity analysis, that is, we consider the data complexity of the problem. Hence, the problems we are going to discuss will always be parametrized via a setting
 $\mathcal{S}$
, and a query Q (for query answering tasks). The first problem we consider is deciding whether a supported solution exists;
$\mathcal{S}$
, and a query Q (for query answering tasks). The first problem we consider is deciding whether a supported solution exists;
 $\mathcal{S}$
is a fixed data exchange setting.
$\mathcal{S}$
is a fixed data exchange setting.

The above problem is very important in data exchange, as one of the main goals is to actually construct a target instance that can be exploited for query answering purposes. Hence, knowing in advance whether at least a supported solution exists is of paramount importance.
Thanks to Item 2 of Theorem 2, all the complexity results for checking the existence of a classical solution can be directly transferred to our problem.
Theorem 4 There exists a data exchange setting
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $\mathsf{EXISTS\text{-}SSOL}(\mathcal{S})$
is undecidable.
$\mathsf{EXISTS\text{-}SSOL}(\mathcal{S})$
is undecidable.
Proof. It follows from Theorem 2 and from the fact that there exists a data exchange setting
 $\mathcal{S}$
such that checking whether a classical solution exists is undecidable (Kolaitis et al. Reference Kolaitis, Panttaja and Tan2006).
$\mathcal{S}$
such that checking whether a classical solution exists is undecidable (Kolaitis et al. Reference Kolaitis, Panttaja and Tan2006).
Despite the negative result above, we also inherit positive results from the literature, when focusing on some of the most important data exchange scenarios, known as weakly-acyclic. Such settings only allow target TGDs to belong to the language of weakly-acyclic TGDs, which have been first introduced in the seminal paper (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005), and is now well-established as the main language for data exchange purposes.
We start by introducing the notion of weak-acyclicity. We recall that for a schema
 $\mathsf{S}$
,
$\mathsf{S}$
,
 $\mathsf{pos}(\mathsf{S})$
denotes the set of all positions R[i], where
$\mathsf{pos}(\mathsf{S})$
denotes the set of all positions R[i], where
 $R/n \in \mathsf{S}$
and
$R/n \in \mathsf{S}$
and
 $i \in \{1,\ldots,n\}$
, and for a TGD
$i \in \{1,\ldots,n\}$
, and for a TGD
 $\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
,
$\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
,
 $\mathsf{fr}(\rho)$
denotes the tuple
$\mathsf{fr}(\rho)$
denotes the tuple
 ${\textbf {y}}$
.
${\textbf {y}}$
.
Definition 5 (Dependency Graph (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005))
Consider a set
 $\Sigma$
of TGDs over a schema
$\Sigma$
of TGDs over a schema
 $\mathsf{S}$
. The dependency graph of
$\mathsf{S}$
. The dependency graph of
 $\Sigma$
is a directed graph
$\Sigma$
is a directed graph
 $\mathsf{dg}(\Sigma)=(N,E)$
, where
$\mathsf{dg}(\Sigma)=(N,E)$
, where
 $N = \mathsf{pos}(\mathsf{S})$
and E contains only the following edges. For each
$N = \mathsf{pos}(\mathsf{S})$
and E contains only the following edges. For each
 $\rho \in \Sigma$
, for each
$\rho \in \Sigma$
, for each
 $x \in \mathsf{fr}(\rho)$
, and for each position
$x \in \mathsf{fr}(\rho)$
, and for each position
 $\pi$
in
$\pi$
in
 $\mathsf{body}(\rho)$
where x occurs:
$\mathsf{body}(\rho)$
where x occurs:
-
there is a normal edge
$(\pi,\pi') \in E$
, for each position
$\pi'$
in
$\mathsf{head}(\rho)$
where x occurs, and -
there is a special edge
$(\pi,\pi') \in E$
, for each position
$\pi'$
in
$\mathsf{head}(\rho)$
where an existentially quantified variable
$z \in \mathsf{exvar}(\rho)$
occurs.







Definition 6 A set of TGDs
 $\Sigma$
is weakly-acyclic if no cycle in
$\Sigma$
is weakly-acyclic if no cycle in
 $\mathsf{dg}(\Sigma)$
contains a special edge. A data exchange setting
$\mathsf{dg}(\Sigma)$
contains a special edge. A data exchange setting
 $\langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
is weakly-acyclic if the set of TGDs in
$\langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
is weakly-acyclic if the set of TGDs in
 $\Sigma_t$
is weakly-acyclic.
$\Sigma_t$
is weakly-acyclic.
Example 5 The settings of Examples 1 and 2 are weakly-acyclic, whereas the data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S} = \{S/2\}$
,
$\mathsf{S} = \{S/2\}$
,
 $\mathsf{T} = \{T/2\}$
,
$\mathsf{T} = \{T/2\}$
,
 $\Sigma_{st} = \{S(x,y) \rightarrow T(x,y)\}$
, and
$\Sigma_{st} = \{S(x,y) \rightarrow T(x,y)\}$
, and
 $\Sigma_t = \{T(x,y) \rightarrow \exists z\, T(y,z)\}$
is not, since (T[2],T[2]) is a special edge in
$\Sigma_t = \{T(x,y) \rightarrow \exists z\, T(y,z)\}$
is not, since (T[2],T[2]) is a special edge in
 $\mathsf{dg}(\Sigma_t)$
.
$\mathsf{dg}(\Sigma_t)$
.
The following result follows.
Theorem 5 For every weakly-acyclic data exchange setting
 $\mathcal{S}$
,
$\mathcal{S}$
,
 $\mathsf{EXISTS\text{-}SSOL}(\mathcal{S})$
is in PTIME.
$\mathsf{EXISTS\text{-}SSOL}(\mathcal{S})$
is in PTIME.
Proof.
It follows from Theorem 2 and (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005, Corollary 3.10).
We now move to the second crucial task: computing supported certain answers. Since this problem outputs a set, it is standard to focus on its decision version. For a fixed data exchange setting
 $\mathcal{S}$
and a fixed query Q, we consider the following decision problem:
$\mathcal{S}$
and a fixed query Q, we consider the following decision problem:

One can easily show that the above problem is logspace equivalent to the one of computing the supported certain answers.
We start by studying the problem in its full generality, and show that there is a price to pay for query answering with general queries.
Theorem 6 There exists a data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, with
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, with
 $\Sigma_t$
having only TGDs, and a query Q over
$\Sigma_t$
having only TGDs, and a query Q over
 $\mathsf{T}$
, such that
$\mathsf{T}$
, such that
 $\mathsf{SCERT}(\mathcal{S},Q)$
is undecidable.
$\mathsf{SCERT}(\mathcal{S},Q)$
is undecidable.
Proof.
We provide a polynomial-time reduction from the Embedding Problem for Finite Semigroups
 $\mathsf{EMB}$
(Reference Kolaitis, Panttaja and Tan
Kolaitis et al. 2006
). The reduction is an adaptation of the one used for proving Proposition 6.1 in (Hernich et al. Reference Hernich, Libkin and Schweikardt2011). Inputs of
$\mathsf{EMB}$
(Reference Kolaitis, Panttaja and Tan
Kolaitis et al. 2006
). The reduction is an adaptation of the one used for proving Proposition 6.1 in (Hernich et al. Reference Hernich, Libkin and Schweikardt2011). Inputs of
 $\mathsf{EMB}$
are pairs of the form A,f, where A is a finite set, and f is a partial function of the form
$\mathsf{EMB}$
are pairs of the form A,f, where A is a finite set, and f is a partial function of the form
 $f: A \times A \rightarrow A$
. The question is whether there exists a finite set
$f: A \times A \rightarrow A$
. The question is whether there exists a finite set
 $B \supseteq A$
, and a total function
$B \supseteq A$
, and a total function
 $g : B \times B \rightarrow B$
, such that g is associative,
Footnote 2
and g extends f, that is, whenever f(a,b) is defined,
$g : B \times B \rightarrow B$
, such that g is associative,
Footnote 2
and g extends f, that is, whenever f(a,b) is defined,
 $g(a,b) = f(a,b)$
.
$g(a,b) = f(a,b)$
.
Let us first introduce some notation. Consider a finite set A and a partial function
 $f : A \times A \rightarrow A$
. We define the instance:
$f : A \times A \rightarrow A$
. We define the instance:
 $$ I_{A,f} = \{\mathsf{F}(a,b,c) \mid a,b,c \in A \text{ and } f(a,b) = c\}.$$
$$ I_{A,f} = \{\mathsf{F}(a,b,c) \mid a,b,c \in A \text{ and } f(a,b) = c\}.$$
Consider now the data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S} = \{\mathsf{F}/3\}$
and
$\mathsf{S} = \{\mathsf{F}/3\}$
and
 $\mathsf{T} = \{\mathsf{G}/3\}$
. Intuitively, the relation
$\mathsf{T} = \{\mathsf{G}/3\}$
. Intuitively, the relation
 $\mathsf{F}$
collects all the triples a,b,c such that
$\mathsf{F}$
collects all the triples a,b,c such that
 $f(a,b) = c$
, whereas the relation
$f(a,b) = c$
, whereas the relation
 $\mathsf{G}$
collects all the triples of the extended associative function g. The sets
$\mathsf{G}$
collects all the triples of the extended associative function g. The sets
 $\Sigma_{st}$
and
$\Sigma_{st}$
and
 $\Sigma_t$
are defined as
$\Sigma_t$
are defined as
 $\Sigma_{st} = \{\mathsf{F}(x,y,z) \rightarrow \mathsf{G}(x,y,z)\}$
and
$\Sigma_{st} = \{\mathsf{F}(x,y,z) \rightarrow \mathsf{G}(x,y,z)\}$
and
 $\Sigma_t = \{\mathsf{G}(x,y,z) \rightarrow \exists x',y',z'\ \mathsf{G}(x',y',z') \wedge \mathsf{Aux}(x,y,z)\}$
. Roughly
$\Sigma_t = \{\mathsf{G}(x,y,z) \rightarrow \exists x',y',z'\ \mathsf{G}(x',y',z') \wedge \mathsf{Aux}(x,y,z)\}$
. Roughly
 $\Sigma_{st}$
is in charge of forcing the function stored in
$\Sigma_{st}$
is in charge of forcing the function stored in
 $\mathsf{G}$
to be an extension of the function stored in
$\mathsf{G}$
to be an extension of the function stored in
 $\mathsf{F}$
, whereas
$\mathsf{F}$
, whereas
 $\Sigma_t$
is in charge of adding additional entries to
$\Sigma_t$
is in charge of adding additional entries to
 $\mathsf{G}$
.
$\mathsf{G}$
.
The difference with the construction of (Hernich et al. Reference Hernich, Libkin and Schweikardt2011) is in the set
 $\Sigma_t$
. Here, the head of the only TGD in
$\Sigma_t$
. Here, the head of the only TGD in
 $\Sigma_t$
has an additional auxiliary atom
$\Sigma_t$
has an additional auxiliary atom
 $\mathsf{Aux}(x,y,z)$
. Intuitively, since the set
$\mathsf{Aux}(x,y,z)$
. Intuitively, since the set
 $\Sigma_t$
is in charge of extending the function defined by the relation
$\Sigma_t$
is in charge of extending the function defined by the relation
 $\mathsf{F}$
by introducing additional terms, in order for these terms to be actually introduced in a supported solution, we require that every body variable is also a frontier variable. Regarding our query Q, it is the same as the one in (Hernich et al. Reference Hernich, Libkin and Schweikardt2011). Hence, instead of giving the precise expression of Q, we only describe its properties. The query Q over
$\mathsf{F}$
by introducing additional terms, in order for these terms to be actually introduced in a supported solution, we require that every body variable is also a frontier variable. Regarding our query Q, it is the same as the one in (Hernich et al. Reference Hernich, Libkin and Schweikardt2011). Hence, instead of giving the precise expression of Q, we only describe its properties. The query Q over
 $\mathsf{T} = \{\mathsf{G}/3\}$
is a Boolean query which is true (i.e., the empty tuple is its only output) if either
$\mathsf{T} = \{\mathsf{G}/3\}$
is a Boolean query which is true (i.e., the empty tuple is its only output) if either
 $\mathsf{G}$
does not encode a function, that is, it maps the same pair (a,b) to different terms, or
$\mathsf{G}$
does not encode a function, that is, it maps the same pair (a,b) to different terms, or
 $\mathsf{G}$
does not encode an associative function, or
$\mathsf{G}$
does not encode an associative function, or
 $\mathsf{G}$
does not encode a total function. In other words, Q checks whether
$\mathsf{G}$
does not encode a total function. In other words, Q checks whether
 $\mathsf{G}$
does not encode a solution for
$\mathsf{G}$
does not encode a solution for
 $\mathsf{EMB}$
.
$\mathsf{EMB}$
.
We are now ready to present the reduction. Let A be a finite set and
 $f : A \times A \rightarrow A$
be a partial function. The reduction constructs the source instance
$f : A \times A \rightarrow A$
be a partial function. The reduction constructs the source instance
 $I_{A,f}$
and the empty tuple
$I_{A,f}$
and the empty tuple
 $\mathbf{t} = ()$
. Clearly,
$\mathbf{t} = ()$
. Clearly,
 $I_{A,f}$
can be constructed in polynomial time w.r.t.
$I_{A,f}$
can be constructed in polynomial time w.r.t.
 $|I|$
. It remains to show that A,f is a “yes”-instance of
$|I|$
. It remains to show that A,f is a “yes”-instance of
 $\mathsf{EMB}$
iff
$\mathsf{EMB}$
iff
 $\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I_{A,f},Q)$
.
$\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I_{A,f},Q)$
.
(Only if direction) Assume
 $\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I_{A,f},Q)$
. Then, there exists a supported solution
$\mathbf{t} \not \in \mathsf{scert}_{\mathcal{S}}(I_{A,f},Q)$
. Then, there exists a supported solution
 $J \in \mathsf{ssol}(I_{A,f},\mathcal{S})$
of
$J \in \mathsf{ssol}(I_{A,f},\mathcal{S})$
of
 $I_{A,f}$
w.r.t.
$I_{A,f}$
w.r.t.
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $\mathbf{t} \not \in Q(J)$
. By definition of supported solution, J is finite and it only contains atoms with relation
$\mathbf{t} \not \in Q(J)$
. By definition of supported solution, J is finite and it only contains atoms with relation
 $\mathsf{G}$
. Thus, by definition of
$\mathsf{G}$
. Thus, by definition of
 $\mathcal{S}$
,
$\mathcal{S}$
,
 $\mathbf{t} \not \in Q(J)$
implies that J necessarily encodes an extension of f, which is also total and associative.
$\mathbf{t} \not \in Q(J)$
implies that J necessarily encodes an extension of f, which is also total and associative.
(If direction) Assume A,f is a “yes”-instance of
 $\mathsf{EMB}$
, and let
$\mathsf{EMB}$
, and let
 $B \supseteq A$
be a finite set, and
$B \supseteq A$
be a finite set, and
 $g : B \times B \rightarrow B$
be the total associative function that extends f. Then, consider the instance J over
$g : B \times B \rightarrow B$
be the total associative function that extends f. Then, consider the instance J over
 $\mathsf{T}$
defined as
$\mathsf{T}$
defined as
 $J = \{\mathsf{G}(a,b,c) \mid a,b,c \in B \text{ and } g(a,b) = c \}$
. It is not difficult to verify that J is a supported solution of
$J = \{\mathsf{G}(a,b,c) \mid a,b,c \in B \text{ and } g(a,b) = c \}$
. It is not difficult to verify that J is a supported solution of
 $I_{A,f}$
w.r.t.
$I_{A,f}$
w.r.t.
 $\mathcal{S}$
. Finally, by construction of J,
$\mathcal{S}$
. Finally, by construction of J,
 $\mathbf{t} \not \in Q(J)$
as needed.
$\mathbf{t} \not \in Q(J)$
as needed.
Although the complexity result above tells us that computing supported certain answers might be infeasible in some settings, we can show that for weakly-acyclic settings, the complexity is more manageable. In particular, we prove that in this case, the problem is in
 $\text{ co}\text{ NP}$
and that this complexity bound is tight (i.e., there exist weakly-acyclic settings and queries for which the problem is
$\text{ co}\text{ NP}$
and that this complexity bound is tight (i.e., there exist weakly-acyclic settings and queries for which the problem is
 $\text{co}\text{NP}\text{-hard}$
). We first focus on the upper bound.
$\text{co}\text{NP}\text{-hard}$
). We first focus on the upper bound.
Theorem 7 For every weakly-acyclic setting
 $\mathcal{S}$
and every query Q,
$\mathcal{S}$
and every query Q,
 $\mathsf{SCERT}(\mathcal{S},Q)$
is in
$\mathsf{SCERT}(\mathcal{S},Q)$
is in
 $\text{co}\text{NP}$
.
$\text{co}\text{NP}$
.
Proof. We provide a non-deterministic polynomial-time procedure for solving the complement of the problem
 $\mathsf{SCERT}(\mathcal{S},Q)$
, when
$\mathsf{SCERT}(\mathcal{S},Q)$
, when
 $\mathcal{S}$
is a weakly-acyclic data exchange setting. That is, given a source instance I of
$\mathcal{S}$
is a weakly-acyclic data exchange setting. That is, given a source instance I of
 $\mathcal{S}$
and a tuple
$\mathcal{S}$
and a tuple
 $\mathbf{t} \in \mathsf{Const}^{ar(Q)}$
, the procedure non-deterministically constructs a supported solution
$\mathbf{t} \in \mathsf{Const}^{ar(Q)}$
, the procedure non-deterministically constructs a supported solution
 $J^*$
of I w.r.t.
$J^*$
of I w.r.t.
 $\mathcal{S}$
(if one exists), and checks whether
$\mathcal{S}$
(if one exists), and checks whether
 $\mathbf{t} \not \in Q(J^*)$
. Let
$\mathbf{t} \not \in Q(J^*)$
. Let
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and consider a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and consider a source instance I of
 $\mathcal{S}$
, a query Q over
$\mathcal{S}$
, a query Q over
 $\mathsf{T}$
, and a tuple
$\mathsf{T}$
, and a tuple
 $\mathbf{t} \in \mathsf{Const}^{ar(Q)}$
.
$\mathbf{t} \in \mathsf{Const}^{ar(Q)}$
.
The procedure is defined in two parts. The first part is in charge of non-deterministically constructing a supported solution
 $J^*$
. If the procedure was not able to construct a supported solution (i.e., no such solution exists, or it followed a wrong computation path), the procedure sets
$J^*$
. If the procedure was not able to construct a supported solution (i.e., no such solution exists, or it followed a wrong computation path), the procedure sets
 $J^* =\; \perp$
. The second part simply verifies whether either
$J^* =\; \perp$
. The second part simply verifies whether either
 $J^*=\; \perp$
, in which case it rejects, or it checks whether
$J^*=\; \perp$
, in which case it rejects, or it checks whether
 $\mathbf{t} \not \in Q(J^*)$
, in which case accepts, otherwise rejects. The second part can be easily implemented by a deterministic polynomial-time procedure; we now show the first procedure constructing
$\mathbf{t} \not \in Q(J^*)$
, in which case accepts, otherwise rejects. The second part can be easily implemented by a deterministic polynomial-time procedure; we now show the first procedure constructing
 $J^*$
.
$J^*$
.
This procedure implements a variation of the so-called semi-oblivious chase algorithm; we refer the reader to (Marnette Reference Marnette2009) for more details. In the following, for each TGD
 $\rho \in \Sigma_{st} \cup \Sigma_t$
, let
$\rho \in \Sigma_{st} \cup \Sigma_t$
, let
 $\mathsf{Chosen}_\rho$
be a fresh relation, not occurring in
$\mathsf{Chosen}_\rho$
be a fresh relation, not occurring in
 $\mathsf{S} \cup \mathsf{T}$
, of arity
$\mathsf{S} \cup \mathsf{T}$
, of arity
 $|\mathsf{fr}(\rho)|$
.
$|\mathsf{fr}(\rho)|$
.
-
1. Let
$J_0 = I$
, and let the current step be
$i = 0$
. -
2. If
$J_i$
does not satisfy the EGDs in
$\Sigma_t$
, then let
$J^* =\; \perp$
and halt; -
3. If
$J_i$
satisfies the EGDs in
$\Sigma_t$
, and no TGD
$\rho \in \Sigma_{st} \cup \Sigma_t$
and homomorphism h from
$\mathsf{body}(\rho)$
to
$J_i$
exist such that
$\mathsf{Chosen}_\rho(h(\mathsf{fr}(\rho))) \not \in J_i$
, then let
$J^*$
be
$J_i$
after removing all atoms over
$\mathsf{S}$
and the atoms using the
$\mathsf{Chosen}$
predicates, and halt. -
4. Otherwise, guess a TGD
$\rho_i \in \Sigma_{st} \cup \Sigma_t$
and a homomorphism
$h_i$
from
$\mathsf{body}(\rho_i)$
to
$J_i$
such that
$\mathsf{Chosen}_{\rho_i}(h_i(\mathsf{fr}(\rho_i))) \not \in J_i$
, and guess an extension
$h_i'$
of
$h_i$
such that, for each
$z \in \mathsf{exvar}(\rho_i)$
,
$h_i'(z)=c^i_z$
, where either
$c^i_z$
is a constant occurring in one of
$\mathcal{S}$
, I, Q, or a fresh new constant. Finally, let
$J_{i+1} = J_i \cup h_i'(\mathsf{head}(\rho_i)) \cup \{\mathsf{Chosen}_{\rho_i}(h_i(\mathsf{fr}(\rho_i))) \}$
. Let
$i := i + 1$
and goto 2.




























To show that the procedure above terminates after a polynomial number of steps, we can use a similar argument to the one given for proving Theorem 3.9 in (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). We now show that, for every target instance J of
 $\mathcal{S}$
, a run of the above procedure halting with
$\mathcal{S}$
, a run of the above procedure halting with
 $J^* = J$
exists iff J is a supported solution of I w.r.t.
$J^* = J$
exists iff J is a supported solution of I w.r.t.
 $\mathcal{S}$
, and the claim will follow. We focus on one of the two directions, as the other direction can be proved in a similar way.
$\mathcal{S}$
, and the claim will follow. We focus on one of the two directions, as the other direction can be proved in a similar way.
Assume there is a run of n steps of the procedure above with
 $J^* = J$
, for some target instance J of
$J^* = J$
, for some target instance J of
 $\mathcal{S}$
, and let
$\mathcal{S}$
, and let
 $\rho_i$
,
$\rho_i$
,
 $h_i,$
and
$h_i,$
and
 $c^i_z$
, for
$c^i_z$
, for
 $z \in \mathsf{exvar}(\rho_i)$
be the TGD, homomorphism, and constants guessed at step i in the run. Let
$z \in \mathsf{exvar}(\rho_i)$
be the TGD, homomorphism, and constants guessed at step i in the run. Let
 $\gamma$
be the ex-choice such that, for each
$\gamma$
be the ex-choice such that, for each
 $i \in \{1,\ldots,n\}$
,
$i \in \{1,\ldots,n\}$
,
 $\gamma(\rho_i,h_i(\mathsf{fr}(\rho_i))) = \{(z,c^i_z) \mid z \in \mathsf{exvar}(\rho_i)\}$
. The fact that
$\gamma(\rho_i,h_i(\mathsf{fr}(\rho_i))) = \{(z,c^i_z) \mid z \in \mathsf{exvar}(\rho_i)\}$
. The fact that
 $\gamma$
is indeed an ex-choice follows from the fact that at each step
$\gamma$
is indeed an ex-choice follows from the fact that at each step
 $i \in \{1,\ldots,n\}$
, a constant
$i \in \{1,\ldots,n\}$
, a constant
 $c^i_z$
is introduced only if
$c^i_z$
is introduced only if
 $\mathsf{Chosen}_{\rho_i}(h_i(\mathsf{fr}(\rho_i))) \not \in J_i$
, which in turn implies that no constant has been chosen at some step
$\mathsf{Chosen}_{\rho_i}(h_i(\mathsf{fr}(\rho_i))) \not \in J_i$
, which in turn implies that no constant has been chosen at some step
 $j<i$
, where
$j<i$
, where
 $h_j(\mathsf{fr}(\rho_j)) = h_i(\mathsf{fr}(\rho_i))$
. By definition of the procedure, J is the instance obtained from
$h_j(\mathsf{fr}(\rho_j)) = h_i(\mathsf{fr}(\rho_i))$
. By definition of the procedure, J is the instance obtained from
 $J_n$
where all the atoms with relations in
$J_n$
where all the atoms with relations in
 $\mathsf{S}$
or of the form
$\mathsf{S}$
or of the form
 $\mathsf{Chosen}_{\rho}$
are removed. Hence, by construction,
$\mathsf{Chosen}_{\rho}$
are removed. Hence, by construction,
 $I \cup J$
satisfies
$I \cup J$
satisfies
 $\Sigma_{st}^\gamma$
and J satisfies all the TGDs in
$\Sigma_{st}^\gamma$
and J satisfies all the TGDs in
 $\Sigma_t^\gamma$
. Since
$\Sigma_t^\gamma$
. Since
 $J \neq\; \perp$
, J also satisfies the EGDs in
$J \neq\; \perp$
, J also satisfies the EGDs in
 $\Sigma_t^\gamma$
. Moreover, no
$\Sigma_t^\gamma$
. Moreover, no
 $J' \subsetneq J$
is such that
$J' \subsetneq J$
is such that
 $I \cup J'$
satisfies
$I \cup J'$
satisfies
 $\Sigma_{st}^\gamma$
and J’ satisfies
$\Sigma_{st}^\gamma$
and J’ satisfies
 $\Sigma_t^\gamma$
. If this is the case, let
$\Sigma_t^\gamma$
. If this is the case, let
 $\alpha \in J \setminus J'$
, and let
$\alpha \in J \setminus J'$
, and let
 $i \in \{1,\ldots,n\}$
be the step in the above run where
$i \in \{1,\ldots,n\}$
be the step in the above run where
 $\alpha$
is added in
$\alpha$
is added in
 $J_{i+1}$
. Then, the TGD
$J_{i+1}$
. Then, the TGD
 $\rho' = h_i(\rho_i) \rightarrow h_i'(\mathsf{head}(\rho_i))$
is in
$\rho' = h_i(\rho_i) \rightarrow h_i'(\mathsf{head}(\rho_i))$
is in
 $\Sigma_{st}^\gamma \cup \Sigma_t^\gamma$
, by construction of
$\Sigma_{st}^\gamma \cup \Sigma_t^\gamma$
, by construction of
 $\gamma$
. However J’ does not satisfy
$\gamma$
. However J’ does not satisfy
 $\rho'$
. The latter, together with the previous discussion implies that J is a supported solution of I w.r.t.
$\rho'$
. The latter, together with the previous discussion implies that J is a supported solution of I w.r.t.
 $\mathcal{S}$
.
$\mathcal{S}$
.
We point out that the above result is in contrast with all the data exchange semantics discussed in the introduction, for which computing certain answers is undecidable, even for weakly-acyclic settings (Hernich et al. Reference Hernich, Libkin and Schweikardt2011; Hernich Reference Hernich2011).
We now move to the lower bound and show that the
 $\text{co}\text{NP}$
upper bound is tight.
$\text{co}\text{NP}$
upper bound is tight.
Theorem 8 There exists a weakly-acyclic setting
 $\mathcal{S}$
that is TGD-only and a query Q such that
$\mathcal{S}$
that is TGD-only and a query Q such that
 $\mathsf{SCERT}(\mathcal{S},Q)$
is
$\mathsf{SCERT}(\mathcal{S},Q)$
is
 $\text{co}\text{NP}\text{-hard}$
.
$\text{co}\text{NP}\text{-hard}$
.
Proof.
The
 $\text{co}\text{NP}\text{-hard}$
ness is proved via a reduction from 3-colorability to the complement of our problem. We encode the input graph
$\text{co}\text{NP}\text{-hard}$
ness is proved via a reduction from 3-colorability to the complement of our problem. We encode the input graph
 $G = (V,E)$
as the instance
$G = (V,E)$
as the instance
 \[ \begin{array}{ll} I_G = & \{\mathsf{V}(u) \mid u \in V\} \cup \{\mathsf{E_s}(u,v) \mid (u,v) \in E\} \cup \\ & \{\mathsf{Col}(c) \mid c \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}\}. \end{array} \]
\[ \begin{array}{ll} I_G = & \{\mathsf{V}(u) \mid u \in V\} \cup \{\mathsf{E_s}(u,v) \mid (u,v) \in E\} \cup \\ & \{\mathsf{Col}(c) \mid c \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}\}. \end{array} \]
Colorings are constructed in the setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, via the source-to-target TGDs (
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, via the source-to-target TGDs (
 $\Sigma_t$
is empty):
$\Sigma_t$
is empty):
 \[ \begin{array}{ll} &\rho_1 = \mathsf{Col}(x) \rightarrow \mathsf{Col_t}(x), \\ &\rho_2 = \mathsf{E_s}(x,y) \rightarrow \mathsf{E_t}(x,y), \\ &\rho_3 = \mathsf{V}(x) \rightarrow \exists z\, \mathsf{HasC}(x,z), \end{array} \]
\[ \begin{array}{ll} &\rho_1 = \mathsf{Col}(x) \rightarrow \mathsf{Col_t}(x), \\ &\rho_2 = \mathsf{E_s}(x,y) \rightarrow \mathsf{E_t}(x,y), \\ &\rho_3 = \mathsf{V}(x) \rightarrow \exists z\, \mathsf{HasC}(x,z), \end{array} \]
where
 $\mathsf{Col_t}$
collects all colors,
$\mathsf{Col_t}$
collects all colors,
 $\mathsf{E_t}$
contains the edges of the graph in the target schema, and
$\mathsf{E_t}$
contains the edges of the graph in the target schema, and
 $\mathsf{HasC}$
assigns a term to each node of the graph.
$\mathsf{HasC}$
assigns a term to each node of the graph.
The Boolean query
 $Q = Q_1 \vee Q_2$
is true over an instance of the target schema iff the instance does not encode a valid 3-coloring. In particular,
$Q = Q_1 \vee Q_2$
is true over an instance of the target schema iff the instance does not encode a valid 3-coloring. In particular,
 $Q_1$
checks whether the “color” used for some node differs from
$Q_1$
checks whether the “color” used for some node differs from
 $\mathsf{r},\mathsf{g}, \mathsf{b}$
:
$\mathsf{r},\mathsf{g}, \mathsf{b}$
:
 $$Q_1 = \exists x,y\, \mathsf{HasC}(x,y) \wedge \neg \mathsf{Col_t}(y),$$
$$Q_1 = \exists x,y\, \mathsf{HasC}(x,y) \wedge \neg \mathsf{Col_t}(y),$$
whereas
 $Q_2$
checks whether the nodes of an edge have the same color:
$Q_2$
checks whether the nodes of an edge have the same color:
 \begin{align*} && Q_2 = \exists x,y,z\, \mathsf{E_t}(x,y) \wedge \mathsf{HasC}(x,z) \wedge \mathsf{HasC}(y,z). && \end{align*}
\begin{align*} && Q_2 = \exists x,y,z\, \mathsf{E_t}(x,y) \wedge \mathsf{HasC}(x,z) \wedge \mathsf{HasC}(y,z). && \end{align*}
We prove that G admits a 3-coloring iff
 $\mathbf{t} = () \not \in \mathsf{scert}_{\mathcal{S}}(I_G,Q)$
.
$\mathbf{t} = () \not \in \mathsf{scert}_{\mathcal{S}}(I_G,Q)$
.
(Only if direction) Assume G admits a 3-coloring
 $\mu$
and consider the instance
$\mu$
and consider the instance
 \[ \begin{array}{ll} J=&\{\mathsf{HasC}(v,\mu(v)) \mid v \in V\} \cup \{\mathsf{E_t}(u,v) \mid (u,v) \in E\} \cup \{\mathsf{Col_t}(c) \mid c \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}\}. \end{array} \]
\[ \begin{array}{ll} J=&\{\mathsf{HasC}(v,\mu(v)) \mid v \in V\} \cup \{\mathsf{E_t}(u,v) \mid (u,v) \in E\} \cup \{\mathsf{Col_t}(c) \mid c \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}\}. \end{array} \]
It is not difficult to see that J is a supported solution of
 $I_G$
w.r.t.
$I_G$
w.r.t.
 $\mathcal{S}$
. Clearly,
$\mathcal{S}$
. Clearly,
 $\mathbf{t} \not \in Q(J)$
and the claim follows.
$\mathbf{t} \not \in Q(J)$
and the claim follows.
(If direction) Assume that G does not admit a 3-coloring, and consider an arbitrary supported solution J of
 $I_G$
w.r.t.
$I_G$
w.r.t.
 $\mathcal{S}$
. Note that for every edge
$\mathcal{S}$
. Note that for every edge
 $(u,v) \in E$
, we have that
$(u,v) \in E$
, we have that
 $\mathsf{E_t}(u,v) \in J$
and
$\mathsf{E_t}(u,v) \in J$
and
 $\mathsf{HasC}(u,c_1),\mathsf{HasC}(v,c_2) \in J$
, for some constants
$\mathsf{HasC}(u,c_1),\mathsf{HasC}(v,c_2) \in J$
, for some constants
 $c_1,c_2$
. We distinguish two cases. Assume that there is an edge
$c_1,c_2$
. We distinguish two cases. Assume that there is an edge
 $(u,v) \in E$
such that
$(u,v) \in E$
such that
 $c_1 \not \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
or
$c_1 \not \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
or
 $c_2 \not \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
. Thus,
$c_2 \not \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
. Thus,
 $\mathbf{t} \in Q_1(J)$
which implies
$\mathbf{t} \in Q_1(J)$
which implies
 $\mathbf{t} \in Q(J)$
. Assume now that for every edge
$\mathbf{t} \in Q(J)$
. Assume now that for every edge
 $(u,v) \in E$
,
$(u,v) \in E$
,
 $c_1,c_2 \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
. Thus, since G does not admit a 3-coloring, for at least one edge
$c_1,c_2 \in \{\mathsf{r},\mathsf{g},\mathsf{b}\}$
. Thus, since G does not admit a 3-coloring, for at least one edge
 $(u,v) \in E$
,
$(u,v) \in E$
,
 $c_1 =c_2$
. Hence,
$c_1 =c_2$
. Hence,
 $\mathbf{t} \in Q_2(J)$
, which implies that
$\mathbf{t} \in Q_2(J)$
, which implies that
 $\mathbf{t} \in Q(J)$
and the claim follows.
$\mathbf{t} \in Q(J)$
and the claim follows.
We point out that the query employed in the proof of the above theorem is a simple Boolean combination of CQs. This kind of FO queries have been studied in the context of incomplete databases, for example, see (Gheerbrant and Libkin Reference Gheerbrant and Libkin2015). However, differently from the incomplete databases setting, where such queries guarantee query answering in polynomial time, the complexity in our setting is higher, due to the presence of TGDs; the latter is true even for weakly-acyclic TGDs, as shown by Theorem 8 above. Similarly, arbitrary FO queries (e.g., involving also universal quantification) behave very differently depending on the given setting. For example, according to Theorem 7, for any FO query, supported certain answers remain in
 $\text{co}\text{NP}$
, under weakly-acyclic settings, while for arbitrary settings, the use of universal quantification makes supported certain answering undecidable; the latter is a consequence of the proof of Theorem 6. Hence, one cannot directly conclude much on the complexity of supported certain answers by considering the query alone, as done for querying incomplete databases.
$\text{co}\text{NP}$
, under weakly-acyclic settings, while for arbitrary settings, the use of universal quantification makes supported certain answering undecidable; the latter is a consequence of the proof of Theorem 6. Hence, one cannot directly conclude much on the complexity of supported certain answers by considering the query alone, as done for querying incomplete databases.
We conclude this section by recalling that for positive queries, supported certain answers coincide with the classical ones (Theorem 3), and computing (classical) certain answers for weakly-acyclic settings, under positive queries, is tractable (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005). Hence, the result below follows.
Corollary 2 For every weakly-acyclic setting
 $\mathcal{S}$
and every positive query Q,
$\mathcal{S}$
and every positive query Q,
 $\mathsf{SCERT}(\mathcal{S},Q)$
is in PTIME.
$\mathsf{SCERT}(\mathcal{S},Q)$
is in PTIME.
5 Exact query answering via logic programming
In this section, we show how to compute supported certain answers exactly by means of a translation into logic programming under the stable model semantics, that is, answer set programming (ASP). First, we need to recall the syntax and semantics of logic programs. In particular, we focus on a fragment of logic programs that is enough for our purposes, which is Datalog with (possibly non-stratified) negation, which means we do not allow for function symbols or disjunctive rules.
Syntax. A literal L is an expression of the form
 $\alpha$
or
$\alpha$
or
 $\neg \alpha$
, where
$\neg \alpha$
, where
 $\alpha$
is either an atom without nulls, or the expression
$\alpha$
is either an atom without nulls, or the expression
 $t_1 = t_2$
, where
$t_1 = t_2$
, where
 $t_1,t_2$
are variables or constants; we write
$t_1,t_2$
are variables or constants; we write
 $t_1 \neq t_2$
for
$t_1 \neq t_2$
for
 $\neg t_1 = t_2$
. We say that L is positive (resp., negative) if
$\neg t_1 = t_2$
. We say that L is positive (resp., negative) if
 $L = \alpha$
(resp.,
$L = \alpha$
(resp.,
 $L = \neg \alpha$
). If a literal contains no variables, it is said to be ground.
$L = \neg \alpha$
). If a literal contains no variables, it is said to be ground.
A rule r is an expression of the form
 $$ H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m .$$
$$ H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m .$$
with
 $n \ge 0$
,
$n \ge 0$
,
 $m \ge 0$
, and where H is either a positive literal or the symbol
$m \ge 0$
, and where H is either a positive literal or the symbol
 $\perp$
,
$\perp$
,
 $A_1,\ldots,A_n$
are positive literals, and
$A_1,\ldots,A_n$
are positive literals, and
 $\neg B_1,\ldots,\neg B_m$
are negative literals. We denote
$\neg B_1,\ldots,\neg B_m$
are negative literals. We denote
 $\mathsf{head}(r) = \{H\}$
as the head of r, while
$\mathsf{head}(r) = \{H\}$
as the head of r, while
 $\mathsf{body}(r) = \{A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m\}$
is the body of r; we use
$\mathsf{body}(r) = \{A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m\}$
is the body of r; we use
 $\mathsf{body}^+(r)$
to denote
$\mathsf{body}^+(r)$
to denote
 $\{A_1,\ldots,A_n\}$
, and
$\{A_1,\ldots,A_n\}$
, and
 $\mathsf{body}^-(r)$
to denote
$\mathsf{body}^-(r)$
to denote
 $\{B_1,\ldots,B_m\}$
. If
$\{B_1,\ldots,B_m\}$
. If
 $H =\; \perp$
, we say that r is a constraint. If
$H =\; \perp$
, we say that r is a constraint. If
 $m=0$
, we say the rule is positive; if r contains no variables, it is said to be ground. We say the rule r is safe if every variable in the rule occurs in some literal of
$m=0$
, we say the rule is positive; if r contains no variables, it is said to be ground. We say the rule r is safe if every variable in the rule occurs in some literal of
 $\mathsf{body}^+(r)$
. We will require every rule to be safe (besides being a common requirement, safe rules suffice for our purposes).
$\mathsf{body}^+(r)$
. We will require every rule to be safe (besides being a common requirement, safe rules suffice for our purposes).
As customary, we will consider two kinds of sets of rules:
-
1. finite sets of rules of the form
$H \text{ :- }$
, with
$H \neq \bot$
(notice that such rules must be ground because of safety), which are commonly used to represent databases – a set of this kind will be called an extensional database; -
2. finite sets of rules of any other form – a set of this kind will be called a program.


Semantics. Let
 $\mathcal{P}$
be a program and
$\mathcal{P}$
be a program and
 $\mathit{ED}$
an extensional database. We will often use
$\mathit{ED}$
an extensional database. We will often use
 $\mathcal{P}_{\mathit{ED}}$
to denote the set
$\mathcal{P}_{\mathit{ED}}$
to denote the set
 $\mathcal{P} \cup \mathit{ED}$
. The Herbrand universe of
$\mathcal{P} \cup \mathit{ED}$
. The Herbrand universe of
 $\mathcal{P}_{\mathit{ED}}$
, denoted
$\mathcal{P}_{\mathit{ED}}$
, denoted
 $\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})$
, is the set of all constants occurring in
$\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})$
, is the set of all constants occurring in
 $\mathcal{P}_{\mathit{ED}}$
. The Herbrand base of
$\mathcal{P}_{\mathit{ED}}$
. The Herbrand base of
 $\mathcal{P}_{\mathit{ED}}$
, denoted
$\mathcal{P}_{\mathit{ED}}$
, denoted
 $\mathsf{base}(\mathcal{P}_{\mathit{ED}})$
, is the set of all atoms that can be built using relations and constants occurring in
$\mathsf{base}(\mathcal{P}_{\mathit{ED}})$
, is the set of all atoms that can be built using relations and constants occurring in
 $\mathcal{P}_{\mathit{ED}}$
. A ground version of a rule
$\mathcal{P}_{\mathit{ED}}$
. A ground version of a rule
 $r \in \mathcal{P}_{\mathit{ED}}$
is a ground rule r’ that can be obtained from r by replacing all occurrences of each variable x of r with some constant from
$r \in \mathcal{P}_{\mathit{ED}}$
is a ground rule r’ that can be obtained from r by replacing all occurrences of each variable x of r with some constant from
 $\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})$
.
$\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})$
.
The grounding of
 $\mathcal{P}_{\mathit{ED}}$
, denoted
$\mathcal{P}_{\mathit{ED}}$
, denoted
 $\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
, is the set of rules obtained from
$\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
, is the set of rules obtained from
 $\mathcal{P}_{\mathit{ED}}$
by replacing each rule
$\mathcal{P}_{\mathit{ED}}$
by replacing each rule
 $r \in \mathcal{P}_{\mathit{ED}}$
with all its ground versions.
$r \in \mathcal{P}_{\mathit{ED}}$
with all its ground versions.
We say that an instance I satisfies a ground positive literal L if either L is of the form
 $\alpha = \beta$
and
$\alpha = \beta$
and
 $\alpha$
and
$\alpha$
and
 $\beta$
are the same constant, or L is an atom occurring in I. Furthermore, we say that I satisfies a ground negative literal
$\beta$
are the same constant, or L is an atom occurring in I. Furthermore, we say that I satisfies a ground negative literal
 $\neg L$
, if I does not satisfy L. Finally, I satisfies a set of ground literals if I satisfies each literal in it.
$\neg L$
, if I does not satisfy L. Finally, I satisfies a set of ground literals if I satisfies each literal in it.
Consider a rule
 $r \in \mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
and an instance I. We say that I satisfies r if, either r is a constraint and I does not satisfy
$r \in \mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
and an instance I. We say that I satisfies r if, either r is a constraint and I does not satisfy
 $\mathsf{body}(r)$
, or I satisfies
$\mathsf{body}(r)$
, or I satisfies
 $\mathsf{body}(r)$
implies that I satisfies
$\mathsf{body}(r)$
implies that I satisfies
 $\mathsf{head}(r)$
(notice that an empty body is always satisfied).
$\mathsf{head}(r)$
(notice that an empty body is always satisfied).
A model of
 $\mathcal{P}_{\mathit{ED}}$
is an instance M such that
$\mathcal{P}_{\mathit{ED}}$
is an instance M such that
 $M \subseteq \mathsf{base}(\mathcal{P}_{\mathit{ED}})$
and such that M satisfies each rule of
$M \subseteq \mathsf{base}(\mathcal{P}_{\mathit{ED}})$
and such that M satisfies each rule of
 $\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
. We say that M is minimal if there is no other model M’ of
$\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
. We say that M is minimal if there is no other model M’ of
 $\mathcal{P}$
such that
$\mathcal{P}$
such that
 $M' \subsetneq M$
. We use
$M' \subsetneq M$
. We use
 $\mathsf{MM}(\mathcal{P}_{\mathit{ED}})$
to denote the set of all minimal models of
$\mathsf{MM}(\mathcal{P}_{\mathit{ED}})$
to denote the set of all minimal models of
 $\mathcal{P}$
.
$\mathcal{P}$
.
The reduct of
 $\mathcal{P}_{\mathit{ED}}$
w.r.t. some instance I is the set of ground rules obtained from
$\mathcal{P}_{\mathit{ED}}$
w.r.t. some instance I is the set of ground rules obtained from
 $\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
by removing each rule r for which I does not satisfy
$\mathsf{ground}(\mathcal{P}_{\mathit{ED}})$
by removing each rule r for which I does not satisfy
 $\mathsf{body}^-(r)$
, and by removing all negative literals from the body of each rule r for which I satisfies
$\mathsf{body}^-(r)$
, and by removing all negative literals from the body of each rule r for which I satisfies
 $\mathsf{body}^-(r)$
.
$\mathsf{body}^-(r)$
.
An instance M is a stable model of
 $\mathcal{P}_{\mathit{ED}}$
if
$\mathcal{P}_{\mathit{ED}}$
if
 $M \in \mathsf{MM}(\mathcal{P}_{\mathit{ED}}')$
, where
$M \in \mathsf{MM}(\mathcal{P}_{\mathit{ED}}')$
, where
 $\mathcal{P}_{\mathit{ED}}'$
is the reduct of
$\mathcal{P}_{\mathit{ED}}'$
is the reduct of
 $\mathcal{P}_{\mathit{ED}}$
w.r.t. M. We use
$\mathcal{P}_{\mathit{ED}}$
w.r.t. M. We use
 $\mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
to denote the set of all stable models of
$\mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
to denote the set of all stable models of
 $\mathcal{P}_{\mathit{ED}}$
.
$\mathcal{P}_{\mathit{ED}}$
.
Cautious Reasoning. Consider an extensional database
 $\mathit{ED}$
, a program
$\mathit{ED}$
, a program
 $\mathcal{P}$
, and a query Q. The cautious answers to Q over
$\mathcal{P}$
, and a query Q. The cautious answers to Q over
 $\mathit{ED}$
and
$\mathit{ED}$
and
 $\mathcal{P}$
is the set:
$\mathcal{P}$
is the set:
 $$ \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q) = \bigcap_{M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})} Q(M).$$
$$ \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q) = \bigcap_{M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})} Q(M).$$
The key task we are interested in, regarding logic programs, is computing cautious answers. In particular, we are interested in its data complexity, that is, when the program and the query are fixed; as usual, we focus on the decision version of the problem. In the following,
 $\mathcal{P}$
and Q denote some program and some query, respectively:
$\mathcal{P}$
and Q denote some program and some query, respectively:

It is well known that for every program
 $\mathcal{P}$
and every query Q,
$\mathcal{P}$
and every query Q,
 $\mathsf{CANS}(\mathcal{P},Q)$
is in
$\mathsf{CANS}(\mathcal{P},Q)$
is in
 $\text{co}\text{NP}$
– e.g., see (Greco et al. Reference Greco, Saccà and Zaniolo1995).
$\text{co}\text{NP}$
– e.g., see (Greco et al. Reference Greco, Saccà and Zaniolo1995).
The choice construct. We now extend logic programs with an additional construct, called choice. We point out that extending logic programs with the choice is purely for syntactic convenience, as this construct can be implemented by means of standard rules with negation.
The choice construct has been introduced in Datalog in (Saccà and Zaniolo Reference Saccà and Zaniolo1990), studied in (Giannotti et al. Reference Giannotti, Pedreschi, Saccà and Zaniolo1991; Greco et al. Reference Greco, Saccà and Zaniolo1995; Greco and Zaniolo Reference Greco and Zaniolo1998; Greco et al. Reference Greco, Zaniolo and Ganguly1992), and implemented in the Datalog systems LDL++ (Arni et al. Reference Arni, Ong, Tsur, Wang and Zaniolo2003) and, in some form, in recent ASP systems (e.g., Potassco (Gebser et al. Reference Gebser, Kaufmann, Kaminski, Ostrowski, Schaub and Schneider2011) and DLV (Alviano et al. Reference Alviano, Faber, Leone, Perri, Pfeifer and Terracina2010)). It is used to enforce functional dependency (FD) constraints on rules of a logic program.
A choice rule r is an expression of the form
 $$ H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m,\textit{choice}((X),(Y)).$$
$$ H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m,\textit{choice}((X),(Y)).$$
where n, m, H,
 $A_1,\ldots,A_n$
, and
$A_1,\ldots,A_n$
, and
 $B_1,\ldots,B_m$
are all defined as for standard rules, while X and Y denote disjoint sets of variables occurring in
$B_1,\ldots,B_m$
are all defined as for standard rules, while X and Y denote disjoint sets of variables occurring in
 $\mathsf{body}(r)$
.
Footnote 3
The original definition of choice rule allows for multiple choice constructs in the rule body; here we focus on choice rules with only one choice construct in the body as this is enough for our purposes.
$\mathsf{body}(r)$
.
Footnote 3
The original definition of choice rule allows for multiple choice constructs in the rule body; here we focus on choice rules with only one choice construct in the body as this is enough for our purposes.
Intuitively, the construct
 $\textit{choice}((X),(Y))$
prescribes that the set of all consequences derived from r must respect the FD
$\textit{choice}((X),(Y))$
prescribes that the set of all consequences derived from r must respect the FD
 $X \rightarrow Y$
.
$X \rightarrow Y$
.
The formal semantics of choice rules is given in terms of a translation to standard rules using negation. In particular, the choice rule r defined above is a shorthand for writing the following set of rules; in what follows,
 $\mathbf{x}$
and
$\mathbf{x}$
and
 $\mathbf{y}$
are the tuples of all variables in X and Y, respectively, in some arbitrary order.
$\mathbf{y}$
are the tuples of all variables in X and Y, respectively, in some arbitrary order.
 \[\begin{array}{ll} r^{(1)}: & \mathsf{Range}_r(\mathbf{y}) \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m. \\ r^{(2)}: & H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m, \mathsf{Chosen}_r(\mathbf{x}, \mathbf{y}). \\ r^{(3)} : & \mathsf{Chosen}_r(\mathbf{x}, \mathbf{y}) \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m, \neg \mathsf{DiffChoice}_r(\mathbf{x}, \mathbf{y}). \\ r^{(4)}_i : & \mathsf{DiffChoice}_r(\mathbf{x}, \mathbf{y}) \text{ :- } \mathsf{Chosen}_r(\mathbf{x}, \mathbf{w}), \mathsf{Range}_r(\mathbf{y}), \mathbf{y}[i] \neq \mathbf{w}[i],\ \forall i \in \{1,\ldots,|Y|\}.\end{array}\]
\[\begin{array}{ll} r^{(1)}: & \mathsf{Range}_r(\mathbf{y}) \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m. \\ r^{(2)}: & H \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m, \mathsf{Chosen}_r(\mathbf{x}, \mathbf{y}). \\ r^{(3)} : & \mathsf{Chosen}_r(\mathbf{x}, \mathbf{y}) \text{ :- } A_1,\ldots,A_n, \neg B_1,\ldots,\neg B_m, \neg \mathsf{DiffChoice}_r(\mathbf{x}, \mathbf{y}). \\ r^{(4)}_i : & \mathsf{DiffChoice}_r(\mathbf{x}, \mathbf{y}) \text{ :- } \mathsf{Chosen}_r(\mathbf{x}, \mathbf{w}), \mathsf{Range}_r(\mathbf{y}), \mathbf{y}[i] \neq \mathbf{w}[i],\ \forall i \in \{1,\ldots,|Y|\}.\end{array}\]
In the above rules,
 $\mathsf{Range}_r$
,
$\mathsf{Range}_r$
,
 $\mathsf{Chosen}_r$
, and
$\mathsf{Chosen}_r$
, and
 $\mathsf{DiffChoice}_r$
are fresh relations not occurring in
$\mathsf{DiffChoice}_r$
are fresh relations not occurring in
 $\mathcal{P}$
, which are used only to rewrite the rule r.
$\mathcal{P}$
, which are used only to rewrite the rule r.
5.1 Implementing supported certain answers via logic programming with choice
The goal of this section is to prove the following key result.
Theorem 9 For every weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and every query Q over
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and every query Q over
 $\mathsf{T}$
, there exists a program
$\mathsf{T}$
, there exists a program
 $\mathcal{P}$
such that
$\mathcal{P}$
such that
 $\mathsf{SCERT}(\mathcal{S},Q)$
reduces to
$\mathsf{SCERT}(\mathcal{S},Q)$
reduces to
 $\mathsf{CANS}(\mathcal{P},Q)$
in polynomial time.
$\mathsf{CANS}(\mathcal{P},Q)$
in polynomial time.
The rest of this section is devoted to prove the above claim. In particular, we show how to convert a weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, together with a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, together with a source instance I of
 $\mathcal{S}$
and a query Q over
$\mathcal{S}$
and a query Q over
 $\mathsf{T}$
, into an extensional database
$\mathsf{T}$
, into an extensional database
 $\mathit{ED}$
and a program
$\mathit{ED}$
and a program
 $\mathcal{P}$
using choice rules, in such a way that
$\mathcal{P}$
using choice rules, in such a way that
 $\mathcal{P}$
depends only on
$\mathcal{P}$
depends only on
 $\mathcal{S}$
and such that
$\mathcal{S}$
and such that
 $\mathsf{scert}_{\mathcal{S}}(I,Q) = \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q)$
.
$\mathsf{scert}_{\mathcal{S}}(I,Q) = \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q)$
.
The main idea of the translation is to derive a program together with an extensional database such that the stable models correspond to a subset of the supported solutions that is enough for computing supported certain answers. For this, we rely on the following useful result that one can extract from the proof of Theorem 4. For a set S of terms and a set of instances
 $\mathcal{I}$
, we use
$\mathcal{I}$
, we use
 $\mathcal{I}_{\downarrow S}$
to denote the set of instances
$\mathcal{I}_{\downarrow S}$
to denote the set of instances
 $\{I \in \mathcal{I} \mid \mathsf{dom}(I) \subseteq S\}$
.
$\{I \in \mathcal{I} \mid \mathsf{dom}(I) \subseteq S\}$
.
Lemma 10 Consider a weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
. There exists a polynomial
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
. There exists a polynomial
 $\mathsf{pol}$
such that, for every source instance I of
$\mathsf{pol}$
such that, for every source instance I of
 $\mathcal{S}$
, and every query Q over
$\mathcal{S}$
, and every query Q over
 $\mathsf{T}$
, the following holds:
$\mathsf{T}$
, the following holds:
 $$ \mathsf{scert}_{\mathcal{S}}(I,Q) = \bigcap\limits_{J \in \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}} Q(J),$$
$$ \mathsf{scert}_{\mathcal{S}}(I,Q) = \bigcap\limits_{J \in \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}} Q(J),$$
where S is the set of all constants occurring in
 $\mathcal{S}$
, I and Q, plus some fixed, arbitrarily chosen constants
$\mathcal{S}$
, I and Q, plus some fixed, arbitrarily chosen constants
 $c_1,\ldots,c_{\mathsf{pol}(|I|)}$
not occurring anywhere in
$c_1,\ldots,c_{\mathsf{pol}(|I|)}$
not occurring anywhere in
 $\mathcal{S}$
, I, or Q.
$\mathcal{S}$
, I, or Q.
Proof. The claim easily follows by construction of the non-deterministic procedure building the instance
 $J^*$
in the proof of Theorem 7, from the fact that it terminates after a polynomial number of steps w.r.t. I, and the fact that it halts with
$J^*$
in the proof of Theorem 7, from the fact that it terminates after a polynomial number of steps w.r.t. I, and the fact that it halts with
 $J^* \neq\; \perp$
iff
$J^* \neq\; \perp$
iff
 $J^*$
is a supported solution in
$J^*$
is a supported solution in
 $\mathsf{ssol}(I,\mathcal{S})$
.
$\mathsf{ssol}(I,\mathcal{S})$
.
The result above tells us that considering supported solutions of a certain polynomial size suffices for computing supported certain answers. The stable models of the program together with the extensional database we are going to define will correspond to such supported solutions.
Definition 7 (Translation)
Consider a data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
 $\mathcal{S}$
, a query Q over
$\mathcal{S}$
, a query Q over
 $\mathsf{T}$
, and the set of constants S as defined in Lemma 10 w.r.t.
$\mathsf{T}$
, and the set of constants S as defined in Lemma 10 w.r.t.
 $\mathcal{S}$
, I and Q.
$\mathcal{S}$
, I and Q.
We use
 $\mathsf{LP}(\mathcal{S})$
to denote the set consisting of the following rules.
$\mathsf{LP}(\mathcal{S})$
to denote the set consisting of the following rules.
-
1. For each TGD
$\rho$
of the form
$\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow \exists \mathbf{z}\, \beta_1 \wedge \cdots \wedge \beta_m$
in
$\Sigma_{st} \cup \Sigma_t$
, with
$\mathbf{y} = \mathsf{fr}(\rho)$
, if
$k = |\mathbf{z}| = 0$
, the following rules are introduced: (1)otherwise, the following rules are introduced:
\begin{equation}\beta_i \text{ :- } \alpha_1,\ldots,\alpha_n,\ \ \ \ i \in \{1,\ldots,m\},\end{equation}
(2)
\begin{equation}\mathsf{ExChoice}_\rho(\mathbf{y},\mathbf{z}) \text{ :- } \alpha_1,\ldots,\alpha_n, \mathsf{Dom}(\mathbf{z}[1]),\ldots,\mathsf{Dom}(\mathbf{z}[k]),\textit{choice}((Y),(Z)),\end{equation}
(3)where Y and Z are the sets of all variables in
\begin{equation}\beta_i \text{ :- } \mathsf{ExChoice}_\rho(\mathbf{y},\mathbf{z}), \ \ \ \ i \in \{1,\ldots,m\},\end{equation}
$\mathbf{y}$
and
$\mathbf{z}$
, respectively, and
$\mathsf{Dom}$
is a fresh predicate.
-
2. For each EGD
$\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow x = y$
in
$\Sigma_t$
, the following constraint is introduced: (4)
\begin{equation}\perp \text{ :- } \alpha_1,\ldots,\alpha_n, x \neq y\end{equation}














We use
 $\mathsf{ED}(\mathcal{S},I,Q)$
to denote the extensional database consisting of the following rules.
$\mathsf{ED}(\mathcal{S},I,Q)$
to denote the extensional database consisting of the following rules.
-
1. For each constant
$c \in S$
, the following rule is introduced: (5)
\begin{equation} \mathsf{Dom}(c) \text{ :- } . \end{equation}
-
2. For each fact
$\alpha \in I$
, the following rule is introduced: (6)
\begin{equation} \alpha \text{ :- } . \end{equation}




Example 6 Considering the data exchange setting
 $\mathcal{S}$
and the source instance I of
$\mathcal{S}$
and the source instance I of
 $\mathcal{S}$
from Example 2, we have that
$\mathcal{S}$
from Example 2, we have that
 $\mathsf{LP}(\mathcal{S})$
is the following logic program:
$\mathsf{LP}(\mathcal{S})$
is the following logic program:

Intuitively, the choice rule associated to the TGD
 $\rho_1$
is in charge of non-deterministically assigning a certain value to the existential variables of
$\rho_1$
is in charge of non-deterministically assigning a certain value to the existential variables of
 $\rho_1$
, for each value its frontier variables can take, that is, the choice rule essentially builds an ex-choice for
$\rho_1$
, for each value its frontier variables can take, that is, the choice rule essentially builds an ex-choice for
 $\rho_1$
. Once the ex-choice is constructed, the rule
$\rho_1$
. Once the ex-choice is constructed, the rule
 $\mathsf{EmpC}(x,z) \text{ :- } \mathsf{ExChoice}_{\rho_1}(x,z)$
simply propagates these choices to the head of
$\mathsf{EmpC}(x,z) \text{ :- } \mathsf{ExChoice}_{\rho_1}(x,z)$
simply propagates these choices to the head of
 $\rho_1$
, as needed. All other TGDs have no existential quantification, and so use no choice construct. Finally, the only EGD
$\rho_1$
, as needed. All other TGDs have no existential quantification, and so use no choice construct. Finally, the only EGD
 $\eta$
is converted to a constraint, so that the stable models of the logic program satisfy
$\eta$
is converted to a constraint, so that the stable models of the logic program satisfy
 $\eta$
.
$\eta$
.
We are now ready to prove Theorem 9.
Proof of Theorem 9. Given an instance I over a schema
 $\mathsf{S}$
, and a schema
$\mathsf{S}$
, and a schema
 $\mathsf{S}' \subseteq \mathsf{S}$
, we use
$\mathsf{S}' \subseteq \mathsf{S}$
, we use
 $I[\mathsf{S}']$
to denote the restriction of I to only its facts referring to relations in
$I[\mathsf{S}']$
to denote the restriction of I to only its facts referring to relations in
 $\mathsf{S}'$
. Notice that for every query Q over
$\mathsf{S}'$
. Notice that for every query Q over
 $\mathsf{S}'$
, the following holds:
$\mathsf{S}'$
, the following holds:
 $Q(I)=Q(I[\mathsf{S}'])$
.
$Q(I)=Q(I[\mathsf{S}'])$
.
Consider a data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, a source instance I of
 $\mathcal{S}$
, a query Q over
$\mathcal{S}$
, a query Q over
 $\mathsf{T}$
, and the set of constants S as defined in Lemma 10 w.r.t.
$\mathsf{T}$
, and the set of constants S as defined in Lemma 10 w.r.t.
 $\mathcal{S}$
, I, and Q.
$\mathcal{S}$
, I, and Q.
Let
 $\mathcal{P}=\mathsf{LP}(\mathcal{S})$
and
$\mathcal{P}=\mathsf{LP}(\mathcal{S})$
and
 $\mathit{ED}=\mathsf{ED}(\mathcal{S},I,Q)$
.
$\mathit{ED}=\mathsf{ED}(\mathcal{S},I,Q)$
.
We want to show
 $ \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q) = \mathsf{scert}_{\mathcal{S}}(I,Q).$
Leveraging Lemma 10, we show that
$ \mathsf{cans}_{\mathcal{P}}(\mathit{ED},Q) = \mathsf{scert}_{\mathcal{S}}(I,Q).$
Leveraging Lemma 10, we show that
 $\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} = \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
$\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} = \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
(1) In the following, we show
 $\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} \subseteq \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
Let
$\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} \subseteq \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
Let
 $X \in \{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\}$
and M be a stable model in
$X \in \{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\}$
and M be a stable model in
 $\mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
such that
$\mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
such that
 $X=M[\mathsf{T}]$
.
$X=M[\mathsf{T}]$
.
-1Let
 $\gamma$
be an ex-choice defined as follows: given a TGD
$\gamma$
be an ex-choice defined as follows: given a TGD
 $\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
in
$\rho = \varphi({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
in
 $\Sigma_{st}\cup \Sigma_t$
and a tuple
$\Sigma_{st}\cup \Sigma_t$
and a tuple
 $\mathbf{t} \in \mathsf{Const}^{|{\textbf {y}}|}$
,
$\mathbf{t} \in \mathsf{Const}^{|{\textbf {y}}|}$
,
 $\gamma$
returns a set
$\gamma$
returns a set
 $\gamma(\rho,\mathbf{t})$
of pairs of the form
$\gamma(\rho,\mathbf{t})$
of pairs of the form
 $(z_i,c)$
, one for each existential variable
$(z_i,c)$
, one for each existential variable
 $z_i \in {\textbf {z}}$
, where c is defined as follows: if
$z_i \in {\textbf {z}}$
, where c is defined as follows: if
 $\mathsf{ExChoice}_\rho(\mathbf{t},c_1,\dots,c_k)\in M$
, then
$\mathsf{ExChoice}_\rho(\mathbf{t},c_1,\dots,c_k)\in M$
, then
 $c=c_i$
, otherwise c is an arbitrary constant of S.
$c=c_i$
, otherwise c is an arbitrary constant of S.
It is easy to see that
 $\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})=S$
, and thus X contains only constants in S. Moreover,
$\mathsf{\mathsf{U}}(\mathcal{P}_{\mathit{ED}})=S$
, and thus X contains only constants in S. Moreover,
 $I \cup X$
satisfies
$I \cup X$
satisfies
 $\Sigma_{st}^\gamma$
, because otherwise M would not satisfy some ground version of the rules derived from the TGDs in
$\Sigma_{st}^\gamma$
, because otherwise M would not satisfy some ground version of the rules derived from the TGDs in
 $\Sigma_{st}^\gamma$
. Also, X satisfies
$\Sigma_{st}^\gamma$
. Also, X satisfies
 $\Sigma_t^\gamma$
, because otherwise M would not satisfy some ground version of the rules derived from the TGDs/EGDs in
$\Sigma_t^\gamma$
, because otherwise M would not satisfy some ground version of the rules derived from the TGDs/EGDs in
 $\Sigma_t^\gamma$
.
$\Sigma_t^\gamma$
.
Since every stable model is also a minimal model, the minimality of M ensures that there is no
 $J' \subsetneq X$
such that
$J' \subsetneq X$
such that
 $I \cup J'$
satisfies
$I \cup J'$
satisfies
 $\Sigma_{st}^\gamma$
and J’ satisfies
$\Sigma_{st}^\gamma$
and J’ satisfies
 $\Sigma_t^\gamma$
. Thus, X is a supported solution of I w.r.t.
$\Sigma_t^\gamma$
. Thus, X is a supported solution of I w.r.t.
 $\mathcal{S}$
containing only constants in S.
$\mathcal{S}$
containing only constants in S.
(2) We now show
 $\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} \supseteq \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
Let
$\{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\} \supseteq \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}.$
Let
 $J \in \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}$
and
$J \in \mathsf{ssol}(I,\mathcal{S})_{\downarrow S}$
and
 $\gamma$
be the ex-choice for which
$\gamma$
be the ex-choice for which
 $I \cup J$
satisfies
$I \cup J$
satisfies
 $\Sigma_{st}^\gamma$
and J satisfies
$\Sigma_{st}^\gamma$
and J satisfies
 $\Sigma_t^\gamma$
. Let
$\Sigma_t^\gamma$
. Let
 $X = I \cup J \cup \{\mathsf{Dom}(c) \mid c \in S\}$
. We show that
$X = I \cup J \cup \{\mathsf{Dom}(c) \mid c \in S\}$
. We show that
 $X \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
.
$X \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})$
.
First, X satisfies each ground rule in
 $\mathsf{ground}(\mathcal{P})$
of the form
$\mathsf{ground}(\mathcal{P})$
of the form
 $\beta_i \text{ :- } \alpha_1,\ldots,\alpha_n$
(cf. (1) in Definition 7), because otherwise the TGD of the form
$\beta_i \text{ :- } \alpha_1,\ldots,\alpha_n$
(cf. (1) in Definition 7), because otherwise the TGD of the form
 $\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow \beta_1 \wedge \cdots \wedge \beta_m$
in
$\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow \beta_1 \wedge \cdots \wedge \beta_m$
in
 $\Sigma_{st}^\gamma$
or
$\Sigma_{st}^\gamma$
or
 $\Sigma_t^\gamma$
would not be satisfied by
$\Sigma_t^\gamma$
would not be satisfied by
 $I \cup J$
or J, respectively.
$I \cup J$
or J, respectively.
Also, X satisfies the ground rules in
 $\mathsf{ground}(\mathcal{P})$
of the form (2)–(3) in Definition 7, derived from a TGD having existential variables, because otherwise such a TGD would not be satisfied by either
$\mathsf{ground}(\mathcal{P})$
of the form (2)–(3) in Definition 7, derived from a TGD having existential variables, because otherwise such a TGD would not be satisfied by either
 $I \cup J$
or J, or J would not be minimal.
$I \cup J$
or J, or J would not be minimal.
Further, X satisfies each ground constraint of the form
 $\perp \text{ :- } \alpha_1,\ldots,\alpha_n, x \neq y$
(cf. (4) in Definition 7) in
$\perp \text{ :- } \alpha_1,\ldots,\alpha_n, x \neq y$
(cf. (4) in Definition 7) in
 $\mathsf{ground}(\mathcal{P})$
as otherwise J would not satisfy the EGD
$\mathsf{ground}(\mathcal{P})$
as otherwise J would not satisfy the EGD
 $\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow x = y$
in
$\alpha_1 \wedge \cdots \wedge \alpha_n \rightarrow x = y$
in
 $\Sigma_t^\gamma$
.
$\Sigma_t^\gamma$
.
Then, X satisfies each rule in
 $\mathit{ED}$
of the form (5) of Definition 7 because
$\mathit{ED}$
of the form (5) of Definition 7 because
 $\{\mathsf{Dom}(c) \mid c \in S\} \subseteq X$
.
$\{\mathsf{Dom}(c) \mid c \in S\} \subseteq X$
.
Finally, X satisfies each rule in
 $\mathit{ED}$
of the form (6) of Definition 7 because X contains I.
$\mathit{ED}$
of the form (6) of Definition 7 because X contains I.
By the minimality of J we obtain the minimality of X, and thus, X is a stable model of
 $\mathcal{P}_{\mathit{ED}}$
. Noting that
$\mathcal{P}_{\mathit{ED}}$
. Noting that
 $X[\mathsf{T}] =J$
, we conclude that
$X[\mathsf{T}] =J$
, we conclude that
 $J\in \{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\}$
.
$J\in \{M[\mathsf{T}] \mid M \in \mathsf{SM}(\mathcal{P}_{\mathit{ED}})\}$
.
 $\Box$
$\Box$
6 Approximate query answering via materialization
As already discussed in the introduction, there might exist scenarios where it is desirable to materialize a target instance starting from the source instance and the schema mapping, in such a way that supported certain query answers can be computed by considering the target instance alone. The goal of this section is thus to study the problem of materializing such an instance, when focusing on our notion of supported solutions.
It would be very useful if such a special target instance could be computed in polynomial-time, already for weakly-acyclic settings. However, due to Theorem 8, this would imply
 $\text{PTIME}=\text{co}\text{NP}$
. Hence, we need something different.
$\text{PTIME}=\text{co}\text{NP}$
. Hence, we need something different.
We introduce a special instance that enjoys the following properties: the answers over this instance are an approximation (i.e., a subset) of the supported certain answers for general queries, but they coincide with supported certain answers for positive queries. We also show that we can compute such an instance in polynomial time for weakly-acyclic settings.
Our approach relies on conditional instances (Imielinski and Lipski Reference Imielinski and Lipski1984), which we introduce in the following.
Conditional instances. A valuation
 $\nu$
is a mapping from
$\nu$
is a mapping from
 $\mathsf{Const} \cup \mathsf{Null}$
to
$\mathsf{Const} \cup \mathsf{Null}$
to
 $\mathsf{Const}$
that is the identity on
$\mathsf{Const}$
that is the identity on
 $\mathsf{Const}$
. A condition
$\mathsf{Const}$
. A condition
 $\phi$
is an expression that can be built using the standard logical connectives
$\phi$
is an expression that can be built using the standard logical connectives
 $\wedge$
,
$\wedge$
,
 $\vee$
,
$\vee$
,
 $\neg$
,
$\neg$
,
 $\Rightarrow$
, and expressions of the form
$\Rightarrow$
, and expressions of the form
 $t = u$
, where
$t = u$
, where
 $t,u \in \mathsf{Const} \cup \mathsf{Null}$
. We will also use
$t,u \in \mathsf{Const} \cup \mathsf{Null}$
. We will also use
 $t \neq u$
as a shorthand for
$t \neq u$
as a shorthand for
 $\neg (t = u)$
. We write
$\neg (t = u)$
. We write
 $\nu \models \phi$
to state that
$\nu \models \phi$
to state that
 $\nu$
satisfies
$\nu$
satisfies
 $\phi$
, and
$\phi$
, and
 $\phi \models \psi$
if all valuations satisfying
$\phi \models \psi$
if all valuations satisfying
 $\phi$
satisfy the condition
$\phi$
satisfy the condition
 $\psi$
. A conditional fact is a pair
$\psi$
. A conditional fact is a pair
 $\langle \alpha,\phi \rangle$
, where
$\langle \alpha,\phi \rangle$
, where
 $\alpha$
is a fact and
$\alpha$
is a fact and
 $\phi$
is a condition. A conditional instance
$\phi$
is a condition. A conditional instance
 $\mathcal{I}$
is a finite set of conditional facts. We also denote
$\mathcal{I}$
is a finite set of conditional facts. We also denote
 $\mathcal{I}[1] = \{\alpha \mid \langle \alpha,\phi \rangle \in \mathcal{I}\}$
. A possible world of a conditional instance
$\mathcal{I}[1] = \{\alpha \mid \langle \alpha,\phi \rangle \in \mathcal{I}\}$
. A possible world of a conditional instance
 $\mathcal{I}$
is an instance I such that there exists a valuation
$\mathcal{I}$
is an instance I such that there exists a valuation
 $\nu$
with
$\nu$
with
 $I = \{ \nu(\alpha) \mid \langle \alpha, \phi\rangle \in \mathcal{I} \text{ and } \nu \models \phi\}$
. We use
$I = \{ \nu(\alpha) \mid \langle \alpha, \phi\rangle \in \mathcal{I} \text{ and } \nu \models \phi\}$
. We use
 $\mathsf{pw}(\mathcal{I})$
to denote the set of all possible worlds of
$\mathsf{pw}(\mathcal{I})$
to denote the set of all possible worlds of
 $\mathcal{I}$
.
$\mathcal{I}$
.
Definition 8 Consider a conditional instance
 $\mathcal{I}$
and a query Q. The conditional certain answers of Q over
$\mathcal{I}$
and a query Q. The conditional certain answers of Q over
 $\mathcal{I}$
is the set
$\mathcal{I}$
is the set
 $\mathsf{con\text{-}cert}(\mathcal{I},Q) = \bigcap_{J \in \mathsf{pw}(\mathcal{I})} Q(J)$
.
$\mathsf{con\text{-}cert}(\mathcal{I},Q) = \bigcap_{J \in \mathsf{pw}(\mathcal{I})} Q(J)$
.
We are now ready to introduce our main tool.
Definition 9 (Approximate Conditional Solution)
Consider a data exchange setting
 $\mathcal{S}$
and a source instance I of
$\mathcal{S}$
and a source instance I of
 $\mathcal{S}$
. A conditional instance
$\mathcal{S}$
. A conditional instance
 $\mathcal{J}$
is an approximate conditional solution of I w.r.t.
$\mathcal{J}$
is an approximate conditional solution of I w.r.t.
 $\mathcal{S}$
, if for every query Q:
$\mathcal{S}$
, if for every query Q:
-
1.
$\mathsf{ssol}(I,\mathcal{S}) \subseteq \mathsf{pw}(\mathcal{J})$
, and thus
$\mathsf{con\text{-}cert}(\mathcal{J},Q) \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
, and -
2. if Q is positive,
$\mathsf{con\text{-}cert}(\mathcal{J},Q) = \mathsf{scert}_{\mathcal{S}}(I,Q)$
.



That is, an approximate conditional solution is a conditional instance that allows to compute approximate answers for general queries, and exact answers for positive queries.
It is easy to observe that there are settings
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and source instances I for which an approximate conditional solution might not exist, even if
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and source instances I for which an approximate conditional solution might not exist, even if
 $\mathcal{S}$
is weakly-acyclic. This is due to the presence of EGDs in
$\mathcal{S}$
is weakly-acyclic. This is due to the presence of EGDs in
 $\Sigma_t$
.
$\Sigma_t$
.
However, for weakly-acyclic settings without EGDs, an approximate conditional solution always exists, and we present a polynomial-time algorithm that is able to construct one. We show how to deal with general weakly-acyclic settings with EGDs in Section 7.
The algorithm is a variation of the well-known chase algorithm, which iteratively introduces new facts, starting from a source instance, whenever a TGD is not satisfied, that is, it triggers the TGD. This variation also allows for a conditional triggering of TGDs, where new atoms are introduced, under the condition that some terms in the body coincide.
Normal TGDs. To simplify the discussion, we consider an extension of TGDs that allow for equality predicates in the body. We will use these TGDs to rewrite standard TGDs in the following normal form. A normal form TGD
 $\rho$
is an expression of the form
$\rho$
is an expression of the form
 $\varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, where
$\varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, where
 $\varphi$
and
$\varphi$
and
 $\psi$
are conjunctions of atoms,
$\psi$
are conjunctions of atoms,
 $\varphi$
uses only variables and each variable in
$\varphi$
uses only variables and each variable in
 $\varphi$
occurs once in
$\varphi$
occurs once in
 $\varphi$
. The formula
$\varphi$
. The formula
 $\eta$
is a conjunction of equalities of the form
$\eta$
is a conjunction of equalities of the form
 $x=t$
, where x is a variable in
$x=t$
, where x is a variable in
 ${\textbf {x}}$
or
${\textbf {x}}$
or
 ${\textbf {y}}$
, and t is either a variable in
${\textbf {y}}$
, and t is either a variable in
 ${\textbf {x}}$
or
${\textbf {x}}$
or
 ${\textbf {y}}$
, or a constant. The above equalities denote which variables should be considered to be the same and which positions should contain a constant. A (set of) standard TGDs
${\textbf {y}}$
, or a constant. The above equalities denote which variables should be considered to be the same and which positions should contain a constant. A (set of) standard TGDs
 $\Sigma$
can be converted in normal form in the obvious way. We denote
$\Sigma$
can be converted in normal form in the obvious way. We denote
 $\mathsf{norm}(\Sigma)$
as the (set of) TGDs in normal form obtained from
$\mathsf{norm}(\Sigma)$
as the (set of) TGDs in normal form obtained from
 $\Sigma$
.
$\Sigma$
.
In the following, fix a conditional instance
 $\mathcal{I}$
, a TGD
$\mathcal{I}$
, a TGD
 $\rho$
with
$\rho$
with
 $\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, and a homomorphism h from
$\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
, and a homomorphism h from
 $\varphi({\textbf {x}},{\textbf {y}})$
to
$\varphi({\textbf {x}},{\textbf {y}})$
to
 $\mathcal{I}[1]$
. We use
$\mathcal{I}[1]$
. We use
 $h(\eta({\textbf {x}},{\textbf {y}}))$
to denote the condition obtained from
$h(\eta({\textbf {x}},{\textbf {y}}))$
to denote the condition obtained from
 $\eta({\textbf {x}},{\textbf {y}})$
by replacing each variable x therein with h(x). Letting
$\eta({\textbf {x}},{\textbf {y}})$
by replacing each variable x therein with h(x). Letting
 $h(\varphi({\textbf {x}},{\textbf {y}})) = \{\alpha_1,\ldots,\alpha_n\}$
, we use
$h(\varphi({\textbf {x}},{\textbf {y}})) = \{\alpha_1,\ldots,\alpha_n\}$
, we use
 $\Phi^{\mathcal{I}}_{\rho,h}$
to denote the set of all conditions of the form
$\Phi^{\mathcal{I}}_{\rho,h}$
to denote the set of all conditions of the form
 $h(\eta({\textbf {x}},{\textbf {y}})) \wedge \phi_1 \wedge \cdots \wedge \phi_n$
, such that
$h(\eta({\textbf {x}},{\textbf {y}})) \wedge \phi_1 \wedge \cdots \wedge \phi_n$
, such that
 $\langle \alpha_i,\phi_i \rangle \in \mathcal{I}$
, for each
$\langle \alpha_i,\phi_i \rangle \in \mathcal{I}$
, for each
 $i \in \{1,\ldots,n\}$
.
$i \in \{1,\ldots,n\}$
.
Example 7 Consider the TGD
 $\rho_3$
of Example 2. The normal form TGD
$\rho_3$
of Example 2. The normal form TGD
 $\mathsf{norm}(\rho_3)$
is
$\mathsf{norm}(\rho_3)$
is
 $$\mathsf{EmpC}(x,y), \mathsf{EmpC}(x',y'), y=y' \rightarrow \mathsf{SameC}(x,x').$$
$$\mathsf{EmpC}(x,y), \mathsf{EmpC}(x',y'), y=y' \rightarrow \mathsf{SameC}(x,x').$$
Consider now the conditional instance
 $$\mathcal{I}=\{\langle \mathsf{EmpC}(\mathsf{\mathsf{john}},\mathsf{miami}),{\perp}_1 = a \rangle, \langle \mathsf{EmpC}(\mathsf{mary},{\perp}_2),\mathsf{true} \rangle\},$$
$$\mathcal{I}=\{\langle \mathsf{EmpC}(\mathsf{\mathsf{john}},\mathsf{miami}),{\perp}_1 = a \rangle, \langle \mathsf{EmpC}(\mathsf{mary},{\perp}_2),\mathsf{true} \rangle\},$$
where a is a constant. Then, the mapping
 $h = \{x/\mathsf{john}, y/\mathsf{miami},x'/\mathsf{mary}, y'/{\perp}_2\}$
is a homomorphism from
$h = \{x/\mathsf{john}, y/\mathsf{miami},x'/\mathsf{mary}, y'/{\perp}_2\}$
is a homomorphism from
 $\{\mathsf{EmpC}(x,y), \mathsf{EmpC}(x',y')\}$
to
$\{\mathsf{EmpC}(x,y), \mathsf{EmpC}(x',y')\}$
to
 $\mathcal{I}[1]$
. Moreover,
$\mathcal{I}[1]$
. Moreover,
 $\Phi^{\mathcal{I}}_{\rho_3,h} = \{{\perp}_2 = \mathsf{miami} \wedge {\perp}_1 = a \}$
.
$\Phi^{\mathcal{I}}_{\rho_3,h} = \{{\perp}_2 = \mathsf{miami} \wedge {\perp}_1 = a \}$
.
We are now ready to define the notion of conditional chase step. In what follows, for a conditional instance
 $\mathcal{I}$
, a TGD
$\mathcal{I}$
, a TGD
 $\rho$
with
$\rho$
with
 $\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
and a homomorphism h from
$\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
and a homomorphism h from
 $\varphi({\textbf {x}},{\textbf {y}})$
to
$\varphi({\textbf {x}},{\textbf {y}})$
to
 $\mathcal{I}[1]$
, we use
$\mathcal{I}[1]$
, we use
 $\mathsf{result}(\mathcal{I},\rho,h)$
to denote the set of atoms obtained from
$\mathsf{result}(\mathcal{I},\rho,h)$
to denote the set of atoms obtained from
 $\mathsf{head}(\mathsf{norm}(\rho))$
, where each frontier variable x in
$\mathsf{head}(\mathsf{norm}(\rho))$
, where each frontier variable x in
 $\mathsf{fr}(\mathsf{norm}(\rho))$
is replaced with h(x), and each existential variable z in
$\mathsf{fr}(\mathsf{norm}(\rho))$
is replaced with h(x), and each existential variable z in
 $\mathsf{exvar}(\mathsf{norm}(\rho))$
is replaced with a fresh null not occurring in
$\mathsf{exvar}(\mathsf{norm}(\rho))$
is replaced with a fresh null not occurring in
 $\mathcal{I}$
.
$\mathcal{I}$
.
Definition 10 (Conditional Chase Step)
Consider a conditional instance
 $\mathcal{I}$
, a TGD
$\mathcal{I}$
, a TGD
 $\rho$
, and let
$\rho$
, and let
 $\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
. A conditional chase step of
$\mathsf{norm}(\rho) = \varphi({\textbf {x}},{\textbf {y}}) \wedge \eta({\textbf {x}},{\textbf {y}}) \rightarrow \exists {\textbf {z}}\, \psi({\textbf {y}},{\textbf {z}})$
. A conditional chase step of
 $\mathcal{I}$
w.r.t.
$\mathcal{I}$
w.r.t.
 $\rho$
is an expression of the form
$\rho$
is an expression of the form
 $\mathcal{I} \stackrel{\rho,h,\phi}{\longrightarrow} \mathcal{J}$
, where (i) h is a homomorphism from
$\mathcal{I} \stackrel{\rho,h,\phi}{\longrightarrow} \mathcal{J}$
, where (i) h is a homomorphism from
 $\varphi({\textbf {x}},{\textbf {y}})$
to
$\varphi({\textbf {x}},{\textbf {y}})$
to
 $\mathcal{I}[1]$
, (ii)
$\mathcal{I}[1]$
, (ii)
 $\phi \in \Phi^{\mathcal{I}}_{\rho,h}$
is such that
$\phi \in \Phi^{\mathcal{I}}_{\rho,h}$
is such that
 $\phi \not \models \mathsf{false}$
, and (iii)
$\phi \not \models \mathsf{false}$
, and (iii)
 $\mathcal{J} = \mathcal{I} \cup \{\langle \alpha,\phi \rangle \mid \alpha \in \mathsf{result}(\mathcal{I},\rho,h)\}$
.
$\mathcal{J} = \mathcal{I} \cup \{\langle \alpha,\phi \rangle \mid \alpha \in \mathsf{result}(\mathcal{I},\rho,h)\}$
.
Example 8 Consider the conditional instance
 $\mathcal{I}$
, the homomorphism h, and the TGD
$\mathcal{I}$
, the homomorphism h, and the TGD
 $\rho_3$
of Example 7. Then,
$\rho_3$
of Example 7. Then,
 $\mathcal{I} \stackrel{\rho_3,h,\phi}{\longrightarrow} \mathcal{J}$
is a conditional chase step, where
$\mathcal{I} \stackrel{\rho_3,h,\phi}{\longrightarrow} \mathcal{J}$
is a conditional chase step, where
 $\phi$
is the condition
$\phi$
is the condition
 ${\perp}_2 = \mathsf{miami} \wedge {\perp}_1 = a$
, and
${\perp}_2 = \mathsf{miami} \wedge {\perp}_1 = a$
, and
 $\mathcal{J} = \mathcal{I} \cup \{\langle \mathsf{SameC}(\mathsf{john},\mathsf{mary}),\phi \rangle\}$
.
$\mathcal{J} = \mathcal{I} \cup \{\langle \mathsf{SameC}(\mathsf{john},\mathsf{mary}),\phi \rangle\}$
.
With the notion of conditional chase step at hand, we can define conditional chase sequences, which are sequences of conditional chase steps. For this we need one additional notion. A conditional tuple is a pair
 $\langle \mathbf{t},\phi \rangle$
, where
$\langle \mathbf{t},\phi \rangle$
, where
 $\mathbf{t}$
is a tuple of constants and nulls, and
$\mathbf{t}$
is a tuple of constants and nulls, and
 $\phi$
a condition. For two conditional tuples
$\phi$
a condition. For two conditional tuples
 $\langle \mathbf{t},\phi \rangle,\langle \mathbf{u},\psi \rangle$
, with
$\langle \mathbf{t},\phi \rangle,\langle \mathbf{u},\psi \rangle$
, with
 $|\mathbf{t}| = |\mathbf{u}| = n$
, we write
$|\mathbf{t}| = |\mathbf{u}| = n$
, we write
 $\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
if
$\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
if
 $\phi \models \psi$
and
$\phi \models \psi$
and
 $\phi \models \mathbf{t} = \mathbf{u}$
, where
$\phi \models \mathbf{t} = \mathbf{u}$
, where
 $\mathbf{t} = \mathbf{u}$
is a shorthand for the condition
$\mathbf{t} = \mathbf{u}$
is a shorthand for the condition
 $\bigwedge^n_{i=1} \mathbf{t}[i] = \mathbf{u}[i]$
. We write
$\bigwedge^n_{i=1} \mathbf{t}[i] = \mathbf{u}[i]$
. We write
 $\langle \mathbf{t},\phi \rangle \not \sqsubseteq \langle \mathbf{u},\psi \rangle$
, if
$\langle \mathbf{t},\phi \rangle \not \sqsubseteq \langle \mathbf{u},\psi \rangle$
, if
 $\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
does not hold.
$\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
does not hold.
Intuitively,
 $\langle \mathbf{t},\phi \rangle, \langle \mathbf{u},\psi \rangle$
should be understood to be two tuples, each of them belonging to a set of “worlds,” described by the valuations that satisfy their conditions. Moreover,
$\langle \mathbf{t},\phi \rangle, \langle \mathbf{u},\psi \rangle$
should be understood to be two tuples, each of them belonging to a set of “worlds,” described by the valuations that satisfy their conditions. Moreover,
 $\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
means that every world in which
$\langle \mathbf{t},\phi \rangle \sqsubseteq \langle \mathbf{u},\psi \rangle$
means that every world in which
 $\mathbf{t}$
occurs, is also a world in which
$\mathbf{t}$
occurs, is also a world in which
 $\mathbf{u}$
occurs (
$\mathbf{u}$
occurs (
 $\phi \models \psi$
), and in each such world,
$\phi \models \psi$
), and in each such world,
 $\mathbf{t}$
and
$\mathbf{t}$
and
 $\mathbf{u}$
are the same tuples.
$\mathbf{u}$
are the same tuples.
Definition 11 (Conditional Chase Sequence)
Consider a TGD-only data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
 $\mathcal{S}$
. A conditional chase sequence of I w.r.t.
$\mathcal{S}$
. A conditional chase sequence of I w.r.t.
 $\mathcal{S}$
is a (possibly infinite) sequence of conditional instances
$\mathcal{S}$
is a (possibly infinite) sequence of conditional instances
 $(\mathcal{J}_i)_{i \ge 0}$
, where for each
$(\mathcal{J}_i)_{i \ge 0}$
, where for each
 $i \ge 0$
,
$i \ge 0$
,
 $\mathcal{J}_i \stackrel{\rho_i,h_i,\phi_i}{\longrightarrow} \mathcal{J}_{i+1}$
, and (i)
$\mathcal{J}_i \stackrel{\rho_i,h_i,\phi_i}{\longrightarrow} \mathcal{J}_{i+1}$
, and (i)
 $\mathcal{J}_0 = \{\langle\alpha,\mathsf{true}\rangle \mid \alpha \in I\}$
, (ii)
$\mathcal{J}_0 = \{\langle\alpha,\mathsf{true}\rangle \mid \alpha \in I\}$
, (ii)
 $\rho_i \in \Sigma_{st} \cup \Sigma_t$
, for
$\rho_i \in \Sigma_{st} \cup \Sigma_t$
, for
 $i \ge 0$
, and (iii) for every
$i \ge 0$
, and (iii) for every
 $j < i$
, if
$j < i$
, if
 $\rho = \rho_i = \rho_j$
, then
$\rho = \rho_i = \rho_j$
, then
 $\langle h_i(\mathsf{fr}(\rho)),\phi_i \rangle \not \sqsubseteq \langle h_j(\mathsf{fr}(\rho)),\phi_j \rangle$
.
$\langle h_i(\mathsf{fr}(\rho)),\phi_i \rangle \not \sqsubseteq \langle h_j(\mathsf{fr}(\rho)),\phi_j \rangle$
.
Intuitively, condition
 ${(iii)}$
of the definition above is required to prevent the chase sequence to apply superfluous steps. That is, at a certain step, a fact is produced only if the possible worlds in which it occurs is not a subset of the possible worlds in which the same fact has already been introduced by previous steps. An example follows.
${(iii)}$
of the definition above is required to prevent the chase sequence to apply superfluous steps. That is, at a certain step, a fact is produced only if the possible worlds in which it occurs is not a subset of the possible worlds in which the same fact has already been introduced by previous steps. An example follows.
Example 9 Consider the data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, with
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, with
 $\mathsf{S} = \{A/1,B/1\}$
,
$\mathsf{S} = \{A/1,B/1\}$
,
 $\mathsf{T} = \{R/2,S/1,T/1\}$
, where the sets
$\mathsf{T} = \{R/2,S/1,T/1\}$
, where the sets
 $\Sigma_{st} = \{\rho_1,\rho_2\}$
and
$\Sigma_{st} = \{\rho_1,\rho_2\}$
and
 $\Sigma_t=\{\rho_3\}$
are such that
$\Sigma_t=\{\rho_3\}$
are such that
 $\rho_1 = A(x) \rightarrow \exists z\, R(x,z)$
,
$\rho_1 = A(x) \rightarrow \exists z\, R(x,z)$
,
 $\rho_2 = B(x) \rightarrow S(x)$
, and
$\rho_2 = B(x) \rightarrow S(x)$
, and
 $\rho_3 = R(x,y), S(y) \rightarrow T(x)$
. Given
$\rho_3 = R(x,y), S(y) \rightarrow T(x)$
. Given
 $I = \{ A(a), B(b_1),B(b_2) \}$
, the following is a conditional chase sequence of I w.r.t.
$I = \{ A(a), B(b_1),B(b_2) \}$
, the following is a conditional chase sequence of I w.r.t.
 $\mathcal{S}$
:
$\mathcal{S}$
:
 \begin{align*} &&\mathcal{J}_0 & = \{\langle A(a),\mathsf{true} \rangle,\langle B(b_1),\mathsf{true} \rangle,\langle B(b_2),\mathsf{true} \rangle\}, & \mathcal{J}_1 &= \mathcal{J}_0 \cup \{ \langle R(a,{\perp}),\mathsf{true} \rangle\}, &&\\ && \mathcal{J}_2 &= \mathcal{J}_1 \cup \{ \langle S(b_1),\mathsf{true} \rangle\}, &\mathcal{J}_3 &= \mathcal{J}_2 \cup \{ \langle S(b_2),\mathsf{true} \rangle\},&& \\ && \mathcal{J}_4 &= \mathcal{J}_3 \cup \{ \langle T(a),{\perp} = b_1 \rangle\}, &\mathcal{J}_5 &= \mathcal{J}_4 \cup \{ \langle T(a),{\perp} = b_2 \rangle\}.&& \end{align*}
\begin{align*} &&\mathcal{J}_0 & = \{\langle A(a),\mathsf{true} \rangle,\langle B(b_1),\mathsf{true} \rangle,\langle B(b_2),\mathsf{true} \rangle\}, & \mathcal{J}_1 &= \mathcal{J}_0 \cup \{ \langle R(a,{\perp}),\mathsf{true} \rangle\}, &&\\ && \mathcal{J}_2 &= \mathcal{J}_1 \cup \{ \langle S(b_1),\mathsf{true} \rangle\}, &\mathcal{J}_3 &= \mathcal{J}_2 \cup \{ \langle S(b_2),\mathsf{true} \rangle\},&& \\ && \mathcal{J}_4 &= \mathcal{J}_3 \cup \{ \langle T(a),{\perp} = b_1 \rangle\}, &\mathcal{J}_5 &= \mathcal{J}_4 \cup \{ \langle T(a),{\perp} = b_2 \rangle\}.&& \end{align*}
For a TGD-only setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
 $\mathcal{S}$
, a finite conditional chase sequence
$\mathcal{S}$
, a finite conditional chase sequence
 $(\mathcal{J}_i)_{0 \le i \le n}$
of I w.r.t.
$(\mathcal{J}_i)_{0 \le i \le n}$
of I w.r.t.
 $\mathcal{S}$
is maximal if there is no conditional instance
$\mathcal{S}$
is maximal if there is no conditional instance
 $\mathcal{J}_{n+1}$
, such that
$\mathcal{J}_{n+1}$
, such that
 $(\mathcal{J}_i)_{0 \le i \le n+1}$
is a conditional chase sequence of I w.r.t.
$(\mathcal{J}_i)_{0 \le i \le n+1}$
is a conditional chase sequence of I w.r.t.
 $\mathcal{S}$
. We call
$\mathcal{S}$
. We call
 $\mathcal{J}_n$
the result of the maximal sequence.
$\mathcal{J}_n$
the result of the maximal sequence.
Example 10 Consider the conditional chase sequence
 $\mathcal{J}_0,\ldots,\mathcal{J}_5$
of Example 9. The sequence is maximal, since any conditional chase step of the form
$\mathcal{J}_0,\ldots,\mathcal{J}_5$
of Example 9. The sequence is maximal, since any conditional chase step of the form
 $\mathcal{J}_5 \stackrel{\rho,h,\phi}{\longrightarrow} \mathcal{J}$
, for some conditional instance
$\mathcal{J}_5 \stackrel{\rho,h,\phi}{\longrightarrow} \mathcal{J}$
, for some conditional instance
 $\mathcal{J}$
, cannot satisfy condition (iii) of Definition 11. The sequence
$\mathcal{J}$
, cannot satisfy condition (iii) of Definition 11. The sequence
 $\mathcal{J}_0,\ldots,\mathcal{J}_4$
is not maximal because although a conditional atom of the form
$\mathcal{J}_0,\ldots,\mathcal{J}_4$
is not maximal because although a conditional atom of the form
 $\langle T(a),\phi \rangle$
is already present in
$\langle T(a),\phi \rangle$
is already present in
 $\mathcal{J}_4$
, an additional conditional atom of the same form needs to be introduced in
$\mathcal{J}_4$
, an additional conditional atom of the same form needs to be introduced in
 $\mathcal{J}_5$
. This is needed to allow the fact T(a) to be present for two different reasons (either because
$\mathcal{J}_5$
. This is needed to allow the fact T(a) to be present for two different reasons (either because
 ${\perp} = b_1$
or
${\perp} = b_1$
or
 ${\perp} = b_2$
), and both reasons should occur in the result of the sequence.
${\perp} = b_2$
), and both reasons should occur in the result of the sequence.
We are now ready to present the main result of this section. In what follows, given a schema
 $\mathsf{S}$
and a conditional instance
$\mathsf{S}$
and a conditional instance
 $\mathcal{I}$
,
$\mathcal{I}$
,
 $\mathcal{I}_{|\mathsf{S}}$
denotes the restriction of
$\mathcal{I}_{|\mathsf{S}}$
denotes the restriction of
 $\mathcal{I}$
to its conditional facts with relations in
$\mathcal{I}$
to its conditional facts with relations in
 $\mathsf{S}$
.
$\mathsf{S}$
.
Theorem 11 Consider a TGD-only setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I of
 $\mathcal{S}$
. If
$\mathcal{S}$
. If
 $\mathcal{J}$
is the result of a maximal conditional chase sequence of I w.r.t.
$\mathcal{J}$
is the result of a maximal conditional chase sequence of I w.r.t.
 $\mathcal{S}$
, then
$\mathcal{S}$
, then
 $\mathcal{J}_{|\mathsf{T}}$
is an approximate conditional solution of I w.r.t.
$\mathcal{J}_{|\mathsf{T}}$
is an approximate conditional solution of I w.r.t.
 $\mathcal{S}$
.
$\mathcal{S}$
.
Proof. To prove the claim, it is enough to prove that each supported solution
 $J \in \mathsf{ssol}(I,\mathcal{S})$
is such that
$J \in \mathsf{ssol}(I,\mathcal{S})$
is such that
 $I \cup J$
is a possible world of
$I \cup J$
is a possible world of
 $\mathcal{J}$
, and that each possible world J of
$\mathcal{J}$
, and that each possible world J of
 $\mathcal{J}$
contains a supported solution. We prove first that each
$\mathcal{J}$
contains a supported solution. We prove first that each
 $J \in \mathsf{ssol}(I,\mathcal{S})$
is such that
$J \in \mathsf{ssol}(I,\mathcal{S})$
is such that
 $I \cup J$
is a possible world of
$I \cup J$
is a possible world of
 $\mathcal{J}$
.
$\mathcal{J}$
.
Let
 $\gamma$
be the ex-choice witnessing that J is a supported solution. Then, J can be characterized as the result of a procedure that computes a sequence
$\gamma$
be the ex-choice witnessing that J is a supported solution. Then, J can be characterized as the result of a procedure that computes a sequence
 $J_0, J_1, \dots J_m$
such that
$J_0, J_1, \dots J_m$
such that
 $J_0=I$
,
$J_0=I$
,
 $J_m=J$
, and each
$J_m=J$
, and each
 $J_i$
with
$J_i$
with
 $i>0$
is obtained from
$i>0$
is obtained from
 $J_{i-1}$
by adding the head of a TGD in
$J_{i-1}$
by adding the head of a TGD in
 $\Sigma_{st}^\gamma \cup \Sigma_t^\gamma$
whose body is contained in
$\Sigma_{st}^\gamma \cup \Sigma_t^\gamma$
whose body is contained in
 $J_{i-1}$
(i.e., the first part of the procedure in the proof of Theorem 7) – notice that such a procedure ensures also the minimality of J. For each step of the aforementioned procedure, there must be a corresponding conditional chase step in the sequence yielding
$J_{i-1}$
(i.e., the first part of the procedure in the proof of Theorem 7) – notice that such a procedure ensures also the minimality of J. For each step of the aforementioned procedure, there must be a corresponding conditional chase step in the sequence yielding
 $\mathcal{J}$
, which in turn induces
$\mathcal{J}$
, which in turn induces
 $I \cup J$
as a possible world.
$I \cup J$
as a possible world.
Regarding whether each possible world J of
 $\mathcal{J}$
contains a supported solution, consider a possible world
$\mathcal{J}$
contains a supported solution, consider a possible world
 $J \in \mathsf{pw}(\mathcal{J})$
. By construction of
$J \in \mathsf{pw}(\mathcal{J})$
. By construction of
 $\mathcal{J}$
,
$\mathcal{J}$
,
 $J = I \cup J'$
, for some instance J’ over
$J = I \cup J'$
, for some instance J’ over
 $\mathsf{T}$
, since all conditional facts in
$\mathsf{T}$
, since all conditional facts in
 $\mathcal{J}$
, which correspond to the facts in I, have the always true condition. Moreover, by construction of
$\mathcal{J}$
, which correspond to the facts in I, have the always true condition. Moreover, by construction of
 $\mathcal{J}$
,
$\mathcal{J}$
,
 $I \cup J'$
satisfies
$I \cup J'$
satisfies
 $\Sigma_{st}$
, and J’ satisfies
$\Sigma_{st}$
, and J’ satisfies
 $\Sigma_t$
. Hence, if we consider the set of TGDs
$\Sigma_t$
. Hence, if we consider the set of TGDs
 $\Sigma_{st}^* \cup \Sigma_t^*$
, where
$\Sigma_{st}^* \cup \Sigma_t^*$
, where
 $\Sigma_{st}^*$
and
$\Sigma_{st}^*$
and
 $\Sigma_t^*$
are the sets of all ground versions of the TGDs in
$\Sigma_t^*$
are the sets of all ground versions of the TGDs in
 $\Sigma_{st}$
and
$\Sigma_{st}$
and
 $\Sigma_t$
, respectively, we have that
$\Sigma_t$
, respectively, we have that
 $I \cup J'$
satisfies
$I \cup J'$
satisfies
 $\Sigma_{st}^* \cup \Sigma_t^*$
and J’ satisfies
$\Sigma_{st}^* \cup \Sigma_t^*$
and J’ satisfies
 $\Sigma_t^*$
. However, since
$\Sigma_t^*$
. However, since
 $\Sigma_{st}^\gamma \subseteq \Sigma_{st}^*$
, and
$\Sigma_{st}^\gamma \subseteq \Sigma_{st}^*$
, and
 $\Sigma_t^\gamma \subseteq \Sigma_t^*$
, for any ex-choice
$\Sigma_t^\gamma \subseteq \Sigma_t^*$
, for any ex-choice
 $\gamma$
, we must have that J’ must contain a supported solution in
$\gamma$
, we must have that J’ must contain a supported solution in
 $\mathsf{ssol}(I,\mathcal{S})$
, as needed.
$\mathsf{ssol}(I,\mathcal{S})$
, as needed.
Example 11 Consider the setting
 $\mathcal{S}$
, the source instance I of
$\mathcal{S}$
, the source instance I of
 $\mathcal{S}$
, and the conditional chase sequence
$\mathcal{S}$
, and the conditional chase sequence
 $\mathcal{J}_0,\ldots,\mathcal{J}_5$
of Example 9. From Theorem 11, we conclude that
$\mathcal{J}_0,\ldots,\mathcal{J}_5$
of Example 9. From Theorem 11, we conclude that
 $\mathcal{J}_5$
is an approximate conditional solution for I w.r.t.
$\mathcal{J}_5$
is an approximate conditional solution for I w.r.t.
 $\mathcal{S}$
.
$\mathcal{S}$
.
We can further show that for TGD-only weakly-acyclic settings, a maximal conditional chase sequence always exists, and its length is polynomial. Moreover, its result can be computed in polynomial time.
Theorem 12 Consider a data exchange setting
 $\mathcal{S}$
that is TGD-only and weakly-acyclic, and a source instance I of
$\mathcal{S}$
that is TGD-only and weakly-acyclic, and a source instance I of
 $\mathcal{S}$
. Every conditional chase sequence
$\mathcal{S}$
. Every conditional chase sequence
 $s = (\mathcal{J}_i)_{0 \le i \le n}$
of I w.r.t.
$s = (\mathcal{J}_i)_{0 \le i \le n}$
of I w.r.t.
 $\mathcal{S}$
is such that n is a polynomial of
$\mathcal{S}$
is such that n is a polynomial of
 $|I|$
, and the result
$|I|$
, and the result
 $\mathcal{J}_n$
of s can be computed in polynomial time w.r.t.
$\mathcal{J}_n$
of s can be computed in polynomial time w.r.t.
 $|I|$
.
$|I|$
.
Proof. To prove that the length of a conditional chase sequence is bounded by a polynomial, it suffices to follow an argument similar to the one given in (Fagin et al. Reference Fagin, Kolaitis, Miller and Popa2005) for proving that the length of a standard chase sequence is polynomial, for weakly-acyclic settings. Let
 $s = (\mathcal{J}_i)_{0 \le i \le n}$
be a conditional chase sequence of I w.r.t.
$s = (\mathcal{J}_i)_{0 \le i \le n}$
be a conditional chase sequence of I w.r.t.
 $\mathcal{S}$
, with
$\mathcal{S}$
, with
 $\mathcal{J}_i \stackrel{\rho_i,h_i,\phi_i}{\longrightarrow} \mathcal{J}_{i+1}$
, for
$\mathcal{J}_i \stackrel{\rho_i,h_i,\phi_i}{\longrightarrow} \mathcal{J}_{i+1}$
, for
 $i \in \{0,\ldots,n-1\}$
. Since n is a polynomial of
$i \in \{0,\ldots,n-1\}$
. Since n is a polynomial of
 $|I|$
, we just need to show that for each
$|I|$
, we just need to show that for each
 $i \in \{0,\ldots,n-1\}$
,
$i \in \{0,\ldots,n-1\}$
,
 $\mathcal{J}_{i+1}$
can be constructed in polynomial time. To this end, it suffices to focus on condition (ii) of Definition 10 and condition (iii) of Definition 11. Since n is polynomial, the maximum number of terms occurring in each condition
$\mathcal{J}_{i+1}$
can be constructed in polynomial time. To this end, it suffices to focus on condition (ii) of Definition 10 and condition (iii) of Definition 11. Since n is polynomial, the maximum number of terms occurring in each condition
 $\phi_i$
is polynomial. Thus, each
$\phi_i$
is polynomial. Thus, each
 $\phi_i$
contains at most polynomially many equalities, and we can easily check whether
$\phi_i$
contains at most polynomially many equalities, and we can easily check whether
 $\phi_i \not \models \mathsf{false}$
, by simply computing the closure of all equalities in
$\phi_i \not \models \mathsf{false}$
, by simply computing the closure of all equalities in
 $\phi_i$
, and checking whether an equality of the form
$\phi_i$
, and checking whether an equality of the form
 $a = b$
can be derived, where a,b are distinct constants. Similarly, for each
$a = b$
can be derived, where a,b are distinct constants. Similarly, for each
 $i \in \{0,\ldots,n-1\}$
, and every
$i \in \{0,\ldots,n-1\}$
, and every
 $j<i$
, we can check whether
$j<i$
, we can check whether
 $\langle h_i(\mathsf{fr}(\rho)),\phi_i \rangle \not \sqsubseteq \langle h_j(\mathsf{fr}(\rho)),\phi_j \rangle$
, by using a similar approach.
$\langle h_i(\mathsf{fr}(\rho)),\phi_i \rangle \not \sqsubseteq \langle h_j(\mathsf{fr}(\rho)),\phi_j \rangle$
, by using a similar approach.
Querying Approximate Conditional Solutions. What now remains to show is how we can compute the conditional certain answers over an approximate conditional solution, for example, obtained via the conditional chase. It is known that the problem of computing the conditional certain answers of a query Q is
 $\text{co}\text{NP}\text{-hard}$
in general, even when we assume all the conditions in the given conditional instance are true (Imielinski and Lipski Reference Imielinski and Lipski1984). Hence, given a data exchange setting
$\text{co}\text{NP}\text{-hard}$
in general, even when we assume all the conditions in the given conditional instance are true (Imielinski and Lipski Reference Imielinski and Lipski1984). Hence, given a data exchange setting
 $\mathcal{S}$
and a source instance I of
$\mathcal{S}$
and a source instance I of
 $\mathcal{S}$
, if an approximate conditional instance
$\mathcal{S}$
, if an approximate conditional instance
 $\mathcal{J}$
of I w.r.t.
$\mathcal{J}$
of I w.r.t.
 $\mathcal{S}$
can be computed in polynomial time w.r.t.
$\mathcal{S}$
can be computed in polynomial time w.r.t.
 $|I|$
, one cannot always compute
$|I|$
, one cannot always compute
 $\mathsf{con\text{-}cert}(\mathcal{J},Q)$
, in polynomial time. Hence, we require an additional step of approximation.
$\mathsf{con\text{-}cert}(\mathcal{J},Q)$
, in polynomial time. Hence, we require an additional step of approximation.
To this end, we exploit an existing algorithm presented in (Greco et al. Reference Greco, Molinaro and Trubitsyna2019) to compute approximate certain answers over incomplete databases. Here we only recall the main properties of the algorithm. For more details, we refer the reader to (Greco et al. Reference Greco, Molinaro and Trubitsyna2019).
For a query Q, the function
 $\dot{Q}_t$
from conditional instances to sets of tuples is defined in (Greco et al. Reference Greco, Molinaro and Trubitsyna2019) and it is such that the following holds.
$\dot{Q}_t$
from conditional instances to sets of tuples is defined in (Greco et al. Reference Greco, Molinaro and Trubitsyna2019) and it is such that the following holds.
Given a conditional instance
 $\mathcal{J}$
over some schema
$\mathcal{J}$
over some schema
 $\mathsf{S}$
and a query Q over
$\mathsf{S}$
and a query Q over
 $\mathsf{S}$
, then
$\mathsf{S}$
, then
-
1.
$\dot{Q}_t(\mathcal{J}) \subseteq \mathsf{con\text{-}cert}(\mathcal{J},Q)$
; -
2. if Q is positive,
$\dot{Q}_t(\mathcal{J}) = \mathsf{con\text{-}cert}(\mathcal{J},Q)$
; -
3. if every condition in
$\mathcal{J}$
is a conjunction of equalities, then
$\dot{Q}_t(\mathcal{J})$
is computable in polynomial time w.r.t.
$|\mathcal{J}|$
.





The theorem above implies that the approximation algorithm provides so-called correctness guarantees (Item 1 of the theorem), that is, the algorithm always constructs a subset of the conditional certain answers, and thus, only returns correct answers. This is the standard notion for measuring the quality of the set of approximate answers these algorithms are able to compute, in the context of querying incomplete databases – for example, see (Libkin Reference Libkin2016; Guagliardo and Libkin Reference Guagliardo and Libkin2016; Console et al. Reference Console, Guagliardo and Libkin2016). To the best of our knowledge, none of the existing approximation algorithms from the literature provide other kinds of theoretical guarantees, for example, w.r.t. to “how complete” the set of approximate answers is.
From the result above, Theorem 12, and Definition 11, we obtain the following crucial result.
Corollary 3 Consider a TGD-only weakly-acyclic setting
 $\mathcal{S}$
. For every source instance I of
$\mathcal{S}$
. For every source instance I of
 $\mathcal{S}$
, an approximate conditional solution
$\mathcal{S}$
, an approximate conditional solution
 $\mathcal{J}$
of I w.r.t.
$\mathcal{J}$
of I w.r.t.
 $\mathcal{S}$
can be constructed in polynomial time, and for every query Q,
$\mathcal{S}$
can be constructed in polynomial time, and for every query Q,
 $\dot{Q}_t$
is such that
$\dot{Q}_t$
is such that
-
1.
$\dot{Q}_t(\mathcal{J}) \subseteq \mathsf{con\text{-}cert}(\mathcal{J},Q) \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
; -
2. if Q is positive,
$\dot{Q}_t(\mathcal{J})$
=
$\mathsf{con\text{-}cert}(\mathcal{J},Q)$
=
$\mathsf{scert}_{\mathcal{S}}(I,Q)$
; -
3.
$\dot{Q}_t(\mathcal{J})$
is computable in polynomial time w.r.t.
$|\mathcal{J}|$
.






7 Dealing with EGDs
We now show how to deal with weakly-acyclic settings with EGDs, when it comes to construct approximate conditional solutions.
Consider a weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I. We assume that
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
and a source instance I. We assume that
 $\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Checking whether
$\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Checking whether
 $\mathsf{ssol}(I,\mathcal{S}) = \emptyset$
is feasible in polynomial time, for weakly-acyclic settings (Theorem 5), and if
$\mathsf{ssol}(I,\mathcal{S}) = \emptyset$
is feasible in polynomial time, for weakly-acyclic settings (Theorem 5), and if
 $\mathsf{ssol}(I,\mathcal{S})$
is empty, no approximate conditional solution can be constructed.
$\mathsf{ssol}(I,\mathcal{S})$
is empty, no approximate conditional solution can be constructed.
The goal is to first construct an approximate conditional solution
 $\mathcal{J}$
for the data exchange setting
$\mathcal{J}$
for the data exchange setting
 $\mathcal{S}^\exists$
obtained from
$\mathcal{S}^\exists$
obtained from
 $\mathcal{S}$
by removing the set
$\mathcal{S}$
by removing the set
 $\Sigma_E$
of all EGDs from
$\Sigma_E$
of all EGDs from
 $\Sigma_t$
. Then, we show that for every query Q, the EGDs in
$\Sigma_t$
. Then, we show that for every query Q, the EGDs in
 $\Sigma_E$
can be embedded in Q, obtaining a query Q’, in such a way that
$\Sigma_E$
can be embedded in Q, obtaining a query Q’, in such a way that
 $$\mathsf{con\text{-}cert}(\mathcal{J},Q') = \bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J).$$
$$\mathsf{con\text{-}cert}(\mathcal{J},Q') = \bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J).$$
As we will see, this will imply that
 $\mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
.
$\mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
.
Thus, modulo a rewriting of Q, we can exploit
 $\mathcal{J}$
to compute an approximation of the supported certain answers of Q. Despite our efforts, we were not able to prove that Q’ is also such that
$\mathcal{J}$
to compute an approximation of the supported certain answers of Q. Despite our efforts, we were not able to prove that Q’ is also such that
 $\mathsf{con\text{-}cert}(\mathcal{J},Q') = \mathsf{scert}_{\mathcal{S}}(I,Q)$
, when Q is positive. It is an open question that we hope to answer in a future work.
$\mathsf{con\text{-}cert}(\mathcal{J},Q') = \mathsf{scert}_{\mathcal{S}}(I,Q)$
, when Q is positive. It is an open question that we hope to answer in a future work.
In what follows, for a data exchange setting
 $\mathcal{S}$
,
$\mathcal{S}$
,
 $\mathcal{S}^{\exists}$
denotes the setting obtained from
$\mathcal{S}^{\exists}$
denotes the setting obtained from
 $\mathcal{S}$
by removing the set
$\mathcal{S}$
by removing the set
 $\Sigma_E$
of all EGDs from
$\Sigma_E$
of all EGDs from
 $\Sigma_t$
.
$\Sigma_t$
.
Lemma 14 Consider a weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and assume I is a source instance of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and assume I is a source instance of
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Moreover, let
$\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Moreover, let
 $\mathcal{J}$
be an approximate conditional solution of I w.r.t.
$\mathcal{J}$
be an approximate conditional solution of I w.r.t.
 $\mathcal{S}^\exists$
. Then, for every query Q, there exists a query Q’, which depends only on Q and the set of EGDs
$\mathcal{S}^\exists$
. Then, for every query Q, there exists a query Q’, which depends only on Q and the set of EGDs
 $\Sigma_E$
in
$\Sigma_E$
in
 $\mathcal{S}$
, such that
$\mathcal{S}$
, such that
 \begin{align*} \mathsf{con\text{-}cert}(\mathcal{J},Q') =\bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J). \end{align*}
\begin{align*} \mathsf{con\text{-}cert}(\mathcal{J},Q') =\bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J). \end{align*}
Proof. Let
 $k = ar(Q)$
. The goal is to construct, for a given query Q, a query Q’ such that, for every target instance J, whenever all the EGDs in
$k = ar(Q)$
. The goal is to construct, for a given query Q, a query Q’ such that, for every target instance J, whenever all the EGDs in
 $\Sigma_E$
are satisfied by J, then
$\Sigma_E$
are satisfied by J, then
 $Q'(J) = Q(J)$
, and
$Q'(J) = Q(J)$
, and
 $Q'(J) = \mathcal{C}^k$
otherwise, where
$Q'(J) = \mathcal{C}^k$
otherwise, where
 $\mathcal{C}$
is the set of all constants occurring in J,
$\mathcal{C}$
is the set of all constants occurring in J,
 $\mathcal{S}$
, and Q. That is, if J does not satisfy
$\mathcal{S}$
, and Q. That is, if J does not satisfy
 $\Sigma_E$
, the query Q’ outputs every possible tuple of length k, using constants from J,
$\Sigma_E$
, the query Q’ outputs every possible tuple of length k, using constants from J,
 $\mathcal{S,}$
and Q. Clearly, if Q’ enjoys the above property, the claim will follow immediately. We now explain how the query Q’ can be constructed, starting from Q and
$\mathcal{S,}$
and Q. Clearly, if Q’ enjoys the above property, the claim will follow immediately. We now explain how the query Q’ can be constructed, starting from Q and
 $\Sigma_E$
. The query Q’ is made of two subqueries, that are put together via a union. That is:
$\Sigma_E$
. The query Q’ is made of two subqueries, that are put together via a union. That is:
 $$Q' = Q_1 \vee Q_2.$$
$$Q' = Q_1 \vee Q_2.$$
 $Q_1$
is such that for every target instance J, if J satisfies
$Q_1$
is such that for every target instance J, if J satisfies
 $\Sigma_E$
, then
$\Sigma_E$
, then
 $Q_1(J) = Q(J)$
, and
$Q_1(J) = Q(J)$
, and
 $Q_1(J) = \emptyset$
, otherwise. On the other hand,
$Q_1(J) = \emptyset$
, otherwise. On the other hand,
 $Q_2$
is such that for every target instance J, if J satisfies
$Q_2$
is such that for every target instance J, if J satisfies
 $\Sigma_E$
, then
$\Sigma_E$
, then
 $Q_2(J) = \emptyset$
, and
$Q_2(J) = \emptyset$
, and
 $Q_2(J) = \mathcal{C}^{k}$
, otherwise. It remains to show how
$Q_2(J) = \mathcal{C}^{k}$
, otherwise. It remains to show how
 $Q_1$
and
$Q_1$
and
 $Q_2$
are constructed. For each EGD
$Q_2$
are constructed. For each EGD
 $\eta \in \Sigma_E$
, we let
$\eta \in \Sigma_E$
, we let
 $Q_{\eta}$
be the boolean query such that for every instance J over
$Q_{\eta}$
be the boolean query such that for every instance J over
 $\mathsf{T}$
,
$\mathsf{T}$
,
 $Q_\eta(J) = \{()\}$
, if
$Q_\eta(J) = \{()\}$
, if
 $\eta$
satisfies J, and
$\eta$
satisfies J, and
 $Q_\eta(J) = \emptyset$
, otherwise. Furthermore, we use
$Q_\eta(J) = \emptyset$
, otherwise. Furthermore, we use
 $Q^{\neg}_{\eta}$
to denote the complement of
$Q^{\neg}_{\eta}$
to denote the complement of
 $Q_{\eta}$
, that is
$Q_{\eta}$
, that is
 $Q^\neg_\eta(J) = \{()\}$
iff
$Q^\neg_\eta(J) = \{()\}$
iff
 $Q_\eta(J) = \emptyset$
. All the above queries can be easily written in FO. Finally, we let
$Q_\eta(J) = \emptyset$
. All the above queries can be easily written in FO. Finally, we let
 $Q_{\mathsf{dom}}$
be the query of arity k, such that, for every target instance J,
$Q_{\mathsf{dom}}$
be the query of arity k, such that, for every target instance J,
 $Q_{\mathsf{dom}}(J)$
is the set of all tuples of length k over the constants in J,
$Q_{\mathsf{dom}}(J)$
is the set of all tuples of length k over the constants in J,
 $\mathcal{S,}$
and Q. The above query can be encoded with a UCQ. Then, we have
$\mathcal{S,}$
and Q. The above query can be encoded with a UCQ. Then, we have
 $$ Q_1(x_1,\ldots,x_k) = Q(x_1,\ldots,x_k) \wedge \bigwedge\limits_{\eta \in \Sigma_E} Q_\eta,$$
$$ Q_1(x_1,\ldots,x_k) = Q(x_1,\ldots,x_k) \wedge \bigwedge\limits_{\eta \in \Sigma_E} Q_\eta,$$
and
 $$ Q_2(x_1,\ldots,x_k) = Q_{\mathsf{dom}}(x_1,\ldots,x_k) \wedge \bigvee\limits_{\eta \in \Sigma_E} Q^\neg_\eta.$$
$$ Q_2(x_1,\ldots,x_k) = Q_{\mathsf{dom}}(x_1,\ldots,x_k) \wedge \bigvee\limits_{\eta \in \Sigma_E} Q^\neg_\eta.$$
By construction,
 $Q_1(J) = Q(J)$
if J satisfies
$Q_1(J) = Q(J)$
if J satisfies
 $\Sigma_E$
and
$\Sigma_E$
and
 $Q_1(J) = \emptyset$
, otherwise, and
$Q_1(J) = \emptyset$
, otherwise, and
 $Q_2(J) = \emptyset$
, if J satisfies
$Q_2(J) = \emptyset$
, if J satisfies
 $\Sigma_E$
, and
$\Sigma_E$
, and
 $Q_2(J) = \mathcal{C}^{k}$
, otherwise.
$Q_2(J) = \mathcal{C}^{k}$
, otherwise.
From the result above, and from the fact that the supported solutions of a data exchange setting
 $\mathcal{S}$
correspond to the supported solutions of
$\mathcal{S}$
correspond to the supported solutions of
 $\mathcal{S}^\exists$
that also satisfy the EGDs of
$\mathcal{S}^\exists$
that also satisfy the EGDs of
 $\mathcal{S}$
, we obtain the main result of this section.
$\mathcal{S}$
, we obtain the main result of this section.
Theorem 15 Consider a weakly-acyclic data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and assume I is a source instance of
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, and assume I is a source instance of
 $\mathcal{S}$
such that
$\mathcal{S}$
such that
 $\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Moreover, let
$\mathsf{ssol}(I,\mathcal{S}) \neq \emptyset$
. Moreover, let
 $\mathcal{J}$
be an approximate conditional solution of I w.r.t.
$\mathcal{J}$
be an approximate conditional solution of I w.r.t.
 $\mathcal{S}^\exists$
. Then, for every query Q, there exists a query Q’, which depends only on Q and the set of EGDs
$\mathcal{S}^\exists$
. Then, for every query Q, there exists a query Q’, which depends only on Q and the set of EGDs
 $\Sigma_E$
in
$\Sigma_E$
in
 $\mathcal{S}$
, such that
$\mathcal{S}$
, such that
 \begin{align*} && \mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q). && \end{align*}
\begin{align*} && \mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q). && \end{align*}
Proof. From Lemma 14, there exists a query Q’, depending only on Q and
 $\Sigma_E$
, such that
$\Sigma_E$
, such that
 \begin{equation}\mathsf{con\text{-}cert}(\mathcal{J},Q') =\bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J).\end{equation}
\begin{equation}\mathsf{con\text{-}cert}(\mathcal{J},Q') =\bigcap\limits_{J \in \mathsf{pw}(\mathcal{J})\text{ and } J \text{ satisfies } \Sigma_E} Q(J).\end{equation}
From the definition of approximate conditional solution, we have that
 $\mathsf{ssol}(I,\mathcal{S}^\exists) \subseteq \mathsf{pw}(\mathcal{J})$
. Moreover, by definition of supported solution,
$\mathsf{ssol}(I,\mathcal{S}^\exists) \subseteq \mathsf{pw}(\mathcal{J})$
. Moreover, by definition of supported solution,
 $\mathsf{ssol}(I,\mathcal{S}) = \{J \in \mathsf{ssol}(I,\mathcal{S}) \mid J \text{ satisfies } \Sigma_E\}$
. Hence,
$\mathsf{ssol}(I,\mathcal{S}) = \{J \in \mathsf{ssol}(I,\mathcal{S}) \mid J \text{ satisfies } \Sigma_E\}$
. Hence,
 $\mathsf{ssol}(I,\mathcal{S}) \subseteq \{ J \in \mathsf{pw}(\mathcal{J}) \mid J \text{ satisfies } \Sigma_E\}$
. The latter inclusion and equation (7) let us conclude that
$\mathsf{ssol}(I,\mathcal{S}) \subseteq \{ J \in \mathsf{pw}(\mathcal{J}) \mid J \text{ satisfies } \Sigma_E\}$
. The latter inclusion and equation (7) let us conclude that
 $\mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
.
$\mathsf{con\text{-}cert}(\mathcal{J},Q') \subseteq \mathsf{scert}_{\mathcal{S}}(I,Q)$
.
The above results tell us that we can still materialize a target instance, even for weakly-acyclic settings that allow for EGDs. Moreover, modulo a rewriting of the query Q, the constructed target instance allows for the construction of a subset of supported certain answers of Q.
8 Connections with other work and next steps
Conditional instances and, more in general, incomplete databases, have already been employed in the context of data exchange. However, in most of previous work, incomplete databases are used to encode source and target instances with incomplete information. In (Arenas et al. Reference Arenas, Pérez and Reutter2013), the authors extend the standard data exchange framework by allowing source and target instances to be incomplete databases, encoded via some representation system, such as conditional instances. There, the main goal is to study the semantics of data exchange under the assumption that the source and target instances can be incomplete. In contrast, in our work, we focus on the classical data exchange setting, where source and target instances are standard (complete) databases. Here we employ incomplete databases, in particular conditional instances, only as a tool to compute the (approximate) certain answers of a query over our set of supported solutions, which are standard databases as well. Adapting our notion of supported solution to the setting of data exchange with incomplete instances is a non-trivial task which we will consider for future work.
In Section 6, we have seen how a conditional extension of the chase procedure, working on a normalized form of TGDs, can be employed to compute in polynomial time, for weakly-acyclic settings, an approximate conditional solution. A similar normal form to the one we employ in our paper is presented in (Gheerbrant and Sirangelo Reference Gheerbrant and Sirangelo2019). However, in that work, the normal form is applied to queries, and the goal is to compute so-called best answers of UCQs over incomplete databases, while in our case, we employ a normal form for TGDs, which we then use to simplify the definition of the conditional chase. Finally, the idea of extending the chase procedure with conditional TGD applications is not new and has been explored in previous work. In particular, the work of (Grahne and Onet Reference Grahne and Onet2011) introduces a conditional version of the chase procedure which is similar to ours. The main difference is that the conditional chase of (Grahne and Onet Reference Grahne and Onet2011) is much simpler, since it is an extension of the simplest variant of the chase algorithm, called oblivious chase, while ours can be seen as an extension of the more refined semi-oblivious (a.k.a. skolem) chase (see, e.g., (Calautti et al. Reference Calautti, Gottlob and Pieris2015; Grahne and Onet Reference Grahne and Onet2018; Calautti and Pieris 2019; Reference Calautti and Pieris2021; Calautti et al. Reference Calautti, Greco, Molinaro and Trubitsyna2022) for more details). For this reason, it is not difficult to show that when considering weakly-acyclic settings, the conditional chase of (Grahne and Onet Reference Grahne and Onet2011) is not guaranteed to terminate, while termination for weakly-acyclic settings is a crucial property for our purposes, since we need to be able to construct a finite conditional instance in this case.
The problem of dealing with non-monotonic queries has been investigated beyond data exchange, as for example for ontology-mediated query answering. In this setting, we are given an instance (database) D, an ontology
 $\Sigma$
encoded in some logical formalism (e.g., via TGDs), and a query
$\Sigma$
encoded in some logical formalism (e.g., via TGDs), and a query
 $Q({\textbf {x}})$
, and the goal is to compute all the certain answers of
$Q({\textbf {x}})$
, and the goal is to compute all the certain answers of
 $Q({\textbf {x}})$
w.r.t. D and
$Q({\textbf {x}})$
w.r.t. D and
 $\Sigma$
, that is, the tuples that are answers to Q in every model of the logical theory
$\Sigma$
, that is, the tuples that are answers to Q in every model of the logical theory
 $D \cup \Sigma$
. A relevant work in this scenario is the one in (Calvanese et al. Reference Calvanese, De Giacomo, Lembo, Lenzerini and Rosati2007), where the authors define the query language EQL-Lite(
$D \cup \Sigma$
. A relevant work in this scenario is the one in (Calvanese et al. Reference Calvanese, De Giacomo, Lembo, Lenzerini and Rosati2007), where the authors define the query language EQL-Lite(
 $\cal Q$
), parametrized with a standard (positive) query language
$\cal Q$
), parametrized with a standard (positive) query language
 $\cal Q$
(e.g., UCQs), and supports a limited form of negation. In particular, an expression
$\cal Q$
(e.g., UCQs), and supports a limited form of negation. In particular, an expression
 $\psi$
in EQL-Lite(
$\psi$
in EQL-Lite(
 $\cal Q$
) is of the form
$\cal Q$
) is of the form
 $\psi := \mathbb{K}\, \rho \mid \psi_1 \wedge \psi_2 \mid \neg \psi_1 \mid \exists x\, \psi_1$
, where
$\psi := \mathbb{K}\, \rho \mid \psi_1 \wedge \psi_2 \mid \neg \psi_1 \mid \exists x\, \psi_1$
, where
 $\rho \in \cal Q$
, and
$\rho \in \cal Q$
, and
 $\psi_1,\psi_2$
are EQL-Lite(
$\psi_1,\psi_2$
are EQL-Lite(
 $\cal Q$
) expressions.
$\cal Q$
) expressions.
Here, the epistemic operator
 $\mathbb{K}\,$
is applied to expressions
$\mathbb{K}\,$
is applied to expressions
 $\rho \in \cal Q$
and returns the certain answers of
$\rho \in \cal Q$
and returns the certain answers of
 $\rho$
w.r.t. the input database D and the ontology
$\rho$
w.r.t. the input database D and the ontology
 $\Sigma$
. The main instantiation of EQL-Lite that the authors study is EQL-Lite(UCQ), that is, where
$\Sigma$
. The main instantiation of EQL-Lite that the authors study is EQL-Lite(UCQ), that is, where
 $\cal Q$
coincides with the set of all UCQs.
$\cal Q$
coincides with the set of all UCQs.
From the above definition, we observe that negation is applied only to (a combination of) the certain answers of positive queries. This gives a semantics to negation that fundamentally differs from ours, as illustrated in the following example.
Consider the data exchange setting
 $\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
$\mathcal{S} = \langle \mathsf{S}, \mathsf{T}, \Sigma_{st}, \Sigma_t \rangle$
, where
 $\mathsf{S}$
stores employees of a company in the unary relation
$\mathsf{S}$
stores employees of a company in the unary relation
 $\mathsf{Emp}$
. The target schema
$\mathsf{Emp}$
. The target schema
 $\mathsf{T}$
contains a unary relation
$\mathsf{T}$
contains a unary relation
 $\mathsf{Emp}'$
storing employees, the ternary relation
$\mathsf{Emp}'$
storing employees, the ternary relation
 $\mathsf{Addr}$
assigning to each employee her work and home address, and the unary relation
$\mathsf{Addr}$
assigning to each employee her work and home address, and the unary relation
 $\mathsf{WorkFromHome}$
, storing employees working from home. Assume we have
$\mathsf{WorkFromHome}$
, storing employees working from home. Assume we have
 $\Sigma_{st} = \{\rho_1 = \mathsf{Emp}(x) \rightarrow \mathsf{Emp}'(x),\rho_2=\mathsf{Emp}(x) \rightarrow \exists z\, \exists w\, \mathsf{Addr}(x,z,w)\}$
and
$\Sigma_{st} = \{\rho_1 = \mathsf{Emp}(x) \rightarrow \mathsf{Emp}'(x),\rho_2=\mathsf{Emp}(x) \rightarrow \exists z\, \exists w\, \mathsf{Addr}(x,z,w)\}$
and
 $\Sigma_t = \{\rho_3=\mathsf{Addr}(x,y,y) \rightarrow \mathsf{WorkFromHome}(x)\}$
.
$\Sigma_t = \{\rho_3=\mathsf{Addr}(x,y,y) \rightarrow \mathsf{WorkFromHome}(x)\}$
.
The above setting copies employees from the source to the target via the TGD
 $\rho_1$
, while the TGD
$\rho_1$
, while the TGD
 $\rho_2$
states that each employee must have a work and home address, denoted via the existential variables z and w, respectively. Finally, the TGD
$\rho_2$
states that each employee must have a work and home address, denoted via the existential variables z and w, respectively. Finally, the TGD
 $\rho_3$
states that if the work and home address of an employee coincide, then this employee works from home.
$\rho_3$
states that if the work and home address of an employee coincide, then this employee works from home.
Assume the source instance is
 $I = \{\mathsf{Emp}(\mathsf{john})\}$
, and let Q be the query asking for all employees who do not work from home, that is,
$I = \{\mathsf{Emp}(\mathsf{john})\}$
, and let Q be the query asking for all employees who do not work from home, that is,
 $Q(x) = \mathsf{Emp}'(x) \wedge \neg \mathsf{WorkFromHome}(x)$
.
$Q(x) = \mathsf{Emp}'(x) \wedge \neg \mathsf{WorkFromHome}(x)$
.
According to (Calvanese et al. Reference Calvanese, De Giacomo, Lembo, Lenzerini and Rosati2007), the query Q corresponds to the EQL-Lite(UCQ) expression
 $Q'(x) = \mathbb{K}\, \mathsf{Emp}'(x) \wedge \neg \mathbb{K}\, \mathsf{WorkFromHome}(x)$
. Letting
$Q'(x) = \mathbb{K}\, \mathsf{Emp}'(x) \wedge \neg \mathbb{K}\, \mathsf{WorkFromHome}(x)$
. Letting
 $D = I$
, and
$D = I$
, and
 $\Sigma = \Sigma_{st} \cup \Sigma_t$
, roughly, the above means that an employee is an answer to the query Q’ if she is present in all models of
$\Sigma = \Sigma_{st} \cup \Sigma_t$
, roughly, the above means that an employee is an answer to the query Q’ if she is present in all models of
 $D \cup \Sigma$
and such that there is at least one model in which the employee does not work from home. Under this interpretation, the answer to Q’ is
$D \cup \Sigma$
and such that there is at least one model in which the employee does not work from home. Under this interpretation, the answer to Q’ is
 $\mathsf{john}$
. However, under our semantics, the answer to Q is empty. Hence, the fundamental difference is that negation, under EQL-Lite, is interpreted as negating classical certain answering, and thus an expression
$\mathsf{john}$
. However, under our semantics, the answer to Q is empty. Hence, the fundamental difference is that negation, under EQL-Lite, is interpreted as negating classical certain answering, and thus an expression
 $\neg \mathbb{K}\, \psi$
is “satisfied” when at least one model/solution does not entail
$\neg \mathbb{K}\, \psi$
is “satisfied” when at least one model/solution does not entail
 $\psi$
, while in our case, we consider the given query as a whole, and require it to be satisfied in every valid solution.
$\psi$
, while in our case, we consider the given query as a whole, and require it to be satisfied in every valid solution.
We conclude by discussing avenues for further research. First, we would like to extend the conditional chase to weakly-acyclic settings with EGDs, and identify relevant data exchange settings for which computing the supported certain answers is tractable. Moreover, we would like to identify other quality measures of our approximation algorithm using techniques such as the ones introduced in (Libkin Reference Libkin, den Bussche and Arenas2018). We also plan to experimentally evaluate both our translation to logic programs for computing exact answers, as well as our materialization-based approaches for computing approximate answers by means of a dedicated benchmark, as done for example, in the context of approximate consistent query answering (Calautti et al. Reference Calautti, Console, Pieris, Libkin, Pichler and Guagliardo2021).
To conclude, we mention that explaining query answering has recently drawn considerable attention under existential rule languages (e.g., see (Lukasiewicz et al. Reference Lukasiewicz, Malizia and Molinaro2022; Ceylan et al. 2021; Reference Ceylan, Lukasiewicz, Malizia, Molinaro and Vaicenavicius2020; Lukasiewicz et al. Reference Lukasiewicz, Malizia and Molinaro2020; Ceylan et al. Reference Ceylan, Lukasiewicz, Malizia, Molinaro and Vaicenavicius2019)), and knowledge representation in general (e.g., in the context of argumentation (Alfano et al. Reference Alfano, Calautti, Greco, Parisi and Trubitsyna2020)). Hence, an interesting direction for future work is to address such issues in our setting. Also, it would be interesting to account for user preferences when answering queries, as recently done in (Calautti et al. Reference Calautti, Greco, Molinaro and Trubitsyna2022) for ontology-mediated queries.
Competing interests
The author(s) declare none.




 Open access
Open access