



Introduction
The General Health Questionnaire (GHQ) was developed in 1972 as a screening tool to identify those who are at risk of identifying psychiatric disorders (Romppel et al., Reference Romppel, Hinz, Finck, Young, Brähler and Glaesmer2017, p. 1). It was designed to identify deterioration in normal functioning and therefore focuses on common mental health problems such as anxiety, depression and social impairment, rather than severe illnesses such as schizophrenia or bipolar disorder (McDowell, Reference McDowell2006, p. 259). There are several versions of the GHQ in use, which can consist of 12, 28, 30 or 70 items (Jackson, Reference Jackson2007, p. 79). The GHQ-12 is one of the most widely used for both individual screening purposes and population research (Hankins, Reference Hankins2008). Concerns have been raised, however, about the relative lack of attention given to measurement equivalence vis-a-vis the GHQ-12 (French & Tait, Reference French and Tait2004). When assessing the mental health profile of individuals and populations, it is assumed that the measurement properties of the survey items are consistent across different groups. That is to say, if differences in mental health are observed between different groups, these disparities are assumed to reflect real differences in health status not artefacts of measurement. This assumption, however, may not always hold. Latent factor structures may vary across groups; individual item loadings may differ across groups; and the estimated mean values of scales and subscales may also differ across social groups even though no real differences pertain. These issues of what are known in the literature as configural, metric and scalar invariance (Allum, Read, & Sturgis, Reference Allum, Read, Sturgis, Davidov, Schmidt, Billiet and Meuleman2018) are of practical importance for the following reason. As part of its long-term plan, the UK's National Health Service is committed to monitoring and improving mental health in all sections of society. A necessary implication is that for the GHQ-12 to play a role in this effort, it needs reliably to measure mental health profiles across, inter alia, different ethnic groups (NHS England, 2017, p. 14). Consequently, generating an instrument valid for all ethnic groups is an important step towards ensuring that such a target can be attained (Eisen, Gerena, Ranganathan, Esch, & Idiculla, Reference Eisen, Gerena, Ranganathan, Esch and Idiculla2006, p. 305).
The potential issue of measurement invariance across different ethnic groups is founded upon the ways in which differences in racial and ethnic identities affect how individuals report psychosocial functioning (Bowe, Reference Bowe2017, p. 90). The concern is that the measurement properties of health metrics, such as the GHQ-12, may differ across ethnic groups because each group defines the same health issue differently and uses different symptoms to identify it. If this is the case, a questionnaire developed to measure mental health for one group will fail to identify other aspects of the construct as understood by another group (Crockett, Randall, Shen, Russell, & Driscoll, Reference Crockett, Randall, Shen, Russell and Driscoll2005, p. 48). Furthermore, different ethnic groups may interpret the response options differently. For example, a score of 28 on a metric for one group may reflect a respondent being moderately distressed, whereas for another group this may reflect a respondent being severely distressed. A scoring system that is optimal for the first group may result in the under or overestimation of mental health for the second group and therefore comparisons of these scores could be misleading (Banh et al., Reference Banh, Crane, Rhew, Gudmundsen, Stoep, Lyon and McCauley2012, p. 354). It is clearly important, then, for health metrics to be invariant to allow for comparisons across ethnic groups to be made. Statistics such as population means and regression coefficients can only be validly estimated if the measures on which they rely are found to be invariant across such different groups (Chen, Reference Chen2008, p. 1005). The aim of this study is to assess the measurement invariance of the GHQ-12 with respect to adult members of six ethnic minority groups in the UK.
Analysis plan
The following analyses focus on the GHQ-12 as it is currently the most popular version due to its brevity and ease of administration (Molina, Rodrigo, Losilla, & Vives, Reference Molina, Rodrigo, Losilla and Vives2014, p. 1031; Romppel et al., Reference Romppel, Hinz, Finck, Young, Brähler and Glaesmer2017, p. 1). We use data from the UK to initially fit a measurement model for the 12 GHQ items for the majority white British group. Extensive literature supports one, two and three-factor models. This has important implications for measurement equivalence; using a suboptimal model will complicate the interpretation of the scores, which could lead to mistaken estimates of mental function (Smith, Fallowfield, Stark, Velikova, & Jenkins, Reference Smith, Fallowfield, Stark, Velikova and Jenkins2010, p. 2). Evaluating the validity of the results from previous research, however, is complicated by the fact that results will be affected by the use of diverse samples and methods. In terms of the former, model solutions have been derived from data generated from both probability and non-probability samples, of varying sizes. In terms of the latter, researchers have taken different approaches to dealing with positive and negative items. While including both can deter acquiescence bias and provide for a better fitting multidimensional solution (Marsh, Reference Marsh1996, p. 810), Hankins (Reference Hankins2008, p. 2), writing about the GHQ, questions whether the multi-factor solutions that have been derived in the literature have simply reflected the inclusion of positive and negative worded items rather any real multidimensionality of health status as measured by the instrument. In our analyses, we assess several alternative formulations that take account of such putative method effects in different ways.
Having fitted a measurement model which takes account of method effects in the white British group, we go on to perform a multi-group confirmatory factor analysis to test for measurement invariance using standard procedures. The only extant research that examines measurement invariance amongst ethnic groups for the GHQ-12 was concerned only with adolescents. Results from this work suggested measurement equivalence was a reasonable assumption but could not speak to adult populations (Banh et al., Reference Banh, Crane, Rhew, Gudmundsen, Stoep, Lyon and McCauley2012; Bowe, Reference Bowe2017; Crockett et al., Reference Crockett, Randall, Shen, Russell and Driscoll2005). The present research, then, represents the first evaluation of the GHQ-12 as a viable multi-ethnic instrument for adults of all ages.
Methods
The data for our analyses come from Wave 6 of Understanding Society, The UK Household Longitudinal Study (UKHLS). The survey employs a proportionately stratified, clustered probability sample design (McFall, Nandi, & Platt, Reference McFall, Nandi and Platt2016, p. 10). UKHLS includes an ethnic minority boost sample designed to yield around 1000 additional respondents from each of five minority groups: Indians, Pakistanis, Bangladeshis, Caribbeans and Africans, as well as a ‘mixed’ group The sample was restricted to those who completed the questionnaire in English (the overwhelming majority) so that cultural and language translation effects were not conflated (Prady et al., Reference Prady, Miles, Pickett, Fairley, Bloor, Gilbody and Wright2013, p. 12). This culminated in an analytical sample size of 35 437 of which 83% are white British (n = 29 432) and 17% are black and minority ethnic (BAME) (n = 6005), 2% identify as mixed race (n = 757), 4% are Indian (n = 1518), 4% are Pakistani (n = 1263), 2% are Bangladeshi (n = 567), 2% are Black Caribbean (n = 804) and 3% are Black African (n = 1096). Ethnic group membership is derived from asking respondents to say with which ethnic group they self-identify.
Individual GHQ items are sometimes recoded and analysed by collapsing the categories to form binary items (see, e.g. Padrón, Galán, Durbín, Gandarillas, & Rodríguez-Artalejo, Reference Padrón, Galán, Durbín, Gandarillas and Rodríguez-Artalejo2012). Retaining the original four-point scale metric is the more common practice (Abubakar & Fischer, Reference Abubakar and Fischer2012; Bowe, Reference Bowe2017; Campbell & Knowles, Reference Campbell and Knowles2007; Cheung, Reference Cheung2002; French & Tait, Reference French and Tait2004; Graetz, Reference Graetz1991; Hankins, Reference Hankins2008; Hu, Stewart-Brown, Twigg, & Weich, Reference Hu, Stewart-Brown, Twigg and Weich2007; Molina et al., Reference Molina, Rodrigo, Losilla and Vives2014; Politi, Piccinelli, & Wilkinson, Reference Politi, Piccinelli and Wilkinson1994; Romppel et al., Reference Romppel, Hinz, Finck, Young, Brähler and Glaesmer2017; Romppel, Braehler, Roth, & Glaesmer, Reference Romppel, Braehler, Roth and Glaesmer2013; Ye, Reference Ye2009). We adopt the latter approach as there seems to be no advantage in discarding information by collapsing the items. The question wording and response scales for the measures of the GHQ used in the survey can be found in Appendix 1. We fit our models using maximum likelihood estimation in the Amos 25 software package (Arbuckle, Reference Arbuckle2017). Four-point ordinal items, as we have here, are suitable for this purpose (Bentler & Chou, Reference Bentler and Chou1987), although other estimation methods for ordered categorical variables are available that make different assumptions. As such, we also fitted our models using the weighted least-squares mean-variance adjusted (WLSMV) estimator in Mplus (Muthén & Muthén, Reference Muthén and Muthén1998) as a sensitivity check. Our conclusions are robust to the choice of estimator, and we include the WLSMV estimates in online Supplementary material S1.
The first stage of our analysis is to estimate an appropriate baseline measurement model on the majority white British sample. We begin with the assumption that mental health as measured by GHQ-12 is substantively a unidimensional construct. Two alternative additions to this basic specification have been proposed in order to deal with response effects due to the mixture of positively and negatively worded items. These are the Correlated Trait, Correlated Uniqueness (CTCU) model and the Correlated Trait, Correlated Methods (CTCM) model (Lindwall et al., Reference Lindwall, Barkoukis, Grano, Lucidi, Raudsepp, Liukkonen and Thøgersen-Ntoumani2012). As applied to the GHQ-12, the CTCM model includes a specific latent method effect factor whereas the CTCU model introduces correlations amongst the error variances of the negatively worded items. The CTCM is more parsimonious but makes assumptions that may not hold in practice (Lance, Noble, & Scullen, Reference Lance, Noble and Scullen2002). Both models have been used in studies employing the GHQ-12. For example, Ye (Reference Ye2009) used the CTCM model whereas Hankins (Reference Hankins2008) and Aguado et al. (Reference Aguado, Campbell, Ascaso, Navarro, Garcia-Esteve and Luciano2012) used the CTCU model. Molina et al. (Reference Molina, Rodrigo, Losilla and Vives2014) compared the fit of both models and found that they both fitted the data well, although the CTCU model fitted the data better.
We follow these authors and assess both CTCM and CTCU models. Figures 1 and 2 present the path diagrams for these models. Figure 1 shows the negatively phrased items with correlated error terms whereas Fig. 2 has an additional method factor, uncorrelated with the substantive factor. The loadings of the method factor are also constrained equal as there is no reason to believe that any one question is more vulnerable to a method effect than any other (Hankins, Reference Hankins2008).
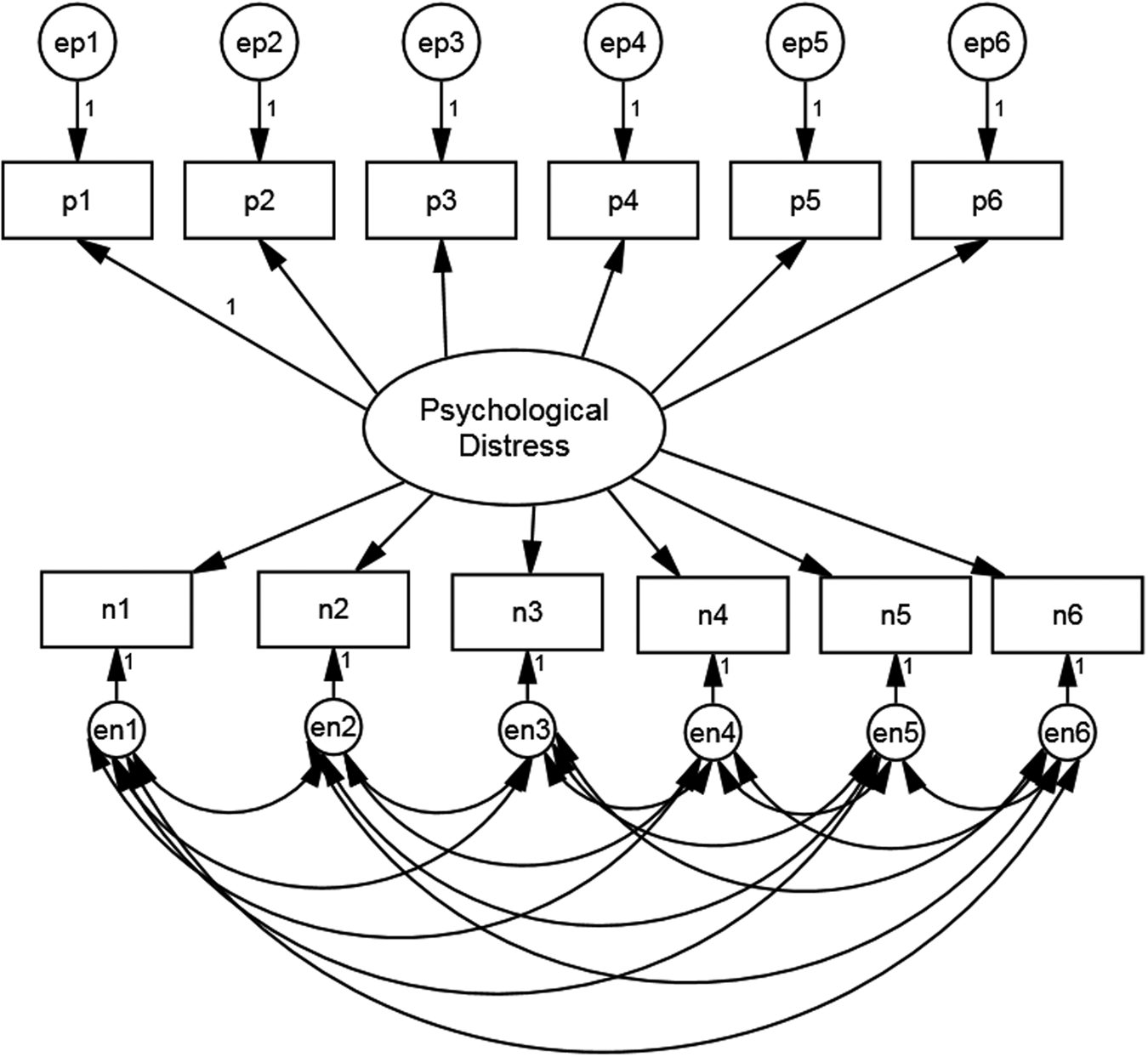
Fig. 1. Model specification for GHQ-12 CTCU model.
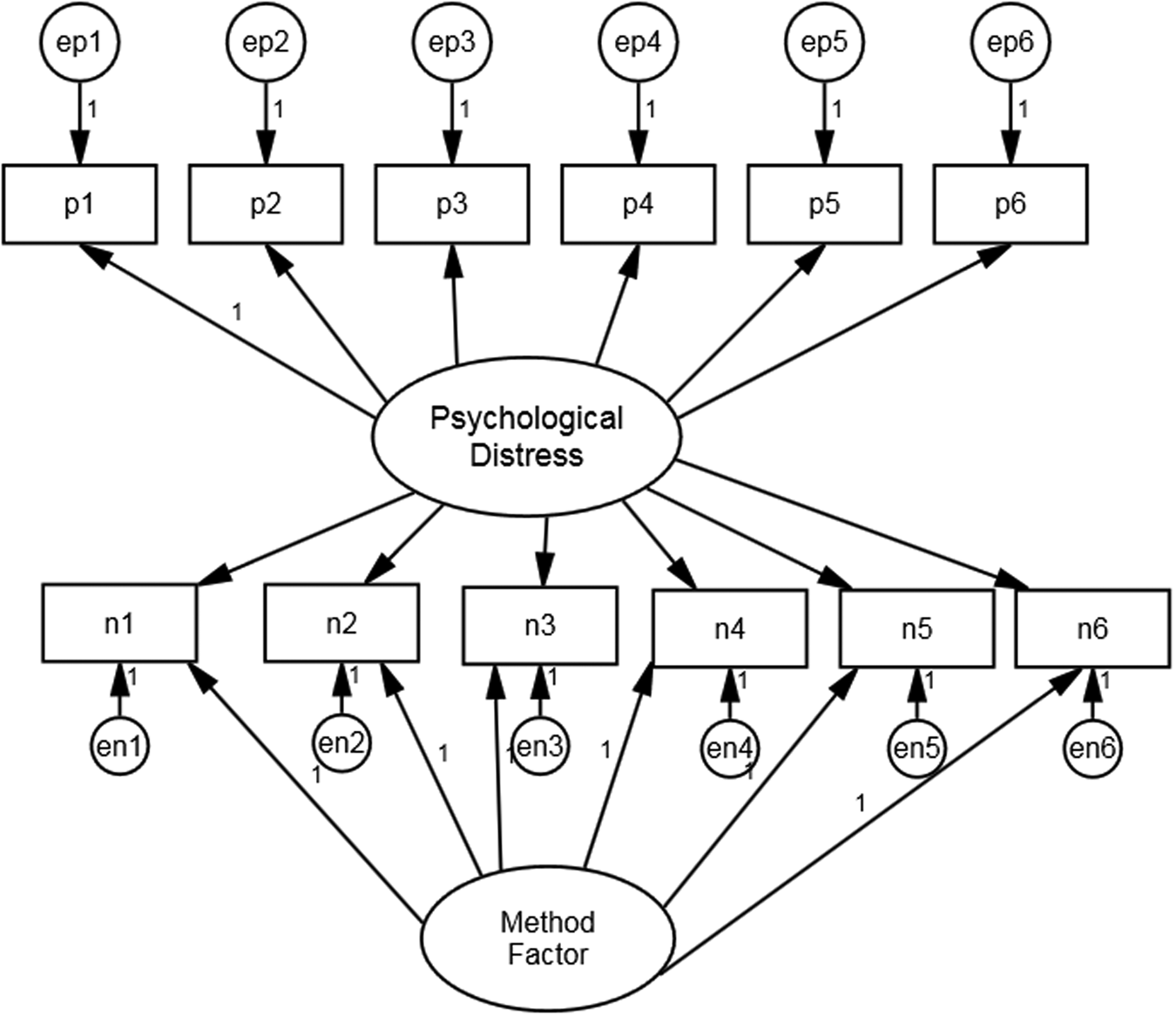
Fig. 2. Model specification for GHQ-12 CTCM model.
After establishing a satisfactory baseline model, we go on to test for measurement invariance between the white British and BAME samples. We proceed by moving from less to more constrained models, assessing fit at each stage (Dimitrov, Reference Dimitrov2010, p. 125; Van der Velde & Saris, Reference Van der Velde, Saris, Davidov, Schmidt and Billet2011, p.).
Specifically, we evaluate models with progressively more restrictive parameter constraints as follows. The configural invariance assesses whether the factor structure of the measurement model is the same across groups (Meuleman & Billiet, Reference Meuleman, Billiet, Davidov, Schmidt and Billet2011, p. 186). At this most basic level, the covariances between GHQ-12 items must be reproducible with the same number of common factors across ethnic groups, and each common factor must be associated with identical item sets across group (Van de Velde, Levecque, & Bracke, Reference Van de Velde, Levecque and Bracke2009, p. 17). Next, we move to the metric invariance model, which tests the hypothesis that the factor loadings are equal across groups. The rationale for this restriction is as follows. In order to be able to compare the mental health of one group compared to another, it is essential that the meanings or interpretations of the questions are consistent between groups. Metric invariance describes the situation where the association between each item and the latent variable is the same for each group (Yap et al., Reference Yap, Donnellan, Schwartz, Kim, Castillo, Zamboanga and Vazonyi2014, p. 439). If this turns out to be the case, one can argue that the questions ‘hang together’ in the same way and that it furthermore makes sense to regard them as valid indicators of the same underlying mental health construct for members of each ethnic group.
Finally, we test for scalar invariance. This requires that not only the factor loadings but the intercepts of each item to be equivalent across ethnic groups (Davidov, Datler, Schmidt, & Schwartz, Reference Davidov, Datler, Schmidt, Schwartz, Davidov, Schmidt and Billet2011, p. 150). That is to say, the expected score on an item for someone of, say, Indian ethnicity who is at the mean on the latent mental health variable (factor means are fixed at zero for identification purposes) should be the same as the expected score on that item for a member of the African group. If this condition is met for all items, it means that comparisons of latent mean levels across groups should be valid. Additionally, and perhaps equally importantly, if scalar invariance is demonstrated, the common practice of creating summated scale scores from the items should also lead to these measures being valid for making ethnic group comparisons of mean mental health levels.
Results
Table 1 shows the goodness-of-fit measures for the two baseline measurement models. Both models included an accommodation for the presumed method effect associated with the negatively worded items. Unsurprisingly, with such a large sample size, neither model fits on the χ2 test statistic, as in both cases the critical value is exceeded. We instead rely on several measures of approximate fit as suggested by Hu and Bentler (Reference Hu and Bentler1999), namely comparative fit index (CFI), Tucker–Lewis index (TLI), root mean square error of approximation (RMSEA) and standardised root mean residual (SRMR). On this basis, the CTCU model shows a good fit; CFI = 0.975; TLI = 0.958; RMSEA = 0.059; SRMR = 0.029. The CTCM model, on the other hand, indicates a much poorer fit, with only the SRMR fit statistic being acceptable (<0.08). These models are non-nested so we also compare the values of AIC and BIC which permit a direct comparison of the two models. This again indicates that the CTCU model fits better with smaller AIC and BIC values; AIC = 4166.573, BIC = 4489.849.
Table 1. Model fits of baseline model (white British) comparing CTCU and CTCM models

† p < 0.10; * p < 0.05; ** p < 0.01; *** p < 0.001.
The CTCU baseline model was subsequently used as the basis for testing for invariance across ethnic groups.
Fit statistics are shown in Table 2. The configural invariance specification indicates a good fitting model. The fit indices from Table 2 demonstrate good fit at the configural level for all ethnic groups, CFI = 0.974; TLI = 0.955; RMSEA = 0.023; SRMR = 0.029.
Table 2. Model fits of free and constrained model and tests of measurement invariance

† p < 0.10; * p < 0.05; ** p < 0.01; *** p < 0.001.
Table 3 shows the standardised factor loadings for the selected baseline model along with the intercepts. There is of course variation in the freely estimated loadings and intercepts but the aim of analysis is to determine whether the more constrained models provide plausible estimates of population parameters. Looking at Table 3, there is a reasonably consistent pattern of factor loadings across ethnic groups. Average standardised factor loadings for each group are in the low 60s with the rank ordering of items similar in each group. N1–N3 tend to load a little more weakly than the other items. This may be because they tap into specific behaviours rather than subjective states. Intercepts show similar patterns over each group except for the African group, which tends to show slightly lower estimated intercepts and the mixed group that shows higher intercepts for the negatively worded items. This group is heterogeneous and it is not possible to account for this observation in our models.
Table 3. Standardised factor loadings (β) and intercepts (α) for configural invariance model

Consistent with these relatively small estimated group differences, the first constrained model, which tests for equal factor loadings, showed a good fit and little change at all from the congeneric model in the approximate fit indices. The difference in χ2 exceeds the critical value for statistical significance at the 5% level but in view of the large sample size, we do not consider this indicative of substantial loss of fit.
Next, the scalar invariance model was tested, by constraining both factor loadings and intercepts to equality across groups. These additional constraints again do not lead to substantial loss of fit, except on the χ2 difference between metric and scalar models, which again exceeds the critical value.
Given that the scalar invariance model turns out to be compatible with the data, this opens the way to being able to compare latent mean levels of mental health across ethnic groups.
To do this, we fitted an additional model, with the same specification as previously but where we fix the white British latent mean at zero and allow the other groups' means to be freely estimated in relation to the white British reference group. These estimates then represent the difference between white British average mental health and that for each other group. They are equivalent to the standardised effect size Glass's Delta, which is from the d-family of such statistics (Rosenthal & DiMatteo, Reference Rosenthal and DiMatteo2001; Steinmetz, Reference Steinmetz, Davidov, Schmidt and Billet2011). It is computed by dividing the difference between treatment and control group means (here the control group is the reference group, white British) by the standard deviation of the control group. For most practical situations where the GHQ-12 is put to use, a summated scale score is computed. We generated a new scale variable computed as the mean of each of the GHQ-12 items (with negatively worded items reverse coded) and then calculated Glass's delta for the differences between white British and each of the other groups on this new scale to generate a measure that is comparable to the latent difference. Both latent and observed standardised effect sizes are displayed in Table 4. The assumption of equal group variances is not required. The p values shown are derived from a z-test in the case of the latent means and a t test in the case of the summative score means.
Table 4. Ethnic group standardised differences in means for GHQ-12 (Glass's Δ)

† p < 0.10; * p < 0.05; ** p < 0.01; *** p < 0.001.
The size of the between-group differences varies somewhat between latent and summated scales. This is likely due in part to the fact that the latent estimates take account of the disparities in factor loadings between the items whereas the simple summated score gives equal weight to each item. None of the effect sizes is large and not all reach statistical significance. For the effects that are significant, both latent and summated score differences have the same sign. The only group for which the estimated differences diverge between latent and summated scale is the Bangladeshi group, and for both estimates, the magnitude is trivial and non-significant.
Scale reliability
Typically, researchers use Cronbach's α to assess the reliability of psychological scales. There are no hard and fast rules for what an acceptable level of reliability is, although for applications where there are consequences for individuals, a higher standard of reliability is needed than where research is aiming only to capture group differences (Nunnally, Reference Nunnally1978). However, α makes the assumption that each item has the same relationship to the underlying target construct (τ-equivalence, equal factor loadings) and that only one dimension is measured. Equation 1 gives the definition of α, where k is the number of items, V(Xi) is the variance of item i and V(O) the variance of the observed sum.

These assumptions are often not met, including in the present case, assuming our factor model is correct. An alternative measure of reliability, ω, was proposed by McDonald (Reference McDonald1970), which takes into account varying factor loadings and is in fact a generalisation of α, as it does not require the assumption of τ-equivalence but reduces to α when this is assumed (Hayes & Coutts, Reference Hayes and Coutts2020). Equation 2 defines ω, where V(ei) is the error variance in item i (from Equation 1); the summation is over all items. The factor loading for each item i is captured in λi. Thus ω is the ratio of the sum of squared factor loadings to the sum of squared loadings and error variances.

We computed ω for each ethnic group using the parameter estimates from the scalar invariance model using the Amos methods described in Hayes and Coutts (Reference Hayes and Coutts2020). We display these alongside the corresponding α in Table 5.
Table 5. Reliability estimates for GHQ-12 scale by ethnic group
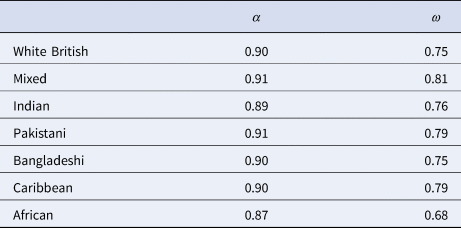
It is readily apparent that α overestimates the reliability of the GHQ-12 in every ethnic group under the incorrect (in this case) assumption of τ-equivalence. The reason for this, as can be deduced from Equation 2, is that in the standard summated scale, the variance due to the substantive mental health construct is mixed with that due to the undifferentiated second dimension, acquiescence response bias.
Our model partials this out through the specification of correlated errors on the negatively worded items. This means that the ratio of substantive to total variance is (correctly) attenuated using ω to estimate reliability. Consistent with the rest of our analysis, there is little variation in ω across groups except for the African respondents, for whom reliability is somewhat lower on both measures.
Discussion
The results of this study demonstrate support for previous studies that have estimated a unidimensional structure of the GHQ-12 once response bias on the negatively worded items is taken into account (Aguado et al., Reference Aguado, Campbell, Ascaso, Navarro, Garcia-Esteve and Luciano2012; Hankins, Reference Hankins2008; Molina et al., Reference Molina, Rodrigo, Losilla and Vives2014; Rey, Abad, Barrada, Garrido, & Ponsoda, Reference Rey, Abad, Barrada, Garrido and Ponsoda2014; Romppel et al., Reference Romppel, Braehler, Roth and Glaesmer2013). Further, the results indicate that the multidimensional models such as the three-factor model proposed by Graetz is the likely result of the inclusion of the positive and negative worded items in the questionnaire. We see no reason to consider the GHQ-12 as capturing more than one dimension of mental health, which partly supports the practice in psychological, clinical and epidemiological research of using a standard summated scale approach.
That said, we do find non-trivial response effects due to the inclusion of negative and positive items and we fit models to correct for this. In this regard, our results replicate the findings of previous studies that suggest that the CTCU model is appropriate (Aguado et al., Reference Aguado, Campbell, Ascaso, Navarro, Garcia-Esteve and Luciano2012; Hankins, Reference Hankins2008) rather than alternative recommendations (e.g. Lance et al., Reference Lance, Noble and Scullen2002) to use the more parsimonious CTCM model. Our data come from a data-generated large, representative random probability sample of a heterogeneous population and it appears that the less restrictive CTCM model is better able to capture method effects that may be multidimensional – to include, for example, question order effects (Lindwall et al., Reference Lindwall, Barkoukis, Grano, Lucidi, Raudsepp, Liukkonen and Thøgersen-Ntoumani2012, p. 201; Molina et al., Reference Molina, Rodrigo, Losilla and Vives2014, p. 1035).
In line with research on adolescents, our results suggest that using the GHQ-12 in the UK across different ethnic adult groups is unlikely to lead to grossly unreliable conclusions. Comparisons between these groups also appear to be justified. These results are consistent with other studies that have examined measurement equivalence with respect to ethnic groups of other mental health instruments (Banh et al., Reference Banh, Crane, Rhew, Gudmundsen, Stoep, Lyon and McCauley2012; Crockett et al., Reference Crockett, Randall, Shen, Russell and Driscoll2005; Eisen et al., Reference Eisen, Gerena, Ranganathan, Esch and Idiculla2006; Kim, Sellbom, & Ford, Reference Kim, Sellbom and Ford2014). An exception is Prady et al. (Reference Prady, Miles, Pickett, Fairley, Bloor, Gilbody and Wright2013) who failed to find invariance using the GHQ-28. However, here the population was pregnant women in a clinical setting and several languages were also used to translate items. In our data, a broader population answered questions as part of a general survey – a very different context. Our conclusions may not hold when using the GHQ-12 in a clinical setting if the items are interpreted in very different ways to the way people answer questions as part of a survey interview in the home. More research comparing these contexts of administration would be useful, both quantitative and qualitative.
A sensitivity analysis where we compared mean differences between groups on both latent and summated scale estimators indicated that similar conclusions would be reached using either formulation, with the pattern of statistical significance and direction being isomorphic. The use of structural equation modelling with latent means will in general permit smaller true differences across groups to be detected, but we do not believe that health researchers will be seriously misled by using a summated scale.
On a less encouraging note, we observed quite substantial differences in estimates of the reliability of the GHQ-12 comparing two different measures, Cronbach's α and McDonald's ω. However, similar magnitudes of difference are evident in all ethnic groups. We conclude that the conventional use of α to estimate the scale reliability of the GHQ-12 may lead to more optimistic assessments than are justifiable, and that caution should be exercised particularly where the instrument is to be used as a screening tool for individuals. More research could examine the predictive validity of the recommended caseness threshold of 3 in the 12-item version of the GHQ in light of this alternative reliability measure, and whether this threshold is appropriate for all ethnic groups.
Conclusion
The purpose of this study has been to directly inform researchers and policy makers on whether we can reliably and accurately estimate the mental health profiles of different ethnic groups using the GHQ-12, a commonly-used instrument. Our results are broadly in the affirmative. An important advantage of our approach compared to previous research stems from the use of data from an adult population, generated from a large representative probability sample. This contrasts with the use of non-probability or special population samples in previous work in this area. Our results indicate that, for the adult UK population, the GHQ-12 can be used to assess mental health within and between a range of ethnic groups. We caveat this by pointing to the lower than previously assumed reliability of the scale and for this reason it may be prudent to consider longer versions of the scale for use as a screening tool for individuals.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0033291721003408.
Conflict of interest
None.
Appendix 1
Table A1 presents the measures of the GHQ used in the survey, with a higher score indicating the most distressed. In order to ease interpretation, the six negatively-phrased items were labelled n1 to n6, and the six positively phrased items were labelled p1 to p6.
Table A1. Item wordings, response scales, and variable names











 Open access
Open access