



1. Introduction
A specter is haunting the theory of imprecise probabilities—the specter of dilation. When dilation occurs, learning new information increases uncertainty. Dilation is especially interesting because, relative to a dilating partition, uncertainty grows no matter which cell an agent learns. This has prompted investigations into the rational status of willingness to pay “negative tuition,” that is, willingness to pay not to learn (e.g., Kadane et al. Reference Kadane, Schervish and Seidenfeld2008). Yet dilation is not the only way for uncertainty to grow relative to every cell of a partition for imprecise probabilities (IP). With dilation, the focus is on the uncertainty about a particular event. But uncertainty about a given event is not the only kind of uncertainty with which we might be concerned. We might instead be concerned about overall uncertainty. In this study, we will be so concerned. Given a set of probabilities and a (positive, measurable) partition, distention occurs when the (supremum of the) total variation distance increases no matter which cell of the partition an agent learns. Since each cell induces an increase in total variation for a set of probabilities, conditional on any cell, the set of probabilities is “more spread” than it is unconditionally. In this sense, uncertainty–not about a particular event, but of a global sort–is sure to grow. Distention, like dilation, then, is a way for evidence to increase uncertainty across an entire evidential partition. As far as we know, ours is the first articulation and investigation of the phenomenon of distention.
Several considerations motivate our study. With their justly celebrated “merging of opinions” theorem, Blackwell and Dubins establish that, relative to just a few assumptions, Bayesians achieve consensus in the limit almost surely (Reference Blackwell and Dubins1962). That priors “wash out” in this way is an important pillar of Bayesian philosophy (Savage Reference Savage1954; Edwards et al. Reference Edwards, Lindman and Savage1963; Gaifman and Snir Reference Gaifman and Snir1982; Earman Reference Earman1992; Huttegger Reference Huttegger2015).Footnote 1 Schervish and Seidenfeld extend Blackwell and Dubins’s result to IP theory, establishing that certain convex polytopes of probabilities exhibit uniform merging (Schervish and Seidenfeld Reference Schervish and Seidenfeld1990, Corollary 1).Footnote 2 But as Herron, Seidenfeld, and Wasserman observe about Blackwell and Dubins’s result, “[w]hat happens asymptotically, almost surely, is not always a useful guide to the short run” (Reference Herron, Seidenfeld and Wasserman1997), 412. Disagreements can persist, or even increase, over finite time horizons even though they vanish in the limit. Herron et al. use this point, however, to motivate an investigation into dilation. The idea seems to be that an increase in disagreement among the elements of a set of probabilities in the dilation sense is the opposite of an increase in agreement among those elements in the merging sense.Footnote 3 But, as we will show, an occurrence of dilation does not imply an increase in disagreement in the Blackwell and Dubins model (section 4). We propose instead to investigate the “short run” behavior of total variation, the metric with which Blackwell and Dubins are concerned. To forestall any misreading, our point here is about a particular motivation and general claim about the significance of dilation. We are not taking issue with formal results on dilation presented in the literature. One way of reading our position in this paper is that some of the attention bestowed on dilation amounts to stolen valor.
Another motivation for investigating distention comes from social epistemology. In Nielsen and Stewart (Reference Nielsen and Stewart2021), we introduce the notions of local and global probabilistic opinion polarization between agents. There, we note 1) that the dilation phenomenon for imprecise probabilities is in some ways analogous to local polarization, and 2) that local and global polarization are logically independent. This presents our context of discovery for distention: it is the phenomenon analogous to global polarization for imprecise probabilities.
Furthermore, in many cases, it is natural to be concerned with overall uncertainty as we construe it in this essay. Many inquiries do not center on just a single event or proposition of interest, but focus on a host of questions. At least, we claim, this is one legitimate way to construe some inquiries. For such inquiries, an agent or group may be concerned with his or their estimates over an entire space of possibilities, and with how new information affects those estimates. In this kind of case, total variation seems the more appropriate measure of increases and decreases of uncertainty.
After rehearsing the basics of dilation (section 2), we define distention precisely (section 3), show that it is logically independent of dilation (section 4, proposition 1), and provide a characterization (section 5, proposition 2). We then draw some connections between local and global polarization in social epistemology, on the one hand, and dilation and distention in IP theory, on the other (section 6). We conclude by considering some further ramifications of distention (section 7).
2. Dilation
Our main interest in this essay is in certain aspects of the theory of imprecise probabilities. We adopt a formalism based on sets of probability measures, though several alternative frameworks have been studied (Walley Reference Walley2000; Augustin et al. Reference Augustin, Coolen, de Cooman and Troffaes2014). There are a number of motivations for IP. Imprecise probabilities are an important tool in robustness analysis for standard Bayesian inference (Walley Reference Walley1991; Berger Reference Berger1994). Sets of probabilities are useful in studying group decision problems (Levi Reference Levi1982; Seidenfeld et al. Reference Seidenfeld and Kadane1989) and opinion pooling (Elkin and Wheeler Reference Elkin and Wheeler2018; Stewart and Ojea Quintana Reference Stewart and Ojea Quintana2018). IP provides more general models of uncertainty that are often championed as superior for a number of normative considerations relevant to epistemology and decision making (Levi Reference Levi1974; Walley Reference Walley1991). Sets of probabilities can also be used to represent partial elicitation of precise subjective probabilities. Some have argued that IP presents a more realistic theory of human epistemology (Arló-Costa and Helzner Reference Arlo-Costa and Helzner2010). IP allows for a principled introduction of incomplete preferences in the setting of expected utility maximization (Seidenfeld Reference Seidenfeld1993; Kaplan Reference Kaplan1996), and has been used to offer resolutions of some of the paradoxes of decision (Levi Reference Levi1986). And there are other considerations driving the development of the theory of imprecise probabilities.
Dilation is the (at least at first blush) counterintuitive phenomenon of learning increasing uncertainty.Footnote 4 For a dilating partition, learning any cell results in greater uncertainty. Take the simple, stock example of flipping a coin. This experiment partitions the sample space into two cells, one corresponding to heads, the other to tails. It could be the case that, for some event A, no matter how the coin lands, the agent’s estimate for A (
 $P(A) = 0.5$
, say) will be strictly included in the agent’s estimate conditional on the outcome of the coin toss (
$P(A) = 0.5$
, say) will be strictly included in the agent’s estimate conditional on the outcome of the coin toss (
 $[0.1,0.9]$
, for example). Example 1 details such a case.
$[0.1,0.9]$
, for example). Example 1 details such a case.
Throughout, let
 $\Omega $
be a sample space of elementary events or possible worlds. Elements of
$\Omega $
be a sample space of elementary events or possible worlds. Elements of
 $\Omega $
can be thought of as maximally specific epistemic possibilities for an agent. Let
$\Omega $
can be thought of as maximally specific epistemic possibilities for an agent. Let
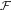 ${\cal F}$
be a sigma-algebra on
${\cal F}$
be a sigma-algebra on
 $\Omega $
, i.e., a non-empty collection of subsets of
$\Omega $
, i.e., a non-empty collection of subsets of
 $\Omega $
closed under complementation and countable unions. Elements of
$\Omega $
closed under complementation and countable unions. Elements of
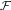 ${\cal F}$
are called events, and
${\cal F}$
are called events, and
 ${\cal F}$
can be thought of as a general space of possibilities (not just maximally specific ones). We assume the standard ratio definition of conditional probability:
${\cal F}$
can be thought of as a general space of possibilities (not just maximally specific ones). We assume the standard ratio definition of conditional probability:
 $$P(A|E) = {{P(A \cap E)} \over {P(E)}},\;\;\;{\kern 1pt} {\rm{when}}\;P(E) \gt 0.$$
$$P(A|E) = {{P(A \cap E)} \over {P(E)}},\;\;\;{\kern 1pt} {\rm{when}}\;P(E) \gt 0.$$
Let
 ${\mathbb P}$
be a set of probability measures. Such a set can be interpreted, for example, as the probability measures an agent regards as permissible to use in inference and decision problems, those distributions he has not ruled out for such purposes. If is convex, it associates with any event in the algebra an interval of probability values (such as
${\mathbb P}$
be a set of probability measures. Such a set can be interpreted, for example, as the probability measures an agent regards as permissible to use in inference and decision problems, those distributions he has not ruled out for such purposes. If is convex, it associates with any event in the algebra an interval of probability values (such as
 $[0.1,0.9]$
).Footnote
5
We can now define dilation precisely.
$[0.1,0.9]$
).Footnote
5
We can now define dilation precisely.
Definition 1 Let
 ${\mathbb P}$
be a set of probabilities on
${\mathbb P}$
be a set of probabilities on
 $(\Omega ,{\cal F})$
; let
$(\Omega ,{\cal F})$
; let
 ${\mathscr B}$
be a positive partition of
${\mathscr B}$
be a positive partition of
 $\Omega$
Footnote
6
, and let
$\Omega$
Footnote
6
, and let
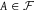 $A \in {\cal F}$
. We say that the partition
$A \in {\cal F}$
. We say that the partition
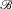 ${\mathscr B}$
dilates A just in case, for each
${\mathscr B}$
dilates A just in case, for each
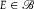 $E \in {\mathscr B}$
,
$E \in {\mathscr B}$
,
 $$\inf \{ P(A|E):P \in \mathbb P\} \lt \inf \{ P(A):P \in \mathbb P\} \le \sup \{ P(A)\!:P \in \mathbb P\} \lt \sup \{ P(A|E):P \in \mathbb P\} .$$
$$\inf \{ P(A|E):P \in \mathbb P\} \lt \inf \{ P(A):P \in \mathbb P\} \le \sup \{ P(A)\!:P \in \mathbb P\} \lt \sup \{ P(A|E):P \in \mathbb P\} .$$
It is clear that precise credal states are dilation-immune since
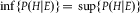 $\inf \{ P(H|E)\} \!= \sup \{ P(H|E)\} $
for all H and E in
$\inf \{ P(H|E)\} \!= \sup \{ P(H|E)\} $
for all H and E in
 ${\cal F}$
such that
${\cal F}$
such that
 $P(H|E)$
is defined.
$P(H|E)$
is defined.
Consider the following common example of dilation, introduced in outline earlier (Herron et al. Reference Herron, Seidenfeld, Wasserman and Potochnik1994; Pedersen and Wheeler Reference Pedersen, Wheeler, Augustin, Doria, Miranda and Quaeghebeur2015). We simplify by assuming that consists of just two probabilities.
Example 1 Let
 ${\mathbb {P}} = \{ {P_1},\,{P_2}\} $
be a set of probabilities on
${\mathbb {P}} = \{ {P_1},\,{P_2}\} $
be a set of probabilities on
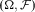 $(\Omega ,{\cal F})$
. Suppose that, for
$(\Omega ,{\cal F})$
. Suppose that, for
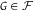 $G \in {\cal F}$
,
$G \in {\cal F}$
,
 ${P_1}(G) = 0.1$
and
${P_1}(G) = 0.1$
and
 ${P_2}(G) = 0.9$
. Relative to
${P_2}(G) = 0.9$
. Relative to
 ${\mathbb P}$
, then, G is a highly uncertain event. Consider the toss of a coin that is fair according to both
${\mathbb P}$
, then, G is a highly uncertain event. Consider the toss of a coin that is fair according to both
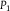 ${P_1}$
and
${P_1}$
and
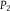 ${P_2}$
:
${P_2}$
:
 ${P_1}(H) = {P_2}(H) = 1/2 = {P_1}({H^c}) = {P_2}({H^c})$
. Suppose that the outcomes of the coin toss are independent of the event G according to both
${P_1}(H) = {P_2}(H) = 1/2 = {P_1}({H^c}) = {P_2}({H^c})$
. Suppose that the outcomes of the coin toss are independent of the event G according to both
 ${P_1}$
and
${P_1}$
and
 ${P_2}$
. Then,
${P_2}$
. Then,
 ${P_1}(G \cap H) = {P_1}(G){P_1}(H)$
and
${P_1}(G \cap H) = {P_1}(G){P_1}(H)$
and
 ${P_2}(G \cap H) = {P_2}(G){P_2}(H)$
. Let A be the “matching” event that either both (G) and (H) occur or both do not. That is,
${P_2}(G \cap H) = {P_2}(G){P_2}(H)$
. Let A be the “matching” event that either both (G) and (H) occur or both do not. That is,
 $A: = (G \cap H) \cup ({G^c} \cap {H^c})$
. Notice that
$A: = (G \cap H) \cup ({G^c} \cap {H^c})$
. Notice that
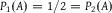 ${P_1}(A) = 1/2 = {P_2}(A)$
. Despite initial agreement concerning (A), the coin toss dilates
${P_1}(A) = 1/2 = {P_2}(A)$
. Despite initial agreement concerning (A), the coin toss dilates
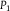 ${P_1}$
and
${P_1}$
and
 ${P_2}$
on (A). For
${P_2}$
on (A). For
 $i \in \{ 1,2\} $
,
$i \in \{ 1,2\} $
,
 $${P_i}(A|H) = {{{P_i}([(G \cap H) \cup ({G^c} \cap {H^c})] \cap H)} \over {{P_i}(H)}} = {{{P_i}(G \cap H)} \over {{P_i}(H)}} = {{{P_i}(G){P_i}(H)} \over {{P_i}(H)}} = {P_i}(G).$$
$${P_i}(A|H) = {{{P_i}([(G \cap H) \cup ({G^c} \cap {H^c})] \cap H)} \over {{P_i}(H)}} = {{{P_i}(G \cap H)} \over {{P_i}(H)}} = {{{P_i}(G){P_i}(H)} \over {{P_i}(H)}} = {P_i}(G).$$
So even though both
 ${P_1}$
and
${P_1}$
and
 ${P_2}$
assign probability
${P_2}$
assign probability
 $1/2$
to A initially, learning that the coin lands heads yields
$1/2$
to A initially, learning that the coin lands heads yields
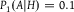 ${P_1}(A|H) = 0.1$
and
${P_1}(A|H) = 0.1$
and
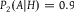 ${P_2}(A|H) = 0.9$
. Hence,
${P_2}(A|H) = 0.9$
. Hence,
 ${P_1}(A|H) \lt {P_1}(A) \le {P_2}(A) \lt {P_2}(A|H)$
. Analogous reasoning establishes that
${P_1}(A|H) \lt {P_1}(A) \le {P_2}(A) \lt {P_2}(A|H)$
. Analogous reasoning establishes that
 ${P_2}(A|{H^c}) \lt {P_2}(A) \le {P_1}(A) \lt {P_1}(A|{H^c}).$
Δ
${P_2}(A|{H^c}) \lt {P_2}(A) \le {P_1}(A) \lt {P_1}(A|{H^c}).$
Δ
Some see in dilation grounds for rejecting the notion that imprecise probabilities provide a normatively permissible generalization of standard Bayesian probability theory (e.g., White Reference White2010; Topey Reference Topey2012). It is not just that it seems intuitively wrong that learning should increase uncertainty. Dilation has further consequences. For example, dilation leads to violations of Good’s Principle. Good’s Principle enjoins us to delay making a terminal decision if presented with the opportunity to first learn cost-free information. For the standard, Bayesian expected utility framework, Good’s Principle is backed up by a theorem. Good famously shows that, in the context of expected utility maximization, the value of making a decision after learning cost-free information is always greater than or equal to the value of making a decision before learning (Good Reference Good1967).Footnote 7 Dilation, however, leads to the devaluation of information (e.g., Pedersen and Wheeler Reference Pedersen, Wheeler, Augustin, Doria, Miranda and Quaeghebeur2015). With dilation, an agent may actually be willing to pay to forgo learning some information, what Kadane et al. label “negative tuition” (Kadane et al. Reference Kadane, Schervish and Seidenfeld2008).
3. Distention
What would it mean for uncertainty to grow with respect to every cell of an experimental partition, though not uncertainty about a single, fixed event? We adopt the same metric that Blackwell and Dubins employ to gauge consensus in the context of merging of opinions. For any two probabilities,
 ${P_1}$
and
${P_1}$
and
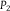 ${P_2}$
, the total variation distance d is given by
${P_2}$
, the total variation distance d is given by
 $$d({P_1},{P_2}) \!= \!\mathop {\sup }\limits_{A \,\in \,{\cal F}} \left|{P_1}(A) - {P_2}(A)\right|.$$
$$d({P_1},{P_2}) \!= \!\mathop {\sup }\limits_{A \,\in \,{\cal F}} \left|{P_1}(A) - {P_2}(A)\right|.$$
When
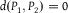 $d({P_1},{P_2}) = 0$
, it follows that
$d({P_1},{P_2}) = 0$
, it follows that
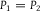 ${P_1} = {P_2}$
. And if
${P_1} = {P_2}$
. And if
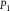 ${P_1}$
and
${P_1}$
and
 ${P_2}$
are within
${P_2}$
are within
 $\varepsilon $
according to d, they are within
$\varepsilon $
according to d, they are within
 $\varepsilon $
for every event in the algebra. We will have occasion to appeal to the fact that, in finite probability spaces, the total variation distance is given by
$\varepsilon $
for every event in the algebra. We will have occasion to appeal to the fact that, in finite probability spaces, the total variation distance is given by
 $$d({P_1},{P_2}) = {P_1}({A_0}) - {P_2}({A_0}),$$
$$d({P_1},{P_2}) = {P_1}({A_0}) - {P_2}({A_0}),$$
where
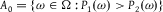 ${A_0} = \{ \omega \in \Omega :{P_1}(\omega ) \gt {P_2}(\omega )\} $
(e.g., Nielsen and Stewart Reference Nielsen and Stewart2021).
${A_0} = \{ \omega \in \Omega :{P_1}(\omega ) \gt {P_2}(\omega )\} $
(e.g., Nielsen and Stewart Reference Nielsen and Stewart2021).
So we take it that for global uncertainty to grow with respect to each cell of an experimental partition is for the total variation to increase conditional on each cell.Footnote
8
That, in turn, means that, for every cell, there is some event such that the “distance” between the probabilities for that event conditional on that cell is greater than the distance between probabilities for any event unconditionally. For an arbitrary set of probabilities, we look at the supremum of the total variation for all elements of the set. To simplify notation, let us adopt some metric space terminology and call
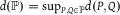 $d({\mathbb {P}}) = {\sup _{P,Q \in {\mathbb {P}}}}d(P,Q)$
the diameter of
$d({\mathbb {P}}) = {\sup _{P,Q \in {\mathbb {P}}}}d(P,Q)$
the diameter of
 ${\mathbb P}$
. If
${\mathbb P}$
. If
 $P(E) \gt 0$
for all
$P(E) \gt 0$
for all
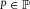 $P \in {\mathbb {P}}$
, then let us write
$P \in {\mathbb {P}}$
, then let us write
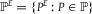 ${{\mathbb {P}}^E} = \{ {P^E}:P \in {\mathbb {P}}\} $
, where
${{\mathbb {P}}^E} = \{ {P^E}:P \in {\mathbb {P}}\} $
, where
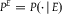 ${P^E} = P( \cdot \,|\,E)$
. We should stress that whenever we write
${P^E} = P( \cdot \,|\,E)$
. We should stress that whenever we write
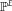 ${{\mathbb{P}}^E}$
, we are assuming that all
${{\mathbb{P}}^E}$
, we are assuming that all
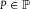 $P \in {\mathbb{P}}$
assign E positive probability.
$P \in {\mathbb{P}}$
assign E positive probability.
Definition 2 Let
 ${\mathbb P}$
be a set of probabilities on
${\mathbb P}$
be a set of probabilities on
 $(\Omega ,{\cal F})$
; let
$(\Omega ,{\cal F})$
; let
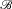 ${\mathscr B}$
be a positive partition of
${\mathscr B}$
be a positive partition of
 $\Omega $
. We say that the partition
$\Omega $
. We say that the partition
 ${\mathscr B}$
distends
${\mathscr B}$
distends
 ${\mathbb P}$
just in case, for each
${\mathbb P}$
just in case, for each
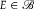 $E \in {\mathscr B}$
,
$E \in {\mathscr B}$
,
 $$d({\mathbb{P}}) \lt d({{\mathbb{P}}^E}).$$
$$d({\mathbb{P}}) \lt d({{\mathbb{P}}^E}).$$
Another way to think of distention is that a partition that distends
 ${\mathbb P}$
pushes the elements of
${\mathbb P}$
pushes the elements of
 ${\mathbb P}$
further from consensus. When
${\mathbb P}$
further from consensus. When
 ${\mathbb P}$
is interpreted as the credal state of a single agent, the closer a set of probabilities gets to “consensus,” the closer it is that uncertainty is reduced to risk—a unique probability function—for an agent. So distention pushes uncertainty further from being reduced to simple risk. Like dilation, then, distention is a way that uncertainty grows whatever the outcome of an experiment. Unlike dilation, though, the focus for distention is on total variation distance and not the probability of a single, fixed event.
${\mathbb P}$
is interpreted as the credal state of a single agent, the closer a set of probabilities gets to “consensus,” the closer it is that uncertainty is reduced to risk—a unique probability function—for an agent. So distention pushes uncertainty further from being reduced to simple risk. Like dilation, then, distention is a way that uncertainty grows whatever the outcome of an experiment. Unlike dilation, though, the focus for distention is on total variation distance and not the probability of a single, fixed event.
As repeatedly noted in the literature (e.g., Seidenfeld and Wasserman,
Reference Seidenfeld and Wasserman1993; Pedersen and Wheeler, Reference Pedersen, Wheeler, Augustin, Doria, Miranda and Quaeghebeur2015), dilation bears certain similarities to non-conglomerability. Let
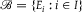 ${\mathscr B} = \{ {E_i}:i \in I\} $
be a positive partition. We say that A is
conglomerable in
${\mathscr B} = \{ {E_i}:i \in I\} $
be a positive partition. We say that A is
conglomerable in
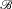 ${\mathscr B}$
when
${\mathscr B}$
when
 $$\inf \{ P(A|E):E \in {\mathscr B}\} \le P(A) \le \sup \{ P(A|E):E \in {\mathscr B}\} .$$
$$\inf \{ P(A|E):E \in {\mathscr B}\} \le P(A) \le \sup \{ P(A|E):E \in {\mathscr B}\} .$$
And we say that P is conglomerable in
 ${\mathscr B}$
if the above inequalities hold for all events A. When A is non-conglomerable in
${\mathscr B}$
if the above inequalities hold for all events A. When A is non-conglomerable in
 ${\mathscr B}$
,
${\mathscr B}$
,
 $P(A)$
cannot be regarded as a weighted average of the probabilities
$P(A)$
cannot be regarded as a weighted average of the probabilities
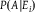 $P(A|{E_i})$
. If
$P(A|{E_i})$
. If
 ${\mathscr B}$
is a countable partition, and P is not conglomerable for
A in
${\mathscr B}$
is a countable partition, and P is not conglomerable for
A in
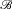 ${\mathscr B}$
, then the law of total probability fails. This happens only when P fails to be countably additive. Schervish et al. prove that, for any merely finitely additive probability P (on a space admitting a countably infinite partition), there is some event A and countable partition
${\mathscr B}$
, then the law of total probability fails. This happens only when P fails to be countably additive. Schervish et al. prove that, for any merely finitely additive probability P (on a space admitting a countably infinite partition), there is some event A and countable partition
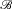 ${\mathscr B}$
such that P fails to be conglomerable for A in
${\mathscr B}$
such that P fails to be conglomerable for A in
 ${\mathscr B}$
(Reference Schervish, Seidenfeld and Kadane1984). One reason non-conglomerability is odd is that it allows for reasoning to foregone conclusions (Kadane et al. Reference Kadane, Schervish and Seidenfeld1996). Merely running an experiment, regardless of the outcome, allows one to uniformly increase (or decrease) one’s estimate in some event. In other words, an experiment could be designed such that, before even running it, the experimenter can be sure that conditionalizing on the outcome will yield a higher (or lower, depending on the case) probability for the event in question. Like dilation, non-conglomerability also leads to the devaluation of information in violation of Good’s Principle (e.g., Pedersen and Wheeler Reference Pedersen, Wheeler, Augustin, Doria, Miranda and Quaeghebeur2015). Distention, like dilation, but unlike non-conglomerability, can occur even on finite sets. So, like dilation, but perhaps unlike non-conglomerability, distention cannot be explained away by poor intuitions concerning infinite sets.
${\mathscr B}$
(Reference Schervish, Seidenfeld and Kadane1984). One reason non-conglomerability is odd is that it allows for reasoning to foregone conclusions (Kadane et al. Reference Kadane, Schervish and Seidenfeld1996). Merely running an experiment, regardless of the outcome, allows one to uniformly increase (or decrease) one’s estimate in some event. In other words, an experiment could be designed such that, before even running it, the experimenter can be sure that conditionalizing on the outcome will yield a higher (or lower, depending on the case) probability for the event in question. Like dilation, non-conglomerability also leads to the devaluation of information in violation of Good’s Principle (e.g., Pedersen and Wheeler Reference Pedersen, Wheeler, Augustin, Doria, Miranda and Quaeghebeur2015). Distention, like dilation, but unlike non-conglomerability, can occur even on finite sets. So, like dilation, but perhaps unlike non-conglomerability, distention cannot be explained away by poor intuitions concerning infinite sets.
4. Distention is logically independent of dilation
Given certain conceptual similarities between distention and dilation, it is natural to ask about their logical relations. The answer to that query is that dilation does not imply distention, nor does distention imply dilation. In other words, dilation and distention are logically independent.Footnote 9
To see that dilation does not imply distention, return to the coin example from earlier.
Example 2 Let
 $\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad A = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad H = \{ {\omega _1},{\omega _4}\} .$
Let
$\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad A = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad H = \{ {\omega _1},{\omega _4}\} .$
Let
 ${\rm{\mathbb P}} = \{ P,\,Q\} $
, given on the following table along with their updates on H and on
${\rm{\mathbb P}} = \{ P,\,Q\} $
, given on the following table along with their updates on H and on
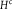 ${H^c}$
.
${H^c}$
.
Table 1. Dilation without Distention
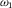 ${\omega _1}$
${\omega _1}$
|
 ${\omega _2}$
${\omega _2}$
|
 ${\omega _3}$
${\omega _3}$
|
 ${\omega _4}$
${\omega _4}$
|
|
| P |
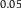 $0.05$
$0.05$
|
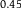 $0.45$
$0.45$
|
 $0.05$
$0.05$
|
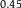 $0.45$
$0.45$
|
| Q |
 $0.45$
$0.45$
|
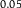 $0.05$
$0.05$
|
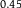 $0.45$
$0.45$
|
 $0.05$
$0.05$
|
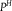 ${P^H}$
${P^H}$
|
 $0.1$
$0.1$
|
 $0$
$0$
|
 $0$
$0$
|
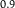 $0.9$
$0.9$
|
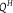 ${Q^H}$
${Q^H}$
|
 $0.9$
$0.9$
|
 $0$
$0$
|
 $0$
$0$
|
 $0.1$
$0.1$
|
 ${P^{{H^c}}}$
${P^{{H^c}}}$
|
 $0$
$0$
|
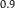 $0.9$
$0.9$
|
 $0.1$
$0.1$
|
 $0$
$0$
|
 ${Q^{{H^c}}}$
${Q^{{H^c}}}$
|
 $0$
$0$
|
 $0.1$
$0.1$
|
 $0.9$
$0.9$
|
 $0$
$0$
|
Take
 ${\mathscr B} = \{ H,{H^c}\} $
as our experimental partition (the outcome of a flip of a fair coin). From the table, we compute
${\mathscr B} = \{ H,{H^c}\} $
as our experimental partition (the outcome of a flip of a fair coin). From the table, we compute
 $P(A) = 0.5 = Q(A)$
. Yet,
$P(A) = 0.5 = Q(A)$
. Yet,
 $P(A|H) = 0.1$
and
$P(A|H) = 0.1$
and
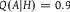 $Q(A|H) = 0.9$
. Similarly,
$Q(A|H) = 0.9$
. Similarly,
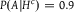 $P(A|{H^c}) = 0.9$
and
$P(A|{H^c}) = 0.9$
and
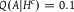 $Q(A|{H^c}) = 0.1$
. So,
$Q(A|{H^c}) = 0.1$
. So,
 ${\mathscr B}$
dilates
${\mathscr B}$
dilates
 ${\mathbb P}$
on A. However, again computing from the table using equation 1, we have
${\mathbb P}$
on A. However, again computing from the table using equation 1, we have
 $d(P,Q) = d({P^H},{Q^H}) = d({P^{{H^c}}},{Q^{{H^c}}}) = 0.8$
. It follows that dilation does not entail distention.Δ
$d(P,Q) = d({P^H},{Q^H}) = d({P^{{H^c}}},{Q^{{H^c}}}) = 0.8$
. It follows that dilation does not entail distention.Δ
To see that distention does not imply dilation, consider the following simple example.
Example 3 Let
 $\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad H = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad {\mathbb {P}} = \{ P, Q\} ,$
given on table 2. Consider the partition
$\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad H = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad {\mathbb {P}} = \{ P, Q\} ,$
given on table 2. Consider the partition
 ${\mathscr B}$
consisting of H and its complement. While
${\mathscr B}$
consisting of H and its complement. While
 $d(P,Q) = 1/10$
,
$d(P,Q) = 1/10$
,
 $d({P^H},{Q^H}\;) = 1/6$
and
$d({P^H},{Q^H}\;) = 1/6$
and
 $d({P^{{H^c}}},{Q^{{H^c}}}) = 3/28$
. So
$d({P^{{H^c}}},{Q^{{H^c}}}) = 3/28$
. So
 ${\mathscr B}$
distends
${\mathscr B}$
distends
 ${\mathbb P}$
. But it does not dilate any event. Not only is there no dilation in
${\mathbb P}$
. But it does not dilate any event. Not only is there no dilation in
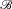 ${\mathscr B}$
, no partition of
${\mathscr B}$
, no partition of
 $\Omega $
dilates any event. This can be checked, a bit tediously, by hand.Footnote
10
Δ
$\Omega $
dilates any event. This can be checked, a bit tediously, by hand.Footnote
10
Δ
A set of probabilities cannot exhibit distention on a smaller sample space. That is because any (non-trivial) partition on a smaller space will have a singleton as a cell. In that case, provided the partition is positive, the distance between probabilities conditional on a singleton is
 $0$
.
$0$
.
Table 2. Distention without Dilation
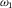 ${\omega _1}$
${\omega _1}$
|
 ${\omega _2}$
${\omega _2}$
|
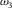 ${\omega _3}$
${\omega _3}$
|
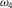 ${\omega _4}$
${\omega _4}$
|
|
|---|---|---|---|---|
| P |
 $1/10$
$1/10$
|
 $1/5$
$1/5$
|
 $1/10$
$1/10$
|
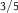 $3/5$
$3/5$
|
| Q |
 $1/10$
$1/10$
|
 $1/10$
$1/10$
|
 $1/5$
$1/5$
|
 $3/5$
$3/5$
|
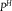 ${P^H}$
${P^H}$
|
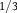 $1/3$
$1/3$
|
 $2/3$
$2/3$
|
 $0$
$0$
|
 $0$
$0$
|
 ${Q^H}$
${Q^H}$
|
 $1/2$
$1/2$
|
 $1/2$
$1/2$
|
 $0$
$0$
|
 $0$
$0$
|
 ${P^{{H^c}}}$
${P^{{H^c}}}$
|
 $0$
$0$
|
 $0$
$0$
|
 $1/7$
$1/7$
|
 $6/7$
$6/7$
|
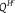 ${Q^{{H^c}}}$
${Q^{{H^c}}}$
|
 $0$
$0$
|
 $0$
$0$
|
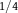 $1/4$
$1/4$
|
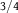 $3/4$
$3/4$
|
We submit that the short run that is relevant to merging of opinions is the short run behavior of total variation distance and not the sort of behavior exemplified by dilation. After all, it is the total variation distance that Blackwell and Dubins use to measure consensus. Examples 2 and 3 show that dilation is in fact orthogonal to distention, but example 4 shows that distention and dilation in a given partition are consistent (see the Appendix). We summarize these findings in the following proposition.
Proposition 1 While a set
 ${\mathbb P}$
can exhibit both dilation and distention simultaneously with respect to a single partition, dilation does not imply distention, nor does distention imply dilation.
${\mathbb P}$
can exhibit both dilation and distention simultaneously with respect to a single partition, dilation does not imply distention, nor does distention imply dilation.
5. A characterization of distention
For any two probabilities P and Q and any two events A and E such that
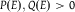 $P(E),Q(E) \gt 0$
, define a function
$P(E),Q(E) \gt 0$
, define a function
 $\bar {\cal B}$
as follows:
$\bar {\cal B}$
as follows:
 $${\overline {\cal B} _{P,Q}}(A,E) = {{P(A)} \over {P(E)}} - {{Q(A)} \over {Q(E)}}.$$
$${\overline {\cal B} _{P,Q}}(A,E) = {{P(A)} \over {P(E)}} - {{Q(A)} \over {Q(E)}}.$$
In a way, the function
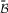 $\bar {\cal B}$
sets the so-called Bayes factor in difference form. The Bayes factor for P and Q with respect to A and E is defined as
$\bar {\cal B}$
sets the so-called Bayes factor in difference form. The Bayes factor for P and Q with respect to A and E is defined as
 $${{\cal B}_{P,Q}}(A,E) = {{P(A)} \over {P(E)}}\bigg/{{Q(A)} \over {Q(E)}}.$$
$${{\cal B}_{P,Q}}(A,E) = {{P(A)} \over {P(E)}}\bigg/{{Q(A)} \over {Q(E)}}.$$
Bayes factors have a distinguished pedigree in Bayesian thought (Good Reference Good1983; Wagner Reference Wagner2002; Jeffrey Reference Jeffrey2004). Wagner, for instance, contends that identical learning experiences for two agents are captured by identical Bayes factors for their respective priors and posteriors rather than by identical posterior opinions. But
 $\bar {\cal B}$
differs substantially in interpretation from a Bayes factor. In particular, it is not assumed that either of P or Q is an update of the other.
$\bar {\cal B}$
differs substantially in interpretation from a Bayes factor. In particular, it is not assumed that either of P or Q is an update of the other.
The function
 $\bar {\cal B}$
allows us to state one simple characterization of distention. Since convexity has played a prominent role in IP theory, we also state an equivalence with the distention of the convex hull.Footnote
11
$\bar {\cal B}$
allows us to state one simple characterization of distention. Since convexity has played a prominent role in IP theory, we also state an equivalence with the distention of the convex hull.Footnote
11
Proposition 2 Let
 ${\mathbb P}$
be a set of probabilities on
${\mathbb P}$
be a set of probabilities on
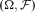 $(\Omega ,{\cal F})$
, and let
$(\Omega ,{\cal F})$
, and let
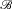 ${\mathscr B}$
be a positive partition of
${\mathscr B}$
be a positive partition of
 $\Omega $
. The following are equivalent.
$\Omega $
. The following are equivalent.
-
(i)
 ${\mathscr B}$
distends
${\mathbb P}$
.
${\mathscr B}$
distends
${\mathbb P}$
. -
(ii) For all
$E \in {\mathscr B}$
there exist
$P,Q \in {\mathbb {P}}$
, and
$A \subseteq E$
such that


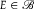
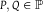

 $${\overline {\cal B} _{P,Q}}(A,E) \gt d({\mathbb {P}}).$$
$${\overline {\cal B} _{P,Q}}(A,E) \gt d({\mathbb {P}}).$$
-
(i)
${\mathscr B}$
distends the convex hull of
${\mathbb P}$
.


We regard proposition 2 as a first pass at characterizing distention. The problem of finding such characterizations is more than a purely formal one. The characterizing conditions should be relatively simple and provide insight into the “wherefore” of distention. It is not clear to us that proposition 2 satisfies the second desideratum.
6. Local and global polarization
Polarization is a social phenomenon. Accordingly, in our previous related study (Reference Nielsen and Stewart2021), we were concerned about its implications for social epistemology. But, as we noted there, social epistemology and the theory of imprecise probability gain much from cross-fertilization. In this paper, we exploit concepts from social epistemology in the hopes of gaining a deeper understanding of the theory of imprecise probabilities.
Like dilation, local polarization is defined in terms of a specific event. Polarization in this sense occurs when shared evidence pushes opinions about a specific event further apart.
Definition 3 Let
 ${P_1}$
and
${P_1}$
and
 ${P_2}$
be probability functions on
${P_2}$
be probability functions on
 $(\Omega ,{\cal F})$
, and let
$(\Omega ,{\cal F})$
, and let
 $A,E \in {\cal F}$
. We say that evidence E polarizes
$A,E \in {\cal F}$
. We say that evidence E polarizes
 ${P_1}$
and
${P_1}$
and
 ${P_2}$
with respect to the event A if
${P_2}$
with respect to the event A if
 $${P_1}(A|E) \lt {P_1}(A) \le {P_2}(A) \lt {P_2}(A|E).$$
$${P_1}(A|E) \lt {P_1}(A) \le {P_2}(A) \lt {P_2}(A|E).$$
The possibility of two agents polarizing when updating on shared evidence may itself come as a surprise to some. In particular, the fact that it is possible for Bayesians to polarize is a challenge to the view that rational agents who share evidence resolve disagreements. Elsewhere, we have labeled this view The Optimistic Thesis About Learning (TOTAL), and, at Gordon Belot’s suggestion, its proponents TOTALitarians (2021). Such a view seems to underwrite many of our ordinary practices (in rational persuasion, advocacy, etc.) as well as positions in current philosophical debates. For example, the view that an epistemic peer’s disagreement is evidence of defect in one’s own beliefs, as some so-called conciliationists allege, seems committed to TOTAL. Bayesian polarization, however, suggests TOTAL is false.
Not only does the definition of local polarization resemble that of dilation, local polarization and dilation can be characterized in terms of similar conditions (cf. Seidenfeld and Wasserman Reference Seidenfeld and Wasserman1993, Result 1; Nielsen and Stewart Reference Nielsen and Stewart2021, Theorem 1). But we can be more precise than mere resemblance. Let
 ${\mathbb {P}} = \{ {P_1},\,{P_2}\} $
and let
${\mathbb {P}} = \{ {P_1},\,{P_2}\} $
and let
 ${\mathscr B}$
be a positive finite partition that dilates A. Then there is some
${\mathscr B}$
be a positive finite partition that dilates A. Then there is some
 $E \in {\mathscr B}$
such that E polarizes
$E \in {\mathscr B}$
such that E polarizes
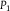 ${P_1}$
and
${P_1}$
and
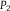 ${P_2}$
with respect to A. If not, then dilation implies that
${P_2}$
with respect to A. If not, then dilation implies that
 $${P_1}(A) \!\le {P_2}(A) \!\lt {P_1}(A\,|\,E)$$
$${P_1}(A) \!\le {P_2}(A) \!\lt {P_1}(A\,|\,E)$$
for all
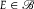 $E \in {\mathscr B}$
, where we have assumed the first inequality without loss of generality. Multiplying by
$E \in {\mathscr B}$
, where we have assumed the first inequality without loss of generality. Multiplying by
 ${P_1}(E)$
and summing over
${P_1}(E)$
and summing over
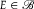 $E \in {\mathscr B}$
yields
$E \in {\mathscr B}$
yields
 $${P_1}(A) = \!\sum\limits_{E \,\in\, {\mathscr B}} {P_1}(A){P_1}(E)\! \lt\!\! \sum\limits_{E \,\in \,{\mathscr B}} {P_1}(A\,|\,E){P_1}(E) \!= \!{P_1}(A),$$
$${P_1}(A) = \!\sum\limits_{E \,\in\, {\mathscr B}} {P_1}(A){P_1}(E)\! \lt\!\! \sum\limits_{E \,\in \,{\mathscr B}} {P_1}(A\,|\,E){P_1}(E) \!= \!{P_1}(A),$$
which is a contradiction. Hence, dilation guarantees that some cell of the dilating partition is polarizing.
Central to the concept of global polarization is a measure of the extent of total disagreement between two probability functions. Again, we adopt the total variation metric to assess total disagreement. Naturally enough, we say that global polarization occurs when shared evidence brings about an increase in total variation between two probability functions.
Definition 4 Evidence E polarizes
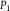 ${P_1}$
and
${P_1}$
and
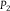 ${P_2}$
globally if
${P_2}$
globally if
 $d({P_1},{P_2}) \!\lt d(P_1^E,P_2^E)$
.
$d({P_1},{P_2}) \!\lt d(P_1^E,P_2^E)$
.
In contrast to the optimistic spin typically put on the Blackwell-Dubins merging result, our consensus-or-polarization law shows that even very mild and plausible weakenings of the relevant assumptions no longer entail almost sure consensus in the limit. Rather, agents achieve consensus or maximally (globally) polarize with probability
 $1$
(Nielsen and Stewart Reference Nielsen and Stewart2021, Theorem 3).
$1$
(Nielsen and Stewart Reference Nielsen and Stewart2021, Theorem 3).
Local and global polarization are logically independent. While probabilities can exhibit local and global polarization simultaneously, global polarization does not imply local polarization, nor does local polarization imply global polarization (Nielsen and Stewart Reference Nielsen and Stewart2021, Proposition 1). As we saw above, the IP analogues of local and global polarization, dilation and distention, respectively, exhibit the same sort of logical independence.
7. Some upshots
7.1 Asymptotic consensus
The primary precondition of Blackwell and Dubins’ merging theorem is absolute continuity.Footnote
12
If P is absolutely continuous with respect to Q, then
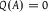 $Q(A) = 0$
implies
$Q(A) = 0$
implies
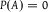 $P(A) = 0$
for all
$P(A) = 0$
for all
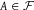 $A \in {\cal F}$
. Their theorem roughly says that if P is absolutely continuous with respect to Q, then P assigns probability
$A \in {\cal F}$
. Their theorem roughly says that if P is absolutely continuous with respect to Q, then P assigns probability
 $1$
to achieving consensus with Q in the limit. The examples above involve regular prior distributions on finite probability spaces. Every probability function is absolutely continuous with respect to a regular distribution. In larger spaces, regularity is not achievable. This makes the issue of absolute continuity non-trivial. Extending the theorem to sets of probability functions presents further complications. Schervish and Seidenfeld establish that closed, convex sets of mutually absolutely continuous probabilities that are generated by finitely many extreme points merge under Bayesian conditionalization (Schervish and Seidenfeld Reference Schervish and Seidenfeld1990, Corollary 1). In previous work, we generalize this result, showing that closed, convex sets of mutually absolutely continuous probabilities that are generated by finitely many extreme points merge under Jeffrey conditioning as well (Stewart and Nielsen Reference Stewart and Nielsen2019, Proposition 1).Footnote
13
For such sets of distributions, the significance of distention depends on the importance of the short run. In our opinion, the importance is clear. For all Blackwell and Dubins’s theorem says, approximate consensus may be achieved only in the very long run. Many things for which consensus is relevant happen in the not very long run. Even if is a set of mutually absolutely continuous probabilities (and so subject to the merging theorem), not only can its elements fail to achieve consensus in the short run, they might collectively distend, moving away from consensus whatever evidence comes. Of course, if an IP set does not consist of mutually absolutely continuous priors, failure of almost sure asymptotic consensus is a foregone conclusion.
$1$
to achieving consensus with Q in the limit. The examples above involve regular prior distributions on finite probability spaces. Every probability function is absolutely continuous with respect to a regular distribution. In larger spaces, regularity is not achievable. This makes the issue of absolute continuity non-trivial. Extending the theorem to sets of probability functions presents further complications. Schervish and Seidenfeld establish that closed, convex sets of mutually absolutely continuous probabilities that are generated by finitely many extreme points merge under Bayesian conditionalization (Schervish and Seidenfeld Reference Schervish and Seidenfeld1990, Corollary 1). In previous work, we generalize this result, showing that closed, convex sets of mutually absolutely continuous probabilities that are generated by finitely many extreme points merge under Jeffrey conditioning as well (Stewart and Nielsen Reference Stewart and Nielsen2019, Proposition 1).Footnote
13
For such sets of distributions, the significance of distention depends on the importance of the short run. In our opinion, the importance is clear. For all Blackwell and Dubins’s theorem says, approximate consensus may be achieved only in the very long run. Many things for which consensus is relevant happen in the not very long run. Even if is a set of mutually absolutely continuous probabilities (and so subject to the merging theorem), not only can its elements fail to achieve consensus in the short run, they might collectively distend, moving away from consensus whatever evidence comes. Of course, if an IP set does not consist of mutually absolutely continuous priors, failure of almost sure asymptotic consensus is a foregone conclusion.
7.2 Group manipulation
Moving now to the social setting, distention implies the possibility of a sort of group manipulation in the short run. Interpret a set
 ${\mathbb P}$
as the (individually precise) probabilities of a group of agents. For certain such sets, an experiment can be designed such that, no matter the outcome, the group will be further from consensus as a result of learning shared evidence. If a policy decision or group choice requires consensus (or a tolerance of only
${\mathbb P}$
as the (individually precise) probabilities of a group of agents. For certain such sets, an experiment can be designed such that, no matter the outcome, the group will be further from consensus as a result of learning shared evidence. If a policy decision or group choice requires consensus (or a tolerance of only
 $\varepsilon $
disagreement) on some algebra of events, such decision-making can be frustrated (at least in the short run) by a devious experimenter no matter the outcome of the experiment.
$\varepsilon $
disagreement) on some algebra of events, such decision-making can be frustrated (at least in the short run) by a devious experimenter no matter the outcome of the experiment.
7.3 Alternative measures of uncertainty
We have focused on total variation distance because of its distinguished role in merging of opinions and, consequently, Bayesian thought, and because of merging’s alleged contrast with dilation. Total variation, however, is one example of a large class of divergences between probabilities known as f-divergences. Another prominent example is Kullback-Leibler (KL) divergence from Q to P defined in discrete spaces by
 $${D_{KL}}(P\parallel Q) = - \sum\limits_i P ({\omega _i})\log {{Q({\omega _i})} \over {P({\omega _i})}}.$$
$${D_{KL}}(P\parallel Q) = - \sum\limits_i P ({\omega _i})\log {{Q({\omega _i})} \over {P({\omega _i})}}.$$
An important fact about KL divergence, often pointed out, is that, unlike total variation, KL divergence is not a true metric. For instance, it is not symmetric. Above, we provided an example of distention without dilation (example 3). This example also establishes that distention does not imply that the KL divergence increases across the partition. In particular,
 ${D_{KL}}(P\parallel Q) \gt {D_{KL}}({P^E}\parallel {Q^E})$
, as can easily be computed from table 2. Still other IP-specific measures of uncertainty have been explored in the literature (e.g., Bronevich and Klir Reference Bronevich and Klir2010). Absent strong reasons to privilege some such measure over the others—and perhaps there are such reasons for total variation—these simple observations urge caution in drawing general lessons from dilation- or distention-type phenomena.
${D_{KL}}(P\parallel Q) \gt {D_{KL}}({P^E}\parallel {Q^E})$
, as can easily be computed from table 2. Still other IP-specific measures of uncertainty have been explored in the literature (e.g., Bronevich and Klir Reference Bronevich and Klir2010). Absent strong reasons to privilege some such measure over the others—and perhaps there are such reasons for total variation—these simple observations urge caution in drawing general lessons from dilation- or distention-type phenomena.
7.4 “Pathologies” of imprecision
The further ramifications of distention remain to be explored. As we point out above, in the social setting, distention implies the possibility of certain sorts of group manipulation. For an individual with an imprecise credal state, an analogous sort of manipulation is possible in contexts in which a precise estimate is desired. For certain credal states, an experimenter can guarantee that the agent gets further (as measured by the total variation metric) from a precise estimate no matter what. How dramatic are the consequences of this sort of manipulation? And what other sorts of surprising effects, like the violations of Good’s Principle for dilation, might distention bring in tow? We hope to explore these issues in future research.
One interesting point, we find, is that none of the alleged pathologies discussed in connection with imprecise probabilities seem to be at all unique to a specific IP phenomenon, nor even unique to IP given social interpretations of sets of probabilities. Violations of Good’s Principle do not require dilation. Non-conglomerability leads to such violations as well. Neither does the strange phenomenon of learning increasing uncertainty imply dilation. With distention, uncertainty increases whatever evidence comes in as well. In a social setting, dilation and distention are somewhat robbed of their apparent counter-intuitive sting. The lesson there is that updating on shared evidence does not guard against various types of group opinion polarization (what could be called “social uncertainty”), as mundane examples illustrate (Nielsen and Stewart Reference Nielsen and Stewart2021).
One might take these anomalies as an argument for restricting to precise probabilities on finite spaces—by our lights, far beyond the pale of what is warranted. For one thing, continuous random variables are essential in many scientific applications and are unavailable in finite spaces. For another, violations of Good’s Principle do not require imprecise probabilities, so the restriction to precise probabilities fails as a safeguard. True, there are no instances of non-conglomerability in finite spaces, but suppose with us that the restriction to such spaces is too costly. By requiring countable additivity, one guarantees conglomerability in countable partitions. But, depending on the theory of conditional probabilities that we adopt, even countably additive probabilities can exhibit non-conglomerability in uncountable partitions. And the moral is more general still (Schervish et al. Reference Schervish, Seidenfeld and Kadane2017). So such proposed restrictions are costly, hasty, and ineffective.
Acknowledgments
We would like to thank Jean Baccelli, Alan Hájek, Ignacio Ojea Quintana, Reuben Stern, Greg Wheeler, and two anonymous referees for helpful feedback. Rush thanks the Center for Advanced Studies at LMU Munich for research leave, and Longview Philanthropy for a global priorities research grant.
Appendix
9. Example 4
The following example shows that a set
 ${\mathbb P}$
can exhibit both dilation and distention simultaneously with respect to a single partition.
${\mathbb P}$
can exhibit both dilation and distention simultaneously with respect to a single partition.
Example 4 Let
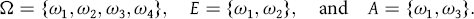 $\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad E = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad A = \{ {\omega _1},{\omega _3}\} .$
We take
$\Omega = \{ {\omega _1},{\omega _2},{\omega _3},{\omega _4}\} ,\quad E = \{ {\omega _1},{\omega _2}\} ,\quad {\rm{and}}\quad A = \{ {\omega _1},{\omega _3}\} .$
We take
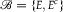 ${\mathscr B} = \{ E,{E^c}\} $
as our experimental partition.
${\mathscr B} = \{ E,{E^c}\} $
as our experimental partition.
Table 3. Distention is Consistent with Dilation
 ${\omega _1}$
${\omega _1}$
|
 ${\omega _2}$
${\omega _2}$
|
 ${\omega _3}$
${\omega _3}$
|
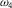 ${\omega _4}$
${\omega _4}$
|
|
|---|---|---|---|---|
| P |
 $1/100$
$1/100$
|
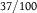 $37/100$
$37/100$
|
 $30/100$
$30/100$
|
 $32/100$
$32/100$
|
| Q |
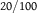 $20/100$
$20/100$
|
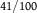 $41/100$
$41/100$
|
 $1/100$
$1/100$
|
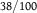 $38/100$
$38/100$
|
 ${P^E}$
${P^E}$
|
 $1/38$
$1/38$
|
 $37/38$
$37/38$
|
 $0$
$0$
|
 $0$
$0$
|
 ${Q^E}$
${Q^E}$
|
 $20/61$
$20/61$
|
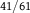 $41/61$
$41/61$
|
 $0$
$0$
|
 $0$
$0$
|
 ${P^{{E^c}}}$
${P^{{E^c}}}$
|
 $0$
$0$
|
 $0$
$0$
|
 $30/62$
$30/62$
|
 $32/62$
$32/62$
|
 ${Q^{{E^c}}}$
${Q^{{E^c}}}$
|
 $0$
$0$
|
 $0$
$0$
|
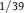 $1/39$
$1/39$
|
 $38/39$
$38/39$
|
Calculating the total variation distance from the table, we have
 $d({\mathbb{P}}) = d(P,Q) = 0.29$
,
$d({\mathbb{P}}) = d(P,Q) = 0.29$
,
 $d({P^E},{Q^E}) \approx 0.302$
, and
$d({P^E},{Q^E}) \approx 0.302$
, and
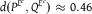 $d({P^{{E^c}}},{Q^{{E^c}}}) \approx 0.46$
. So
$d({P^{{E^c}}},{Q^{{E^c}}}) \approx 0.46$
. So
 ${\mathscr B}$
distends
${\mathscr B}$
distends
 ${\mathbb P}$
. For dilation, notice that
${\mathbb P}$
. For dilation, notice that
 $Q(A) = 21/100$
and
$Q(A) = 21/100$
and
 $P(A) = 31/100$
. But
$P(A) = 31/100$
. But
 ${P^E}(A) = 1/38 \lt 21/100 \!\lt 31/100 \lt 20/61 = {Q^E}(A)$
. Similarly,
${P^E}(A) = 1/38 \lt 21/100 \!\lt 31/100 \lt 20/61 = {Q^E}(A)$
. Similarly,
 ${Q^{{E^c}}}(A) = 1/39 \lt 21/100 \lt 31/100 \lt 30/62 = {P^{{E^c}}}(A)$
. So,
${Q^{{E^c}}}(A) = 1/39 \lt 21/100 \lt 31/100 \lt 30/62 = {P^{{E^c}}}(A)$
. So,
 ${\mathscr B}$
dilates A.
${\mathscr B}$
dilates A.
10. Proof of proposition 2
Proof. We start by showing that (i) and (ii) are equivalent. Suppose that (ii) holds and let
 $E \in {\mathscr B}$
. Then there exist
$E \in {\mathscr B}$
. Then there exist
 $P,Q \in {\mathbb{P}}$
, and
$P,Q \in {\mathbb{P}}$
, and
 $A \subseteq E$
such that
$A \subseteq E$
such that
 $$d({\mathbb {P}}) \!\lt |{P^E}(A) - {Q^E}(A)| \le d({P^E},{Q^E}) \le d({{\mathbb {P}}^E}).$$
$$d({\mathbb {P}}) \!\lt |{P^E}(A) - {Q^E}(A)| \le d({P^E},{Q^E}) \le d({{\mathbb {P}}^E}).$$
Hence,
 ${\mathscr B}$
distends
${\mathscr B}$
distends
 ${\mathbb P}$
, so (II) implies (I).
${\mathbb P}$
, so (II) implies (I).
Conversely, suppose that
 ${\mathscr B}$
distends
${\mathscr B}$
distends
 ${\mathbb P}$
and let
${\mathbb P}$
and let
 $E \in {\mathscr B}$
. Then there are
$E \in {\mathscr B}$
. Then there are
 $P,Q \in {\mathbb{P}}$
such that
$P,Q \in {\mathbb{P}}$
such that
 $$d({\mathbb{P}}) \lt d({P^E},{Q^E}).$$
$$d({\mathbb{P}}) \lt d({P^E},{Q^E}).$$
Let p and q be densities for P and Q, respectively, with respect to any common dominating measure m; that is, both P and Q are absolutely continuous with respect to m. (Let
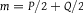 $m = P/2 + Q/2$
, for instance.) Define
$m = P/2 + Q/2$
, for instance.) Define
 $${p^E} = {{{{\bf{1}}_E}p} \over {P(E)}}\;\;\;{\kern 1pt} {\rm{and}}\;\;\;{\kern 1pt} {q^E} = {{{{\bf{1}}_E}q} \over {Q(E)}},$$
$${p^E} = {{{{\bf{1}}_E}p} \over {P(E)}}\;\;\;{\kern 1pt} {\rm{and}}\;\;\;{\kern 1pt} {q^E} = {{{{\bf{1}}_E}q} \over {Q(E)}},$$
so that
 ${p^E}$
and
${p^E}$
and
 ${q^E}$
are densities for
${q^E}$
are densities for
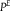 ${P^E}$
and
${P^E}$
and
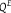 ${Q^E}$
with respect to m. Note that the set
${Q^E}$
with respect to m. Note that the set
 $A = \{ \omega \in \Omega :{p^E}(\omega ) \gt {q^E}(\omega )\} $
is a subset of E, because if
$A = \{ \omega \in \Omega :{p^E}(\omega ) \gt {q^E}(\omega )\} $
is a subset of E, because if
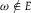 $\omega \ \notin\ E$
, then
$\omega \ \notin\ E$
, then
 ${p^E}(\omega ) = 0 = {q^E}(\omega )$
. We now have,
${p^E}(\omega ) = 0 = {q^E}(\omega )$
. We now have,
 $$d({\mathbb {P}}) \!\lt d({P^E},{Q^E}) = {P^E}(A) - {Q^E}(A) = {{P(A)} \over {P(E)}} - {{Q(A)} \over {Q(E)}} = {\overline {\cal B} _{P,Q}}(A,E),$$
$$d({\mathbb {P}}) \!\lt d({P^E},{Q^E}) = {P^E}(A) - {Q^E}(A) = {{P(A)} \over {P(E)}} - {{Q(A)} \over {Q(E)}} = {\overline {\cal B} _{P,Q}}(A,E),$$
where the first equality is the general version of (1). This establishes (ii), and shows that (i) and (ii) are equivalent.
Next, we show that (i) is equivalent to (iii). We use the following lemmas and include proofs for the reader’s convenience.
Lemma 1
For any set of probabilities
 ${\mathbb P}$
,
${\mathbb P}$
,
 $d({\mathbb {P}}) = d(co({\mathbb {P}}))$
.
$d({\mathbb {P}}) = d(co({\mathbb {P}}))$
.
Proof of Lemma 1. Since
 ${\mathbb P} \subseteq {{\rm co(\mathbb P)}}$
,
${\mathbb P} \subseteq {{\rm co(\mathbb P)}}$
,
 $d({\mathbb {P}}) \le d(co({\mathbb {P}})$
. To show the reverse inequality, let
$d({\mathbb {P}}) \le d(co({\mathbb {P}})$
. To show the reverse inequality, let
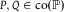 $P,Q \in {\rm{co({\mathbb {P}})}}$
be arbitrary. Then
$P,Q \in {\rm{co({\mathbb {P}})}}$
be arbitrary. Then
 $P = \sum\nolimits_{i \,= \,1}^n {a_i}{P_i}$
,
$P = \sum\nolimits_{i \,= \,1}^n {a_i}{P_i}$
,
 $Q = \sum\nolimits_{j \,=\, 1}^m {b_j}{P_j}$
for some
$Q = \sum\nolimits_{j \,=\, 1}^m {b_j}{P_j}$
for some
 $n,\,m\, \in \,{\mathbb{N}}$
,
$n,\,m\, \in \,{\mathbb{N}}$
,
 ${P_i},\,{P_j} \in {\mathbb{P}}$
, and
${P_i},\,{P_j} \in {\mathbb{P}}$
, and
 ${a_i},{b_j} \ge 0$
with
${a_i},{b_j} \ge 0$
with
 $\sum\nolimits_i {a_i} = 1 = \sum\nolimits_j {b_j}$
. For all
$\sum\nolimits_i {a_i} = 1 = \sum\nolimits_j {b_j}$
. For all
 $A \in {\cal F}$
,
$A \in {\cal F}$
,
 $$|P(A) - Q(A)| = \left|\sum\limits_{i \,=\, 1}^n {a_i}{P_i}(A) - \sum\limits_{j \,= \,1}^m {b_j}{P_j}(A)\right| = \left|\sum\limits_{i \,= \,1}^n {a_i}\sum\limits_{j \,= \,1}^m {b_j}{P_i}(A) - \sum\limits_{j \,= \,1}^m {b_j}\sum\limits_{i \,= \,1}^n {a_i}{P_j}(A)\right|$$
$$|P(A) - Q(A)| = \left|\sum\limits_{i \,=\, 1}^n {a_i}{P_i}(A) - \sum\limits_{j \,= \,1}^m {b_j}{P_j}(A)\right| = \left|\sum\limits_{i \,= \,1}^n {a_i}\sum\limits_{j \,= \,1}^m {b_j}{P_i}(A) - \sum\limits_{j \,= \,1}^m {b_j}\sum\limits_{i \,= \,1}^n {a_i}{P_j}(A)\right|$$
 $$\leq \left|{\sum\limits_{i \,= \,1}^n {{a_i}} \sum\limits_{j \,= \,1}^m {{b_j}{P_i}(A)\,} - {P_j}(A)\,} \right| \le \sum\limits_{i\, =\, 1}^n {{a_i}} \sum\limits_{j\, = \,1}^m {{b_j}d({\mathbb {P}})\, = d({\mathbb {P}})}. $$
$$\leq \left|{\sum\limits_{i \,= \,1}^n {{a_i}} \sum\limits_{j \,= \,1}^m {{b_j}{P_i}(A)\,} - {P_j}(A)\,} \right| \le \sum\limits_{i\, =\, 1}^n {{a_i}} \sum\limits_{j\, = \,1}^m {{b_j}d({\mathbb {P}})\, = d({\mathbb {P}})}. $$
Since this holds for all
 $A \in {\cal F}$
, we have
$A \in {\cal F}$
, we have
 $$d(P,Q) \le d({\mathbb {P}}).$$
$$d(P,Q) \le d({\mathbb {P}}).$$
And since this holds for all
 $P,Q \in { {\rm co(\mathbb P)}}$
, we have
$P,Q \in { {\rm co(\mathbb P)}}$
, we have
 $$d(\rm co({\mathbb {P}})) \le d({\mathbb {P}}),$$
$$d(\rm co({\mathbb {P}})) \le d({\mathbb {P}}),$$
which proves the lemma.
Lemma 2
For any set of probabilities
 ${\mathbb P}$
,
${\mathbb P}$
,
 ${\rm {co}}({{\mathbb {P}}^E}) = { {co({\mathbb P}})^E} $
.
${\rm {co}}({{\mathbb {P}}^E}) = { {co({\mathbb P}})^E} $
.
Proof of Lemma 2
. First, let
 $P \in {\rm{co}}({{\mathbb P}^E})$
. Then
$P \in {\rm{co}}({{\mathbb P}^E})$
. Then
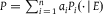 $P = \sum\nolimits_{i\, =\, 1}^n {a_i}{P_i}( \cdot\, |\,E)$
for some
$P = \sum\nolimits_{i\, =\, 1}^n {a_i}{P_i}( \cdot\, |\,E)$
for some
 $n\, \in \,{\mathbb{N}}$
,
$n\, \in \,{\mathbb{N}}$
,
 ${P_i} \in {\mathbb{P}}$
and
${P_i} \in {\mathbb{P}}$
and
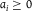 ${a_i} \ge 0$
with
${a_i} \ge 0$
with
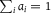 $\sum\nolimits_i {a_i} = 1$
. Let
$\sum\nolimits_i {a_i} = 1$
. Let
 ${b_i} = {{{a_i}} \over {{P_i}(E)N}} \ge 0$
, where
${b_i} = {{{a_i}} \over {{P_i}(E)N}} \ge 0$
, where
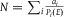 $N = \sum\nolimits_i {{{{a_i}} \over {{P_i}(E)}}} $
is a normalizing constant that ensures
$N = \sum\nolimits_i {{{{a_i}} \over {{P_i}(E)}}} $
is a normalizing constant that ensures
 $\sum\nolimits_i {b_i} = 1$
. Then,
$\sum\nolimits_i {b_i} = 1$
. Then,
 $$P=\sum\limits_{i\,=\,1}^n a_{i}P_{i}(\cdot\,|\,E)={{{\sum_{i}{{a_{i}P_{i}(\cdot\cap E)}\over{NP_i(E)}}\over{\sum_{i}{{a_{i}P_{i}(E)}\over{NP_{i}(E)}}}}}}={{\sum_{i}b_i\,P_i(\cdot\cap E)}\over{\sum_{i}b_{i}P_{i}(E)}}=\!\left(\sum\limits_{i}b_i\,P_i\right)(\cdot|E)\!\in\!{\rm co}(\mathbb{P})^{E} $$
$$P=\sum\limits_{i\,=\,1}^n a_{i}P_{i}(\cdot\,|\,E)={{{\sum_{i}{{a_{i}P_{i}(\cdot\cap E)}\over{NP_i(E)}}\over{\sum_{i}{{a_{i}P_{i}(E)}\over{NP_{i}(E)}}}}}}={{\sum_{i}b_i\,P_i(\cdot\cap E)}\over{\sum_{i}b_{i}P_{i}(E)}}=\!\left(\sum\limits_{i}b_i\,P_i\right)(\cdot|E)\!\in\!{\rm co}(\mathbb{P})^{E} $$
Hence,
 ${\rm{co}}({{\mathbb{P}}^E}) \subseteq {\rm{co}}{({\mathbb{P}})^E}$
.
${\rm{co}}({{\mathbb{P}}^E}) \subseteq {\rm{co}}{({\mathbb{P}})^E}$
.
Next, suppose that
 $P \in {\rm{co}}({{\mathbb{P}}^E})$
. Then
$P \in {\rm{co}}({{\mathbb{P}}^E})$
. Then
 $P = (\sum\nolimits_{i \,= \,1}^n {a_i}{P_i})( \cdot \,|\,E)$
for some
$P = (\sum\nolimits_{i \,= \,1}^n {a_i}{P_i})( \cdot \,|\,E)$
for some
 $n\, \in \,{\mathbb{N}}$
,
$n\, \in \,{\mathbb{N}}$
,
 ${P_i} \in {\mathbb{P}}$
and
${P_i} \in {\mathbb{P}}$
and
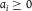 ${a_i} \ge 0$
with
${a_i} \ge 0$
with
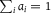 $\sum\nolimits_i {a_i} = 1$
. Let
$\sum\nolimits_i {a_i} = 1$
. Let
 ${b_i} = {{{a_i}{P_i}(E)} \over N}$
and
${b_i} = {{{a_i}{P_i}(E)} \over N}$
and
 $N = \sum\nolimits_i {a_i}{P_i}(E)$
. Then
$N = \sum\nolimits_i {a_i}{P_i}(E)$
. Then
 $$P = \left(\sum\limits_i {{a_i}} {P_i}\right)( \cdot \,|\,E) = {{\sum\limits_i {{a_i}} {P_i}( \cdot \cap E)} \over {\sum\limits_i {{a_i}} {P_i}(E)}} = \sum\limits_i {{{{a_i}{P_i}(E)} \over N}} {{{P_i}( \cdot \cap E)} \over {{P_i}(E)}}$$
$$P = \left(\sum\limits_i {{a_i}} {P_i}\right)( \cdot \,|\,E) = {{\sum\limits_i {{a_i}} {P_i}( \cdot \cap E)} \over {\sum\limits_i {{a_i}} {P_i}(E)}} = \sum\limits_i {{{{a_i}{P_i}(E)} \over N}} {{{P_i}( \cdot \cap E)} \over {{P_i}(E)}}$$
 $$=\sum\limits_i\,b_i {{{P_i(\cdot\cap E)}\over{P_i(E)}}} =\sum\limits_{i}b_{i}P_{i}(\cdot|E)\in {\rm co}(\mathbb{P}^E). $$
$$=\sum\limits_i\,b_i {{{P_i(\cdot\cap E)}\over{P_i(E)}}} =\sum\limits_{i}b_{i}P_{i}(\cdot|E)\in {\rm co}(\mathbb{P}^E). $$
Hence,
 ${\rm{co}}({{\mathbb {P}}^E}) \subseteq {\rm{co}}{({\mathbb {P}})^E}$
, and the proof is complete.
${\rm{co}}({{\mathbb {P}}^E}) \subseteq {\rm{co}}{({\mathbb {P}})^E}$
, and the proof is complete.
Using Lemmas 1 and 2, if (i) holds, then for all
 $E \in {\mathscr B}$
,
$E \in {\mathscr B}$
,
 $${{d(\rm co}}({\mathbb {P}})) \!= d({\mathbb {P}}) \!\lt d({{\mathbb {P}}^E}) \!= d({\rm{co(}}{{\mathbb {P}}^E}{\rm{)}}) \!= d({\rm co}{({\mathbb {P}})^E}).$$
$${{d(\rm co}}({\mathbb {P}})) \!= d({\mathbb {P}}) \!\lt d({{\mathbb {P}}^E}) \!= d({\rm{co(}}{{\mathbb {P}}^E}{\rm{)}}) \!= d({\rm co}{({\mathbb {P}})^E}).$$
Hence, (iii) holds. And if (iii) holds, then for all
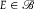 $E \in {\mathscr B}$
,
$E \in {\mathscr B}$
,
 $${{d (\mathbb P}}) \!= \!d({\rm{co(\mathbb P)}}) \!\lt d({\rm{co(\mathbb P}}{{\rm{)}}^E}) \!= d({\rm{co(}}{{\mathbb {P}}^E}{\rm{)}}) \!= d{({\mathbb {P}})^E}.$$
$${{d (\mathbb P}}) \!= \!d({\rm{co(\mathbb P)}}) \!\lt d({\rm{co(\mathbb P}}{{\rm{)}}^E}) \!= d({\rm{co(}}{{\mathbb {P}}^E}{\rm{)}}) \!= d{({\mathbb {P}})^E}.$$
Hence, (i) holds. This shows that (i) and (iii) are equivalent.











 Open access
Open access