


2.1 Introduction
The case study is a broad church. Case studies come in a great variety of forms, for a great variety of purposes, using a great variety of methods – including both methods typically labelled ‘qualitative’ and ones typically labelled ‘quantitative’.Footnote 1 My focus here is on case studies that aim to establish causal conclusions about the very case studied. Much of the discussion about the advantages and disadvantages of case study methods for drawing causal conclusions supposes that the aim is to draw causal conclusions that can be expected to hold more widely than in the case at hand. This is not my focus. My focus is the reverse. I am concerned with using knowledge that applies more widely, in consort with local knowledge, to construct a case study that will help predict what will happen in the single case – this case, involving this policy intervention, here and now. These involve what philosophers call a ‘singular causal claim’ – a claim about a causal connection in a specific single individual case, whether the individual is a particular person, a class, a school, a village or an entire country, viewed as a whole. It is often argued that causal conclusions require a comparative methodology. On this view the counterfactual is generally supposed to be the essence of singular causality: In situations where treatment T and outcome O both occur, ‘T caused O’ meansFootnote 2 ‘If T had not occurred, then O would not have’.Footnote 3 And it is additionally supposed that the only way to establish that kind of counterfactual is by contrasting cases where T occurs with those where T does not occur in circumstances that are the same as the first with respect to all other factors affecting O other than the occurrence of T and its downstream effects.
My discussion aims to show that neither of these suppositions is correct.Footnote 4 Nor do we take them to be correct, at least if the dictum ‘actions speak louder than words’ is to be believed. We all regularly, in daily life and in professional practice, bet on causal claims about single individuals and guide our actions by these bets without the aid of comparison. Juries decide whether the defendant committed the crime generally without consulting a case just like this one except for the defendant’s actions; I confidently infer that it was my second daughter (not the first, not my granddaughter, not Santa) who slipped Northanger Abbey into my Christmas stocking; and the NASA investigating team decided that the failure of an O-ring seal in the right solid rocket booster caused the Challenger disaster in which all seven crew were killed.
It might be objected that these causal judgments are made without the rigor demanded in science and wished for in policy. That would be surprising if it were generally true since we treat a good many of these as if we can be reasonably certain of them. Some 975 days after the Challenger disaster, Space Shuttle Discovery – with redesigned solid rocket boosters – was launched with five crew members aboard (and it returned safely four days later). Though not much of practical importance depends on it, I am sure who gave me Northanger Abbey. By contrast, people’s lives are seriously affected by the verdicts of judges, juries, and magistrates. Though we know that mistakes here are not uncommon, nobody suggests that our abilities to draw singular causal conclusions in this domain are so bad that we might as well flip a coin to decide on guilt or innocence.
I take it to be clear that singular causal claims like these can be true or false, and that the reasoning and evidence that backs them up can be better or worse. The question I address in Section 2.3, with a ‘potted’ example in Section 2.4, is: What kinds of information make good evidence for singular causal claims about the results of policy interventions, both post-hoc evaluations – ‘Did this intervention achieve the targeted outcome when it was implemented here in this individual case?’ – and ex ante predictions – ‘Is this intervention likely to produce the targeted outcome if implemented here in this individual case?’ I believe that the catalogue of evidence types I outline wears its plausibility on its face. But I do not think that is enough. Plausible is, ceteris paribus, better than implausible, but it is better still when the proposals are grounded in theory – credible, well argued, well-warranted theory. To do this job I turn to a familiar theory that is commonly used to defend other conventional scientific methods for causal inference, from randomized controlled trials (RCTs) to qualitative comparative analysis, causal Bayes nets (Bayesian networks) methods, econometric instrumental variables, and others. In Section 2.5, I outline this theory and explain how it can be used to show that the kinds of facts described in the evidence catalogue are evidence for causation in the single case.
So, what kinds of facts should we look for in a case study to provide evidence about a singular casual claim there – for instance, a claim of the kind we need for program evaluation: Did this program/treatment (T) as it was implemented in this situation (S) produce an outcome (O) of interest here? Did T cause O in S?
I call the kinds of evidence one gets from case studies for singular causal claims individualized evidence. This is by contrast with RCTs, which provide what I call anonymous evidence for singular causal claims. I shall explain this difference before proceeding to my catalogue because it helps elucidate the relative advantages and disadvantages of RCTs versus case studies for establishing causal claims.
2.2 What We Can Learn from an RCT
Individualized evidence speaks to causal claims about a particular identified individual; anonymous evidence speaks about one or more unidentified individuals. RCTs and group-comparison observational studies provide anonymous evidence about individual cases. This may seem surprising since a standard way of talking makes it sound as if RCTs establish general causal claims – ‘It works’ – and not claims about individuals at all. But RCTs by themselves establish a claim only about averages, and about averages only in the population enrolled in the experiment. What kind of claim is that? To understand the answer a little formalism is required. [See Appendix 2.1 for more complete development.]
A genuinely positive effect size in an RCT where the overall effects of other ‘confounding’ variables are genuinely balanced between treatment and control groups – let’s call this an ‘ideal’ RCT – would establish that at least some individuals in the study population were caused by the treatment to have the targeted outcome. This is apparent in the informal argument that positive results imply causal claims: ‘If there are more cases of the outcome in the treatment than in the control group, something must have caused this. If the only difference between the two groups is the treatment and its downstream effects, then the positive outcomes of at least some of the individuals in the treatment group must have been caused by the treatment.’
This is established more formally via the rigorous account of RCT results in common use that traces back to Reference RubinRubin (1974) and Reference HollandHolland (1986), which calls on the kind of theory appealed to in Section 2.5. We assume that whether one factor causes another in an individual is not arbitrary but that there is something systematic about it. There is a fact of the matter about what factors at what levels in what combinations produce what levels for the outcome in question for each individual. Without serious loss of generality, we can represent all the causal possibilities that are open for an individual i in a simple linear equation, called a potential outcomes equation:
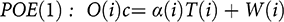
In this equation the variable O on the left represents the targeted outcome; c= signifies that the two sides of the equation are equal and that the factors on the right are causes of those on the left. T(i), which represents the policy intervention under investigation, may or may not genuinely appear there; that is, α(i) may be zero. The equation represents the possible values the outcome can take given various combinations of values a complete set of causes for it takes. W(i) represents in one fell swoop all the causes that might affect the level of the outcome for this individual that do not interact with the treatment.Footnote 5 α represents the overall effect of factors that interact with the treatment. ‘Interact’ means that the amount the treatment contributes to the outcome level for individual i depends on the value of α(i). Economists and statisticians call these ‘interactive’ variables; psychologists tend to call them ‘moderator’ variables; and philosophers term them ‘support’ variables. For those not familiar with support factors, consider the standard philosopher’s example of striking a match to produce a flame. This only works if there is oxygen present; oxygen is a support factor without which the striking will not produce a flame.
Interactive/support variables really matter to understanding the connection between the statistical results of an RCT and the causal conclusions inferred from them. The statistical result that is normally recorded in an RCT is the effect size. ‘Effect size’ can mean a variety of things. But all standard definitions make it a function of this: the difference in outcome means between treatment and control groups. What can this difference in the average value of the outcome in the two groups teach us about the causal effects of the treatment on individuals enrolled in the experiment? What can readily be shown is that in an ideal RCT this difference in means between treatment and control is the mean value of α(i), which represents the support factors – the mean averaged across all the individuals enrolled in the experiment. So the effect size is a function of the mean of the support/interactive variables – those variables that determine whether, and to what extent, the treatment can produce the outcome for the individual. If the average of α(i) is not zero, then there must be at least some individuals in that population for which α(i) was not zero. That means that for some individuals – though we know not which – T genuinely did contribute to the outcome. Thus, we can conclude from a positive mean difference between treatment and control in an ideal RCT that ‘T caused O in some members of the population enrolled in the experiment.’Footnote 6
You should also note one other feature of α(i). Suppose that we represent the value of the policy variable in the control group from which it is withheld by 0. This is another idealization, especially for social experiments and even for many medical ones, where members of the control groups may manage to get the treatment despite being assigned to control. But let’s suppose it. Then α(i)T(i) – α(i)C(i) = α(i)T(i) – 0 = α(i)T(i), letting C represent the value of the treatment when that treatment is not experienced. So α(i) represents also the ‘boost’ to O that i gets from receiving the policy treatment. This is often called ‘the individual treatment effect’.
When could we expect the same positive average effect size in an RCT on a new population? In the abstract that is easy to say. First, T must be capable of producing O in the new population. There must be possible support factors that can get it to work. If there aren’t, no amount of T will affect O for anyone. Again, philosophers have a potted example: No amount of the fertility drug Clomiphene citrate will make any man get pregnant. In development studies we might use Angus Reference DeatonDeaton’s (2010) fanciful example of a possible World Bank proposal to reduce poverty in China by building railway stations, a proposal that is doomed to failure when looked at in more detail because the plan is to build them in deserts where nobody lives. Then the two experiments will result in the same effect size just in case the mean of T’s support factors is the same in the two. And how would we know this? That takes a great deal of both theoretical and local knowledge about the two populations in question – knowledge that the RCTs themselves go no way toward providing.Footnote 7
Much common talk makes it sound as if RCTs can do more, in particular that they can establish what holds generally or what can be expected in a new case. Perhaps the idea is that if you can establish a causal conclusion then somehow, because it is causal, it is general. That’s not true, neither for the causal results established for some identified individuals in an RCT nor for a causal result for a single individual subject that might be established in a case study. Much causality is extremely local: local to toasters of a particular design, to businesses with a certain structure, to fee-paying schools in university towns in the south of England, to families with a certain ethnic and religious background and immigration history … The tendency to generalize seems especially strong if ‘the same’ results are seen in a few cases – which they seldom are, as can be noted from a survey of meta-analyses and systematic reviews. But that is induction by simple enumeration, which is a notoriously bad way to reason (swan 1 is white, swan 2 is white … so all the swans in Sydney Harbour are white).
A study – no matter whether it is a case study or it uses the methodology of the RCT, Bayes nets methods for causal inference, instrumental variables, or whatever – by itself can only show results about the population on which the data is collected. To go beyond that, we need to know what kinds of results travel, and to where. And to do that takes a tangle of different kinds of studies, theories, conceptual developments, and trial and error. This is underlined by work in science studiesFootnote 8 and by recent philosophical work on evidence and induction. See, for instance, John Reference NortonNorton’s (2021) material theory of induction: Norton argues that inductive inferences are justified by facts, where facts include anything from measurement results to general principles. Parallel lessons follow from the theory of evidence I endorse (Reference Cartwright, Karakostas and DieksCartwright 2013), the argument theory, in which a fact becomes evidence for a conclusion in the context of a good argument for that conclusion, an argument that inevitably requires other premises.
What I want to underline here with respect to RCTs is that, without the aid of lots of other premises, their results are confined to the population enrolled in the study; and what a positive result in an ideal RCT shows is that the treatment produced the outcome in some individuals in that population. For all we know these may be the only individuals in the world that the treatment would affect that way. The same is true if we use a case study to establish that T caused O in a specific identified individual. Perhaps this is extremely unlikely. But the study does nothing to show that; to argue it – either way – requires premises from elsewhere.
I also want to underline a number of other facts that I fear are often underplayed.
The RCT provides anonymous evidence. We may be assured that T caused O in some individuals in the study population, but we know not which. I call this ‘Where’s Wally?’ evidence. We know he’s there somewhere, but the study does not reveal him.
The study establishes an average; it does not tell us how the average is made up. Perhaps the policy is harmful as well as beneficial – it harms a number of individuals, though on average the effect is positive.
We’d like to know about the variance, but that is not so easy to ascertain. Is almost everyone near the average or do the results for individuals vary widely? The mean of the individual effect sizes can be estimated directly from the difference in means between the treatment and the control groups. But the variance cannot be estimated without substantial statistical assumptions about the distribution. Yet one of the advantages of RCTs is supposed to be that we can get results without substantial background assumptions.
I have been talking about an ideal RCT in a very special sense of ‘ideal’: one in which the net effect of confounding factors is genuinely balanced between treatment and control. But that is not what random allocation guarantees for confounders even at baseline. What randomization buys is balance ‘in the long run’. That means that if we did the experiment indefinitely often on exactly the same population, the observed difference in means between treatment and control groups would converge on the true difference.
That’s one reason we want experiments to have a large number of participants: it makes it more likely that what we observe in a single run is not far off the true average, though we know it still should be expected to be off a bit, and sometimes off a lot. Yet many social experiments, including many development RCTs, are done on small experimental populations.
Randomization only affects the baseline distribution of confounders. What happens after that? Blinding is supposed to help control differences, but there are two problems. First, a great many social experiments are poorly blinded: often everybody knows who is in treatment versus control – from the study subjects themselves to those who administer the policy to those who measure the outcomes to those who do the statistical analyses – and all of these can make significant differences. Second, without reasonable local background knowledge about the lives of the study participants (be they individuals or villages), it is hard to see how we have reason to suppose that no systematic differences affect the two groups post randomization.
Sometimes people say they want RCTs because RCTs measure average effect sizes and we need these for cost–benefit analyses. They do, and we do. But the RCT measures the average effect size in the population enrolled in the experiment. Generally, we need to do cost–benefit analysis for a different population, so we need the average effect size there. The RCT does not give us that.
I do not rehearse these facts to attack RCTs. RCTs are a very useful tool for causal inference – for inferring anonymous singular causal claims. I only list these cautions so that they will be kept in mind in deciding which tool – an RCT or a case study or some other method or some combination – will give the most reliable inference to singular causal claims in any particular case.
I turn now to the case study and how it can warrant singular causal claims – in this case, individualized ones.
2.3 A Category Scheme for Types of Evidence for Singular Causation That a Case Study Can Provide
Suppose a program T has been introduced into a particular setting S in hopes of producing outcome O there. We have good reason to think O occurred. Now we want to know whether T, as it was in fact implemented in S, was (at least partly) responsible.Footnote 9 What kinds of information should we try to collect in our case study to provide evidence about this? In this section I offer a catalogue of types of evidence that can help. I start by drawing some distinctions. However, it is important to make a simple point at the start. I aim to lay out a catalogue of kinds of evidence that, if true, can speak for or against singular causal claims. How compelling that evidence is will depend on:
how strong the link, if any, is between the evidence and the conclusion,
how sure we can be about the strength of this link, and
how warranted we are in taking the evidence claim to be true.
All three of these are hostages to ignorance, which is always the case when we try to draw conclusions from our evidence. In any particular case we may not be all that sure about the other factors that need to be in place to forge a strong link between our evidence claim and our conclusion, we may worry whether what we see as a link really is one, and we may not be all that sure about the evidence claim itself. The elimination of alternatives is a special case where the link is known to be strong: If we have eliminated alternatives then the conclusion follows without the need for any further assumptions. But, as always, we still face the problem of how sure we can be of the evidence claim. Have we really succeeded in eliminating all alternatives? No matter what kind of evidence claim we are dealing with, it is a rare case when we are sure our evidence claims are true and we are sure how strong our links are, or even if they are links at all. That’s why, when it comes to evidence, the more the better.
The first distinction that can help provide a useful categorization for types of evidence for singular causal claims is that between direct and indirect evidence:
Direct: Evidence that looks at aspects of the putative causal relationship itself to see if it holds.
Indirect: Evidence that looks at features outside the putative causal relationship that bear on the existence of this relationship.
Indirect. The prominent kind of indirect evidence is evidence that helps eliminate alternatives. If O occurred in S, and anything other than T has been ruled out as a cause of O in S’s case, then T must have done it. This is what Alexander Reference BirdBird (2010, 345) calls ‘Holmesian inference’ because of the famous Holmes remark that when all the other possibilities have been eliminated, what remains must be responsible even if improbable. RCTs provide indirect evidence, eliminating alternative explanations by (in the ideal) distributing all the other possible causes of O equally between treatment and control groups. But we don’t need a comparison group to do this. We can do this in the case study as well, if we know enough about what the other causes might be like, and/or about the history of the situation S. We do this in physics experiments regularly. But we don’t need physics to do it. It is, for instance, how I know it was my cat that stole the pork chop from the frying pan while I wasn’t looking.
Direct. I have identified at least four different kinds of direct evidence possible for the individualized singular causal claim that T caused O in S:
1. The character of the effect: Does O occur at the time, in the manner, and of the size to be expected had T caused it? (For those who are familiar with his famous paper on symptoms of causality, Reference Bradford HillBradford Hill (1965) endorses this type of evidence.)
2. Symptoms of causation: Not symptoms that T occurred but symptoms that T caused the outcome, side effects that could be expected had T operated to produce O. This kind of inference is becoming increasingly familiar as people become more and more skilled at drawing inferences from ‘big data’. As Suzy Moat puts it, “People leave this large amount of data behind as a by-product of simply carrying on with their lives.” Clever users of big data can reconstruct a great deal about our individual lives from the patterns they find there.Footnote 10
3. Presence of requisite support factors (moderator/interactive variables): Was everything in place that needed to be in order for T to produce O?
4. Presence of expectable intermediate steps (mediator variables): Were the right kinds of intermediate stages present?
Which of these types of evidence will be possible to obtain in a given case will vary from case to case. Any of them that we can gather will be equally relevant for post-hoc evaluation and for ex ante prediction, though we certainly won’t ever be able to get evidence of type 2 before the fact. I am currently engaged in an NSF-funded research project, Policy Prediction: Making the Most of the Evidence, that aims to use the situation-specific causal equations model (SCEM) framework sketched in Section 2.5 to expand this catalogue of evidence types and to explore more ways to use it for policy prediction.
2.4 A Diagrammatic Example
Let me illustrate with one of those diagrammatic examples we philosophers like, this one constructed from my simple-minded account of how an emetic works. It may be a parody of a real case study, but it provides a clear illustration of each of these types of evidence.

Imagine that yesterday I inadvertently consumed a very harmful poison. Luckily, I realized I had done so and thereafter swallowed a strong emetic. I vomited violently and have subsequently not suffered any serious symptoms of poisoning. I praise the emetic: It saved me! What evidence could your case study collect for that?
Elimination of alternatives: There are very low survival rates with this poison. So it is not likely my survival was spontaneous. And there’s nothing special about me that would otherwise explain my survival having consumed the poison. I don’t have an exceptional body mass, I hadn’t been getting slowly acclimatised to this poison by earlier smaller doses, I did not take an antidote, etc.
Presence of required support factors (other factors without which the cause could not be expected to produce this effect): The emetic was swallowed before too much poison was absorbed from the stomach.
Presence of necessary intermediate step: I vomited.
Presence of symptoms of the putative causes acting to produce the effect: There was much poison in the vomit, which is a clear side effect of the emetic’s being responsible for my survival.
Characteristics of the effect: The amount of poison in the vomit was measured and compared with the amount I had consumed. I suffered just the effects of remaining amount of poison; and the timing of the effect and size were just right.
2.5 Showing This Kind of Information Does Indeed Provide Evidence about Singular Causation
I developed the scheme in Section 2.3 for warranting singular causal claims bottom-up by surveying case studies in engineering, applied science, policy evaluation, and fault diagnoses, inter alia. But a more rigorous grounding is possible: these types all provide information relevant for filling in features of a situation-specific causal equations model (SCEM). Once you see what a SCEM is, this is apparent by inspection, so I will not belabor that point. Instead, I will spend time defending the SCEM framework itself.
A SCEM is a set of equations that express (one version of) what is sometimes called the ‘logic model’ of the policy intervention: a model of how the policy treatment T is supposed to bring about the targeted outcome O, step by step. Each of the equations is itself what in Section 2.2 was called a ‘potential outcomes equation’. (In situations where the kind of quantitative precision suggested by these equations seems impossible or inappropriate, there is an analogous Boolean form for yes–no variables, familiar in philosophy from Reference MackieMackie (1965) and in social science from qualitative comparative analysis [e.g., Reference Rihoux and RaginRihoux and Ragin 2008].)
To build a SCEM, start with the outcome O of interest. Just what should the policy have led to at the previous stage that will produce O at the final stage? Let’s call that ‘O-1’. Recalling that a single cause is seldom enough to produce an effect on its own, what are the support factors necessary for O-1 to produce O? Represent the net effect of all the support factors by ‘α-1’. Establishing that these support factors were/will be in place or not provides important evidence about whether O can be brought about by O-1. If not, then certainly T cannot produce O (at least not in the way you expect). Consider as well what other factors will be in place at the penultimate stage that will affect O. These affect the size or level of O. You want to know about those because they provide alternative explanations for the level of O that occurs; they are also relevant for judging the size T’s contribution would have to be if T were to contribute to the outcome. Represent the net effect of all these together by ‘W-1’. How O depends on all these factors can then be represented in a potential outcomes equation like this:
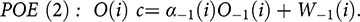
Work backwards, step by step, constructing a potential outcomes equation for each stage until the start, where T is introduced. The resulting set of equations is the core of the SCEM for this case.
But there is more. Think about the support factors (represented by the αs) that need to be in place at each stage. These are themselves effects; they have a causal history that can be expressed in a set of potential outcomes equations that can be added to the core SCEM. This is important information too: Knowing about the causes of the causes of an effect is a clue to whether the causes will occur and thus to whether the effect can be expected. The factors that do not interact with O-1 (represented by W-1) but that also affect O have causal histories as well that can be represented in a series of potential outcomes equations and added to the SCEM. So too with all the Ws in the chain. For purposes of evaluation, we may also want to include equations in which O figures as a cause since seeing that the effects of O obtain gives good evidence that O itself occurred. We can include as much or as little of the causal histories of various variables in the SCEM as we find useful.
I am not suggesting that we can construct SCEMs that are very complete, but I do suggest that this is what Nature does. Even in the single case, what causes what is not arbitrary – at least not if there is to be any hope that we can make reasonable predictions, explanations, and evaluations. There is a system to how Nature operates, and we have learned that generally this is what the system is like: Some factors can affect O in this individual and some cannot. All those that can affect an outcome appear in Nature’s own potential outcomes equation for that outcome. Single factors seldom contribute on their own so the separate terms in Nature’s equations will generally consist of combinations of mutually interacting factors. So Nature’s equations look much like ours. Or, rather, when we do it well, ours look much like Nature’s since hers are what we aim to replicate.
So: A successful SCEM for a specific individual provides a concise representation of what causal sequences are possible for that individual given the facts about that individual and its situation – what values the quantities represented can take in relation to values of their causes and effects. Some of the features represented in the SCEM will be ones we can influence, and some of these are ones we would influence in implementing the policy; others will take the values that naturally evolve from their causal past. The interpretation of these equations will become clearer as I defend their use.
I offer three different arguments to support my claim that SCEMs are good for treating singular causation: 1) their use for this purpose is well developed in the philosophy literature; 2) singular causation thus treated satisfies a number of common assumptions; 3) the potential outcomes equations that make up a SCEM are central to the formal defense I described in Section 2.2 that RCTs can establish causal conclusions.Footnote 11
1) The SCEM framework is an adaptation for variables with more than two values of J. L. Reference MackieMackie’s (1965) famous account in which causes are INUS conditions for their effects. In the adaptation, causes are INUS conditions for contributions to the effect,Footnote 12 where an INUS condition for a contribution to O(i) is an Insufficient but Necessary part of an Unnecessary but Sufficient condition for a contribution to it. Each of the additive terms (α(i)T(i) and W(i)) on the right of the equation O(i) c= α(i)T(i) + W(i) represents a set of conditions that together are sufficient for a contribution to O(i) but they are unnecessary since many things can contribute to O; and each component of an additive term (e.g., α(i) and T(i)) is an insufficient but necessary part of it – both are needed and neither is enough alone. This kind of situation-specific causal equations model for treating singular causation is also familiar in the contemporary philosophy of science literature, especially because of the widely respected work of Christopher Hitchcock.Footnote 13
2) The SCEM implies a number of characteristics for singular causal relations that they are widely assumed to have:
the causal relation is irreflexive (nothing causes itself)
the causal relation is asymmetric (if T causes O, O does not cause T)
causes occur temporally before their effects
there are causes to fix every effect
causes of causes of an effect are themselves causes of that effect (since substituting earlier causes of the causes in an equation yields a POE valid for a different coarse-graining of the time)Footnote 14
causal relations give rise to noncausal correlations.Footnote 15
3) Each equation in a SCEM is a potential outcomes equation of the kind that is used in the Rubin/Holland argument I laid out in Section 2.2 to show that RCTs can produce causal conclusions: A SCEM is simply a reiteration of the POE used to represent singular causation in the treatment of RCTs, expanded to include causes of causes of the targeted outcome and, sometimes, further effects as well. So, if we buy the Rubin/Holland argument about why a positive difference in means between treatment and control groups provides evidence that the treatment has caused the outcome in at least some members of the treatment group, it seems we are committed to taking POEs, and thus SCEMs, as a good representation of the causal possibilities open to individuals in the study population.
Warning: Equations like these are sometimes treated as if they represent ‘general causal principles’. That is a mistake. To see why, it is useful to think in terms of a threefold distinction among equations we use in science and policy, and similarly for more qualitative principles:
Equations and principles that represent the context-relative causal possibilities that obtain for a specific single individual, as in the SCEMs discussed here.
Equations and principles that represent the context-relative causal possibilities for a specific population. These often look just like a SCEM so it appears as if the causal possibilities are the same for every member of the population. This can be misleading for two reasons. First, for some individuals in the population some of the α(i)s may be fixed at 0 so that the associated cause can never contribute to the outcome for them. Second, the W(i)s can contain a variable that applies only to the single individual i (as noted in footnote 5). So there can be unique causal possibilities for each member of the population despite the fact that the equation makes it look as if they are all the same.
Equations and principles that hold widely. I suggest reserving the term ‘general principles’ for these, which are relatively context free, like the law of the lever or perhaps ‘People act so as to maximize their expected utility.’ These are the kinds of principles that we suppose ground the single-case causal possibilities represented in SCEMs and the context-relative principles that describe the causal possibilities for specific populations. These general principles tend to employ very abstract concepts, by contrast with the far more concrete, operationalizable ones that describe study results on individuals or populations – abstract concepts such as ‘utility’, ‘force’, ‘democracy’. They are also generally different in form from SCEMs. Think, for instance, about the form of Maxwell’s equations, which ground the causal possibilities for any electromagnetic device: these are not SCEM-like in form at all. It is in an instantiation of these in a real concrete arrangement located in space and time that genuine causal possibilities, of the kind represented in SCEMs, arise.
I note the differences between equations representing general principles and those representing causal possibilities for a single case or for a specific population to underline that knowing general principles is not enough to tell us what we need to know to predict policy outcomes for specific individuals, whether these are individual students or classes or villages, considered as a whole, or specific populations in specific places. Knowing Maxwell’s principles will not tell you how to repair your Christmas-tree lights. For that you need context-specific local knowledge about what the local arrangements are that call different general principles into play, both together and in sequence. That’s what will enable you to build a good SCEM that you can use for predicting and explaining outcomes. The same unfortunately is true for the use of general principles to predict the results of development and other social policies. Good general principles should be very reliable, but it takes a lot of thinking and a lot of local knowledge to figure out how to deploy them to model concrete situations. This is one of the principal reasons why we need case studies.
Thinking about how local arrangements call different general principles into play or not is key to how to make good use of our general knowledge to build local SCEMs. Consider a potted version of the case of the failure of the class-size reduction program that California implemented in 1996/97 based on the successes of Tennessee’s STAR project (which was attested by a good RCT) and Wisconsin’s SAGE program. Let us suppose for purposes of illustration that these three general principles obtain widely:
Smaller classes are conducive to better learning outcomes.
Poor teaching inhibits learning.
Poor classroom facilities inhibit learning.
Imagine that in Tennessee there were good teacher-training schools with good routes into local teaching positions and a number of new schools with surplus well-equipped classrooms that had resulted from a vigorous, well-funded school-building program. In California there was a great deal of political pressure and financial incentivization to introduce the program all at once (it was rolled out in most districts within three months of the legislation being passed); there were few well-trained unemployed teachers and no vigorous program for quick recruitment; and classrooms, we can suppose, were already overcrowded. These arrangements in California called all three principles into play at once; thus – so this story goes – the good effects promised by the operation of the first principle were outweighed by the harmful effects of the other two. Learning outcomes did not improve across the state, and in some places they got worse.Footnote 16 The arrangements in Tennessee called into play only the first principle, which accounts for the improved outcomes there.
How would you know whether to expect the results in California to match those of Tennessee and Wisconsin? Not by looking for superficial ‘similarities’ between the two. I recommend a case study, one that builds a SCEM for California, modelling the sequential steps by which the policy is supposed to achieve the targeted outcomes and then modelling what factors are needed in order for each step to lead to the next and what further causes are supposed to ensure that these factors are in place. We can’t do this completely, but reviewing the California case, it seems there was ample evidence – evidence of the kinds laid out in the catalogue of Section 2.3 – to fill in enough of the SCEM to see that a happy outcome was not to be expected.
2.6 Conclusion
How much evidence of the kinds in my catalogue and in what combinations must a case study deliver, and how secure must it be, in order to provide a reasonable degree of certainty about a causal claim about the case? There’s no definitive answer. That’s a shame. But this is not peculiar to case studies; it is true for all methods for causal inference.
Consider the RCT. If we suppose the treatment does satisfy the independence assumptions noted in Appendix 2.1, we can calculate how likely a given positive difference in means is if the treatment had no effect and the difference was due entirely to chance. But for most social policy RCTs there are good reasons to suppose the treatment does not satisfy the independence assumptions. The allocation mechanism often is not by a random-outcome device; there is not even single blinding let alone the quadruple we would hope for (of the subjects, the program administrators and overseers, those who measure outcomes, and those who do the statistical analysis); numbers enrolled in the experiment are often small; dropouts, noncompliance, and control group members accessing the treatment outside the experiment are not carefully monitored; sources of systematic differences between treatment and control groups after randomization are not well thought through and controlled; etc. – the list is long and well known. Often this is the best we can do, and often it is better than nothing. The point is that there are no formulae for how to weigh all this up to calculate what level of certainty the experiment provides that the treatment caused the outcome in some individuals in the experimental population. Similarly with all other methods of causal inference. Some things can be calculated – subject to assumptions. But there is seldom a method for calculating how the evidence that the assumptions are satisfied stacks up, and we often have little general idea about what that evidence should even look like. Judgment – judgment without rules to fall back on – is required in all these cases. I see no good arguments that the judgments are systematically more problematic in case studies than anywhere else.
The same holds when it comes to expecting the same results elsewhere. Maybe if you have a big effect size in an RCT with lots of subjects enrolled and good reason to think that the independence assumptions were satisfied, you have reason to think that in a good number of individuals the treatment produced the outcome. For a single case study, you can have at best good reason to think that the treatment caused the outcome in one individual. Perhaps knowing it worked for a number of individuals gives better grounds for expecting it to work in the next. Perhaps not. Consider economist Angus Reference DeatonDeaton’s (2015) suggestions about St. Mary’s school, which is thinking about adopting a new training program because a perfect RCT elsewhere has shown it improves test scores by X. But St. Joseph’s down the road adopted the program and got Z. What should St. Mary’s do? It is not obvious, or clear, that St. Joseph’s is not a better guide than the RCT, or indeed an anecdote about another school. After all, St. Mary’s is not the mean, and may be a long way from it. Which is a better guide – or any guide at all – depends on how similar, in just the right ways, the individual/individuals in the study are to the new one we want predictions about. And how do we know what the right ways are? Well, a good case study at St. Joseph’s can at least show us what mattered for it to work there, which can be some indication of what it might take to work at St. Mary’s since they share much underlying structure.Footnote 17 In this case it looks like the advantage for exporting the study result may lie with the case study and not with the higher numbers.
Group-comparison studies do have the advantage that they can estimate an effect size – for the study population. That may be just what we need – for instance, in a post-hoc evaluation where the program contractors are to be paid by size of result. But we should beware of the assumption that this number is useful elsewhere. We have seen that it depends on the mean value of the net contribution of the interactive/support factors in the study population. It takes a lot of knowledge to warrant the assumption that the support factors at work in a new situation will have the same mean.
What can we conclude in general, then, about how secure causal conclusions from case studies are or how well they can be exported? Nothing. But other methods fare no better.
There is one positive lesson we can draw. We often hear the claim that case studies may be good for suggesting causal hypotheses but it takes other methods to test them. That is false. Case studies can test causal conclusions. And a well-done case study can establish causal results more securely than other methods if they are not well carried out or we if have little reason to accept the assumptions it takes to justify causal inference from their results.
3.1 Introduction
Experiments of all kinds have once again become popular in the social sciences (Reference Druckman, Green, Kuklinski and LupiaDruckman et al. 2011). Of course, psychology has long used them. But in my own field of political science, and in adjacent areas such as economics, far more experiments are conducted now than in the twentieth century (Reference JamisonJamison 2019). Lab experiments, survey experiments, field experiments – all have become popular (for example, Reference Karpowitz and MendelbergKarpowitz and Mendelberg 2014; Reference MutzMutz 2011; and Reference Gerber and GreenGerber and Green 2012, respectively; Reference AchenAchen 2018 gives an historical overview).
In political science, much attention, both academic and popular, has been focused on field experiments, especially those studying how to get citizens to the polls on election days. Candidates and political parties care passionately about increasing the turnout of their voters, but it was not until the early twenty-first century that political campaigns became more focused on testing what works. In recent years, scholars have mounted many field experiments on turnout, often with support from the campaigns themselves. The experiments have been aimed particularly at learning the impact on registration or turnout of various kinds of notifications to voters that an election was at hand. (Reference Green, McGrath and AronowGreen, McGrath, and Aronow 2013 reviews the extensive literature.)
Researchers doing randomized experiments of all kinds have not been slow to tout the scientific rigor of their approach. They have produced formal statistical models showing that an RCT is typically vastly superior to an observational (nonrandomized) study. In statistical textbooks, of course, experimental randomization has long been treated as the gold standard for inference, and that view has become commonplace in the social sciences. More recently, however, critics have begun to question this received wisdom. Reference CartwrightCartwright (2007a, Reference Cartwright, Chao and Reiss2017, Chapter 2 this volume) and her collaborators (Reference Cartwright and HardieCartwright and Hardie 2012) have argued that RCTs have important limitations as an inferential tool. Along with Reference Heckman and SmithHeckman and Smith (1995), Reference DeatonDeaton (2010) and others, she has made it clear what experiments can and cannot hope to do.
So where did previous arguments for RCTs go wrong? In this short chapter, I take up a prominent formal argument for the superiority of experiments in political science (Reference Gerber, Green, Kaplan and TeeleGerber et al. 2014). Then, building on the work of Reference Stokes and TeeleStokes (2014), I show that the argument for experiments depends critically on emphasizing the central challenge of observational work – accounting for unobserved confounders – while ignoring entirely the central challenge of experimentation – achieving external validity. Once that imbalance is corrected, the mathematics of the model leads to a conclusion much closer to the position of Cartwright and others in her camp.
3.2 The Gerber–Green–Kaplan Model
Reference Gerber, Green, Kaplan and TeeleGerber, Green, and Kaplan (2014) make a case for the generic superiority of experiments, particularly field experiments, over observational research. To support their argument, they construct a straightforward model of Bayesian inference in the simplest case: learning the mean of a normal (Gaussian) distribution. This mean might be interpreted as an average treatment effect across the population of interest if everyone were treated, with heterogeneous treatment effects distributed normally. Thus, denoting the treatment-effects random variable by Xt and the population variance of the treatment effects by
 , we have the first assumption:
, we have the first assumption:
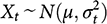
Gerber et al. implicitly take
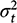 to be known; we follow them here.2
to be known; we follow them here.2
In Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014)’s setup, there are two ways to learn about µ. The first is via an RCT, such as a field experiment. They take the view that estimation of population parameters by means of random sampling is analogous to the estimation of treatment effects by means of randomized experimentation (Reference Gerber, Green, Kaplan and TeeleGerber et al. 2014, 32 at fn. 8). That is, correctly conducted experiments are always unbiased estimates of the population parameter.
Following Gerber et al.’s mathematics but making the experimental details a bit more concrete, suppose that the experiment has a treatment and a control group, each of size n, with individual outcomes distributed normally and independently:
 in the experimental group and
in the experimental group and
 in the control group. That is, the mathematical expectation of outcomes in the treatment group is the treatment effect µ, while the expected effect in the control group is 0. We assume that the sampling variance is the same in each group and that this variance is known. Let the sample means of the experimental and control groups be
in the control group. That is, the mathematical expectation of outcomes in the treatment group is the treatment effect µ, while the expected effect in the control group is 0. We assume that the sampling variance is the same in each group and that this variance is known. Let the sample means of the experimental and control groups be
 and
and
 respectively, and let their difference be
respectively, and let their difference be
 .
.
Then, by the textbook logic of pure experiments plus familiar results in elementary statistics, the difference
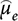 is distributed as:
is distributed as:
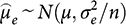 (2)
(2)
which is unbiased for the treatment effect µ. Thus, we may define a first estimate of the treatment effect by
 : It is the estimate of the treatment effect coming from the experiment. This is the same result as in Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 12), except that we have spelled out here the dependence of the variance on the sample size.
: It is the estimate of the treatment effect coming from the experiment. This is the same result as in Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 12), except that we have spelled out here the dependence of the variance on the sample size.
Next, Gerber et al. assume that there is a second source of knowledge about µ, this time from an observational study with m independent observations, also independent of the experimental observations. Via regression or other statistical methods, this study generates a normally distributed estimate of the treatment effect µ, with known sampling variance
 . However, because the methodology is not experimental, Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 12–13) assume that the effect is estimated with confounding, so that its expected value is distorted by a bias term β. Hence, the estimate from the observational study
. However, because the methodology is not experimental, Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 12–13) assume that the effect is estimated with confounding, so that its expected value is distorted by a bias term β. Hence, the estimate from the observational study
 is distributed as:
is distributed as:
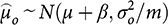
We now have two estimates,
 and
and
 , and we want to know how to combine them. One can proceed by constructing a minimum-mean-squared error estimate in a classical framework, or one can use Bayesian methods. Since both approaches give the same result in our setup and since the Bayesian logic is more familiar, we follow Gerber et al. in adopting it. In that case, we need prior distributions for each of the unknowns.
, and we want to know how to combine them. One can proceed by constructing a minimum-mean-squared error estimate in a classical framework, or one can use Bayesian methods. Since both approaches give the same result in our setup and since the Bayesian logic is more familiar, we follow Gerber et al. in adopting it. In that case, we need prior distributions for each of the unknowns.
With all the variances assumed known, there are just two unknown parameters, µ and β. An informative prior on µ is not ordinarily adopted in empirical research. At the extreme, as Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 15) note, a fully informative prior for µ would mean that we already knew the correct answer for certain and we would not care about either empirical study, and certainly not about comparing them. Since our interest is in precisely that comparison, we want the data to speak for themselves. Hence, we set the prior variance on µ to be wholly uninformative; in the usual Bayesian way we approximate its variance by infinity.Footnote 1
The parameter β also needs a prior. Sometimes we know the likely size and direction of bias in an observational study, and in that case we would correct the observational estimate by subtracting the expected size of the bias, as Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 14) do. For simplicity here, and because it makes no difference to the argument, we will assume that the direction of the bias is unknown and has prior mean zero, so that subtracting its mean has no effect. Then the prior distribution is:
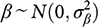 (4)
(4)
Here
 represents our uncertainty about the size of the observational bias. Larger values indicate more uncertainty. Standard Bayesian logic then shows that our posterior distribution for the observational study on its own is
represents our uncertainty about the size of the observational bias. Larger values indicate more uncertainty. Standard Bayesian logic then shows that our posterior distribution for the observational study on its own is
 .
.
Now, under these assumptions, Bayes’ Theorem tells us how to combine the observational and experimental evidence, as Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 14) point out. In accordance with their argument, the resulting combined or aggregated estimate
 is a weighted average of the two estimates
is a weighted average of the two estimates
 and
and
 :
:
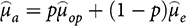 (5)
(5)
where p is the fraction of the weight given to the observational evidence, and
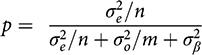 (6)
(6)
This result is the same as Gerber et al.’s, except that here we had no prior information about µ, which simplifies the interpretation without altering the implication that they wish to emphasize.
That implication is this: Since
 ,
,
 , n, and m are just features of the observed data, the key aspect of p is our uncertainty about the bias term
, n, and m are just features of the observed data, the key aspect of p is our uncertainty about the bias term
 , which is captured by the prior variance
, which is captured by the prior variance
 . Importantly, Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 15) argue that we often know relatively little about the size of likely biases in observational research. In the limit, they say, we become quite uncertain, and
. Importantly, Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 15) argue that we often know relatively little about the size of likely biases in observational research. In the limit, they say, we become quite uncertain, and

 . In that case, obviously,
. In that case, obviously,
 in Equation (6), and the observational evidence gets no weight at all in Equation (5), not even if its sample size is very large.
in Equation (6), and the observational evidence gets no weight at all in Equation (5), not even if its sample size is very large.
This limiting result is Reference Gerber, Green, Kaplan and TeeleGerber et al.’s (2014, 15) Illusion of Observational Learning Theorem. It formalizes the spirit of much recent commentary in the social sciences, in which observational studies are thought to be subject to biases of unknown, possibly very large size, whereas experiments follow textbook strictures and therefore reach unbiased estimates. Moreover, in an experiment, as the sample size goes to infinity, the correct average treatment effect is essentially learned with certainty.Footnote 2 Thus, only experiments tell us the truth. The mathematics here is unimpeachable, and the conclusion and its implications seem to be very powerful. Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 19–21) go on to demonstrate that under conditions like these, little or no resources should be allocated to observational research. We cannot learn anything from it. The money should go to field experiments such as those they have conducted, or to other experiments.
3.3 A Learning Theorem with No Thumb on the Scale
Gerber et al.’s Illusion of Observational Learning Theorem follows rigorously from their assumptions. The difficulty is that those assumptions combine jaundiced cynicism about observational studies with gullible innocence about experiments. As they make clear in the text, the authors themselves are neither unrelievedly cynical nor wholly innocent about either kind of research. But the logic of their mathematical conclusion turns out to depend entirely on their becoming sneering Mr. Hydes as they deal with observational research, and then transforming to kindly, indulgent Dr. Jekylls when they move to RCTs.
To see this, consider the standard challenge of experimental research: external validity, discussed in virtually every undergraduate methodology text (for example, Reference Kellstedt and WhittenKellstedt and Whitten 2009, 75–76). Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 22–23) mention this problem briefly, but they see it as a problem primarily for laboratory experiments because the inferential leap to the population is larger than for field experiments. The challenges that they identify for field experiments consist primarily in administering them properly. Even then, they suggest that statistical adjustments can often correct the biases induced (Reference Gerber, Green, Kaplan and TeeleGerber et al. 2014, 23–24). The flavor of their remarks may be seen in the following sentence:
The external validity of an experiment hinges on four factors: whether the subjects in the study are as strongly influenced by the treatment as the population to which a generalization is made, whether the treatment in the experiment corresponds to the treatment in the population of interest, whether the response measure used in the experiment corresponds to the variable of interest in the population, and how the effect estimates were derived statistically.
What is missing from this list are the two critical factors emphasized in the work of recent critics of RCTs: heterogeneity of treatment effects and the importance of context. A study of inducing voter turnout in a Michigan Republican primary cannot be generalized to what would happen to Democrats in a general election in Louisiana, where the treatment effects are likely to be very different. There are no Louisianans in the Michigan sample, no Democrats, and no general election voters. Hence, no within-sample statistical adjustments are available to accomplish the inferential leap. Biases of unknown magnitude remain, and these are multiplied when one aims to generalize to a national population as a whole. As Reference CartwrightCartwright (2007a; Chapter 2 this volume), Reference Cartwright and HardieCartwright and Hardie 2012, Reference DeatonDeaton (2010), and Reference Stokes and TeeleStokes (2014) have spelled out, disastrous inferential blunders occur commonly when a practitioner of field experiments imagines that they work the way Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014) assume that they work in their Bayesian model assumptions. Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 32 at fn. 6) concede in a footnote: “Whether bias creeps into an extrapolation to some other population depends on whether the effects vary across individuals in different contexts.” But that crucial insight plays no role in their mathematical model.
What happens in the Gerber et al. model when we take a more evenhanded approach? If we assume, for example, that experiments have a possible bias
 stemming from failures of external validity, then in parallel to the assumption about bias in observational research, we might specify our prior beliefs about external invalidity bias as normally and independently distributed:
stemming from failures of external validity, then in parallel to the assumption about bias in observational research, we might specify our prior beliefs about external invalidity bias as normally and independently distributed:
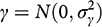 (7)
(7)
Then the posterior distribution of the treatment estimate from the experimental research would be
 , and the estimate combining both observational and experimental evidence would become:
, and the estimate combining both observational and experimental evidence would become:
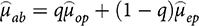 (8)
(8)
where q is the new fraction of the weight given to the observational evidence, and
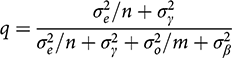 (9)
(9)
A close look at this expression (or taking partial derivatives) shows that the weight given to observational and experimental evidence is an intuitively plausible mix of considerations.
For example, an increase in m (the sample size of the observational study) reduces the denominator and thus raises q; this means that, all else equal, we should have more faith in observational studies with more observations. Conversely, increases in n, the sample size of an experiment, raise the weight we put on the experiment. In addition, the harder that authors have worked to eliminate confounders in observational research (small
 ), the more we believe them. And the fewer the issues with external validity in an experiment (small
), the more we believe them. And the fewer the issues with external validity in an experiment (small
 ), the more weight we put on the experiment. That is what follows from Gerber et al.’s line of analysis when all the potential biases are put on the table, not just half of them. But, of course, all these implications have been familiar for at least half a century. Carried out evenhandedly, the Bayesian mathematics does no real work and brings us no real news.
), the more weight we put on the experiment. That is what follows from Gerber et al.’s line of analysis when all the potential biases are put on the table, not just half of them. But, of course, all these implications have been familiar for at least half a century. Carried out evenhandedly, the Bayesian mathematics does no real work and brings us no real news.
Gerber et al. arrived at their Illusion of Observational Learning Theorem only by assuming away the problems of external validity in experiments. No surprise that experiments look wonderful in that case. But one could put a thumb on the other side of the scale: Suppose we assume that observational studies, when carefully conducted, have no biases due to omitted confounders, while experiments continue to have arbitrarily large problems with external validity. In that case,
 and
and
 . A look at Equations (8) and (9) then establishes that in that case, we get an Illusion of Experimental Learning Theorem: Experiments can teach us nothing, and no one should waste time and money on them. But of course, this inference is just as misleading as Gerber et al.’s original theorem.
. A look at Equations (8) and (9) then establishes that in that case, we get an Illusion of Experimental Learning Theorem: Experiments can teach us nothing, and no one should waste time and money on them. But of course, this inference is just as misleading as Gerber et al.’s original theorem.
Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014, 11–12, 15, 26–30) concede that observational research sometimes works very well. When observational biases are known to be small, they see a role for that kind of research. But they never discuss a similar condition for valid experimental studies. Even in their verbal discussions, which are more balanced than their mathematics, they continue to write as if experiments had no biases: “experiments produce unbiased estimates regardless of whether the confounders are known or unknown” (Reference Gerber, Green, Kaplan and TeeleGerber et al. 2014, 25). But that sentence is true only if external validity is never a problem. Their theorem about the unique value of experimental work depends critically on that assumption. Alas, the last decade or two have taught us forcefully, if we did not know it before, that their assumption is very far from being true. Just as instrumental variable estimators looked theoretically attractive when they were developed in the 1950s and 1960s but often failed in practice (Reference BartelsBartels 1991), so too the practical limitations of RCTs have now come forcefully into view.
Experiments have an important role in political science and in the social sciences generally. So do observational studies. But the judgment as to which of them is more valuable in a particular research problem depends on a complex mixture of prior experience, theoretical judgment, and the details of particular research designs. That is the conclusion that follows from an evenhanded set of assumptions applied to the model Reference Gerber, Green, Kaplan and TeeleGerber et al. (2014) set out.
3.4 Conclusion
Causal inference of any kind is just plain hard. If the evidence is observational, patient consideration of plausible counterarguments, followed by the assembling of relevant evidence, can be, and often is, a painstaking process.Footnote 3 Faced with those challenges, researchers in the current intellectual climate may be tempted to substitute something that looks quicker and easier – an experiment.
The central argument for experiments (RCTs) is that the randomization produces identification of the key parameter. That is a powerful and seductive idea, and it works very well in textbooks. Alas, this modus operandi does not work nearly so well in practice. Without an empirical or theoretical understanding of how to get from experimental results to the relevant population of interest, stand-alone RCTs teach us just as little as casual observational studies. In either case, there is no royal road to secure inferences, as Nancy Cartwright has emphasized. Hard work and provisional findings are all we can expect. As Reference CartwrightCartwright (2007b) has pungently remarked, experiments are not the gold standard, because there is no gold standard.
4.1 Introduction
What lessons can be learned from the international community’s slow and piecemeal response to the Ebola epidemic in Guinea, Sierra Leone, and Liberia in 2014? Are the histories and outcomes of microfinance programs in one country or by one lender relevant beyond each country or lender? How can we judge whether the early results of a medical or other experiment are so powerfully indicative of either success or failure that the experiment should be stopped even before all cases are treated or all the evidence is in?
Case studies are one approach to addressing such questions. Yet one of the most common critiques of case study methods is that the results of individual case studies cannot be readily generalized. Oxford professor Bent Flyvbjerg notes that when he first became interested in in-depth case study research in the 1990s, his teachers and colleagues tried to dissuade him from using case studies, arguing “you cannot generalize from a single case.” Flyvbjerg concluded that this view constitutes a conventional wisdom that “if not directly wrong, is so oversimplified as to be grossly misleading” (Reference FlyvbjergFlyvbjerg, 2006: 219). Similarly, the present chapter notes that the conventional wisdom is not fully wrong, as techniques for generalizing from individual case studies are complex and potentially fallible. The chapter concurs with Flyvbjerg, however, in concluding that we have means of assessing which findings will and will not generalize. For some case studies and some findings, generalization beyond the individual case is not warranted. In other contexts, we can make contingent generalizations from one or more case studies, or generalizations to a subset of a population that shares a well-defined set of features. In still other instances, sweeping generalizations to large and diverse populations are possible even from a single case study. The answer to whether case studies generalize is “It depends.” It depends on our prior causal knowledge, our prior knowledge of populations of cases and of the frequency of contextual variables that enable or disable causal mechanisms, the evidence that emerges from process tracing on case studies (see Chapter 7), and how that evidence updates our prior knowledge of causal mechanisms and the contexts in which they do and do not operate.
A second, and related, critique of case studies is that their findings do not cumulate into successive improvements in theories. The present chapter, in contrast, argues that case studies can contribute to developing two different kinds of progressively better theories. First, case studies can lead to improved theories about individual causal mechanisms and the scope conditions under which they operate. Claims about causal mechanisms are one of the most common kinds of theory in both the social and physical sciences. Second, case studies can contribute to improved “typological theories,” or theories about how combinations of causal mechanisms interact in specified issue areas and distributions of resources, stakeholder interests, legitimacy, and institutions. Later case studies can build upon, test, qualify, and extend typological theories developed in earlier ones.
This chapter first clarifies different conceptions of “generalization” in statistical and case study research. It then discusses four kinds of generalization from case studies: generalization from the selection and study of “typical” cases, generalization from most- and least-likely cases, mechanism-based generalization, and generalization via typological theories. The chapter uses studies of the 2014 Ebola epidemic as a running example to illustrate many of these kinds of generalization, and it draws on studies of microfinance programs and medical experiments to illustrate particular kinds of generalization.
4.2 Statistical Versus Case Study Views on “Generalization”
While the accurate explanation of individual historical cases is important and useful, the ability to generalize beyond individual cases is rightly considered a key component of both theoretical progress and policy relevance. Theories are abstractions that simplify the task of perceiving and operating in the world, and without some degree and kind of generalization little simplification is possible. But “generalization” can take on several meanings, and scholars and policy-makers vary in their views on what kinds of generalizations are either possible or pragmatically useful, partly depending on whether their methodological training was mostly in quantitative or qualitative approaches. Thus, it is important to clarify the different meanings that scholars in different methodological traditions typically give to the term “generalization.”
Among researchers whose main methods are statistical analysis of observational data, “generalization” is commonly treated as a question of the “average effect” observed between a specified independent variable and the dependent variable of interest in a population. This average effect is represented by the coefficients on the statistically significant independent variables in a regression equation.Footnote 1 Similarly, for researchers who use experimental methods, generalization takes the form of the estimated “average treatment effect,” measured as the average difference in outcomes between the treated and untreated groups from a large number of randomly selected units.Footnote 2
Generalization from statistical analysis of observational data depends on several assumptions, most notably: 1) that the treatment of one unit does not affect the outcome of another unit (the Stable Unit Treatment Value Assumption, or SUTVA); and, 2) that independent variables have “constant effects” across the units (or, related, the “unit homogeneity” assumption that two units will have the same value on the dependent variable when they have the same value on the explanatory variable).Footnote 3 These are very demanding assumptions, and they do not hold up when there are interaction effects among independent variables, or when there are learning or selection effects through which the outcome (or expected outcome) in one individual or group affects the behavior, treatment, or outcome of another individual or group.
For statistical methods, the possibility that there may in fact be interaction effects, selection effects, and learning can create what is known as the “ecological inference problem.” Specifically, even if a statistical correlation holds up for a population, and even if the correlation is causal, it is a potential fallacy to infer that any one case in the population is causally explained by the correlation that is observed at the population level. When interaction effects exist, a variable that raises the average outcome for a population may have a greater or smaller effect, or zero effect or even a negative effect, on the outcome for an individual case.
For example, in the 1960s, on the basis of statistical and other evidence, it became generally (and rightly) accepted as true that smoking increases the general prevalence of lung cancer for large groups of people. This generalization is an adequate basis for the policy recommendation that governments should discourage smoking. Yet the generalization that smoking on average increases the incidence of lung cancer does not tell us whether any one individual contracted lung cancer due to smoking.Footnote 4 Some people who smoke develop lung cancer but others do not, and some people who do not smoke develop lung cancer.Footnote 5 Scientists using statistical methods to assess epidemiological and experimental data have more recently begun to understand some of the genetic, environmental, and behavioral factors (in addition to the decision on whether to smoke) that affect the probability that a specific individual will develop lung cancer. This supports more targeted policy recommendations on whether an individual with particular genes is at especially high risk if they choose to smoke. For example, recent studies indicate that individuals with a mutation in a region on chromosome 15 will have a greatly increased risk of contracting lung cancer if they smoke (Reference PrayPray 2008: 17). Even in this subgroup, however, it cannot be said with certainty that any one individual developed lung cancer because of smoking, as not every individual with this mutation gets lung cancer even if they smoke.Footnote 6
Statistical researchers are well aware that strong assumptions are required to extend inferences from populations to individual cases, and they are typically careful to make clear that their models do not necessarily explain individual cases (although the results of statistical studies are often oversimplified in media reports and applied to individual cases). Case study researchers in the social sciences tend to be particularly skeptical about strong assumptions regarding constant effects, unit homogeneity, and independence of cases. These researchers often think that high-order interaction effects, interdependencies among cases across space or time, and other forms of complexity are common in social life. Consequently, qualitative researchers in the social sciences typically doubt whether there are many nontrivial single-variable generalizations that apply in consistent ways across large populations of cases in society.
Case study researchers thus face the obverse of the ecological inference problem: often it is neither possible nor desirable to “generalize” from one or a few case studies to a population in the sense of developing estimates of average causal effects. Yet, at the same time, case study researchers do aspire to derive conclusions from case studies that are useful beyond the specific cases studied. Instead of seeking estimates of average effects for a population, case study researchers attempt to identify narrower “contingent generalizations” that apply to subsets of a population that share combinations of independent variables. Case study researchers thus develop “typological” or “middle range” theories about how similar combinations of variables lead to similar outcomes through similar processes or pathways. These researchers often focus on hypothesized causal mechanisms and their scope conditions, posing research questions in the following form: “Under what conditions does this mechanism have a positive effect on the outcome, under what conditions does it have zero effect, and under what conditions does it have a negative effect?”
Contingent generalizations are similar in form to the generalizations sought by statistical researchers: they apply to defined populations, they may have anomalous cases whose outcomes do not fit the generalization, and they are potentially fallible as even cases that have the expected outcome may have arrived at that outcome through mechanisms different from those associated with the theory behind the generalization. The difference is that case studies arrive at generalizations through methods that are for the most part associated with Bayesian rather than frequentist logic (see Chapter 7). Bayesian logic treats probabilities as degrees of belief in alternative explanations, and it updates initial degrees of belief (called “priors”) by using assessments of the probative value of new evidence vis-à-vis alternative explanations (the updated degree of belief is known as the “posterior”). With ample cases and strong or numerous independent pieces of evidence, Bayesian and frequentist methods converge on similar conclusions, but unlike frequentism, Bayesian analysis does not need a minimum number of cases to get off the ground. Bayesianism is thus better suited to contexts in which cases are few or diverse, as is often true in the study of complex phenomena such as development.Footnote 7
These different logics translate into differences in practice on what constitutes an acceptable generalization. Case study researchers are often happy with a generalization that holds up well for, say, five or six cases that share similar values on a half-dozen independent variables, and they are also usually curious about or troubled by individual cases that do not fit such a generalization. This is because case study researchers base their arguments on the probative value of evidence within a Bayesian framework. Within this framework, a single piece of powerful evidence can sharply discriminate between one explanation and many alternative explanations, while many pieces of weak evidence cannot support any updating unless all or most of them point in the same direction. In a frequentist framework, which treats probabilities as constituting the likelihood that a sample drawn from a population is or is not representative of the population, nothing can be said about five or six cases with seven or eight independent variables because of the “degrees of freedom” problem. Frequentists also often have little curiosity about individual cases that do not fit a correlation established through a large sample, as they expect that such outliers will occasionally happen, whether by quantum randomness or by the fact that numerous weak variables left out of a model can sometimes line up in ways that create outliers.
The different logics also lead to different ways of establishing generalizations. The above-described frequentist approach starts and ends with populations: the population is studied at the population level through the study of the full population (or the random selection of cases from the population) to make population-level claims on average effects. Case studies, in contrast, begin from within-case analysis of individual cases, or process tracing, of cases not selected at random. Process tracing uses Bayesian logic to make inferences from the evidence within a single case about alternative explanations of the outcome of that case (see Chapter 7). Depending on the results of the within-case analysis and the principle used in selecting the cases studied, case study researchers decide whether to generalize contingently (to populations that share several specified features), widely (to populations that share fewer features), or not at all. The decision on whether and how to generalize depends on the understanding that emerges from the case study regarding the mechanisms that generated the outcome of the case, and also on new and prior knowledge about the nature and prevalence of the contexts that enable those mechanisms to operate. Put another way, the study of an individual case can lead to a new understanding of causal mechanisms and the scope conditions in which they do and do not operate, and the researcher may have prior knowledge on the frequency with which the necessary scope conditions exist (and hence of the population to which the case findings are relevant).
This overall description of generalizing from case studies includes four approaches to developing generalizations: generalization from “typical” cases, generalization from most- or least-likely cases, mechanism-based generalization, and typological theorizing.Footnote 8 The sections that follow address each in turn.
4.3 Generalization from a “Typical” Case
A first approach to generalization from cases is to select a case that is thought to be “typical” or representative of a population (Reference Gerring and SeawrightGerring and Seawright 2008: 299–301). In the medical literature, for example, case studies are often presented as being typical of a particular disease or condition. If indeed a case is representative of a population – a key assumption – then process tracing on the case can identify or verify relationships that generalize to the population. If an existing theory predicts a population-level correlation, and statistical analysis of the relevant population exhibits the expected correlation, close study of a typical case can strengthen the inference that the correlation is causal if process tracing on the case shows the hypothesized mechanisms were indeed in operation. A typical case can also undermine causal claims if it shows that no plausible mechanisms connect the hypothesized independent variable to the outcome, or if it demonstrates that the mechanisms that generated the outcome were different from those initially theorized (Reference Gerring and SeawrightGerring and Seawright 2008: 299).
These inferences all depend on whether the case studied is in fact representative of the population. One way to choose a case that may be typical is to construct a statistical model and then identify a case with a small error term vis-à-vis the model, or to choose randomly from among several cases with small error terms (Reference Gerring and SeawrightGerring and Seawright 2008: 299). Added criteria for typicality could include choosing a case that is near the mean or median values on most or all variables. One problem with these criteria is that if the statistical model is mis-specified – for example, if it omits relevant variables – a case may appear to be representative when it is in fact atypical (Reference Gerring and SeawrightGerring and Seawright 2008: 300). For example, the case may include two omitted variables that occur only rarely, one of which pushes the case toward the outcome of interest and one of which inhibits or lessens the outcome, so these variables may have cancelled out each other’s effects and resulted in a low error term. The case would have therefore had a low error term for reasons that would not apply to the majority of cases in the population that do not have the rare variables. One way to reduce the likelihood of this problem is to do process tracing on several cases thought to be typical.
When the population of cases is small and the hypothesized relationship involves interaction effects or different paths to the outcome that have little in common, it may be difficult or impossible to specify or identify a case that is “typical.” When these conditions hold, as they often do in the study of social phenomenon, the more theory-based forms of generalization discussed herein may prove more useful than attempts to generalize from a “typical” case.
4.4 Generalization from Most- or Least-Likely Case Studies
The most-likely and least-likely cases approach uses extant theories and preliminary knowledge about the values of the variables in particular cases to estimate case-specific priors on how likely it is that alternative theories will prove to be good explanations of a case. A case is most-likely for a theory, or an easy test case, if we expect the theory to be a strong explanation for the case’s outcome. The case is least-likely for a theory, or a tough test case, if we have reason to believe the theory should not account very well for the outcome of the case. The degree to which we can generalize from a case then depends on whether the theory passes or fails tough or easy test cases. A theory that succeeds in a least-likely case might be given broader scope conditions. For example, if a study shows that anarchist groups are hierarchically organized even though we should have expected them to be the least-likely kind of social organization to be hierarchical, we might conclude that hierarchy is a common feature in a wide range of social groups. Conversely, a theory that fails in a most-likely case should be assigned narrower scope conditions.Footnote 9 A theory’s successful explanation of most-likely cases, or its failure to explain least-likely cases, has little impact on our estimates of its scope conditions.
Determining whether a case is most- or least-likely for a theory depends on whether the variables in the theory point strongly to an outcome, whether the variables in alternative theories point strongly to an outcome, and whether the main theory of interest and the collective alternative explanations point to the same outcome or to different outcomes. The strongest possible basis for generalizing from a case is when a theory modestly pushes toward one outcome, countervailing alternative explanations point strongly to the opposite outcome, and the first theory proves correct regarding the outcome. The strongest basis for narrowing the scope conditions of a theory exists when the theory and all the alternative explanations point strongly to the same outcome, and yet they are all wrong. Other combinations lead to different degrees of updating of scope conditions (Reference RapportRapport, 2015).
An analysis of the international response to the 2014 West Africa Outbreak illustrates these issues.Footnote 10 In this outbreak the US government mobilized considerable resources – albeit later than it should have – and the UK government stepped in to assist in Sierra Leone, while France was slower to play a role and the UN system lagged.Footnote 11 There are several possible alternative explanations for the variation in these responses.Footnote 12 One possible explanation for the pattern of assistance that emerged is “Finance”: the ability to summon substantial financial resources quickly. A second is “Capacity”: ability to mobilize organizational resources, transportation, and medical materials rapidly. A third is “Authority”: Whether there is an interagency process that allows institutions responsible for medical emergencies to work with institutions responsible for disaster response, without having to create a whole new organization for that purpose. A fourth is “Cohesion”: Whether the decision to act lies within the power of one person or a few people, or whether there are many veto points.
Table 4.1 Mobilization during 2014 Ebola outbreak: World Health Organization, United States, United Kingdom, and France
| Country or International Organization | Finance | Capacity | Authority | Cohesion | Expected Outcome (E) and Observed Outcome (O) |
|---|---|---|---|---|---|
| WHO | N | N | N | N |
|
| United States | Y | Y | Y | Y |
|
| United Kingdom | Mixed | Y | Mixed | Y |
|
| France | N | ? | ? | ? |
|
With respect to “Finance,” the USA had disaster response discretionary funds it could use to put people on the ground quickly, while the UK and France could mobilize money less easily and the UN system would have to pass the hat for contributions from member states. With respect to “Capacity,” the WHO’s emergency response capacity had eroded, while the USA had an Office of Foreign Disaster Assistance with a rapid response capability in place. With respect to “Authority,” there was no quick way within the UN system to merge a public health or medical response (a World Health Organization matter) with a disaster response (based at the UN Office for the Coordination of Humanitarian Affairs). Finally, with respect to “Cohesion,” in the USA a single decision-maker, the president, could authorize action, while the UN agencies required the assent of member-state representatives.
In this instance, there are no strong or generalizable surprises from the most- and least-likely cases: the USA was the most-likely case for early and strong mobilization, the WHO was the least likely, and both had the expected outcomes. Had the USA failed to mobilize, or the WHO succeeded in doing so, these cases might challenge the four-factor theory of mobilization and its scope conditions.
The most interesting and strongest generalization to emerge from the international response to the 2014 Ebola outbreak is that the main bottleneck internationally was not finances or capacity, which would require financial investments to fix, but authority and cohesion, which require political attention to fix. The UK, France, and especially the USA had unused capacity in their militaries and national health systems for addressing Ebola, and the USA in particular mobilized substantial resources. However, many of these resources translated into operations only after the number of new infections per week had started to diminish. The USA deployed 3,000 troops to build 11 Ebola treatment centers in Africa, but only 28 Ebola patients received treatment at these centers, and 9 of the 11 centers never treated a single Ebola patient (Reference OnishiOnishi 2015). In the UK, Public Health England (PHE) and the Department for International Development (DFID) coordinated in responding to Ebola, but only after initial delays that a parliamentary report attributed to over-reliance on WHO medical warning systems and DFID’s inflexibility in dispersing small amounts of money early in the outbreak (House of Commons, 2016: 3). In addition, some UK health care personnel willing to volunteer for the fight against Ebola in Africa had to first negotiate leaves of absence from their respective organizations (Reference Reece, Brown, Dunning, Chand, Zambon and Jacobs.Reece et al. 2017). A stronger and more coordinated early response would have been less costly and more effective than the slow and piecemeal responses that emerged.
4.5 Mechanism-Based Generalization from Cases
Typical, most-likely, and least-likely cases can provide a basis for a general claim that scope conditions should be broadened or narrowed, but they do not provide much detail on exactly how, or to what subpopulations, they might be extended, or from what subpopulations they might be withdrawn. The third, mechanism-based approach to generalizing from case studies provides some clues to this process, often by building on new theories about causal mechanisms derived from the study of individual cases.
To understand the logic of this kind of generalization, consider two polar opposite examples, the first of which leads to very limited generalizability and the second of which leads to sweeping generalizations. In the first example, imagine that a researcher studying voter behavior finds evidence that a voter, according to the variables identified by every standard theory of voter choice (party affiliation, ideology, etc.) should have voted for candidate A, but in fact it is known that the voter chose candidate B. Imagine further that the researcher is able to ask the voter “Why did you vote for B?” and the voter replies “B is my sister-in-law.” This new variable, which we might call “immediate kinship relations,” provides a convincing explanation, but the mechanisms involved in the explanation suggest that it will generalize only to a very small number of cases in any election involving a large electorate.Footnote 13
Now consider an opposite example: Charles Darwin undertook an observational study of several bird species and came up with the theory of evolutionary selection. In view of the mechanisms that this theory posits, the theory should apply to an extremely large group: all living things. Here again, the hypothesized mechanisms involved in the theory – genetic mutation, procreation, and environmental selection – provide clues on the expected scope conditions of the theory. In part, these expectations are built, in Bayesian fashion, on prior knowledge of the base rates of the enabling conditions of the theory: immediate relatives of a candidate are rare among big populations of voters, whereas living things are common.
The lessons experts drew from the early mishandling of the 2014 Ebola outbreakFootnote 14 provide a real example of generalization from an improved understanding of causal mechanisms. Here, findings on the relevant causal mechanisms are not only those concerning the medical details of the Ebola virus itself, but the interaction of the virus with local health systems, international organizations, social media, and local customs. An early opportunity to suppress the 2014 outbreak was missed because international experts did not realize that reported numbers of cases had dropped not because the outbreak had been contained, but because fearful communities had chased away health workers and sick patients were avoiding health clinics, which they associated with high rates of death (Reference Sack, Fink, Belluck and NossiterSack, Fink, Belluck, and Nossiter, 2014). In addition, the virus spread in part because of cultural commitments to hands-on washing of the dead, which points to the need for “culturally appropriate outreach and education” to prevent the spread of future outbreaks (Reference Frieden, Damon, Bell, Kenyon and NicholFrieden et al., 2014). These findings, and not just differences in the availability of health care and quarantine technologies, help explain why Ebola spread rapidly in West Africa but not in Europe or the United States despite the arrival of infected patients in the latter regions.
Generalizations based on improved theories about causal mechanisms have two very important properties. First, they can be highly relevant for making policy decisions. For many policy decisions, we are less interested in questions such as “what is the average causal effect of X on Y in a population” than in questions such as “what will be the effect of increasing X in this particular case.” Improved knowledge of how causal mechanisms work, and of the contexts in which they have positive and negative effects on the outcome of interest, is directly relevant to estimating case-specific effects.
Second, an improved understanding of causal mechanisms can allow generalizing to individual cases, and kinds of cases or contexts, that are different from or outside of the sample of the cases studied. This is a very important property of theoretical understandings derived from the close observation of causal mechanisms in individual cases, as both statistical studies and artificial intelligence algorithms are often weak at “out of sample” predictions. A powerful example here is the development of an effective “cocktail” of drugs to treat HIV-AIDS. This medical advance was greatly fostered by the close study of individual patients who responded far better to treatments than other patients. Researchers concluded upon close examination of such patients that administration of a combination of drugs earlier in the progression of the disease than previous experimental treatments could keep it in check (Reference SchoofsSchoofs, 1998). This illustrates that when a researcher comes up with a new theory or explanation from the study of a case, their new understanding of the hypothesized mechanisms through which the theory operates can itself give insights into the expected scope conditions of the theory, as in the above-mentioned “sister-in-law” and Darwin examples.
While researchers might derive new understandings of causal mechanisms from many types of case studies, two kinds of case selection are particularly oriented toward developing new understandings of mechanisms and their scope conditions: studies of “deviant” (or outlier) cases, and studies of cases that have high values on an independent variable of interest.Footnote 15 Deviant cases, or cases with an unexpected outcome or a high error term relative to extant theories, are good candidates for the purpose of looking inductively for new explanations or omitted variables. In these cases, new insights and theories may arise from the inductive use of process tracing to connect “clues” – pieces of evidence that do not on first examination fit into extant theories – in a new explanation.Footnote 16
An interesting and important dilemma here concerns decisions on whether to stop trial experiments on medical or other treatments sooner than planned when the early subjects undergoing the treatment show signs of either catastrophic failures or remarkable successes. Continuing a trial after a treatment has shown signs of being powerfully effective can be unethical as it delays treatment of other individuals or communities who might benefit. Even worse, continuing a trial treatment after catastrophic outcomes arise in early cases can cost lives. Much of the discussion of this issue in the medical literature warns against premature termination of medical experiments, regardless of unexpectedly good or bad early results, due to the frequentist argument that small samples can be unrepresentative and do not allow powerful conclusions. There is indeed a risk that trials stopped early for benefit might catch the observed treatment effect at a “random high,” which later can yield to a “regression to the truth effect” in subsequent trials or clinical use (Reference Montori, Devereaux and AdhikariMontori et al., 2005). Yet qualitative evidence from individual cases can provide additional analytical leverage over decisions on whether to continue experiments after strong early results, particularly when that evidence, combined with existing expert knowledge, strongly illuminates the causal mechanisms at work. Experts on clinical trials have thus noted that “formal statistical methods should be used as tools to guide decision-making rather than as hard rules” (Reference Sydes, Spiegelhalter, Altman, Babiker and ParmarSydes et al., 2004: 60) and that “predefined statistical stopping boundaries for benefit provide a useful objective guideline, but the reality of making wise judgements on when to stop involves an evaluation of the totality of evidence available” (Reference PocockPocock, 2006: 516).
Bayesian logic and process tracing provide a useful perspective on this issue. As noted, whereas frequentism treats probabilities as representing the likelihood that a sample is representative of a population, Bayesians view probability as representing degrees of belief in different explanations. Consequently, when evidence is uniquely consistent with one explanation, Bayesians can update their confidence in alternative explanations even with small numbers of cases. In medical applications, this involves looking at process-tracing evidence on why a treatment succeeded or failed, not just whether it succeeded or failed. While much of the thinking behind clinical trials still reflects a frequentist outlook, a more Bayesian and process-tracing approach has been influential in epidemiology and experimental medicine as well. Early on in the debates on the relationship between smoking and cancer, the English epidemiologist Sir Austin Bradford Hill developed nine criteria for assessing evidence on a potential causal relationship between a presumed cause and an observed effect. These include process-tracing types of criteria, such as the specificity of the observed relationship, the temporal precedence of the cause over the effect, and the existence of a plausible theorized mechanism linking the cause and the effect. As a later study of Hill’s criteria concluded: “Whereas a trial is often open to the objection that it is an anomaly or not generalizable, if we supplement the evidence from the trial with strong mechanistic and parallel evidence, it becomes increasingly difficult to question the results of the study and its applicability to a wider target population” (Reference Howick, Glasziou and AronsonHowick, Glasziou, and Aronson, 2009: 193).
An example here concerns the early application of chimeric antigen receptor T-cell (CAR-T) therapy. In CAR-T therapy, physicians alter a patient’s T-cells (a type of white blood cell critical to the immune system) so that these T-cells can better target and destroy cancer cells. The physicians then introduce the altered T-cells back into the patient’s body. Of the first patients with ordinarily fatal cancers given this experimental treatment, three had complete remissions, four improved without a full remission, one improved and then relapsed, and two showed no effect. While these early results included too few cases for any strong conclusion using frequentist statistics, they looked promising given the extremely low remission rates of untreated patients with the kinds of cancers included in the initial study, and research on CAR-T therapy continued.
The most revealing case arose when doctors chose to administer CAR-T therapy in 2012 to Emily Whitehead, a young patient with a likely terminal case of Acute Lymphoblastic Leukemia. Like some previous CAR-T patients, within a few days Emily developed life-threatening immune response symptoms, including a fever of 105 degrees, and appeared to be hours away from death. Fortunately, her doctors quickly found that the cause was an elevation of cytokines, inflammatory factors secreted by T-cells and their target cells. Emily had one cytokine in particular, IL-6, that was 1,000 times higher than normal. In a sense, given her doctors’ already well-developed understanding of their therapeutic approach, this showed that the CAR-T process was working: the chimeric T-cells were targeting and destroying cancer cells at an astonishing rate. Yet the associated side effect of inflammation might have killed Emily, as it had a previous patient named Jesse Gelsinger. Luckily, one of Emily’s doctors knew of a recently approved drug that blocks IL-6, and Emily experienced a remarkably quick and full recovery once she received this drug. Seven years later, she remained cancer-free (Reference MukherjeeMukherjee, 2019).
This example demonstrates that the efficacy and generalizability of an intervention should rely not only on the number of successes or failures and frequentist statistical assumptions about sampling, but also on Bayesian inference, prior theoretical knowledge, and process-tracing evidence. Here, despite the small number of prior cases, the results were striking: deadly in some cases, remarkably curative for some who survived the inflammatory response. Emily’s case provided the key process-tracing clue regarding the “cytokine storm” that was threatening patients. Fortunately, a drug was at hand to treat her particular IL-6 cytokine spike, and doctors used their prior causal knowledge to decide to administer this drug. Emily’s recovery spurred further CAR-T research, and while not every patient has benefited in trials and several challenges remain, the therapy continues to show promise. Yet given the frequentist tilt of extant practices in medical research, the future of CAR-T therapy hinged on Emily’s personal outcome to a far larger degree than it should have. As one physician later commented (Reference RosenbaumRosenbaum, 2017: 1314):
anecdote can easily break a field rather than make it: the death of Jesse Gelsinger in a trial at Penn had set the field of gene therapy back at least a decade. And as both June and Stephan Grupp, the Children’s Hospital oncologist and principal investigator of the CART-19 trial in children, emphasized, had Emily died, the CAR-T field would probably have died with her.
In addition to studying cases with remarkable outcomes on the dependent variable, the study of cases with high values on an independent variable of interest can contribute to better and generalizable understandings of causal mechanisms. This is often the intuition behind selecting cases that have high value on both an independent variable and the dependent variable. An example here is a study of “hybrid” microfinance organizations, or commercial organizations that combine elements of profit-making lending and development-oriented lending, by Julie Battilana and Silvia Dorado. These authors chose two such organizations in Bolivia that they knew to be “pioneering” and high-performing in order to carry out a “comparative inductive study” (Reference Battilana and DoradoBattilana and Dorado, 2010:1435) of the factors behind their success. They concluded from close study of these two organizations that their innovative hiring and socialization processes accounted for their high portfolio growth. The authors suggest that this finding is relevant to hybrid organizations more generally, although they also note “limits to the influence of hiring and socialization policies in mitigating tensions between institutional logics within organizations” (Reference Battilana and DoradoBattilana and Dorado, 2010: 1420).
Of course, researchers can make mistakes in either over-generalizing or under-generalizing the expected scope conditions that emerge from their understanding of a new theory. For this reason, while researchers may have warrant for making claims on the scope conditions of new theories derived from cases, these claims must remain provisional pending testing in other cases. Researchers should be particularly careful of selecting “best practices” cases on the basis of performance or outcomes, or selecting on the dependent variable, and then making inferences on the practices in these cases as the causes of high performance. If a population is large, some units may perform well even over long periods of time just by chance. Researchers have often claimed to have found the best practices that underlie unusually good performance in companies’ stock market strategies and management practices, for example, only to find later that the same companies later experienced average or even below average performance, exhibiting regression toward the mean.Footnote 17
4.6 Typological Theorizing and Generalization
The fourth approach to generalization from case studies, typological theorizing, systematically combines process tracing and small-N comparisons. The goal is to develop a theory on different combinations of independent variables, or types, so that contingent generalizations can be made about the processes and outcomes of cases within each type.Footnote 18 To develop and test these contingent generalizations, researchers first build a typological theory, starting deductively and then iterating between their initial theoretical understanding of the phenomenon they are studying and their initial knowledge of the measures of the variables in the cases in the relevant population. Once they have built a typological theory using this initial knowledge, the researchers can use it to choose which cases they will study, and then they can use process tracing (see Chapter 7) to study those cases.
While a full discussion of typological theorizing is beyond the scope of this chapter,Footnote 19 the paragraphs that follow outline a process for developing typological theories. As an illustrative example, the discussion considers the puzzle of why, in response to epidemics such as Ebola or flu, governments sometimes resort to isolation strategies while at other times they employ quarantines. Isolation involves treating and limiting the movement of symptomatic patients suspected of having a contagious disease, while quarantines seek to limit the movement into and out of designated areas (including neighborhoods or whole cities) of individuals who may have been exposed to an illness but are not themselves symptomatic. Isolation is uncontroversial, while quarantines raise more difficult issues regarding civil liberties. Quarantines can also create unintended consequences by inhibiting patients who might be sick from seeking care, or motivating individuals to flee from high-infection quarantined areas to low-infection areas, possibly spreading the epidemic in the process. For present purposes of illustrating a typological theory, however, I focus not on the policy question of when quarantines might be efficacious, or the ethical question of when they might be justified, but the political question of when they are attempted.
To build a typological theory, the researcher first defines or conceptualizes the outcome of interest (the dependent variable) and decides how to measure this outcome. Often in typological theories the dependent variable is categorized by nominal measures (such as “democracy” and “non-democracy”), but it can also be categorized by ordinal measures (such as high, medium, and low levels of growth in the percentage of children attending school), or by conceptual typologies (such as combinations of variables that constitute three types of “welfare capitalism” (Reference Esping-AndersenEsping-Andersen, 1990)). In our example of isolation versus quarantine, there are gradations of both (How many symptoms qualify a patient for isolation? How geographically broad or narrow is a quarantine and does it allow many or few exceptions for work or family reasons?), but the overall conceptual difference between isolation and quarantine is clear. For present purposes, the discussion therefore uses a simple dichotomized dependent variable of isolation versus quarantine, but subsequent research could consider gradations and kinds of isolations and quarantines.
Second, the researcher draws on existing theories to identify the key independent variables from individual theories, or constituent theories that relate to the outcome of interest. By convention, these independent variables constitute the columns in a table laying out the typological theory, while the individual cases (or clusters of cases with the same combination of independent variables, or “types”) constitute the rows in the typological table. In our example I offer three independent variables that may affect choices between isolation strategies and quarantines. First, airborne epidemics, which typically spread quickly, are more likely to be subject to quarantine than those transmitted only by direct bodily contact. This may even be a nearly sufficient condition for quarantines. Second, isolation is more likely when a country has a high-capacity health care system that can treat a large number of individuals. Third, quarantines are a more tempting option when individuals in the quarantined area have few transportation or other options for escaping the quarantine area. Additional variables may matter as well, such as levels of social media, levels of trust or distrust in the government and the health system, and state capacity for coercion, but for illustrative purposes the present example includes only three independent variables and treats each as dichotomous.
Third, the researcher builds a table – a “typological space” (sometimes called a “possibility space” or a “property space” in the philosophy of logic) of all the possible combinations of the independent variables of the constituent theories.Footnote 20 Because a typological space becomes combinatorially more complex with additional variables and finer levels of measurement of these variables, for the purpose of presenting and thinking through the typological table, researchers typically include six or fewer independent variables and use nominal, dichotomous, or trichotomous measures of these variables. Researchers can relax the simplifications on the number and measurement of variables as they move from the simplified typological theory to the within-case analysis of individual cases. In our example, with three dichotomous variables, we have two to the power of three or eight possible combinations. These are outlined in Table 4.2.
Table 4.2 A typological theory on government choices of isolation versus quarantine strategies in epidemics
| Case | Air or Direct Transmission | High or Low Health Care Capacity | High or Low Ability to Escape Quarantine |
Outcome: Expected (E) and Observed (O) |
|---|---|---|---|---|
| SARS 2003 in Taiwan, Canada, | Air | H | H | Unclear Prediction;Quarantine (O) |
| SARS 2003 in Hong Kong, Singapore | Air | H | L |
|
| SARS 2003 in Vietnam | Air | L | H | Quarantine (E)Quarantine (O) |
| SARS 2003 in China | Air | L | L | Quarantine (E)Quarantine (O) |
| Ebola 2013–2015 in the United States, EU countries | Direct | H | H | Isolation (E)Isolation (O) |
| No cases | Direct | H | L | Isolation (E) |
| Ebola 2013–2015 in Guinea, Liberia, Sierra Leone | Direct | L | H | Unclear Prediction; Liberia attempted quarantine, others did not |
| No cases | Direct | L | L | Unclear Prediction |
Fourth, the researcher deductively thinks through how each combination of variables might interact and what the expected outcome should be for each row. This is the step at which the researcher integrates the constituent theories that created the typological space into a single typological theory that provides the expected outcome for every combination of variables. In practice, a typological theory is rarely fully specified, as the researcher may lack a strong theoretical prior for every possible combination of the independent variables. Still, it is useful to think through possible interactions and specify expected outcomes deductively to the extent possible. Table 4.2 identifies the expected outcome for combinations that lead to clear and strong predictions on outcomes, such as combinations where all three independent variables point to the same expected outcome and interaction effects are unlikely. Table 4.2 codes a question mark for combinations in which the independent variables push toward different outcomes.
Fifth, after this deductive construction of the first draft of the typological theory, the researcher can use their preliminary empirical knowledge of extant historical cases to classify these cases into their respective types or rows. This stage allows for some iteration between the researcher’s preliminary theoretical expectations and their initial knowledge of the empirical cases. Quick initial comparisons of the cases might lead to revisions to the theoretical typology and/or to the remeasurement and reclassification of cases. For example, if cases are in the same row – that is, they have fully similar combinations of the values of the independent variables – but they have different outcomes, they pose anomalies for the emerging theory. A quick examination of these cases might lead to revisions in the typology or the measurement of the variables in the cases in question, or deeper process tracing may be necessary to analyze why the cases have different outcomes. The example in Table 4.2 includes countries that had a significant number of SARS cases in 2003 or Ebola cases in 2013–2015, and it also includes some countries that had a few Ebola cases but public debates over a possible quarantine. The codings are based on very limited and preliminary knowledge of the values of the variables in each case, particularly the measurement of the ability of individuals to escape quarantined areas.
After iterating between the typological theory and the classification of extant cases to resolve all the discrepancies that can be addressed quickly and easily with the benefit of secondary sources, the researcher can undertake the sixth step: using the refined typological theory to select cases for deeper research that uses process tracing. The refined typological theory makes it easy to assess which cases fit various comparative research designs and inferential purposes: most-similar cases (cases that differ on one independent variable and on the outcome), least-similar cases (cases with the same outcome and only one independent variable in common), deviant cases (cases without the predicted outcome), cases with a high value on one independent variable, and typologically similar cases (cases in the same type or row and with the same outcome). In this example, interesting cases worth studying are those of Liberia, Sierra Leone, and Guinea. The theory does not make a strong prediction for the combination of variables evident in the cases of Sierra Leone, Guinea, and Liberia in 2013–2015 because the high ability of individuals to escape quarantine and the low capacity to isolate and treat patients push in opposite directions. Comparisons among these cases could prove fruitful in understanding why only Liberia attempted a quarantine.
Vietnam is also an interesting case worthy of study, as it was fairly successful in containing SARS despite limited health resources (Reference Rothstein, Alcalde and ElsterRothstein et al., 2003: 107). This makes it a least-likely case that succeeded. Canada and Taiwan are worthy of study as well, as the theory does not give a strong prediction on how countries with high health care capacity (and here, strong democratic cultures) would respond to airborne epidemics, and both countries resorted to quarantines.
This is a “building block” approach in several senses: it builds on theories about individual variables or mechanisms, theorizes about different combinations of these variables, uses individual case studies to validate the theorization on each combination of variables or “type” of case, and cumulatively charts out different types or paths to the outcome of interest. If there are limited interaction effects, individual variables, or even combinations of variables, will behave similarly across types, but typological theorizing does not presume or require such constant or simple interaction effects. Its strongest generalizations focus on the cases within each type. This prioritizes theoretical intension – making strong statements about well-defined subtypes that cover relatively few cases – while it sacrifices some degree of parsimony, as each combination or path can have its own explanation. Typological theorizing does not necessarily aspire to single-variable generalizations that apply to the whole population, but if such generalizations exist, it can still uncover them. In our example, both the theory and the extant cases suggest that quarantines are far more likely for airborne epidemics.
4.7 Generalizing – Carefully and Contingently – from Cases
Researchers in both the qualitative and quantitative traditions are rightly cautious about generalizing from individual case studies to broad populations. Case studies are not optimal for generalizing in the sense of estimating average effects for a population, as statistical studies aim to do. In addition, when process tracing reveals that the outcome in a case was due to mechanisms whose enabling conditions are rare or unique, little or no generalization beyond the case is possible. Even when findings do generalize from individual cases, it can be difficult to identify exactly the scope conditions in which they apply.
Yet case studies contribute to forms of generalization that are different from average population-level effects and that are pragmatically useful for policy-makers. Cases that are typical, most-likely, least-likely, deviant, and high on the value of a particular independent variable can all contribute to various forms of generalization even if they do not always provide clear guidelines on the scope conditions for generalizations. And sometimes cases do allow inferences about scope conditions – the clearer understanding of causal mechanisms that often emerges from process tracing can provide information on the conditions under which these mechanisms operate, and prior knowledge can indicate how common those conditions are. Just as a case study can uncover causal mechanisms that are relatively unique, it can also identify mechanisms that prove generalizable to large populations. In addition, typological theorizing can develop contingent generalizations about cases that share combinations of variables. Researchers can also develop cumulatively better knowledge of a phenomenon as they build upon and revise typological theories through the study of additional or subsequent cases.
These forms of generalization from case studies are Bayesian in the sense that they depend on prior theoretical knowledge and knowledge about the prevalence of the scope conditions thought to enable causal mechanisms to operate. Prior knowledge on both how causal mechanisms operate and where/under what conditions they operate can be updated through the study of individual cases. As prior knowledge is usually incomplete, however, generalization from cases is potentially fallible. Researchers can make the mistake of either over-generalizing or under-generalizing from cases. Process-tracing research on additional cases, as well as statistical studies of newly modeled mechanisms, can further test whether generalizations about causal mechanisms hold, and whether they need to be modified. Careful generalizations from case studies can thus contribute to cumulating policy-relevant knowledge about causal processes and the conditions under which they operate.
Immersion in the particular proved, as usual, essential for the catching of anything general.
[T]he bulk of the literature presently recommended for policy decisions … cannot be used to identify “what works here”. And this is not because it may fail to deliver in some particular cases [; it] is not because its advice fails to deliver what it can be expected to deliver … The failing is rather that it is not designed to deliver the bulk of the key facts required to conclude that it will work here.
5.1 Introduction: In Search of ‘Key Facts’
Over the last two decades, social scientists across the disciplines have worked tirelessly to enhance the precision of claims made about the impact of development projects, seeking to formally verify ‘what works’ as part of a broader campaign for ‘evidence-based policy-making’ conducted on the basis of ‘rigorous evaluations’.Footnote 3 In an age of heightened public scrutiny of aid budgets and policy effectiveness, and of rising calls by development agencies themselves for greater accountability and transparency, it was deemed no longer acceptable to claim success for a project if selected beneficiaries or officials merely expressed satisfaction, if necessary administrative requirements had been upheld, or if large sums had been dispersed without undue controversy. For their part, researchers seeking publication in elite empirical journals, where the primary criteria for acceptance was (and remains) the integrity of one’s ‘identification strategy’ – that is, the methods deployed to verify a causal relationship – faced powerful incentives to actively promote not merely more and better impact evaluations, but methods, such as randomized controlled trials (RCTs) or quasi-experimental designs (QEDs), squarely focused on isolating the singular effects of particular variables. Moreover, by claiming to be adopting (or at least approximating) the ‘gold standard’ methodological procedures of biomedical science, champions of RCTs in particular could impute to themselves the moral and epistemological high ground as ‘the white lab coat guys’ of development research.
The heightened focus on RCTs as the privileged basis on which to impute causal claims in development research and project evaluation has been subjected to increasingly trenchant critique,Footnote 4 but for present purposes my objective is not to rehearse, summarize, or contribute to these debates per se; it is, rather, to assert that these preoccupations have drained attention from an equally important issue, namely our basis for generalizing any claims about impact from different types of interventions across time, contexts, groups, and scales of operation. If identification and causality are debates about ‘internal validity’, then generalization and extrapolation are concerns about ‘external validity’.Footnote 5 It surely matters for the latter that we first have a good handle on the former, but even the cleanest estimation of a given project’s impact does not axiomatically provide warrant for confidently inferring that similar results can be expected if that project is scaled up or replicated elsewhere.Footnote 6 Yet too often this is precisely what happens: having expended enormous effort and resources in procuring a clean estimate of a project’s impact, and having successfully defended the finding under vigorous questioning at professional seminars and review sessions, the standards for inferring that similar results can be expected elsewhere or when ‘scaled up’ suddenly drop away markedly. The ‘rigorous result’, if ‘significantly positive’, slips all too quickly into implicit or explicit claims that ‘we know’ the intervention ‘works’ (even perhaps assuming the status of a veritable ‘best practice’), the very ‘rigor’ of ‘the evidence’ invoked to promote or defend the project’s introduction into a novel (perhaps highly uncertain) context. In short, because an intervention demonstrably worked ‘there’, we all too often and too confidently presume it will also work ‘here’.
Even if concerns about the weak external validity of RCTs/QEDs – or, for that matter, any methodology – of development interventions are acknowledged by most researchers, decision-makers still lack a usable framework by which to engage in the vexing deliberations surrounding whether and when it is at least plausible to infer that a given impact result (positive or negative) ‘there’ is likely to obtain ‘here’. Equally importantly, we lack a coherent system-level imperative requiring decision-makers to take these concerns seriously, not only so that we avoid intractable, nonresolvable debates about the effectiveness of entire portfolios of activity (‘community health’, ‘justice reform’) or abstractions (‘do women’s empowerment programs work?’Footnote 7), but, more positively and constructively, so that we can enter into context-specific discussions about the relative merits of (and priority that should be accorded to) roads, irrigation, cash transfers, immunization, legal reform, etc., with some degree of grounded confidence – that is, on the basis of appropriate metrics, theory, experience, and (as we shall see) trajectories and theories of change.
Though the external validity problem is widespread and vastly consequential for lives, resources, and careers, this chapter’s modest goal is not to provide a “tool kit” for “resolving it” but rather to promote a broader conversation about how external validity concerns might be more adequately addressed in the practice of development. (Given that the bar, at present, is very low, facilitating any such conversations will be a nontrivial achievement.) As such, this chapter presents ideas to think with. Assessing the extent to which empirical claims about a given project’s impact can be generalized is only partly a technical endeavor; it is equally a political, organizational, and philosophical issue, and as such usable and legitimate responses will inherently require extended deliberation in each instance. To this end, the chapter is structured in five sections. Following this introduction, Section 5.2 provides a general summary of selected contributions to the issue of external validity from a range of disciplines and fields. Section 5.3 outlines three domains of inquiry (‘causal density’, ‘implementation capabilities’, ‘reasoned expectations’) that, for present purposes, constitute the key elements of an applied framework for assessing the external validity of development interventions generally, and ‘complex’ projects in particular. Section 5.4 considers the role analytic case studies can play in responding constructively to these concerns. Section 5.5 concludes.
5.2 External Validity Concerns Across the Disciplines: A Short Tour
Development professionals are far from the only social scientists, or philosophers or scientists of any kind, who are confronting the challenges posed by external validity concerns.Footnote 8 Consider first the field of psychology. It is safe to say that many readers of this chapter, in their undergraduate days, participated in various psychology research studies. The general purpose of those studies, of course, was (and continues to be) to test various hypotheses about how and when individuals engage in strategic decision-making, display prejudice toward certain groups, perceive ambiguous stimuli, respond to peer pressure, and the like. But how generalizable are these findings? In a detailed and fascinating paper, Reference Henrich, Heine and NorenzayanHenrich, Heine, and Norenzayan (2010a) reviewed hundreds of such studies, most of which had been conducted on college students in North American and European universities. Despite the limited geographical scope of this sample, most of the studies they reviewed readily inferred (implicitly or explicitly) that their findings were indicative of ‘humanity’ or reflected something fundamental about ‘human nature’. Subjecting these broad claims of generalizability to critical scrutiny (for example, by examining the results from studies where particular ‘games’ and experiments had been applied to populations elsewhere in the world), Henrich et al. concluded that the participants in the original psychological studies were in fact rather WEIRD – western, educated, industrialized, rich and democratic – since few of the findings of the original studies could be replicated in “non-WEIRD” contexts (see also Reference Henrich, Heine and NorenzayanHenrich, Heine, and Norenzayan 2010b).
Consider next the field of biomedicine, whose methods development researchers are so often invoked to adopt. In the early stages of designing a new pharmaceutical drug, it is common to test prototypes on mice, doing so on the presumption that mouse physiology is sufficiently close to human physiology to enable results for the former to be inferred for the latter. Indeed, over the last several decades a particular mouse – known as ‘Black 6’ – has been genetically engineered so that biomedical researchers around the world are able to work on mice that are literally genetically identical. This sounds ideal for inferring causal results: biomedical researchers in Norway and New Zealand know they are effectively working on clones, and thus can accurately compare findings. Except that it turns out that in certain key respects mouse physiology is different enough from human physiology to have compromised “years and billions of dollars” (Reference KolataKolata 2013: A19) of biomedical research on drugs for treating burns, trauma, and sepsis, as reported in a New York Times summary of a major (thirty-nine coauthors) paper published in the prestigious Proceedings of the National Academy of Sciences (see Reference Seok, Warren and CuencaSeok et al. 2013). In an award-winning science journalism article, Reference EngberEngber (2011) summarized research showing that Black 6 was not even representative of mice – indeed, upon closer inspection, Black 6 turns out to be “a teenaged, alcoholic couch potato with a weakened immune system, and he might be a little hard of hearing.” An earlier study published in The Lancet (Reference RothwellRothwell 2005) reviewed nearly 200 RCTs in biomedical and clinical research in search of answers to the important question “To whom do the results of this trial apply?” and concluded, rather ominously, that the methodological quality of many of the published studies was such that even their internal validity, let alone their external validity, was questionable. Needless to say, it is more than a little disquieting to learn that even the people who do actually wear white lab coats for a living have their own serious struggles with external validity.Footnote 9
Consider next a wonderful simulation paper in health research, which explores the efficacy of two different strategies for identifying the optimal solution to a given clinical problem, a process the authors refer to as “searching the fitness landscape” (Reference Eppstein, Horbar, Buzas and KauffmanEppstein et al. 2012).Footnote 10 Strategy one entails adopting a verified ‘best practice’ solution: you attempt to solve the problem, in effect, by doing what experts elsewhere have determined is the best approach. Strategy two effectively entails making it up as you go along: you work with others and learn from collective experience to iterate your way to a customized ‘best fit’Footnote 11 solution in response to the particular circumstances you encounter. The problem these two strategies confront is then itself varied. Initially the problem is quite straight forward, exhibiting what is called a ‘smooth fitness landscape’ – think of being asked to climb an Egyptian pyramid, with its familiar symmetrical sides. Over time the problem being confronted is made more complex, its fitness landscape becoming increasingly rugged – think of being asked to ascend a steep mountain, with craggy, idiosyncratic features. Which strategy is best for which problem? It turns out the ‘best practice’ approach is best – but only as long as you are climbing a pyramid (i.e., facing a problem with a smooth fitness landscape). As soon as you tweak the fitness landscape just a little, however, making it even slightly ‘rugged’, the efficacy of ‘best practice’ solutions fall away precipitously, and the ‘best fit’ approach surges to the lead. One can over-interpret these results, of course, but given the powerful imperatives in development to identify “best practices” (as verified, preferably, by an RCT/QED) and replicate “what works,” it is worth pondering the implications of the fact that the ‘fitness landscapes’ we face in development are probably far more likely to be rugged than smooth, and that compelling experimental evidence (supporting a long tradition in the history of science) now suggests that promulgating best practice solutions is a demonstrably inferior strategy for resolving them.
Two final studies demonstrate the crucial importance of implementation and context for understanding external validity concerns in development. Reference Bold, Kimenyi, Mwabu, Ng’ang’a and SandefurBold et al. (2013) deploy the novel technique of subjecting RCT results themselves to an RCT test of their generalizability using different types of implementing agencies. Earlier studies from India (e.g., Reference Banerjee, Cole, Duflo and LindenBanerjee et al. 2007, Reference Duflo, Dupas and KremerDuflo, Dupas, and Kremer 2012, Reference Muralidharan and SundararamanMuralidharan and Sundararaman 2010) famously found that, on the basis of an RCT, contract teachers were demonstrably ‘better’ (i.e., both more effective and less costly) than regular teachers in terms of helping children to learn. A similar result had been found in Kenya, but as with the India finding, the implementing agent was an NGO. Bold et al. took essentially an identical project design but deployed an evaluation procedure in which 192 schools in Kenya were randomly allocated either to a control group, an NGO-implemented group, or a Ministry of Education-implemented group. The findings were highly diverse: the NGO-implemented group did quite well relative to the control group (as expected), but the Ministry of Education group actually performed worse than the control group. In short, the impact of “the project” was a function not only of its design but, crucially and inextricably, of its implementation and context. As the authors aptly conclude, “the effects of this intervention appear highly fragile to the involvement of carefully-selected non-governmental organizations. Ongoing initiatives to produce a fixed, evidence-based menu of effective development interventions will be potentially misleading if interventions are defined at the school, clinic, or village level without reference to their institutional context” (Reference Bold, Kimenyi, Mwabu, Ng’ang’a and SandefurBold et al. 2013: 7).Footnote 12
A similar conclusion, this time with implications for the basis on which policy interventions might be ‘scaled up’, emerges from an evaluation of a small business registration program in Brazil (see Reference Bruhn and McKenzieBruhn and McKenzie 2013). Intuition and some previous research suggests that a barrier to growth faced by small unregistered firms is that their very informality denies them access to legal protection and financial resources; if ways could be found to lower the barriers to registration – for example, by reducing fees, expanding information campaigns promoting the virtues of registration, etc. – many otherwise unregistered firms would surely avail themselves of the opportunity to register, with both the firms themselves and the economy more generally enjoying the fruits. This was the basis on which the state of Minas Gerais in Brazil sought to expand a business start-up simplification program into rural areas: a pilot program that had been reasonably successful in urban areas now sought to ‘scale up’ into more rural and remote districts, the initial impacts extrapolated by its promoters to the new levels and places of operation. At face value, this was an entirely sensible expectation, one that could also be justified on intrinsic grounds: one could argue that all small firms, irrespective of location, should as a matter of principle be able to register. Deploying an innovative evaluation strategy centered on the use of existing administrative data, Bruhn and McKenzie found that despite faithful implementation the effects of the expanded program on firm registration were net negative; isolated villagers, it seems, were so deeply wary of the state that heightened information campaigns on the virtues of small business registration only confirmed their suspicions that the government’s real purposes were probably sinister and predatory, and so even those owners that once might have registered their business now did not. If only with the benefit of hindsight, ‘what worked’ in one place and at one scale of operation was clearly inadequate grounds for inferring what could be expected elsewhere at a much larger one.Footnote 13
In this brief tourFootnote 14 of fields ranging from psychology, biomedicine, and clinical health to education, regulation, and criminology we have compelling empirical evidence that inferring external validity to given empirical results – that is, generalizing findings from one group, place, implementation modality, or scale of operation to another – is a highly fraught exercise. As the opening epigraph wisely intones, evidence supporting claims of a significant impact ‘there’, even (or especially) when that evidence is a product of a putatively rigorous research design, does not “deliver the bulk of the key facts required to conclude that it will work here.” What might those missing “key facts” be? Clearly some interventions can be scaled and replicated more readily than others, so how might the content of those “facts” vary between different types of interventions?
In the next section, I propose three categories of issues that can be used to interrogate given development interventions and the basis of the claims made regarding their effectiveness; I argue that these categories can yield potentially useful and usable “key facts” to better inform pragmatic decision-making regarding the likelihood that results obtained ‘there’ can be expected ‘here’. In Section 2.4 I argue that analytic case studies can be a particularly fruitful empirical resource informing the tone and terms of this interrogation, especially for complex development interventions. I posit that this fruitfulness rises in proportion to the ‘complexity’ of the intervention: the higher the complexity, the more salient (even necessary) inputs from analytic case studies become as contributors to the decision-making process.
5.3 Elements of an Applied Framework for Identifying ‘Key Facts’
Heightened sensitivity to external validity concerns does not axiomatically solve the problem of how exactly to make difficult decisions regarding whether, when, and how to replicate and/or scale up (or, for that matter, cancel) interventions on the basis of an initial empirical result, a challenge that becomes incrementally harder as interventions themselves, or constituent elements of them, become more ‘complex’ (defined below). Even if we have eminently reasonable grounds for accepting a claim about a given project’s impact ‘there’ (with ‘that group’, at this ‘size’, implemented by ‘these people’ using ‘this approach’), under what conditions can we confidently infer that the project will generate similar results ‘here’ (or with ‘this group’, or if it is ‘scaled up’, or if implemented by ‘those people’ deploying ‘that approach’)? We surely need firmer analytical foundations on which to engage in these deliberations; in short, we need more and better “key facts,” and a corresponding theoretical framework able to both generate and accurately interpret those facts.
One could plausibly defend a number of domains in which such “key facts” might reside, but for present purposes I focus on three:Footnote 15 ‘causal density’ (the extent to which an intervention or its constituent elements are ‘complex’); ‘implementation capability’ (the extent to which a designated organizational entity in the new context can in fact faithfully implement the type of intervention under consideration); and ‘reasoned expectations’ (the extent to which claims about actual or potential impact are understood within the context of a grounded theory of change specifying what can reasonably be expected to be achieved by when). I address each of these domains in turn.
5.3.1 Causal Density
Conducting even the most routine development intervention is difficult, in the sense that considerable effort needs to be expended at all stages over long periods of time, and that doing so may entail carrying out duties in places that are dangerous (‘fragile states’) or require navigating morally wrenching situations (dealing with overt corruption, watching children die).Footnote 16 If there is no such thing as a ‘simple’ development project, we need at least a framework for distinguishing between different types and degrees of complexity, since this has a major bearing on the likelihood that a project (indeed, a system or intervention of any kind) will function in predictable ways, which in turn shapes the probability that impact claims associated with it can be generalized.
One entry point into analytical discussions of complexity is of course ‘complexity theory’, a field to which social scientists engaging with policy issues have increasingly begun to contribute and learn,Footnote 17 but for present purposes I will create some basic distinctions using the concept of ‘causal density’ (see Reference ManziManzi 2012). An entity with low causal density is one whose constituent elements interact in precisely predictable ways: a wrist watch, for example, may be a marvel of craftsmanship and micro-engineering, but its genius actually lies in its relative ‘simplicity’: in the finest watches, the cogs comprising the internal mechanism are connected with such a degree of precision that they keep near perfect time over many years, but this is possible because every single aspect of the process is perfectly understood. Development interventions (or aspects of interventionsFootnote 18) with low causal density are ideally suited for assessment via techniques such as RCTs because it is reasonable to expect that the impact of a particular element can be isolated and empirically discerned, and the corresponding adjustments or policy decisions made. Indeed, the most celebrated RCTs in the development literature – assessing deworming pills, textbooks, malaria nets, classroom size, cameras in classrooms to reduce teacher absenteeism – have largely been undertaken with interventions (or aspect of interventions) with relatively low causal density. If we are even close to reaching “proof of concept” with interventions such as immunization and iodized salt it is largely because the underlying physiology and biochemistry has come to be perfectly understood, and their implementation (while still challenging logistically) requires relatively basic, routinized behavior on the part of front-line agents (see Reference Pritchett and WoolcockPritchett and Woolcock 2004). In short, attaining “proof of concept” means the proverbial ‘black box’ has essentially been eliminated – everything going on inside the ‘box’ (i.e., the dynamics behind every mechanism connecting inputs and outcomes) is known or knowable.Footnote 19
Entities with high causal density, on the other hand, are characterized by high uncertainty, which is a function of the numerous pathways and feedback loops connecting inputs, actions, and outcomes, the entity’s openness to exogenous influences, and the capacity of constituent elements (most notably people) to exercise discretion (i.e., to act independently of or in accordance with rules, expectations, precedent, passions, professional norms, or self-interest). Parenting is perhaps the most familiar example of a high causal density activity. Humans have literally been raising children forever, but as every parent knows, there are often many factors (known and unknown) intervening between their actions and the behavior of their offspring, who are intensely subject to peer pressure and willfully act in accordance with their own (often fluctuating, seemingly quixotic) wishes. Despite millions of years and billions of ‘trials’, we have not produced anything remotely like “proof of concept” with parenting, even if there are certainly useful rules of thumb. Each generation produces its own bestselling ‘manual’ based on what it regards as the prevailing scientific and collective wisdom, but even if a given parent dutifully internalizes and enacts the latest manual’s every word it is far from certain that his/her child will emerge as a minimally functional and independent young adult; conversely, a parent may know nothing of the book or unwittingly engage in seemingly contrarian practices and yet happily preside over the emergence of a perfectly normal young adult.Footnote 20
Assessing the veracity of development interventions (or aspects of them) with high causal density (e.g., women’s empowerment projects, programs to change adolescent sexual behavior in the face of the HIV/AIDS epidemic) requires evaluation strategies tailored to accommodate this reality. Precisely because the ‘impact’ (wholly or in part) of these interventions often cannot be truly isolated, and is highly contingent on the quality of implementation, any observed impact is very likely to change over time, across contexts, and at different scales of implementation; as such, we need evaluation strategies able to capture these dynamics and provide correspondingly usable recommendations. Crucially, strategies used to assess high causal density interventions are not “less rigorous” than those used to assess their low causal density counterpart; any evaluation strategy, like any tool, is “rigorous” to the extent it deftly and ably responds to the questions being asked of it.Footnote 21
To operationalize causal density we need a basic analytical framework for distinguishing more carefully between these ‘low’ and ‘high’ extremes: we can agree that a lawn mower and a family are qualitatively different ‘systems’, but how can we array the spaces in between?Footnote 22 Four questions can be proposed to distinguish between different types of problems in development.Footnote 23 First, how many person-to-person transactions are required?Footnote 24 Second, how much discretion is required of front-line implementing agents?Footnote 25 Third, how much pressure do implementing agents face to do something other than respond constructively to the problem?Footnote 26 Fourth, to what extent are implementing agents required to deploy solutions from a known menu or to innovate in situ?Footnote 27 These questions are most useful when applied to specific operational challenges; rather than asserting that (or trying to determine whether) one ‘sector’ in development is more or less ‘complex’ than another (e.g., ‘health’ versus ‘infrastructure’), it is more instructive to begin with a locally nominated and prioritized problem (e.g., how can workers in this factory be afforded adequate working conditions and wages?) and asking of it the four questions posed above to interrogate its component elements. An example of an array of such problems within ‘health’ is provided in Table 5.1; by providing categorical yes/no answers to these four questions we can arrive at five discrete kinds of problems in development: technocratic, logistical, implementation intensive services, implementation intensive obligations, and complex.
| Local discretion? | Transaction intensive? | Contentious; Tempting alternatives? | Known technology? | Type of implementation challenge | |
|---|---|---|---|---|---|
| Iodization of salt | No | No | No | Yes |
|
| Vaccinations | No | Yes | No | Yes |
|
| Ambulatory curative care | Yes | Yes | No(ish) | Yes | Implementation Intensive Services (welcomed, expected) |
| Regulating private providers | Yes | Yes | Yes | Yes |
|
| Promoting preventive health | Yes | Yes | No | No |
|
So understood, problems are truly ‘complex’ that are highly transaction intensive, require considerable discretion by implementing agents, yield powerful pressures for those agents to do something other than implement a solution, and have no known (ex ante) solution.Footnote 28 The eventual solutions to these kinds of problems are likely to be highly idiosyncratic and context specific; as such, and irrespective of the quality of the evaluation strategy used to discern their ‘impact’, the default assumption regarding their external validity should be, I argue, zero. Put differently, in such instances the burden of proof should lie with those claiming that the result is in fact generalizable. (This burden might be slightly eased for ‘implementation intensive’ problems, but some considerable burden remains nonetheless.) I hasten to add, however, that this does not mean others facing similarly ‘complex’ (or ‘implementation intensive’) challenges elsewhere have little to learn from a successful (or failed) intervention’s experiences; on the contrary, it may be highly instructive, but its “lessons” reside less in the content of its final design characteristics than in the processes of exploration and incremental understanding by which a solution was proposed, refined, supported, funded, implemented, refined again, and assessed – that is, in the ideas, principles, and inspiration from which, over time, a solution was crafted and enacted. This is the point at which analytic case studies can demonstrate their true utility, as I discuss in the following sections.
5.3.2 Implementation Capability
Another danger stemming from a single-minded focus on a project’s design characteristics as the causal agent determining observed outcomes is that implementation dynamics are largely overlooked, or at least assumed to be nonproblematic. If, as a result of an RCT (or series of RCTs), a given conditional cash transfer (CCT) program is deemed to have ‘worked’,Footnote 29 we all too quickly presume that it can and should be introduced elsewhere, in effect ascribing to it “proof of concept” status. Again, we can be properly convinced of the veracity of a given evaluation’s empirical findings and yet have grave concerns about its generalizability. If from a ‘causal density’ perspective our four questions would likely reveal that in fact any given CCT comprises numerous elements, some of which are ‘complex’, from an ‘implementation capability’ perspective the concern is more prosaic: how confident can we be that any designated implementing agency in the new country or context (e.g., Ministry of Social Welfare) would in fact have the capability to do so, at the designated scale of operation?
Recent research and everyday experience suggests, again, that the burden of proof should lie with those claiming or presuming that the designated implementing agency in the proposed context is indeed up to the task (Reference Pritchett and SandefurPritchett and Sandefur 2015). Consider the delivery of mail. It is hard to think of a less contentious and ‘less complex’ task: everybody wants their mail to be delivered accurately and punctually, and doing so is almost entirely a logistical exercise.Footnote 30 The procedures to be followed are unambiguous, universally recognized (by international agreement), and entail little discretion on the part of implementing agents (sorters, deliverers). A recent empirical test of the capability of mail delivery systems around the world, however, yielded sobering results. Reference Chong, La Porta, Lopez-de-Silanes and ShleiferChong et al. (2014) sent letters to 10 nonexistent addresses in 159 countries, all of which were signatories to an international convention requiring them simply to return such letters to the country of origin (in this case the United States) within 90 days. How many countries were actually able to perform this most routine of tasks? In 25 countries none of the 10 letters came back within the designated timeframe; of countries in the bottom half of the world’s education distribution the average return rate was 21 percent of the letters. Working with a broader cross-country dataset documenting the current levels and trends in state capability for implementation, Reference Andrews, Pritchett and WoolcockAndrews, Pritchett, and Woolcock (2017) ruefully conclude that, by the end of the twenty-first century, only about a dozen of today’s low-income countries will have acquired levels of state capability equal to that of today’s least-rich OECD countries.Footnote 31
The general point is that in many developing countries, especially the poorest, implementation capability is demonstrably low for ‘logistical’ tasks, let alone for ‘complex’ ones. ‘Fragile states’, almost by definition, cannot readily be assumed to be able to undertake complex tasks (such as responding to medical emergencies after natural disasters) even if such tasks are desperately needed there. And even if they are in fact able to undertake some complex projects (such as regulatory or tax reform), which would be admirable, yet again the burden of proof in these instances should reside with those arguing that such capability to implement the designated intervention does indeed exist (or can readily be acquired). For complex interventions as here defined, high-quality implementation is inherently and inseparably a constituent element of any success they may enjoy (see Honig 2018); the presence in novel contexts of implementing organizations with the requisite capability thus should be demonstrated rather than assumed by those seeking to replicate or expand ‘complex’ interventions.
5.3.3 Reasoned Expectations
The final domain of consideration, which I call ‘reasoned expectations’, focuses attention on an intervention’s known or imputed trajectory of change. By this I mean that any empirical claims about a project’s putative impact, independently of the method(s) by which the claims were determined, should be understood in the light of where we should reasonably expect a project to be by when. As I have documented elsewhere (Reference WoolcockWoolcock 2009), the default assumption in the vast majority of impact evaluations is that change over time is monotonically linear: baseline data is collected (perhaps on both a ‘treatment’ and a ‘control’ group) and after a specified time follow-up data is also obtained; following necessary steps to control for the effects of selection and confounding variables, a claim is then made about the net impact of the intervention, and, if presented graphically, is done by connecting a straight line from the baseline scores to the net follow-up scores. The presumption of a straight-line impact trajectory is an enormous one, however, which becomes readily apparent when one alters the shape of the trajectory (to, say, a step-function or a J-curve) and recognizes that the period between the baseline and follow-up data collection is mostly arbitrary (or chosen in accordance with administrative or political imperatives); with variable time frames and nonlinear impact trajectories, however, vastly different accounts can be provided of whether or not a given project is “working.”
Consider Figure 5.1. If one was ignorant of a project impact’s underlying functional form, and the net impact of four projects was evaluated “rigorously” at point C, then remarkably similar stories would be told about these projects’ positive impact, and the conclusion would be that they all unambiguously “worked.” But what if the impact trajectory of these four interventions actually differs markedly, as represented by the four different lines? And what if the evaluation was conducted not at point C but rather at points A or B? At point A one tells four qualitatively different stories about which projects are “working”; indeed, if one had the misfortune to be the team leader on the J-curve project during its evaluation by an RCT at point A, one may well face disciplinary sanction for not merely having “no impact” but for making things worse – as verified by “rigorous evidence”! If one then extrapolates into the future, to point D, it is only the linear trajectory that turns out to yield continued gains; the rest either remain stagnant or decline markedly.

The conclusions reached in an otherwise seminal paper by Reference Casey, Glennerster and MiguelCasey, Glennerster, and Miguel (2012) embody these concerns. Using an innovative RCT design to assess the efficacy of a ‘community driven development’ project in Sierra Leone, the authors sought to jointly determine the impact of the project on participants’ incomes and the quality of their local institutions. They found “positive short-run effects on local public goods and economic outcomes, but no evidence for sustained impacts on collective action, decision-making, or the involvement of marginalized groups, suggesting that the intervention did not durably reshape local institutions” (Reference Casey, Glennerster and Miguel2012: 1755). This may well be true empirically, but such a conclusion presumes that incomes and institutions change at the same pace and along the same trajectory; most of what we know from political and social history would suggest that institutional change in fact follows a trajectory (if it has one at all) more like a step-function or a J-curve than a straight line, and that our ‘reasoned expectations’ against which to assess the effects of an intervention trying to change ‘local institutions’ should thus be guided accordingly.Footnote 32
Recent work deftly exemplifies the importance of such considerations. Reference Baird, McIntosh and ÖzlerBaird, McIntosh, and Özler (2019:182) provide interesting findings from an unconditional cash transfer program in Malawi, in which initially significant declines in teen pregnancy, HIV prevalence, and early marriage turned out, upon a subsequent evaluation conducted two years after the program had concluded, to have dissipated. On the other hand, a conditional cash transfer (CCT) program in the same country offered to girls who were not in school led to “sustained program effects on school attainment, early marriage, and pregnancy for baseline dropouts receiving CCTs. However, these effects did not translate into reductions in HIV, gains in labor market outcomes, or increased empowerment.” Same country, different projects, both with variable nonlinear impact trajectories, and thus different conclusions regarding program effectiveness.Footnote 33 One surely needs to have several, sophisticated, contextually grounded theories of change to anticipate and accurately interpret such diverse findings at a given point in time – and especially to inform considerations about the programs’ likely effectiveness over time in different country contexts. But, alas, this is rarely the case.Footnote 34
Again, the key point here is not that the empirical strategy per se is flawed (it clearly is not – in this instance, in fact, it is exemplary); it is that (a) we rarely have more than two data points on which to base any claims about impact, and, when we do, it can lead to rather different interpretations about impact ‘there’ (and thus its likely variable impact ‘here’); and (b) rigorous (indeed all) results must be interpreted against a theory of change. Perhaps it is entirely within historical experience to see no measurable change on institutions for a decade; perhaps, in fact, one needs to toil in obscurity for two or more decades as the necessary price to pay for any ‘change’ to be subsequently achieved and discerned;Footnote 35 perhaps seeking such change is a highly ‘complex’ endeavor, and as such has no consistent functional form, or has one that is apparent only with the benefit of hindsight, and is an idiosyncratic product of a series of historically contingent moments and processes (see Reference Woolcock, Szreter and RaoWoolcock, Szreter, and Rao 2011). In any event, the interpretation and implications of “the evidence” from any evaluation of any intervention is never self-evident; it must be discerned in the light of theory and benchmarked against reasoned expectations, especially when that intervention exhibits high causal density and necessarily requires robust implementation capability.Footnote 36
In the first instance this has important implications for internal validity, but it also matters for external validity, since one dimension of external validity is extrapolation over time. As Figure 5.1 shows, the trajectory of change between the baseline and follow-up points bears not only on the claims made about ‘impact’ but also on the claims made about the likely impact of this intervention in the future. These extrapolations only become more fraught once we add the dimensions of scale and context, as the Reference Bruhn and McKenzieBraun and McKenzie (2013) and Reference Bold, Kimenyi, Mwabu, Ng’ang’a and SandefurBold et al. (2013) papers reviewed earlier show. The abiding point for external validity concerns is that decision-makers need a coherent theory of change against which to accurately assess claims about a project’s impact ‘to date’ and its likely impact ‘in the future’; crucially, claims made on the basis of a “rigorous methodology” alone do not solve this problem.
5.3.4 Integrating These Domains into a Single Framework
The three domains considered in this analysis – causal density, implementation capability, and reasoned expectations – comprise a basis for pragmatic and informed deliberations regarding the external validity of development interventions in general and ‘complex’ interventions in particular. While data in various forms and from various sources can be vital inputs into these deliberations (see Reference Bamberger, Rao, Woolcock, Tashakkori and TeddlieBamberger, Rao, and Woolcock 2010; Reference Woolcock, Nagatsu and RuzzeneWoolcock 2019), when the three domains are considered as part of a single integrated framework for engaging with ‘complex’ interventions, it is extended deliberations on the basis of analytic case studies, I argue, that have a particular comparative advantage for eliciting the “key facts” necessary for making hard decisions about the generalizability of those interventions (or their constituent elements). Indeed, it is within the domains of causal density, implementation capability, and reasoned expectations, I argue, that the “key facts” themselves reside.
These deliberations move from the analytical and abstract to the decidedly concrete when hard decisions have to be made about the impact and generalizability of claims pertaining to truly complex development interventions, such as those seeking to empower the marginalized, enhance the legitimacy of justice systems, or promote more effective local government. The Sustainable Development Goals have put issues such as these squarely and formally on the global agenda, and in the years leading up to 2030 there will surely be a flurry of brave attempts to ‘measure’ and ‘demonstrate’ that all countries have indeed made ‘progress’ on them. Is fifteen years (2015–2030) a ‘reasonable’ timeframe over which to expect any such change to occur? What ‘proven’ instruments and policy strategies can domestic and international actors wield in response to such challenges? There aren’t any, and there never will be, at least not in the way there are now ‘proven’ ways in which to build durable roads in high rainfall environments, tame high inflation, or immunize babies against polio. But we do have an array of tools in the social science kit that can help us navigate the distinctive challenges posed by truly complex problems – we just need to forge and protect the political space in which they can be ably deployed. Analytic case studies, so understood, are one of those tools.
5.4 Harnessing the Distinctive Contribution of Analytic Case Studies
When carefully compiled and conveyed, case studies can be instructive for policy deliberations across the analytic space set out in Table 5.2. Our focus here is on development problems that are highly complex, require robust implementation capability, and unfold along nonlinear context-specific trajectories, but this is only where the comparative advantage of case studies is strongest (and where, by extension, the comparative advantage of RCTs for engaging with external validity issues is weakest). It is obviously beyond the scope of this chapter to provide a comprehensive summary of the theory and strategies underpinning case study analysis,Footnote 37 but three key points bear some discussion (which I provide below): the distinctiveness of case studies as a method of analysis in social science beyond the familiar qualitative/quantitative divide; the capacity of case studies to elicit causal claims and generate testable hypotheses; and (related) the focus of case studies on exploring and explaining mechanisms (i.e., identifying how, for whom, and under what conditions outcomes are observed – or “getting inside the black box”).
Table 5.2 An integrated framework for assessing external validity claims
The rising quality of the analytic foundations of case study research has been one of the underappreciated (at least in mainstream social science) methodological advances of the last few decades (Reference MahoneyMahoney 2007). Where everyday discourse in development research typically presumes a rigid and binary ‘qualitative’ or ‘quantitative’ divide, this is a distinction many contemporary social scientists (especially historians, historical sociologists, and comparative political scientists) feel does not aptly accommodate their work – if ‘qualitative’ is primarily understood to mean ethnography, participant observation, and interviews. These researchers see themselves as occupying a distinctive epistemological space, using case studies (across varying units of analysis: countries to firms to events) to interrogate instances of phenomena – with an ‘N’ of, say, 30, such as revolutions – that are “too large” for orthodox qualitative approaches and “too small” for orthodox quantitative analysis. (There is no inherent reason, they argue, why the problems of the world should array themselves in accordance with the bimodal methodological distribution social scientists otherwise impose on them.)
More ambitiously, perhaps, case study researchers also claim to be able to draw causal inferences (see Reference MahoneyMahoney 2000; Reference LevyLevy 2008; Cartwright, Chapter 2 this volume). Defending this claim in detail requires engagement with philosophical issues beyond the scope of this chapter,Footnote 38 but a pragmatic application can be seen in the law (Reference HonoréHonoré 2010), where it is the task of investigators to assemble various forms and sources of evidence (inherently of highly variable quality) as part of the process of building a “case” for or against a charge, which must then pass the scrutiny of a judge or jury: whether a threshold of causality is reached in this instance has very real (in the real world) consequences. Good case study research in effect engages in its own internal dialogue with the ‘prosecution’ and ‘defense’, posing alternative hypotheses to account for observed outcomes and seeking to test their veracity on the basis of the best available evidence. As in civil law, a “preponderance of the evidence” standardFootnote 39 is used to determine whether a causal relationship has been established. This is the basis on which causal claims (and, needless to say, highly ‘complex’ causal claims) affecting the fates of individuals, firms, and governments are determined in courts every day; deploying a variant on it is what good case study research entails.
Finally, by exploring ‘cases within cases’ (thereby raising or lowering the instances of phenomena they are exploring), and by overtly tracing the evolution of given cases over time within the context(s) in which they occur, case study researchers seek to document and explain the processes by which, and the conditions under which, certain outcomes are obtained. (This technique is sometimes referred to as process tracing – or, as noted earlier, assessing the ‘causes of effects’ as opposed to the ‘effects of causes’ approach characteristic of most econometric research.) Case study research finds its most prominent place in applied development research and program assessment in the literature on ‘realist evaluation’,Footnote 40 where the abiding focus is exploiting, exploring, and explaining variance (or standard deviations): that is, on identifying what works for whom, when, where, and why.Footnote 41 In their study of service delivery systems across the Middle East and North Africa, Reference Brixi, Lust and WoolcockBrixi, Lust, and Woolcock (2015) use this strategy – deploying existing household survey data to ‘map’ broad national trends in health and education outcomes, complementing it with analytical case studies of specific locations that are positive ‘outliers’ – to explain how, within otherwise similar (and deeply challenging) policy environments, some implementation systems become and remain so much more effective than others (see also McDonnell 2020). This is the signature role that case studies can play for understanding, and sharing the lessons from, ‘complex’ development interventions on their own terms, as has been the central plea of this chapter.
5.5 Conclusion
The energy and exactitude with which development researchers debate the veracity of claims about ‘causality’ and ‘impact’ (internal validity) has yet to inspire corresponding firepower in the domain of concerns about whether and how to ‘replicate’ and ‘scale up’ interventions (external validity). Indeed, as manifest in everyday policy debates in contemporary development, the gulf between these modes of analysis is wide, palpable, and consequential: the fates of billions of dollars, millions of lives, and thousands of careers turn on how external validity concerns are addressed, and yet too often the basis for these deliberations is decidedly shallow.
It does not have to be this way. The social sciences, broadly defined, contain within them an array of theories and methods for addressing both internal and external validity concerns; they are there to be deployed if invited to the table (see Reference Stern, Stame, Mayne, Forss, Davies and BefaniStern et al. 2012). This chapter has sought to show that ‘complex’ development interventions require evaluation strategies tailored to accommodate that reality; such interventions are square pegs which when forced into methodological round holes yield confused, even erroneous, verdicts regarding their effectiveness ‘there’ and likely effectiveness ‘here’. In the early twenty-first century, development professionals routinely engage with issues of increasing ‘complexity’: consolidating democratic transitions, reforming legal systems, promoting social inclusion, enhancing public sector managementFootnote 42 – the list is endless. These types of issues are decidedly (wickedly) ‘complex’, and responses to them need to be prioritized, designed, implemented, and assessed accordingly. Beyond evaluating such interventions on their own terms, however, it is as important to be able to advise front-line staff, senior management, and colleagues working elsewhere about when and how the “lessons” from these diverse experiences can be applied. Deliberations centered on causal density, implementation capability, and reasoned expectations have the potential to usefully elicit, inform, and consolidate this process.








 Open access
Open access