




INTRODUCTION
Central to variationist sociolinguistics is the tenet that there is not a one-to-one relationship between linguistic form and meaning. That is, a single function can be expressed through multiple forms, but there tend to be linguistic and extralinguistic patterns governing the variation (Bybee et al., Reference Bybee, Perkins and Pagliuca1994; Chambers, Reference Chambers2008; Labov, Reference Labov1994; Walker, Reference Walker2010). While research in this vein originally focused on the variable linguistic production of native speakers (NSs), subsequent studies have delved into native listeners’ perceptions of linguistic variation (Barnes, Reference Barnes2015; Chappell, Reference Chappell2016, Reference Chappell2019; Johnson, Reference Johnson, Johnson and Mullennix1997; Mack, Reference Mack2009), on the one hand, and the way in which nonnative speakers produce (e.g., Adamson & Regan, Reference Adamson and Regan1991; Geeslin & Long, Reference Geeslin and Long2014; Kanwit, Reference Kanwit2017; Knouse, Reference Knouse2013; Raish, Reference Raish2015; Rehner, Reference Rehner2002; Salgado-Robles, Reference Salgado-Robles2014; Segalowitz & Freed, Reference Segalowitz and Freed2004; Solon et al., Reference Solon, Linford and Geeslin2018) and perceive (e.g., Davydova et al., Reference Davydova, Tytus and Schleef2017; Shin & Hudgens Henderson, Reference Shin and Hudgens Henderson2017; Stephan, Reference Stephan and Schneider1997; Sullivan & Karst, Reference Sullivan and Karst1996) linguistic variation, on the other.
Research on the L2 acquisition of variable linguistic features can be divided into investigations of Type I and Type II variation (Rehner, Reference Rehner2002; for an overview, see Kanwit, Reference Kanwit and Geeslin2018). In the former case, also known as vertical variation because it reveals learner development (Adamson & Regan, Reference Adamson and Regan1991), learners vary between a nativelike form and a nonnativelike variant, such as alternating between past forms went and goed. In Type II, also referred to as horizontal, variation, learners vary between two nativelike forms and thus neither form is considered developmental in nature, as exemplified by variation between went and has gone or [s] and aspirated [h] in Spanish codas. Research on Type II variation has increasingly uncovered aspects of learner grammars that reveal a sophisticated, contextualized understanding of when to use a particular form over another. This sociolinguistic competence, in addition to strategies for successful communication (i.e., strategic competence) and the more straightforward grammatical competence targeted in traditional classrooms, contributes to communicative competence (Canale & Swain, Reference Canale and Swain1980; Tarone, Reference Tarone2007). This work has predominantly focused on development within variable areas of learner grammars (i.e., morphosyntactic variability), although the L2 perception of sociophonetic variation is of increasing attention to researchers (e.g., Del Saz, Reference Del Saz2019; Escalante, Reference Escalante2018; Geeslin & Schmidt, Reference Geeslin, Schmidt, Sanz and Morales-Front2018; Schmidt, Reference Schmidt2018; Schoonmaker-Gates, Reference Schoonmaker-Gates2017).
The present study explores the sociophonetic perception of L1-American English listeners in their L2, Spanish. Using a matched-guise test, we target a specific feature with an extensive geographic reach and salient social meanings, coda /s/ reduction (e.g., esquina “corner” variably realized as [es.ˈki.na] or [eh.ˈki.na]), with the goal of determining whether L2 listeners can use sociophonetic information to identify regional and social characteristics of unfamiliar (i.e., previously unknown) speakers. Additionally, our study seeks to establish what factors, including Spanish proficiency, study abroad (SA) experience, and explicit phonetic instruction, condition learners’ sensitivity to sociophonetic information. To this end, the article first introduces relevant information about the research context, including theoretical models that have been proposed to account for L2 perception and sociophonetic perception, a brief overview of coda /s/ reduction, and previous work specifically focused on the L2 acquisition of variation. Next, the methods and quantitative procedures employed in this study are outlined, followed by the results of the statistical analysis. Finally, we discuss the broader significance of the results in light of previous research and offer concluding remarks.
THE RESEARCH CONTEXT
THEORETICAL BACKGROUND
Across numerous theoretical models of speech perception, there is general consensus that learners are able to gain sensitivity to which contrasts are meaning-bearing in the L2 and that this sensitivity increases as learners are exposed to more target-language input and a diversity of speakers and language varieties. The Perceptual Assimilation Model-L2 (PAM-L2), the Speech Learning Model (SLM), and the Second Language Linguistic Perception Model (L2LP) all account for the ability to differentiate between two different phonemes and two allophones of the same phoneme in cases where the first language (L1) and L2 offer differing contrasts. The PAM-L2 (Best & Tyler, Reference Best, Tyler, Munro and Bohn2007) is adapted from the original PAM (Best, Reference Best and Strange1995), which is a direct-realist model accounting for the perception of articulatory gestures rather than phonetic properties per se. The PAM-L2 predicts that L2 learners will begin like naïve listeners (similar to the naïve monolinguals in the PAM), initially struggling to differentiate between two sounds that would be perceived within the same category in the L1 (i.e., conducting Single Category Assimilation) while more easily discriminating between sounds that would fall into different categories in the L1.Footnote 1 The model allows for L2 learners to undergo the perceptual learning of new categories as they gain experience in the L2, although they will likely still lag behind native listeners.
The PAM-L2 differs from the PAM in that it allows adult learners to diverge from naïve listeners as they acquire knowledge of the phonetic and phonological components of the L2 system and further develop their lexicons, especially at more advanced stages. Accordingly, in the PAM-L2 perceptual assimilation can encompass the level of articulatory gestures (as in the PAM), but also the levels of phonetics and phonology. The PAM-L2 treats the phonological aspect from a lexical-functional perspective, meaning that a learner may recognize that L1 and L2 phones are functionally equivalent, even if they demonstrate phonetic differences.
The SLM (Flege, Reference Flege and Strange1995) similarly predicts that L2 sounds will be assimilated into existing L1 categories, as both languages’ phonetic systems share the same phonological space. Like the PAM-L2, the SLM allows for L2 phonetic systems to be adaptive in perception (and production), enabling learners who have gained more access to input to make gains compared to their less experienced counterparts. Unlike the PAM-L2, perception in the SLM is context specific, with L1 and L2 sounds relating in a position-specific allophonic manner, rather than abstractly at the phonemic level.
In its Full Copying Hypothesis, the L2LP model (Escudero, Reference Escudero2005) also predicts that L2 learners begin with the L1 perception system mapped onto the L2, as they assign two L2 sounds to one or more L1 categories based on their similarities to L1 alternatives. Similar to the SLM and PAM-L2, the L2LP predicts that with increasing input, learners can create new perceptual categories and edit prior mappings. The L2LP mirrors the SLM and diverges from the PAM-L2 in its context-specific nature, with allophonic detail encoded at the phonetic representational level (van Leussen & Escudero, Reference van Leussen and Escudero2015). Moreover, although all three of the models note the difficulty in dividing L1 categories to create meaningful contrasts in the L2, only the L2LP explicitly addresses the learnability problem of facing comparatively fewer phonemic categories in the L2 in the Subset scenario (Escudero, Reference Escudero2005; van Leussen & Escudero, Reference van Leussen and Escudero2015; Vasiliev & Escudero, Reference Vasiliev, Escudero and Geeslin2014). In this scenario, learners face the challenge of modifying L1 boundaries and reducing the number of phonemic categories, as in the case of coda /s/ reduction, in which learners might erroneously map [s] and [h] onto /s/ and /h/, respectively, rather than reducing the mapping of these categories to only /s/, although English /h/ is not expected in coda position.Footnote 2 In other words, the importance of context (i.e., the coda) is a detail noted in the L2LP and SLM but not the PAM-L2, and the L2LP is the only model of the three that accounts for the category reduction relevant to the present example.
Broadening the scope of traditional L2 speech perception studies, the present article explores learners’ understanding of the social meaning indexed by phonetic variants in their L2. Usage-based exemplar models of phonological representation (Bybee, Reference Bybee2001, Reference Bybee2002, Reference Bybee2006, Reference Bybee2017) provide a helpful theoretical framework to shed light on the link between phonetic variants and social properties (Docherty & Foulkes, Reference Docherty and Foulkes2014). More specifically, these models posit that individuals catalog their contextualized experiences with phonetic variants in the mind, creating exemplars that are reinforced or molded through new tokens of experience. Individuals map these experiences onto exemplars, or clusters of exemplars, which may be encoded with both linguistic and extralinguistic information, including semantic, pragmatic, and social properties (Johnson, Reference Johnson, Johnson and Mullennix1997). In turn, these exemplars condition the variant’s contextualized use, cyclically contributing to the production and reproduction of social meaning.
The many social meanings of a variant can be visualized as a fluid indexical field, or, according to Eckert (Reference Eckert2008), a “constellation of ideologically related meanings, any one of which can be activated in the situated use of the variable” (p. 454). The concept of the indexical field advances Silverstein’s (Reference Silverstein2003) indexical order framework, which emphasizes the recursive nature of social meaning-making based on linguistic variants. In other words, the indexical value of a variant is always available for reinterpretation in context, and the new social meaning is then available for reconstrual as well, making the indexical enterprise a constant and iterative social practice. For example, in their study of intervocalic /s/ voicing, Chappell and García (Reference Chappell and García2017) contend that physiological factors likely served as the original source of voicing among Costa Rican men, as larger vocal tracts and thicker vocal folds make vocal fold cessation between vowels more difficult. Given men’s high rates of intervocalic [z] production, the variant became increasingly associated with masculinity over time, which, in turn, allowed it to then become imbued with other social meanings linked to masculinity in the community, including confidence.
In sum, the PAM-L2, SLM, and L2LP share the prediction that at the earliest levels, perceptual identification will be guided by extant L1 perceptual norms and that perceptual systems may continue to be adaptive throughout a speaker’s life span. The SLM and L2LP differ from the PAM-L2 by acknowledging that perception may be context specific (e.g., dependent on a segment’s location within a given word). Of the three models, the L2LP is unique in its emphasis on the learnability problem in which the existence of fewer phonemic categories in the L2 thus requires category reduction. However, none of these models links learner perception to the social characteristics of the providers of input (i.e., the speakers), which makes consideration of indexicality and exemplar models a critical contribution to our knowledge of L2 speech perception.
CODA /s/ REDUCTION IN SPANISH AND ITS SOCIAL PERCEPTION AMONG NSs
Coda /s/ reduction among L1 Spanish speakers occurs in approximately 50% of the Spanish-speaking world, including the Caribbean, Central America, South America, and southern Spain (Lipski, Reference Lipski2005), and articulatory principles help explain that [h] serves as a debuccalized and less physiologically complex variant of /s/ (Guitart, Reference Guitart1976; Ranson, Reference Ranson1989). According to Lipski (Reference Lipski, Gutiérrez-Rexach and Martínez-Gil1999), /s/ weakening advances both diachronically and synchronically in predictable ways. /s/ weakening initially appears before a consonant (e.g., pasta “paste” as [ˈpah.ta] or más pequeño “smaller” as [ˈmah.pe.ˈke.ɲo]), and is later extended to prepausal contexts (e.g., así es “that’s it” as [a.ˈsi.ˈeh]). In the final stage of extension, coda /s/ weakening also appears word-finally before a vowel (e.g., más alto “taller” as [ˈma.ˈhal.to]),Footnote 3 leveling the paradigm and reducing /s/ to [h] in all syllable-final positions.
Coda /s/ reduction is both the most frequently studied phonological process in Hispanic linguistics (Brown & Torres Cacoullos, Reference Brown and Torres Cacoullos2002) and a salient marker of regional and social identity for laypeople (Chappell, Reference Chappell2019; Mason, Reference Mason1994). In Latin America, /s/ retention is common in highland varieties of Spanish, whereas /s/ reduction is characteristic of lowland, coastal, and island regions (Lipski, Reference Lipski2005). Conditioned by numerous linguistic factors (e.g., phonological context, stress, and word length), the process is also socially constrained, with greater /s/ reduction among older speakers, men, and lower socioeconomic classes in more informal styles (see, e.g., Bernate, Reference Bernate2016; Cedergren, Reference Cedergren1973; Dohotaru, Reference Dohotaru1998; Terrell, Reference Terrell1978).Footnote 4 While these broad generalizations apply across most varieties of Spanish, local norms and attitudes influence the social motivations that guide /s/ reduction or retention (e.g., Carvalho, Reference Carvalho2006; Lafford, Reference Lafford, Cedeño, Páez and Guitart1986).
In terms of its social perception among NSs, coda /s/ reduction is associated with heteronormativity (Mack, Reference Mack2009) as well as lower status and higher friendliness (Walker et al., Reference Walker, García, Cortés and Campbell-Kibler2014). Additionally, native listeners link coda /s/ weakening to a Caribbean place of origin and a more relaxed, down-to-earth personality (Chappell, Reference Chappell2019). In other words, NSs link coda /s/ reduction to both place of origin and numerous social characteristics.
RELEVANT RESEARCH ON THE L2 ACQUISITION OF VARIATION
The body of research on the L2 acquisition of variable structures has tended to focus more on morphosyntax than sociophonetics (see Geeslin, Reference Geeslin, Malovrh and Benati2018 for an overview), and the smaller set of studies on the acquisition of sociophonetic variation has usually focused on the production of phonetic variants. For example, Solon et al. (Reference Solon, Linford and Geeslin2018) investigated the spirantization and deletion of Spanish intervocalic /d/ in 13 highly advanced learners and NSs. Learner production largely reflected sensitivity to the same factors as NSs (e.g., preceding vowel, grammatical category, and stress), although there was greater similarity in conditioning for deletion than for reduction. The authors subsequently called for further study into the social and linguistic factors that may affect the production and perception of variable phenomena. Although numerous studies have found that learners may not integrate a new regional phonetic variant into their inventory following an immersion period (e.g., [g] vs. [dʒ] in Egyptian Arabic [Raish, Reference Raish2015] or /θ/ in Peninsular Spanish [Knouse, Reference Knouse2013]), the lack of use of a sociophonetic variant does not mean that a learner has not gained knowledge of the way in which the variant is used, including its social and linguistic correlates.
Before learners can link phonetic variation with social meaning, they must first learn to associate different variants with a single variable, and three recent studies explored how learners perceive the variants of coda /s/ (Del Saz, Reference Del Saz2019; Escalante, Reference Escalante2018; Schmidt, Reference Schmidt2018). These studies usually appeal to some combination of the aforementioned PAM-L2, SLM, and L2LP models. In the first of these recent perceptual studies, Escalante (Reference Escalante2018) analyzed 14 learners’ perception of aspirated /s/ in the context of a volunteer experience in Ecuador. All target stimuli were aspirated nonce words produced by a Cuban speaker. Results revealed that /s/-weakening was easier to perceive before consonants and beginning at 2 months postarrival abroad. Learner proficiency was not significant overall, although intermediate-high learners performed better than intermediate-low learners who, in turn, performed better than novice learners.
Next, Schmidt (Reference Schmidt2018) analyzed perceptual identification of bisyllabic nonce words produced by a man from Caracas or a woman from Buenos Aires. Unlike Escalante (Reference Escalante2018), Schmidt used stimuli of both aspirated and alveolar /s/, asking the two speakers to produce both formal (i.e., as if approximating a newscaster) and informal (i.e., as if speaking with loved ones) styles. Five learner levels were analyzed, ranging from second semester to the graduate level, with learners generally improving at identifying [h] as a variant of /s/ across levels. Prior to stages of successful identification, learners at lower levels tended to indicate that aspirated /s/ was a realization of /f/. With respect to SA experience, learners who had studied in aspirating dialects were significantly better at correctly identifying aspirated /s/ than those who had studied in /s/-conserving regions or those who had not studied abroad. Similarly, learners who had previously completed a linguistics course performed significantly better at identifying aspirated /s/ than those with no such experience, as did those who reported interacting frequently with people from aspirating dialects in comparison to those who did not report such interaction. In sum, the study revealed the importance of experience with aspiration, either through SA, domestic interaction, or course material.
In the most recent study (Del Saz, Reference Del Saz2019), perception of Western Andalusian aspiration of word-final /s/ was compared in contexts of quiet and noise for three groups of learners (18 learners prior to SA, 14 within the third week of immersion in Seville, and 20 after 2 months in Seville). Unlike the prior studies, real, rather than nonce, words were used and learners were required to select what sentence had been uttered among two options of sentences in which the contrast was between either a second- or third-person present verb or a singular versus plural noun (i.e., whether the form ended with /s/). Three levels of signal-to-noise ratios were manipulated. Results revealed that perception decreased as noise increased, especially for learners in the intermediate group of experience abroad, and all groups were more accurate at identifying alveolar as opposed to aspirated /s/.
In addition to identifying phonemes and allophones in the L2, language learners are also faced with the challenge of recognizing and comprehending dialectal features. A diverse body of research has shown that L2 speech perception is not static, and learner perception can improve through exposure and practice (e.g., Pruitt et al., Reference Pruitt, Jenkins and Strange2006). Although immersed learners may still lag behind NSs in terms of accuracy of dialect identification and attention to relevant cues (Clopper & Bradlow, Reference Clopper and Bradlow2009), previous studies demonstrate that lengthier immersion may be beneficial (e.g., Cunningham-Andersson, Reference Cunningham-Andersson1996), that learners may be more successful at identifying some dialects than others (e.g., Stephan, Reference Stephan and Schneider1997; Sullivan & Karst, Reference Sullivan and Karst1996), and that explicit instruction on dialectal features may be beneficial in bridging these gaps (e.g., Agostinelli-Fucile, Reference Agostinelli-Fucile and Garrett-Rucks2017; Lord, Reference Lord2010), whereas explicit phonetics instruction without the dialectal component may not be (Kissling, Reference Kissling2015).
For example, Davydova et al. (Reference Davydova, Tytus and Schleef2017) showed that German-speaking learners of English associated the use of English be like with an American background, similar to American NSs, although British NSs associated the feature with a British background (Buchstaller, Reference Buchstaller2014). Despite the United Kingdom’s closer geographic proximity to Germany, learners’ association of be like with American English may reflect the prevalence of American speech in popular culture available in Germany.Footnote 5 In other research that has documented learner difficulty at identifying the geographic origin of speakers through regionally variable speech patterns, Schoonmaker-Gates (Reference Schoonmaker-Gates2017) explored a range of features associated with particular regions of the Spanish-speaking world (i.e., aspiration of /s/, the interdental fricative, velarization of /n/, lateralization of /r/, and palatalization of orthographic ll and y). She found that learners who had received instruction on regional variation performed no better at dialect recognition than learners who had not, although the former did perform significantly better at a comprehension task. While participants did not improve at identifying multiple varieties of Spanish in a single semester, participants differed in their recognition of Castilian Spanish based on their degree of exposure at home or through an SA experience, as learners who had been exposed to the variety were significantly better at identifying it than other learners.
Moving beyond dialect identification, Geeslin and Schmidt (Reference Geeslin, Schmidt, Sanz and Morales-Front2018) investigated whether undergraduate L2 learners attended to prestige and kindness in a verbal guise task, which presented the voices of male speakers from North-Central Spain, Buenos Aires, Puerto Rico, and Mérida, Mexico to L2 listeners from first year to fourth year of Spanish study. Learners marked Mexican speakers as significantly higher in kindness and prestige than Puerto Rican speakers overall, and SA appeared to change attitudes, with participants who had studied in Spain ranking Castilian Spanish as more prestigious than other varieties and individuals who had studied in Argentina providing higher rankings of kindness for that variety. As the verbal guise study had each speaker produce one unmanipulated recording, it remains unclear what role speaker played, as individual voices tend to be evaluated differently, and it is not clear if the listener evaluations are due to the macrodialectal features present in the stimulus or the speaker. It is also unclear how specific linguistic variables might have played a role in the participants’ evaluations (e.g., coda /s/ reduction, lateralization).
A more explicit link between a specific linguistic variant and social properties is apparent in Davydova et al. (Reference Davydova, Tytus and Schleef2017). In addition to their dialectal associations, German learners of English connected be like to lower intelligence and ambition but not to other characteristics like honesty or urbanity. However, their learners, who tended to be more proficient and experienced in immersion settings than our learners, did associate other social meanings with be like (e.g., extroversion and cheerfulness), suggesting that associations between linguistic forms and covert social prestige (e.g., localness, friendliness, or toughness) may develop later in L2 learners’ trajectories.
In light of the contributions of these previous studies, we aim to answer the following four research questions:
-
1. Are L2-Spanish language learners able to perceive the social meanings of coda /s/ reduction in their L2?
-
2. If so, what social properties will L2 learners associate with coda [h]?
-
3. What educational and experiential factors influence L2 learners’ ability to perceive sociophonetic meaning?
-
4. How will our learners’ sociophonetic evaluations compare with those of NSs described in previous studies?
METHOD
PARTICIPANTS
Seventy-six language learners were recruited to participate in this experiment, with the requirement that the participants be 18 years of age or older, have been born and raised in the United States with American English as their only native language, and have started learning Spanish as a foreign language in the classroom. Before the perception task began, participants were first asked to provide demographic information, including education level, gender, age, profession, and place(s) of residence in the United States. They also detailed their experience with the Spanish language, including age of onset of acquisition, the Spanish classes they had taken, where they had studied abroad and for how long, and the ways in which they used Spanish in their daily lives. Finally, they had to evaluate their domain-specific competence in Spanish reading, writing, speaking, and listening on a five-point scale (1 = poor, 2 = needs work, 3 = good, 4 = very good, 5 = NS command) as well as their overall Spanish proficiency (understand and can speak with great difficulty, understand and speak with some difficulty, understand and speak comfortably with little difficulty, understand and speak fluently like an NS).
The participants’ demographic information, Spanish experience, and self-evaluated Spanish proficiency are presented in Table 1. The learners who had studied abroad had spent time in a variety of countries, including Argentina, Bolivia, Chile, Costa Rica, Cuba, Ecuador, El Salvador, Guatemala, Honduras, Mexico, Nicaragua, Panama, Peru, Spain (both Southern and Central/Northern), and Uruguay.
TABLE 1. Participants’ demographic information.

Note: Contact with aspiration was determined based on participants’ responses on the demographic questionnaire. Participants indicated prior contact with aspiration in a number of ways, including through study abroad in an aspirating region, prior romantic relationships with speakers from aspirating regions, and prior instructors and coworkers from these regions.
MATCHED-GUISE TEST
The 76 listeners were asked to participate in a matched-guise testFootnote 6 (Lambert et al., Reference Lambert, Hodgson, Gardner and Fillenbaum1960), which featured five audio files from Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014). Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014) originally recorded seven male speakers in total, four from Mexico and three from Puerto Rico who had moved to the Midwestern United States as adults, as they completed a map task. In other words, the speakers were recorded as they provided directions on a fictitious map that included street names and destinations with coda /s/ (e.g., escuela “school”). Following the completion of the map task, each speaker also engaged in an imitation task with the second author (García), who produced target words like esquina “corner” with both coda [s] and coda [h] and asked each speaker to imitate her pronunciation, resulting in [es.ˈki.na] and [eh.ˈki.na], respectively.
The combination of a map task, which generated the content for the perception task, and an imitation task, which yielded clear articulations of both variants in a specific phonological context, allowed for the creation of the target audio files. First, Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014) selected from each speaker’s recording one utterance that included at least two cases of word-medial coda /s/ (and no other cases of /s/) and used the productions from the imitation task to create two guises: (a) a sibilance guise that exclusively presented coda /s/ as [s] and (b) an aspiration guise that exclusively presented coda /s/ as [h]. For instance, Al llegar a la Avenida de la República, está junto al hospital “When you get to the Avenue of the Republic, it’s next to the hospital” would involve manipulation of the coda /s/ in both está and hospital, resulting in (a) [es.ˈta] and [os.pi.ˈtal] and (b) [eh.ˈta] and [oh.pi.ˈtal], respectively. Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014) note that the final stimuli were reviewed by three trained linguists, all of whom could clearly determine whether the guise was alveolar or glottal and agreed that the stimuli would be perceived as naturalistic to naïve listeners.
In an attempt to prevent participant attrition in a lengthy task, only five of the seven recordings from Walker et al. (Reference Walker, García, Cortés and Campbell-Kibler2014) were included in this experiment: three speakers of Mexican Spanish and two speakers of Puerto Rican Spanish. These five baseline utterances, manipulated to form two guises, resulted in 10 target audio files. These files were uploaded and arranged in SurveyGizmo (Vanek & McDaniel, Reference Vanek and McDaniel2006) alongside 24 filler audio filesFootnote 7 to create separation between the guises of each voice. In terms of presentation order, the same voices were maximally separated, and there was separation of both the Puerto Rican and Mexican voices and the guises, with half of the aspiration and half of the sibilance guises presented first.
Before beginning the experiment, listeners were given instructions in English and presented with a practice page, where the voice of a native Spanish speaker not heard elsewhere in the perception task played automatically. On this practice page and in all following pages, participants evaluated the speaker in the audio file along a series of six-point scales, including perceived intelligence (less intelligent–more intelligent), work ethic (not hardworking–very hardworking), niceness (meaner–nice), Hispanicity (Anglo–Hispanic), confidence (insecure–confident), humility (down to earth–stuck up), good Spanish (speaks good Spanish–speaks bad Spanish), and masculinity/femininity (more masculine–more feminine). The rightmost pole of each scale was intentionally designed to include both more positive (e.g., more intelligent) and more negative (e.g., speaks bad Spanish) attributes to discourage the selection of a single number across all social properties.
Next, the listeners had to determine the speaker’s age range and likely region of origin, which included the true origin of all speakers in the experiment and an “Other/I don’t know” option. Finally, an optional comment box was provided for participants to write any additional observations about the speaker based on his voice. While the comment box was optional and some participants chose to leave it blank, all other evaluations were required, and participants could not advance to the next screen until they had answered each question. A screen capture of what the participants saw on each page is provided in Figure 1.

FIGURE 1. Screen capture of the questions answered by the participants upon hearing each audio file.
STATISTICAL ANALYSIS
When all of the participants’ responses were collected, some degree of data transformation was necessary in R (R Core Team, 2018) before models could be created. First, scales that featured a more negative social property on the rightmost pole (i.e., “speaks bad Spanish” and “stuck up”) were inverted to facilitate comparisons among scales, and the checkbox evaluations of perceived age were converted to a scale, for example, 15–19 = 1, 20–24 = 2, and so forth. As this procedure resulted in a seven-point scale as compared to the six-point scale used for social property evaluations, all scales had to be standardized to enable comparisons. Additionally, the scales were centered to make 0 the central point of each scale. That is, positive numbers in the models and figures that follow indicate higher evaluations and negative numbers indicate lower evaluations for each scale. Participants’ anonymized and transformed responses can be found in IRIS at https://www.iris-database.org/iris/app/home/detail?id=york%3a938870&ref=search
Following data transformation, matched-guise analyses often make use of a Factor Analysis (FA) or Principal Components Analysis (PCA) to determine which scales are correlated, enabling the conflation of social properties that are evaluated in similar ways (see Barnes, Reference Barnes2015; Chappell, Reference Chappell2016, Reference Chappell2019; Walker et al., Reference Walker, García, Cortés and Campbell-Kibler2014). Following suit, we conducted an FA and used the Kaiser Rule to establish which properties should be combined and analyzed as joint factors in the model-construction procedure. The FA motivated the creation of three combined factors: (a) a status factor (loading for intelligence and work ethic), (b) a confident Spanish-speaker factor (loading for Hispanicity, confidence, and good Spanish), and (c) a solidarity factor (loading for niceness and humility). As no other factors appeared to be correlated, they were explored independently.
Mixed-effects regression models were then created using the lme4 (Bates et al., Reference Bates, Maechler, Bolker and Walker2017) and lmerTest (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2016) packages in R (R Core Team, 2018), and individual models were fitted to the following dependent variables: (a) status (intelligence/work ethic), (b) confident Spanish speaker (Hispanicity/confidence/good Spanish), (c) solidarity (niceness/humility), (d) age, (e) femininity, and (f) perceived speaker origin.Footnote 8 Treatment contrasts were used, and the random effects in each model included the listener and the presentation order of the stimuli.Footnote 9 The independent variables tested in each model include variant ([s] or [h]), speaker type (Mexican or Puerto Rican), having taken a phonetics class (yes or no), most advanced Spanish class taken divided into four collapsed categories (elementary, intermediate low, intermediate high, and advanced),Footnote 10 number of weeks spent studying abroad (continuous), experience abroad with an aspirating variety (yes or no), whether participants use Spanish regularly with NSs (yes or no), whether participants use Spanish regularly at work (yes or no), whether participants listen regularly to Spanish media (e.g., shows, podcasts, movies, music [yes or no]), listener age (continuous), and listener gender (man, woman, or other).Footnote 11 Ultimately, education level was not included as an independent variable as the vast majority of participants were either college students or college graduates. It should be noted that the most advanced Spanish class the participants had taken was significantly associated with the participants’ self-evaluations of overall Spanish proficiency and Spanish competence in the domains of reading, writing, listening, and speaking; consequently, these predictors could not be used together in a single model. As previous studies have found that individuals often under- or overestimate their L2 proficiency based on their anxiety levels (MacIntyre et al., Reference MacIntyre, Noels and Clément1997) or experiential factors (Ross, Reference Ross1998), the most advanced Spanish class taken by the participant was selected as a less biased gauge of the participants’ proficiency. In other words, participants’ self-evaluations of proficiency were excluded from the models as independent variables, with the highest level of Spanish study serving as a more neutral proxy.Footnote 12
With the aid of the step() function and random forests to determine which independent variables were likely to be the best predictors, the best fit for each model was determined by adding independent variables one at a time and comparing the two models with the anova() function (R Core Team, 2018), which established if the model’s fit was significantly better given the additional independent variable, justifying the increased complexity of the model. Motivated interactions between main effects were tested and kept in the model if they significantly improved the model’s fit.
RESULTS
As this study seeks to establish whether language learners are sensitive to salient sociophonetic variation, in this case coda /s/ as either [s] or [h], only models in which variant emerged as a significant predictor of listener evaluations will be discussed. The statistical analysis found variant heard to significantly alter listeners’ evaluations in two models:Footnote 13 (a) the model fitted to the speakers’ perceived place of origin and (b) the model fitted to the joint factor of perceived intelligence/work ethic. In both models, there is an interaction effect involving the variant heard.
First, as shown in Table 2, the interaction between variant and having completed a phonetics class was found to be a significant predictor of listener evaluations of speaker origin (Caribbean vs. other).Footnote 14 Additionally, the inclusion of the participant’s highest Spanish class significantly improved the model’s fit. More specifically, less advanced listeners rated speaker origin differently than more advanced listeners and, for these more advanced learners, having participated in a phonetics course significantly altered the way in which they interpreted speaker origin based on guise ([s] or [h]). The reference levels to which the given levels in Table 2 were compared include Variant = [s], Phonetics Class = No, and Highest Class = Advanced.
TABLE 2. Best-fit model for listener evaluations of perceived speaker origin (Caribbean vs. other).

To clarify this rather complex relationship, a conditional inference tree is provided in Figure 2. Conditional inference trees are a nonparametric class of tree-structure regression models that perform binary splits of a dependent variable to identify significant improvements in the model’s fit (see Hothorn et al., Reference Hothorn, Hornik and Zeileis2006). At the base of the tree, the proportion score indicates the portion of responses each option received at the final split. As shown by the first binary split, less advanced listeners were more likely to evaluate all speakers, regardless of guise, as Mexican or from an unknown place. For the more advanced learners, however, having taken a phonetics course resulted in significantly higher evaluations of Caribbean origin for the aspirated guises.

FIGURE 2. Conditional inference tree showing listener evaluations of perceived speaker origin.
Second, the results of the best-fit model for listener evaluations of the joint factor of speaker intelligence/work ethic, provided in Table 3, show another interaction effect, this time between variant heard and having studied abroad in an aspirating country. That is, learners who had studied abroad in an aspirating country responded differently to aspiration than listeners who had not experienced prolonged exposure to aspiration. Additionally, the best model included the listeners’ most advanced Spanish class taken. The reference levels to which the given levels in Table 3 were compared include Variant = [s], Aspiration Contact = No, and Highest Class = Advanced.
TABLE 3. Best-fit model of listener evaluations of speaker intelligence/work ethic.

To elucidate this interaction, Figure 3 provides another conditional inference tree to show the most relevant splits in the data. In this conditional inference tree, rather than proportion scores, the base of the tree provides a boxplot to facilitate the interpretation of the continuous evaluations. In these boxplots, the horizontal black line indicates the median value. The middle 50% of listener evaluations are shown within the gray boxes, and the top and bottom quartile are represented by the vertical lines above and below the boxes. Finally, Figure 4 simplifies the interaction effect even more clearly; in this interaction plot it becomes apparent that learners who had not studied abroad in an aspirating country provided relatively static evaluations of speaker regardless of variant heard, while the learners with a more prolonged exposure to aspiration significantly decreased their evaluations of speaker intelligence/work ethic in the aspirated guise.

FIGURE 3. Conditional inference tree showing the principal binary splits in listeners’ evaluations of speakers’ intelligence/work ethic.
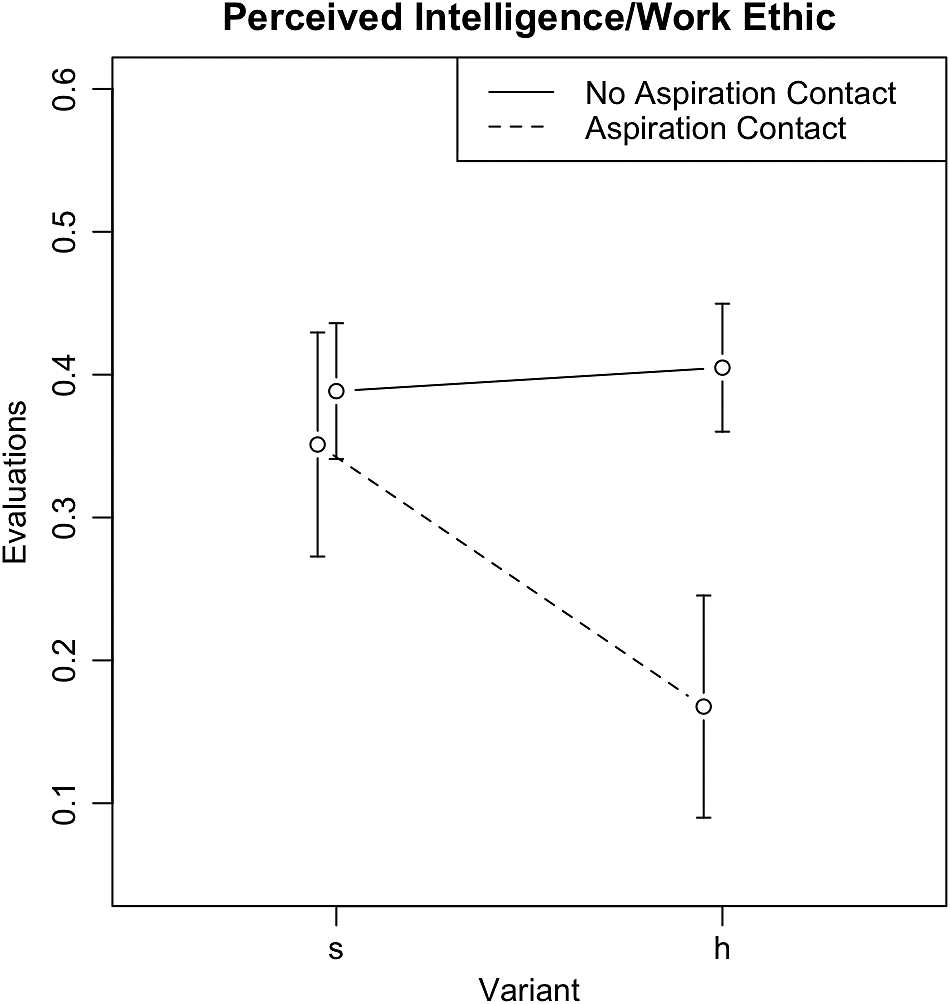
FIGURE 4. Interaction plot showing the advanced listeners’ evaluations of the speakers’ intelligence/work ethic given the guise heard and listeners’ contact with aspiration.
Finally, qualitative support from the optional comment box on each page echoed the quantitative conclusions outlined in the preceding text. Although these written responses were optional, several more proficient L2 listeners noted the [h] guises, specifically pointing to coda /s/ reduction as a shibboleth indicative of regional origin. Four unaltered examples are provided here.
-
(1) “Maybe Puerto Rican because of the way he says escuela without a prominent S sound”
(Participant #59, woman, 25 years old, from Georgia, ESL teacher/school administrator who has lived for 2 years in Costa Rica)
-
(2) “I chose the Caribbean because I heard less pronunciation in their S-particularly in está”
(Participant #129, woman, 20, from Houston, college student, has studied Spanish in high school/college and spent a week in Cuba)
-
(3) “Can tell from the Caribbean because he had a lisp and didn’t pronounce some letters like the S”
(Participant #105, man, 37, from Illinois, middle school Spanish teacher, has not studied abroad but uses Spanish at work and in Spanish-speaking neighborhoods in the United States)
-
(4) “Doesn’t really pronounce the ‘s’ in escuela- regional”
(Participant #116, woman, 20, from Minnesota, college student, has taken Spanish since eighth grade and spent 3 weeks in Costa Rica)
DISCUSSION
THE INTERSECTION OF OUR FINDINGS WITH PREVIOUS RESEARCH
The current study was designed to ascertain the perception of learners regarding the social significance of coda /s/ production and any extralinguistic factors that may influence such perception in a matched-guise task. Results revealed that the more advanced participants (i.e., advanced and high intermediate learners according to both highest course completion and self-assessment) were able to link reduced /s/ to region of origin and social status, whereas less experienced learners (i.e., beginner and low intermediate) did not make these connections.Footnote 15 Within the more advanced participant group, learners who had completed a phonetics course were significantly more likely to identify an /s/ reducer as Caribbean.
The greater difficulty of less proficient learners in linking /s/ to geographic and social characteristics supports a wide range of studies on the acquisition of variation. On the one hand, less proficient learners require greater attentional resources in linking form to meaning, which indicates that they are unlikely to capture the meaning of all forms presented in the input and that more nuanced meanings may not be gleaned (Ellis, Reference Ellis and Ellis2005; Schmidt, Reference Schmidt and Robinson2001). A growing body of recent research supports the claim that less advanced learners misidentify [h] as belonging to a phoneme other than /s/ (Escalante, Reference Escalante2018; Schmidt, Reference Schmidt2018), and our findings also suggest that such learners do not map [s] and [h] to relevant extralinguistic meanings. In other words, if learners cannot accurately perceive the segment in question, then it follows that they might also struggle to identify the origin of the producer of the segment.
Furthermore, more formal variants tend to be overrepresented in learner input, meaning that less proficient learners may lack experience with the more informal categories of a variable structure (Tarone, Reference Tarone2007).Footnote 16 Recall that learners are first known to demonstrate variation by differentiating between nativelike and nonnativelike forms in so-called vertical (Rehner, Reference Rehner2002) or Type I variation (Adamson & Regan, Reference Adamson and Regan1991). Only after gaining greater proficiency and experience in the L2 do learners then progress toward integrating two or more nativelike forms, demonstrating horizontal or Type II variation. This also supports general claims of the strength of one-to-one form and meaning relationships in learner grammars before the gradual spread of multifunctionality, or the ability to associate one meaning with multiple forms or one form with multiple meanings (Andersen, Reference Andersen1984, Reference Andersen, VanPatten and Lee1990; Bardovi-Harlig, Reference Bardovi-Harlig, Howard and Leclercq2017).
Next, our results indicated that learners in the more advanced group who had completed a phonetics course were significantly more likely to identify an /s/ reducer as Caribbean. The success of this subset of learners bolsters the arguments of more general claims for the value of presenting language as variable, rather than as a static standard (Geeslin & Long, Reference Geeslin and Long2014; Gutiérrez & Fairclough, Reference Gutiérrez, Fairclough, Salaberry and Lafford2006; Shin & Hudgens Henderson, Reference Shin and Hudgens Henderson2017). These results support empirical research on L2 sociophonetic variation that has demonstrated that learners who received phonetic instruction made greater gains in areas such as comprehension (Schoonmaker-Gates, Reference Schoonmaker-Gates2017) and perception (Schmidt, Reference Schmidt2018).
Additionally, our findings revealed that learners who had been immersed in aspirating varieties perceived a social relationship between aspiration and status, affording significantly greater social capital to [s], unlike those who lacked such experience. SA learners may gain access to a wider range of registers and relatively larger exposure to more informal language use (Lafford & Uscinski, Reference Lafford, Uscinski and Geeslin2013) compared to the traditional at-home (AH) learning setting (Tarone, Reference Tarone2007), with comparative studies of the two settings revealing greater gains in oral fluency for the former (Collentine, Reference Collentine2004; Llanes & Muñoz, Reference Llanes and Muñoz2009; Segalowitz & Freed, Reference Segalowitz and Freed2004). Learners who study in different regions have also demonstrated differential development toward local targets for a range of variable structures, including phonetic (Baker & Smith, Reference Baker and Smith2010; Escudero & Boersma, Reference Escudero and Boersma2004) and morphosyntactic variables (Geeslin et al., Reference Geeslin, Fafulas, Kanwit, Howe, Blackwell and Quesada2013; Kanwit & Solon, Reference Kanwit, Solon, Aaron, Amaro, Lord and de Prada Pérez2013; Salgado-Robles, Reference Salgado-Robles2014). Consequently, many learners appear to gain sensitivity to the local variants present in the input during SA, and their subsequent ability to perceive, interpret, and produce regional variants may be closely linked to this experience.
Our results complement recent studies on SA and coda /s/ perception in Spanish, which have shown that, during a sojourn, learners became significantly more accurate at identifying [h] than they were prearrival (Escalante, Reference Escalante2018) and that learners who had studied in /s/-weakening regions were significantly more effective at identifying [h] as a production of /s/ than those had studied in /s/-conserving zones (Schmidt, Reference Schmidt2018). The success of our advanced learners who had studied abroad in /s/-weakening regions, in conjunction with that of the phonetics group, lends credence to the hypothesis that learners who had first been instructed on language variation (e.g., sociophonetics, pragmatics) may benefit more from a sojourn abroad (Cohen & Shively, Reference Cohen and Shively2007; Lord, Reference Lord2010; Shively, Reference Shively2011).
Although our more advanced learners connected coda [s] to overt prestige, they did not associate [h] with other social characteristics that have been found for NS responses like heteronormativity (Mack, Reference Mack2009; Walker et al., Reference Walker, García, Cortés and Campbell-Kibler2014) or a more down-to-earth demeanor (Chappell, Reference Chappell2019). Our results for /s/ perception parallel previous work on morphosyntactic perception, which has found that NSs cultivate richer social associations with be like, such as honesty or an urban origin (Buchstaller, Reference Buchstaller2014), than learners (Davydova et al., Reference Davydova, Tytus and Schleef2017). However, the most advanced learners in the latter study linked be like with social characteristics like extroversion and cheerfulness, which suggests that learners first develop an awareness of a linguistic variant’s regional use and overt prestige before associations between a feature and covert social properties develop. As the learners in the present study were less advanced than those in Davydova et al. (Reference Davydova, Tytus and Schleef2017), our more advanced learners were able to link coda [h] with status but have not yet developed more nuanced social connections. We now consider how these findings can be explained within theories of L2 speech perception.
THEORETICAL IMPLICATIONS
Several theories predict that learners with more course experience will exhibit more successful perception in their L2. The finding that more advanced learners would be able to adapt their phonological systems to perceive [h] as a realization of /s/ whereas beginners may struggle is supported by models such as the PAM-L2 (Best & Tyler, Reference Best, Tyler, Munro and Bohn2007), SLM (Flege, Reference Flege and Strange1995), and L2LP (Escudero, Reference Escudero2005). These models all allow, following an initial difficulty, for the gradual ability to differentiate between two allophones of the same phoneme in cases where the L1 and L2 offer differing contrasts. Critical to the present structure of interest, the fact that /s/ is only reduced in syllable-final context is not accounted for in the context-free predictions of the PAM-L2, although context does inform the SLM and L2LP. Recall that perception in the SLM is context-specific, with L1 and L2 sounds relating in a position-specific allophonic fashion, as opposed to only abstractly at the phonemic level. Similarly, the L2LP echoes the SLM and departs from the PAM-L2 in its context-specific orientation, encoding allophonic detail at the phonetic representational level (van Leussen & Escudero, Reference van Leussen and Escudero2015).
In addition to its context-specific orientation, the L2LP offers another advantage over the two other models relevant to the learnability problem at hand: although the three models account for the difficulty in dividing L1 categories into meaningful contrasts in the L2, only the L2LP explicitly addresses facing comparatively fewer phonemic categories in the L2. Whereas /s/ and /h/ are always phonemic in American English (e.g., sat and hat), [s] and [h] are both variants of coda /s/ in Spanish.Footnote 17 In the L2LP’s Subset scenario, learners are tasked with modifying L1 boundaries and reducing the number of categories, as is the case with /s/ and its weakening. As a result, we support the conclusions of prior studies that, among these three popular models, the L2LP is uniquely able to account for the learnability problem of /s/ and its syllable-final allophones (Schmidt, Reference Schmidt2018).
While the L2LP successfully accounts for the L2 perception of coda /s/ in Spanish, it does not explain how learners come to link social meaning with [s] and [h]. To this end, we suggest a union of the L2LP with exemplar models of phonological representation (Bybee, Reference Bybee2001, Reference Bybee2002, Reference Bybee2006, Reference Bybee2017) and indexical meaning (Eckert, Reference Eckert2008; Silverstein, Reference Silverstein2003). Within this unified framework, learners first modify their L1 boundaries to perceive coda [s] and [h] as variants of /s/, at which point these new categories can become exemplars in the learners’ minds, adaptable to new tokens of linguistic and social experience. Of course, a certain quantity of input is necessary to accomplish this feat, as learners cannot create exemplars until their L1 boundaries have shifted toward those of the L2. After learners gain experience in the L2, an indexical field can form as they connect individuals who produce coda [h] to sociodemographic categories, mapping this social information onto the exemplar stored in memory.
In line with the results of our study, learners’ indexical fields may be more primitive than those of NSs, but they appear to develop in a predictable pattern. Explicit instruction significantly improves more proficient learners’ ability to identify coda /s/ weakening as a shibboleth, which suggests that when their attention is drawn to the geographic distribution of aspiration, they quickly learn to link coda [h] with specific regions. However, SA experience with an aspirating variety may be necessary to connect coda /s/ aspiration to social status, as such a sojourn provides the social interaction necessary to meaningfully associate the [h] exemplar with macrosociological categories. Finally, our learners did not associate coda [h] with more nuanced social properties like a down-to-earth demeanor or heteronormativity as NSs do (Chappell, Reference Chappell2019; Mack, Reference Mack2009; Walker et al., Reference Walker, García, Cortés and Campbell-Kibler2014), but studies with more advanced learners have shown these subtler connections to develop for other variable structures (Davydova et al., Reference Davydova, Tytus and Schleef2017). Taken together, our findings highlight the complex interplay among proficiency, explicit instruction, and dialectal exposure in the development of L2 sociophonetic perception.
CONCLUSIONS, LIMITATIONS, AND FUTURE DIRECTIONS
The present study demonstrated that more advanced participants connected reduced /s/ to place of origin and social status, unlike less experienced learners. Within the former group, learners who had completed a phonetics course were significantly more likely to identify an /s/ reducer as Caribbean. Additionally, more advanced learners who had sojourned in an aspirating country were more likely to afford greater social capital to [s]. We contended that learners’ developing sociophonetic perception can best be explained by unifying different theoretical approaches, namely the L2LP, exemplar models of phonological representation (Bybee, Reference Bybee2001, Reference Bybee2002, Reference Bybee2006, Reference Bybee2017), and the construct of indexical meaning (Eckert, Reference Eckert2008; Silverstein, Reference Silverstein2003).
Future work would do well to determine the extent to which more advanced participants’ ability to perceive social and regional characteristics associated with coda /s/ would correlate with these participants’ production. Prior research has indicated that heightened perceptual abilities and favorable attitudes still may not yield production of the target variant (Knouse, Reference Knouse2013). Moreover, although our less experienced learners did not identify speakers’ countries of origin based on coda /s/, it is possible that other segments may offer greater salience at lower proficiency levels (e.g., as shown for the interdental fricative and its association with Spain in Schoonmaker-Gates, Reference Schoonmaker-Gates2017). Finally, a more detailed, open-ended questionnaire would complement this experiment, allowing for a nuanced understanding of prior coursework and specific experiences abroad. While L2 sociophonetic perception remains ripe for further research, the results of this experiment lay bare the intricate relationship among proficiency, explicit instruction, and dialectal exposure in learners’ developing sociophonetic competence.








 Open access
Open access