



1 Introduction
Gradual typing promises to combine the benefits of static and dynamic typing in a single language. In the original formulation by Siek & Taha (Reference Siek and Taha2006), the goal is to bring the documentation and safety of static typing to a dynamically typed language. In their formalization, function parameters have dynamic types by default but can be explicitly annotated with static types. The resulting type system provides the same safety guarantees as static typing for expressions using type-annotated variables, yet allows the flexibility of dynamic typing for expressions with unannotated variables.
In gradual typing research, it is quite common to start with simply typed lambda calculus and extend it with annotations for dynamic types (Siek & Vachharajani Reference Siek and Vachharajani2008; Rastogi et al., Reference Rastogi, Chaudhuri and Hosmer2012; Garcia & Cimini Reference Garcia and Cimini2015). A function parameter can be annotated with
 $\star$
(the type of dynamic code) when dynamically typed behavior is needed or when the programmer is unsure whether all definitions are type correct but wants to test the runtime behavior.
$\star$
(the type of dynamic code) when dynamically typed behavior is needed or when the programmer is unsure whether all definitions are type correct but wants to test the runtime behavior.
1.1 Challenges applying gradual typing
By integrating static and dynamic typing, gradual typing not only enjoys the benefits of both typing disciplines but also suffers from their respective shortcomings. For example, statically typed parts of the code have more restricted expressiveness and may contain static type errors that yield cryptic error messages (Tobin-Hochstadt et al., Reference Tobin-Hochstadt, Felleisen, Findler, Flatt, Greenman, Kent, St-Amour, Strickland and Takikawa2017), while dynamically typed parts of the code may contain dynamic type errors that are not captured until after the software is deployed. More interestingly, combining statically and dynamically typed code together can raise new challenges; for example, Takikawa et al., (Reference Takikawa, Feltey, Greenman, New, Vitek and Felleisen2016) address the challenge of performance degradation in sound gradual typing at the boundaries between statically typed and dynamically typed code. This work, extending Campora et al., (Reference Campora, Chen, Erwig and Walkingshaw2018a), investigates the problem of migrating gradual programs to be as static as possible without introducing type errors.
To fully realize the benefits of gradual typing, we need the ability to navigate along a program’s dynamic-static typing spectrum, in order to make it more static or more dynamic when and where the respective strengths of each are desired. Answering the following three questions will help harness the full power of gradual typing. Footnote 1
-
Q1. Can we make a gradually typed program as static as possible while maintaining its well-typedness to keep it executable?
-
Q2. Can we introduce as few dynamic types as possible to migrate an ill-typed program to a type correct one while still enjoying the benefits of static typing for the well-typed parts?
-
Q3. Can we address the previous questions while keeping some user-indicated parts static or dynamic? Such parts may be indicated, for example, to reduce the granularity of boundaries between static and dynamic code during execution, in order to maintain performance.
The answers to these questions are not obvious. Furthermore, if the answers are yes, it is not clear whether we can implement the operations suggested by the questions efficiently. In the first part (up until Section 7), we develop machinery for addressing the question Q1. We develop solutions for Questions Q2 and Q3 in Sections 8 and 9.3, respectively.
We illustrate the challenges regarding 1 by considering the following program written in the calculus by Garcia & Cimini (Reference Garcia and Cimini2015) extended with Haskell functions and notations, where parameters annotated with
 $\star$
have dynamic types and those without annotations are inferred to have static types. In the rest of the paper, we say these parameters are dynamic and static, respectively. This program is adapted from van Keeken (Reference van Keeken2006) for formatting rows of a table according to a given width by trimming long rows and padding short rows with empty spaces.
$\star$
have dynamic types and those without annotations are inferred to have static types. In the rest of the paper, we say these parameters are dynamic and static, respectively. This program is adapted from van Keeken (Reference van Keeken2006) for formatting rows of a table according to a given width by trimming long rows and padding short rows with empty spaces.

The local variable
 $\mathtt{width}$
represents the width of the table and is computed by the argument
$\mathtt{width}$
represents the width of the table and is computed by the argument
 $\mathtt{widthFunc}$
, either by applying it to
$\mathtt{widthFunc}$
, either by applying it to
 $\mathtt{fixed}$
if
$\mathtt{fixed}$
if
 $\mathtt{fixed}$
is true, or to
$\mathtt{fixed}$
is true, or to
 $\mathtt{widest}$
, the size of largest row in the
$\mathtt{widest}$
, the size of largest row in the
 $\mathtt{table}$
. The argument
$\mathtt{table}$
. The argument
 $\mathtt{border}$
is added to the beginning and end of each row and is also used to generate the header or footer row when the Boolean argument
$\mathtt{border}$
is added to the beginning and end of each row and is also used to generate the header or footer row when the Boolean argument
 $\mathtt{headOrFoot}$
is true. If we bind the variable
$\mathtt{headOrFoot}$
is true. If we bind the variable
 $\mathtt{tbl}$
to a list of strings, we can then call
$\mathtt{tbl}$
to a list of strings, we can then call
 $\mathtt{rowAtI}$
in many ways, such as rowAtI False True (const 3) tbl “_” 0, rowAtI False False id tbl “_” 1, and rowAtI True False id tbl ’_’ 0.
$\mathtt{rowAtI}$
in many ways, such as rowAtI False True (const 3) tbl “_” 0, rowAtI False False id tbl “_” 1, and rowAtI True False id tbl ’_’ 0.
After some testing, suppose we want to migrate
 $\mathtt{rowAtI}$
to a version that is as static as possible by removing
$\mathtt{rowAtI}$
to a version that is as static as possible by removing
 $\star$
annotations. Removing
$\star$
annotations. Removing
 $\star$
annotations turns out to be much trickier than we may expect. First, if we remove all
$\star$
annotations turns out to be much trickier than we may expect. First, if we remove all
 $\star$
annotations, then type inference fails for
$\star$
annotations, then type inference fails for
 $\mathtt{rowAtI}$
, since it contains multiple static type errors, for example, the then branch requires
$\mathtt{rowAtI}$
, since it contains multiple static type errors, for example, the then branch requires
 $\mathtt{border}$
to have type
$\mathtt{border}$
to have type
 $\mathtt{Char}$
while the else branch requires it to have type
$\mathtt{Char}$
while the else branch requires it to have type
 $\mathtt{[Char]}$
. Second, if we remove
$\mathtt{[Char]}$
. Second, if we remove
 $\star$
annotations in a left-to-right order, we will encounter a type error as soon as the annotation for
$\star$
annotations in a left-to-right order, we will encounter a type error as soon as the annotation for
 $\mathtt{widthFunc}$
is removed. (In this paper, we follow the spirit of Garcia & Cimini Reference Garcia and Cimini2015 to infer static types only.) However, this does not necessarily indicate that the error was solely caused by
$\mathtt{widthFunc}$
is removed. (In this paper, we follow the spirit of Garcia & Cimini Reference Garcia and Cimini2015 to infer static types only.) However, this does not necessarily indicate that the error was solely caused by
 $\mathtt{widthFunc}$
being statically typed. In fact, the type error involving
$\mathtt{widthFunc}$
being statically typed. In fact, the type error involving
 $\mathtt{widthFunc}$
is due to the interaction with
$\mathtt{widthFunc}$
is due to the interaction with
 $\mathtt{fixed}$
when computing the value of
$\mathtt{fixed}$
when computing the value of
 $\mathtt{width}$
. At this point, we can restore the well-typedness of
$\mathtt{width}$
. At this point, we can restore the well-typedness of
 $\mathtt{rowAtI}$
by either re-annotating
$\mathtt{rowAtI}$
by either re-annotating
 $\mathtt{fixed}$
or
$\mathtt{fixed}$
or
 $\mathtt{widthFunc}$
with
$\mathtt{widthFunc}$
with
 $\star$
. Unfortunately, we cannot easily gauge which annotation is better for typing the rest of the function. If we choose to re-annotate
$\star$
. Unfortunately, we cannot easily gauge which annotation is better for typing the rest of the function. If we choose to re-annotate
 $\mathtt{fixed}$
, we will encounter another type error when the
$\mathtt{fixed}$
, we will encounter another type error when the
 $\star$
annotation for
$\star$
annotation for
 $\mathtt{border}$
is removed. Does this type error go away if we instead mark
$\mathtt{border}$
is removed. Does this type error go away if we instead mark
 $\mathtt{fixed}$
as static and
$\mathtt{fixed}$
as static and
 $\mathtt{widthFunc}$
as dynamic? The easiest way to tell is by trying it out.
$\mathtt{widthFunc}$
as dynamic? The easiest way to tell is by trying it out.
The example illustrates that parameters give rise to complicated typing interactions. The type error caused by making one parameter static may be avoided by making another parameter dynamic, or the type error caused by making two parameters static can be fixed by making another dynamic, and so on. In general, we must examine all possible combinations of static versus dynamic parameters to identify a program that is both well-typed and as static as possible. We refer to all of the potential programs produced by adding or removing
 $\star$
annotations as a migration space. The act of moving from one potential program to another by changing types is known as a migration. We say a program in the migration space has a most static type if removing any
$\star$
annotations as a migration space. The act of moving from one potential program to another by changing types is known as a migration. We say a program in the migration space has a most static type if removing any
 $\star$
from the program will make it ill-typed. We call a migration that yields a program with a most static type a most static migration. Due to the nature of type interactions, the most static type, and thus the most static migration, is not unique. Since every parameter can be either static or dynamic, the size of the migration space is exponential in the number of parameters for all functions in the program. For the program consisting of only
$\star$
from the program will make it ill-typed. We call a migration that yields a program with a most static type a most static migration. Due to the nature of type interactions, the most static type, and thus the most static migration, is not unique. Since every parameter can be either static or dynamic, the size of the migration space is exponential in the number of parameters for all functions in the program. For the program consisting of only
 $\mathtt{rowAtI}$
, which has six parameters, we would need to try out all
$\mathtt{rowAtI}$
, which has six parameters, we would need to try out all
 $2^6=64$
combinations to identify the most static migrations.
$2^6=64$
combinations to identify the most static migrations.
The challenges posed by migration between more and less static programs may prevent programmers from fully realizing the potential of gradual type systems. As evidence for this, the CircleCI project recently abandoned Typed Clojure mainly because the cost of adding type annotations to Clojure programs was perceived to exceed the benefits. Footnote 2 Similarly, Tobin-Hochstadt et al., (Reference Tobin-Hochstadt, Felleisen, Findler, Flatt, Greenman, Kent, St-Amour, Strickland and Takikawa2017) reported that migration of Racket modules to Typed Racked requires too much effort.
1.2 Migrating gradual types
In this paper, we address Q1 by (1) developing a type system that efficiently types the entire migration space and (2) designing a method to traverse the result of typing the migration space, calculating which
 $\star$
annotations can be removed. In this paper, we mainly consider the removal of
$\star$
annotations can be removed. In this paper, we mainly consider the removal of
 $\star$
annotations to support migrating to a more statically typed program; that is, we make types more precise (Siek & Taha Reference Siek and Taha2006). However, in Section 8, we describe how a dual approach can be developed to support the addition of
$\star$
annotations to support migrating to a more statically typed program; that is, we make types more precise (Siek & Taha Reference Siek and Taha2006). However, in Section 8, we describe how a dual approach can be developed to support the addition of
 $\star$
annotations (addressing Q2). Also, in Section 9, we describe how the approach can be extended to support further migration scenarios (addressing Q3). In this work, our development focuses on the ITGL calculus. We leave the migration problem in presence of other dynamic and static language features to future work.
$\star$
annotations (addressing Q2). Also, in Section 9, we describe how the approach can be extended to support further migration scenarios (addressing Q3). In this work, our development focuses on the ITGL calculus. We leave the migration problem in presence of other dynamic and static language features to future work.
As demonstrated in Section 1.1, in general, finding the most static migration requires exploring the entire migration space, which is exponential in size. This rules out a simple brute-force approach that type checks each possibility and compares the results to find the best one.
To illustrate how we can improve on a brute-force search, let us focus on a single parameter, say
 $\mathtt{i}$
in the
$\mathtt{i}$
in the
 $\mathtt{rowAtI}$
function from Section 1.1. To decide whether we can remove the
$\mathtt{rowAtI}$
function from Section 1.1. To decide whether we can remove the
 $\star$
annotation, we need to type two programs: one where
$\star$
annotation, we need to type two programs: one where
 $\mathtt{i}$
is static and one where
$\mathtt{i}$
is static and one where
 $\mathtt{i}$
is dynamic. Observe that the two typing processes differ only slightly. Of the three let-bound variables, only the typing of the second (
$\mathtt{i}$
is dynamic. Observe that the two typing processes differ only slightly. Of the three let-bound variables, only the typing of the second (
 $\mathtt{row}$
) is affected by whether
$\mathtt{row}$
) is affected by whether
 $\mathtt{i}$
is static or dynamic. The typing of the other two let-bound variables is identical in both cases. Moreover, since the type of
$\mathtt{i}$
is static or dynamic. The typing of the other two let-bound variables is identical in both cases. Moreover, since the type of
 $\mathtt{row}$
is determined to be the same regardless of whether
$\mathtt{row}$
is determined to be the same regardless of whether
 $\mathtt{i}$
is static or dynamic, the typing of the body of the let-expression is also identical.
$\mathtt{i}$
is static or dynamic, the typing of the body of the let-expression is also identical.
This observation suggests that we should reuse typing results while exploring the migration space to determine which
 $\star$
annotations can be removed. A systematic way to support this reuse is provided by variational typing (Chen et al., Reference Chen, Erwig and Walkingshaw2012, Reference Chen, Erwig and Walkingshaw2014). In this paper, we develop a type system that integrates gradual types (Siek & Taha Reference Siek and Taha2006) and variational types (Chen et al., Reference Chen, Erwig and Walkingshaw2014) to support reuse when typing the migration space. This type system supports efficiently typing the entire migration space, in roughly linear time, even in the presence of type errors.
$\star$
annotations can be removed. A systematic way to support this reuse is provided by variational typing (Chen et al., Reference Chen, Erwig and Walkingshaw2012, Reference Chen, Erwig and Walkingshaw2014). In this paper, we develop a type system that integrates gradual types (Siek & Taha Reference Siek and Taha2006) and variational types (Chen et al., Reference Chen, Erwig and Walkingshaw2014) to support reuse when typing the migration space. This type system supports efficiently typing the entire migration space, in roughly linear time, even in the presence of type errors.
After typing the migration space, we want to find the point in that space that is most static. Although the number of results to be considered is large, this step can be made efficient by exploiting several relationships between the resulting types. To illustrate these relationships, we list a subset of the migration space for the
 $\mathtt{rowAtI}$
example and their corresponding types in Figure 1.
$\mathtt{rowAtI}$
example and their corresponding types in Figure 1.

Figure 1. Types for a sample of the migration space for the
 $\mathtt{rowAtI}$
function. The second column contains a sequence of + and – symbols, indicating whether the
$\mathtt{rowAtI}$
function. The second column contains a sequence of + and – symbols, indicating whether the
 $\star$
annotation is kept or removed, respectively, for each of the five parameters annotated with in
$\star$
annotation is kept or removed, respectively, for each of the five parameters annotated with in
 $\mathtt{rowAtI}$
. For example, for program 2, all parameters except
$\mathtt{rowAtI}$
. For example, for program 2, all parameters except
 $\mathtt{fixed}$
keep their
$\mathtt{fixed}$
keep their
 $\star$
annotations. The
$\star$
annotations. The ![]() entries denote that the corresponding program is ill-typed.
entries denote that the corresponding program is ill-typed.
The first observation is that some parameters, whether they are static or dynamic, do not affect the type correctness of the program. In the example, the 3rd and 5th parameters (
 $\mathtt{table}$
and
$\mathtt{table}$
and
 $\mathtt{i}$
, respectively) are examples of such parameters. Given this knowledge and the fact that program 2 is well-typed, we can deduce that program 3 is also well-typed since they differ only in the
$\mathtt{i}$
, respectively) are examples of such parameters. Given this knowledge and the fact that program 2 is well-typed, we can deduce that program 3 is also well-typed since they differ only in the
 $\star$
annotations of the 3rd and 5th parameters. Similarly, given that program 8 is type incorrect, we can deduce that program 7 is also type incorrect for the same reason.
$\star$
annotations of the 3rd and 5th parameters. Similarly, given that program 8 is type incorrect, we can deduce that program 7 is also type incorrect for the same reason.
The second observation is that if a program is well-typed after removing
 $\star$
annotations from a set of parameters P, then (1) removing
$\star$
annotations from a set of parameters P, then (1) removing
 $\star$
annotations from a subset of P will also yield a well-typed program (this corresponds to the static gradual guarantees of Siek et al., Reference Siek, Vitousek, Cimini and Boyland2015), and (2) the program with all
$\star$
annotations from a subset of P will also yield a well-typed program (this corresponds to the static gradual guarantees of Siek et al., Reference Siek, Vitousek, Cimini and Boyland2015), and (2) the program with all
 $\star$
annotations removed from P is the most statically typed of these programs. For example, program 3 has a more static type than program 2, which in turn has a more static type than program 1. Similarly, this relation holds for the sequence of programs 5, 4, and 1. Note that the number of removed
$\star$
annotations removed from P is the most statically typed of these programs. For example, program 3 has a more static type than program 2, which in turn has a more static type than program 1. Similarly, this relation holds for the sequence of programs 5, 4, and 1. Note that the number of removed
 $\star$
annotations does not provide the same ordering. For example, program 3 removes more
$\star$
annotations does not provide the same ordering. For example, program 3 removes more
 $\star$
annotations than program 4, but program 4 has a more static type.
$\star$
annotations than program 4, but program 4 has a more static type.
The third observation is that if removing all
 $\star$
annotations for a set of parameters causes a type error, then removing the
$\star$
annotations for a set of parameters causes a type error, then removing the
 $\star$
annotations for any superset of those parameters must also cause a type error. For example, given that making the 4th parameter (
$\star$
annotations for any superset of those parameters must also cause a type error. For example, given that making the 4th parameter (
 $\mathtt{border}$
) static in program 7 causes a type error, we can deduce that additionally making the 3rd (
$\mathtt{border}$
) static in program 7 causes a type error, we can deduce that additionally making the 3rd (
 $\mathtt{table}$
) and 5th (
$\mathtt{table}$
) and 5th (
 $\mathtt{i}$
) parameters static in program 8 will also cause a type error.
$\mathtt{i}$
) parameters static in program 8 will also cause a type error.
These three observations enable an efficient method for finding the most static program. For
 $\mathtt{rowAtI}$
, we immediately discover that programs 3 and 5 are most static (neither one is more static than the other). In this case, we can either pick one of the results or have a programmer specify the preferable program. In Section 5, we show that these three observations hold for arbitrary programs, which allows us to develop an efficient method for finding desired programs in general.
$\mathtt{rowAtI}$
, we immediately discover that programs 3 and 5 are most static (neither one is more static than the other). In this case, we can either pick one of the results or have a programmer specify the preferable program. In Section 5, we show that these three observations hold for arbitrary programs, which allows us to develop an efficient method for finding desired programs in general.
1.3 Relations with other work in program migration
The work by Migeed & Palsberg (Reference Migeed and Palsberg2019) also studied the problem of program migration. However, there are many significant difference between our work and theirs.
Differences in techniques There is a fundamental difference in finding the migrations in these two approaches. For a given program, their approach finds migrations in the following steps. First, it generates a set of programs where each program replaces a
 $\star$
in the current program with a
$\star$
in the current program with a
 $\mathtt{Int}$
,
$\mathtt{Int}$
,
 $\mathtt{Bool}$
, or
$\mathtt{Bool}$
, or
 $\star\to\star$
. Second, it uses the type checking algorithm from Garcia & Cimini (Reference Garcia and Cimini2015) to type check the each program from the set. If a program does not type check, then it is not a migration of the original program. Otherwise, it is a migration, and the whole migration process is continued from the current program. The two-step process stops when no more programs type check. After this process finishes, all programs that type check are considered as possible migrations of the original program.
$\star\to\star$
. Second, it uses the type checking algorithm from Garcia & Cimini (Reference Garcia and Cimini2015) to type check the each program from the set. If a program does not type check, then it is not a migration of the original program. Otherwise, it is a migration, and the whole migration process is continued from the current program. The two-step process stops when no more programs type check. After this process finishes, all programs that type check are considered as possible migrations of the original program.
Figure 2 left illustrates the migration process of Migeed & Palsberg (Reference Migeed and Palsberg2019) for the expression
 $\lambda{x}:{\star}.{x\ x}$
. In the first step, three programs are generated, each replacing the
$\lambda{x}:{\star}.{x\ x}$
. In the first step, three programs are generated, each replacing the
 $\star$
with a more precise type. The programs
$\star$
with a more precise type. The programs
 $\lambda{x}:{\mathtt{Int}.}{x\ x}$
and
$\lambda{x}:{\mathtt{Int}.}{x\ x}$
and
 $\lambda{x}:{\mathtt{Bool}}{x\ x}$
do not type check. Therefore, they are not migrations of
$\lambda{x}:{\mathtt{Bool}}{x\ x}$
do not type check. Therefore, they are not migrations of
 $\lambda{x}:{\star.}{x\ x}$
. In contrast, the program
$\lambda{x}:{\star.}{x\ x}$
. In contrast, the program
 $\lambda{x}:{\star.}{x\ x}$
type checks and is a migration. Moreover, program migrations are searched starting from
$\lambda{x}:{\star.}{x\ x}$
type checks and is a migration. Moreover, program migrations are searched starting from
 $\lambda{x}.{\star\to\star}.{x\ x}$
.
$\lambda{x}.{\star\to\star}.{x\ x}$
.

Figure 2. Programs explored for searching possible migrations in Migeed & Palsberg (Reference Migeed and Palsberg2019) (left) and this work (right). Programs in blue type check and those in red do not type check. The dashed lines in the left subfigure denote that an infinite number of programs were omitted from it.
Putting aside variational typing, our approach can be viewed as generating all the programs that are obtained by removing all combinations of the
 $\star$
s in the program. After that, we use the type inference algorithm from Garcia & Cimini (Reference Garcia and Cimini2015) to check the type correctness and infer the type of each program. All programs that are type correct are migrations of the original programs. Figure 2 right shows all programs generated in our approach. Since there is only one
$\star$
s in the program. After that, we use the type inference algorithm from Garcia & Cimini (Reference Garcia and Cimini2015) to check the type correctness and infer the type of each program. All programs that are type correct are migrations of the original programs. Figure 2 right shows all programs generated in our approach. Since there is only one
 $\star$
in the expression, there are only two possible expressions that we need to investigate for migrations: the original expression and the one that removes the
$\star$
in the expression, there are only two possible expressions that we need to investigate for migrations: the original expression and the one that removes the
 $\star$
.
$\star$
.
To give a more straight view about what the whole search space looks like, we present in Figure 3 all the programs that are generated for finding migrations for
 $\mathtt{rowAtI}$
. Since
$\mathtt{rowAtI}$
. Since
 $\mathtt{rowAtI}$
contains five
$\mathtt{rowAtI}$
contains five
 $\star$
s, the total number of programs we need to investigate is 32. The figure uses a sequence of five
$\star$
s, the total number of programs we need to investigate is 32. The figure uses a sequence of five
 $+$
or minus; characters to denote each generated program. If the ith character is a +, then the ith
$+$
or minus; characters to denote each generated program. If the ith character is a +, then the ith
 $\star$
is kept. Otherwise, it is removed.
$\star$
is kept. Otherwise, it is removed.

Figure 3. Programs explored for finding migrations for
 $\mathtt{rowAtI}$
in our approach. These programs (configurations) constitute the full migration lattice (Takikawa et al., Reference Takikawa, Feltey, Greenman, New, Vitek and Felleisen2016) for the program
$\mathtt{rowAtI}$
in our approach. These programs (configurations) constitute the full migration lattice (Takikawa et al., Reference Takikawa, Feltey, Greenman, New, Vitek and Felleisen2016) for the program
 $\mathtt{rowAtI}$
. Each configuration is identified by a sequence of “+/-” signs, with “+” (“-”) indicating that the corresponding
$\mathtt{rowAtI}$
. Each configuration is identified by a sequence of “+/-” signs, with “+” (“-”) indicating that the corresponding
 $\star$
is kept (removed). A configuration with strictly more “-”s is more precise. We present several lines relating program precision and omit most of them for clarity.
$\star$
is kept (removed). A configuration with strictly more “-”s is more precise. We present several lines relating program precision and omit most of them for clarity.
As argued in Section 1.1, in general it is necessary to explore all the generated programs to find the programs that remove as many
 $\star$
s as possible. Our main goal in this paper is to use variational typing to make the exploration process efficient.
$\star$
s as possible. Our main goal in this paper is to use variational typing to make the exploration process efficient.
In summary, the main technical difference is that while Migeed & Palsberg (Reference Migeed and Palsberg2019) intertwine program generation and type checking to find migrations, our approach can be viewed as an efficient way of first generating all programs and then using type inference to find all migrations.
Differences in behaviors The differences in techniques lead to several significant behavioral differences in these two approaches, discussed below.
First, the migration space could be infinite in Migeed & Palsberg (Reference Migeed and Palsberg2019) but it is always finite in our approach. The main reason is that in their approach if a program in the migration space type checks, then programs with more precise type annotations will be generated, which may be well-typed, yielding more programs being generated. One such example is in Figure 2. Replacing the original
 $\star$
with
$\star$
with
 $\star\to\star$
makes the expressions type checks, and replacing any
$\star\to\star$
makes the expressions type checks, and replacing any
 $\star$
with
$\star$
with
 $\star\to\star$
will also type check. This process may be repeated infinitely. In Figure 2, we use dashed lines to indicate such infiniteness.
$\star\to\star$
will also type check. This process may be repeated infinitely. In Figure 2, we use dashed lines to indicate such infiniteness.
Instead, our approach generates exactly
 $2^n$
programs, where n is the number of
$2^n$
programs, where n is the number of
 $\star$
s in the expression. For example, for the expression
$\star$
s in the expression. For example, for the expression
 $\lambda{x}:{\star}.{x\ x}$
, our approach generates two expressions (including the original one), as can be seen from Figure 2.
$\lambda{x}:{\star}.{x\ x}$
, our approach generates two expressions (including the original one), as can be seen from Figure 2.
Second, as Migeed & Palsberg (Reference Migeed and Palsberg2019) use type checking from Garcia & Cimini (Reference Garcia and Cimini2015) while our approach uses type inference from Garcia & Cimini (Reference Garcia and Cimini2015) and it is well-known that type inference is often incomplete, their approach can lead to more precise program migrations than ours for certain programs. For example, for the expression
 $\lambda{x}:{\star}.{x\ x}$
, their approach will generate a program
$\lambda{x}:{\star}.{x\ x}$
, their approach will generate a program
 $\lambda{x}:{\star\to\star}.{x\ x}$
. As this program type checks, it is a valid migration. However, in our approach, we will check the expression
$\lambda{x}:{\star\to\star}.{x\ x}$
. As this program type checks, it is a valid migration. However, in our approach, we will check the expression
 $\lambda x.x\,x$
, obtained by removing the
$\lambda x.x\,x$
, obtained by removing the
 $\star$
from the expression. For this expression, type inference generates two constraints:
$\star$
from the expression. For this expression, type inference generates two constraints:
 $\beta = \beta_1 \to \beta_2$
and
$\beta = \beta_1 \to \beta_2$
and
 ${\beta_1}\sim{\beta}$
, where
${\beta_1}\sim{\beta}$
, where
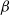 $\beta$
,
$\beta$
,
 $\beta_1$
, and
$\beta_1$
, and
 $\beta_2$
are three type variables. The unification algorithm in Garcia & Cimini (Reference Garcia and Cimini2015) fails to solve these two constraints due to occurs check. Consequently, type inference fails for this expression. As our type inference is a variational version of the one in Garcia & Cimini (Reference Garcia and Cimini2015), we also fail to infer a type for
$\beta_2$
are three type variables. The unification algorithm in Garcia & Cimini (Reference Garcia and Cimini2015) fails to solve these two constraints due to occurs check. Consequently, type inference fails for this expression. As our type inference is a variational version of the one in Garcia & Cimini (Reference Garcia and Cimini2015), we also fail to infer a type for
 $\lambda x.x\,x$
. As a result, no improvement is possible in our approach for
$\lambda x.x\,x$
. As a result, no improvement is possible in our approach for
 $\lambda{x}:{\star}.{x\ x}$
. In Section 9.2, we present an extension to our approach that could infer more precise types, including finding a migration for the expression
$\lambda{x}:{\star}.{x\ x}$
. In Section 9.2, we present an extension to our approach that could infer more precise types, including finding a migration for the expression
 $\lambda{x}:{\star}.{x\ x}$
.
$\lambda{x}:{\star}.{x\ x}$
.
Their work uses the term “maximal migration” to denote a migration that cannot be made more precise (any such effort leads to ill-typed programs). For certain programs, no maximal migrations exist. The expression
 $\lambda{x}:{\star}.{x\ x}$
is one such example. The reason is that a
$\lambda{x}:{\star}.{x\ x}$
is one such example. The reason is that a
 $\star$
in any migration can be replaced by a
$\star$
in any migration can be replaced by a
 $\star \to \star$
, thus more precise, without making the program ill-typed. In our work, we use the term “most static migration” to refer to migrations where no more
$\star \to \star$
, thus more precise, without making the program ill-typed. In our work, we use the term “most static migration” to refer to migrations where no more
 $\star$
s could be removed and replaced with fully static types. For
$\star$
s could be removed and replaced with fully static types. For
 $\lambda{x}:{\star}.{x\ x}$
, the most static migration is itself (our extension in Section 9.2 finds more static migrations). In our approach, most static migrations always exist because among a finite number of migrations we can always find migrations that remove most
$\lambda{x}:{\star}.{x\ x}$
, the most static migration is itself (our extension in Section 9.2 finds more static migrations). In our approach, most static migrations always exist because among a finite number of migrations we can always find migrations that remove most
 $\star$
s. In case no
$\star$
s. In case no
 $\star$
s can be removed and replaced with fully static types, the original expression is considered as the most static migration. Maximal migrations and most static migrations may coincide. For example, the programs in Figure 3 that are in blue and in fourth column are maximal and most static migrations.
$\star$
s can be removed and replaced with fully static types, the original expression is considered as the most static migration. Maximal migrations and most static migrations may coincide. For example, the programs in Figure 3 that are in blue and in fourth column are maximal and most static migrations.
Third, while Migeed & Palsberg (Reference Migeed and Palsberg2019) find maximal migrations by generating more precise programs and type checking them individually, we use variational typing to increase the efficiency of finding most static migrations. We have done a simple evaluation and find out that their approach has an exponential complexity. In particular, adding a parameter with
 $\star$
type essentially increases the running time by three times. For example, it takes about
$\star$
type essentially increases the running time by three times. For example, it takes about
 $4.7\times10^{-5}$
s to find the max migration for the expression
$4.7\times10^{-5}$
s to find the max migration for the expression
 $\lambda{x}:{\star.}{\mathtt{succ}(\mathtt{succ}\ x)}$
,
$\lambda{x}:{\star.}{\mathtt{succ}(\mathtt{succ}\ x)}$
,
 $1.5\times10^{-4}$
s for the expression
$1.5\times10^{-4}$
s for the expression
 $\lambda{x}:{\star.}{\lambda{y}:{\star}.{x + y}}, 28.67$
s for
$\lambda{x}:{\star.}{\lambda{y}:{\star}.{x + y}}, 28.67$
s for
 $\lambda x:\star.x1:\star.x2:\star.x3:\star.x4:\star.x5:\star.y:\star.y+\mathtt{succ}(x5(x4(\mathtt{succ}x3)(\mathtt{succ}(x2(x1+x+y)))))$
, and 93.8 s for
$\lambda x:\star.x1:\star.x2:\star.x3:\star.x4:\star.x5:\star.y:\star.y+\mathtt{succ}(x5(x4(\mathtt{succ}x3)(\mathtt{succ}(x2(x1+x+y)))))$
, and 93.8 s for
 $\lambda x:\star.x1:\star.x2:\star.x3:\star.x4:\star.x5:\star.x6:\star.y:\star.y+\mathtt{succ}(x5(x6+x4(\mathtt{succ}x3)(\mathtt{succ}(x2(x1+x+y)))))$
. For these four expressions, our approach takes
$\lambda x:\star.x1:\star.x2:\star.x3:\star.x4:\star.x5:\star.x6:\star.y:\star.y+\mathtt{succ}(x5(x6+x4(\mathtt{succ}x3)(\mathtt{succ}(x2(x1+x+y)))))$
. For these four expressions, our approach takes
 $4.1\times 10^{-4}$
,
$4.1\times 10^{-4}$
,
 $5.9\times 10^{-4}$
,
$5.9\times 10^{-4}$
,
 $1.7\times 10^{-3}$
, and
$1.7\times 10^{-3}$
, and
 $1.9\times 10^{-3}$
s, respectively. The timing result indicates that the idea of variational typing indeed improves efficiency. We present more comprehensive performance evaluation in Section 10.
$1.9\times 10^{-3}$
s, respectively. The timing result indicates that the idea of variational typing indeed improves efficiency. We present more comprehensive performance evaluation in Section 10.
1.4 Additions in the journal version and contributions
This paper extends Campora et al., (Reference Campora, Chen, Erwig and Walkingshaw2018a) with the following additions.
-
• In Section 1.3, we discuss in depth the relation between our work and the work by Migeed & Palsberg (Reference Migeed and Palsberg2019).
-
• In Section 8, we present a solution to fixing static type errors by introducing as few dynamic types as possible (question Q2), a dual problem to removing as many as dynamic types (question Q1).
-
• In Section 9.2, we present an extension to our constraint solving algorithm that enables us to find more precise migrations that the approach in Campora et al., (Reference Campora, Chen, Erwig and Walkingshaw2018a) was not able to.
-
• In addition to the migration questions Q1 and Q2, we consider many other migration scenarios, such as finding the migrations that migrate the greatest number of parameters. We present the approaches to support them in Section 9.3. These approaches reuse or slightly adapt the machinery for supporting Q1, which demonstrates the potential of our approach for developing more complex migration scenarios.
-
• In Section 10, we expand our evaluation by converting programs in Grift Kuhlenschmidt et al., (Reference Kuhlenschmidt, Almahallawi and Siek2019) to our language and measure their performances.
-
• We updated related work to discuss the relation with the latest work on gradual typing, including Migeed & Palsberg (Reference Migeed and Palsberg2019), Campora et al., (Reference Campora, Chen and Walkingshaw2018b), and Phipps-Costin et al., (Reference Phipps-Costin, Anderson, Greenberg and Guha2021).
We defer the proofs of this paper to Campora et al., (Reference Campora, Chen, Erwig and Walkingshaw2022). Overall, this paper makes the following contributions.
-
1. In Section 1.1, we identify three questions, Q1 through Q3, for migrating gradual program to fully harness the benefits of gradual typing.
-
2. In Section 4, we present a type system that integrates gradual types (Siek & Taha Reference Siek and Taha2006), variational types (Chen et al., Reference Chen, Erwig and Walkingshaw2014), and error-tolerant typing (Chen et al., Reference Chen, Erwig and Walkingshaw2012). The type system is correct and efficiently types the whole migration space. We detail the proofs for important cases of the theorems and lemmas that are introduced.
-
3. In Section 5, we investigate the relationship between different candidate migrations and develop a method for computing the most static migrations.
-
4. In Sections 6 and 7, we generate and solve constraints to provide type inference for migrational typing typing and prove that the constraint solving algorithm is correct.
-
5. In Section 8, we develop a dual to migrational typing to address the migration question Q2
-
6. In Section 9, we describe extensions to support additional common language features. We also discuss other migration scenarios and solutions supporting them.
-
7. In Section 10, we study the performance of our implementation by applying it to synthesized programs. The result shows that our approach scales linearly with program size.
To improve readability, the following table summarizes where important terms and operations are introduced. In the “F | P” column, F i and P i are shorthands for Figure i and Page i, respectively.

2 Background and preparation
In this section, we briefly introduce two areas of previous work that our type system for migrating gradual types builds on. In Section 2.1, we present a simple gradually typed language that represents the starting point for our work. This language is adapted from Garcia & Cimini (Reference Garcia and Cimini2015), but includes some minor differences to set up the presentation in Section 4. In Section 2.2, we introduce the concept of variational typing (Chen et al., Reference Chen, Erwig and Walkingshaw2014), which is the key technique that allows us to efficiently type the entire migration space.
2.1 Gradual typing
Gradual typing allows the interoperability of statically typed and dynamically typed code. The original formalization by Siek & Taha (Reference Siek and Taha2006) defined gradual typing for a simply typed lambda calculus extended with dynamic types. Siek & Vachharajani (Reference Siek and Vachharajani2008) and Garcia & Cimini (Reference Garcia and Cimini2015) further investigated gradual typing in the presence of type inference.
In this paper, we consider the migration of programs in implicitly typed gradual languages. In Figure 4, we present the syntax and type system of one such language, ITGL, which is adapted from Garcia & Cimini (Reference Garcia and Cimini2015) and forms the basis for this work. In the syntax, c ranges over constant values, x over variables,
 $\gamma$
over constant types, and
$\gamma$
over constant types, and
 $\alpha$
over type variables. There are two cases for abstraction expressions, one where the parameter is annotated by
$\alpha$
over type variables. There are two cases for abstraction expressions, one where the parameter is annotated by
 $\star$
and one where it is not. The rest of the cases are standard. The type system will be explained below.
$\star$
and one where it is not. The rest of the cases are standard. The type system will be explained below.

Figure 4. Syntax and type system of ITGL, an implicitly typed gradual language. The operations dom, cod, and
 $\sqcap$
are undefined for cases that are not listed here.
$\sqcap$
are undefined for cases that are not listed here.
The presentation of ITGL in Figure 4 differs from the original in Garcia & Cimini (Reference Garcia and Cimini2015) in two ways. First, our syntax is more restrictive: we omit a case for explicit type ascription of expressions, and we do not allow arbitrary type annotations on abstraction parameters. We also do not consider let-polymorphism here. These restrictions are made to simplify our formalization later, but we show in Section 9 how they can be lifted. Second, the typing rules are parameterized by a statifier,
 ${\omega}$
, which is used in the full migrational type system later (Section 4). A statifier is a mapping that maps parameter names that have
${\omega}$
, which is used in the full migrational type system later (Section 4). A statifier is a mapping that maps parameter names that have
 $\star$
s to static types, making an expression to have a more static type. The statifier specifies what static types to assign to parameters whose
$\star$
s to static types, making an expression to have a more static type. The statifier specifies what static types to assign to parameters whose
 $\star$
annotations will be removed. For simplicity, we assume parameters have unique names. In the type system as defined in Figure 4,
$\star$
annotations will be removed. For simplicity, we assume parameters have unique names. In the type system as defined in Figure 4,
 ${\omega}$
is always empty, corresponding to the type system in Garcia & Cimini (Reference Garcia and Cimini2015).
${\omega}$
is always empty, corresponding to the type system in Garcia & Cimini (Reference Garcia and Cimini2015).
In the type system for ITGL in Figure 4, the typing rules for constants and variables are standard. There are two rules for abstractions, Abs for unannotated parameters which must have static types, and Absdyn for annotated parameters which may have dynamic types. In Absdyn, we use
 $or(\omega(x),\star)$
to return
$or(\omega(x),\star)$
to return
 ${\omega}(x)$
if
${\omega}(x)$
if
 $x \in dom{(\omega)}$
or
$x \in dom{(\omega)}$
or
 $\star$
otherwise. Therefore, if
$\star$
otherwise. Therefore, if
 ${\omega}$
is empty, then
${\omega}$
is empty, then
 $or(\omega(x),\star)$
will always be
$or(\omega(x),\star)$
will always be
 $\star$
.
$\star$
.
Note that a statifier maps parameters to fully static types only, as can be seen from the definition of
 ${\omega}$
in Figure 4. As such, mappings such as
${\omega}$
in Figure 4. As such, mappings such as
 $x\mapsto\star\rightarrow\mathtt{Int}$
or
$x\mapsto\star\rightarrow\mathtt{Int}$
or
 $y\mapsto\star\rightarrow\star$
do not belong to
$y\mapsto\star\rightarrow\star$
do not belong to
 ${\omega}$
. This follows the spirit of Garcia & Cimini (Reference Garcia and Cimini2015) that inferred types should be fully static. Consequently, we cannot find an
${\omega}$
. This follows the spirit of Garcia & Cimini (Reference Garcia and Cimini2015) that inferred types should be fully static. Consequently, we cannot find an
 ${\omega}$
to make the expression
${\omega}$
to make the expression
 $\lambda{x}:{\star}.{x\ x}$
well-typed, even though the expression
$\lambda{x}:{\star}.{x\ x}$
well-typed, even though the expression
 $\lambda{x}:{\star\to\star}.{x\ x}$
is.
$\lambda{x}:{\star\to\star}.{x\ x}$
is.
Typing applications is tricky, since dynamically typed arguments can be passed to functions with statically typed parameters and vice versa. For example, assuming the function,
 $\mathtt{succ}$
, has static type
$\mathtt{succ}$
, has static type
 $\mathtt{Int}\to\mathtt{Int}$
, both of the following programs in our Haskell-like notation should be accepted by gradual typing.
$\mathtt{Int}\to\mathtt{Int}$
, both of the following programs in our Haskell-like notation should be accepted by gradual typing.
The App rule accommodates this with the help of a consistency relation,
 $\sim$
, that dictates when two unequal types are compatible with each other. An application is well-typed if the domain of the LHS (i.e. the parameter type) is consistent with the RHS, and the type of the application is the codomain of LHS. The auxiliary functions dom and cod return the domain and codomain of a function type, respectively, or
$\sim$
, that dictates when two unequal types are compatible with each other. An application is well-typed if the domain of the LHS (i.e. the parameter type) is consistent with the RHS, and the type of the application is the codomain of LHS. The auxiliary functions dom and cod return the domain and codomain of a function type, respectively, or
 $\star$
for a dynamic type (reflecting the fact that
$\star$
for a dynamic type (reflecting the fact that
 $\star$
is equivalent to
$\star$
is equivalent to
 $\star\to\star$
).
$\star\to\star$
).
The gradual type consistency relation is defined in Figure 4 by four rules: C1 defines that consistency is reflexive, C2 and C3 define that a dynamic type is consistent with any type, and C4 defines that two functions types are consistent if their respective argument and return types are consistent. As a result,
 $\mathtt{Int}\to\mathtt{Int}\sim\mathtt{Int}\to\star$
but not
$\mathtt{Int}\to\mathtt{Int}\sim\mathtt{Int}\to\star$
but not
 $\mathtt{Int}\to\mathtt{Int}\sim\mathtt{Bool}\to\star$
, since the argument types are not consistent in the latter case. Note that the consistency relation is not transitive. Due to C2 and C3, transitivity would lead every static type to be consistent with every other static type, which is clearly undesirable.
$\mathtt{Int}\to\mathtt{Int}\sim\mathtt{Bool}\to\star$
, since the argument types are not consistent in the latter case. Note that the consistency relation is not transitive. Due to C2 and C3, transitivity would lead every static type to be consistent with every other static type, which is clearly undesirable.
Typing conditional expressions relies on the meet operation,
 $\sqcap$
, on gradual types. Intuitively, meet chooses the more static of two base types when one is
$\sqcap$
, on gradual types. Intuitively, meet chooses the more static of two base types when one is
 $\star$
. For two equal static types, meet is idempotent. For two function types, meet is applied recursively to their respective argument and return types. The meet operation helps assign types to conditionals when the two branches might not have an identical type but still have consistent types. Intuitively, meet favors the type of the more static branch of the conditional expression.
$\star$
. For two equal static types, meet is idempotent. For two function types, meet is applied recursively to their respective argument and return types. The meet operation helps assign types to conditionals when the two branches might not have an identical type but still have consistent types. Intuitively, meet favors the type of the more static branch of the conditional expression.
2.2 Variational typing
Variational typing (Chen et al., Reference Chen, Erwig and Walkingshaw2012, Reference Chen, Erwig and Walkingshaw2014) enables efficiently inferring types for variational programs. A variational program represents many different variant programs that share some parts among each other and which can each be generated through a static process of selection.
The theoretical foundation for variational typing is the choice calculus (Erwig & Walkingshaw Reference Erwig and Walkingshaw2011), a formal language for representing variational programs. The essence of the choice calculus is that static variability in programs can be locally captured in variation points called choices, as demonstrated by the following example.
This program contains a choice named A with two alternatives,
 $\mathtt{succ}$
and
$\mathtt{succ}$
and
 $\mathtt{even}$
. We write
$\mathtt{even}$
. We write
 $\lfloor e \rfloor_{d.i}$
to indicate the selection of the ith alternative of each choice named d in e. So,
$\lfloor e \rfloor_{d.i}$
to indicate the selection of the ith alternative of each choice named d in e. So,
 $\lfloor \mathtt{vfun} \rfloor_{A.1}$
yields the program
$\lfloor \mathtt{vfun} \rfloor_{A.1}$
yields the program
 $\mathtt{succ\,1}$
and
$\mathtt{succ\,1}$
and
 $\lfloor \mathtt{vfun} \rfloor_{A.2}$
yields
$\lfloor \mathtt{vfun} \rfloor_{A.2}$
yields
 $\mathtt{even 1}$
. We call d.i a selector and use s to range over selectors. We call d.1 and d.2 the left and right selectors of d, respectively.
$\mathtt{even 1}$
. We call d.i a selector and use s to range over selectors. We call d.1 and d.2 the left and right selectors of d, respectively.
A decision is a set of selectors; we use
 $\delta$
to range over decisions. For each choice d, a decision contains only one or neither of d.1 and d.2. The elimination of choices extends naturally to decisions by selecting with each selector in the decision. An expression e is called plain if it does not contain any choices and is called variational if it does contain choices. A plain expression obtained by eliminating all choices in a variational expression is called a variant. For example,
$\delta$
to range over decisions. For each choice d, a decision contains only one or neither of d.1 and d.2. The elimination of choices extends naturally to decisions by selecting with each selector in the decision. An expression e is called plain if it does not contain any choices and is called variational if it does contain choices. A plain expression obtained by eliminating all choices in a variational expression is called a variant. For example,
 $\mathtt{succ\,1}$
is a plain expression and a variant of the variational expression
$\mathtt{succ\,1}$
is a plain expression and a variant of the variational expression
 $\mathtt{vfun}$
.
$\mathtt{vfun}$
.
A variational expression may contain several choices. Choices with the same name are synchronized and independent otherwise. For example, the variational expression ![]() has two variants,
has two variants,
 $\mathtt{succ\,2}$
and
$\mathtt{succ\,2}$
and
 $\mathtt{even\,3}$
, obtained by the decisions
$\mathtt{even\,3}$
, obtained by the decisions
 $\{A.1\}$
and
$\{A.1\}$
and
 $\{A.2\}$
, respectively. The program
$\{A.2\}$
, respectively. The program
 $\mathtt{succ\,3}$
cannot be obtained through selection and so is not a variant of this expression. On the other hand, the variational expression
$\mathtt{succ\,3}$
cannot be obtained through selection and so is not a variant of this expression. On the other hand, the variational expression ![]() has four variants, and we can obtain the variant
has four variants, and we can obtain the variant
 $\mathtt{succ\,3}$
with the decision
$\mathtt{succ\,3}$
with the decision
 $\{A.1,B.2\}$
.
$\{A.1,B.2\}$
.
In general, an expression with n distinct choice names can be configured in
 $2^n$
different ways. Since variational programs can easily contain hundreds or thousands of independent choice names (Apel et al., Reference Apel, Batory, Kästner and Saake2016), checking the type correctness of all variants is intractable by a brute-force strategy of generating all of the variants and typing each one individually (Thüm et al., Reference Thüm, Apel, Kästner, Schaefer and Saake2014). Variational typing solves this problem by sharing the typing process across all variants, which is achieved by defining and reasoning about variational types.
$2^n$
different ways. Since variational programs can easily contain hundreds or thousands of independent choice names (Apel et al., Reference Apel, Batory, Kästner and Saake2016), checking the type correctness of all variants is intractable by a brute-force strategy of generating all of the variants and typing each one individually (Thüm et al., Reference Thüm, Apel, Kästner, Schaefer and Saake2014). Variational typing solves this problem by sharing the typing process across all variants, which is achieved by defining and reasoning about variational types.
Variational types are types extended with choices. We define variational types in Figure 5. They include constant types (
 $\gamma$
), such as
$\gamma$
), such as
 $\mathtt{Int}$
and
$\mathtt{Int}$
and
 $\mathtt{Bool}$
, type variables (
$\mathtt{Bool}$
, type variables (
 $\alpha$
), function types, and choices over two alternatives.
$\alpha$
), function types, and choices over two alternatives.

Figure 5. Variational types, selection, and type equivalence.
All concepts and operations on variational expressions carry over to variational types. For example, Figure 5 defines selections on types. Selecting constant types (and type variables) with any selector yield themselves. For a function type, selection is recursively applied on the parameter type and return type. Selecting a choice type ![]() with a selector that has the same choice name (
with a selector that has the same choice name (
 $d.i$
) will yield the ith alternative. The selection is recursively applied to the alternative to eliminate all choices with the same name. For example, if we do not recursively select,
$d.i$
) will yield the ith alternative. The selection is recursively applied to the alternative to eliminate all choices with the same name. For example, if we do not recursively select, ![]() yields
yields ![]() while
while
 $\mathtt{Int}$
is the expected result, which could be achieved by recursively selecting
$\mathtt{Int}$
is the expected result, which could be achieved by recursively selecting ![]() with A.1. Selecting a choice type
with A.1. Selecting a choice type ![]() with a selector (
with a selector (
 $d_1.i$
) that has a different choice name will apply the selection to both alternatives. Finally, selecting a type with a decision (
$d_1.i$
) that has a different choice name will apply the selection to both alternatives. Finally, selecting a type with a decision (
 $s:\delta$
) is recursively defined as first selecting the type with s and then selecting the resulting type with the decision
$s:\delta$
) is recursively defined as first selecting the type with s and then selecting the resulting type with the decision
 $\delta$
.
$\delta$
.
It is natural to assign variational types to variational expressions. For example, ![]() has type
has type ![]() . Similar to gradual typing, typing applications in the presence of variation is complicated by the fact that “compatible” types may not be syntactically equal. In particular, 1. the LHS is traditionally expected to be a function type but in variational typing may be a (nested) choice of function types, and 2. when checking whether the type of the argument matches the type of the parameter, we must take into account that either or both may be variational. For example, the type of the function on the LHS of
. Similar to gradual typing, typing applications in the presence of variation is complicated by the fact that “compatible” types may not be syntactically equal. In particular, 1. the LHS is traditionally expected to be a function type but in variational typing may be a (nested) choice of function types, and 2. when checking whether the type of the argument matches the type of the parameter, we must take into account that either or both may be variational. For example, the type of the function on the LHS of
 $\mathtt{vfun}$
is
$\mathtt{vfun}$
is ![]() , which is not a function type directly, but both variants of
, which is not a function type directly, but both variants of
 $\mathtt{vfun}$
,
$\mathtt{vfun}$
,
 $\mathtt{succ 1}$
and
$\mathtt{succ 1}$
and
 $\mathtt{even\,1}$
, are well-typed.
$\mathtt{even\,1}$
, are well-typed.
Typing applications is supported in variational typing through the definition of a type equivalence relation (Chen et al., Reference Chen, Erwig and Walkingshaw2014), which is presented in Figure 5. Essentially, type equivalence specifies when a type can be transformed into another without affecting its semantics. The semantics of a variational type maps decisions to the variant plain types obtained by selecting from the type using the decision. For example, ![]() , and
, and ![]() are all equivalent because selecting from each of them with
are all equivalent because selecting from each of them with
 $\{A.1\}$
yields the same type
$\{A.1\}$
yields the same type
 $\mathtt{Int}\to\mathtt{Int}$
and selecting from each of them with
$\mathtt{Int}\to\mathtt{Int}$
and selecting from each of them with
 $\{A.2\}$
yields the same type
$\{A.2\}$
yields the same type
 $\mathtt{Int}\to\mathtt{Bool}$
. As a result, we can say that
$\mathtt{Int}\to\mathtt{Bool}$
. As a result, we can say that
 $\mathtt{vfun}$
has the type
$\mathtt{vfun}$
has the type ![]() , which is a function type with the argument type
, which is a function type with the argument type
 $\mathtt{Int}$
matching the type of
$\mathtt{Int}$
matching the type of
 $\mathtt{1}$
. We can thus assign the type
$\mathtt{1}$
. We can thus assign the type ![]()
![]() to
to
 $\mathtt{vfun}$
.
$\mathtt{vfun}$
.
An important result of variational typing is that choice elimination preserves typing. More specifically, if e has the type V, then
 $\lfloor e \rfloor_{\delta}$
has the type
$\lfloor e \rfloor_{\delta}$
has the type
 $\lfloor V \rfloor_{\delta}$
for any decision
$\lfloor V \rfloor_{\delta}$
for any decision
 $\delta$
. For example,
$\delta$
. For example,
 $\lfloor \mathtt{vfun} \rfloor_{A.1}$
yields
$\lfloor \mathtt{vfun} \rfloor_{A.1}$
yields
 $\mathtt{succ\ 1}$
, which has the type
$\mathtt{succ\ 1}$
, which has the type
 $\mathtt{Int}$
, the same as
$\mathtt{Int}$
, the same as
 $\lfloor V_{\mathtt{vfun}} \rfloor_{A.1}$
. An implication of this result is that the type of any variant can be easily obtained by making an appropriate selection into the result type of the variational program. Another important result of variational typing is that it is significantly faster than the brute-force approach.
$\lfloor V_{\mathtt{vfun}} \rfloor_{A.1}$
. An implication of this result is that the type of any variant can be easily obtained by making an appropriate selection into the result type of the variational program. Another important result of variational typing is that it is significantly faster than the brute-force approach.
3 Road map to migrating gradual types
In Section 1.1, we argued that the complexity of the tasks implied by the questions Q1– Q3, involving the migration of gradual programs, is exponential. In Section 2.2, we have shown that variational typing can efficiently type a set of similar programs. A main idea of this paper is to reduce the problem of typing the migration space to variational typing. Specifically, we assign each parameter with a
 $\star$
annotation a choice type whose the first alternative is a
$\star$
annotation a choice type whose the first alternative is a
 $\star$
and whose second alternative is a static type (In Section 9.1, we deal with parameter types that are partially static, such as
$\star$
and whose second alternative is a static type (In Section 9.1, we deal with parameter types that are partially static, such as
 $\mathtt{Int}\to\star$
). Consider, for example, the following function
$\mathtt{Int}\to\star$
). Consider, for example, the following function
 $\mathtt{widthV}$
that represents the variationally typed version of the function
$\mathtt{widthV}$
that represents the variationally typed version of the function
 $\mathtt{width}$
(also shown below) for computing the table width in
$\mathtt{width}$
(also shown below) for computing the table width in
 $\mathtt{rowAtI}$
.
$\mathtt{rowAtI}$
.
The function
 $\mathtt{widthV}$
encodes all four possible migrations of
$\mathtt{widthV}$
encodes all four possible migrations of
 $\mathtt{width}$
. If
$\mathtt{width}$
. If
 $V_{\mathtt{widthV}}$
is the type of
$V_{\mathtt{widthV}}$
is the type of
 $\mathtt{widthV}$
, then
$\mathtt{widthV}$
, then
 $\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.1,B.1\}}$
is the type for
$\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.1,B.1\}}$
is the type for
 $\mathtt{width}$
with no
$\mathtt{width}$
with no
 $\star$
annotations removed,
$\star$
annotations removed,
 $\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.2,B.1\}}$
is the type that replaces
$\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.2,B.1\}}$
is the type that replaces
 $\star$
with
$\star$
with
 $\mathtt{Bool}$
for
$\mathtt{Bool}$
for
 $\mathtt{fixed}$
and keeps
$\mathtt{fixed}$
and keeps
 $\star$
for
$\star$
for
 $\mathtt{widthFunc}$
,
$\mathtt{widthFunc}$
,
 $\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.1,B.2\}}$
is the type that keeps
$\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.1,B.2\}}$
is the type that keeps
 $\star$
for
$\star$
for
 $\mathtt{fixed}$
but replaces
$\mathtt{fixed}$
but replaces
 $\star$
with
$\star$
with
 $\mathtt{Int} \to \mathtt{Int}$
for
$\mathtt{Int} \to \mathtt{Int}$
for
 $\mathtt{widthFunc}$
, and
$\mathtt{widthFunc}$
, and
 $\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.2,B.2\}}$
is the type that removes both
$\lfloor V_{\mathtt{widthV}}\rfloor_{\{A.2,B.2\}}$
is the type that removes both
 $\star$
annotations.
$\star$
annotations.
In order to successfully employ variational typing to improve the performance of migrational typing, several technical challenges must be addressed. Figure 6 presents challenges and relevant theorems. The challenge C2 (error tolerance) does not have any theorems associated with it so we omit it from the figure.
-
C1. We refer to this challenge type compatibility. In the presence of dynamic and variational types, we need to combine the type equivalence relation between variational types (marked as
 $V\equiv$
in Figure 6) and the consistency relation between gradual types(marked as
$G\sim$
in the figure), which we refer to as the compatibility relation (marked as
$M\approx$
in the figure). After introducing the syntax of the migrational type system in Section 4.1, we address this problem in Section 4.2. Theorems 1 through 3 prove that the combination is correct.
$V\equiv$
in Figure 6) and the consistency relation between gradual types(marked as
$G\sim$
in the figure), which we refer to as the compatibility relation (marked as
$M\approx$
in the figure). After introducing the syntax of the migrational type system in Section 4.1, we address this problem in Section 4.2. Theorems 1 through 3 prove that the combination is correct. -
C2. We refer to this challenge error tolerance. In general, some variants of the variational program that encodes the migration space may contain type errors. We need the typing process to continue even in the presence of type errors to determine the types of all variants. In Section 4.3, we address this problem and give a declarative specification of our type system.
-
C3. We refer to this challenge best typing. In the brute-force approach, we need to generate all expressions (
$e_1,e_2,\ldots$
in Figure 6) from the given expression (e in the figure) by removing all combinations of
$\star$
s. These expressions will need to be typed using the type system
$\vdash_{GC}$
introduced in Figure 4. Our type system (presented in Section 4.4) types the expression e directly once without generating other programs (the judgment
$\pi$
;
$\Gamma\vdash e:M|\Omega$
in Figure 6). We thus need to show that our type system, by typing only one expression, essentially types all possible expressions that could be generated. Theorems 4.5 and 4.5 prove that this is indeed the case.









Figure 6. Relations between theorems and challenges. The notations in the figure are discussed in Section 3.
In
 $\mathtt{widthV}$
, we explicitly assigned static types to each parameter. One may wonder whether these are the best types to assign. Maybe other static types could improve the typing result and produce more general types or fewer type errors. Theorem 4.5 in Section 4.5 proves that in our type system, there exists a best typing derivation that contains the fewest errors and yields most static and general result types.
$\mathtt{widthV}$
, we explicitly assigned static types to each parameter. One may wonder whether these are the best types to assign. Maybe other static types could improve the typing result and produce more general types or fewer type errors. Theorem 4.5 in Section 4.5 proves that in our type system, there exists a best typing derivation that contains the fewest errors and yields most static and general result types.
-
C4. We refer to this challenge migration extraction. In brute-force approach, we need to compare typing results for all generated expressions to determine the most static migrations. While we could type just the original expression once with the best migrational typing, we need to find out the most static migrations from the typing result. This may also require the comparison of an exponential number of result types for the migration space. Fortunately, Theorems 7 through 10 prove that an efficient algorithm exists for finding most static migrations. In Section 5.2, we develop such an algorithm.
-
C5. We refer to this challenge type inference. In challenge C3 (best typing) we claimed that a best migrational typing exists, but how do we find it? We answer this question by solving the type inference problem in Sections 6 (constraint generation
$\vdash_C$
in Figure 6) and 7 (constraint solving in Figure 6). Theorems 11 through 15 prove desired properties of type inference.

4 Migrational type system
This section addresses the challenges C1 (type compatibility)-C3 (best typing) from Section 3 to support efficient migrational typing. After introducing the syntax of types and expressions in Section 4.1, the compatibility relation is defined in Section 4.2, addressing C1 (type compatibility). A pattern-constrained typing relation is introduced in Section 4.3 and defined via typing rules in Section 4.4, addressing C2 (error tolerance). Finally, the properties of this type system are discussed in Section 4.5, addressing C3 (best typing).
4.1 Syntax
The syntax of expressions, types, and environments is given in Figure 7. The metavariables we use to range over the relevant symbol domains are listed at the top of the figure. For type variables, we typically use
 $\beta$
to denote the result type of a function application during constraint generation and
$\beta$
to denote the result type of a function application during constraint generation and
 $\kappa$
to denote fresh type variables generated during constraint generation and solving (see Sections 6 and 7). For choice names, we typically use A and B to denote arbitrary specific choices in examples and d as a generic metavariable to range over choices names in definitions.
$\kappa$
to denote fresh type variables generated during constraint generation and solving (see Sections 6 and 7). For choice names, we typically use A and B to denote arbitrary specific choices in examples and d as a generic metavariable to range over choices names in definitions.

Figure 7. Syntax of expressions, types, and environments.
The syntax of expressions, static types, and gradual types is repeated from Section 2.1. To this, we add variational types, which are static types extended with choices, and migrational types, which are gradual types extended with choices. Note that each top-level parameter is assigned a restricted form of migrational type, which is either a fully static type, a
 $\star$
, or a choice of restricted migrational types; however, the more general syntax defined in Figure 7 is needed during the typing process. In Section 9.1, we extend our framework to allow an arbitrary mix of
$\star$
, or a choice of restricted migrational types; however, the more general syntax defined in Figure 7 is needed during the typing process. In Section 9.1, we extend our framework to allow an arbitrary mix of
 $\star$
and static types for top-level parameters. We also define type context to facilitate our presentations of both the type system and proofs.
$\star$
and static types for top-level parameters. We also define type context to facilitate our presentations of both the type system and proofs.
The type system relies on three kinds of environments: a type environment maps variables to migrational types, a substitution maps type variables to variational types, and a variational statifier maps variables to variational types. As described in Section 2.1, a statifier
 ${\omega}$
records one way of making a program more static (by removing some subset of
${\omega}$
records one way of making a program more static (by removing some subset of
 $\star$
annotations). A variational statifier
$\star$
annotations). A variational statifier
 ${\Omega}$
instead compactly encodes all possible statifiers for an expression. Since we want migration in our formalization to assign static types to parameters whose
${\Omega}$
instead compactly encodes all possible statifiers for an expression. Since we want migration in our formalization to assign static types to parameters whose
 $\star$
annotations are removed,
$\star$
annotations are removed,
 ${\Omega}$
maps parameters to variational types, but not migrational types.
${\Omega}$
maps parameters to variational types, but not migrational types.
Substitutions map type variables to variational types rather than migrational types since substituting dynamic types is unsound. For example, suppose we have
 $\mathtt{f}\mapsto\alpha\to\alpha\to\alpha\to\alpha$
and
$\mathtt{f}\mapsto\alpha\to\alpha\to\alpha\to\alpha$
and
 $x\mapsto\star$
in
$x\mapsto\star$
in
 $\Gamma$
. Now, when typing the application
$\Gamma$
. Now, when typing the application
 $\mathtt{f x}$
, we will substitute
$\mathtt{f x}$
, we will substitute
 $\{\alpha\mapsto\star\}$
, yielding
$\{\alpha\mapsto\star\}$
, yielding
 $\star\to\star\to\star$
as the type of
$\star\to\star\to\star$
as the type of
 $\mathtt{f x}$
. However, this implies that
$\mathtt{f x}$
. However, this implies that
 $\mathtt{f x 2 True}$
is well-typed, even though this violates the initial static type of f. The idea of substituting type variables with variational types but not migrational types is reminiscent of Guha et al., (Reference Guha, Matthews, Findler and Krishnamurthi2007), where only certain contracts could be used to instantiate parametric contract variables. Type substitution, written as
$\mathtt{f x 2 True}$
is well-typed, even though this violates the initial static type of f. The idea of substituting type variables with variational types but not migrational types is reminiscent of Guha et al., (Reference Guha, Matthews, Findler and Krishnamurthi2007), where only certain contracts could be used to instantiate parametric contract variables. Type substitution, written as
 $\theta(M)$
, is defined in the conventional way.
$\theta(M)$
, is defined in the conventional way.
4.2 Type compatibility
In the rest of this section, we use the
 $\mathtt{widthV}$
example from Section 3 to motivate the technical development of the migration type system and investigate the properties of the type system. The motivating goal is to type the condition
$\mathtt{widthV}$
example from Section 3 to motivate the technical development of the migration type system and investigate the properties of the type system. The motivating goal is to type the condition
 $\mathtt{fixed}$
and the application
$\mathtt{fixed}$
and the application
 $\mathtt{widthFunc 5}$
in
$\mathtt{widthFunc 5}$
in
 $\mathtt{widthV}$
.
$\mathtt{widthV}$
.
According to the annotation of
 $\mathtt{widthV}$
, the parameter
$\mathtt{widthV}$
, the parameter
 $\mathtt{fixed}$
has type
$\mathtt{fixed}$
has type ![]() . Since
. Since
 $\mathtt{fixed}$
is used as a condition, it should have type
$\mathtt{fixed}$
is used as a condition, it should have type
 $\mathtt{Bool}$
. Since both alternatives of the choice are consistent with
$\mathtt{Bool}$
. Since both alternatives of the choice are consistent with
 $\mathtt{Bool}$
, this use should be considered well-typed. The variable
$\mathtt{Bool}$
, this use should be considered well-typed. The variable
 $\mathtt{widthFunc}$
has type
$\mathtt{widthFunc}$
has type ![]() , which can be considered equivalent to
, which can be considered equivalent to ![]() . (In Section 4.4, we show how to achieve this formally with dom and cod.) The constant
. (In Section 4.4, we show how to achieve this formally with dom and cod.) The constant
 $\mathtt{5}$
has type
$\mathtt{5}$
has type
 $\mathtt{Int}$
. Since both alternatives of
$\mathtt{Int}$
. Since both alternatives of ![]() are consistent with
are consistent with
 $\mathtt{Int}$
,
$\mathtt{Int}$
,
 $\mathtt{widthFunc\,5}$
should also be considered well-typed.
$\mathtt{widthFunc\,5}$
should also be considered well-typed.
These two examples demonstrate that we need a notion of compatibility between two migrational types to express that all of their variants are consistent. Intuitively, the compatibility relation incorporates both type equivalence for variational types (Chen et al., Reference Chen, Erwig and Walkingshaw2014) and type consistency for gradual types (Siek & Taha Reference Siek and Taha2006). The definition of compatibility (
 $M_1\approx M_2$
) is given in Figure 8. The relation is reflexive (MT-Refl) and symmetric (MT-Sym). The relation is transitive (MT-VtTrans) in the case that no
$M_1\approx M_2$
) is given in Figure 8. The relation is reflexive (MT-Refl) and symmetric (MT-Sym). The relation is transitive (MT-VtTrans) in the case that no
 $\star$
s are present, which we indicate by using the metavariable for variational types (V).
$\star$
s are present, which we indicate by using the metavariable for variational types (V).

Figure 8. Rules defining type compatibility.
The rules MT-Idemp and MT-DeadElim specify compatibility under choice type simplification. Rule MT-Idemp states that a choice with identical alternatives is compatible with its alternatives. Rule MT-DeadElim says that two types are compatible under elimination of dead alternatives. Note that the operation
 $\lfloor M_1 \rfloor_{d.1}$
in the first alternative of d replaces each occurrence of a d choice in
$\lfloor M_1 \rfloor_{d.1}$
in the first alternative of d replaces each occurrence of a d choice in
 $M_1$
with its first alternative and thus removes the second alternative, which is unreachable due to choice synchronization. For example,
$M_1$
with its first alternative and thus removes the second alternative, which is unreachable due to choice synchronization. For example, ![]() , since
, since
 $\mathtt{Bool}$
is unreachable in
$\mathtt{Bool}$
is unreachable in ![]() because selection with either A.1 or A.2 yields
because selection with either A.1 or A.2 yields
 $\mathtt{Int}$
. A corresponding relationship holds for
$\mathtt{Int}$
. A corresponding relationship holds for
 $\lfloor M_2\rfloor_{d.2}$
.
$\lfloor M_2\rfloor_{d.2}$
.
The rule MT-Cong defines that compatibility is a congruence relation. This rule allows us to replace a type
 $M_1$
in a context M[] with a compatible type
$M_1$
in a context M[] with a compatible type
 $M_2$
. For example, since
$M_2$
. For example, since ![]() , we have
, we have ![]() if we view
if we view ![]() as the context. Finally, the rule MT-DynIntro states that if two types are compatible, replacing part of one type with
as the context. Finally, the rule MT-DynIntro states that if two types are compatible, replacing part of one type with
 $\star$
preserves compatibility. This rule is correct because
$\star$
preserves compatibility. This rule is correct because
 $\star$
is compatible with anything. By choosing M to be an empty context, this rule encodes
$\star$
is compatible with anything. By choosing M to be an empty context, this rule encodes
 $M\approx\star$
and thus
$M\approx\star$
and thus
 $\star\approx M$
through MT-Sym.
$\star\approx M$
through MT-Sym.
To illustrate compatibility, we show ![]() . This should hold, since both choice types only produce
. This should hold, since both choice types only produce
 $\mathtt{Int}$
or
$\mathtt{Int}$
or
 $\star$
, which are consistent with each other and themselves. We can start by
$\star$
, which are consistent with each other and themselves. We can start by ![]() via MT-Idemp and
via MT-Idemp and ![]() via MT-Idemp and MT-Sym. We can then use MT-VtTrans to derive
via MT-Idemp and MT-Sym. We can then use MT-VtTrans to derive ![]() . After that, we can apply MT-DynIntro to replace the first
. After that, we can apply MT-DynIntro to replace the first
 $\mathtt{Int}$
in B with a
$\mathtt{Int}$
in B with a
 $\star$
, apply MT-Sym, and apply another MT-DynIntro to replace the second
$\star$
, apply MT-Sym, and apply another MT-DynIntro to replace the second
 $\mathtt{Int}$
in the choice A with a
$\mathtt{Int}$
in the choice A with a
 $\star$
, yielding
$\star$
, yielding ![]() . By applying MT-Sym one more time, we can derive the original goal.
. By applying MT-Sym one more time, we can derive the original goal.
With
 $\approx$
, we can formalize the application rule as follows.
$\approx$
, we can formalize the application rule as follows.
Based on this rule and
 $\approx$
, we can calculate the type
$\approx$
, we can calculate the type ![]() for
for
 $\mathtt{widthFunc 5}$
.
$\mathtt{widthFunc 5}$
.
We demonstrate the correctness of
 $\approx$
by establishing its connection with type equivalence (
$\approx$
by establishing its connection with type equivalence (
 $\equiv$
) from Chen et al., (Reference Chen, Erwig and Walkingshaw2014) and type consistency (
$\equiv$
) from Chen et al., (Reference Chen, Erwig and Walkingshaw2014) and type consistency (
 $\sim$
) from Siek & Taha (Reference Siek and Taha2006) through the following theorems. In the theorems, we write
$\sim$
) from Siek & Taha (Reference Siek and Taha2006) through the following theorems. In the theorems, we write
 $\lfloor M \rfloor_{\delta}\in V$
and
$\lfloor M \rfloor_{\delta}\in V$
and
 $\lfloor M \rfloor_{\delta}\in G$
to denote that
$\lfloor M \rfloor_{\delta}\in G$
to denote that
 $\lfloor M \rfloor_{\delta}$
yields a variational type (no
$\lfloor M \rfloor_{\delta}$
yields a variational type (no
 $\star$
) and a gradual type (no variations), respectively. The first two theorems state the soundness of
$\star$
) and a gradual type (no variations), respectively. The first two theorems state the soundness of
 $\approx$
; the third theorem states its completeness.
$\approx$
; the third theorem states its completeness.
Theorem 1 (Compatibility encodes equivalence.) If
 $M_{1}\approx M_2$
, then
$M_{1}\approx M_2$
, then
 $\forall\delta.\lfloor M_1 \rfloor_{\delta} \in V\wedge \lfloor M_2 \rfloor \in V \Rightarrow \lfloor M_1 \rfloor_{\delta}\equiv \lfloor M_2 \rfloor_{\delta}$
$\forall\delta.\lfloor M_1 \rfloor_{\delta} \in V\wedge \lfloor M_2 \rfloor \in V \Rightarrow \lfloor M_1 \rfloor_{\delta}\equiv \lfloor M_2 \rfloor_{\delta}$
Theorem 2 (Compatibility encodes consistency) If
 $M_{1}\approx M_2$
, then
$M_{1}\approx M_2$
, then
 $\forall\delta.\lfloor M_1 \rfloor_{\delta} \in G\wedge \lfloor M_2 \rfloor \in G \Rightarrow \lfloor M_1 \rfloor_{\delta}\tilde \lfloor M_2 \rfloor_{\delta}$
.
$\forall\delta.\lfloor M_1 \rfloor_{\delta} \in G\wedge \lfloor M_2 \rfloor \in G \Rightarrow \lfloor M_1 \rfloor_{\delta}\tilde \lfloor M_2 \rfloor_{\delta}$
.
Theorem 3 (Equivalence and consistency imply compatibility)
 $\forall\delta.\lfloor M_1 \rfloor_{\delta} \equiv \lfloor M_2 \rfloor_{\delta} \vee \lfloor M_1 \rfloor_{\delta} \tilde \lfloor M_2 \rfloor_{\delta}\Rightarrow M_1 \approx M_2$
$\forall\delta.\lfloor M_1 \rfloor_{\delta} \equiv \lfloor M_2 \rfloor_{\delta} \vee \lfloor M_1 \rfloor_{\delta} \tilde \lfloor M_2 \rfloor_{\delta}\Rightarrow M_1 \approx M_2$
4.3 Pattern-constrained judgments
The goal in this subsection is to type the application
 $\mathtt{widthFunc fixed}$
in
$\mathtt{widthFunc fixed}$
in
 $\mathtt{widthV}$
, thus solving challenge C2 (error tolerance) for migrational typing. According to the type annotation of
$\mathtt{widthV}$
, thus solving challenge C2 (error tolerance) for migrational typing. According to the type annotation of
 $\mathtt{widthV}$
,
$\mathtt{widthV}$
,
 $\mathtt{widthFunc}$
has type
$\mathtt{widthFunc}$
has type ![]() , and
, and
 $\mathtt{fixed}$
has type
$\mathtt{fixed}$
has type ![]() . Since it is impossible to derive
. Since it is impossible to derive ![]() (where the former is the domain of the function type and the latter is the type of the argument), the application rule from Section 4.2 fails to assign a type to
(where the former is the domain of the function type and the latter is the type of the argument), the application rule from Section 4.2 fails to assign a type to
 $\mathtt{widthFunc fixed}$
. If we terminate the typing process, we will not be able to compute any type for
$\mathtt{widthFunc fixed}$
. If we terminate the typing process, we will not be able to compute any type for
 $\mathtt{widthV}$
, failing to provide support for program migration.
$\mathtt{widthV}$
, failing to provide support for program migration.
While the compatibility check between ![]() and
and ![]() fails, we observe that
fails, we observe that
 $\star$
, the first alternative of A, is compatible with
$\star$
, the first alternative of A, is compatible with ![]() and
and
 $\mathtt{Int}$
, the second alternative of A, is compatible with
$\mathtt{Int}$
, the second alternative of A, is compatible with
 $\star$
, the first alternative of B. This suggests that we should describe compatibility at a more fine-grained level than simply saying whether or not two migrational types are compatible. We employ the idea of typing patterns (
$\star$
, the first alternative of B. This suggests that we should describe compatibility at a more fine-grained level than simply saying whether or not two migrational types are compatible. We employ the idea of typing patterns (
 ${\pi}$
) (Chen et al., Reference Chen, Erwig and Walkingshaw2012) to formalize this idea (see Figure 9). The patterns T and
${\pi}$
) (Chen et al., Reference Chen, Erwig and Walkingshaw2012) to formalize this idea (see Figure 9). The patterns T and
 $\perp$
denote that the compatibility check succeeds and fails, respectively, and the choice pattern
$\perp$
denote that the compatibility check succeeds and fails, respectively, and the choice pattern ![]() describes the success or failure of compatibility checking within the context of choice d.
describes the success or failure of compatibility checking within the context of choice d.

Figure 9. Patterns and pattern-constrained relations and operations.. op can be any unary or binary operation on types. The is defined stipulations in the premise mean that the operations are defined on their input types, as specified in Figure 4. The is defined in the conclusion indicates that the operation can be safely carried out on the migrational type when constricted by
 ${\pi}$
.
${\pi}$
.
In Figure 9, we also define selection on patterns, which is similar to selection on types (
 $\lfloor V \rfloor_{\delta}$
) in Figure 5. On page 13, we gave a detailed explanation on selection on types, and we skip the explanation of selection on patterns here.
$\lfloor V \rfloor_{\delta}$
) in Figure 5. On page 13, we gave a detailed explanation on selection on types, and we skip the explanation of selection on patterns here.
We can now express the partial compatibility between ![]() and
and ![]() by the typing pattern
by the typing pattern ![]() . It is also possible to give some pattern that has an identical effect, such as the pattern
. It is also possible to give some pattern that has an identical effect, such as the pattern ![]() .
.
In Figure 9, we define
 $M_1 \approx_{\pi} M_2$
such that
$M_1 \approx_{\pi} M_2$
such that
 $M_1$
and
$M_1$
and
 $M_2$
are compatible for all variants of
$M_2$
are compatible for all variants of
 ${\pi}$
that are T. In contrast, there is no requirement between
${\pi}$
that are T. In contrast, there is no requirement between
 $M_1$
and
$M_1$
and
 $M_2$
at other places. For example,
$M_2$
at other places. For example, ![]() , since
, since
 $\mathtt{Int}\approx\mathtt{Int}$
at A.2 (and since we do not care that
$\mathtt{Int}\approx\mathtt{Int}$
at A.2 (and since we do not care that
 $\mathtt{Int}$
and
$\mathtt{Int}$
and
 $\mathtt{Bool}$
are incompatible at A.1).
$\mathtt{Bool}$
are incompatible at A.1).
The idea of constraining compatibility with patterns is quite powerful. We can even generalize it to typing judgments. Specifically, the typing relation
 $\pi$
;
$\pi$
;
 $\Gamma \vdash e:M$
holds if
$\Gamma \vdash e:M$
holds if
 $\lfloor \Gamma \rfloor_{\delta} \vdash \lfloor e \rfloor_{\delta}: \lfloor M \rfloor_{\delta}$
for all
$\lfloor \Gamma \rfloor_{\delta} \vdash \lfloor e \rfloor_{\delta}: \lfloor M \rfloor_{\delta}$
for all
 $\delta$
such that
$\delta$
such that
 $\lfloor \pi \rfloor_{\delta}=T$
. The advantage is that we do not need to worry about the typing in variants where
$\lfloor \pi \rfloor_{\delta}=T$
. The advantage is that we do not need to worry about the typing in variants where
 ${\pi}$
has
${\pi}$
has
 $\perp$
s. That also means that we should not use (or trust) the typing result at variants where
$\perp$
s. That also means that we should not use (or trust) the typing result at variants where
 ${\pi}$
has
${\pi}$
has
 $\perp$
s. We formally define this relation in Figure 9. For example, since
$\perp$
s. We formally define this relation in Figure 9. For example, since
 $\Gamma \vdash \mathtt{1}:\mathtt{Int}$
we have
$\Gamma \vdash \mathtt{1}:\mathtt{Int}$
we have ![]() , even though
, even though
 $\mathtt{Int}$
does not have the type
$\mathtt{Int}$
does not have the type
 $\mathtt{Int}$
. We can also generalize this idea to other operations, such as dom and cod, again defined in Figure 9.
$\mathtt{Int}$
. We can also generalize this idea to other operations, such as dom and cod, again defined in Figure 9.
As shown in the rule PatUnary, we can also use patterns to constrain unary functions so that they need to be defined for where only the pattern have
 $\top$
. In the rule, op could be instantiated to any unary functions, such as dom and cod. We use the following function dom to illustrate this idea.
$\top$
. In the rule, op could be instantiated to any unary functions, such as dom and cod. We use the following function dom to illustrate this idea.
The function dom is defined for three cases and is undefined for all other inputs. For example
 $dom(\mathtt{Int}\to\mathtt{Bool})=\mathtt{Int}$
but
$dom(\mathtt{Int}\to\mathtt{Bool})=\mathtt{Int}$
but
 $dom(\mathtt{Int})$
is undefined. How about
$dom(\mathtt{Int})$
is undefined. How about ![]() ? We can observe that it is defined for the first alternative but not the second alternative. In such case, we can constrain dom with a pattern to indicate that the function does not need to be defined for all alternatives of variations. For our example, we can use the pattern
? We can observe that it is defined for the first alternative but not the second alternative. In such case, we can constrain dom with a pattern to indicate that the function does not need to be defined for all alternatives of variations. For our example, we can use the pattern ![]() to convey that we only need the first alternative of A to be defined (because the pattern there is a
to convey that we only need the first alternative of A to be defined (because the pattern there is a
 $\top$
) while ignore whether the second alternative is defined or not (because the pattern there is a
$\top$
) while ignore whether the second alternative is defined or not (because the pattern there is a
 $\perp$
). With this idea,
$\perp$
). With this idea, ![]() is defined in both alternatives of A. Moreover, for the second alternative, we can say the result dom is any type because
is defined in both alternatives of A. Moreover, for the second alternative, we can say the result dom is any type because
 $\perp$
in that alternative indicates that the typing result will be discarded. Only typing results in variants where typing pattern has
$\perp$
in that alternative indicates that the typing result will be discarded. Only typing results in variants where typing pattern has
 $\top$
are valid and considered.
$\top$
are valid and considered.
Similarly, we can define
 $cod_{\pi}$
if we have a function cod, which we define in Figure 10. The rule PatBinary allows us to constrain binary operations or functions in the same way.
$cod_{\pi}$
if we have a function cod, which we define in Figure 10. The rule PatBinary allows us to constrain binary operations or functions in the same way.

Figure 10. Typing rules. The operations dom, cod, and
 $\sqcap$
are undefined for cases that are not listed here. The process for obtaining
$\sqcap$
are undefined for cases that are not listed here. The process for obtaining
 $dom_{\pi}$
from dom is detailed in Section 4.3. The operations
$dom_{\pi}$
from dom is detailed in Section 4.3. The operations
 $cod_{\pi}$
and
$cod_{\pi}$
and
 $\sqcap_{\pi}$
can be obtained similarly through Figure 9.
$\sqcap_{\pi}$
can be obtained similarly through Figure 9.
Based on the idea of pattern-constrained judgments, we can define the following rule for typing function applications (where dom is defined above and cod will be defined in Figure 10):
With this new rule, which accounts for migrational types with type errors, we can revisit the problem of typing
 $\mathtt{widthFunc fixed}$
. Let
$\mathtt{widthFunc fixed}$
. Let ![]() . Since
. Since ![]() belongs to
belongs to
 $\Gamma$
, we have
$\Gamma$
, we have
 $\pi;\Gamma\vdash\mathtt{widthFunc}:M$
, where
$\pi;\Gamma\vdash\mathtt{widthFunc}:M$
, where ![]() . Similarly, we have
. Similarly, we have ![]() . Next,
. Next, ![]()
![]() . As we have seen earlier,
. As we have seen earlier, ![]() . Thus, all the premises of the application rule are satisfied, and we can derive
. Thus, all the premises of the application rule are satisfied, and we can derive ![]() . Based on the result pattern, we should not trust the typing information at the variant
. Based on the result pattern, we should not trust the typing information at the variant
 $\{A.2,B.2\}$
since
$\{A.2,B.2\}$
since
 $\lfloor \pi \rfloor_{\{A.2,B.2\}}=\perp$
.
$\lfloor \pi \rfloor_{\{A.2,B.2\}}=\perp$
.
While pattern-constrained judgments simplify the presentation, we still face the challenge of finding appropriate patterns, which are inputs to the typing relation. However, the pattern is determined by the typing constraints among the subexpressions. For example, the type of the argument must match the argument type of the function. The reason we use ![]() in typing
in typing
 $\mathtt{widthFunc fixed}$
is that the application is ill-typed at
$\mathtt{widthFunc fixed}$
is that the application is ill-typed at
 $\{A.2,B.2\}$
. Therefore, in a language with type inference, the pattern will be computed during the inference process (Sections 6 and 7).
$\{A.2,B.2\}$
. Therefore, in a language with type inference, the pattern will be computed during the inference process (Sections 6 and 7).
4.4 Typing rules
The typing rules are shown in Figure 10. They are based on the compatibility relation (Section 4.2) and pattern-constrained judgments (Section 4.3). The typing judgment has the form
 $\pi;\Gamma\vdash e:M|\Omega$
and expresses that e has type M under environment
$\pi;\Gamma\vdash e:M|\Omega$
and expresses that e has type M under environment
 $\Gamma$
constrained by the pattern
$\Gamma$
constrained by the pattern
 ${\pi}$
. The mapping
${\pi}$
. The mapping
 ${\Omega}$
collects the types that will be assigned to parameters if their
${\Omega}$
collects the types that will be assigned to parameters if their
 $\star$
s are removed. We assume that parameter names from different functions are uniquely identified in the domain of
$\star$
s are removed. We assume that parameter names from different functions are uniquely identified in the domain of
 ${\Omega}$
. The goal of
${\Omega}$
. The goal of
 ${\Omega}$
is to connect the typing rules here with those from Figure 4. We discuss this aspect in more detail in Section 4.5 where we investigate the properties of the type system.
${\Omega}$
is to connect the typing rules here with those from Figure 4. We discuss this aspect in more detail in Section 4.5 where we investigate the properties of the type system.
The rules for constants (Con) and variables (Var) are straightforward. They hold for arbitrary patterns
 ${\pi}$
because constants and bound variables are always well-typed. Moreover, since the types remain unchanged,
${\pi}$
because constants and bound variables are always well-typed. Moreover, since the types remain unchanged,
 ${\Omega}$
is always
${\Omega}$
is always
 $\varnothing$
. The rule Abs for an abstraction whose parameter is not annotated with
$\varnothing$
. The rule Abs for an abstraction whose parameter is not annotated with
 $\star$
is conventional. In rule Absdyn for an abstraction whose parameter is annotated with
$\star$
is conventional. In rule Absdyn for an abstraction whose parameter is annotated with
 $\star$
, we assign the parameter a choice type where the first alternative is
$\star$
, we assign the parameter a choice type where the first alternative is
 $\star$
implying that the
$\star$
implying that the
 $\star$
is kept and the second alternative can be any type for the body to be well-typed. As a result, when variations are first introduced, their first alternatives are
$\star$
is kept and the second alternative can be any type for the body to be well-typed. As a result, when variations are first introduced, their first alternatives are
 $\star$
s. This change information is recorded by extending the
$\star$
s. This change information is recorded by extending the
 ${\Omega}$
returned from typing the body of the abstraction.
${\Omega}$
returned from typing the body of the abstraction.
The App rule for applications is similar to the one in Section 4.3 except that we must combine the variational statifiers from typing the two subexpressions. The operations
 $dom_{\pi}$
and
$dom_{\pi}$
and
 $cod_{\pi}$
can be obtained from dom and cod respectively using the idea of pattern-constrained operations discussed in Section 4.3.
$cod_{\pi}$
can be obtained from dom and cod respectively using the idea of pattern-constrained operations discussed in Section 4.3.
The rule If types conditionals; it relies on an extended version of the meet operation (
 $\sqcap$
) from Figure 4 that also handles choices. The definition
$\sqcap$
) from Figure 4 that also handles choices. The definition
 $\sqcap_{\pi}$
can be obtained from Figure 9 by instantiating the op in rule ParBinary with
$\sqcap_{\pi}$
can be obtained from Figure 9 by instantiating the op in rule ParBinary with
 $\sqcap$
. In Section 4.3, we gave a detailed example of deriving
$\sqcap$
. In Section 4.3, we gave a detailed example of deriving
 $dom_{\pi}$
from dom and
$dom_{\pi}$
from dom and
 $\sqcap_{\pi}$
can be derived from
$\sqcap_{\pi}$
can be derived from
 $\sqcap$
similarly.
$\sqcap$
similarly.
The Weaken rule states that if a typing pattern can be used to derive a typing, then we can use a less-defined pattern to derive the same typing. The operation
 $=_{{\pi}_1}$
in the premise specifies that its arguments must be the same for places where
$=_{{\pi}_1}$
in the premise specifies that its arguments must be the same for places where
 $\pi_1$
has
$\pi_1$
has
 $\top$
s. A typing pattern
$\top$
s. A typing pattern
 $\pi_1$
is less defined than
$\pi_1$
is less defined than
 $\pi_2$
if it contains
$\pi_2$
if it contains
 $\perp$
values at least everywhere
$\perp$
values at least everywhere
 $\pi_2$
does. The purpose of Weaken is to make the typing process compositional. Without this rule, the whole typing derivation must use the same
$\pi_2$
does. The purpose of Weaken is to make the typing process compositional. Without this rule, the whole typing derivation must use the same
 ${\pi}$
. With this rule, we can use different patterns for typing the children of a construct but adjust them to use the same pattern when typing the construct itself. To illustrate, consider typing an application
${\pi}$
. With this rule, we can use different patterns for typing the children of a construct but adjust them to use the same pattern when typing the construct itself. To illustrate, consider typing an application
 $e_1 e_2$
. It is likely that
$e_1 e_2$
. It is likely that
 $e_1$
and
$e_1$
and
 $e_2$
will contain errors at different variants, and thus, the typing patterns for typing them will be different.ithout Weaken, we should use a single pattern for typing these two subexpressions. With Weaken, we can use different patterns for typing subexpressions, and before typing the application itself we can apply Weaken to the typing derivation for either or both
$e_2$
will contain errors at different variants, and thus, the typing patterns for typing them will be different.ithout Weaken, we should use a single pattern for typing these two subexpressions. With Weaken, we can use different patterns for typing subexpressions, and before typing the application itself we can apply Weaken to the typing derivation for either or both
 $e_1$
and
$e_1$
and
 $e_2$
to make their patterns the same. After that, we can apply the App rule.
$e_2$
to make their patterns the same. After that, we can apply the App rule.
The less-defined relation on patterns, written as
 $\pi_1 \leq \pi_2$
, is formally defined in Figure 10. The rules Pat-Ok and Pat-Err define that any pattern is less defined than
$\pi_1 \leq \pi_2$
, is formally defined in Figure 10. The rules Pat-Ok and Pat-Err define that any pattern is less defined than
 $\top$
and more defined than
$\top$
and more defined than
 $\perp$
. The rule Pat-Trans defines that the relation is transitive. The last three rules handle variational patterns. The rule Pat-Sinchc states that a pattern is less defined than a variational pattern if it is less defined than both alternatives of the variational pattern. The rule Pat-Chcsin states that a variational pattern is less defined than a pattern if both alternatives are. Finally, the rule Pat-ChcChc says that two variational patterns satisfy the less-defined relation if their corresponding alternatives do.
$\perp$
. The rule Pat-Trans defines that the relation is transitive. The last three rules handle variational patterns. The rule Pat-Sinchc states that a pattern is less defined than a variational pattern if it is less defined than both alternatives of the variational pattern. The rule Pat-Chcsin states that a variational pattern is less defined than a pattern if both alternatives are. Finally, the rule Pat-ChcChc says that two variational patterns satisfy the less-defined relation if their corresponding alternatives do.
4.5 Properties
This subsection investigates the properties of the type system. Since the goal of migrational typing in Figure 10 is to type all possible programs that remove
 $\star$
s for a given program at once, we want to investigate whether migrational typing does it currently for individual programs and whether it indeed types all programs that remove
$\star$
s for a given program at once, we want to investigate whether migrational typing does it currently for individual programs and whether it indeed types all programs that remove
 $\star$
s. To this end, we consider the relationship of the rules for migrational typing in Figure 10 and the original rules for gradual typing in Figure 4. We also consider the relation between different typing derivations
$\star$
s. To this end, we consider the relationship of the rules for migrational typing in Figure 10 and the original rules for gradual typing in Figure 4. We also consider the relation between different typing derivations
 $\pi;\Gamma\vdash e: M|\Omega$
when different
$\pi;\Gamma\vdash e: M|\Omega$
when different
 ${\pi}$
s and Ms are used for the same
${\pi}$
s and Ms are used for the same
 $\Gamma$
and e, which addresses challenge C3 (best typing) from Section 3.
$\Gamma$
and e, which addresses challenge C3 (best typing) from Section 3.
We start by introducing some notation. We say a decision
 $\delta$
is complete for an expression e if it contains d.1 or d.2 for each d created while typing e. For
$\delta$
is complete for an expression e if it contains d.1 or d.2 for each d created while typing e. For
 ${\pi}$
, a decision
${\pi}$
, a decision
 $\delta$
is complete if
$\delta$
is complete if
 $\lfloor \pi \rfloor_{\delta}$
yields
$\lfloor \pi \rfloor_{\delta}$
yields
 $\top$
or
$\top$
or
 $\perp$
. Note that a complete decision for
$\perp$
. Note that a complete decision for
 ${\pi}$
may not be complete for the expression since patterns compactly represent where typing succeeds and where it fails. For instance, while typing
${\pi}$
may not be complete for the expression since patterns compactly represent where typing succeeds and where it fails. For instance, while typing
 $\mathtt{rowAtI}$
, we created five choices A, B, D, E, and F for the dynamic parameters from left to right, respectively. Thus, each complete decision for
$\mathtt{rowAtI}$
, we created five choices A, B, D, E, and F for the dynamic parameters from left to right, respectively. Thus, each complete decision for
 $\mathtt{rowAtI}$
contains five selectors. One typing pattern for
$\mathtt{rowAtI}$
contains five selectors. One typing pattern for
 $\mathtt{rowAtI}$
is:
$\mathtt{rowAtI}$
is:
Both
 $\{A.1,E.1\}$
and
$\{A.1,E.1\}$
and
 $\{B.2,B.2\}$
are complete decisions for
$\{B.2,B.2\}$
are complete decisions for
 $\pi_a$
but not for
$\pi_a$
but not for
 $\mathtt{rowAtI}$
. In the case that the whole migration space for an expression is well-typed, then the pattern is simply
$\mathtt{rowAtI}$
. In the case that the whole migration space for an expression is well-typed, then the pattern is simply
 $\top$
and the complete decision is. We use the notation
$\top$
and the complete decision is. We use the notation
 $\delta|2$
to collect all of choice names d such that
$\delta|2$
to collect all of choice names d such that
 $d.2 \in \delta$
.
$d.2 \in \delta$
.
The notions of decisions (
 $\delta$
), variational statifier (
$\delta$
), variational statifier (
 ${\Omega}$
), and statifier (
${\Omega}$
), and statifier (
 ${\omega}$
) are closely related. Specifically, during typing, for each dynamic parameter x,
${\omega}$
) are closely related. Specifically, during typing, for each dynamic parameter x,
 ${\Omega}$
includes a mapping
${\Omega}$
includes a mapping
 $x\mapsto V$
, where V is the type that will be assigned to the parameter once its
$x\mapsto V$
, where V is the type that will be assigned to the parameter once its
 $\star$
annotation is removed. Therefore, given
$\star$
annotation is removed. Therefore, given
 ${\Omega}$
and
${\Omega}$
and
 $\delta$
, we can generate a statifier as follows, where chc(x) returns the name of the choice created for x.
$\delta$
, we can generate a statifier as follows, where chc(x) returns the name of the choice created for x.
 \begin{equation*}statifierForDesc(\Omega,\delta)=\{x\mapsto\lfloor V \rfloor_{\delta}|x\mapsto V\in\Omega \wedge chc(x)\in\delta|2\}\end{equation*}
\begin{equation*}statifierForDesc(\Omega,\delta)=\{x\mapsto\lfloor V \rfloor_{\delta}|x\mapsto V\in\Omega \wedge chc(x)\in\delta|2\}\end{equation*}
For example, let
 \begin{equation*}\Omega_{a}=\{\mathtt{fixed}\mapsto\mathtt{Bool},\mathtt{widthFunc}\mapsto\mathtt{Int}\to\mathtt{Int}\}\qquad\delta_{a}=\{A.2,B.1\}\end{equation*}
\begin{equation*}\Omega_{a}=\{\mathtt{fixed}\mapsto\mathtt{Bool},\mathtt{widthFunc}\mapsto\mathtt{Int}\to\mathtt{Int}\}\qquad\delta_{a}=\{A.2,B.1\}\end{equation*}
then
 $statifierForDesc(\Omega_{a},\delta_{a})$
.
$statifierForDesc(\Omega_{a},\delta_{a})$
.
The notation
 $G_1\sqsubseteq G_2$
means that
$G_1\sqsubseteq G_2$
means that
 $G_2$
is more static than
$G_2$
is more static than
 $G_1$
; it is defined as follows.
$G_1$
; it is defined as follows.
We further say that
 $G_2$
is better than
$G_2$
is better than
 $G_1$
, written as
$G_1$
, written as
 $G_1\preceq G_2$
, if
$G_1\preceq G_2$
, if
 $G_1\sqsubseteq G_2$
or
$G_1\sqsubseteq G_2$
or
 $G_1 = \theta_2(G_2)$
for some
$G_1 = \theta_2(G_2)$
for some
 $\theta_2$
. Intuitively,
$\theta_2$
. Intuitively,
 $G_1\preceq G_2$
if
$G_1\preceq G_2$
if
 $G_2$
is equally or more static than
$G_2$
is equally or more static than
 $G_1$
or they are equally static and for any static part in
$G_1$
or they are equally static and for any static part in
 $G_1$
,
$G_1$
,
 $G_2$
has the same static type or a type variable. For example, we have
$G_2$
has the same static type or a type variable. For example, we have
 $\star\to\alpha\preceq\mathtt{Int}\to\mathtt{Int}$
and
$\star\to\alpha\preceq\mathtt{Int}\to\mathtt{Int}$
and
 $\mathtt{Int}\to\mathtt{Int}\preceq\mathtt{Int}\to\alpha$
.
$\mathtt{Int}\to\mathtt{Int}\preceq\mathtt{Int}\to\alpha$
.
We next demonstrate the correctness of our type system by showing that, at the places where the typing pattern is valid, it assigns the same types to all the programs in the migration space as the brute-force approach does.
Theorem 4 (
 $\star$
removal soundess) If
$\star$
removal soundess) If
 $\pi;\Gamma\vdash e:M|\Omega$
, then
$\pi;\Gamma\vdash e:M|\Omega$
, then
 $\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow statifierForDesc(\Omega,\delta);\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta}$
.
$\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow statifierForDesc(\Omega,\delta);\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta}$
.
This theorem states that, for any removal of
 $\star$
annotations, the typing result encoded in migrational typing is the same as by typing the program with ITGL. For example, for
$\star$
annotations, the typing result encoded in migrational typing is the same as by typing the program with ITGL. For example, for ![]() we get
we get
 $\pi_{a}^{\prime};\Gamma\vdash\mathtt{width}:M_{a}|\Omega_{a}$
, where
$\pi_{a}^{\prime};\Gamma\vdash\mathtt{width}:M_{a}|\Omega_{a}$
, where ![]()
![]() and
and
 $\Omega_{a}$
is as defined earlier. We can verify
$\Omega_{a}$
is as defined earlier. We can verify
 $statifierForDesc(\Omega_{a},\delta_{a});\Gamma\vdash_{GC}\mathtt{width}:\mathtt{Bool}\to\star\to\star$
and
$statifierForDesc(\Omega_{a},\delta_{a});\Gamma\vdash_{GC}\mathtt{width}:\mathtt{Bool}\to\star\to\star$
and
 $\lfloor M_{a} \rfloor_{\delta_{a}}=\mathtt{Bool}\to\star\to\star$
, where
$\lfloor M_{a} \rfloor_{\delta_{a}}=\mathtt{Bool}\to\star\to\star$
, where
 $\delta_{a}$
is as defined earlier.
$\delta_{a}$
is as defined earlier.
Conversely, any removal of
 $\star$
that yields a well-typed program is encoded in some typing derivation in migrational typing, as expressed in the following theorem.
$\star$
that yields a well-typed program is encoded in some typing derivation in migrational typing, as expressed in the following theorem.
Theorem 5 (
 $\star$
removal completeness) If
$\star$
removal completeness) If
 $\omega;\Gamma\vdash_{GC}e:G$
, then there exists some typing
$\omega;\Gamma\vdash_{GC}e:G$
, then there exists some typing
 $\pi;\Gamma\vdash e:M|\Omega$
such that
$\pi;\Gamma\vdash e:M|\Omega$
such that
 $\lfloor \pi\rfloor_{\delta}=\top$
,
$\lfloor \pi\rfloor_{\delta}=\top$
,
 $\lfloor M\rfloor_{\delta}=G$
, and
$\lfloor M\rfloor_{\delta}=G$
, and
 $statifierForDesc(\Omega,\delta)=\omega$
for some
$statifierForDesc(\Omega,\delta)=\omega$
for some
 $\delta$
.
$\delta$
.
We can observe that for a given expression, there may be multiple typing derivations based on the typing rules in Figure 10. The reason is that, for example, the variational types used for typing the same Absdyn in different typings could be different. Particularly, we want to know if there exists a best typing derivation that is more static and more defined (the corresponding typing pattern contains
 $\perp$
in fewest variants) than all other derivations. Fortunately, this is indeed the case (Lemma 2). We next investigate the relation between different typings. In Lemma 1, we will show that different typings can be combined to make the result as correct as possible (that is, to minimize
$\perp$
in fewest variants) than all other derivations. Fortunately, this is indeed the case (Lemma 2). We next investigate the relation between different typings. In Lemma 1, we will show that different typings can be combined to make the result as correct as possible (that is, to minimize
 $\perp$
s in the result pattern). In Lemma 2, we show different typing can be combined to be made as good as possible (that is, to make types more static and more general). Note that the typing process records all dynamic parameters and corresponding variational types in
$\perp$
s in the result pattern). In Lemma 2, we show different typing can be combined to be made as good as possible (that is, to make types more static and more general). Note that the typing process records all dynamic parameters and corresponding variational types in
 ${\Omega}$
. As a result, the domain of
${\Omega}$
. As a result, the domain of
 ${\Omega}$
s in different typings are the same. However, the ranges could be different because different typings may use different Vs in Absdyn.
${\Omega}$
s in different typings are the same. However, the ranges could be different because different typings may use different Vs in Absdyn.
Lemma 1. If
 $\pi_1;\Gamma\vdash e:M|\Omega$
and
$\pi_1;\Gamma\vdash e:M|\Omega$
and
 $\pi_2;\Gamma\vdash e:M|\Omega$
, then there is some typing
$\pi_2;\Gamma\vdash e:M|\Omega$
, then there is some typing
 $\pi;\Gamma\vdash e:M|\Omega$
such that
$\pi;\Gamma\vdash e:M|\Omega$
such that
 $\pi_1\leq\pi$
and
$\pi_1\leq\pi$
and
 $\pi_2\leq\pi$
.
$\pi_2\leq\pi$
.
The following lemma states that we can always find a better (in the sense of the better relation defined at the beginning of this section, in Page 24) variational statifier and typing for any expression.
Lemma 2. If
 $\pi;\Gamma\vdash e:M_{1} |\Omega_{1}$
and
$\pi;\Gamma\vdash e:M_{1} |\Omega_{1}$
and
 $\pi;\Gamma\vdash e:M_{2}|\Omega_{2}$
, then there is some typing
$\pi;\Gamma\vdash e:M_{2}|\Omega_{2}$
, then there is some typing
 $\pi;\Gamma\vdash e:M|\Omega$
such that
$\pi;\Gamma\vdash e:M|\Omega$
such that
 $\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow\lfloor M_1\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}\wedge\lfloor M_2 \rfloor_{\delta}\preceq\lfloor M \rfloor\wedge statifierForDesc(\Omega_1,\delta)\preceq statifierForDesc(\Omega,\delta)\wedge statifierForDesc(\Omega_2,\delta)\preceq statifierForDesc(\Omega,\delta)$
.
$\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow\lfloor M_1\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}\wedge\lfloor M_2 \rfloor_{\delta}\preceq\lfloor M \rfloor\wedge statifierForDesc(\Omega_1,\delta)\preceq statifierForDesc(\Omega,\delta)\wedge statifierForDesc(\Omega_2,\delta)\preceq statifierForDesc(\Omega,\delta)$
.
The properties captured by the previous two lemmas can be combined to show that for any expression there exists a typing that has the most defined pattern and the most static and general result type. We refer to this typing as the most general static migrational typing, abbreviated as the MGSM typing.
Theorem 6 (MGSM Typing). For any e and
 $\Gamma$
, there is a MGSM typing
$\Gamma$
, there is a MGSM typing
 $\pi;\Gamma\vdash e:M|\Omega$
such that for any
$\pi;\Gamma\vdash e:M|\Omega$
such that for any
 $\pi_1;\Gamma\vdash e:M_{1}|\Omega_{1}$
,
$\pi_1;\Gamma\vdash e:M_{1}|\Omega_{1}$
,
 $\forall\delta.\lfloor\pi_{1}\rfloor_{\delta}=\top\Rightarrow\lfloor\pi\rfloor_{\delta}=\top\wedge\lfloor M_{1}\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}$
.
$\forall\delta.\lfloor\pi_{1}\rfloor_{\delta}=\top\Rightarrow\lfloor\pi\rfloor_{\delta}=\top\wedge\lfloor M_{1}\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}$
.
Proof of Theorem 6 The proof of the best typing is a direct consequence of Lemmas 1 and 2, meaning that we can produce a most precise and general typing and then give a most defined pattern to it.
 $\square$
$\square$
To illustrate the use of Theorem 6, the MGSM typing for
 $\mathtt{width}$
is
$\mathtt{width}$
is
 $\pi_{b};\Gamma\vdash\mathtt{width}:M_{b}$
, where
$\pi_{b};\Gamma\vdash\mathtt{width}:M_{b}$
, where
Theorem 6 implies that while an infinite number of typings may be derived (due to the
 $\perp$
pattern), we need only care about the MGSM typing since it encodes all the typings for the whole migration space. Sections 6 and 7 investigate the problem of computing the MGSM typing.
$\perp$
pattern), we need only care about the MGSM typing since it encodes all the typings for the whole migration space. Sections 6 and 7 investigate the problem of computing the MGSM typing.
5 Finding the best migration
This section addresses challenge C4 (migration extraction) from Section 3, that is, given the MGSM typing, how can we find the most static migrations? We address it by investigating the relationship between different migrations in Section 5.1 and developing an algorithm for extracting the most static migration from the typing pattern of an MGSM typing in Section 5.2.
We use the term eliminator to refer to complete decisions. We say that an eliminator
 $\delta_{2}$
is stricter than an eliminator
$\delta_{2}$
is stricter than an eliminator
 $\delta_{2}$
, written
$\delta_{2}$
, written
 $\delta_{1}\gg\delta_{2}$
, if
$\delta_{1}\gg\delta_{2}$
, if
 $\delta_{2}$
does not select the left alternative (corresponding to
$\delta_{2}$
does not select the left alternative (corresponding to
 $\star$
) in more choices than
$\star$
) in more choices than
 $\delta_{1}$
. Formally,
$\delta_{1}$
. Formally,
 \begin{equation*}\delta_{1}\gg\delta_{2}:\Leftrightarrow\forall d.d.1\in\delta_{2}\Rightarrow d.1\in\delta_{1}\end{equation*}
\begin{equation*}\delta_{1}\gg\delta_{2}:\Leftrightarrow\forall d.d.1\in\delta_{2}\Rightarrow d.1\in\delta_{1}\end{equation*}
We say an eliminator
 $\delta$
is valid if
$\delta$
is valid if
 $\lfloor \pi \rfloor_{\delta}=\top$
where
$\lfloor \pi \rfloor_{\delta}=\top$
where
 ${\pi}$
should be clear from the context. We will use
${\pi}$
should be clear from the context. We will use
 $\delta^{v}$
to denote valid eliminators. For example, let
$\delta^{v}$
to denote valid eliminators. For example, let
 \begin{equation*}\delta_{a}^{v}=\{A.1,B.1\}\qquad\delta_{b}^{v}=\{A.1,B.2\}\qquad\delta_{c}^{v}=\{A.2,B.1\}\qquad\delta_{d}=\{A.2,B.2\}\end{equation*}
\begin{equation*}\delta_{a}^{v}=\{A.1,B.1\}\qquad\delta_{b}^{v}=\{A.1,B.2\}\qquad\delta_{c}^{v}=\{A.2,B.1\}\qquad\delta_{d}=\{A.2,B.2\}\end{equation*}
then
 $\delta_{a}^{v}\gg\delta_{b}^{v}$
and
$\delta_{a}^{v}\gg\delta_{b}^{v}$
and
 $\delta_{b}^{v}\gg\delta_{d}$
, but
$\delta_{b}^{v}\gg\delta_{d}$
, but
 $\delta_{b}^{v}\gg\delta_{c}^{v}$
. The eliminators
$\delta_{b}^{v}\gg\delta_{c}^{v}$
. The eliminators
 $\delta_{a}^{v}$
,
$\delta_{a}^{v}$
,
 $\delta_{b}^{v}$
, and
$\delta_{b}^{v}$
, and
 $\delta_{c}^{v}$
are valid, while
$\delta_{c}^{v}$
are valid, while
 $\delta_{d}$
is not, with respect to
$\delta_{d}$
is not, with respect to
 $\pi_{b}$
from Section 4.5.
$\pi_{b}$
from Section 4.5.
5.1 Relationships between migrations
Since every migration can be identified by an eliminator for the MGSM typing, and since stricter eliminators correspond to more static migrations, the problem of computing the most static migrations can be reduced to the problem of finding the strictest valid eliminators.
Instead of considering all valid eliminators for an expression (which is exponential in the number of dynamic parameters), we instead consider the valid eliminators of the typing pattern for the MGSM typing of the expression. The reason is that typing patterns are usually small, yielding fewer eliminators that we have to consider (in fact, later results will show that we do not have to consider even all of these). For example, the pattern
 $\pi_a$
from Section 4.5 for
$\pi_a$
from Section 4.5 for
 $\mathtt{rowAtI}$
has only 5 eliminators while the expression itself has 32. As another example, from the pattern
$\mathtt{rowAtI}$
has only 5 eliminators while the expression itself has 32. As another example, from the pattern
 $\pi_{b}$
, defined at the end of Section 4.5 (page 25), we can see that
$\pi_{b}$
, defined at the end of Section 4.5 (page 25), we can see that
 $\delta_{ab}^{v}=\{A.1\}$
compactly represents
$\delta_{ab}^{v}=\{A.1\}$
compactly represents
 $\delta_{a}^{v}$
and
$\delta_{a}^{v}$
and
 $\delta_{b}^{v}$
for
$\delta_{b}^{v}$
for
 $\mathtt{width}$
.
$\mathtt{width}$
.
Our first question is whether any eliminator that is stricter than an invalid eliminator could be valid. This question seems irrelevant for this example because the invalid eliminator
 $\delta_{d}$
is already the strictest for
$\delta_{d}$
is already the strictest for
 $\pi_{b}$
. However, this is not the case in general, and knowing the answer to this question helps us to prune the search space. For example, the eliminator
$\pi_{b}$
. However, this is not the case in general, and knowing the answer to this question helps us to prune the search space. For example, the eliminator
 $\{A.1,B.1,E.2\}$
is invalid for
$\{A.1,B.1,E.2\}$
is invalid for
 $\pi_{a}$
, and we want to know whether any of the stricter eliminators—
$\pi_{a}$
, and we want to know whether any of the stricter eliminators—
 $\{A.1,B.2,E.2\}$
,
$\{A.1,B.2,E.2\}$
,
 $\{A.2,B.1,E.2\}$
and
$\{A.2,B.1,E.2\}$
and
 $\{A.2,B.2,E.2\}$
—are valid. The following theorem answers this question.
$\{A.2,B.2,E.2\}$
—are valid. The following theorem answers this question.
Theorem 7 (Error Irrecoverability) Let
 $\pi;\Gamma\vdash e:M|\Omega$
be an MGSM typing for e and
$\pi;\Gamma\vdash e:M|\Omega$
be an MGSM typing for e and
 $\Gamma$
. If
$\Gamma$
. If
 $\lfloor \pi \rfloor_{\delta}=\vdash$
, then
$\lfloor \pi \rfloor_{\delta}=\vdash$
, then
 $\forall \delta_{1}.\delta\gg\delta_{1}\Rightarrow\lfloor \pi \rfloor_{\delta_{1}}=\vdash$
.
$\forall \delta_{1}.\delta\gg\delta_{1}\Rightarrow\lfloor \pi \rfloor_{\delta_{1}}=\vdash$
.
This theorem implies that we can simply ignore invalid eliminators and focus on valid ones, since all invalid eliminators lead to ill-typed expressions.
Proof. by contradiction. Assume there is some
 $\delta_{1}$
such that
$\delta_{1}$
such that
 $\delta\gg{\delta_{1}}$
but
$\delta\gg{\delta_{1}}$
but
 $\lfloor \pi \rfloor_{\delta_{1}}=\vdash$
. According to Theorem 4, we have
$\lfloor \pi \rfloor_{\delta_{1}}=\vdash$
. According to Theorem 4, we have
 $statifierForDesc(\Omega,\delta_{1});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta_{1}}$
, which means that e is well-typed under the statifier
$statifierForDesc(\Omega,\delta_{1});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta_{1}}$
, which means that e is well-typed under the statifier
 $statifierForDesc({{\Omega}},{\delta_{1}})$
. Based on the definition of statifier generation (Section 4.5), we know that
$statifierForDesc({{\Omega}},{\delta_{1}})$
. Based on the definition of statifier generation (Section 4.5), we know that
 $\delta_{1}$
implies that
$\delta_{1}$
implies that
 $statifierForDesc(\Omega,\delta)\subseteq statifierForDesc(\Omega,\delta_{1})$
. Therefore, applying
$statifierForDesc(\Omega,\delta)\subseteq statifierForDesc(\Omega,\delta_{1})$
. Therefore, applying
 $statifierForDesc(\Omega,\delta_{1})$
to e yields a less static expression than
$statifierForDesc(\Omega,\delta_{1})$
to e yields a less static expression than
 $statifierForDesc(\Omega,\delta_{1})$
does. Based on the static gradual guarantee for ITGL (Miyazaki et al., Reference Miyazaki, Sekiyama and Igarashi2019), the typing relation
$statifierForDesc(\Omega,\delta_{1})$
does. Based on the static gradual guarantee for ITGL (Miyazaki et al., Reference Miyazaki, Sekiyama and Igarashi2019), the typing relation
 $statifierForDesc(\Omega,\delta);\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta}$
is satisfied. According to Theorem 6, this implies that
$statifierForDesc(\Omega,\delta);\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta}$
is satisfied. According to Theorem 6, this implies that
 $\lfloor\pi\rfloor_{\delta}=\top$
, which contradicts our condition that
$\lfloor\pi\rfloor_{\delta}=\top$
, which contradicts our condition that
 $\lfloor\pi\rfloor_{\delta}=\vdash$
. Therefore, there is no
$\lfloor\pi\rfloor_{\delta}=\vdash$
. Therefore, there is no
 $\delta_{1}$
such that
$\delta_{1}$
such that
 $\delta\gg\delta_{1}$
but
$\delta\gg\delta_{1}$
but
 $\lfloor\pi\rfloor_{\delta_{1}}=\top$
exists, completing the proof.
$\lfloor\pi\rfloor_{\delta_{1}}=\top$
exists, completing the proof. ![]()
A valid eliminator for the typing pattern corresponds to potentially many valid eliminators for the expression. We say that a valid pattern eliminator
 $\delta_{1}$
covers a valid expression eliminator
$\delta_{1}$
covers a valid expression eliminator
 $\delta_{2}$
if
$\delta_{2}$
if
 $\delta_{1}\subseteq\delta_{2}$
. Among all the expression eliminators covered by a pattern eliminator, one is strictest. For example, the eliminator
$\delta_{1}\subseteq\delta_{2}$
. Among all the expression eliminators covered by a pattern eliminator, one is strictest. For example, the eliminator
 $\delta_{ab}^{v}$
for pattern
$\delta_{ab}^{v}$
for pattern
 $\pi_{b}$
covers the eliminators
$\pi_{b}$
covers the eliminators
 $\delta_{a}^{v}$
and
$\delta_{a}^{v}$
and
 $\delta_{b}^{v}$
for typing
$\delta_{b}^{v}$
for typing
 $\mathtt{width}$
, and
$\mathtt{width}$
, and
 $\delta_{b}^{v}$
is the strictest. As another example, the valid eliminator
$\delta_{b}^{v}$
is the strictest. As another example, the valid eliminator
 $\delta_{ae}^{v}=\{A.1,E.1\}$
for pattern
$\delta_{ae}^{v}=\{A.1,E.1\}$
for pattern
 $\pi_{a}$
covers eight valid eliminators (two options for each of the three choice names that do not appear in the pattern) for typing
$\pi_{a}$
covers eight valid eliminators (two options for each of the three choice names that do not appear in the pattern) for typing
 $\mathtt{rowAtI}$
, and
$\mathtt{rowAtI}$
, and
 $\{A.1,E.1,B.2,D.2,F.2\}$
is the strictest among them.
$\{A.1,E.1,B.2,D.2,F.2\}$
is the strictest among them.
Among all expression eliminators covered by a pattern eliminator, stricter ones yield better result types. This is expressed by the following theorem.
Theorem 8 [Strict eliminators select better result types] If
 $\pi;\Gamma\vdash e:M|\Omega$
is the MGSM typing for e and
$\pi;\Gamma\vdash e:M|\Omega$
is the MGSM typing for e and
 $\Gamma$
, then
$\Gamma$
, then
 $\delta_{1}^{v}\gg\delta_{2}^{v}\wedge\lfloor\pi\rfloor_{\delta_{1}^{v}}=\top\wedge\lfloor\pi\rfloor_{\delta_{2}^{v}}=\top\Rightarrow\lfloor M\rfloor_{\delta_{1}^{v}}\preceq\lfloor M\rfloor_{\delta_{2}^{v}}$
.
$\delta_{1}^{v}\gg\delta_{2}^{v}\wedge\lfloor\pi\rfloor_{\delta_{1}^{v}}=\top\wedge\lfloor\pi\rfloor_{\delta_{2}^{v}}=\top\Rightarrow\lfloor M\rfloor_{\delta_{1}^{v}}\preceq\lfloor M\rfloor_{\delta_{2}^{v}}$
.
Proof. Based on Theorem 4, we have
 $statifierForDesc(\Omega,\delta_{1}^{v});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta_{1}^{v}}$
and
$statifierForDesc(\Omega,\delta_{1}^{v});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M\rfloor_{\delta_{1}^{v}}$
and
 $statifierForDesc(\Omega,\delta_{2}^{v});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M \rfloor_{\delta_{2}^{v}}$
, we have
$statifierForDesc(\Omega,\delta_{2}^{v});\lfloor\Gamma\rfloor_{\delta}\vdash_{GC}e:\lfloor M \rfloor_{\delta_{2}^{v}}$
, we have
 $statifierForDesc(\Omega,\delta_{1}^{v})\subseteq statifierForDesc(\Omega,\delta_{2}^{v})$
based on the definition of statifier generation (Section 4.5). As a result, more precise types are given to variables in a well-typed manner and the gradual guarantee (Siek et al., Reference Siek, Vitousek, Cimini and Boyland2015) gives us
$statifierForDesc(\Omega,\delta_{1}^{v})\subseteq statifierForDesc(\Omega,\delta_{2}^{v})$
based on the definition of statifier generation (Section 4.5). As a result, more precise types are given to variables in a well-typed manner and the gradual guarantee (Siek et al., Reference Siek, Vitousek, Cimini and Boyland2015) gives us
 $\lfloor M\rfloor_{\delta_{1}^{v}}\preceq\lfloor M\rfloor_{\delta_{2}^{v}}$
.
$\lfloor M\rfloor_{\delta_{1}^{v}}\preceq\lfloor M\rfloor_{\delta_{2}^{v}}$
. ![]()
As an example illustrating Theorem 8, consider
 $\delta_{a}^{v}$
,
$\delta_{a}^{v}$
,
 $\delta_{b}^{v}$
, and
$\delta_{b}^{v}$
, and
 $M_b$
, introduced in Section 4.5. We can verify that both
$M_b$
, introduced in Section 4.5. We can verify that both
 $\delta_{a}^{v}\gg\delta_{b}^{v}$
and
$\delta_{a}^{v}\gg\delta_{b}^{v}$
and
 $\lfloor M_{b}\rfloor_{\delta_{a}^{v}}\preceq\lfloor M_{b}\rfloor_{\delta_{b}^{v}}$
, where
$\lfloor M_{b}\rfloor_{\delta_{a}^{v}}\preceq\lfloor M_{b}\rfloor_{\delta_{b}^{v}}$
, where
 $\lfloor M_{b}\rfloor_{\delta_{a}^{v}}=\star\to\star\to\star$
, and
$\lfloor M_{b}\rfloor_{\delta_{a}^{v}}=\star\to\star\to\star$
, and
 $\lfloor M_{b}\rfloor_{\delta_{b}^{v}}=\mathtt{Bool}\to\star\to\star$
.
$\lfloor M_{b}\rfloor_{\delta_{b}^{v}}=\mathtt{Bool}\to\star\to\star$
.
Theorem 8 provides a way to order the eliminators covered by a single pattern eliminator, but how about ordering different valid eliminators of the typing pattern? Considering pattern
 $\pi_b$
, neither of the valid eliminators
$\pi_b$
, neither of the valid eliminators
 $\delta_{b}^{v}$
or
$\delta_{b}^{v}$
or
 $\delta_{c}^{v}$
is stricter than the other. Similarly, for pattern
$\delta_{c}^{v}$
is stricter than the other. Similarly, for pattern
 $\pi_a$
, neither of the valid eliminators is stricter than the other. In fact, this property holds not only for these two examples but also for a class of typing patterns that are in pattern normal form. We say a pattern is in normal form if it does not contain idempotent choices (choices with identical alternatives) and does not nest a choice in another choice with the same name (no dead alternatives). We capture this property in the following theorem.
$\pi_a$
, neither of the valid eliminators is stricter than the other. In fact, this property holds not only for these two examples but also for a class of typing patterns that are in pattern normal form. We say a pattern is in normal form if it does not contain idempotent choices (choices with identical alternatives) and does not nest a choice in another choice with the same name (no dead alternatives). We capture this property in the following theorem.
Theorem 9 (Eliminator Incomparability) Let
 $\pi;\Gamma\vdash e:M|\Omega$
be MGSM typing for e and
$\pi;\Gamma\vdash e:M|\Omega$
be MGSM typing for e and
 $\Gamma$
and
$\Gamma$
and
 ${\pi}$
is in normal form, then
${\pi}$
is in normal form, then
 $\nexists\delta^{v}.\delta_{1}^{v}\gg\delta^{v}\wedge\delta_{2}^{v}\gg\delta^{v}$
if
$\nexists\delta^{v}.\delta_{1}^{v}\gg\delta^{v}\wedge\delta_{2}^{v}\gg\delta^{v}$
if
 $\delta_{1}^{v}$
and
$\delta_{1}^{v}$
and
 $\delta_{2}^{v}$
are distinct.
$\delta_{2}^{v}$
are distinct.
Proof of Theorem 9 Proof by contradiction. Assume there exists such a
 $\delta^{v}$
. First,
$\delta^{v}$
. First,
 $\delta_{1}^{v}$
contains at least one selector of the form d.1 for some d. Otherwise, the program can be fully migrated to be static, and the typing pattern will be
$\delta_{1}^{v}$
contains at least one selector of the form d.1 for some d. Otherwise, the program can be fully migrated to be static, and the typing pattern will be
 $\top$
, making
$\top$
, making
 $\delta_{1}^{v}$
and
$\delta_{1}^{v}$
and
 $\delta_{2}^{v}$
be the same. Similarly, this holds for
$\delta_{2}^{v}$
be the same. Similarly, this holds for
 $\delta_{2}^{v}$
. Without loss of generality, we assume
$\delta_{2}^{v}$
. Without loss of generality, we assume
 $\delta_{1}^{v}$
contains
$\delta_{1}^{v}$
contains
 $d_1.1$
and
$d_1.1$
and
 $\delta_{2}^{v}$
contains
$\delta_{2}^{v}$
contains
 $d_2.1$
. We consider several cases.
$d_2.1$
. We consider several cases.
-
•
$\delta_{1}^{v}=\{d_{1}.1,d_2.1\}$
and
$\delta_{2}^{v}=\{d_{1}.1,d_2.1\}$
or
$\{d_{1}.2,d_{2}.2\}$
. Based on
$\delta_{2}^{v}$
,
$\delta_{3}^{v}=\{d_{1}.1,d_{2}.2\}$
is a valid eliminator based on the inverse of the implication in Theorem 7. From
$\delta_{1}^{v}$
and
$\delta_{3}^{v}$
, we can infer that both alternatives of
$d_2$
are
$\top$
, meaning that it is an idempotent variation and
${\pi}$
is not in normal form. -
•
$\delta_{1}^{v}=\{d_{1}.1,d_2.1\},\{D_{1}.2,d_{2}.1\}$
or
$\{d_{1}.2,d_{2}.2\}$
. The reasoning is similar to the previous case by showing that the variation
$d_2$
is idempotent. -
•
$\delta_{1}^{v}=\{d_{1}.1\}$
and
$\delta_{2}^{v}=\{d_{1}.2,d_{2}.1\}$
. The decision
$\delta=\{d_{1}.2,d_{2}.2\}$
satisfies
$\delta_{1}^{v}\gg\delta\wedge\delta_{2}^{v}\gg\delta$
. If
$\delta$
is a valid eliminator, then we can again show that
$d_2$
is idempotent, a contradiction that
${\pi}$
is in normal form.




















We could swap the assignments to
 $\delta_{1}^{v}$
and
$\delta_{1}^{v}$
and
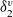 $\delta_{2}^{v}$
, but this will yield the same proof result.
$\delta_{2}^{v}$
, but this will yield the same proof result. ![]()
It follows from the theorem that for any two valid eliminators
 $\delta_{1}^{v}$
and
$\delta_{1}^{v}$
and
 $\delta_{2}^{v}$
for
$\delta_{2}^{v}$
for
 $\pi_1$
,
$\pi_1$
,
 $\delta_{1}^{v}\gg\delta_{2}^{v}$
and
$\delta_{1}^{v}\gg\delta_{2}^{v}$
and
 $\delta_{2}^{v}\gg\delta_{1}^{v}$
. Two eliminators that are incomparable with respect to
$\delta_{2}^{v}\gg\delta_{1}^{v}$
. Two eliminators that are incomparable with respect to
 $\gg$
will remove
$\gg$
will remove
 $\star$
s for different parameters for the same expression, leading to types that are incomparable by
$\star$
s for different parameters for the same expression, leading to types that are incomparable by
 $\sqsubseteq$
(defined in Section 4), and thus incomparable by
$\sqsubseteq$
(defined in Section 4), and thus incomparable by
 $\preceq$
. For example, since
$\preceq$
. For example, since
 $\delta_{b}^{v}\gg\delta_{c}^{v}$
and
$\delta_{b}^{v}\gg\delta_{c}^{v}$
and
 $\delta_{c}^{v}\gg\delta_{b}^{v}$
, we have
$\delta_{c}^{v}\gg\delta_{b}^{v}$
, we have
 $G_{b}\preceq G_{c}$
and
$G_{b}\preceq G_{c}$
and
 $G_{c}\preceq G_{b}$
, where
$G_{c}\preceq G_{b}$
, where
 $G_{b}=\lfloor M_{b}\rfloor_{\delta_{b}^{v}}=\star\to(\mathtt{Int}\to\beta)\to\beta$
and
$G_{b}=\lfloor M_{b}\rfloor_{\delta_{b}^{v}}=\star\to(\mathtt{Int}\to\beta)\to\beta$
and
 $G_{c}=\lfloor M_{b}\rfloor_{\delta_{c}^{v}}=\mathtt{Bool}\to\star\to\star$
.
$G_{c}=\lfloor M_{b}\rfloor_{\delta_{c}^{v}}=\mathtt{Bool}\to\star\to\star$
.
Combining Theorems 8 and 9 yields the following result about finding most static migrations. We develop an algorithm for extracting such migrations in Section 5.2.
Theorem 10 (Uniqueness of most static migrations) Let
 $\pi;\Gamma\vdash e:M|\Omega$
be the MGSM typing for e and
$\pi;\Gamma\vdash e:M|\Omega$
be the MGSM typing for e and
 $\Gamma$
, and
$\Gamma$
, and
 ${\pi}$
is in normal form. Then, the number of most static migrations for e equals the number of valid eliminators for
${\pi}$
is in normal form. Then, the number of most static migrations for e equals the number of valid eliminators for
 ${\pi}$
.
${\pi}$
.
Proof of Theorem 10 The proof follows directly from Theorems 9 and 8. Theorem 9 implies that complete decisions are not comparable, and no other complete decisions are better than them. Theorem 8 implies that tighter selectors yields more precise types. By definition, each complete decision yields a most static migration, since no types better than those produced by complete decisions can be assigned to the expression. ![]()
It follows from the theorem that e has a unique most static migration if
 $\pi_1$
has only one valid eliminator.
$\pi_1$
has only one valid eliminator.
5.2 Extracting most static migrations
The most static migrations for a program are identified by valid eliminators that describe whether to pick the
 $\star$
annotation or the inferred type for each parameter. We compute this set of eliminators from an MGSM typing in three steps: (1) simplify the typing pattern to its normal form, (2) collect the valid eliminators for the normal form, and (3) expand each valid eliminator into a strictest eliminator for the corresponding expression.
$\star$
annotation or the inferred type for each parameter. We compute this set of eliminators from an MGSM typing in three steps: (1) simplify the typing pattern to its normal form, (2) collect the valid eliminators for the normal form, and (3) expand each valid eliminator into a strictest eliminator for the corresponding expression.
Simplifying a typing pattern to its normal form has two advantages. First, the valid eliminators are fewer and smaller. Second, we can use the result of Theorem 10 to find most static migrations. We use the following rules to simplify patterns to normal forms.
The first two rules remove idempotent choices and dead alternatives. The third rule enables simplifying parts of a larger pattern. For example, we can use the third and the first rule to simplify the pattern ![]() to pattern
to pattern
 $\pi_a$
from Section 4.5.
$\pi_a$
from Section 4.5.
We use the function
 $(\pi)$
to build the set of valid eliminators for a pattern
$(\pi)$
to build the set of valid eliminators for a pattern
 ${\pi}$
in normal form.
${\pi}$
in normal form.
To illustrate the definition of ve, we consider the calculation process for the pattern ![]() .
. ![]()
![]() . This means that the set of valid eliminators for
. This means that the set of valid eliminators for ![]() contains only one element:
contains only one element:
 $\{A.1\}$
. Similarly,
$\{A.1\}$
. Similarly, ![]() . As another example,
. As another example,
 $ve(\pi_a)$
yields
$ve(\pi_a)$
yields
 $\{\delta_{o}^{v},\delta_{p}^{v}\}$
, where
$\{\delta_{o}^{v},\delta_{p}^{v}\}$
, where
 $\delta_{o}^{v}=\{A.1,E.1\}$
and
$\delta_{o}^{v}=\{A.1,E.1\}$
and
 $\delta_{p}^{v}=\{A.2,B.1,E.1\}$
.
$\delta_{p}^{v}=\{A.2,B.1,E.1\}$
.
Finally, we use the following function
 $expand(\delta,\mathscr{D})$
to compute the strictest expression eliminator from the given pattern eliminator
$expand(\delta,\mathscr{D})$
to compute the strictest expression eliminator from the given pattern eliminator
 $\delta$
and the set
$\delta$
and the set
 $\mathscr{D}$
of all choice names in the expression.
$\mathscr{D}$
of all choice names in the expression.
 \begin{equation*}expand(\delta,\mathscr{d})=\delta\cup\{d.2|d\in\mathscr{D}\wedge d.1\in\delta\}\end{equation*}
\begin{equation*}expand(\delta,\mathscr{d})=\delta\cup\{d.2|d\in\mathscr{D}\wedge d.1\in\delta\}\end{equation*}
For example, the set of choice names
 $\mathscr{D}$
for typing
$\mathscr{D}$
for typing
 $\mathtt{rowAtI}$
is
$\mathtt{rowAtI}$
is
 $\{A,B,D,E,F\}$
, and
$\{A,B,D,E,F\}$
, and
 $expand(\delta_{o}^{v},\mathscr{D})$
yields
$expand(\delta_{o}^{v},\mathscr{D})$
yields
 $\{A.1,E.1,B.2,D.2,F.2\}$
and
$\{A.1,E.1,B.2,D.2,F.2\}$
and
 $expand(\delta_{p}^{v},\mathscr{D})$
yields
$expand(\delta_{p}^{v},\mathscr{D})$
yields
 $\{A.2,B.1,E.1,D.2,F.2\}$
.
$\{A.2,B.1,E.1,D.2,F.2\}$
.
Each expanded valid eliminator is a best eliminator that specifies how to migrate the program. For example, the first best eliminator for
 $\mathtt{rowAtI}$
above removes the
$\mathtt{rowAtI}$
above removes the
 $\star$
annotation for
$\star$
annotation for
 $\mathtt{widthFunc}$
,
$\mathtt{widthFunc}$
,
 $\mathtt{table}$
, and
$\mathtt{table}$
, and
 $\mathtt{i}$
, while the other best eliminator removes the
$\mathtt{i}$
, while the other best eliminator removes the
 $\star$
annotation for
$\star$
annotation for
 $\mathtt{fixed}$
,
$\mathtt{fixed}$
,
 $\mathtt{table}$
, and
$\mathtt{table}$
, and
 $\mathtt{i}$
.
$\mathtt{i}$
.
Formally, given an expression e and its MGSM typing
 $\pi;\Gamma\vdash e:M||\Omega$
, then for any expanded valid eliminator
$\pi;\Gamma\vdash e:M||\Omega$
, then for any expanded valid eliminator
 $\delta^{v}$
, we can generate the most static migration using
$\delta^{v}$
, we can generate the most static migration using
 $statifierForDesc(\Omega,\delta^{v})$
, defined in Page 23.
$statifierForDesc(\Omega,\delta^{v})$
, defined in Page 23.
Overall, these three steps provide a simple way to extract the most static migration from an MGSM typing. In Section 10, we show that these steps lead to an efficient implementation. Usually, the normal form of a typing pattern is small and has only a few valid eliminators. For example, if the program is still well-typed after removing all
 $\star$
annotations, then the pattern will be
$\star$
annotations, then the pattern will be
 $\top$
, which has only one valid eliminator (the empty set). Similarly, if the program is ill-typed if any
$\top$
, which has only one valid eliminator (the empty set). Similarly, if the program is ill-typed if any
 $\star$
annotation is removed, then there is again just one valid eliminator.
$\star$
annotation is removed, then there is again just one valid eliminator.
Since normal forms are ideal, we will show in Section 7 how we can efficiently maintain patterns to be in normal form throughout the type inference process.
6 Constraint generation
The constraint generation rules are presented in Figure 11. The judgment
 $\Gamma\vdash_{c}e:M|C$
states that under
$\Gamma\vdash_{c}e:M|C$
states that under
 $\Gamma$
, the expression e has type M when the constraint C is solved. Accordingly, e and
$\Gamma$
, the expression e has type M when the constraint C is solved. Accordingly, e and
 $\Gamma$
are inputs, while M and C are outputs. Note that we now omit the statifier
$\Gamma$
are inputs, while M and C are outputs. Note that we now omit the statifier
 ${\Omega}$
in constraint judgments since it is not needed for type inference. We also omit
${\Omega}$
in constraint judgments since it is not needed for type inference. We also omit
 ${\pi}$
since
${\pi}$
since
 ${\pi}$
is an input in the declarative typing but will be computed through solving constraints generated here. Constraint solving will be discussed in Section 7. The syntax of constraints are as follows:
${\pi}$
is an input in the declarative typing but will be computed through solving constraints generated here. Constraint solving will be discussed in Section 7. The syntax of constraints are as follows:
The first form represents type compatibility constraints. Often it is the case that two types are only partially compatible. Note, when
 $M_1\approx^{?}$
is solved, it is not necessary that
$M_1\approx^{?}$
is solved, it is not necessary that
 $M_1$
and
$M_1$
and
 $M_2$
are compatible everywhere. As a result, constraint solving result includes a typing pattern, which indicates where
$M_2$
are compatible everywhere. As a result, constraint solving result includes a typing pattern, which indicates where
 $M_1$
and
$M_1$
and
 $M_2$
are indeed compatible.
$M_2$
are indeed compatible.

Figure 11. Constraint generation rules.
The constraint
 $C_1 \wedge C_2$
defines the conjunction of two constraints
$C_1 \wedge C_2$
defines the conjunction of two constraints
 $C_1$
and
$C_1$
and
 $C_2$
, while the constraint
$C_2$
, while the constraint ![]() defines a choice between two constraints. The constraint
defines a choice between two constraints. The constraint
 $\varepsilon$
represents an empty constraint. This is needed to represent a judgment where no constraints are generated.
$\varepsilon$
represents an empty constraint. This is needed to represent a judgment where no constraints are generated.
Finally, the constraint
 $\mathtt{Fail}$
represents a constraint that, when solved, always leads to a failure. Such a constraint is needed when, for example,
$\mathtt{Fail}$
represents a constraint that, when solved, always leads to a failure. Such a constraint is needed when, for example,
 $dom(\mathtt{Int})$
is calculated during the constraint generation process. As
$dom(\mathtt{Int})$
is calculated during the constraint generation process. As
 $\mathtt{Int}$
is not a function type,
$\mathtt{Int}$
is not a function type,
 $dom(\mathtt{Int})$
will always fail. We generate a
$dom(\mathtt{Int})$
will always fail. We generate a
 $\mathtt{Fail}$
to communicate this failure to the constraint solver. The constraint
$\mathtt{Fail}$
to communicate this failure to the constraint solver. The constraint
 $\mathtt{Fail}$
was absent from the original paper (Campora et al., Reference Campora, Chen, Erwig and Walkingshaw2018a). Without it, that work outputs a typing pattern and returns a
$\mathtt{Fail}$
was absent from the original paper (Campora et al., Reference Campora, Chen, Erwig and Walkingshaw2018a). Without it, that work outputs a typing pattern and returns a
 $\perp$
as the typing pattern to denote that certain constraint will definitely fail to solve.
$\perp$
as the typing pattern to denote that certain constraint will definitely fail to solve.
A drawback of that approach is that both constraint generation and constraint solving output typing patterns, and these patterns have to be combined into a single pattern, which is one part of type inference result. That work used the notion of “pattern placeholders,” which are introduced during constraint generation and will be plugged in with concrete patterns during constraint solving. The introduction of
 $\mathtt{Fail}$
simplifies the handling of patterns. Specifically, only constraint solving outputs a pattern, and we do not need the notion of “pattern placeholders.” Also, the typing pattern has no longer to be part of the constraint generation judgment. Moreover, with
$\mathtt{Fail}$
simplifies the handling of patterns. Specifically, only constraint solving outputs a pattern, and we do not need the notion of “pattern placeholders.” Also, the typing pattern has no longer to be part of the constraint generation judgment. Moreover, with
 $\mathtt{Fail}$
we have simplified the judgments and definitions of several auxiliary functions (Figures 11 and 12) in this version.
$\mathtt{Fail}$
we have simplified the judgments and definitions of several auxiliary functions (Figures 11 and 12) in this version.

Figure 12. Auxiliary constraint generation functions.
We now walk through each constraint generation rule. The rule Conc, generating constraints for constants, has a very similar form to Con in Figure 10.
The rule Varc for variable references is similar to Var and, like Conc, generates the empty constraint.
The rule AbsDync generates constraints for abstractions with dynamic parameters. It helps facilitate migration by creating a fresh choice type with a left alternative containing
 $\star$
and a right alternative containing a fresh type variable. The type variable is used to infer a new static type for the parameter, if possible. The rules Appc and Ifc are more involved because constraints from premises have to be combined. The rules Appc and Ifc use many auxiliary functions to generate constraints. The functions, defined in Figure 12, take the form:
$\star$
and a right alternative containing a fresh type variable. The type variable is used to infer a new static type for the parameter, if possible. The rules Appc and Ifc are more involved because constraints from premises have to be combined. The rules Appc and Ifc use many auxiliary functions to generate constraints. The functions, defined in Figure 12, take the form:
 $domCst(M_1,M_2)\hookrightarrow C$
,
$domCst(M_1,M_2)\hookrightarrow C$
,
 $codCst(M_1)\hookrightarrow(M_2,C)$
, and
$codCst(M_1)\hookrightarrow(M_2,C)$
, and
 $M_1\sqcap M_2\hookrightarrow(M_{3},C)$
, where the objects to the left of
$M_1\sqcap M_2\hookrightarrow(M_{3},C)$
, where the objects to the left of
 $\hookrightarrow$
are inputs and those to the right are outputs. Essentially, they implement the dom, cod, and
$\hookrightarrow$
are inputs and those to the right are outputs. Essentially, they implement the dom, cod, and
 $\sqcap$
operations defined for the declarative type system in Figure 10. Note, in these functions
$\sqcap$
operations defined for the declarative type system in Figure 10. Note, in these functions
 $\kappa$
denote fresh type variables. We will use such variables in this and next sections.
$\kappa$
denote fresh type variables. We will use such variables in this and next sections.
We illustrate domCst by considering the example ![]() . Since the first argument is a choice type, domCst proceeds to recursively call on each alternative of A, leading to two subproblems
. Since the first argument is a choice type, domCst proceeds to recursively call on each alternative of A, leading to two subproblems
 $domCst(\star,\mathtt{Int})$
and
$domCst(\star,\mathtt{Int})$
and
 $domCst(\alpha,\mathtt{Int})$
. The first subproblem is handled by the case for
$domCst(\alpha,\mathtt{Int})$
. The first subproblem is handled by the case for
 $\star$
, which immediately returns
$\star$
, which immediately returns
 $\varepsilon$
, meaning that no further constraints need to be solved. The second subproblem is handled by the case of domCst for type variables. Since dom always expects a function type, the constraint
$\varepsilon$
, meaning that no further constraints need to be solved. The second subproblem is handled by the case of domCst for type variables. Since dom always expects a function type, the constraint
 $\alpha\approx^{?}\mathtt{Int}\to\kappa_{2}$
is generated. The constraints for subproblems are combined together with the choice A, yielding the final constraint
$\alpha\approx^{?}\mathtt{Int}\to\kappa_{2}$
is generated. The constraints for subproblems are combined together with the choice A, yielding the final constraint ![]() .
.
The following soundness (Theorem 11) and completeness (Theorem 12) theorems state that the constraint generation rules correspond to the declarative typing rules presented in Figure 10. In particular, Theorem 12 implies that constraint generation finds the MGSM typing. Following the spirit of Vytiniotis et al., (Reference Vytiniotis, Peyton Jones, Schrijvers and Sulzmann2011), we use the idea of sound and most general solutions (
 $\theta$
) for constraints (C) in the following theorems (Vytiniotis et al., (Reference Vytiniotis, Peyton Jones, Schrijvers and Sulzmann2011) used the term guess-free). (
$\theta$
) for constraints (C) in the following theorems (Vytiniotis et al., (Reference Vytiniotis, Peyton Jones, Schrijvers and Sulzmann2011) used the term guess-free). (
 $\theta,\pi$
) is sound for a constraint of the form
$\theta,\pi$
) is sound for a constraint of the form
 $M_{1}\approx^{?}M_{2}$
if
$M_{1}\approx^{?}M_{2}$
if
 $\theta(M_1)\approx_{\pi}\theta(M_2)$
, is sound for a constraint
$\theta(M_1)\approx_{\pi}\theta(M_2)$
, is sound for a constraint
 $C_{1}\wedge C_{2}$
or
$C_{1}\wedge C_{2}$
or ![]() if it is sound for both
if it is sound for both
 $C_1$
and
$C_1$
and
 $C_2$
, is sound for
$C_2$
, is sound for
 $\mathtt{Fail}$
if
$\mathtt{Fail}$
if
 ${\pi}$
is
${\pi}$
is
 $\perp$
, and is always sound for
$\perp$
, and is always sound for
 $\varepsilon$
. In Section 7, we provide a unification algorithm that generates solutions with these desired properties.
$\varepsilon$
. In Section 7, we provide a unification algorithm that generates solutions with these desired properties.
Theorem 11 (Soundness of Constraint Generation). If
 $\Gamma\vdash_{C}e:M|C$
, then
$\Gamma\vdash_{C}e:M|C$
, then
 $\pi;\theta(\Gamma)\vdash e:\theta(M)|\Omega$
for some
$\pi;\theta(\Gamma)\vdash e:\theta(M)|\Omega$
for some
 ${\Omega}$
, where
${\Omega}$
, where
 $(\Omega,{\pi})$
is a sound solution for C.
$(\Omega,{\pi})$
is a sound solution for C.
Theorem 12 (Completeness of Constraint Generation). If
 $\pi;\theta(\Gamma)\vdash e:\theta(M)|\Omega$
then
$\pi;\theta(\Gamma)\vdash e:\theta(M)|\Omega$
then
 $\Gamma\vdash_{C}e:M_{1}|C$
such that
$\Gamma\vdash_{C}e:M_{1}|C$
such that
 $\pi\leq\pi_{1}$
,
$\pi\leq\pi_{1}$
,
 $\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow\lfloor\pi_{1}\rfloor_{\delta}=\top\wedge\lfloor M\rfloor_{\delta}\preceq\lfloor\theta_{1}(M_1)\rfloor_{\delta}\wedge\lfloor\theta\rfloor_{\delta}=\lfloor\theta'\rfloor_{\delta}\cdot\lfloor\theta_{1}\rfloor_{\delta}$
for some
$\forall\delta.\lfloor\pi\rfloor_{\delta}=\top\Rightarrow\lfloor\pi_{1}\rfloor_{\delta}=\top\wedge\lfloor M\rfloor_{\delta}\preceq\lfloor\theta_{1}(M_1)\rfloor_{\delta}\wedge\lfloor\theta\rfloor_{\delta}=\lfloor\theta'\rfloor_{\delta}\cdot\lfloor\theta_{1}\rfloor_{\delta}$
for some
 $\theta'$
, where
$\theta'$
, where
 $(\theta_1,\pi_1)$
is a sound and most-general solution for C.
$(\theta_1,\pi_1)$
is a sound and most-general solution for C.
In the theorem, we define
 $\lfloor\theta\rfloor_{\delta}$
as
$\lfloor\theta\rfloor_{\delta}$
as
 $\{\alpha\mapsto\lfloor V\rfloor_{\delta}|\alpha\mapsto V\in\theta\}$
.
$\{\alpha\mapsto\lfloor V\rfloor_{\delta}|\alpha\mapsto V\in\theta\}$
.
Two constraint generation examples The following table lists the constraint generation process for the expression
 $\lambda x:\star.\mathtt{succ}(x \mathtt{True})$
. In each row, we list the subexpression visited, the type of that subexpression, and the constraint generated. Assume the fresh choice and variable generated for the parameter are A and
$\lambda x:\star.\mathtt{succ}(x \mathtt{True})$
. In each row, we list the subexpression visited, the type of that subexpression, and the constraint generated. Assume the fresh choice and variable generated for the parameter are A and
 $\alpha$
, respectively.
$\alpha$
, respectively.

 \begin{equation*}C_{1}=\alpha\approx^{?}\kappa_{1}\to\kappa_{2}\quad C_{2}=\alpha\approx^{?}\mathtt{Bool}\to\kappa_{4} C_{4}=\mathtt{Int}\approx^{?}\kappa_{2}\end{equation*}
\begin{equation*}C_{1}=\alpha\approx^{?}\kappa_{1}\to\kappa_{2}\quad C_{2}=\alpha\approx^{?}\mathtt{Bool}\to\kappa_{4} C_{4}=\mathtt{Int}\approx^{?}\kappa_{2}\end{equation*}
The constraints
 $C_1$
and
$C_1$
and
 $C_2$
are generated from the third and fourth premises of Appc for typing
$C_2$
are generated from the third and fourth premises of Appc for typing
 $x\ mathtt{True}$
, respectively. The constraint
$x\ mathtt{True}$
, respectively. The constraint
 $C_4$
is generated from the fourth premise of Appc for handling the application
$C_4$
is generated from the fourth premise of Appc for handling the application
 $\mathtt{Succ} (x\ \mathtt{True})$
.
$\mathtt{Succ} (x\ \mathtt{True})$
.
Continuing from the fifth row of the table above, the following table lists additional constraints that will be generated from the expression
 $\lambda x:\star.x(\mathtt{Succ}(x \mathtt{True}))$
.
$\lambda x:\star.x(\mathtt{Succ}(x \mathtt{True}))$
.

 \begin{equation*}C_{5}=\alpha\approx^{?}\kappa_{5}\to\kappa_{6}\qquad C_{6}=\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}\end{equation*}
\begin{equation*}C_{5}=\alpha\approx^{?}\kappa_{5}\to\kappa_{6}\qquad C_{6}=\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}\end{equation*}
7 Unification
This section presents a unification algorithm for solving the constraints generated in Section 6, thus completing the road map presented in Section 3.
7.1 Solving compatibility constraints
We first motivate the structure and design of the algorithm with the following examples. ()
-
(i)
$\alpha\approx^{?}\star\to\mathtt{Int}$
-
(ii)

Our solver must adhere to certain rules to ensure the correctness of type inference, including:
-
I.
$\star$
is compatible with any type (Section 2.1). -
II. Type variables are only substituted by static types (Section 4).
-
III. The typing pattern produced must be as defined as possible (Section 4).

Problem (i) helps illustrate rule (II). Intuitively,
 $\alpha$
should be substituted by a function type whose codomain is
$\alpha$
should be substituted by a function type whose codomain is
 $\mathtt{Int}$
, but what should the domain be? Essentially, the domain should be an unconstrained type variable so that it can unify with a static type later, if necessary. As a result, we generate the substitutions
$\mathtt{Int}$
, but what should the domain be? Essentially, the domain should be an unconstrained type variable so that it can unify with a static type later, if necessary. As a result, we generate the substitutions
 $\{\kappa_{2}\mapsto\mathtt{Int}\}\circ\{\alpha\mapsto\kappa_{1}\to\kappa_{2}\}$
. Since
$\{\kappa_{2}\mapsto\mathtt{Int}\}\circ\{\alpha\mapsto\kappa_{1}\to\kappa_{2}\}$
. Since
 $\kappa_1$
is a fresh type variable that is not mapped to anything, it is unconstrained. In contrast,
$\kappa_1$
is a fresh type variable that is not mapped to anything, it is unconstrained. In contrast,
 $\kappa_2$
is mapped to
$\kappa_2$
is mapped to
 $\mathtt{Int}$
. This substitution satisfies both rules (I) and (II).
$\mathtt{Int}$
. This substitution satisfies both rules (I) and (II).
Problem (ii) demonstrates the need for error tolerance in solving constraints. The natural way to solve a choice constraint is to decompose it into two constraints. Doing this on constraint (ii) yields two subconstraints,
 $\star\approx^{?}\mathtt{Int}$
and
$\star\approx^{?}\mathtt{Int}$
and
 $\mathtt{Bool}\approx^{?}\mathtt{Int}$
, where
$\mathtt{Bool}\approx^{?}\mathtt{Int}$
, where ![]() . According to rule (I), the first constraint is solved successfully and
. According to rule (I), the first constraint is solved successfully and
 $\pi_1$
is updated to
$\pi_1$
is updated to
 $\top$
. The second constraint, however, fails to solve, since
$\top$
. The second constraint, however, fails to solve, since
 $\mathtt{Bool}$
cannot be made compatible with
$\mathtt{Bool}$
cannot be made compatible with
 $\mathtt{Int}$
, so we update
$\mathtt{Int}$
, so we update
 $\pi$
to
$\pi$
to
 $\perp$
. Consequently, we update
$\perp$
. Consequently, we update
 ${\pi}$
to
${\pi}$
to ![]() to reflect that constraint solving fails in A.2. Choosing instead
to reflect that constraint solving fails in A.2. Choosing instead
 $\perp$
for
$\perp$
for
 ${\pi}$
would yield a consistent result but would violate rule (III).
${\pi}$
would yield a consistent result but would violate rule (III).
7.2 A unification algorithm
Figure 13 presents a unification algorithm
 $\mathscr{U}$
, which takes a constraint and produces a substitution
$\mathscr{U}$
, which takes a constraint and produces a substitution
 $\theta$
and a pattern
$\theta$
and a pattern
 ${\pi}$
. The algorithm can be understood as extending Robinson’s unification algorithm (Robinson Reference Robinson1965) to handle variational types and dynamic types and to support error tolerance. To support error tolerance, the unification not only returns a substitution but also a typing pattern. The unification is successful at variants where the pattern has
${\pi}$
. The algorithm can be understood as extending Robinson’s unification algorithm (Robinson Reference Robinson1965) to handle variational types and dynamic types and to support error tolerance. To support error tolerance, the unification not only returns a substitution but also a typing pattern. The unification is successful at variants where the pattern has
 $\top$
and is failed at variants where the pattern has
$\top$
and is failed at variants where the pattern has
 $\perp$
. In the algorithm, cases (a) and (a*) deal with dynamic types, cases (c), (d), and (d*) deal with variations. Cases (g) through (j) deal with non-compatibility constraints. Other cases of the algorithm resemble their counterparts in Robinson’s algorithm but still need to account for occurrences of
$\perp$
. In the algorithm, cases (a) and (a*) deal with dynamic types, cases (c), (d), and (d*) deal with variations. Cases (g) through (j) deal with non-compatibility constraints. Other cases of the algorithm resemble their counterparts in Robinson’s algorithm but still need to account for occurrences of
 $\star$
s and variations.
$\star$
s and variations.

Figure 13. A unification algorithm.
In the figure, we use the following conventions and helper functions. We use
 $\kappa$
s to denote fresh type variables. The function choices(M) returns the set of choice names in M; vars(M) returns the set of type variables in V. The predicate hasDyn(M) determines whether
$\kappa$
s to denote fresh type variables. The function choices(M) returns the set of choice names in M; vars(M) returns the set of type variables in V. The predicate hasDyn(M) determines whether
 $\star$
occurs anywhere in M. The function merge combines the substitutions from solving the subproblems of a choice constraint. For example, given d,
$\star$
occurs anywhere in M. The function merge combines the substitutions from solving the subproblems of a choice constraint. For example, given d,
 $\theta_1=\{\alpha\mapsto\mathtt{Int}\}$
, and
$\theta_1=\{\alpha\mapsto\mathtt{Int}\}$
, and
 $\theta_{2}=\{\alpha\mapsto\mathtt{Int}\}$
, we have
$\theta_{2}=\{\alpha\mapsto\mathtt{Int}\}$
, we have ![]() . Formally, the definition of merge (for each
. Formally, the definition of merge (for each
 $\alpha$
in
$\alpha$
in
 $\theta_1 \cup \theta_2$
) is:
$\theta_1 \cup \theta_2$
) is:

Intuitively, if
 $\alpha\in dom(\theta)$
, then
$\alpha\in dom(\theta)$
, then
 $get(\alpha,\theta)$
returns the image of
$get(\alpha,\theta)$
returns the image of
 $\alpha$
in
$\alpha$
in
 $\theta$
. Otherwise,
$\theta$
. Otherwise,
 $get(\alpha,\theta)$
returns a fresh type variable. Recall that
$get(\alpha,\theta)$
returns a fresh type variable. Recall that
 $\kappa$
denotes a fresh type variable.
$\kappa$
denotes a fresh type variable.
We now briefly walk through each case of
 $\mathscr{U}$
. Some cases of
$\mathscr{U}$
. Some cases of
 $\mathscr{U}$
have dual cases, and names of such cases differ by a
$\mathscr{U}$
have dual cases, and names of such cases differ by a
 $\star$
. Essentially, the starred version delegates the real solving task to the case without a
$\star$
. Essentially, the starred version delegates the real solving task to the case without a
 $\star$
. Case (a) handles the trivial constraints involving
$\star$
. Case (a) handles the trivial constraints involving
 $\star$
. Such constraints are simply discarded without generating any mapping. We return
$\star$
. Such constraints are simply discarded without generating any mapping. We return
 $\top$
as the pattern, since
$\top$
as the pattern, since
 $\star$
is compatible with any type. More importantly for
$\star$
is compatible with any type. More importantly for
 $\alpha\approx^{?}\star$
, case (a) takes priority over (b), ensuring that the substitution
$\alpha\approx^{?}\star$
, case (a) takes priority over (b), ensuring that the substitution
 $\{\alpha\mapsto\star\}$
is not generated.
$\{\alpha\mapsto\star\}$
is not generated.
Case (b) unifies a type variable
 $\alpha$
with a migrational type M. This case includes many subcases. First, if M does not contain
$\alpha$
with a migrational type M. This case includes many subcases. First, if M does not contain
 $\star$
and
$\star$
and
 $\alpha$
does not occur in M, then
$\alpha$
does not occur in M, then
 $\alpha$
is directly mapped to M. For example, given
$\alpha$
is directly mapped to M. For example, given ![]() , the substitution
, the substitution ![]() is returned, and
is returned, and
 ${\pi}$
is updated to
${\pi}$
is updated to
 $\top$
. Second, if M contains variation, the result is computed via case (d). For example, the problem
$\top$
. Second, if M contains variation, the result is computed via case (d). For example, the problem ![]() is transformed into
is transformed into ![]()
![]() .
.
Next, if M is a function type that contains
 $\star$
and
$\star$
and
 $\alpha$
does not occur in M, then we transform
$\alpha$
does not occur in M, then we transform
 $\alpha$
into a function type by using fresh type variables and delegate the solving to case (f). The problem (i) in Section 7.1 falls in this case. This case essentially solves two constraints, and we will have two typing patterns (
$\alpha$
into a function type by using fresh type variables and delegate the solving to case (f). The problem (i) in Section 7.1 falls in this case. This case essentially solves two constraints, and we will have two typing patterns (
 $\pi_{1}$
and
$\pi_{1}$
and
 $\pi_{2}$
in the algorithm). We need to combine them into one. The resulting pattern must be restricted enough to create a valid solving result but well defined enough to give useful information about where constraint solving succeeds. The operation
$\pi_{2}$
in the algorithm). We need to combine them into one. The resulting pattern must be restricted enough to create a valid solving result but well defined enough to give useful information about where constraint solving succeeds. The operation
 $\sqcap$
, can be viewed as a meet operation over the less defined partial order on typing patterns in Figure 10. It creates the greatest lower bound of two patterns, ensuring that the most defined pattern is used for solving the constraint.
$\sqcap$
, can be viewed as a meet operation over the less defined partial order on typing patterns in Figure 10. It creates the greatest lower bound of two patterns, ensuring that the most defined pattern is used for solving the constraint.
Back to case (b), if all previous subcases fail,
 $\perp$
is returned, indicating that the constraint failed to solve.
$\perp$
is returned, indicating that the constraint failed to solve.
Case (c) handles constraints involving two choice types that share an outer choice name. It decomposes the constraint into two smaller problems and solves them individually. For instance, consider the constraint ![]() . This constraint will be decomposed into
. This constraint will be decomposed into
 $\star\approx^{?}\mathtt{Int}$
and
$\star\approx^{?}\mathtt{Int}$
and
 $\alpha\approx^{?}\mathtt{Bool}$
, which will be solved by (a) and (b), respectively. Case (d) unifies a choice type with another type not handled by case (c). This case employs a similar implementation idea as case (c) does. For example, for
$\alpha\approx^{?}\mathtt{Bool}$
, which will be solved by (a) and (b), respectively. Case (d) unifies a choice type with another type not handled by case (c). This case employs a similar implementation idea as case (c) does. For example, for ![]() , the two smaller constraints to be solved are
, the two smaller constraints to be solved are
 $\star\approx^{?}\mathtt{Int}$
and
$\star\approx^{?}\mathtt{Int}$
and
 $\mathtt{Int}\approx^{?}\mathtt{Int}$
. Case (e) unifies two static types and is delegated to Robinson’s unification algorithm (Robinson Reference Robinson1965). Case (f) unifies two function types by unifying their respective argument and return types. Cases (g), (h), (i), and (j) deal with non-compatibility constraints.
$\mathtt{Int}\approx^{?}\mathtt{Int}$
. Case (e) unifies two static types and is delegated to Robinson’s unification algorithm (Robinson Reference Robinson1965). Case (f) unifies two function types by unifying their respective argument and return types. Cases (g), (h), (i), and (j) deal with non-compatibility constraints.
To keep patterns in normal form, we also perform the following optimizations to prevent idempotent choices patterns from being created. In cases (c) and (f), when creating the choice pattern ![]() , we check if
, we check if
 $\pi_1$
and
$\pi_1$
and
 $\pi_2$
are the same; if so, the choice pattern is replaced by
$\pi_2$
are the same; if so, the choice pattern is replaced by
 $\pi_1$
. In the last two cases of
$\pi_1$
. In the last two cases of
 $\sqcap$
in Section 6, we perform the same optimization. After this, the algorithm maintains patterns in normal forms, since the generated constraints do not contain dead alternatives and since the case (d) of
$\sqcap$
in Section 6, we perform the same optimization. After this, the algorithm maintains patterns in normal forms, since the generated constraints do not contain dead alternatives and since the case (d) of
 $\mathscr{U}$
prevents dead alternatives from being introduced.
$\mathscr{U}$
prevents dead alternatives from being introduced.
Unification examples In Section 6, we generated two constraints for the expressions
 $\lambda x:\star.\mathtt{succ}(x \mathtt{True})$
and
$\lambda x:\star.\mathtt{succ}(x \mathtt{True})$
and
 $\lambda x:\star.x(\mathtt{Succ}(x \mathtt{True}))$
. We use these two constraints to illustrate the unification process.
$\lambda x:\star.x(\mathtt{Succ}(x \mathtt{True}))$
. We use these two constraints to illustrate the unification process.
The first constraint is ![]() . For this constraint, case (h) applies, which breaks the variational constraint into two smaller constraints in each alternative and then combine the results from alternatives. The left alternative has the constraint
. For this constraint, case (h) applies, which breaks the variational constraint into two smaller constraints in each alternative and then combine the results from alternatives. The left alternative has the constraint
 $\varepsilon$
, which will be solved by case (g) with the solution
$\varepsilon$
, which will be solved by case (g) with the solution
 $(\theta_{l},\top)$
, where
$(\theta_{l},\top)$
, where
 $\theta_{l}=\varnothing$
. The right alternative has the constraint
$\theta_{l}=\varnothing$
. The right alternative has the constraint
 $C_1 \wedge C_2 \wedge C_4$
. We will repeatedly use case (i) to handle each subconstraint
$C_1 \wedge C_2 \wedge C_4$
. We will repeatedly use case (i) to handle each subconstraint
 $C_1$
through
$C_1$
through
 $C_4$
. Since there are no
$C_4$
. Since there are no
 $\star$
s and variations in these constraints, they degenerate to conventional type equality constraints. We can use Robinson’s unification algorithm to solve them. The unifier is
$\star$
s and variations in these constraints, they degenerate to conventional type equality constraints. We can use Robinson’s unification algorithm to solve them. The unifier is
 \begin{equation*}\theta_{r}=\{\alpha\mapsto\mathtt{Bool}\to\mathtt{Int},\kappa_{1}\mapsto\mathtt{Bool},\kappa_{2}\mapsto\mathtt{Int},\kappa_{4}\mapsto\mathtt{Int}\}\end{equation*}
\begin{equation*}\theta_{r}=\{\alpha\mapsto\mathtt{Bool}\to\mathtt{Int},\kappa_{1}\mapsto\mathtt{Bool},\kappa_{2}\mapsto\mathtt{Int},\kappa_{4}\mapsto\mathtt{Int}\}\end{equation*}
The typing pattern for solving them is
 $\top$
as the solving for each constraint returns
$\top$
as the solving for each constraint returns
 $\top$
.
$\top$
.
After we have the solutions for both alternatives, we will now combine them together. First, the combined typing pattern is ![]() , which simplifies to
, which simplifies to
 $\top$
, meaning that the type inference succeeds everywhere. Next, we combine unifiers with the function merge defined earlier in this subsection. Note, since
$\top$
, meaning that the type inference succeeds everywhere. Next, we combine unifiers with the function merge defined earlier in this subsection. Note, since
 $\theta_{l}$
is
$\theta_{l}$
is
 $\varnothing$
, the second case of merge will handle each mapping in
$\varnothing$
, the second case of merge will handle each mapping in
 $\theta_{r}$
. For example, as
$\theta_{r}$
. For example, as
 $\alpha\mapsto\mathtt{Bool}\to\mathtt{Int}\in\theta_{r}$
, then the merged substitution includes
$\alpha\mapsto\mathtt{Bool}\to\mathtt{Int}\in\theta_{r}$
, then the merged substitution includes ![]() , where
, where
 $\kappa_8$
is s fresh type variable. Here we use a fresh type variable in the first alternative to denote that the first alternative for
$\kappa_8$
is s fresh type variable. Here we use a fresh type variable in the first alternative to denote that the first alternative for
 $\alpha$
is not constrained yet, allowing future unification with any type, if necessary. Overall, let
$\alpha$
is not constrained yet, allowing future unification with any type, if necessary. Overall, let
 $\theta_m$
be the substitution after merging
$\theta_m$
be the substitution after merging
 $\theta_l$
and
$\theta_l$
and
 $\theta_{r}$
, then
$\theta_{r}$
, then
Substituting the result type ![]() with
with
 $\theta_m$
yields the type
$\theta_m$
yields the type ![]() , which simplifies to the type
, which simplifies to the type ![]() after we eliminate the unreachable alternative
after we eliminate the unreachable alternative
 $\kappa_8$
. Since the combined typing pattern is
$\kappa_8$
. Since the combined typing pattern is
 $\top$
and selecting
$\top$
and selecting
 $\top$
with
$\top$
with
 $\{A.2\}$
yields
$\{A.2\}$
yields
 $\top$
, it means that we can migrate x, the parameter associated with the choice A. Moreover, based on the result type of
$\top$
, it means that we can migrate x, the parameter associated with the choice A. Moreover, based on the result type of ![]() , we know the migrated expression has the type
, we know the migrated expression has the type
 $(\mathtt{Bool}\to\mathtt{Int})\to\mathtt{Int}$
.
$(\mathtt{Bool}\to\mathtt{Int})\to\mathtt{Int}$
.
Now we solve the constraint ![]() generated for the expression
generated for the expression
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
. We proceed similarly as before. In particular, constraint solving
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
. We proceed similarly as before. In particular, constraint solving
 $C_1$
through
$C_1$
through
 $C_4$
yields the unifier
$C_4$
yields the unifier
 $\theta_{r}$
mentioned above. We then need to solve
$\theta_{r}$
mentioned above. We then need to solve
 $C_5$
and
$C_5$
and
 $C_6$
from
$C_6$
from
 $\theta_r$
. When solving
$\theta_r$
. When solving
 $C_6$
, we need to unify
$C_6$
, we need to unify
 $\mathtt{Bool}\to\mathtt{Int}$
with
$\mathtt{Bool}\to\mathtt{Int}$
with
 $\mathtt{Int}\to\kappa_{8}$
, which fails. The pattern returned is thus
$\mathtt{Int}\to\kappa_{8}$
, which fails. The pattern returned is thus
 $\perp$
. Therefore, the pattern for solving the whole constraint is
$\perp$
. Therefore, the pattern for solving the whole constraint is ![]() . Based on the pattern, we know that we cannot migrate x.
. Based on the pattern, we know that we cannot migrate x.
Note, even though our approach cannot migrate x, types more precise than
 $\star$
could actually be assigned to x, such as
$\star$
could actually be assigned to x, such as
 $\star\to\mathtt{Int}$
. The reason we cannot find this migration is that
$\star\to\mathtt{Int}$
. The reason we cannot find this migration is that
 $\lambda x.x(\mathtt{succ}(x\mathtt{True}))$
is not well-typed under type inference by Garcia & Cimini (Reference Garcia and Cimini2015), and our type inference can be considered as the variational version of theirs. We provide an extension to the unification algorithm
$\lambda x.x(\mathtt{succ}(x\mathtt{True}))$
is not well-typed under type inference by Garcia & Cimini (Reference Garcia and Cimini2015), and our type inference can be considered as the variational version of theirs. We provide an extension to the unification algorithm
 $\mathscr{U}$
to infer more precise types in Section 9.2.
$\mathscr{U}$
to infer more precise types in Section 9.2.
7.3 Properties
We now investigate the properties of
 $\mathscr{U}$
. First,
$\mathscr{U}$
. First,
 $\mathscr{U}$
is terminating.
$\mathscr{U}$
is terminating.
Theorem 13. (Termination) Given C,
 $\mathscr{U}(C)$
terminates.
$\mathscr{U}(C)$
terminates.
Next, we show that
 $\mathscr{U}$
is correct by showing that it is both sound and complete. For simplicity, we state the result for constraints of the form
$\mathscr{U}$
is correct by showing that it is both sound and complete. For simplicity, we state the result for constraints of the form
 $M_{1}\approx^{?}M_{2}$
only. In fact, we can transform other forms into this form. For example,
$M_{1}\approx^{?}M_{2}$
only. In fact, we can transform other forms into this form. For example, ![]() can be transformed into
can be transformed into ![]() Note that
Note that
 ${\pi}$
in the constraint is just a placeholder and will be updated when the constraint solving finishes.
${\pi}$
in the constraint is just a placeholder and will be updated when the constraint solving finishes.
Theorem 14 (Soundness) If
 $\mathscr{U}(M_{1}\approx^{?}M_{2})=(\theta,\pi')$
, then
$\mathscr{U}(M_{1}\approx^{?}M_{2})=(\theta,\pi')$
, then
 $\theta(M_{1})\approx_{\pi'}\theta(M_{2})$
.
$\theta(M_{1})\approx_{\pi'}\theta(M_{2})$
.
Theorem 15 (Completeness) Given
 $M_{1}\approx^{?}M_{2}$
, if
$M_{1}\approx^{?}M_{2}$
, if
 $\theta_{1}(M_{1})\approx_{\pi_{1}}\theta_{1}(M_{2})$
, then
$\theta_{1}(M_{1})\approx_{\pi_{1}}\theta_{1}(M_{2})$
, then
 $\mathscr{U}(M_{1}\approx^{?}M_{2})=(\theta_{2},\pi_{2})$
such that
$\mathscr{U}(M_{1}\approx^{?}M_{2})=(\theta_{2},\pi_{2})$
such that
 $\pi_{1}\leq\pi_{2}$
and
$\pi_{1}\leq\pi_{2}$
and
 $\theta_{1}=\theta\circ\theta_{2}$
for some
$\theta_{1}=\theta\circ\theta_{2}$
for some
 $\theta$
.
$\theta$
.
The idea of the proof is to go through all possible constructs of the type M and show that
 $\mathscr{U}$
covers all possibilities. To establish that most general unifiers exist, we get the results directly from the induction hypothesis (and compose the mgus of the subterms) or use proof by contradiction. As the proof is standard and lengthy, we omit it here.
$\mathscr{U}$
covers all possibilities. To establish that most general unifiers exist, we get the results directly from the induction hypothesis (and compose the mgus of the subterms) or use proof by contradiction. As the proof is standard and lengthy, we omit it here.
8 Introducing dynamism for fixing static type errors
Fixing static type errors by introducing
 $\star$
s could be useful under several scenarios. First, when migrating a program, the user may have added static types that cause type errors. To pass static type checking of gradual typing, some added type annotations should be removed. Second, the addition of dynamic types can be used to silence type errors and defer the reporting of type errors to runtime (Bayne et al., Reference Bayne, Cook and Ernst2011; Vytiniotis et al., Reference Vytiniotis, Peyton Jones and Magalhães2012). This idea is particularly intriguing for fixing static type errors as type error messages generated by compilers are often opaque and difficult to understand (Marceau et al., Reference Marceau, Fisler and Krishnamurthi2011a, b; Pavlinovic et al., Reference Pavlinovic, King and Wies2014; Loncaric et al., Reference Loncaric, Chandra, Schlesinger and Sridharan2016; Serrano & Hage Reference Serrano and Hage2016; Munson & Schilling Reference Munson and Schilling2016). For example, the work by Bayne et al., (Reference Bayne, Cook and Ernst2011) shows that obtaining even partial result of ill-typed programs helps programmers to understand type errors and accelerate program development. Our recent work indicates that gradual typing leads to more concrete feedback than deferred type errors for ill-typed programs (Chen & Campora Reference Chen and Campora2019). In particular, in some situations while deferred type errors dump compile-time error messages, gradual typing returns values to the programmer.
$\star$
s could be useful under several scenarios. First, when migrating a program, the user may have added static types that cause type errors. To pass static type checking of gradual typing, some added type annotations should be removed. Second, the addition of dynamic types can be used to silence type errors and defer the reporting of type errors to runtime (Bayne et al., Reference Bayne, Cook and Ernst2011; Vytiniotis et al., Reference Vytiniotis, Peyton Jones and Magalhães2012). This idea is particularly intriguing for fixing static type errors as type error messages generated by compilers are often opaque and difficult to understand (Marceau et al., Reference Marceau, Fisler and Krishnamurthi2011a, b; Pavlinovic et al., Reference Pavlinovic, King and Wies2014; Loncaric et al., Reference Loncaric, Chandra, Schlesinger and Sridharan2016; Serrano & Hage Reference Serrano and Hage2016; Munson & Schilling Reference Munson and Schilling2016). For example, the work by Bayne et al., (Reference Bayne, Cook and Ernst2011) shows that obtaining even partial result of ill-typed programs helps programmers to understand type errors and accelerate program development. Our recent work indicates that gradual typing leads to more concrete feedback than deferred type errors for ill-typed programs (Chen & Campora Reference Chen and Campora2019). In particular, in some situations while deferred type errors dump compile-time error messages, gradual typing returns values to the programmer.
A simple approach for removing type errors is adding
 $\star$
annotations to all parameters, which are static by default. However, this approach is undesirable for several reasons. First, adding a
$\star$
annotations to all parameters, which are static by default. However, this approach is undesirable for several reasons. First, adding a
 $\star$
annotation to every single parameter is laborious to programmers. Second, adding all
$\star$
annotation to every single parameter is laborious to programmers. Second, adding all
 $\star$
s hurts the efforts of migrating programs to be static. Third, the program is likely to lose useful type information in many locations.
$\star$
s hurts the efforts of migrating programs to be static. Third, the program is likely to lose useful type information in many locations.
For this reason, our goal here is to develop a solution to question Q2. Specifically, for a statically ill-typed program, we aim to find a minimum set of parameters such that replacing them with
 $\star$
s removes the type error. It turns out that introducing as few dynamic types as possible for answering Q2 is equally tricky as removing as many dynamic types as possible. To illustrate, consider the following program
$\star$
s removes the type error. It turns out that introducing as few dynamic types as possible for answering Q2 is equally tricky as removing as many dynamic types as possible. To illustrate, consider the following program
 $\mathtt{rowAtISt}$
, which shares the body with
$\mathtt{rowAtISt}$
, which shares the body with
 $\mathtt{rowAtI}$
but removes
$\mathtt{rowAtI}$
but removes
 $\star$
s from all its parameters.
$\star$
s from all its parameters.

This function is ill-typed since, for example, the then branch for computing
 $\mathtt{Width}$
requires
$\mathtt{Width}$
requires
 $\mathtt{widthFunc}$
to have the type
$\mathtt{widthFunc}$
to have the type
 $\mathtt{Bool} \to \mathtt{Int}$
and the else branch requires it to have the type
$\mathtt{Bool} \to \mathtt{Int}$
and the else branch requires it to have the type
 $\mathtt{Int} \to \mathtt{Int}$
.
$\mathtt{Int} \to \mathtt{Int}$
.
The difficulties in adding
 $\star$
s are similar to the ones espoused for removing
$\star$
s are similar to the ones espoused for removing
 $\star$
s in Section 1.1. There is an exponential number of ways
$\star$
s in Section 1.1. There is an exponential number of ways
 $\star$
s can be added to the program; adding
$\star$
s can be added to the program; adding
 $\star$
s to all parameters introduces more dynamism than desired. Some dynamism can be avoided by adding
$\star$
s to all parameters introduces more dynamism than desired. Some dynamism can be avoided by adding
 $\star$
annotations in a left-to-right manner, but this is inefficient and can still add unnecessary dynamism. For example, following this process on
$\star$
annotations in a left-to-right manner, but this is inefficient and can still add unnecessary dynamism. For example, following this process on
 $\mathtt{rowAtISt}$
leads to a migration that add
$\mathtt{rowAtISt}$
leads to a migration that add
 $\star$
s from
$\star$
s from
 $\mathtt{headOrFoot}$
to
$\mathtt{headOrFoot}$
to
 $\mathtt{border}$
, since only then
$\mathtt{border}$
, since only then
 $\mathtt{rowAtISt}$
becomes well-typed. In fact, however, the dynamism on, for example,
$\mathtt{rowAtISt}$
becomes well-typed. In fact, however, the dynamism on, for example,
 $\mathtt{table}$
is unnecessary. If the programmer wants to remove such unnecessary dynamism, they encounter the exact same difficulties detailed in Section 1.1. The similarity in difficulties inspires our solution to introducing dynamism, which is detailed in the next subsection.
$\mathtt{table}$
is unnecessary. If the programmer wants to remove such unnecessary dynamism, they encounter the exact same difficulties detailed in Section 1.1. The similarity in difficulties inspires our solution to introducing dynamism, which is detailed in the next subsection.
8.1 Duality to removing dynamism
The program
 $\mathtt{rowAtISt}$
can be thought of as one of the programs in the migration space of
$\mathtt{rowAtISt}$
can be thought of as one of the programs in the migration space of
 $\mathtt{rowAtI}$
in Figure 1. In fact, it is the bottom-most program in the figure had we listed out the full migration space there. Recall that programs 3 and 5 were the most static migrations for program 1. While introducing
$\mathtt{rowAtI}$
in Figure 1. In fact, it is the bottom-most program in the figure had we listed out the full migration space there. Recall that programs 3 and 5 were the most static migrations for program 1. While introducing
 $\star$
s for
$\star$
s for
 $\mathtt{rowAtISt}$
, programs 3 and 5 are likewise the programs we desire since they keep as many static types as possible and are still well-typed.
$\mathtt{rowAtISt}$
, programs 3 and 5 are likewise the programs we desire since they keep as many static types as possible and are still well-typed.
We can envision organizing the whole migration space into a lattice where more dynamic programs are in the upper portions of the lattice (Takikawa et al., Reference Takikawa, Feltey, Greenman, New, Vitek and Felleisen2016). The process of removing dynamism to make the program static keeps going down the lattice before a type error appears. The process of introducing dynamism to fix type errors keeps going up the lattice until type errors disappear. Overall, these two processes are dual. This fact inspires our formal development to realize the process of introducing dynamism, which we shall see next.
Typing rules. In removing dynamism, we introduce variations for parameters whose type annotations are
 $\star$
s and not to others. Based on the duality, we should now introduce variations to parameters without
$\star$
s and not to others. Based on the duality, we should now introduce variations to parameters without
 $\star$
annotations and not to others. Specifically, we define a new type system using the judgment form
$\star$
annotations and not to others. Specifically, we define a new type system using the judgment form
 $\pi;\Gamma\vdash_{D} e:M|\Omega$
. This judgment has the same meaning as the one in Figure 10 and shares the same rules as that one except for Abs and Absdyn, for which typing rules are as follows.
$\pi;\Gamma\vdash_{D} e:M|\Omega$
. This judgment has the same meaning as the one in Figure 10 and shares the same rules as that one except for Abs and Absdyn, for which typing rules are as follows.

These two rules are dual to the corresponding ones in Figure 10. For an abstraction with a static type, the type error may be removed by changing its parameter to have the dynamic type. We express this by creating a fresh variation with its first alternative being
 $\star$
, as can be seen in the Abs rule. The rule then records the changes in the variational statifier. For Absdyn, no changes will be made for the parameter type, and thus no variations are created in the rule, since our goal is to fix static type errors and not to migrate programs towards using more static typing.
$\star$
, as can be seen in the Abs rule. The rule then records the changes in the variational statifier. For Absdyn, no changes will be made for the parameter type, and thus no variations are created in the rule, since our goal is to fix static type errors and not to migrate programs towards using more static typing.
Using the given typing rules, we can derive the following type for
 $\mathtt{rowAtISt}$
, assuming the variation names for parameters from left to right are A, B, D, E, F, G.
$\mathtt{rowAtISt}$
, assuming the variation names for parameters from left to right are A, B, D, E, F, G.
The typing pattern for it is:
Connection to ITGL. Each variational statifier (in this context perhaps it should be renamed to dynamifier) generated by the
 $\vdash_{D}$
type system now collects parameters for which
$\vdash_{D}$
type system now collects parameters for which
 $\star$
annotations are added (instead of removed as was done previously). From the variational statifier, we can generate a statifier for each given decision as follows.
$\star$
annotations are added (instead of removed as was done previously). From the variational statifier, we can generate a statifier for each given decision as follows.
 \begin{equation*}\Omega[\delta]=\{x\mapsto\lfloor M\rfloor_{\delta}|x\mapsto M\in\Omega\}\end{equation*}
\begin{equation*}\Omega[\delta]=\{x\mapsto\lfloor M\rfloor_{\delta}|x\mapsto M\in\Omega\}\end{equation*}
The generated statifier coerces certain parameters to have type
 $\star$
s and leaves others to their original types. We can define a type system similar to the type system in Figure 4 that types gradual expressions under updates from statifiers. The new type system is the same as the one in Figure 4 except for the rules Abs and Absdyn, which are presented below.
$\star$
s and leaves others to their original types. We can define a type system similar to the type system in Figure 4 that types gradual expressions under updates from statifiers. The new type system is the same as the one in Figure 4 except for the rules Abs and Absdyn, which are presented below.
In Abs, a parameter with a static type is maybe assigned a
 $\star$
if the
$\star$
if the
 ${\omega}$
specifies so. For functions with
${\omega}$
specifies so. For functions with
 $\star$
parameters, handled by Absdyn, the typing rule does not update their types.
$\star$
parameters, handled by Absdyn, the typing rule does not update their types.
Finding error fixes. The
 $\vdash_{D}$
typing relation indeed finds correct and complete fixes to type errors, as captured in the following theorems, which serve a similar goal as Theorems 4 through 6 served in the type system of removing dynamism. The proofs of these theorems thus follow those closely and are omitted here.
$\vdash_{D}$
typing relation indeed finds correct and complete fixes to type errors, as captured in the following theorems, which serve a similar goal as Theorems 4 through 6 served in the type system of removing dynamism. The proofs of these theorems thus follow those closely and are omitted here.
Theorem 16 (Error Fixing Soundness) Given e, and
 $\Gamma$
assume e cannot be typed in ITGL under
$\Gamma$
assume e cannot be typed in ITGL under
 $\Gamma$
. Let
$\Gamma$
. Let
 $\pi;\Gamma\vdash_{D} e:M|\Omega$
. If
$\pi;\Gamma\vdash_{D} e:M|\Omega$
. If
 $\lfloor\pi\rfloor_{\delta}=\top$
, then
$\lfloor\pi\rfloor_{\delta}=\top$
, then
 $\Omega[\delta];\Gamma\vdash_{GCD}e:G$
for some type G.
$\Omega[\delta];\Gamma\vdash_{GCD}e:G$
for some type G.
Theorem 17 (Error Fixing Completeness) If
 $\omega;\Gamma\vdash_{GCD}e:G$
, then there exists some typing
$\omega;\Gamma\vdash_{GCD}e:G$
, then there exists some typing
 $\pi;\Gamma\vdash_{D} e:M|\Omega$
where
$\pi;\Gamma\vdash_{D} e:M|\Omega$
where
 $\lfloor M\rfloor_{\delta}=G$
and
$\lfloor M\rfloor_{\delta}=G$
and
 $\Omega[\delta]$
for some decision
$\Omega[\delta]$
for some decision
 $\delta$
.
$\delta$
.
The previous theorem indicates that we can use migrational typing to fix errors but does not state that the fixes are minimal. The following theorem states that we can find a most general, least dynamic fix for a program. We call this the MGDM typing.
Theorem 18 (Existence of the MGDM typing) Given any e and
 $\Gamma$
, there is a MGDM typing
$\Gamma$
, there is a MGDM typing
 $\pi;\Gamma\vdash_{D} e:M|\Omega$
such that for any
$\pi;\Gamma\vdash_{D} e:M|\Omega$
such that for any
 $\pi;\Gamma\vdash_{D} e:M_{1}|\Omega_{1}$
we have
$\pi;\Gamma\vdash_{D} e:M_{1}|\Omega_{1}$
we have
 $\forall\delta.\lfloor \pi_{1}\rfloor_{\delta}=\top\Rightarrow\lfloor\pi\rfloor_{\delta}=\top\wedge\lfloor M_{1}\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}$
.
$\forall\delta.\lfloor \pi_{1}\rfloor_{\delta}=\top\Rightarrow\lfloor\pi\rfloor_{\delta}=\top\wedge\lfloor M_{1}\rfloor_{\delta}\preceq\lfloor M\rfloor_{\delta}$
.
From the typing pattern
 ${\pi}$
in MGDM, we can reuse the machinery to find the best migration in Section 5.2 for finding migrations that fix type errors by introducing fewest
${\pi}$
in MGDM, we can reuse the machinery to find the best migration in Section 5.2 for finding migrations that fix type errors by introducing fewest
 $\star$
s to parameters. For example, the
$\star$
s to parameters. For example, the
 ${\pi}$
for the MGDM of
${\pi}$
for the MGDM of
 $\mathtt{rowAtISt}$
is
$\mathtt{rowAtISt}$
is
 ${\pi}_d$
given earlier. This pattern indicates that either
${\pi}_d$
given earlier. This pattern indicates that either
 $\mathtt{fixed}$
and
$\mathtt{fixed}$
and
 $\mathtt{border}$
should have
$\mathtt{border}$
should have
 $\star$
s to remove the type error, or
$\star$
s to remove the type error, or
 $\mathtt{widthFunc}$
and
$\mathtt{widthFunc}$
and
 $\mathtt{border}$
should have
$\mathtt{border}$
should have
 $\star$
s.
$\star$
s.
8.2 Discussion
This section demonstrates that migrational typing is flexible and can be easily adapted to solve another interesting program migration problem. The fundamental reason is that migrational typing provides an efficient method to explore the typing of the full migration space and extract the desired migrations from that space, which naturally lends itself to solving other migration problems.
It is interesting to see if we can fix type errors and migrate programs to utilizing more static typing simultaneously. Essentially, such a process first adds
 $\star$
annotations to remove the type error and then inspects to see if other
$\star$
annotations to remove the type error and then inspects to see if other
 $\star$
annotations can be safely removed after the error is fixed. Note that typing rules in Figure 10 introduce variations for parameters with
$\star$
annotations can be safely removed after the error is fixed. Note that typing rules in Figure 10 introduce variations for parameters with
 $\star$
s and those in this section introduce variations for parameters that have no
$\star$
s and those in this section introduce variations for parameters that have no
 $\star$
s. This suggests that the type system that simultaneously fixes type errors and migrates programs should create variations for all parameters. Specifically, the Absdyn rule should be the same as the one in Figure 10 while Abs be the same to the one in
$\star$
s. This suggests that the type system that simultaneously fixes type errors and migrates programs should create variations for all parameters. Specifically, the Absdyn rule should be the same as the one in Figure 10 while Abs be the same to the one in
 $\vdash_D$
. After that, we can use the method descried in Section 5.2 to extract the migration that removes type errors as well as migrate the program to be as static as possible.
$\vdash_D$
. After that, we can use the method descried in Section 5.2 to extract the migration that removes type errors as well as migrate the program to be as static as possible.
The simplicity of the type system for this purpose echoes our early observation about the flexibility and adaptability of migrational typing.
9 Extensions
In this section, we consider how to support additional language features in our migrational type system. First, we show that our migrational type system is flexible and can support extensions that make the source language more expressive for programmers. Then, we cover other uses of migrational typing, for example allowing programmers to indicate which regions they want to remain dynamic or static.
9.1 Other language features
Our version of ITGL, given in Figure 10, restricts parameters to be either unannotated or annotated by
 $\star$
. The formulation of gradual typing by Garcia & Cimini (Reference Garcia and Cimini2015) allows arbitrary gradual type annotations on parameters and also supports type ascription, that is, asserting by
$\star$
. The formulation of gradual typing by Garcia & Cimini (Reference Garcia and Cimini2015) allows arbitrary gradual type annotations on parameters and also supports type ascription, that is, asserting by
 $e::G$
that expression e has type G.
$e::G$
that expression e has type G.
We can extend our type system to support arbitrary gradual type annotations as follows. Given an abstraction
 $\lambda x:G.e$
, if
$\lambda x:G.e$
, if
 $G=\star$
or G is fully static, type the abstraction as usual; if G is a complex type containing
$G=\star$
or G is fully static, type the abstraction as usual; if G is a complex type containing
 $\star$
types, replace G by a choice whose first alternative is G and whose second alternative replaces all dynamic parts by arbitrary types. For example, if
$\star$
types, replace G by a choice whose first alternative is G and whose second alternative replaces all dynamic parts by arbitrary types. For example, if
 $G=\mathtt{Int}\to\star\to\star$
, then the type of the parameter is
$G=\mathtt{Int}\to\star\to\star$
, then the type of the parameter is ![]() , where d is fresh. To generate the corresponding constraint (Section 6), we replace
, where d is fresh. To generate the corresponding constraint (Section 6), we replace
 $V_1$
and
$V_1$
and
 $V_2$
by fresh type variables. Note that this extension still tries to assigns full static types for
$V_2$
by fresh type variables. Note that this extension still tries to assigns full static types for
 $\star$
s. As such, this extension will not be find a migration for
$\star$
s. As such, this extension will not be find a migration for
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
, as shown in Section 1.3. The extension in Section 9.2 is able to infer partial static types.
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
, as shown in Section 1.3. The extension in Section 9.2 is able to infer partial static types.
We can extend our type system to support type ascription with the following typing rule.
The second premise ensures that the static parts of the ascribed type G are copied to the second alternative of the choice. The third premise ensures that the type of the expression M is compatible with the ascribed type and also a corresponding type V with all
 $\star$
types removed. We can update the structure of
$\star$
types removed. We can update the structure of
 ${\Omega}$
to accommodate this rule by defining its domain to be program locations rather than parameter names. We use e here as shorthand for the location of e.
${\Omega}$
to accommodate this rule by defining its domain to be program locations rather than parameter names. We use e here as shorthand for the location of e.
Finally, we can also add support for let-polymorphism. The approach is straightforward, but the notations become heavier. We use
 $\overline{\alpha}$
to denote a list of type variables and
$\overline{\alpha}$
to denote a list of type variables and
 $\{\overline{\alpha\mapsto V}\}$
to denote a set that includes
$\{\overline{\alpha\mapsto V}\}$
to denote a set that includes
 $\alpha_{1}\mapsto V_{1},\ldots,\alpha_{n}\mapsto V_{n}$
. The function vars(
$\alpha_{1}\mapsto V_{1},\ldots,\alpha_{n}\mapsto V_{n}$
. The function vars(
 $\cdot$
) returns the free type variables in its argument. The typing rules are standard except that when typing variable references (Var) we can only instantiate type schemas with variational types (V) and not migrational types (M).
$\cdot$
) returns the free type variables in its argument. The typing rules are standard except that when typing variable references (Var) we can only instantiate type schemas with variational types (V) and not migrational types (M).

In support of all of these extensions, the other machinery of our approach, including constraint generation, unification, and extracting the most static migration, can be reused.
9.2 Inferring more precise types
The example in Section 7.1 shows that our approach fails to find a migration for the expression
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
, even though
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
, even though
 $\lambda x:\star\to\mathtt{Int}.x(\mathtt{succ}(x\mathtt{True}))$
can be a more precise migration. Recall from Section 6 that during constraint generation we assigned the variational type
$\lambda x:\star\to\mathtt{Int}.x(\mathtt{succ}(x\mathtt{True}))$
can be a more precise migration. Recall from Section 6 that during constraint generation we assigned the variational type ![]() to the parameter type x and the generated constraint is
to the parameter type x and the generated constraint is ![]() .
.
To investigate why our approach cannot find a migration and how we can potentially improve this situation, we list the constraint solving process for the constraint
 $C_{1}\wedge C_{2}\wedge C_{4}\wedge C_{5}\wedge C_{6}$
below. The first column lists the constraint being solved, and the latter two columns list the unifier and pattern from solving the constraint.
$C_{1}\wedge C_{2}\wedge C_{4}\wedge C_{5}\wedge C_{6}$
below. The first column lists the constraint being solved, and the latter two columns list the unifier and pattern from solving the constraint.

The constraint solving fails when we need to solve the constraint
 $\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}$
, since our solution before that point contains
$\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}$
, since our solution before that point contains
 $\alpha\mapsto\mathtt{Bool}\to\mathtt{Int}$
. When constraint solving fails, the returned pattern is
$\alpha\mapsto\mathtt{Bool}\to\mathtt{Int}$
. When constraint solving fails, the returned pattern is
 $\perp$
, and the content of the unifier will no longer be used. As a result, we leave the content of the unifier as the same after solving
$\perp$
, and the content of the unifier will no longer be used. As a result, we leave the content of the unifier as the same after solving
 $\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}$
.
$\alpha\approx^{?}\mathtt{Int}\to\kappa_{8}$
.
The main reason our approach fails to find a migration is that, as we were solving the first constraint
 $\alpha\approx^{?}\kappa_{1}\to\kappa_{2}$
, we made three requirements: (1) the type that
$\alpha\approx^{?}\kappa_{1}\to\kappa_{2}$
, we made three requirements: (1) the type that
 $\alpha$
maps to is constructed by the
$\alpha$
maps to is constructed by the
 $\to$
type constructor, (2) the parameter type of
$\to$
type constructor, (2) the parameter type of
 $\to$
be a static type, and (3) the return type of
$\to$
be a static type, and (3) the return type of
 $\to$
be a static type. However, in
$\to$
be a static type. However, in
 $x\, (\mathtt{succ} (x\ \mathtt{true}))$
, the body of the function, x, is used as functions and applied to both
$x\, (\mathtt{succ} (x\ \mathtt{true}))$
, the body of the function, x, is used as functions and applied to both
 $\mathtt{Bool}$
and
$\mathtt{Bool}$
and
 $\mathtt{Int}$
values. As a result, no static type could be assigned to x. We can address this problem by relaxing the three requirements for
$\mathtt{Int}$
values. As a result, no static type could be assigned to x. We can address this problem by relaxing the three requirements for
 $\alpha$
. To address this problem, we observe that
$\alpha$
. To address this problem, we observe that
 $\alpha$
denotes the type for x when the
$\alpha$
denotes the type for x when the
 $\star$
for x is removed, and we are finding a more precise migration than
$\star$
for x is removed, and we are finding a more precise migration than
 $\star$
. Thus, instead of constraining
$\star$
. Thus, instead of constraining
 $\alpha$
with all the three requirements at once, we can relax the latter two requirements and require
$\alpha$
with all the three requirements at once, we can relax the latter two requirements and require
 $\alpha$
be unified with a type whose type constructor is
$\alpha$
be unified with a type whose type constructor is
 $\to$
only. From now on, we call type variables that are introduced to replace
$\to$
only. From now on, we call type variables that are introduced to replace
 $\star$
s for dynamic parameters migration type variables. Migration type variables appear in the right alternatives of choices when choices are first created. We will use
$\star$
s for dynamic parameters migration type variables. Migration type variables appear in the right alternatives of choices when choices are first created. We will use
 $\alpha$
to range over migration type variables.
$\alpha$
to range over migration type variables.
Overall, the idea of our solution is that when a migration variable is unified against a function type, we require only that the migration variable be mapped to a function type but allow the parameter type and return type to remain a
 $\star$
. The typing that happens later decides whether the parameter type and/or return type could be made precise than a
$\star$
. The typing that happens later decides whether the parameter type and/or return type could be made precise than a
 $\star$
. As a result, a parameter can now be migrated to a function type whose parameter or return type remains a
$\star$
. As a result, a parameter can now be migrated to a function type whose parameter or return type remains a
 $\star$
.
$\star$
.
One technical challenge is that for the parameter type and return type, we need to explore two possibilities: the
 $\star$
and a more precise type. Our machinery with variational typing provides a nice solution. Specifically, when a migration variable
$\star$
and a more precise type. Our machinery with variational typing provides a nice solution. Specifically, when a migration variable
 $\alpha$
is unified with a function type
$\alpha$
is unified with a function type
 $M_{1}\to M_{2}$
, we refine
$M_{1}\to M_{2}$
, we refine
 $\alpha$
to a function type
$\alpha$
to a function type ![]() (We refer to this process as refinement) and unify this function type against
(We refer to this process as refinement) and unify this function type against
 $M_{1}\to M_{2}$
. Here,
$M_{1}\to M_{2}$
. Here,
 $A_1$
,
$A_1$
,
 $\alpha_{1}$
,
$\alpha_{1}$
,
 $A_2$
, and
$A_2$
, and
 $\alpha_{2}$
are fresh and
$\alpha_{2}$
are fresh and
 $\alpha_{1}$
and
$\alpha_{1}$
and
 $\alpha_{2}$
are migration variables, which could be further refined to function types whose parameter and return types are
$\alpha_{2}$
are migration variables, which could be further refined to function types whose parameter and return types are
 $\star$
s. The function type
$\star$
s. The function type ![]() encodes four possibilities: both the parameter type and the return type could be
encodes four possibilities: both the parameter type and the return type could be
 $\star$
or a more precise type.
$\star$
or a more precise type.
Following this idea, the constraint solving process for the constraints
 $C_1$
through
$C_1$
through
 $C_7$
is updated to the following. In the “Solution” column below, we omitted the mappings
$C_7$
is updated to the following. In the “Solution” column below, we omitted the mappings
 $\alpha$
and
$\alpha$
and
 $\alpha_{2}\mapsto\kappa_{2}$
to save space.
$\alpha_{2}\mapsto\kappa_{2}$
to save space.

From Section 6 (page 32), we know that the type of
 $\lambda x:\star.x(\mathtt{succ}(x \mathtt{True}))$
is
$\lambda x:\star.x(\mathtt{succ}(x \mathtt{True}))$
is ![]() . Plugging in the solution for
. Plugging in the solution for
 $\alpha$
from the unifier above, the type for
$\alpha$
from the unifier above, the type for
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
is
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
is ![]() . Moreover, the pattern for the whole function is
. Moreover, the pattern for the whole function is ![]() . Note,
. Note,
 $A_2$
does not appear in the result pattern because whether we choose
$A_2$
does not appear in the result pattern because whether we choose
 $\star$
or
$\star$
or
 $\mathtt{Int}$
for the return type of the function type for
$\mathtt{Int}$
for the return type of the function type for
 $\alpha$
, the well-typedness of the expression remains the same. Applying the operations ve and expand, defined in Section 5.2, to the pattern
$\alpha$
, the well-typedness of the expression remains the same. Applying the operations ve and expand, defined in Section 5.2, to the pattern ![]() , we know that the best migration for this expression corresponds to the valid eliminator
, we know that the best migration for this expression corresponds to the valid eliminator
 $\{A.2,A_{1}.1,A_{2}.2\}$
. Selecting
$\{A.2,A_{1}.1,A_{2}.2\}$
. Selecting
 $M_{dp}$
with
$M_{dp}$
with
 $\{A.2,A_{1}.1,A_{2}.2\}$
yields the type
$\{A.2,A_{1}.1,A_{2}.2\}$
yields the type
 $(\star\to\mathtt{Int})\to\mathtt{Int}$
, the type of
$(\star\to\mathtt{Int})\to\mathtt{Int}$
, the type of
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
after migrating the parameter x. This means that our extension could indeed find a more precise migration for
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
after migrating the parameter x. This means that our extension could indeed find a more precise migration for
 $\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
.
$\lambda x:\star.x(\mathtt{succ}(x\mathtt{True}))$
.
An extension to the unification algorithm Figure 14 presents an extension to the unification algorithm that implements our idea from above. We briefly go through the cases. First, the cases (bR) and (bR*) replace cases (b) and (b*) in Figure 13, by renaming the type variables
 $\alpha$
to
$\alpha$
to
 $\beta$
. Note that from now on, we use
$\beta$
. Note that from now on, we use
 $\beta$
to denote migration variables and
$\beta$
to denote migration variables and
 $\beta$
to denote all other variables. The cases (b1) through (b4) handle unification between a migration variable and itself, a constant type, a non-migration type variable, and a variational type.
$\beta$
to denote all other variables. The cases (b1) through (b4) handle unification between a migration variable and itself, a constant type, a non-migration type variable, and a variational type.

Figure 14. An extension to the unification algorithm in Figure 13.
Case (b5) handles the unification between a migration variable and a function type. This case uses an auxiliary function AllLvsDynMvs to determine if the leaves of a given input type are all
 $\star$
s or migration type variables. For example, all
$\star$
s or migration type variables. For example, all
 $AllLvsDynMvs(\alpha_{1}\to\alpha)$
,
$AllLvsDynMvs(\alpha_{1}\to\alpha)$
,
 $AllLvsDynMvs(\alpha_{2})$
, and
$AllLvsDynMvs(\alpha_{2})$
, and
 $AllLvsDynMvs((\star\to\alpha)\to\alpha_{2})$
are true, while
$AllLvsDynMvs((\star\to\alpha)\to\alpha_{2})$
are true, while
 $AllLvsDynMvs(\alpha_{1}\to\mathtt{Int})$
and
$AllLvsDynMvs(\alpha_{1}\to\mathtt{Int})$
and
 $AllLvsDynMvs((\alpha_{1}\to\mathtt{Bool})\to\alpha_{2})$
are false. This function helps avoid non-termination in our extension. To illustrate, consider the constraint
$AllLvsDynMvs((\alpha_{1}\to\mathtt{Bool})\to\alpha_{2})$
are false. This function helps avoid non-termination in our extension. To illustrate, consider the constraint
 $\alpha\approx^{?}\alpha\to\beta$
. Such a constraint arises when typing a self application, such as in the expression
$\alpha\approx^{?}\alpha\to\beta$
. Such a constraint arises when typing a self application, such as in the expression
 $\lambda x:\star.x.x$
. This constraint fails to solve using the constraint solving algorithm in Figure 13 due to the occurs check.
$\lambda x:\star.x.x$
. This constraint fails to solve using the constraint solving algorithm in Figure 13 due to the occurs check.
With the extension in Figure 14, we will turn the constraint
 $\alpha\approx^{?}\alpha\to\beta$
into
$\alpha\approx^{?}\alpha\to\beta$
into ![]() . This constraint encodes four constraints, and one of them is
. This constraint encodes four constraints, and one of them is
 $\alpha_{1}\to\alpha_{2}\approx^{?}(\alpha_{1}\to\alpha_{2})\to\beta$
(if we select the variational constraint with the decision
$\alpha_{1}\to\alpha_{2}\approx^{?}(\alpha_{1}\to\alpha_{2})\to\beta$
(if we select the variational constraint with the decision
 $\{A_{1}.2,A_{2}.2\}$
). We observe that this problem is larger than the original problem
$\{A_{1}.2,A_{2}.2\}$
). We observe that this problem is larger than the original problem
 $\alpha\approx^{?}\alpha\to\beta$
and the constraint between the parameter types (
$\alpha\approx^{?}\alpha\to\beta$
and the constraint between the parameter types (
 $\alpha_{1}\approx^{?}\alpha_{1}\to\alpha_{2}$
) resembles the original problem. We can envision that the unification will not terminate if we keep on refining migration variables as we did above.
$\alpha_{1}\approx^{?}\alpha_{1}\to\alpha_{2}$
) resembles the original problem. We can envision that the unification will not terminate if we keep on refining migration variables as we did above.
There are two potential ways to address this problem. The first is that we use a heuristic, such as allowing a single migration variable be refined by up to a certain number of times only. Any further refinement attempt on the same migration variable would be rejected and treated as a unification failure. The second is to detect the unification that unifies a migration variable (
 $\alpha$
) against a function type that contains the migration variable (
$\alpha$
) against a function type that contains the migration variable (
 $\alpha$
) and all other leaves are other migration variables or
$\alpha$
) and all other leaves are other migration variables or
 $\star$
s. Such a unification does not reflect any program structure information but is resulted from refining a unification variable to a function type, since constraint generation (Figure 11) does not generate such a constraint. If such a unification problem is detected, we can terminate the unification with a failure.
$\star$
s. Such a unification does not reflect any program structure information but is resulted from refining a unification variable to a function type, since constraint generation (Figure 11) does not generate such a constraint. If such a unification problem is detected, we can terminate the unification with a failure.
Note, even though unification will fail for
 $\alpha_{1}\to\alpha_{2}\approx^{?}(\alpha_{1}\to\alpha_{2})\to\beta$
, which means the typing pattern returned for unifying it will be
$\alpha_{1}\to\alpha_{2}\approx^{?}(\alpha_{1}\to\alpha_{2})\to\beta$
, which means the typing pattern returned for unifying it will be
 $\vdash$
, the typing pattern for unifying
$\vdash$
, the typing pattern for unifying ![]() will not be
will not be
 $\vdash$
. It is
$\vdash$
. It is ![]() . This means that the pattern for solving
. This means that the pattern for solving
 $\alpha\approx^{?}\alpha\to\beta$
is not
$\alpha\approx^{?}\alpha\to\beta$
is not
 $\vdash$
.
$\vdash$
.
In this extension, we use the second way to address this problem. Concretely, we capture it in the first subcase of case (b5). In the second subcase,
 $\alpha$
does not occur in the function type and all leaves are migration variables, then we directly map
$\alpha$
does not occur in the function type and all leaves are migration variables, then we directly map
 $\alpha$
to the function type. In the third subcase, the function type contains some
$\alpha$
to the function type. In the third subcase, the function type contains some
 $\star$
s. We need to refine
$\star$
s. We need to refine
 $\alpha$
to a function type, but without creating new variations. The last subcase implements the idea of refining a migration variable into a function type whose both parameter and return types are variations.
$\alpha$
to a function type, but without creating new variations. The last subcase implements the idea of refining a migration variable into a function type whose both parameter and return types are variations.
With this extension, let’s now turn to finding migrations for the term
 $\lambda{x}:{\star}.{x\ x}$
. First, we generate the constraint
$\lambda{x}:{\star}.{x\ x}$
. First, we generate the constraint ![]() and the type for the term is
and the type for the term is ![]() . This constraint will be solved using case (d) of Figure 13, which will solve two constraints originated from the two alternatives of A. For the left alternative, the constraint is
. This constraint will be solved using case (d) of Figure 13, which will solve two constraints originated from the two alternatives of A. For the left alternative, the constraint is
 $\star\approx^{?}\star\to\beta$
, which will be solved by case (a) of Figure 13 with the solution (
$\star\approx^{?}\star\to\beta$
, which will be solved by case (a) of Figure 13 with the solution (
 $\varnothing,\top$
). For the right alternative, the constraint is
$\varnothing,\top$
). For the right alternative, the constraint is
 $\alpha\approx^{?}\alpha\to\beta$
. This constraint will be handled by the fourth subcase of case (b5) in Figure 14, and it will be transformed to
$\alpha\approx^{?}\alpha\to\beta$
. This constraint will be handled by the fourth subcase of case (b5) in Figure 14, and it will be transformed to ![]()
![]() .
.
With a few steps, this problem can be solved and the solution is ![]() and the pattern is
and the pattern is ![]() . Substituting the type of the term with this solution yields
. Substituting the type of the term with this solution yields ![]() and the overall pattern is
and the overall pattern is ![]() . From this pattern, we can use ve and expand defined in Section 5.2 to calculate the strictest valid eliminator
. From this pattern, we can use ve and expand defined in Section 5.2 to calculate the strictest valid eliminator
 $\{A.2,A_{1}.1,A_{2}.2\}$
. Selecting the type
$\{A.2,A_{1}.1,A_{2}.2\}$
. Selecting the type ![]() with this eliminator leads to the type
with this eliminator leads to the type
 $(\star\to\beta) \to \beta$
, which is a most static migration for
$(\star\to\beta) \to \beta$
, which is a most static migration for
 $\lambda{x}:{\star}.{x\ x}$
. This shows that with the extended constraint solving algorithm, we could find a more precise migration for
$\lambda{x}:{\star}.{x\ x}$
. This shows that with the extended constraint solving algorithm, we could find a more precise migration for
 $\lambda{x}:{\star}.{x\ x}$
that we could not find earlier.
$\lambda{x}:{\star}.{x\ x}$
that we could not find earlier.
9.3 Further migration scenarios
Sections 4 and 5 provide a type system and a method for finding all best migrations. In practice, there may be different migration requirements. In this subsection, we explore a few of them and show how to support them with machinery developed in earlier sections. Specifically, we consider the following migration scenarios.
-
i. Can the programmer control which parameters must or must not be migrated?
-
ii. If migrating a set of indicated parameters yields a type error, can we still migrate a subset of these parameters?
-
iii. Given a set of parameters, can we find which parameters cannot be migrated in unison?
-
iv. Can we find the migrations that migrate the greatest number of parameters?
We use the program
 $\mathtt{rowAtI}$
to illustrate these scenarios and the development of corresponding machinery. Recall that the variations introduced for the parameters
$\mathtt{rowAtI}$
to illustrate these scenarios and the development of corresponding machinery. Recall that the variations introduced for the parameters
 $\mathtt{fixed}$
,
$\mathtt{fixed}$
,
 $\mathtt{widthFunc}$
,
$\mathtt{widthFunc}$
,
 $\mathtt{table}$
,
$\mathtt{table}$
,
 $\mathtt{border}$
, and
$\mathtt{border}$
, and
 $\mathtt{i}$
are A, B, D, E, and F, respectively. The typing pattern for this program is shown in Section 4.5 and is reproduced here for readability.
$\mathtt{i}$
are A, B, D, E, and F, respectively. The typing pattern for this program is shown in Section 4.5 and is reproduced here for readability.
We next go through each scenario.
Scenario i: We begin with a concrete case. Assume that the programmer requires that
 $\mathtt{table}$
must be migrated and
$\mathtt{table}$
must be migrated and
 $\mathtt{widthFunc}$
must not be migrated. We can build a decision
$\mathtt{widthFunc}$
must not be migrated. We can build a decision
 $\delta_{r}$
for refining the pattern
$\delta_{r}$
for refining the pattern
 $\pi_{a}$
based on this requirement. To express that
$\pi_{a}$
based on this requirement. To express that
 $\mathtt{table}$
must be migrated, we extend
$\mathtt{table}$
must be migrated, we extend
 $\delta_{r}$
with D.2, as D is the variation introduced for
$\delta_{r}$
with D.2, as D is the variation introduced for
 $\mathtt{table}$
. For
$\mathtt{table}$
. For
 $\mathtt{widthFunc}$
to be not migrated, we extend
$\mathtt{widthFunc}$
to be not migrated, we extend
 $\delta_{r}$
with B.1, making
$\delta_{r}$
with B.1, making
 $\delta_{r}=\{B.1,D.2\}$
. After that, we refine
$\delta_{r}=\{B.1,D.2\}$
. After that, we refine
 $\pi_{a}$
with
$\pi_{a}$
with
 $\delta_{r}$
, yielding the new pattern
$\delta_{r}$
, yielding the new pattern ![]() , which could be simplified to
, which could be simplified to
 $E\langle\top,\vdash\rangle$
. We can now apply the method developed in Section 5 to the pattern
$E\langle\top,\vdash\rangle$
. We can now apply the method developed in Section 5 to the pattern
 $E\langle\top,\vdash\rangle$
to find the best migrations for
$E\langle\top,\vdash\rangle$
to find the best migrations for
 $\mathtt{rowAtI}$
while honoring the requirements. Based on the pattern
$\mathtt{rowAtI}$
while honoring the requirements. Based on the pattern
 $E\langle\top,\vdash\rangle$
, the migration result is that
$E\langle\top,\vdash\rangle$
, the migration result is that
 $\mathtt{border}$
, the parameter corresponds to E, cannot be migrated, and all other parameters can be migrated. Overall, the migration is that we can migrate
$\mathtt{border}$
, the parameter corresponds to E, cannot be migrated, and all other parameters can be migrated. Overall, the migration is that we can migrate
 $\mathtt{fixed}$
,
$\mathtt{fixed}$
,
 $\mathtt{i}$
, and
$\mathtt{i}$
, and
 $\mathtt{table}$
.
$\mathtt{table}$
.
In general, for a program and its typing pattern
 ${\pi}$
generated from MGSM, we follow the following steps to handle this scenario. enumi enumi
${\pi}$
generated from MGSM, we follow the following steps to handle this scenario. enumi enumi
-
1. For each parameter that must be migrated, we extend
$\delta_{r}$
with d.2, where d is the variation introduced for the parameter. -
2. For each parameter that must not be migrated, we extend
$\delta_{r}$
with d.1, where d is the variation introduced for the parameter. -
3. We refine the pattern
${\pi}$
with
$\delta_{r}$
. -
4. With the resulting pattern from the last step, we use the method for finding most static migrations outlined in Section 5.2 to find desired migrations.




Scenario ii: Assume that the programmer requires to migrate all
 $\mathtt{fixed}$
,
$\mathtt{fixed}$
,
 $\mathtt{widthFunc}$
, and
$\mathtt{widthFunc}$
, and
 $\mathtt{table}$
. According to the process of calculating
$\mathtt{table}$
. According to the process of calculating
 $\delta_{r}$
given earlier,
$\delta_{r}$
given earlier,
 $\delta_{r}=\{A.2,B.2,D.2\}$
. We observe that
$\delta_{r}=\{A.2,B.2,D.2\}$
. We observe that
 $\lfloor\pi_{a}\rfloor_{\delta_{r}}=\vdash$
, indicating that not all these parameters can be migrated at the same time. However, the
$\lfloor\pi_{a}\rfloor_{\delta_{r}}=\vdash$
, indicating that not all these parameters can be migrated at the same time. However, the
 $\vdash$
does not indicate that none of the parameters can be migrated.
$\vdash$
does not indicate that none of the parameters can be migrated.
To figure out if a parameter within the specified set could be migrated, we could list all decisions yielding best migrations and check if the parameter appears in any set. For example, based on Section 5.2, the decisions corresponding to best migrations for
 $\mathtt{rowAtI}$
are
$\mathtt{rowAtI}$
are
 $\{A.2, B.1, D.2, E.1, F.2\}$
and
$\{A.2, B.1, D.2, E.1, F.2\}$
and
 $\{A.1, B.2, D.2, E.1, F.2\}$
. From the first set, we could decide that
$\{A.1, B.2, D.2, E.1, F.2\}$
. From the first set, we could decide that
 $\mathtt{fixed}$
(since
$\mathtt{fixed}$
(since
 $\mathtt{fixed}$
corresponds to A and A belongs to the set) and
$\mathtt{fixed}$
corresponds to A and A belongs to the set) and
 $\mathtt{table}$
of the desired set could be migrated. From the second set, we could decide that
$\mathtt{table}$
of the desired set could be migrated. From the second set, we could decide that
 $\mathtt{widthFunc}$
and
$\mathtt{widthFunc}$
and
 $\mathtt{table}$
could be migrated. In this case, we have two different such sets. In other cases, we may have only one such set. For example, if the programmer indicated that they wanted to migrate
$\mathtt{table}$
could be migrated. In this case, we have two different such sets. In other cases, we may have only one such set. For example, if the programmer indicated that they wanted to migrate
 $\mathtt{fixed}$
and
$\mathtt{fixed}$
and
 $\mathtt{border}$
, then the unique migration corresponds to the decision is
$\mathtt{border}$
, then the unique migration corresponds to the decision is
 $\{A.2, B.1, D.2, E.1, F.2\}$
, indicating that only
$\{A.2, B.1, D.2, E.1, F.2\}$
, indicating that only
 $\mathtt{fixed}$
within the two parameters could be migrated.
$\mathtt{fixed}$
within the two parameters could be migrated.
Scenario iii: During program migration, it is quite common that migrating one parameter may preclude the migration of others. For example, in
 $\mathtt{rowAtI}$
, we could not migrate
$\mathtt{rowAtI}$
, we could not migrate
 $\mathtt{widthFunc}$
if we have migrated
$\mathtt{widthFunc}$
if we have migrated
 $\mathtt{fixed}$
and vice versa. Therefore, presenting the unison parameters that could no longer be migrated can be useful to programmers.
$\mathtt{fixed}$
and vice versa. Therefore, presenting the unison parameters that could no longer be migrated can be useful to programmers.
Assume that the programmer has migrated
 $\mathtt{fixed}$
and that we want to calculate the impact it has on other parameters. We must now consider two cases. The first case migrates
$\mathtt{fixed}$
and that we want to calculate the impact it has on other parameters. We must now consider two cases. The first case migrates
 $\mathtt{fixed}$
, and the decision is
$\mathtt{fixed}$
, and the decision is
 $\delta_{r}=\{A.2\}$
. The second case does not migrate
$\delta_{r}=\{A.2\}$
. The second case does not migrate
 $\mathtt{fixed}$
, and the decision is
$\mathtt{fixed}$
, and the decision is
 $\delta_{\neg r}=\{A.1\}$
. Let
$\delta_{\neg r}=\{A.1\}$
. Let
 $\pi_{r}$
and
$\pi_{r}$
and
 $\pi_{r}$
denote the typing patterns resulted from selecting
$\pi_{r}$
denote the typing patterns resulted from selecting
 $\pi_{a}$
with
$\pi_{a}$
with
 $\delta_{r}$
and
$\delta_{r}$
and
 $\delta_{\neg r}$
, respectively, we have
$\delta_{\neg r}$
, respectively, we have
In the first case, from
 $\pi_{r}$
, we have two decisions that lead to
$\pi_{r}$
, we have two decisions that lead to
 $\vdash:\{B.1,E.2\}$
and
$\vdash:\{B.1,E.2\}$
and
 $\{B.2\}$
. In the second case, from
$\{B.2\}$
. In the second case, from
 $\pi_{\neg r}$
, only one decision leads to
$\pi_{\neg r}$
, only one decision leads to
 $\vdash:\{E.2\}$
. By comparing the decisions in these two cases, we observe that both cases contain E.2. This implies that migrating
$\vdash:\{E.2\}$
. By comparing the decisions in these two cases, we observe that both cases contain E.2. This implies that migrating
 $\mathtt{border}$
, the parameter corresponding to E, always causes an error, meaning that
$\mathtt{border}$
, the parameter corresponding to E, always causes an error, meaning that
 $\mathtt{fixed}$
being migrated was irrelevant to the reason
$\mathtt{fixed}$
being migrated was irrelevant to the reason
 $\mathtt{border}$
cannot be migrated. On the other hand, only a decision in the first case contains B.2 while none in the second case contains it. This implies that the reason
$\mathtt{border}$
cannot be migrated. On the other hand, only a decision in the first case contains B.2 while none in the second case contains it. This implies that the reason
 $\mathtt{widthFunc}$
cannot be migrated is because
$\mathtt{widthFunc}$
cannot be migrated is because
 $\mathtt{fixed}$
was migrated. Consequently, the parameter that cannot be migrated in unison with
$\mathtt{fixed}$
was migrated. Consequently, the parameter that cannot be migrated in unison with
 $\mathtt{fixed}$
is
$\mathtt{fixed}$
is
 $\mathtt{widthFunc}$
.
$\mathtt{widthFunc}$
.
Given an expression e and
 ${\pi}$
for its MGSM typing, and assume the parameter x is migrated and the introduced variation for x is d, the following steps list the process of finding parameters that cannot be migrated due to the migration of x.
${\pi}$
for its MGSM typing, and assume the parameter x is migrated and the introduced variation for x is d, the following steps list the process of finding parameters that cannot be migrated due to the migration of x.
-
1. Let
$\pi_{r}=\lfloor\pi\rfloor_{d.1}$
and
$\pi_{\neg r}=\lfloor\pi\rfloor_{d.2}$
. -
2. Collect the decisions that produce
$\vdash$
when selecting
${\pi}$
with
$\pi_{r}$
. -
3. Collect the decisions that produce
$\vdash$
when selecting
${\pi}$
with
$\pi_{\neg r}$
. -
4. For any d’, if
$d'.2$
appears in some decisions from step (3) but not from any of decision in step (2), then the parameter that corresponds to d’ cannot be migrated in unison with x.









Scenario iv: This scenario aims to find out the migrations that migrate the greatest number of parameters, which we refer to as maximal migrations. For example, if one most static migration migrates two parameters while another migrates four, then the latter is a maximal migration if no other migrations migrate more than four parameters. In some situation, maximal migration are not unique. For example, two most static migrations for
 $\mathtt{rowAtI}$
migrate three parameters and both are maximal.
$\mathtt{rowAtI}$
migrate three parameters and both are maximal.
Given an expression and its typing pattern
 ${\pi}$
for its MGSM, a simple process to find maximal migrations is generate all best migrations from
${\pi}$
for its MGSM, a simple process to find maximal migrations is generate all best migrations from
 ${\pi}$
and filter out the migrations that migrate the greatest number of parameters.
${\pi}$
and filter out the migrations that migrate the greatest number of parameters.
This process is straightforward and necessitates no changes to our existing machinery, but is computationally expensive. We can improve the efficiency by slightly adapting the ve function for collecting best migrations from Section 5.2. Specifically, for each internal node of the typing pattern, we compare the cardinality of the decisions from the left and right subtrees and discard the decisions that have more left selectors, which are selectors of the form d.1 for some d (see Section 2.2). We express this idea in the following function mve.

In the definition,
 $\delta|_{1}$
(introduced in Section 4.5) returns all left selectors in
$\delta|_{1}$
(introduced in Section 4.5) returns all left selectors in
 $\delta$
. The notation lmve[0] returns any member from the set lmve. This is valid because all of the members in lmve include the same number of left selectors, and so do those in rmve. The set
$\delta$
. The notation lmve[0] returns any member from the set lmve. This is valid because all of the members in lmve include the same number of left selectors, and so do those in rmve. The set
 $\mathscr{D}$
(introduced in Section 5.2) contains all variations introduced in typing e. Note, given a decision
$\mathscr{D}$
(introduced in Section 5.2) contains all variations introduced in typing e. Note, given a decision
 $\delta$
, if
$\delta$
, if
 $d.1\in\delta$
then the parameter corresponding to d cannot be migrated. Therefore,
$d.1\in\delta$
then the parameter corresponding to d cannot be migrated. Therefore,
 $|\mathscr{D}| - |lmve[0]|_{1}|$
gives the number of parameters that can be migrated in lmve[0].
$|\mathscr{D}| - |lmve[0]|_{1}|$
gives the number of parameters that can be migrated in lmve[0].
mve is always more efficient than ve since the former keeps the set of decisions that yield maximal migrations only while the latter keeps all best migrations. In particular, if there is a unique maximal migration, then mve returns only one decision.
Discussion. Supporting these scenarios by reusing or slightly adapting existing machinery demonstrates the generality of our approach. We can also support variations or combinations of scenarios we looked at with ease. For example, a combination of scenarios i and iv could be supported by following the first three steps outlined in Scenario i and then applying the mve function to the resulting pattern. As another example, we may be interested in the scenario of finding the maximal migration within a given set of parameters. To support this scenario, we first select the typing pattern of the MGSM typing with selectors of the form d.1, where d corresponds to a parameter that does not belong to the given set. The selection result is a pattern, to which we apply mve to find the maximal migration within that parameter set.
Overall, the generality of our approach demonstrates that it could be a useful foundation for developing more complex and significant migration supports in practice.
10 Evaluation
This section evaluates the performance of migrational typing. For this purpose, we have implemented a prototype in Haskell. The prototype implements the techniques developed in this paper. Besides the features presented in Sections 4.1 and 9.1, the prototype also supports recursive functions, a built-in list type, a built-in
 $\mathtt{Vector}$
type, and a tuple type, which are needed to encode the examples described below.
$\mathtt{Vector}$
type, and a tuple type, which are needed to encode the examples described below.
To evaluate the performance of our idea in practice, we have converted programs in Grift to the language supported by our prototype. We used all the programs from Kuhlenschmidt et al., (Reference Kuhlenschmidt, Almahallawi and Siek2019) except the program sieve, which uses recursive types that are not supported in our prototype. Since these converted programs are all well-typed, we seed errors in the programs by randomly applying between 2 and 25 changes in each. Each change replaces one leaf of the AST (a variable reference or constant) with another leaf. These programs are summarized in columns 2–5 of Figure 15, showing size in lines of non-blank code, number of functions, number of dynamic parameters, and the number of leaves that were changed.

Figure 15. Running time (in seconds) of migrational typing on programs converted from Grift (Kuhlenschmidt et al., Reference Kuhlenschmidt, Almahallawi and Siek2019). For each row, columns 2 through 4 give the metric of the program, including the number of lines of non-blank code, the number of functions, the number of dynamic parameters, and the number of changes we made to the program. Times are measured on a ThinkPad with 2.4GHz i7-5500U 4-core processor and 8GB memory running GHC 8.0.2 on Ubuntu 16.04. Each time is an average of 10 runs. The symbol – indicates that typing timed out after 1,000 s.
For each evaluated program, we compared the runtime of migrational typing with standard gradual typing and with a brute-force strategy for most static migration for the program, shown in columns 7 through 9 of the table. In standard gradual typing, we run our implementation without creating any variations. We also report the number of most static migrations in column “# Best,” computed using the method in Section 5.2. The time for gradual typing can be considered a baseline—this is the time to simply type the given program. The time for the brute-force strategy represents a naive approach to migrational typing, generating
 $2^n$
variants of a program with n dynamic parameters, and gradually typing all of them. In Section 1.1, we discussed that an exploration of all programs are needed to find best migrations. We omit the time for computing the most static migrations from the figure because the time is always within 0.04 s.
$2^n$
variants of a program with n dynamic parameters, and gradually typing all of them. In Section 1.1, we discussed that an exploration of all programs are needed to find best migrations. We omit the time for computing the most static migrations from the figure because the time is always within 0.04 s.
We observe that the brute-force approach, as expected, is exponentially slower than gradual typing, and it successfully types only the programs that have fewer than 10 parameters. On the other hand, migrational typing scales linearly with the size of the program and exhibits only a 2–3.5 times overhead over gradual typing.
We have also investigated the impact of the ratio of typed parameters on migrational typing time, and we presented the results in Figure 16. Note that the x-axis cuts off at 93% because, as we made random changes to the program, not all parameters can be given static types. In general, a higher ratio of typed parameters leads to fewer variations being created and thus takes shorter time for migrational typing to finish.

Figure 16. Relations between ratios of typed parameters and migrational typing times for the nbody benchmark.
11 Related work
11.1 Annotation upgrading and migratory typing
Tansey & Tilevich (Reference Tansey and Tilevich2008) studied the problem of automatically upgrading annotations (such as types and access modifiers in Java) in legacy applications in response to the upgrading of, for example, testing frameworks and libraries. This is similar to our work in that it tackles the problem of migrating programs to a new version by changing annotations in the program. Their methodology is quite different; however, in that it needs two example programs illustrating how annotations change between framework versions, so that their inference rules can learn the changes made in the examples. In contrast, our approach only needs to reason about how type annotations affect the typing of the program, so migrating annotations requires only information attainable through the type system.
Moreover, the kind of migrations are orthogonal. Their goal is to upgrade an entire codebase automatically to use a new framework, which means that they have one endpoint. Migrational typing presents all of the ways a programmer might want to change the types of their program by adjusting
 $\star$
annotations, meaning that there are multiple endpoints.
$\star$
annotations, meaning that there are multiple endpoints.
Migratory typing (Tobin-Hochstadt et al., Reference Tobin-Hochstadt, Felleisen, Findler, Flatt, Greenman, Kent, St-Amour, Strickland and Takikawa2017) provides another approach to migrating dynamically typed code to statically typed code by creating a statically typed sister language that interfaces seamlessly with the dynamically typed language. In general the focus of this work is about designing such a sister language such that types can be assigned to existing programs in the dynamic language with minimal refactoring. While programmers have to manually add type annotations to make programs more static in migratory typing, migrational typing supports systematically typing the whole migration space and automatically finding the best migrations.
This means that a large focus of migratory typing is orthogonal to our work in that we assume we are working within a given gradual language and that we do not have to design a static sister language to a dynamic language. On the other hand, if we were given a static language and gradualized it via the idea of Garcia et al., (Reference Garcia, Clark and Tanter2016), Cimini & Siek (Reference Cimini and Siek2016); Cimini & Siek (Reference Cimini and Siek2017) we conjecture we could design a migration tool for gradualized languages that supported unification based type inference.
11.2 Gradual typing migration
As discussed in Section 1.3, this work is closely related to the work by Migeed & Palsberg (Reference Migeed and Palsberg2019) on finding maximal migrations for gradual programs. There are several similarities in their work and ours. For example, they consider a set of possible migrations for a gradually typed programs and try to find all of the maximal migrations. These maximal migrations are migrations that cannot add any more type information to the program without causing a static type error, which are similar to our most static migrations. They show that the process of finding maximal migrations is NP hard.
Their work has some notable differences with our work, however. Mainly, the language they consider is a version of GTLC (Siek et al., Reference Siek, Vitousek, Cimini and Boyland2015) with the ability to add
 $\mathtt{Bool}$
and
$\mathtt{Bool}$
and
 $\mathtt{Int}$
annotations. In contrast, we start with ITGL, a gradualized version of the Hindley-Milner language, which has a principal type inference that works on unannotated terms. Essentially, while both work aims to find maximal migrations, they use different techniques and criteria. In their work, they continuously generate more precise programs by replacing a
$\mathtt{Int}$
annotations. In contrast, we start with ITGL, a gradualized version of the Hindley-Milner language, which has a principal type inference that works on unannotated terms. Essentially, while both work aims to find maximal migrations, they use different techniques and criteria. In their work, they continuously generate more precise programs by replacing a
 $\star$
with a more precise type and tests the well-typedness of the generated program. They find a maximal migration if no more
$\star$
with a more precise type and tests the well-typedness of the generated program. They find a maximal migration if no more
 $\star$
s exist or no more
$\star$
s exist or no more
 $\star$
could be replaced with any more precise type. A migration in our work is maximal if no further
$\star$
could be replaced with any more precise type. A migration in our work is maximal if no further
 $\star$
can be eliminated with respect to ITGL Garcia & Cimini (Reference Garcia and Cimini2015) constraint solving. As a result, their approach may find types that are rejected by the ITGL inference that we adapt. For example, for
$\star$
can be eliminated with respect to ITGL Garcia & Cimini (Reference Garcia and Cimini2015) constraint solving. As a result, their approach may find types that are rejected by the ITGL inference that we adapt. For example, for
 $\lambda x:\star.x(succ(x\mathtt{True}))$
, their approach infers that x can be given the type
$\lambda x:\star.x(succ(x\mathtt{True}))$
, their approach infers that x can be given the type
 $\star\to\mathtt{Int}$
, whereas our approach respects ITGL, which considers the use of x to be ill-typed (Our extension in Section 9.2 does infer that x may be migrated to the type
$\star\to\mathtt{Int}$
, whereas our approach respects ITGL, which considers the use of x to be ill-typed (Our extension in Section 9.2 does infer that x may be migrated to the type
 $\star\to\mathtt{Int}$
.
$\star\to\mathtt{Int}$
.
Finally, we have evaluated the efficiency of our approach on large programs, and we observed that finding all best migrations in our approach is usually within a factor of 2 of typing each possible migration. The efficiency in their approach is unclear. It would be interesting as future work to see if our machinery could be exploited to improve the efficiency of their work.
Phipps-Costin et al., (Reference Phipps-Costin, Anderson, Greenberg and Guha2021) developed a framework named TypeWhich for migrating gradual types. While both our work and the work by Migeed & Palsberg (Reference Migeed and Palsberg2019) aim at maximizing type precision during migration, TypeWhich allows users to consider not only type precision, but also type safety (such that migration does not introduce runtime errors) and type compatibility (such that migration does not break the interoperability between migrated and un-migrated code). As such, some migrations in our work and that by Migeed & Palsberg (Reference Migeed and Palsberg2019) may introduce dynamic runtime errors, but not in the safety or compatibility mode of TypeWhich. The latter two modes are particularly useful because migrations are often not done for the whole project and the migration process should not break code interactions.
In addition, our work and TypeWhich differ in many aspects. First, our work can find all best migrations for a given program whereas TypeWhich finds just one best migration by default. Further migrations may be returned by TypeWhich through model extraction by the underlying SMT solver. While returning the first model is efficient, the complexity of extracting all migrations is unclear.
Consider, for example, the following expression.
 \begin{equation*}\mathtt{width fixed widthFunc = 2 + (if fixed then widthFunc fixed else widthFunc 33)}\end{equation*}
\begin{equation*}\mathtt{width fixed widthFunc = 2 + (if fixed then widthFunc fixed else widthFunc 33)}\end{equation*}
TypeWhich displays the following migration first for this function when prioritizing type precision.
Our work finds two best migrations for the function
 $\mathtt{width}$
, and neither is more precise than the other. In the first migration, the type for
$\mathtt{width}$
, and neither is more precise than the other. In the first migration, the type for
 $\mathtt{fixed}$
remains to be
$\mathtt{fixed}$
remains to be
 $\star$
whereas the type for
$\star$
whereas the type for
 $\mathtt{widthFunc}$
is
$\mathtt{widthFunc}$
is
 $\mathtt{Int}\to \mathtt{Int}$
, as shown below.
$\mathtt{Int}\to \mathtt{Int}$
, as shown below.
In the second migration, the type for
 $\mathtt{fixed}$
is migrated to
$\mathtt{fixed}$
is migrated to
 $\mathtt{Bool}$
and the type for
$\mathtt{Bool}$
and the type for
 $\mathtt{widthFunc}$
is migrated to
$\mathtt{widthFunc}$
is migrated to
 $\star->\mathtt{Int}$
(without the extension in Section 9.2 the type for
$\star->\mathtt{Int}$
(without the extension in Section 9.2 the type for
 $\mathtt{widthFunc}$
will remain
$\mathtt{widthFunc}$
will remain
 $\star$
). The migrated program is shown below.
$\star$
). The migrated program is shown below.
For programs that cannot be fully statically typed, it is likely that hundreds of best migrations exist. Our approach finds all of them in time linear to the size of the program. Since our approach may find a large number of best migrations simultaneously, it is helpful to allow users to specify preferences about where migrations are desired. We support them through extensions in Section 9.3. Since TypeWhich finds best migrations sequentially, developing such supports could be harder.
Second, by design, TypeWhich may ascribe a
 $\star$
type to a subexpression even though the subexpression has a static type during static type checking. This design allows more parameters to be migrated when precision is maximized. For example, in the migration for
$\star$
type to a subexpression even though the subexpression has a static type during static type checking. This design allows more parameters to be migrated when precision is maximized. For example, in the migration for
 $\mathtt{width}$
above, TypeWhich ascribed
$\mathtt{width}$
above, TypeWhich ascribed
 $\star$
to
$\star$
to
 $\mathtt{fixed}$
that has the type
$\mathtt{fixed}$
that has the type
 $\mathtt{Int}$
for the condition so that
$\mathtt{Int}$
for the condition so that
 $\mathtt{fixed}$
can be used where a
$\mathtt{fixed}$
can be used where a
 $\mathtt{Bool}$
is needed. Without the ascription, the migrated program is statically ill-typed. Our approach does not use ascription for maximizing migrations. Third, our approach supports polymorphism through let (Section 9.1) while TypeWhich does not.
$\mathtt{Bool}$
is needed. Without the ascription, the migrated program is statically ill-typed. Our approach does not use ascription for maximizing migrations. Third, our approach supports polymorphism through let (Section 9.1) while TypeWhich does not.
Henglein & Rehof (Reference Henglein and Rehof1995) developed an approach for embedding Scheme programs in ML by inserting coercions into subexpressions whose type correctness cannot be statically verified. Their approach uses type inference to reduce coercions that will be inserted, making it behave similarly to TypeWhich that prioritizes type safety. Technically, their approach is more involved. Given a program, it collects typing constraints, builds a simple value flow graph, and decides where coercions are needed.
11.3 Relation to gradual typing
Work on gradual typing can be broadly defined along three dimensions. The first investigates the integration of gradual typing with advanced typing features, such as objects (Siek & Taha Reference Siek and Taha2007), ownership types (Sergey & Clarke Reference Sergey and Clarke2012), refinement types (Wadler & Findler Reference Wadler and Findler2009; Lehmann & Tanter Reference Lehmann and Tanter2017; Jafery & Dunfield Reference Jafery and Dunfield2017; Williams et al., Reference Williams, Morris and Wadler2018), session types (Igarashi et al., Reference Igarashi, Thiemann, Vasconcelos and Wadler2017), and union and intersection types (Siek & Tobin-Hochstadt Reference Siek and Tobin-Hochstadt2016; Castagna & Lanvin Reference Castagna and Lanvin2017; Toro & Tanter Reference Toro and Tanter2017; Castagna et al., Reference Castagna, Lanvin, Petrucciani and Siek2019). From this perspective, our type system studies the combination of variational types with gradual types. Gradual languages with type inference (Siek & Vachharajani Reference Siek and Vachharajani2008; Rastogi et al., Reference Rastogi, Chaudhuri and Hosmer2012; Garcia & Cimini Reference Garcia and Cimini2015) were a large influence on migrational typing. While ITGL was used as the basis for formalizing our type system, we expect that our approach can be extended to handle other features in this line of work. The reason is that the idea and manipulation of variations is orthogonal to other type system features. In particular, the idea of type compatibility in Section 4.2 and the handling of type errors in Section 4.3 can be easily extended.
The second dimension studies runtime error localization and performance issues with sound gradual typing. The blame calculus (Tobin-Hochstadt & Felleisen Reference Tobin-Hochstadt and Felleisen2006; Wadler & Findler Reference Wadler and Findler2007; Wadler & Findler Reference Wadler and Findler2009) adapts the contract system notion of blame so that less precise parts of a program are blamed when cast errors occur. Ahmed et al., (Reference Ahmed, Findler, Siek and Wadler2011, Reference Ahmed, Jamner, Siek and Wadler2017) extended that work to further handle polymorphic types. Since those works, there has been a number of papers involving parametricity in the gradually typed setting (Toro et al., Reference Toro, Labrada and Tanter2019; New et al., Reference New, Jamner and Ahmed2019). Takikawa et al., (Reference Takikawa, Feltey, Greenman, New, Vitek and Felleisen2016) showed that sound gradually typed languages suffer from performance issues as more interactions between static code and dynamic code leads to frequent value casts. Confined Gradual Typing (Allende et al., Reference Allende, Fabry, Garcia and Tanter2014) provides constructs to control the flow of values between static and dynamic code, mitigating performance issues and making gradual typing more predictable.
The final dimension studies the production of gradual type systems from specifications of static type systems. For example, Garcia et al., (Reference Garcia, Clark and Tanter2016) presented a way to create gradual type systems from static ones using techniques from abstract interpretation. The Gradualizer (Cimini & Siek Reference Cimini and Siek2016, Reference Cimini and Siek2017) can produce a gradual type system and dynamic semantics for a statically typed language given its formal semantics. It is thus interesting to investigate how these approaches interact with variations in the future. Siek et al., (Reference Siek, Vitousek, Cimini and Boyland2015) discussed the criteria for gradual typing. We employed the criteria of the underlying ITGL to prove Theorem 7.
11.4 Type inference
The goal of gradual typing is to find out what parameters can be given static types. As such, gradual typing is closely related to the idea of type inference.
Gradual type inference with flow-based typing (Rastogi et al., Reference Rastogi, Chaudhuri and Hosmer2012) has been explored to make programs in dynamic object-oriented languages more performant. Since our work is formalized on ITGL, our work inherits the relations between ITGL and flow-based inference (Garcia & Cimini Reference Garcia and Cimini2015). Additionally, while flow-based inference ensures that inferred type annotations do not cause runtime errors, our current formalization does not have this property as our approach is not flow-directed.
The inference in flow (Chaudhuri et al., Reference Chaudhuri, Vekris, Goldman, Roch and Levi2017) is also flow-based and was specifically designed to not produce false positives for idioms that are commonly used in JavaScript. It is possible that migrational typing can help the inference process for languages like JavaScript by using variations to reason about idioms in messy scenarios. A flow-based inference was also employed over Reticulated Python’s cast inserted transient translation. The inference was used to optimize program performance, removing unnecessary casts where the inference indicated that it was safe.
A few type systems, such as Guha et al., (Reference Guha, Saftoiu and Krishnamurthi2011), Chugh et al., (Reference Chugh, Rondon and Jhala2012), Pearce (Reference Pearce2013), support flow-based reasoning but do not perform type inference.
SimTyper, developed by Kazerounian et al., (Reference Kazerounian, Foster and Min2021), aims to infer usable types for Ruby. Unlike most type inference algorithms, the goal of SimTyper is not to infer most general (precise) types, which could be verbose and hard to use in presence of subtyping, structural types, overloading, and other dynamic language features. Instead. the goal of SimTyper is to infer usable types that programmers often write. SimTyper is built on InferDL Kazerounian et al., (Reference Kazerounian, Ren and Foster2020), a heuristics-based type inference algorithm, and a type equality prediction method based on machine learning. Essentially, when SimTyper discovers an overly general, complicated type, it uses the type equality predictor to find a type that is more concise and is equal. SimTyper then uses that more concise type to replace the complicated one and check if that replacement violates any typing constraint. It accepts the concise type if no violations detected and rejects the type and look for another concise type otherwise.
Wei et al., (Reference Wei, Goyal, Durrett and Dillig2020) developed LambdaNet for inferring types for TypeScript. Given a program, LambdaNet first transforms it to a type dependency graph, where nodes are type variables for subexpressions in the programs and hyperedges express constraints (such as the subtyping relation or type equality). Hyperedges may also provide hints to type inference, such as variables giving rise to the connected type variables have similar names. All type variables are then converted to vectors of numbers (known as embedding in machine learning) and, LambdaNet uses a set of rules to propagate type information across the dependency graphs. These rules manipulate the embedding in each node. As with deep learning (Neocleous & Schizas Reference Neocleous and Schizas2002), the intuitions behind such rules are unclear. Finally, after propagation completes, inferred types are readout from embeddings.
11.5 Variational typing and others
This work reuses much machinery from variational typing (Chen et al., Reference Chen, Erwig and Walkingshaw2012, Reference Chen, Erwig and Walkingshaw2014) to support reuse when typing the whole migration space. Thus, migrational typing can be viewed as an application of variational typing. Variational typing has been employed to improve type inference of generalized algebraic data types (Chen & Erwig Reference Chen and Erwig2016), which uses variation types to represent potentially many types for a single expression. Variational typing has also been used to improve error locating in functional programs using counter-factual typing (CFT) (Chen & Erwig Reference Chen and Erwig2014a; b). Both migrational typing and CFT use variational types to efficiently explore a large number of hypothetical situations. A technical difference between CFT and migrational typing is that CFT tries to find a minimal change that would make an ill-typed program type correct. In contrast, migrational typing tries to remove
 $\star$
annotations from as many parameters as possible. The process of extracting the maximum change for migrational typing (as described in Section 5.2) is well defined while finding the minimum change in CFT has to rely on heuristics due to the nature of type error debugging. Another difference is that migrational typing considers the interaction between variational types and gradual types. The idea of using pattern-constrained judgments in Section 4.3 yields a declarative specification for handling type errors, while previous applications of variational typing have had to explicitly track the introduction and propagation of type errors.
$\star$
annotations from as many parameters as possible. The process of extracting the maximum change for migrational typing (as described in Section 5.2) is well defined while finding the minimum change in CFT has to rely on heuristics due to the nature of type error debugging. Another difference is that migrational typing considers the interaction between variational types and gradual types. The idea of using pattern-constrained judgments in Section 4.3 yields a declarative specification for handling type errors, while previous applications of variational typing have had to explicitly track the introduction and propagation of type errors.
The variational cost analysis by Campora et al., (Reference Campora, Chen and Walkingshaw2018b) provided an approach that harmonizes type safety and gradual typing performance. The motivation of that work was that migrating programs will likely slowdown program performance. The solution in that work was constructing a “cost lattice” that estimates the runtime overhead induced by type annotations and comparing costs of different migrations. The solution supports different migration scenarios while adding type annotations, for example finding the migrations that yield the best performance. Technically, that work adapted cost analysis for functional programs (Danner et al., Reference Danner, Licata and Ramyaa2015) to a gradually typed language. That work also used the machinery of variational typing to reusing typing and cost analysis to efficiently build the cost lattice.
It is possible that type annotations added by programmers during migrations may cause runtime type errors. Campora & Chen (Reference Campora and Chen2020) presented a static type system for detecting runtime type errors, finding out the
 $\star$
s that prevent the runtime type errors from being detected by the static type system, and suggesting fixes to remove dynamic runtime type errors.
$\star$
s that prevent the runtime type errors from being detected by the static type system, and suggesting fixes to remove dynamic runtime type errors.
Variational typing is defined in terms of the choice calculus (Erwig & Walkingshaw Reference Erwig and Walkingshaw2011). Other applications of the choice calculus include the development of variational data structures (Walkingshaw et al., Reference Walkingshaw, Kästner, Erwig, Apel and Bodden2014; Meng et al., Reference Meng, Meinicke, Wong, Walkingshaw and Kästner2017; Smeltzer & Erwig Reference Smeltzer and Erwig2017) to support variational program execution (Erwig & Walkingshaw Reference Erwig and Walkingshaw2013; Nguyen et al., Reference Nguyen, Kästner and Nguyen2014; Chen et al., Reference Chen, Erwig and Walkingshaw2016), and view-based editing of variational programs (Walkingshaw & Ostermann Reference Walkingshaw and Ostermann2014; Stănciulescu et al., Reference Stănciulescu, Berger, Walkingshaw and Wasowski2016).
Typing patterns in our work have a close resemblance to BDD (Binary Decision Diagrams) of Boolean formulas (Akers Reference Akers1978; Bryant Reference Bryant1992). For example, choices in patterns correspond to internal nodes in BDD,
 $\perp$
and
$\perp$
and
 $\top$
correspond to leaves 0 and 1 in BDDs, respectively, and selecting the right alternative of a choice corresponds to following the high edge of an internal node. Moreover, the idea of pattern normal forms, introduced before Theorem 9, are similar to reduced BDDs. Variable ordering has a significant impact on the size of a BDD. The number of nodes of a BDD may be linear to the number of variables under one ordering but it could be exponential under another. Similarly, the ordering of choice names impact the size of a typing pattern. For example, the pattern
$\top$
correspond to leaves 0 and 1 in BDDs, respectively, and selecting the right alternative of a choice corresponds to following the high edge of an internal node. Moreover, the idea of pattern normal forms, introduced before Theorem 9, are similar to reduced BDDs. Variable ordering has a significant impact on the size of a BDD. The number of nodes of a BDD may be linear to the number of variables under one ordering but it could be exponential under another. Similarly, the ordering of choice names impact the size of a typing pattern. For example, the pattern ![]() has three internal nodes and four leaves, while an equivalent pattern
has three internal nodes and four leaves, while an equivalent pattern ![]() has four internal nodes and five leaves.ue to the reasons below, we conjecture that the ordering problem in our work is not as critical as in BDDs. First, the ordering problem becomes more conspicuous when the leaves mix
has four internal nodes and five leaves.ue to the reasons below, we conjecture that the ordering problem in our work is not as critical as in BDDs. First, the ordering problem becomes more conspicuous when the leaves mix
 $\perp$
s and
$\perp$
s and
 $\top$
s. Instead, due to the fact that left alternatives of choices have
$\top$
s. Instead, due to the fact that left alternatives of choices have
 $\star$
s when they are created and
$\star$
s when they are created and
 $\star$
s unify with any types, left subtrees of patterns tend to have
$\star$
s unify with any types, left subtrees of patterns tend to have
 $\top$
s. Section 5.1 gives a formal account of this. For such patterns, the impact of ordering on sizes decreases. For example,
$\top$
s. Section 5.1 gives a formal account of this. For such patterns, the impact of ordering on sizes decreases. For example, ![]() has seven nodes, and
has seven nodes, and ![]() , an equivalent pattern but with different ordering, also has seven nodes. Second, as explained in Section 5.2 (the last second paragraph), typing patterns are usually small, this makes the ordering less important, as even a suboptimal ordering will not cause the pattern to have too many nodes.
, an equivalent pattern but with different ordering, also has seven nodes. Second, as explained in Section 5.2 (the last second paragraph), typing patterns are usually small, this makes the ordering less important, as even a suboptimal ordering will not cause the pattern to have too many nodes.
12 Conclusion
We have presented migrational typing, a type system that allows programs in an implicitly typed gradual language to be assigned a new type based on the possible removals of dynamic type annotations in the original program. Migrational typing solves an important unaddressed problem in gradual typing, namely having a safe and efficient way to move around in the possible dynamic-static typing space for a program. It achieves this by conceptually typing the whole migration space, marking where type errors occur so that it can safely present the possible migrations for the program. We have shown that the system can infer the most static possible types that can be assigned to a program and that this process can be constrained according to user-defined criteria. Moreover, the migrational type system is sound and complete with respect to removing dynamic annotations in ITGL, and its constraint generation and unification algorithms are sound and complete.
We have also shown that this approach is scalable, performing nearly exponentially better than the brute-force approach of generating and typing the migration space separately. Later, we showed that migrational typing can be adapted to statically reason about the number of dynamic casts that will be generated by different points in the migration space so that we can support migration scenarios that consider programmers’ typing goals and performance goals (Campora et al., Reference Campora, Chen and Walkingshaw2018b). In future work, we plan to see if we can adapt migrational typing to work with a non-unification based inference. This will allow it to analyze gradual languages with object-oriented features like Reticulated Python or TypeScript with greater ease. We also plan to explore whether migrational typing can be adapted to provided an analysis of the runtime safety of casts in gradual programs.
Acknowledgments
We thank the anonymous POPL and JFP reviewers and Jens Palsberg for their constructive feedback, which have significantly improved both the content and presentations of this paper. This work was partially supported by the National Science Foundation under the grant CCF-1750886.
Conflicts of interest
none.































 Open access
Open access
Discussions
No Discussions have been published for this article.