



1. Introduction
Many, if not all, language users are bi- or multilectal: that is, their linguistic competence encompasses two or more closely related systems, which we may label dialects, sociolects, registers or simply ‘lects’. Most language users can understand varieties closely related to their native dialect and possibly adjust their speech to accommodate to these varieties as well. In addition, most speakers can handle a standardised written language, which may differ considerably from the spoken dialect with respect to lexicon, syntax, morphology and even phonology, to the extent that phonological representations are activated during reading (see e.g. Leinenger Reference Leinenger2014 for arguments that quite detailed phonological representations are activated during reading, both at the segmental and suprasegmental level). Whether such a default state of multi-lectism is qualitatively different from more well-established situations of bi/multilingualism is still unknown. Some recent proposals within the generative field has stated that anyone who masters several registers or dialects with a different set of linguistic features should be seen as having access to multiple grammars, see especially Roeper’s Universal Bilingualism (Roeper Reference Roeper1999), and the extensive discussion in Eide & Åfarli (2020 - this volume). We wish to contribute to this discussion in the current article, by addressing the nature of intraspeaker variation. Every speaker’s output contains, at least on the surface, variable patterns: alternative ways of saying the same thing (Labov Reference Labov1972). The variability is often highly structured, i.e. conditioned by speech situation or subtle semantic features. However, the conditioning often appears to be probabilistic rather than deterministic in nature, which suggests that the mappings from meaning to form are partly underspecified. We thus appear to be dealing with partly probabilistic grammars. The scenario of default muliti-lectism sketched above does however open up for the possibility of treating different cases of syntactic variability as switching between two or more non-variable ‘lects’, similar to code-switching in more obvious multilingual contexts (see e.g. Kroch Reference Kroch1989, Roeper Reference Roeper1999). In this paper, we address the role of register/dialect mixing in accounting for syntactic variation within speakers: can apparent syntactic optionality be modelled as a higher level switching between fully deterministic grammars, or is optionality better modelled as underspecification within one grammar? This question, as we will see, is only meaningful as long as we either associate a grammar with a set of shared linguistic attributes or connect it to a specific sociolinguistic context. Once a grammar has been identified, either through linguistic properties or context, we can investigate if certain syntactic patterns co-vary with a set of lexical, morphological and phonological forms. If they do, we have good support for a theory of syntactic variation as code-switching, but if syntactic variation turns out to be completely independent of variation in lexical, morphological and phonological forms the syntactic variation is better modelled as within-grammar optionality.
The hypothesis that syntactic variability can be accounted for in terms of switching between two or more fully deterministic grammars has been around for more than 30 years, and it has been considered an alternative to probabilistic approaches to grammars (see especially discussions in Kroch Reference Kroch1989, Roeper Reference Roeper1999 and, in this volume, Eide & Åfarli Reference Eide and Åfarli2020). As far as we are aware, this hypothesis has not previously been tested in any large-scale systematic studies, partly due to both methodological and terminological challenges (see Section 4 below).
In this study, we test the Universal Bilingualism hypothesis by systematically investigating syntactic intraspeaker variability in Norwegian, with a focus on the Tromsø dialect (Northern Norwegian). Norwegian has a large number of spoken dialects, and in addition two written standards (Nynorsk and Bokmål). No single language variety has been authorised as a standard for spoken Norwegian. Nonetheless, Sandøy (Reference Sandøy, Kristiansen and Coupland2011) describes normalmål, which he translates as ‘language norm authorised by the state’, as the spoken variety of Norwegian standardised with respect to vocabulary, syntax and morphology though not phonology (e.g. replacing dialect words, adapting to the standard’s pronominal case forms and declensional classes). This standard is used in formal settings, on television and on the theatre stage (see also Vikør Reference Vikør1993) and is also ‘how we read texts aloud at school’ (Sandøy Reference Sandøy, Kristiansen and Coupland2011:119). Local spoken varieties are used in all other situations, from dialog with friends and family to education, politics and increasingly in media as well (Kerswill Reference Kerswill1994). As a result, speakers in Norway will continuously encounter not only numerous spoken dialect varieties of Norwegian, but also a standard language, both in writing, and to some extent in speech. There is thus little doubt that most Norwegians are to some extent multilectal, which in the terms of Roeper (Reference Roeper1999) means that they have knowledge of several grammars. In this paper, we focus specifically on the modern Tromsø dialect. In (1) we give an example of how the local dialect (1b) differs from the orthographic representation of the standard written Bokmål (1a).

There are many differences between the two varieties: in the Tromsø dialect, a preproprial article is inserted before the subject (morphology), the present tense ending of the strong verb drikke is missing (morphophonology), the adverb alltid is changed to bestandig (lexicon), the complex preposition sammen med ‘together with’ is changed to i lamme (lit. ‘in group with’) (lexicon), and the form of the definite suffix in the two final nouns as well as the possessive has changed from the standardised common gender form (-en, sin) to its regular feminine form (-a, si). Differences between the local dialect and the standard language can be found also in the syntax. We illustrate this in example (2) below, where the dialect differs from the written standard in word order, here, verb placement, in addition to morphological (preproprial article) lexical (form or the wh-word) and phonological features (/til/ -> /ti/) features:
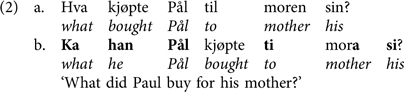
In (2a), the finite verb appears in its typical second position, while in the Tromsø dialect, it appears in the third position. Importantly, the Tromsø dialect also seems to allow the verb to surface in the second position, as in (2a).
The syntactic phenomenon we investigate in this study is variable verb second (V2) in a number of different syntactic contexts, including questions as in (2) above. We investigate to what extent it is possible to account for the syntactic variation within speakers in terms of (dia)lect mixing. We explore this by conducting a twofold elicited production study in a local high school in Tromsø where we examine various variables at different levels of the grammar. We manipulate the elicitation method in the study: in one experiment we use standardised written language and in the other we use spoken dialect as the elicitation source. This method will be described in detail in Section 4, followed by the results in Section 5. We will start with a more in-depth discussion of optionality, specifically tied to the Northern Norwegian situation, followed by a description of variable V2 in Norwegian. The implications of the results are discussed in the Section 6.
2. The phenomenon of optionality
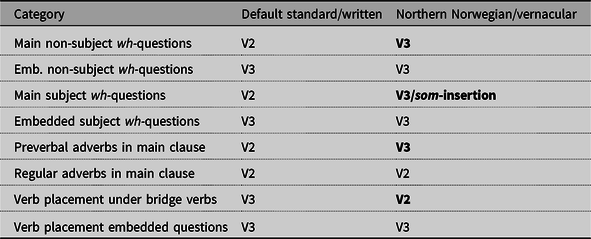
In examples (1)–(2) above we illustrated some differences between the Tromsø dialect and the Norwegian written standard Bokmål. As was already noted above, the differences between the two systems however do not appear to be fully categorical. Often, both the local and the standard forms are available in the local dialect. In other words, the local form is only licensed in the local dialect, but the standard form is available in both the local and the standard dialect. This is the case for the V3 order in questions as illustrated in Table 1 (see also example (2) above).
Table 1. Availability of standard and local forms in wh-questions.

There is thus an asymmetric optionality here with respect to dialect – one dialect being more permissive and allowing both forms as options, with the other dialect categorically licensing only one of the options.
Another type of asymmetry with respect to variability is related to meaning. As will be discussed in Section 3, embedded V2 is licensed only in the context of a certain pragmatic force, which we will call assertive force here. However, embedded non-V2 is equally available in this context, as illustrated in Table 2. Thus, optionality of word order choice is present in one of the pragmatic contexts (in this case, an assertive context), but only one variant is licensed in the other context (non-assertive contexts).
Table 2. Availability of standard and local forms in embedded clauses.

This article is about the right-hand column in both these tables, where both forms are in principle available. What is the nature of the syntactic optionality in these cases? Is all variation meaningful, either as expressing linguistic contrast or stylistic/register contrast, or do individual grammars contain non-deterministic mappings from message to form?
Within the generative framework, some researchers have gone as far as completely rejecting the possibility of optionality within a grammar: a given message has one and only one form in a given grammar. In cases where we find optionality, i.e. more than one form corresponding to the same message, we have either missed subtle semantic or pragmatic factors in our analysis (i.e. the two forms map onto two different meanings), or the two forms belong to different grammars or registers, schematised in Figure 1.

Figure 1. Strict mapping message to form via different grammars.
The most radical proposal in this vein of research is Roeper’s (Reference Roeper1999) Universal Bilingualism, where optionality is ruled out in the very definition of grammar. Optionality is rather modelled as a higher order choice of a grammar, see also Kroch (Reference Kroch1989) and Yang (Reference Yang2000). There are also developmental approaches that question optionality in grammars. One of the most influential attempts is Clark’s (Reference Clark and MacWhinney1987) principle of contrast, which states that the language learner always infers contrast in meaning from contrast in form. Clark’s idea builds mainly on the scarcity of true lexical synonymy: different forms tend to be associated with different meanings. Clark argues that the principle of contrast has to be present during language acquisition in order to get the acquisition going: the language learner simply does not have the time or resources to evaluate whether every new item she encounters means the same as a previously learned item, but will rather assume that it has a different meaning. This reasoning can in principle be carried over from lexical items to syntactic constructions, including word order choices (see Clark Reference Clark and MacWhinney1987) so that a given choice of word order tends to indicate a certain meaning. However, it may be too much to expect from the language learner that she should associate certain low frequent word order patterns with either a certain meaning or a certain register.
Within other frameworks, the optionality has been incorporated as a central component of the grammar. Most obviously this can be seen in the contemporary exploration of probabilistic syntax (Bresnan Reference Bresnan, Featherston and Sternefeld2007). In phonetics and phonology, probabilistic processes have been integrated for a long time, from Labov’s (Reference Labov1972) formalisation of variable rules to more recent attempts to build in stochastic processes in Optimality Theory (OT) grammars, for example Partially Ordered OT (Anttila Reference Anttila, Hinskens, van Hout and Wetzels1997), Stochastic OT (Boersma Reference Boersma1997), and Harmonic OT (McCarthy Reference McCarthy and Hirotani2000). Although probabilistic and strict approaches to syntax may appear as radically opposing at first glance, the differences start to look more rhetorical and less substantial as the definition of the notions ‘grammars’ and ‘language’ are narrowed. If two grammars differ only in one property, i.e. in the mapping from one meaning feature to one form, and if those two grammars are not necessarily associated with a specific set of phonetic forms, a lexicon or a specific speaker group or social context, then observed variation may either be described as a higher order probabilistic choice of ‘grammar’, or as a within-grammar probabilistic choice of a specific realisation of a variable. The contrast between ‘multiple grammars’ and ‘probabilistic grammar’ is thus only meaningful under the assumption that a grammar caries a set of defining linguistic attributes (lexical, phonological and syntactic properties), or is associated with a specific sociolinguistic context.
The register/grammar shift account of variation relies on the fact that the speaker has acquired several clearly separated grammars, each with strict message-to-form mappings. In the more classical standard cases of bi/multilingualism, code-mixing will be easily detected, as the two codes are associated with different lexicons and grammars. However, if the two varieties share a large part of the lexicon and grammar, code-mixing will be hard or impossible to detect. In this scenario, code-mixing could in principle only be detected if variation is banned from the grammar on principled grounds (as in Roeper Reference Roeper1999, but see e.g. Haider Reference Haider1999 for criticism). Equally likely in this scenario, is that the learner assumes a non-deterministic mapping from message to form, as illustrated in Figure 2.
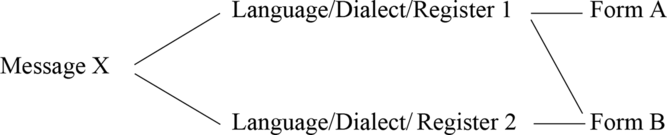
Figure 2. Variation as a result of partially underspecified grammars.
We have little reason to doubt that some intraspeaker variation can be modelled as switching between grammars. A long tradition of studies of code-switching has shown that a switch from one language to another can take place within one sentence (see e.g. Poplack Reference Poplack1980), and possibly even within a word (Riksem et al. Reference Riksem, Grimstad, Terje and Åfarli2019) in bi- or multi-lingual speakers, and that these switches may target only one level of the grammar, e.g. syntax but not phonology. As long as we conceive of multi-lectal competence as identical to multi-lingual competence, code-switching should be equally likely in both situations. We neither have any reason to doubt that variation could be deterministically conditioned by the meaning/message that is to be expressed. The question is whether some linguistic alternations are completely void of meaning in a certain context, i.e. whether some choices of variants lack both linguistic and sociolinguistic meaning. For clarity, we list three sources underlying intra-speaker variation below.
-
i. Register/dialect. The choice of a variant is associated with a certain dialect or register (Northern Norwegian/Standard/Colloquial/Formal). This extends to more standard situations of bilingualism: A Norwegian-English bilingual speaks English in an English-speaking context and Norwegian in a Norwegian-speaking context. Code-switching may be utilised for a stylistic effect or may appear as an effect of exhausted processing resources (see iii).
-
ii. Meaning/structure. The variant is chosen to express a particular relevant meaning, e.g. assertion, quantificational scope, thematic structure.
-
iii. Language processing/chance. The governing grammatical rule is genuinely underspecified, and a myriad of processing factors influence the final choice of form for variable (frequencies, current activation of a form, construction frequency, etc.).
By looking at variation in verb placement in Norwegian, we examine whether this syntactic variation can be fully explained by factors i and ii above. We focus mainly on the first factor and try to control for the second factor by using similar meaning contexts in an experimental setting.
3. Variable V2 in Norwegian
Norwegian is an asymmetric V2 language, which means that the verb is in second position in main clauses (3a), but in a vP-internal position in embedded clauses (3b). Because Norwegian is SVO, many subject-initial clauses are not unambiguously V2. The asymmetric V2 properties are, however, visible in non-subject initial sentences or in the presence of sentence adverbs:

There are, however, a number of cases where the main-embedded distinction disappears, and it is these cases we will focus on in our study. The three cases we focus on are the following: variable V2 word order in wh-questions; ‘V3-adverbs’; and finally, optional V2 in assertive embedded clauses. We will discuss these three cases in this section.
In standard/Bokmål Norwegian, main clause wh-questions are typical V2 structures, while embedded wh-questions are typically verb-in-situ structures, as illustrated with a non-subject question in (4) (note the lack of subject–verb inversion in (4b)).

However, in the Tromsø dialect, as well as in many other Northern and Western Norwegian dialects, main clause non-subject questions can also have the verb in situ, resulting in a non-V2 structure with the subject preceding the verb, as in (5):

A similar pattern is seen in subject questions: a main clause subject question can surface with what looks like an embedded word order. Here, we see the main–embedded asymmetry in the presence of the complementiser/relative marker som: compare the standard Norwegian main and embedded subject question (6) with the Tromsø subject question in (7).

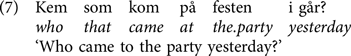
The standard V2 word order is also found in the Tromsø dialect. The non-V2 word order is in addition constrained by certain linguistic features, in different ways in different dialects: in the Tromsø dialect, only ‘short’ wh-words allow V3 and som-insertion. Longer wh-words and phrases such as kordan ‘how’ or kosn bil ‘which car’ do not occur with this word order. For discussion of the dialect variation, the use of som and word orders in wh-questions see e.g. Westergaard, Vangsnes & Lohndal (Reference Westergaard, Vangsnes and Lohndal2017) and Westendorp (Reference Westendorp2018). Non-V2 is highly regionally and linguistically constrained, but it is not obvious if these two factors (corresponding to i and ii in Section 2) can fully explain the distribution, or if there are traces of true optionality involved as well.
The second case of variable V2 is found in sentences with so-called preverbal or ‘V3’- adverbs. These adverbs usually directly modify the lexical semantics of the verb or put focus on the verb. Though these sentences seem to have non-V2 word order, it has been argued that the adverb–verb order in these cases is not a result of the verb staying in situ, but is rather due to the adverb attaching high, or directly to the verb (seen in the fact that subject–verb inversion is still licit) (see e.g. Julien Reference Julien2018, Lundquist Reference Lundquist2018 for discussion of these adverbs in Norwegian). On the surface though, the main clauses and the embedded clauses look similar, as shown in (8).

This phenomenon is not restricted to any particular dialect. The non-V2 order in (8a) seems to have a more colloquial flavour, although this has not been studied, as far as we are aware. Crucially, the reading available in (8a) would be equally available with the standard V2 word order. Again, we have a word order that is only licensed in a linguistically constrained context (type of adverb, reading of adverb), but in this context, the particular word order is only optional.
The last case of variable V2 is word order in embedded clauses. Several types of embedded clauses allow for main clause word order with the finite verb preceding the sentence adverb, see (9a, b). In these contexts, topicalisation and subject–verb inversion is in general possible as well.

The main clause word order tends to carry certain pragmatic or semantic entailments (although these are hard to pin down) related to assertive mood or factivity (see e.g. Julien Reference Julien2007, Wiklund et al. Reference Wiklund, Bentzen, Hrafnbjargarson and Hróarsdóttir2009, Bentzen Reference Bentzen2014). As a result, the main clause word order is generally unavailable in non-assertive clauses, such as embedded questions (and also relative clauses), see (10a–c).

An exception is found with certain sentence adverbs like ofte ‘often’ and alltid ‘always’, which can either appear in a typical sentence adverb position (inside TP/IP as in (11a)) or inside the verb phrase1 and as a result allow for embedded V2 (11b) (for discussion see Bentzen Reference Bentzen2007).

Several studies have shown that embedded V2 is far more common in speech than in writing in all the Scandinavian languages (Heycock et al. Reference Heycock, Sorace, Hansen, Wilson and Vikner2012, Jensen & Christensen Reference Jensen and Christensen2013, Djärv, Heycock & Rohde Reference Djärv, Heycock, Rohde, Bailey and Sheehan2017, Ringstad Reference Ringstad2019). There are a few possible explanations for this variation. First of all, normative pressures may be reducing the number of embedded V2 in written language and more formal contexts more generally. If this is the case, we may hypothesise a more categorical rule in the spoken register, yielding embedded V2 in assertive contexts and verb in situ in non-assertive contexts. In the written register on the other hand, this rule would be (partly) overridden by the normative pressure. Another possible explanation is that spoken dialog contains a slightly different linguistic content where other pragmatic factors are at play. Spoken language for example contains a significantly higher amount of first-person singular subjects, as well as more embedding with a speaker-oriented flavour (e.g. I think, I know, I said …). It is not implausible that these contexts favour embedded V2 to a higher degree. If this is the case, embedded V2 is only indirectly conditioned by register.
To investigate if these variable syntactic patterns can be modelled as register or dialect switching, or if the variability is inherent within one lect/grammar, we set up an experimental study in a local Tromsø high school. We will now discuss the methodology of the study.
4. Aim and methodology of the study
4.1. Research questions and hypotheses
Code-switching or code-mixing is a natural part of the communication of most multilingual groups. In most cases, code-switching is easy to detect, due to the fact that the two languages in the mix can be identified based on their lexical and phonetic properties, and possibly their syntactic properties. This is not necessarily the case when two lects are very close to each other, as in the case of mixing of two (mutually intelligible) dialects. For the three syntactic variables discussed in the previous section, we do not know if any of the dialects are associated with one specific values of the syntactic variable, or if they contain more than one value. Furthermore, it is unclear if the local dialect speakers we investigate associate particular syntactic traits with any of the registers they master. One especially intriguing issue is the ‘register’ that is associated with the standardised written language. Written language is a major source of non-local dialect input for young people today – the amount of exposure to written language from e.g. school curriculum, books, newspapers and subtitles should not be underestimated. As we have seen above, the standard written language may differ from a spoken dialect both with respect to lexicon and morphology, and even syntax. Still, we have a very poor understanding of how the orthographic representations map to an internal grammar and lexicon. Research has shown that quite detailed phonological representations are activated during reading, both on segmental and suprasegmental levels (see e.g. Fodor Reference Fodor and Hirotani2002, Leinenger Reference Leinenger2014). One intriguing issue is whether Norwegian dialect speakers activate standardised written forms when they read the standard language, or if they directly activate forms from their own spoken dialect.
To shed light on these issues, we will elicit lexical, phonological, morphological and syntactical variables in two experiments with equivalent stimuli but diverging elicitation methods. In the first experiment, we use standardised written language as our elicitation source in a read aloud + (modified) repetition paradigm (we call this the ‘written test’). In the second (‘spoken’) experiment, we set up a ‘gamified’ dialogue paradigm with spoken dialect as the elicitation source. In both cases, we elicit spoken language. This gives us three measures for each of the lexical, morphological and phonological variables: (i) reading aloud standardised text, (ii) repeat and modify written input and (iii) gamified dialogue in dialect. For the syntactic variables, only measures in (ii) and (iii) will be relevant as speakers are merely repeating invariable written sentences in the first measure.
By directly comparing the amount of non-dialect lexical, morphological and phonetic forms from the three different measures, we will be able to provide an answer to whether a standard/non-dialect grammar is activated in the presence of written language (compare Labov’s (Reference Labov and Fishman1971) study on phonetic variables elicited across different spoken and read-out modes). Next, we can investigate co-variation between syntactic and phonological/morphological/lexical (PhonMorphLex) variables, and thereby directly test the variation-as-code-switching hypothesis. As was already mentioned, we face several methodological challenges when addressing this hypothesis, and it is not straightforward how to falsify or verify the hypothesis. We will lay out two different ways for assessing the hypothesis using our data. First, if we assume minimal independence between syntactic and PhonMorphLex variables: the syntax of a language is only activated in the presence of the PhonMorphLex of the language. In this case the code-switching hypothesis would be falsified if we find a set of utterances with variable syntax and only dialect forms of the PhonMorphLex variables. Now, as was discussed in Section 2, code-switching could in principle target also only one dimension of the grammar in a sentence, i.e. syntax could be switched without phonology being affected. A certain independence between linguistic dimensions is therefore expected, and we may instead just look for correlations between proportions of standard/dialect syntax patterns and standard/dialect PhonMorphLex forms. This can be done on two levels. First, we can compare contexts: are there more standard language syntax patterns in contexts where we find more PhonMorphLex standard forms? Secondly, we can look at correlations at the level of the individual: do speakers who often switch to standard PhonMorphLex forms also tend to switch to standard syntactic patterns? In short, this study is about whether syntactic variation is fully independent, fully dependent, or statistically dependent on PhonMorphLex variation. If it turns out that syntactic variation takes place fully independently of PhonMorphLex variation, we have to reject the variation-as-code-switching hypothesis.
4.2. Experimental set-up
We use a modified version of the elicitation experiment originally used in developing the Nordic Word order Database (NWD; see Lundquist et al. Reference Lundquist, Larsson, Westendorp, Tengesdal and Nøklestad2019). The aim of NWD was to test a wide range of syntactic variables within the North Germanic languages. In the current study, we included only the part of the NWD-test targeting verb placement and main clause/embedded clause asymmetries. In addition, we modified several of the stimuli sentences, to include as many lexical, morphological and phonological dialect variables as possible. The original experiment only elicited speech based on written stimuli. For the present study, we first adapted the original experiment and then modified the experiment to use spoken elicitation stimuli. Below we will refer to the two experiments as the written test and the spoken test, based on the elicitation methods (recall that the data collected is always spoken data). We will first introduce the written test and then discuss the modifications we made for the spoken test.
The experiments were set-up in OpenSesame (Mathôt, Schreij & Theeuwes Reference Mathôt, Schreij and Theeuwes2012) and built on a simple sentence manipulation paradigm. A participant is presented with a sentence on a computer screen, which we will refer to as the background sentence, such as the following example (12):

Here, the sentence is preceded by a name and a colon, suggesting that the utterance was made by Anne. After the participant reads the sentence out aloud, the start of a new sentence appears on the screen below the first sentence (see (13) in italics). The participant is prompted to read the cue and complete the sentence by using the material from the background sentence (in square brackets).

The background main clause obligatory has V2 (at least in this context), but verb movement is variable in the elicited embedded clause, and the participant can produce the sentence with the verb in second position or in situ (here, after the sentence adverbial). This set-up allows us to test (variable) embedded word order in assertive contexts, but also in embedded questions. The first half of the experiment uses this main-to-embedded transformation. The second half uses the reversed version, that is, an embedded-to-main transformation, as exemplified in (14).

Here, the cue is only a name (14b). In the example above, the embedded background sentence (14a) has a potential V3 adverb, which may surface either before or after the verb in a main clause (14b). Using this second transformation we test placement of V3-adverbs as well as V2-deviations in main clause wh-questions. The items were presented in randomised order, but the part with the embedded-to-main transformation always preceded the main-to-embedded part to ensure that we did not prime participants with embedded adverb–verb sequences (as in (14a)). Each trial in the written experiment followed the following sequence:
-
i. Trigger/background sentence on a screen, white font on black background (1000 ms);
-
ii. Beep-sound (300 ms) after which the sentence turns red to prompt the participant to read the sentence out loud;
-
iii. A button touch by the experimenter, at which the beginning of new sentence appeared in white font below the first sentence (which remains visible throughout);
-
iv. Beep-sound (300 ms) after which the sentence turns red to prompt the participant to complete the sentence.
The strict timing of the experiment ensured that participants got into a steady rhythm which prevented them from consciously planning the word order. The experiments started with between two and four practice items, but otherwise contained minimal instructions. As the test is very intuitive, most participants got into a steady rhythm already after the first practice item. The participants were instructed to imagine a relaxed situation, for example at home with the family or with friends, where they would read aloud e.g. a newspaper headline or a sentence from a book. Some participants asked if they were supposed to ‘speak dialect’, to which we replied that it would be OK, if that felt most natural for them. In general, the purpose was to make to speakers read out or produce sentences in a maximally relaxed setting, where they were not aware of registers. The exact design of the experiment and the formulation of instructions were based on extensive piloting of the test and previous data collection for the Nordic Word order Database.
In the spoken experiment, the background sentences were not written on a computer screen, but instead uttered by a native speaker of the local dialect. There were always two local dialect speakers present to administrate the experiment, as well as two participants. We chose this design to mimic as much as possible a casual dialog and create a more relaxed setting for the participants. After one of the experimenters produced the background sentence (15a)/(16a), participants were asked to pass on this sentence to the other experimenter present, as in (15b)/(16b), respectively. Like the written experiment, the spoken test used both the embedded-to-main (15) and the main-to-embedded transformation (16).


The written and spoken tests targeted exactly the same syntactic variables. The test material was to a large extent the same as well, though some carrier phrases had to be changed slightly in the spoken experiment to fit with the dialogue setting. The spoken test set-up with two participants also meant that all the participants did not produce exactly the same items (see Supplementary Materials for grouping of participants in the spoken test). An important feature of the experiment design and the choice of material, is that the background sentence never has variable word order, e.g. in the main-to-embedded test, the adverb in the main clause background sentence is always a typical V2-adverb; and the wh-phrases are phrases that could not occur in non-V2 questions (at least not in the Tromsø dialect).
4.3. Material and linguistic variables
All stimuli in the written part were represented in what is called ‘moderate’ or ‘conservative’ Bokmål, characterised by e.g. lack of all type of feminine grammatical gender exponents, and -et rather than -a as the first conjugation past tense suffix (Vikør Reference Vikør2015). Out of all possible dialect variables, we focus in this study on 13 morphological, phonological variables (PhonMorphLex) in addition to the syntactic variables. The PhonMorphLex variables are given in Table 3.
Table 3. An overview of PhonMorphLex variables.
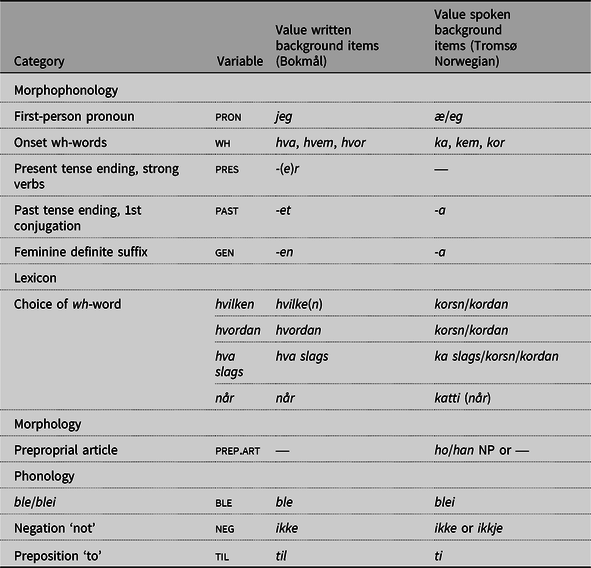
Due to limits of space we cannot in detail describe the dialectal and sociolectal distribution of the variables. What is relevant is the following: the forms in the third column are what was presented in the written test (Bokmål). The forms in the rightmost column are the expected Tromsø dialect forms, and these are the forms provided in the background sentence in the spoken test. Many of these forms are not unique to the Tromsø dialect but are present in many or most of the spoken dialects of Norway. For example, the two morphophonological variables past tense and feminine definite. suffix are realised as -a even in many Eastern Norwegian dialects. However, young speakers from Oslo are very likely to produce a spoken form directly corresponding to the orthographic Bokmål form, i.e. -et and -en, when presented with these forms. The interested reader is encouraged to listen to the sound files from an Eastern Norwegian participant doing the written test in the online Nordic Word order Database (https://tekstlab.uio.no/nwd, select participant KO29), who produces all the variables as given in the third column.
The syntactic variables were already presented in Section 3. We give an overview in Table 4. The values that have been claimed to be either more common or exclusive to a spoken (dialect) register are bold-faced in the table.
Table 4. An overview of syntactic variables. Bold indicates values that are more common/exclusive to a spoken (dialect) register.
4.4. Participants and data collection
Twenty-six participants from the same local high school class (15–17 years old) participated in both the written and the spoken experiment. All participants grew up in Northern Norway. Twenty-four of the participants had Norwegian as their first language, though three of these participants grew up in a bilingual household; the final two participants were non-native (L2) speakers of Norwegian who lived in Northern Norway their entire lives and had learned Norwegian from a very young age. The class as a whole was paid 50 NOK (4.93 euro) per participant per session.
The participants were recorded at two separate occasions. The written experiment was conducted first, individually with each participant, at UiT The Arctic University of Norway in Tromsø. Three months later, when the participants had presumably forgotten the experimental items, the spoken experiment was conducted at the local high school.
4.5. Analysis and annotations
Across the two experiments, we collected three types of relevant utterances per item for the non-syntactic variables (see Section 4.1). We will refer to these as the read (read background sentence in written experiment), produce (target modified repetition in written experiment) and spoken task (target gamified dialogue in spoken experiment). For the syntactic variables, we only have two values, as the background sentence does not contain any word order variation – the participants are simply expected to read the words in the order presented on the screen.
The audio files from the experiment sessions were automatically segmented on the basis of time stamps collected in the experimental software. Minimal annotations were added in ELAN (Wittenburg et al. Reference Wittenburg, Brugman, Russel, Klassmann and Sloetjes2006) indicating which word order was produced, e.g. AV (Adverb–Verb) or VA (Verb–Adverb). The non-syntactic variables, such as the form of the wh-words were coded manually across selected items. Although we often find more than two possible realisations of each variable, we try to give a binary classification of most variables in the description of the results, usually tagged as dialect and written standard. This is primarily done to facilitate the statistical analysis where we mainly use mixed effects logistic regressions (from the r-package lme4, Bates et al. Reference Bates, Mächler, Bolker and Walker2015), with the number of dialect exponents as our dependent variable. For correlations between variables, we apply regular linear models with the proportion of dialect realisations as dependent variables and predictors. As set out in Section 4.1, we are interested in finding out if (i) the syntax is invariable in contexts were the PhonMorphLex forms are invariable, and if not, (ii) if the syntactic patterns co-vary with PhonMorphLex (a) between contexts and (b) speakers.
5. Results
We have analysed a total of 6051 observations, split over the two experiments and 26 participants and across all different types of variables. We will present the results from the set of non-syntactic variables in Section 5.1. The result will directly show us to which extent non-dialect phonological, morphological and lexical forms are activated by dialect speakers when they are faced with standardised orthographic forms. From the results of the spoken test, we will be able to tell to which extent the different dialect features vary in the local dialect. In Section 5.2 we present the results from the syntactic variables, which will be directly compared to the non-syntactic results, in order to determine the association between specific word order patterns and the set of morphological and phonological forms.
5.1. Non-syntactic dialect variables
We present the results from the non-syntactic variables in Sections 5.1.1–5.1.4 below, following the classification in Table 3. We start with the morphophonological variables, where we expect to find most categorical results. With these results we establish the amount of dialect variation within the whole group, within and between speakers as well as experiments. This will be the baseline to which we can compare phonological, lexical and morpho-syntactic variation.
5.1.1. Morphophonological dialect variables
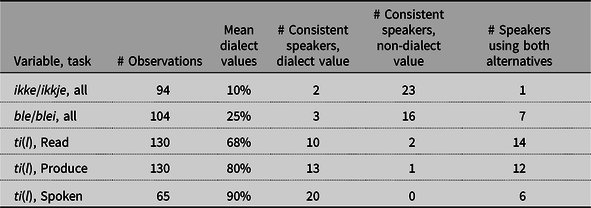
There are five clear morphophonological dialect variables: (i) form of first-person pronoun, (ii) onset in wh-words, (iii) past tense suffix in first declension verbs, (iv) present tense ending of strong verbs and (v) definite singular suffix of feminine nouns. We have in total 1511 observations of these variables. In Table 5 we repeat the morphological forms in the dialect and the written standard for the five variables, and the number of observations per variable and per task. Note that these variables are not pure phonetic variables: the drop of the voiceless glide /j/ only takes place in the first-person pronoun and not in other words, initial /hv/ or /v/ is not pronounced /k/ in most other words, and the suffixes -et, -er and -en exist in the dialect in other contexts (e.g. neuter definite suffix, present tense weak verb and definite masculine nouns, respectively). The results from the three tasks are given in Figure 3.
Table 5. Morphological forms in dialect and written standard. Bold is used to highlight differences between the two varieties.
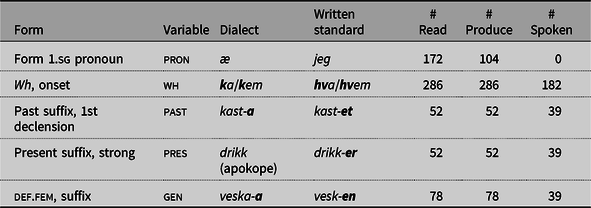
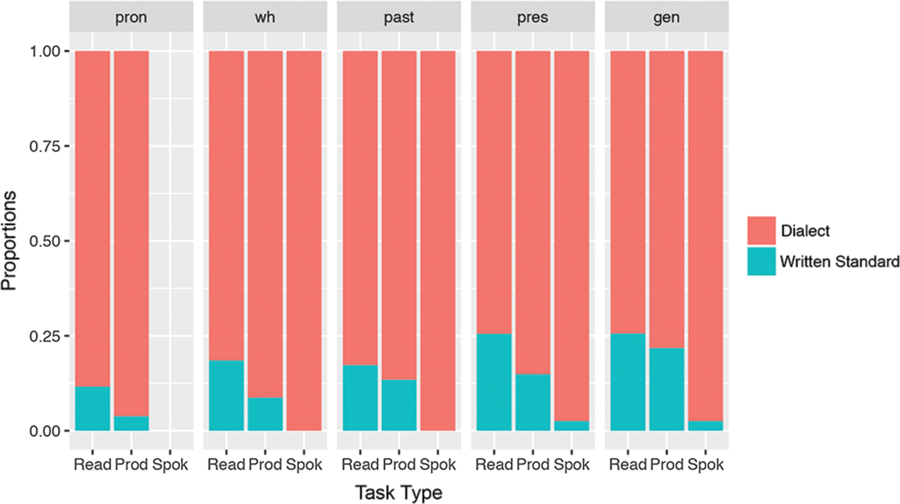
Figure 3. Proportion of use of morphophonological dialect variables vs. written standard forms across tasks: Read, Prod(uce) and Spok(en).
We see from this figure that the participants overall mainly use the dialect forms (88.5% of the trials). There is also a clear effect of Test: in the spoken test, the written standards forms are as good as absent (two observations in total with written forms). In the written test, we also see a significant difference between the Read task (18% written stand) and the Produce task (10.5% written standard, χ2(1) = 32, p < .001).2 There is also an effect of Variable (χ2(4) = 46, p < .001), driven by the relatively high amount of written forms for the variables gen (19.5%) and pres (15%) compared to pron and wh (8.6–8.7%).
The written standard forms are not evenly distributed across the participants. In Figure 4, we plot the proportion of written forms per participant in the Read and Produce task (remember that both these measures are from the written experiment). As we see, most participants are almost fully consistent in their use of dialect forms in the Read and Produce task: eight participants did not produce a single written form, 12 participants were consistent in the Produce task, three participants follow the orthographic form in the Read task, but only one of them sticks to the written form in the Produce task. However, note that all the participants consistently switched to the dialect form in the Spoken task (Figure 3). In short, we see that the phonological forms that match the orthographic representation are rarely produced in any of the tasks of the experiment, with the exception of a handful participants. Below we will correlate the values from the morphophonological variables with lexical, phonological and syntactic variables. The five different morphophonological variables correlate with each other (all rs .4–.95), e.g. participants who produce written past tense forms are likely to produce written feminine forms. We will therefore use the averaged values presented in Figure 3 as the measure of comparison (this value will be referred to as ‘MPWrit’, for ‘MorphoPhonological Written form’ below).

Figure 4. Proportion of written forms per participant in the Read and Produce task.
5.1.2. Lexical variation: Wh-words
For the lexical variation, we will focus on wh-words, mainly due to the fact that we have many data points here. Here we will not consider the realisation of the onset discussed above (v/k), but only focus on the lexical choice. We investigate the following four wh-elements: hvilken ‘which’, når ‘when’, hvordan ‘how’/‘which’ and hva slags ‘what kind’/‘which’. For some question words, separate dialectal forms exist. One of these is the form korsn (also pronounced koss or kossn) which can cover the semantics of a range of other the wh-words hvordan ‘how’, hvilken ‘which’ and hva slags ‘what kind’. For the temporal wh-word når ‘when’, there is a dialect form that is used in addition to the Bokmål-variant namely kat.ti ‘what.time’ (also ka tid). The wh-word hvilken is not present in the spoken dialect at all (the forms korsn, kordan and ka slags cover the meanings of hvilken).
We have 702 observations in total. In Table 6 we give the relevant dialect forms of the wh-elements, as well as an overview over the number of observations per task. Note that three of the variables exist in the dialect as well, but with adjusted phonology (hv > k). In the Spoken task, the form provided in the background sentences for hvilken and hvordan was consistently korsn, the form for når was katti and the form for hva slags was ka slags. In coding the results, we treated korsn, kordan and ka slags as dialect forms of hvilken; katti as the dialect form of når; korsn for hvordan; and kordan and korsn for hva slags (we discuss the split between korsn and kordan further below). The results for the four variables across the three tasks are given in Figure 5.
Table 6. Dialect forms of wh-elements.
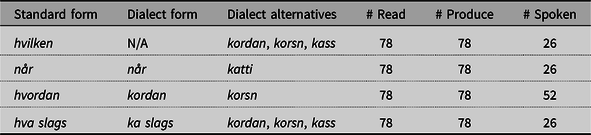

Figure 5. Proportion of use of dialect vs. written standard forms for the four wh-variables across tasks: Read, Prod(uce) and Spok(en).
We see an effect of Test for these lexical variables, similar to the morphophonological variables: the number of written forms is lower in the Produce and Spoken task compared to the Read task. Unsurprisingly, hvilken is not produced in the Spoken task at all. Both når and kordan/hvordan are used, despite the fact that they were not given in the spoken background sentence. We find a main effect of Test (χ2(1) = 79, p < .001) and a main effect of Variable (χ2(3) = 151, p < .001), as well as an interaction between Test and Variable (χ2(3) = 8.2, p = .042).
We now investigate if the lexical choice of wh-word on the individual level correlates with the morphophonological measures discussed in Section 5.1.1. We do this by adding the average written standard measure ‘MPWrit’ per individual participant into the model. There is no main effect of MPWrit, but a strong interaction between Lexical Variable and MPWrit (χ2(6) = 49, p < .001). We find that both hvilken ‘which’ and når ‘when’ correlate with MPWrit (both p < .05): speakers who produce hvilken and når produce more standardised written forms of the morphophonological variables. However, the effect is considerably stronger for hvilken than for når. We can tentatively conclude that hvilken is a marker of the written standard/Bokmål, while katti (instead of når meaning ‘when’) is a marker of the local dialect. The high use of når (for ‘when’), however, indicates that this form is not exclusive to the written register. We plot the individual variation for hvilken in the Read and Produce task with comparison to the baseline written forms (MPWrit) in Figure 6. The plot also illustrates the robust avoidance of hvilken by the majority of the speakers in the Produce task (17/26 participants).

Figure 6. Proportion of use of hvilken in Read and Produce task compared to average use of written morphological forms (MPWrit).
In the majority of the trials with hvordan and hva slags in the written experiment, the participants chose the direct dialect equivalent kordan and ka slags. However, kordan is sometimes used for the hva slags variable (but never the other way around), and the dialect wh-word korsn can be used for hvordan, hva slags and hvilken. Only two participants use ka slags for hvilken. Our results thus indicate that both korsn and kordan indeed serve as dialect forms for a wide array of wh-expressions (‘which type’, ‘which item’, ‘how’) as expected. There are, however, clear individual preferences: some speakers prefer kordan over korsn and vice versa, but the preferences do not correlate with the dialect features discussed above (morphophonological choices; hvilken or når). We plot the individual preferences for korsn and kordan over the three tasks and the three variables hvordan, hva slags and hvilken in Figure 7. We find both categorical kordan-users, and categorical korsn-users, and speakers who alternate between the two forms (possibly conditioned by meaning or task). In Figure 7 we also plot the average use of written morphological forms to show the lack of correlation between wh-choice and dialect morphophonology.

Figure 7. Proportion of use of kordan and korsn compared to average use of written morphological forms (MPWrit).
Summarizing, we conclude that both når and katti are available in the dialect for a temporal wh-expression ‘when’. Korsn, kordan and ka slags are all available for a large array of wh-functions, and most of the variation in their distribution is governed by individual speaker preferences (though we still do not know if factors like the individual’s ‘dialect’ or gender predict form here). Hvilken is not present in the spoken dialect and is most often exchanged in the Read (aloud) task, and rarely produced in the repetition task (Produce). The participants who still produce it, are to a large extent the same participants who fail to suppress standardised written morphophonological forms for other variables.
5.1.3. Morphosyntax: Preproprial articles
In many Norwegian dialects, proper names are preceded by a third person personal pronoun such as ho Marit ‘she Marit’ or han Ole ‘he Ole’. The use of the pronoun in this way is referred to as ‘preproprial article’. In Northern Norwegian dialects, the preproprial article is often used with all names, as well as with family relations like ‘mother’ or ‘father’ (Johannessen Reference Johannessen2008:170, see also Bull Reference Bull, Jahr and Skare1996). According to some descriptions, the preproprial article is in fact obligatory in the Northern Norwegian dialects (see e.g. Johannessen & Garbacz Reference Johannessen and Garbacz2014). In the written standard Bokmål, the preproprial article is never used.
In our material we have annotated 546 observations of contexts where preproprial articles could occur (78 in Read, 312 in Produce and 156 in Spoken task). This variable differs from the other variables tested, since the participants have to add a morpheme, not just change a phoneme, morpheme or word order. In the spoken test the participants were often given the preproprial article in the background sentence, but this was not fully consistent, as one of our elicitors did not use the article.
We find a clear effect of Test in our results (χ2(1) = 71, p < .001). In the Read task, we find the article in only 10.2% of the trials, compared to 21.2% for Produce, and 50.6% for Spoken. Only three of the speakers used the article in the Read task (two consistently), while as many as 16 used the article at least once in the Produce task, though no one used it consistently. Surprisingly, there is no significant correlation between the use of the article in the Produce task (or any other task) and the use of written standard morphophonological forms (all ps > .1). However, the lexical variables når ‘when’ and hvilken ‘which’ are both reliable predictors of article use, i.e. speakers who produce few instances of the standard forms når and hvilken are more likely to produce preproprial articles in the Produce task (p = .015 and p = .01). Note though that these are just statistical patterns, which do not reflect the existence of categorical grammars: we find, for example, speakers who consistently use the dialect form katti (for når) but never use the preproprial article, and speakers who consistently use når and often insert the preproprial article.
In the Spoken task, there are two strong predictors for the outcome: (i) presence of article in the background sentence and (ii) use of article in the Produce task. Participants use the article in 78% of the trials when they heard the article in the background sentence, but only in 37% of the trials where it is absent in the background sentence. This may suggest that the variation in the result is solely an effect of priming/shadowing, but it turns out that the second factor (ii) is an equally reliable predictor: participants who used the article at least once in the Produce task (N = 16) had an average of 60% articles in the Spoken task, while the corresponding average for the speakers who never used the article in the Produce task (N = 10) was 30% (R 2 = .43, p < .001). Note also that only five of our 26 participants consistently produced the prepropial article in the Spoken task. This strongly suggest that the preproprial article, in contrast to the morphophonological variables and the absence of hvilken, is not an obligatory feature of a spoken register of the participants. The big difference between the Read (10%) and Spoken (50%) task results also suggests that preproprial articles are not activated/generated when dialect speakers encounter names in written language (in contrast to e.g. glide-less first-person singular pronouns, and -en to -a shifts in definite feminine nouns).
5.1.4. Phonological variables
There are a number of interesting phonological variables to test with speakers of the Tromsø-dialect. We include the following: the passive auxiliary ble ‘become’, the form of the negative adverb ikke ‘not’, the phonological form of the preposition til.
The auxiliary ble/blei is an exponent of an isogloss that runs between Eastern Norwegian (and Swedish) and the rest of Norway. Eastern Norwegian has monophtongised historical diphthongs (e.g. Mæhlum & Røyneland Reference Mæhlum and Røyneland2012), whereas these to a large extent have been preserved in most other varieties (compare sten/stein ‘stone’, ben/bein ‘bone’). Both blei and ble are allowed in the Bokmål orthography, but ble is clearly the least marked. There is significant variation in the form of the negative adverb ‘not’ in Norwegian. The two variants of interest here are ikke and ikkje. In large parts of Northern Norway, the latter variant is used. In the far north (northern parts of Troms as well as Finnmark), however, the variant ikke is more common (Jahr & Skare Reference Jahr, Skare, Jahr and Skare1996:56). The standard Bokmål orthography is ikke. It has been reported that younger generations in Tromsø also use the variant ikke, as opposed to the traditional dialect form ikkje which is used more by speakers over the age of 30 (Sollid Reference Sollid2014:118–120). The preposition til/ti/te/tel ‘to’ has no variability in any of the codified written norms: it is unequivocally til. In the dialects, however, we find variation, even within dialects. The historical variant til seems to have been retained in some contexts but varies between the variants ti/te/tel depending on context and/or dialect. This variation is reported in old sources (Aasen Reference Aasen1850:518), as well as newer ones (Norsk Ordbok 2014). We only code our data for the presence or absence of the coda /l/, not the quality of the vowel.
The variables and the results for the three phonological variables are given in Table 7. None of the phonological variables that we tested correlated with other values for syntactic or morpho(phonological) markedness. The marked form of the passive auxiliary blei is used by very few speakers; the majority of speakers use the monophtongised ble. For the preposition til ‘to’, we see an effect of Task: more use of the dialect form ti in the Produce and Spoken utterances, but this variable does not correlate with other dialect features. However, it is interesting to see that the /l/ is more present in Read than Produce and Spoken tasks, indicating that the visual orthographic form affects the pronunciation to some extent. It is maybe not very surprising that we find no correlations for the phonological variables, i.e. Norwegian speakers are expected to accommodate or standardise their language with respect to vocabulary, syntax and morphology but seldomly standardise the phonology of their local dialect (Sandøy Reference Sandøy, Kristiansen and Coupland2011:119).
Table 7. Overview of phonological variables.
5.1.5. Summary and discussion non-syntactic variables
In the subsections above, we have seen that the school class we are investigating is a fairly homogenous group at least for the core morphophonological variables. The standard written forms are entirely absent in the spoken test, and they are surprisingly infrequent in the written test.
For the lexical variables, we see that the non-dialect item hvilken patterns like the morphophonological variables: most participants automatically replace it with a suitable dialect word during reading and repetition. None of the participants use it in the spoken test. We find that many participants change når to katti in the repetition (Produce) task, but når is still produced in a majority of the Produce task, and some speakers changes the input katti to når in the Spoken task, which suggest that når, in contrast to hvilken, is not exclusively indexed to the standard written register. We see a similar pattern for the preproprial article. The article is only added in 10% of the trials during reading, but this number goes up during repetition (Produce task) to 20%. In the Spoken task the preproprial article is still only present in 50% of the trials. Most speakers produce proper names both with and without the article, but there are individual differences in the baseline use, as indicated by the within-speaker consistency across the two experiments. This is unlikely to be an effect of rampant code-switching but should rather be treated as an inherently variable pattern. We will return to this in the concluding discussion.
We find effects of Task across all variables: there are more non-dialect forms in the Read than in the Produce task, and more non-dialect forms in Produce than Spoken, i.e. the dialect forms increase the further away from the written source we get. The effect of task for the phonological variable til, as well as the morphophonological variables past, present and gender, suggest that the graphemes present in the elicitation stimulus sometimes affect the pronunciation, and thereby trigger the production of standard written forms. The effect of task is also clear for preproprial articles and lexical choice of wh-words and present for most speakers. Some speakers are better at directly activating the dialect lexicon/grammar and show little or no interference from the written forms.
As we move on to the syntactic variables, we have now established two different contexts (i.e, the written and spoken elicitation modes/experiments) that differ in the amount of standard (written) PhonMorphLex exponents, and we can now investigate if the syntactic variables differ in a similar way between the two contexts. We have also established that there is inter-speaker variation, such that some speakers are more likely to produce standard PhonMorphLex exponents than others, and we can now test if the same participants are more likely to produce non-dialect syntactic patterns.
5.2. Syntactic variables
For the syntactic variables, we only have two measures per variable: the Produce and the Spoken task (the Read task sentence is invariable). Below we will start looking at the most obvious dialectal or colloquial variables, and then look at variables less obviously tied to a dialect/vernacular.
5.2.1. Non-V2 in questions
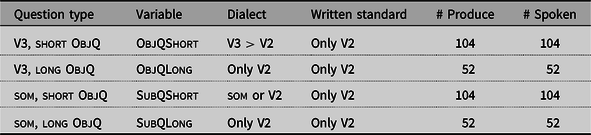
The first variable we look at are the characteristic Northern/Western Norwegian V2-exceptions in wh-questions. We investigate two types of non-subject questions and two types of subject questions: questions with short wh-words (kem ‘who’, ka ‘what’, kor ‘where’) and questions with long wh-words (når/katti ‘when’, kordan/korsn ‘how’); see Table 8.
Table 8. Overview of types of wh-questions in the experiment.
We elicit these questions with the embedded-to-main transformation. Participants can in principle give three types of felicitous responses in this task: a regular main clause V2 question, a question with embedded word order, i.e. V3, or a cleft question. We give examples of the three alternatives for non-subject questions following a background sentence in (17).

In the coding we use the abbreviations SV (Subject–Verb, i.e. V3), VS (Verb–Subject, i.e. V2) and CLEFT for non-subject questions. For the subject-questions there are also three possible realisations: a regular main clause question (V2, coded as NON), an embedded structure with the complementiser som (coded as SOM), or a cleft question. The results for the main clause wh-questions in the two experiments are shown in Figure 8 with non-subject questions on the left and subject wh-questions on the right.

Figure 8. Left panel: Proportion of word orders in non-subject questions with long and short wh-words across the two experiments (SV = Subject–Verb, VS = Verb–Subject). Right panel: Proportion of word orders in subject questions with long and short wh-words across the two experiments (NON = no complementiser, SOM = with complementiser).
We will first discuss non-subject questions. Here, we find that V3 word order (SV) is categorically absent for the long wh-phrases, as expected. However, this result is important, as it shows that the participants are not simply repeating the word order in the embedded background sentence (i.e. V3/SV). We see an effect of Test for the short wh-words: V3 word order is more common in the spoken test (40.8%) compared to the written test (18.3%). Clefts are produced only rarely. These results initially suggest that the written stimulus is directly responsible for the low proportion of V3 in the written test. However, the set-up and the material in the spoken test differ from the written in several aspects. The material was set up so that the questions often yielded second person pronominal subjects, e.g. ‘Ask Eline where she lives’ (background) – ‘Where do you live?’ (target), and as is already known, pronominal subjects are more likely to trigger V3 than noun phrase subjects (e.g. Westergaard & Vangsnes Reference Westergaard and Vangsnes2005). A closer look at the material reveals that the items with second person pronominal subject have V3 in a majority of the trials (62.5%), while the non-pronominal subjects in the spoken test have V3 frequency similar to the written test. The difference between the two modalities may thus be triggered by the linguistic content, and not the modality per se. We also find a strong correlation between the individual response patterns in the written and spoken experiment: people who produced V3-questions in the Produce task were more likely to produce a large proportion of V3 questions in the Spoken task (R 2 = .38, p < .001). Still, most participants produced both V2 and V3 across experiments, and no-one produced V3 consistently (in the constructions where this is grammatical in the dialect).
Turning now to the subject wh-questions (Figure 8, right panel), we see that, as expected, the embedded word order (som) is not used with long wh-words. This again suggests that participants do not simple copy the word order from the background sentence in their responses. For the short wh-words, we see no effect of Test: the embedded structure (som) is produced in 27% of the trials in both tests. We see a correlation between the response patterns in the Written and the Spoken test, but less strong than for the non-subject questions (R 2 = .17, p < .01). The response patterns for the subject questions and the non-subject questions correlate strongly (R 2 = .51, p < .001), i.e. participants who produce a high proportion of V3 object questions also tend to produce a high proportion of V3 subject questions. We further find that a small group of the participants fully avoid the non-V2 structures in the written test (N = 6). Again, none of the participants produce non-V2 consistently across the two experiments (one speaker consistently uses non-V2 in the spoken task) and in the spoken experiment, the majority of the participants alternate between V2 and non-V2.
We can tell from the recordings that no trial contains a non-V2 question produced with any of the written standard morphophonological features. Yet, we find plenty of V2 questions (i.e. standard form) produced in utterances that only contain dialect forms of the PhonMorphLex variables. Furthermore, we find no correlations between the participants’ general non-V2 production (in either spoken or written test) and their overall use of written standard morphophonology (our measure MPWrit). Surprisingly, we also find no significant correlations between non-V2 and the use of preproprial articles, or choice of lexical wh-element either (all R 2 < .05 for both written and spoken values). In the sample we find participants who consistently use the preproprial article while never producing a non-V2 question and vice versa. In short, there is no evidence for co-variation between PhonMorphLex variables and this syntactic variable.
5.2.2. V3 with adverbs
We have in total 598 observations of Adverb–Verb sequences, distributed over two conditions (V3 adverbs and regular V2 adverbs) and the two tests as shown in Table 9. We show the results for the two types of adverbs in the two tests in Figure 9. For this variable we have more than two possible realisation options: the adverb may turn up in sentence-initial or sentence-final position, in addition to the expected V2/V3 position (coded as AV/VA). In addition, the adverb is sometimes dropped.
Table 9. Overview of V2 and V3 adverbs across tests.


Figure 9. Proportion of different word orders in main clauses with regular (V2) adverbs and preverbal (V3) adverbs across the two experiments.
We find a relatively small amount of ‘errors’ with the regular V2 adverbs (i.e. V3 order with regular adverbs (pink colour)) which look mainly like random production errors (3 participants in the Produce task, and 5 participants in the Spoken task). There is a noticeably high amount of adverb-initial clauses in the Produce task as compared to the Spoken task, which we currently cannot explain.
For the V3 adverbs, we see a significant effect of Test (28% – 46%, χ2(1) = 12.8, p < .001). The effect is partly driven by a large amount of adverb-drop responses in the Produce task. Partially, this difference is explained by the fact that some adverbs were changed between the tests, due to noticed difficulties in the written experiment. Still, even when we take this into consideration, there is a small effect of Test, indicating that the V3 structures are slightly more accessible in a fully spoken setting. We find a weak correlation between the results in the Produce and Spoken task (R 2 = .2, p = .013), i.e. speakers who produce V3 in the written test are more likely to produce V3 in the spoken test. No correlations are found between V3 with adverbs and any of the other dialect/spoken register indicators (preproprial articles, non-V2 in questions, wh-lexicon or morphophonological variables). We also find that many speakers alternate between V2 and V3 orders for this variable within the experiment. Furthermore, the V2 order with preverbal adverbs is often produced in utterances which contain no written standard PhonMorphLex exponents.
5.2.3. Main clause word order in embedded clauses
In the previous section we looked at word order in main clauses. We will now turn to embedded clause word order which we elicited with the main-to-embedded transformation. We look at two types of embedded clauses below: that-clauses with sentence adverbs in the assertive complement of a bridge verb, and embedded questions (subject or non-subject questions). An overview of the variables and the number of observations per variable and test is given in Table 10.
Table 10. Overview of types of embedded clauses.

We start with investigating embedded V2 under bridge verbs, i.e. assertive contexts. Two of the adverbs used (alltid ‘always’ and ofte ‘often’) in the test can be used either as VP-internal adverbs or TP adverbs, while the other two are strict TP adverbs (aldri ‘never’ and ikke ‘not’) (see discussion in Section 3). We show the results in Figure 10, adverb by adverb. We find no effect of Test (χ2(1) = 0.001, ns), but we find an effect of Adverb Type (χ2(1) = 9.7, p < .01): there are significantly fewer Verb–Adverb orders with the unambiguous TP-adverbs (ikke/aldri, 8%) compared to potential VP-adverbs (alltid/ofte, 22.5%). There is no interaction between Test and Adverb Type. Overall, we see very few instances of Verb–Adverb order with the unambiguous TP-adverbs. Only 4 participants in total produce this order: two of them only once, but the other two more consistently. As we will discuss below, this variable patterns more with other ‘ungrammatical’ variables such V3 with sentence adverbs, and main clause word order in embedded questions, than the dialect/colloquial variables like V3 in questions. Note that this does not mean that embedded V2 with negation is ungrammatical in Northern Norwegian; it should rather indicate that the context we set up is not a suitable context for embedded V2 (for reasons we do not yet know, see Westendorp Reference Westendorp2020 for discussion).

Figure 10. Proportion of word orders across the two experiments with different adverbs.
For the potential VP-adverbs, we find more variation within and between participants: 16 of 26 participants produce both Verb–Adverb and Adverb–Verb order in the experiment, one participant produce Verb–Adverb consistently and nine participants stick to Adverb–Verb. We find a within-speaker correlation between the Produce task and the Spoken task (R 2 = .28, p < .01), i.e. participants behave similarly across the two tasks. It should also be noted that the two participants that produced a substantial amount of Verb–Adverb order with ikke/aldri, also produced a high amount of Verb–Adverb orders with the potential VP-adverbs. We find only a weak correlation between VA with potential VP-adverbs and non-V2 in main clause questions (p = .039). We find no correlations between embedded Verb–Adverb and the morphophonological, phonological, morpho-syntactic or other syntactic variables.
The final variable we looked at was main clause word order in embedded questions. Here, we were interested in seeing if participants sometimes used a main clause structure in an embedded clause (as signalled by verb and subject placement). For non-subject questions, this means we would find subject–verb inversion in an embedded clause (‘I wonder what bought Mary in the store’), and in subject questions this means the lack of the complementiser/relative marker som. None of these structures are available in either the written standard or the spoken dialect, other than as echo-questions or quotes. The results revealed only scattered main clause word orders, that were slightly higher for subject questions (drop of som, 8.9%) than for objects questions (subject-verb inversion, 4.6%). This difference is almost fully explained by the production of one English-Norwegian bilingual participant, who consistently dropped som in the subject questions (as in English), while producing target-like Subject–Verb orders in object questions (again, just as in English). Otherwise, we find non-systematic scattered ‘errors’, probably due to a quotation strategy. Note, however, the proportion of main clause word orders for this variable is similar to the proportion of embedded Verb–Adverb order with the TP adverbs ikke/aldri ‘not/never’ (Figure 10). This may suggest that the few attested Verb–Neg orders in the results are indeed full main clauses.
5.2.4 Summary syntactic variables
For all the syntactic variables tested, we found that participants produced both the ‘standard’ and the ‘vernacular’ word order, and the variation was abundant even in the utterances that only contained dialect forms of the PhonMorphLex variables. Noticeably, the word order associated with the vernacular/dialect was not produced in more than 50% of the trials for any of the variables in the spoken test, which was otherwise characterised by almost a categorical use of dialect PhonMorphLex exponents.
Overall, we find still a significant effect of Test: there are more dialectal/colloquial elicited word orders in the spoken elicitation experiment (24.9%) than in the written elicitation experiment (14.8, χ2(1) = 19.8, p < .001). The effect of Test is driven by two variables: V3 in non-subject questions, and V3 in sentences with preverbal adverbs. However, as was mentioned in the relevant subsections, for both these variables the stimuli were slightly changed between the tests, and these changes account for some or all of the difference in the results. The remaining effect of elicitation method is negligible. On the level of the individual there were no correlations between the syntactic and PhonMorphLex variables, i.e. speakers who produced many dialect PhonMorphLex forms, did not produce more vernacular/dialect word orders.
In the conditions where we in principle could elicit ungrammatical responses (non-V2 with long wh-words, V3 with sentence adverbs, main clause word order in embedded questions), we find no difference between the two modalities (3.8% written, 4.8% spoken).
We find a high degree of intra-speaker consistency between the two experiments: speakers who produced a high proportion of a certain form in the written test, were also likely to produce a high amount of that form in the spoken test. There were further correlations between some of the ‘grammatical’ syntactic variables, namely non-V2 in subject and non-subject questions and embedded V2 with ofte/alltid ‘often/always’. We plot the within-speaker consistency between the two tests in Figure 11. Note that none of the participants are categorical in their responses.

Figure 11. Within-speaker consistency between the two tests (Spoken vs. Written).
Overall, the variation seems to be conditioned more by the speakers than the mode of elicitation. In Appendix Table A1 we give a full overview of the correlations within individuals per variable, and the effect of the elicitation mode per variable.
6. Discussion
6.1. Summary of results
We see a trend throughout this study that more dialectal or colloquial features are present in the spoken test compared to the written test, and within the written test, we see this trend between the Read and Produce task as well. That is, the further away from the written source, the more dialect features we see, which is not surprising. However, the results look different depending on what type of variable we focus on. The morphophonological standard forms are completely absent in the spoken mode (Section 5.1.1). This is true for the written standard wh-word hvilken as well. However, even in the written test, the standard forms of these variables are rarely produced, and most speakers never produce them at all. For the choice of wh-word (Section 5.1.2) and presence of preproprial articles (Section 5.1.3), we find a strong effect of task as well. For these variables, we find plenty of variation both within and between participants even in the Spoken task, e.g. alternation between korsn – kordan, når – katti, and presence/absence of the preproprial article.
The pattern looks different for the syntactic variables. The effect of task is much less reliable here. For subject questions and embedded word order, we find no effect of task at all. For object questions and main clause V3 with preverbal adverbials, we find an effect of task/elicitation method in the expected direction (i.e. more dialect/vernacular forms in the spoken test). However, this effect seems to be due to the change of stimuli rather than elicitation method, especially for the object questions: the spoken test included more pronominal subjects, which increased the responses of non-V2 questions. In most of our elicited responses in the Spoken task, we find variable syntax in the absence of phonological, morphological and lexical variation. We furthermore find no syntax–PhonMorphLex correlations on the individual level, and as discussed above, we find no straightforward effect of ‘context’ (here, elicitation method) on the choice of word order. In short, there is nothing in our results that suggest that the syntactic variation tracks the variation of the non-syntactic variables.
6.2. Discussion of results
These results give rise to two questions: (i) can we account for the syntactic variation in terms of shifting between different grammars, and (ii) to which extent do young dialect speakers access a special ‘standard’ register that is at least partially different from a spoken register when reading? Starting with the first question, we can conclude that the syntactic variation is present in the written test, and most crucially, the syntactic variation is persistent in the spoken test, where standard morphophonological features are completely absent. As was stated at the start of the article, contrasting a code-switching account of variability to a within-grammar optionality account is only meaningful if we assume that a grammar is characterised by a shared set of lexical, morphological, phonological and syntactic properties, or alternatively strongly associated with a certain sociolinguistic context. If we find syntactic variation in phonologically, lexically and morphologically invariant contexts, the variation cannot meaningfully be characterised as language mixing. However, one may still argue that the activation of different linguistic levels may be partly dissociated, e.g. the syntactic dimension of a grammar may be more likely to be activated than the morphology in a certain context (for whatever reason). We do not find support for this idea in our results. Apart from attesting syntactic variability in morpho/phono/lexically invariant contexts, we find no clear evidence of a higher degree of activation of non-dialect syntactic patterns in the presence of non-dialect features. For most of our syntactic variables, the vernacular/dialect forms were produced to an equal extent when the standardised language was highly present (written test) as when standardised language was fully absent (spoken test).
As discussed in Section 2, the main source of variation in speech is presumably semantics and pragmatics: people vary their linguistic output because they want to convey different linguistic messages, e.g. the choice between the order ‘the dog chased the cat’ and ‘the cat chased the dog’ is presumably fully dependent on the message you want to convey. When studying syntactic variability, it is always hard if not impossible to rule out meaning-based explanation of the variation. Can we ever be sure that a speaker who utters Ka du sa? (‘what you said’) intends to convey the same message as a speaker who utters Ka sa du? (‘what said you’). In our study, we tried to limit the impact of semantic and pragmatic factors by sticking to a highly constrained elicitation paradigm. We find it unlikely that semantic and/or pragmatic factors can account for the variation in our results, yet we cannot fully rule it out.
For the second question, our results suggest that in general, a written input signal activates the same grammar as spoken input. As stated above, we see a significant effect of elicitation mode, but this is to a large extent driven by a small set of participants. Most participants seem to directly access the morphophonology of the dialect grammar. Of course, participants were instructed to read the sentences in a colloquial style, but the very smooth access to the dialect forms (as evident from the audio recordings) and the small number of intrusion errors in the reading suggest that phonological representations of the native/dialect forms are directly accessed through written standard orthographic forms. In some sense, the fact that a Northern Norwegian speaker accesses the phonological representation /kem/ when s/he is exposed to the word hvem ‘who’ is no different from an English speaker accessing the representation /hu/ when exposed to who. Here, we would like to speculate how the written language affects the spoken dialect. In principle, one could imagine dialect speakers treating the standard written input and the spoken dialect as completely different languages. The written language could in principle activate a phonology and a morpho-syntax that is different from the spoken language. If this was the case, one would expect relatively little influence of the written standard on the spoken dialect. However, if we assume that dialect speakers directly access the morphophonology of the dialect when reading, e.g. æ for jeg ‘I’, venta for ventet ‘waited’, veska for vesken ‘the bag’, the written input should presumably be treated as ‘dialect input’, and this input could potentially have a huge effect on the spoken dialect. It seems, however, less likely that speakers automatically access word order templates or syntactic structures associated with the spoken dialect. That is, reading Hva drikker du? ‘What do you drink?’ may activate the local morphophonological forms (ka, drikk) but not necessarily an inverted word order (wh–subject–verb). Furthermore, it is unlikely that words or morphemes that are never present in the written source would be activated during reading, e.g. preproprial articles or som in main clause subject questions. The written input can thus be seen as a dialect input completely void of the morpho-syntactic dialect markers (e.g. V3 in questions, preproprial articles). This presumably leads to parts of the dialect grammar being directly affected: the overall proportion of V2-questions and names without preproprial articles in the speaker’s input will depend on how much of their input is in written form. This should give rise to both different speaker-specific baselines and general optionality. We find some evidence for this in the fact that there is a general consistency within participants across the two tests, which suggests that some of the variation is explained by speaker-specific baseline ratios. Still, only a small number of the participants are consistent throughout the two tests with respect to any of the variables. Follow-up studies should directly focus on correlating between reading habits and dialect syntax patterns within individuals, and also investigate whether individuals who are more prone to dissociate written language from spoken language display less optionality in their spoken dialect production.
6.3. Open questions and speculations
The proportion of colloquial or dialect forms in our material is admittedly lower than in corpus studies based on spontaneous spoken language. Non-V2 word order in questions in the Tromsø dialect is estimated to be around 70% (Vangsnes & Westergaard Reference Vangsnes and Westergaard2019); V2 in embedded that-clauses with negation is found in 43% of the relevant clauses (Ringstad Reference Ringstad2019, see also Bentzen Reference Bentzen2014); and according to Johannessen & Garbacz (Reference Johannessen and Garbacz2014), preproprial articles are obligatory in most Norwegian dialects, including the Tromsø dialect. The discrepancy between these numbers and our numbers makes it tempting to conclude that we have not managed to access or activate a true dialect register in our study. Before concluding that, a couple of things should be taken into consideration. First, in for example the Nordic Dialect Corpus (the corpus used in the studies mentioned above, Johannessen et al. Reference Johannessen, Priestley, Hagen, Åfarli, Vangsnes, Jokinen and Bick2009), the speakers are slightly older, and usually also handpicked for the recordings because they are known to speak the local dialect. In Tromsø today, as in most larger towns in Norway, we can assume that many speakers have a more mixed dialect background, even though they still often conform to the classic dialect traits of their hometown. It is therefore highly likely that the high school students of today speak a more levelled dialect compared to the speakers in the Nordic Dialect Corpus. Secondly, spontaneous speech in a conversation often has a high amount of formulaic expressions, such as simple questions like Ka du sa? ‘What did you say?’ and Ka du tror? ‘What do you think?’, which may push up the number of non-V2 questions reported in corpora. Something similar can be said for embedded V2. As we discussed earlier, the high proportion of first- person subjects in conversations may increase the potential contexts for embedded V2 (‘I think that…’/‘I believe that…’/‘I said that…’). Likewise, there may be other patterns in how proper names are used in conversations (names will refer to people known to both speaker and hearer), while in our experiment, the names refer to unknown people. We thus feel relatively confident that we have captured the vernacular of Tromsø teenagers in our spoken elicitation paradigm.
7. Final thoughts
To successfully acquire a language, the learner needs a huge amount of input. Only by aggregating over data from a large number of speakers and contexts may a learner approach native-like competence. This is especially true in the acquisition of subtle morphosyntactic patterns that are scarce in the input. First language (L1) learners may not fully master some of these patterns until they are well into their school years (see e.g. Anderssen et al. (Reference Anderssen, Bentzen, Rodina, Westergaard, Anderssen, Bentzen and Westergaard2010) on acquisition of object shift). At this point most individuals have received plenty of input from sources outside the local speech community, e.g. from written texts, TV and friends, family and teachers with different linguistic backgrounds. Although it is clear that a learner does not build up a new grammar for every new person or language source she encounters, it is also clear that the learner may detect that not all of the linguistic input belongs to the same grammar. In a prototypical bilingual setting, the L1 language learner will from early on separate the input into different ‘languages’ (see e.g. Meisel Reference Meisel, Bhatia and Ritchie2004). A child growing up in a bilingual environment will learn that certain word orders, morphological classes, phonemic contrasts and lexical items are restricted to only one of the languages in the environment. Now, we do not know how different the input from two speakers or contexts has to be for a language learner to identify them as two different ‘languages’. We do not even know if sociolinguistic context is a more important factor than typological similarity for language separation. This question is particularly relevant in a linguistic context like the one in Norway, where speakers are constantly exposed to different dialects. Previous experimental research on this topic has shown that young speakers in Western Norway who use Nynorsk rather than Bokmål as their main written language appear to make a strict division between their local dialect and the Eastern Norwegian/Oslo dialect, which they associate with the written language Bokmål (see Lundquist & Vangsnes Reference Lundquist and Vangsnes2018). As for the Northern Norwegian dialects, which mainly consist of speakers who read and write in Bokmål, we have not found equally strong indications of language separation between the local dialect and the ‘standard’ or Eastern Norwegian language (see Lundquist et al. Reference Lundquist, Rodina, Sekerina and Westergaard2016 for discussion). The results from the current study strongly suggest that the Northern Norwegian speakers/learners treat the written Bokmål input as part of their ‘language’. During acquisition (which goes on for at least the first 10–15 years of life), we assume the learner will extract morphosyntactic patterns from both the written and spoken sources to build up a grammar. As our results indicate, this grammar contains a certain amount of optionality, i.e. non-deterministic mappings from meaning to form. It is not unlikely that the syntactic variables we investigate in this paper were more categorical at an earlier stage, and that variation in previous generations was better characterised as code-switching between a vernacular and a national standard language. Through increased contact between different dialects, and possibly as a result of a more important role of the written language over the last 100 years, the discussed syntactic patterns appear to be part of the local dialect today. As we see in our data, the proportion of the ‘standard’ word order patterns is above 50% for all variables we investigate. If this indeed is what the input looks like for the Northern Norwegian language learners, it is unlikely that these word orders are not associated with the L1 grammar.
There are clearly many questions remaining. The relation between a written language and a spoken language is still in many respects a mystery, especially with respect to dialectal micro-variation. We have assumed in this article that a written input activates linguistic representations in the reader that are in many ways similar to the representations that are activated during both speaking and spoken language perception. We base this assumption on recent psycholinguistic research on the activation of phonology during reading. Note also that a long tradition of neuro- and psycholinguistic research has found similar behavioural and neural responses in experiments based on written and spoken stimuli. Still, even if the representations activated in the reader are, as we speculate, similar to those activated during speaking and listening, it is still obvious that the reader has expectations about the surface syntactic patterns of the standard written language. For example, a Northern Norwegian dialect speaker would not expect a V3 question in written standard Bokmål. It is also clear that the Northern Norwegian dialect speaker has knowledge about which word orders, lexical forms and prosodic patterns are licit in spoken Eastern Norwegian, to the extent where they can pick up patterns and reproduce them e.g. in role-playing language (see, in this volume, Strand Reference Strand2020).
Acknowledgements
This research was funded by the Research Council of Norway (RCN) project ‘Variation and Change in the Scandinavian Verb Phrase’ (project number: 250755, PI: Ida Larsson), which covered expenses associated with fieldwork and project development. Additional funding was provided by the LAVA Lab at UiT The Arctic University of Norway for data collection in Tromsø and data analysis. Westendorp was funded for her Ph.D. project by the same university. Lundquist was funded by the RCN-funded projects ‘Micro-variation in Multilingual Acquisition & Attrition Situations’ (project number: 250857) and ‘Experimental Approaches to Syntactic Optionality’ (project number: 302524). We would like to thank all the participants who gave their time to work with us. The work would not have been possible without the native speakers that helped us set up the experimental material: Kristine Bentzen, Eline Grønvoll, Tor Håvard Solhaug and Marit Westergaard. We would like to thank Tor Willy Knudsen and Anna Katharina Pilsbacher for their help with the data collection, and Gillian Ramchand for discussion and comments on previous drafts. Lastly, we would like to thank the NJL referees and the editors of this special issue for their helpful comments. The authors are responsible for all mistakes that remain despite all this assistance.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0332586520000190
Appendix
Table A1. Overview of the correlations within individuals for syntactic variables.
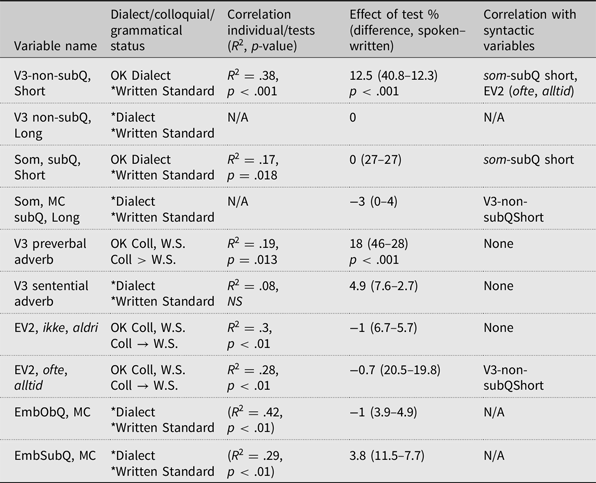
In second column: Coll = colloquial, W.S. = Written Standard; the asterisk marks ungrammaticality; the arrow indicates that the form is more natural in the left-hand variety.

























 Open access
Open access