



1 Introduction
Payroll management is a critical business task that concerns the administration and management of staff financial reports, such as wages, salaries, deductions, and bonuses. Manual preparation of staff’s salaries is often error-prone and time-consuming due to the large number of relevant rules. Automated payroll management systems are therefore being used to speed up the process. The set of applicable rules can vary widely based on the sector and the country in which the company operates, and on company-specific agreements that have been made. Correctly implementing and maintaining a payroll system can thus be a challenging exercise (Doody et al., Reference Doody1982). Based on talks with the company ProTime, a market leader in the area of time registration, we have identified the following three key challenges for such a system.
-
1. When deploying the system for a new company or updating it for an existing customer, HR consultants are typically employed to figure out the rules that apply. If they need to communicate all their knowledge to software engineers before it can be entered into the system, this introduces a lot of overhead, delays, and the risk of communication errors. Therefore, the HR consultants should be able to configure as much of the system as possible without the help of a software engineer. Due to the complexity of the rules, a simple configuration file does not suffice and a more elaborate knowledge representation language is needed. Providing such a language that is both powerful enough and easy to use for HR consultants is an important challenge.
-
2. There are essentially no restrictions on the kinds of rules that the HR consultants may encounter. It is therefore not possible to cover all the expressivity that the HR consultants might need up-front. Therefore, the language in which they write down the rules must not only be easy to use for them, but it should also be possible to easily extend it with new language features, without invalidating models that have been built earlier.
-
3. Finally, despite the required flexibility, the solution should still be computationally efficient. In particular, a single employee shift should be handled in < 1s. This is very challenging, as shifts may run over several days, and it is necessary to determine the employee’s wages at each point in time. Moreover, it is impossible to know up-front at which points in time the pay rate will change, because this can be determined by the rules in a complex way.
In this paper, we propose an approach based on a combination of multi-shot answer set programming (ASP) and decision tables to tackle these challenges. Throughout the paper, we use the following real-life example to illustrate our approach:
An employee receives a normal wage of 20![]() per hour and an overtime premium of 20% for any work done after 8 hours of working. The employee should also receive a night premium of 25% for any work done at night or any work done in the evening that continues into the night, provided that more time was spent in the night than in the evening. Employees are also allowed to take a break, but breaks are only paid as (official) rest breaks after their shift has been going for at least one hour.
per hour and an overtime premium of 20% for any work done after 8 hours of working. The employee should also receive a night premium of 25% for any work done at night or any work done in the evening that continues into the night, provided that more time was spent in the night than in the evening. Employees are also allowed to take a break, but breaks are only paid as (official) rest breaks after their shift has been going for at least one hour.
The paper is structured as follows: we begin by introducing ASP, the decision model and notation standard, and event calculus (EC) in Section 2. Next, we introduce a discrete, multi-valued variant of the EC in Section 3. After that, we elaborate our approach to tackle the above-mentioned key challenges of a payroll system in Section 4 and present a first implementation of it in Section 5. We present a more efficient multi-shot implementation in Section 6. After that, we discuss the implementations and their results in Section 7 and discuss related work in Section 8. Finally, we conclude in Section 9.
2 Preliminaries
2.1 Answer set programming
ASP is a declarative paradigm for solving knowledge-intensive computational problems (Brewka et al., Reference Brewka, Eiter and Truszczyński2011; Gebser et al., Reference Gebser, Kaminski, Kaufmann and Schaub2012). The idea of ASP is to represent a problem as a logic program whose models, called answer sets (Gelfond and Lifschitz, Reference Gelfond and Lifschitz1991) correspond to the solutions. A normal ASP logic program Π is a finite set of rules r of the form:
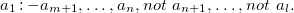 $$ a_{1} :- a_{m+1}, \ldots, a_{n}, not \ a_{n+1}, \ldots, not \ a_{l}. $$
$$ a_{1} :- a_{m+1}, \ldots, a_{n}, not \ a_{n+1}, \ldots, not \ a_{l}. $$
where each a
i
is an atom of the form p(t
1,…,t
k
) with p being a predicate symbol and t
1, …, t
k
terms. Atom a
1 is called the head atom, head(r), while a
m + 1 to a
n
and not a
n + 1 to not a
l
are referred to as positive and negative body literals. The positive and negative sets of atoms (body
+(r) and body
−(r), respectively) compose the body of rule r, referred to as body(r). The informal meaning of a normal rule is that if the body is true, then so is the head. A rule r is called a fact if it consists of only one head atom and no body atoms. An integrity constraint r is a rule that contains no head atom. An integrity constraint r is satisfied if body(r) is false. By insisting that integrity constraints are satisfied in an answer set, they effectively rule out answer sets for which this is not the case. An expression is said to be ground if it contains no variables. Furthermore, in the original (non-ground) program, every normal rule or constraint r must be safe; that is, every variable which occurs in r must occur at least once in body
+(r). The logic operator not denotes negation as failure, allowing ASP to perform non-monotonic reasoning (Clark, Reference Clark1978). Aggregate functions, denoted as f(S), where S is a set and f can be #count, #min, #max, #sum, or #times, are represented as L
g
 $\prec$
1
f(S)
$\prec$
1
f(S)
 $\prec$
2
R
g
. Here, f(S) is the aggregate function,
$\prec$
2
R
g
. Here, f(S) is the aggregate function,
 $\prec$
1,
$\prec$
1,
 $\prec$
2
$\prec$
2
 $\in$
{=,<,≤,>, ≥ }, and L
g
(left guard) and R
g
(right guard) are terms. Either L
g
$\in$
{=,<,≤,>, ≥ }, and L
g
(left guard) and R
g
(right guard) are terms. Either L
g
 $\prec$
1 or
$\prec$
1 or
 $\prec$
2
R
g
can be omitted, defaulting to ‘0” and “ + ∞” respectively (Faber et al., Reference Faber, Pfeifer, Leone, Dell’Armi and Ielpa2008). The standard semantics of aggregates include counting, finding the minimum and maximum, summing, and multiplying atoms in a multiset S.
$\prec$
2
R
g
can be omitted, defaulting to ‘0” and “ + ∞” respectively (Faber et al., Reference Faber, Pfeifer, Leone, Dell’Armi and Ielpa2008). The standard semantics of aggregates include counting, finding the minimum and maximum, summing, and multiplying atoms in a multiset S.
Semantically, a logic program induces a set of stable models, being distinguished models of the program determined by the stable model semantics (Gelfond and Lifschitz, Reference Gelfond and Lifschitz1988). ASP systems like Clingo (Gebser et al., Reference Gebser, Kaminski, Kaufmann and Schaub2014) and DLV (Leone et al., Reference Leone, Pfeifer, Faber, Eiter, Gottlob, Perri and Scarcello2006) use a grounder to replace variables with constants and a solver to search for answer sets.
2.1.1 Multi-shot answer set programming
Standard ASP always follows this two-step process in computing the answer sets of logic programs. However, this paradigm is limited in the sense that it cannot handle efficiently cases in which data or constraints should be added, deleted, or replaced as part of the solving process.
Recently, Gebser et al. (Reference Gebser, Kaminski, Kaufmann and Schaub2019) extended the traditional ground-and-solve paradigm of ASP to multi-shot solving. Here, the user defines a number of parametrised ASP programs and writes an imperative program, for example in Python, to manipulate these programs. The idea is to consider evolving grounding and solving processes where the internal state of the logic program can be manipulated by certain operations. Such operations allow for adding, grounding, and solving logic programs as well as setting truth values of (external) atoms (Gebser et al., Reference Gebser, Kaminski, Kaufmann and Schaub2019). Multi-shot ASP solving is an iterative approach that incorporates this idea and is geared for problems where the logic program is continuously changing. To this end, clingo complements ASP’s declarative input language with different ways of controlling the grounding and solving process. An imperative programming interface allows a continuous assembly of the program and gives control over the grounding and solving functions. A new #program directive is also introduced that allows to structure a program into subprograms or modules, making the solving process completely modular. Each subprogram has a name and an optional list of parameters. Subprogram base is a dedicated subprogram that collects all the rules not preceded by any #program directive. Finally, #external directives are used within subprograms to set external atoms to some truth value via the Python interface of clingo. Rules that include such external atoms in the body can be selectively (de)activated to direct the search.
The module theorem (Oikarinen and Janhunen, Reference Oikarinen and Janhunen2006; Janhunen et al., Reference Janhunen, Oikarinen, Tompits and Woltran2009) lays out a theoretical foundation for establishing a modular structure in logic programs operating under the stable model semantics. This theoretical framework ensures that each module possesses a clearly defined input/output interface, crucial for achieving composability among answer sets of distinct modules. As long as the requirements outlined in the module theorem are met, we can carry out the module-by-module computation of answer sets for an ASP program. Two critical implications arise from the concept of compositionality as defined in the module theorem. First, it mandates that all rules defining a specific (ground) literal must be contained within the same module. Second, the module theorem specifies that positive rule cycles must be confined within individual modules. This theoretical requirement is essential for preventing unintended interactions between modules and preserving the integrity of the computational process.
2.2 DMN
Decision model and notation (DMN) (Object Management Group, 2015) is a standardized modelling language and notation for expressing business rules. It is designed to be easy to use and understand by business experts (Silver and Sayles, Reference Silver and Sayles2016), while still being expressive enough to capture complex decision-making logic. DMN models consist of two main components: a decision requirements diagram (DRD) and one or more decision tables.
The DRD is a graphical representation of the overall structure and dependencies of a DMN model. It shows the connections between the various inputs, decisions, and knowledge sources that are used in the model, making it easier for end-users to interpret and understand the model (Hasić et al., Reference Hasić, Seng and Neureiter2017).
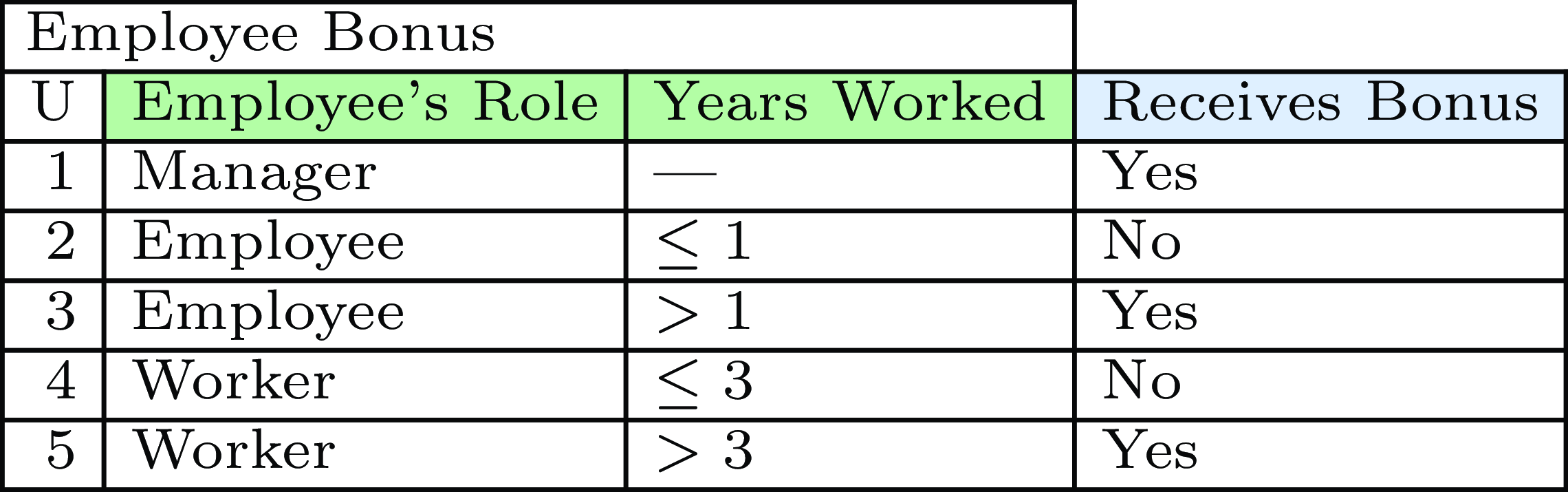
Fig. 1. Example of DMN table determining eligibility for holiday bonus.
Decision tables contain the detailed business logic that is used to make decisions. Each decision table consists of a number of input columns and at least one output column. Rows in the table specify the conditions under which a given output should be produced, based on the values of the input columns. A classical example of a decision table is shown in Figure 1. It defines whether an employee receives a holiday bonus based on their role in the company and the number of years they have worked at the company. The decision table has input columns for the employee’s role and the number of years they have worked, and an output column for whether they receive a bonus. Rows in the table correspond to different kinds of employees and specify for each kind whether they are eligible for a bonus. For example, a manager always receives a holiday bonus while a worker only receives one if they have worked for more than 3 years at the company.
Overall, DMN provides a user-friendly and intuitive way of expressing business rules and decision-making logic, making it well-suited for use in a variety of applications (Sooter et al., Reference Sooter, Hasley, Lario, Rubin and Hasić2019; Hasić and Vanthienen, Reference Hasić and Vanthienen2020). It has already been successfully used in many case studies and is becoming increasingly popular as a modelling language for decision management (Hasić et al., Reference Hasić, Seng and Neureiter2016).
2.3 Event calculus
The event calculus (EC) is a logical formalism used in artificial intelligence and knowledge representation to reason about events and their effects (Kowalski and Sergot, Reference Kowalski and Sergot1986). It is based on first-order logic and has a temporal component, allowing it to represent the changing state of a system over time. The EC has been applied to a wide range of AI tasks, including planning (Eshghi, Reference Eshghi1988; Shanahan, Reference Shanahan2000), cognitive robotics (Shanahan, Reference Shanahan1996, Reference Shanahan1999b), and legal reasoning (Kowalski, Reference Kowalski1995). It has also been used to model the effects of actions in multi-agent systems, allowing for the formalization and analysis of complex interactions between agents (Kowalski and Sadri, Reference Kowalski and Sadri1999). A complete EC model consists both of domain-independent and domain-dependent axioms. The general theory of how properties evolve through time is captured in the domain-independent axioms, which cover notions such as persistence and causality. The domain-dependent axioms, on the other hand, describe which actions affect which fluents under various circumstances in a certain domain and state when these actions do occur.
The original formulation of EC uses circumscription (McCarthy, Reference McCarthy1980), or the minimization of the extensions of predicates, to allow default reasoning. In particular, it reflects the assumptions that (1) the only events that occur are those known to occur and (2) the only effects of events are those that are known. The closed world assumption of most logic programming semantics, including the stable model semantics, allows the same assumptions to be incorporated in an arguably more elegant way. This makes ASP a very suitable formalism for implementing the EC.
Different variants of the EC have been proposed over the years; in this paper, we will use an implementation based on the functional event calculus (FEC) (Ma et al., Reference Ma, Miller, Morgenstern and Patkos2014a) and discrete event calculus (DEC) (Mueller, Reference Mueller2004a).
The FEC extends the EC with non-boolean fluents. This sets the EC on a par with formalisms such as the Situation Calculus in this respect. In the FEC, there are four sorts: A for actions (a, a ′, a 1, …), F for fluents (f, f ′, f 1, …), V for values (v, v ′, v 1, …), and T for timepoints (t, t ′, t 1, …). The key predicates and functions of the FEC are: Happens ⊆ A × T, ValueOf : F × T → V, CausesValue ⊆ A × F × V × T and PossVal ⊆ F × V. To describe the general relationship between these predicates, two auxiliary predicates are defined: ValueCaused ⊆ F × V × T, OtherValCausedBetween ⊆ F × V × T × T. Here, ValueCaused(F,V,T) means that some action happens at T that gives cause for F to take value V, and OtherValCausedBetween(F,V,T1,T2) means that some action happens at some point in the half-open interval [T1, T2) that gives cause for F to take a value other than V. Note that ‘gives cause” is a weaker notion than the standard ‘causes”: non-deterministic actions do not cause specific predictable effects. For example, rolling a die gives cause for each number to be shown, but we cannot predict which number will be shown. The FEC then consists of the following axioms:
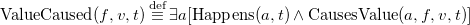 \begin{equation} \text {ValueCaused} (f, v, t) \stackrel {\text {def}}{\equiv } \exists a \Big [\text {Happens}(a, t) \wedge \text {CausesValue}(a, f, v, t)\Big ]\end{equation}
\begin{equation} \text {ValueCaused} (f, v, t) \stackrel {\text {def}}{\equiv } \exists a \Big [\text {Happens}(a, t) \wedge \text {CausesValue}(a, f, v, t)\Big ]\end{equation}
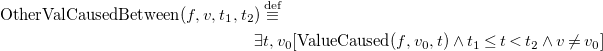 \begin{multline} {\rm OtherValCausedBetween}(f, v, t_1, t_2) \stackrel{{\rm def}}{\equiv }\\ \exists t, v_0 \Big [{\rm ValueCaused}(f, v_0, t) \wedge t_1 \leq t < t_2 \wedge v \neq v_0 \Big ] \end{multline}
\begin{multline} {\rm OtherValCausedBetween}(f, v, t_1, t_2) \stackrel{{\rm def}}{\equiv }\\ \exists t, v_0 \Big [{\rm ValueCaused}(f, v_0, t) \wedge t_1 \leq t < t_2 \wedge v \neq v_0 \Big ] \end{multline}
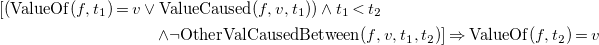 \begin{multline} \left [\left ({\rm ValueOf} (f, t_1)=v \vee {\rm ValueCaused}(f, v, t_1)\right ) \wedge t_1 < t_2 \right .\\ \left .\wedge \neg {\rm OtherValCausedBetween}(f, v, t_1, t_2)\right ] \Rightarrow {\rm ValueOf} (f, t_2)=v \end{multline}
\begin{multline} \left [\left ({\rm ValueOf} (f, t_1)=v \vee {\rm ValueCaused}(f, v, t_1)\right ) \wedge t_1 < t_2 \right .\\ \left .\wedge \neg {\rm OtherValCausedBetween}(f, v, t_1, t_2)\right ] \Rightarrow {\rm ValueOf} (f, t_2)=v \end{multline}
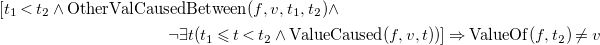 \begin{multline} \left [t_1 < t_2 \wedge {\rm OtherValCausedBetween}(f, v, t_1, t_2) \wedge \right . \\ \quad \left . \neg \exists t(t_1 \leqslant t < t_2 \wedge {\rm ValueCaused}(f, v, t))\right ] \Rightarrow {\rm ValueOf} (f, t_2) \neq v \end{multline}
\begin{multline} \left [t_1 < t_2 \wedge {\rm OtherValCausedBetween}(f, v, t_1, t_2) \wedge \right . \\ \quad \left . \neg \exists t(t_1 \leqslant t < t_2 \wedge {\rm ValueCaused}(f, v, t))\right ] \Rightarrow {\rm ValueOf} (f, t_2) \neq v \end{multline}
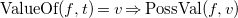 \begin{equation} \text {ValueOf} (f, t)=v \Rightarrow \text {PossVal}(f, v) \end{equation}
\begin{equation} \text {ValueOf} (f, t)=v \Rightarrow \text {PossVal}(f, v) \end{equation}
The notions of cause, effect, and inertia are captured in the first two FEC axioms. Axiom (FEC3) states that a fluent has a particular value at a particular time if (i) it already had that value at an earlier time or (ii) was given cause to take that value from an earlier time, and in the meantime (including that earlier time) nothing has happened that might give cause for it to take an alternative value. Conversely, (FEC4) states that fluent f cannot have value v at time t 2 if its most recent causal influences prior to t 2 do not include a cause for v. Finally, (FEC5) additionally constrains each fluent’s value to be at all times among the set of values defined by PossVal.
The DEC is a version of the EC that models time as a discrete quantity, with events happening at specific points in time (Mueller, Reference Mueller2004a). In the DEC, the duration of events is not represented and events are assumed to happen instantaneously. This makes the DEC well-suited for modeling systems where the duration of events is not important.
3 Discrete functional event calculus
In this paper, we introduce a variant of the DEC that includes non-Boolean fluents: the discrete functional event calculus (DFEC). We’ll start from the DEC axioms described by Mueller (Reference Mueller2004a) and in a way similar to how FEC extends the EC, the DFEC extends the DEC to allow for non-boolean fluents. The key predicates and functions of the DFEC are:
-
Happens(a,t): action a occurs at time t.
-
ValueOf(f,t): the value of fluent f at time t.
-
PossVal(f,v): value v is a possible value of fluent f.
-
CausesValue(a,f,v): action a causes fluent f to take value v.
-
ValueCaused(f,v,t): at timepoint t, fluent f has a cause to take value v
-
Initiated(f,v,t): fluent f will have value v and not be released from the commonsense law of inertia at t + 1.
-
Terminated(f,v,t): fluent f will no longer have value v and not be released from the commonsense law of inertia at t + 1.
-
Releases(a,f): if action a occurs, fluent f will be released from the commonsense law of inertia.
-
ReleasedAt(f,t): fluent f is released from the commonsense law of inertia at time t.
-
Trajectory(f 1 ,v 1 ,t 1 ,f 2 ,v 2 ,t 2 ): if value v 1 of fluent f 1 is initiated by an action that occurs at timepoint t 1, and t 2 > 0, then fluent f 2 will have value v 2 at timepoint t 1 + t 2.
-
AntiTrajectory(f 1 ,v 1 ,t 1 ,f 2 ,v 2 ,t 2 ): if value v 1 of fluent f 1 is terminated by an action that occurs at timepoint t 1, and t 2 > 0, then fluent f 2 will have value v 2 at timepoint t 1 + t 2.
The Trajectory predicate, first proposed by Shanahan (Reference Shanahan1990), is used to capture continuous change. If we would, for example, want to model the water level in a sink under a tap with flow rate FR, we could specify:
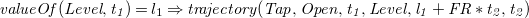 $$ \mathit {valueOf(Level,t_{1})}=l_{1} \Rightarrow \mathit {trajectory(Tap,Open,t_{1},Level,l_{1}+FR*t_{2},t_{2})} $$
$$ \mathit {valueOf(Level,t_{1})}=l_{1} \Rightarrow \mathit {trajectory(Tap,Open,t_{1},Level,l_{1}+FR*t_{2},t_{2})} $$
The AntiTrajectory predicate is analogous to the Trajectory predicate, except that it is brought into play when a value of a fluent is terminated rather than initiated by an occurring event.

Fig. 2. Axioms of the discrete functional event calculus.
The commonsense law of inertia (Shanahan et al., Reference Shanahan1997) states that a fluent’s value persists unless the fluent is affected by an event. When a fluent is released from this law, its value can fluctuate. Fluents that are released from the commonsense law of inertia can be used to model nondeterministic effects (Shanahan, Reference Shanahan1999a) and indirect effects (Shanahan, Reference Shanahan1999b).
Let DFEC be the conjunction of definitions (DFEC1)-(DFEC5) and axioms (DFEC6)-(DFEC15) in Figure 2. Note that free variables are implicitly universally quantified and the notation
 $\Gamma _{1} \stackrel{{\rm def}}{\equiv }\Gamma _{2}$
defines Γ
1 as an abbreviation for Γ
2. That is,
$\Gamma _{1} \stackrel{{\rm def}}{\equiv }\Gamma _{2}$
defines Γ
1 as an abbreviation for Γ
2. That is,
 $\Gamma _{1} \stackrel{{\rm def}}{\equiv }\Gamma _{2}$
means that all occurrences of the expression Γ
1 are to be replaced with the expression Γ
2.
$\Gamma _{1} \stackrel{{\rm def}}{\equiv }\Gamma _{2}$
means that all occurrences of the expression Γ
1 are to be replaced with the expression Γ
2.
Here is a short explanation of the axioms:
-
DFEC6: If value v 1 is initiated for fluent f 1 at t 1 and this value is not stopped between t 1 and t 1 + t 2 with t 2 > 0, then fluent f 2 has value v 2 at t 1 + t 2.
-
DFEC7: If value v 2 is terminated for fluent f 1 at t 1 and this value is not started between t 1 and t 1 + t 2 with t 2 > 0, then fluent f 2 has value v 2 at t 1 + t 2.
-
DFEC8: If a fluent f has value v at timepoint t, the fluent is not released from the commonsense law of inertia at t + 1, and value v of fluent f is not terminated at t, then the fluent has the same value v at t + 1.
-
DFEC9: If a fluent is released from the commonsense law of inertia at timepoint t and no value is either initiated or terminated by any action that occurs at t, then the fluent is released from the commonsense law of inertia at t + 1.
-
DFEC10: If a fluent is not released from the commonsense law of inertia at timepoint t and the fluent is not released by any action that occurs at t, then the fluent is not released from the commonsense law of inertia at t + 1.
-
DFEC11: If value v of fluent f is initiated at timepoint t, then the value of fluent f is v at timepoint t + 1.
-
DFEC12: If value v of fluent f is terminated at timepoint t, then the value of fluent f is no longer v at timepoint t + 1.
-
DFEC13: If a fluent is released by some action that occurs at timepoint t, then the fluent is released from the commonsense law of inertia at t + 1.
-
DFEC14: If there is value v of fluent f that is initiated or terminated at timepoint t, then the fluent is not released from the commonsense law of inertia at t + 1.
-
DFEC15: If a fluent has a value at timepoint, then this value should be a possible value of this fluent.
The DFEC can find application in diverse areas, including planning, cognitive robotics, legal reasoning, and software engineering, among others. It is specifically well suited for situations where the duration of events is not important and fluents can take on several values. Our payroll management application does not require all the features of this DFEC. In particular, in our setting, we do not need to model continuous change, with one exception, namely, that we need to keep track of the passage of time. Rather than using the general Trajectory-predicate for this, we will find it easier to introduce a special-purpose kind of fluent, which we will call count fluents to track for how long fluents have had their values. Consequently, besides Trajectory and AntiTrajectory, Releases and ReleasedAt predicates are deemed unnecessary. Our implementation will thus adopt a simplified version of the DFEC, detailed in Figure 3 with the relevant definitions and axioms.

Fig. 3. Axioms of the simplified discrete functional event calculus.
3.1 ASP implementation DFEC
In the context of a limited domain, the integration of EC and DEC formulas into ASP programs is feasible, as demonstrated by Kim et al. (Reference Kim, Lee and Palla2009). They showed that it is possible to embed circumscriptive theories into stable models, and thus that ASP is a viable approach to computing circumscriptive theories like EC. Our implementation of the DFEC axioms in ASP, shown in A, is closely related to their implementation of the DEC axioms.
The DFEC implementation is designed to yield, at most, one solution. This deterministic outcome is rooted in the stratified nature of the DFEC. Specifically, when provided with a coherent set of fluents, actions, and effects, the DFEC implementation guarantees there is precisely one solution. A normal logic program Π is stratified if there exists a level mapping f assigning each ground predicate symbol a natural number such that, for every rule r
 $\in$
Π and every predicate P
1 and P
2,
$\in$
Π and every predicate P
1 and P
2,
-
1. if P 1 occurs in head(r) and P 2 occurs in body +(r) then f(P 1) ≥ f(P 2);
-
2. if P 1 occurs in head(r) and P 2 occurs in body −(r) then f(P 1) > f(P 2).
To prove that the ASP implementation of the DFEC is stratified, we introduce such a level mapping. Assigning a level is based on the structure of each atom in the program. Specifically, atoms of the form stoppedIn(J,F,V,I) or startedIn(J,F,V,I) are assigned level I. Atoms of the form initiated(F,V,I), terminated(F,V,I), releasedAt(F,V,I) and valueOf(F,V,I), are assigned level I + 1, while all other atoms are assigned level 0. It can be easily confirmed that this mapping is correct. As an example, consider axiom (DFEC6). In this rule, the level of the head T1 + T2 + 1 is demonstrated to be greater than or equal to the level T1 of the positively occurring atom initiated(F1,V1,T1). Moreover, it is strictly greater than the level of the negatively occurring atom
stoppedIn(T1,F1,V1,T1+T2). Similar verification can be conducted for the remaining axioms, thereby establishing the correctness of the level mapping. The level mapping of the DFEC implementation is provided in B.
4 Proposed approach
We will now outline our general approach to tackling the three challenges described in the introduction.
To tackle the first challenge, we base ourselves on a generic implementation of the DFEC defined in Section 3. The HR experts can then represent the rules for a specific company by defining a concrete set of actions and fluents. Facilitating a user-friendly approach to this task, we leverage decision model and notation (DMN) decision tables to define actions, fluents, and consequently, the payroll rules. This approach empowers HR experts to understand the underlying logic of the payroll system and enables them to take on most of the work of maintaining it. However, the DMN notation has no notion of time and thus temporal properties cannot be expressed in standard DMN. To provide the necessary expressive power, we extend this notation using simple temporal logic and interval logic, which we will describe below.
To cope with the second challenge, we define the semantics of the language that is provided to the HR experts by means of a declarative ASP. Known for its flexibility and elaboration tolerance, ASP allows us to implement this language in such a way that new language features can easily be added when necessary, with minimal running risk of introducing bugs in the existing models. Once the HR experts articulate the payroll rules within DMN tables, the system can then automatically transform these tables into an ASP program.
One downside of using the expressive declarative ASP formalism is that the third challenge, that is that of computational efficiency, may be hard to meet. Indeed, as we show below, the usual ground-and-solve approach of ASP solvers falls far short of the required performance. To address this issue, we make use of the multi-shot solving capabilities of the ASP solver clingo. Thus, upon the translation of the tables into ASP, the resulting program is handed over to clingo for efficient processing and execution of the payroll operations.
We now define the temporal and interval logic to extend the DMN notation with the possibility to express temporal properties.
4.1 Temporal logic
Some of the domain knowledge that the consultants need to express concerns temporal properties. For instance, overtime starts after an employee has been working for 8 h. We represent such knowledge using the following simple linear time logic:
-
An atomic temporal formula is of the form f = v, with f a fluent and v a value from the domain of f;
-
If
 $\phi$
and
$\psi$
are temporal formulas, then so are
$\phi$
∧
$\psi$
and
$\lnot\phi$
;
$\phi$
and
$\psi$
are temporal formulas, then so are
$\phi$
∧
$\psi$
and
$\lnot\phi$
; -
If
$\phi$
is a temporal formula and n
$\in \mathbb{N}$
, then [≥n]
$\phi$
is a temporal formula, which intuitively represents that
$\phi$
has been true for at least the n most recent time points, including the present one.









Given a time line T = (I
0,I
1,…) and a time point i ≥ 0, we define that a temporal formula
 $\phi$
holds in (T,i), denoted as (T,i) ⊨
$\phi$
holds in (T,i), denoted as (T,i) ⊨
 $\phi$
, as follows:
$\phi$
, as follows:
-
For an atomic temporal formula, (T,i) ⊨ f = v if f I i = v that is the value of fluent f in the state of the world I i at time point i is equal to v;
-
For a conjunction
$\phi$
∧
$\psi$
, (T,i) ⊨
$\phi$
∧
$\psi$
if (T,i) ⊨
$\phi$
and (T,i) ⊨
$\psi$
; -
For a negation
$\lnot\phi$
, (T,i) ⊨
$\lnot\phi$
if (T,i)
$\nVDash$
$\phi$
; -
For [≥n]
$\phi$
, (T,i) ⊨ [≥n]
$\phi$
if i ≥ n and for all i − n < j ≤ i, (T,j) ⊨
$\phi$
.













We also introduce an abbreviation [=n]
 $\phi$
for the formula [≥n]
$\phi$
for the formula [≥n]
 $\phi$
∧
$\phi$
∧
 $\lnot$
[≥n+1]
$\lnot$
[≥n+1]
 $\phi$
. As we will show in Section 5.2, this temporal logic is easily defined in ASP.
$\phi$
. As we will show in Section 5.2, this temporal logic is easily defined in ASP.
4.2 Interval logic
The wages of employees are not defined in terms of individual timepoints but in terms of intervals. The consultants can define which fluents are considered relevant for the wages of employees. Within an interval, all the relevant fluents keep their value, that is the boundaries of the interval are timepoints at which the value of a relevant fluent changes. We consider half-open intervals [i,j) where i is a timepoint at which the value of a relevant fluent changes and j is the next such timepoint. An interval property describes a characteristic of an interval. It is either a relevant fluent f, or an aggregate function like length. We denote the value of an interval property p in an interval [i, j) as p [i, j). Given a timeline T = (I 0,I 1,…), we define this value in the following way:
-
For a relevant fluent f, f [i, j) = f I i , that is, the value of fluent f at the start of the interval. Because f is a relevant fluent, this is also the value that f has in all following I k for k
$\in$
[i, j). -
For the aggregate function length, length [i, j) = j − i.

In addition to interval properties, we also define interval terms. An interval term is an expression that refers to a specific interval. The atomic interval term this refers to the current interval. For an interval term t, next(t) refers to the next interval, and prev(t) to the previous one. Given a sequence of intervals
 $S = (\mathcal{I}_0, \mathcal{I}_1,\ldots)$
, we define
$S = (\mathcal{I}_0, \mathcal{I}_1,\ldots)$
, we define
 $\mathit{this}^{(S,i)} = \mathcal{I}_i$
and for every interval term t with
$\mathit{this}^{(S,i)} = \mathcal{I}_i$
and for every interval term t with
 $t^{(S,i)} = \mathcal{I}_j$
, we define
$t^{(S,i)} = \mathcal{I}_j$
, we define
 $next(t)^{(S,i)} = \mathcal{I}_{j+1}$
and
$next(t)^{(S,i)} = \mathcal{I}_{j+1}$
and
 $prev(t)^{(S,i)} = \mathcal{I}_{j-1}$
.
$prev(t)^{(S,i)} = \mathcal{I}_{j-1}$
.
An interval value is then of the form [t]p and refers to the value of the interval property p for the interval that is indicated by the interval term t. We define this value as [t]p = p t (S,i) . We define an atomic interval formula as vθw where v and w are two interval values and θ is a comparison operator. Finally, we combine these atomic interval formulas with the standard boolean operators, as usual.
5 Single-shot Implementation
First, we introduce an implementation designed for utilization with a conventional single-shot solver. Afterwards, we show how a more efficient implementation can be developed that uses the multi-shot solving capabilities of clingo.
5.1 Discrete functional event calculus
The core of our generic model is an implementation of the simplified version of the DFEC described in Section 3. The timeline considered in our model consists of a number of discrete timepoints 0..n, represented by the time(T) predicate. Each timepoint corresponds to a certain duration in wall-clock time. For the moment, we consider timepoints that are 10 mins long. The ts(Days, Hours, Minutes, Stamp) predicate links a duration expressed in real-world Days, Hours and Minutes to the corresponding timepoint Stamp (lines 2–5).

The situation of the employee at a certain time point is described by a complete set of fluents. Fluents have a domain of possible values. An example is the boolean fluent present, which indicates whether the employee is currently clocked in. At each point in time, a fluent has a certain value, as represented by the predicate value(F,V,T). At timepoint 0, the fluent’s value is specified by the initially(F,V) predicate. The cause(F,V,T) predicate represents that at timepoint T there is a cause for the value of F to change to V, which leads to the current value of F being terminated at T + 1 and the value V being initiated (lines 11–14).

The only reason for a fluent to change is because an action changes it. In general, the effect of an action may depend on the state of the world at the time the action occurs. However, for the moment, we will consider only actions that have the fixed effect of causing a Fluent to take on a specific Value, as represented by the causes(Action,Fluent,Value) predicate on line 21. For now, we define 2 types of actions. A user action is an action that is performed by the user in an intentional way (i.e., the employee). A wall-time action happens at a specific wall-clock time. Both wall-time actions and user actions thus happen at a given absolute time, represented by the userDoes(A,T) and actionTime(A,T) predicates.

With these concepts, we now represent the case-specific knowledge in an easy-to-read tabular representation. The case-specific knowledge for our running example is shown in Figure 4. Each table enumerates a single predicate, for example the first table corresponds to the initially(F,V) predicate, etc.
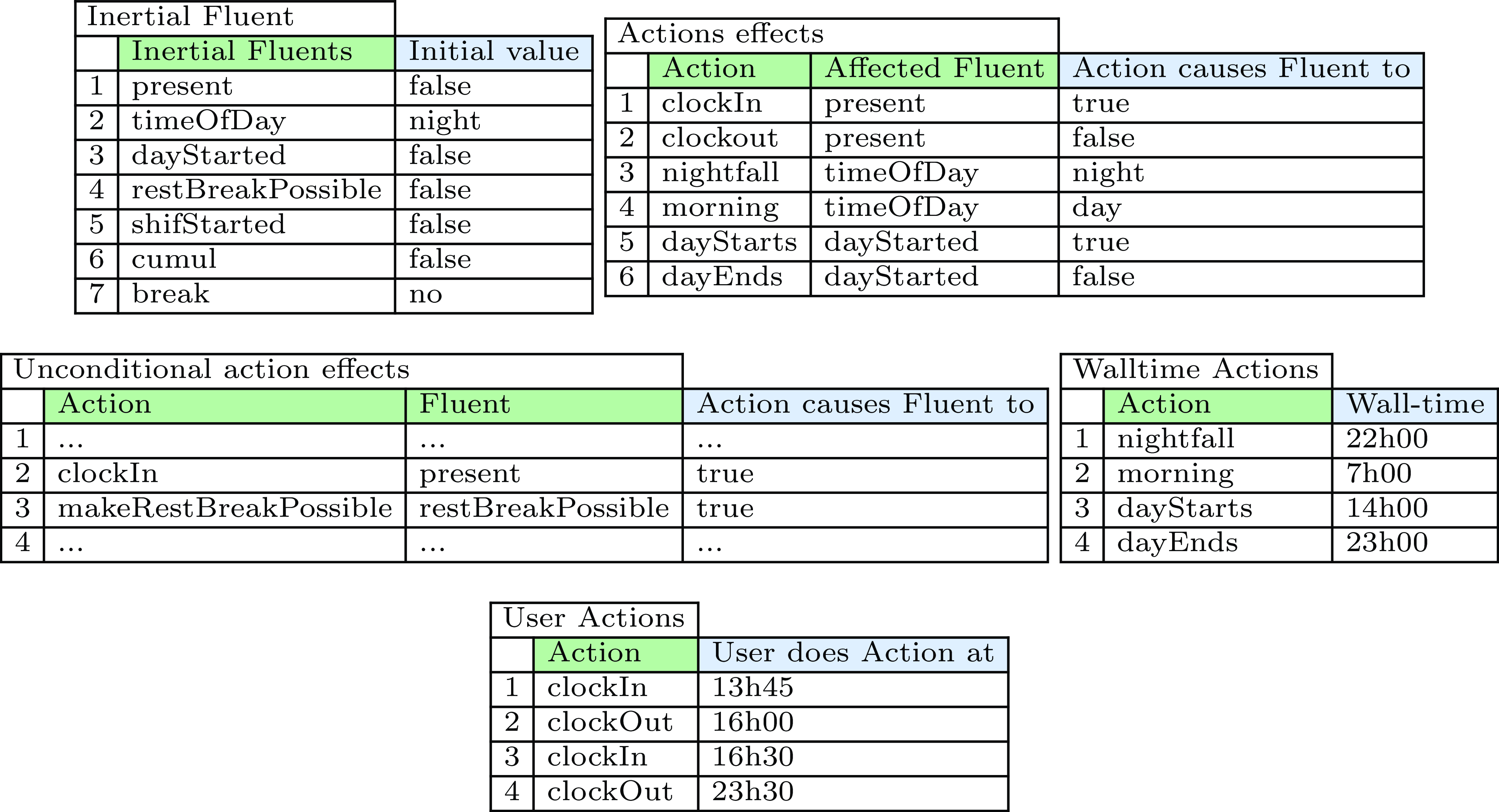
Fig. 4. Case-specific representation of a basic scenario.
5.2 Conditional effects
The effect of an action may depend on the current state of the world. We describe such a conditional effect with a ccauses(Action, Fluent, Value, Condition) predicate.
Conditions are formatted in the temporal logic of Section 4.1. In the tables, we use a slightly more user-friendly syntax, writing, for example
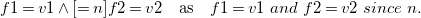 $$ f1=v1 \wedge [=n] f2=v2 \quad \text {as} \quad f1=v1\ and\ f2 = v2 \ since\ n. $$
$$ f1=v1 \wedge [=n] f2=v2 \quad \text {as} \quad f1=v1\ and\ f2 = v2 \ since\ n. $$
In our ASP implementation, we represent each such condition as a set of facts. For instance, the above condition cond1 is represented as follows:
Here the and(C,N) predicate denotes that condition C is a conjunction of N sub-conditions, each represented by a sub(C,I,SC) fact, with 0 ≤ I < N. The holds(Cond,T) predicate specifies whether a condition Cond holds at a certain timepoint T. For Cond = v(F,V), we just check whether Fluent F has Value V (line 25). Cond = since(F,V,D), representing whether a fluent F has had a value V for D timepoints, is defined by two rules. The first rule states that the initiation of V for F at T − 1 marks timepoint T as the start of a period in which F has value V (line 26). The recursive rule on line 27 extends such a period with one timepoint if F still has value V at T. Finally, if Cond is a conjunction, we check whether the number of conjuncts that hold at T matches its total number of conjuncts N (line 28).

We can now represent scenarios where these conditional effects come into play in the tabular representation. In the first table of Figure 5, we specify that a shift starts if an employee clocks in when the workday has already started or when the day starts and the employee is already clocked in.
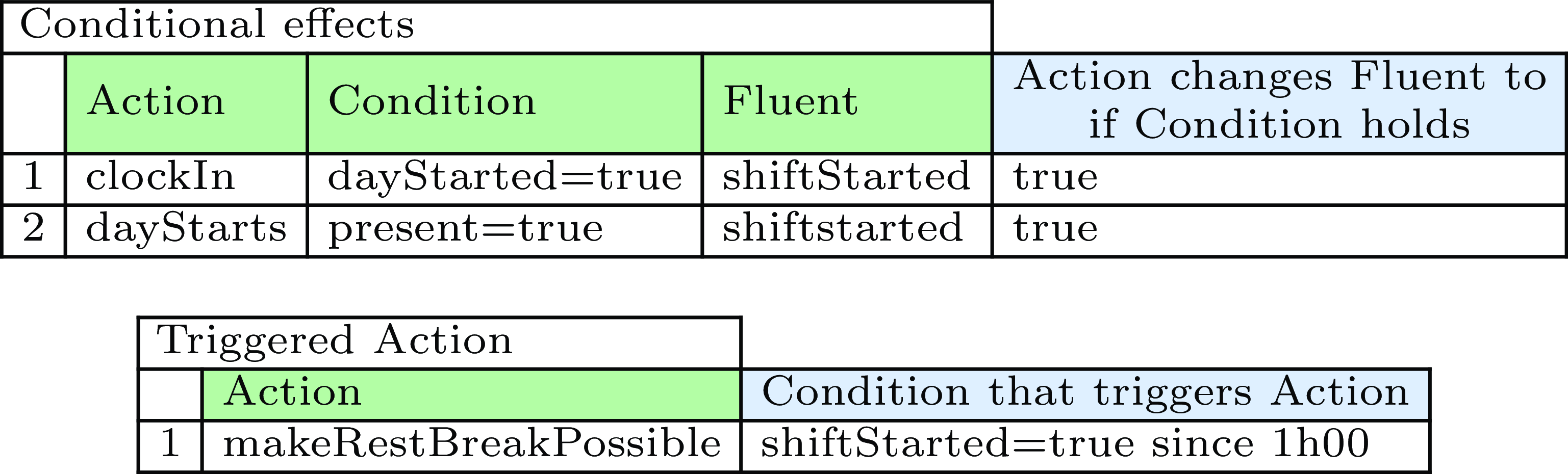
Fig. 5. Case-specific representation of conditional effects and triggered actions.
5.3 Automatically triggered actions
An action can also be automatically triggered if a certain temporal condition is fulfilled. To specify that an employee’s break is paid as an (official) rest break after their shift has lasted for one hour, we specify an action makeRestBreakPossible, which causes fluent restbreakPossible to be true. Such actions are not performed by the user but happen automatically after a certain fluent F has had a certain value V for a specific duration D, as represented by an after(F,V,D,A) predicate (line 31). Figure 5 represents triggered action makeRestBreakPossible in our tabular form.
5.4 Defined fluents
To avoid repeated use of complex fluent formulas, we introduce defined fluents as defined by Denecker and Ternovska (Reference Denecker and Ternovska2007) and used in action languages like
 $\mathcal{AL}_d$
(Gelfond and Inclezan, Reference Gelfond and Inclezan2009). The value of a defined fluent is completely determined by the values of the other fluents. Therefore, they provide no additional information about the state of the world; they simply make it easier to track its properties. The value of a defined fluent is defined by a set of rule(F,V,C) facts: if condition C holds, the defined fluent F has the value V (line 32). To cover the case that no rules are applicable, each defined fluent must have a default value (line 33). We do not allow fluents to be defined by negated predicates, therefore there are no cycles in our solution. As stated by Gelfond and Inclezan (Reference Gelfond and Inclezan2013), acyclic behaviour arises when there are no paths from defined fluents to their negations. Given that acyclic behaviour is a sufficient condition for well-foundedness, we can deduce that our defined fluents will consistently have, at most, one value.
$\mathcal{AL}_d$
(Gelfond and Inclezan, Reference Gelfond and Inclezan2009). The value of a defined fluent is completely determined by the values of the other fluents. Therefore, they provide no additional information about the state of the world; they simply make it easier to track its properties. The value of a defined fluent is defined by a set of rule(F,V,C) facts: if condition C holds, the defined fluent F has the value V (line 32). To cover the case that no rules are applicable, each defined fluent must have a default value (line 33). We do not allow fluents to be defined by negated predicates, therefore there are no cycles in our solution. As stated by Gelfond and Inclezan (Reference Gelfond and Inclezan2013), acyclic behaviour arises when there are no paths from defined fluents to their negations. Given that acyclic behaviour is a sufficient condition for well-foundedness, we can deduce that our defined fluents will consistently have, at most, one value.

For example, to indicate whether an employee is working, we introduce the defined fluent atWork = true if and only if the inertial fluents present and shiftStarted are true. Figure 6 represents this in our tabular representation.
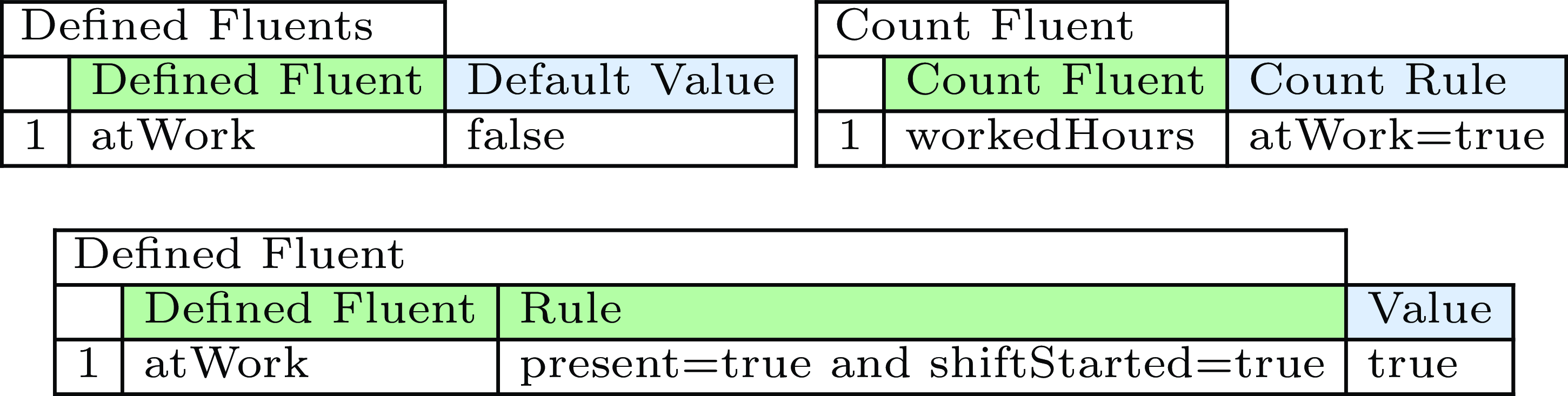
Fig. 6. Case-specific representation of defined and count fluents.
5.5 Count fluents
An employee receives a bonus for any overtime done after they have already worked eight hours. This can be modelled with a third type of fluents, the count fluents. These fluents keep track of the past states of the world by counting the foregoing timepoints in which a certain condition holds, upon a certain timepoint. Each count fluent is defined by a rule of the form countRule(CF,Cond), which specifies that the fluent CF counts the timepoints at which the condition Cond holds (lines 36–39).

In Figure 6, we define the count fluent workedHours, which, at each timepoint, keeps track of how long the fluent atWork has been true up to that point.
Count fluents can also trigger actions. The predicate when(CF,V,A) states that if count fluent CF reaches a certain value V, an action A is triggered. To make sure that an action is not triggered multiple times if the desired value is maintained for multiple timepoints, we state that the value of the count fluent in the previous timepoint should be smaller than the desired value (line 40).
For example, the overtime bonus is applied by triggering an action cumulPremiumAction after eight hours of work. Figure 7, adds this triggered action and its effect to the existing tables for triggered actions and effects (Figures 4 and 5). Note that conditions specifying that a fluent F has had a value V for a duration D are translated in ASP as an after(F,V,D,A) predicate and those that specify value V for a count fluent CF are translated as a when(CF,V,A) predicate.

Fig. 7. Extended case-specific representation of triggered actions and effects.

Fig. 8. Case-specific representation of relevant fluents.
5.6 Reasoning about intervals
Up to now, we have only reasoned about individual timepoints. To calculate the total wages of employees we consider intervals. As described in Section 4, within intervals all of the ‘relevant” fluents keep their value. By restricting attention to only the relevant fluents, we avoid creating too many small intervals. A relevant fluent is annotated by the relevant(Fluent) predicate. We denote the relevant fluents by introducing a new column in the inertial and defined fluent table (Figures 4 and 6), as can be seen in Figure 8. The boundaries of intervals are those timepoints at which the value of at least one relevant fluent changes (lines 41–42).
To define the intervals, we assign an id to each boundary. The intervals are of the form [B(i), B(i+1)), where B(i) denotes the boundary with id i. The stretchesTo(Id,T) predicate denotes that interval Id includes timepoint T. We model this with two rules. The first one states that if the interval includes the previous timepoint T − 1 and timepoint T is not a boundary then the interval includes T as well (line 47). Boundaries themselves are included in the time interval that they start (line 48). Timepoint T is thus a boundary of time interval I + 1 if timepoint T − 1 is included in the previous interval I and T is a boundary (line 46). A boundary thus denotes the start of an interval (intervalFrom(Id,From) predicate) and the end of the previous interval (intervalTo(Id,To) predicate) (lines 44–45).

In principle, there could be as many intervals as there are timepoints. Typically, there will be far fewer. To speed up the program, we assume an upper bound of at most 20 intervals. We require that the final interval id be not used. If this ever happens, the upper bound should be increased. Next, as described in the interval logic of Section 4.2, we define interval terms, such as prev(this) in lines 55 to 57.

To clearly track the characteristics of the interval and avoid repeated use of complex interval formulas, we introduce defined interval properties. The value of a defined property is specified by a set of intRule(P,V,C) facts. If the condition C holds in the current interval, the defined property P has the value V (line 72). These conditions are formatted in the interval logic of Section 4.2. The intHolds(Cond,Id) predicate specifies when a condition for an interval holds. To check whether a condition holds, we define the value of the properties described in the interval logic of Section 4.2. A valueOfProp(P,V,Id) predicate denotes that an interval property P has value V in interval Id. If P is a relevant fluent, this is simply the case if this fluent has that value (line 58). If P = length, its value is the length of interval Id (lines 60–62). The value of an interval atom [IntTerm]P, which we denote in ASP as at(IntTerm,P), is the value of a property P in the interval that IntTerm refers to. We define when two such atom values are equal (line 65), when one atom value is smaller than another (line 69), and when an atom value has a certain value from its domain (line 67). Finally, a conjunction C holds in an interval, if all N of its conjuncts, specified by the iand(C,N) predicate, hold (lines 70–71).

In Figure 9, to specify the wages in a certain interval, we introduce some defined properties. The normalwage property is 20 euros if an employee is working, and 0 if they are not. They receive a nightpremium of 20% for any interval in the night or in the day if the interval precedes an interval in the night, provided that the night interval is larger. Finally, the employee receives an cumulPremium of 25%. Note that compared to the interval logic of Section 4.2 we omit the interval term this in our tables to improve readability.

Fig. 9. Case-specific representation of relevant fluents and output.
5.7 Calculating the total wages
In general, our goal is to compute the wages as a sum
 $\sum _{interval\ i} totalWage(i)$
with the totalWage property determining the hourly wage in each interval. We translate this to an ASP sum as follows:
$\sum _{interval\ i} totalWage(i)$
with the totalWage property determining the hourly wage in each interval. We translate this to an ASP sum as follows:
In total, an HR consultant only needs 10 tables to specify the specific rules. A concrete scenario can be represented as the single-user action table.
6 Multi-shot Implementation
In the previous section, we presented a model for use by a standard single-shot ASP solving. This model may produce large groundings, which form a bottleneck for realistic instances. Indeed, to handle a scenario of two days with an accuracy of one minute, for instance, we need 60 × 48 timepoints. Because the grounding size is quadratic in the number of timepoints, this is problematic. In this section, we show how we can use multi-shot solving to drastically reduce the grounding size, by restricting attention to only those timepoints at which the state of the world changes. We refer to these timepoints as changepoints. Our multi-shot model is purely an optimised version of the single-shot model: functionally, it is still the same, and it still allows the HR consultant to represent his knowledge in the same user-friendly way. It consists of 3 parts: a static part, a dynamic part, and an interval part.
6.1 Static code
The static part of the code contains the non-temporal information, which consists of rules that contain no predicates with a timepoint argument. For example, in the last code listing of the Functional EC paragraph in Section 5.1, the first two lines, which state that user actions and walltime actions are two kinds of actions, are included in the static part, while the last two rules, which define at which timepoints such actions happen, does not. We collect the static code in a subprogram #static(), that takes no parameters.
6.2 Dynamic code
The dynamic program defines the current state of the world in terms of the previous state. It therefore takes two changepoints as parameters. The program first asserts that the current changepoint cp is a new timepoint, which follows the previous changepoint pp. In addition to this, the dynamic program also contains all rules that include predicates that take a timepoint as an argument. These rules typically define the value of some dynamic predicate at T + 1 in terms of the values of dynamic predicates at timepoint T. Such rules now undergo a minor syntactic change, where we replace all such terms T + 1 by the parameter cp of the program and the terms T by its parameter pp. In effect, this change is what allows us to ‘skip ahead” to the next changepoint, instead of having to go through each timepoint individually. This necessitates a number of other small changes in the code, documented online,Footnote 1 the specifics of which we will not describe in detail.
6.3 Multi-shot solving algorithm
Algorithm 1 shows how the static and dynamic programs can be used to implement the desired behavior, employing clingo’s multi-shot solving. This algorithm uses the following notations: For a program P(x
1,…x
n
) with parameters x
i
and constants c
1, …, c
n
, we denote by AnswerSet(P(c
1,..,c
n
)) the unique answer set of P(c
1,…,c
n
). For a predicate p, we denote by p
X
the set of all tuples
 $\vec{c}$
such that
$\vec{c}$
such that
 $p(\vec{c}) \in X$
.
$p(\vec{c}) \in X$
.
Algorithm 1 Solving algorithm

At line 1, the static program P static , is solved. Its answer set provides the upper-bound max of the timeline and the list upfrontPoints of all changepoints that are already known up-front, that is all the time points at which wall-time actions or user actions happen. We also include the greatest time point max in this list, to ensure termination of the while-loop (line 6). In each iteration, this loop instantiates the dynamic program P dynamic for the next changepoint. The if-test (line 8) distinguishes two cases: either the next changepoint comes from the list upfrontPoints, or else it corresponds to a triggered action. The next timepoints at which such a triggered action occurs are not known up-front but are computed in each iteration of this loop by the function searchNext.
The searchNext algorithm (Algorithm 2) considers both actions that are triggered by a fluent maintaining its value for a certain time, represented by the after-predicate (line 3), and those triggered by a count fluent reaching a certain value, represented by the when-predicate (line 8). The result of the algorithm is the smallest timepoint next > current at which such an action happens (or ∞ if no such timepoint exists). Once the main while-loop of Algorithm 1 ends, the program P dynamic has been grounded for all changepoints. The predicate boundary now identifies all the timepoints that delineate an interval. The for-loop in line 16 then introduces an identifier i for each such interval [b i , b i + 1). Finally, these intervals are then passed to the program #intervals, which gathers all of the rules concerning intervals, unchanged from our single-shot implementation.
Algorithm 2 searchNext algorithm

In our solution, we organized our logic program into three distinct modules: static, dynamic, and interval. Importantly, we ensured the independence of these modules by strictly confining the definition of predicates within each module. Even for the dynamic module undergoing iterative grounding and solving with the current and previous changepoint, this principle holds. The introduction of the ’current < possible’ constraint in the searchNext algorithm guarantees a logical sequence, where each changepoint is always greater than the previous one. Since there are no head predicates inferred for both the previous and current changepoint within the same iteration, this design ensures that no ground literals are inferred across different iterations. Our approach aligns with the principles outlined in the module theorem, as described in Section 2.
7 Experimental results and discussion
As discussed before, the grounding size of the single-shot implementation is quadratic in the number of timepoints. Consequently, the number of timepoints has a large effect on the computational performance of this approach. Figure 10 shows how the duration of a single timepoint affects the computation time for a two-day scenario, the minimum for a realistic scenario. The company we collaborated with would like a single scenario to be handled in under a second of computation time. At the same time, a granularity in which a single time point is more than five minutes in length is unacceptable for them. Figure 10 therefore clearly shows that the single-shot implementation is not feasible.
The multi-shot approach drastically reduces the impact of the total number of timepoints on the computation time. Indeed, the main parameter is now the number of changepoints, which means that the run-time is mainly determined by the scenario that needs to be handled, rather than by the granularity of the timepoints. Figure 10 shows that if we change the granularity and the number of timepoints increases, the computation time of our multi-shot approach barely increases. Figure 11 shows how the computation time of our multi-shot implementation depends on the number of changepoints. In a practical two-day scenario, the number of changepoints typically falls within the range of fifteen to twenty-five, as highlighted in the grey area on the graph. In this range, the performance is deemed acceptable. Note also that even for sixty changepoints, the run-time remains well under that of the single-shot implementation for all but the coarsest granularities of times. We also implemented scenarios stretching over a week using our multi-shot implementation. Although there is a small increase in run-time compared to a two-day scenario with the same number of changepoints (probably due to the grounding size of the static part of the code), we can still conclude that the run-time indeed depends on the number of changepoints instead of the total number of timepoints. On both graphs, namely Figures 10 and 11, the average computation time per scenario is displayed based on 5 consecutive runs conducted on an Intel i5–8265U CPU. A repository containing all used scenarios is available online.Footnote 2
To use the system in practice, the continuous timeline needs to be split up into a number of independent scenarios. Typically this can be done by a single rule, for example in our example the end of a scenario coincides with the end of the shift of an employee, happening when they are absent for more than 4 h.
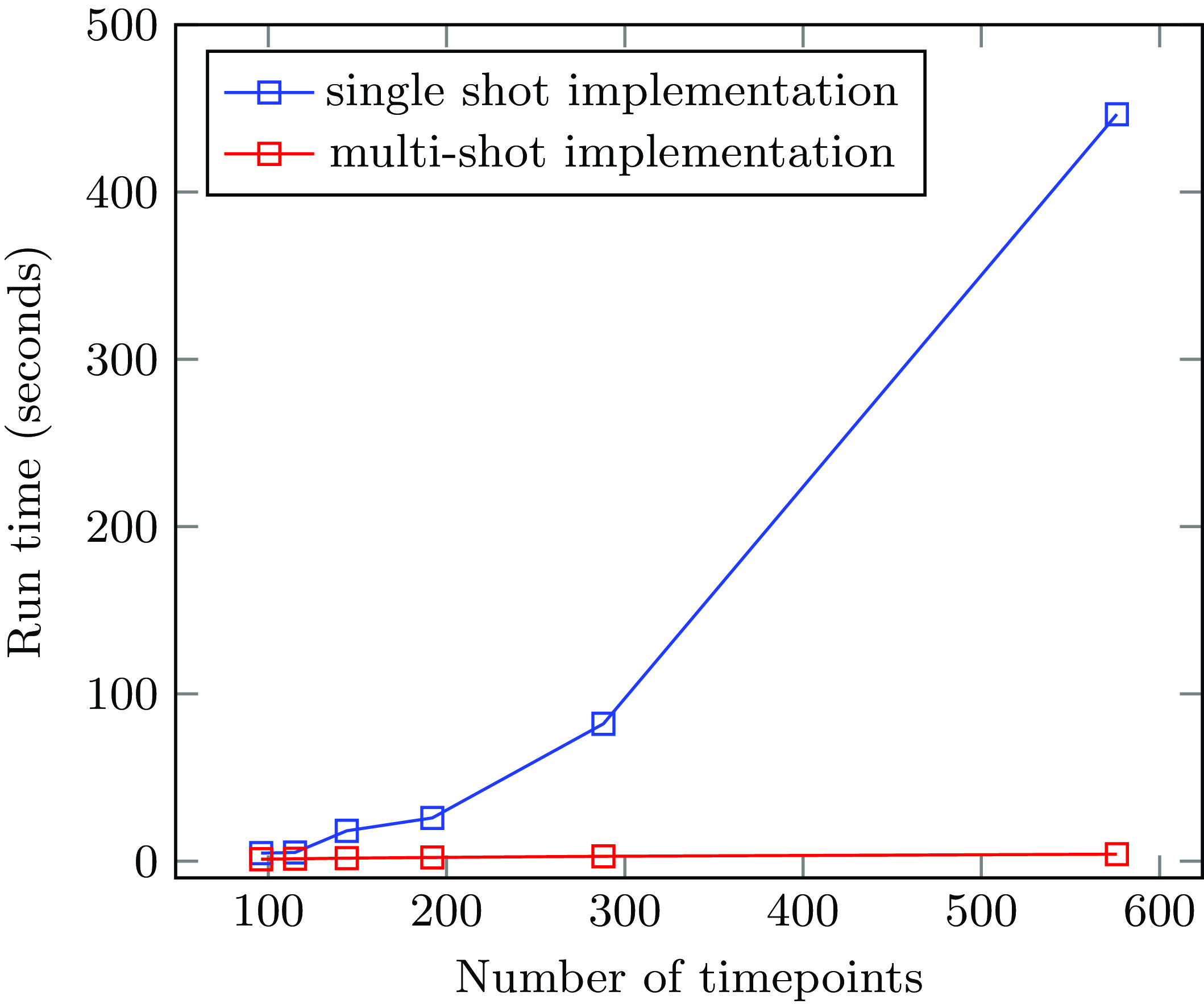
Fig. 10. Computation time of single-shot and multi-shot implementation.
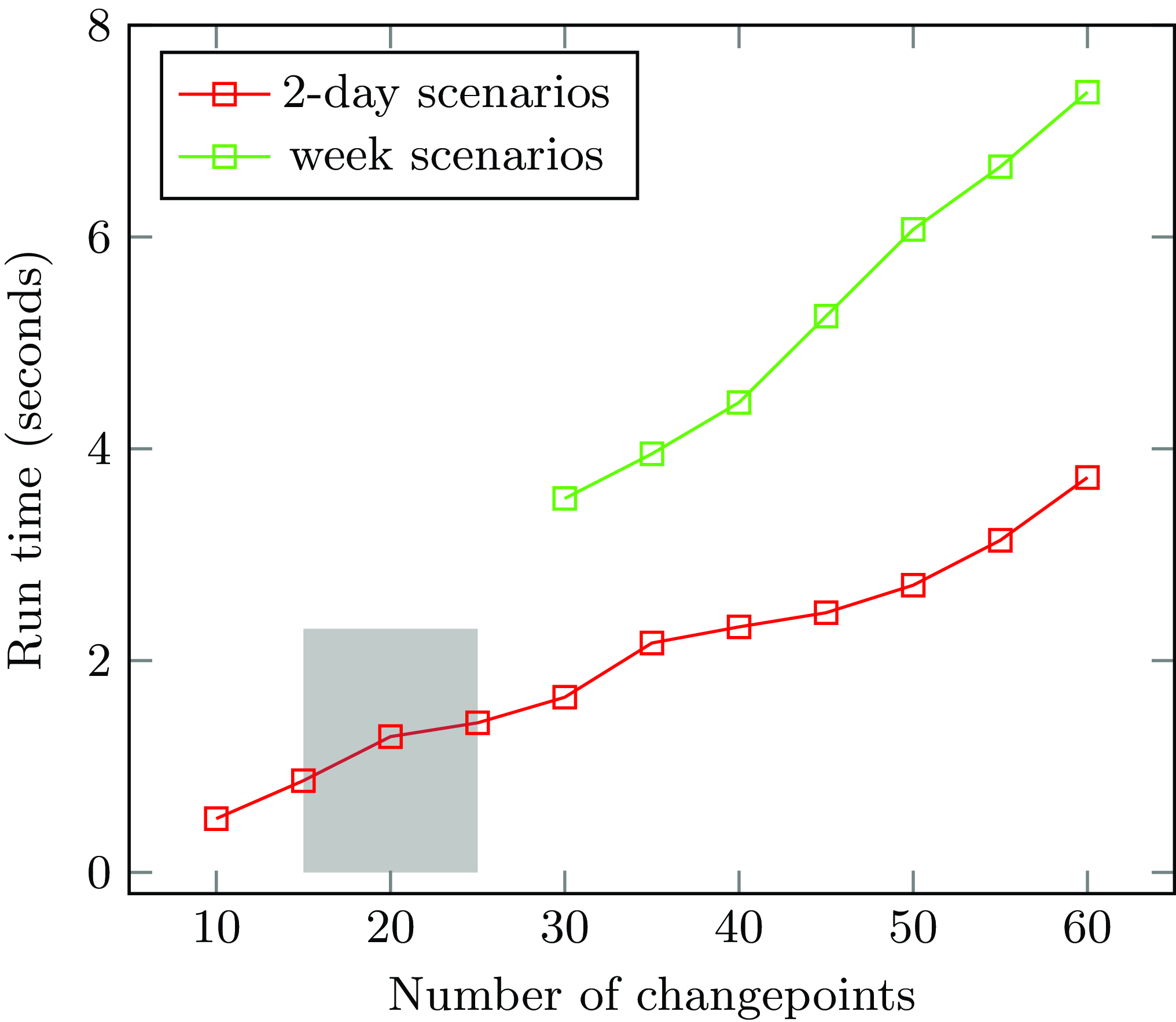
Fig. 11. Run time of multi-shot approach for various numbers of changepoints.
8 Related work
Different versions of the EC were formulated in ASP throughout the years. These implementations are both fast and expressive in comparison to previous SAT- or Prolog-based encodings, such as the DEC Reasoner introduced by Mueller (Reference Mueller2004b) and Kim et al. (Reference Kim, Lee and Palla2009). Given a finite domain, EC2ASP (and its evolution, F2LP) can compile both the EC and DEC formulas into ASP programs (Kim et al., Reference Kim, Lee and Palla2009; Lee and Palla, Reference Lee and Palla2009). Our implementation of the DFEC axioms is closely related to their implementation of the DEC axioms.
The Functional EC and its implementation to ASP were developped by Ma et al. (Reference Ma, Miller, Morgenstern, Patkos, Mcmillan, Middeldorp, Sutcliffe and Voronkov2014b). Their Epistemic Functional EC is able to deal with triggered, concurrent, non-deterministic, and conflicting action occurrences in a uniform manner under both discrete and continuous models of time. In this way, it can be used as a basis for a ‘possible-worlds” style approach to epistemic and causal reasoning in a narrative setting. Recently, s(CASP) was also used to implement the EC formalism and reason about events without grounding the whole ASP program (Arias et al., Reference Arias, Chen, Carro and Gupta2022). s(CASP) is a top-down, goal-driven ASP system that can evaluate ASP programs with function symbols without grounding them (Arias et al., Reference Arias, Carro, Salazar, Marple and Gupta2018). Due to the top-down nature of s(CASP), it is possible to elegantly model dense domains, such as time, as continuous quantities. In previous work (Mellarkod et al., Reference Mellarkod, Gelfond and Zhang2008; Lee and Palla, Reference Lee and Palla2012) such domains had to be discretized, thereby losing precision or even soundness. s(CASP) is thus able to faithfully model a continuous EC. The translation of EC axioms into a s(CASP) program is similar to that of the systems EC2ASP (Lee and Palla, Reference Lee and Palla2012) but differs in some key aspects that improve performance and are relevant for expressiveness. However, since the task we try to solve in this paper explicitly requires us to consider the state of the employee at each timepoint, we would not benefit from the top-down approach of s(CASP). For similar reasons, a solution based on an EC implementation in Prolog, as done by Arias and Carro (Reference Arias and Carro2019), would not result in beneficiary results.
As recommended by Kim et al. (Reference Kim, Lee and Palla2009), we use the clingo solver for our EC implementation. In addition to being an efficient single-shot solver, clingo also allows us to make use of a multi-shot solving strategy. Next to clingo, DLV also developed an ASP solver with multi-shot reasoning capabilities: the Incremental-DLV2 system by Calimeri et al. (Reference Calimeri, Ianni, Pacenza, Perri and Zangari2022). The system is built upon a proper integration of the overgrounding-based I 2-DLV incremental grounder (Ianni et al., Reference Ianni, Pacenza and Zangari2020) into DLV2, which employs the propositional WASP solver (Alviano et al., Reference Alviano, Amendola, Dodaro, Leone, Maratea and Ricca2019). In comparison to clingo, the approach of the Incremental-DLV2 is oriented towards declarative and transparent usage. Incremental-DLV2 implements overgrounding with tailoring (Ianni et al., Reference Ianni, Pacenza and Zangari2020), an incremental grounding technique which, without requiring any operational statements from the user, incrementally drives the computation. In an XML file, the users can specify which parts of the logic program should be consecutively taken into account. Clingo, on the other hand, allows to procedurally control not only which parts of the logic program have to be taken into account during consecutive shots, but also how. In this way, clingo offers greater flexibility but also requires specific knowledge about how the system internally performs its computation and how the domain at hand is structured. Because these flexible control capabilities are needed to implement our multi-shot algorithm, we could only use clingo.
To our knowledge, there are no EC implementations in ASP that use the multi-shot solving capabilities in a similar way to efficiently reason about events and their effects.
9 Conclusion
In this paper, we have presented an approach to payroll management. We identified three key challenges for a payroll management system. HR consultants should be able to configure as much of the system as possible and the language in which they write down the rules must not only be easy to use for them, but it should also be possible to easily extend it with new language features. Finally, despite the required flexibility, the solution should still be computationally efficient. To tackle these challenges, we have split up the model into a generic EC-based ASP program, and a decision-table-based model of the specific rules that apply in one particular set of circumstances. For the generic ASP program, we introduced a variant of the discrete EC that allows for non-boolean fluents: the DFEC. This approach is not restricted to payroll management: its applicability can be extended to various domains, including planning and the monitoring of administrative processes, among other potential applications.
When used with a standard single-shot ASP solver, our implementation does not meet the computational requirements, due to the large number of timepoints that must be considered. We also present a multi-shot approach that eliminates this dependency on the absolute number of timepoints, by only considering those timepoints at which the state of the world changes. This multi-shot approach does reach the required performance.
In our future work, we aim to implement payroll rules from a more diverse set of companies, spanning a wider range of countries and sectors to ensure comprehensive coverage. Additionally, we propose a formal validation of the complexity involved in defining payroll rules using our DMN tables, specifically targeting HR experts. Lastly, we intend to implement payroll rules that align with a company’s legal obligations, including collective labor agreements. This approach would allow us to assess a company’s compliance with legal standards.
Competing interests
The author(s) declare none.
Appendix A ASP implementation of DFEC

Appendix B Proof of stratification DFEC implementation
To prove that DFEC implementation in ASP within a finite domain is stratified, a level mapping of the DFEC implementation is displayed in Table 1. Note that for all predicates, 0 < I holds. For stoppedIn(J,F,V,I) and startedIn(J,F,V,I), 0 < J < I holds.
Table B1. Level mapping of DFEC implementation

Appendix C General ASP multi-shot implementation
















 Open access
Open access