



1. IntroductionFootnote 1
Chahar Mahal va Bakhtiari Province (hereafter C&B) is nestled in the heights of the Zagros Range in western Iran, with the mountains opening down onto the Iranian Plateau in the north-east. The topography is reflected in the linguistic situation: the Southwestern Iranic language Bakhtiari dominates the mountainous areas that cover most of the province, and two other linguistic groups are intermingled in the lower areas of the north-east: Charmahali, which is also Southwestern Iranic; and Turkic.
C&B is one of Iran’s smaller provinces in terms of area as well as population (ISC, 2011/2016) but, as we will show in this paper, it exhibits significant linguistic diversity. However, the character of the province as a linguistic area remains for the most part unstudied. Until 1973, C&B was part of Esfahan Province and—perhaps because of this—the languages of this area were overlooked in the great surveys of the early 20th century (e.g., Mann, Reference Mann1910; Zhukovsky, Reference Zhukovskij and Ol’denburg1923; Christensen, Reference Christensen1930, 1935). Even now, Bakhtiari is the only one of the three main varieties that has been documented, and its dialectological characteristics have not been probed in many parts of the province. Existing language maps of the area (TAVO, Reference Orywal1988; Irancarto, Reference Hourcade, Hubert Mazurek and Taleghani2012; Izady, Reference Izady2013, among others) have been general and incomplete, and contradict one another.
In this paper, we address this gap in the literature through a first fine-grained and geographically representative study of the language situation in C&B Province. Our research has been conducted as part of the Atlas of the Languages of Iran (ALI) research programme (section 2), and it is in this province that our work is most advanced. The paper is divided into two main sections: a detailed description of initial work in bibliographic research and the investigation of language distribution (section 3), both of which were essential in preparing for collection and analysis of linguistic data from 30 language varieties in 26 locations across the province; and exploration of the language situation through analysis of lexicon and phonological correspondences associated with cognate sets (section 4). Preliminary lexicostatistic analyses of the data set the stage for a global understanding of the language situation, and are followed and refined by detailed analysis of individual lexical items.
Our analysis concentrates on the relationship between the two Southwestern Iranic varieties of the province, Bakhtiari and Charmahali, alongside the national language Persian (also Southwestern Iranic). The lexical data show many shared structures among the three Southwestern groups, but several isoglosses distinguish the two regional groups from Persian. Bundling of isoglosses dividing Bakhtiari and Charmahali is even stronger, although several varieties are transitional; and where the larger groups two differ, Charmahali almost always patterns with Persian. In terms of internal linguistic diversity, a putative dichotomy between Rural vs. Urban Charmahali that we observed during the language distribution phase is not borne out by the results of our analysis. In contrast, Bakhtiari shows several clear dialect areas across the province. In the final section of our analysis, we consider Turkic, concentrating on contact-related patterns of structural similarity between Turkic and the Iranic varieties. While most borrowing is from Iranic (both Persian and the local Southwestern varieties) to Turkic, some structures suggest that Turkic has also made significant contributions to Iranic lexicon and phonology in the region. Results of our study include two language distribution maps and five sample linguistic data maps.
The closing section of this paper re-examines C&B Province as a linguistic area. We bring together salient aspects of the language situation, reflect on limitations in the present study, and identify promising directions for ongoing research.
2. The Atlas of the Languages of Iran (ALI) research programme
The current study was conducted in the context of the Atlas of the Languages of Iran (ALI) research programme. Initiated in 2009, ALI is now an online, open-access resource (http://iranatlas.net) that is being developed by an international group of institutional partners and scholars.Footnote 2 In this section, we provide a summary of the overview written up in Anonby, Taheri-Ardali, and Hayes (Reference Anonby, Taheri-Ardali and Hayes2019).
The overall goal of the ALI research programme is to enable work toward a systematic understanding of the language situation in Iran. This initiative, which has the online Atlas at its core, is guided by a set of interrelated themes and questions:
-
Linguistic and areal typology: What are important linguistic features of Iran’s languages and dialects, and how are they distributed geographically?
-
Language distribution: Where are these language varieties spoken, and how does this compare to the distribution of linguistic features?
-
Language classification: How do scholars and speakers classify these language varieties, and how can scholarly classifications be improved?
-
Language documentation: A record of the linguistic situation in Iran and a repository of linguistic data in the face of declining linguistic diversity with the extension of Standard, Tehran-type varieties of Persian as a mother tongue across the country.
To begin work toward these goals, the Atlas team has reviewed existing efforts to document, classify and map languages of Iran (Taheri-Ardali et al., Reference Taheri-Ardali and Erik Anonby2021). An ever-expanding bibliography of linguistic resourcesFootnote 3 is accompanied by a working classification of all language varieties (language families, languages, and dialects).Footnote 4 Further, a “multi-dimensional language relation web” has been developed in the Atlas as a way of accounting for competing scholarly classifications and complementary perspectives on language identity, both of which impact the ways in which Atlas users expect language maps to be drawn (Anonby, Hayes & Oikle, Reference Anonby, Hayes, Oikle, Larson, Moradi and Samiian2020; Anonby & Sabethemmatabadi, Reference Anonby, Sabethemmatabadi, Fraser Taylor, Anonby and Murasugi2019).
The Atlas is being built using the Nunaliit Atlas Framework (GCRC, 2006–2021), an open-source document-oriented data platform (Hayes et al., Reference Hayes, Pulsifer, Fiset, Fraser Taylor and Lauriault2014; Hayes & Taylor, Reference Hayes, Fraser Taylor, Fraser Taylor, Anonby and Murasugi2019) that embodies the interactive, multi-modal, and collaborative ethos of the cybercartographic approach to mapping (Taylor, Reference Taylor1997, Reference Taylor and Peterson2003, Reference Taylor and Fraser Taylor2005; Taylor & Lauriault, Reference Fraser and Lauriault2014; Taylor et al., Reference Taylor, Fraser and Murasugi2019). Inside a Nunaliit atlas, each piece of data is stored as a document with a flexible set of attributes, and each of these documents can be related to any other document in the atlas. This type of data structure necessitates more initial set-up work in building an atlas, but once an atlas is operational, relations between data are easy to build, navigate, and process. Another key feature of a Nunaliit-designed atlas is its dynamic online platform, which enables direct remote contributions by researchers, and by atlas users generally, from anywhere that has an internet connection, as well as collection and subsequent upload of data from locations without such a connection. To help ensure consistency and reliability, a system for moderation and double-checking of data is an integral part of the data contribution process. In ALI, once data are approved by the editorial team, they are immediately available to Atlas users and are accompanied by clear referencing of the data’s source. The Atlas platform therefore serves simultaneously as data repository, collaborative research environment, and publication venue.
Because of the sizable geographic scope of the work, we are proceeding on a province-by-province basis, and further dividing the research into topical areas of activity according to the availability and expertise of Atlas team members. Currently, we have embarked on research for 19 of Iran’s 31 provinces, with modest initial results presented and published for six provinces:
-
Hormozgan (Mohebbi Bahmani, Rashidi, et al., Reference Mohebbi Bahmani and Ali Rashidi2015; Taheri-Ardali, Reference Taheri-Ardali2017b; Leitner et al., Reference Leitner, Anonby, El Zarka and Taheri-Ardali2021);
-
Kordestan (Mohammadirad et al., Reference Mohammadirad, Erik Anonby, Taheri-Ardali, Amos Hayes, Oikle, Stone, Rezaei, Wang, Nikravan, Sabethemmatabadi, Ghaharbeighi, Mohammadi, Tadjalli, Kiani, Salisbury, Anonby and Taheri-Ardali2016; Anonby, Mohammadirad & Sheyholislami, Reference Anonby, Mohammadirad, Sheyholislami, Songül Gündoğdu, Haig and Anonby2019);
-
Chahar Mahal va Bakhtiari (Taheri-Ardali et al., Reference Taheri-Ardali, Erik Anonby, Amos Hayes, Robert Oikle and Mahnaz Talebi-Dastenaee2015; Taheri-Ardali, Reference Taheri-Ardali2017a; Taheri-Ardali & Anonby, Reference Taheri-Ardali and Anonby2019);
-
Ilam (Gheitasi et al., Reference Gheitasi2017; Aliakbari et al., Reference Aliakbari, Gheitasi and Anonby2014; Anonby, Gheitasi & Aliakbari, Reference Anonby, Gheitasi and Aliakbari2017);
-
Bushehr (Nemati, Ghasemi et al., Reference Nemati and Shakiba Ghasemi2017); and
-
Kermanshah (Fattahi et al., Reference Fattahi2018).
For each province, the Atlas team’s first step is assembling a bibliography of documentary studies and scholarly classifications, along with areal overviews and language maps whenever available. This is followed by initial inquiry into language distribution, accompanied by recording of local pronunciations of place names. Results of this preliminary fieldwork are published in the Atlas as province-level language distribution maps, which in turn inform the selection of sites for gathering linguistic data.
Linguistic data is collected by means of a typologically oriented questionnaire designed specifically for the languages of Iran (Anonby, Taheri-Ardali, Haig, et al., Reference Anonby and Mortaza Taheri-Ardali2020; for a detailed description of sources, historical development, content, and justification, see Anonby, Taheri-Ardali & Hayes, Reference Anonby, Taheri-Ardali and Hayes2019:217–20). The ALI questionnaire is divided into four sections: sociolinguistic context, lexicon, morphosyntax, and numbers. A separate section on phonology has now been integrated into the other sections. Instructions for data collection, along with justification for and explanation of the types of linguistic data that the questionnaire aims to gather, are provided as accompanying materials in the ALI Dataverse (https://dataverse.scholarsportal.info/dataverse/ali). Published language data are also available there via a permanent link (https://doi.org/10.5683/SP2/FVLDLZ).
The Atlas research process is cyclical, with linguistic data informing earlier findings and refining hypotheses for language classification and language distribution. Of all the provinces of Iran, work on C&B is most advanced, with linguistic data collected from 30 varieties in 26 locations across the province (see 3.1 below). The remainder of this article describes the research conducted there including results generated by preparatory activities (section 3) and an analysis of the lexical questionnaire data, with a focus on the Iranic varieties of the province (section 4). The morphosyntactic questionnaire data as well as data on the province’s Turkic varieties are robust and have necessitated separate studies; these are currently being undertaken elsewhere (Anonby, Schreiber & Taheri-Ardali, Reference Anonby, Schreiber and Taheri-Ardali2020; Anonby, Taheri-Ardali, Schreiber et al., Reference Anonby, Mortaza Taheri-Ardali, Christiane Bulut, Peiman Pishyar Dehkordi, Fatemeh Shahverdi, Masoud Mohammadirad, Zohreh Rahnema, Elham Izady, Öpengin and Nemati2020; Schreiber et al., Reference Schreiber, Haig, Taheri-Ardali and Anonby2021; Anonby et al., in preparation).
3. Research process for Chahar Mahal va Bakhtiari (C&B) Province
In this section, we describe the process for research we have carried out in C&B Province. We first introduce the research context: the research team and relevant bibliographic materials available to orient the research (3.1). We then provide an overview of the language distribution phase of research (3.2). We present and compare language distribution maps of two types for C&B: an interactive point-based map and a static polygon map. Reflecting on our initial findings, we bring together important research questions related to C&B as a linguistic area (3.3). The activities of language distribution research phase, and in particular the language distribution maps, have facilitated selection of sites for collection of linguistic data using the ALI questionnaire (3.4, 3.5).
3.1 Research context
The research we present here is the result of ongoing work by a large and diverse team. Researchers who contributed to ALI activities for C&B, listed according to their affiliation and specific roles, are as follows:
-
Mortaza Taheri-Ardali (Shahrekord) Atlas co-editor, C&B section leader, language distribution, map construction, linguistic data collection and analysis
-
Erik Anonby (Carleton/Leiden) Atlas editor, map construction, linguistic data analysis
-
Adam Stone (Carleton) Map construction, linguistic data analysis
-
D.R. Fraser Taylor (Carleton/GCRC) Project co-investigator
-
Amos Hayes (GCRC) Atlas design, geographic information technology
-
J.-P. Fiset (GCRC) Atlas programming
-
Robert Oikle (Carleton/GCRC) Atlas design, map construction
-
Laura Salisbury (Carleton/GCRC) Map construction
-
Mahnaz Talebi-Dastenaee (Alzahra) Linguistic data collection, map construction
-
Peyman Pishyar (Allameh Tabataba’i) Linguistic data collection
-
Maryam Amani-Babadi (Payame Noor) Bibliography, map construction
-
Fatemeh Shahverdi (Tarbiat Modarres) Linguistic data collection
-
Elham Hasanpour (Islamic Azad, Esfahan–Khorasgan) Linguistic data collection
-
Reza Rezvani-Borujeni (Islamic Azad, Khomein) Linguistic data collection
In preparation for field research, we first searched out and reviewed existing literature on the languages of the province, including work on their typological features, classification, and geographic distribution. As mentioned in the introduction, C&B Province was passed over in the great linguistic surveys of the early 20th century. To our knowledge, no language maps that focus on the province have been produced prior to the present study. General country-wide language maps such as those of TAVO (Orywal, Reference Orywal1988), Izady (2006–Reference Izady2013), Windfuhr (Reference Windfuhr and Windfuhr2009) and Irancarto (Hourcade et al., Reference Hourcade, Hubert Mazurek and Taleghani2012) indicate three language varieties: Bakhtiari (sometimes subsumed into a larger Lori language grouping), varieties labelled as “Persian,” and Turkic. However, the geographic extent shown for each varies greatly. Linguistic work on the province’s languages is similarly incomplete: we are not aware of any studies on Persian or Turkic of C&B. Bakhtiari, on the other hand, is more extensively documented. Bibliographies of research on Bakhtiari, covering C&B Province, are found in Anonby & Asadi (Reference Anonby and Ashraf2014, Reference Anonby, Taheri-Ardali, Khan and Haig2018) and Anonby & Taheri-Ardali (Reference Anonby, Taheri-Ardali, Khan and Haig2018).
Demographic data for C&B have been drawn from the Iranian national census (ISC, 2011, 2016), and settlement-related geographic data are also publicly available on the internet (NCC, 2015; Roostanet, 2016). These data sets provide listings and locations of all populated places, which are needed for language distribution research (3.2) and the subsequent construction of language distribution and linguistic data maps.
3.2 Language distribution: research process
Language distribution research is carried out in ALI for each province by linguists familiar with the language situation. This paper’s second author Mortaza Taheri-Ardali organized and led this phase of research for C&B. Taheri-Ardali, born and raised in Ardal in central C&B Province, has worked on Bakhtiari for over a decade and is himself a native speaker of the language. Despite his deep familiarity with the geolinguistic context, the systematic—albeit preliminary—nature of the language distribution research led to a number of new insights, some of which were unexpected. We will discuss these in later sections.
For each of the 840 populated places (cities, towns, and villages) in the census data for C&B, we asked the following basic research questions in relation to language distribution:
-
1) What languages, and what subvarieties of these languages, are spoken as a mother tongue in this settlement?
-
2) In the case that more than one variety is spoken in the settlement, what is the estimated proportion of mother tongue speakers of each variety?
At the same time, on the topic of local place names, we asked: What is/are the local name(s) of this place, as pronounced locally?
Field research on language distribution and local place names was carried out over a 3-month period in early 2015 by Taheri-Ardali, with additional time spent analyzing and verifying the data.Footnote 5 The process and results of research are detailed in Taheri-Ardali (Reference Taheri-Ardali2020) and summarized here. Because of logistical difficulties in visiting over 800 settlements, research was undertaken through a network of participants from across the province. The assembled data were based on a convenience sampling of various sources: local knowledge of the field researcher; the field researcher’s existing contacts with people from other regions; and additional contacts provided by administrative offices. For advantages and limitations of this sampling approach, as well as its necessity, see the discussion in Anonby, Mohammadirad, and Sheyholislami (Reference Anonby, Mohammadirad, Sheyholislami, Songül Gündoğdu, Haig and Anonby2019:16–18, 21–22).
Results from this phase of the research constitute a very general, preliminary approach to the language situation, but they make several key contributions to the overall research process. A first contribution is the place of local knowledge as a starting point complementary to the assessments of experts consulted in the bibliographic research phase. The collection of local pronunciations of place names provides a point of connection for speakers from various regions as potential users of the Atlas. Through transcription and checking of local place names, the field researcher encounters a diversity of language varieties and linguistic structures from across the province. Responses to the language distribution questions allow for a first, fine-grained overview of the language situation in the form of a language distribution map. Here is a screenshot of the resulting interactive point-based map that we have constructed in the Atlas (Map 1):

Map 1. Interactive map of language distribution in C&B Province. From: http://iranatlas.net/module/language-distribution.chahar_mahal_va_bakhtiari
Due to design-related constraints, only the main mother tongue reported from each community is indicated through colour; and in the case that no single variety is reported as a mother tongue for more than half of the population, the community is simply indicated as “mixed.” However, as the following screenshot shows (Map 2), Atlas users can find a full listing of reported varieties by hovering over each point, and more detailed estimates for proportions of each language variety are provided in the side panel.

Map 2. Lists and proportions of language varieties in each place (example). From: http://iranatlas.net/module/language-distribution.chahar_mahal_va_bakhtiari
Although the level of detail provided by the map might appear to imply a complete picture of the language situation, we recognize that its assessments are both preliminary and general. This underscores the importance of the Atlas’ moderated user contribution feature (section 2 above), where scholars or members of language communities with more detailed or accurate knowledge of the linguistic composition of a given place can confirm or refine the assessment presented in the language distribution map.
An alternative language distribution map, which is static (non-interactive) and uses polygons rather than points to show language distribution, is introduced in 3.4 below as part of the discussion of research site selection.
3.3 Reflecting on language distribution
As mentioned in the research context (3.1) above, existing general language maps of C&B Province show three language varieties: Bakhtiari, Persian, and Turkic. We are not aware of existing published counts or proportions of language communities in the province, but the ethnic composition of the province—often taken as a proxy for linguistic affiliation—is shown in an anonymous infographic in the Persian version of Wikipedia as 56.3% Bakhtiari, 30.5% Persian, 12.1% Qashqai (a Turkic group), 0.6% “other” and 0.5% unknown (https://fa.wikipedia.org/wiki/استان_چهارمحال_و_بختیاری, accessed 10 July, 2019).
Taheri-Ardali’s initial assessment of language varieties in C&B, based on our own language distribution research, presents a significantly different assessment of the language situation. As evident from the map (3.2), we identified four main language groupings in the province: Bakhtiari; Rural Charmahali and Urban Charmahali; and Turkic. Standard-type Persian (defined later in this section) is also spoken and is gaining strength as a mother tongue among all the groups. Formerly, an Armenian language community was also found. Combining estimated language distribution proportions for each settlement with population data from the 2011 census (the latest census data available at the time of initiating research), we calculated the following percentages for number of speakers of each language grouping (Table 1).
Table 1. Estimated percentages of mother tongue language speakers in C&B based on ALI language distribution data

Here, we introduce each of the language communities and conclude this section with a set of open questions related to the language situation in the province.
3.3.1 Bakhtiari
Bakhtiari (autoglottonym: baxtiyāri), a Southwestern Iranic language with over a million speakers (Anonby & Taheri-Ardali, 2019:445), is the largest and most clearly defined language community in C&B Province. The greater Bakhtiari language area is divided among four provinces of Iran (C&B, Khuzestan, Lorestan, and Esfahan Provinces), but only in C&B does it constitute a linguistic majority. Members of the traditionally nomadic ethnic group who speak this language are found throughout the mountainous western part of the province, and spread down onto the Iranian plateau in the eastern areas. While the lowest areas of the province—in the south-east—are also predominantly Bakhtiari-speaking, the language gives way to Charmahali and Turkic in the north-east corner (see Map 1). There has been a significant migration of Bakhtiari speakers to the capital city of Shahr-e Kord and, with about a third of the population of the city speaking Bakhtiari as a first language, it is now likely the largest mother tongue there.
3.3.2 Rural Charmahali and Urban Charmahali
The label “Charmahali” comes from the Persian geographic term čahār mahāl (P., lit. ‘four regions’), referring to four historical districts in the north-east corner of the province (Lār, Kiār, Mizdej, and Gandomān).Footnote 6 Linguistically, this is a heterogenous area, including Turkic-speaking and Bakhtiari-speaking communities as well as other Southwestern Iranic varieties, but the label “Charmahali” can be applied to the Southwestern varieties of C&B Province that are not clearly Bakhtiari or standard-type Persian. Prior to conducting this language distribution research, Taheri-Ardali, who is a native speaker of Bakhtiari, held the (perhaps representative “Bakhtiari”) view that Charmahali varieties are essentially a kind of Bakhtiari. On the other hand, speakers of standard-type Persian across Iran, outside of the province, tend to view them as Persian dialects (as noted by Anonby & Sabethemmatabadi, Reference Anonby, Sabethemmatabadi, Fraser Taylor, Anonby and Murasugi2019). However, neither perspective is shared by speakers, whose linguistic identity is further subdivided according to a rural vs. urban distinction: Taheri-Ardali notes that in rural areas, speakers refer to their language as Charmahali (autoglottonym: čārmāhāli), but in four of the largest cities of the province, speakers refer to their language principally in relation to the name of their city: dehkordi (in Shahr-e Kord), ġafarrokhi (in Farrokh Shahr), heyšeguni (in Hafshejān), and urǰeni or boruǰeni (in Borujen). Urban speakers feel that their dialects are similar to the urban Southwestern Iranic varieties of Esfahan Province to the east. While older speakers of Rural and Urban Charmahali varieties see both similarities and differences between their language and Persian, younger speakers—whose language in fact appears to be hybridizing with standard-type Persian—consider themselves speakers of Persian (Taheri-Ardali & Anonby, Reference Taheri-Ardali and Anonby2019).
3.3.3 Turkic
The very broad label of “Turkic” is a direct translation of the term torki, which local speakers use as the primary point of reference to their own language.Footnote 7 But what kind of Turkic? According to Taheri-Ardali (field notes 2015–17), speakers typically respond to this question by referring to the name of their village (for example, “Turkic of Kiān”), and there is little discussion of belonging to any larger dialect grouping within Turkic; for example, they do not view their own variety as a kind of Azerbaijani (āzeri), the largest Turkic variety in the country. In the more southerly Turkic-speaking communities of C&B (Sulegān, Boldāji, Naqneh, Juneqān), speakers have an awareness of their historical belonging to the Qashqai tribal confederation of Fars Province, even though there is no longer much contact with this group; in response to the question, “What kind of Turkic?”, people from these places answer that they speak Qashqai (autoglottonym: ġašġāi) Turkic. However, they do not feel that the Turkic variety they speak is significantly different from varieties spoken in other parts of the province. Further north in C&B, speakers do not identify with Qashqai or with any other subgroup within Turkic, and simply state that they speak Turkic of their own town or village. Some Turkic speakers in various parts of C&B note that the Turkic variety spoken in Ben (one of the linguistic data collection sites; see 3.4 below) is different from the other varieties spoken in the province, but there is no label that unifies or sets apart the “non-Ben” varieties. In the absence of other labels, and pending further analysis of dialect differences among Turkic varieties of the province (Schreiber et al., Reference Schreiber, Haig, Taheri-Ardali and Anonby2021; Anonby et al., in preparation), we refer to all these varieties as “Turkic of Chahar Mahal va Bakhtiari.”
3.3.4 Persian
Standard-type spoken Persian, which brings together elements of ketābi (Standard, written) Persian and the Persian dialect of Tehran, and admits varying degrees of substrate influence from regional languages, has entered C&B province as a mother tongue through two channels. First, there is now a sizeable population of immigrants from other provinces of Iran, many of them Persian-speaking, especially in the larger cities of C&B. Even more significantly, Persian is emerging as a mother tongue among existing communities in most areas of the province, as Bakhtiari, Charmahali, and Turkic parents teach Persian to their children as a first language at home. This trend, which began to take shape here about 15 years ago, is most advanced in urban areas. In Taheri-Ardali’s (Reference Taheri-Ardali2015) study of multilingualism in the traditionally Bakhtiari city of Ardal, a regional capital of just over 10,000 inhabitants, he estimates that a quarter of the city’s population now speaks Persian as a mother tongue. The current generation of children from Bakhtiari families continues to understand the Bakhtiari language and often gains competency in the language through interactions with older relatives and peers outside the home, but Persian is their first language and remains dominant.
3.3.5 Armenian
Until recently, Armenian was spoken in the central-east part of the province, in at least nine towns to the south of Shahr-e Kord: Sirak, Geshniz Jān, Shahrak-e Galugerd, Shalamzār, Qal’eh Mamakā, Boldāji, Ma’mureh, Gandomān, and Vastegān. Most Armenian speakers emigrated to Esfahan during past decades, but they return from time to time to visit the Armenian graveyards in these villages. According to current Charmahali-speaking residents of Sirak, the last Armenian speaker in the village—and possibly in the province—died in 2015 (Mortaza Taheri-Ardali, field notes 2018).
3.3.6 Open questions on the language situation
Several interrelated questions are raised by the assessments that speakers—both inside and outside language communities—as well as “experts” offer in relation to language identification and distribution in C&B, and they need to be addressed before a coherent, stable picture of the language situation can even be put forward. Some of these questions relate more closely to issues of linguistic identity, and others are concerned with genealogical (historical linguistic) relationship or typological similarity.
-
What is the relationship of Bakhtiari, Charmahali, and Persian within Southwestern Iranic?
-
Should linguists consider Charmahali as a kind of Persian, a kind of Bakhtiari, or even as a distinct language? On what basis?
-
In areas where Charmahali and Bakhtiari are spoken alongside each other, is there a clear linguistic distinction between them?
-
Are there consistent, defining linguistic differences between Rural Charmahali and Urban Charmahali, or does this putative distinction stem from social perceptions?
-
Are there other salient linguistic sub-groupings of Bakhtiari, Charmahali, and Turkic in C&B Province?
-
Does the Persian spoken in C&B Province have an areal character, whether as a result of contact with other languages in the province, or as a substrate that shows up among speakers that have shifted from these other languages?
We will not attempt to answer these questions directly right here, but we will keep them in suspension as we examine linguistic data from across the province, and return to them in the conclusion as a way of informing the initial picture of the language situation that emerges.
3.4 Selection of sites for linguistic data collection
A judicious choice of sites for linguistic data collection using the ALI questionnaire is critical. Each questionnaire interview takes about three hours to carry out, plus travel time; and a single filled-out questionnaire takes several days to transcribe and analyze, along with further time for write-up and construction of linguistic data maps. Although the initial activities leading up to linguistic data collection (3.1-3.3) are also time-intensive, our resulting understanding of the language situation is what facilitates the selection of sites most important to the research goals of the Atlas. Generally, in each šahrestān (provincial sub-district) we aim to collect a minimum of one questionnaire in an urban centre, and one in a rural village with limited access to transportation to other areas. This helps provide a representative sample of varieties which are influenced by Standard Persian to different degrees. In districts where our language distribution research (3.2) has identified several language varieties, we plan for collection of the questionnaire in each variety. In some cases, such as for studies of language contact, bilingualism, or generational differences in language structures within a community, we collect more than one questionnaire from the same location. In C&B province, we selected 30 sites (30 varieties in 26 communities), divided among the major language groupings and organized geographically within each grouping in Table 2. Three-letter codes for each site, used in analysis tables later in this article, are also provided.
Table 2. ALI questionnaire locations for C&B Province

Subsequent analysis also includes formal Standard Persian (PRS) and Bakhtiari of Masjed Soleymān (MJS) as reference varieties.
As Table 2 shows, 11 questionnaires were collected from Bakhtiari speakers, 11 from Charmahali speakers, including the 4 urban locations where it is spoken (cf. 3.3 above), and 8 from Turkic speakers. In 2 settlements (Juneqān and Boldāji), both Bakhtiari and Turkic questionnaires were collected, and in 2 other settlements (Shurāb Kabir and Naqneh), we gathered Charmahali and Turkic questionnaires.
In addition, for the purposes of inquiry into effects of language contact and bilingualism on linguistic structures where two minority languages co-exist, we collected supplementary questionnaires from second-language speakers of Bakhtiari and Turkic in the town of Juneqān. The first-language data is included in the present study, but we have reserved the second-language data, which is not comparable to the first-language data collected across the province, for description and analysis elsewhere (Anonby, Schreiber & Taheri-Ardali, Reference Anonby, Schreiber and Taheri-Ardali2020).
ALI research sites for C&B province are summarized on the following map (Map 3), with a simplified static polygon representation of language distribution as a backdrop. This map is based on the same language distribution data as the interactive point-based map above (3.2), but spaces between settlements have been filled in using contiguous “Voronoi” polygons (see Burrough, McDonnell & Lloyd, Reference Burrough, McDonnell and Lloyd2015:160–63). In addition, pending a more definitive analysis of the relationship between Rural and Urban Charmahali (see section 5), we have combined them and represented them with a single colour for the purposes of this map. Although the representation here is not interactive, it has the advantage of being able to show more than one language in a single settlement, and in relative proportions. This static polygon map further provides a simpler backdrop ideal for presenting the ALI research sites for C&B.

Map 3. ALI research site selection for C&B. From: http://iranatlas.net/module/language-distribution.chahar_mahal_va_bakhtiari_static
3.5 Collecting linguistic data with the ALI questionnaire
Over a two-year period from 2015 to 2017, Taheri-Ardali led work in collecting linguistic data by carrying out the ALI questionnaire, sometimes in conjunction with other ALI team members, in each of these 30 sites. All of the questionnaire sessions were recorded, and the sound files are being prepared for upload to interactive linguistic data maps in the Atlas. Full research metadata and linguistic data are archived and available from a permanent link (https://doi.org/10.5683/SP2/FVLDLZ).
Introduced in section 2 above, the questionnaire carried out for this study contained five sections: sociolinguistic context, lexicon, phonology, morphosyntax, and numbers. The sociolinguistic context section of the questionnaire provides a much fuller picture of the linguistic situation at the research location than the very cursory information collected in the earlier language distribution research phase (3.2 above); here, we also have the opportunity to ask questions about ethnicity vs. language identity, second/additional languages, fluency in Persian across the community, and language shift and endangerment.
The lexicon section of the questionnaire, which will be the focus of the analysis in the remainder of the present study, contains 80 words. These words have been selected based on their inclusion in other important wordlists and studies (Swadesh, Reference Swadesh and Sherzer1971; Leipzig-Jakarta [Haspelmath & Tadmor, Reference Haspelmath and Tadmor2009]; Persian Academy, 2009) as well as “classical” Iranic isoglosses (e.g., Oranskij, Reference Oranskij1979; Schmitt, Reference Schmitt1989) and other areal patterns that scholars have identified while working on languages of Iran (e.g., Stilo, Reference Stilo2016). As we will show, analysis of the geographic distribution of lexical items is important for understanding the language situation (3.2, 3.3), but analysis of the distribution of shared phonological forms among cognates is also valuable for assessing patterns of change and diffusion (section 4). The 2400 lexical data items we collected and analyzed—the 80 questionnaire items from each of the 30 research locations—are inventoried in Appendix 1, along with lists of 80 items for two reference varieties: formal Standard Persian of Tehran, and Bakhtiari of Masjed Soleymān in Khuzestan Province. While this article provides general discussion on the Turkic lexicon, we focus on the Iranic varieties of the province: Bakhtiari, and Rural and Urban Charmahali.
Because of the richness of the patterns we have observed in the lexical data in their own right, the phonology, morphosyntax and numbers sections of the questionnaire are beyond the scope of this study. The morphosyntactic data are certainly complementary and of equal importance in understanding C&B as a linguistic area, but they are even richer and more complex than the lexical data, and they need to be treated in one, or perhaps several, additional dedicated articles. Topics of special typological interest that we have observed in the morphosyntactic data are plural marking, definiteness, differential object marking, person marking, and noun phrase structure.
As mentioned just above, the lexical data are relevant for an understanding of some aspects of phonology, particularly in relation to its historical and geographic patterning. In contrast, because of the system- and discourse-dependent nature of phonology, responses to the phonology section of the questionnaire did not enable us to establish a satisfactorily coherent or comprehensive picture of the topics we investigated: consonant, vowel, and diphthong inventories, and dominant stress and intonation patterns, among others.
The data we collected on numbers, based on Chan’s (2008–2019) questionnaire, are much clearer. As a homogeneous set within the lexicon and susceptibility to borrowing, they also constitute a cohesive topic on their own; we will therefore also treat them in a separate study.
Subsequent to the field research carried out for the present study as well as field research at 20 other locations across Iran, a group of scholars met in Bamberg, Germany in July 2017 to test and revise the questionnaire.Footnote 8 Going forward, the improvements made possible through this process will further ground the results of our research.
4. Analysis of linguistic data
In this section, which forms the second major thrust of the paper, we analyze and compare lexical data from Bakhtiari (henceforth B.) and Charmahali (Ch.) as well as Turkic (T.) varieties across the province. The archived data set (Taheri-Ardali, Anonby et al., Reference Anonby and Mortaza Taheri-Ardali2020) comprises full research metadata plus 80 lexical items from the 30 research locations introduced above (3.5). These 2400 lexical data items are catalogued in Appendix 1, along with lists of 80 items from Standard Persian as well as Bakhtiari of Masjed Soleymān as reference varieties. We also refer to colloquial Persian in the analysis when relevant. Each of the sound correspondences discussed in this section is catalogued in Appendix 2.
In order to provide a general impression of relative structural similarity between and within these main linguistic groupings, our analysis begins with lexicostatistic analysis using calculations of cognate percentages between pairs of lexical data sets (4.1). As we will point out, these measures of similarity are in many ways limited. The larger part of our analysis therefore concentrates on identifying recurrent distributional patterning of lexical and phonological structures, and seeks to account for them as part of a meaningful areal picture of linguistic contact, change, and diffusion. Analysis is concentrated on the Iranic varieties B. and Ch., which cover most of the province, and attempts to address questions of their debated relation to each other as well as the internal variability of each. We first affirm the place of B. and Ch. alongside Persian within the Southwestern group of the Iranic family (4.2). We then look at linguistic structures common to the Iranic languages of C&B but not found in Standard Persian (4.3). Isoglosses distinguishing B. and Ch. are identified (4.4) and compared with the local perceptions of language identification introduced above (3.3), and tendencies in the geographic distribution of linguistic structures across the B. language area in particular are delineated (4.6). Tabulation and discussion of shared sound correspondences provides a finer-grained, summative overview of patterns of similarity among Iranic varieties (4.7). Finally, we consider data from Turkic varieties alongside the Iranic varieties (4.8). This final component, albeit cursory, provides insight into the regional patterning of language contact and helps to complete the picture of C&B as a linguistic area.
4.1 Lexicostatistic analysis
Lexicostatistic analysis measures structural similarity between lexical items with equivalent meanings in different language varieties. The most common metric for calculating lexical similarity is by counting the proportion of cognates—that is, sets of related words—for pairs of language varieties (early examples include Swadesh, Reference Swadesh1950 and Dyen, Reference Dyen1962). Cognates can be established through prior historical-comparative analysis or, in cases where such analysis has not been carried out or is not intended, through the simpler but more subjective measure of apparent similarity. Although a high number of cognates is often taken as an indicator of close relation between languages, there are other reasons that languages may share cognates, such as borrowing between languages and universal tendencies for some lexical domains. Further, lexicon is only one component of language, and each particular list of lexical meanings will generate a different proportion of similar items. While the lexical items gathered in this study are based in part on well-known tools such as the 100-item Swadesh (Reference Swadesh and Sherzer1971) and Leipzig-Jakarta (Haspelmath & Tadmor, Reference Haspelmath and Tadmor2009) lists, other words have been included in light of their importance for the Iranian linguistic context (3.5). For these reasons, the cognate percentages generated here should be taken only as a relative indicator of similarity, and relevant for this particular set of words, as a means of highlighting general tendencies that will be refined through detailed analysis in the following sections of this study.
Using the program Wordsurv (http://lingtransoft.info/apps/wordsurv), we grouped words into cognate sets and tabulated shared cognate percentages for the 30 language varieties treated in this article, along with Persian and Bakhtiari of Masjed Soleymān as reference varieties. In the following table (Table 3), B. of Masjed Soleymān (MJS, top row) is followed by 11 other B. varieties from Sar Āqā Seyyed (SAS) in the north-west to Chilteh Duderā (CHT) in the south. Ch. varieties follow a similar progression across the north-east part of the province from Cham Chang (CHC) in the north to Naqneh (NQC) to the south-east. Persian (PRS) is placed after the Ch. varieties, with which it shares many structural similarities. T. varieties run parallel to Ch. varieties in the north-east corner, running from Ben (BEN) in the north to Sulegan (SUL) in the south-east.
Table 3. Percentages of shared cognates in the 80-item wordlist
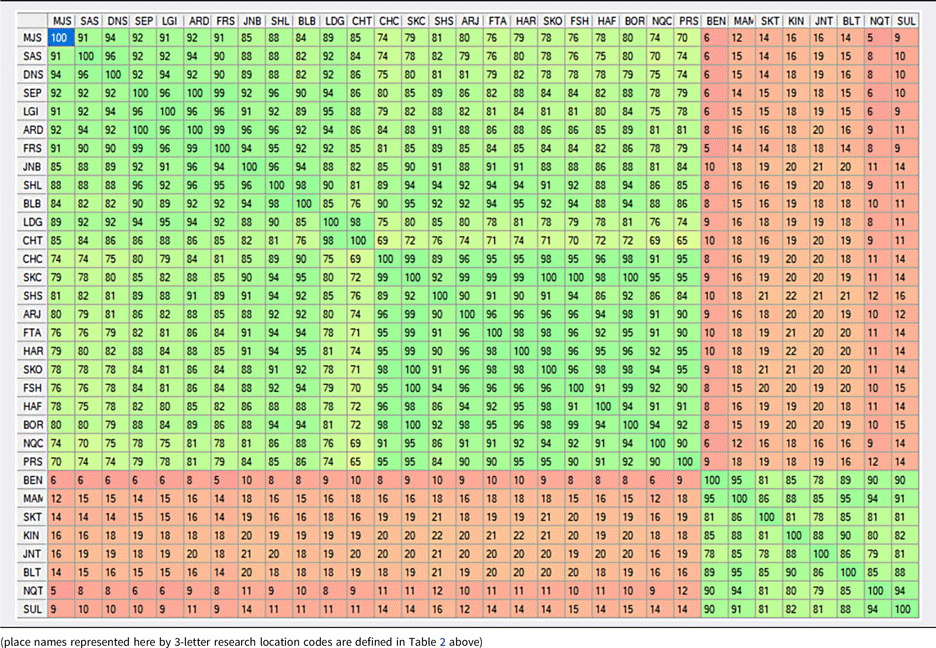
Percentage of shared cognates between each of the 32 language varieties are as follows (Table 3). Footnote 9
Several general lexicostatistic patterns are evident from Table 3.
1. Most obviously, Iranic and Turkic varieties are clearly differentiated by their vocabulary. The highest percentage of cognates shared by the two families, almost all of which are attributable to borrowing of Iranic words into Turkic (4.8), is found between T. of Shahr-e Kiān (SHK) and two Ch. sites (22%); there are six other T.–Ch. wordlist pairs that have a similar level of 21% lexical similarity. At the other end, the lowest proportion of shared cognates between the two families, between T. of Ben (BEN) and B. of Fārsān (FRS), is just 5%. T. of Sulegān (SUL) and Naqneh (NQT) also show low levels of similarity with Iranic vocabulary. There is a general, but modest, trend of higher levels of similarity between T. and Ch. (which are more often geographically proximate) than between T. and B. varieties.
2. Ch. varieties show a high level of lexical similarity to Persian (with one exception, above 90%), but B. varieties show varied levels ranging from 65% to 86%. The B. locations with the lowest levels of similarity to Persian are found at the north-west and south ends of the province (north-west: SAS, DNS; south: LDG, CHT).
3. Ch. varieties show a high level of lexical homogeneity. The words collected from Shurāb Kabir Ch. (SKC) are cognate with 100% of wordlist items from three other Ch. sites.Footnote 10 The lowest level of pairwise lexical similarity between two Ch. varieties, Sheykh Shabān (SHS) and Naqneh Ch. (NQC), is a still relatively high value of 86%.
4. B. varieties show varying levels of lexical similarity with one another. As for a few pairs of Ch. varieties, where all wordlist items exhibit cognates, 100% of items from the B. communities of Ardal (ARD) and Sepidāneh (SEP) share cognates. In contrast, B. of Chilteh Duderā (CHT) in the far south and Boldāji (BLB) in the west share cognates for only 76% of items.
5. The patterning of lexical similarity between Ch. and B. shows an interesting areal trend. B. varieties at the north-west and south ends of the province, which show the lowest levels of similarity to Persian (point 2 above), also show relatively low levels of similarity to Ch. varieties. However, B. varieties in the centre of the province, generally in close proximity to Ch. and T. varieties, are in general quite similar to Ch. In fact, B. of Shalamzār (SHL) and Boldāji (BLB) both have minimally 85% lexical similarity with all Ch. varieties in the sample. This pattern will be explored further at various points in the paper (see especially 4.6 4.7).
6. The T. varieties in the data show a fairly high level of lexical similarity, ranging from 78% shared cognates between T. of Juneqān (JNT) and two other locations, to 95% between Ben (BEN) and Margh Malek (MAM). The modest sample of 8 T. varieties does not show any clear geographic pattern of areal variation in the lexical similarity counts.
As underscored above, these results of lexicostatistic analysis are limited to helping sketch out a preliminary initial picture of the language situation based on relative similarities between varieties in a single structural domain (lexicon). However, they have enabled the identification of several patterns of varying clarity and significance. Subsequent analysis (4.2–4.8), which focuses on individual data items, and moves from lexical similarity to analysis of sound correspondences, allows for the evaluation and refinement of these patterns.
4.2 Structures common to Bakhtiari, Charmahali, and Persian
Because of common Southwestern Iranic ancestry, B. and Ch. share many structures with each other and with Persian. In fact, of the 80 lexical items in the ALI questionnaire, 5 are identical across the 11 B. locations, 11 Ch. locations, and Persian: 4. guš ‘ear,’ 15. pā ‘foot,’ 34. gorg ‘wolf,’ 44. ruz ‘day,’ and 52. gerdu ‘walnut.’ This pattern is shown in Map 4 for gorg ‘wolf,’ where the Iranic items are uniform but the Turkic equivalents are everywhere ġurt. Not only are these lexical items cognate across the Iranic varieties examined; they are also phonologically uniform as a result of shared sound changes. Together, this points to a shared historical origin and path, and underlines the relative proximity of the genealogical relationship between B., Ch., and Persian.

Map 4. Lexical variation in C&B Province: ‘wolf.’ From: http://iranatlas.net/module/linguistic-data.cb-lexicon-wolf
For a further 5 items, the words are generally uniform in all questionnaire data sets and in Persian:
-
8. ‘arm’ (P. dast) and 9. ‘hand’ (P. dast): these items, for which the semantic delimitation and distinction is challenging in the Iranian context, are served by a single word in most given locations, but the variants dast and das appear with equivalent frequency across both B. and Ch. language areas (exceptions: dahs [daːs]Footnote 11 in the most southerly research location of Chilteh Duderā (B.), as well as distinctive lexical items čel and bāyi ‘arm’ and panga ‘hand’ elicited in the B. villages of the far north-west);
-
13. ‘leg’ (P. pā), which is pā in most varieties (parallel to 15. pā ‘foot,’ mentioned in this section above), but given as leng in a handful of both B. and Ch. locations, and tekeraʋ/tekerun in peripheral B. sites (regarding a B. “periphery,” see 4.6 below);
-
48. ‘winter’ (P. zemestān), where B. and Ch. are always cognate with the Persian equivalent, but with considerable variation in vowels (first syllable ze ∼ za; second syllable me ∼ ma ∼ meh [mϵ:]), word-internal st ∼ ss ∼ s, and word-final codas (usually un [ũː]/[ũn], but also on [õː]/[õn], oʋn [
 ], aʋn [], aʋ [əw] and u [uː]); and
], aʋn [], aʋ [əw] and u [uː]); and -
54. ‘thirsty’ (P. tešne), given everywhere as tešne, except for the most southerly location of Chilteh Duderā (B.), where the word-final support vowel is different (tešna).
Further cases of cognacy, but for which sound changes and correspondences pattern significantly between varieties or over geographic areas, are treated in the relevant sections below (4.3–4.8).
One typically Southwestern sound change common to B., Ch., and most spoken varieties of Persian (but not found in formal registers of Standard Persian), is historical raising of ā (usually to u) before a nasal n or m. Although the exact shape of the affected lexical items is highly variable, the sound change applies consistently. Example items are found in Table 4.
Table 4. Words exhibiting historical ā > u before nasals in colloquial Persian, Charmahali and Bakhtiari

For the word 14. ‘knee,’ (P. zānu) which (for whatever reason) has not undergone historical raising in colloquial Persian (coll. P. also zānu), the vowel is raised in 17 of the 22 Iranic varieties in the sample: zuni is the most common form of the word there.
For 5. ‘mouth,’ there are two variants in Persian: dahan, and dahān (the latter of which is more formal). Interestingly, Ch. (dahan, dahn, dan) patterns with the first variant in 10 of 11 locations, and B. (dohun, dun, etc.) exhibits a form closer to the second variant in all of the 10 locations where a cognate is found.
4.3 Bakhtiari and Charmahali together against Persian
Structural similarities found between Bakhtiari and Charmahali, but not shared by Persian, suggest close relation between the region’s two Iranic groups, a pattern of areal borrowing and convergence, or both.
Regionally distinctive vocabulary. A couple of regionally distinctive words in the lexical data are shared by B. and Ch., but different from Persian:
-
72. ‘s/he swept’ (P. ǰāru kard)Footnote 13 appears as roft (especially B.) or ruft (especially Ch.) alongside or in place of ǰāru kerd (or similar) in all but 5 of the 22 Iranic locations.
-
79. ‘tomorrow’)P. fardā) is found as variants of the word sobā/soʋā/soʋah (cf. Ar. sabh ‘morning’) and its cognate sob/soʋ/sohʋ (cf. Ar. via P. sobh ‘morning’) in all B. and Ch. locations, although fardā is found as a doublet in three Ch. locations. (For geographic distribution of b vs ʋ in this item, which is significant, see 4.4.) A similar areal pattern exists for the lexical item 80. ‘day after tomorrow’ (P. pasfardā), for which variants of passobā, passoʋa, pahsoʋah, etc., are used in all Iranic varieties of the region.
In addition, three recurrent phonological isoglosses (i.e., isophones) distinguish all of the region’s Iranic varieties from Standard Persian: historical fronting of u, retention of i in open word-initial syllables of selected words, and historical softening of b in codas.
Historical fronting of u. The first of these sound changes is the historical fronting of u to i (or sometimes only to the intermediate form ü [y]), generally in the environment of coronals. This fronting has taken place in 1. ‘hair’ (P. mu), which is found as mi or mü in 17 of the 19 Iranic locations where a cognate item is used; 7. ‘throat’ (P. galu, gelu), found with a fronted vowel (gili, gülü, gelü) in 19 of the 22 Iranic locations; 14. ‘knee’ (P. zānu), with a final fronted vowel (zuni, zāni, zaʋu, zuʋi) in 20 of 22 sites; and 17. ‘blood’ (P. xun), found with a fronted vowel (xin, hin, xün, hün) in all 22 locations, but sometimes alongside the non-fronted form characteristic of Persian (see Map 5).

Map 5. Phonological variation in Iranic of C&B Province: Historical fronting of u in xun ‘blood.’ From: http://iranatlas.net/module/linguistic-data.cb-historical-phonology
For all four of these words, doublets identical to Persian are also in use in a handful of locations; these locations are not consistent, but parallel or exclusive use of non-fronted (=Persian) forms is more common in Ch., and in the Ch. variety of the city of Shahr-e Kord in particular.
The historical fronting process appears to have been active into post-hamleh history (that is, subsequent to the Arab conquest of Persia in the 7th century), applying to the Arabic borrowing 31. ‘bride’ (Ar. ʕarūs > P. arus) in a few Ch. and B. locations, where the form āris is used.
Even though 44. ‘day’ (P. ruz) exhibits a phonological environment where u fronting would be expected to take place, it is uniformly ruz in the Iranic varieties in the sample. This could be due to the presence of a different historical vowel ō (cf. Middle Persian [=MP] rōz) when the sound change was taking place; a result of avoiding confusion with the existing Southwestern Iranic word riz ‘fine, tiny’; or the prominence of the Persian word for ‘day’ in shared cultural contexts. Interestingly, 77. ‘yesterday’ (P. diruz) undergoes fronting in 11 of the 13 locations where a (partial) cognate is used (diriz, dürüz, periz Footnote 14), as does 78. ‘day before yesterday’ (P. pariruz), which shows a fronted vowel in 6 of the 18 cognate forms (paririz, peririz). This inconsistent historical application of the sound change suggests that phonological conditioning is only partially determinative, and that additional factors such as lexical semantics or contact-related influence from Persian are also significant for sound changes.
Retention of i in word-initial open syllables. Another isogloss distinguishing Iranic varieties of C&B from (Standard or Tehrani-type) Persian is the presence of i in word-initial open syllables in four words in the C&B data where Persian has e: 7. ‘throat’ (P. galu, gelu) is gili in 10 of 11 B. varieties and exhibits varied forms with an initial high vowel (gili, gilu, gülü) in all Ch. locations; for 11. ‘stomach’ (P. šekam), B. varieties do not contain i, ostensibly due to the different shape of the cognate (ešgam, eškam, kom) (see 4.4), but all 9 of the 11 Ch. varieties with a cognate item exhibit the form šikam; in 20. ‘liver’ (Standard P. ǰegar, coll. P. ǰigar), a high vowel is used in 9 of 11 B. locations (ǰiyar, ǰigar), and all 11 Ch. locations (ǰigar); and in 61. ‘white’ (P. sefid), the first vowel is i in all Ch. locations (again, most B. varieties have a different shape here—esbid, etc.—and the first vowel is non-high). As Agnes Korn (pers. comm. 2020) has pointed out, it is in fact Standard/Tehrani-type Persian which has undergone a broader, unconditioned change in vowel quality (i > e) here, whereas Iranic varieties of C&B retain a non-lowered historical i in these words. The vowel e is, however, found in word-initial open syllables in several other items from Iranic of C&B (e.g., 48. ‘winter,’ 50. ‘rice,’ 57. ‘long’), so phonological conditioning with initial palatal(-alveolar) obstruents š (in ‘stomach’), ǰ (in ‘liver’) and g Footnote 15 (in ‘throat’), or harmonization with a following i (in ‘throat’ and ‘white’), appears to be correlated to the retention of a high vowel.
Historical softening of b in codas. A third feature characteristic of all Iranic varieties in the C&B data is the historical softening of b in coda position, usually to a glide ʋ ([w] in coda position), but in a couple of cases also further shifted to y [j] (see 4.6), coalesced with the preceding vowel, or dropped completely. This takes place in 43. ‘sun’ (P. xoršid, āftāb), which appears in the Iranic varieties of the province as aftaʋ, āftaʋ, aftoʋ, aftay, oftaʋ, oftoʋ and ofto; 45. ‘night’ (P. šab), which is found in cognates throughout with a sonorant coda, as šaʋ, šay, šey, šeʋ, šoʋ, šö, and še; and 47. ‘water’ (P. āb), given variously as aʋ, oʋ, o, and ay.
4.4 Isoglosses between Bakhtiari and Charmahali
There is a strong bundling of isoglosses dividing Bakhtiari and Charmahali. This pattern, which includes a number of lexical items as well as several phonological correspondences, is stronger than the areal grouping of B. with Ch. against Persian (4.3). However, as signalled in the lexicostatistic analysis above (4.1) and confirmed in the table of shared correspondences later in the paper (4.7, Table 10), some of the varieties—particularly those of Boldāji (B.), Shalamzār (B.), and Shurāb Kabir (Ch.)—do not fall neatly to one side or the other. This topic is examined throughout this section. Here, we have selected the clearest isogloss patterns in the data, both lexical and phonological, but we note that there are many other patterns, not discussed in detail here, which are geographically ambiguous or indeterminate.
Distinctive Bakhtiari lexical items. In the lexicon, there are a number of widespread and distinctive B. words, as shown in Table 5.
Table 5. Lexical isoglosses distinguishing Charmahali and Bakhtiari

For all of these words, and in most locations, Ch. patterns with Persian, and the B. items are distinct.
Regarding exceptions on the B. side: since Persian exhibits a marked influence on all other languages of Iran, it is not surprising when items characteristic of Persian (like the occasional B. āris ‘bride’ and šāxe ‘branch’) are used in B. However, this occurs variably between the locations where people view themselves as speakers of B.: 8 of the 12 words in Boldāji are aligned with Persian and Ch.; this is the case for 6 of the 12 words in Shalamzār; 4 in Juneqān; 2 in Fārsān and Ardal; and in two other locations, 1 of the 12 words (‘bride’ in both cases). At very least, this signals overlap in the distribution of lexical structures between B. and Ch.; but it also shows the importance of structural comparisons among all varieties considered by their speakers to be “Bakhtiari,” since some might be more prototypically B. than others.
The appearance of B.-type words rather than typical P./Ch. words in varieties considered by speakers to be “Charmahali” is perhaps less expected, but when it occurs, it likewise raises questions about the affiliation of these varieties. This situation does in fact arise in a few locations: Shurāb Kabir, where 3 of the 12 items in this list align with the distinctive B. form; Borujen and Arjenak, 2 items; and in Sheykh Shabān and Hāruni, each exhibiting 1 typical B. word.
For one additional item, 59. ‘big’ (P. bozorg), B. typically uses the term gahp or gapu, but the main Ch. term is gonde. In this case, there is a three-way isogloss distinction between Persian, Ch., and B. Exceptions for this word are found in locations overlapping those of the other lexical exceptions just mentioned: the typical Ch. form for ‘big’ is found in the “Bakhtiari” communities of Boldāji and Shalamzār, and the usual B. form shows up in the “Charmahali” town of Shurāb Kabir, as well as Hafshejān. The Persian word bozorg, perhaps a borrowing, is used alongside the regionally distinctive words for ‘big’ in 6 Ch. locations.
The same pattern of distinction between B. and Ch. shows up in the alignment of two recurrent phonological isoglosses in cognates: historically softened intervocalic b in B., and B. h where Ch. and P. have x. There are several further sound correspondences that distinguish B. from Ch., but which show up in only one or two words in the data.
Historical softening of intervocalic b. In 4.3 above, we showed that historical b is weakened, in codas, in all Ch. as well as B. varieties in the province. In B., this sound change typically extends to intervocalic position, as the following words show (Table 6).
Table 6. Weakening of intervocalic b in Bakhtiari

In Boldāji, one of the “Bakhtiari” locations that sometimes aligns with Ch. for differentiated lexical items (as discussed in this section above and below), weakening of b to ʋ does not apply to any of the words here; but it occurs consistently in the other locations. Conversely, it shows up for 2 of the 4 words in Sheykh Shabān, a Ch. location that occasionally exhibits typical B. structures, as mentioned elsewhere in this section.
Correspondences between x and h. There are 5 items in the data where Ch. and P. x correspond to B. h. In one further item (28. ‘daughter’), x has no corresponding phoneme in the B. data from C&B, although it is reflected as h in Bakhtiari varieties elsewhere (Anonby & Asadi, Reference Anonby and Ashraf2014:168). These correspondences occur in a variety of word positions, as Table 7 shows.
Table 7. Correspondences between x and h

For several of the B. items (28. ‘daughter,’ 49. ‘house,’ 55. ‘bitter,’ 60. ‘red’), the occurrence of h can be confidently traced to historical debuccalization (that is, loss of an oral place of articulation) of x, since Old Iranic (=OIr) sources contain this phoneme (cf. Av. suxra ‘red’) or it is consistently attested in Middle Iranic (=MIr) (Manichaean Middle Persian = MMP duxt, Pahlavi Middle Persian = PMP duxtar ‘daughter’; MMP, PMP xānag ‘house’; MMP, PMP taxl ‘bitter’).Footnote 18 However, in the case of 58. ‘dry,’ OIr contained an h (Av. huška-) that was subsequently hardened (before w and u) to x in some MIr varieties (PMP xušk, but cf. MMP hušk), so it is possible that the B. form of this word either represents a continuation of OIr h or, in keeping with the other words here, a late debuccalization of a hardened MIr x.
In 7 of the 11 B. locations, this x/h correspondence applies in all 6 items in Table 7. However, in Shalamzār and Boldāji—the “Bakhtiari” locations that pattern with Ch. for several distinctive lexical items (as discussed immediately above)—a cognate with x is used for all 6 words. (The segment x is also found in a couple of words in the southernmost locations of Lordegān and Chilteh Doderā; see 4.6.) Conversely, this typically B. sound change shows up in one “Charmahali” location—that of Shurāb Kabir—for 3 of the 6 words. This also confirms the intermediate status of Shurāb Kabir that was noted for the lexicon.
Notably, weakening of x to h does not take place anywhere in the data, including B., in three Iranic words where x comes from a prior historical x w (cf. Early New Persian ustux w ān ‘bone,’ PMP x w āb ‘sleep (n.),’ PMP x w ard ‘s/he ate’); and in a further item (‘blood’), the occurrence of h is geographically restricted to the three north-western B. locations (Table 8; see also 4.6).
Table 8. Exceptions to weakening of x in Charmahali and Bakhtiari

The non-application of the x > h sound change in these items suggests that it may have applied only to historical x, and not x w , at a time when both phonemes were still contrastive in these varieties. In at least one B.-speaking location in the south part of the province (Milās, near Lordegān; not part of this study), the segment x w is still used, as evidenced in the word x w ard ‘s/he ate’ (Mortaza Taheri-Ardali, field notes 2017). As is the case for 58. ‘dry’ above, the presence of h in 17. ‘blood’ in the 3 northernmost B. locations can technically be traced to a historical h (cf. Av. vohuni),Footnote 19 but a late debuccalization of a hardened MIr x (cf. MMP, PMP xōn) is also possible.
Other distinguishing sound changes and correspondences. Along with these two recurrent and generally regular B. phonological innovations, a substantial set of other sound changes and correspondences in the data distinguishes B. from Ch., although they are found in individual items rather than a large set of words. Some of these isoglosses distinguish B. from Ch. more sharply than others.
-
11. ‘stomach (belly)’ is found as kom in 9 of the 11 B. locations, and eškam/ešgam in the remaining 2 (see 61. ‘white’ in this list below for a similar pattern). However, in all of the 9 Ch. sites where a cognate word is used, the form šikam is found (cf. P. šekam).
-
As in P. (bače, bačče), 25. ‘child’ has a consistent first vowel a in B. bače, etc., but e (Ch. beče) in 9 of the 11 Ch. locations. The opposite pattern is true for cognate forms of 21. ‘man’ (B. merd, Ch. mard) and the light verb ‘s/he did’ (B. kerd, but Ch. mostly kard) in 67. ‘s/he thought.’
-
With a single exception, 30. ‘groom’ ends with d in Ch. dumād (as in P.), but the final d is absent in all B. locations (duma, doʋā). Similarly, Ch. emruz, amruz ‘today’ (cf. P. emruz) invariably ends with z, but for 7 of 11 B. locations word-final z is absent from this item (amru, emru, omru).
-
In 39. ‘wood’ (P. čub), B. is found as ču (in line with the b-weakening pattern in codas given in 4.3 above), but the typical Ch. form is čuġ.Footnote 20 In the “Charmahali” location of Shurāb Kabir, the typical B. form ču is used; and the typical P. form čub, which is likely a recent borrowing from P., is found alongside the regional forms in four locations (3 Ch., 1 B.).
-
46. ‘star’ has a consistent CVC word onset in Ch. (setāre, = P.), but in B. a word-initial VCC sequence is prevalent (āstāre, āsāre, ostāra). The CVC-initial form setāre is used in 5 of the B. locations—alongside a typical B. form in 4 sites, and exclusively in one place. Similarly, 61. ‘white’ is given with a CVC word onset (sifid, sefid) in all but one of the Ch. locations (Sheykh Shaban ispid; also, a second form espit is used in Arjenak). In B., word-initial VCC sequences dominate (espid, espi, espir), but CVC forms (sefid, safid, sebeyd) are found in 4 of the 11 B. locations. As pointed out by Agnes Korn (pers. comm. 2020), it is worth noting that for both items, the prevalent B. shape aligns with MMP (istārag, ispēd) rather than with its PMP counterpart (stārag, spēd.)
-
As in Persian, codas which historically contained x followed by a liquid have been metathesized in the Ch. words 55. talx ‘bitter’ (= P.; cf. MMP, PMP taxl) and 60. ‘red’ sorx (= P.; cf. PMP suxr, MMP suhr). The corresponding B. words (cf. Table 7 above) are tahl and sohr. Lack of metathesis in B. corresponds almost exactly to the historical weakening of x to h: the two “Bakhtiari” locations where metathesis occurs—Shalamzār and Boldāji—are the same places where, as in Ch., x has not been weakened to h (see the discussion of x > h in the preceding paragraphs).
-
With a couple of exceptions, 64. ‘s/he slept’ is found as xābid in Ch. (= P.), but as xaʋsi(d) in B.
-
The word 65. ‘s/he ate’ is xord in Ch. (= P. again in this case), but xard in B. (with the exceptions of Boldāji and Shalamzār, which once more follow typical Ch. forms). This distinction actually reflects two separate innovations, since the initial portions of both present-day forms originate in a historical x w a segment (cf. PMP x w ard; see also the discussion of x > h in this section above).
-
70. ‘hit’ contains the segment ey in B. (zeyd, zey), but a in Ch. (zad = P.). In Shalamzār and Fārsān (both “Bakhtiari”), the Ch./P. form is used, and in Hāruni (Ch.) both forms are attested.
-
In 72. ‘s/he swept,’ the vowel o appears in all B. locations (roft, roh), but in only one of the 7 Ch. locations where a cognate term is used (Sheykh Shabān); the usual Ch. form for this item contains the vowel u (ruft, ruf). A similar division is found, albeit less neatly, for 71. ‘it burned (intr.)’: the vowel o is used in all B. sites (sohd, soxt), and u in a majority of Ch. sites (suxt, sux; cf. P. suxt). However, for this word the 4 remaining Ch. sites employ the more typically B. form with o.
-
To continue with 71. ‘it burned (intr.)’: a final t is found in 9 of the 11 Ch. locations (suxt), but only 4 of the 11 B. locations: Shalamzār, Boldāji, and the two southern sites of Lordegān and Chilteh Duderā. Remaining B. locations exhibit the forms sohd and soh.
-
The words 73. ‘here’ and 74. ‘there’ contain č in most B. locations (ičo/očo), but ǰ in Ch. (inǰā/unǰā, cf. P. inǰā/ānǰā). The B. locations of Boldāji and Shalamzār once again pattern with Ch. for this feature (unǰo). The second portions of the two forms usually differ in both consonant voicing and vowel quality, but the phonologically intermediate forms inǰo/unǰo (also found in the Ch. locations of Hafshejān and Hāruni) suggest that they have undergone phonological changes in both directions, likely induced by language contact.
Ambivalent isoglosses. The distinction between Ch. and B. is the clearest internal division for Iranic varieties of C&B, but some isoglosses do not line up neatly with this binary distinction. The phonological isoglosses in the list immediately above are scalar, with some more clear than others. In the same way, lexical isoglosses can be ambivalent. This is the case for 42. ‘leaf,’ which is found as pahr or par for all of the B. locations, but also in 4 of the 11 Ch. locations, in place of or alongside the more common Ch. forms barg (=P.) and balg. Should pahr/par be considered a “typical B.” item which is used in several Ch. locations, or a “typical regional Iranic” item contrasting with the “typical P.” form? Debate over “typical” forms offers diminishing returns in such ambivalent cases.
Summary of distinctions between Charmahali and Bakhtiari. Taken together, the data in this section show a strong bundling of lexical isoglosses distinguishing Charmahali and Bakhtiari, and a number of sound correspondences—some recurrent in the data, and others occurring in only one or two words but with consistent and meaningful distribution between the two varieties. Other distinctive traits are ambivalent. Interestingly, the data have highlighted a number of cases where typically Ch. structures are used in locations where people view themselves as speakers of B., and vice versa. The most significant misalignments are in the “Bakhtiari” communities of Boldāji and Shalamzār and, on the other side, the “Charmahali” village of Shurāb Kabir.
4.5 Geographic variation within Charmahali
As mentioned in 3.3, differences in the language variety labels used for rural vs. urban Charmahali communities raised the possibility that there is a dialectological difference between the two groups. The preliminary lexicostatistic analysis (4.1) does not bear this out, and in fact, neither does the detailed lexical and phonological analysis here. We have reviewed each of the 80 items and found no significant structural patterns that correspond to a rural vs. urban distinction, or to any other geographic grouping of Ch. varieties.
4.6 Geographic variation within Bakhtiari
Since the Bakhtiari research locations are widely spread across the province, it is conceivable that they exhibit geographically significant patterns in the distribution of linguistic structures. In fact, this is borne out by the data. Here, we look at patterns of lexical distribution as well as phonological correspondences that we have identified in three areas of the province: the north-west corner; the south end; and B. varieties in the east and centre which, although they look like a dialectal “core” in the context of the present study, may in fact be best viewed as a periphery in relation to the wider B. language area.
The north-west corner. The clearest linguistic grouping among the B. research locations is found in the north-west sector of the province, covering three sites: Sar Āqā Seyyed, Deh Now Soflā, and Sepidāneh. Of the three locations, Sar Āqā Seyyed, located in the far north-west corner, is the most distinctive.
A couple of basic lexical items show up only in the north-west: pange (Sar Āqā Seyyed) and panga (Deh Now Soflā) are used for 9. ‘hand,’ in contrast to dast (= P.) and cognates used everywhere else; and čel is used only in Sar Āqā Seyyed in place of the same cognate set (dast) used for the meaning 8. ‘arm.’ Also unique to Sar Āqā Seyyed, the word tešni is used alongside the more common Iranic item gelu, gili, etc., for 7. ‘throat’ (cf. common B., common Ch., and P. tešne for 54. ‘thirsty’).
Distinctive sound changes are especially prominent in this area. As one often finds with Kurdish much further to the north (see, for example, data in Anonby, Reference Anonby2004/5:18), intervocalic m has shifted here to ʋ. Interestingly, intervocalic n has also undergone this change in Sar Āqā Seyyed and Deh Now Soflā (Table 9).
Table 9. Shift of m, n > ʋ in north-western Bakhtiari sites

The shift of m to ʋ in ‘s/he came’ (and some other words) is widespread in B. of Khuzestan Province (see Anonby & Asadi, Reference Anonby and Ashraf2014), and even in C&B it has taken place in 4 of the 8 B. locations outside the north-west: ʋey in Loshtar Gorui, oʋey in Juneqān, aʋey in Ardal, and eʋeyd in Boldāji. Thus, for this particular item, the conservative form with m may be exceptional in the context of the wider B. language area.
In Sar Āqā Seyyed, the typical B. allophonic realization of d as [![]() ] following vowels and glides (Windfuhr, Reference Windfuhr1988; Anonby & Asadi, Reference Anonby and Ashraf2014:48) is taken further: d has merged with r in this position. Examples of this sound change, which takes place consistently in the data from Sar Āqā Seyyed, are as follows: 12. ‘stomach’ mehre (typical B. mehde); 61. ‘white’ esbir (typical B. esbid); and 70. ‘s/he hit’ zeyr (typical B. zeyd).
] following vowels and glides (Windfuhr, Reference Windfuhr1988; Anonby & Asadi, Reference Anonby and Ashraf2014:48) is taken further: d has merged with r in this position. Examples of this sound change, which takes place consistently in the data from Sar Āqā Seyyed, are as follows: 12. ‘stomach’ mehre (typical B. mehde); 61. ‘white’ esbir (typical B. esbid); and 70. ‘s/he hit’ zeyr (typical B. zeyd).
Two other sound shifts that have taken place in Sar Āqā Seyyed are related to phonological changes already discussed. First, the weakening of b to ʋ, which takes place in both Iranic groups (Ch. and B.) word-finally after a vowel (4.2), and also intervocalically in B. (4.3), extends to historical b as the second unit in consonant clusters in Sar Āqā Seyyed: 19. ‘heart’ is qalʋ (typical B. ġalb), and 33. ‘cat’ gorʋe (typical B. gorbe).
Second, secondary ʋ—generated by the historical post-vocalic weakening of b to ʋ (see the previous paragraph and 4.3-4.4 above)—appears to undergo a subsequent shift to y in Sar Āqā Seyyed: 43. ‘sun’ aftay (typical B. aftaʋ); 45. ‘night’ šay (typical B. šaʋ); 47. ‘water’ ay (typical B. aʋ); and 62. ‘s/he came’ aye (typical B. oʋeyd, umad; see Table 9 above). For ‘night’ in particular, it should be noted that there are also 4 Ch. locations, far away in the east part of the province, with the form šay, but this pattern does not show up in other Ch. words.Footnote 21 Softening of g to y in the item 32. ‘dog’ (sag, say) is limited to Sar Āqā Seyyed and Deh Now Soflā. However, this process occurs more widely in other words (see “Core and periphery” below).
The south end. Like the B. research sites in the north-west corner of the province, those at the south end—most clearly the southernmost site of Chilteh Duderā but also the southern city of Lordegān to some degree—exhibit distinctive structures. Distinctive lexical items are: 1. ‘hair (of head)’ mel Footnote 22 (typical B. mi) and 5. ‘mouth’ čil (typical B. dohun) in both locations; 32. ‘dog’ as ketu and kotu in Chilteh Duderā and Lordegān respectively (typical B. sag); and 73., 74., ‘here,’ ‘there’ are iro, uro (typical B. ičo, učo; this item is further discussed in 4.4 and 4.8). In Chilteh Duderā specifically, fir is used for 3. ‘nose,’, and the words bot and xor for 7. ‘throat’ (typical B. gili); the metathesized form geǰar is used for 20. ‘liver’ (typical B. ǰigar, ǰiyar); and ġalāk and galāk are both used for 41. ‘stick’ (typical B. ču, tarke, gorz), as in B. of Masjed Soleyman in Khuzestan Province (Anonby & Asadi, Reference Anonby and Ashraf2014:203). In the data, the word dindarakul is found for 37. ‘scorpion’ (typical B. gaždin, gādim) only in Lordegān. Interestingly, the words mel ‘hair’ and bot ‘throat’ are also found in the Southern Lori language area immediately to the south (Anonby, Reference Anonby2003b:186).
The word-final support vowel, a low vowel a in Middle Persian but e in modern Standard Persian, is phonetically somewhat unstable among the Iranic varieties of this province, but in almost all of them e is dominant. In Chilteh Duderā, however, it is consistently a. To cite some of the examples in the data: 18. ‘urine’ is mehsa (typical B. mehse, mesta); 22. ‘husband’ is mira (typical B. mire); 23. ‘woman’ is zine (typical B. zina); 25. ‘child’ is bača (typical B. bače); and 54. thirsty’ is tešna (typical B. tešne). For this feature, the dialect of Chilteh Duderā again patterns with the word-final a characteristic of Southern Lori (Anonby, Reference Anonby2003a:92).
Core and periphery. For several lexical items, there appears to be a core/periphery division, where research sites in the north-west, west, and south share one form, and the locations in the east and centre share another. These are as follows:
-
10. ‘finger’ is found as kelek in Sar Āqa Seyyed and Deh Now Soflā (in the north-west), as well as kilič/čelik in Lordegān and Chilteh Duderā (in the south), contrasting with the typical B. item angost or angošt (the latter also Ch. and P.).
-
16. ‘bone’ is found as hast in Deh Now Soflā (north-west), xas in Loshtar Gorui (west), and hahs in Chilteh Duderā (south), contrasting with typical B. (as well as Ch. and colloquial P.) ostoxun.
-
21. ‘man’ is piyā in Sar Āqa Seyyed and Deh Now Soflā (north-west), Loshtar Gorui (west), and Lordegān and Chilteh Duderā (south), in contrast with the typical B. form mire. This pattern is mapped out in Map 6.
-
31. ‘bride’ is behüg in Sar Āqa Seyyed and behig in Deh Now Soflā (both in the north-west); behig in Loshtar Gorui (west) and Juneqān (centre-west), beheyg in Ardal (centre-west); beyig in Lordegān and baʋig in Chilteh Doderā (both in the south). This stands apart from the B. forms common in the middle of the province (arus, āris) (as in Ch. and P.), and also used as a synonym in Loshtar Gorui, Juneqān, Ardal, and Lordegān, which originate from the Arabic equivalent ʕarūs.
-
33. ‘cat’ is found as gulu and gulubiš in Loshtar Gorui (west) and Lordegān (south), and as gelu (not ‘throat’!—see this item in this section above) in Chilteh Doderā (also in the south), in contrast to typical B. (as well as Ch. and P.) gorbe.
-
51. ‘egg’ is found as hāga in Deh Now Soflā (north), both xāʋe and xāye in Loshtar Gorui (west), and xāg in Lordegān (south) (cf. MP xāyag; cf. also coll. P., where the meaning of the reflex xāye has shifted to ‘testicle’Footnote 23 ). In the other B. sites, the forms toxmorġ and toxmemorġ (= Ch.; cf. P. toxmemorġ) is used.
Rather than indicating close historical relation among the B. varieties around the periphery, the simplest explanation for these forms is that the varieties in the centre of the province have innovated. In the lexicon, this has happened through borrowing: demonstrably in the case of ‘bride,’ for which the central varieties use an Arabic-derived term (likely via Persian); but ostensibly also for other terms (‘finger,’ ‘bone,’ ‘cat,’ and ‘egg’), and from Persian, since the geographically central forms of these words are similar or identical to Persian. In the case of ‘man,’ the B. term for 22. ‘husband’ mire has been generalized to ‘man’ in the same area—possibly a local semantic innovation, although equivalent shifts have been attested elsewhere in Iranic (Hassandoust, Reference Hassandoust2011:490–91). In addition, at least 4 of the 6 “peripheral” variants here are found in B. of Masjed Soleymān, at the far edge of the B. language area in Khuzestan Province to the west (see the lexicon in Anonby & Asadi, Reference Anonby and Ashraf2014). Considering all of these factors, the “peripheral” forms in C&B should most likely be viewed as shared retentions rather than shared innovations.
The same pattern holds true for phonological correspondences. 19. ‘heart (organ)’ retains a voiceless initial uvular obstruent (qalb) in Sar Āqa Seyyed (north-west) and Chilteh Duderā (south) (in keeping with B. of Masjed Soleymān), but as in Ch. and P., is voiced (ġalb) in all other B. locations. In the case of 20. ‘liver’ (P. ǰegar), historical g has been softened to y (ǰiyar) in the 3 north-western sites (Sar Āqā Seyyed, Deh Now Soflā, and Sepidāneh) as well as Loshtar Gorui (west), Juneqān, and Ardal (centre-west). In the remaining 5 B. sites, which are found in the centre and south areas of the province, the g characteristic of the Ch. form ǰigar (and P. ǰegar) is retained. Similarly, for 10. ‘finger’ in the 6 remaining locations (cf. kelek etc. in the list immediately above), the first consonant of the word-final cluster is s (angost) in the more peripheral locations of Deh Now Soflā, Sepidāneh, and Ardal, and š (angošt, = Ch., P.) in the 3 locations toward the centre of the province (Boldāji, Shalamzār, and Fārsān). Both variants are attested in Juneqān (centre-west). The same pattern shows up for 53. ‘hungry,’ generally gosne in B., but gošne in the same 4 central locations. This brings us full circle to the isoglosses distinguishing Ch. and B. (4.4), where the “Bakhtiari” locations of Boldāji and Shalamzār in particular often pattern with Ch.
4.7 Tabulation of sound correspondences between Iranic varieties
In the preceding sections (4.2–4.6), we delineated 80 instances of sound correspondences within cognate sets that show clear geographic patterning. In addition, we have identified 34 other instances of recurrent but (what appear to us to be) geographically ambiguous sound correspondences. The complete list of 114 correspondences is inventoried in Appendix 2.
Using the program Wordsurv, we have grouped and tabulated individual correspondences for 24 Iranic language varieties: the 22 Iranic varieties in our sample from C&B, along with Standard Persian and Bakhtiari of Masjed Soleymān as reference varieties. In the following table (Table 10), as for the table of cognate comparisons in 4.1 above (Table 3), B. of Masjed Soleymān (MJS, top row) is followed by 11 other B. varieties from Sar Āqā Seyyed (SAS) in the north-west to Chilteh Duderā (CHT) in the south. Ch. varieties follow a similar progression across the north-east corner of the province from Cham Chang (CHC) in the north to Naqneh (NQC) in the south-east. Persian (PRS) is shown in the bottom row of the table. Percentage of shared values for these correspondences is as follows (Table 10).
These percentages of shared sound correspondences provide a picture of the language situation which is finer-grained than the results of lexicostatistic analysis (4.1) but confirms the same overall patterns. It also helps to visualize trends in the subsequent analysis sections above (4.2–4.6). When focusing on sound correspondences, Persian (bottom line) is recognizably distinct from both Ch. and B., but much more so from B. (cf. 4.3). B. and Ch. pattern differently for many of the sound correspondences although, as highlighted in 4.4 above, forms given by B. speakers from Shalamzār (SHL) and Boldāji (BOL) in particular pattern with Ch. varieties more closely than with some B. varieties. Conversely, the Ch. variety of Sheykh Shabān (SHS) shows a high percentage of shared sound correspondences with most B. varieties. In keeping with the observations given in 4.5, Ch. is an internally coherent grouping. B., however, covers a large geographic area across the province and is internally heterogeneous. As outlined in 4.6, the north-west corner, the south end, and the entire western periphery of the B. language area each show higher levels of internal similarity than they do with the B. language area as a whole. The B. geographic “core,” which includes Fārsān (FRS), Juneqān (JNB), Shalamzār (SHL), and Boldāji (BOL), shows some internal consistency as well as shared similarity to neighbouring Ch. varieties.
4.8 Turkic and Iranic
Up to this point, we have focused on analysis of the Iranic (Ir.) varieties of C&B (4.2–4.6), both because they cover most of the province and because the internal relations between these varieties are key to understanding the language situation. However, there are also important points to be elaborated regarding the internal dialect structure of the province’s Turkic (T.) varieties, as well as structural convergence between T. and Ir. varieties in the region. Within the scope of the present paper, it is not possible to give a complete account of these topics, but a fuller analysis is undertaken elsewhere (Schreiber et al., Reference Schreiber, Taheri-Ardali, Anonby and Haig2017, Reference Schreiber, Haig, Taheri-Ardali and Anonby2021; Anonby, Schreiber & Taheri-Ardali, Reference Anonby, Schreiber and Taheri-Ardali2020; Anonby, Taheri-Ardali, Schreiber et al., Reference Anonby, Schreiber and Taheri-Ardali2020).
Linguistically, the 8 T.-speaking locations where data have been collected are relatively homogeneous. The differences between them are generally due to varying degrees of convergence with neighbouring Ir. varieties—both B. and Ch., depending on the part of the province. This topic is introduced briefly in this section, but is treated in more detail in Schreiber et al. (Reference Schreiber, Taheri-Ardali, Anonby and Haig2017, Reference Schreiber, Haig, Taheri-Ardali and Anonby2021).
As expected, and as shown already in the preliminary lexicostatistic analysis (4.1), the T. varieties of the province are unquestionably distinct from the Ir. varieties, and the majority of structures are unrelated. This is shown for a representative sampling of lexical items, shown in Table 11, for which there are no cognates shared between the two families.
Table 10. Percentage of shared values for identified sound correspondences

Table 11. Examples of distinct Turkic vocabulary in C&B
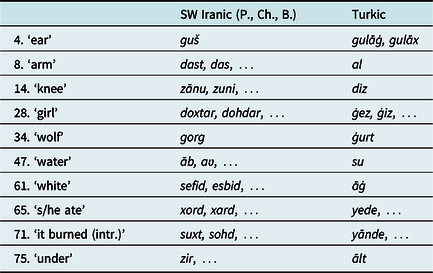
Interestingly, for all 11 verbs in the data, there are no cases where verbal roots are borrowed from Iranic into Turkic.Footnote 24
Still, there is significant overlap for some lexical items. For some words (20. ‘liver,’ 40. ‘branch,’ 42. ‘leaf,’ 56. ‘fresh’), borrowing from Ir. has taken place in all of the T.-speaking sites in the data, but for other words (19. ‘heart,’ 35. ‘fox,’ 38. ‘tree,’ 79. ‘tomorrow’) it occurs only sporadically. A cursory observation from our limited data set, as evidenced by some of these items, points to nature-related vocabulary as one domain that is susceptible to borrowing.
Contact-induced change in Turkic of Iran is often attributed to influence from Persian (Kıral, Reference Kıral, Johanson and Utas2000; Erfani, Reference Erfani2012), perhaps because Persian is better known than other Ir. varieties in direct contact with Turkic. Since, as we have shown, Ir. varieties of C&B differ in many respects from Standard Persian and from one another—and, as Map 1 shows, some T.-speaking communities are in contiguous to B., and others are beside Ch.—it is possible to trace the path of language contact more precisely here.
Technical vocabulary, such as medical terminology like 11. ‘stomach’ and 19. ‘heart,’ has been borrowed from Arabic into Persian and from there into most other Ir. varieties, so it is not unlikely that Persian could serve as a direct source language for these items in T. as well. For both of these items, a Persian-type word is found in 7 of the 8 T. locations (Table 12), although in one or two cases for each word, is it used alongside a T. term.
Table 12. Technical vocabulary borrowed into Turkic

In Persian, the term ‘red’ is expressed as either ġermez or sorx. Whereas almost all B. and Ch. varieties in the data show cognates of sorx (but admit ġermez as an alternate term in three locations), in T. ‘red’ is invariably cognate with ġermez.Footnote 26 This suggests that the T. word for ‘red’ has been borrowed from Persian rather than the Ir. languages of C&B.
However, in other cases it is more clearly the local Ir. languages which are lexifiers (Table 13).
Table 13. Evidence of local borrowings into Turkic

Further underlining the local character of borrowing, there are direct correspondences between the particular forms used by T. speakers in a given location, and the equivalent structures—cognate grouping as well as the specific phonological content—in the adjacent Ir. varieties. To illustrate: in the data, T. always borrows the Ir. word for ‘leaf,’ but even more specifically, it usually exhibits the term pahr when near B. areas that use pahr, and barg next to Ch. areas that use barg. This is shown for cognate groupings of ‘leaf’ in the following map (Map 7).

Map 6. Lexical variation in C&B Province: ‘man.’ From: http://iranatlas.net/module/linguistic-data.cb-lexicon-man
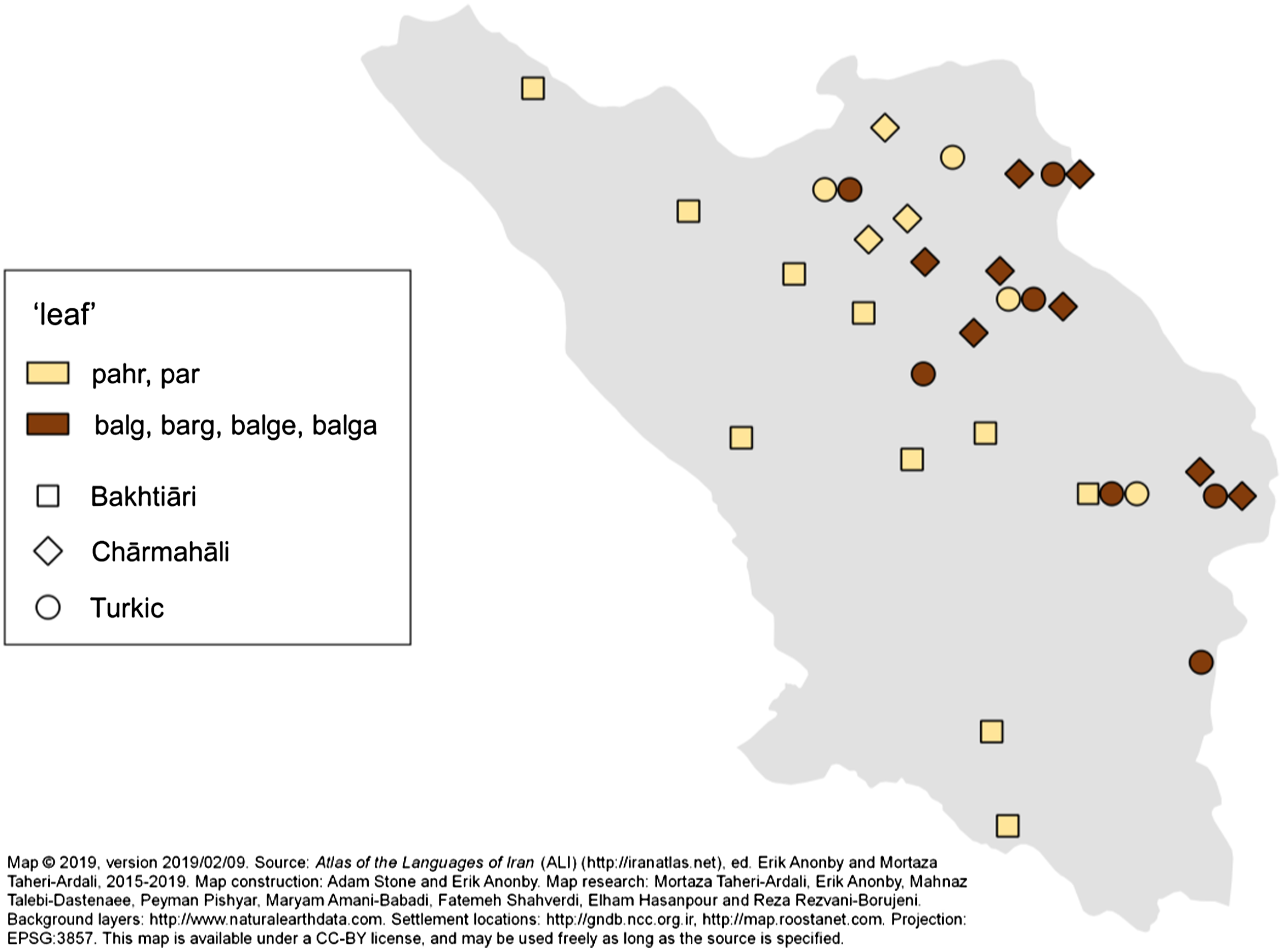
Map 7. Lexical variation in C&B Province: ‘leaf.’ From: http://iranatlas.net/module/linguistic-data.cb-lexicon-leaf
Several additional words provide probable evidence of contact, but the source and direction of borrowing is less clear.
First, the term ǰeġele shows up for 26. ‘boy’ in all three languages: 8 times for Ch. (usually alongside other Ir. terms), 4 times for B., and once for T. (with the variant ǰeġela). The conspicuously similar terms oġol, oġlān, and oġel are more common for T. Are all of these words related? Was the term ǰeġele borrowed from T. into Ir., but (given the significant yet consistent differences between the forms) at an earlier point in history?
Item 52. ‘walnut’ also presents a puzzle. In all of the Ir. varieties in the data sample, this word is rendered as gerdu, which itself is probably an innovation in Ir.; the Middle Persian term, and that of many Ir. varieties today, is gōz. In Arabic (outside of this study), the equivalent is ǰawz (and similar variants), and in all of the T. varieties in the data the word ġoz is given. Perhaps the T. term has been borrowed from Persian (or elsewhere in Ir.), but this must have happened at an early point in time, since the vowel o (attributable to the MIr vowel ō rather than the New Ir. vowel ū/u) is used.
The Wanderwort Footnote 27 33. ‘cat’ presents a further riddle. In both Ir. groupings in the province, the geographically dominant term is gorbe (= P.). Two T. varieties in the data also use a cognate of gorbe, but the related forms pišig, püšüg, and pišug are used in five other T. locations (and mali in a final, single T. site).Footnote 28 The form pišuli, found in Ch. of Shahr-e Kord, clearly patterns here with the more usual T. forms. Has it been borrowed from local T.? Do all of the piš-type words for cat originate in an earlier (possibly) Ir. prototype, since a similar term is found in distantly-related Ir. varieties?Footnote 29 Or perhaps both explanations are relevant?
As mentioned in 4.6, the words 73., 74., ‘here,’ ‘there’ are iro, uro in Lordegān and Chilteh Duderā, the two southernmost B. sites. These terms appear to combine the phonological content of typical B. locationals ičo/učo with T. equivalents bura/burā and ora/orā. (Alternatively, the B. term rah ‘way, path’ (Anonby & Asadi, 2018:217; P. rāh), and/or historical r-type locationals attested elsewhere in IranicFootnote 30 may have contributed to both Turkic and Bakhtiari r-type locationals.)
Further, the main term for 7. ‘throat’ in the T. data is boġāz, similar to the term boġāzi, used in some Southern Lori varieties to the south (Anonby, Reference Anonby2003b:186), and the term xerrex, found in two T. locations, resembles the term xor in the southerly B. location of Chilteh Duderā, and even more closely the B. form xer attested elsewhere (ibid.). All of these lexicon-related scenarios deserve further analysis in the light of additional comparative material from T. and Ir.
Two final cases of structural convergence between T. and Ir. come from the phonology. The first concerns front rounded vowels ü and ö. Although front rounded vowels are not a typical feature of Southwestern Ir., they appear sporadically across Iranic (e.g., Okati et al., Reference Okati, Anonby, Ali Ahangar and Jahani2010), including a number of the Ir. varieties in C&B that are in contact with T. (see also 4.3 above). Conversely, as occurs intermittently in T. varieties elsewhere in Iran (especially Qashqai of Fars Province; see Bulut, Reference Bulut, Csató, Johanson, Róna-Tas and Utas2016), front rounded vowels have been lost in the phonological inventories of some of the T. varieties in C&B, presumably as a consequence of contact with neighbouring Ir. varieties. Map 8 shows that the presence vs. absence of front rounded vowels in C&B is more easily attributable to areal similarity than to the family—T. or Ir.—to which a variety belongs.Footnote 31

Map 8. Phonological variation in C&B Province: Front rounded vowels. From: http://iranatlas.net/module/linguistic-data.cb-phonology
A second sound correspondence which also appears to be shared is shift of postvocalic ʋ to y. For Iranic, this occurs in three words in Sar Āqā Seyyed (B.; see 4.8), for which a shifted form for 48. ‘night’ is shared with 4 Charmahali locations. This occurs separately for 4 of the 8 Turkic locations in 49. ‘house,’ which is evenly divided between the more typical Turkic eʋ (also öʋ in one location) and the local reflexes ey, öy.
5. Findings and prospects
Over the history of documentation of the languages of Iran, going back more than a century, Chahar Mahal va Bakhtiari (C&B) Province has been for the most part passed over. While a few studies have appeared on Bakhtiari varieties of the province, its Charmahali and Turkic varieties are almost absent in the literature. This paper seeks to provide a picture of the language situation in C&B which is both global and fine-grained, although still initial.
Our study was conducted in the context of the Atlas of the Languages of Iran (ALI) research programme (section 2). It opens with a description of the activities that were necessary to frame and enable a coherent understanding of C&B province as a linguistic area, including an initial period of literature review (3.1) and a longer phase of language distribution research (3.2). Reflection on the detailed, emergent picture of language distribution (3.3) raised key research questions and facilitated the selection of sites (3.4) for linguistic data collection with the ALI questionnaire (3.5).
The second half of the paper (section 4) treats the linguistic data collected by the research team in 30 sites across the province between 2015 and 2018: 11 Bakhtiari, 11 Charmahali, and 8 Turkic. Because of the richness of the lexical data set—80 words in each of the 30 varieties—in this first study we limit our analysis to lexicon, along with phonological correspondences associated with cognate sets. In our general overview of the province, we look at all three language groupings. However, our detailed analysis focuses on relationships and internal structure of the Iranic varieties. The discussion of Turkic is cursory here, concentrating on issues of language contact; analysis of internal relationships among the Turkic varieties is reserved for a separate study.
Even within the limitations of the scope of this study, a first clear overview of the language situation emerges through analysis of the lexical and phonological data, and subsequent reinterpretation of language distribution data in light of this analysis. Preparatory lexicostatistic analysis (4.1) makes it clear that the lexicon of Turkic in C&B is fundamentally different from that of Iranic, and it also shows structural divergences between Bakhtiari, Charmahali, and Persian. However, it does not confirm any structural distinction between the Rural and Urban Charmahali groupings suggested by the labels that speakers use.
The more detailed analysis we have carried out shows a number of significant patterns, providing insight into the questions raised in 3.3 above.
-
1) Charmahali and Bakhtiari exhibit a strong base of lexical items and phonological forms shared with Persian, confirming their place alongside Persian within the Southwestern branch of Iranic (4.2).
-
2) There is a small but clear set of lexical items and shared sound changes common to the Iranic varieties of the region (Ch. and B.) but distinct from Persian (4.3).
-
3) A robust bundling of isoglosses distinguishes Charmahali and Bakhtiari, both for lexicon (where 12 of 80 items show a general binary distinction) and for phonological patterning in cognates, where about a dozen diagnostic correspondences of varying strength have been identified (4.4). In most of these cases, the Charmahali structures are aligned with Persian, and sometimes even identical to it. In a small number of cases, each of the three groupings (P., Ch., B.) exhibits a distinctive form. With the exception of a single item (25. ‘child’), alignment of Bakhtiari lexicon with Persian, to the exclusion of Charmahali, is not attested in the data. A binary distinction between Charmahali and Bakhtiari does not pattern neatly for all locations, however. Bakhtiari varieties in the centre of the province, and in particular Boldāji and Shalamzār, show a higher level of lexical and phonological similarity with neighbouring Charmahali varieties than they do with Bakhtiari varieties at the geographical peripheries of the province (see point 6 below). On the other side, in the Charmahali village of Shurāb Kabir, many structures are shared with Bakhtiari. Other exceptions to the general distinction between Charmahali and Bakhtiari can be attributed to widespread adoption of Persian forms for specific words.
-
4) Although we considered a possible Rural vs. Urban Charmahali dialect distinction for the 80 words in the data, were we unable to identify any structural patterns that distinguished the two groups, or any other dialectological group within Charmahali (4.5).
-
5) Within Bakhtiari, the geographic distribution of lexical and sound correspondence patterns support the positing of a north-west dialect area; a separate dialect zone in the south; and a surprisingly well-defined core/periphery pattern, where Bakhtiari dialects in the centre of the province exhibit innovations that distinguish them from dialects in the north-west, west, and south (4.6). What first appears to be a dialectal “core” area in the centre of the province, is likely better viewed as a periphery in the context of the Bakhtiari language area as a whole. We have confirmed the divergence of Bakhtiari in the central area by comparison with lexicon and sound correspondences in the Bakhtiari reference variety of Masjed Soleymān in Khuzestan Province. The general pattern of divergence in the central area, which includes the two strongly Charmahali-leaning Bakhtiari locations of Boldāji and Shalamzār, appears to be due to areal convergence between Charmahali and Bakhtiari or the influence of Persian.
-
6) The Turkic varieties of C&B are fundamentally different from the Iranic varieties (Ch. and B.), but there are significant patterns of contact-induced change. Most cases are examples of lexical borrowing of Iranic vocabulary into Turkic (4.8). However, the source and path of contact effects are uncertain or, in fact, ambivalent—pointing in both directions—for several lexical items, as well as two phonological features: the shared geographical distribution of front rounded vowels ü and ö in the data, and an apparent shared ʋ > y sound change.
Taken together, these findings offer a first fine-grained and geographically representative overview of the language situation in Chahar Mahal va Bakhtiari Province, and have helped to set the direction of the research process for other provinces in the Atlas of the Languages of Iran, including the refinement of the ALI linguistic data questionnaire. They also point to outstanding questions for ongoing work on C&B Province: Will morphosyntactic data confirm the emergent picture of the language situation, or will they pattern differently from the lexical and phonological data? What are internal relationships among Turkic varieties of the province, and how do these varieties fit in to Turkic of Iran more generally? As we wondered earlier but did not investigate here, does the Persian emerging in C&B have an areal character, whether as a result of contact with other languages in the province, or a substrate that shows up among speakers that have shifted from these other languages? And in the wider scheme, to what degree do the boundaries of C&B as a linguistic area—in the more technical sense of Sprachbund—follow the province’s borders? How will an extension of our research to related language varieties in other provinces impact the way that we understand the language situation in C&B Province?
Here, we add some final notes regarding language identification, which was a further issue raised in 3.3 above, and one which necessarily shapes the way that linguists frame and discuss the language varieties of the province. Although such assessments are always to some degree subjective, it is clear to us, based on speakers’ perspectives as well as structural considerations highlighted in the analysis, that Bakhtiari can be considered a language distinct from Charmahali and Persian, although there is a significant level of convergence between Bakhtiari and Charmahali in the central areas of the province. The status of Charmahali, especially in relation to Persian, is less clear even when the question is considered from both of these directions. Will a detailed analysis of morphosyntax shed further light on the depth and pervasiveness of Charmahali’s structural distinctiveness, or will it continue to yield ambivalent results? Or, perhaps, comparison with neighbouring Southwestern Iranic varieties in Esfahan Province will bring clarity to the issue. Finally, for communities of speakers that consider themselves “Bakhtiari” or “Charmahali” but use structures more typical of the other language group, studies of language contact situations and oral histories of migration can be an important means of untangling the threads of the province’s linguistic tapestry.
Acknowledgments
Earlier versions of portions of this paper were presented by Erik Anonby and Mortaza Taheri-Ardali at the 7th International Conference on Iranian Linguistics (ICIL7), Lomonosov Moscow State University, 28–30 August 2017, and by Erik Anonby at the Linguistics Summer School Evening Lecture Series, Leiden University, 16 July 2018. The authors wish to thank each of the 44 consultants who contributed data for this study. We also acknowledge the dedicated and valuable contributions of ALI colleagues for Chahar Mahal va Bakhtiari (C&B) Province in carrying out field research for this article; a full list is provided in section 3.1. Finally, we are grateful to Agnes Korn, Don Stilo, and an anonymous reviewer for detailed critique on specific aspects of this study. Various elements of the research were supported by SSHRC (Social Sciences and Humanities Research Council of Canada), Carleton University, Universität Bamberg, and the Alexander von Humboldt Foundation.
Data availability statement
Consultant and researcher names, other metadata, and linguistic data for each research location are available in the ALI Dataverse at the permanent link: https://doi.org/10.5683/SP2/FVLDLZ.
Appendix 1. Lexical data set (archived data set with full accompanying metadata is available at: https://doi.org/10.5683/SP2/FVLDLZ)






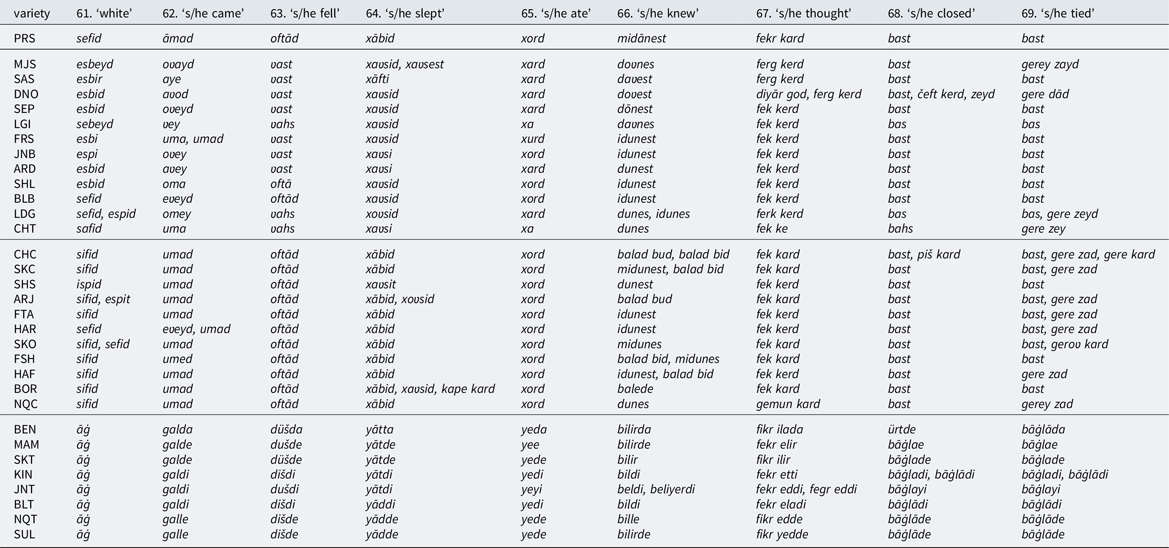


Appendix 2. Inventory of sound correspondences identified in the lexical data
The following table lists the sound correspondences we identified in the lexical data. The clearest patterns are discussed in the article; these are presented first and listed according to the relevant article sections. Other correspondences are roughly grouped together according to theme and the order of items in the wordlist.























 Open access
Open access
{kind=link}