





Introduction
Cognates are words that share semantic, orthographic, and phonological characteristics across languages and are widely used in psycholinguistic research to further our understanding of bilingual language comprehension and production (Costa et al., Reference Costa, Caramazza and Sebastian-Galles2000). Words, for instance, with common Latin origins, can appear in very similar form across many related languages (e.g., English: expression, Spanish: expresión, Italian: espressione, French: expression, Portuguese: expressão, Romanian: expresie). A central finding in bilingual reading research is that word-forms that occur in more than one language known to a multilingual language-user (e.g., English: paper, Portuguese: papel) are processed faster and more accurately than word-forms that occur in only one language (e.g., English: house, Portuguese: casa, Costa et al., Reference Costa, Comesaña and Soares2022). This cognate facilitation effect (recent reviews in Kroll et al., Reference Kroll, Gullifer, Zirnstein, Nicoladis and Montanari2016; Lauro & Schwartz, Reference Lauro and Schwartz2017; Lijewska, Reference Lijewska, Heredia and Cieślicka2020) has been found in a wide range of experimental paradigms, including visual word recognition (e.g., Cristoffanini et al., Reference Cristoffanini, Kirsner and Milech1986; De Groot & Nas, Reference De Groot and Nas1991; Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Peeters et al., Reference Peeters, Dijkstra and Grainger2013; Voga & Grainger, Reference Voga and Grainger2007), auditory word recognition (e.g., Blumenfeld & Marian, Reference Blumenfeld and Marian2007; Marian & Spivey, Reference Marian and Spivey2003), word production (e.g., Costa et al., Reference Costa, Caramazza and Sebastian-Galles2000; Kroll & Stewart, Reference Kroll and Stewart1994), and recently also in written word production (Woumans et al., Reference Woumans, Clauws and Duyck2021). Cognate facilitation in visual word recognition is evident across languages known to a language-user, and cognates are generally easier to process than non-cognates in a reader's first language (Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Titone et al., Reference Titone, Libben, Mercier, Whitford and Pivneva2011; Van Assche et al., Reference Van Assche, Duyck, Hartsuiker and Diependaele2009; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), second language (Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004; Schwartz & Kroll, Reference Schwartz and Kroll2006; Titone et al., Reference Titone, Libben, Mercier, Whitford and Pivneva2011; Van Assche et al., Reference Van Assche, Duyck, Hartsuiker and Diependaele2009, Reference Van Assche, Duyck and Brysbaert2013; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), and third language (Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002). A number of factors are known to influence the cognate facilitation effect (Kroll et al., Reference Kroll, Gullifer, Zirnstein, Nicoladis and Montanari2016; Lauro & Schwartz, Reference Lauro and Schwartz2017; Lijewska, Reference Lijewska, Heredia and Cieślicka2020). The more languages a cognate occurs in that are familiar to a multilingual reader, the stronger its facilitating effect on word recognition (Lemhöfer et al., Reference Lemhöfer, Dijkstra and Michel2004). Cognate facilitation effects are typically stronger in languages other than readers’ L1, and stronger in tasks requiring overt responses such as naming and lexical decisions, compared to more natural sentence reading in eye movement studies (Lauro & Schwartz, Reference Lauro and Schwartz2017; Lijewska, Reference Lijewska, Heredia and Cieślicka2020). The degree of facilitation is also influenced by language proficiency, cognate facilitation effects being generally smaller for high compared to low proficiency language-users (Bultena et al., Reference Bultena, Dijkstra and Van Hell2014; Libben & Titone, Reference Libben and Titone2009; Pivneva et al., Reference Pivneva, Mercier and Titone2014). However, quite fundamental questions remain about whether cognate facilitation effects depend on the presence of orthographically identical cognates in experimental designs (e.g., Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022), and about the role of phonology in cognate facilitation, given that cognate pronunciations often differ between languages even when their spelling is identical (e.g., Costa et al., Reference Costa, Comesaña and Soares2022; Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021).
Theoretical basis of cognate facilitation
The cognate facilitation effect is generally assumed to be a consequence of an integrated mental lexicon, in which orthographic representations of different languages known to a language-user are stored in a single network. Both the Bilingual Interactive Activation model (BIA+, Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002) and the Multilink model (Dijkstra & Rekké, Reference Dijkstra and Rekké2010; Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Van Halem, Al-jibouri, De Korte and Rekké2019) assert that, in the initial stage of lexical processing, a visually presented letter string activates stored orthographic and phonological representations in this network that share specific features. Activation does not depend on the language of the input, only its correspondence with stored representations, and is therefore assumed to be language non-selective. When a bilingual language-user reads a word that shares common features across the languages known to the reader, representations of the word in all the languages known to the reader are activated, inhibiting other dissimilar words and co-activating their common semantic representation, thus facilitating word recognition. Language tagging of orthographic input is added by language nodes after lexical access, and therefore does not play a role in the initial stages of word recognition. The BIA+ model does, however, also accommodate for linguistic influences on lexical processes such that syntactic and semantic sentence context information from different languages can influence word recognition during sentence reading. Contextual influences may explain why cognate facilitation effects are attenuated in more natural sentence reading experiments compared to single word recognition studies (Lauro & Schwartz, Reference Lauro and Schwartz2017).
An alternative explanation for the faster processing of words that share word-form and meaning across languages is their greater cumulative frequency of occurrence (Midgley et al., Reference Midgley, Holcomb and Grainger2011; Peeters et al., Reference Peeters, Dijkstra and Grainger2013; Voga & Grainger, Reference Voga and Grainger2007; Winther et al., Reference Winther, Matusevych and Pickering2021). According to the cumulative frequency hypothesis, encountering words that share form-meaning associations across languages known to a multilingual language-user results in an accumulated activation benefit (e.g., Midgley et al., Reference Midgley, Holcomb and Grainger2011). Hence, words read in L2 that share orthography and meaning with the readers’ L1 benefit from the L1 exposure. In unbalanced bilinguals, the accumulated exposure explanation predicts a stronger cognate facilitation effect in L2 than L1, as the accumulated exposure in L1 is a greater influence on L2 processing than the lesser exposure in L2 on L1 processing (Midgley et al., Reference Midgley, Holcomb and Grainger2011). Computational language models are able to simulate cognate facilitation effects based on the cumulative frequency of exposure to words that share characteristics in L1 and L2, although only when simulated exposure to L1 is higher than to L2 (Winther et al., Reference Winther, Matusevych and Pickering2021). Unlike other established models such as the BIA+ (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002) and the Multilink model (Dijkstra & Rekké, Reference Dijkstra and Rekké2010; Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Van Halem, Al-jibouri, De Korte and Rekké2019), frequency-based explanations of the cognate facilitation effect do not assume that identical cognates have a special status in the bilingual mind, beyond their greater cumulative cross-language frequency.
In either case, the cognate facilitation effect is generally accepted as a marker effect for non-selective activation in bi- and multilingual reading (Lauro & Schwartz, Reference Lauro and Schwartz2017; Van Assche et al., Reference Van Assche, Duyck and Hartsuiker2012).
Orthographic and phonological similarity
An important factor that influences the cognate facilitation effect is the degree of cross-language similarity. Cognates are sometimes orthographically identical (e.g., hand, spelled Hand in German) but often differ to a small degree (e.g., wine, spelled Wein in German). Recent studies have shown that cognate facilitation effects can be experimentally modulated by changing the proportion of identical to non-identical cognates in experimental materials (Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022; Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015). Arana et al. (Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022), for instance, found that altering the ratio of identical to non-identical cognates from 50-50, 25–75, 12–88, to 0–100, gradually decreased the magnitude of the cognate facilitation effect in lexical decision tasks conducted with Portuguese–English bilinguals in their L2, suggesting that orthographically identical cognates drive the cognate facilitation effect. Supporting this conclusion, Vanlangendonck et al. (Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020) found that identical cognates (e.g., drama spelled identically in both English and Dutch) produced considerably larger cognate facilitation effects than non-identical close cognates (e.g., round, spelled rond in Dutch) in a lexical decision task performed by Dutch–English bilinguals in their L2. This could point towards a discrete difference in the facilitation effects elicited by identical and close cognate words.
However, cognate facilitation has been described both in terms of discrete effects (identical cognates vs. close cognates), and continuous effects in lexical decision, sentence reading, and text reading studies. Van Assche et al. (Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011), for instance, reported significantly faster L2 reading times for cognates than non-cognates in Dutch–English bilinguals in both lexical decision latencies and eye movement measures in sentence reading. The authors also assessed the gradual influence of cross-language overlap, using Van Orden's (Reference Van Orden1987) measure of orthographic similarity, ranging from 0 to 1 (e.g., English–Dutch identical cognate: ring–ring, 1.00; non-identical cognate: shoulder-schouder, 0.81; non-cognate: witch-heks, 0.06), and a combined measure of highly correlated (r = .94) human ratings of orthographic and phonological similarity. Lexical decision latencies and fixation durations in bilinguals’ L2 reading decreased linearly with increasing orthographic and phonological similarity.
Similarly, Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) reported a gradual orthographic similarity effect for non-identical cognates, using human ratings of orthographic overlap as a measure of cross-language similarity. Lexical decision latencies for identical cognates in Dutch–English bilinguals’ L2 were shorter compared to close cognates and non-cognates. The significant drop in response latency from close to identical cognates was interpreted as a discontinuity of the cognate facilitation effect, i.e., a significantly greater cognate facilitation effect of identical compared to close cognates. To disambiguate orthographic from phonological cross-language overlap, Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) regressed the phonological ratings on the orthographic ratings and used the residuals of the linear model as a measure of phonological similarity, independent of orthographic similarity. Lexical decision latency for identical cognates was facilitated by cross-language phonological similarity. The same pattern of effects was found for lexical decision accuracy, suggesting that both cross-language orthographic and phonological similarity contribute to the cognate facilitation effect.
Carrasco-Ortiz et al. (Reference Carrasco-Ortiz, Amengual and Gries2021) similarly found a continuous effect of orthographic similarity in L1 and L2 lexical decision tasks performed by English–Spanish bilinguals and Spanish-dominant Spanish heritage speakers. Orthographic and phonological similarity measures were computed using Levenshtein distance scores of phonological transcriptions (e.g., animal, transcribed as /ænəməl/ vs. /animal/) and spelling, i.e., the number of insertions, deletions and substitutions needed to edit a target word into the translation word. To account for the high correlation between orthographic and phonological similarity, these measures were residualized as in Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010). Interestingly, a continuous facilitation effect of phonological similarity was found only for Spanish words, which have more consistent grapheme-to-phoneme correspondence rules than English.
Cognate facilitation effects are not limited to single sentence contexts, as Cop et al. (Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017) demonstrated in an eye tracking experiment in which Dutch–English bilinguals read an entire novel in their L1 and L2. Cop et al. (Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017) found cognate facilitation effects in bilingual readers’ L1 and L2, suggesting that cross-language activation in bilingual readers persists even when reading a long, semantically and syntactically complex monolingual text. Cop et al. (Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017) used normalized Levenshtein distance scores as a continuous measure of orthographic overlap (see Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). A differentiation of the cognate facilitation effect between identical and close cognates was found in bilinguals’ early eye movement measures (first fixation duration) while reading in their L2, with significantly shorter fixation durations for identical cognates compared to close cognates. Continuous effects of orthographic similarity were found in L2 in late eye movement measures (total viewing time and gopast time) for frequent words.
So far, the studies discussed have generally reported facilitating effects of orthographic and in some cases phonological similarity on word recognition in single word, sentence, and text reading experiments. The relevance of phonology should not be surprising, given that even when cognates share all letter identities across languages, their pronunciation rarely overlaps completely (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999). For example, the identically spelled English–German cognate “hand” is pronounced /hænd/ in English and /hant/ in German, differing in two out of four phonemes. The cross-language activation of phonological representations may thus complicate the facilitation effect of cross-language orthographic similarity, if the degree of cross-language similarity differs between orthography and phonology. Indeed, there is some evidence that two distinct phonological representations associated with cognate words in the readers’ L1 and L2 are activated and compete for selection during word recognition (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Schwartz et al., Reference Schwartz, Kroll and Diaz2007).
A clear demonstration of the independent influence of phonology and orthography was provided by Dijkstra et al. (Reference Dijkstra, Grainger and Van Heuven1999), who presented Dutch–English bilinguals with cognates, false friends (words that share orthography or phonology but not meaning across languages, such as gift, spelled identically as Gift in German, but meaning poison), and control words in their L2 in a progressive demasking task and visual lexical decision task. Word recognition for words with shared orthography (false friends) or orthography and semantics (cognates) was faster and less error-prone than for non-cognate controls. When words shared phonology but not orthography, however, word recognition latencies were slower compared to controls.
Similarly, Schwartz et al. (Reference Schwartz, Kroll and Diaz2007) demonstrated independent influences of phonological and orthographic cross-language overlap in a word naming study. English–Spanish bilinguals were presented with words in their L1 and L2 in monolingual language blocks, containing cognate and non-cognate target words. The authors selected word pairs to obtain a fully crossed orthography by phonology experimental design. Orthographic similarity of the cognates was estimated using the method detailed by Van Orden (Reference Van Orden1987), while phonological similarity was generated using human similarity judgments of recordings made by native-speakers’ pronunciations of the word pairs. Word naming speed and accuracy increased with cross-language orthographic similarity. Schwartz et al. (Reference Schwartz, Kroll and Diaz2007) also found an interaction of orthographic and phonological similarity on naming latency and accuracy: responses were slower and more error-prone for cognates with high orthographic similarity when they were phonologically dissimilar (e.g., escape, with identical spelling but low perceived phonological similarity ratings), compared to when they were phonologically similar (e.g., actor, with identical spelling and high perceived phonological similarity ratings). This was interpreted as the potentially inhibitory influence of cognate words being mapped onto two distinct pronunciations across languages.
Frances et al. (Reference Frances, Navarra-Barindelli and Martin2021) conducted an auditory and visual lexical decision study with a subset of Spanish–English cognates in which orthographic and phonological similarity were orthogonally manipulated. Phonological similarity was determined using the ALINE algorithm for the alignment of phonetic sequences (Kondrak, Reference Kondrak2000). The orthogonal design was achieved by a median split on the orthographic and phonological similarity variables, defining four groups of words with high and low phonological and orthographic similarity, without including cognates with identical orthography. In the visual modality, orthographic similarity had a facilitation and phonological similarity an inhibition effect, while the opposite pattern was evident in the auditory modality. The effect of orthographic similarity was greater for identical cognates than for close cognates in both modalities, facilitating in the visual modality and inhibiting in the auditory modality.
Several single word recognition studies therefore appear to suggest an inhibitory role of phonology and attenuation of the facilitation effect of orthographic similarity when phonological cross-language overlap is low.
Reading words in isolation and in context
Reading is a complex task that requires the coordination of perceptual and cognitive processes, from low-level visual processing of word form, control of when and where the eyes move (Rayner, Reference Rayner1998), activation of orthographic and phonological codes in the mental lexicon, to higher levels of linguistic processing (Norris, Reference Norris2013). Reading researchers have consequently studied word recognition using a wide range of tasks. In the domain of psycholinguistics and second language research, the lexical decision task (Forster & Chambers, Reference Forster and Chambers1973) and eye tracking (reviews in Rayner, Reference Rayner1998, Reference Rayner2009) are two of the most widely employed methods (Dirix et al., Reference Dirix, Brysbaert and Duyck2019).
In the lexical decision task, participants decide whether presented letter-stings are valid words or non-words, typically by pressing one of two keys in a speeded response task. This requires a decision and a button press, introducing additional cognitive processing, physical execution, and a speed component into the word recognition task. Response times are therefore not necessarily direct measures of the time taken to identify a word (Norris, Reference Norris2013). The lexical decision task also relies on the use of non-word stimuli that are not encountered in natural reading. The difficulty of the task is influenced by the word-likeness of the non-word letter-strings included (e.g., Gibbs & Van Orden, Reference Gibbs and Van Orden1998).
Tracking participants’ eye movements allows the measurement of more natural reading without the confounding effects of a specific task response (Rayner, Reference Rayner1998, Reference Rayner2009). However, eye movement measurements also have both practical and theoretical limitations. Eye tracking, for instance, involves technical equipment and expertise, as well as elaborate stimuli, making it resource intensive and expensive to collect large amounts of data. The interpretation of fixation durations as a direct measure of word processing time is also not entirely straightforward. The utility of fixation durations as estimates of the processing difficulty of words relies on two theoretical assumptions (Kliegl et al., Reference Kliegl, Nuthmann and Engbert2006; Rayner, Reference Rayner1998, Reference Rayner2009). The first is that the processing of a word occurs immediately when it is encountered (the immediacy-of-processing assumption; Just & Carpenter, Reference Just and Carpenter1980), and the second is that a reader fixates a word for as long as the processing of a word is ongoing (the eye-mind assumption; Just & Carpenter, Reference Just and Carpenter1980). The well-documented influence of sentence context on fixation durations (Staub, Reference Staub2015), as well as parafoveal processing of upcoming words (Schotter et al., Reference Schotter, Angele and Rayner2012), and parafoveal-on-foveal effects of upcoming words on current fixation durations (e.g., Kliegl, Reference Kliegl, Risse and Laubrock2007) indicate that these assumptions do not hold in a very strict sense. Furthermore, leading computational models of eye movement control during reading explicitly incorporate mechanisms to account for the decoupling of attention and saccade planning (e.g., EZ-Reader; Reichle et al., Reference Reichle, Warren and McConnell2009; Reichle, Reference Reichle2021), or parallel processing of multiple words (e.g., SWIFT; Engbert et al., Reference Engbert, Nuthmann, Richter and Kliegl2005; Seelig et al., Reference Seelig, Rabe, Malem-Shinitski, Risse, Reich and Engbert2020).
A small number of studies have used experimental data, lexical decision mega-studies (e.g., English Lexicon Project; Balota et al., Reference Balota, Yap, Cortese, Hutchison, Kessler, Loftis, Neely, Nelson, Simpson and Treiman2007; Dutch Lexicon Project; Keuleers et al., Reference Keuleers, Diependaele and Brysbaert2010), and eye movement corpora (e.g., Schilling corpus; Schilling et al., Reference Schilling, Rayner and Chumbley1998; Dundee corpus; Kennedy & Pynte, Reference Kennedy and Pynte2005; DEMONIC; Kuperman et al., Reference Kuperman, Dambacher, Nuthmann and Kliegl2010) to assess the correlation and reliability of reading times of words read in isolation and in more natural discourse context (Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Everatt & Underwood, Reference Everatt and Underwood1994; Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013; Schilling et al., Reference Schilling, Rayner and Chumbley1998). Four general observations can be made across these studies. First, the correlations between lexical decision latencies and eye movement measures are generally modest and are greater in small experimental designs (e.g., Everatt & Underwood, Reference Everatt and Underwood1994; Schilling et al., Reference Schilling, Rayner and Chumbley1998), compared to studies using large databases of lexical decisions and eye movement corpora (e.g., Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013). Second, the shared variance of lexical decision latencies and eye movements is mainly explained by word frequency and length effects (Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013), indicating that both methods tap into similar word recognition processes. Third, the correlations of eye movement measures on identical words in different corpora is very low (Dirix et al., Reference Dirix, Brysbaert and Duyck2019), suggesting that the context in which a word is read is highly relevant to how easy it is to read. Finally, correlations between lexical decision latencies and eye movement measures are very similar in L1 and L2 corpora (Dirix et al., Reference Dirix, Brysbaert and Duyck2019).
These studies, which combine data from single word reading mega-studies and eye movement corpora, suggest that word reading times are highly context dependent when words are read in a discourse context. Fixation durations may therefore most closely reflect lexical processing when a word is not predictable from its prior context and is positioned in carefully controlled experimental sentence frames (Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013). Lexical decision times, on the other hand, are likely a closer approximation of the average processing time of a word across different contexts (Dirix et al., Reference Dirix, Brysbaert and Duyck2019). These widely used methods may therefore provide slightly different information about the nature of reading and it is largely unclear whether these differences have an impact on the expression of cognate facilitation effects in bilingual reading.
The present study
While the cognate facilitation effect is a well-studied phenomenon in bi- and multilingual reading, questions regarding certain aspects of the effect remain unresolved. Recent studies suggest that facilitation is reliant on a high proportion of identical cognate stimuli in experimental designs (Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022; Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015). However, studies showing a continuous effect of orthographic similarity suggest that the magnitude of the cognate facilitation effect may simply be reduced if identical cognates, which elicit the greatest facilitation, are not included (Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). A further issue that has received comparatively little attention is the influence of phonological overlap, which has been shown to have a lesser but independent effect on cognate facilitation in single word recognition studies (e.g., Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Schwartz et al., Reference Schwartz, Kroll and Diaz2007). While cross-language phonological similarity has in some cases been found to facilitate word recognition (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011), other studies report an inhibitory effect on word recognition and an interaction with orthographic facilitation (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Schwartz et al., Reference Schwartz, Kroll and Diaz2007).
This study aimed to further investigate these two issues. The first main goal was to test whether identical cognates (e.g., English hand, German Hand) are processed more efficiently than close cognates, matched on relevant characteristics including word length, frequency, orthographic neighbourhood size, and contextual predictability, but differing in a small proportion of letter identities and/or letter positions (e.g., English wine, German Wein). Cognate facilitation was expected to be greater for identical cognates and close cognates, compared to non-cognate language equivalents (e.g., English raft, German Floß), matched on the same variables. Several studies have suggested that cognate facilitation is best described as a linear effect of cross-language similarity. As argued by Van Assche et al. (Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011), a gradual cognate effect that increases in magnitude with orthographic and phonological cross-language similarity is compatible with computational interactive activation models of bilingual word recognition, assuming that the level of cross-language activation in the multilingual mental lexicon is modulated by the extent of cross-language similarity (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002; Thomas & Van Heuven, Reference Thomas, Van Heuven, Kroll and De Groot2005; Van Hell & De Groot, Reference Van Hell and De Groot1998). A gradual orthographic similarity effect is also compatible with a frequency-based account of cognate facilitation (Midgley et al., Reference Midgley, Holcomb and Grainger2011), assuming partial cross-language activation of non-identical cognates, resulting in a lower cumulative frequency of close cognates compared to identical cognates. In this study, a continuous cognate facilitation effect was tested across identical cognates, close cognates, and non-cognates with varying degrees of cross-language orthographic overlap. It should be noted that significant categorical cognate facilitation effects and continuous effects of orthographic similarity are not mutually exclusive (e.g., Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). Instead, facilitation that increases in magnitude with cross-language similarity would provide evidence that a continuous orthographic similarity effect underlies the well-established categorical cognate facilitation effect.
Effects of phonological similarity over and above those of orthographic similarity have been found for the magnitude of the cognate facilitation effect in single word recognition (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011) and sentence reading experiments (Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). The influence of phonological similarity on the cognate facilitation effect has both theoretical and practical relevance, as the selection and definition of cognate words in experimental studies is typically solely based on orthographic overlap. Depending on the consistency of grapheme-phoneme correspondences across languages (Ziegler & Goswami, Reference Ziegler and Goswami2006), cognates can vary considerably in their phonological similarity. The English word “olive” annotated in DISC (Baayen et al., Reference Baayen, Piepenbrock and Van Rijn1993) as /QlIv/ (IPA equivalent /ˈɒl.ɪv/) is written identically in German as “Olive”, resulting in an orthographic Levenshtein distance of zero. The cognate olive/Olive is however pronounced quite differently in German as /olivE/ (IPA equivalent /oˈliːvə/), resulting in a cross-language phonological Levenshtein distance of 0.6. It is therefore evidently possible for words that share identical spelling across languages also to differ extensively in their pronunciation. The second main aim of this study was therefore to test for independent influences of continuous orthographic and phonological cross-language similarity by extracting and testing the uncorrelated effects of orthography and phonology on the processing of identical and close cognates.
Although several studies have previously compared processing of identical and close cognates in L2 reading, few have tested the consistency of these differences across reading tasks (e.g., Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011, Reference Van Assche, Duyck and Brysbaert2013). Word processing time has been shown to differ between single word and sentence processing tasks, possibly due to the added availability of contextual language information (Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013). It is plausible that the increased language context in sentence reading could attenuate both the effects of orthographic and phonological similarity on fixation durations during reading. A third aim of this study was therefore to test the consistency of orthographic and phonological similarity effects across single word recognition and sentence reading tasks.
To achieve these aims, two experiments were conducted. In Experiment 1, German–English bilinguals performed a lexical decision task (LDT) in their L1 and L2 with equal numbers of matched identical cognates, close cognates, and non-cognates. In Experiment 2, an independent sample of German–English bilinguals read the same target words embedded in translation equivalent sentences. Data and reproducible code for both experiments are available on the Open Science Framework: https://osf.io/k6mj4.
Experiment 1: Cognate Facilitation in Word Recognition
Method
Participants
One-hundred German–English bilinguals were recruited via the Prolific website to participate in the online experiment. Ninety-seven participants who stated German to be their L1 and English to be their L2, and who fully completed the study, were considered for analysis. Participants were on average 31.5 years old (SD = 11, range 18–70) and predominantly male (61%). Table 1 provides an overview of the participants’ rated language proficiency, proportion of language use, and preferred language, which shows that participants were unbalanced bilinguals, but proficient L2-users. Participants were remunerated with a proportionate fee of $6.94 per hour. All participants gave informed consent prior to participation. The university board of ethics granted ethical approval for this study.
Table 1. Bilinguals’ Self-report Ratings of Language Use and L2 Age of Acquisition
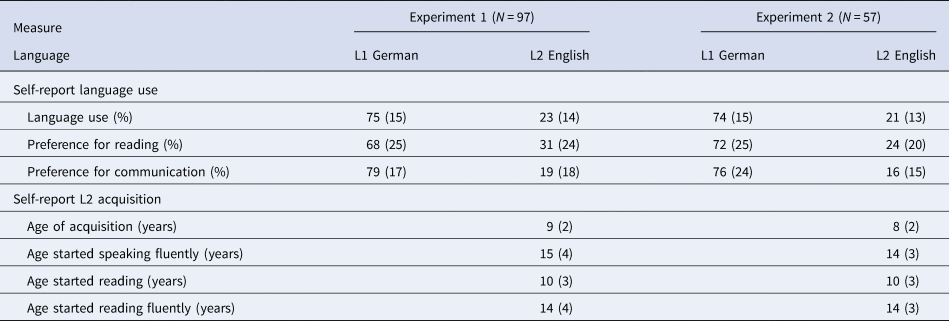
Note. Self-report language use and L2 acquisition ratings did not differ significantly between samples, all ts < |1.96|.
Lexical decision task
Word stimuli
A total of 162 English–German word pairs were selected for this study (see Table S1 in the Supplementary Materials). Of these, 54 pairs were identical cognates, 54 pairs were close cognates, and 54 pairs were non-cognates. The word length, frequency and orthographic neighbourhood size of the words in English and German are summarized in Table 2, as well as the normalized orthographic and phonological Levenshtein distances of the word pairs (NLD, Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). Exact cognates necessarily had an orthographic NLD of zero. Target words were considered to be close cognates in the orthographic NLD range of .1 to .5 (i.e., with up to half of their letters differing between languages); and words in the orthographic NLD range of .67 to 1 (i.e., differing in at least two-thirds of their letters between languages) were considered non-cognates. Importantly, the three categories of cognate status were non-overlapping as far as orthographic similarity between languages was concerned. The stimuli were tested for further differences between cognate status categories within each language using ANOVAs. The identical cognates, close cognates, and non-cognate words did not differ in their average word length, frequency, or orthographic neighbourhood size (OLD20, Yarkoni et al., Reference Yarkoni, Balota and Yap2008), all Fs < 2 (see Table 2). Word length and frequency were uncorrelated within each cognate status category in both languages, all ts < |1.96|.
Table 2. Characteristics of the Identical Cognates, Close Cognates, and Non-Cognate Target Words in Experiments 1 and 2
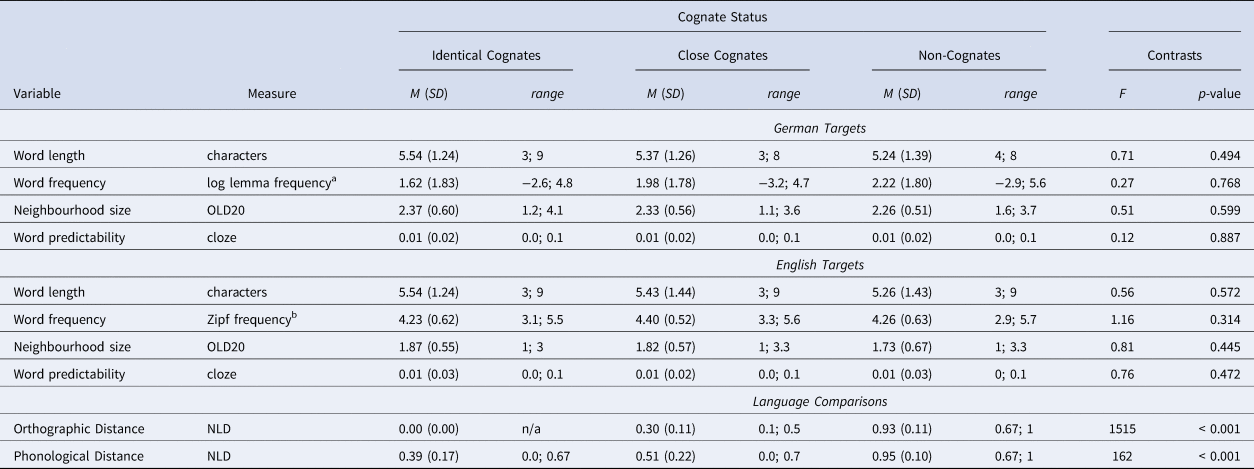
Note.OLD20: Levenshtein Distance to 20 closest orthographic neighbours; NLD: Normalized Levenshtein Distance (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012).
aGerman DWDS corpus (Heister et al., Reference Heister, Würzner, Bubenzer, Pohl, Hanneforth, Geyken and Kliegl2011); b English Subtlex-UK corpus (Van Heuven et al., Reference Van Heuven, Mandera, Keuleers and Brysbaert2014).
The orthographic similarity of the English–German identical cognate, close cognate, and non-cognate word pairs was estimated using the normalized orthographic Levenshtein distances (Table 2), by dividing the Levenshtein distance of the word pairs by the longer word length in characters (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). Phonology was coded according to the DISC system detailed by Baayen et al. (Reference Baayen, Piepenbrock and Van Rijn1993), which represents each phoneme of the International Phonetic Alphabet (IPA) with a single ASCII character. Phonological similarity was computed using normalized Levenshtein distances, analogous to orthographic similarity. Orthographic and phonological similarity estimates were highly correlated, r = .80. ANOVAs and Tukey Honestly Significant Tests were used to test for differences in orthographic and phonological similarities between identical cognate, close cognate, and non-cognate word pairs. Identical cognate word pairs had significantly higher orthographic similarity than close cognates, M diff = 0.30, 95% CI[.25,.34], p < 0.001, and close cognates had higher orthographic similarity than non-cognates, M diff = 0.93, 95% CI[.89,.97], p < 0.001. Similarly, identical cognate word pairs had significantly higher phonological similarity than close cognates, M diff = 0.12, 95% CI[.04,.19], p < 0.001, and close cognates had higher phonological similarity than non-cognates, M diff = 0.44, 95% CI[.36,.52], p < 0.001.
For the analysis of uncorrelated influences of orthographic and phonological similarity on word recognition, a principal components analysis was performed to extract uncorrelated variance components. The first principal component explained about 90% of the variance and was highly correlated with both normalized cross-language orthographic (.82) and phonological (.57) similarity. The second principal component explained the remaining 10% of the variance and was positively correlated with orthographic (.57) and negatively correlated with phonological (-.82) similarity. The loadings of the two principal components were extracted and used as uncorrelated indicators of predominantly orthographic and phonological cross-language similarity, respectively. The polarity of the phonological component was inverted so that higher values in both orthographic and phonological components indicated greater cross-language distance.
This approach to differentiating orthographic and phonological similarity was chosen for several reasons. First, using the DISC system (Baayen et al., Reference Baayen, Piepenbrock and Van Rijn1993) to annotate phonology made it possible to estimate comparable measures of orthographic and phonological similarity, i.e., the number of insertions, deletions and substitutions of orthographic or phonological units needed to edit a target word into the translation word (Levenshtein distance). Second, this approach therefore did not rely on subjective judgements of orthographic or phonological similarity. Third, the principal component analysis allowed the components related to predominantly orthographic vs. phonological similarity to be separated, consequently allowing their independent effects on reading times to be estimated. This is particularly relevant, as orthographic and phonological similarity are typically highly correlated in cognates across European languages (e.g., Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). Other methods of dealing with the problem of correlated predictors, such as using residuals from one regression model as a measure for another, are not universally endorsed (e.g., McElreath, Reference McElreath2020, p.137).
Pseudoword stimuli
A total of 162 pseudowords were generated using the Wuggy software application (Keuleers & Brysbaert, Reference Keuleers and Brysbaert2010), which constructs pseudowords by replacing elements of words (e.g., onset, nucleus, coda) with equivalent elements of other words of the same language. Ten pseudowords were generated for each target word. Of these, one pronounceable pseudoword with matching word length and similar orthographic neighbourhood size was selected for each target word. The pseudowords generated for the identical cognates, close-cognates, and non-cognates did not differ from the word stimuli in their length in English, t(323) = -0.04, p = 0.968, or German, t(323) = 0.08, p = 0.931. The pseudoword stimuli had a greater orthographic neighbourhood size (M = 1.98) than the word stimuli (M = 1.81) in English, t(315) = 2.51, p = .013, but not in German, t(315) = -0.81, p = 0.419. However, this small difference of 0.17 orthographic neighbours between words and pseudoword was not considered problematic for the English LDT.
Procedure
The experiment was conducted using Milliseconds’ Inquisit 6 Web application. Participants first completed an informed consent form. The stimuli were split into two non-overlapping lists, each of which comprised 27 identical cognates, 27 close cognates, and 27 non-cognates, as well as their corresponding 81 pseudowords. Participants were randomly assigned to one list in the German language condition and the other in the English language condition. The order of words and pseudowords was randomised for each participant and the language order of the lists was randomized between participants. After the LDT, participants completed an abbreviated form of the LEAP-Q language background questionnaire and received a debriefing about the aim of the study.
Results
Only responses to target words were analysed. Response accuracy and latency to pseudowords are reported in Table 3 for completeness only. Data were cleaned and analysed separately for English and German stimuli. To crop outliers, unrealistically short response latencies under 300 ms, or longer than 1.5 seconds for English, and 1.1 seconds for German stimuli were removed. These cut-offs were established with visual inspection of the lower and upper 1% of the response latency distributions. Latencies with residuals deviating more than 2.5 SD from mean decision times for words or participants were also removed (Baayen et al., Reference Baayen, Davidson and Bates2008). This excluded less than 4% of the L2 English and L1 German data. (Generalized) linear mixed-effects models (GLMM) were used to analyse decision accuracy and decision latency for correct responses with the glmer and lmer functions of the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) in the R environment (R Core Team, 2017). Decision latencies had a significant right-tailed skew, and a box cox analysis (Box & Cox, Reference Box and Cox1964) suggested that a log-transformation of the data was appropriate. Accordingly, all response latencies were log-transformed. Participants and items were included as fully crossed random effects (Baayen et al., Reference Baayen, Davidson and Bates2008; Barr et al., Reference Barr, Levy, Scheepers and Tily2013).
Table 3. Mean response latencies, accuracy and Eye Movement Measures and Proportion Correct for Identical Cognates, Close Cognates, and Non-cognates in L1 German and L2 English
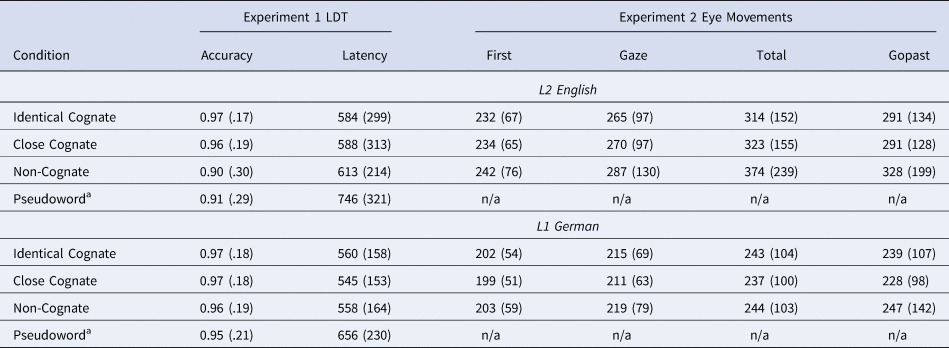
Note. Standard deviations are reported in brackets.
a Pseudoword decision accuracy and latency were not analysed and are included for completeness only.
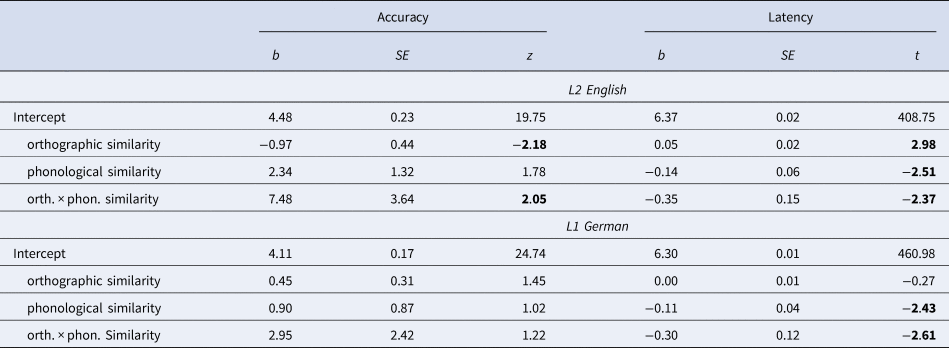
A priori contrasts (Schad et al., Reference Schad, Vasishth, Hohenstein and Kliegl2020) were defined to test the effect of cognate condition (identical cognate, close cognate, non-cognate). Helmert contrasts were chosen to first compare response latency and accuracy between identical cognates and close cognates in Contrast 1, and second to compare responses between cognates and non-cognates in Contrast 2. A significant result for the Contrast 1 would indicate a difference in the processing of identical compared to close cognates. A significant result for Contrast 2 would confirm the overall processing facilitation effect of cognates compared to non-cognates. In the continuous models, the uncorrelated principle components representing orthographic and phonological similarity were entered as continuous fixed effects, as well as their interaction. Random slopes for the cognate condition contrasts were included for participants, as were random slopes for orthographic and phonological similarity for participants in the continuous models, but removed for models in which their inclusion led to convergence problems. The observed response accuracy and latency for correct responses are displayed in Table 3 and the (G)LMM results in Tables 4 for the analyses of categorical cognate condition, and Table 5 for the analyses of the continuous predictors.
Table 4. Regression Results for the Effect of Cognate Status on Lexical Decision Accuracy and Latency in L2 English and L1 German
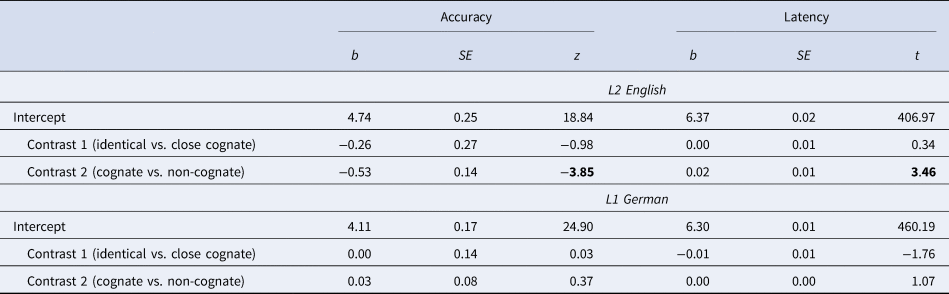
Note. Effects are considered significant when t/z > |1.96| and are marked in bold.
Table 5. Regression Results for the Continuous Effects of Orthographic and Phonological Similarity on Lexical Decision Accuracy and Latency in L2 English and L1 German
Note. Effects are considered significant when t/z > |1.96| and are marked in bold.
L2 English LDT
In the L2 English lexical decision task, the results for Contrast 1 revealed that there was no significant difference in response latency between identical and close cognates, while the results for Contrast 2 indicated that response latency was significantly longer for non-cognates compared to cognates (see Table 4). When orthographic and phonological similarity between English–German word pairs were modelled as uncorrelated continuous variables, both cross-language orthographic and phonological similarity had significant main effects on response latency. Higher orthographic similarity (i.e., low normalized Levenshtein distance) resulted in shorter response latencies, and higher phonological similarity (i.e., low normalized Levenshtein distance) resulted in longer response latencies (see Table 5). The significant interaction effect of orthographic and phonological similarity on response latency indicated that the effect of cross-language orthographic similarity was greater for words with high cross-language phonological similarity than for low phonological similarity (see Figure 1, panel L2).
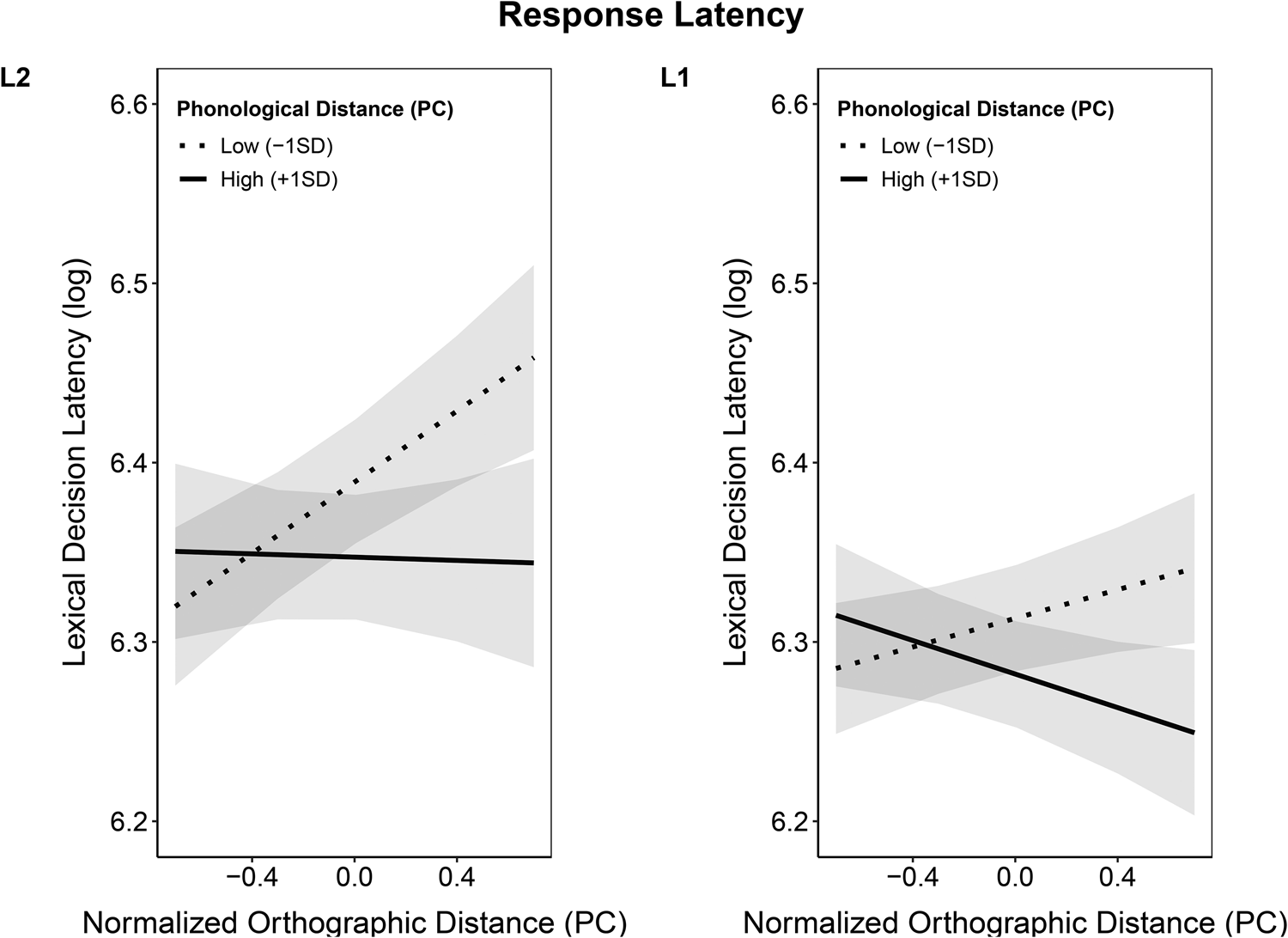
Figure 1. Interaction Effect of Orthographic and Phonological Similarity on Lexical Decision Latency in L2 English and L1 German
Note. The x-axis depicts the principle component representing the number of operations distinguishing the orthography and phonology of cross-language word pairs. Positive numbers therefore represent greater orthographic or phonological distance; negative numbers represent greater orthographic or phonological similarity.
The overall pattern was similar for response accuracy. In the L2 English lexical decision task, the results for Contrast 1 revealed that there was no significant difference in response accuracy between identical and close cognates, while the results for Contrast 2 indicated that response accuracy was significantly lower for non-cognates compared to cognates (Table 4). When orthographic and phonological similarity between English–German word pairs were modelled as uncorrelated continuous variables, cross-language orthographic similarity had a significant main effect on response accuracy, in that higher similarity resulted in more accurate responses (Table 5). The significant interaction effect of orthographic and phonological similarity on response accuracy indicated that the orthographic facilitation effect was greater for words with high phonological similarity, than for words with low phonological similarity (Figure 2, panel L2).
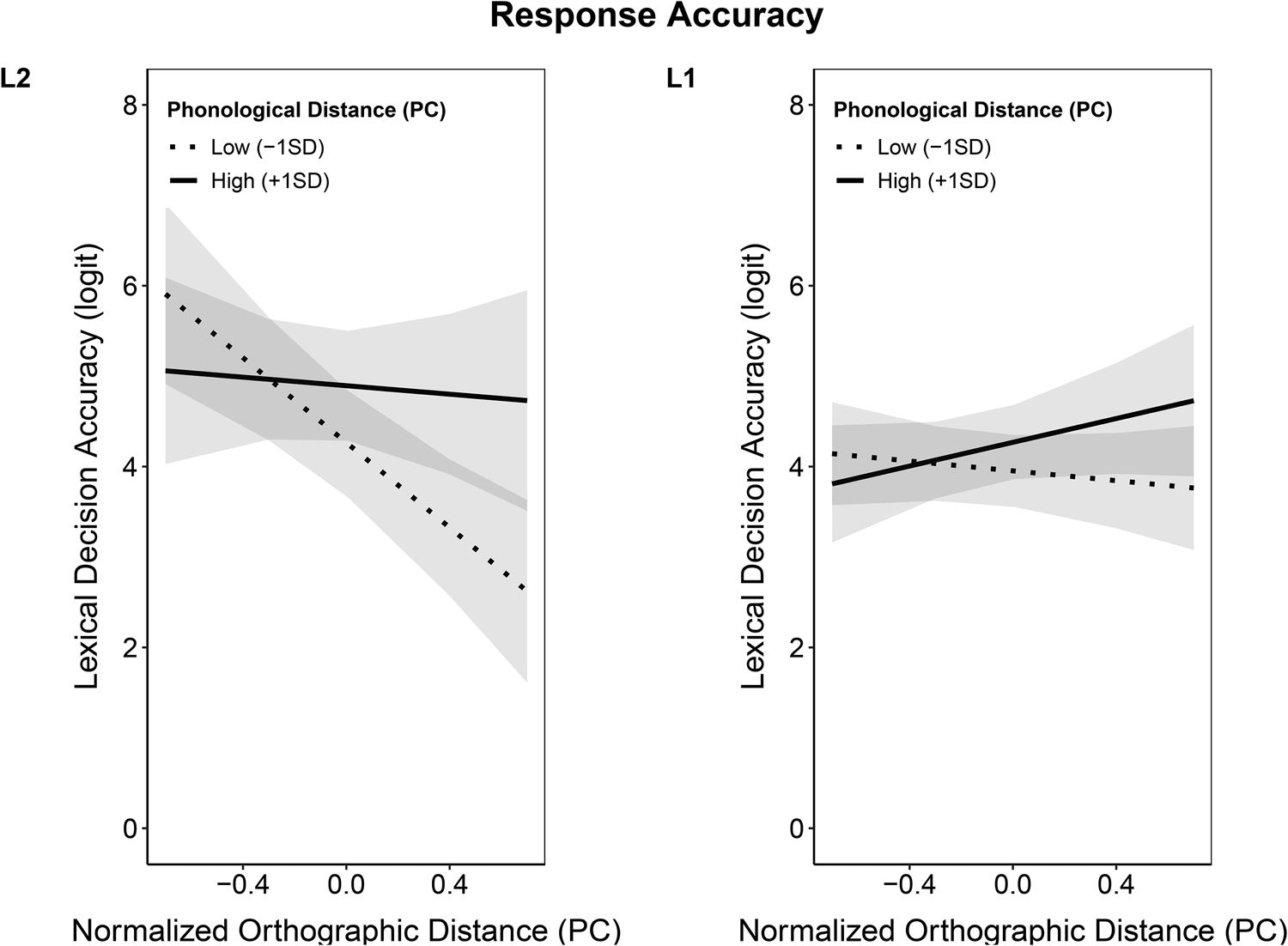
Figure 2. Interaction Effect of Orthographic and Phonological Similarity on Lexical Decision Accuracy in L2 English and L1 German
Note. The x-axis depicts the principle component representing the number of operations distinguishing the orthography and phonology of cross-language word pairs. Positive numbers therefore represent greater orthographic or phonological distance; negative numbers represent greater orthographic or phonological similarity.
A further set of models was run to assess whether the continuous effect of orthographic similarity could best be described as linear or non-linear. This was done by comparing the model fit of a series of nested models in which linear, quadratic, and cubic effects of orthographic similarity and their interaction with phonological similarity were progressively added and compared using likelihood ratio tests (Cohen et al., Reference Cohen, Cohen, West and Aiken2013; Glover & Dixon, Reference Glover and Dixon2004). Negative quadratic effects (e.g., a steep rise and then a flattening of the curve) would be expected if, for instance, the orthographic similarity effect was driven only by identical cognates and response latencies increased steeply from identical to close cognates and non-cognates, as described by Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010). Positive quadratic effects (e.g., an initial flat progression and then steep incline of the curve) would be expected if response latencies increased only for non-cognates. A summary of the model comparisons is provided in Table S2 in the Supplementary Materials, which suggests that the orthographic and phonological similarity and their interaction effects on response accuracy and latency were best described as continuous linear effects. The addition of non-linear effects of orthographic similarity did not significantly improve model fit, all χ2 (df = 2) < 6.
L1 German LDT
For the German stimuli, the planned contrasts found no differences between identical and close cognates, or between cognates and non-cognates. However, when orthographic and phonological similarity between English–German word pairs were modelled as uncorrelated continuous variables, cross-language phonological similarity had a significant effect on response latency, in that higher phonological similarity resulted in longer response latencies (Table 5). The significant interaction effect of orthographic and phonological similarity on response latency indicated that the effect of cross-language orthographic similarity was greater for words with high cross-language phonological similarity than for low phonological similarity (see Figure 2, panel L1).
Model comparisons were again used to assess whether the orthographic similarity effect on response accuracy and latency could best be described as linear or non-linear. The results of the nested model comparisons, summarized in Table S2 in the Supplementary Materials, indicate that the orthographic similarity effect and its interaction with phonological similarity could best be described as a continuous linear effect. The addition of non-linear effects of orthographic similarity did not significantly improve model fit, all χ2 (df = 2) < 6.
Discussion
In Experiment 1, German–English bilinguals completed a lexical decision task comprising identical cognates, close cognates, non-cognates, and matched pseudowords. They were presented half of the stimuli in English and the other in German in a fully randomized and counterbalanced design. There was a clear pattern of cognate facilitation in the participants’ L2. Both identical and close cognates were processed more accurately and faster than non-cognates and there was no discrete difference in the cognate facilitation effect between identical and close cognates. There was also clear evidence for a continuous linear orthographic similarity effect on response accuracy and latency, in that responses were more accurate and faster with increasing cross-language orthographic similarity. Conversely, there was also a clear inhibitory effect of cross-language phonological similarity in response latency. Importantly, the results suggest that orthographic similarity only had a strong facilitation effect when phonological similarity was also high. Model comparisons further suggested that the continuous effect of orthographic similarity on response accuracy and latency was best described as a linear effect, rather than a more complex non-linear effect.
In the readers’ L1, there were no clear differences in response accuracy or latency between identical cognates, close cognates, or non-cognates. However, phonological similarity did have an inhibitory effect on response latency, and orthographic similarity appeared only to have a facilitation effect when phonological similarity was high.
These results fully replicate the cognate facilitation effect in word recognition in bilinguals’ L2 (Lauro & Schwartz, Reference Lauro and Schwartz2017), although there was no clear evidence of a discrete difference in the facilitation effect between identical and close cognates. There was limited evidence of an orthographic facilitation effect for cognates with high phonological similarity in the bilinguals’ L1. To test whether this pattern of results could be replicated during more complex language comprehension, i.e., when reading words in the context of a sentence, the same stimuli were used in Experiment 2 in which the identical cognates, close cognates, and non-cognates were embedded in simple sentence frames and read by an independent sample of German–English bilinguals.
Experiment 2: Cognate facilitation in sentence reading
Method
Participants
Participants were 58 students recruited at the University of Würzburg. All participants gave informed consent prior to participation and were reimbursed in course credits or at the minimum wage rate. The university board of ethics granted ethical approval for this study. To assess language dominance, participants completed a language history questionnaire based on the Language Experience and Proficiency Questionnaire (LEAP-Q; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007). One participant did not state German as their first language and their data were excluded from the analyses. The remaining N = 57 participants reported German as their L1 and English as either their L2 (95%) or L3 (5%). They were on average 27 years old (SD = 9.6, range = 19–65), and were predominantly female (84%). Table 1 provides an overview of the participants’ language proficiency, proportion of language use, and preferred language.
Sentence reading task
For each target word pair used in Experiment 1, an English and a German equivalent sentence was constructed (see Table 6). The sentences were semantically and syntactically identical across language versions and were on average 9 words long (range 6 to 14 words). Each target word was preceded by an adjective. In a preliminary study, 39 university students, who did not take part in the main study, completed a cloze task (Taylor, Reference Taylor1995) in which they read each sentence up to the pretarget adjective in a self-paced moving window experiment. They then typed the next word of the sentence, i.e., the target word. The average predictability of the target words was close to zero in both languages and did not vary significantly between cognate conditions (see Table 2).
Table 6. Example Sentences for L1 German and L2 English Sentences with Embedded Identical Cognate, Close Cognate, and Non-Cognate Target Words
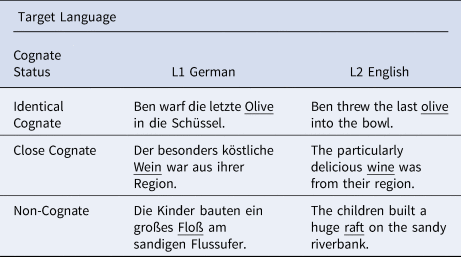
Note. Target words are underlined for demonstration purposes only.
Procedure
At the beginning of the test session, each participant completed the language questionnaire on a laptop. A Dual Portable eye-tracker (SR Research, Ontario, Canada) was used to record eye-movements during reading at a rate of 1000 Hz and spatial resolution of 0.01°. Stimuli sentences were presented on a LCD monitor with a resolution of 1024 x 768 pixels. Participants sat at a viewing distance of 65 cm with an assisting chin rest to reduce head movements. Sentences were presented in Courier New font in black, size 16, on a white background using the Experiment Builder software (SR Research). A nine-dot calibration of the eyetracker was then conducted and validated with each participant until a calibration accuracy of at least 0.5° was achieved. Four practice sentences were each followed by a yes-no comprehension question, to which participants had to respond on a gamepad. The eyetracker was recalibrated after the practice trials and as necessary when x or y-axis drift was detected. Reading was binocular while the right eye was recorded. Each sentence was preceded by a fixation cross on the left of the screen and presented on a single line. Participants ended the trial by pressing a button on a gamepad and all sentences were followed by a forced-choice comprehension question to which participants responded yes or no with buttons on the gamepad. As the target words were always either the subject (An enormous taxi took her home, target word in italics) or object (Tobias found the last gold in the mine) of the sentence, the comprehension questions were closely related to the target words (e.g., Did the taxi bring her home? Did Tobias find the gold?). Comprehension was high for all participants in English (all > 84%) and German (all > 90%).
Analogous to Experiment 1, sentence stimuli were split into two non-overlapping lists, each of which comprised 27 identical cognates, 27 close cognates, and 27 non-cognates. Participants were randomly assigned to one list in the German language condition and the other in the English language condition. An additional 15 sentences were initially presented in each language version but dropped for analyses, as the target words did not correspond to the identical, close, and non-cognate definitionsFootnote 1. Trial order was randomised for each participant and the language order of the lists was randomized between participants.
Results
The eye movement data were cleaned and analysed separately for English and German sentences. In the first stage, fixations of less than 80 ms were combined with an adjacent fixation if this was within .5° distance. Shorter fixations of 40 ms were merged with an adjacent fixation within 1.25° distance. Trials were deleted in which a blink occurred on the target word, or the target word was skipped on first-pass reading of the sentence, removing 5.4% of the German and 5.8% of the English data.
Four eye movement measures were calculated (Rayner, Reference Rayner1998, Reference Rayner2009), including first fixation duration (the only fixation or the first of multiple fixations on a target), gaze duration (all fixations on a target before the first saccade exits the target), total viewing time (all fixations on a target), and gopast time (all fixations on a target before the first saccade exits the target in a progressive manner). The first two measures represent first-pass processing, whereas the latter two include processes of rereading and reanalysis. Fixation durations were deleted if their residuals deviated more than 2.5 SD from the mean for participants or items (Baayen et al., Reference Baayen, Davidson and Bates2008). Less than 2% of fixation durations were deleted in this way for each dependent measure.
Analogous to Experiment 1, the effect of cognate condition (identical cognate, close cognate, non-cognate) was tested by defining a priori Helmert contrasts (Schad et al., Reference Schad, Vasishth, Hohenstein and Kliegl2020). All eye movement measures had a right-hand skewed distribution and a box cox analysis suggested a log-transformation of the data. The eye movement measures were accordingly log-transformed and analysed using linear mixed effects models (LMM) in the R environment (R Core Team, 2017) with the lmer function of the lme4 package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015). Random slopes for the cognate condition contrasts were not included for participants due to high correlations and consequent convergence issues. The observed eye movement measures are displayed in Table 3 and the LMM results in Table 7 and Table 8.
Table 7. Regression Results for the Effect of Cognate Status on eye Movement Measures in L2 English and L1 German
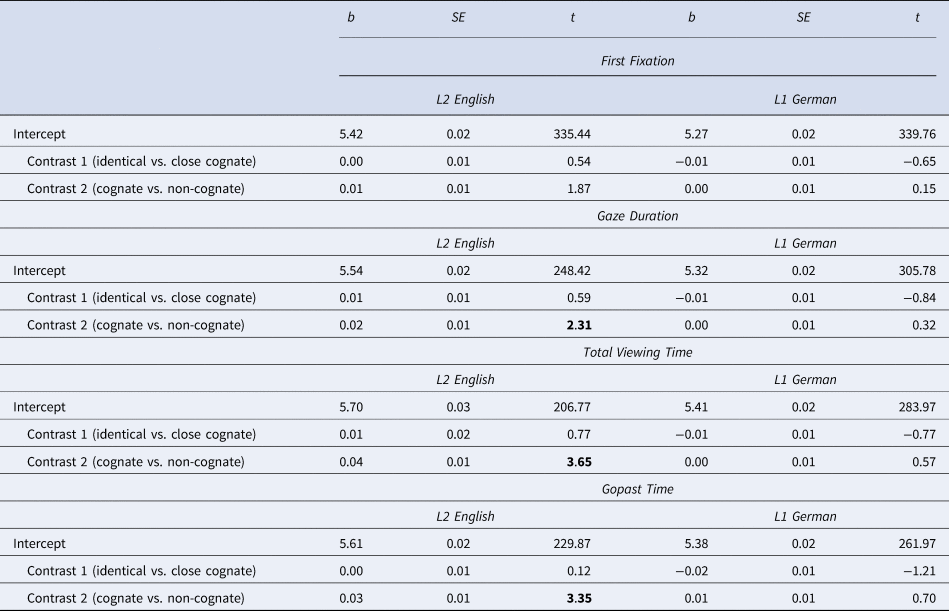
Note. Effects are considered significant when t > |1.96| and are marked in bold.
Table 8. Regression Results for the Continuous Effects of Orthographic and Phonological Similarity on Eye Movement Measures in L2 English and L1 German

Note. Effects are considered significant when t > |1.96| and are marked in bold.
L2 English sentence reading
For L2 English sentence reading, the results for Contrast 1 indicated that there were no significant differences in first fixations, gaze duration, total viewing time, or gopast time between identical and close cognates. However, the significant results for Contrast 2 in gaze duration, total viewing time, and gopast time indicated shorter reading durations on cognates compared to non-cognate target words (Table 7). When cross-language orthographic and phonological similarity were modelled as uncorrelated continuous variables, cross-language orthographic similarity had a significant main effect in gaze duration, total viewing time, and gopast time, in that higher similarity resulted in shorter reading durations (Table 8). There was no significant additional effect of phonology on any eye movement measure.
As in Experiment 1, model comparisons were again used to assess whether the orthographic similarity effect on eye movement measures and its interaction with phonological similarity could best be described as linear or non-linear. The results of the nested model comparisons, summarized in Table S2 in the Supplementary Materials, indicate that orthographic similarity and its interaction effect with phonological similarity could best be described as a continuous linear effect, all χ2 (df = 2) < 6.
L1 German sentence reading
For L1 German sentence reading, the planned contrasts found no differences between identical and close cognates, or between cognates and non-cognates (Table 7). Continuous cross-language orthographic and phonological similarity had no significant effects on the eye movement measures, regardless of whether linear, quadratic, or cubic effects were included in the models (see Table S2).
Discussion
In Experiment 2, the same words used in Experiment 1 were embedded in translation-equivalent English and German sentence frames and read by an independent sample of German–English bilinguals. Participants were presented half of the sentences in English and the other in German in a fully randomized and counterbalanced design. As in Experiment 1, there was a clear cognate facilitation effect for both identical cognates and close cognates, compared to non-cognates in eye movement measures. When cross-language orthographic similarity was included as a continuous predictor, gaze duration, total viewing time, and gopast time decreased linearly with increasing cross-language orthographic similarity. There were no discrete or continuous effects of cross-language orthographic similarity on fixations durations in the participants’ L1 German. These results fully replicate the cognate facilitation effect in word recognition in bilinguals’ L2 and in Experiment 1, although there was no evidence of a facilitation or inhibition effect in the bilinguals’ L1. Unlike in Experiment 1, there was no significant additional effect of phonological similarity over and above the facilitation effect of orthographic similarity.
General discussion
This study addressed three outstanding issues concerning the cognate facilitation effect in reading. The first goal was to test whether identical cognates (e.g., English hand, German Hand) are processed more efficiently than close cognates, matched on relevant word characteristics, but differing in a small proportion of letter identities and/or letter positions (e.g., English wine, German Wein), compared to non-cognates (e.g., English raft, German Floß). The significant cognate facilitation effects in both the single word recognition task in Experiment 1, and the sentence reading task in Experiment 2, replicate previous findings supporting a language non-selective account of bilingual lexical access (e.g., Caramazza & Brones, Reference Caramazza and Brones1979; Comesaña et al., Reference Comesaña, Soares, Sánchez-Casas and Lima2012, Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015; Cristoffanini et al., Reference Cristoffanini, Kirsner and Milech1986; De Groot & Nas, Reference De Groot and Nas1991; Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999, Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Guasch et al., Reference Guasch, Boada, Ferré and Sánchez-Casas2013; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004; Lemhöfer et al., Reference Lemhöfer, Spalek and Schriefers2008; Midgley et al., Reference Midgley, Holcomb and Grainger2011; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002). However, there was no evidence of a significant discrete difference in the magnitude of the cognate facilitation effect between identical cognates and close cognates in either experiment. Instead, likelihood ratio tests of models including linear and increasingly complex non-linear effects provided a clear indication of a linear, continuous facilitation effect of cross-language orthographic similarity. Although these findings are not consistent with recent evidence for discrete differences between the facilitation effect of identical cognates and close cognates (e.g., Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020), they do fit the general picture of facilitation effects that increase in magnitude with the degree of cross-language similarity (e.g., Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011).
A second goal was to incorporate and test the independent influence of cross-language phonological overlap on the reading of cognate and non-cognate words. The results of the continuous models of uncorrelated orthographic and phonological similarity found evidence in the single word recognition task that phonology modulated the facilitation effect of orthographic similarity. The results of Experiment 1 suggest that the facilitation effect of orthographic similarity was strongest for words with high phonological overlap, supporting the notion that phonology plays a secondary, but significant role in cognate facilitation (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). Specifically, the facilitation effect of orthographic similarity appeared to be attenuated when phonological similarity was low, suggesting that the activation of competing phonological representations may impact cognate facilitation effects (Dijkstra et al., Reference Dijkstra, Grainger and Van Heuven1999; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Schwartz et al., Reference Schwartz, Kroll and Diaz2007).
The third goal of this study was to assess the generalizability of cognate facilitation effects across reading tasks that involve subtly different cognitive processes. As previously alluded to, the expression of the orthographic similarity effect was very similar across word recognition and sentence reading tasks. However, the effect of phonological similarity was not evident in the sentence-reading task in Experiment 2, indicating that the greater language context of the sentence frames may have reduced the influence of phonology. Language context and task demands therefore appear to influence the extent to which phonology plays a role in cross-language activation in multilingual readers.
Cognate facilitation and orthographic similarity
The distinction between cognate and non-cognate words is widely used in psycholinguistic research and has greatly contributed to our understanding of bi- and multilingual language processing (Kroll et al., Reference Kroll, Gullifer, Zirnstein, Nicoladis and Montanari2016; Lauro & Schwartz, Reference Lauro and Schwartz2017; Lijewska, Reference Lijewska, Heredia and Cieślicka2020). However, for both practical and empirical reasons, this distinction may be better considered as a simplification of a continuum of cross-language overlap. First, words categorized as cognates are typically a mix of identical and non-identical cognates, which reflects the reality that there are many words that are orthographically similar but not identical across languages, and very few that are spelled identically (Frances et al., Reference Frances, Navarra-Barindelli and Martin2021). Second, there is evidence that orthographic similarity not only varies in magnitude across words contained in language corpora (Frances et al., Reference Frances, Navarra-Barindelli and Martin2021), but also that the magnitude of the cognate facilitation effect is influenced by the extent of orthographic and phonological cross-language similarity (Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). Defining cut-offs for continuous variables, such as word length, frequency, and predictability, is a widely used method in orthogonal experimental designs – for example, to compare reading times between long and short, or frequent and infrequent, or predictable and unpredictable words (e.g., Kliegl et al., Reference Kliegl, Grabner, Rolfs and Engbert2004). However, the cut-offs which exclude, for instance, words that are neither long nor short, are necessarily arbitrary, which can make comparisons of results across studies difficult and can mask interaction effects with other word characteristics (see Balota et al., Reference Balota, Cortese, Sergent-Marshall, Spieler and Yap2004 for a discussion).
From a theoretical perspective, it seems highly plausible that identical cognates need not have a special status in the bilingual mind, beyond their greater cumulative frequency across languages. In the present study, there was no significant difference in the magnitude of the facilitation effect between identical cognates and non-identical (close) cognates. There was, however, evidence of a gradual effect of cross-language similarity, influenced by both orthographic and phonological cross-language overlap. Theoretically, this is compatible with computational models of bilingual word processing, assuming that non-identical cognates produce partial cross-language activation and therefore elicit less facilitation than identical cognates. Current interactive activation models of bilingual word recognition assume that a visually presented letter-string activates representations stored in an integrated mental lexicon, which share orthographic and phonological features (e.g., Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002; Thomas & Van Heuven, Reference Thomas, Van Heuven, Kroll and De Groot2005; Van Hell & De Groot, Reference Van Hell and De Groot1998; Van Heuven et al., Reference Van Heuven, Dijkstra and Grainger1998). The degree of activation depends on the degree of the overlap of orthographic and phonological features. A cognate read in an L2 sentence thus activates the corresponding L1 representation of the cognate to the degree of the cross-language similarity. For English–German cognates such as hand/Hand, co-activation is therefore high, while co-activation for near-cognates such as wine/Wein is lower. Importantly, the degree of cross-language activation, and thus cognate facilitation, should be a function of the similarity of the lexical representations (Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). The gradual facilitation effect of cross-language similarity is also compatible with frequency-based accounts of cognate facilitation (Midgley et al., Reference Midgley, Holcomb and Grainger2011; Peeters et al., Reference Peeters, Dijkstra and Grainger2013; Voga & Grainger, Reference Voga and Grainger2007; Winther et al., Reference Winther, Matusevych and Pickering2021), assuming that exposure to identical cognates in multiple languages elicits a greater cumulative frequency effect than non-identical, close cognates.
This study adds to the evidence that the cognate facilitation effect can be viewed as a continuous effect of orthographic similarity, which increases in magnitude with cross-language overlap of word representations. However, this does not mean that cognate facilitation and orthographic similarity effects are different phenomena, rather that a continuous orthographic similarity effect underlies the well-established categorical cognate facilitation effect. Whether researchers refer to one or the other will depend on their chosen experimental design, as the continuum of orthographic (or phonological) similarity can be partitioned to define categories of varying cross-language similarity, but these cut-offs are essentially arbitrary and may vary across studies.
The role of phonology
The attenuation of the orthographic similarity effect in the single word recognition task when phonological similarity was low indicated cross-language activation of phonological codes. This finding is relevant to both the selection of cognate stimuli for future studies and the interpretation of cognate facilitation effects across different languages, as phonological overlap can vary considerably across orthographically similar cognate word pairs (Costa et al., Reference Costa, Comesaña and Soares2022; Frances et al., Reference Frances, Navarra-Barindelli and Martin2021). Importantly, orthographic and phonological similarity are highly correlated, regardless of whether human ratings or objective similarity measures are used (e.g., Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010; Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011), potentially obscuring independent and interaction effects. Different approaches have been used to address this issue. One option is to select stimuli to obtain an orthogonal experimental design (e.g., Frances et al., Reference Frances, Navarra-Barindelli and Martin2021; Schwartz et al., Reference Schwartz, Kroll and Diaz2007). This, however, has the drawback that only a few cognates will qualify as having low orthographic and high phonological overlap and vice versa, and phonologically identical cognate pairs are exceedingly rare (see Frances et al., Reference Frances, Navarra-Barindelli and Martin2021). Other studies have used an alternative method of using residualized scores of phonological similarity (Carrasco-Ortiz et al., Reference Carrasco-Ortiz, Amengual and Gries2021; Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010). This study demonstrates the option of using DISC annotations of phonology (Baayen et al., Reference Baayen, Piepenbrock and Van Rijn1993) to generate comparable normalized Levenshtein distance scores for orthography and phonology (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012), together with principle component analysis to extract uncorrelated orthographic and phonological similarity components. The presented results add to the growing evidence that phonological similarity should be taken into account when designing cognate facilitation studies and interpreting their results.
The influence of task demands
This study employed two of the most widely employed methods of investigating word recognition processes in reading: the lexical decision task and eye tracking during sentence reading. Comparisons of word reading times in eye movement corpora and lexical decision mega-studies find only moderate correlations between decision latencies and eye movement measures on the same wordsFootnote 2 (Dirix et al., Reference Dirix, Brysbaert and Duyck2019; Kuperman et al., Reference Kuperman, Drieghe, Keuleers and Brysbaert2013). A plausible explanation for these low correlations is that lexical decisions require an active response from a participant, which in turn requires them to activate the representation of a presented string of letters in their mental lexicon. According to models of word recognition, this involves a spread of activation across orthographic, phonological, and semantic representations of a word. In the case of bi- or multilingual readers, activation may spread across representations of words belonging to different languages known to the reader, resulting in greater cumulative activation for words with high cross-language overlap in their features. Eye movement studies of reading, on the other hand, do not typically require an overt response and, in the case of silent reading, do not assess the accuracy of individual word processing. Indeed, eye movement studies of sentence reading typically do not exclude trials in which participants respond incorrectly to comprehension questionsFootnote 3. The added sentence context also introduces complex factors such as syntactic and semantic constraints, which influence both word prediction and integration during reading (Staub, Reference Staub2015). Sentence context may also activate language nodes that can provide top-down constraints on word activation to words of the target language, or constrain pre-activation of lexical candidates for upcoming words (Altarriba et al., Reference Altarriba, Kroll, Sholl and Rayner1996; Van Assche et al., Reference Van Assche, Duyck and Hartsuiker2012). Furthermore, several decades of work on reader's misinterpretation of sentences with non-canonical sentence structure (e.g., The dog was bitten by the man) or ambiguous sentence structure (e.g., Mary saw the man with the binoculars), suggests that language processing is sometimes only partial and semantic representations can be incomplete, superficial, or inaccurate (“good enough” processing, Ferreira et al., Reference Ferreira, Bailey and Ferraro2002; Karimi & Ferreira, Reference Karimi and Ferreira2016). Alternatively, misinterpretations of implausible or ambiguous information due to such “good enough” processing may be attributed to post-interpretative retrieval processes, rather than incorrect initial parsing of information (Cutter et al., Reference Cutter, Paterson and Filik2022).
Taken together, reading a word in the context of a sentence introduces many factors that complicate the language comprehension process, including language context, which may be responsible for attenuating cognate facilitation effects in eye movement studies. It therefore seems plausible that the subtle inhibitory effect of phonology on cognate facilitation may be evident in single word recognition, but masked in sentence reading contexts due to the greater influence of higher-level language processes.
Further considerations
The results of the two presented experiments differ in some relevant aspects to other published studies of cognate facilitation. The most prominent difference is the absence of a consistent cognate facilitation effect in the bilinguals’ L1 in either the lexical decision or sentence reading experiment. The only influence on L1 reading was found for the facilitation effect of orthographic similarity in single word reading for cognates with high cross-language phonological overlap. Previous research has found evidence of cognate facilitation effects in multilinguals’ L1 word recognition (e.g., Dutch–English–French trilinguals, Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), sentence reading (e.g., English-French bilinguals, Titone et al., Reference Titone, Libben, Mercier, Whitford and Pivneva2011; Dutch–English bilinguals, Van Assche et al., Reference Van Assche, Duyck, Hartsuiker and Diependaele2009) and text reading (e.g., Dutch–English bilinguals, Cop et al., Reference Cop, Dirix, Van Assche, Drieghe and Duyck2017). A plausible explanation for this difference may lie in the nature of language exposure, which has been shown to vary extensively across multilingual language-users (for recent discussions, see Gullifer & Titone, Reference Gullifer and Titone2020; Titone & Tiv, Reference Titone and Tiv2022). The participants in this study were all native German-speakers, who learned English as a foreign language at school. However, it may be that the extent of their daily L2 exposure was not sufficient to elicit an influence on native language performance. An alternative explanation may be that the overall level of language proficiency of the predominantly university educated bilinguals attenuated any L2 influence on L1 word processing, particularly as the stimuli were selected to have average word frequencies to allow an exact matching of identical cognates, close cognates, and non-cognates.
It should also be noted that recent studies have shown that the proportion of identical cognates used in lexical decision studies influences the expression of cognate facilitation effects (Arana et al., Reference Arana, Oliveira, Fernandes, Soares and Comesaña2022; Comesaña et al., Reference Comesaña, Ferré, Romero, Guasch, Soares and García-Chico2015). The present study employed equal proportions of identical cognate, close cognate, and non-cognate target words in the LDT and eye-tracking experiments, leading to a high proportion of cognate to non-cognate words, which may have increased the cognate facilitation effect to some extent. However, due to the abundance of non-cognate words in the language equivalent sentence frames (~95%), this effect is likely to be negligible in the eye movement experiment. It is therefore plausible that the attenuation of the cognate facilitation effect commonly found in sentence reading compared to lexical decision studies may in part be due to the far lower ratio of cognate to non-cognate words in sentence contexts.
Conclusion
Taken together, there is abundant experimental evidence across different tasks and languages that multilingual language-users do not “switch off” a non-target language during language comprehension (Vanlangendonck et al., Reference Vanlangendonck, Peeters, Rueschemeyer and Dijkstra2020), and that cross-language similarity facilitates word recognition, consistent with the assumption of language non-selectivity in theoretical and computational models of bilingual language processing (Dijkstra & Van Heuven, Reference Dijkstra and Van Heuven2002; Van Heuven & Dijkstra, Reference Van Heuven and Dijkstra2010; Winther et al., Reference Winther, Matusevych and Pickering2021). The apparent absence of a discrete difference in the expression of the cognate facilitation effect between identical and close cognates in word recognition and sentence reading in this study, together with the clear evidence for continuous linear orthographic similarity effects, supports the gradual facilitation account of cross-language overlap in word recognition (Van Assche et al., Reference Van Assche, Drieghe, Duyck, Welvaert and Hartsuiker2011). However, as reported in previous studies, effects of cross-language overlap appear to be weaker in tasks involving greater language context (Lauro & Schwartz, Reference Lauro and Schwartz2017). In single word recognition, the facilitation effect of orthographic similarity appeared to be dependent on a high degree of phonological cross-language overlap. This suggests that studies employing cognates to investigate the effects of cross-language similarity on multilingual language processing should account for the independent influence of phonology in their experimental designs, particularly when studying language pairs with large cross-language differences in phonology or inconsistent grapheme-phoneme correspondences. Studies of cognate facilitation should also either use stimuli representing the full range of orthographic similarity evident in language corpora, or clearly state the decision process behind defining cut-offs on the scale of orthographic similarity to define cognate and non-cognate categories.
Supplementary Material
The supplementary material for this article can be found at https://doi.org/10.1017/S1366728923000949
Table S1
Table S1 lists the 162 English–German word pairs that were selected for this study, of which 54 pairs were identical cognates, 54 pairs were close cognates, and 54 pairs were non-cognates.
Table S2
Table S2 summarizes the likelihood ratio tests (Cohen et al., Reference Cohen, Cohen, West and Aiken2013, pp. 508–509; example in Glover & Dixon, Reference Glover and Dixon2004) for the analyses of linear and non-linear effects of orthographic similarity of response accuracy, latency, and eye movement measures. Model complexity is progressively increased by first adding quadratic (x2), and then cubic effects (x3) of orthographic similarity. The model fit of each model is compared with the previous, less complex model.
Acknowledgments
Simon P. Tiffin-Richards is now at the Department of Educational Research and Educational Psychology, Leibniz Institute for Science and Mathematics Education, Kiel, Germany. This research was funded by a grant from the German Research Foundation (Deutsche Forschungsgemeinschaft, TI 711/1-1).













 Open access
Open access