



Introduction
On 31 December 2019, the WHO China Country Office was informed that cases of pneumonia of unknown aetiology were found in Wuhan City, Hubei Province of China [Reference Lu, Stratton and Tang1–Reference Na4]. On 7 January 2020, the Chinese authorities identified a new type of coronavirus. And the coronavirus study group of the International Committee on Taxonomy of Viruses named it as severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) on 11 February 2020 [5]. On the same day, WHO named this new infectious disease as coronavirus disease 2019 (COVID-19) [6].
On 23 January 2020, the Chinese government initiated the first-level response to major public health emergencies. The central and all levels of governments took a combination of measures to prevent and control the outbreak of COVID-19. Until 12 March 2020, the number of daily confirmed cases out of Hubei had reduced to 3. Considering the limited number of active COVID-19 cases, the levels of response to major public health emergency in many regions were adjusted to second- or third level. Until the end of June, only 2750 local cases were newly confirmed out of Hubei, averaging 25 cases per day.
In the meantime, the outbreak of COVID-19 has become a global health threat as more than 200 countries and regions from Africa, America, eastern Mediterranean, Europe, South-East Asia and western Pacific are being influenced by COVID-19. Until 30 June 2020, a total of 10 185 374 cases had been confirmed around the world, including 503 862 deaths [7]. The growing trend of confirmed COVID-19 cases has not been effectively contained globally. Previous studies have reported the aetiological, epidemiological, clinical characteristics and treatment of COVID-19 cases [Reference Jantien8–Reference Dawei13], but few researchers have analysed the knots of COVID-19 case number with spline regression. After the implementation of controlling measure, the number of COVID-19 cases showed non-linear characteristics and non-trend patterns. Splines allow for smooth transitions and subtle structural shifts by piecing together different polynomial line segments, which is an alternative model to deal with the characteristics of COVID-19 case number. Agiwal's study [Reference Agiwal14] showed spline function is useful to convert the non-linear trend of newly COVID-19 cases into a linear pattern. Sousa et al. [Reference Sousa15] proposed an automatic method based on the minimisation of the sum of squared residuals plus a penalty to estimate the knot number and locations. Demertzis et al. [Reference Demertzis16] applied regression splines of random knots and complex-network regression splines to fit cumulative COVID-19 infection, death and ICU patient curve of Greece, which performed better than cubic fittings. In these studies, social and medical factors were not considered, which would influence the spread of SARS-CoV-2. And as far as we know, there were no studies analysing the data of COVID-19 cases in China with spline terms.
Therefore, this study was conducted to analyse the cumulative COVID-19 case number during the first-level response in provinces out of Hubei, who experienced importing, spreading and containing stages during this period. Influencing factors at province level were considered, too. The first confirmed cases in the provinces out of Hubei were all imported cases, indicating the influence of transient population from Hubei. Detection, diagnosis, isolation and treatment of COVID-19 cases heavily relied on the public health resources in each province, and population susceptibility might be influenced by demographic characteristics, economic status and access to COVID-19 information. Stepwise procedure was used to select knot numbers, locations and covariates, which were statistically selected [Reference Marsh17]. The objectives of this study were: (1) to locate the knots of COVID-19 case number, (2) to describe the change pattern of each segment; (3) to explore the difference of change patterns among eastern, central and western provinces.
Methods
Data collection
The daily numbers of newly confirmed COVID-19 cases between 19 January 2020 and 12 March 2020 for all provinces (except Hubei) were obtained from the websites of Provincial Municipal Health Commission. This 54 day research period was chosen specifically because the first COVID-19 case out of Hubei was confirmed on 19 January 2020 and 26 provinces adjusted emergency response to second- or third level before 12 March 2020. Provinces initiating the first-level response to major public health emergency between 23 January 2020 and 25 January 2020 were included, and provinces with incomplete data or reporting less than 100 cases during the research period were excluded.
Daily transient population size at the province level was obtained from Qianxi Map, an open data platform funded by Baidu [18]. Baidu provides mobile termination service for more than 1.1 billion people and location-based service (LBS) over 120 billion times per day in China. When a customer sends a service request to Baidu, his or her location is included in the request. Therefore, the transient population to any provinces and regions are recognised through the location-based system, no matter what types of transportation they take. Migration scale index, calculated based on LBS data, represents the size of the transient population. It is comparable horizontally among provinces or regions, and one migration scale index is equal to about 56 137 travellers [Reference Yuan19]. For each included province, daily migration scale index from Hubei was collected.
Baidu index (BI) of two variances of novel coronavirus and three variances of novel coronavirus pneumonia was used to reflect public attention to COVID-19. This index was calculated based on the number of times that a word appeared in Baidu search engine, which was the largest search engine in China, holding 63.56%–72.72% market share in China from January 2020 to March 2020 [20, 21]. These variances had the highest searching frequency in Baidu search engine among the ones related to COVID-19 during the research period.
Yearly demographic, economic and public health resource data of each province in China were extracted from Chinese Health Statistical Yearbook 2019, published by Chinese National Municipal Health Commission on 1 August 2019 [22]. This book presented Chinese health care and inhabitant's health status in the whole nation and each province in 2018. Provinces were grouped into eastern, central and western, according to the geographic location. Population by age groups (0–14 years old, 15–64 years old and over 65 years old) and sex ratio (male/female) at province level were extracted from this book, since previous studies had reported older age and gender as potential factors affecting the risk of COVID-19 at personal level [Reference Sun23, Reference Bulut and Kato24]. Per capita gross domestic product (GDP), per capita health care expenditure, number of registered doctors, nurses, beds in infectious disease department and public health professionals per 1000 population at province level were collected as well, because they probably would reflect economic status related to general health and public health resources related to infectious disease.
Data analysis
Continuous variables were presented as median and inter-quartile range (IQR). Categorical variables were described as frequencies and percentages. Pearson correlation was conducted to explore the correlation among daily-reported variables, and Spearman rank-order correlation was conducted among annually reported variables. Annually or daily reported variables, among which there was no correlation, would be included in multivariate regression. Interaction terms of included variables would be included, if their effects on containing pandemic might be related. Then, multivariable analysis with spline terms was conducted to fit the number of cumulative COVID-19 cases at province level. In order to explore the possibility of different knots in eastern, central and western regions, four models were built based on data of eastern, central, western and all included provinces, respectively. The general model for k knots in an n degree polynomial regression was

where Y was cumulative COVID-19 case number and X represented the number of days since 19 January 2020. The X values of the k knots were designated ti where i = 1,2…k. Since the number and location of spline knots were unknown, a series of dummy variables (Di) were created as follows:
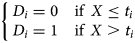
where ti = 1,2,…,53. Linear (n = 1), quadratic (n = 2) and cubic (n = 3) adjustments were applied, respectively. Stepwise regression was used to select the degree of adjustment, knot locations and covariates. Variance inflation factor (VIF) was used to assess co-linearity. Adjusted R-square (R 2) and Akaike information criterion (AIC) were used to evaluate the performance of the models. All the analysis was performed with Statistical Analysis System (SAS, version 9.4, SAS Institute).
Results
Characteristics of provinces out of Hubei
Data from 22 provinces in China were analysed in this study. As of 12 March 2020, the median of cumulative COVID-19 case number in the 22 provinces was 459 (IQR: 245–935), while Guangdong, Henan, Zhejiang and Hunan reached over 1000 cases (Fig. 1). Central provinces had a median of 962 cases, when the data for eastern and western provinces were 346 and 252, respectively (Table 1).

Fig. 1. Cumulative number of COVID-19 cases for 22 provinces from 19 January 2020 to 12 March 2020.
Table 1. Characteristics of provinces out of Hubei (median, inter-quartile range)

Migration scale index out of Hubei from 19 January to 12 March are shown in Figure 2. Before 23 January 2020, migration scale index out of Hubei was higher than 6, which was similar to that in 2019. On 24 January, the Chinese government locked down 14 cities in Hubei due to the quick spread of COVID-19, when migration scale index dropped to less than 5. In order to contain SARS-CoV-2 spreading further, the whole province was locked down before 27 January. Then, the index plunged to less than 1, but the data were experiencing an upward trend in 2019. Until 12 March, the index stayed at around 0.4, which was much lower than that in 2019. Figure 3 showed the change of migration scale index from Hubei to eastern, central and western provinces. The peak value of migration scale index was much lower in western provinces than that in eastern or central provinces, as well as the total migration scale (Table 1).
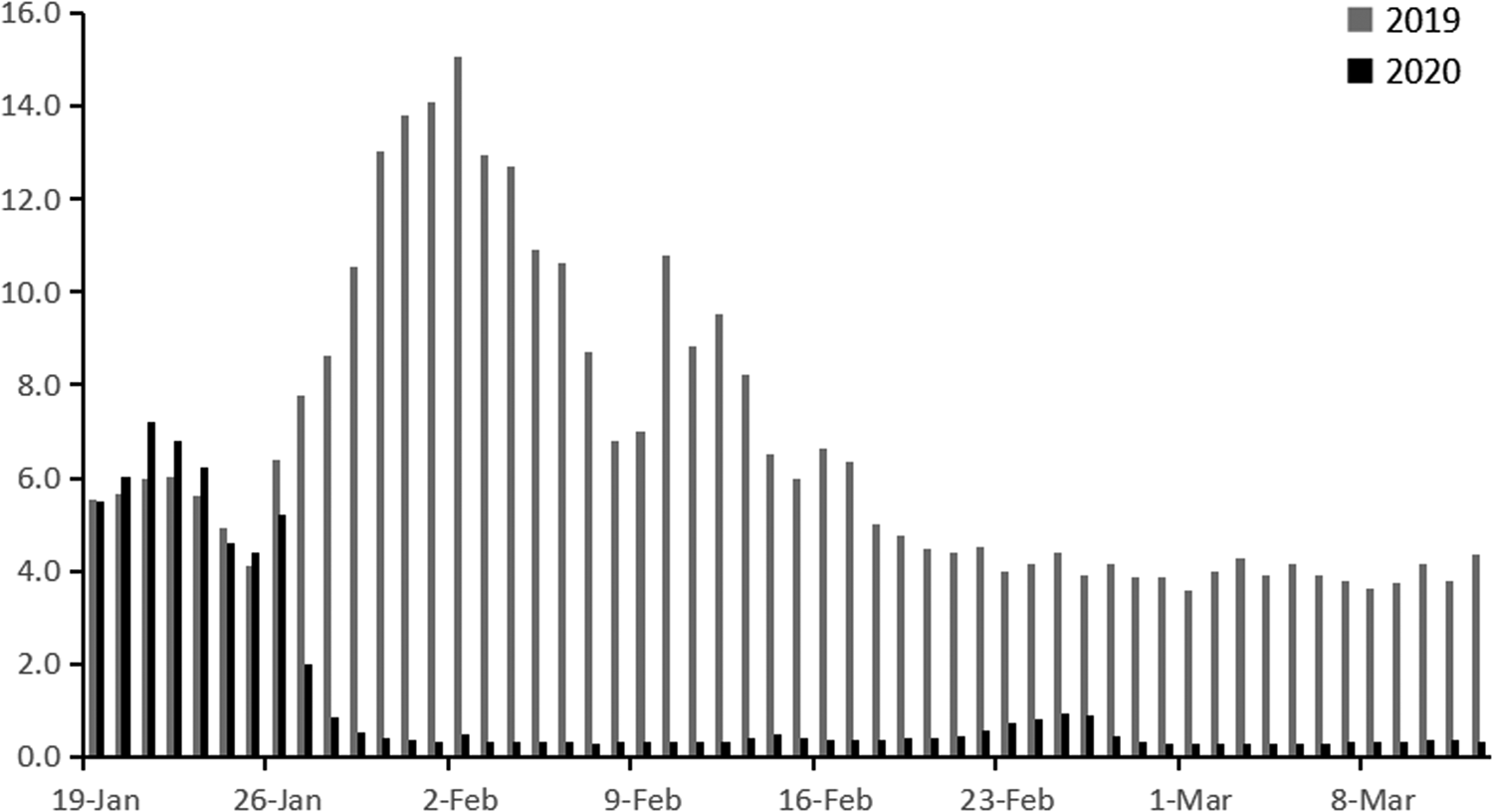
Fig. 2. Migration scale index out of Hubei from 19 January 2019 to 12 March 2019 and from 19 January 2020 to 12 March 2020.
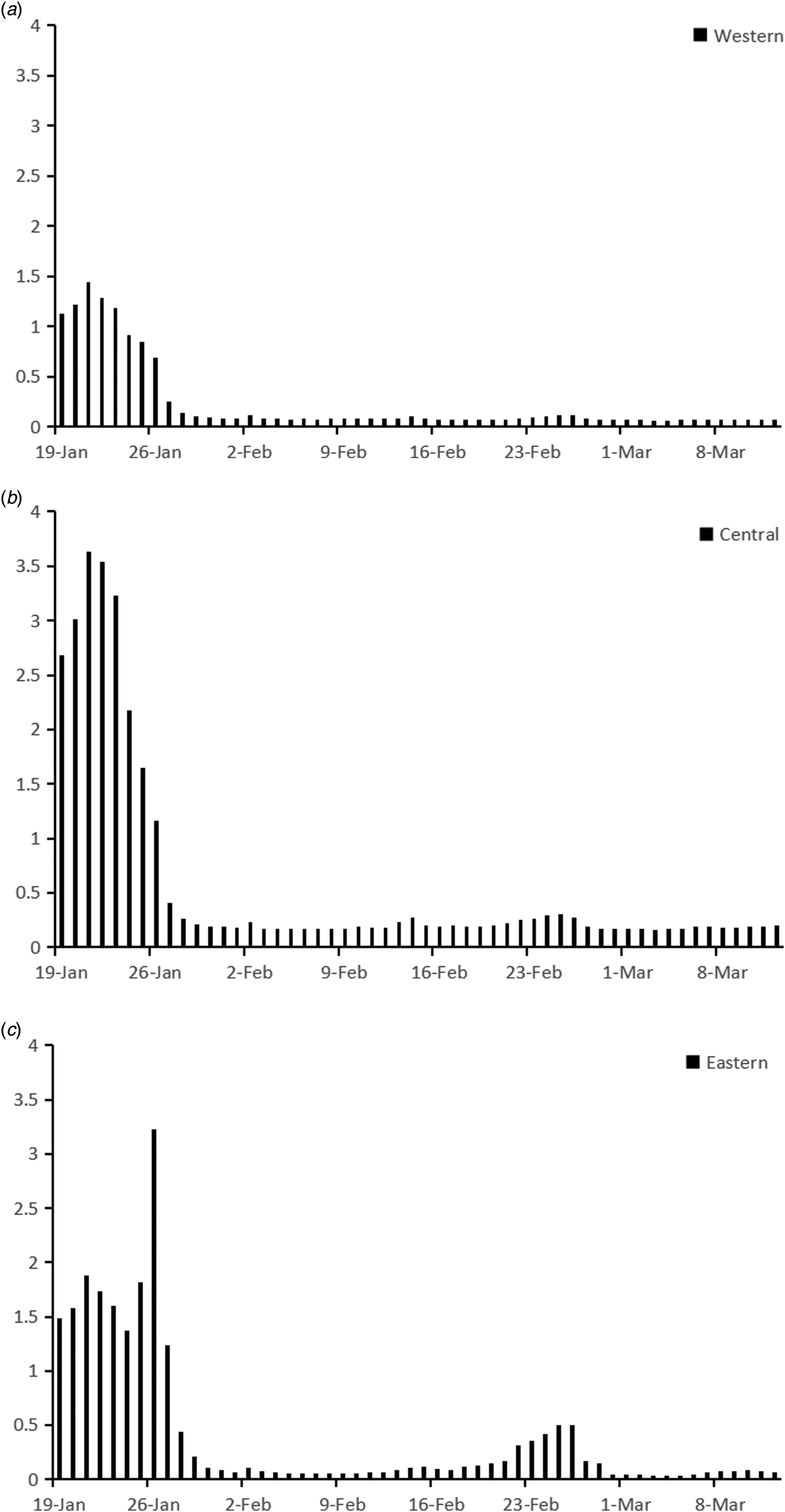
Fig. 3. Migration scale index from Hubei to eastern, central or western province from 19 January 2020 to 12 March 2020.
BI from 19 January 2020 to 12 March is shown in Figure 4. Before 19 January, BI for COVID-19 was less than 10 000 in China. After that, it surged from 34 506 on 19 January to the top of 2 490 679 on 25 January. Then the index decreased gradually to around 500 000 at the end of February and fluctuated between 400 000 and 500 000 before 12 March. Among the eastern, central and western provinces, change patterns of BI were similar, but in western provinces the value of BI was lower (Fig. 4 and Table 1).
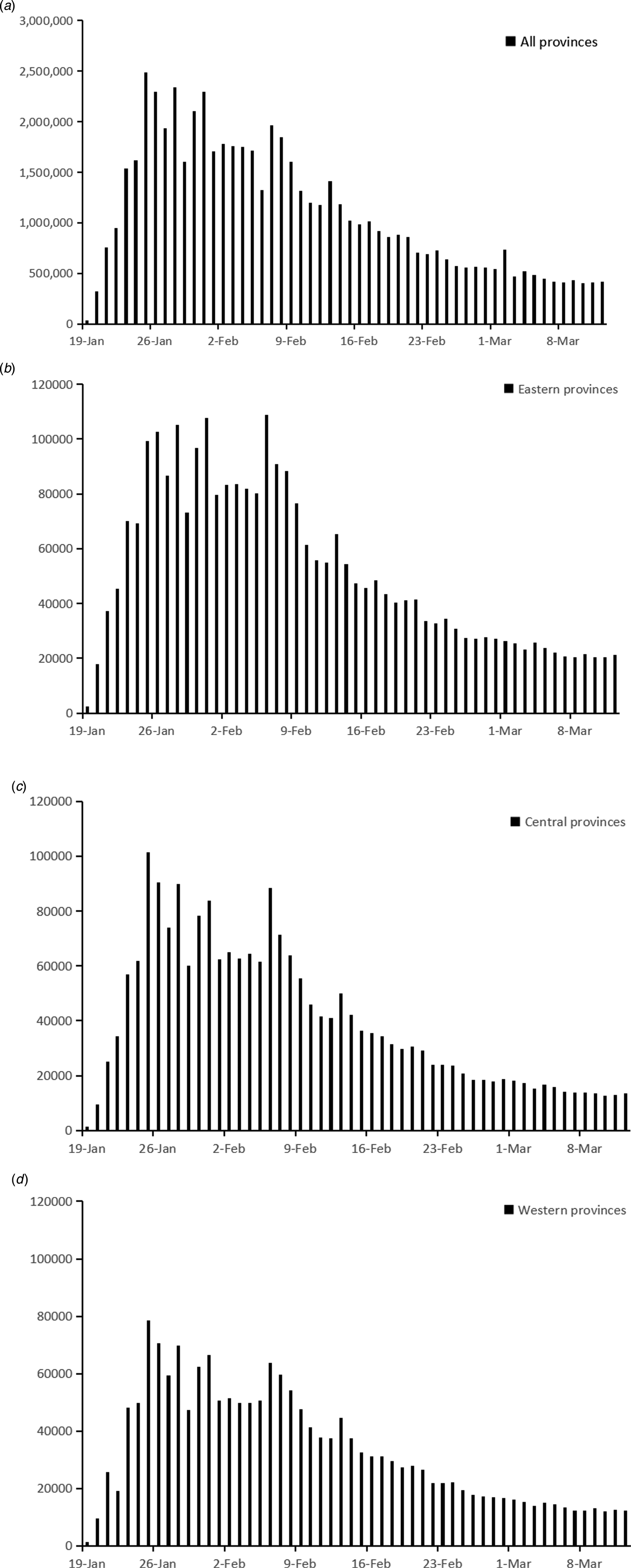
Fig. 4. BI for COVID-19 from 19 January 2020 to 12 March 2020.
The annually reported data of eastern, central and western provinces were shown in Table 1. Medians of population by age groups were highest in central provinces, when sex ratios were similar among the three regions. With regard to public health resource per 1000 population, the medians of registered doctors and nurses were highest in eastern provinces, while the western provinces owned the highest median of public health professionals. With regard to economic status, eastern provinces had significantly higher per capita GDP and health care expenditure.
Correlation analysis
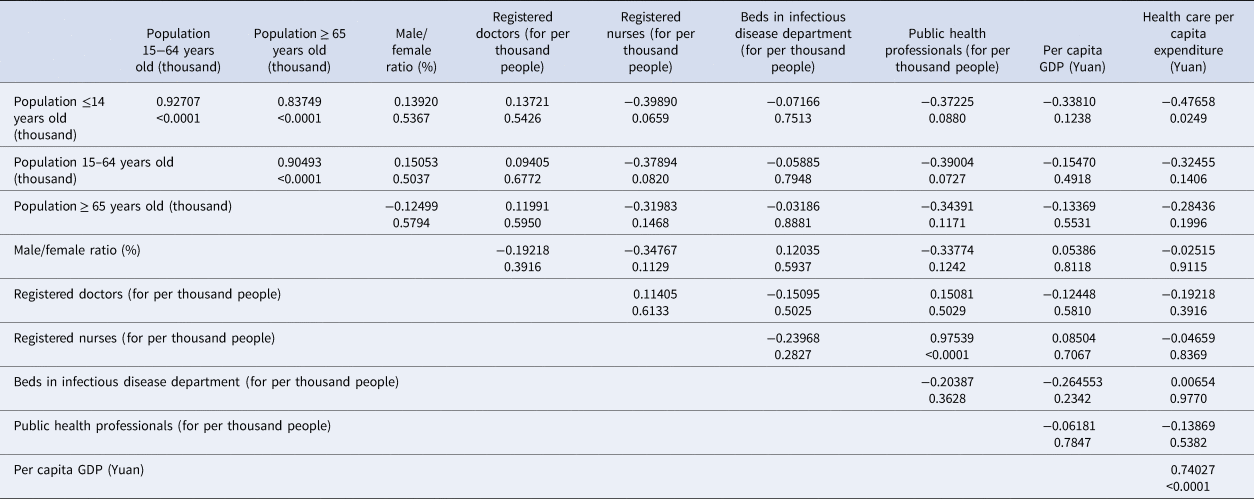
Pearson's correlation analysis was applied to migration scale index and BI, which showed significant correlation (rx ,y = 0.4262, P < 0.0001). Spearman's rank-order correlation was conducted among annually reported variables. The results are shown in Table 2. Population ≤14 years old was significantly correlated with population of other two age groups and per capita health care expenditure. Population of 15–64 years old was significantly correlated with population ≥65 years old. As for variables related to public health resource, the number of registered nurses was significantly correlated with public health professional number. And the correlation between per capita GDP and per capita health care expenditure was significant, too. Therefore, daily and annually reported variables, except cumulative BI, population ≤14 years old, population of 15–64 years old, registered nurse and per capita health care expenditure, were included into multivariate regression. In addition, interaction items among public health professionals, registered doctors and beds in infectious department were included, because their roles and effects were related in preventing and controlling COVID-19 pandemic. Public health professionals and doctors both participated in epidemic investigation and COVID-19 testing, while doctors and beds in infectious disease department reflected the capacity of COVID-19 admissions.
Table 2. Spearman's rank-order correlation analysis among annually reported variables (rx ,y, sig.)
Regression splines
Spline regression model was applied to fit cumulative COVID-19 case number in eastern, central, western and all provinces, respectively. The results are shown in Table 3. Models with knots and covariates fitted the data better than the ones with knots only. No quadratic or cubic terms were included. In the model of all provinces, estimated knots were 8th and 24th days, which were similar with knots of eastern and central province models. But in the model of western provinces, knots were located at 7th and 31st days. As for covariates, migration scale index from Hubei was included in each model for eastern, central and western provinces, which was positively correlated with cumulative COVID-19 case number. Other included covariates were different among the three regions.
Table 3. Spline regression of cumulative COVID-19 case number in eastern, central, western and all provinces

a Model with knots fitting cumulative COVID-19 case number in all provinces.
b Model with knots and covariates fitting cumulative COVID-19 case number in all provinces.
c Model with knots fitting cumulative COVID-19 case number in eastern provinces.
d Model with knots and covariates fitting cumulative COVID-19 case number in eastern provinces.
e Model with knots fitting cumulative COVID-19 case number in central provinces.
f Model with knots and covariates fitting cumulative COVID-19 case number in central provinces.
g Model with knots fitting cumulative COVID-19 case number in western provinces.
h Model with knots and covariates fitting cumulative COVID-19 case number in western provinces.
Discussion
In this study, COVID-19 case number out of Hubei during first-level response was analysed with spline regression model. A stepwise procedure was used to select the number, location and degree of polynomial, as well as covariates. In order to explore the change patterns of COVID-19 case number in different regions, spline models were used to fit the data of eastern, central and western provinces, respectively. The research period was divided into three stages by two knots in all models, but the locations of knots were different in the three regions (Fig. 5).
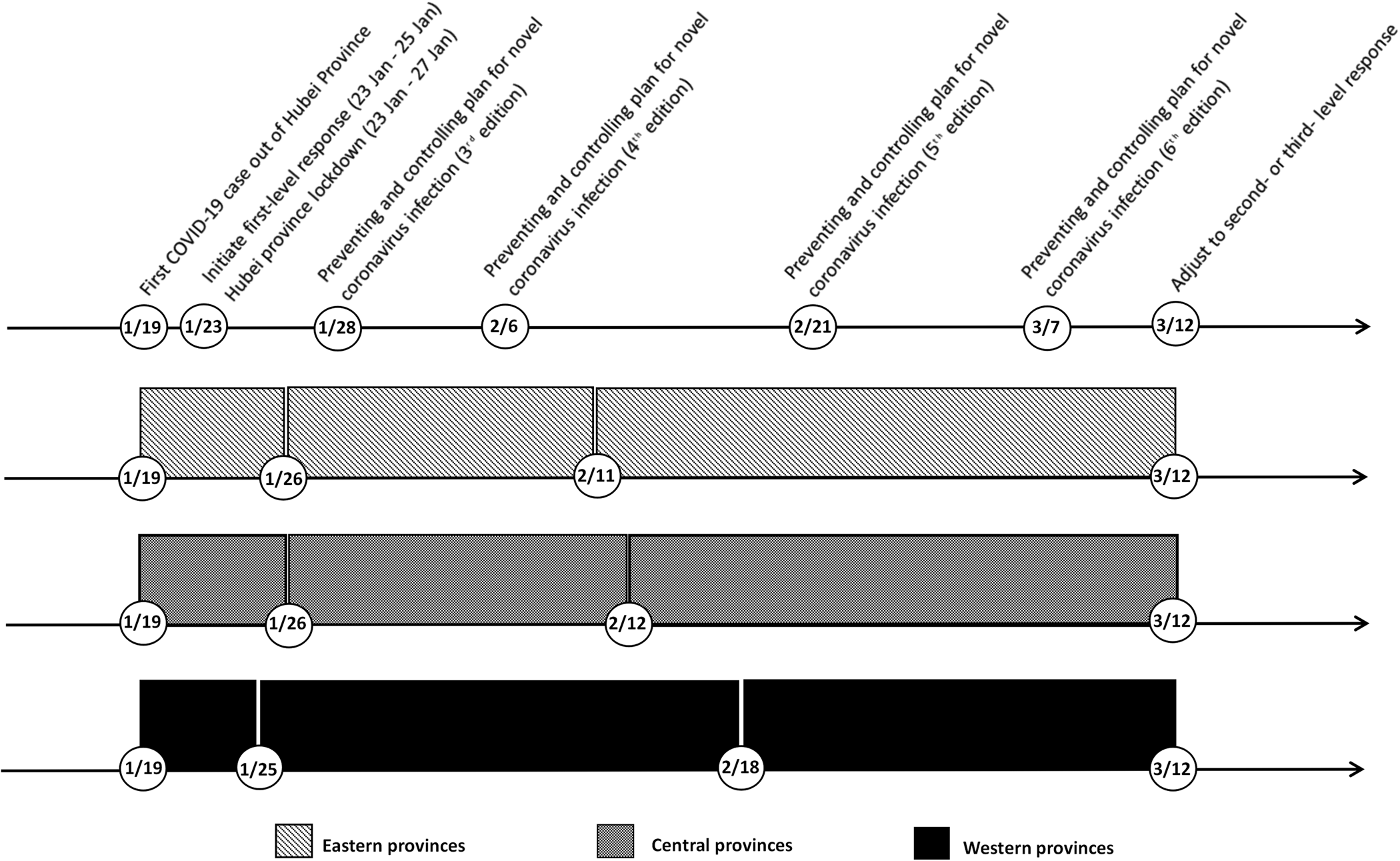
Fig. 5. Timeline of implemented measures in China and the three stages in eastern, central and western provinces.
The first stage was similar among the three regions, lasting from 19 January to around 26 January. In this stage, cumulative COVID-19 case number was associated with covariates, such as migration scale index out of Hubei, public health professionals and registered doctors, but not the number of days since 19 January. The daily situation reports of Guizhou, Tianjin and Shanghai, which released the exposure history of each COVID-19 case, provided an insight into this situation [25–27]. In the first 8 days of outbreak, imported cases mainly contributed to the increase of COVID-19 case number, taking a proportion of 50.0%~88.9%. In order to prevent case spilling over, Hubei province was gradually locked down since 23 January, which decreased the risk of case importation for other provinces. In the second stage, cumulative COVID-19 case number started to increase rapidly with time. Imported case proportion decreased, and indigenous case proportion surged, ranging from 43.7% to 73.5%. In this stage, SARS-CoV-2 spread among inhabitants and secondary infection cases were diagnosed extensively. The Chinese government took a combination of preventing and controlling measures to contain the pandemic. In eastern and central provinces, the growth slowed down since 11 or 12 February. However, in western provinces, it slowed down after 18 February. Cumulative COVID-19 case number of western provinces increased more slowly in the second stage, while eastern and central provinces experienced a sharper increase in a shorter second stage.
Previous studies mostly fitted the data of COVID-19 with regression models at national or global level. Ekum et al. [Reference Ekum and Ogunsanya28] conducted hierarchical polynomial regression with daily cases of COVID-19 globally, which indicated cubic model fitted the data better than linear or quadratic models. Demertzis et al. [Reference Demertzis16] applied spline model and cubic model to the cumulative number of COVID-19 infections, deaths and ICU patients in Greece. In their study, spline models outperformed cubic ones with each outcome. Sousa et al. [Reference Sousa15] and Agiwal et al. [Reference Agiwal14] fitted the daily reported COVID-19 cases of European, American and Asian countries with linear and cubic spline terms, identifying the knots of each country. However, change patterns might be different among various regions in a country. In this study, models with different knots and parameters were developed for eastern, central and western provinces, which showed the specific change patterns of COVID-19 among the three regions. Therefore, in addition to studies at global and national levels, analysis with province data was needed. The difference might be attributed to regional risk of case importation, local epidemiological features, applicability of preventing and controlling measures and public compliance. To reveal the cause of different change pattern at province level, studies with more detailed data on case characteristics, implementation of controlling measures and public behaviours were required.
Meanwhile, previous studies exploring the knots of COVID-19 case number did not include other explanatory variables. In this study, stepwise procedure was used to select knot number, locations and covariates. There were different systematic methods to estimate the number and locations of knots. Friedman [Reference Friedman29] and Silverman et al. [Reference Friedman and Silverman30] discussed stepwise-based method, Osborne et al. [Reference Osborne, Presnell and Turlach31] proposed an algorithm based on the LASSO estimator and Denison et al. [Reference Denison, Mallick and Smith32] considered the bayesian method. All these methods were successful. Stepwise procedure allowed for any combination of adjustments (linear, quadratic and cubic) in each segment and took into account other explanatory variables at the same time. It provided the added utility of a simple, unconstrained function which can be easily implemented in non-linear trend analysis. This study showed the models with knots and covariates fitted the data better than the models with knots only. In addition to the segments of time, variance of cumulative COVID-19 case number was attributed to transient population from Hubei, population ≥65 years old and variables reflecting health resources at the province level. These findings were consistent with other studies' result. Chen's study showed migration scale index from Hubei was associated with confirmed COVID-19 cases per day in China except Hubei from 20 January to 2 February [Reference Chen33]. Data from seven countries, including Spain, Canada, Netherlands, Italy, Germany and Korean, revealed that older population with low immunity had higher risk of infection, taking 27%–58.1% of the confirmed cases [34–39]. A comparison analysis between COVID-19 and H1N1 outbreaks proved public health professionals and doctors played a crucial role in public health emergency response [Reference Wang40, Reference Murthy41]. These findings supported the assumption; spline regression models with other explanatory variables might provide better insight into the trend pattern of COVID-19 cases.
This study had several potential limitations. Firstly, the cumulative number of COVID-19 cases did not equal to the total number of infections due to unconfirmed cases. Asymptomatic cases might not be recognised due to the lack of symptoms and infected patients could ignore the mild symptoms at early stage resulting in delay to diagnosis. Secondly, the data extracted from the Chinese Health Statistical Year book was based on the latest available national survey finished in 2018, which might not match the medical resources and population characters during outbreak period completely. Thirdly, some covariates related to the spread of SARS-CoV-2, such as testing intensity, were not included in this study, because no corresponding public database were available.
Conclusion
This study analysed cumulative COVID-19 case number during the first-level response with spline regression models at province level out of Hubei. Inclusion of covariates made spline models fit COVID-19 data better. The research period was divided into three stages by two knots. The spline models of eastern, central and western provinces demonstrated different trend patterns in each region. Spline function with covariates would be a practical tool to analyse the non-linear trend of COVID-19 data. Analysis at province level was necessary to explore the change patterns of COVID-19 data in corresponding regions. To reveal more information about the regional characteristics of COVID-19 pandemic, studies with more detailed data at province level were needed. A better understanding of COVID-19 pandemic will help the policy makers to more effectively control the spread of SARS-CoV-2 and lessen the adverse social effect to a greater extent.
Author contributions
Chen Liang and Li Shen contributed equally to this work. They designed the experiment, collected the data, performed the analysis and wrote this paper. All authors read and approved the final paper.
Financial support
This research was not supported by any funding.
Conflict of interest
All authors declare no conflicts of interest relevant to this paper.
Ethical standards
Not applicable.
Data
The datasets used in this study is available from the corresponding author Chen Liang on reasonable request (Email: [email protected]).









 Open access
Open access