



Introduction
Usage-based approaches propose that, to learn a language, speakers must accumulate experience of regular linguistic patterns through exposure to the input (Bybee, Reference Bybee, Robinson and Ellis2008; Ellis & Wulff, Reference Ellis and Wulff2014; Ellis et al., Reference Ellis, O’Donnell and Römer2013; Tomasello, Reference Tomasello2005). But what work in recent years has highlighted is that exposure to just any form of input may not be sufficient for successful language learning. Importantly, previous research has reported that the ability to learn new constructions from the input may be facilitated by specific frequency distributions, such as low variability input distributions that present a few prototypical lexical exemplars with very high frequency. In fact, such low variability (or “skewed”) input distributions are pervasive in natural language (Zipf’s law; e.g., Lavi-Rotbain & Arnon, Reference Lavi-Rotbain and Arnon2023) and are believed to facilitate novel pattern detection during language acquisition (Goldberg et al., Reference Goldberg, Casenhiser and Sethuraman2004). It has been proposed that constructions are learnable in part thanks to the presence of highly prototypical exemplars, which facilitate the formation of new categories and the integration of less frequent non-prototypical exemplars (e.g., Abbot-Smith & Tomasello, Reference Abbot-Smith and Tomasello2006; Bybee & Eddington, Reference Bybee and Eddington2006; Ibbotson et al., Reference Ibbotson, Theakston, Lieven and Tomasello2012; Goldberg, Reference Goldberg, Hoffmann and Trousdale2013). In contrast, highly variable (or “balanced”) input, in which multiple lexical items are equally frequent, is believed to make pattern detection more difficult.
Support for the superiority of skewed input comes from early work with children and adults by Goldberg and colleagues. In a series of experiments that investigated the learning of a novel construction,Footnote 1 learning was found to be significantly improved when linguistic input presented a skewed distribution (Goldberg et al., Reference Goldberg, Casenhiser and Sethuraman2004; Reference Goldberg, Casenhiser and White2007; Casenhiser & Goldberg, Reference Casenhiser and Goldberg2005). More specifically, in a study with adult native English speakers—which extended previous work with children (Casenhiser & Goldberg, Reference Casenhiser and Goldberg2005)—Goldberg and colleagues (Reference Goldberg, Casenhiser and White2007) found that skewed input significantly improved learning when the same exemplars were presented repeatedly at the beginning of exposure (this was called “skewed first” input), relative to input in which frequencies were randomly skewed or balanced across lexical items. Therefore, later studies that have investigated skewed input have typically employed “skewed first”—rather than “skewed random”—input.Footnote 2
However, subsequent L2 research on the effectiveness of skewed input has produced mixed results. Several subsequent experiments with L2 learners reported either no differences between skewed and balanced input or even an advantage for balanced input (Nakamura, Reference Nakamura2012; McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014; McDonough & Trofimovich, Reference McDonough and Trofimovich2013; Year & Gordon, Reference Year and Gordon2009). In an experiment that investigated Thai speakers’ acquisition of the English double-object construction, McDonough and Nekrasova-Becker (Reference McDonough and Nekrasova-Becker2014) found a significant advantage for learners exposed to balanced, rather than skewed, input. The authors proposed that the failure to find an advantage for skewed input in L2 learners might be due to differences in the mechanisms engaged by adults during categorization and particularly their tendency towards explicit learning strategies and rule searching.
Specifically, rule-based learning allows individuals to engage in hypothesis testing upon each encounter with new stimuli—a strategy that may be most productive when input is more variable, as is the case with balanced, rather than skewed, input. This idea was supported by McDonough and Trofimovich (Reference McDonough and Trofimovich2013), who found that when explicit rules were provided (i.e., “deductive” exposure), only balanced input led to significant learning; in contrast, in the absence of rules (“inductive” exposure), balanced input led to below-chance accuracy and was inferior to skewed input. Therefore, some previous results suggest that learners’ ability to engage in hypothesis testing deeply influences the effectiveness of skewed or balanced input.
This idea is relatable to work that has found an important effect of individual learner cognitive resources under explicit, but not implicit, learning conditions. Previous data have shown that, even when different learners are exposed to the same input, individual differences in working memory (WM) are associated with variability in how exemplars become categorized (DeCaro et al., Reference DeCaro, Thomas and Beilock2008), as well as variability in linguistic performance (Navarro et al., Reference Navarro-Torres, Dussias and Kroll2022). More specifically, within the literature on L2 acquisition, a considerable body of evidence has found that individual WM capacity is a significant predictor of learning in explicit conditions (Reber et al., Reference Reber, Walkenfeld and Hernstadt1991; Robinson, Reference Robinson2005; Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011; Reference Tagarelli, Mota, Rebuschat, Wen, Mota and McNeill2015). Given this, exploring the contribution of individual differences provides a promising avenue to clarify the mixed findings regarding the effect of exposure to input that is skewed or balanced.
The notion that specific input conditions may unequally benefit different learners, based on individual aptitude-based differences such as WM, is in line with research on so-called aptitude-by-treatment interactions (ATI) within second language acquisition (DeKeyser, Reference DeKeyser2012; Robinson, Reference Robinson2001). The ATI approach is based on the idea that the effectiveness of language learning depends on the interaction between an individual’s skill and the type of treatment they receive (DeKeyser, Reference DeKeyser2021; Skehan, Reference Skehan1989; Vatz et al., Reference Vatz, Tare, Jackson, Doughty, Granena and Long2013).Footnote 3 Therefore, a primary goal focuses on identifying and matching individual learners’ aptitudes with learning conditions that may enhance language learning outcomes. In this logic, it is conceivable—or, even, expected—that the effectiveness of a particular type of treatment (skewed or balanced input) may be modulated by individual learner traits.
Very limited previous work within the ATI framework has considered how individual differences might modulate the effect of skewed or balanced input, and none have—to the best of the author’s knowledge—considered the role of individual WM. In a study that considered the role of individual learner traits during exposure to skewed and balanced input, Brooks and colleagues (Reference Brooks, Kwoka and Kempe2017) examined the potential effect of nonverbal intelligence on the acquisition of Russian morphology. Based on previous work in which the authors examined the effect of input variability (by manipulating the number of new vocabulary items presented, rather than input skewness; Brooks & Kempe, Reference Brooks and Kempe2013), they predicted learners would benefit from balanced input only if they had higher nonverbal intelligence (as measured by section of the Culture Fair Intelligence Test). Contrary to their predictions, no significant interactions were found between skewed/balanced input and their measure of nonverbal intelligence on the acquisition of morphology.
So far, Brooks and colleagues’ study appears to be the only previous work that explicitly examined the role of individual differences during exposure to skewed or balanced input, with no previous studies having considered the role of WM in this regard. That is, despite that fact that well-documented variability in learning outcomes has been associated with differences in WM capacity, the contribution of individual differences to learning from input that is skewed or balanced has not been adequately explored.
The limited current understanding of this issue limits L2 research and risks disfavoring at least a portion of learners for whom specific input properties may not be most adequate. Taking an ATI approach, the goal of the present study is to investigate how individual differences in cognitive skill—specifically in WM—modulate learners’ ability to form categories from the input. The experiment reported below capitalizes on a well-studied set of verbs in Spanish, termed verbs of “becoming,” to investigate learners’ ability to learn new L2 categories under different input conditions. The following section reviews prior evidence on how variability in WM, as a central cognitive resource for processing information, may modulate individuals’ ability to learn from different types of input.
Alternative learning pathways: the role of WM and verbalizable rules in learning
The extant neuropsychological theory has underscored that category learning (as other aspects of human cognition) is characterized by the existence of more than one system with the ability to perform a similar function. In particular, previous work has pointed at competition between explicit verbal learning (i.e., when learning is guided by verbalizable rules) and implicit learning systems (Ashby et al., Reference Ashby, Alfonso-Reese and Waldron1998; Green et al., Reference Green, Crinion and Price2006). There is good evidence that the explicit and implicit learning systems recruit different cognitive resources and that these systems are in fact neurally dissociable (Chandrasekaran et al., Reference Chandrasekaran, Yi and Maddox2014).
Importantly, previous work in cognitive psychology and in L2 learning indicates that differences in cognitive profile (e.g., in WM) may modulate the effectiveness of specific pathways engaged during input processing and category learning. In particular, tasks that can be conducted by relying on explicit information depend on WM resources. WM is believed to play a particularly important role in rule-based (“deductive”) learning: conditions in which rules are available and thus encourage explicit hypothesis testing during processing (McDonough & Trofimovich, Reference McDonough and Trofimovich2013) have been found to place greater demands on WM resources (Tagarelli et al., Reference Tagarelli, Mota, Rebuschat, Wen, Mota and McNeill2015, Waldron & Ashby, Reference Waldron and Ashby2001). In contrast, implicit information-integration learning is thought to rely on the procedural learning system and functions independently of WM span (Ashby et al., Reference Ashby, Alfonso-Reese and Waldron1998; Chandrasekaran et al., Reference Chandrasekaran, Yi and Maddox2014).Footnote 4
Some valuable insight on the engagement of WM comes from studies in cognitive science that have focused on learning of nonlinguistic stimuli, as well as learning of (semi)artificial languages, to examine the role of individual differences under controlled learning conditions. In an influential study on visual category learning, Waldron and Ashby (Reference Waldron and Ashby2001) found that in an explicit learning condition—in which distinctions between stimuli were easy to verbalize via an explicit rule—learning ability was predicted by individuals’ ability to rely on WM; in fact, when WM resources were overtaxed by a secondary task, learning was disrupted. In contrast, in implicit learning conditions—in which stimuli properties were difficult to verbalize via explicit rules—the level of WM load did not modulate learning ability (for further evidence of a dual-learning system see Chandrasekaran et al., Reference Chandrasekaran, Yi and Maddox2014; Maddox et al., Reference Maddox, Chandrasekaran, Smayda and Yi2013; although for potential interactions between explicit and implicit learning, see, e.g., Forkstam & Petersson, Reference Forkstam and Petersson2005).
Similar evidence on the involvement of WM is found within the realm of language learning. In a study examining the learning of linguistic structure via explicit rules or incidentally, Tagarelli et al. (Reference Tagarelli, Mota and Rebuschat2011) employed a semi-artificial language consisting of English lexicon and German syntax; using a semi-artificial language allowed the authors to investigate learning of verb order in the absence of lexical learning demands. Tagarelli and colleagues hypothesized that learning performance would be correlated with WM, to the extent that learners relied on a rule to engage in explicit hypothesis testing; however, they also hypothesized that WM should not influence learning in a condition with no explicit rules, which favored implicit information-integration learning. To test this idea, they exposed participants to conditions in which learners could either rely on a verbalizable rule or not, while examining the contribution of WM in each condition. Their results showed that only when a verbal rule was available—enabling hypothesis-testing during input exposure—did high-WM individuals achieve higher learning rates than those with lower WM.
Interestingly, work on category learning has also suggested that individuals with higher WM are not always at a learning advantage when acquiring the defining aspects of a new category. Some insightful evidence comes from the role of WM during learning of nonlinguistic categories, under exposure to verbalizable or non-verbalizable patterns (e.g., when visual categories are defined by cues such as shape, color). Indeed, in contexts in which learners cannot rely on verbalizable rules, and therefore require engaging in bottom-up categorization, individuals with lower WM abilities have been found to outperform higher-WM individuals (DeCaro et al., Reference DeCaro, Thomas and Beilock2008). More generally, conditions that tax WM have been found to impair rule-based learning, while they tend to leave implicit category learning unaffected (e.g., Markman et al., Reference Markman, Maddox and Worthy2006; Waldron & Ashby, Reference Waldron and Ashby2001).
The acknowledgement of variability in cognitive pathways engaged during learning across individuals has important theoretical and practical ramifications for research on learning (Green et al., Reference Green, Crinion and Price2006). The studies reviewed above suggest that individual learners might benefit best from exposure to input conditions that encourage the optimal input-processing strategy based on their individual abilities (for a similar approach see, e.g., Perrachione et al., Reference Perrachione, Lee, Ha and Wong2011). In particular, these findings indicate that considering WM capacity may allow to identify and match the optimal learning conditions for individuals with different levels of cognitive skill, in line with aptitude-by-treatment interaction (ATI) approaches in L2 acquisition (see also, e.g., Indrarathne & Kormos, Reference Indrarathne and Kormos2018; Perrachione et al., Reference Perrachione, Lee, Ha and Wong2011, or the studies in DeKeyser, Reference DeKeyser2021).
As noted above, however, almost no previous studies have examined the role of individual differences during exposure to skewed or balanced input (with the exception of Brooks et al., Reference Brooks, Kwoka and Kempe2017), and no previous work has considered the role of WM on the ability to learn from different input distributions. Given the significant role of WM in previous studies that investigated explicit L2 learning conditions, the experiment reported below seeks to clarify the mixed evidence on the influence of skewed and balanced input by taking into account diversity in WM capacity among the learner population.
Present study
The goal of the present study is to investigate how individual differences in cognitive resources (specifically in WM span) modulate the effectiveness of skewed and balanced input, by examining learning in deductive (rule-based) and inductive (without explicit rules) learning conditions. This rationale is in line with an ATI approach (e.g., DeKeyser, Reference DeKeyser2012; Reference DeKeyser2021; Robinson, Reference Robinson2001). That is, given that learners differ in their internal resources available during input processing, it should not be assumed that the same input will engage the same processing strategies across different learners.
Taking direction from the evidence reviewed above, firstly, the present study manipulated the type of Input Distribution. I hypothesized that, by facilitating the learning of high-frequency exemplars, skewed input distributions may alleviate learners’ cognitive burden. In contrast, balanced input—which is, by definition, more highly variable—would pose a higher burden on WM. As such, balanced input may be beneficial for learners with relatively higher WM resources, while skewed input would be more beneficial for lower-WM learners.
Secondly, to create conditions that differed in their level of demand on WM, the present study manipulated the Instruction Type. Following McDonough and Trofimovich (Reference McDonough and Trofimovich2013), the present study employed deductive and inductive learning conditions, which differed on whether learners were provided with an explicit rule that guided their learning prior to being exposed to the input (“deductive” learning) or whether no rule was provided to guide input processing (“inductive learning”).Footnote 5 In deductive learning, participants are better able to engage in hypothesis testing by testing an explicit rule upon each encounter with new stimuli. As reviewed above, previous work has indicated that deductive hypothesis testing places higher demands on WM and leads to learning outcomes that are predicted by individual WM span (DeCaro et al., Reference DeCaro, Thomas and Beilock2008; Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011).
The two variables (Input Distribution and Instruction Type) will allow to explore the conditions that may facilitate (or hinder) learning for individuals of different cognitive profiles (see the detailed hypotheses and predictions described in “Hypotheses and Predictions”).
To investigate the influence of these variables on learners’ ability to learn new L2 categories, the experiment reported below capitalizes on a well-studied set of verbs in Spanish, termed verbs of “becoming.” Spanish verbs of becoming, which comprise a number of quasi-synonymous verbs including ponerse, quedarse, or volverse (all functionally equivalent to “become”), are a case in point for categorization that involves L1–L2 incongruent constructions. Because usage of the specialized verbs of becoming relies on knowledge of different semantic categories of adjectives, speakers of languages such as English must develop new categories into which to group known adjectives.
Analogical extension has been identified as a reliable rule for successful categorization (Bybee & Eddington, Reference Bybee and Eddington2006). In other words, a prototypical adjective often becomes the basis for generalization when using a specific [verb + adjective] construction, such as [ponerse + adjective], or [ quedarse + adjective]. In a study of L1 speaker corpus and similarity judgments, Bybee and Eddington (Reference Bybee and Eddington2006) showed that adjectives used in discourse with each verb of becoming—for example, ponerse and volverse—formed well-defined semantic categories around a high-frequency, prototypical adjective. For example, a prototypical verb–adjective combination such as ponerse + nervioso (“nervous”) accounted for verb choices with less frequent and even innovative adjectives. Given a prototypical adjective for a specific verb (ponerse + nervioso), less frequent and even innovative combinations (histérico “hysterical,” agresivo “aggressive,” or furioso “furious”) were readily accounted for through semantic similarity, as confirmed by semantic association networks based on native speaker semantic judgements.
Of the verbs of becoming, two verbs—namely, volverse and ponerse—are selected here, as they form categories that are best defined based on semantic clusters (Bybee & Eddington, Reference Bybee and Eddington2006; Eddington, Reference Eddington1999). Previous work has highlighted the difficulty of formulating rules to guide categorization of Spanish verbs of becoming. Verb selection based on rules that describe, for example, slow/fast change or passive/active change, is somewhat overlapping and not clear-cut (Bybee & Eddington, Reference Bybee and Eddington2006; Eddington, Reference Eddington1999; Ibarretxe-Antuñano & Cheikh-Khamis, Reference Ibarretxe-Antuñano and Cheikh-Khamis2019), making acquisition a notable challenge for L2 speakers. Instead, previous usage-based work that examined actual usage in corpus data (Brown & Cortés-Torres, 2012; Bybee & Eddington, Reference Bybee and Eddington2006) suggests that a prototype-based rule may be most effective at guiding learners in the formation of semantic adjective clusters. Therefore, learners are expected to successfully categorize exemplars when directed by an explicit rule indicating that categories are built around a prototype (i.e., “ponerse is used with words related in meaning to the word ‘nervous,’ and quedarse with words related to the word ‘still’”). Mirroring the frequencies of natural corpus data, the skewed condition employed here presented with higher frequency two adjectives (i.e., nervioso, “nervous” and quieto “still”) that have been identified as central, given their high frequency of use with each verb in previous work (Bybee & Eddington, Reference Bybee and Eddington2006). However, in order to develop semantic categories (i.e., groups of semantically related adjectives) structured around a prototypical member (e.g., ponerse nervioso), it is not clear whether, and to what degree, variability is beneficial.
Following previous work discussed above (e.g., Goldberg et al., Reference Goldberg, Casenhiser and White2007; McDonough & Trofimovich, Reference McDonough and Trofimovich2013), the present study employed a paradigm consisting of exposure followed by generalization. That is, to learn the new linguistic categories, participants are first exposed to a small set of items under different experimental learning conditions. Subsequently, they are asked to make generalizations on a new set of untrained items based on the recently learned categories.
Thus, to summarize, the present experiment was based on a 2×2 design. Learners were exposed to one of two types of input distribution: skewed input, in which a prototypical adjective was presented with higher frequency for each verb; or balanced input, in which all adjectives associated with each verb appeared with equal frequency. Additionally, training was manipulated based on instruction type: inductive learning, for which no explicit rules were provided; or deductive learning, for which an explicit verbal rule encouraged hypothesis testing during exposure. Finally, the effect of individual WM on learning under each context was examined.
Research questions
Guided by the findings reviewed above, this study examined the following research questions.
RQ 1: How does skewed input, which provides high-frequency exposure to a prototypical adjective, facilitate the learning of the categories of the verbs of “becoming” constructions?
RQ 2: How does the deductive instruction type, in which a verbal rule is explicitly provided, modulate the effect of skewed or balanced input?
RQ 3: How does individual WM capacity modulate the effects of input distribution and instruction type?
Hypotheses and predictions
The experiment reported below will allow to test three different hypotheses and their associated predictions grounded in the previous literature:
Skewed input hypothesis
This hypothesis would predict a main effect of input distribution, such that skewed input facilitates acquisition of constructions by maximizing exposure to a highly frequent “pathbreaker” item.
Previous mixed findings suggest that, even within this view, it must be assumed that there is variability in skewed input benefitting some learners, while not having an effect in others. In this scenario, skewed input may still bear an advantage even if only for some learners. For example, at the group level, skewed input may provide stability in the transmission of linguistic structures by allowing all speakers to acquire regular patterns in the input with no trade-off (e.g., Goldberg et al., Reference Goldberg, Casenhiser and White2007; Lavi-Rotbain & Arnon, Reference Lavi-Rotbain and Arnon2022), while no advantage for balanced input would be predicted. This hypothesis remains agnostic toward the potential effect of instruction type and WM.
Rule-Testing hypothesis
This hypothesis would predict that, rather than seeing a benefit of skewed input, balanced input should be beneficial for L2 learners, particularly in deductive learning conditions.
Previous L2 studies with adult learners have proposed that balanced input is more beneficial because it provides more variability for hypothesis testing. This view is supported by work that found an advantage of balanced input when combined with an explicitly stated rule (McDonough & Trofimovich, Reference McDonough and Trofimovich2013; McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014). No specific prediction is made for WM on the basis of this hypothesis, although a general benefit of higher WM would be expected.
Available cognitive resources hypothesis
This hypothesis attempts to reconcile previous findings by predicting that WM will modulate the effect of input distributions: Higher-WM learners may benefit from balanced input in deductive conditions (rule-testing hypothesis), whereas lower-WM learners will benefit from skewed input.
The view proposed here is that both hypotheses above are true under specific circumstances. Taking direction from evidence in the adult categorization literature and in L2 learning (e.g., DeCaro et al., Reference DeCaro, Thomas and Beilock2008; Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011), it is hypothesized that skewed input may be more beneficial when cognitive resources are burdened or limited. This may be due to learner-internal causes (individual learners inherently have lower cognitive resources available, e.g., lower WM) or due to learner-external causes (cognitive load is high, e.g., during explicit hypothesis testing in deductive learning). In conditions that promote hypothesis testing, balanced input may be beneficial but only as long as learners’ cognitive resources are on par with task demands. In other words, this view makes the specific prediction that skewed input should be more beneficial than balanced input at baseline (inductive learning) but that in more cognitively demanding learning conditions (deductive learning), skewed input will mainly benefit low-WM learners, while high-WM learners will benefit from balanced input. In concrete terms, an interaction between WM, input distribution and instruction type would be expected.
Methodology
Participants
Monolingual native speakers of English (N=115) were recruited through Prolific (www.prolific.co) to participate in an online experiment implemented on Gorilla (www.gorilla.sc; Anwyl-Irvine et al., Reference Anwyl-Irvine, Massonié, Flitton, Kirkham and Evershed2019). Five participants were excluded because they reported more than minimal knowledge of Spanish in their responses to a language history questionnaire (i.e., self-ratings greater than the minimum value of 1 in a scale from 1 to 7). Nine additional participants were excluded due to inattentiveness during the training phase (accuracy < 80%), and 17 were excluded because they failed to adequately learn the verb-adjective pairings after training exposure (test accuracy < 70%). The final pool for analysis consisted of 82 participants (29 female, 52 male, 1 not specified), distributed across inductive skewed (N=21), inductive balanced (N=18), deductive skewed (N=25), and deductive balanced (N=18); the total exclusion rates were roughly evenly distributed across inductive balanced (27.36%), inductive skewed (29.3%), deductive balanced (26.33%), and deductive skewed (27.36%). Twenty-two participants reported low-proficiency knowledge of other languages (French, German, Japanese, Chinese, Gaelic, Welsh), which do not mirror the verb-based categories targeted here (see Table 1 for a summary of proficiency). All provided informed consent and received compensation at a rate of 10 USD/hour. As part of a larger project, participants in the inductive learning condition were invited to complete a second session, which will be reported elsewhere.
Table 1. Summary of individual differences measures

Individual differences measures
Participants completed a series of individual differences measures to characterize their linguistic profile and WM span. Basic demographic information was available through Prolific. The tasks are described in this section and the results are summarized in Table 1 (by-condition information is provided in Table S1). The materials of the individual differences tasks are available at https://osf.io/5dcx8/?view_only=1a1fc062f4fd4286884f29b9d05c3e94.
Language history questionnaire
A language history questionnaire was used to gather data on relevant aspects of individuals’ linguistic background, including experience and proficiency with any additional languages. Basic demographic data (age and gender) was obtained from Prolific.
Picture naming
The picture naming task was employed to measure participants’ individual lexical ability (based on Gollan et al., Reference Gollan, Montoya, Cera and Sandoval2008) and was employed to control for individual differences in vocabulary skill, by including it as a covariate in the analysis. The task took approximately five minutes. Participants saw 80 black and white line drawings, which were presented one at a time in randomized order. In each trial, participants were asked to type the name for the image displayed in a text box. The first nine trials were used as practice. The accuracy of typed responses was coded off-line; up to one character permutation or misspelling was allowed.
Operation span
Participants completed the Operation Span (O-Span) task as a measure of WM. In this task participants were presented with simple math problems alongside a potential solution and were asked to indicate whether the solution was correct or not. The O-Span task was employed given its widespread use in the language learning literature (e.g., Linck & Weiss, Reference Linck and Weiss2015; Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011; Reference Tagarelli, Mota, Rebuschat, Wen, Mota and McNeill2015), and it relies to a lesser extent on verbal skills than other tasks such as the reading span.Footnote 6 Following each operation, an English word appeared on the screen, which participants should memorize for later recall at the end of the trial. There were three trials at each set size ranging from a two to a six word span. The individual score of memory span was calculated as the total number of words correctly recalled. Completing the task took approximately 10 minutes.
Materials
A list of 50 Spanish adjectives were selected based on previous corpus work reported by Bybee and Eddington (Reference Bybee and Eddington2006), with each half of the list consisting of adjectives, respectively, associated with ponerse and quedarse. Data from the Corpus del Español (web/dialects section, containing over two billion words) confirmed that the selected adjectives were used preeminently with their corresponding target verb (mean proportion of use with target verb: 89.5%, SD: 12.37). Given that the goal was to examine the reorganization of existing concepts into new categories, the use of English translations allowed learners to fully understand the meaning of adjectives, without the considerable burden of learning the meaning of 50 items in a new language. Adjectives were thus translated into English (e.g., caliente “hot,” nervous “nervioso,” muerto “dead,” delgado “slim,” etc.) with contextualized searches of verb+adjective using Linguee (linguee.com), a machine learning translation tool based on a corpus of paired bilingual texts, and were checked with two online bilingual dictionaries (the Collins Spanish Dictionary and WordReference, which are combined on one same site, wordreference.com). From the list of 50 adjectives, 10 adjectives were selected for training (half associated with each verb) and the remaining 40 were not trained but were reserved for the generalization task.
Two lists of training materials—one for each of the two conditions—were created based on the subset of training items. In the list for the balanced input condition, each adjective was repeated nine times, for a total of 90 training trials. In the list for the skewed input condition, the prototypical adjective within each verb category (i.e., “nervous” for the verb ponerse and “still” for quedarse) was repeated 25 times each, while the rest of the adjectives were repeated 5 times each; that is, the prototypical verbs were five times more frequent than any of the other non-prototypical verbs. For the training phase, a recording of each of the two target Spanish verbs was made by the author, who is a native speaker of Spanish.
Procedure
Participants completed one session lasting approximately one hour. They first completed the English picture naming task, followed by the training task, an immediate test, and the generalization task. After this, they completed the O-Span task and language history questionnaire. Participants were assigned to one of the two types of instruction (inductive or deductive) and of input distribution (balanced or skewed).
Training task procedure
During the training task, participants saw an adjective displayed in the center of the screen, as well as each of the two verbs, one on the bottom left and the other on the bottom right corner of the screen. The position of the verbs was counterbalanced across participants. Participants were instructed to listen to the verb presented auditorily and press a button on their keyboard assigned to each verb; all verb forms were presented in the infinitive. At the beginning of each trial, the adjective and verb were displayed for 2,000 ms; this long interval was selected to encourage participants to pay attention to the trained adjective and actively anticipate the upcoming verb.Footnote 7 The target verb was then presented auditorily, and participants pressed the button on their keyboard corresponding to the location of the target verb (“z” for left, “m” for right). The timing of the stimuli allowed time for participants to anticipate the upcoming verb; as a result, hearing the verb confirmed or disconfirmed their prediction, allowing them to learn from erroneous predictions, even without getting explicit correction (for a recent review on prediction error in L2 learning, see, e.g., Bovolenta & Marsden, Reference Bovolenta and Marsden2022).Footnote 8
Participants had to make a response to advance to the next trial; responses were disabled before the audio for the verb was played. Immediately after a response was recorded, the adjective disappeared and only the verbs remained on display for 300 ms before the next trial. The sequencing is illustrated in Figure 1. Five practice trials were presented to allow participants to familiarize themselves with the tasks; to avoid any descriptive adjectives that might be semantically related to the experimental materials, the proper adjectives “Chilean” and “Mexican” were employed for practice.

Figure 1. Sample trial for the adjective “nervous” and the target verb “ponerse.” The audio was played 2,000 ms after the adjective was displayed. The position of each of the two verbs on the screen (bottom left and right corners) was counterbalanced across participants but remained constant for a given participant.
Importantly, different instructions were presented to participants in each condition. Participants in the inductive learning condition were simply warned that they would see and hear two verbs, both of which were equivalent to “become” but that Spanish required using one or the other based on the accompanying adjective. Participants were simply asked to do their best to learn the verb-adjective pairing in the task. This was consistent with an inductive learning approach, in which any generalizations are derived directly from a body of observations, without a priori rules that guide input processing (Motha, Reference Motha2013; Seliger, Reference Seliger1975). In contrast, participants in the deductive learning group were explicitly presented with a “critical rule,” which indicated that ponerse was used with words related in meaning to the word “nervous” and quedarse about words related to the word “still” (this rule was directly based on the research on verbs of becoming reviewed above by Bybee and Eddington, Reference Bybee and Eddington2006). They were also warned that they should not try to come up with other rules, as that would confuse them. The instructions text for the training, test and generalization tasks is provided in Appendix B. Completing the training took less than 10 minutes.Footnote 9
Test procedure
Immediately after the training task, participants were asked to complete a test using the same procedure as for training but without the auditory cues guiding selection. This allowed to assess whether participants had learned the verb-adjective combinations during the previous exposure phase. Each item was presented twice in order to mitigate the possibility that a participant might correctly guess the correct answer.
Generalization task procedure
Participants were informed that they would be seeing new untrained adjectives and that they should choose the verb that they deemed most appropriate in each case. Critically, as in the training task, participants in the inductive learning group received no additional guidance, while participants in the deductive learning group were reminded of the rule described above.
The procedure of the generalization task was very similar to that of the test, with the important difference that the adjectives presented were the rest of the items that had not been previously trained, and each item was presented only once. Participants were given up to 10 seconds to make a decision; if no response was made, they were prompted to respond faster. No feedback was provided during this task and, given that it closely mirrored the training task, no practice trials were included.Footnote 10 Completing the test and generalization tasks took less than five minutes.
Analysis
The results from the immediate test revealed that a majority of participants remembered the target verb-adjective pairings with high accuracy following exposure during the training phase (mean: 95.15%, SD: 7.61); there were no significant differences in the immediate test results across the skewed and balanced subgroups (t(69.30) = –0.98, p = 0.33). Participants who failed to reach 70% test accuracy were excluded; these were approximately evenly distributed across the exposure conditions (seven skewed, nine balanced). Because it would not be possible for learners to generalize on recently learned knowledge unless sufficient knowledge is gained during training, this threshold was set as an minimum level of learned items following exposure upon which to make generalizations. The 70% minimum was selected as it was the cut-off threshold employed in previous work using a similar paradigm to examine the effect of skewed input (McDonough & Trofimovich, Reference McDonough and Trofimovich2013) and in previous work in our lab (e.g., Pulido, Reference Pulido2021); this threshold provides a practical compromise for accuracy higher than chance (50%) while it avoids setting an overly high threshold.
Data from the Generalization task were submitted to a generalized mixed effects regression analysis using R (R Core Team, 2023). Data and script are available at https://osf.io/5dcx8/?view_only=1a1fc062f4fd4286884f29b9d05c3e94. Response accuracy during generalization was employed as the dependent variable. The model included fixed effects for input distribution (skewed, balanced) and instruction type (inductive, deductive), as well as individual scores for test accuracy, English picture naming, and WM (O-Span) and their two-way interactions with input distribution and instruction type and a three-way interaction for WM, input distribution, and input type, to test the available cognitive resources hypothesis described above. Following attempts that resulted in convergence failure, the final random-effects structure included random intercepts for subjects and items, as well as by-item random slopes for learning type. Categorical variables were sum-contrast coded, and continuous variables were centered. Collinearity variance inflation scores were found to be acceptable (< 2.0 for all variables). Cronbach’s alpha was calculated as a reliability index for the O-Span task and found to be acceptable at α = 0.86 (i.e., within a range from 0.70 to 0.90; Streiner, Reference Streiner2003; Tavakol & Dennick, Reference Tavakol and Dennick2011). Because the raw O-span data had a skewed distribution (skewness = –1.52, kurtosis = –6.74); the analysis was performed on Box–Cox transformed O-Span data (skewness = –0.81, kurtosis = –3.47); this was employed instead of log-transformation, which had the opposite effect (skewness = –2.95, kurtosis = –16.76). More importantly, the residuals of the regression model were normally distributed, as confirmed with the DHARMa package (Hartig, Reference Hartig2022).Footnote 11 The results of the final model are presented in Table 2.
Table 2. Output summary of the mixed-effects regression analysis

Results
The results of the mixed-effects regression analysis (Table 2) revealed a significant effect of test scores, suggesting that higher knowledge of the exemplars presented during training increased performance in generalization. A crucial three-way interaction emerged between instruction type, WM, and input distribution (β = –0.21, SE = 0.09, p = 0.02). The interaction, which is visualized Figure 2, suggested no effect of input in the inductive learning group, and an interaction of WM and input type within the deductive learning group. Further, the results suggested that skewed input was more beneficial only for learners in the deductive group but that this effect was reversed at high levels of WM span. To follow up on this interaction, as a first step, the model was rerun using treatment contrasts. With the instruction type reference level set to inductive learning, results for both skewed and balanced input indicated no significant effects of WM or input distribution and no significant interaction (all p-values > 0.85). In comparison, a main effect of WM emerged only for the deductive balanced exposure (β = 0.64, SE = 0.22, p < 0.004). Additionally, the output for deductive learning indicated a significant interaction of WM and input distribution, suggesting that within deductive learning, WM was associated with higher accuracy for balanced input (β = 0.78, SE = 0.28, p < 0.004) but with an opposite polarity effect for skewed input (β = –0.78, SE = 0.28, p < 0.004). The effect of WM in the interaction is further illustrated in Figures 2–3 (the median split in Figure 3 is employed only for visualization; the analysis was performed on the continuous WM variable).
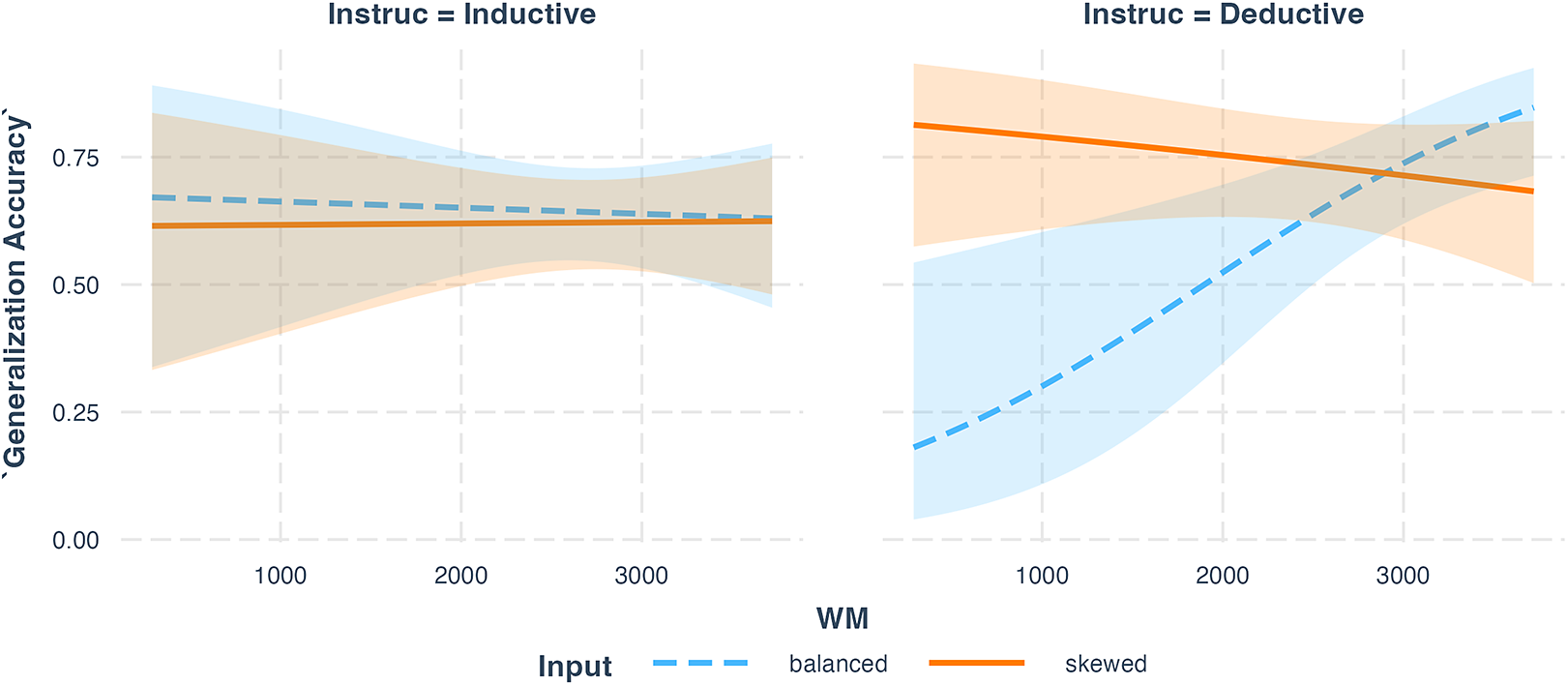
Figure 2. Interaction between input distribution, instruction type and WM based on mixed-effects model estimates. Ribbons represent 95% CIs.

Figure 3. Accuracy in generalization by input distribution, input type, and WM. A median split of WM scores is applied here only for illustration purposes. Error bars represent 95% CIs.
These results guided the follow-up comparisons with the emmeans package (reported comparisons are False Discovery Rate-corrected). For WM, comparisons were performed for ± 1 SD from the mean WM scores; this made it possible to examine the effect of WM as a continuous variable, rather than as a dichotomized factor. Post-hoc comparisons for the interaction between WM and input distribution revealed no differences within the inductive instruction type (all p-values > 0.99); in contrast, for deductive learners, comparisons indicated that lower-WM learners exposed to balanced input performed significantly worse than both higher-WM learners also exposed to balanced input (p = 0.021) and lower-WM learners exposed to skewed input (p = 0.037) but was not different from higher-WM learners exposed to skewed input (p = 0.234). Finally, comparisons across instruction type at the same level of WM confirmed that, at higher-WM, balanced input led to significantly higher performance for deductive than for inductive learning (p = 0.039), and skewed input at lower-WM was marginally higher for deductive than inductive learning (p = 0.074; for the complete set of FDR-corrected comparisons, see Tables S2–S3 in the appendix).
Discussion
Previous work has produced various findings on the effect of skewed input. While some studies found it to be advantageous (e.g., Casenhiser & Goldberg, Reference Casenhiser and Goldberg2005; Goldberg et al., Reference Goldberg, Casenhiser and White2007; Madlener, Reference Madlener, Behrens and Pfänder2016; Zhang and Dong, Reference Zhang and Dong2019, study 2; Zhang & Mai, Reference Zhang and Mai2023, study 2), subsequent L2 studies reported either no advantage for skewed input (Nakamura, Reference Nakamura2012; Year & Gordon, Reference Year and Gordon2009; Zhang & Mai, Reference Zhang and Mai2023, study 1) or even an advantage for balanced input (Brooks et al., Reference Brooks, Kwoka and Kempe2017; McDonough & Trofimovich, Reference McDonough and Trofimovich2013; McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014; Zhang & Dong, study 1). In line with previous work that explored ATI in SLA (for a review, see, e.g., Vatz et al., Reference Vatz, Tare, Jackson, Doughty, Granena and Long2013), this study explored the effect of individual WM capacity in modulating the effect of skewed and balanced input under inductive and deductive conditions. The experiment reported here capitalized on Spanish verbs of “becoming,” a set of verbs (approximately equivalent to “become” in English), which selectively collocate with subsets of adjectives, requiring L2 learners to develop a new categorization of adjective groups. Specifically, the materials targeted the selection of adjective subsets that collocated with two verbs (ponerse and quedarse), requiring the formation of two new semantic categories for adjectives. The experiment employed a 2 × 2 design by crossing the instruction type (deductive or inductive—that is, with or without explicit rules, respectively) and input distribution (skewed or balanced) to test the role of each factor and their potential interaction with WM.
A main goal of the study was to test the hypothesis that individual diversity in cognitive resources (specifically, in WM) mediates the effect of skewed input. Couched within evidence in the adult categorization literature and in L2 learning (e.g., DeCaro et al., Reference DeCaro, Thomas and Beilock2008; Kempe et al., Reference Kempe, Brooks and Kharkhurin2010; Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011), I hypothesized that skewed input would facilitate learning when cognitive resources are limited—whether due to learner-internal traits (e.g., lower WM) or to learner-external causes (e.g., when engaging in real-time rule testing during input processing). On the other hand, under explicit rule-based learning conditions, balanced frequency distributions may provide optimal input to facilitate hypothesis testing but only as long as learners’ cognitive resources are on par with task demands. In short, the available cognitive resources hypothesis would predict that, when an explicit rule is being concurrently held in WM, skewed input will tend to benefit low-WM learners, while high-WM learners will benefit from balanced input. This hypothesis is in line with previous studies within the ATI approach, which found that lower-aptitude learners benefitted from reduced variability in the input, in contrast with higher-aptitude learners, who tended to benefit from higher variability in the input (Brooks et al., Reference Brooks, Kempe and Sionov2006; Perrachione et al., Reference Perrachione, Lee, Ha and Wong2011). The results indeed showed ample variability across conditions based on individual WM in support of previous ATI research suggesting that learners with different aptitude levels may benefit from learning under different input conditions (e.g., Brook et al., Reference Brooks, Kempe and Sionov2006; Perrachione et al., Reference Perrachione, Lee, Ha and Wong2011). Critically, when WM capacity was factored in, variability in subgroups was systematic and replicated previous seemingly contradictory findings in the literature. The results are discussed next in connection with the three research questions.
To recapitulate, the first research question asked whether and how skewed input (i.e., higher frequency in exposure to a prototypical adjective for each category) facilitates the formation of new L2 categories. The results revealed no main effect of input distribution, i.e., no overall effect of skewed or balanced input exposure. At face value, this result is congruent with later studies that, in contrast to earlier work (e.g., Goldberg et al., Reference Goldberg, Casenhiser and Sethuraman2004; Reference Goldberg, Casenhiser and White2007), reported either no advantage for skewed input or even an advantage for balanced input (McDonough & Trofimovich, Reference McDonough and Trofimovich2013; McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014; Nakamura, Reference Nakamura2012). However, a beneficial effect of skewed input emerged precisely where predicted by the available cognitive resources hypothesis during the generalization task: After being exposed to deductive training, in which an explicit verbalizable rule was provided, lower-WM learners experienced a significant benefit from reduced variability in the skewed input, while balanced input resulted in lower accuracy for lower-WM learners. This finding supports the proposal originally made by L1 researchers that lower variability in skewed input conditions may facilitate the development of a new category through a “pathbreaker” prototypical exemplar. However, an essential qualification must be made in what concerns adult L2 learners, where the effect was far from being present in a majority of learners.
Instead, the more common finding in later L2 studies has suggested that a combination of deductive instruction type, in which a verbal rule is explicitly provided, and balanced input might be more conducive to learning by allowing adult learners to engage in hypothesis testing (McDonough & Trofimovich, Reference McDonough and Trofimovich2013). This possibility was directly addressed through the second research question, which asked whether the effect of skewed or balanced input was contingent on the provision of an explicit verbal rule during instruction. This account leads to the straightforward prediction of an interaction between input distribution and instruction type, by which balanced input conditions should become beneficial when combined with an explicit verbal rule that allows for hypothesis testing. Once again, this hypothesis was partly born out but with a critical qualification. As predicted by the cognitive resources hypothesis, the availability of an explicit rule in combination with balanced input facilitated learning only for those learners with higher WM (recall that at higher-WM, balanced input led to significantly higher performance for deductive than for inductive learning) but not for lower-WM participants. As noted above, for learners with lower WM, when instruction provided explicit rules, skewed input was significantly more beneficial than balanced input.
Interestingly, when exposure occurred in the absence of explicit rules, no differences between skewed and balanced input were found. This finding is congruent with data previously reported by Year and Gordon (Reference Year and Gordon2009) and McDonough and Trofimovich (Reference McDonough and Trofimovich2013) who found no contribution of skewed input relative to balanced input in the absence of rules (although in the case of Year and Gordon’s study, the manipulation involved skewed random, rather than skewed first input; see also McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014, for an advantage of balanced input).
Similarly, no significant influence of WM was observed for inductive conditions in the present results. This is despite the fact that learning was quite explicit in all cases, with no other concurrent task nor additional linguistic context. However, the finding that WM did not modulate learning during inductive exposure is in line with the previous work that indicated an effect of WM only when learners were exposed to explicit rules (e.g., Tagarelli, Reference Tagarelli, Mota and Rebuschat2011) and that suggested that the absence of rules favored a bottom-up or “information-integration” approach.
Comparison of present and previous findings on the effect of input distributions
Altogether, the pattern of results based on learners ranging across the WM spectrum fits well within the previous literature. Crucially, by considering the joint effect of input distribution, instruction type, and WM, the present study helps reconcile previous mixed findings. The present data fit well within previous studies that reported aptitude-based interactions and help identify the contexts in which skewed input presents an advantage in adults. In particular, the results provide insight into the cognitive mechanisms that underlie the skewed-input effect and suggest that populations with lower WM (subsets of adult learners but also, e.g., younger children) may particularly benefit from exposure to skewed input.
Nonetheless, some unanswered questions and discrepancies remain. For example, in some cases, previous data still found an advantage for balanced input in the absence of rules (McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014). In other cases, balanced input was advantageous with explicit rules but, in the absence of rules, numerically inferior to skewed learning (McDonough & Trofimovich, Reference McDonough and Trofimovich2013). Results were also mixed in work from other labs (Namakura, Reference Nakamura2012; Year & Gordon, Reference Year and Gordon2009). A relevant aspect that appears to have received little attention is the potential influence of the specific linguistic constructions investigated. For example, Nakamura (Reference Nakamura2012) examined the influence of skewed and balanced input on the acquisition of the “appearance” construction used in the original studies by Goldberg and colleagues, as well as on the Samoan ergative construction. It seems revealing that, although no clear effect skewed or balanced input was observed for the Samoan ergative, the results did replicate the advantage of skewed input for the “appearance” construction. In this regard, it is worth considering how the input distribution affected linguistic elements across studies. The verbs of becoming construction targeted in the present study may have been more similar to the lexically based “appearance” construction than some of the morpheme-based constructions examined in other studies (e.g., the Samoan ergative, which is marked by the particle “e,” in Nakamura, Reference Nakamura2012; or the Esperanto direct object-marker “-n,” in McDonough & Trofimovich, Reference McDonough and Trofimovich2013). Notably (and unlike the lexically based constructions), in those morpheme-based constructions, the skewed/balanced manipulation affected the lexical items that co-occurred with the target particles but not the distribution of the target particles themselves. While examining and discussing the potential differences across the constructions examined in previous work is beyond the scope of the present paper, this is an aspect that merits further investigation in future studies.
Another important issue concerns the question of the conditions that may give rise to an advantage of skewed input. As discussed above, the present study found that, modulated by WM, skewed input influenced learning in the deductive learning condition. In the original studies by Goldberg and colleagues, an advantage of skewed was found in learning conditions that might seem most comparable to the inductive learning condition in the present study, as no explicit rule was provided. Why these differences across instruction types? It is also worth noting that, although L2 studies have typically failed to find an effect of skewed input, a previous study by McDonough and Trofimovich (Reference McDonough and Trofimovich2013) reported a numerical advantage for skewed input in inductive conditions, somewhat resembling the pattern in the original studies by Goldberg and colleagues (e.g., Reference Goldberg, Casenhiser and Sethuraman2004; Reference Goldberg, Casenhiser and White2007). It is plausible that differences across studies may also lie in the level of explicitness of learning conditions (as well as, no doubt, on the level of complexity of the linguistic construction under consideration). In the original studies by Goldberg and colleagues, learning was incidental and meaning oriented during exposure to sentences and visual input. Similarly, McDonough and Trofimovich (Reference McDonough and Trofimovich2013) employed a meaning-focused task in which learners were presented with pictures and sentences and had to identify the object (rather than the agent). In contrast, given the complexity of the construction targeted, in the present study exposure was more explicit and involved a categorization task. In this study exposure was based on collocations (two-word verb-adjective combinations), rather than on sentences. This lexical approach (without sentences) was employed as a first step because learning the verbs of “becoming” construction does not involve morphosyntax, in contrast with the previous studies that explored morphosyntactic constructions (and thus required stimuli consisting of sentences, e.g., Goldberg et al., Reference Goldberg, Casenhiser and White2007; McDonough & Trofimovich, Reference McDonough and Trofimovich2013; McDonough & Nekrasova-Becker, Reference McDonough and Nekrasova-Becker2014; Year & Gordon, Reference Year and Gordon2009). Additionally, no visual aid was employed, given the difficulty of accurately depicting a large number of often related adjectives. The focus on explicit learning of the target categories in the present task (rather than on incidental learning during sentence processing) would seem to have substantially altered the level of attentional resources allocated to the target structure, rather than to meaning processing. That is, because previous meaning-oriented tasks required learners to focus their attention on processing sentence meanings, while attending to visual input, these conditions may have imposed greater demands on WM than in the inductive learning condition employed here. Therefore, in what concerns WM demands, it is not clear that the incidental conditions of previous studies (with no explicit rules) employing multimodal input are directly comparable to the inductive condition of the present study.Footnote 12 The question of how different paradigms may impinge on WM resources remains a question for future research to address.
Clearly, future work will be needed to replicate and extend the present findings to increase our understanding of how skewed input impacts learning, including in classroom-based settings (e.g., Madlener, Reference Madlener, Behrens and Pfänder2016). In this sense, the present dataset provides an opportunity to inform future experimental efforts. Based on a power simulation performed on the present dataset with the mixedpower package in R (Kumle et al., Reference Kumle, Võ and Draschkow2018), future work seeking to replicate the three-way interaction reported here (with 80% power) may need a sample of ≥140 participants.
Implications for input optimization and personalization
At the core of the interest in investigating the potential benefits of skewed L2 input is the idea that the input can be optimized for learning. Ellis (Reference Ellis2009) proposed that language learning can be regarded as a sampling problem, in that speakers must develop linguistic representations based on limited data. Given the limited exposure to input affecting L2 speakers in particular, designing input based on criteria such as function, frequency, and representativeness, among others, seems of particular importance. This proposal is in line with research conducted within an ATI approach during the last two decades or so (e.g., Vatz et al., Reference Vatz, Tare, Jackson, Doughty, Granena and Long2013; DeKeyser, Reference DeKeyser2012), which suggested that input optimality may be relative to individual traits. For instance, in a study that examined L2 learners’ ability to learn tone contrasts, Perrachione et al. (Reference Perrachione, Lee, Ha and Wong2011) found that higher variability in exposure to multiple speakers helped learners with high acoustic perception acquire L2 tones; however, for learners with lower acoustic perceptual abilities, high-variability training was in fact detrimental, and they benefited from reduced variability instead. Research by Brooks et al. (Reference Brooks, Kempe and Sionov2006) found that a cognitive measure of executive function predicted the extent to which individual participants learning Russian gender benefitted from greater lexical variability in the input. The approach taken here adds evidence indicating that, even if each individual is exposed to the same stimuli, input efficacy should be expected to vary systematically based on individual cognitive traits and specifically WM.
The implications of the present and previous studies that revealed ATIs are potentially far-reaching, suggesting that no one type of input is beneficial across the board but that optimized input must necessarily be, to some extent, individualized input. This approach opens opportunities for L2 researchers to identify the contexts that may trigger specific learning pathways and engage alternative systems to achieve a similar outcome (Ashby et al., Reference Ashby, Alfonso-Reese and Waldron1998; Green et al., Reference Green, Crinion and Price2006). Relying on well-established constructs in psycholinguistics—such as WM (Tagarelli et al., Reference Tagarelli, Mota and Rebuschat2011), executive control (Chen et al., Reference Chen, Zhao, Xu, Liu and Deng2023), or acoustic perception (Perrachione et al., Reference Perrachione, Lee, Ha and Wong2011)—should allow to develop a systematic program of research on the optimization of input. Future work should also consider other well-studied individual-differences measures in the SLA literature—for example, language analytic ability or metalinguistic awareness (Jessner, Reference Jessner2008; Ranta, Reference Ranta and Robinson2002). In sum, taking into consideration diversity among learners is a prerequisite to develop a more inclusive science of L2 learning.
Conclusion
By investigating diversity in cognitive skill—specifically, WM—among L2 learners, the present study found significant variability in the type of input that could be considered as “optimal” for L2 category learning. Following training in learning conditions that exposed participants to skewed or balanced input, and with or without explicit rules, the results indicated an important role of individual WM capacity in modulating the type of input that improved learning gains for subgroups of individuals. While the availability of explicit rules tended to enhance learning gains, in line with previous work, its combination with balanced input was detrimental for lower-WM learners, while being beneficial only for high-WM individuals. Altogether, the results help clarify the variety of results in previous research and suggest that the issue of what L2 input is optimal for learning must be examined in conjunction with individual variability in cognitive resources.
Acknowledgments
The author is grateful to Dr. Andrea Révész and to five anonymous reviewers for their helpful input. This work was supported by the College of Liberal Arts at Penn State. Thanks Carly Danielson, Rachyl Hietpas, Erica Hsieh, and Tiff Rodríguez-Cruz for their help with the implementation of the experiment and with data processing.
Competing interest
The author declares none.
Appendix A
Table S1. Individual measures by group (measures were included as covariates in analysis)

Table S2. Post-hoc contrasts for input distribution at ± 1 SD WM scores (FDR-corrected)

Table S3. Post-hoc contrasts for instruction type at ± 1 SD WM scores (FDR-corrected)

Appendix B
Instructions for training task:
Inductive and deductive conditions:
“This is an experiment investigating language learning. In this task, you will see English words presented on the screen as text. These words will be adjectives (i.e., descriptor words such as ‘beautiful,’ ‘small,’ ‘big,’ ‘difficult’). In addition, you will also *hear* one of two Spanish verbs in each screen (‘ponerse’ and ‘quedarse’). Both Spanish verbs translate as ‘become’ in English, but Spanish requires that you sometimes use one verb and sometimes the other, depending on the particular adjective. Your task is to listen to the verb and select the correct verb, while trying to learn what Spanish verb to use with each English word.
The experiment contains two short practice blocks before the experimental block. The whole task takes less than 10 minutes. There will be one break during the main task.”
Additional rule provided for deductive condition only: “In addition to the examples, there is one critical RULE: One category is associated with the verb ‘ponerse.’ These are words that are related to the word ‘nervous’ and are to some extent similar in meaning. The other category is associated with the verb ‘quedarse.’ This group of words is related to the word ‘still.’ You shouldn’t try to come up with other rules, as that will confuse you! The rule to remember is that ‘ponerse’ is about words related to ‘nervous,’ and ‘quedarse’ about words related to ‘still.’”
Instructions for test following training: “Now you will complete a test. This will look very similar to the training you just completed. However, you will *not* hear what verb each word should go with. Do your best to remember and choose the correct verb.”
Instructions for generalization task: “This task is related to a previous task in which you practiced selecting and learning what Spanish verb to use with different adjectives. This task will work the same way. But this time you will see different adjectives and you will *not* be told what verb is correct.
Your task will be to select the verb that seems most appropriate based on the critical rule that you learned.
REMEMBER: ‘Ponerse’ will be associated with words that are related to the word ‘nervous’ and are to some extent similar in meaning. # ‘Quedarse’ is associated with words related to the word ‘still.’ You shouldn’t try to come up with other rules, as that will confuse you. Do your best to categorize words based on this rule.”









 Open access
Open access