



1 Introduction
Sound changes are a popular area of phonetic and phonological research, with work focusing on the theory of sound change (Labov Reference Labov1981) and the acoustic and articulatory properties of sounds undergoing change (Rutter Reference Rutter2011). Among the most attested types of sound changes documented in languages of the world are phonological mergers (e.g. Wedel, Kaplan & Jackson Reference Wedel, Kaplan and Jackson2013) and contextual neutralization (Chitoran Reference Chitoran2002, Kochetov Reference Kochetov2004, Warner et al. Reference Warner, Jongman, Sereno and Kemps2004, Lee & Jongman Reference Lee and Jongman2016, Wade Reference Wade2017, Bongiovanni Reference Bongiovanni2021, Conrad published online 15 April Reference Conrad2021). Included among these are a handful of cases in Hong Kong Cantonese (Yu Reference Yu2007, Reference Yu2016; Mok, Zuo & Wong Reference Mok, Zuo and Wong2013; Fung & Lee Reference Fung and Lee2019), where contextually neutralized forms may coexist with non-neutralized forms for several generations (Bauer Reference Bauer1982, Newman Reference Newman1987). In this study, we examine a case of contextual neutralization, where /kʷ/ and /k/ may be pronounced equivalently when produced before the rounded back vowel /ɔ/, such that the syllable [kɔk] may either refer to either /kʷɔk3/ ‘country’ or /kɔk3/ ‘corner’. We suggest that, for at least one group of speakers of Hong Kong Cantonese, numerous acoustic properties are preserved in the neutralizing environment, with different speakers either maintaining a clear distinction between /kʷ/ and /k/ or showing incomplete neutralization.
1.1 Contextual neutralization as sound change in progress
Acoustic studies of contextual neutralizations have demonstrated that additional care must be taken when evaluating their status: acoustic components of a sound are not always impacted equally. For example, Slowiaczek & Dinnsen (Reference Slowiaczek and Dinnsen1985) examined word-final devoicing in Polish, finding that devoicing is a case of incomplete neutralization, although the way in which the distinction between underlying voiced and voiceless obstruents is preserved differs based on several factors. Kharlamov (Reference Kharlamov2014) examined word-final obstruents in Russian, finding that neutralized underlyingly voiced obstruents maintain a distinction in terms of both consonant duration and glottal pulsing and that these acoustic measures interact with each other differently depending upon orthography, number of syllables in a word, and speech style. In other words, whereas a basket of acoustic measures may be subject to change in a neutralizing environment, these acoustic measures may not all be impacted or may not be impacted equally.
Previous studies have also examined the role of social group in sound change (Lippi-Green Reference Lippi-Green1989), and have indicated that high levels of individual variation may be present with respect to sound change coming from sociolinguistic factors such as age or generation, gender, social group and status, and ethnicity (Bauer Reference Bauer1982, Milroy & Milroy Reference Milroy and Milroy1985, Hall-Lew Reference Hall-Lew2013). Dinnsen & Charles-Luce (Reference Dinnsen and Charles-Luce1984), for example, examined the incomplete neutralization of word-final obstruent devoicing in Catalan, finding that while vowel duration, consonant closure duration and voicing into consonant closure were all neutralized overall, individuals showed different patterns of change to closure duration and voicing into closure in neutralizing environments.
Of interest to this paper is the incomplete neutralization of the labialized velar stop /kʷ/ and its plain counterpart /k/ when preceding rounded vowels in Hong Kong Cantonese, where multiple acoustic properties may be at play to various extents. While /k/ preceding rounded vowels was reported to show a significant degree of anticipatory labialization comparable to that of its contrastive /kʷ/ preceding unrounded vowels in Nawuri (a Kwa language spoken in Ghana), the secondary labialization with /w/ preceding rounded vowels has been described as generally not very audible as a principle of speech perception (Casali Reference Casali1990). Despite the inaudibility of the secondary labialization, in languages like Marshallese (an Austronesian language spoken on the Marshall Islands), the phonetic realization of vowels were found to be systematically determined by the secondary articulations in their surrounding consonants (Choi Reference Choi1995). The situation gets more complicated when there is an asymmetry between labial-initial and non-labial-initial sequences. In Romanian, different representations were necessary for [ea] vs. [ja] whereas phonetic neutralization was found for [oa] vs. [wa]. Chitoran (Reference Chitoran2002) explained such findings with language-specific frequency differences and contrast maintenance, urging for detailed phonetic studies for better understanding of the phonology of the language.
The /kʷ/–/k/ neutralization has been described as one of a handful of ongoing sound changes over the last century in Cantonese (Bauer Reference Bauer1982, Newman Reference Newman1987), together with tone merger (Yu Reference Yu2007, Mok et al. Reference Mok, Zuo and Wong2013, Fung & Lee Reference Fung and Lee2019) and individual variation in the coarticulation of /s/ in different vowel contexts (Yu Reference Yu2016), for example. The /kʷɔ/–/kɔ/ neutralization has been recognized since 1972 (To, Mcleod & Cheung Reference To, McLeod and Cheung2015) and shown to be nearly complete in rapid speech in the early 1980s (Bauer Reference Bauer1982). Bauer (Reference Bauer1982) observed that /kʷɔ/ sequences were produced without labialization (as [kɔ]) a majority of the time by most subjects at varying socioeconomic statuses and ages for numerous lexical items. Yet a more recent study found a higher degree of maintenance of the distinction between the two stops for a single lexical item, /pʰiŋ21.kʷɔ25/ ‘apple’ (To et al. Reference To, McLeod and Cheung2015). While these previous studies have focused on perceptual categorization of /kʷɔ/ productions as [kʷɔ] or [kɔ], this paper aims at offering a detailed examination of the acoustic properties involved in the realization of /kʷ/ when put in rounded versus unrounded environments. Worth noting is that such neutralization also exists with the aspirated labialized velar /kʷʰ/, although there is a higher level of uncertainty regarding the phonemic representation of individual words with /kʷʰ/ and /kʰ/ as evidenced by dictionary entries Cheung et al. Reference Cheung, Chin, Chung, Lee, Lun, Man and Wing Tang2016, Sheik Reference Sheik2017). As such, a full discussion of the aspirated phonemes is outside the scope of the current study.
1.2 The status of /kʷ/ in the Cantonese phonological inventory
The labialized velar onset /kʷ/ in Cantonese is considered a complex onset segment instead of a sequence composed of [k] followed by [w], and contrasts phonemically with the plain velar stop /k/ (Bauer & Benedict Reference Bauer and Benedict1997). In terms of articulation, the velar stop [k] and labiovelar [w] are pronounced simultaneously or nearly simultaneously. The back of the tongue is held against the velum for [k] while the lips are tightly rounded for [w]. In terms of syllable structure, Cantonese syllables are considered to have maximally one consonant in the onset position (and at most one consonant in coda position). Because this type of labialization occurs solely with velar stops, Cantonese is frequently interpreted as having a labialized velar phoneme rather than a velar–glide sequence (Bauer Reference Bauer1982, Newman Reference Newman1987, Yip Reference Yip1993, Matthews & Yip Reference Matthews and Yip2011, To et al. Reference To, McLeod and Cheung2015). Thus /kʷɔk/ would be a valid syllable, but /kwɔk/ would not. Identifying this as a single consonant with a secondary articulation therefore fits with Cantonese phonotactics.
In terms of the Cantonese syllabary (Bauer & Benedict Reference Bauer and Benedict1997), /kʷ/ tends not to combine with rimes ending in labial consonants (i.e. /w m p/) whereas /k/ combines freely with them. Furthermore, while /kʷ/ occurs with four vowels, the environments in which /kʷ/ occurs demonstrate a meaningful contrast with /k/, supporting the claim that the segments in question are two distinct phonemes, and that the process of interest is indeed neutralization of the two in certain environments.
The labialized velar stop /kʷ/ occurs in onset position before four vowels: /a ɔ i ɐ/ (Kao Reference Kao1971). Examples of these, as well as the vowels with which /kʷ/ cannot occur, are shown in (1): below.

Note that /i/ in the context of interest is produced as [ɪ], as in (1c). It is important to understand that the number of phonemes in the vowel inventory of Hong Kong Cantonese is subject to a certain amount of debate, as there is significant allophonic variation in production (Bauer & Benedict Reference Bauer and Benedict1997). As a result, researchers may come to different conclusions about the phonemic inventory (Zee Reference Zee1991, Bauer & Benedict Reference Bauer and Benedict1997). We follow Kao (Reference Kao1971) in selecting an inventory of eight vowels based upon patterns of distribution rather than the fourteen described by (Bauer & Benedict Reference Bauer and Benedict1997) on the basis of position-based phonetic quality. This is done for the sake of simplicity, as the vowels examined in this study are the same in both inventories.
In all except (1b), the acoustic distinction between the labialized velar stop and its velar counterpart is consistently produced. The fact that this loss of labialization takes place before the only rounded vowel with which /kʷ/ occurs is unsurprising, as other languages are also shown to disprefer labialized stops before back rounded vowels (Ohala & Kawasaki-Fukumori Reference Ohala, Kawasaki-Fukumori, Eliasson and Jahr1997). Kim (Reference Kim2010) demonstrates that English avoids labiovelar glides before high rounded vowels, and Korean does not allow any labialized segment before a rounded back vowel; Stonham & Kim (Reference Stonham and Kim2008) likewise observe the loss of labialization on phonemically labialized stops before /u/ in Nuuchahnulth. This is further supported by Bauer & Benedict (Reference Bauer and Benedict1997), who observe that of 31 of 34 possible Cantonese rimes containing rounded vowels are unattested after labialized velar stops; only rimes /ɔŋ/, /ɔk/ and /ɔ/ are attested.
1.3 Acoustic properties of labialization
In order to evaluate how the acoustic properties of labialization are altered in the neutralizing environment, those properties must be identified and evaluated. Labialization as a secondary articulation tends to affect both the labialized consonants and the following vowels, especially portions of the vowel immediately after consonant release (Flemming, Ladefoged & Thomason Reference Fleming, Ladefoged and Thomason2008, Beeley Reference Beeley2015). These differences in acoustic measurements are a direct result of the lip rounding that is a crucial characteristic of both labialized segments and rounded vowels. Specific acoustic properties of interest in productions involving lip rounding are vowel duration, the first three formants, and rise time of intensity.
In the case of Hong Kong Cantonese, the initial consonant /kʷ/ is a coarticulated labialized-velar stop, as often indicated by the raised [w] in its narrow phonetic transcription, its incompatibility with rimes ending in labial consonants, and the absence of consonant clusters (Bauer & Benedict Reference Bauer and Benedict1997). In order to pronounce the voiceless velar stop [k] and the voiced labial approximant [w] simultaneously, the lips are rounded for [w] while the back of the tongue is held against the velum for [k]. The labialized-velar stop /kʷ/ is often tightly rounded (with lip corner compression) so as to contrast with its plain counterpart /k/. When this tight lip rounding occurs, lips are further extended, increasing the length of the vocal apparatus and further lowering formant values.
Differences in duration have been documented when comparing a velar stop–labiovelar glide sequence with a labialized velar phoneme (Suh Reference Suh2007). Catford (Reference Catford1988) furthermore demonstrates that, even within the realm of what is considered phonetically to be a labialized velar stop, there is a possible range of differences in the points of maximal stricture for the velar closure and the labial constriction. In other words, an articulation that is described as a production of a single labialized velar stop may have maximal labial constriction occur slightly after the velar stop is produced. When this happens, the release of the labial constriction may lengthen the sequence, similar to how a labial–velar glide sequence lengthens the following vowel.
Previous work has highlighted that labialization results in lower values for F1, F2, and F3 due to lip protrusion, which slightly increases the length of the vocal tract (Stevens Reference Stevens1998, Sturman et al. Reference Sturman, Baker-Smemoe, Carreño and Miller2016). Stevens indicates that it may take 50–100 ms to fully return the lips to a neutral position after rounding, which means that rounding on an onset consonant will necessarily affect values on at least the first portion of the following vowel.
A further complication arises when considering the interplay of a labialized onset consonant and a rounded vowel. It has been reported that the labialized-velar stop /kʷ/ has lost its lip labial friction for [w] when preceding rounded vowels (Benedict Reference Benedict1942), as a result of the co-occurrence of two similar labial sounds in sequence. This neutralization of /k/ and /kʷ/, however, is still expected to leave room for some lip-rounding on the neutralized /kʷ/ as an anticipatory cue of the following rounded vowels. In view of the above gestural coordination on formants, according to Stevens (Reference Stevens1998), when lip rounding is added, F1 is lowered more for low vowels than for high vowels, and is relatively stable for /i/. Back rounded vowels, such as /ɔ/, tend to have lower F2 values than front vowels. Because labialization on consonants also corresponds to lower F2 at the vowel onset, a labialized stop followed by an unrounded vowel, especially a front vowel, will demonstrate a large increase in F2 at the start of the vowel, whereas a labialized stop followed by a rounded back vowel will have a less dramatic increase in F2 (Flemming et al. Reference Fleming, Ladefoged and Thomason2008). Finally, Sturman et al. (Reference Sturman, Baker-Smemoe, Carreño and Miller2016) reported that labialization as a secondary articulation frequently results in lower F3 values than non-labialized counterparts. Beeley (Reference Beeley2015) further determined that F3 at vowel onset was a better measure of labialization than F2 in a dialect of British English.
Rise time of intensity, the amount of time it takes for amplitude to increase from the start of a vowel towards its maximum, may additionally be lengthened by onset labialization. This is because labialization as a secondary articulation on an onset consonant is phonetically similar to a glide–vowel sequence (Flemming et al. Reference Fleming, Ladefoged and Thomason2008). Because this labialization lowers amplitude (Stevens Reference Stevens1998) and, if it occurs slightly after the velar closure, extends the length of the following vowel, it may take longer for amplitude to increase after the labialized velar /kʷ/ than after /k/.
Table 1 summarizes the anticipated effects of labialization upon each of the acoustic properties examined in this study. Vowel duration should increase in the labialized condition. Each of the formants is expected to be lower in labialized conditions than in their corresponding plain velar conditions, while rise time of intensity is expected to be longer after labialized onsets than plain velar onsets.
Table 1 Summary of effects of lip rounding on relevant acoustic measures.

1.4 Predictions
Based on the previous research into incomplete neutralization as sound change in progress and its relevance to /kʷɔ/ neutralized as [k] in Cantonese, we predict the following:
-
(i) Some acoustic properties associated with labialization will be preserved in the /kʷɔ/ environment, while others will be neutralized.
-
(ii) Speakers vary in the extent to which they produce different acoustic properties associated with labialization. That is, some speakers will preserve the distinction of fewer properties than other speakers.
In order to evaluate prediction (i), we examine the acoustic properties associated with labialization in the neutralization environment, and compare these with the same properties in non-neutralizing environments. Acoustic properties preserved in the /kʷɔ/ environment are expected to differ significantly from those in the /kɔ/ environment. To confirm the relevance of these acoustic properties in onset labialization in Hong Kong Cantonese, there should also be a significant difference in non-neutralizing environments. When the values of an acoustic property do not differ significantly between /kʷɔ/ and /kɔ/, there is evidence of contextual neutralization of this property. These properties may be impacted by differences in the extent to which individuals round their lips in the /kʷɔ/ environment, whether or not they use lip compression during lip rounding, or by the timing of the maximal labial constriction relative to the velar closure.
If speakers do not engage in as much lip rounding in the /kʷɔ/ environment as they do in other /kʷ/ environments, the coarticulatory rounding from the vowel /ɔ/ will result in the same amount of lowering to F1, F2, and F3 values in /kʷɔ/ and /kɔ/ conditions. Likewise, unless labial constriction peaks at the same time for both the /kʷɔ/ and /kɔ/ sequences, there should be a difference in vowel duration for the two. Other vowel contexts, meanwhile, should have slightly longer duration after labialized velars than after plain velar stops.
Prediction (ii) highlights the importance of individual difference by predicting that some speakers will show greater preservation of the contrast, while others will show more complete neutralization. A speaker showing greater preservation of contrast will produce significantly different values for all or most acoustic properties associated with labialization between /kʷɔ/ and /kɔ/ sequences, whereas a speaker showing greater neutralization will show fewer significant differences among these properties. To do this, some speakers may produce /kʷɔ/ sequences with a smaller degree of lip rounding than other /kʷV/ sequences, while others may alter the timing of maximal labial constriction relative to velar closure in /kʷɔ/ relative to other /kʷV/ conditions.
2 Method
2.1 Participants
Fourteen native speakers of Hong Kong Cantonese (eight male, six female) participated in the study. Participants were recruited through a public university in Hong Kong and were between the ages of 18 years and 29 years at the time of the study. All participants indicated that their primary language was Cantonese, that they grew up in Hong Kong, and that they felt comfortable to complete the consent process and a language background questionnaire in English. All participants were fluent readers of traditional Chinese, and all had prior exposure to Mandarin. Furthermore, all participants indicated that they had no known history of hearing impairments or speech disorders. Responses to the language background questionnaire indicate that all participants use Cantonese regularly with their peers, and all but one use Cantonese with their parents and grandparents.
Overall articulation rates (calculated as number of syllables per second of phonation) were automatically calculated for each participant using a Praat script (De Jong & Wempe Reference De Jong and Wempe2009). The participants had a mean articulation rate of 4.41 syllables per second, with a standard deviation of 0.35 syllables per second. Participant m4 had the lowest articulation rate at 3.96 syllables per second, while participant m3 had the highest articulation rate at 4.98 syllables per second.
2.2 Stimuli
The stimuli consisted of 132 target words and 129 fillers, all of which are real words and morphemes of Cantonese. Participants produced one token with /kʷʰ/ rather than /kʷ/, as perceived by a native Cantonese-speaking author, so it was not considered for analysis. Each target word began with either /kʷ/ or /k/ followed by /a/, /ɐ/, /i/, or /ɔ/ with one of three coda conditions in the target syllable: /ŋ/, /k/ or no coda. The distribution of target syllables is shown below in Table 2.
Table 2 Frequency of each syllable condition in the stimuli. Where possible, ten stimuli were included per condition; eleven stimuli were included in the /a/ condition as there were limited other /kʷa/ stimuli. Unattested syllables are presented with a dash. Note that the word included in the stimulus list for condition /kʷaŋ/ was produced as [kʷʰaŋ], and was therefore removed from analysis. For the complete list of target and filler stimuli, please see the appendix.

Targets were matched as closely as possible across onset and vowel conditions, although this was frequently not possible as only real morphemes of Cantonese were used. Thus, targets included such real words as /kʷɔk3.jɐn21/ ‘countryman’ and /kɔk3.jɐn21/ ‘everyone, each person’, but not the corresponding non-words */kʷik.jɐn/ or */kik.jɐn/. The uneven number of items in Table 2 alludes to the difficulties both of finding acceptable tokens and of matching stimuli across conditions. For example, sequences /kʷɐ/ and /kʷi/ are rare in the language, occurring only in closed syllables and primarily only with coda /ŋ/; /kʷak/ is similarly an uncommon syllable in the language. In total, 1,834 target tokens were analyzed, with 131 tokens analyzed per participant.
Fillers were also real words and morphemes of Cantonese (such as /pɐk5/ ‘north’ and /lø ŋ21.tsʰa21/ ‘herbal tea’, although they began with non-target syllables. One hundred and fourteen fillers ended in /t/ or /k/ in order to serve as distractors for participants who were looking for patterns in the stimuli. A full list of target and filler stimuli appears in the appendix.
2.3 Procedures
Participants were recorded in a sound-proof booth in the Laboratory of Phonetics and Phonology at The University of Hong Kong using a digital speech recorder with a high-quality head-mounted microphone at a sampling rate of 44.1 kHz. Participants were seated at a desk with a Macbook laptop, which displayed one written stimulus at a time on a slide viewer. Each stimulus was produced in the carrier phrase /kʰøy23.kɔŋ25.tsɔ25/ TARGET /jɐt5.tsʰi33/ ‘s/he said TARGET one time’, which was written at the bottom of each slide in traditional Chinese characters in case they forgot it. The carrier phrase was intended to provide a neutral semantic context in which to produce each word, although it is possible that the inclusion of the /kɔ/ sequence in /kɔŋ/ might have a subtle impact upon productions of target stimuli.
Stimuli were presented a single time in a pseudo-random order with no more than two consecutive target words with the same onset–vowel sequence and no more than three total consecutive target words, as well as at most four consecutive fillers. Each participant was presented with the stimuli in the same pseudo-random order. Participants were instructed to speak at a normal pace, as though talking to their friends.
2.4 Measurements
Following are descriptions of the acoustic measures calculated on all vowels following either /kʷ/ or /k/. These measurements were: vowel duration, F1, F2, and F3 values at voicing onset, F1, F2, and F3 values at vowel midpoint, and rise time in intensity. All boundaries in target vowels were marked by identifying onset and offset of visible F2 in a spectrogram, and acoustic measurements were automatically extracted from the recordings using Praat (Boersma & Weenink Reference Boersma and Weenink2018). The automatically extracted values were then carefully examined for accuracy by comparing them with visible formant structures in a spectrogram. The Praat script used for formant extraction was modified from Kroos, Bundgaard-Nielsen & Tyler (Reference Kroos, Bundgaard-Nielson and Tyler2010), and the script for rise time was altered from the intensity extraction script from Kawahara (Reference Kawahara2010).
2.4.1 Duration
Vowel duration was measured by identifying the start and end of the visible F2 using spectrograms generated by Praat. Identification of the start and end of F2 was completed manually, with vowel boundaries indicated through a textgrid tier and the interboundary length extracted automatically to provide the duration measurement.
2.4.2 Formant measurements
F1, F2 and F3 values were extracted at 5 ms post-onset of voicing and at the vowel midpoint. These time points were selected to show the labialization during formant transition from the onset consonant to the vowel and the steady state of the vowel. Measurements were checked for accuracy. And, in places where errors were noted (e.g. where the value selected as F2 was in fact taken from F3, and where F3 was taken from F4), values were altered by manual formant measurement using their Praat spectrograms. These corrections resulted in calculations that could be reliably analyzed in linear mixed effects models.
Formant measurements were normalized in order to create a consistent comparison across speakers. This was done with the R Vowels package (Kendall & Thomas Reference Kendall and Thomas2018) by using Labov normalization, which uses the method presented in Labov, Ash & Boberg (Reference Labov, Ash and Boberg2008) by scaling individual speakers’ formant productions to normalized Hertz values.
2.4.3 Rise time of intensity
Rise time of the intensity of the vowel (often called Amplitude Rise Time) refers to the increase in the amplitude of a syllable or sound sequence (Nittrouer, Lowenstein & Tarr Reference Nittrouer, Lowenstein and Tarr2014). To calculate rise time, intensity was first measured at 40 ms intervals over the first half of the vowel, the standard sampling interval in Praat. Minimum intensity near vowel onset and maximum intensity over the first half of the vowel were calculated, and their difference was taken. Parabolic interpolation was applied to the intensity measurements in order to produce continuous estimates over the vowel. Parabolic interpolation was selected also due to its higher accuracy relative to linear interpolation and the relatively long intervals between intensity measurements (Boersma & Weenink Reference Boersma and Weenink2018). Points on this continuous curve where the minimum intensity passed 10
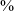 $\%$
and 90
$\%$
and 90
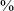 $\%$
of the difference between minimum and maximum intensity were extracted. The time from 10
$\%$
of the difference between minimum and maximum intensity were extracted. The time from 10
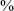 $\%$
to 90
$\%$
to 90
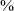 $\%$
of the change in intensity was recorded as rise time in intensity. The calculation for rise time of intensity is shown in Figure 1.
$\%$
of the change in intensity was recorded as rise time in intensity. The calculation for rise time of intensity is shown in Figure 1.

Figure 1 A schematic representation of rise time calculation. The rise time (yellow double-ended arrow) is calculated by identifying the points at 10
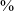 $\%$
and 90
$\%$
and 90
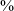 $\%$
of the difference between minimum and maximum intensity along the intensity curve and calculating the length of time between them.
$\%$
of the difference between minimum and maximum intensity along the intensity curve and calculating the length of time between them.
2.5 Statistical analysis
Linear mixed effects models were used to examine significance of the different acoustic properties measured. All acoustic measurements were examined as dependent variables in these models, with phonemic labialization (labialized, plain) or vowel (/ɔ ɐ a i/) as fixed effects, depending on the model, with random slopes and intercepts for participant and random intercepts for items; random effects structure was simplified only when required based on non-convergence or singular fit. This combination of random slopes and intercepts for random effects was selected due to the within-subjects but between-items nature of the experiment. Model selection was based on the keep-it-maximal principle (Barr et al. Reference Barr, Levy, Scheepers and Tily2013), with random slopes and intercepts selected to represent the maximal model expected based on predictions. Labialized velars and following vowel /ɔ/ were set as the reference levels to directly examine how measurements in the neutralizing environment pattern relative to other environments.
All statistical models were created using R Studio (Rstudio Team 2020, R Core Team 2021). P-values were calculated in the package lmerTest in R (Kuznetsova, Brockhoff & Christensen Reference Kuznetsova, Brockhoff and Christensen2017) using the Satterthwaite approximation, which Luke (Reference Luke2017) has shown to be among the most accurate methods of p-value calculation for linear mixed effects models, especially with a smaller number of subjects. While larger LMEs were initially calculated, interactions of labialization and vowel caused difficulty of interpretation of effects, so models were simplified to compare vowel contexts for labialized velars only and to compare labialized and plan velar onset conditions for each vowel separately. Results were visualized using ggplot2 (Wickham Reference Wickham2016).
3 Results
The results of this experiment provide information about the extent to which productions of /kʷɔ/ sequences were neutralized by these speakers, both in terms of the data overall and in terms of the differences among participants. The following sections outline first the results as a whole, then provide an examination of the data across participants in order to better understand their variability.
3.1 Overall results
The overall results were used to examine which among the basket of relevant acoustic properties show significant differences in all environments, suggesting maintenance of contrast, and which were significantly different in all environments except the neutralizing environment. This was done by comparing /kʷ/ to /k/ in each vowel environment (/ɔ ɐ a i/) to determine whether there were significant differences in each environment. Further tests compared productions of /kʷ/ in each vowel environment to determine differences between environments.
3.1.1 Duration measurements
The differences in vowel duration for /kʷ/ and /k/ before each of the four vowels are shown in Figure 2. Duration is longer for vowels /ɔ/ and /a/ than for vowels /ɐ/ and /i/. Labialized velar onsets have numerically longer duration than plain velar onsets for all four vowels. There is higher variability for vowels /ɔ/ and /a/ than for vowels /ɐ/ and /i/.

Figure 2 Mean vowel duration for plain and labialized velar stops by following vowel.
The results of linear mixed effects models for duration, in Table 3, show a significant difference in values between labialized and plain velar onsets for vowels /a ɐ i/, but no significant difference between duration of the vowel /ɔ/ between /kʷ/ and /k/. There are furthermore significant differences in duration for stimuli in the /kʷɔ/ condition relative to labialized stimuli in each of the other vowel conditions. These results indicate that the speakers do not maintain the length distinction between /kʷ/ and /k/, instead showing signs of neutralization with the vowel /ɔ/.
Table 3 Linear mixed effects model results for duration (ms); /kʷ/ and /ɔ/ are set as reference levels.

** p<.01; *** p<.001
3.1.2 F1 measurements
Figure 3 shows the mean F1 values at onset and midpoint of the following vowel (a and b, respectively). F1 values at vowel onset are higher for /k/ with vowels /ɔ/, /a/, and /ɐ/ than for /kʷ/, although F1 values for /i/ are the same for both onset consonants. In the /ɔ/ environment, mean F1 is slightly lower after both types of velars than values for /a/ and /ɐ/. F1 values for all four vowels in both velar conditions are higher at vowel midpoint, although there is the least change for /ki/ sequences. At vowel midpoint, there is a clear difference between /kʷ/ and /k/ for vowel /ɔ/. To determine whether the F1 values for vowels following /kʷ/ and /k/ are significantly different in each vowel condition, linear mixed results models were calculated for each.

Figure 3 Mean normalized F1 values (Hz) at onset (a) and midpoint (b) of the following vowel. Mean F1 values are higher for vowels /ɔ/, /a/, and /ɐ/ that follow plain velars at both onset and midpoint, though values for /i/ are lower after plain velar at midpoint. The value of F1 is fairly stable at onset regardless of the following vowel, although this trend has disappeared by vowel midpoint.
Linear mixed effect models for F1 values are shown in Table 4. Results of these models reveal significant differences between labialized and plain velar onsets in both the neutralization environment and other vowel environments. At vowel onset, there is no significant difference in F1 values between labialized and plain velar onsets preceding vowel /i/, although there is a significant difference for vowels /ɐ/, /a/, and /ɔ/. This is consistent with the observation by Stevens (Reference Stevens1998) that F1 is not affected by lip rounding for a high vowel such as /i/. There is furthermore a significant difference between F1 values for words beginning with /kʷɔ/ and words beginning with /kʷ/ in each of the other vowel conditions. At vowel midpoint, mean F1 values are significantly different between plain and labialized onsets followed by all four vowels. As at vowel onset, there is again a significant difference between F1 values for /kʷɔ/ items and items in other /kʷV/ conditions. As all vowels show significant differences in F1 values between labialized and plain velar onset conditions, these results suggest that this group of speakers maintains the F1 distinction between /kʷɔ/ and /kɔ/.
Table 4. Linear mixed effects model results for F1 values at vowel onset (left) and midpoint (right); /kʷ/ and /ɔ/ are set as reference levels.

** p<.01; *** p<.001
3.1.3 F2 measurements
Figure 4 shows the mean F2 values at onset and midpoint of the following vowel (a and b, respectively). At onset of the following vowel, F2 after labialized velars is consistently lower than after plain velars, which is consistent with literature on the effects of rounding on F2 (Stevens Reference Stevens1998). Plain velars show varied F2 values according to vowel, which is expected and reflects the difference in quality between these vowels.

Figure 4 Mean normalized F2 values (Hz) at onset (a) and midpoint (b) of the following vowel. Mean F2 values at onset are similar for all four vowels after a labialized velar, although the decrease in F2 is smallest in the neutralizing environment. By vowel midpoint, the difference between F2 values between velar phonemes is still smallest in the neutralizing environment.
F2 values in the sequence /kʷi/ are slightly higher than for the other three vowels. The difference in F2 after plain and labialized velars is much smaller for vowel /ɔ/ than for the other vowels. By vowel midpoint, F2 has increased for all vowels following labialized velars and has decreased for all vowels following plain velars. At vowel midpoint, the neutralizing environment still shows the smallest difference in F2 relative to the same following vowel after a plain velar.
Linear mixed effects models for F2 values at onset and midpoint (in Table 5) of the following vowel show that, despite the smallest differences in F2 values being between /kɔ/ and /kʷɔ/, these differences are still significant at both vowel onset and vowel midpoint. This observation is true before all unrounded vowels, as well. There is furthermore a significant difference among F2 values in each vowel condition with onset /kʷ/. As with F1, results of these models suggest that this group of speakers as a whole maintains the F2 distinction between labialized and plain velar onsets in the rounded vowel /ɔ/ environment. The preservation of this distinction may be due to the use of F2 as a major cue to labialization in languages of the world (Stevens Reference Stevens1998, Sturman et al. Reference Sturman, Baker-Smemoe, Carreño and Miller2016).
Table 5. Linear mixed effects model results for F2 values at vowel onset (left) and midpoint (right); /kʷ/ and /ɔ/ are set as reference levels.

*** p<.001
3.1.4 F3 measurements
Sturman et al. (Reference Sturman, Baker-Smemoe, Carreño and Miller2016) indicate that labialization as a secondary articulation frequently results in lower F3 values than for non-labialized counterparts. However, the opposite appears true for the neutralizing environment in Hong Kong Cantonese: Figure 5 demonstrates that, with the exception of vowel /i/, F3 values at onset are numerically slightly higher for vowels following labialized velars than for those following plain velars. The difference between the means is smallest for vowel /ɔ/, however.

Figure 5 Mean normalized F3 values (Hz) at onset (a) and midpoint (b) of the following vowel. F3 values for vowels /ɔ/, /a/, and /ɐ/ following labialized velars are slightly higher than for the same vowels following plain velars at both onset and midpoint. F3 values pattern similarly for these three vowels at onset, although values are higher for /ɔ/ by vowel midpoint.
Table 6 reveals that at vowel onset, F3 values for /kʷɔ/ and /kɔ/ are not significantly different; however, F3 values between labialized and plain onsets are significantly different in all other vowel conditions. As before, there is a significant difference in values between each of the four vowels in the labialized velar onset condition. These model results provide the first evidence that these speakers engage in neutralization of some acoustic properties examined here, as the difference in F3 is neutralized in the /ɔ/ condition but not in other vowel environments.
Table 6. Linear mixed effects model results for F3 values at vowel onset (left) and midpoint (right); /kʷ/ and /ɔ/ are set as reference levels.

* p<.05; ** p<.01; *** p<.001
The pattern in F3 values remains the same at vowel midpoint. Labialized onsets are not associated with a significantly different F3 value from plain velar onsets in the /ɔ/ vowel condition, although they are significantly different in all other vowel environments. This result indicates that speakers show signs of neutralization in F3 values at both vowel onset and vowel midpoint.
3.1.5 Rise time of intensity
Rise time of intensity was measured across the first half of each vowel in target stimuli. Figure 6 shows bar charts of non-normalized rise time in milliseconds (a) and log rise times (b) for vowels after labialized and plain velars. In (a), mean rise time is longer after labialized velars than plain velars, with a large amount of variability for vowels /ɔ/ and /a/. The variability in /kʷɔ/ may be indicative that rise time is altered in instances of incomplete neutralization, where tokens with short rise times are more likely to be produced as plain velars. The log-transformed rise time measures in (b) demonstrate that this transformation has greatly reduced variability. Comparing the pattern of rise times across conditions for each vowel in (b) to those in (a), the same patterns are evident in the log-transformed data that existed in the original data.

Figure 6 Mean rise time (a) and log rise time (b) of intensity on vowels following plain and labialized velars. Rise time is longer after labialized velars than plain velars, with much more variability in rise time for vowels /ɔ/ and /a/. Higher values in (b) correspond to longer rise time, while numbers closer to zero indicate shorter rise time.
A linear mixed effects model was used to analyze the effects of vowel and labialization on log rise time of intensity. Log rise time was used because the residuals for untransformed rise time demonstrated violations of heteroskedasticity and clear deviations from normal distribution on a quantile-quantile plot. Log-transforming the data resulted in residuals that no longer violated the assumption of normal distribution of residuals.
Results of the log-transformed linear mixed effects model, presented in Table 7, demonstrate that there is a significant difference in rise time values for /kʷ/ and /k/ across all vowel conditions. For items beginning with /kʷ/, there is no significant difference between the /ɔ/ and /a/ conditions, although /ɔ/ differs significantly from /i/ and /ɐ/. As with the results of F1 and F2 values at onset and midpoint, these results suggest that this group of speakers maintains the distinction in rise time in the /ɔ/ environment. Because there is a large amount of variability in rise time in the /ɔ/ environment, however, there may be individual differences in this measure. As such, it is important to consider the systematic variability across speakers in the study.
Table 7. Linear mixed effects model results for rise time (log); /kʷ/ and /ɔ/ are set as reference levels.

** p<.01; *** p<.001
3.1.6 Summary of overall results
The overall results demonstrate that this group of speakers overall continues to maintain distinction between /kʷɔ/ and /kɔ/ in terms of F1 values, F2 values, and rise time; however, there are signs of neutralization in terms of vowel duration and F3 values. There is furthermore a large degree of variability in both duration and rise time, indicating that there may be substantial individual differences in the maintenance or collapsing of these acoustic measures in the neutralization environment.
3.2 Results by participants
While the overall results showed overall maintenance of the /kʷɔ/–/kɔ/ contrast in terms of F1, F2 and rise time and loss of distinction for vowel duration and F3, there may be salient individual differences in the data. This section examines the interspeaker differences in maintenance and loss of distinction for each of the individual acoustic measures seen above. This examination allows for further insight into the contrast maintenance or incomplete neutralization by this group of speakers. To statistically examine these results, two-sample Welch’s t-tests were performed to compare acoustic measure values for /kʷɔ/–/kɔ/ for each speaker separately. Results of these tests appear in Table 8.
Table 8 Results of two sample Welch’s t-tests comparing acoustic measure values between /kʷɔ/ and /kɔ/ items for each speaker. Bold marks .

* p<.05; ** p<.01; *** p<.001
3.2.1 Vowel duration
Measures of vowel duration by participant for /kɔ/ and /kʷɔ/ can be seen in Figure 7. Duration measurements differed significantly between the two onset conditions for speakers f1, f4, f5, and m5. For each of these speakers, duration of /kɔ/ was significantly shorter than duration of /kʷɔ/. For the remaining ten speakers, there was no significant difference between duration of the vowel in /kɔ/ and /kʷɔ/.

Figure 7 Vowel duration by participant for vowel /ɔ/.
Interestingly, while half of the female speakers maintained the distinction in duration between /kɔ/ and /kʷɔ/, only one out of eight male speakers did so. Taken together, the results of duration by participant suggest that, although overall results indicate a loss of distinction in duration between /kɔ/ and /kʷɔ/, this contrast may be maintained by a subset of speakers.
3.2.2 F1 at vowel onset and midpoint
F1 values show the clearest signs of distinction of maintenance out of all the acoustic measures analyzed. Every speaker realized the distinction between /kɔ/ and /kʷɔ/ through F1. The normalized F1 values are shown in Figure 8. This figure demonstrates that at vowel onset, normalized F1 values for /kɔ/ are significantly higher than those of /kʷɔ/, with a very clear distinction between these values. Speaker m6 shows the closest mean normalized values for F1 between /kɔ/ and /kʷɔ/, although there is still a distinct separation between the two. At vowel midpoint, mean normalized F1 values are still significantly higher for /kɔ/ than for /kʷɔ/ for 13 of the 14 speakers, although by the point F1 values are much closer together. At vowel midpoint, speaker m1 shows the closest mean F1 values between the two onset conditions, and indeed is the only speaker whose normalized F1 values for /kɔ/ are not significantly higher than those of /kʷɔ/.

Figure 8 Normalized F1 values at vowel onset and midpoint by participant for vowel /ɔ/.
3.2.3 F2 at vowel onset and midpoint
Normalized F2 values at vowel onset and midpoint show a similar pattern to F1 values, as can be seen in Figure 9. At vowel onset, F2 values for /kɔ/ are significantly higher than those of /kʷɔ/ for 13 of the 14 speakers. As above, speaker m1 is the only participant whose values do not differ significantly between onset conditions. At vowel midpoint, F2 values for /kɔ/ and /kʷɔ/ are much closer together, although still significantly higher for /kɔ/ for all participants except m1.

Figure 9 Normalized F2 values at vowel onset and midpoint by participant for vowel /ɔ/.
3.2.4 F3 at vowel onset and midpoint
In Section 3.1.4 above, an overall loss of distinction was shown for F3 values at both vowel onset and vowel midpoint. The comparisons of this measure across participants are shown in Figure 10. At vowel onset, normalized F3 values are significantly lower in /kɔ/ than in /kʷɔ/ for speakers f2, f3, f4, m3, m4, m6, and m7, significantly higher for speakers f5 and m8, and not significantly different for speakers f1, f6, m1, m2, and m5. These results suggest that, while there is loss of distinction of F3 at vowel onset for some speakers others maintain this contrast.

Figure 10 Normalized F3 values at vowel onset and midpoint by participant for vowel /ɔ/.
At vowel midpoint, results are likewise mixed. Speakers f2, f4, m2, and m4 have significantly lower normalized F3 values in /kɔ/ than in /kʷɔ/, while the other ten speakers have no significant difference in F3 values. As with F3 at vowel onset, these results suggest that some speakers maintain the F3 contrast between /kɔ/ and /kʷɔ/, while others show loss of distinction for F3 at vowel midpoint.
3.2.5 Rise time of intensity
Results by participant for rise time show that, once again, some speakers maintain the rise time contrast between /kɔ/ and /kʷɔ/ whereas others demonstrate a loss of this contrast, as shown in Figure 11. For log rise time, participants f4, f6, m1, m2, m3, m5, m6, m7, and m8 have a significant difference between rise times for /kɔ/ and /kʷɔ/. The other speakers do not show a difference in rise time values. Interestingly, rise time shows a pattern opposite to that of vowel duration in terms of the gender of speakers who show loss of distinction: four out of six female participants show no significant difference in rise time values between onset conditions, whereas the same pattern holds for only one of eight male participants. Nevertheless, the contrast in these two properties of labialization does not appear in a complementary distribution, so this observation may be an artefact of the data rather than representative of a systematic difference in the realization of the /kɔ/–/kʷɔ/ contrast.

Figure 11 Log rise time values by participant for vowel /ɔ/.
3.2.6 Summary of results by participants
Examining the results of acoustic measures by participants for /kɔ/ and /kʷɔ/ demonstrates that there is a large degree of maintenance of the contrast between the two in terms of acoustic properties, although the only distinction maintained universally by these speakers was for F1 at vowel onset. While one speaker, f4, maintained the distinction between /kɔ/ and /kʷɔ/ for all acoustic measures, speaker m1 showed a loss of distinction in six of the eight acoustic measures examined. The variation in contrast maintenance suggests that, within this group of speakers, there are signs of incomplete neutralization.
Interestingly, there did not appear to be a relationship between articulation rate and maintenance or collapsing of contrast in specific acoustic measures. Both m4, who had the lowest articulation rate, and m3, who had the highest, preserved the distinction between /kʷɔ/ and /kɔ/ for six of the eight acoustic properties examined. M1, on the other hand, who only maintained the distinction between /kʷɔ/ and /kɔ/ in F1 at onset of vowel and rise time, had an articulation rate of 4.13 syllables per second of phonation, just below the average of 4.41 syllables per second. Overall, this suggests that the participants were speaking at a similar enough rate to not have a different impact of articulation rate on production of the phonetic properties examined here.
4 Discussion
This study examined the extent to which speakers neutralize /kʷ/ and /k/ before the rounded back vowel /ɔ/ in Hong Kong Cantonese. The results demonstrate that speakers of Hong Kong Cantonese show maintenance of the contrast between the two to different extents with regard to different acoustic measures. Speakers demonstrate an overall loss of distinction in F3 values at vowel onset and vowel midpoint, as well as vowel duration, but maintenance of the contrast in F1 and F2 values at vowel onset and vowel midpoint, as well as rise time of intensity. These results suggest that speakers produce /kʷ/ with less labialization in the /ɔ/ environment, and equally that the point of maximum constriction on the labial articulation in the /kʷɔ/ environment is equivalent to the point of maximum constriction from coarticulatory labialization present on the /k/ in the /kɔ/ environment. The results furthermore demonstrate that, while some speakers maintain differences in all or most of the acoustic properties of the onset velar, others produce incompletely neutralized versions of /kʷ/, where many or most acoustic measures are not significantly different between /kʷ/ and /k/.
While F1 and F2 values are consistent with a distinction between labialized and plain velars characterized by lip rounding, F3 values do not show the same pattern. The loss of distinction in F3 values is indicative of a lower degree of articulatory difference between /kʷɔ/ and /kɔ/ than other /kʷ/–/k/ pairs, likely due to the lip rounding required for the vowel /ɔ/. Further work would benefit from examining this distinction in terms of articulation through analysis of labial positioning during production of each /kʷ/–/k/ pair.
Analysis of rise time of intensity and vowel duration measures reveals that this group of speakers does not differentiate /kʷɔ/ from /kɔ/ in terms of vowel duration, and that many individual speakers do not differentiate the two sounds in terms of rise time of intensity, although these measures for the /kʷ/–/k/ pair are significantly different in other vowel environments. This may be caused by an articulatory difference in the /kʷɔ/ environment, where the point of maximal labial constriction occurs closer to simultaneously with the point of velar closure than in other /kʷV/ environments. As with the above observations, an articulatory study examining the timing of labial and velar constriction would shed light on whether this possibility accounts for the differences in acoustic properties identified in this study.
The results of this study provide evidence that many speakers of Hong Kong Cantonese may still maintain the distinction between /kʷ/ and /k/ before /ɔ/ in production, a finding that is somewhat different from previous work on the topic (Bauer Reference Bauer1982). As in previous work, there is individual variation in production, although in this study there are signs that neutralization is incomplete even for the speakers who maintain the fewest phonetic contrasts between the two phonemes.
For future research, the use of lexical frequency as a manipulated factor would be beneficial. If F3 and vowel length demonstrate consistently different patterns of production in the neutralizing environment across groups, speech styles, and levels of frequency, while others do not, it is likely that the /kʷɔ/–/kɔ/ distinction is maintained more frequently than shown by previous studies. If, on the other hand, other conditions lead to complete neutralization of the distinction between /kʷɔ/ and /kɔ/, then this distinction would continue to be made only by certain speakers in specific circumstances, which is consistent with (Bauer Reference Bauer1982).
Additional acoustic analysis of this sound change could examine the patterns of these acoustic properties across sociolinguistic groups and registers in Hong Kong. As we have seen differences among participants in terms of their productions of the /kʷɔ/–/kɔ/ distinction, future research may wish to further explore variation in this phenomenon. One good way of examining these differences is through an understanding of how the contextual neutralization of /kʷɔ/ diffuses through the population, including a mapping of the phenomenon through social groups.
Acknowledgements
We would like to acknowledge the help and support of Natasha Warner, Mike Hammond, Jonathan Yip, Diana Archangeli, and Paul Boersma, as well as JIPA Associate Editor Alexei Kochetov and two anonymous reviewers for their helpful feedback.
Appendix. List of target and filler stimuli























 Open access
Open access