



Introduction
In epidemiology, accurately estimating indicators such as prevalence is crucial to study and monitor a disease in the general public and specific populations, and to implement appropriate public health measures. One approach to estimate the prevalence of a specific infection is to ask people to self-report their infection as part of a survey [Reference Hagan1]. However, only people aware of their infection, who fully understand the question and who agree to disclose their status, can do so. Therefore, the most suitable way to estimate prevalence is to conduct an epidemiological survey in which a biological assay specific to this infection is performed on all survey participants. Such assays are most often performed by laboratories on biological samples (or matrices) from well-defined populations (such as blood donors). The assay cut-off value – established using reference material and standard conditions (biological matrices (traditionally, serum or plasma), commercial biological kits and storage) – is often provided by the manufacturer. This cut-off value allows the classification of biological quantitative measurements into a ‘positive’ result (infection or past infection), a ‘negative’ result (not infected) or an ‘inconclusive’ result. In the latter, a reanalysis of the biological sample is necessary, otherwise the sample is considered positive or negative or excluded from the epidemiological study, or remains inconclusive.
According to this classification, estimating seroprevalence is usually straightforward if the assay is performed under the conditions recommended by the manufacturer [Reference Soulier2].
The sensitivity and the specificity of a biological assay can be modified if not performed according to the manufacturer's instructions. In an epidemiological survey, the choice of the format of biological/serological assay to use depends on several factors. The most important of these are: target population, ease of use, implementation conditions of the survey (whether within dedicated care/prevention services or outside of such services), testing laboratory and cost. Seroprevalence estimates may be biased when a biological assay is applied to a population and/or to a biological matrix different from those used to calibrate and validate the assay [Reference Soulier2–Reference Tuaillon5].
To avoid inconclusive classifications arising from the use of fixed or arbitrary biological cut-off values, an approach using a mixture of distributions – to model the distribution of the biological quantitative measurements – was proposed in the literature [Reference Kafatos6]. Called the ‘direct approach’, it differs from the classic cut-off approach [Reference Bollaerts7].
In this article, our objective was to estimate the prevalence of anti-HCV antibodies (anti-HCV) among drug users (DU) in France, from a biological test performed on dried blood spots (DBS) collected during the ANRS-Coquelicot survey in 2011 [Reference Léon8, Reference Weill-Barillet9]. However, in 2011, we did not have a cut-off value for DBS and we could not use the values for serum or plasma, knowing that the DBS value was not necessarily the same. The distribution of the biological quantitative measurements (signal-to-cut-off (s/co) ratios) used to detect anti-HCV antibodies was estimated using a Bayesian framework incorporating a two-component mixture model with age-dependent mixing proportions using penalised splines [Reference Vink10]. We compared our results with three other approaches (two model-based approaches published recently [Reference Léon8] and the classic biological cut-off approach).
Methods
Data sources
ANRS-Coquelicot was a French cross-sectional serosurvey performed in 2011 among DU recruited in five French metropolitan cities (Lille, Strasbourg, Paris, Bordeaux and Marseille) and two administrative departments in the Paris area (Seine-Saint-Denis and Seine-et-Marne) [Reference Weill-Barillet9]. Inclusion criteria were as follows: individuals >18 years who had injected or snorted drugs ‘at least once in his/her life’, spoke French and agreed to participate in the survey (providing informed consent). The survey's main objectives were to estimate the prevalence of anti-HIV and anti-HCV antibodies, to assess at-risk practices associated with HCV transmission and to evaluate the dynamics of the HIV and HCV epidemics in this population. DU were selected using time-location sampling [Reference Léon, Jauffret-Roustide and Le Strat11] and interviewed about their socio-demographic situation, health status, access to HIV and HCV screening, knowledge of HIV and HCV transmission modes, drug use in their lifetime and in the previous month, at-risk practices and access to care. In the present sub-study, we focus on the estimation of anti-HCV prevalence. Blood samples on blotting paper were collected during the interview by participants who agreed to provide self-obtained finger-prick blood samples on DBS for anti-HIV and anti-HCV antibody testing.
Biological samples
Screening for anti-HCV antibodies was performed using ELISA with the HCV 3.0 Ortho assay (Raritan, NJ, USA). Details on the serological data analysis are available in a previous paper [Reference Léon8]. Briefly, the DBS were cut out with a punch to obtain a circle 6 mm in diameter, which was first placed in 250 µl of 0.01 M sodium phosphate buffer containing 10% bovine serum albumin and 0.05% Tween 20, then incubated at room temperature for 1 h in an ultrasonic cleaner. The eluted serum samples were directly used to fill the wells of ELISA microplates (200 µl per well). Subsequent steps were carried out in strict compliance with the manufacturer's recommendations. We used the s/co ratios (i.e. absorbance over the manufacturer's cut-off) to measure the concentration of anti-HCV antibodies. For quantitative analysis, absorbance, also known as optical density (a measure of the quantity of light absorbed by a sample), was measured using spectroscopy. Manufacturers establish cut-off values from absorbance readings of negative (and sometimes positive) controls. The s/co ratio enables serological samples to be normalised, as slight variations may arise from one set of manipulations to another. Manufacturers usually define samples with an s/co ratio of ≥ 1.0 as positive.
Mixture modelling
For each DU i (i = 1, …, n), let us consider his age a i and the variable of interest y i corresponding to the log-transformed concentration of anti-HCV antibodies. We modelled the variable of interest using a two-component mixture model, each component representing seropositive or seronegative DU for HCV. Following the methodology and the notations used by Vink et al. [Reference Vink10], each DU i contributes to the likelihood: f (y i) = (1 − I i) f 0 (y i) + I if 1 (y i) with I i equals zero if i belongs to the seronegative component f 0 and I i equals one if i belongs to the seropositive component f 1. We assumed that the random variable I i followed a Bernoulli distribution of parameter p i where p i was the age-dependent probability of being seropositive. To estimate p i, we performed a logit regression including age modelled by penalised splines:
 $${\rm logit}\,{\rm (}p_i{\rm )}\, = \,s\,(a_i),$$
$${\rm logit}\,{\rm (}p_i{\rm )}\, = \,s\,(a_i),$$where the smooth function of age s is a B-penalised-spline model. The term s (a) can be expressed by: s (a) = BXβ + BZb. Here B is a n × k cubic-B-spline with k equally spaced knots, X is a d × k matrix such as X β is a polynomial of degree d − 1 and Z = D T (DD T)−1 is ak × (k − d) matrix, where D is a (k − d) × k difference matrix of order d. β is a vector of length d and b is a vector of length k − d. In our study, we put knots on 10 equally distributed age groups and penalised second-order differences (i.e. k = 10 and d = 2).
Each component density f j was assumed to be normally distributed, independent of age, with mean μ j and standard deviation σ j where j = 0 (resp. j = 1) was associated with the seronegative component (resp. seropositive component).
We used weakly-informative priors for the unknown parameters. Parameters were estimated using the Bayesian framework through Gibbs sampling, using Just another Gibbs Sampler (JAGS) [Reference Plummer12]. We ran four parallel Markov chain Monte Carlo (MCMC) models and retained 5000 samples in total. Details of the estimation procedure are available elsewhere [Reference Vink10] and our R code is provided in the Appendix.
Mixture model validation
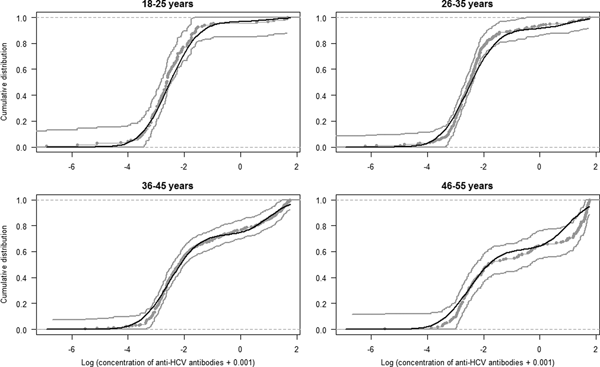
To assess whether the model provided a reasonable fit of the data by age group (18–25, 26–35, 36–45 and 46–55), first, we calculated the empirical cumulative distribution function (ECDF) of the data with the 95% confidence intervals. The procedure to generate the confidence intervals consists of using an asymptotic approximation (Approximate Critical Values for Kolmogorov–Smirnov's D) [Reference Bickel and Doksun13]. Second, we plotted the ECDF, the 95% CI and the predicted ECDF obtained from the posterior predictive distribution of the data according to the log concentration of anti-HCV antibodies. For the latter model, we used the estimated parameters 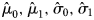 $\hat{\mu} _0, \hat{\mu} _1,\hat{\sigma} _0,\hat{\sigma} _1$ and the estimated seroprevalence per age group, calculated as the weighted mean of the age-specific seroprevalences.
$\hat{\mu} _0, \hat{\mu} _1,\hat{\sigma} _0,\hat{\sigma} _1$ and the estimated seroprevalence per age group, calculated as the weighted mean of the age-specific seroprevalences.
Estimation of the prevalence
To produce estimates in the DU population, all the analyses took into account the sampling design (sampling weights, stratifications, primary sampling units).
A biological result was indicated ‘over’ when the quantitative measurement exceeded the upper limit of absorbance of the spectrophotometer (≥10.0). It is a very frequent phenomenon with any ELISA. The signal reaches quickly a plateau when a sample is strongly positive. There is a continuous antigenic stimulation by HCV antigens in any chronically infected individual that leads to a high level of antibody. This is why most of the positive samples are ‘over’ the plateau. ‘Over’ results were excluded from the mixture model for two reasons: (1) they did not need to be classified because they were obviously defined as positive; (2) keeping them would involve an artificial distribution of the quantitative results with right censored data impacting the mixture model (Fig. 1). We defined n over as the number of DU with an anti-HCV concentration result indicated ‘over’. Furthermore, anti-HCV prevalence was estimated in two steps: (1) estimation of prevalence, 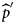 ${{{\widehat p}^{\prime}}}$ using the mixture model excluding the ‘over’ results, and then (2) estimation of the final prevalence
${{{\widehat p}^{\prime}}}$ using the mixture model excluding the ‘over’ results, and then (2) estimation of the final prevalence 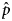 ${\hat p}$ including the ‘over’ results.
${\hat p}$ including the ‘over’ results.

Fig. 1. Results of the 2-component mixture model performed on the log transformed-concentration (log(x+0.001)) without the results over the upper limit of absorbance of the spectrophotometer. The dashed curve represents the component for the seronegative results and the solid curve represents the component for the seropositive results. The solid bars represent the distribution of quantitative results and the last hashed bar represents the results over the upper limit of absorbance of the spectrophotometer (≥ 10.0).
Step 1. Estimation of prevalence  ${{{\widehat p}^{\prime}}}$ using the mixture model excluding the ‘over’ results
${{{\widehat p}^{\prime}}}$ using the mixture model excluding the ‘over’ results
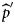
We estimated the probability of being seropositive at age a, 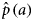 ${\hat p}\,(a)$, by the mean probability of being seropositive for age a from the 5000 generated samples. Using
${\hat p}\,(a)$, by the mean probability of being seropositive for age a from the 5000 generated samples. Using 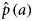 ${\hat p}\,(a)$ and the estimated proportion of DU by age, we calculated the prevalence
${\hat p}\,(a)$ and the estimated proportion of DU by age, we calculated the prevalence 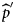 ${{{\widehat p}^{\prime}}}$. The proportion of DU of age a, denoted by q (a), was estimated using the Horvitz–Thompson estimator
${{{\widehat p}^{\prime}}}$. The proportion of DU of age a, denoted by q (a), was estimated using the Horvitz–Thompson estimator 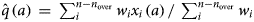 $\hat{q}\,(a)\, = \,\sum\nolimits_i^{n-n_{{\rm over}}} {w_ix_i\,(a)\,/} \,\sum\nolimits_i^{n-n_{{\rm over}}} {w_i} $, where w i is the sampling weight of the individual i, x i (a) = 1 if the individual i is of age a and 0 otherwise, and where n is the survey sample size [Reference Horvitz and Thompson14]. The prevalence was expressed by
$\hat{q}\,(a)\, = \,\sum\nolimits_i^{n-n_{{\rm over}}} {w_ix_i\,(a)\,/} \,\sum\nolimits_i^{n-n_{{\rm over}}} {w_i} $, where w i is the sampling weight of the individual i, x i (a) = 1 if the individual i is of age a and 0 otherwise, and where n is the survey sample size [Reference Horvitz and Thompson14]. The prevalence was expressed by 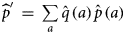 ${{{\widehat p}^{\prime}}}\, = \,\sum\limits_a {\hat{q}\,(a)\,{\hat p}\,(a)} $.
${{{\widehat p}^{\prime}}}\, = \,\sum\limits_a {\hat{q}\,(a)\,{\hat p}\,(a)} $.
Step 2. Estimation of the final prevalence ${\hat p}$
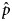
The final estimated prevalence 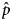 ${\hat p}$ was obtained with the formula:
${\hat p}$ was obtained with the formula: 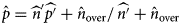 ${\hat p} = {{{\widehat n}^{\prime}}}\widehat{{{p}^{\prime}}} + \hat{n}_{{\rm over}}/\,\widehat{{{n}^{\prime}}} + \hat{n}_{{\rm over}}$.
${\hat p} = {{{\widehat n}^{\prime}}}\widehat{{{p}^{\prime}}} + \hat{n}_{{\rm over}}/\,\widehat{{{n}^{\prime}}} + \hat{n}_{{\rm over}}$.
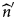 ${{{\widehat n}^{\prime}}}$ is the estimated number of DU with a biological quantitative result and
${{{\widehat n}^{\prime}}}$ is the estimated number of DU with a biological quantitative result and 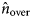 $\hat{n}_{{\rm over}}$ is the estimated number of DU with a concentration result indicated ‘over’.
$\hat{n}_{{\rm over}}$ is the estimated number of DU with a concentration result indicated ‘over’.
Comparison of different approaches proposed to estimate the prevalence
Four methods were compared:
• Model 1: estimation using the two-component Bayesian mixture model presented above,
• Model 2: estimation using a five-component EM mixture model. Each component corresponded to a level reactivity. Levels 1–3, corresponding to the lowest reactivity, represented the negative results of the anti-HCV test. Levels 4–5 were assumed to represent the positive results of the test [Reference Léon8],
• Model 3: estimation using a logistic regression model as a function of age and time [Reference Léon8],
• Model 4: estimation using the classic biological cut-off method, using a cut-off value of one. Indeed, there was no cut-off value for DBS assay but the cut-off value for serum was equal to 1. We used this cut-off value assuming that the cut-off value was the same on DBS or serum which is a strong assumption.
All analyses were performed using R 3.3.2 software and the running time to perform computations was about 3 min using a standard personal computer.
Results
In the ANRS-Coquelicot survey, 1568 DU were included and 92% of the respondents agreed to provide a finger-prick blood sample, corresponding to 1442 blotting papers collected. Two hundred blotting papers were excluded due to insufficient or inadequate biological material. A total of 1242 DBS samples were retained for the analysis [Reference Léon8]. Among them, 289 DU had a concentration result indicated ‘over’, and were thus classified anti-HCV seropositive.
Mixture model and validation model
The estimated parameters of the mixture model are shown in Table 1 and the normal density functions of the components (f 0 and f 1) in Figure 1. Figure 2 shows, for each age group, the ECDF of the anti-HCV log concentration with the model-predicted cumulative distribution function. For each age group, the model-predicted result stands between the 95% confidence intervals of the empirical results.
Table 1. Parameters of the mixture model


Fig. 2. Model fit. Curves represent the empirical cumulative distribution function and 95% CI of the anti-HCV log-transformed concentration per age group (gray curves) and the model predicted cumulative distribution function (black curve).
Estimation of the prevalence
We estimated anti-HCV prevalence among DU in France at 43.3% (95% CI 36.2–50.3). As expected, anti-HCV prevalence increased with age (Fig. 3). We compared our current method to estimate age-dependent prevalence of HCV with three other methods: (1) estimation using a five-component mixture model [Reference Léon8], (2) estimation using a logistic regression model [Reference Léon8] and (3) estimation using the biological cut-off approach (Table 2 and Figs 3 and 4). In the first of these three methods (model 2), each of the five components corresponded to an anti-HCV reactivity level. We observed similar results between our current method and two other methods: model 2 and model 3. Using a cut-off value of 1.0, the biological cut-off approach provided a lower HCV prevalence, estimated at 39.9% (95% CI 35.9–44.1). Most estimates by age group were lower using the third method (model 4) than using our reference method (Table 2).

Fig. 3. Age-dependent HCV prevalence estimates, from the 5-component mixture model (stars), from the 2-component Bayesian mixture model (squares) and using the biological cutoff method (circles).

Fig. 4. Age-dependent HCV prevalence estimates, from a 5-component mixture model (light gray circles), from a logit regression model (line) and from the 2-component Bayesian mixture method (dark gray circles). The circles’ sizes are proportional to the number of participants.
Table 2. Comparison of four different approaches to estimate HCV prevalence among drug users, ANRS-Coquelicot survey, France, 2011

Discussion
In serosurveys, biological assays are used to estimate seroprevalence. The choice of specific biological assays and the practical conditions have an impact on the estimation of seroprevalence. Usually, they depend on diagnostic cut-off values, biological matrices used and the studied populations. Traditionally, virological assays are assessed using serum or plasma samples collected from venous puncture. The advent of alternative biological matrices to venous blood samples, such as gingival crevicular fluid (taken from the lip and gum), capillary blood (taken from the finger), hair samples and home urine specimens, means that biological testing can now occur in the patient's home environment (point of care testing) [Reference Rambaud and Fillol15, Reference Xia16]. DBS samples are often preferred for collecting biological measurements in hard to reach or vulnerable populations at high risk of infectious diseases [Reference Snijdewind17]. For example, venipuncture is inadequate for epidemiological studies on homeless people [Reference Arnaud18], men who have sex with men [Reference van Loo19] and injecting DU, due to venous access sometimes being difficult because of repeated injections [Reference White20] and to study implementation protocols (e.g. data collection for DU performed by outreach teams in the streets). Cut-off values using these alternative biological matrices are usually different from those for sera samples. They are not easy to obtain and sometimes are not provided by the biologist [Reference Soulier2, Reference Dokubo3, Reference Tuaillon5, Reference Snijdewind17, Reference Gay21]. If the cut-off value is unknown, the serological status will be subject to misclassification due to an arbitrary choice of the cut-off value. An inaccurate use of the manufacturer's instructions can lead to a different sensitivity and specificity than those expected. This has a direct impact on positive/negative classification, and in turn on the estimation of seroprevalence [Reference Gay21]. When two cut-off values (upper and lower) are provided by the manufacturer, individuals with a result under the lower cut-off value are considered seronegative, those with a result over the upper cut-off value seropositive and those with a result between the two inconclusive [Reference Woestenberg22].
In our point of view, the estimation of prevalence using biological measurements can be treated statistically without using a cut-off value, and therefore can be viewed as a statistical challenge rather than a biological one.
Today, mixture models are used for various diseases to determine the cut-off value for diagnostic reasons [Reference Trang23], to estimate seroprevalences [Reference Vink10, Reference Rota24, Reference Del Fava25] and to differentiate different levels of antibody reactivity [Reference Rota24, Reference Ades26]. This article presents a method for estimating anti-HCV prevalence by age, without using an assay cut-off, an arbitrary cut-off or a level reactivity of anti-HCV detection. We used an age-dependent normal mixture model on the log-transformed anti-HCV concentrations, without classifying measurements as positive or negative. Parameters were estimated using a Bayesian framework. We estimated anti-HCV prevalence among DU in France at 43.3% (95% CI 36.2–50.3). This work follows various attempts to estimate the prevalence of hepatitis C among DU in France.
In 2011, because DBS had lower sensitivity to detect anti-HCV antibodies and because of inconsistency in some classifications (i.e. where some DU testing negative (i.e. s/co ratio ≤ 1.0) were classified anti-HCV antibody seropositive or HCV cured, because their s/co ratio was close to 1.0), the DBS cut-off value was modified. Specifically, a group was formed composed of biologists, epidemiologists, sociologists and biostatisticians to propose a DBS cut-off value. This group proposed a classification algorithm based on DU characteristics and s/co ratio values. The recommendation was to choose a threshold value for DBS samples at 0.64 IU/l. Using this empirical cut-off value, Weill-Barillet et al. estimated the HCV prevalence at 44% (95% CI 39.6–47.9), which was very close to our estimate [Reference Weill-Barillet9].
This first approach having shown that the choice of the biological cut-off could be difficult, we tried other approaches.
The naïve approach (corresponding to model 4) was to choose a cut-off value equal to 1 (as used for serum), knowing that it was a highly improbable value.
We then tried to estimate the prevalence from a logistic regression including age and time as covariates (model 3). However, the variable of interest was the result of a binary classification of the biological quantitative measurements, which still did not allow to estimate a prevalence by avoiding the choice of a cut-off value.
We then applied a five-component mixture model (model 2), using the standard EM algorithm for normal mixtures, which maximises the conditionally expected complete-data log-likelihood at each M-step of the algorithm [Reference Léon8]. HCV prevalence among DU using that model (model 2) was estimated at 43.2% (95% CI 38.8–47.7), close to our HCV prevalence estimate (model 1) [Reference Léon8]. The main limitation of this five-component model is to have to choose, a posteriori, which components should be considered as corresponding to the negative or the positive HCV status. This choice is quite arbitrary and can be influenced by the results obtained with the previous approaches.
The approach proposed in this paper overcomes this difficulty. Unlike the five-component mixture model and the logit regression model, our model does not need a classification step (i.e. classifying positive or negative status) to estimate anti-HCV antibody seroprevalence. We do not have to choose a threshold to treat posterior probabilities.
However, fitting a mixture model to quantitative measurements may be difficult for a number of reasons: the possibility that a low proportion of measurements may belong to one of the underlying components, the possibility of a visually unimodal distribution of quantitative measurements, the difficulty to choose normal distributions vs. other distributions (such as the skew-normal) or the interest to take into account biological characteristics of individuals (vaccination, co-infection). For this last point, these characteristics can be included as covariables in a multivariate regression model to explain the probabilities of being seropositive.
Despite limitations specific to the use of mixture modelling, our approach remains a valid alternative method to estimate prevalence from serosurvey data when one has no information on assay cut-off value. Our method can be applied to populations with special characteristics (e.g. at high risk of infectious diseases, co-infected individuals and children) or with a serological response different to the population(s) used to calibrate biological tests. Furthermore, our approach allows a detection cut-off value to be estimated, when the traditional conditions for using biological tests are modified or unavailable (blood samples, laboratory conditions, study populations, etc.) and may contribute to help biologists, public health researchers and decision-makers.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268819001043.
Author ORCIDs
L. Léon, 0000-0002-0871-3510.
Acknowledgements
We gratefully thank all the ANRS-Coquelicot Group 2011 involved in the conception of the survey, supervision of data collection and data analysis: Thérèse Benoit, Stéphane Chevaliez, Caroline Semaille and Lucile Weill-Barillet.
Conflict of interest
None.








 Open access
Open access