



1. Introduction
Mobile learning has provided many opportunities for language learning (McQuiggan, Kosturko, McQuiggan & Sabourin, Reference McQuiggan, Kosturko, McQuiggan and Sabourin2015) due to its accessibility outside the classroom. One area that has attracted researchers’ attention is using mobiles for learning vocabulary (see Lin & Lin, Reference Lin and Lin2019). Limited time in classrooms urges teachers to find alternative approaches to teaching vocabulary. An excellent strategy to compensate for the problem is to empower learners with autonomous abilities to learn new vocabulary incidentally outside the classroom by extensive listening or reading (Rashtchi & Pourmand, Reference Rashtchi and Pourmand2014; van Zeeland & Schmitt, Reference van Zeeland and Schmitt2013; Waring & Nation, Reference Waring, Nation, Albrechtsen, Haastrup and Henriksen2004). Incidental vocabulary learning is defined as “learning of vocabulary as the by-product of any activity not explicitly geared to vocabulary learning” (Hulstijn, Reference Hulstijn2001: 270). However, learning new words outside the classroom has some drawbacks (Huckin & Coady, Reference Huckin and Coady1999). For instance, the lack of understandable contextual information could make correct inferencing difficult for learners. Using glosses was proposed as a remedy to aid the correctness of inferencing, avoiding misleading guessing, and consequently effective incidental vocabulary learning (Hu, Vongpumivitch, Chang & Liou, Reference Hu, Vongpumivitch, Chang and Liou2014; Laufer, Reference Laufer2000). Using gloss as a vocabulary enhancement technique can be regarded as an opportunity to be implemented in mobiles.
Many studies have investigated the effects of using glosses, mostly in computer-assisted language learning (CALL) context (e.g. Boers, Warren, He & Deconinck, Reference Boers, Warren, He and Deconinck2017; Mohsen & Balakumar, Reference Mohsen and Balakumar2011; Ramezanali & Faez, Reference Ramezanali and Faez2019). However, most of these studies have focused on the effects of glosses on L2 reading comprehension, while incidental vocabulary learning through L2 listening has received little attention (Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Mohsen & Balakumar, Reference Mohsen and Balakumar2011), though some studies have addressed incidental vocabulary learning through viewing (Çekiç, Reference Çekiç2024; Hsieh, Reference Hsieh2020; Montero Perez, Peters & Desmet, Reference Montero Perez, Peters and Desmet2018). In addition, the effectiveness of the language of glossing (L1 or L2) has been investigated by several studies in reading comprehension (Ramezanali, Uchihara & Faez, Reference Ramezanali, Uchihara and Faez2021; Yanagisawa, Webb & Uchihara, Reference Yanagisawa, Webb and Uchihara2020). A recent meta-analysis by Yanagisawa et al. (Reference Yanagisawa, Webb and Uchihara2020) found that L1 glosses led to more vocabulary learning than L2 glosses in reading comprehension. Furthermore, previous studies have shown that when a text gloss is combined with a picture, its effectiveness increases for incidental vocabulary acquisition in reading comprehension (Ramezanali et al., Reference Ramezanali, Uchihara and Faez2021; Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020; Yeh & Wang, Reference Yeh and Wang2004; Yoshii & Flaitz, Reference Yoshii and Flaitz2002). However, it is not clear whether the same patterns emerge when there is a listening task on mobile phones. Previous studies on listening comprehension focused on L1 glosses only (e.g. Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Jones & Plass, Reference Jones and Plass2002; van Zeeland & Schmitt, Reference van Zeeland and Schmitt2013; Vidal, Reference Vidal2011), and further research is needed to compare the effectiveness of L1 and L2 glosses (both alone and combined with pictures) in incidental vocabulary learning through listening (see Mohsen & Balakumar, Reference Mohsen and Balakumar2011). Therefore, this study seeks to address these gaps by examining the effectiveness on incidental vocabulary learning of using L1 and L2 glosses with and without pictures while listening to a story on mobile phones.
2. Literature review
2.1 Theoretical foundations
The present paper begins with a review of the theoretical foundations of glossing. One of the theoretical bases for implementing multimedia glosses for vocabulary learning is the dual coding theory (DCT) proposed by Paivio (Reference Paivio1990). The DCT focuses on the cognitive dimensions of processing new information. According to the DCT, there are two interrelated systems in information processing: “one specialized for the representation and processing of information concerning nonverbal objects and events, the other specialized for dealing with language” (Paivio, Reference Paivio1990: 53).
Paivio (Reference Paivio1990) claims that new information presented to learners leaves a trace in each system and is coded differently. For example, abstract and verbal information leaves verbal traces, while concrete concepts and pictorial information leave both visual and verbal traces, which are coded differently in two systems (Boers, Warren, Grimshaw & Siyanova-Chanturia, Reference Boers, Warren, Grimshaw and Siyanova-Chanturia2017). Paivio believed that information that is coded dually or has compound traces (received both verbally and nonverbally) leads to richer interactions between two systems and, consequently, more effective learning.
Building upon the foundations of the DCT, one of the most comprehensive theories of multimedia learning is Mayer’s (Reference Mayer2014) cognitive theory of multimedia learning (CTML). The CTML describes the underlying processes of learning in a multimedia environment. It consists of three main assumptions: the dual channels assumption, the limited capacity assumption, and the active processing assumption. The assumption of dual channels is based on Paivio’s DCT (1990) just described. The assumption of limited capacity states that verbal and visual channels have their limited capacity, meaning that learners can only process a finite amount of information at a given time through each channel. Finally, the assumption of active processing proposes that learning involves actively selecting relevant visual or verbal information, filtering them through each channel, organizing information in separate systems, and integrating verbal and visual representations with each other and with prior knowledge (Mayer, Reference Mayer2014). Like Paivio (Reference Paivio1990), Mayer noted that “people learn more deeply from words and pictures than from words alone” (Mayer, Reference Mayer2009: 47), and thus it has been argued that by using words and appropriate pictures together, more connections between mental representations and meanings are created (Çakmak & Erçetin, Reference Çakmak and Erçetin2018).
Finally, Kroll and Stewart (Reference Kroll and Stewart1994) proposed a revised hierarchical model (RHM) to explain language processing among bilinguals whose L1 is the dominant language. The RHM states that at the early stages of bilingualism, since learners’ L1 is dominant and has more substantial access to concepts, L2 words require L1 translation to access concepts. This process happens until the L2 proficiency level increases to the point where learners can directly associate concepts with L2 words without mediating via the L1 (Kroll, Van Hell, Tokowicz & Green, Reference Kroll, Van Hell, Tokowicz and Green2010). Based on this model, it is expected that L1 glosses may lead to better vocabulary learning when L2 proficiency is low (Hu et al., Reference Hu, Vongpumivitch, Chang and Liou2014; Yoshii, Reference Yoshii2006).
2.2 Multimedia gloss in vocabulary learning
Traditional glosses were mainly used on the margins of pages to explain complex terms of texts or provide examples in relation to the main content of a text. Nowadays, an electronic gloss (e-gloss) consists of a hypertext embedded within texts that does not take up any space on the page or distract readers and listeners. Advances in technologies have allowed additional forms of glosses (e.g. pictures, videos, and audio), which can be presented through different modalities (visual, textual, and auditory, respectively). The term multimedia gloss refers to textual glosses that are accompanied by sounds or pictures, whether static or animated (Elekaei, Faramarzi & Koosha, Reference Elekaei, Faramarzi and Koosha2015). In a recent review of the role of multimedia glosses in L2 skills development, Zhang and Zou (Reference Zhang and Zou2022) reported on 41 studies between 2009 and 2020, among which 24 studies (58.5%) were devoted to vocabulary knowledge, with a smaller proportion focusing on listening, reading, and grammar knowledge. It should be noted that very few studies focused on incidental vocabulary learning by listening comprehension on a mobile device (see Çakmak & Erçetin, Reference Çakmak and Erçetin2018, for an exception). Moreover, of the 24 studies devoted to lexical learning, most were conducted on computers: only six studies used mobile devices. This shift towards e-glosses and multimedia resources reflects a broader trend in language education, which increasingly values the integration of technology in learning environments.
Glosses can be used for different purposes. Glossing complex texts enables learners to read and listen above their current level (Widdowson, Reference Widdowson1978) and reduces inaccurate guessing of meanings for low-ability readers when they encounter unknown words (Khezrlou, Ellis & Sadeghi, Reference Khezrlou, Ellis and Sadeghi2017). Moreover, glossing can attract learners’ attention to difficult words that might be missed (Boers, Warren, Grimshaw & Siyanova-Chanturia, Reference Boers, Warren, Grimshaw and Siyanova-Chanturia2017). Due to the rapid developments in computer technologies, different multimedia forms of glossing can be used. Several studies have investigated the effectiveness of implementing different types of glosses on L2 vocabulary learning through reading (Akbulut, Reference Akbulut2007; Hu et al., Reference Hu, Vongpumivitch, Chang and Liou2014; Lin & Lin, Reference Lin and Lin2019; Yeh & Wang, Reference Yeh and Wang2004; Yoshii, Reference Yoshii2006; Yoshii & Flaitz, Reference Yoshii and Flaitz2003), listening (Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Jones & Plass, Reference Jones and Plass2002), and viewing (Çekiç, Reference Çekiç2024; Hsieh, Reference Hsieh2020; Montero Perez et al., Reference Montero Perez, Peters and Desmet2018). Moreover, several review studies have indicated that multimedia glosses can be effective in improving vocabulary learning, listening comprehension, reading comprehension, and grammar knowledge (see Ramezanali et al., Reference Ramezanali, Uchihara and Faez2021; Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020; Zhang & Zou, Reference Zhang and Zou2022).
2.3 L1 and L2 glosses in vocabulary learning
As noted earlier, a primary concern in multimedia glossing is the choice of language (Mohsen & Balakumar, Reference Mohsen and Balakumar2011; Ramezanali et al., Reference Ramezanali, Uchihara and Faez2021; Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020). Previous studies that compared the effectiveness of L1 and L2 glosses showed mixed results. Some studies found an advantage for L1 over L2 glosses (e.g. Arpaci, Reference Arpaci2016; Choi, Reference Choi2016; Kim, Lee & Lee, Reference Kim, Lee and Lee2024; Xu, Reference Xu2010), while others found no significant difference (Jacobs, Dufon & Hong, Reference Jacobs, Dufon and Hong1994; Yoshii, Reference Yoshii2006). Yoshii (Reference Yoshii2006) found that the retention rate was better for L2 plus picture glosses than for L1 plus picture glosses in the definition-supply test (DST), a measure where participants are asked to provide the definitions of words without any cues, thus assessing their ability to recall vocabulary actively. However, the results of Yanagisawa et al.’s (Reference Yanagisawa, Webb and Uchihara2020) meta-analysis showed that L1 glosses were generally more efficient than L2 glosses in vocabulary learning. They proposed that this result can be explained by learners’ greater familiarity with L1 words, meaning that connections between L1 words and target words can be made more easily than between L2 words and target words. Another meta-analysis by Kim et al. (Reference Kim, Lee and Lee2024) also reported the superiority of L1 glosses over L2 glosses for vocabulary learning. This advantage was greater in immediate post-test conditions than in delayed post-tests.
Previous research has also indicated that proficiency level might affect the effectiveness of L1 and L2 glosses (Hu et al., Reference Hu, Vongpumivitch, Chang and Liou2014; Ko, Reference Ko2017, Yoshii, Reference Yoshii2006). For instance, Hu et al. (Reference Hu, Vongpumivitch, Chang and Liou2014) investigated the effects of online L1 and L2 glosses on incidental vocabulary learning in learners with lower and higher L2 proficiency using the RHM (Kroll & Stewart, Reference Kroll and Stewart1994) as their theoretical foundation. They found that “L1 conceptual links are stronger than L2 conceptual links in the early stages of L2 acquisition (i.e. lower proficiency level)” (Hu et al., Reference Hu, Vongpumivitch, Chang and Liou2014: 95). They tested this hypothesis by conducting experiments that measured the strength of conceptual links through tasks that assessed the recall and recognition of L2 vocabulary, comparing the performance of participants at different proficiency levels. In their meta-analysis, in contrast, Yanagisawa et al. (Reference Yanagisawa, Webb and Uchihara2020) found no significant interaction between proficiency and glossing languages, explaining that regardless of proficiency level of the participants, L1 glosses were more effective than L2 glosses. This issue was also investigated by Kim et al. (Reference Kim, Lee and Lee2024), who found L1 glossing to be more effective for beginners than for higher-proficiency language learners. However, as mentioned by Yanagisawa et al. (Reference Yanagisawa, Webb and Uchihara2020), because very few studies have reported learner proficiency, the results of these studies cannot be considered sufficient support for this claim.
2.4 Gloss mode and type in vocabulary learning
As mentioned, glosses can be presented in different modes: textual, pictorial, auditory, and video (Ramezanali et al., Reference Ramezanali, Uchihara and Faez2021; Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020). Previous studies have examined single gloss mode (i.e. only one type of gloss), dual gloss mode (i.e. a combination of two glosses), multimodal glossing (i.e. three different glosses). Results of the meta-analysis by Ramezanali et al. (Reference Ramezanali, Uchihara and Faez2021) indicated that dual glossing had more effect on vocabulary learning than single glossing, but no difference was found between dual and triple glossing modes. They further found that the addition of another mode to a single L2 textual gloss is more beneficial for vocabulary learning than the addition of another mode to a single L1 textual gloss. Previous studies have also indicated the superiority of pictorial-textual glosses over textual-only or pictorial-only glosses in vocabulary learning (Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Jones & Plass, Reference Jones and Plass2002; Yanguas, Reference Yanguas2009; Yeh & Wang, Reference Yeh and Wang2004; Yoshii & Flaitz, Reference Yoshii and Flaitz2003). Moreover, glosses can be presented in two different types: noninteractive and interactive glosses (see Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020). The former refers to glosses put in a fixed place (e.g. in the margin of a text, next to the word, or at the end of the text). Interactive glosses require an action on the part of the learners, such as hyperlinked glosses, which need clicking on the word, or multiple-choice glosses, where learners have to choose the correct meaning from different options (Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020).
2.5 Using gloss in a listening context
In this section, we delve into the application of glosses in a listening context, examining how different types of glosses (i.e. textual, pictorial, and a combination of both) affect vocabulary acquisition and text recall, starting with reviewing a study that has utilized mobile devices for glossing (e.g. Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Jones & Plass, Reference Jones and Plass2002). In one study, Çakmak and Erçetin (Reference Çakmak and Erçetin2018) examined how different gloss types affected text recall and vocabulary learning while participants listened to a story on their mobile phones. Participants were assigned to one of three different glossing conditions or a control group without glossing treatment. The gloss conditions consisted of two single-channel groups (textual-only and pictorial-only) and one dual-channel group (pictorial plus textual glosses). The findings indicated a positive effect of glossing on incidental vocabulary learning, with no significant differences across glossing conditions. The authors speculated that glossing new words both visually and verbally might increase the cognitive load on low-ability learners, preventing an expected advantage for the dual-channel group.
In a similar study, Jones and Plass (Reference Jones and Plass2002) investigated the outcomes of using multimedia glossing on listening comprehension and vocabulary learning in a CALL environment and obtained differential results. Participants were randomly assigned into four groups: (a) listening without any glosses, (b) listening with only textual glosses, (c) listening with only pictorial glosses, and (d) listening with both textual and pictorial glosses. The findings in both immediate and delayed post-tests indicated that participants in gloss conditions had significantly better performance in both immediate and delayed vocabulary tests compared to the no-gloss group. Participants who had access to both textual and pictorial glosses while listening had significantly higher scores on the vocabulary test than either textual-only or pictorial-only groups in the immediate post-test, with no significant difference between the single-mode conditions. At delayed post-test, the dual-mode group outperformed the textual gloss group, but not the pictorial gloss group. These findings support Mayer’s (Reference Mayer2014) CTML for listening comprehension and vocabulary learning.
To conclude this review of recent glossing research, it is essential to recognize the limitations and potential areas for further investigation that have emerged from the existing body of work. Both Çakmak and Erçetin (Reference Çakmak and Erçetin2018) and Jones and Plass (Reference Jones and Plass2002) used only L1 glosses. They did not compare L1 textual glosses with L2 textual glosses and how their combination with pictures might affect incidental vocabulary learning. As mentioned by Mohsen and Balakumar (Reference Mohsen and Balakumar2011) in their review of glosses in CALL research, “in an L2 listening context, the comparison between L1 and L2 annotation types has not yet been explored. All the studies reviewed used native language annotations … and this issue should be considered in future research studies” (p. 151). The present study thus sought to address this issue by comparing L1 and L2 textual glosses. It also builds on recent research on dual-mode glossing to investigate how L1 textual-pictorial glosses might differ from L2 textual-pictorial glosses in incidental vocabulary learning through listening comprehension.
3. The present study
The first aim of this study is to examine the possible differences of using glosses in participants’ L1 (Persian) and L2 (English) to see which condition has better outcomes for incidental vocabulary learning while listening to a story. The second goal was to investigate the role of adding pictures to L1 and L2 textual glosses in the immediate post-test and in the delayed post-test. Taken together, we had four different conditions: L1 text-only (Group A), L1 textual-pictorial (Group B), L2 text-only (Group C), and L2 textual-pictorial (Group D). We adopted a pre-/post-/delayed post-test design among a sample of teaching English as a foreign language (TEFL) students at a university in Iran. We sought to answer two research questions (RQs):
-
1. How does gloss language (L1 and L2) affect incidental vocabulary learning?
-
2. How does adding pictures to L1 and L2 textual glosses affect incidental vocabulary learning?
4. Research method
4.1 Participants
Participants in this study were 118 undergraduate students (55% female) of TEFL from four intact classes at a university in north-east Iran. Their ages ranged from 18 to 22 years old (M = 19.5, SD = 1.14). Before this study, all participants took the second version of the Oxford Quick Placement Test of Proficiency. Participants’ proficiency scores were between 16 and 35, including elementary (A2, 46%), pre-intermediate (B1, 38%), and upper-intermediate (B2, 16%) levels of proficiency based on the Common European Framework of Reference for Languages. Participants did not have any prior listening activity using glosses in their courses. The experiment and data gathering took place in the classrooms during regular class hours, and the environment and setting for all participants were similar.
4.2 Instrumentation
4.2.1 Designing and developing the mobile application
We developed a listening application using Java and Kotlin for Android mobile phones. Special attention was given to the user interface design to ensure that the glosses were properly displayed, making efficient use of the diverse screen sizes of the participants’ phones. A separate application was developed to display each of the four types of glosses to be compared in the study. The target words with their corresponding glosses appeared on screen as they were narrated in the story. The time of exposure of each gloss was set to four seconds. Participants could adjust the listening file by pausing and going back and forth, while simultaneously being able to see the related gloss on the screen. The pictures used in textual-pictorial glosses were taken from freely available online materials. To ensure the pictures were an appropriate representation of the target words and unambiguous, we consulted two experts in teaching English and two native English speakers for their opinions. Figure 1 shows screenshots for the four glossing conditions. In the L1 text-only condition (Figure 1A), when participants listen to the story, and the relevant target word is mentioned, they could see the target word with its Persian translation on the screen. In the L1 textual-pictorial condition (Figure 1B), in addition to the Persian translation of the target word, participants could see the relevant picture on the screen. In the L2 text-only condition (Figure 1C), participants could see the L2 definitions of the target words on the screen. Finally, in the L2 textual-pictorial condition (Figure 1D), participants could see the target word with its L2 definition and the picture, which was also used for the L1 textual-pictorial condition. In order to accommodate the various screen sizes of participants’ mobile phones, certain written glosses were adjusted slightly in terms of font size and position to ensure optimal fit on the screen.

Figure 1. Screenshot from the L1 text-only condition (A), L1 textual-pictorial condition (B), L2 text-only condition (C), and L2 textual-pictorial condition (D).
4.2.2 Listening material
Participants listened to a story from stage five of the Oxford Bookworm Series. The story’s title was “Wuthering Heights” and the total length of the audio file was 12:48 minutes, including 1,927 words. The story consisted of narrational descriptions of events and dialogues between fictional characters, with some minor sound effects. The readability index from the Flesch Reading Ease Formula (Flesch, Reference Flesch1948) found to be 87.9 for the story’s text. To establish the vocabulary profile of the listening text, we used BNC/COCA word family lists (Nation, Reference Nation2017). Respectively, 74.56% and 12.08% of word types belonged to K-1 and K-2 frequency levels, 8.54% belonged to K-3 to K-5 frequency levels, and only 4.82% belonged to higher frequency levels. With regard to the target vocabulary items, 57.7% of the words belonged to levels K2-5, 26.93% to K6-8, and 15.39% to K10-12. The listening task had an average sentence length of 12.69 words. The average number of characters per word was 4.4. The speech rate was 109 words per minute, while the articulation rate was 137 words per minute. The speech rate refers to the average number of words spoken per minute during the entire audio file, including pauses and other non-speaking intervals. On the other hand, the articulation rate measures the number of words spoken per minute, but only during the periods when speech is actually occurring. The articulation rate is typically higher than the speech rate because it only considers the time when words are being spoken and not the silent intervals. Additionally, phrase pauses were 0.71 seconds on average.
4.2.3 Vocabulary tests
Selecting target lexical items began with identifying the most appropriate words for glossing in the story. Forty-eight words suitable for glossing, both textually and visually, and six distractors were selected for the pre-test. The pre-test was a DST that required participants to write the meaning of the words either in Farsi or English. To choose target words, 25 words unknown to over 90% of the participants were selected for glossing. The target lexical items consisted of five verbs, eight nouns, and 12 adjectives (see online supplementary materials).
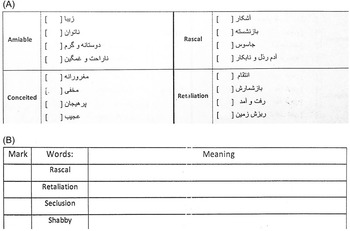
After choosing 25 lexical items, two unannounced vocabulary tests were used immediately after treatment (i.e. immediate post-test) and two weeks after treatment (i.e. delayed post-test). These post-tests consisted of a DST and a meaning-recognition test (MRT). The DST was designed to evaluate meaning-recall vocabulary knowledge. The items consisted of all 25 target words, and the participants had to provide the meaning either in their L1 (Farsi) or L2 (English). The MRT was designed to measure participants’ meaning-recognition vocabulary knowledge. Each item in the MRT consisted of four multiple-choice alternatives. Moreover, we used two versions of MRT, one with alternatives in Persian for L1 gloss groups and one with alternatives in English for L2 gloss groups, to ensure that the test did not favor a particular group. Participants had to select the most appropriate and closest definition to the given word (sample items have been provided in Figure 2; see supplementary materials for the complete list of items for tests).

Figure 2. Example items of meaning-recognition (A) and definition-supply (B) tests.
4.3 Procedure
As we used non-random sampling in this study, a quasi-experimental design was used in four intact classes. All data in pre-test, immediate post-test, and delayed post-test were gathered during regular classroom hours. Participation in the study was voluntary, with students awarded extra credit for participation; all students took part in the study.
First, students were asked to write the meaning of the 48 potential target words and six distractors selected for the pre-test. The treatment concerning the same 25 target words was conducted in a single session. Participants were randomly assigned to four different groups: (a) L1 text-only (n = 29), (b) L1 textual-pictorial (n = 29), (c) L2 text-only (n = 30), and (d) L2 textual-pictorial (n = 30). Then, we explained the task (title of the story and its duration) and how to download and install the applications on their mobile devices. Participants were already informed to bring their earphones to the class. Moreover, they were informed that they could see definitions of some unknown words on their mobile screens and could use pause or back-and-forth buttons. Furthermore, we did not tell them they would take vocabulary tests.
Immediately after the treatment, the immediate post-tests took place in the same session. The test began with DST to reduce the possibility of learning from MRT. Each correct answer in the DST scored one point, and no point was given for blank, wrong, or incomplete answers. For the MRT, correct responses received one point, and blank or inaccurate responses, none. The maximum possible score for each test was therefore 25.
Finally, delayed post-tests took place two weeks after immediate post-tests; participants took the same vocabulary tests with a changed order of items. The setting, time, and situations for the four groups were similar to the immediate post-tests. The design of the study is summarized in Figure 3.

Figure 3. Research design of the present study.
4.4 Data analysis
We used SPSS Version 25.0 for data analysis. There were two dependent variables (DST and MRT) that can be explained by one between-group variable (treatment) with four levels (A-D) and one within-group variable (time). There is also a pre-test score serving as a control variable. Therefore, a mixed multivariate analysis of covariance (MANCOVA) was utilized.
For the pre-test DST, the Cronbach’s alpha reliability coefficient was .90. In the immediate post-test, the Cronbach’s alphas of DST and MRT were 0.84 and 0.88, respectively. Moreover, in the delayed post-test, the Cronbach’s alphas of DST and MRT were 0.83 and 0.88, respectively. Hence, all vocabulary tests had high-reliability estimates.
5. Results
5.1 Preliminary data analysis
We first checked the assumptions of the mixed MANCOVA (see online supplementary materials). In what follows, we report the results of immediate and delayed post-tests based on participants’ performance in DST and MRT tests. To make the interpretation more straightforward, we answer RQ1 and RQ2 for immediate and delayed post-tests separately.
5.2 The results of immediate post-test for DST and MRT
The results of MANCOVA showed the differences in between-subject design was statistically significant, Wilks’s lambda = 0.643, F(6, 170) = 7.012, p < .001, partial η 2 = 0.198. Moreover, there was a significant interaction effect between conditions and time, Wilks’s lambda = 0.842, F(6, 170) = 2.551, p = .022, partial η 2 = 0.083. Table 1 shows descriptive statistics for immediate post-tests.
Table 1. Descriptive statistics for DST and MRT vocabulary tests in the immediate post-test

Note. DST = definition-supply test; MRT = meaning-recognition test; Group A = L1 text-only; Group B = L1 textual-pictorial; Group C = L2 text-only; Group D = L2 textual-pictorial; CI = confidence interval.
The result of MANCOVA in immediate post-tests revealed a significant main effect of treatment on dependent variables, Wilks’s lambda = 0.658, F(6, 170) = 6.601, p < .001, partial η 2 = 0.189. A univariate ANCOVA was conducted for a more detailed distinction in each dependent variable. The results revealed that there was a significant difference among the four groups in both DST, F(3, 86) = 11.266, p < .001, partial η 2 = 0.282, and MRT, F(3, 86) = 9.039, p < .001, partial η 2 = 0.240. Table 2 provides the results of the Tukey post-hoc analysis of pairwise comparisons, which were conducted to compare the different performances of each paired condition based on the RQs.
Table 2. The results of pairwise comparisons in relation to DST and MRT vocabulary measures in immediate post-test

Note. DST = definition-supply test; MRT = meaning-recognition test; Group A = L1 text-only; Group B = L1 textual-pictorial; Group C = L2 text-only; Group D = L2 textual-pictorial; MD = mean difference; CI = confidence interval.
Concerning the differences between L1 and L2 textual glosses (RQ1) in immediate post-tests, Group A had a higher mean than Group B in both immediate DST and MRT tests. Regarding the role of pictures (RQ2) in immediate post-tests, participants who received glosses with pictures showed higher vocabulary scores in the immediate DST in comparison with groups without pictorial glosses. However, for immediate MRT, while Group D showed improved performance in vocabulary scores in comparison with Group C, Group B did not show any significant difference with Group A.
Taken together, in immediate DST, Group B had a significantly higher mean than the other three groups. Moreover, Group A and Group D had significantly higher means than that of Group C. For the immediate MRT test, Group A, Group B, and Group D had significantly higher means than that of Group C.
5.3 The results of delayed post-tests for DST and MRT
Table 3 shows descriptive statistics of the four groups in DST and MRT for the delayed post-test. The result of MANCOVA in delayed post-tests revealed a significant main effect of treatment on dependent variables, Wilks’s lambda = 0.656, F(6, 170) = 6.657, p < .001, partial η 2 = 0.190. A univariate ANCOVA was conducted for a more detailed distinction in each dependent variable. The result revealed that there was a significant difference among four groups in both DST, F(3, 86) = 11.266, p < .001, partial η 2 = 0.282, and MRT, F(3, 86) = 9.039, p < .0005, partial η 2 = 0.240. Table 4 provides the results of Tukey post-hoc analysis of pairwise comparisons, which were conducted to compare the different performances of each paired condition based on the RQs.
Table 3. Descriptive statistics for vocabulary tests in the delayed post-test

Note. DST = definition-supply test; MRT = meaning-recognition test; Group A = L1 text-only; Group B = L1 textual-pictorial; Group C = L2 text-only; Group D = L2 textual-pictorial; CI = confidence interval.
Table 4. The results of pairwise comparisons in relation to DST and MRT vocabulary measures in delayed post-test

Note. DST = definition-supply test; MRT = meaning-recognition test; Group A = L1 text-only; Group B = L1 textual-pictorial; Group C = L2 text-only; Group D = L2 textual-pictorial; MD = mean difference; CI = confidence interval.
Concerning the differences between L1 and L2 textual glosses (RQ1) in delayed post-tests, Group A had a higher mean than Group B in both the delayed DST and MRT. Regarding the role of pictures (RQ2) in delayed post-tests, participants who received glosses with pictures showed higher vocabulary scores in the delayed DST in comparison with groups without pictorial glosses. Moreover, for the delayed MRT, participants in Group D demonstrated enhanced vocabulary retention in comparison with Group C, whereas Group B did not exhibit a significant improvement in scores in comparison with Group A.
Taken together, in the delayed DST, Group B had a significant higher mean than that of Group A and Group C. Group A and Group D had significantly higher means than that of Group C. In the delayed MRT test, Group A, Group B, and Group D had significant higher means than that of Group C.
6. Discussion
The first research question examined whether L1 and L2 glosses had differential effects on vocabulary learning. The immediate post-test results showed that participants who had access to L1 textual glosses during listening had significantly higher vocabulary gains than participants who received L2 textual glosses. Similarly, after two weeks of delayed post-tests, participants in the L1 text-only group outperformed participants in the L2 text-only group in both vocabulary tests. These findings are congruent with several empirical studies that found an advantage of L1 glosses over L2 glosses in vocabulary acquisition (Arpaci, Reference Arpaci2016; Choi, Reference Choi2016; Xu, Reference Xu2010) as well as two recent meta-analyses (Kim et al., Reference Kim, Lee and Lee2024; Yanagisawa et al., Reference Yanagisawa, Webb and Uchihara2020). An explanation for these results is that the majority of participants in this study were elementary and lower-intermediate proficiency learners, and based on Kroll and Stewart’s (Reference Kroll and Stewart1994) RHM, learners who have weaker abilities in L2 are more likely to associate new concepts and meanings of unknown words through L1 words and learn better from glosses that are provided in their L1. This can also explain why some previous studies found L2 glossing to be more helpful than L1 glossing or found no significant difference in L1 and L2 glossing in reading comprehension (Cheng & Good, Reference Cheng and Good2009; Jacobs et al., Reference Jacobs, Dufon and Hong1994; Yoshii, Reference Yoshii2006). Therefore, familiarity with L1 words rather than L2 words leads to better connections with target words for lower-proficiency learners.
The second research question examined whether adding pictures to glosses has a beneficial effect on vocabulary learning. Since the findings differed in the DST and the MRT, in what follows, the differences between textual and textual-pictorial groups in each vocabulary test are explained. In the DST that assessed meaning-recall aspects of learning target words, the findings showed that supplementing textual glosses with pictures was beneficial. When pictures were added to both L1 and L2 text-only glosses, the resulting dual glossing modes were more effective in vocabulary learning than their corresponding text-only glosses, both in immediate and delayed tests. These findings confirm the “picture superiority” in Mayer’s (Reference Mayer2014) CTML as well as Ramezanali et al.’s (Reference Ramezanali, Uchihara and Faez2021) meta-analysis. In the DST, participants had to rely on their memory to remember the meaning of words without any clue or assistance from the test itself (Yoshii, Reference Yoshii2006). Therefore, based on the CTML, incorporating pictures in textual glosses could further assist learners in future recall processes by providing more memory traces. Mayer (Reference Mayer2014) mentioned that providing visual input alongside verbal information helps to form more connections in learners’ minds, since words and pictures are processed through different channels and more interactions between verbal and visual systems lead to better understanding.
In the MRT, while comparing L2 textual-pictorial glosses and L2 text-only glosses in both immediate and delayed tests, it was found that the L2 textual-pictorial group obtained higher scores than the L2 text-only glosses. However, this pattern was not found while comparing L1 textual-pictorial glosses with L1 text-only glosses. Therefore, the presence of pictures did not have any significant effect when glosses were provided in participants’ first language. This finding can be explained based on the results of Ramezanali et al.’s (Reference Ramezanali, Uchihara and Faez2021) meta-analysis that adding another gloss mode to L2 textual glosses was more effective than adding the same mode to L1 textual glosses. They explain that the reason for this finding might be that L1 glosses by themselves are so effective that adding another mode (i.e. pictures) does not make much difference, suggesting a ceiling effect of L1 glosses. Taken together, based on the results of our study, adding pictures to both L1 and L2 textual glosses was effective in a recall test, but in a recognition test, adding pictures was only effective for L2 textual glosses.
Additional support for this interpretation is provided by Yoshii (Reference Yoshii2006). According to this author, this phenomenon could be attributed to the nature of visual and textual supplementary input in glosses, which are intended to help learners make conceptual links between the form and meaning of unknown words. In a gloss that is provided in L2, low-ability learners might have difficulties making a connection between the form of an unknown word and its meaning by L2 explanation alone. Therefore, providing an additional picture as a visual cue could assist them. However, in L1 glosses, translations are clear and easy to understand, since the learners’ L1 conceptual repertoire is rich, and conceptual links could be established firmly between the forms and meanings of unknown words. In this situation, providing further visual cues might not improve learners’ understanding of the meaning of unknown words.
Although the results of this study are in line with those of the previous studies in favor of dual-modality glosses (Babaie Shalmani & Khalili Sabet, Reference Babaie Shalmani and Khalili Sabet2010; Kost, Foss & Lenzini, Reference Kost, Foss and Lenzini1999; Warren, Boers, Grimshaw & Siyanova-Chanturia, Reference Warren, Boers, Grimshaw and Siyanova-Chanturia2018), some studies have produced contradictory findings (e.g. Boers, Warren, He & Deconinck, Reference Boers, Warren, He and Deconinck2017; Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Yanguas, Reference Yanguas2009). The studies mentioned above found no difference between pictorial-textual glosses and textual-only glosses. One possible explanation for this contradictory result might be due to the study design, method, and participants. As Çakmak and Erçetin (Reference Çakmak and Erçetin2018) mentioned, using excessive pictorial glosses might distract learners, especially in a listening context where there are some limitations in controlling the flow of listening and using glosses simultaneously. Some studies showed that lower-proficiency learners are more likely to use glosses (e.g. Babaie Shalmani & Khalili Sabet, Reference Babaie Shalmani and Khalili Sabet2010). However, when the target word is abstract, using pictures is unsuitable for conveying the meaning and could lead to cognitive overload in these learners (Ariew & Ercetin, Reference Ariew and Ercetin2004; Hu et al., Reference Hu, Vongpumivitch, Chang and Liou2014). When comparing all four groups in both immediate and delayed tests, students who had access to L1 pictorial glosses had the best performance, and those who had access to L2 text-only glosses had the weakest performance in recall and recognition tests.
7. Pedagogical implications and limitations
Some implications regarding the use of glossing in EFL listening for incidental vocabulary learning can be drawn from the findings of this study. First, the findings serve as a reminder to pay more attention to the beneficial role of multimedia annotation in L2 vocabulary learning, especially considering implementing glossing in listening materials that are designed for mobile devices. Therefore, future listening materials could be augmented with different types of annotations to help learners improve their vocabulary knowledge as a by-product of engaging in listening activities. Second, materials developers can consider using pictures in glosses instead of presenting textual information alone, since the findings of this study supported the superiority of textual-pictorial glosses in L2 dual-modality glosses for incidental vocabulary learning (Paivio, Reference Paivio1990). However, care must be taken, since providing excessive visual supportive cues could lead to overload in underachieving learners’ cognitive capacity (Çakmak & Erçetin, Reference Çakmak and Erçetin2018; Mayer, Reference Mayer2014). Third, as we found that L1 textual glossing worked better than L2 textual glossing for our participants who were mainly at elementary and lower-intermediate levels, we recommend that teachers use L1 textual glossing for these proficiency levels rather than L2 textual glossing. Finally, given that adding pictures to L2 texts was more effective than adding to L1 texts in recognition tests, it can be concluded that using L1 text-only glosses was as effective as L1 textual-pictorial glosses for knowledge of recognition. Therefore, if teachers aim to develop language learners’ receptive knowledge of vocabulary, L1 text-only glosses are sufficient.
There are some limitations to the current study that should be considered. First, participants of this study were Iranian EFL students and mostly low proficiency learners. The generalizability of the findings is limited to this group, and more research is needed to generalize to other contexts. The second limitation was the setting in which the experiment was conducted. Mobile devices are designed to access information anytime and anywhere without any restriction, and most mobile-assisted vocabulary learning takes place outside the classroom (Ma, Reference Ma2017). The setting of this study was a formal classroom, which is not ideal for participants to exploit the full potential of MALL. Third, it might be of interest to investigate the effect of other gloss types (e.g. aural and video glosses) on incidental vocabulary learning with high-level proficiency learners. Mayer (Reference Mayer2014) stated that using a static or dynamic picture in glossing might affect reading comprehension and vocabulary learning differently. Fourth, we did not measure listening comprehension in this study. Measuring listening comprehension can give us a deeper understanding of the relationship between glossing and vocabulary learning. Fifth, we did not measure the frequency of access to each gloss, although this can affect learning of the words. Sixth, we used only a DST as a measure of participants’ vocabulary knowledge in the pre-test. This only measured their productive vocabulary knowledge. Future research can include both DST and MRT in the pre-test to have a more accurate measure of vocabulary knowledge. Finally, as Choi (Reference Choi2016) mentioned, using a longer retention phase could help to better understand the forgetting rate of different types of glossing from listening.
Despite these limitations, the study has demonstrated the potential of MALL in enhancing incidental vocabulary learning, even within the constraints of a formal classroom setting. This underscores the importance of glosses as a complementary educational tool and invites further exploration into its applications across diverse learning environments and proficiency levels. The findings contribute to the growing body of research advocating for the integration of technology in language education, highlighting the need for adaptive learning strategies that cater to the evolving landscape of student engagement.
8. Conclusion
In this article we demonstrated that multimedia glossing, particularly with L1 textual and pictorial elements, significantly enhanced vocabulary learning from listening tasks on mobile devices. The findings confirmed that L1 glosses were more effective than L2 glosses for lower-proficiency learners, and the addition of pictorial information to glosses improved recall of vocabulary. While pictorial glosses had a notable impact when combined with L2 textual glosses, they did not significantly affect vocabulary learning when paired with L1 glosses. This study’s results support the RHM and Mayer’s CTML, suggesting that dual coding and visual aids can be beneficial in language learning. The research advocates for incorporating native language support and multimedia elements in language learning tools for elementary and lower-intermediate learners, aligning with previous studies that favor dual-modality glossing.
Supplementary material
To view supplementary material referred to in this article, please visit https://doi.org/10.1017/S0958344024000193
Acknowledgements
The authors would like to thank Dr Shona Whyte and three anonymous reviewers for providing us with insightful comments on earlier drafts of the paper.
Ethical statement and competing interests
Ethical considerations, such as voluntary participation, anonymity, and confidentiality of the learners, were considered in this study. The authors declare no competing interests. The authors declare no use of generative AI.
About the authors
Arman Shahipanah is a lecturer with a master’s degree in teaching English as a foreign language (TEFL) from the University of Bojnord. His research interests include mobile-assisted language learning, generative artificial intelligence, e-learning, and digital media.
Gholam Hassan Khajavy (PhD) is an associate professor of applied linguistics at the University of Bojnord and postdoctoral researcher at University of Graz. His main research interests are the psychology of language learning and teaching and instructed second-language acquisition. He has published in various international journals such as TESOL Quarterly and Language Learning.
Majid Elahi Shirvan is an associate professor at the University of Bojnord, Iran. His main research interest is the dynamics of psychological aspects of foreign language learning and teaching. He has published in different leading international journals such as Ecological Psychology, Foreign Language Annals, and Studies in Second Language Acquisition.









 Open access
Open access