



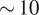
Impact Statement
In the past few years, single-particle cryo-electron microscopy (cryo-EM) has become the state-of-the-art method for resolving the atomic structure and dynamics of biological molecules. We design an efficient algorithm to enhance the quality of the highly noisy cryo-EM experimental images. The enhanced images can be used in a wide variety of tasks in the algorithmic pipeline of cryo-EM, including two-dimensional classification, removal of uninformative images, ab initio modeling, dimensionality reduction, symmetry detection, quick assessment of the data set, and as templates for particle picking. We provide a documented Python code. The algorithm includes built-in quality measures to mitigate the risk of model bias.
1. Introduction
In the past few years, single-particle cryo-electron microscopy (cryo-EM) has become the state-of-the-art method for resolving the atomic structure and dynamics of biological molecules(Reference Bai, McMullan and Scheres 1 –Reference Murata and Wolf 5 ). A cryo-EM experiment results in a large set of images, each corresponding to a noisy tomographic projection of the molecule of interest, taken from an unknown viewing direction. In addition, the electron doses transmitted by the microscope must be kept low to prevent damage to the radiation-sensitive biological molecules, inducing signal-to-noise ratio (SNR) levels that might be as low as –20 dB (i.e., the power of the noise is 100 times greater than the signal)(Reference Bendory, Bartesaghi and Singer 6 ). The low SNR level is one of the main challenges in processing cryo-EM data sets. In particular, different tasks in the computational pipeline of cryo-EM require enhancing the quality of the highly noisy raw images. Specifically, the high-quality enhanced images can be used as two-dimensional (2D) class averages, to remove uninformative images (e.g., pure noise images, contamination), to construct ab initio models based on the common-lines property(Reference Greenberg and Shkolnisky 7 , Reference Singer and Shkolnisky 8 ),Footnote 1 as templates for particle picking, to provide a quick assessment of the particles, for dimensionality reduction, and for symmetry detection(Reference Bendory, Bartesaghi and Singer 6 , Reference Singer and Sigworth 11 ).
In this paper, we propose a new signal enhancement algorithm that quickly produces multiple enhanced images that represent different viewing directions of the molecule of interest. The algorithm begins by performing steerable principal component analysis (sPCA) that reduces the dimensionality of the data and allows rotating (steering) the images easily(Reference Zhao, Shkolnisky and Singer 12 ). Next, we randomly choose a subset of the images and find their nearest neighbors based on (approximately) rotationally invariant operations. Hereafter, we refer to each image and its neighbors as a class. Then, we apply two stages for refining the classes. We first remove low-quality classes, and then also remove individual images which are inconsistent with their classes. These stages are based on inspecting the spectra of designed matrices, called synchronization matrices. The spectra of these matrices (that is, the distribution of their eigenvalues) provide a built-in quality measure to assess the consistency of each class. This is essential to support downstream tasks, such as ab initio modeling. Finally, we run an expectation–maximization (EM) algorithm for each class independently. This step aligns and averages the remaining images in each class, producing high SNR enhanced images. The different steps of the algorithm are elaborated in Section 2.
Our algorithm is inspired by and builds on the general scheme of(Reference Zhao and Singer 13 ). In particular, the authors of(Reference Zhao and Singer 13 ) suggest finding the rotationally invariant nearest neighbors of each image based on the bispectrum: a third-order rotationally invariant feature(Reference Bendory, Boumal, Ma, Zhao and Singer 14 ). Then, a high-quality image is produced by aligning all neighbors and averaging. While this method works quite well in many cases, the bispectrum inflates the dimensionality of the problem, boosts the noise level (which is already high in typical data sets), and does not offer a systematic way to assess the performance of the algorithm. Section 2 elaborates on the differences between(Reference Zhao and Singer 13 ) and our proposed algorithm.
Our work also shares similarities with 2D classification algorithms, which cluster the particle images and average them to produce high SNR images, dubbed class averages. 2D classification is a standard routine in all contemporary cryo-EM computational pipelines and is mostly used to remove uninformative images that are associated with low-quality class averages and to provide a quick assessment of the particles; our algorithm can be used for those tasks as well. A popular solution to the 2D classification task, implemented in the software RELION, is based on maximizing the posterior distribution of the classes, while marginalizing over the rotations and translations, using an EM algorithm(Reference Scheres 15 ); we describe this methodology in more detail in Section 2.5. A large number of class averages leads, however, to high computational complexity and to low-quality results because only a few images are assigned to each class. In addition, EM tends to suffer from the “rich get richer” phenomenon (also dubbed the attraction problem): most experimental images would correlate well with, and thus be assigned to, the class averages that enjoy higher SNR. As a result, EM tends to output only a few informative classes(Reference Sorzano, Bilbao-Castro and Shkolnisky 16 ). We circumvent this phenomenon since we apply the EM to each class separately.
Another related research thread considers denoising at the image or at the micrograph level. One example of the former is denoising based on Wiener filtering(Reference Bhamre, Zhang and Singer 17 ). A popular micrograph denoising technique is TOPAZ(Reference Bepler, Kelley, Noble and Berger 18 ), which is based on deep learning methods; see also(Reference Li, Zhang, Wan, Yang, Li, Li, Han, Zhu and Zhang 19 , Reference Palovcak, Asarnow, Campbell, Yu and Cheng 20 ). However, these techniques do not harness the similarity between particle images to suppress the noise, and thus their denoising quality is limited. For example, we use the enhanced images (the outputs of our algorithm) to directly construct molecular structures at a low to intermediate resolution. As far as we know, this has not been done using the said methods.
The paper is organized as follows. Section 2 outlines our method. In Section 3, we present results on four experimental data sets. We attain high-quality images that can be used to construct ab initio models with resolutions between
 $ \sim 10 $
Å to
$ \sim 10 $
Å to
 $ \sim 20 $
Å. Section 4 concludes the paper and delineates future work to improve the algorithm.
$ \sim 20 $
Å. Section 4 concludes the paper and delineates future work to improve the algorithm.
2. Method
This section describes the main steps of the proposed algorithm. A documented Python code is available at https://github.com/TamirBendory/CryoEMSignalEnhancement.
2.1. Preprocessing
The algorithm begins with a few standard preprocessing steps: we apply phase-flipping to approximately correct the effect of the CTF, down-sample the images to a size of
 $ 89\times 89 $
pixels, and whiten the noise in the images. The down-sampling has a minor effect on the nearest neighbors search, and is thus used to accelerate the running time of the algorithm. Then, we further reduce the dimension of the images using sPCA, which learns a steerable, data-driven basis for the data set(Reference Zhao, Shkolnisky and Singer
12
). Under this basis, the
$ 89\times 89 $
pixels, and whiten the noise in the images. The down-sampling has a minor effect on the nearest neighbors search, and is thus used to accelerate the running time of the algorithm. Then, we further reduce the dimension of the images using sPCA, which learns a steerable, data-driven basis for the data set(Reference Zhao, Shkolnisky and Singer
12
). Under this basis, the
 $ i $
th image can be approximated by a finite expansion
$ i $
th image can be approximated by a finite expansion
 $$ {I}_i\left(\xi, \theta \right)\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}{a}_{k,q}^i{\psi}_c^{k,q}\left(\xi, \theta \right),\hskip1em i=1,\dots, N, $$
$$ {I}_i\left(\xi, \theta \right)\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}{a}_{k,q}^i{\psi}_c^{k,q}\left(\xi, \theta \right),\hskip1em i=1,\dots, N, $$
where
 $ N $
is the number of images in the data set,
$ N $
is the number of images in the data set,
 $ \left(\xi, \theta \right) $
are polar coordinates,
$ \left(\xi, \theta \right) $
are polar coordinates,
 $ {\psi}_c^{k,q} $
are the sPCA eigenfunctions,
$ {\psi}_c^{k,q} $
are the sPCA eigenfunctions,
 $ {a}_{k,q}^i $
are the corresponding coefficients,
$ {a}_{k,q}^i $
are the corresponding coefficients,
 $ c=1/2 $
is the bandlimit of
$ c=1/2 $
is the bandlimit of
 $ I $
, and
$ I $
, and
 $ {k}_{max} $
and
$ {k}_{max} $
and
 $ {q}_k $
are determined as described in(Reference Zhao, Shkolnisky and Singer
12
). Remarkably, under this representation, an in-plane rotation translates into a phase shift in the expansion coefficients
$ {q}_k $
are determined as described in(Reference Zhao, Shkolnisky and Singer
12
). Remarkably, under this representation, an in-plane rotation translates into a phase shift in the expansion coefficients
 $$ {I}_i(\xi, \theta -\alpha )\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}{a}_{k,q}^i{e}^{-\iota k\alpha }{\psi}_c^{k,q}(\xi, \theta ), $$
$$ {I}_i(\xi, \theta -\alpha )\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}{a}_{k,q}^i{e}^{-\iota k\alpha }{\psi}_c^{k,q}(\xi, \theta ), $$
where
 $ \iota =\sqrt{-1} $
is the imaginary unit, and, for real-valued images, a reflection translates into conjugation
$ \iota =\sqrt{-1} $
is the imaginary unit, and, for real-valued images, a reflection translates into conjugation
 $$ {I}_i\left(\xi, \pi -\theta \right)\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}\overline{a_{k,q}^i}{\psi}_c^{k,q}\left(\xi, \theta \right). $$
$$ {I}_i\left(\xi, \pi -\theta \right)\approx \sum \limits_{k=-{k}_{max}}^{k_{max}}\sum \limits_{q=1}^{q_k}\overline{a_{k,q}^i}{\psi}_c^{k,q}\left(\xi, \theta \right). $$
The sPCA dramatically reduces the dimensionality of the images. We use 500 sPCA coefficients to represent the images. Henceforth, with a slight abuse of notation, we refer to the vector of sPCA coefficients of the
 $ i $
th image
$ i $
th image
 $ {\mathbf{a}}_i:= {\left\{{a}_{k,q}^i\right\}}_{k,q} $
as the image.
$ {\mathbf{a}}_i:= {\left\{{a}_{k,q}^i\right\}}_{k,q} $
as the image.
We mention that the final stage of the algorithm, the EM step, uses the raw images, which are not affected by these preprocessing steps.
2.2. Nearest neighbor search
Next, we randomly choose
 $ {N}_c $
images
$ {N}_c $
images
 $ {I}_{r_1},\dots, {I}_{r_{N_c}} $
from the data set and find the
$ {I}_{r_1},\dots, {I}_{r_{N_c}} $
from the data set and find the
 $ K $
nearest neighbors of each image. The underlying assumption is that the nearest neighbors arise from similar viewing directions. We refer to an image and its
$ K $
nearest neighbors of each image. The underlying assumption is that the nearest neighbors arise from similar viewing directions. We refer to an image and its
 $ K $
neighbors as a class.
$ K $
neighbors as a class.
The nearest neighbors search is based on a correlation measure which is approximately invariant under in-plane rotations and reflection. Let
 $ \Theta $
be a predefined set of
$ \Theta $
be a predefined set of
 $ {N}_{\theta } $
angles; we typically use
$ {N}_{\theta } $
angles; we typically use
 $ \Theta =\frac{i}{36}\pi, i=0,\dots, 71 $
so that
$ \Theta =\frac{i}{36}\pi, i=0,\dots, 71 $
so that
 $ {N}_{\theta }=72. $
We define the approximately invariant correlation, between two images
$ {N}_{\theta }=72. $
We define the approximately invariant correlation, between two images
 $ {\mathbf{a}}_i $
and
$ {\mathbf{a}}_i $
and
 $ {\mathbf{a}}_j $
, by
$ {\mathbf{a}}_j $
, by
 $$ \underset{\theta \in \Theta}{\max}\left[\max \right(\mathrm{corr}\left({e}^{i\boldsymbol{k}\theta}\cdot {\boldsymbol{a}}_{\boldsymbol{i}},{\boldsymbol{a}}_{\boldsymbol{j}}\right),\mathrm{corr}\left({e}^{i\boldsymbol{k}\theta}\cdot {\boldsymbol{a}}_{\boldsymbol{i}},\overline{{\boldsymbol{a}}_{\boldsymbol{j}}}\right)\Big], $$
$$ \underset{\theta \in \Theta}{\max}\left[\max \right(\mathrm{corr}\left({e}^{i\boldsymbol{k}\theta}\cdot {\boldsymbol{a}}_{\boldsymbol{i}},{\boldsymbol{a}}_{\boldsymbol{j}}\right),\mathrm{corr}\left({e}^{i\boldsymbol{k}\theta}\cdot {\boldsymbol{a}}_{\boldsymbol{i}},\overline{{\boldsymbol{a}}_{\boldsymbol{j}}}\right)\Big], $$
where
 $$ \mathrm{corr}\left(\boldsymbol{u},\boldsymbol{v}\right)=\frac{{\left(\boldsymbol{u}-\overline{\boldsymbol{u}}\right)}^{\ast}\left(\boldsymbol{v}-\overline{\boldsymbol{v}}\right)}{\sigma_{\boldsymbol{u}}{\sigma}_{\boldsymbol{v}}}, $$
$$ \mathrm{corr}\left(\boldsymbol{u},\boldsymbol{v}\right)=\frac{{\left(\boldsymbol{u}-\overline{\boldsymbol{u}}\right)}^{\ast}\left(\boldsymbol{v}-\overline{\boldsymbol{v}}\right)}{\sigma_{\boldsymbol{u}}{\sigma}_{\boldsymbol{v}}}, $$
and where
 $ \boldsymbol{k} $
is a radial frequency vector,
$ \boldsymbol{k} $
is a radial frequency vector,
 $ \cdot $
denotes element-wise product, and
$ \cdot $
denotes element-wise product, and
 $ {\sigma}_{\boldsymbol{a}} $
is the standard deviation of a vector
$ {\sigma}_{\boldsymbol{a}} $
is the standard deviation of a vector
 $ \boldsymbol{a} $
. The nearest neighbors of the
$ \boldsymbol{a} $
. The nearest neighbors of the
 $ i $
-th image are chosen as the
$ i $
-th image are chosen as the
 $ K $
images with the highest correlation (2.4).
$ K $
images with the highest correlation (2.4).
The nearest neighbors search requires computing
 $ N $
correlations for each of the
$ N $
correlations for each of the
 $ {N}_c $
selected images, resulting in a total of
$ {N}_c $
selected images, resulting in a total of
 $ {N}_cN $
correlations. For each image, the correlations can be computed using a couple of matrix multiplications using established linear algebra libraries. The computational complexity of this stage is governed by the multiplication of matrices of size
$ {N}_cN $
correlations. For each image, the correlations can be computed using a couple of matrix multiplications using established linear algebra libraries. The computational complexity of this stage is governed by the multiplication of matrices of size
 $ {N}_{\theta}\times {N}_{\mathrm{co}} $
and
$ {N}_{\theta}\times {N}_{\mathrm{co}} $
and
 $ {N}_{\mathrm{co}}\times N $
, where
$ {N}_{\mathrm{co}}\times N $
, where
 $ {N}_{\mathrm{co}} $
is the number of sPCA coefficients. For the experiments in Section 3, this stage took less than a minute.
$ {N}_{\mathrm{co}} $
is the number of sPCA coefficients. For the experiments in Section 3, this stage took less than a minute.
Two comments are in order. First, the approximately invariant correlation can be, in principle, replaced with invariant polynomials called the bispectra, giving rise to analytical rotationally invariant features(Reference Zhao and Singer
13
, Reference Bendory, Boumal, Ma, Zhao and Singer
14
) or approximately rotationally and translationally invariant features(Reference Bendory, Hadi and Sharon
21
) However, the dimension of the bispectrum far exceeds the dimension of the image, and thus we preferred to use the more direct expression of (2.4). Second, we choose the
 $ {N}_c $
images at random in order to cover different viewing directions. In a future work, we hope to replace this random strategy with a deterministic technique that finds a set of images covering all viewing directions.
$ {N}_c $
images at random in order to cover different viewing directions. In a future work, we hope to replace this random strategy with a deterministic technique that finds a set of images covering all viewing directions.
We next describe a method to rank and remove low-quality classes resulting from our random sampling strategy. This method provides a built-in measure of the quality of the classes, and thus of the enhanced images.
2.3. Sorting the classes
Until now, we have randomly chosen a set of images
 $ {I}_i,i=1,\dots .{N}_c $
, and found
$ {I}_i,i=1,\dots .{N}_c $
, and found
 $ K $
nearest neighbors per class. However, since the images
$ K $
nearest neighbors per class. However, since the images
 $ {I}_i $
were chosen randomly, it is plausible that some of them will be uninformative in the sense that they do not have close neighbors. To discard uninformative images and their classes, we aim to rank the classes according to their quality.
$ {I}_i $
were chosen randomly, it is plausible that some of them will be uninformative in the sense that they do not have close neighbors. To discard uninformative images and their classes, we aim to rank the classes according to their quality.
We define a good class as a class where all of its members were taken from a similar viewing direction, up to an in-plane rotation and, possibly, a reflection. For each pair of images in the class, we compute the most likely relative in-plane rotation and reflection; this is a by-product of computing the correlations in (2.4) so no additional computations are required. We denote the estimated relative rotation angle between the
 $ i $
th and
$ i $
th and
 $ j $
th members of the
$ j $
th members of the
 $ k $
th class by
$ k $
th class by
 $ {\theta}_{i,j}^{(k)} $
. If no reflection is involved, the relative rotation can be represented by a
$ {\theta}_{i,j}^{(k)} $
. If no reflection is involved, the relative rotation can be represented by a
 $ 2\times 2 $
rotation matrix
$ 2\times 2 $
rotation matrix
 $$ {\boldsymbol{R}}_{\boldsymbol{i},\boldsymbol{j}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cc}\cos {\theta}_{i,j}^{(k)}& -\sin {\theta}_{i,j}^{(k)}\\ {}\sin {\theta}_{i,j}^{(k)}& \cos {\theta}_{i,j}^{(k)}\end{array}\right]. $$
$$ {\boldsymbol{R}}_{\boldsymbol{i},\boldsymbol{j}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cc}\cos {\theta}_{i,j}^{(k)}& -\sin {\theta}_{i,j}^{(k)}\\ {}\sin {\theta}_{i,j}^{(k)}& \cos {\theta}_{i,j}^{(k)}\end{array}\right]. $$
If the pair of images are also reflected, then
 $$ {\boldsymbol{R}}_{\boldsymbol{i},\boldsymbol{j}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cc}\cos {\theta}_{i,j}^{(k)}& -\sin {\theta}_{i,j}^{(k)}\\ {}-\sin {\theta}_{i,j}^{(k)}& -\cos {\theta}_{i,j}^{(k)}\end{array}\right]. $$
$$ {\boldsymbol{R}}_{\boldsymbol{i},\boldsymbol{j}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cc}\cos {\theta}_{i,j}^{(k)}& -\sin {\theta}_{i,j}^{(k)}\\ {}-\sin {\theta}_{i,j}^{(k)}& -\cos {\theta}_{i,j}^{(k)}\end{array}\right]. $$
We then construct a Hermitian block matrix
 $ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}\in {\mathrm{\mathbb{R}}}^{2K\times 2K} $
$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}\in {\mathrm{\mathbb{R}}}^{2K\times 2K} $
 $$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cccc}{\boldsymbol{R}}_{\mathbf{1},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\mathbf{1},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\mathbf{1},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\\ {}{\boldsymbol{R}}_{\mathbf{2},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\mathbf{2},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\mathbf{2},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\\ {}\vdots & \vdots & \ddots & \vdots \\ {}{\boldsymbol{R}}_{\boldsymbol{K},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\boldsymbol{K},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\boldsymbol{K},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\end{array}\right]. $$
$$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}=\left[\begin{array}{cccc}{\boldsymbol{R}}_{\mathbf{1},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\mathbf{1},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\mathbf{1},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\\ {}{\boldsymbol{R}}_{\mathbf{2},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\mathbf{2},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\mathbf{2},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\\ {}\vdots & \vdots & \ddots & \vdots \\ {}{\boldsymbol{R}}_{\boldsymbol{K},\mathbf{1}}^{\left(\boldsymbol{k}\right)}& {\boldsymbol{R}}_{\boldsymbol{K},\mathbf{2}}^{\left(\boldsymbol{k}\right)}& \cdots & {\boldsymbol{R}}_{\boldsymbol{K},\boldsymbol{K}}^{\left(\boldsymbol{k}\right)}\end{array}\right]. $$
The matrix
 $ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
is a synchronization matrix over the dihedral group(Reference Bendory, Edidin, Leeb and Sharon
22
). If indeed all
$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
is a synchronization matrix over the dihedral group(Reference Bendory, Edidin, Leeb and Sharon
22
). If indeed all
 $ K $
class members are the same image up to an in-plane rotation and, possibly, a reflection (namely, an element of the dihedral group), then
$ K $
class members are the same image up to an in-plane rotation and, possibly, a reflection (namely, an element of the dihedral group), then
 $ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
is of rank two. In other words, only the first two largest eigenvalues
$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
is of rank two. In other words, only the first two largest eigenvalues
 $ {\lambda}_1^{(k)},{\lambda}_2^{(k)} $
of
$ {\lambda}_1^{(k)},{\lambda}_2^{(k)} $
of
 $ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
are nonzero. In practice, since the images were not taken precisely from the same viewing direction, and because of the noise, the matrix is not of rank two. Therefore, as a measure of the quality of this class, it is only natural to compute how “close” is
$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
are nonzero. In practice, since the images were not taken precisely from the same viewing direction, and because of the noise, the matrix is not of rank two. Therefore, as a measure of the quality of this class, it is only natural to compute how “close” is
 $ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
to a rank two matrix, namely,
$ {\boldsymbol{R}}^{\left(\boldsymbol{k}\right)} $
to a rank two matrix, namely,
 $$ {G}^{(k)}=\frac{\lambda_1^{(k)}+{\lambda}_2^{(k)}}{2K}, $$
$$ {G}^{(k)}=\frac{\lambda_1^{(k)}+{\lambda}_2^{(k)}}{2K}, $$
where we note that
 $ {\sum}_i{\lambda}_i^{(k)}=\mathrm{Tr}\left({\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}\right)=2K $
. We refer to
$ {\sum}_i{\lambda}_i^{(k)}=\mathrm{Tr}\left({\boldsymbol{R}}^{\left(\boldsymbol{k}\right)}\right)=2K $
. We refer to
 $ {G}^{(k)}\in \left[0,1\right] $
as the grade of the
$ {G}^{(k)}\in \left[0,1\right] $
as the grade of the
 $ k $
th class. We repeat this procedure for each class, and remove the classes with the lowest grades. In practice, we found that removing half of the classes yields good results. Since we need to extract the two leading eigenvalues of
$ k $
th class. We repeat this procedure for each class, and remove the classes with the lowest grades. In practice, we found that removing half of the classes yields good results. Since we need to extract the two leading eigenvalues of
 $ {N}_c $
synchronization matrices, the typical computational complexity of this stage is
$ {N}_c $
synchronization matrices, the typical computational complexity of this stage is
 $ O\left({K}^2{N}_c\right) $
.
$ O\left({K}^2{N}_c\right) $
.
The empirical distributions of the eigenvalues, or the grades
 $ {G}^{(k)} $
, provide a measure to assess the performance of the algorithm. This is important since the output of the signal enhancement algorithm may be used in downstream procedures, for example, to construct ab initio models. Thus, producing poor output may bias the entire computational pipeline with unpredictable consequences(Reference Henderson
23
).
$ {G}^{(k)} $
, provide a measure to assess the performance of the algorithm. This is important since the output of the signal enhancement algorithm may be used in downstream procedures, for example, to construct ab initio models. Thus, producing poor output may bias the entire computational pipeline with unpredictable consequences(Reference Henderson
23
).
2.4. Sorting images within classes
After removing classes of low quality, we wish to improve each of the remaining classes by removing inconsistent images. We follow the same strategy as before, and look for, within each class, a subset of images that are consistent with each other, namely, that form an approximately rank-two synchronization matrix (2.8).
Let
 $ {\hat{\mathbf{R}}}^{(k)}={\mathbf{V}}^{(k)}{\left({\mathbf{V}}^{(k)}\right)}^{\ast } $
be the best rank-two approximation of
$ {\hat{\mathbf{R}}}^{(k)}={\mathbf{V}}^{(k)}{\left({\mathbf{V}}^{(k)}\right)}^{\ast } $
be the best rank-two approximation of
 $ {\mathbf{R}}^{(k)} $
, where the columns of
$ {\mathbf{R}}^{(k)} $
, where the columns of
 $ {\mathbf{V}}^{(k)}\in {\mathrm{\mathbb{R}}}^{2K\times 2} $
are the eigenvectors of
$ {\mathbf{V}}^{(k)}\in {\mathrm{\mathbb{R}}}^{2K\times 2} $
are the eigenvectors of
 $ {\mathbf{R}}^{(k)} $
associated with the two leading eigenvalues. Let
$ {\mathbf{R}}^{(k)} $
associated with the two leading eigenvalues. Let
 $ {\hat{\mathbf{R}}}^{(k)}\left[i,j\right] $
and
$ {\hat{\mathbf{R}}}^{(k)}\left[i,j\right] $
and
 $ {\mathbf{R}}^{(k)}\left[i,j\right] $
be the
$ {\mathbf{R}}^{(k)}\left[i,j\right] $
be the
 $ \left(i,j\right) $
th entries of
$ \left(i,j\right) $
th entries of
 $ {\hat{\mathbf{R}}}^{(k)} $
and
$ {\hat{\mathbf{R}}}^{(k)} $
and
 $ {\mathbf{R}}^{(k)} $
, respectively. To determine whether the
$ {\mathbf{R}}^{(k)} $
, respectively. To determine whether the
 $ i $
th class member is consistent with its other class members, we compute the average distance between
$ i $
th class member is consistent with its other class members, we compute the average distance between
 $ {\hat{\mathbf{R}}}^{(k)}\left[i,j\right] $
and
$ {\hat{\mathbf{R}}}^{(k)}\left[i,j\right] $
and
 $ {\mathbf{R}}^{(k)}\left[i,j\right] $
for all
$ {\mathbf{R}}^{(k)}\left[i,j\right] $
for all
 $ j=1,\dots, K $
. Namely, the grade of the
$ j=1,\dots, K $
. Namely, the grade of the
 $ i $
th member of the
$ i $
th member of the
 $ k $
-th class is defined by
$ k $
-th class is defined by
 $$ {g}_i^{(k)}=-\frac{1}{K}\sum \limits_{j=1}^K{\left\Vert {\hat{\mathbf{R}}}^{(k)}\left[i,j\right]-{\mathbf{R}}^{(k)}\Big[i,j\Big]\right\Vert}_2. $$
$$ {g}_i^{(k)}=-\frac{1}{K}\sum \limits_{j=1}^K{\left\Vert {\hat{\mathbf{R}}}^{(k)}\left[i,j\right]-{\mathbf{R}}^{(k)}\Big[i,j\Big]\right\Vert}_2. $$
We found that producing classes with 300 images, and removing 150 images with the lowest score
 $ {g}_i^{(k)} $
(per class) yields good results.
$ {g}_i^{(k)} $
(per class) yields good results.
2.5. Expectation–maximization
After pruning out low-quality classes, and inconsistent images within each class, we are ready for the last stage of our algorithm: aligning the images within each class and averaging them to produce a high SNR output image. To this end, we apply the EM algorithm that aims to maximize the likelihood function of the observed images. The EM algorithm is applied to the raw images corresponding to each class separately (before down-sampling, phase-flipping, and so forth.)
The EM algorithm assumes that all observed images are rotated, translated, and noisy versions of a single image; this image is denoted by
 $ X $
and corresponds to the high SNR image we wish to estimate. The generative model of the images within a specific class is given by
$ X $
and corresponds to the high SNR image we wish to estimate. The generative model of the images within a specific class is given by
 $$ {I}_i={L}_{t_i}X+{\varepsilon}_i,\hskip1em i=1,\dots, K, $$
$$ {I}_i={L}_{t_i}X+{\varepsilon}_i,\hskip1em i=1,\dots, K, $$
where
 $ {t}_i $
encodes the unknown rotation and translation of the
$ {t}_i $
encodes the unknown rotation and translation of the
 $ i $
th image,
$ i $
th image,
 $ {L}_t $
is a linear rotation and translation operator (may also include the CTF), and
$ {L}_t $
is a linear rotation and translation operator (may also include the CTF), and
 $ {\varepsilon}_i $
is an i.i.d. Gaussian noise with variance
$ {\varepsilon}_i $
is an i.i.d. Gaussian noise with variance
 $ {\sigma}^2 $
. Our goal is to maximize the marginalized log-likelihood, which is equal, up to a constant, to
$ {\sigma}^2 $
. Our goal is to maximize the marginalized log-likelihood, which is equal, up to a constant, to
 $$ \log \hskip0.4em p\left({I}_1,\dots, {I}_K;X\right)=\sum \limits_{i=1}^K\log \sum \limits_{t_{\mathrm{\ell}}\in \mathcal{T}}p\left({t}_{\mathrm{\ell}}\right){e}^{-\frac{1}{2{\sigma}^2}\parallel {I}_i-{L}_{t_{\mathrm{\ell}}}X\parallel }, $$
$$ \log \hskip0.4em p\left({I}_1,\dots, {I}_K;X\right)=\sum \limits_{i=1}^K\log \sum \limits_{t_{\mathrm{\ell}}\in \mathcal{T}}p\left({t}_{\mathrm{\ell}}\right){e}^{-\frac{1}{2{\sigma}^2}\parallel {I}_i-{L}_{t_{\mathrm{\ell}}}X\parallel }, $$
where
 $ \mathcal{T} $
denotes the set of possible rotations and translations. While optimizing (2.12) is a challenging non-convex problem, EM has been proven to be an effective technique for optimizing (2.12) for cryo-EM images(Reference Bendory, Bartesaghi and Singer
6
, Reference Sigworth
24
). In particular, we used the implementation of RELION(Reference Scheres
15
). We note that this implementation does not correct for reflections, and thus we correct for reflections before running the EM algorithm. In particular, we construct a symmetric matrix whose
$ \mathcal{T} $
denotes the set of possible rotations and translations. While optimizing (2.12) is a challenging non-convex problem, EM has been proven to be an effective technique for optimizing (2.12) for cryo-EM images(Reference Bendory, Bartesaghi and Singer
6
, Reference Sigworth
24
). In particular, we used the implementation of RELION(Reference Scheres
15
). We note that this implementation does not correct for reflections, and thus we correct for reflections before running the EM algorithm. In particular, we construct a symmetric matrix whose
 $ \left(i,j\right) $
entry is −1 if the
$ \left(i,j\right) $
entry is −1 if the
 $ i $
-th and
$ i $
-th and
 $ j $
-th images are likely to be reflected, and 1 if not. This is a by-product of previous steps, described in Section 2.3, so no additional computations are required. Since this matrix is ideally a rank-one matrix (if all pair-wise estimations are consistent), we extract its leading eigenvector and round its entries into
$ j $
-th images are likely to be reflected, and 1 if not. This is a by-product of previous steps, described in Section 2.3, so no additional computations are required. Since this matrix is ideally a rank-one matrix (if all pair-wise estimations are consistent), we extract its leading eigenvector and round its entries into
 $ \pm 1 $
. This algorithm is known as the spectral algorithm for group synchronization(Reference Bendory, Edidin, Leeb and Sharon
22
, Reference Singer
25
).
$ \pm 1 $
. This algorithm is known as the spectral algorithm for group synchronization(Reference Bendory, Edidin, Leeb and Sharon
22
, Reference Singer
25
).
As mentioned in the introduction, a popular solution to the 2D classification task (which shares similarities with the signal enhancement problem) is to run EM on the observed images, before clustering the images. In this case, the generative model reads
 $$ {I}_i={L}_{t_i}{X}_{m_i}+{\varepsilon}_i,\hskip1em i=1,\dots, N, $$
$$ {I}_i={L}_{t_i}{X}_{m_i}+{\varepsilon}_i,\hskip1em i=1,\dots, N, $$
where
 $ {X}_1,\dots, {X}_{N_c} $
are the class averages to be estimated. While the implementation of the EM algorithm for (2.13) follows the same lines as the EM algorithm we use, it tends to output only a few informative classes because of the “rich get richer” phenomenon(Reference Sorzano, Bilbao-Castro and Shkolnisky
16
). We evade this pitfall by first finding the nearest neighbors of the chosen images, and running EM on each class separately to optimize (2.12). In addition, since we run multiple independent instances of the EM algorithm, they can be run in parallel, resulting in a significant acceleration.
$ {X}_1,\dots, {X}_{N_c} $
are the class averages to be estimated. While the implementation of the EM algorithm for (2.13) follows the same lines as the EM algorithm we use, it tends to output only a few informative classes because of the “rich get richer” phenomenon(Reference Sorzano, Bilbao-Castro and Shkolnisky
16
). We evade this pitfall by first finding the nearest neighbors of the chosen images, and running EM on each class separately to optimize (2.12). In addition, since we run multiple independent instances of the EM algorithm, they can be run in parallel, resulting in a significant acceleration.
We mention that the EM algorithm can be replaced by alternative computational strategies such as stochastic gradient descent or rotationally and translationally aligning the images, and then averaging them. The latter strategy, used by(Reference Zhao and Singer 13 ), is much faster than EM, and thus will significantly accelerate the algorithm, at the cost of lower image quality.
3. Experimental Results
In the following experiments, we produced 3000 classes and kept the best
 $ {N}_c=1500 $
classes according to the method explained in Section 2.3. Each class consists of 300 images, from which only the best
$ {N}_c=1500 $
classes according to the method explained in Section 2.3. Each class consists of 300 images, from which only the best
 $ K=150 $
images were used to estimate the class average, as explained in Section 2.4. We used the EM implementation of RELION(Reference Scheres
15
) with seven iterations. Based on the class averages, we reconstructed ab initio models using the common-lines method implemented in the ASPIRE package(
26
). All data sets were processed using an Intel(R) Xeon(R) Gold 6252 CPU @ 2.10 GHz containing 24 cores, and a GeForce RTX 2080 Ti GPU. The run times of all stages in the process are provided in Table 1. The resolution was computed based on the Fourier Shell Correlation (FSC) criterion with cutoff of 0.5, where the reference volume was downloaded from EMDB(Reference Lawson, Patwardhan and Baker
27
).
$ K=150 $
images were used to estimate the class average, as explained in Section 2.4. We used the EM implementation of RELION(Reference Scheres
15
) with seven iterations. Based on the class averages, we reconstructed ab initio models using the common-lines method implemented in the ASPIRE package(
26
). All data sets were processed using an Intel(R) Xeon(R) Gold 6252 CPU @ 2.10 GHz containing 24 cores, and a GeForce RTX 2080 Ti GPU. The run times of all stages in the process are provided in Table 1. The resolution was computed based on the Fourier Shell Correlation (FSC) criterion with cutoff of 0.5, where the reference volume was downloaded from EMDB(Reference Lawson, Patwardhan and Baker
27
).
Table 1. Runtime.

Abbreviation: EM, expectation–maximization; sPCA, steerable principal component analysis.
3.1. EMPIAR 10028
We begin with a data set of the Plasmodium falciparum 80S ribosome bound to the anti-protozoan drug emetine, available as the entry 10028 in EMPIAR(Reference Iudin, Korir, Salavert-Torres, Kleywegt and Patwardhan
28
) (the corresponding entry in EMDB is EMD-2660)(Reference Wong, Bai and Brown
29
). This data set contains 105,247 images of size
 $ 360\times 360 $
pixels.
$ 360\times 360 $
pixels.
Figure 1 shows examples of raw data images, the corresponding class averages, and a 3D structure reconstructed using the class averages; the resolution of the reconstructed structure is 10.41 Å. The nearest neighbor’s stage took 2.5 min, and the overall process took around 75 min.

Figure 1. EMPIAR 10028. The resolution of the reconstructed structure is 10.41 Å.
3.2. EMPIAR 10073
This data set of the yeast spliceosomal U4/U6.U5 tri-snRNP is available as the entry 10073 of EMPIAR (the corresponding entry in EMDB is EMD-8012)(Reference Nguyen, Galej and Bai
30
). This data set contains 138840 images of size
 $ 380\times 380 $
pixels. The nearest neighbors search took 2.5 min and producing 1500 class averages took roughly 100 min. The results are presented in Figure 2. The resolution of the reconstructed structure is 19.58 Å.
$ 380\times 380 $
pixels. The nearest neighbors search took 2.5 min and producing 1500 class averages took roughly 100 min. The results are presented in Figure 2. The resolution of the reconstructed structure is 19.58 Å.

Figure 2. EMPIAR 10073. The resolution of the reconstructed structure is 19.58 Å.
3.3. EMPIAR 10081
This data set of the human HCN1 hyperpolarization-activated cyclic nucleotide-gated ion channel is available as the entry 10081 of EMPIAR (the corresponding entry in EMDB is EMD-8511)(Reference Lee and MacKinnon
31
). This data set contains 55870 images of size
 $ 256\times 256 $
pixels. The nearest neighbors search took less than 3 min and producing 1500 high-quality images took roughly 1 hr. Figure 3 shows the results. The resolution of the reconstructed structure is 11.25 Å.
$ 256\times 256 $
pixels. The nearest neighbors search took less than 3 min and producing 1500 high-quality images took roughly 1 hr. Figure 3 shows the results. The resolution of the reconstructed structure is 11.25 Å.

Figure 3. EMPIAR 10081. The resolution of the reconstructed structure is 11.25 Å.
3.4. EMPIAR 10061
This data set of the beta-galactosidase in complex with a cell-permeant inhibitor is available as the entry 10061 of EMPIAR (the corresponding entry in EMDB is EMD-2984)(Reference Bartesaghi, Merk and Banerjee
32
). This data set contains 41123 images of size
 $ 768\times 768 $
pixels. The nearest neighbors search took less than 3 min and producing 1500 class averages took roughly 2.5 hr. Figure 4 shows results, where the 3D structure was reconstructed from the enhanced images using the spectral algorithm implemented in ASPIRE(Reference Rosen and Shkolnisky
33
). Although the class averages look of good quality, the resolution of the reconstructed structure is only 22.63 Å.
$ 768\times 768 $
pixels. The nearest neighbors search took less than 3 min and producing 1500 class averages took roughly 2.5 hr. Figure 4 shows results, where the 3D structure was reconstructed from the enhanced images using the spectral algorithm implemented in ASPIRE(Reference Rosen and Shkolnisky
33
). Although the class averages look of good quality, the resolution of the reconstructed structure is only 22.63 Å.

Figure 4. EMPIAR 10061. The resolution of the reconstructed structure is 22.63 Å.
4. Discussion
In this paper, we have presented a new algorithm to enhance the quality of cryo-EM images, which can be used for various tasks in the computational pipeline of cryo-EM. The algorithm is based on(Reference Zhao and Singer 13 ), but extends it in several ways, which are crucial to improve its performance and to design built-in quality measures. The algorithm is computationally efficient and can be executed on large experimental data sets.
For larger data sets, the brute-force nearest neighbors search we use can be replaced by efficient randomized algorithms(Reference Jones, Osipov and Rokhlin 34 ), resulting in a better asymptotic computational complexity. However, for contemporary data sets, the running times of both approaches are comparable. Our classification is approximately invariant under in-plane rotations and reflections; see also(Reference Cahill, Iverson, Mixon and Packer 35 ) for a related approach. While it can be extended to translation invariance by explicitly considering different translations, it will significantly increase the running time. A possible alternative approach would be to employ polynomials that are approximately invariant under the group of in-plane rotations and translations (namely, the group of rigid motions SE(Reference Bendory, Hadi and Sharon 21 ).
To improve the quality of the nearest neighbors search, the classes are refined by analyzing the spectra of synchronization matrices. This provides a validation measure that can be computed directly from the data, which is crucial to mitigate the risk of model bias in downstream tasks, such as ab initio modeling. We have demonstrated that the enhanced images are of high quality so that they can be used to construct ab initio models. To cover all viewing angles, we randomly sample the data set. This is clearly not optimal, and we intend to study different deterministic strategies to sample the data. A successful sampling strategy may make the class sorting stage of Section 2.3 unnecessary.
Competing interests
The authors declare no competing interests exists.
Authorship contributions
Guy Sharon, Yoel Shkolnisky, and Tamir Bendory conceptualized the study, developed the models and algorithms, and wrote the software code and the manuscript.
Funding statement
T.B. is partially supported by the NSF-BSF award 2019752, the BSF grant no. 2020159, and the ISF grant no. 1924/21. Y.S. was supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (grant agreement 723991 - CRYOMATH) and by the NIH/NIGMS Award R01GM136780–01.
Data availability statement
Source code and user manual are available at https://github.com/TamirBendory/CryoEMSignalEnhancement.






 Open access
Open access