



Adult second language acquisition (SLA) is a multifaceted phenomenon whose process and product are greatly affected not only by factors related to experience (e.g., how second language [L2] learners have practiced the target language), but also by those that are learner-internal (e.g., to what extent they are cognitively and socially adept at L2 pronunciation learning). Adopting a longitudinal approach (i.e., where learners engaged in practice activities inside and outside English-as-a-Foreign-Language [EFL] classrooms over one academic year), the current study examined how 40 college-level Japanese students with various aptitude scores (in terms of sound sequence recognition, phonemic coding, and associative memory) could improve the global (comprehensibility), segmental (consonant/vowel errors), syllabic (schwa vowel insertion), prosodic (wrong/missing stress), and temporal (breakdown, speed, fluency) dimensions of their L2 pronunciation.
BACKGROUND
EXPERIENCE, INDIVIDUAL DIFFERENCES, AND SECOND LANGUAGE ACQUISITION
In the field of SLA, many scholars would at least agree with the fundamental view that much improvement takes place as long as L2 learners make consistent efforts to practice the target language. Such experience effects (i.e., more practice is better) could be strong especially when L2 learners have started learning the target language under new environments (see Derwing, Thomson, & Munro, Reference Derwing, Thomson and Munro2006 for longitudinal evidence). However, these experience factors alone may not fully explain the extent to which L2 learners can promptly, substantially, and continuously improve their proficiency, as they engage in more practice opportunities with different types of native and nonnative interlocutors in various social settings. The quality of SLA beyond the early stage of L2 learning could be susceptible to a great deal of individual variability and is arguably linked to certain learner-intrinsic (rather than learner-extrinsic) factors, such as professional motivation (Moyer, Reference Moyer2014), affect (Gkonou, Daubney, & Dewaele, Reference Gkonou, Daubney and Dewaele2017), and aptitude (Granena & Long, Reference Granena and Long2013).
Whereas the relevant discussion on experience and individual differences has been primarily concerned with naturalistic SLA, a growing number of researchers have begun to explore the generalizability of the research findings to foreign language (FL) classroom contexts, where access to the L2 is restricted to several hours of instruction per week—the focus of the current study. Under such limited input conditions, L2 learners’ improvement patterns could be strongly tied to different FL learning backgrounds in terms of length and type of instruction (Spada & Tomita, Reference Spada and Tomita2010). According to previous investigations, adult L2 learners in various FL classrooms can develop a range of L2 skills as a function of increased input and practice inside and outside classrooms (Zhang & Lu, Reference Zhang and Lu2013 for lexical knowledge; Larson-Hall, Reference Larson-Hall2008 for grammar knowledge; Muñoz, Reference Muñoz and Muñoz2006 for listening proficiency). Furthermore, certain learners appear to be capable of achieving high-level L2 performance after receiving an extensive amount of FL instruction (6–10 years) (Muñoz, Reference Muñoz2014). To account for the incidence of successful foreign language learning, especially at the relatively later stages of classroom SLA, a great deal of research attention has been directed toward one learner-internal factor in particular—aptitude.
FOREIGN LANGUAGE APTITUDE
Foreign language aptitude refers to a set of perceptual and cognitive abilities that are assumed to help L2 learners acquire a target language in an effective and efficient fashion. Different from other individual difference variables in SLA (e.g., motivation), aptitude is considered to be a relatively stable trait that is unlikely to change with varying amounts of L2 learning experience. An abundance of aptitude research was launched in the 1950s, when Carroll and Sapon (Reference Carroll and Sapon1959) proposed their influential aptitude framework relevant to successful FL learning. This initial framework included such concepts as associative memory (remembering new word form-meaning pairings) and phonemic coding ability (analyzing and remembering unfamiliar sounds), and led to the development of an aptitude test still widely used today—the Modern Language Aptitude Test (MLAT). According to earlier validation studies (e.g., Carroll, Reference Carroll1965), MLAT scores were found to be correlated with L2 learners’ test performance and grades in various FL classrooms, which were, at the time, rife with the use of explicit learning strategies to acquire the target language across a limited number of short-term, language-focused classes.
Although the original concept of aptitude was strongly tied to the initial stage of form-oriented FL learning, more recent studies have expounded what dimensions of aptitude relate to L2 learners’ ultimate attainment after years of varied L2 learning experience in both classroom and naturalistic settings. By using a composite test battery consisting of 11 cognitive tasks (i.e., Hi-LAB), Linck et al. (Reference Linck, Hughes, Campbell, Silbert, Tare, Jackson and Doughty2013) investigated the aptitude profiles of 450+ personnel from the U.S. government and military who had studied various foreign languages for a long period (> 10 years). According to the results, those with high-level reading and listening performance according to the Defense Language Proficiency Tests had similarly high explicit language learning ability (associative memory), working memory (phonological short-term memory), and implicit learning ability (serial reaction time).
A growing number of empirical studies have found that LLAMA test scores—developed by Meara (Reference Meara2005) and used in the current study—can successfully predict various aspects of L2 lexicogrammar development. Extending the MLAT, the LLAMA test incorporates not only key elements for form-focused FL learning (associative memory, phonemic coding, grammatical inferencing), but also a new measure for the ability to recognize sound sequence patterns in spoken language in a relatively incidental fashion (sound sequence recognition)—a crucial component for successful L1 acquisition (Saffran, Reference Saffran2014), that is also linked to L2 grammatical attainment (Granena, Reference Granena2013). Under FL learning conditions (the context of the study), explicit learning aptitude (associative memory, phonemic coding, grammatical inferencing) has been found to successfully predict the extent to which L2 learners benefit from their teachers’ explicit instruction (Yalçin & Spada, 2016) and corrective feedback (Yilmaz & Granena, Reference Yilmaz and Granena2016).
In his synthesis of research on aptitude and SLA, Skehan (Reference Skehan, Granena, Jackson and Yilmaz2016) argued that different constructs of aptitude may be uniquely related to different putative stages of SLA: analyzing incoming input → automatizing partially acquired knowledge → attaining advanced-level use of language. In this view, those dimensions of aptitude related to auditory processing, such as phonemic coding, enhance the phonological buffer component of working memory. This in turn allows L2 learners to hold more information regarding unfamiliar sounds (i.e., input processing), and makes it available for more detailed and refined linguistic analyses (i.e., noticing). Thus, L2 learners with such auditory processing abilities (e.g., phonemic coding) can better focus on improving the accurate use of their L2 speech thanks to their enhanced ability to analyze input, especially when they are explicitly asked to do so under classroom conditions (Yilmaz & Koylu, Reference Yilmaz, Koylu, Granena, Jackson and Yilmaz2016). Certain talented L2 learners can also rely on associative memory to establish stronger form-meaning mappings by quickly combining relevant linguistic forms with what they signify. They can remember, maintain, and control even vast amounts of declarative knowledge (e.g., what to say and how to convey it) during actual use of language (i.e., proceduralization). After much practice in various conversational settings, learners with good memory can become more accurate and fluent (i.e., automatization) in their language use (Schneiderman & Desmarais, Reference Schneiderman and Desmarais1988).Footnote 1
The attainment of advanced-level L2 proficiency requires L2 learners to further improve their representational systems and processing abilities in the target language. To this end, L2 learners may need not only explicit and intentional but also implicit and incidental learning aptitude (e.g., serial reaction time, sound sequence recognition). Learners with such high aptitude scores can make the most of their L2 experience by not only processing/analyzing incoming pronunciation, vocabulary, and grammar units of language during the explicit learning process, but also by attending to more abstract and intuitive combinations of sound and word sequences without awareness (i.e., lexicalization). In fact, the latter type of aptitude (incidental and implicit one) has been found to facilitate the mastery of nativelike L2 use among experienced L2 learners in naturalistic settings (Abrahamsson & Hyltenstam, Reference Abrahamsson and Hyltenstam2008; Granena, Reference Granena2013).
To date, the existing literature comprises a wealth of cross-sectional investigations on the role of aptitude in L2 lexicogrammar learning (see Li, Reference Li2016 for a meta-analysis). However, comparatively less is known about influence aptitude has on the development of L2 pronunciation proficiency, particularly from a longitudinal perspective. The main objective of the current study is to further the existing aptitude research agenda by moving the past investigation of L2 lexicogrammar learning, and exploring aptitude’s link with L2 pronunciation learning.
SECOND LANGUAGE PRONUNCIATION PROFICIENCY
Traditionally, second language pronunciation proficiency has been conceptualized and analyzed through a range of global, segmental, syllabic, prosodic, and temporal measures. Given that achieving nativelike L2 pronunciation is difficult even for early bilinguals relative to other domains of language such as vocabulary and grammar (Granena & Long, Reference Granena and Long2013), many researchers have emphasized the importance of assessing the global quality of adult L2 learners’ speech in terms of “comprehensibility” (i.e., to what degree L2 learners’ pronunciation is easy to understand) rather than “accentedness” (i.e., the extent to which L2 speech sounds like native speaker baseline) (Derwing & Munro, Reference Derwing and Munro1997). With respect to specific constructs of L2 pronunciation, many researchers (e.g., Trofimovich & Isaacs, Reference Trofimovich and Isaacs2012) have illustrated: (a) how L2 learners can accurately pronounce new consonantal and vocalic sounds (i.e., segmentals) in both simple (e.g., Consonant-Vowel [CV]) and complex (e.g., CVC, CCVCC) syllable structures with the correct placement of stress (i.e., prosody); and (b) how such pronunciation forms can be delivered without many pauses and repetitions with optimal tempo (i.e., fluency).
Derwing, Munro, and Thomson’s (Reference Derwing, Munro and Thomson2008) longitudinal investigation of adult L2 English learners in Canada showed that the participants significantly enhanced the overall comprehensibility (but not accentedness) of their speech over the course of two years of immersion when their main language communication was L2 rather than L1. There is ample cross-sectional evidence that a great amount of L2 experience (e.g., more than 10 years of residence) may be needed for the acquisition of more refined segmental (e.g., Schmid, Gilbers, & Nota, Reference Schmid, Gilbers and Nota2014) and prosodic (e.g., Trofimovich & Baker, Reference Trofimovich and Baker2006) accuracy, as well as the development of more nativelike fluency (e.g., Lahmann, Steinkrauss, & Schmid, Reference Lahmann, Steinkrauss and Schmid2017).
To explore the extent to which L2 learners can ultimately improve their pronunciation proficiency in FL settings, our precursor research (Saito, Reference Saito2017) elucidated the linguistic and learning profiles of 50 Japanese L2 learners of English with extensive FL backgrounds. Whereas the participants’ overall pronunciation forms were generally considered to be intelligible, certain learners with greater explicit learning aptitude demonstrated more advanced-level L2 oral ability, owing particularly to their better command of difficult phonological features. According to the results of the correlation analyses, phonemic coding ability was moderately correlated with the segmental and prosodic qualities of L2 speech, and associative memory was weakly associated with the temporal qualities of L2 speech. However, their relatively incidental learning ability (i.e., sound sequence recognition) was unrelated to any aspects of their speech performance (for similar results in naturalistic SLA, see Granena & Long, Reference Granena and Long2013).
Whereas the results here provide some evidence to support the interaction between different types of aptitude (phonemic coding vs. associative memory) and speech (pronunciation accuracy vs. fluency) (Skehan, Reference Skehan, Granena, Jackson and Yilmaz2016), such findings need to be interpreted with caution due to the cross-sectional nature of the dataset. Although L2 learners with high aptitude scores demonstrated relatively greater accurate and fluent L2 pronunciation performance at the time of the project, the results could be explained not only by differences in their aptitude levels, but also by differences in the nature of the FL input (in and outside the classroom) they had obtained throughout their FL learning experience—another crucial affecting factor for the outcomes of L2 learning in FL classrooms. As a remedy, multiple data collection points are needed to track not only L2 learners’ developmental patterns, but also their experience within specific timescales; such longitudinal designs would shed light on the full-fledged picture of aptitude effects in SLA while controlling for relevant experience variables. The current study is designed to respond to these concerns.
CURRENT STUDY
RESEARCH OBJECTIVES
This study reports on a longitudinal investigation of the complex relationship between aptitude, experience, and L2 pronunciation learning over one academic year among 40 first-year Japanese university students with six years of FL education. Spontaneous speech samples were elicited from the learners at the beginning, middle, and end of the year, and analyzed for global (comprehensibility) and specific (segmentals, syllables, prosody, fluency) constructs of L2 pronunciation proficiency. Following Meara’s (Reference Meara2005) framework, three components of aptitude potentially related to pronunciation development were featured and measured using the LLAMA test—(a) associative memory (LLAMA-B), (b) phonemic coding (LLAMA-E), and (c) sound sequence recognition (LLAMA-D). Most notably, care was taken in this study to track all participants’ FL experience (inside/outside classrooms) within a specific time framework of the study—one academic year.
PREDICTIONS
In keeping with Skehan’s (Reference Skehan, Granena, Jackson and Yilmaz2016) acquisition-oriented model of aptitude reviewed earlier, auditory processing (phonemic coding) is assumed to be instrumental to input processing and noticing; associative memory to proceduralization and automatization; and sound sequence recognition to high-level L2 proficiency attainment. Accordingly, three predictions were formulated. First, L2 learners with higher phonemic coding abilities (LLAMA-E) would show more gains in the global, segmental, syllabic, and prosodic accuracy aspects of L2 pronunciation proficiency, given their presumed higher ability to process and analyze the phonetic subunits of words in the L2 input. Next, those with greater associative memory would deliver their L2 speech more rapidly and smoothly (breakdown/repair fluency) by drawing on their stronger and more durable access to what they had already acquired (speed fluency). Because such explicit learning aptitude is assumed to facilitate the speed of classroom learning (Carroll, Reference Carroll1965), high-aptitude learners are expected to show gains especially within the first semester, when they have just entered university and begun to study L2 English in a new FL environment.
Comparatively, incidental learning is hypothesized to relate to how much (rather than quickly) L2 learners can enhance their proficiency, when they receive ample L2 input over a long time span; such outcomes of incidental learning could be gradual, but consistent and extensive even after their rate advantage (i.e., considerable/quick learning during the first semester) (Hulstijn, Reference Hulstijn, Doughty and Long2003). In this regard, certain students, who had the relatively high incidental learning aptitude—sound sequence recognition (LLAMA-D), would continue to improve their pronunciation proficiency during the first semester and the second semester. By maximizing their FL experience through processing input explicitly as well as implicitly, these exceptional learners were presumed to be better able to detect and integrate segmental/prosodic patterns in the L2 input into their representation systems. Owing to this, it was assumed that they could further refine their phonological accuracy and access efficiency in production to approach more sophisticated, nativelike levels.
METHOD
PARTICIPANTS
As a part of a larger project that set out to examine the speaking abilities of 100+ Japanese FL students at several universities in the Tokyo area in Japan, the data collection for the current study was conducted during spring (Semester 1: 15 weeks) and fall 2013 (Semester 2: 15 weeks) semesters. A total of 40 first-year students (19 males, 21 females) enrolled in various arts and social sciences programs (e.g., business, marketing, psychology, international relations) at a large university in Tokyo were carefully recruited as participants for the study based on the following conditions. All were native speakers of Japanese (with both of their parents being L1 Japanese speakers). They were freshman students in their first semester at the university, and ranged in age from 18 to 19 years. They had started learning English from secondary school (grade 7), and lacked any prior study-abroad experience. Given their length of FL learning (i.e., six years), the participants were considered as relatively experienced FL learners (for a similar definition, see Muñoz, Reference Muñoz2014). At the outset of the project, the participants’ general proficiency test scores (i.e., TOEIC) varied from 490 to 845 out of 990 (M = 643.6, SD = 113.2), suggesting that their CEFR bands could be considered from B1/B2 (independent users) to C1 (proficient users).
To survey their FL experience and record their L2 speech, an individual interview was scheduled with each participant (30 min per session) at the beginning (T1: April) and end of Semester 1 (T2: July) as well as the end of Semester 2 (T3: March). Approximately one month after the end of the final posttest (T3), the participants took the LLAMA aptitude test (40 min per session).
Although the screening criteria ensured some degree of similar demographic attributes among the participants, the participants demonstrated much individual variability in terms of their FL experience within the time framework of the project (one academic year). In our preliminary analyses (reported in another venue: Saito & Hanzawa, Reference Saito and Hanzawa2017), we surveyed the extent to which they had practiced L2 English inside and outside classrooms throughout the project (one academic year). Subsequently, we examined how their varied FL experience backgrounds influenced various aspects of their oral performance at T1, T2, and T3, measured through native raters’ subjective pronunciation/lexicogrammar judgments.
According to the post-hoc interviews, none of the participants received any specialized pronunciation training throughout the project—a typical phenomenon in many foreign languages (Saito, Reference Saito2014) and second language (Derwing et al., Reference Derwing, Munro and Thomson2008) classrooms. In addition, the results identified small correlations between the number of classes and fluency development only during Semester 1. However, such experience effects were not found during Semester 2, suggesting that other individual difference factors beyond experience variables, such as aptitude, could have had a comparatively greater impact on successful L2 pronunciation learning.
In the current study, we revisited the dataset to elucidate how different types of aptitude (explicit vs. incidental learning aptitude) could facilitate two supposedly different phases of their pronunciation learning—Semesters 1 and 2. For the former, the associations between experience factors and L2 pronunciation development could be relatively strong; for the latter, such experience effects could be lessened. To reflect the multifaceted nature of L2 pronunciation proficiency, the global, syllabic, prosodic, and temporal qualities of the participants’ speech were also scrutinized by a total of seven measures developed specifically for the current project.
APTITUDE TEST
The LLAMA test was used to measure the participants’ associative memory (LLAMA-B), phonemic coding (LLAMA-E), and sound sequence recognition (LLAMA-D) (Meara, Reference Meara2005). Using visual and verbal materials adapted from a British-Columbian indigenous language and a Central-American language (rather than digits and symbols unrelated to natural language), the LLAMA test is considered to measure aptitude specific to human language learning.
To reduce the participants’ awareness toward what they were doing (i.e., intentional/explicit learning) and correspond to their incidental learning aptitude, especially during the LLAMA-D session, the tests were given in the following order: LLAMA-D → LLAMA-B → LLAMA-E. Subtests were automatically scored out of 75 for the LLAMA-D and 100 for LLAMA-B and -E.
LLAMA-D
This subtest assesses participants’ ability to detect and memorize novel sound sequences and abstract phonetic regularitiesFootnote 2 in a language without awareness. Such phonological aptitude is believed to help L2 learners segment aural streams of speech into lexical units to identify words in comprehension, and automatize their lexical access in production (Speciale, Ellis, & Bywater, Reference Speciale, Ellis and Bywater2004). First, the participants listened to 10 sound strings from a computer to check if they could hear them without any difficulty. At this stage, the participants were not told about the presence/purpose of the test to avoid evoking the participants’ intentional learning.Footnote 3 Subsequently, the participants proceeded to the testing phase, where they listened to 30 items and then detected whether they had heard them during the initial sound-check session.
LLAMA-B
This subtest gauges the participants’ ability to memorize new vocabulary items based on the association between alphabetical strings (2–7 letters) and corresponding objects (cf. the paired-associates test in MLAT). First, the participants were explicitly told about the objective of the subtest (learning vocabulary followed by recollection) and asked to memorize a relatively large amount of new vocabulary items (N = 20) within two minutes. In the following testing phase, the participants were asked to match randomly chosen names with the corresponding visuals (20 items).
LLAMA-E
This subtest evaluates the participants’ ability to learn new sound-symbol correspondences by associating sound strings with unfamiliar alphabetical symbols (i.e., phonemic coding) (cf. the phonetic script test in MLAT). First, they were explicitly asked to learn and remember the relationship between 24 recorded syllables and their corresponding phonetic symbols within two minutes. Subsequently, their recollection memory was tested to see if they could correctly identify corresponding symbols after listening to a combination of two syllables (a total of 20 items).
EXPERIENCE SURVEY
At the end of Semester 1 (T2) and Semester 2 (T3), all the students were individually interviewed to estimate how they had practiced L2 English throughout the term. As was operationalized in previous FL studies (e.g., Muñoz, Reference Muñoz2014), they reported in a retrospective manner two experience factors directly related to successful classroom SLA—(a) the total hours of English classes they had taken per week (i.e., the length of classroom learning) and (b) the total number of hours they had weekly spent practicing English through informal conversations with other native and nonnative speakers of English (i.e., extracurricular activities). For the former (L2-use inside classrooms), the students were given the option to register in not only language-focused classes (comprising reading, listening, writing, and speaking activities with a primary focus on form), but also content-based classes (delivering various subject matter lessons in L2 English), which is increasingly common in many FL classrooms all over the world (e.g., Content and Language Integrated Learning). For the latter (L2 use outside classrooms), some students sought conversation opportunities especially with international students at the university, whereas others rarely used L2 English outside classrooms for conversational purposes.
SPEAKING TASK
Given that adult L2 learners can carefully monitor their correct use of language using explicit knowledge, especially when their performance is tested through controlled production tasks (e.g., word and sentence readings), many SLA researchers (e.g., Abrahamsson & Hyltenstam, Reference Abrahamsson and Hyltenstam2008) have emphasized the importance of adopting spontaneous production tasks (e.g., picture narratives) to examine the present state of L2 learners’ oral competence. In these tasks, learners are encouraged to pay equal attention to all linguistic domains of L2 speech (pronunciation, fluency, vocabulary, grammar) to convey their communicative intentions under communicative pressure (without much planning time) (Spada & Tomita, Reference Spada and Tomita2010).
Accordingly, following previous L2 speech studies (e.g., Derwing & Munro, Reference Derwing and Munro1997), a timed picture description task was adopted in the current study. As conceptualized and piloted in Saito and Hanzawa (Reference Saito and Hanzawa2016), the picture description task was designed to elicit a certain length of spontaneous speech data without excessive hesitations and dysfluencies from L2 learners, even those with low proficiency levels. In this task, participants described seven separate pictures with three keywords printed as hints for each picture; this differs from previous research that has asked participants to explain a series of thematically linked images without any linguistic support (e.g., Derwing & Munro, Reference Derwing and Munro1997). To equalize participants’ familiarity with the task format, the first four pictures were used for practice and the last three were targeted for analyses. To minimize any conscious speech monitoring during each picture description, the participants were given only a very small amount of planning time (i.e., 5 sec) before describing each picture.
MATERIALS
The three target pictures depicted a table left out in a driveway in heavy rain (keywords: rain, table, driveway); three men playing rock music with one singing a song and the other two playing guitars (keywords: three guys, guitar, rock music); and a long stretch of road under a cloudy blue sky (keywords: blue sky, road, cloud). The keywords were all considered as frequent (among the first 3,000 most frequent words according to the British National Corpus) and were intentionally chosen to push Japanese learners to use challenging segmental, syllabic, and prosodic features (without using any avoidance strategies). For instance, Japanese speakers have been reported to neutralize the English /r/-/l/ contrast (“rain, rock, brew, crowd” vs. “lane, lock, blue, cloud”) and to insert epenthetic vowels between consecutive consonants (/dəraɪvə/ for “drive,” /θəri/ for “three,” /səkaɪ/ for “sky”) and after word-final consonants (/teɪbələ/ for “table,” /myuzɪkə/ for “music”) in borrowed words (i.e., Katakana). Due to the cross-linguistic differences at the prosodic level between Japanese (mora-timed) and English (syllable-timed), L1 Japanese learners typically have difficulty in pronouncing bi-syllabic words (e.g., guiTAR, MUsic), applying incorrect word stress (GUItar, muSIC) or equal stress on each syllable (GUITAR, MUSIC).
PROCEDURE
To keep track of the participants’ pronunciation proficiency development over one academic year, their spontaneous speech was collected using the timed picture description task at three testing points (T1, T2, T3).Footnote 4 All picture descriptions were recorded by means of a Marantz PMD 660 recorder with a Shure SM 10A-CN microphone (44.1 kHz sampling rate with 16-bit quantization) in a soundproof booth at the Japanese university. For each testing session (T1, T2, T3), instructions were given orally by the researcher in Japanese to ensure that all speakers understood the procedures. After four pictures were presented for the participants to practice, they proceeded to describing the remaining three pictures, which were used for the final analyses.
The first 10 seconds of each of the three picture descriptions were extracted, combined, and stored in a single file for each participant at T1, T2, and T3, respectively. In total, 120 speech samples were generated (40 FL students × 3 testing points). Considering previous studies, we believe that the length of the speech samples in this study (30 sec per participant at T1, T2, and T3) provided sufficient phonological information for the analyses of global comprehensibility (Derwing & Munro, Reference Derwing and Munro1997 for 10–15 sec), pronunciation accuracy (Isaacs & Trofimovich, Reference Isaacs and Trofimovich2012 for 30 sec), and fluency (Bosker, Pinget, Quené, Sanders, & De Jong, Reference Bosker, Pinget, Quené, Sanders and De Jong2013 for 20 sec).
GLOBAL ANALYSES
Raters
In the current study, we asked untrained listeners (without much linguistic and pedagogical experience) to make intuitive judgments of overall L2 oral ability on the continuum of comprehensibility, without any detailed descriptors or training (the raters received only a brief explanation on the definitions of comprehensibility; for training scripts and onscreen labels, see Supporting Documents). Such intuitive (rather than deliberate) judgment of extemporaneous L2 speech is believed to well reflect what native speakers do in real life when communicating with nonnative speakers (Derwing & Munro, Reference Derwing and Munro1997). Five native speakers of English (two males, three females) were recruited at an English-speaking university in Montreal, Canada. Their mean age was 22.5 years. They were born and raised in English-speaking homes in Montreal. All the raters were undergraduate students with nonlinguistic backgrounds (e.g., business, psychology) and reported no previous teaching experience in L2 classrooms. They reported relatively low familiarity with Japanese-accented English (M = 1.5 from 1 = Not at all to 6 = Very much). None of the raters reported any hearing problems.
Procedure
The 120 speech samples were randomly presented to the raters using the MATLAB software. After listening to each file in its entirety, the raters used a free-moving slider on a computer screen to assess comprehensibility. If the slider was placed at the leftmost end of the continuum, labeled with a frowning face (indicating very negative), it was recorded as “0”; if it was placed at the rightmost end of the continuum, labeled with a smiley face (indicating very positive), it was recorded as “1,000.” To tap into the initial intuitions and impressions of comprehensibility, each sample was played only once for the raters’ judgment.
The rating session took place for approximately 1.5 hours in a quiet room at the university. First, the raters familiarized themselves with the picture prompts and key words, and received a brief explanation of comprehensibility from a trained research assistant. Next, they practiced the procedure with five speech samples (not included in the dataset), and then proceeded to the global judgment of the tokens.
Inter-rater Reliability
Similar to previous research (e.g., Derwing & Munro, Reference Derwing and Munro1997), the five inexperienced raters showed high inter-rater agreement for their comprehensibility ratings (Cronbach’s alpha = .94). Thus, mean scores were calculated by pooling the scores of the five inexperienced raters. The mean scores were then applied to each token produced by the participants.
SEGMENTAL, SYLLABIC, AND PROSODIC ANALYSES
In conjunction with Isaacs and Trofimovich’s (Reference Trofimovich and Isaacs2012) coding scheme for L2 pronunciation accuracy, three domain-specific measures were devised to analyze the segmental, syllabic, and prosodic qualities of L2 speech.
Experienced Coder
The pronunciation accuracy analyses were conducted by an L1 Japanese researcher with a great deal of L2 speech analysis experience, and near-nativelike proficiency in L2 English. Different from many previous studies, where native speakers have typically been recruited as coders (e.g., Derwing & Munro, Reference Derwing and Munro1997; Trofimovich & Isaacs, Reference Trofimovich and Isaacs2012), our unique decision here (i.e., recruiting the coder who had much experience with both L1 and L2) was made for the following reasons. Because the goal of L2 speech learning concerns comprehensible and intelligible pronunciation rather than nativelike accuracy, the validity of the native speakers’ subjective, dichotomous judgments of nonnative speech (“targetlike” vs. “nontargetlike”) remains open to discussion (Jenkins, Reference Jenkins2002). Instead, the pronunciation quality of L2 speech in the study was assessed based on whether the participants continued to use L1 Japanese forms or demonstrated any effort to use L2 English forms in obligatory contexts (rather than to what degree their pronunciation simply approximated the native baseline). As seen in some L2 speech studies with similar FL learners (e.g., Riney, Takada, & Ota, Reference Riney, Takada and Ota2000 for college-level Japanese FL learners), we believe that a L1 Japanese speaker with near nativelike L2 English proficiency (rather than native speakers of English) would be better qualified as a coder to capture the subtle changes in L2 learners’ interlanguage pronunciation forms.Footnote 5
Procedure
The Japanese coder carefully listened to each speech sample, and analyzed for the following three categories:
Segmental Error Ratio
This category was analyzed by dividing the number of L1 substitution errors (e.g., Japanese /ɾ/ for English /ɹ/, Japanese /s/ for English /θ/) by the total number of segments articulated (for more details, see also Supporting Information).
Syllable Error Ratio
This category was analyzed by dividing the number of consonant and vowel insertions (e.g., “blue” pronounced as /bəlu/) by the total number of syllables articulated.
Prosodic Error Ratio
This category was analyzed by dividing the number of the absence of primary stress errors (e.g., “DRIVEway” pronounced as “driveway” [no primary stress] or “DRIVEWAY” [equal primary stress]) and the misplacement of primary stress errors (e.g., “DRIVEway” pronounced as “driveWAY” by the total number of multisyllabic words).
Inter-coder Reliability
To check the reliability of the Japanese coder’s analyses, she and another coder (L1 Japanese speaker with coding experience) first separately analyzed a total of 40 similar speech samples produced by Japanese learners of English that were not a part of the current study. According to the inter-coder sessions, relatively high correlations were found for their judgments of segmentals, syllables, and word stress (Cronbach alpha > .90). Afterward, the first coder proceeded to the analysis of the main dataset on her own (a total of 120 speech samples).
TEMPORAL ANALYSES
Following De Jong, Steinel, Florijn, Schoonen, and Hulstijn’s (Reference De Jong, Steinel, Florijn, Schoonen, Hulstijn, Housen, Kuiken and Vedder2012) notion of fluency, three measures were developed to objectively analyze the three temporal aspects of L2 pronunciation proficiency: (a) breakdown (how effortlessly speech is articulated without many pauses and hesitations), (b) speed (how many words/syllables are produced within a certain period), and (c) repair (how often corrections and repetitions are present in speech) (see also Bosker et al., Reference Bosker, Pinget, Quené, Sanders and De Jong2013).
Breakdown Fluency (Pause Ratio)
Breakdown fluency was measured by dividing the total number of filled pauses (e.g., eh, ah, oh) and unfilled pauses (i.e., silence) over the total number of words. The number of filled pauses was counted based on raw transcripts, and the number of unfilled silent pauses was automatically calculated using a script programmed in Praat with the minimum length of silence set at 250 milliseconds (for a similar decision, see De Jong et al., Reference De Jong, Steinel, Florijn, Schoonen, Hulstijn, Housen, Kuiken and Vedder2012).
Speed Fluency (Articulation Rate)
One dimension of speed fluency—articulation rate—was measured by dividing the total phonation time (without all filled pauses) by the total number of syllables.
Repair Fluency (Repair Ratio)
Repair fluency was calculated by dividing the total number of repetitions (repeating words and phrases) and reformulations (self-correcting nontargetlike forms) by the total number of words (based on raw scripts).
RESULTS
APTITUDE AND EXPERIENCE PROFILES
The first objective of the statistical analyses was to report the relationship within and between participants’ aptitude and experience profiles (descriptively summarized in Table 1). For the sake of comparison, the participants’ aptitude scores (LLAMA-D, -B, -E) were converted into z-scores. With respect to the experience variables, the participants widely differed in terms of the number of English classes they had received (i.e., form- and content-based classes) and the number of hours they had spent conversing outside classrooms (with native and nonnative speakers) in Semesters 1 and 2, respectively.
TABLE 1. Descriptive statistics of learner aptitude and experience profiles
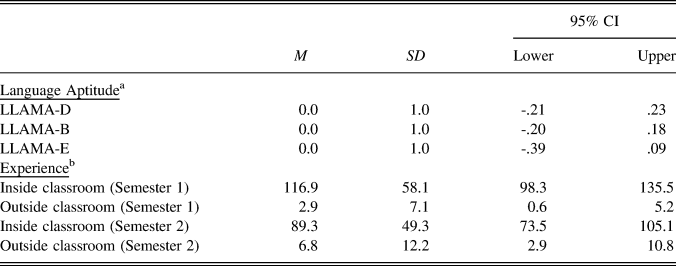
a All aptitude scores were converted to z scores.
b The experience factors refer to the total hours of L2 use inside and outside FL classrooms per semester.
Next, a set of Pearson correlation analyses were performed on the aptitude scores (LLAMA-D, -B, -E) and experience variables (the amount of L2 use during Semesters 1 and 2). According to the results summarized in Table 2, the participants’ scores on the three aptitude tests were not significantly correlated with each other (p > .05). As proposed by Meara (Reference Meara2005), the findings here indicate that the LLAMA test in the study appeared to tap into three different constructs of cognitive abilities: sound sequence recognition (LLAMA-D), associative memory (LLAMA-B), and phonemic coding (LLAMA-E). In terms of their FL experience, significant correlations were observed between L2-use inside and outside classrooms during both Semesters 1 and 2, suggesting that participants who took more English classes likely spent more time on conversation activities with native and nonnative speakers outside classrooms. Overall, the strength of the aptitude-experience link was relatively weak (r < .2) and nonsignificant (p > .05). The exception was their performance on the LLAMA-E, which was significantly correlated with the number of FL classes they had received during Semester 1 (r = .32, p < .05).
TABLE 2. Interrelationships between aptitude and experience factors
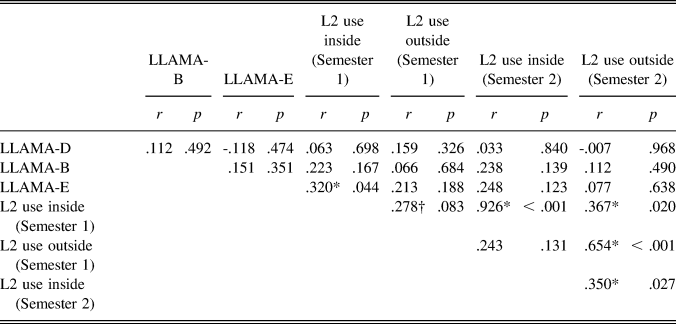
Note. *Indicates statistical significance at p < .05 and † indicates marginal significance at p < .10.
PRONUNCIATION PROFICIENCY PROFILES
The second objective of the statistical analyses was to illustrate how the global (comprehensibility) and specific (segmentals, syllables, prosody, fluency) dimensions of L2 pronunciation proficiency were interrelated. To this end, the relative weights of the participants’ segmental, syllabic, prosodic, and temporal scores in terms of their global comprehensibility scores at three different points (T1, T2, T3) were examined using a linear mixed-effects regression analysis. Their comprehensibility scores were used as a dependent variable relative to six independent variables (segmentals, syllables, word stress, breakdown/speed/repair fluency).
The model identified three significant fixed effects for segmentals, B = -0.89, t =, -2.69, p = .008; syllables, B = -0.89, t = -2.62, p = .010; and breakdown fluency, B =-0.41, t = -4.36, p < .001. The results here suggest that the native judges relied on, in particular, three aspects of pronunciation information (segmentals, syllables, fluency) during their overall comprehensibility judgments at T1, T2, and T3.
To further examine the interrelationships between the six specific pronunciation measures (segmentals, syllables, prosody, breakdown/speed/repair fluency), another set of mixed-effects model analyses were performed on each of the six specific pronunciation scores as dependent variables and the other measures as predictor variables. According to the results, strong associations were found between segmentals and syllables, B = 0.27, t = 4.27, p < .001; syllables and breakdown fluency, B = -0.62, t = -2.06, p = .047; and syllables and speed fluency, B = -0.01, t = -3.80, p = .001.
In sum, a total of seven global and specific pronunciation measures adopted in the study appeared to correspond to four different aspects of the participants’ pronunciation proficiency. This included their ability to produce correct pronunciation forms (segmentals, syllables) with adequate prosody (word stress), and connect them to form sentences at optimal speed (speed fluency, syllables) by making fewer long pauses (breakdown fluency, syllables), all of which were somewhat tied to the global impression of L2 speech (comprehensibility).
PRONUNCIATION DEVELOPMENT
The third objective of the statistical analyses was to probe how the participants’ various dimensions of L2 pronunciation proficiency—comprehensibility, segmentals, word stress, fluency—changed over one academic semester. The participants’ global and specific pronunciation scores at three different time points (T1, T2, T3) are summarized in Table 3. The descriptive statistics showed that the participants’ improvement patterns were involved with a great deal of individual variability across all the pronunciation measures over one academic year. The results here were not surprising, as these students were substantially different in terms of aptitude (the extent to which they were adept at L2 pronunciation learning) and experience (how they practiced the target language in Semesters 1 and 2) (see Table 1).
TABLE 3. Descriptive statistics of pronunciation proficiency at the beginning (T1), middle (T2), and end (T3) of the project

APTITUDE, EXPERIENCE, AND PROFICIENCY LINK
The final objective of the statistical analyses was to delve into the extent to which the participants’ individual differences in their L2 pronunciation development could be related to their aptitude and experience profiles.
Correlation Analyses
To provide a general picture of the relationship between aptitude, experience, and L2 speech learning, we conducted a set of partial correlation analyses. The participants’ gain scores in Semester 1 (T2 minus T1 scores) and Semester 2 (T3 minus T2 scores) were used as dependent variables, and the participants’ aptitude (LLAMA-D, -B, -E) and experience (L2 use inside and outside classrooms for Semesters 1 and 2) were used as independent variables.
Although our main interest lies in the participants’ gain scores over Semester 1 (T1 → T2) and Semester 2 (T2 → T3), it is noteworthy that their initial pronunciation performance was substantially different between individuals even at the beginning of the term (T1, T2). This could be due to a combination of learner-extrinsic (how the participants had practiced the target language prior to the data collection) and learner-intrinsic (the extent to which their different levels of aptitude, motivation, and affect promoted or debilitated their SLA) factors, a result whose discussion was beyond the scope of the study, and closely examined in our precursor research (Saito & Hanzawa, Reference Saito and Hanzawa2017).
As has been the case with similar longitudinal aptitude research (Yalçin & Spada, 2016), the decision was made to use the participants’ initial performance (T1 for Semester 1, T2 for Semester 2) as a covariate, and statistically remove its effect from the rest of the subsequent analyses. In this way, we were able to focus on analyzing the participants’ L2 pronunciation learning within specific timescales—Semester 1 (T1 → T2) and Semester 2 (T2 → T3)—without any conflation with their previous FL experience outside of the project.Footnote 6
As shown in Table 4, three aspects of the participants’ pronunciation proficiency improvement (comprehensibility, syllables, speed fluency) were correlated with the number of classes they had received during Semester 1. In contrast, their gains in prosodic and temporal abilities were weakly associated with explicit sound learning aptitude—associative memory (LLAMA-B) for breakdown fluency, and phonemic coding ability (LLAMA-E) for word stress and speed fluency. These results indicate that a great deal of L2 use may have initially facilitated the development of comprehensibility, as the participants could enhance the syllabic qualities of their L2 speech (i.e., reducing schwa insertion errors) in relation to an increasing amount of classroom experience. Furthermore, explicit aptitude—associative memory (LLAMA-B) and phonemic coding (LLAMA-E)—appeared to help certain L2 learners further improve their prosodic and temporal abilities, which are considered to be relatively difficult aspects of L2 speech learning.
TABLE 4. Results of partial correlations between aptitude, experience, and pronunciation scores at Semester 1 (T1 → T2)
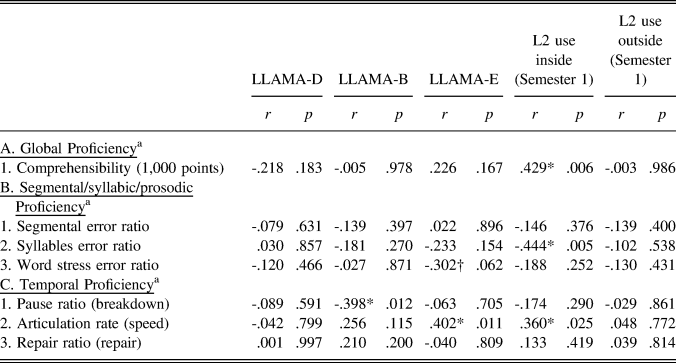
a Their pronunciation scores at T2 were used as dependent variables and their T1 scores were used as a covariate.
Note. *Indicates statistical significance at p < .05 and † indicates marginal significance at p < .10.
For Semester 2 (summarized in Table 5), the extent to which the participants continued to develop their L2 pronunciation skills appeared to be unrelated to any of the experience factors. Rather, the amount of global (comprehensibility) and specific (segmentals, syllables, breakdown fluency) improvement in pronunciation proficiency was moderately correlated with their incidental learning aptitude (sound sequence recognition: LLAMA-D) and weakly with their intentional learning aptitude (associative memory: LLAMA-B). Taken together, the results here suggest that when L2 learners’ pronunciation development is unrelated to any experience variables, these learners may ultimately need some form of innate language learning talent—for example, sound sequence recognition—to further improve and attain advanced-level L2 comprehensibility (relative to other participants) by reducing not only schwa insertion errors (syllables), but also L1 substitution errors (segmentals).
TABLE 5. Results of partial correlations between aptitude, experience, and pronunciation scores at Semester 2 (T2 → T3)
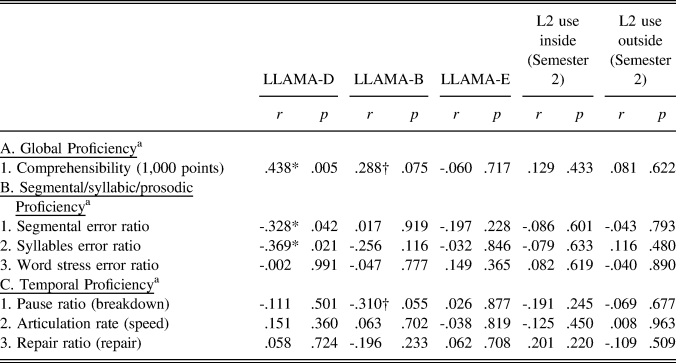
a Their pronunciation scores at T3 were used as dependent variables and their T2 scores were used as a covariate.
Note. *Indicates statistical significance at p < .05 and † indicates marginal significance at p < .10.
Multiple Regression Analyses
To confirm the suggested relationship between aptitude, experience, and L2 pronunciation development, and to further examine the potentially different contributions of the aptitude and experience effects witnessed during Semesters 1 and 2, we next performed a set of multiple regression analyses. The participants’ gain scores in comprehensibility, segmentals, syllables, prosody, and fluency were used as dependent variables, while their aptitude and experience scores were used as independent variables. Similar to the aforementioned partial correlation analyses, the participants’ pronunciation scores at T1 and T2 were also selected as an independent variable to control for the influence of the participants’ previous FL experience prior to Semesters 1 and 2.
To avoid multicollinearity problems, the decision was made to reduce the number of predictors by using only significant and marginally significant predictors identified in the partial correlation analysis (i.e., LLAMA-D, -B, -E; L2 use inside classrooms). The power of the dataset (N = 40 with five predictors) to find a medium effect size was .68, which could be considered as beyond the minimum requirement in the field of SLA research (> .50) (Larson-Hall, Reference Larson-Hall2010).
As summarized in Table 6, the regression models showed that the participants’ pronunciation learning during Semester 1 were substantially impacted by their initial performance—an indication of their six years of EFL experience. As for experience effects, some variance in L2 comprehensibility (9.9%) and syllable (38.9%) development was significantly explained by the amount of L2 use inside classrooms throughout the first term. In terms of aptitude effects, two aspects of improved fluency—speed (8.5%) and breakdown (9.5%)—were moderately related to LLAMA-E and LLAMA-B.
TABLE 6. significant results of multiple regression analyses using aptitude, experience, and initial performance as predictors of L2 pronunciation gains during Semester 1
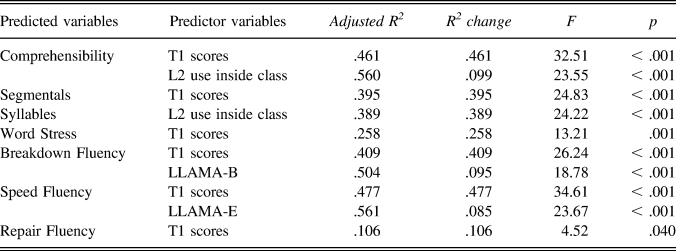
Note. The variables entered into the regression equations included LLAMA-D, LLAMA-B, LLAMA-E, L2 use inside class, and T1 pronunciation scores.
The results of the significant predictors for the participants’ L2 speech learning during Semester 2 are summarized in Table 7. Different from Semester 1, neither explicit aptitude nor the experience factors significantly accounted for the variance in the participants’ gains across the second term. It was rather the participants’ incidental learning aptitude—LLAMA-D—that played a pivotal role in their continuous development of comprehensibility (12.7%), segmentals (5.9%), and syllables (7.7%) at the later phase of the project.
TABLE 7. Significant results of multiple regression analyses using aptitude, experience, and initial performance as predictors of L2 pronunciation gains during Semester 2
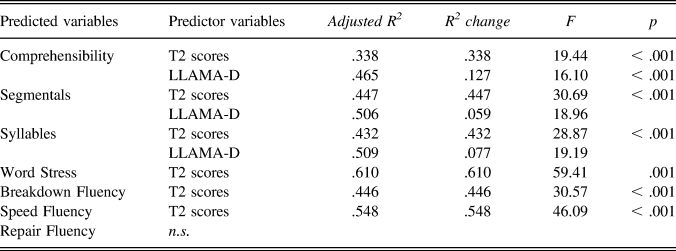
Note. The variables entered into the regression equations included LLAMA-D, LLAMA-B, LLAMA-E, L2 use inside class, and T2 pronunciation scores.
DISCUSSION AND CONCLUSION
In the context of 40 Japanese first-year university students in FL settings, the current study examined how different constructs of aptitude (sound sequence recognition, associative memory, phonemic coding) interact to affect the longitudinal development of L2 global, segmental, syllabic, prosodic, and temporal proficiency while they differently practiced the target language in quantity and quality over one academic year. Overall, the results showed that the participants’ aptitude and experience scores uniquely predicted L2 pronunciation development at different time points (T1 → T2 → T3). With respect to Semester 1 (T1 → T2), aptitude demonstrated relatively small effects on L2 pronunciation learning. Explicit learning aptitude—associative memory (LLAMA-B) and phonemic coding (LLAMA-E)—weakly predicted the development of prosody and fluency. The development of global comprehensibility was strongly associated with the amount of L2 experience especially inside the FL classroom, as the participants significantly enhanced the syllabic aspects of their L2 pronunciation proficiency. With respect to Semester 2 (T2 → T3), the amount of the participants’ L2 pronunciation performance was not significantly related to any experience factors. It was rather the incidental learning ability (sound sequence recognition measured by LLAMA-D) that significantly predicted the extent to which certain learners could continue to improve and ultimately attain advanced-level L2 comprehensibility (relative to the other learners), especially thanks to the refinement of segmental accuracy.
The results here in turn indicate several possible interpretations of the complex relationship between aptitude, experience, and L2 pronunciation development. When L2 learners start learning the target language under new classroom conditions, their pronunciation proficiency quickly develops as a function of increased L2 use. This could be true for even experienced L2 learners, notably for learners such as the first-year university students in the current study, who had six years of FL experience prior to the project. In this case, experience effects are readily observable in the acquisition of relatively easy phonological features, such as reduced vowel insertions in complex syllables—a primary interlanguage strategy that many FL students have been reported to use to attain minimally successful comprehensibility in L2 speech (Lin, Reference Lin2001). In the long run, however, the aptitude factor may steadily impact the acquisition of relatively difficult pronunciation features, which otherwise require a tremendous amount of input, interaction, and practice, such as segmentals (Schmid et al., Reference Schmid, Gilbers and Nota2014), word stress (Trofimovich & Baker, Reference Trofimovich and Baker2006), and fluency (Lahmann et al., Reference Lahmann, Steinkrauss and Schmid2017).
In essence, the findings presented here supported the predictions that we presented earlier based on Skehan’s (Reference Skehan, Granena, Jackson and Yilmaz2016) aptitude-acquisition model: phonemic coding for accuracy, associative memory for fluency, and sound sequence recognition for continuous, long-term development. According to the results, explicit learning aptitude—associative memory and phonemic coding—allowed L2 learners to show not only quick, but also robust improvement in their L2 pronunciation proficiency even over a short period (i.e., Semester 1). The results suggest that L2 learners with greater associative memory may have the capacity to hold a substantial amount of information in their phonological store that will, as a result, free up their cognitive resources for use in delivering L2 utterances fluently (see O'Brien, Segalowitz, Collentine, & Freed, Reference O’Brien, Segalowitz, Collentine and Freed2006 for the effect of phonological short-term memory—a similar construct to associative memory). L2 learners with greater phonemic coding ability may also have the capacity to identify and analyze the prosodic information of words in the incoming input to produce individual words with correct stress patterns (see Cebrian, Reference Cebrian2006 for the effect of phonological awareness).
Whereas associative memory may continue to make marginal contributions to the development of fluency beyond Semester 1—a crucial indication of automatization, L2 learners may need not only explicit but also incidental learning aptitude (sound sequence recognition) to attain more refined segmental accuracy—a crucial characteristic of advanced-level L2 comprehensibility (Saito, Trofimovich, & Isaacs, Reference Saito, Trofimovich and Isaacs2016). Echoing Skehan’s (Reference Skehan, Granena, Jackson and Yilmaz2016) proposal, the participants in the current study could have done this (i.e., attaining high-level proficiency) by exploiting the full acquisitional value of the L2 input in FL classrooms, especially during Semester 2. According to the L1 acquisition literature (e.g., Saffran, Reference Saffran2014), sound sequence recognition ability plays a key role in successful implicit language learning in several respects. For one, it is believed to induce humans to statistically analyze characteristics of native phoneme categories, phonotactic regularities, and word stress patterns without awareness. Such knowledge is stored in long-term memory, enables learners to segment speech streams into word units, and helps learners recognize and produce these units more automatically (Mattys, Jusczyk, Luce, & Morgan, Reference Mattys, Jusczyk, Luce and Morgan1999). Though few, some SLA studies have provided preliminary findings that adult L2 learners with higher sound sequence recognition ability could establish more robust lexical (Speciale et al., Reference Speciale, Ellis and Bywater2004) and morphosyntactic (Granena, Reference Granena2013) representations in the target language.
When it comes to L2 pronunciation learning, the current study added that the sound sequence recognition ability may relate to, in particular, the refinement of L2 segmental representations. According to recent L2 speech learning models (e.g., Bundgaard-Nielsen, Best, Kroos, & Tyler, Reference Bundgaard-Nielsen, Best, Kroos and Tyler2012 for L2 Vocab Model), L2 learners tend to start paying special attention to improving their segmental accuracy as they move onto more advanced L2 pronunciation proficiency, after meeting the minimum requirements for successful social interaction (e.g., vocabulary size > 6,000–7,000 word families). These theoretical accounts agree that achieving nativelike segmental representations is crucial in the later stages of L2 speech learning, given that this phonological reattunement is believed to push L2 learners to develop, expand, and access many L2 lexicons more accurately and quickly without becoming confused by phonologically similar words—that is, vocabulary spurt (ibid.).
Finally, it is intriguing to remember that the results of the current study (which were longitudinally obtained) did not concur with those of the two cross-sectional studies, where sound sequence recognition ability (LLAMA-D) was unrelated to any dimensions of L2 pronunciation proficiency in naturalistic (Granena & Long, Reference Granena and Long2013) and FL classroom (Saito, Reference Saito2017) settings. One reason for the discrepancy in the results could be due to the different nature of the dataset in the individual studies (longitudinal vs. cross-sectional methods). In the cross-sectional studies (Granena & Long, Reference Granena and Long2013; Saito, Reference Saito2017), the aptitude factor was linked to L2 learners’ final attainment after years of L2 learning experience, which could have resulted from a combination of explicit and implicit learning at different time points in various learning contexts. However, the longitudinal design of the current study allowed us to pinpoint the effect aptitude has during different stages of L2 speech learning. That is, our study revealed an aptitude-proficiency link at two different time points—(a) explicit learning aptitude was a significant predictor during Semester 1, during the rapid stage of L2 pronunciation development tied to an increasing amount of experience (i.e., experience phase); and (b) incidental learning aptitude was a significant predictor during Semester 2, when L2 pronunciation learning was unrelated to additional experience.
Taken together, these results provide two tentative hypotheses as to the predictive power of explicit and incidental learning aptitude in accordance with the timing of L2 speech learning. First, cross-sectional studies have hinted that adult L2 speech learning mainly involves explicit and intentional learning over an extensive period (Granena & Long, Reference Granena and Long2013; Saito, Reference Saito2017). The present longitudinal study suggests that a certain amount of incidental learning occurs in the relatively later stages of L2 speech learning, where the relationship between experience and proficiency is relatively weak.
To close, two limitations to this exploratory study should be acknowledged for future research. First, the analyses of L2 pronunciation proficiency in this study were based on a particular group of L2 learners (40 Japanese students learning L2 English in FL settings) who engaged in a single task—a timed picture description. Because the linguistic characteristics of L2 learners’ speech have been found to vary according to different types of task conditions (e.g., Ahmadian & Tavakoli, Reference Ahmadian and Tavakoli2011 for task repetition; Yuan & Ellis, Reference Yuan and Ellis2003 for pretask and online planning time) and learner factors (e.g., De Jong et al., Reference De Jong, Steinel, Florijn, Schoonen, Hulstijn, Housen, Kuiken and Vedder2012 for proficiency levels; Lahmann et al., Reference Lahmann, Steinkrauss and Schmid2017 for age of testing), the findings of the current study need to be replicated with larger samples of participants with various ages (young/adult) and linguistic (L1/L2) backgrounds while adopting multiple task modalities and demands.
Second, the incidental learning aptitude in this study was analyzed using only LLAMA-D. Thus, another promising future direction is concerned with the development, elaboration, and sophistication of new aptitude test batteries for measuring, in particular, incidental and implicit pronunciation learning. Although the LLAMA-D was used to measure sound sequence recognition, the validity of the test has been questioned (cf. Granena, Reference Granena2013). Whereas serial reaction time has also been used to measure L2 learners’ sequence learning ability without any awareness (implicit learning aptitude), the relationship between tests using nonlinguistic materials (digits, symbols) and L2 pronunciation learning remains unclear. According to Skehan’s (Reference Skehan, Granena, Jackson and Yilmaz2016) review, the LLAMA-D is considered one of the few aptitude tests to measure relatively incidental learning aptitude based on natural language materials (North American indigenous languages). Thus, it would be intriguing to expand the current design of the LLAMA-D to more closely align with the way L2 learners acquire complex sound systems in new languages in an incidental (and implicit) manner. To this end, for example, speech samples that L2 learners are exposed to during the test should include not only simple monotonous sound sequences (CV), with but also complex ones with varied syllable structures (not only CV, but also CVC, CCVCC) and varying prosodic patterns (signaling of word stress through various pitch contours). For the recall section of the test, participants should be tested not only on their memory of old items, but also on their intuitive judgments of the “wordlikeness” of novel items in the language, which has been previously identified as a firm psycholinguistic phenomenon directly related to incidental and implicit language learning in L1 acquisition (e.g., Gathercole, Frankish, Pickering, & Peaker, Reference Gathercole, Frankish, Pickering and Peaker1999) and L2 acquisition (e.g., Gullberg, Roberts, Dimroth, Veroude, & Indefrey, Reference Gullberg, Roberts, Dimroth, Veroude and Indefrey2010).
SUPPLEMENTARY MATERIAL
To view supplementary material for this article, please visit https://doi.org/10.1017/S0272263117000432









