


1 Introduction
This paper presents an acoustic study of manner and voicing variation in the plain uvular /q/ in a variety of South Bolivian Quechua. Across the Quechua language family, the etymological plain uvular has undergone many changes, including lenition and change to a velar. In Bolivian varieties of Quechua, this sound constitutes the plain member of the ternary laryngeal contrast between plain, aspirated and ejective stops or affricates, and also patterns phonologically as a stop in terms of syllable structure and laryngeal cooccurrence constraints (Gallagher Reference Gallagher2019). Variation in the realization of the uvular /q/ (and also of velar /k/) in South Bolivian Quechua, particularly voicing and lenition, has long been noted in the literature, though it has not been studied instrumentally.
The main goal of the current paper is to provide a description of the realization of /q/, in both spontaneous speech and word list speech. Spontaneous speech provides mostly intervocalic and post-rhotic tokens of /q/, where a voiced continuant realization is found to be most frequent. Post-nasally, a voiced stop is the favored realization. Perhaps most interesting is the realization of /q/ in post-pausal position. Some speakers show increased rates of voiceless stop production in post-pausal position, consistent with a variable, prosodically driven lenition pattern for this sound. Some speakers, however, still produce a voiced continuant in post-pausal position, even in careful word list speech; voiced stop tokens are also well attested in post-pausal position.
Further background on Quechua and lenition more generally is found in Section 2, followed by the analysis of /q/ in Section 3. Section 4 presents a second, follow-up analysis, which looks at intervocalic vs. post-pausal productions of the other three plain stops in the language /p t k/, and confirms that the high rate of lenition found for /q/ is a unique property of this sound category, as opposed to a general property of connected speech. Section 5 discusses the results with respect to findings from lenition studies in other languages and the phonology of South Bolivian Quechua, and outlines areas for future work. Section 6 concludes.
2 Background
2.1 Quechua
The data in this paper come from interviews with Quechua speakers from the city of Cochabamba, Bolivia and the nearby city of Sacaba, Bolivia. This variety of Quechua falls within the language designated as South Bolivian Quechua, in the IIC branch of the Quechua family (Torero Reference Torero and Pottier1983).
South Bolivian Quechua is a highly agglutinative, suffixing language, with primarily penultimate stress (though there are also fewer forms with final stress), and a simple CV(C) syllable structure. The consonantal inventory is given in Table 1.Footnote 1
Table 1 The consonantal phonemes of South Bolivian Quechua.

Of note in the inventory of South Bolivian Quechua is the three-way laryngeal distinction among plain, aspirated and ejective stops or affricates, at five places of articulation. All three series are restricted to onset position in the modern language, only occurring before vowels. Etymological stops in pre-consonantal or word final position have continuant correspondents in many southern Quechua varieties, including South Bolivian, e.g. * runap > [runaχ] 'man, genitive' (Adelaar with Muysken Reference Adelaar and Muysken2004).
There are three phonemic vowels in the language /i u a/, each of which shows substantial variation in quality based on syllable structure, stress and surrounding consonants. Perhaps the most salient aspect of this variation is lowering and/or retraction in the vicinity of a uvular consonant, e.g. [kusa] 'good' vs. [qosa] 'husband' (for phonetic descriptions of vowel lowering, see Gallagher Reference Gallagher2016, Holliday & Martin Reference Holliday and Martin2017).
2.2 The plain uvular /q/
As shown in Table 1, the plain uvular /q/ is the plain member of the three-way laryngeal contrast at the uvular place of articulation. While the other sounds in the plain series are unaspirated stops (or an unaspirated affricate), the uvular may be realized as a voiceless or voiced stop or a voiceless or voiced continuant. Using symbols from the International Phonetic Alphabet, the plain uvular /q/ may correspond to (at least) [q ɢ χ ʁ].
The variation in the production of /q/ in South Bolivian Quechua has been well known for many years, though existing descriptions do not provide full phonological or phonetic detail. Albó (Reference Albó1964, Reference Albó1970) cites free variation for voicing in both the plain velar and uvular; Lastra (Reference Lastra1968) reports free variation between [q] and [ʁ]. Bills, Troike & Vallejo (Reference Bills, Troike and Vallejo1971) describe a continuant pronunciation of this sound as the most common, and designate the pronunciation with orthographic <g>, further raising questions about its place of articulation. Adelaar with Muysken (Reference Adelaar and Muysken2004) refer to the plain uvular as a fricative in Bolivian Quechua (the authors do not designate South vs. North Bolivian Quechua).
More recently, Pierrard (Reference Pierrard2018, Reference Pierrard2020) gives a more thorough description. In initial position, /q/ is most often pronounced as either [ɢ], [χ] or [ʁ], depending on the speaker. The sound may also be a velar for younger urban speakers, resulting in a merger with the Spanish /ɡ/ sound, [ɡ] or [ɣ]. In intervocalic position, /q/ is most often realized as an approximant, and in post-nasal position, a voiced stop is found. Pierrard also gives quotes from Quechua speakers commenting on the various productions of /q/, particularly the production of this sound as a velar.
Across the Quechua language family, the plain uvular stop is unstable and has undergone many different changes (Adelaar with Muysken Reference Adelaar and Muysken2004). In Quechua IIB dialects, *q has merged with *k to [k] (the result is no uvulars at all in these languages). In Ayacucho Quechua, Pacaraos Quechua and Junín, *q is a voiceless fricative [x] or [χ]. In Tarma and Jauja varieties of Quechua, *q is [h], and in Huánuco, it is a voiced stop (it is unclear from the text whether this voiced stop is uvular or velar, Adelaar and Muysken report that <g> is used in the orthography). The etymological uvular has also been deleted in some contexts and dialects.
In sum, variation in the phonetic realization of /q/ in South Bolivian Quechua and its propensity to undergo sound changes across the Quechua family are well known. However, no phonetic studies exist (to my knowledge) documenting the realization of /q/ in South Bolivian Quechua. Filling this gap is the main goal of this paper. Before turning to the acoustic studies in Sections 3 and 4, the following section summarizes results from the literature on lenition phenomena in other languages, to structure expectations for what might be seen in South Bolivian Quechua.
2.3 Lenition
The position-dependent variation reported for /q/ in South Bolivian Quechua by Pierrard (Reference Pierrard2018, Reference Pierrard2020) is likely a type of spirantizing lenition, a general class of phenomena in which stops, or obstruents more generally, are produced as continuants, with approximant realizations being common. General overviews of lenition patterns across the world’s languages may be found in Kirchner (Reference Kirchner1998) and Gurevich (Reference Gurevich2003), and Katz (Reference Katz2016) provides an insightful synthesis of the literature. In a canonical synchronic lenition pattern of the type termed 'continuity' lenition in Katz (Reference Katz2016), stop productions of a sound are found in utterance initial position (or at other prosodic boundaries), and an approximant is found phrase medially, a lenition/fortition alternation that Kingston (Reference Kingston, Colantoni and Steele2008) argues helps the listener to identify prosodic boundaries.
Lenition is affected by segmental context as well as prosodic context: spirantization to a continuant sound is observed most often between vowels, and post-nasal position may favor a stop realization (e.g. in Spanish and Kinande – Katz Reference Katz2016). Three suffixes contribute the majority of uvulars in the recordings of spontaneous speech analyzed in this paper, allowing a confident assessment of /q/ realization in three segmental contexts: the topicalizer -qa, which provides a uvular most often in intervocalic position, the experiential past tense marker -rqa, which provides a post-rhotic uvular, and the reportative past tense marker -sqa, with a post-sibilant uvular. A word list task was designed to supplement spontaneous speech, and allow a balanced comparison of uvular realization in post-pausal, post-nasal and intervocalic positions.
Stress placement is also known to influence lenition. In American English, post-stress position is correlated with higher lenition rates for both coronals /t d/, which undergo a phonological alternation to flap, and labials and velars, which are variably shortened and spirantized (Lavoie Reference Lavoie2001, Warner & Tucker Reference Warner and Tucker2011, Bouavichith & Davidson Reference Bouavichith and Davidson2013). Bouavichith & Davidson (Reference Bouavichith and Davidson2013) further find that pre-stress position favors a stop production for voiced labials and velars. In Campidanese Sardinian, Katz & Pitzanti (Reference Katz and Pitzanti2019) find a greater drop in intensity for lenited stops in post-stress position, and Broś et al. (Reference Broś, Żygis, Sikorski and Wołłejko2021) find greater lenition in unstressed syllables than in stressed syllables in the Spanish of Gran Canaria. Post-stress position is also the environment for spirantization in Kuna (Gurevich Reference Gurevich, Marc van Oostendorp, Hume and Rice2011), though Warlpiri and other Australian languages are reported to show the opposite pattern, where post-stress position correlates with lengthening and strengthening of consonants (Butcher & Harrington Reference Butcher and Harrington2003, Fletcher & Butcher Reference Fletcher, Butcher, Koch and Nordlinger2015).
Lenition in South Bolivian Quechua has primarily been described for the uvular /q/, with some mention of voicing and spirantization of the velar /k/ as well. In particular, the velar is known to voice post-nasally and to voice and/or spirantize after /j/, in suffixes like /-jku/ '1pl, exclusive' or /-jki/ '2sg' (Pierrard Reference Pierrard2018, Reference Pierrard2020). While the study in Section 3 looks at /q/ in all contexts in spontaneous speech, a second set of analyses in Section 4 compares post-pausal and word-medial intervocalic tokens of all four plain stops /p t k q/, to establish what aspects of lenition of /q/ are particular to this category as opposed to general reductions found in running speech. Across languages, place of articulation differences in lenition are well attested. Kirchner (Reference Kirchner1998) claims that there are no implications or generalizations about how place may interact with lenition: there are languages where all stops undergo lenition, or where it is specific to any particular place of articulation. He names Tigrinya as a language where uvulars and velars undergo lenition, but coronals and labials do not. Other languages with continuant variants of the uvular plosive are Persian (Bijankhan & Nourbakhsh Reference Bijankhan and Nourbakhsh2009) and Gulf Arabic (Feghali Reference Feghali2008). In Lomongo, only labials undergo lenition while coronals and dorsals are unaffected. In American English, coronals are subject to flapping, while labials and dorsals are not part of a categorical lenition process, though they do show gradient reduction in intervocalic positions (Lavoie Reference Lavoie2001, Warner & Tucker Reference Warner and Tucker2011, Bouavichith & Davidson Reference Bouavichith and Davidson2013). While lenition for /p t k/ has not been previously noted in intervocalic position in South Bolivian Quechua, it is possible that these sounds also vary (to some degree) in their production by prosodic position. The analysis in Section 4 allows for an assessment of what variation in the plain uvular is attributable specifically to that category.
2.4 Questions
Based on the existing literature on both South Bolivian Quechua and lenition more generally, the two studies in Sections 3 and 4 address the following questions:
-
1. In general, how often is /q/ in South Bolivian Quechua produced as a voiceless stop, voiced stop, voiceless continuant or voiced continuant ([q ɢ χ ʁ])?
-
2. How is the realization of /q/ impacted by phrase-medial vs. post-pausal prosodic context, preceding segment and surrounding stress?
-
3. Do the non-uvular stops /p t k/ show lenition in intervocalic position in running speech, and how does any such variation in these sounds differ from the variation seen for the uvular /q/?
The literature also raises questions about the stability of a uvular place of articulation for /q/, particularly its voiced stop variant, which may be velar for some speakers. Place of articulation is not investigated systematically in this paper, for a number of reasons. First is that voiced stop variants were relatively rare overall, and extremely skewed across participants. More importantly, determining place of articulation requires establishing the speaker dependent correlates of the contrast between velars and putative uvulars, which in turn necessitates controlling for the following vowel and stress placement. A preliminary look at the available tokens for the two speakers who produced the most voiced stop realizations revealed that the data were not sufficient to confidently establish the correlates of the uvular–velar contrast, and so this dimension of the realization of /q/ is left for future work.
3 The realization of the plain uvular /q/
In this section, I present an analysis of /q/ production in spontaneous and word-list speech, based on visual inspection and coding of spectrograms. The primary focus is on the production of /q/ as a stop or continuant, looking at the effect of both segmental context and stress placement. The distribution of voicing in both stop and continuant realizations will also be analyzed.
3.1 Method
3.1.1 Participants
The data in this paper come from eight speakers of South Bolivian Quechua, five females and three males, between the ages of 23 and 29 (age was accidentally not collected for two participants, but they were recruited from the same pool of university students and appear to be in the same age range). Six of the participants are from Sacaba, Bolivia, a town just east of the city of Cochabamba, and two are from the city of Cochabamba itself. All participants are fully bilingual in Spanish, and report having spoken Quechua with their parents or grandparents from birth. The participants were recruited on Facebook from the applied linguistics program at the Universidad Mayor de San Simón in Cochabamba, and thus all had some exposure to the normalized, written Quechua taught in schools and universities in Bolivia.
The participants included in the current study are a subset of a broader pool of 20 participants who completed interviews during the same time period. This set of eight speakers was chosen because of their similar geographical origins. There is substantial phonetic and phonological variation between regions within the zone designated as South Bolivian Quechua (as detailed in Pierrard Reference Pierrard2018, Reference Pierrard2020); the full sample of 20 participants did not allow for assessing the effect of region independently from individual variation, since the remaining participants were from many different areas across the Quechua speaking regions of Bolivia. This set of eight participants controls for the effect of geographic variation.
All eight participants completed an interview and a short word list task; due to error, the word list task for one participant (M1) was not recorded. Participants were paid for their time.
3.1.2 Procedure
Spontaneous speech was collected via an interview procedure. Participants were interviewed entirely in Quechua by a female native speaker of Quechua in her early thirties, who had grown up between the city of Cochabamba and a rural town about three hours away, and speaks a variety of Quechua similar to that of the participants. The interviews were conducted in Cochabamba in June 2019. Each interview lasted about 30 minutes, and included three components. The first component, up to four minutes, consisted of demographic questions, with the participant answering questions about their age, places they have lived, and their linguistic experience with Quechua.
The bulk of the interview time was spent in a semi-structured conversation. The interviewer asked all participants to describe the town where they were from, and from there asked further questions as needed to keep the conversation going. Frequent questions included asking the participant to describe the typical crops, foods or festivals in their hometown, as well as any notable land features (rivers or mountains) or traditional stories; participants were also asked about their experiences traveling within and outside of Bolivia and studying at the university. The goal of the interview was simply to collect spontaneous speech.
Finally, participants completed a small word list task to collect recordings of words with a structured and balanced set of phonological properties. In this task, the interviewer said a noun in its bare form in Quechua, and the participant was asked to produce the 2sg possessed version of the noun. For example, the interviewer would say quwi 'guinea pig' and the participant would then say quwiyki 'your guinea pig'. This method of elicitation was chosen to avoid direct repetition without needing to resort to the use of either orthography (if participants were asked to read) or Spanish (if participants were asked to translate). This methodology has been used in previous studies by the author and has been found to lead to easy and confident productions from participants. While this procedure is effective for eliciting data and does not involve direct repetition, it is still possible that the participant’s production is influenced by the interviewer’s production. For this reason, the word list data are interpreted with caution and in conjunction with the natural speech data. The word list task included 15 items with uvulars in three contexts. There were five words with an initial uvular, five words with an intervocalic uvular, and five words with a post-nasal uvular. The items are given in Table 2. The surrounding vowels were controlled as much as possible, while selecting words that speakers were sure to be familiar with.
Table 2 Items in the word list task, by phonological context of the uvular consonant.

All interviews were audio and video recorded using a Zoom Q8 video recorder and an Audio Technica 831b lapel microphone. The audio was sampled at 44.1 kHz. The video and audio files as well as the accompanying transcriptions are all available on the Archive of the Indigenous Languages of Latin America (https://ailla.utexas.org/islandora/object/ailla%3A275864).
3.1.3 Analysis
From the video files, the audio was extracted in .wav format for analysis. All interviews were fully transcribed into the normalized Bolivian orthography for Quechua by a native speaker. From these transcriptions, all words with a pre-vocalic plain uvular were extracted, and then each of these words was segmented in the recordings in Praat (Boersma & Weenink Reference Boersma and Weenink2020). Words were not segmented or analyzed if there was excessive background noise, or creak or devoicing of the vowel following the uvular (both common in phrase final position). For the word list data, all fifteen items were segmented for each participant.
For both spontaneous and word list data, each token of the uvular was coded as [q ɢ χ ʁ] based on visual inspection of its phonetic properties. The symbols [χ ʁ] are used to represent the continuant realizations of /q/, but are not meant to imply that these realizations are fricatives. No attempt is made to quantify the degree of constriction in continuant tokens, but as in other studies of lenition, frication noise for voiced continuants was rare or nonexistent.
A token was coded as a voiceless stop [q] if there was a burst, however weak or fricated; items coded as [q] varied in the length of VOT as well as the duration of the closure and the amount of noise during the closure. The VOT of a [q] token in the data ranged from 5 ms to 87 ms, with a median value of 20 ms. The majority of tokens of [q] had an incomplete closure with some noise throughout (51 out of 73 tokens, as seen in the examples in Figure 1) and two tokens that were coded as [q] had carry over voicing for about half of their closure duration. Two examples of [q] tokens are shown in Figure 1.

Figure 1 Two examples of tokens of /q/ coded as a voiceless stop [q], from speaker F1, in the words /qanta/ ‘2sg acc’ (left) and /nisqa/ ‘3sg said’ (right). Rectangles mark the portion of the spectrogram that corresponds to the target uvular.
A token was coded as a voiced stop [ɢ] if there was voicing during the closure period, followed by a short VOT burst. An example of a [ɢ] token in word initial position is shown in Figure 2.

Figure 2 A token of /q/ coded as a voiced stop [ɢ], from speaker F3, in the word /qan/ ‘2sg’. A rectangle marks the portion of the spectrogram that corresponds to the target uvular.
A token was coded as a voiceless uvular continuant [χ] if there was voiceless frication throughout the closure and no burst. In eight tokens coded as [χ], there was some carry over voicing for less than half of the duration of the fricative. Two examples are given in Figure 3.Footnote 2
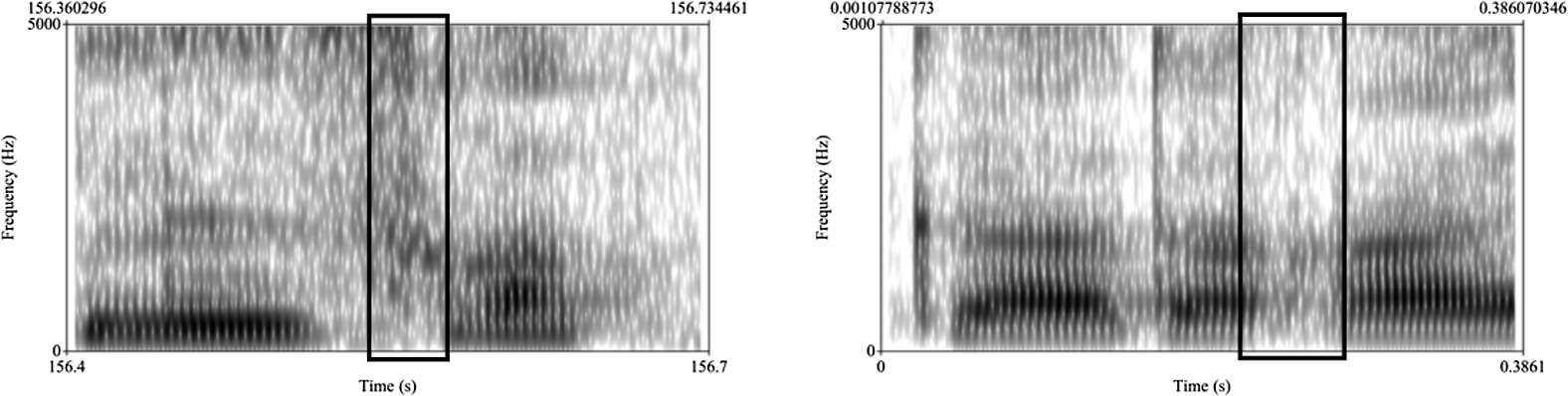
Figure 3 Two examples of tokens of /q/ coded as a voiceless continuant [χ], from speaker F3, from the words /nisqataqa/ ‘what 3sg said’ (left) and /karqachus/ ‘what it was’ (right). Rectangles mark the portion of the spectrogram that corresponds to the target uvular.
A token was coded as a voiced continuant [ʁ] if there was no burst and voicing throughout the consonant. Tokens coded as [ʁ] varied in degree of stricture, as shown in the two examples in Figure 4. Some tokens have a strong dip in amplitude (as in the example on the left), while others are nearly continuous with surrounding vowels (as in the example on the right). In most tokens of [ʁ], formant structure continued throughout the closure and voicing was strong, consistent with an approximant realization. In two tokens of [ʁ], there was partial devoicing for a short period.

Figure 4 Two examples of tokens of /q/ coded as a voiced continuant [ʁ], from speaker F5, from the words /nuqayku/ ‘1pl exclusive’ (left) and /haqaypi/ ‘there’ (right). Rectangles mark the portion of the spectrogram that corresponds to the target uvular.
In their studies of lenition in Gurindji and Campidanese Sardinian, Ennever, Meakins & Round (Reference Ennever, Meakins and Round2017) and Katz & Pitzanti (Reference Katz and Pitzanti2019) elaborate on the trouble of quantifying lenition. In particular, coding with symbols from the International Phonetic Alphabet or with phonetic properties (e.g. whether a burst or voicing is present) maps continuous phonetic variables onto discrete categories, and is subject both to the analyst’s determination as well as the settings of phonetic software. Coding with symbols risks missing distinctions where they are present, for example, coding a stop as a continuant if the burst is too weak to be visible, but also glosses over distinctions which may be relevant to listeners or reflective of linguistic structure, for example, the length of VOT or the duration of a stop closure. While Ennever et al. (Reference Ennever, Meakins and Round2017) propose a sophisticated method for measuring a continuous degree of lenition, Katz & Pitzanti (Reference Katz and Pitzanti2019) also show that phonetic coding returns qualitatively similar results for most measures. Broś et al. (Reference Broś, Żygis, Sikorski and Wołłejko2021) similarly use phonetic coding to distinguish stop and approximant realizations, supporting their categorization with measures of intensity, duration and the harmonics-to-noise ratio.
Phonetic coding for stop vs. continuant and voiced vs. voiceless was determined to be sufficient for the purposes of this paper, which aims primarily at a description of the realization of /q/ (as opposed to disentangling shortened duration from the other phonetic properties of reduction, which has been a goal of the cited work). The coding scheme described above has some biases. In particular, the presence or absence of a visible burst was primary in determining whether a token was a stop or a continuant. It is possible that this leads to undercounting stop realizations by excluding those with a very weak burst.
In addition to the four realizations described above, the plain uvular /q/ was occasionally deleted. Deleted tokens are not considered in the results in Section 3.2.1. Deleted tokens are almost entirely from the experiential past tense marker -rqa (120 out of 130 deleted tokens), and these deletions represent a variable, morpheme-specific process that has been reported for other varieties of Quechua (Parker Reference Parker1969, Cerrón-Palomino Reference Cerrón-Palomino1987, Adelaar with Muysken Reference Adelaar and Muysken2004, Povilonis de Vilchez Reference Povilonis de Vilchez2021).
All tokens were coded for preceding context and stress. The preceding context could be (i) a pause, (ii) a vowel or glide, (iii) the rhotic tap, (iv) a sibilant [s ʃ], or (v) a lateral [l ʎ]. For stress, there was either stress on the preceding vowel, stress on the following vowel, or no stress on either the preceding or following vowel.
The nature of spontaneous speech is that the distribution of uvulars is imbalanced by both context and participant. A total of 1327 instances of /q/ were analyzed from spontaneous speech. Almost half of these (595 tokens) are in post-vocalic (thus intervocalic) position. The number of tokens per participant ranged from 60 to 329, with most speakers producing between 100 and 200 tokens. The results for the spontaneous speech analysis in Section 3.2.1 are presented in light of these imbalances, with focus on the most well-represented environments and plots visualizing the number of tokens in each contextual category or for each participant. The results of the word list task serve to provide a balanced number of tokens in post-pausal and post-nasal positions, two contexts that are relatively infrequent in spontaneous speech.
3.2 Results
3.2.1 Spontaneous speech
The primary realization of /q/ for all participants in all contexts is as a voiced continuant [ʁ], accounting for 72
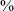 $\%$
of all /q/ productions in spontaneous speech. The breakdown of realizations by segmental context is shown in Figure 5.
$\%$
of all /q/ productions in spontaneous speech. The breakdown of realizations by segmental context is shown in Figure 5.

Figure 5 Realization of /q/ in spontaneous speech, by preceding segmental context.
While the majority of productions are post-vocalic or post-rhotic, there are also a good number of post-sibilant tokens, where a voiceless continuant [χ] has an increased frequency (occurring about equally often as [ʁ]). In the smaller number of post-nasal tokens, a voiced stop variant is prevalent [ɢ], and in the small number of post-pausal tokens, voiced stops [ɢ], voiceless stops [q] and the voiced continuant [ʁ] are all more or less equally frequent. The realization of /q/ in post-nasal and post-pausal contexts will be addressed further in the word list data in Section 3.2.2.
Two statistical analyses were run on the data. The first compares stop vs. continuant production among the three frequent segmental contexts that favor continuants – post-vocalic, post-rhotic and post-sibilant – and looks for an effect of stress. The second analysis looks at the distribution of voicing in continuants in post-vocalic, post-rhotic and post-sibilant contexts. All models were run as binomial logistic regressions, using glmer in the lme4 package (Bates et al. Reference Bates, Mächler, Bolker and Walker2015) in R (R Core Team 2021); the optimizer was chosen to allow for inclusion of random slopes by participant, using the all_fit command in the afex package (Singmann et al. Reference Singmann, Ben Bolker, Aust and Ben-Shachar2021), following Winter (Reference Winter2020).
The first analysis compared the rate of stop vs. continuant productions across the three most frequent contexts (post-vocalic, post-rhotic, post-sibilant), which all favor continuants, and by stress placement. The dependent variable was coded as 1 for stops and 0 for continuants. There were Helmert coded predictors of segmental context (post-vocalic, post-rhotic or post-sibilant) and stress (after a stressed vowel, before a stressed vowel and no stress). Helmert coding compares one level a variable to the mean of subsequent levels of the variable, and was chosen because the predictors of segmental context and stress have more than two levels. Given the structure of the data in this study, Helmert coding allows the differences between the three levels of these predictors to be interpreted without additional post-hoc models; difference coding could also have been used here. The model included a random intercept for participant (models with random slopes resulted in a singular fit, indicating overfitting). Interactions between stress and context were not significant, so these were removed from the final model, which is shown in Table 3.
Table 3 Stop vs. continuant production ([q ɢ] vs. [χ ʁ]) by segmental context and stress. Shading indicates a factor with p-value over .05.

The model finds that there are fewer stops (negative coefficient for context 1) in post-rhotic context than in post-sibilant or post-vocalic contexts (the reference level for each predictor is on the right in the comparison column in the table). The continuant rate is high in all three contexts, but stops account for 9.8
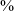 $\%$
of productions in post-sibilant context and 7.4
$\%$
of productions in post-sibilant context and 7.4
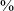 $\%$
of productions in post-vocalic context as compared to just 2.9
$\%$
of productions in post-vocalic context as compared to just 2.9
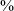 $\%$
in post-rhotic context. There are fewer stops (negative coefficient for stress 1) after a stressed vowel (9.6
$\%$
in post-rhotic context. There are fewer stops (negative coefficient for stress 1) after a stressed vowel (9.6
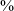 $\%$
of /q/ productions are stops) than after an unstressed vowel (13.6
$\%$
of /q/ productions are stops) than after an unstressed vowel (13.6
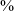 $\%$
of productions are stops).
$\%$
of productions are stops).
The second statistical analysis compared the distribution of voicing in the continuant variants, by context and stress placement. The dependent variable was coded as 1 for voiced [ʁ] and as 0 for voiceless [χ]. The independent variables were again Helmert-coded predictors of segmental context (post-vocalic, post-rhotic or post-sibilant) and stress (before stress, after stress or no stress). The factor coding for stress was the same as in the first model but the factor coding for segmental context was restructured to compare post-sibilant position (where voicelessness is more frequent) to post-rhotic and post-vocalic positions. The model included a random intercept by participant (models with random slopes again led to singular fit). Interactions between predictors were not significant, so these were removed from the final model, which is reported in Table 4.
Table 4 Voicing rate of continuant forms ([ʁ] vs. [χ]) by segmental context and stress. Shading indicates a factor with p-value over .05.

The model finds significant effects of segmental context on voicing, but no effects of stress. In post-sibilant position, continuants are voiced in 48
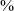 $\%$
of productions, which is much lower than in post-rhotic or post-vocalic position; this can be seen as an assimilatory affect, since sibilants themselves are voiceless in Bolivian Quechua. There is also a highly significant difference in voicing rate between post-rhotic and post-vocalic positions, though this difference is much smaller in absolute terms: 88
$\%$
of productions, which is much lower than in post-rhotic or post-vocalic position; this can be seen as an assimilatory affect, since sibilants themselves are voiceless in Bolivian Quechua. There is also a highly significant difference in voicing rate between post-rhotic and post-vocalic positions, though this difference is much smaller in absolute terms: 88
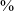 $\%$
of continuants are voiced in post-vocalic position compared to 84
$\%$
of continuants are voiced in post-vocalic position compared to 84
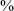 $\%$
in post-rhotic position.
$\%$
in post-rhotic position.
The three panels in Figure 6 show the distribution of /q/ realizations broken down by participant, in post-vocalic, post-rhotic and post-sibilant contexts. All participants produce primarily continuant variants, but there are differences. In post-vocalic position, for example, M3 uses [ʁ] 100
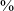 $\%$
of the time, while participant F3 shows a comparatively high rate of [q] and [χ] (and also produces a few voiced stops). In post-rhotic position, half of the participants (M2, F1, F2 and F3) account for all of the productions of [χ], which the statistical analysis above found were overall slightly more frequent in post-rhotic position than in post-vocalic position.Footnote 3 In post-sibilant position, there is perhaps the most variation among participants, particularly with regards to the distribution of voicing in continuant realizations ([ʁ] vs. [χ]).
$\%$
of the time, while participant F3 shows a comparatively high rate of [q] and [χ] (and also produces a few voiced stops). In post-rhotic position, half of the participants (M2, F1, F2 and F3) account for all of the productions of [χ], which the statistical analysis above found were overall slightly more frequent in post-rhotic position than in post-vocalic position.Footnote 3 In post-sibilant position, there is perhaps the most variation among participants, particularly with regards to the distribution of voicing in continuant realizations ([ʁ] vs. [χ]).

Figure 6 The realization of /q/ in post-vocalic (left), post-rhotic (middle) and post-sibilant (right) positions in spontaneous speech, broken down by participant (M = male; F = female).
In sum, the voiced continuant [ʁ] is by far the most frequent realization of /q/ in spontaneous speech, though stop productions are relatively more common in post-pausal and post-nasal contexts. There are small effects of preceding segment on voicing and lenition rate. The word list data analyzed in the next section provides a cleaner and more balanced data set for further exploring post-pausal and post-nasal contexts (which were relatively infrequent in spontaneous speech), as well as providing more information about differences among individual participants.
3.2.2 Word list data
The word list productions of /q/ confirm the primary realization of this category as a voiced continuant in post-vocalic position, with [ʁ] accounting for 60
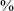 $\%$
of productions. The distribution of the four variants [q ɢ χ ʁ] across post-pausal, post-vocalic and post-nasal positions is shown on the left in Figure 7.
$\%$
of productions. The distribution of the four variants [q ɢ χ ʁ] across post-pausal, post-vocalic and post-nasal positions is shown on the left in Figure 7.

Figure 7 Realizations of /q/ in post-pausal, post-vocalic and post-nasal positions, in the word list data (left) and spontaneous speech (right).
Consistent with a continuity lenition pattern, post-pausal position shows increased rates of stop production, with voiced or voiceless stops accounting for 49
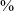 $\%$
of the data (solid colors in the figure), and post-nasal position favors voiced stops. There are also elements of the distribution of variants that are not expected from a standard lenition analysis, however. Even in post-pausal position, a continuant sound is found 51
$\%$
of the data (solid colors in the figure), and post-nasal position favors voiced stops. There are also elements of the distribution of variants that are not expected from a standard lenition analysis, however. Even in post-pausal position, a continuant sound is found 51
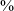 $\%$
of the time (stripes in the figure), showing that the manner of this category is not fully conditioned by prosodic context. This is particularly striking due to the nature of the word list task, which is expected to elicit a careful, canonical pronunciation of a form. The increased frequency of voiced stops in post-pausal position relative to post-vocalic position (in both data sets) is also notable, as initial position (unlike post-nasal position) does not favor voicing.
$\%$
of the time (stripes in the figure), showing that the manner of this category is not fully conditioned by prosodic context. This is particularly striking due to the nature of the word list task, which is expected to elicit a careful, canonical pronunciation of a form. The increased frequency of voiced stops in post-pausal position relative to post-vocalic position (in both data sets) is also notable, as initial position (unlike post-nasal position) does not favor voicing.
For comparison, the distribution of uvular productions in these same three contexts in spontaneous speech is shown in the right panel of Figure 7. The data is shown as a percentage out of 100
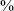 $\%$
, though it should be kept in mind that in spontaneous speech there are many more tokens in post-vocalic position (595) than in post-nasal (81) or post-pausal (36) positions, and these tokens are not evenly distributed across participants. In the word list data, there are 35 tokens in each category, with five produced from each of seven participants. The distribution of variants in post-pausal position appears quite similar between the word list and spontaneous speech data sets. In post-vocalic position, the preference for a voiced continuant is stronger in spontaneous speech, where [ʁ] accounts for 88
$\%$
, though it should be kept in mind that in spontaneous speech there are many more tokens in post-vocalic position (595) than in post-nasal (81) or post-pausal (36) positions, and these tokens are not evenly distributed across participants. In the word list data, there are 35 tokens in each category, with five produced from each of seven participants. The distribution of variants in post-pausal position appears quite similar between the word list and spontaneous speech data sets. In post-vocalic position, the preference for a voiced continuant is stronger in spontaneous speech, where [ʁ] accounts for 88
 $\%$
of tokens, than in the word list, where it accounts for just 60
$\%$
of tokens, than in the word list, where it accounts for just 60
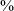 $\%$
. The slower and more careful productions in the word list seem to result in more voiceless continuants than in spontaneous speech, though a continuant pronunciation is still the overwhelming majority of the data (continuants account for 93
$\%$
. The slower and more careful productions in the word list seem to result in more voiceless continuants than in spontaneous speech, though a continuant pronunciation is still the overwhelming majority of the data (continuants account for 93
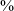 $\%$
of post-vocalic productions in spontaneous speech and 91
$\%$
of post-vocalic productions in spontaneous speech and 91
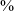 $\%$
in the word list data). In post-nasal context, there is a higher proportion of voiced stops in the word list data than in spontaneous speech, and a commensurate lower proportion of voiced continuants in the word list data.
$\%$
in the word list data). In post-nasal context, there is a higher proportion of voiced stops in the word list data than in spontaneous speech, and a commensurate lower proportion of voiced continuants in the word list data.
A logistic regression model compared the rate of stop vs. continuant productions across contexts and data types. The model included a Helmert-coded predictor of context (post-vocalic, post-nasal or post-pausal) and a centered binary predictor of data type, comparing word list and spontaneous speech. There was a random intercept for participant and random slopes by participant for data type. The model, given in Table 5, returns a main effect confirming that there are significantly fewer stops (negative coefficient, the reference level is on the right in the comparison column for each predictor) in post-vocalic position in both the word list data and the spontaneous speech data. There is also a significant interaction between data type and the post-nasal vs. post-pausal context predictor. The interaction arises because there are more stops in post-nasal position (91
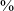 $\%$
) than in post-pausal position (49
$\%$
) than in post-pausal position (49
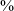 $\%$
) in the word list data, but in spontaneous speech there is a small difference in the opposite direction (56
$\%$
) in the word list data, but in spontaneous speech there is a small difference in the opposite direction (56
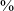 $\%$
stops in post-nasal position and 61
$\%$
stops in post-nasal position and 61
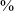 $\%$
stops in post-pausal position).
$\%$
stops in post-pausal position).
Table 5 Stop vs. continuant production ([q ɢ] vs. [χ ʁ]) by segmental context and data type. Shading indicates a factor with p-value over .05.

The three plots in Figure 8 show the data by participant, for each position. All participants favor a lenited variant in post-vocalic position (stripes in the middle panel) and a voiced stop in post-nasal position (light grey in the right panel). In post-pausal position, however, there are differences among participants. Some participants (F1, F5) show a clear continuity lenition pattern, with stops in post-pausal position, while some other participants (M2, M3) use a continuant variant in post-pausal position, and some show variation (F2, F3, F4). A final observation is that Speaker F2 produces two voiced stops intervocalically, a production that is quite rare (though attested, 15/595 tokens) in spontaneous speech.

Figure 8 Realizations of /q/ in post-pausal (left), post-vocalic (middle) and post-nasal (right) positions in word list productions, by speaker and segmental context (M = male; F = female).
3.3 Summary
The analysis of /q/ in both spontaneous speech and word list productions shows that this sound is primarily produced as a continuant. The voiced continuant production [ʁ] is frequent in all positions, but a voiceless continuant [χ] is particularly likely following a voiceless sibilant and in word list speech. Stop productions increase in both post-pausal and post-nasal positions.
4 Intervocalic and post-pausal realizations of the plain stops /p t k q/
The analysis in this section compares the lenition pattern established for /q/ in the preceding section to the realization of the other three plain stops /p t k/ in post-vocalic and post-pausal positions. By looking at post-vocalic position, the goal is to assess to what degree the frequency of lenition found for /q/ in the previous section is a property of this specific phonemic category as opposed to a general property of the realization of stops in spontaneous speech in the language. The comparison of stop realizations between post-vocalic and post-pausal positions, to the extent allowable by the data, serves to assess the existence of a general continuity lenition pattern in the language, which may be connected to the high degree of lenition observed for the uvular.
4.1 Method
The same interview recordings from the same eight participants as described in Section 3 were used for the analysis in this second analysis.
The tokens included in this analysis contained a pre-vocalic /p t k q/ sound in either word-medial, post-vocalic position or post-pausal position. To keep the amount of data manageable (/p t k/ are all much more frequent in spontaneous speech than /q/, partly due to their presence in the large number of Spanish-origin lexical items), word-initial but phrase-medial tokens were not analyzed. Spanish-origin lexical items were included in the analysis if the word had Quechua morphology (e.g. tesisniy ‘my thesis’ is made up of the Spanish word tesis ‘thesis’ and the Quechua suffixes -ni-y which mark 1sg possession); Spanish items used without any Quechua morphology were not analyzed (e.g. tesis ‘thesis’ without any Quechua suffixes).
Each token was coded as either a voiceless stop, voiced stop, voiceless continuant or voiced continuant based on visual inspection of the phonetic properties of the sound in Praat. The coding criteria were the same as in the previous section. Voiceless stops [p t k q] were coded if there was a voiceless closure and a stop burst. A voiced stop [b d g ɢ] was coded if there was sustained voicing throughout the stop closure. Voiceless continuants [ɸ 㬈 x χ] had a voiceless closure but no visible burst and voiced continuants had sustained voicing throughout the closure and no burst [β ð ɣ ʁ]. This coding strategy imposes categorical labels on continuous variables, as in the previous analysis of uvulars. In particular, the presence of a burst, however weak, was given primary importance in coding a token as a stop or a continuant, and a token was only coded as voiced if voicing was sustained throughout the whole closure (many intervocalic tokens coded as voiceless were characterized by carry over voicing from a preceding vowel).
As mentioned in Section 2, the velar /k/ has been reported to voice and spirantize after /j/. Impressionistically, voicing and lenition as well as deletion of /k/ were frequent in post-[j] context for the speakers in this data set as well. While these variations in the production of /k/ are a type of lenition, they are specific to this post-[j] environment, and do not seem to be a general property of this sound in post-vocalic position. As such, description of /k/ variation in post-[j] context is a topic for future study, and is not attempted here.
4.2 Results
The comparison of all four plain stops shows that the production of the uvular is different than the production of plain stops at the other three places of articulation, as shown in Figure 9. First, in post-vocalic position (left panel), the uvular stop is produced as a voiceless stop just 4
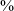 $\%$
of the time, compared to 77
$\%$
of the time, compared to 77
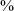 $\%$
for the labial, 85
$\%$
for the labial, 85
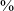 $\%$
for the velar and 96
$\%$
for the velar and 96
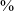 $\%$
for the dental. Second, in post-pausal position (right panel, note the smaller number of tokens), the labial, dental and velar stops are produced as voiceless stops almost all of the time, while voiceless stop production for the uvular is increased to just 25
$\%$
for the dental. Second, in post-pausal position (right panel, note the smaller number of tokens), the labial, dental and velar stops are produced as voiceless stops almost all of the time, while voiceless stop production for the uvular is increased to just 25
 $\%$
. Third, the uvular is produced as a voiced stop in post-pausal position 36
$\%$
. Third, the uvular is produced as a voiced stop in post-pausal position 36
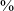 $\%$
of the time, more often than as a voiceless stop, while no other place of articulation shows voicing in initial position.
$\%$
of the time, more often than as a voiceless stop, while no other place of articulation shows voicing in initial position.
A binomial, mixed effects regression model was run to test for the effect of place of articulation, prosodic context, and stress on lenition rate. The dependent variable was stop vs. continuant realization, with stops coded as 1 and continuants coded as 0. The predictors in the model were place of articulation, stress placement and prosodic context. Place of articulation was Helmert-coded, with each level of the four-level factor (uvular, labial, velar, dental, ordered according to lenition rate) being compared to the preceding levels combined. Stress placement was also Helmert-coded and had three levels: after stress, before stress and no stress. Prosodic context was a centered predictor comparing post-pausal context to post-vocalic context. The model also included a random intercept for subject and random slopes for context.
Interactions between place of articulation and segmental context, and between place of articulation and stress placement were found not to be significant. A model with an interaction between segmental context and stress placement is ill defined, because there are no post-pausal, post-stress tokens. Interactions were removed from the final model, which is reported in Table 6.
Table 6 Stop vs. continuant production by place of articulation, preceding context and stress placement. Shading indicates a factor with p-value over .05.


Figure 9 Realization of the four stops /p t k q/ in post-vocalic (left) and post-pausal (right) positions.
The three predictors of place and the effect of context are all significant. There are significantly fewer stops at the uvular place than at the other three places (negative coefficient for place1), and similarly labial place has fewer stops than velar or dental place (negative coefficient for place2) and velar place in turn has fewer stops than dental place (negative coefficient for place3). The significant effect of segmental context shows that stops are overall more common (positive coefficient) in post-pausal context than in post-vocalic context. The effects of stress are not significant, contrasting with the model for uvulars alone that found a small increase in lenition after a stressed vowel.
4.3 Summary
The data from all stops show that the high degree of lenition of /q/ is specific to this phoneme category. First, while /p t k/ do all show some lenition in post-vocalic position, it is much less than is seen for /q/. Second, intervocalic uvular continuants are mostly voiced, while labials, velars and dentals all show more voiceless continuants than voiced. Third, in post-pausal position, labials, velars and dentals are produced almost exclusively as stops, while uvulars are still produced as continuants about half of the time. A final difference between uvulars and the other stops is that post-pausal uvular stops are often voiced.
5 Discussion
This paper has documented a lenition pattern in the plain uvular in South Bolivian Quechua, and has further shown that the patterning of variation in the uvular is unique to this phoneme. The results here confirm the description in Pierrard (Reference Pierrard2018) that approximant productions are most common in intervocalic position, while both stop and continuant productions are found in initial position (and vary by individual), and elaborate on earlier descriptions (Albó Reference Albó1964, Reference Albó1970; Lastra Reference Lastra1968; Bills et al. Reference Bills, Troike and Vallejo1971; Adelaar with Muysken Reference Adelaar and Muysken2004), which cited variation in the production of this sound but did not describe the effect of phonological context.
While the plain uvular /q/ is primarily produced as a voiced continuant, the other stops /p t k/ are primarily produced as voiceless stops. All stops, including the uvular, show prosodic conditioning, with stops being more frequent in post-pausal position than in post-vocalic position, but continuant productions for uvulars are still frequent in post-pausal position. Continuant uvulars in South Bolivian Quechua are primarily voiced with formant structure throughout, as has been reported for other languages where lenition results in an approximant production (e.g. Lavoie Reference Lavoie2001 for English and Spanish, Katz Reference Katz2016 for Kinande and Venezuelan Spanish, Katz & Pitzanti Reference Katz and Pitzanti2019 for Campidanese Sardinian, and Broś et al. Reference Broś, Żygis, Sikorski and Wołłejko2021 for the Spanish of Gran Canaria). In contrast, the less frequent lenition seen for intervocalic stops at other places of articulation primarily results in a voiceless continuant.
Continuant realizations of uvulars in initial position are particularly common for some speakers, suggesting that these speakers may have fully reanalyzed this sound as a continuant, as opposed to a stop that undergoes medial lenition. The continuant rate for uvulars in post-pausal position in South Bolivian Quechua is 61
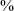 $\%$
in spontaneous speech and 49
$\%$
in spontaneous speech and 49
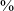 $\%$
in the word list data. In comparison, Katz & Pitzanti coded a stop release in 65
$\%$
in the word list data. In comparison, Katz & Pitzanti coded a stop release in 65
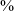 $\%$
of post-pausal tokens in Campidanese Sardinian, and 85
$\%$
of post-pausal tokens in Campidanese Sardinian, and 85
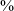 $\%$
of utterance initial tokens. The few tokens without a burst in these positions in Campidanese Sardinian were voiceless (as opposed to voiced as in medial position), in further contrast with South Bolivian Quechua, where post-pausal continuant uvulars are still primarily voiced.
$\%$
of utterance initial tokens. The few tokens without a burst in these positions in Campidanese Sardinian were voiceless (as opposed to voiced as in medial position), in further contrast with South Bolivian Quechua, where post-pausal continuant uvulars are still primarily voiced.
A further observation about initial uvulars, in both spontaneous and word list speech, is the number of voiced stop productions. Unlike voiced continuants, voiced stops in initial position cannot be attributed to an extension of a medial variant, since intervocalic voicing does not appear to be common for uvular stops (though it is attested in a handful of tokens). The source of the initial voiced stop realization is unclear, though it may be associated with a change from uvular to velar place of articulation. A topic for future work is to systematically assess the uvular-velar contrast in South Bolivian Quechua, and how the correlates of this contrast vary with voicing and manner of articulation.
The voiced continuant realization of /q/, and its extension to post-pausal position for some speakers, is particularly interesting because this phonetic change interacts with the phonology of stops in the language. There are three synchronic aspects of /q/ that point to this sound being phonologically a stop, even though its phonetic realization may be primarily continuant for many speakers, and fully continuant for some. First, /q/ is the plain counterpart to the aspirated and ejective uvulars (though, impressionistically, the aspirated uvular itself is often a fricative).
Second, stops and affricates may not precede an ejective or aspirate later in a root, as shown in (1):

Ejectives and aspirates may be initial or medial in a root, but in roots with a medial ejective or aspirate, the initial consonant is never a stop.
The restriction in (1) is the focus of Gallagher (Reference Gallagher2019), which finds that South Bolivian Quechua speakers make significant errors in repeating nonce words with unattested stop combinations. Of particular interest is that nonce words with [ʁ]-ejective combinations (e.g. [ʁap'i]) are repeated significantly less accurately than controls. Phonetically, [ʁap'i] should be phonotactically licit, since it contains an initial voiced continuant (and thus is phonetically parallel to attested words like [wajk'uj] 'to cook'). Phonologically, however, hypothetical [ʁap'i] would derive from /qap'i/, where the surface [ʁ] is the reflex of a phonological or underlying stop /q/. The realization of /q/ as [ʁ] has not changed the distribution of this sound in the lexicon of South Bolivian Quechua, nor does it appear to have disrupted speakers’ phonotactic grammar. Future work should investigate how the treatment of hypothetical forms with uvular–ejective combinations, like [ʁap'i], correlates with a speaker’s own production of the uvular. In particular, it would be interesting to know if errors on this type of nonce form are higher for speakers who produce more stop realizations of /q/ than for speakers who produce almost entirely [ʁ].
Third, stops and affricates in South Bolivian Quechua do not appear in coda position, and this is true of /q/ as well. Examples of words with attested codas are given in (2):

The dorsal fricative [x]∼[χ] is the modern reflex of coda /p k q/, and it is an open question whether speakers consider the dorsal fricative to be an independent phoneme or an allophone of one or more of the stops. The place of articulation of this sound and its interaction with vowel quality (recall that vowels typically retract surrounding uvulars) is also open; to reflect the orthographic representation of these words with <q>, I have followed the convention of transcribing [χ] in the words in (2) above. It is possible that the continuant realizations in coda position may reinforce continuant realizations of /q/ in onset position, and the overall re-analysis of this sound, if speakers do consider [x]∼[χ] to be an allophone of /q/. A full acoustic study of the dorsal fricative was not carried out for this paper, but such a study could look at the range of realizations of this sound and how it is different from /q/ in onset position. In particular, I have been transcribing the dorsal fricative as [x] or [χ], and also using the symbol [χ] to refer to the voiceless continuant realization of onset /q/, raising the question of whether the dorsal fricative in coda position is the same phonetic category as the voiceless continuant in onset position, or whether there is more structured variation between syllabic positions. Another major question regarding the dorsal fricative is the range of voicing and manner realizations that are attested for this sound.
6 Conclusion
This paper has provided a description of variation in the realization of onset /q/ in South Bolivian Quechua. While this sound is etymologically a stop, and is part of the stop system in the language’s inventory and phonotactic structure, it is phonetically realized as a continuant most of the time. Based on data from spontaneous speech and word list speech, I have shown that [ʁ] is the principal realization of this sound, though both voiced and voiceless stops are attested and are particularly likely in initial or post-nasal positions. A comparison with the other three stops in the language /p t k/ confirms that the reduction seen for /q/ is particular to this phonemic category, and is not a general property of stop realization in running speech.
Acknowledgements
This work would have been impossible without the assistance of Gladys Camacho Rios and Noemy Condori Arias. I am grateful to Jessica Huancacuri-Harlow for invaluable work in preparing the interview materials for archiving. This work has benefited from discussion with Jonah Katz and Alexis Pierrard, as well as audiences at the University of Delaware and the University of California, Los Angeles. Finally, the paper has benefitted from the comments of three anonymous reviews and the Associate Editor Marzena Żygis. The work was supported in part by National Science Foundation grant BCS-1724753.















 Open access
Open access