



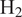
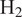
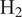
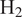

Impact Statement
Large eddy simulation (LES) plays a key role in the design of new combustion chambers for robust and safe combustion of carbon-free fuels such as
 $ {\mathrm{H}}_2 $
. It is a very efficient method that consists of filtering and modeling small-scale flow physics that would otherwise be very computationally expensive to resolve. However, the high molecular diffusion of
$ {\mathrm{H}}_2 $
. It is a very efficient method that consists of filtering and modeling small-scale flow physics that would otherwise be very computationally expensive to resolve. However, the high molecular diffusion of
 $ {\mathrm{H}}_2 $
challenges current subfilter-scale modeling approaches for lean premixed mixtures. By establishing a framework for data-driven machine learning modeling of LES burning rates, this work can enable high-fidelity simulation of hydrogen combustion systems. These combustion systems are essential for achieving a low-carbon economy.
$ {\mathrm{H}}_2 $
challenges current subfilter-scale modeling approaches for lean premixed mixtures. By establishing a framework for data-driven machine learning modeling of LES burning rates, this work can enable high-fidelity simulation of hydrogen combustion systems. These combustion systems are essential for achieving a low-carbon economy.
1. Introduction
The urgent need to drastically reduce our greenhouse gas emissions requires us to develop alternative solutions to fossil fuel combustion. Sustainably produced hydrogen (
 $ {\mathrm{H}}_2 $
) is a promising energy carrier for the decarbonization of combustion systems where there is no viable technology to be a substitute. This is the case, for example, with gas turbines for power generation or aviation, as well as some industrial burners. However, compared with conventional fuels,
$ {\mathrm{H}}_2 $
) is a promising energy carrier for the decarbonization of combustion systems where there is no viable technology to be a substitute. This is the case, for example, with gas turbines for power generation or aviation, as well as some industrial burners. However, compared with conventional fuels,
 $ {\mathrm{H}}_2 $
-air combustion involves higher flame temperatures, much higher flame speeds, and a very wide flammability range. These characteristics pose considerable challenges to the design of new
$ {\mathrm{H}}_2 $
-air combustion involves higher flame temperatures, much higher flame speeds, and a very wide flammability range. These characteristics pose considerable challenges to the design of new
 $ {\mathrm{H}}_2 $
combustion devices, ensuring stable, robust, and safe operation. In this context, high-fidelity simulation of turbulent combustion plays a key role. It is essential both for a fundamental understanding of flame behavior and as an aid to the design of industrial combustion devices. It is also crucial for modeling safety scenarios, with hydrogen expected to be widely used to decarbonize the industry.
$ {\mathrm{H}}_2 $
combustion devices, ensuring stable, robust, and safe operation. In this context, high-fidelity simulation of turbulent combustion plays a key role. It is essential both for a fundamental understanding of flame behavior and as an aid to the design of industrial combustion devices. It is also crucial for modeling safety scenarios, with hydrogen expected to be widely used to decarbonize the industry.
The community nowadays uses Large Eddy Simulation (LES) methods, which involve simulating only the largest flow structures, to compute real complex configurations at an affordable computing cost. The smaller scales are modeled, according to subfilter-scale models (Poinsot and Veynante, Reference Poinsot and Veynante2011; Fiorina et al., Reference Fiorina, Veynante and Candel2015). In LES, a filtered quantity
 $ \varphi $
is defined as
$ \varphi $
is defined as
 $$ \overline{\varphi}\left(\mathbf{x},t\right)={\int}_{-\infty}^{\infty}\varphi \left({\mathbf{x}}^{\prime },t\right)F\left(\mathbf{x}-{\mathbf{x}}^{\prime}\right)d{\mathbf{x}}^{\prime }, $$
$$ \overline{\varphi}\left(\mathbf{x},t\right)={\int}_{-\infty}^{\infty}\varphi \left({\mathbf{x}}^{\prime },t\right)F\left(\mathbf{x}-{\mathbf{x}}^{\prime}\right)d{\mathbf{x}}^{\prime }, $$
where
 $ F $
is the LES filter. Balance equations are obtained by applying the filter
$ F $
is the LES filter. Balance equations are obtained by applying the filter
 $ F $
to the multispecies Navier–Stokes equations. The filtered transport equation of a reactive scalar
$ F $
to the multispecies Navier–Stokes equations. The filtered transport equation of a reactive scalar
 $ \varphi $
reads
$ \varphi $
reads
 $$ {\partial}_t\left(\overline{\rho}\tilde{\varphi}\right)+\nabla \cdot \left(\overline{\rho}\tilde{\boldsymbol{u}}\tilde{\varphi}\right)-\nabla \cdot \left(\overline{\rho}{\tilde{D}}_{\varphi}\nabla \tilde{\varphi}\right)=\nabla \cdot {\Gamma}_{\varphi }+{\overline{\dot{\omega}}}_{\varphi }, $$
$$ {\partial}_t\left(\overline{\rho}\tilde{\varphi}\right)+\nabla \cdot \left(\overline{\rho}\tilde{\boldsymbol{u}}\tilde{\varphi}\right)-\nabla \cdot \left(\overline{\rho}{\tilde{D}}_{\varphi}\nabla \tilde{\varphi}\right)=\nabla \cdot {\Gamma}_{\varphi }+{\overline{\dot{\omega}}}_{\varphi }, $$
where
 $ \tilde{\cdot} $
denotes density-weighted Favre filtering (i.e.
$ \tilde{\cdot} $
denotes density-weighted Favre filtering (i.e.
 $ \tilde{\cdot}=\overline{\rho \cdot }/\overline{\rho} $
), with density
$ \tilde{\cdot}=\overline{\rho \cdot }/\overline{\rho} $
), with density
 $ \rho $
, time
$ \rho $
, time
 $ t $
, velocity
$ t $
, velocity
 $ \boldsymbol{u} $
.
$ \boldsymbol{u} $
.
 $ {D}_{\varphi } $
,
$ {D}_{\varphi } $
,
 $ {\Gamma}_{\varphi } $
and
$ {\Gamma}_{\varphi } $
and
 $ {\dot{\omega}}_{\varphi } $
are the molecular diffusivity, subfilter-scale flux, and source term of
$ {\dot{\omega}}_{\varphi } $
are the molecular diffusivity, subfilter-scale flux, and source term of
 $ \varphi $
. The filtering operation produces unclosed terms located on the RHS of Eq. (1.2) that must be modeled. The subfilter-scale flux comprises the transport of
$ \varphi $
. The filtering operation produces unclosed terms located on the RHS of Eq. (1.2) that must be modeled. The subfilter-scale flux comprises the transport of
 $ \varphi $
by unresolved fluctuations of molecular diffusive flux and momentum
$ \varphi $
by unresolved fluctuations of molecular diffusive flux and momentum
 $$ {\Gamma}_{\varphi }={\Gamma}_{\varphi, D}-{\Gamma}_{\varphi, C}\hskip0.48em \mathrm{with}\;\hskip0.24em {\Gamma}_{\varphi, D}=\overline{\rho {D}_{\varphi}\nabla \varphi }-\overline{\rho}{\tilde{D}}_{\varphi}\nabla \tilde{\varphi}\hskip0.48em \mathrm{and}\;\hskip0.24em {\Gamma}_{\varphi, C}=\overline{\rho \mathbf{u}\varphi }-\overline{\rho}\tilde{\mathbf{u}}\tilde{\varphi}. $$
$$ {\Gamma}_{\varphi }={\Gamma}_{\varphi, D}-{\Gamma}_{\varphi, C}\hskip0.48em \mathrm{with}\;\hskip0.24em {\Gamma}_{\varphi, D}=\overline{\rho {D}_{\varphi}\nabla \varphi }-\overline{\rho}{\tilde{D}}_{\varphi}\nabla \tilde{\varphi}\hskip0.48em \mathrm{and}\;\hskip0.24em {\Gamma}_{\varphi, C}=\overline{\rho \mathbf{u}\varphi }-\overline{\rho}\tilde{\mathbf{u}}\tilde{\varphi}. $$
It is usually modeled as neglecting
 $ {\Gamma}_{\varphi, D} $
and involving gradient transport models for
$ {\Gamma}_{\varphi, D} $
and involving gradient transport models for
 $ {\Gamma}_{\varphi, C} $
with a turbulent viscosity hypothesis (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998). The countergradient phenomenon can be taken into account via more complex modeling (Tullis and Cant, Reference Tullis and Cant2002a, Reference Tullis, Cant, Moreau, Pollard and Candel2002b), although a large part will be described at the resolved scale in LES (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998). Alternatively,
$ {\Gamma}_{\varphi, C} $
with a turbulent viscosity hypothesis (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998). The countergradient phenomenon can be taken into account via more complex modeling (Tullis and Cant, Reference Tullis and Cant2002a, Reference Tullis, Cant, Moreau, Pollard and Candel2002b), although a large part will be described at the resolved scale in LES (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998). Alternatively,
 $ {\Gamma}_{\varphi } $
can be tabulated within the filtered tabulated chemistry framework (Fiorina et al., Reference Fiorina, Vicquelin, Auzillon, Darabiha, Gicquel and Veynante2010) or modeled via Machine Learning (ML) algorithms (Seltz et al., Reference Seltz, Domingo, Vervisch and Nikolaou2019). Modeling of the filtered chemical source term
$ {\Gamma}_{\varphi } $
can be tabulated within the filtered tabulated chemistry framework (Fiorina et al., Reference Fiorina, Vicquelin, Auzillon, Darabiha, Gicquel and Veynante2010) or modeled via Machine Learning (ML) algorithms (Seltz et al., Reference Seltz, Domingo, Vervisch and Nikolaou2019). Modeling of the filtered chemical source term
 $ {\overline{\dot{\omega}}}_{\varphi } $
is extremely challenging because combustion generally occurs within reaction fronts that are smaller than the LES computational mesh. Furthermore, there is a strong interaction between turbulence and chemistry: chemical heat release influences turbulence, while turbulence, in turn, modifies flame structure, which can either enhance or inhibit chemical reactions.
$ {\overline{\dot{\omega}}}_{\varphi } $
is extremely challenging because combustion generally occurs within reaction fronts that are smaller than the LES computational mesh. Furthermore, there is a strong interaction between turbulence and chemistry: chemical heat release influences turbulence, while turbulence, in turn, modifies flame structure, which can either enhance or inhibit chemical reactions.
To overcome these difficulties, several approaches have been proposed in the context of premixed combustion, which is the focus of this article. A common technique is to artificially thicken the reaction front, enabling it to be resolved on the given computational mesh. This is the basis of the Thickened Flame (TF) model, which achieves this by increasing all diffusivities by a factor
 $ F $
while decreasing all reaction rates by the same factor to maintain the correct flame propagation speeds (Butler and O’Rourke, Reference Butler and O’Rourke1977). The LES modeling then focuses on an efficiency function
$ F $
while decreasing all reaction rates by the same factor to maintain the correct flame propagation speeds (Butler and O’Rourke, Reference Butler and O’Rourke1977). The LES modeling then focuses on an efficiency function
 $ E $
taking into account the effects of thickening on flame propagation, such as the loss of flame wrinkling (Colin et al., Reference Colin, Ducros, Veynante and Poinsot2000; Charlette et al., Reference Charlette, Meneveau and Veynante2002; Poinsot and Veynante, Reference Poinsot and Veynante2011). Another approach consists of filtering the flame front with a LES filter larger than the mesh size (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998; Duwig, Reference Duwig2007). Filtering is usually done on the equation of a reaction progress variable
$ E $
taking into account the effects of thickening on flame propagation, such as the loss of flame wrinkling (Colin et al., Reference Colin, Ducros, Veynante and Poinsot2000; Charlette et al., Reference Charlette, Meneveau and Veynante2002; Poinsot and Veynante, Reference Poinsot and Veynante2011). Another approach consists of filtering the flame front with a LES filter larger than the mesh size (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998; Duwig, Reference Duwig2007). Filtering is usually done on the equation of a reaction progress variable
 $ c $
representing the evolution of combustion within the flame front. The balance equation for
$ c $
representing the evolution of combustion within the flame front. The balance equation for
 $ \tilde{c} $
may be recast as a level set G-equation (Kerstein et al., Reference Kerstein, Ashurst and Williams1988).
$ \tilde{c} $
may be recast as a level set G-equation (Kerstein et al., Reference Kerstein, Ashurst and Williams1988).
 $$ {\partial}_t\left(\overline{\rho}\tilde{c}\right)+\nabla \cdot \left(\overline{\rho}\tilde{\boldsymbol{u}}\tilde{c}\right)+\nabla \cdot \left(\overline{\rho \boldsymbol{u}c}-\overline{\rho}\tilde{\boldsymbol{u}}\tilde{c}\right)=\nabla \left(\overline{\rho {D}_c\nabla \cdot c}\right)+{\overline{\dot{\omega}}}_c=\overline{\rho {s}_d\mid \nabla c\mid }, $$
$$ {\partial}_t\left(\overline{\rho}\tilde{c}\right)+\nabla \cdot \left(\overline{\rho}\tilde{\boldsymbol{u}}\tilde{c}\right)+\nabla \cdot \left(\overline{\rho \boldsymbol{u}c}-\overline{\rho}\tilde{\boldsymbol{u}}\tilde{c}\right)=\nabla \left(\overline{\rho {D}_c\nabla \cdot c}\right)+{\overline{\dot{\omega}}}_c=\overline{\rho {s}_d\mid \nabla c\mid }, $$
which gives rise to a flame front displacement term at speed
 $ {s}_d $
,
$ {s}_d $
,
 $ \overline{\rho {s}_d\mid \nabla c\mid } $
, which requires modeling. Another way to close the equation is to tabulate all the closure terms from filtered laminar premixed flames (Fiorina et al., Reference Fiorina, Vicquelin, Auzillon, Darabiha, Gicquel and Veynante2010), assuming the turbulent flame can be represented as an ensemble of locally One-Dimensional (1D) laminar flamelets (Peters, Reference Peters1988). In all cases, a model to retrieve the subfilter-scale effects on the thickened/filtered flame front is needed.
$ \overline{\rho {s}_d\mid \nabla c\mid } $
, which requires modeling. Another way to close the equation is to tabulate all the closure terms from filtered laminar premixed flames (Fiorina et al., Reference Fiorina, Vicquelin, Auzillon, Darabiha, Gicquel and Veynante2010), assuming the turbulent flame can be represented as an ensemble of locally One-Dimensional (1D) laminar flamelets (Peters, Reference Peters1988). In all cases, a model to retrieve the subfilter-scale effects on the thickened/filtered flame front is needed.
Modeling subfilter-scale phenomena is particularly challenging for hydrogen combustion. Indeed,
 $ {\mathrm{H}}_2 $
is a very peculiar fuel due to its small Lewis number. Its high molecular diffusion, much faster than heat, gives rise to unique phenomena, especially when burned lean (that is with excess air) and premixed. First, lean
$ {\mathrm{H}}_2 $
is a very peculiar fuel due to its small Lewis number. Its high molecular diffusion, much faster than heat, gives rise to unique phenomena, especially when burned lean (that is with excess air) and premixed. First, lean
 $ {\mathrm{H}}_2 $
flames are prone to thermodiffusive instabilities. The disparity between heat and
$ {\mathrm{H}}_2 $
flames are prone to thermodiffusive instabilities. The disparity between heat and
 $ {\mathrm{H}}_2 $
mass fluxes (called differential diffusion) amplify small flame front perturbations, inducing significant flame wrinkling and strong variations of the reaction rates along the flame front (Poinsot and Veynante, Reference Poinsot and Veynante2011; Berger et al., Reference Berger, Attili and Pitsch2022a, Reference Berger, Attili and Pitsch2022b). Second, burning rates increase significantly when lean
$ {\mathrm{H}}_2 $
mass fluxes (called differential diffusion) amplify small flame front perturbations, inducing significant flame wrinkling and strong variations of the reaction rates along the flame front (Poinsot and Veynante, Reference Poinsot and Veynante2011; Berger et al., Reference Berger, Attili and Pitsch2022a, Reference Berger, Attili and Pitsch2022b). Second, burning rates increase significantly when lean
 $ {\mathrm{H}}_2 $
flame is subjected to a strain (Petrov and Ghoniem, Reference Petrov and Ghoniem1994; Vagelopoulos et al., Reference Vagelopoulos, Egolfopoulos and Law1994), up to a certain limit. The resulting increase in flame speed can be substantial. For example, the experimental work in Vagelopoulos et al. (Reference Vagelopoulos, Egolfopoulos and Law1994) reports a three-fold enhancement in flame speed compared to an unstrained flame.
$ {\mathrm{H}}_2 $
flame is subjected to a strain (Petrov and Ghoniem, Reference Petrov and Ghoniem1994; Vagelopoulos et al., Reference Vagelopoulos, Egolfopoulos and Law1994), up to a certain limit. The resulting increase in flame speed can be substantial. For example, the experimental work in Vagelopoulos et al. (Reference Vagelopoulos, Egolfopoulos and Law1994) reports a three-fold enhancement in flame speed compared to an unstrained flame.
These phenomena invalidate usual Flame Surface Density (FSD) approaches (Pope, Reference Pope1988; Trouvé and Poinsot, Reference Trouvé and Poinsot1994; Marble and Broadwell, Reference Marble and Broadwell1997; Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998) based on the assumption that subfilter-scale effects are limited to an increase in flame surface density through wrinkling due to turbulence alone. Aniello et al. (Reference Aniello, Laera, Berger, Attili and Poinsot2022) have recently attempted to address this issue by multiplying the filtered chemical source terms by a corrective factor, determined from Direct Numerical Simulation (DNS) (Berger et al., Reference Berger, Attili and Pitsch2022a, Reference Berger, Attili and Pitsch2022b), decoupling the enhancement of combustion rates due to thermodiffusion instabilities and usual turbulence wrinkling. However, this is no longer possible when the wrinkling scales induced by turbulent eddies become smaller than the characteristic lengths at which the instabilities occur. Moreover, Berger et al. (Reference Berger, Attili and Pitsch2022c) have reported complex and synergistic interactions between thermodiffusion instabilities and turbulence, casting doubt on the possibility of decoupling these phenomena. Gaucherand et al. (Reference Gaucherand, Schulze-Netzer, Laera and Poinsot2024b) attempted to correct unresolved straining effects by multiplying the filtered chemical source terms by a strain-to-unstrained flame speed ratio determined using 1D flames. The strain rate was assumed to be constant over the entire domain at a value of
 $ 2000 $
$ 2000 $
 $ {\mathrm{s}}^{-1} $
, not taking into account the very wide strain variation along the turbulent flame. Additional efforts must be made to account for local strain effects, which is extremely difficult in LES because the information on the strain that a turbulent flame actually undergoes at the subfilter-scale level is unknown. Subfilter Probability Density Function (PDF) modeling for
$ {\mathrm{s}}^{-1} $
, not taking into account the very wide strain variation along the turbulent flame. Additional efforts must be made to account for local strain effects, which is extremely difficult in LES because the information on the strain that a turbulent flame actually undergoes at the subfilter-scale level is unknown. Subfilter Probability Density Function (PDF) modeling for
 $ {\mathrm{H}}_2 $
turbulent combustion is also being developed (Berger et al., Reference Berger, Attili, Wang, Maeda and Pitsch2022d; Ferrante et al., Reference Ferrante, Eitelberg and Langella2024; Pitsch, Reference Pitsch2024; Yao and Blanquart, Reference Yao and Blanquart2024), where the subfilter-scale distribution of thermochemical variables is usually modeled using
$ {\mathrm{H}}_2 $
turbulent combustion is also being developed (Berger et al., Reference Berger, Attili, Wang, Maeda and Pitsch2022d; Ferrante et al., Reference Ferrante, Eitelberg and Langella2024; Pitsch, Reference Pitsch2024; Yao and Blanquart, Reference Yao and Blanquart2024), where the subfilter-scale distribution of thermochemical variables is usually modeled using
 $ \beta $
-PDF. The turbulence-chemistry interactions are described through the subfilter PDF while the flamelet assumption (Peters, Reference Peters1988) links local thermochemical variables to those of the laminar flame elements. Thus, a set of 1D laminar flames is needed to be computed, assuming a specific flame archetype a priori. Defining the subfilter PDF is a particular challenge. For example, Berger et al. (Reference Berger, Attili, Wang, Maeda and Pitsch2022d) and Yao and Blanquart (Reference Yao and Blanquart2024) use a Dirac function for the mixture fraction distribution, while it is reported in Pitsch (Reference Pitsch2024) that it leads to modeling errors. Indeed, preferential diffusion in
$ \beta $
-PDF. The turbulence-chemistry interactions are described through the subfilter PDF while the flamelet assumption (Peters, Reference Peters1988) links local thermochemical variables to those of the laminar flame elements. Thus, a set of 1D laminar flames is needed to be computed, assuming a specific flame archetype a priori. Defining the subfilter PDF is a particular challenge. For example, Berger et al. (Reference Berger, Attili, Wang, Maeda and Pitsch2022d) and Yao and Blanquart (Reference Yao and Blanquart2024) use a Dirac function for the mixture fraction distribution, while it is reported in Pitsch (Reference Pitsch2024) that it leads to modeling errors. Indeed, preferential diffusion in
 $ {\mathrm{H}}_2 $
-air mixtures can lead to fluctuation of the mixture fraction at the subfilter-scale level. Furthermore, the effect of unstable modes that occur partially at the subfilter scale must be included in the subfilter PDF to avoid underestimating the flame consumption speed (Lapenna et al., Reference Lapenna, Remiddi, Molinaro, Indelicato and Creta2024; Pitsch, Reference Pitsch2024).
$ {\mathrm{H}}_2 $
-air mixtures can lead to fluctuation of the mixture fraction at the subfilter-scale level. Furthermore, the effect of unstable modes that occur partially at the subfilter scale must be included in the subfilter PDF to avoid underestimating the flame consumption speed (Lapenna et al., Reference Lapenna, Remiddi, Molinaro, Indelicato and Creta2024; Pitsch, Reference Pitsch2024).
The phenomena involved in
 $ {\mathrm{H}}_2 $
turbulent combustion are extremely complex, not well understood, and still subject to discussion, we propose to change the paradigm by developing a data-driven method based on ML instead of trying to model turbulent
$ {\mathrm{H}}_2 $
turbulent combustion are extremely complex, not well understood, and still subject to discussion, we propose to change the paradigm by developing a data-driven method based on ML instead of trying to model turbulent
 $ {\mathrm{H}}_2 $
burning rates by physical description. This work is motivated by the positive results of such an approach for the approximation of the subfilter flame surface density both a priori and a posteriori for methane-air combustion (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019; Ho et al., Reference Ho, Talei, Brouzet, Chung, Sharma and Ihme2024). The strategy is adapted to hydrogen combustion by training a Neural Network (NN) to estimate the
$ {\mathrm{H}}_2 $
burning rates by physical description. This work is motivated by the positive results of such an approach for the approximation of the subfilter flame surface density both a priori and a posteriori for methane-air combustion (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019; Ho et al., Reference Ho, Talei, Brouzet, Chung, Sharma and Ihme2024). The strategy is adapted to hydrogen combustion by training a Neural Network (NN) to estimate the
 $ {\mathrm{H}}_2 $
burning rate directly. In this way, no assumptions are made about the turbulent combustion regime, and the model can theoretically be applied to any combustion regime encountered during training. Firstly, a database of fully resolved turbulent
$ {\mathrm{H}}_2 $
burning rate directly. In this way, no assumptions are made about the turbulent combustion regime, and the model can theoretically be applied to any combustion regime encountered during training. Firstly, a database of fully resolved turbulent
 $ {\mathrm{H}}_2 $
-air premixed flames are generated using DNS, taking into account preferential and differential diffusion effects. The database includes five different equivalence ratios to assess the ability of the model to account for air/fuel ratio variation. The database is then filtered and downsampled to emulate data from LES. Three different filter sizes are used to assess the ability of the model to account for subfilter effects at different scales. From the emulated LES fields, a Convolutional Neural Network (CNN) is trained to estimate the LES burning rates based on known LES scalar quantities such as the filtered mixture fraction and progress variable. Once trained, the model is found to approximate the burning rates on solutions never seen during training with high accuracy. In addition to this, the model is able to approximate burning rates on filter sizes and equivalence ratios other than those used for training.
$ {\mathrm{H}}_2 $
-air premixed flames are generated using DNS, taking into account preferential and differential diffusion effects. The database includes five different equivalence ratios to assess the ability of the model to account for air/fuel ratio variation. The database is then filtered and downsampled to emulate data from LES. Three different filter sizes are used to assess the ability of the model to account for subfilter effects at different scales. From the emulated LES fields, a Convolutional Neural Network (CNN) is trained to estimate the LES burning rates based on known LES scalar quantities such as the filtered mixture fraction and progress variable. Once trained, the model is found to approximate the burning rates on solutions never seen during training with high accuracy. In addition to this, the model is able to approximate burning rates on filter sizes and equivalence ratios other than those used for training.
First, the problem statement is described, with the definition of the input/output variables of the model (Section 2.1). Then the NN set up to approximate the burning rate function is detailed (Section 2.2). Next, the data generation and training strategy is explained (Section 2.3). Finally, training results are presented and discussed (Section 3).
2. Background and methodology
2.1. Problem statement
The simulation of turbulent flows at high Reynolds numbers cannot generally be performed with sufficient resolution to represent all the scales of the flow. LES aims to simulate only a part of the turbulent spectrum to achieve a reasonable computational cost. Scales are cut by spatial filtering, and unresolved scales are modeled using so-called subfilter-scale models. In the LES framework, the Favre-filtered transport equation for the mass fraction of the
 $ {k}^{\mathrm{th}} $
species
$ {k}^{\mathrm{th}} $
species
 $ {Y}_k $
follows Eq. (1.2). As discussed in the introduction, modeling the filtered chemical source terms in LES of reacting flows is extremely challenging because chemistry largely occurs at the subfilter-scale level in most cases. This is further complicated in lean premixed
$ {Y}_k $
follows Eq. (1.2). As discussed in the introduction, modeling the filtered chemical source terms in LES of reacting flows is extremely challenging because chemistry largely occurs at the subfilter-scale level in most cases. This is further complicated in lean premixed
 $ {\mathrm{H}}_2 $
-air mixtures because of thermodiffusive effects, causing additional flame wrinkling and pronounced fluctuations in reaction rates along the flame front. A precise description of the preferential and differential diffusion, turbulence wrinkling, and their interactions (Berger et al., Reference Berger, Attili and Pitsch2022c) at the subfilter-scale level is required.
$ {\mathrm{H}}_2 $
-air mixtures because of thermodiffusive effects, causing additional flame wrinkling and pronounced fluctuations in reaction rates along the flame front. A precise description of the preferential and differential diffusion, turbulence wrinkling, and their interactions (Berger et al., Reference Berger, Attili and Pitsch2022c) at the subfilter-scale level is required.
In this work, we focus on the development of a data-driven model for the filtered chemical source term of
 $ {\mathrm{H}}_2 $
in lean premixed turbulent combustion. ML is used to discover structural relations between resolved scalar quantities and subfilter-scale turbulence-chemistry interactions. We develop this method for the
$ {\mathrm{H}}_2 $
in lean premixed turbulent combustion. ML is used to discover structural relations between resolved scalar quantities and subfilter-scale turbulence-chemistry interactions. We develop this method for the
 $ {\mathrm{H}}_2 $
filtered “burning rate”
$ {\mathrm{H}}_2 $
filtered “burning rate”
 $ \overline{\dot{\omega}} $
, defined as
$ \overline{\dot{\omega}} $
, defined as
 $$ \overline{\dot{\omega}}=-{\overline{\dot{\omega}}}_{{\mathrm{H}}_2}, $$
$$ \overline{\dot{\omega}}=-{\overline{\dot{\omega}}}_{{\mathrm{H}}_2}, $$
with the aim of establishing an ML-based modeling framework and a proof of concept for
 $ {\mathrm{H}}_2 $
turbulent combustion. The final implementation will depend on the given LES modeling framework. For example, the ML model could replace the tabulation method proposed in Lapenna et al. (Reference Lapenna, Berger, Attili, Lamioni, Fogla, Pitsch and Creta2021, Reference Lapenna, Remiddi, Molinaro, Indelicato and Creta2024) for the chemical source term of the progress variable. This is what has been done in Seltz et al. (Reference Seltz, Domingo, Vervisch and Nikolaou2019) with direct mapping of the closure terms for a methane-air flame. The ML framework could also be based on a database with a one-step chemistry (Millán-Merino and Boivin, Reference Millán-Merino and Boivin2024; Schiavone et al., Reference Schiavone, Detomaso, Torresi and Laera2024) to close the LES multi-species transport equations.
$ {\mathrm{H}}_2 $
turbulent combustion. The final implementation will depend on the given LES modeling framework. For example, the ML model could replace the tabulation method proposed in Lapenna et al. (Reference Lapenna, Berger, Attili, Lamioni, Fogla, Pitsch and Creta2021, Reference Lapenna, Remiddi, Molinaro, Indelicato and Creta2024) for the chemical source term of the progress variable. This is what has been done in Seltz et al. (Reference Seltz, Domingo, Vervisch and Nikolaou2019) with direct mapping of the closure terms for a methane-air flame. The ML framework could also be based on a database with a one-step chemistry (Millán-Merino and Boivin, Reference Millán-Merino and Boivin2024; Schiavone et al., Reference Schiavone, Detomaso, Torresi and Laera2024) to close the LES multi-species transport equations.
The basic ingredients to describe turbulent flames remain the quantities introduced for laminar flame analysis: the progress variable
 $ c $
and the mixture fraction
$ c $
and the mixture fraction
 $ \xi $
. The progress variable equals zero in fresh gas, and one in burnt gas, and varies monotonically during combustion. Mixture fraction
$ \xi $
. The progress variable equals zero in fresh gas, and one in burnt gas, and varies monotonically during combustion. Mixture fraction
 $ \xi $
or the equivalence ratio
$ \xi $
or the equivalence ratio
 $ \phi $
is used to inform the ML-based model of the composition of the mixture, which impacts burning rates. The mixture fraction is based on Bilger’s definition (Bilger et al., Reference Bilger, Stårner and Kee1990).
$ \phi $
is used to inform the ML-based model of the composition of the mixture, which impacts burning rates. The mixture fraction is based on Bilger’s definition (Bilger et al., Reference Bilger, Stårner and Kee1990).
 $$ \xi =\frac{\beta -{\beta}^o}{\beta^f-{\beta}^o}\hskip0.24em \mathrm{with}\hskip0.24em \;\beta =\frac{Z_{\mathrm{H}}}{2{W}_{\mathrm{H}}}-\frac{Z_{\mathrm{O}}}{W_{\mathrm{O}}}, $$
$$ \xi =\frac{\beta -{\beta}^o}{\beta^f-{\beta}^o}\hskip0.24em \mathrm{with}\hskip0.24em \;\beta =\frac{Z_{\mathrm{H}}}{2{W}_{\mathrm{H}}}-\frac{Z_{\mathrm{O}}}{W_{\mathrm{O}}}, $$
where
 $ {Z}_m $
and
$ {Z}_m $
and
 $ {W}_m $
are the elemental mass fraction and atomic mass of the element
$ {W}_m $
are the elemental mass fraction and atomic mass of the element
 $ m $
. The superscripts
$ m $
. The superscripts
 $ o $
and
$ o $
and
 $ f $
denote oxidizer and fuel stream. The filtered progress variable
$ f $
denote oxidizer and fuel stream. The filtered progress variable
 $ \tilde{c} $
is defined as
$ \tilde{c} $
is defined as
 $$ \tilde{c}=\frac{Y_{{\mathrm{H}}_2}^u\left(\tilde{\xi}\right)-{\tilde{Y}}_{{\mathrm{H}}_2}}{Y_{{\mathrm{H}}_2}^u\left(\tilde{\xi}\right)-{Y}_{{\mathrm{H}}_2}^b\left(\tilde{\xi}\right)}=\frac{\tilde{\xi}-{\tilde{Y}}_{{\mathrm{H}}_2}}{\tilde{\xi}-\max \left(0,\frac{\tilde{\xi}-{\xi}_s}{1-{\xi}_s}\right)}, $$
$$ \tilde{c}=\frac{Y_{{\mathrm{H}}_2}^u\left(\tilde{\xi}\right)-{\tilde{Y}}_{{\mathrm{H}}_2}}{Y_{{\mathrm{H}}_2}^u\left(\tilde{\xi}\right)-{Y}_{{\mathrm{H}}_2}^b\left(\tilde{\xi}\right)}=\frac{\tilde{\xi}-{\tilde{Y}}_{{\mathrm{H}}_2}}{\tilde{\xi}-\max \left(0,\frac{\tilde{\xi}-{\xi}_s}{1-{\xi}_s}\right)}, $$
where superscripts
 $ u $
and
$ u $
and
 $ b $
denote values in unburnt and burnt gas and
$ b $
denote values in unburnt and burnt gas and
 $ {\xi}_s $
is the mixture fraction value at stoichiometry. We have arbitrarily chosen to base the progress variable on the
$ {\xi}_s $
is the mixture fraction value at stoichiometry. We have arbitrarily chosen to base the progress variable on the
 $ {\mathrm{H}}_2 $
mass fraction. It is shown in Supplementary Material that it is also possible to base the progress variable on the
$ {\mathrm{H}}_2 $
mass fraction. It is shown in Supplementary Material that it is also possible to base the progress variable on the
 $ {\mathrm{H}}_2 $
O mass fraction without any impact on the training and prediction accuracy of the model. In this framework, the challenge is now to model
$ {\mathrm{H}}_2 $
O mass fraction without any impact on the training and prediction accuracy of the model. In this framework, the challenge is now to model
 $ \overline{\dot{\omega}} $
as a function of
$ \overline{\dot{\omega}} $
as a function of
 $ \tilde{c} $
and
$ \tilde{c} $
and
 $ \tilde{\xi} $
fields.
$ \tilde{\xi} $
fields.
2.2. Machine learning framework
The aim of the ML-based model is to approximate the function
 $$ \overline{\dot{\omega}}=f\left(\tilde{c},\tilde{\xi}\hskip0.22em \mathrm{or}\hskip0.22em \tilde{\phi},\dots \right). $$
$$ \overline{\dot{\omega}}=f\left(\tilde{c},\tilde{\xi}\hskip0.22em \mathrm{or}\hskip0.22em \tilde{\phi},\dots \right). $$
The evolution of the reaction rate depends on the thermochemical state described by the progress variable and mixture fraction, but also on the flow. Indeed, the level of turbulence, flame curvature, and strain, have a major influence on the reaction rate (Poinsot and Veynante, Reference Poinsot and Veynante2011). In this work, we propose to include the topological information by means of spatial convolutions using a CNN. The CNN is found to perform better when the equivalence ratio
 $ \tilde{\phi} $
is used instead of the mixture fraction
$ \tilde{\phi} $
is used instead of the mixture fraction
 $ \tilde{\xi} $
. The filtered equivalence ratio can be approximated as
$ \tilde{\xi} $
. The filtered equivalence ratio can be approximated as
 $$ \tilde{\phi}=\frac{\tilde{\xi}\left(1-{\xi}_s\right)}{\xi_s\left(1-\tilde{\xi}\right)}. $$
$$ \tilde{\phi}=\frac{\tilde{\xi}\left(1-{\xi}_s\right)}{\xi_s\left(1-\tilde{\xi}\right)}. $$
The CNN takes as input the field of
 $ \tilde{c} $
and
$ \tilde{c} $
and
 $ \tilde{\phi} $
over a domain
$ \tilde{\phi} $
over a domain
 $ \Omega $
, performs successive convolutions and operations, and outputs an approximation of
$ \Omega $
, performs successive convolutions and operations, and outputs an approximation of
 $ \overline{\dot{\omega}} $
over the same domain
$ \overline{\dot{\omega}} $
over the same domain
 $ \Omega $
. The function
$ \Omega $
. The function
 $ {f}_{\mathrm{CNN}} $
therefore reads
$ {f}_{\mathrm{CNN}} $
therefore reads
 $$ {\overline{\dot{\boldsymbol{\omega}}}}^{\mathrm{NN}}={f}_{\mathrm{CNN}}\left(\tilde{\boldsymbol{c}},\tilde{\boldsymbol{\phi}}\right)\approx \overline{\dot{\boldsymbol{\omega}}}. $$
$$ {\overline{\dot{\boldsymbol{\omega}}}}^{\mathrm{NN}}={f}_{\mathrm{CNN}}\left(\tilde{\boldsymbol{c}},\tilde{\boldsymbol{\phi}}\right)\approx \overline{\dot{\boldsymbol{\omega}}}. $$
CNNs were designed to learn spatial hierarchies of features, from low- to high-level patterns. They are therefore well fitted for recognizing complex flame topology and learning associated burning rates. Furthermore, the convolutions enable to train models on large inputs via parameter sharing. The application of CNNs to the modeling of flame features has already been successfully performed in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019), Seltz et al. (Reference Seltz, Domingo, Vervisch and Nikolaou2019) and Nikolaou et al. (Reference Nikolaou, Chrysostomou, Vervisch and Cant2019) for fuel-air mixture without significant preferential diffusion effects, unlike the
 $ {\mathrm{H}}_2 $
-air mixtures considered in this article.
$ {\mathrm{H}}_2 $
-air mixtures considered in this article.
The CNN architecture used is inspired by the U-net architecture originally developed for image segmentation (Ronneberger et al., Reference Ronneberger, Fischer, Brox, Navab, Hornegger, Wells and Frangi2015) (Figure 1). However, the output activation function is replaced by a linear activation function for the regression task considered in this work. A similar architecture for the approximation of flame surface density has already been used successfully (Lapeyre et al., Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019). Using
 $ 64 $
channels in the first multi-channel feature map instead of
$ 64 $
channels in the first multi-channel feature map instead of
 $ 32 $
in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019) increased the accuracy of the approximation of
$ 32 $
in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019) increased the accuracy of the approximation of
 $ \overline{\dot{\omega}} $
(Eq. (2.6)) in the present work. In total, the network comprises
$ \overline{\dot{\omega}} $
(Eq. (2.6)) in the present work. In total, the network comprises
 $ \mathrm{5,424,193} $
trainable parameters.
$ \mathrm{5,424,193} $
trainable parameters.

Figure 1. U-net-type architecture is used in the present work. Each black box corresponds to a multi-channel feature map. The number of channels is denoted on top of the box. The input sample has three channels:
 $ \tilde{c} $
,
$ \tilde{c} $
,
 $ \tilde{\phi} $
and
$ \tilde{\phi} $
and
 $ {\delta}_L^0/{\delta}_L^1 $
. The ratio
$ {\delta}_L^0/{\delta}_L^1 $
. The ratio
 $ {\delta}_L^0/{\delta}_L^1 $
is the inverse of the laminar flame thickening due to filtering (Section 2.3.2). The original size of the cubic sample is
$ {\delta}_L^0/{\delta}_L^1 $
is the inverse of the laminar flame thickening due to filtering (Section 2.3.2). The original size of the cubic sample is
 $ {N}^3 $
. It is then reduced to
$ {N}^3 $
. It is then reduced to
 $ {\left(N/2\right)}^3 $
and
$ {\left(N/2\right)}^3 $
and
 $ {\left(N/4\right)}^3 $
during the contracting path before going back to the original size during the expansive path. Gray boxes represent copied feature maps. The arrows denote the different operations.
$ {\left(N/4\right)}^3 $
during the contracting path before going back to the original size during the expansive path. Gray boxes represent copied feature maps. The arrows denote the different operations.
2.3. Data generation and training strategy
The data generation strategy consists of filtering and downsampling data from DNS to emulate LES data with known filtered quantities. The configuration chosen to generate training data is a slot burner (Figure 2) at constant pressure
 $ P=1 $
atm and fresh gas temperature
$ P=1 $
atm and fresh gas temperature
 $ {T}^u=300 $
K, as in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019). The physical domain consists of a central inlet where a premixed
$ {T}^u=300 $
K, as in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019). The physical domain consists of a central inlet where a premixed
 $ {\mathrm{H}}_2 $
-air mixture flows at a bulk velocity
$ {\mathrm{H}}_2 $
-air mixture flows at a bulk velocity
 $ {U}_b=24\;\mathrm{m}/\mathrm{s} $
with velocity fluctuation
$ {U}_b=24\;\mathrm{m}/\mathrm{s} $
with velocity fluctuation
 $ {u}^{\prime }=2.4\;\mathrm{m}/\mathrm{s} $
, surrounded by two laminar coflows where burnt gas flows at a bulk velocity
$ {u}^{\prime }=2.4\;\mathrm{m}/\mathrm{s} $
, surrounded by two laminar coflows where burnt gas flows at a bulk velocity
 $ {U}_c=3.6\;\mathrm{m}/\mathrm{s} $
. The injection of turbulence at the central inlet corresponds to homogeneous and isotropic turbulence using a Passot-Pouquet turbulence spectrum (Passot and Pouquet, Reference Passot and Pouquet1987) with an integral length scale
$ {U}_c=3.6\;\mathrm{m}/\mathrm{s} $
. The injection of turbulence at the central inlet corresponds to homogeneous and isotropic turbulence using a Passot-Pouquet turbulence spectrum (Passot and Pouquet, Reference Passot and Pouquet1987) with an integral length scale
 $ {l}_t=2 $
mm. The domain is rectangular with periodic boundary conditions in the
$ {l}_t=2 $
mm. The domain is rectangular with periodic boundary conditions in the
 $ z $
-direction. Adiabatic walls are specified in the
$ z $
-direction. Adiabatic walls are specified in the
 $ y $
-direction. Both inlets and outlets are specified in the
$ y $
-direction. Both inlets and outlets are specified in the
 $ x $
-direction. Exact dimensions are annotated on Figure 2. The configuration is very similar to that used in Berger et al. (Reference Berger, Attili and Pitsch2022c), Coulon et al. (Reference Coulon, Gaucherand, Xing, Laera, Lapeyre and Poinsot2023), and Gaucherand et al. (Reference Gaucherand, Laera, Schulze-Netzer and Poinsot2024a) to study
$ x $
-direction. Exact dimensions are annotated on Figure 2. The configuration is very similar to that used in Berger et al. (Reference Berger, Attili and Pitsch2022c), Coulon et al. (Reference Coulon, Gaucherand, Xing, Laera, Lapeyre and Poinsot2023), and Gaucherand et al. (Reference Gaucherand, Laera, Schulze-Netzer and Poinsot2024a) to study
 $ {\mathrm{H}}_2 $
-air and
$ {\mathrm{H}}_2 $
-air and
 $ {\mathrm{H}}_2 $
/
$ {\mathrm{H}}_2 $
/
 $ {\mathrm{NH}}_3 $
-air premixed turbulent flames. This configuration is computed for five different equivalence ratios (Table 1) to assess the ability of the CNN to approximate the reaction rate over a range of equivalence ratios. All other parameters are kept constant. The Reynolds number of the central inlet is about
$ {\mathrm{NH}}_3 $
-air premixed turbulent flames. This configuration is computed for five different equivalence ratios (Table 1) to assess the ability of the CNN to approximate the reaction rate over a range of equivalence ratios. All other parameters are kept constant. The Reynolds number of the central inlet is about
 $ \mathrm{10,000} $
for all cases.
$ \mathrm{10,000} $
for all cases.

Figure 2. Diagram of the slot burner configuration used to generate the DNS database. The flame is depicted by an iso-surface at a progress variable
 $ c=0.5 $
colored by
$ c=0.5 $
colored by
 $ \dot{\omega}=-{\dot{\omega}}_{{\mathrm{H}}_2} $
. The dimensions of the domain are annotated on the right. The length
$ \dot{\omega}=-{\dot{\omega}}_{{\mathrm{H}}_2} $
. The dimensions of the domain are annotated on the right. The length
 $ {L}_x $
is adapted to the length of the turbulent flame brush, which is a function of the global equivalence ratio
$ {L}_x $
is adapted to the length of the turbulent flame brush, which is a function of the global equivalence ratio
 $ {\phi}_g $
.
$ {\phi}_g $
.
Table 1. Global equivalence ratio
 $ {\phi}_g $
for the five different DNS cases
$ {\phi}_g $
for the five different DNS cases

The laminar flame characteristic values are also indicated.
 $ {S}_L^0 $
is the laminar flame speed,
$ {S}_L^0 $
is the laminar flame speed,
 $ {\delta}_{th,L}^0 $
the laminar thermal flame thickness,
$ {\delta}_{th,L}^0 $
the laminar thermal flame thickness,
 $ {T}^{ad} $
the adiabatic flame temperature.
$ {T}^{ad} $
the adiabatic flame temperature.
The data generation and training strategy is based on processing multiple snapshots from the five DNS (Figure 3):
-
a. The five DNS cases (Table 1) are computed for
 $ 59 $
ms from a statistically steady state. Three-Dimensional (3D) instantaneous solutions are saved every ms. Solutions with an index multiple of 10 are set aside for testing after training. All other solutions are used for training and validation data. This generates 6 solutions for testing and 54 solutions for training and validation data for each DNS case.
$ 59 $
ms from a statistically steady state. Three-Dimensional (3D) instantaneous solutions are saved every ms. Solutions with an index multiple of 10 are set aside for testing after training. All other solutions are used for training and validation data. This generates 6 solutions for testing and 54 solutions for training and validation data for each DNS case. -
b. A spatial filtering is performed on each solution to obtain
$ \overline{\rho} $
,
$ \overline{\rho {Y}_{{\mathrm{H}}_2}} $
,
$ \overline{\rho \xi} $
and
$ {\overline{\dot{\omega}}}_{{\mathrm{H}}_2} $
. The filtered variables are downsampled to a coarser grid, representing an LES grid. The filtering and downsampling operation is described in Section 2.3.2. -
c. The filtered progress variable
$ \tilde{c} $
is calculated using Eq. (2.3) with
$ {\tilde{Y}}_{{\mathrm{H}}_2}=\overline{\rho {Y}_{{\mathrm{H}}_2}}/\overline{\rho} $
and
$ \tilde{\xi}=\overline{\rho \xi}/\overline{\rho} $
. The filtered equivalence ratio
$ \tilde{\phi} $
is calculated using Eq. (2.5) with
$ \tilde{\xi}=\overline{\rho \xi}/\overline{\rho} $
. The filtered burning rate
$ \overline{\dot{\omega}} $
is calculated using Eq. (2.1) with
$ {\overline{\dot{\omega}}}_{{\mathrm{H}}_2} $
. -
d. It is important that the CNN does not learn the specific configuration of the slot burner, but only learns generic flame elements. Depending on the effective receptive field of the CNN, training using the emulated LES solutions directly could encode in the network information on the distance to the inlets, outlet, or the wall for example. This would drastically reduce CNN’s ability to generalize and must be avoided. To address this, training is performed on randomly selected cubes in the domain as in Lapeyre et al. (Reference Lapeyre, Misdariis, Cazard and Poinsot2018, Reference Lapeyre, Misdariis, Cazard, Veynante and Poinsot2019). This also enables the CNN to be invariant to translation (Biscione and Bowers, Reference Biscione and Bowers2021).
-
e. The CNN is trained to approximate
$ \overline{\dot{\omega}} $
(Eq. (2.6)) using data from the cubic samples. 10% of samples are randomly selected and set aside for validation, the rest are used for training. The complete description of the training is given in Section 2.3.3.














Figure 3. Diagram of the strategy used to generate data and train the CNN.
 $ {\delta}_L^0/{\delta}_L^1 $
is the inverse of the laminar flame thickening due to filtering (Section 2.3.2).
$ {\delta}_L^0/{\delta}_L^1 $
is the inverse of the laminar flame thickening due to filtering (Section 2.3.2).
 $ \tilde{\phi} $
is calculated from
$ \tilde{\phi} $
is calculated from
 $ \tilde{\xi} $
using Eq. (2.5).
$ \tilde{\xi} $
using Eq. (2.5).
2.3.1. Direct numerical simulation
DNS of the slot burner cases (Table 1) are performed using the AVBP (Schonfeld and Rudgyard, Reference Schonfeld and Rudgyard1999; Gicquel et al., Reference Gicquel, Gourdain, Boussuge, Deniau, Staffelbach, Wolf and Poinsot2011) massively parallel code solving the compressible multi-species Navier–Stokes equations. A third-order accurate Taylor–Galerkin scheme is adopted for the discretization of the convective terms (Colin and Rudgyard, Reference Colin and Rudgyard2000). Navier–Stokes Characteristic Boundary Conditions (NSCBCs) (Poinsot and Lelef, Reference Poinsot and Lelef1992) are imposed at the inlets (relaxation factor of
 $ 1000 $
$ 1000 $
 $ {\mathrm{s}}^{-1} $
) and at the outlet (relaxation factor of
$ {\mathrm{s}}^{-1} $
) and at the outlet (relaxation factor of
 $ 200 $
$ 200 $
 $ {\mathrm{s}}^{-1} $
). Dynamic viscosity
$ {\mathrm{s}}^{-1} $
). Dynamic viscosity
 $ \mu $
follows a power law function of temperature
$ \mu $
follows a power law function of temperature
 $ T $
.
$ T $
.
 $$ \mu ={\mu}_0{\left(\frac{T}{T_0}\right)}^{\gamma }, $$
$$ \mu ={\mu}_0{\left(\frac{T}{T_0}\right)}^{\gamma }, $$
with
 $ {\mu}_0=8.062\times {10}^{-5} $
$ {\mu}_0=8.062\times {10}^{-5} $
 $ \mathrm{kg}/\mathrm{m}/\mathrm{s} $
,
$ \mathrm{kg}/\mathrm{m}/\mathrm{s} $
,
 $ {T}_0=2.645\times {10}^3 $
K and
$ {T}_0=2.645\times {10}^3 $
K and
 $ \gamma =6.481\times {10}^{-1} $
. Thermal diffusivity is computed from the viscosity using a constant Prandtl number:
$ \gamma =6.481\times {10}^{-1} $
. Thermal diffusivity is computed from the viscosity using a constant Prandtl number:
 $ \Pr =0.66 $
. Species diffusivities are computed using a constant Schmidt number specific for each species (Table 2). This approach takes into account non-unity Lewis numbers and preferential diffusion between the different species. It is verified that the errors made by the simplified transport description are negligible by comparing the results with simulations using a mixture-averaged transport model, see Supplementary Material. Soret and Dufour transport processes are ignored in the simulations of the present work. Including these transport, processes could enhance thermodiffusive instabilities and increase source terms and flame surface curvature (Schlup and Blanquart, Reference Schlup and Blanquart2018). Although this would require another training on the new database, it does not affect the conclusions of this work. Indeed, it has been shown that neglecting these effects still leads to simulations that capture much of the peculiar behavior of lean-premixed
$ \Pr =0.66 $
. Species diffusivities are computed using a constant Schmidt number specific for each species (Table 2). This approach takes into account non-unity Lewis numbers and preferential diffusion between the different species. It is verified that the errors made by the simplified transport description are negligible by comparing the results with simulations using a mixture-averaged transport model, see Supplementary Material. Soret and Dufour transport processes are ignored in the simulations of the present work. Including these transport, processes could enhance thermodiffusive instabilities and increase source terms and flame surface curvature (Schlup and Blanquart, Reference Schlup and Blanquart2018). Although this would require another training on the new database, it does not affect the conclusions of this work. Indeed, it has been shown that neglecting these effects still leads to simulations that capture much of the peculiar behavior of lean-premixed
 $ {\mathrm{H}}_2 $
-air flames including thermodiffusive instabilities and enhanced burning rates (Aspden et al., Reference Aspden, Day and Bell2015; Aspden, Reference Aspden2017; Schlup and Blanquart, Reference Schlup and Blanquart2018; Pitsch, Reference Pitsch2024). Hydrogen chemical kinetics relies on the San Diego mechanism (Saxena and Williams, Reference Saxena and Williams2006), already successfully used for
$ {\mathrm{H}}_2 $
-air flames including thermodiffusive instabilities and enhanced burning rates (Aspden et al., Reference Aspden, Day and Bell2015; Aspden, Reference Aspden2017; Schlup and Blanquart, Reference Schlup and Blanquart2018; Pitsch, Reference Pitsch2024). Hydrogen chemical kinetics relies on the San Diego mechanism (Saxena and Williams, Reference Saxena and Williams2006), already successfully used for
 $ {\mathrm{H}}_2 $
-air premixed combustion in Coulon et al. (Reference Coulon, Gaucherand, Xing, Laera, Lapeyre and Poinsot2023). This mechanism comprises
$ {\mathrm{H}}_2 $
-air premixed combustion in Coulon et al. (Reference Coulon, Gaucherand, Xing, Laera, Lapeyre and Poinsot2023). This mechanism comprises
 $ 9 $
species and
$ 9 $
species and
 $ 21 $
reactions.
$ 21 $
reactions.
Table 2. Schmidt
 $ {\mathrm{Sc}}_k $
and Lewis
$ {\mathrm{Sc}}_k $
and Lewis
 $ {\mathrm{Le}}_k $
numbers for the species used for the DNS of
$ {\mathrm{Le}}_k $
numbers for the species used for the DNS of
 $ {\mathrm{H}}_2 $
-air flames
$ {\mathrm{H}}_2 $
-air flames

Table 3. Flame characteristics for the three sets of LES parameters (
 $ \sigma $
, DSF) used in this work
$ \sigma $
, DSF) used in this work

 $ {\Delta}_x $
is the grid cell size, equal to DSF times the original cell size of
$ {\Delta}_x $
is the grid cell size, equal to DSF times the original cell size of
 $ 0.1 $
mm.
$ 0.1 $
mm.
 $ {\delta}_{c,L}^0 $
and
$ {\delta}_{c,L}^0 $
and
 $ {\delta}_{c,L}^1 $
are the laminar flame thickness based on the progress variable of a non-filtered and filtered 1D flame (Eq. (2.9)).
$ {\delta}_{c,L}^1 $
are the laminar flame thickness based on the progress variable of a non-filtered and filtered 1D flame (Eq. (2.9)).
 $ \mathrm{RI}={\delta}_{c,L}^1/{\Delta}_x+1 $
is the resolution index of the filtered flame on the LES grid.
$ \mathrm{RI}={\delta}_{c,L}^1/{\Delta}_x+1 $
is the resolution index of the filtered flame on the LES grid.
The mesh is a homogeneous cartesian grid with constant element size
 $ {\Delta}_x=0.1 $
mm. This gives a resolution index
$ {\Delta}_x=0.1 $
mm. This gives a resolution index
 $ \mathrm{RI}={\delta}_{th,L}^0/{\Delta}_x+1 $
that varies between
$ \mathrm{RI}={\delta}_{th,L}^0/{\Delta}_x+1 $
that varies between
 $ 12.5 $
and
$ 12.5 $
and
 $ 5.2 $
for
$ 5.2 $
for
 $ {\phi}_g $
between
$ {\phi}_g $
between
 $ 0.35 $
and
$ 0.35 $
and
 $ 0.7 $
.
$ 0.7 $
.
 $ {\delta}_{th,L}^0 $
is the laminar thermal flame thickness. A mesh sensitivity study was carried out where we verified that turbulent combustion statistics are not affected by mesh refinements. This study is included as Supplementary Material. The length of the domain in the
$ {\delta}_{th,L}^0 $
is the laminar thermal flame thickness. A mesh sensitivity study was carried out where we verified that turbulent combustion statistics are not affected by mesh refinements. This study is included as Supplementary Material. The length of the domain in the
 $ x $
-direction
$ x $
-direction
 $ {L}_x $
is adapted to the length of the turbulent flame brush. It varies from
$ {L}_x $
is adapted to the length of the turbulent flame brush. It varies from
 $ 76 $
mm for
$ 76 $
mm for
 $ {\phi}_g=0.35 $
to
$ {\phi}_g=0.35 $
to
 $ 36 $
mm for
$ 36 $
mm for
 $ {\phi}_g=0.7 $
(Figure 2). The number of grid points accordingly varies from
$ {\phi}_g=0.7 $
(Figure 2). The number of grid points accordingly varies from
 $ 39 $
to
$ 39 $
to
 $ 19 $
million. Calculations were carried out on the new Alps Research Infrastructure at the Swiss National Supercomputing Centre (CSCS) using AMD EPYC 7742 CPUs. A total of
$ 19 $
million. Calculations were carried out on the new Alps Research Infrastructure at the Swiss National Supercomputing Centre (CSCS) using AMD EPYC 7742 CPUs. A total of
 $ 1.6 $
million core hours were used to generate the database. Depending on the grid size, computations are performed using between
$ 1.6 $
million core hours were used to generate the database. Depending on the grid size, computations are performed using between
 $ \mathrm{5,120} $
and
$ \mathrm{5,120} $
and
 $ \mathrm{2,560} $
computing cores with good efficiency thanks to the massively parallel computing ability of the AVBP code.
$ \mathrm{2,560} $
computing cores with good efficiency thanks to the massively parallel computing ability of the AVBP code.
2.3.2. Filtering and downsampling
A spatial filtering is performed to obtain
 $ \overline{\rho} $
,
$ \overline{\rho} $
,
 $ \overline{\rho {Y}_{{\mathrm{H}}_2}} $
,
$ \overline{\rho {Y}_{{\mathrm{H}}_2}} $
,
 $ \overline{\rho \xi} $
and
$ \overline{\rho \xi} $
and
 $ \overline{{\dot{\omega}}_{{\mathrm{H}}_2}} $
, in order to calculate
$ \overline{{\dot{\omega}}_{{\mathrm{H}}_2}} $
, in order to calculate
 $ \tilde{c} $
,
$ \tilde{c} $
,
 $ \tilde{\phi} $
and
$ \tilde{\phi} $
and
 $ \overline{\dot{\omega}} $
(Eqs (2.3), (2.5), and ((2.1)). The filtered quantity of a variable
$ \overline{\dot{\omega}} $
(Eqs (2.3), (2.5), and ((2.1)). The filtered quantity of a variable
 $ \varphi $
from the DNS field is defined by Eq. (1.1). The filtered 3D fields are obtained by successively filtering in each direction
$ \varphi $
from the DNS field is defined by Eq. (1.1). The filtered 3D fields are obtained by successively filtering in each direction
 $ x $
,
$ x $
,
 $ y $
and
$ y $
and
 $ z $
using a 1D Gaussian filter. The 1D filter function is written in discrete form as
$ z $
using a 1D Gaussian filter. The 1D filter function is written in discrete form as
 $$ F(u)=\left\{\begin{array}{ll}{e}^{-\frac{1}{2}{\left(\frac{u}{\sigma}\right)}^2}& \mathrm{if}\;u\in \left[-z..+z\right]\\ {}0& \mathrm{otherwise}\end{array}\right.\hskip0.22em \mathrm{with}\hskip0.22em z=4\sigma, $$
$$ F(u)=\left\{\begin{array}{ll}{e}^{-\frac{1}{2}{\left(\frac{u}{\sigma}\right)}^2}& \mathrm{if}\;u\in \left[-z..+z\right]\\ {}0& \mathrm{otherwise}\end{array}\right.\hskip0.22em \mathrm{with}\hskip0.22em z=4\sigma, $$
and then normalized by its sum
 $ {\sum}_{u=-z}^zF(u) $
. The filtered fields are then downsampled to a coarser grid to emulate LES fields. Three different standard deviations
$ {\sum}_{u=-z}^zF(u) $
. The filtered fields are then downsampled to a coarser grid to emulate LES fields. Three different standard deviations
 $ \sigma $
are used in this work to emulate three different LES resolutions (Table 3). For each
$ \sigma $
are used in this work to emulate three different LES resolutions (Table 3). For each
 $ \sigma $
, a downsampling factor DSF is associated. It is chosen so as to have a LES grid with a resolution index
$ \sigma $
, a downsampling factor DSF is associated. It is chosen so as to have a LES grid with a resolution index
 $ \mathrm{RI}={\delta}_{c,L}^1/{\Delta}_x+1 $
of about 6.
$ \mathrm{RI}={\delta}_{c,L}^1/{\Delta}_x+1 $
of about 6.
 $ {\delta}_{c,L}^0 $
and
$ {\delta}_{c,L}^0 $
and
 $ {\delta}_{c,L}^1 $
are the laminar flame thickness based on the progress variable of a non-filtered and filtered 1D flame
$ {\delta}_{c,L}^1 $
are the laminar flame thickness based on the progress variable of a non-filtered and filtered 1D flame
 $$ {\delta}_{c,L}^0={\left(\max \left|\nabla c\right|\right)}^{-1}\hskip0.1em \mathrm{and}\hskip0.22em {\delta}_{c,L}^1={\left(\max \left|\nabla \tilde{c}\right|\right)}^{-1}. $$
$$ {\delta}_{c,L}^0={\left(\max \left|\nabla c\right|\right)}^{-1}\hskip0.1em \mathrm{and}\hskip0.22em {\delta}_{c,L}^1={\left(\max \left|\nabla \tilde{c}\right|\right)}^{-1}. $$
2.3.3. Training method
The generated cubic samples (Figure 3) of size
 $ 16\times 16\times 16 $
points are used to train the CNN to approximate
$ 16\times 16\times 16 $
points are used to train the CNN to approximate
 $ \overline{\dot{\omega}} $
(Eq. (2.6)). A set of 10% of the samples is randomly selected to form a validation dataset and monitor overfitting. The remaining samples are used for training. At each epoch, each cubic sample in the training dataset has a
$ \overline{\dot{\omega}} $
(Eq. (2.6)). A set of 10% of the samples is randomly selected to form a validation dataset and monitor overfitting. The remaining samples are used for training. At each epoch, each cubic sample in the training dataset has a
 $ 25 $
% probability of undergoing between one and three
$ 25 $
% probability of undergoing between one and three
 $ {90}^{\circ } $
rotations along any axis, or of being flipped in any direction. It is done to add variability to the orientation of the flame front in the dataset. The model must have no preferential orientation and learn an isotropic function.
$ {90}^{\circ } $
rotations along any axis, or of being flipped in any direction. It is done to add variability to the orientation of the flame front in the dataset. The model must have no preferential orientation and learn an isotropic function.
Training is accomplished by backpropagation. The trainable parameters of the CNN are updated iteratively on batches of data from the training dataset by stochastic gradient descent with the AdamW optimizer (Kingma and Ba, Reference Kingma and Ba2017; Loshchilov and Hutter, Reference Loshchilov and Hutter2019). The parameters are adjusted to minimize the Mean Squared Error (MSE) loss function overall output pixels of the prediction compared to the target. The batch size per GPU is
 $ 200 $
and the training is terminated after
$ 200 $
and the training is terminated after
 $ \mathrm{1,500} $
epochs. The base learning rate equals
$ \mathrm{1,500} $
epochs. The base learning rate equals
 $ {10}^{-3} $
. The evolution of the loss function on the training and validation datasets during training is given in Section 3.
$ {10}^{-3} $
. The evolution of the loss function on the training and validation datasets during training is given in Section 3.
The PyTorch (Ansel et al., Reference Ansel, Yang, He, Gimelshein, Jain, Voznesensky, Bao, Bell, Berard, Burovski, Chauhan, Chourdia, Constable, Desmaison, DeVito, Ellison, Feng, Gong, Gschwind, Hirsh, Huang, Kalambarkar, Kirsch, Lazos, Lezcano, Liang, Liang, Lu, Luk, Maher, Pan, Puhrsch, Reso, Saroufim, Siraichi, Suk, Zhang, Suo, Tillet, Zhao, Wang, Zhou, Zou, Wang, Mathews, Wen, Chanan, Wu and Chintala2024) Python library is used to implement and train the CNN. The Distributed Data-Parallel (DDP) feature in PyTorch is employed to parallelize the training process across four NVIDIA H100 GPUs. Each GPU performs its own forward and backward pass on a subset of the training dataset. The gradients computed on each GPU are then synchronized and averaged to update the model parameters. Training performances are reported in Section 3.
3. Results and discussion
3.1. Training and testing
The training and validation database comprises
 $ 40\times 54\times 5\times 3=\mathrm{32,400} $
cubic samples (
$ 40\times 54\times 5\times 3=\mathrm{32,400} $
cubic samples (
 $ 40 $
random cubes per solution,
$ 40 $
random cubes per solution,
 $ 54 $
solutions per case,
$ 54 $
solutions per case,
 $ 5 $
different equivalence ratios,
$ 5 $
different equivalence ratios,
 $ 3 $
different sets of LES parameters (filtering and downsampling)).
$ 3 $
different sets of LES parameters (filtering and downsampling)).
 $ \mathrm{3,240} $
(
$ \mathrm{3,240} $
(
 $ 10 $
%) of these cubes are randomly set aside for validation. Training the CNN model for
$ 10 $
%) of these cubes are randomly set aside for validation. Training the CNN model for
 $ \mathrm{1,500} $
epochs on this database takes
$ \mathrm{1,500} $
epochs on this database takes
 $ 47 $
minutes.
$ 47 $
minutes.
 $ \mathrm{1,500} $
epochs are sufficient because the loss function evaluated on the validation dataset no longer decreases significantly (Figure 4). The set of model parameters giving rise to the lowest loss is selected as the best model (black circle in Figure 4). This best model is used to assess the ability of the CNN to approximate burning rates on the test solutions (full domain, never seen during training). The Normalized Mean Absolute Error (NMAE) is used to estimate the accuracy of the CNN model (Figure 4). It is defined as follows:
$ \mathrm{1,500} $
epochs are sufficient because the loss function evaluated on the validation dataset no longer decreases significantly (Figure 4). The set of model parameters giving rise to the lowest loss is selected as the best model (black circle in Figure 4). This best model is used to assess the ability of the CNN to approximate burning rates on the test solutions (full domain, never seen during training). The Normalized Mean Absolute Error (NMAE) is used to estimate the accuracy of the CNN model (Figure 4). It is defined as follows:
 $$ \mathrm{NMAE}=\frac{1}{\mathrm{mean}\left({\overline{\dot{\omega}}}^{\ast}\right)}\frac{1}{N}\sum \limits_{i=1}^N\left|{\overline{\dot{\omega}}}_i^{\ast }-{\overline{\dot{\omega}}}_i^{\mathrm{NN}}\right|, $$
$$ \mathrm{NMAE}=\frac{1}{\mathrm{mean}\left({\overline{\dot{\omega}}}^{\ast}\right)}\frac{1}{N}\sum \limits_{i=1}^N\left|{\overline{\dot{\omega}}}_i^{\ast }-{\overline{\dot{\omega}}}_i^{\mathrm{NN}}\right|, $$
where
 $ {\overline{\dot{\omega}}}^{\ast } $
is the filtered burning rate from the DNS dataset and
$ {\overline{\dot{\omega}}}^{\ast } $
is the filtered burning rate from the DNS dataset and
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
is the filtered burning rate modeled by the CNN. The mean absolute error is only about
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
is the filtered burning rate modeled by the CNN. The mean absolute error is only about
 $ 5 $
% of the average burning rate for all cases. The very high accuracy of the CNN model is confirmed by the distribution of CNN-modeled burning rate
$ 5 $
% of the average burning rate for all cases. The very high accuracy of the CNN model is confirmed by the distribution of CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
(Figure 5). The log-normalized Two-Dimensional (2D) histograms show a large majority of points on the
$ {\overline{\dot{\omega}}}^{\ast } $
(Figure 5). The log-normalized Two-Dimensional (2D) histograms show a large majority of points on the
 $ x=y $
axis (that is perfect agreement). Figure 6 shows a visualization of the result using a planar cut through a test solution for the case
$ x=y $
axis (that is perfect agreement). Figure 6 shows a visualization of the result using a planar cut through a test solution for the case
 $ {\phi}_g=0.4 $
and for the three sets of LES parameters
$ {\phi}_g=0.4 $
and for the three sets of LES parameters
 $ \left(\sigma, \mathrm{DSF}\right) $
. One can see the ability of the CNN to retrieve the extremely complex turbulent flame topology for all filter sizes. Even the burning pockets detached from the main flame brush are correctly modeled by the CNN. This is true for all other equivalence ratios. The visualization of the cases
$ \left(\sigma, \mathrm{DSF}\right) $
. One can see the ability of the CNN to retrieve the extremely complex turbulent flame topology for all filter sizes. Even the burning pockets detached from the main flame brush are correctly modeled by the CNN. This is true for all other equivalence ratios. The visualization of the cases
 $ {\phi}_g=0.35 $
,
$ {\phi}_g=0.35 $
,
 $ 0.5 $
,
$ 0.5 $
,
 $ 0.6 $
and
$ 0.6 $
and
 $ 0.7 $
are given as Supplementary Material to avoid overloading the manuscript.
$ 0.7 $
are given as Supplementary Material to avoid overloading the manuscript.

Figure 4. Left: Evolution of the RMSE during training, evaluated over the training dataset (red circles) and the validation dataset (blue squares). Black solid lines are moving averages of the RMSE. The black circle shows the lowest RMSE over the validation dataset. The model parameters at this specific epoch are selected. Right: Normalized mean absolute error over the testing solutions (Eq. (3.1)) for the different equivalence ratios and LES parameters used for building the training dataset. Error bars show the first and third quartiles of the data points.

Figure 5. Scatter plots with 2D histograms: CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. The points used for the histograms have a progress variable
$ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. The points used for the histograms have a progress variable
 $ c $
:
$ c $
:
 $ 0.05\le c\le 0.95 $
. Histogram values below the color scale are transparent. Gray dashed line indicates
$ 0.05\le c\le 0.95 $
. Histogram values below the color scale are transparent. Gray dashed line indicates
 $ x=y $
(that is zero error). Each column corresponds to a global equivalence ratio. Each row corresponds to a set of LES parameters (filtering and downsampling). Data are collected from the testing solutions.
$ x=y $
(that is zero error). Each column corresponds to a global equivalence ratio. Each row corresponds to a set of LES parameters (filtering and downsampling). Data are collected from the testing solutions.

Figure 6. Planar cut normal to the
 $ z $
-axis, in the middle of the domain, colored by the ground-truth filtered burning rate
$ z $
-axis, in the middle of the domain, colored by the ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
and the CNN-modeled burning rate
$ {\overline{\dot{\omega}}}^{\ast } $
and the CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
for three sets of LES parameters. The global equivalence ratio is
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
for three sets of LES parameters. The global equivalence ratio is
 $ {\phi}_g=0.4 $
. The complex turbulent flame topology of the burning rates is remarkably well reproduced by the CNN.
$ {\phi}_g=0.4 $
. The complex turbulent flame topology of the burning rates is remarkably well reproduced by the CNN.
3.2. Generalization ability
The ability of the CNN model to generalize outside the cases for which it has been trained is now assessed. For this, two new sets of LES parameters
 $ \left(\sigma =6,\mathrm{DSF}=3\right) $
and
$ \left(\sigma =6,\mathrm{DSF}=3\right) $
and
 $ \left(\sigma =12,\mathrm{DSF}=6\right) $
, and two new equivalence ratios
$ \left(\sigma =12,\mathrm{DSF}=6\right) $
, and two new equivalence ratios
 $ {\phi}_g=0.45 $
and
$ {\phi}_g=0.45 $
and
 $ 0.55 $
are used.
$ 0.55 $
are used.
Filtering and downsampling with the two new sets of LES parameters are performed on test solutions of the existing DNS with global equivalence ratios
 $ {\phi}_g=0.35 $
,
$ {\phi}_g=0.35 $
,
 $ 0.4 $
,
$ 0.4 $
,
 $ 0.5 $
,
$ 0.5 $
,
 $ 0.6 $
and
$ 0.6 $
and
 $ 0.7 $
. Although the distribution of points
$ 0.7 $
. Although the distribution of points
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus
 $ {\overline{\dot{\omega}}}^{\ast } $
is a little more scattered (Figure 7), the majority of the CNN-modeled burning rates are in very good agreement with their ground-truth counterparts. This demonstrates the ability of the model to generalize between two LES filter sizes for which it has been trained. It is important to note, however, that training with all three filter sizes (Table 3) is necessary to achieve this result. We have tried to train the CNN with only two filter sizes:
$ {\overline{\dot{\omega}}}^{\ast } $
is a little more scattered (Figure 7), the majority of the CNN-modeled burning rates are in very good agreement with their ground-truth counterparts. This demonstrates the ability of the model to generalize between two LES filter sizes for which it has been trained. It is important to note, however, that training with all three filter sizes (Table 3) is necessary to achieve this result. We have tried to train the CNN with only two filter sizes:
 $ \sigma =4 $
and
$ \sigma =4 $
and
 $ 16 $
, and found that the resulting model has a significant bias for
$ 16 $
, and found that the resulting model has a significant bias for
 $ \sigma =8 $
, see Supplementary Material.
$ \sigma =8 $
, see Supplementary Material.

Figure 7. Scatter plots with 2D histograms: CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. The points used for the histograms have a progress variable
$ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. The points used for the histograms have a progress variable
 $ c $
:
$ c $
:
 $ 0.05\le c\le 0.95 $
. Histogram values below the color scale are transparent. Gray dashed line indicates
$ 0.05\le c\le 0.95 $
. Histogram values below the color scale are transparent. Gray dashed line indicates
 $ x=y $
(that is zero error). Each column corresponds to a global equivalence ratio. Each row corresponds to a set of LES parameters (filtering and downsampling). Data are collected from solutions with two sets of LES parameters that were not included in the training dataset. The CNN approximates the burning rates with good accuracy, demonstrating the ability to generalize to other LES parameters from which it has been trained.
$ x=y $
(that is zero error). Each column corresponds to a global equivalence ratio. Each row corresponds to a set of LES parameters (filtering and downsampling). Data are collected from solutions with two sets of LES parameters that were not included in the training dataset. The CNN approximates the burning rates with good accuracy, demonstrating the ability to generalize to other LES parameters from which it has been trained.
The ability of the model to approximate burning rates for other global equivalence ratios is now assessed. For this, two new DNSs are performed with a global equivalence ratio
 $ {\phi}_g=0.45 $
and
$ {\phi}_g=0.45 $
and
 $ 0.55 $
and six solutions per DNS (snapshot every
$ 0.55 $
and six solutions per DNS (snapshot every
 $ 1 $
ms) are used to evaluate the model on the filter sizes
$ 1 $
ms) are used to evaluate the model on the filter sizes
 $ \sigma =4 $
,
$ \sigma =4 $
,
 $ 8 $
and
$ 8 $
and
 $ 16 $
(Figure 8). The distribution of points
$ 16 $
(Figure 8). The distribution of points
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
versus
 $ {\overline{\dot{\omega}}}^{\ast } $
is a little more scattered compared to inference on solutions with a global equivalence ratio used for training. The majority of the points are nevertheless clustered along the
$ {\overline{\dot{\omega}}}^{\ast } $
is a little more scattered compared to inference on solutions with a global equivalence ratio used for training. The majority of the points are nevertheless clustered along the
 $ x=y $
axis: the approximation of the burning rates is still very good. The planar cuts show a flame topology very well retrieved by the CNN model. These excellent results are due to the large number of equivalence ratios included in the training dataset. We have trained the CNN with only
$ x=y $
axis: the approximation of the burning rates is still very good. The planar cuts show a flame topology very well retrieved by the CNN model. These excellent results are due to the large number of equivalence ratios included in the training dataset. We have trained the CNN with only
 $ {\phi}_g=0.35 $
,
$ {\phi}_g=0.35 $
,
 $ 0.4 $
,
$ 0.4 $
,
 $ 0.6 $
and
$ 0.6 $
and
 $ 0.7 $
(that is without
$ 0.7 $
(that is without
 $ {\phi}_g=0.5 $
) and that model is flawed for the global equivalence ratio
$ {\phi}_g=0.5 $
) and that model is flawed for the global equivalence ratio
 $ {\phi}_g=0.5 $
, see Supplementary Material.
$ {\phi}_g=0.5 $
, see Supplementary Material.

Figure 8. Scatter plots and 2D histograms together with planar cuts comparing CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
to ground-truth filtered burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
to ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
. See caption of Figure 5 for a full description of how the histograms are constructed. The two global equivalence ratios
$ {\overline{\dot{\omega}}}^{\ast } $
. See caption of Figure 5 for a full description of how the histograms are constructed. The two global equivalence ratios
 $ {\phi}_g=0.45 $
and
$ {\phi}_g=0.45 $
and
 $ 0.55 $
were not included in the training dataset. The CNN approximates the burning rates with high accuracy, demonstrating the ability to generalize to other equivalence ratios from which it has been trained.
$ 0.55 $
were not included in the training dataset. The CNN approximates the burning rates with high accuracy, demonstrating the ability to generalize to other equivalence ratios from which it has been trained.
These generalization results are very promising and show that a CNN model can generalize with a reasonable amount of training cases. This is particularly important with regard to the global equivalence ratio
 $ {\phi}_g $
. Computing a DNS for each global equivalence ratio has a significant computing cost. In contrast, the computational cost of a filtering and downsampling operation to produce a new set of LES parameters
$ {\phi}_g $
. Computing a DNS for each global equivalence ratio has a significant computing cost. In contrast, the computational cost of a filtering and downsampling operation to produce a new set of LES parameters
 $ \left(\sigma, \mathrm{DSF}\right) $
is negligible.
$ \left(\sigma, \mathrm{DSF}\right) $
is negligible.
3.3. Comparison with a filtered tabulated chemistry approach
A filtered tabulated chemistry modeling is implemented to compare CNN results with an established approach for modeling filtered burning rates. In the filtered tabulated chemistry framework, the flame structure in the direction normal to the flame front is assumed identical to the structure of a planar 1D freely propagating premixed laminar flame (Fiorina et al., Reference Fiorina, Vicquelin, Auzillon, Darabiha, Gicquel and Veynante2010). For a given filter size, it is then possible to apply the filter operation introduced in Section 2.3.2 (Eqs (1.1) and (2.8)) to a precomputed 1D flame at a given global equivalence ratio
 $ {\phi}_g $
and extract the burning rates directly as
$ {\phi}_g $
and extract the burning rates directly as
 $$ \overline{\dot{\omega}}\approx {\overline{\dot{\omega}}}^{+}\left(\tilde{c},{\phi}_g\right), $$
$$ \overline{\dot{\omega}}\approx {\overline{\dot{\omega}}}^{+}\left(\tilde{c},{\phi}_g\right), $$
where
 $ {\overline{\dot{\omega}}}^{+} $
is the filtered burning rate of the 1D flame, mapped as a function of the filtered progress variable
$ {\overline{\dot{\omega}}}^{+} $
is the filtered burning rate of the 1D flame, mapped as a function of the filtered progress variable
 $ \tilde{c} $
for a given filter size
$ \tilde{c} $
for a given filter size
 $ \sigma $
. To account for the local fluctuation of the equivalence ratio in the domain, it is possible to retrieve the reaction rate in a 1D flame computed with the local equivalence ratio
$ \sigma $
. To account for the local fluctuation of the equivalence ratio in the domain, it is possible to retrieve the reaction rate in a 1D flame computed with the local equivalence ratio
 $ \phi $
used to define the fresh gas composition. In this case, we write
$ \phi $
used to define the fresh gas composition. In this case, we write
 $$ \overline{\dot{\omega}}\approx {\overline{\dot{\omega}}}^{+}\left(\tilde{c},\tilde{\phi}\right). $$
$$ \overline{\dot{\omega}}\approx {\overline{\dot{\omega}}}^{+}\left(\tilde{c},\tilde{\phi}\right). $$
Flame wrinkling at the subfilter-scale level is lost in LES. A subfilter-scale wrinkling factor
 $ \Xi $
needs to be applied to compensate for the loss in flame surface (Poinsot and Veynante, Reference Poinsot and Veynante2011). The filtered burning rate for filtered tabulated chemistry modeling therefore reads
$ \Xi $
needs to be applied to compensate for the loss in flame surface (Poinsot and Veynante, Reference Poinsot and Veynante2011). The filtered burning rate for filtered tabulated chemistry modeling therefore reads
 $$ {\overline{\dot{\omega}}}^F=\Xi \hskip0.1em {\overline{\dot{\omega}}}^{+}\left(\tilde{c},{\phi}_g\right)\;\mathrm{or}\;{\overline{\dot{\omega}}}^{FC}=\Xi \hskip0.1em {\overline{\dot{\omega}}}^{+}\left(\tilde{c},\tilde{\phi}\right), $$
$$ {\overline{\dot{\omega}}}^F=\Xi \hskip0.1em {\overline{\dot{\omega}}}^{+}\left(\tilde{c},{\phi}_g\right)\;\mathrm{or}\;{\overline{\dot{\omega}}}^{FC}=\Xi \hskip0.1em {\overline{\dot{\omega}}}^{+}\left(\tilde{c},\tilde{\phi}\right), $$
depending on whether the global or local equivalence ratio is used to define the fresh gas composition in the corresponding 1D flame. The wrinkling factor
 $ \Xi $
is usually modeled by algebraic expressions. Models based on a fractal description of the flame front (Gouldin, Reference Gouldin1987; Gouldin et al., Reference Gouldin, Bray and Chen1989) are very common. They assume that in a range of physical scales bounded by an inner cutoff
$ \Xi $
is usually modeled by algebraic expressions. Models based on a fractal description of the flame front (Gouldin, Reference Gouldin1987; Gouldin et al., Reference Gouldin, Bray and Chen1989) are very common. They assume that in a range of physical scales bounded by an inner cutoff
 $ \eta $
and an outer cutoff
$ \eta $
and an outer cutoff
 $ L $
, the flame front is a fractal surface of dimension
$ L $
, the flame front is a fractal surface of dimension
 $ 2\le {D}_f\le 3 $
. The wrinkling factor is given by
$ 2\le {D}_f\le 3 $
. The wrinkling factor is given by
 $$ \Xi ={\left(\frac{L}{\eta}\right)}^{D_f-2}. $$
$$ \Xi ={\left(\frac{L}{\eta}\right)}^{D_f-2}. $$
 $ L $
corresponds to the size of the largest unresolved wrinkles, which is of the order of the thickness of the LES flame estimated as
$ L $
corresponds to the size of the largest unresolved wrinkles, which is of the order of the thickness of the LES flame estimated as
 $ {\delta}_{c,L}^1 $
(Eq. (2.9)).
$ {\delta}_{c,L}^1 $
(Eq. (2.9)).
 $ \eta $
is the size of the smallest wrinkles and varies from
$ \eta $
is the size of the smallest wrinkles and varies from
 $ \eta =L $
(that is no unresolved wrinkling,
$ \eta =L $
(that is no unresolved wrinkling,
 $ \Xi =1 $
) to
$ \Xi =1 $
) to
 $ \eta ={\delta}_{c,L}^0 $
(that is filling of the space by a flame surface of fractal dimension
$ \eta ={\delta}_{c,L}^0 $
(that is filling of the space by a flame surface of fractal dimension
 $ {D}_f $
between cut-off scales
$ {D}_f $
between cut-off scales
 $ {\delta}_{c,L}^0 $
and
$ {\delta}_{c,L}^0 $
and
 $ L $
,
$ L $
,
 $ \Xi ={\left(L/{\delta}_{c,L}^0\right)}^{D_f-2} $
). The latter situation is reached when turbulence intensity is sufficiently high, which is often the case in practice (Veynante et al., Reference Veynante, Schmitt, Boileau and Moureau2012; Veynante and Moureau, Reference Veynante and Moureau2015). We then assume
$ \Xi ={\left(L/{\delta}_{c,L}^0\right)}^{D_f-2} $
). The latter situation is reached when turbulence intensity is sufficiently high, which is often the case in practice (Veynante et al., Reference Veynante, Schmitt, Boileau and Moureau2012; Veynante and Moureau, Reference Veynante and Moureau2015). We then assume
 $ \eta ={\delta}_{c,L}^0 $
in Eq. (3.5), maximizing the flame surface density at the subfilter-scale level. The fractal dimension is estimated as
$ \eta ={\delta}_{c,L}^0 $
in Eq. (3.5), maximizing the flame surface density at the subfilter-scale level. The fractal dimension is estimated as
 $ {D}_f=2.5 $
following the work of Charlette et al. (Reference Charlette, Meneveau and Veynante2002). The set of 1D flames is computed using the San Diego mechanism (Saxena and Williams, Reference Saxena and Williams2006) for the chemical kinetics (same as the training database for the CNN) and a mixture-averaged transport model for the diffusivities.
$ {D}_f=2.5 $
following the work of Charlette et al. (Reference Charlette, Meneveau and Veynante2002). The set of 1D flames is computed using the San Diego mechanism (Saxena and Williams, Reference Saxena and Williams2006) for the chemical kinetics (same as the training database for the CNN) and a mixture-averaged transport model for the diffusivities.
CNN-based modeling significantly outperforms the filtered tabulated chemistry one, especially for the lean cases (e.g.
 $ {\phi}_g=0.35 $
in Figure 9). Due to the extremely high thermodiffusive effects in very lean cases, the burning rates of the turbulent 3D field can be much higher than those in a freely propagating planar flame at the same equivalence ratio. For example, for the case
$ {\phi}_g=0.35 $
in Figure 9). Due to the extremely high thermodiffusive effects in very lean cases, the burning rates of the turbulent 3D field can be much higher than those in a freely propagating planar flame at the same equivalence ratio. For example, for the case
 $ {\phi}_g=0.35 $
,
$ {\phi}_g=0.35 $
,
 $ \sigma =4 $
,
$ \sigma =4 $
,
 $ \mathrm{DSF}=2 $
, the maximum burning rate in the 3D field
$ \mathrm{DSF}=2 $
, the maximum burning rate in the 3D field
 $ \max \left({\overline{\dot{\omega}}}^{\ast}\right) $
is about
$ \max \left({\overline{\dot{\omega}}}^{\ast}\right) $
is about
 $ 17 $
times greater than that in a laminar planar flame
$ 17 $
times greater than that in a laminar planar flame
 $ \max \left({\overline{\dot{\omega}}}^{+}\right) $
. This is due to the fact that flame strain is not considered in the tabulation method applied and that the subfilter wrinkling factor
$ \max \left({\overline{\dot{\omega}}}^{+}\right) $
. This is due to the fact that flame strain is not considered in the tabulation method applied and that the subfilter wrinkling factor
 $ \Xi $
only takes into account turbulence-induced wrinkling, ignoring that induced by thermodiffusive instabilities and their interactions with turbulence (Berger et al., Reference Berger, Attili and Pitsch2022c). This
$ \Xi $
only takes into account turbulence-induced wrinkling, ignoring that induced by thermodiffusive instabilities and their interactions with turbulence (Berger et al., Reference Berger, Attili and Pitsch2022c). This
 $ {\phi}_g=0.35 $
case is a truly extreme test case to illustrate the strength of the CNN model. Tabulated chemistry modeling does not fail so spectacularly for equivalence ratios close to stoichiometry, where preferential and differential diffusion effects are less pronounced (Berger et al., Reference Berger, Attili and Pitsch2022b) (e.g.
$ {\phi}_g=0.35 $
case is a truly extreme test case to illustrate the strength of the CNN model. Tabulated chemistry modeling does not fail so spectacularly for equivalence ratios close to stoichiometry, where preferential and differential diffusion effects are less pronounced (Berger et al., Reference Berger, Attili and Pitsch2022b) (e.g.
 $ {\phi}_g=0.7 $
in Figure 9). The CNN results are still much more accurate thanks to the consideration of the 3D flame structure via successive convolutions. To further demonstrate the CNN’s ability to learn from flame topology, training has been performed without information on the equivalence ratio for the case
$ {\phi}_g=0.7 $
in Figure 9). The CNN results are still much more accurate thanks to the consideration of the 3D flame structure via successive convolutions. To further demonstrate the CNN’s ability to learn from flame topology, training has been performed without information on the equivalence ratio for the case
 $ {\phi}_g=0.35 $
. This study is given as Supplementary Material. It is found that the burning rate approximation is still very accurate, proving our initial claim that a CNN is capable of recognizing complex flame topology and inferring associated burning rates by learning spatial hierarchies of features.
$ {\phi}_g=0.35 $
. This study is given as Supplementary Material. It is found that the burning rate approximation is still very accurate, proving our initial claim that a CNN is capable of recognizing complex flame topology and inferring associated burning rates by learning spatial hierarchies of features.

Figure 9. Scatter plots of the CNN-modeled burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
and the filtered tabulated chemistry burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{NN}} $
and the filtered tabulated chemistry burning rate
 $ {\overline{\dot{\omega}}}^{\mathrm{F}} $
or
$ {\overline{\dot{\omega}}}^{\mathrm{F}} $
or
 $ {\overline{\dot{\omega}}}^{\mathrm{FC}} $
(Eq. (3.4)) versus ground-truth filtered burning rate
$ {\overline{\dot{\omega}}}^{\mathrm{FC}} $
(Eq. (3.4)) versus ground-truth filtered burning rate
 $ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. Gray dashed line indicates
$ {\overline{\dot{\omega}}}^{\ast } $
. Individual values are normalized by the maximum burning rate in the datasets. Gray dashed line indicates
 $ x=y $
(that is zero error). Two cases of LES parameter sets are presented for two global equivalence ratios: the lowest equivalence ratio
$ x=y $
(that is zero error). Two cases of LES parameter sets are presented for two global equivalence ratios: the lowest equivalence ratio
 $ {\phi}_g=0.35 $
for which the filtered tabulated chemistry is significantly flawed due to very strong thermodiffusive effects; the highest equivalence ratio
$ {\phi}_g=0.35 $
for which the filtered tabulated chemistry is significantly flawed due to very strong thermodiffusive effects; the highest equivalence ratio
 $ {\phi}_g=0.7 $
for which thermodiffusive effects are less important.
$ {\phi}_g=0.7 $
for which thermodiffusive effects are less important.
4. Conclusion and future work
Trustworthy LES of lean premixed hydrogen combustion requires advanced modeling methods considering thermodiffusive effects on burning rates at the subfilter-scale level. These effects are extremely complex and their coupling with turbulence is controversial, making the derivation of analytical models very difficult. We therefore propose a pure ML approach where a CNN is trained to approximate LES burning rates from emulated LES fields, generated by explicitly filtering many DNS snapshots. The configuration used to generate the training data is a slot burner where a turbulent flow of premixed
 $ {\mathrm{H}}_2 $
-air mixture is placed in between two coflows of burnt gas burnt at the same equivalence ratio. The training dataset is built up by performing five DNSs of this configuration, each with a unique global equivalence ratio. The DNS solutions are then filtered and downsampled using three different sizes to emulate LES solutions. Many small cubes are extracted from the solutions to train the CNN model so that it does not learn the specific configuration but rather generic flame elements, improving its generalization ability later on.
$ {\mathrm{H}}_2 $
-air mixture is placed in between two coflows of burnt gas burnt at the same equivalence ratio. The training dataset is built up by performing five DNSs of this configuration, each with a unique global equivalence ratio. The DNS solutions are then filtered and downsampled using three different sizes to emulate LES solutions. Many small cubes are extracted from the solutions to train the CNN model so that it does not learn the specific configuration but rather generic flame elements, improving its generalization ability later on.
The trained CNN model retrieves burning rates with very high accuracy on the 3D full-scale test solutions. It is able to model burning rates in a very complex turbulent flame topology with flame elements detached from the main flame brush. In addition, the CNN approximates burning rates with low errors for filter and downsampling parameters and global equivalence ratios other than those for which it has been trained. The ML-based modeling outperforms a priori a classical filtered tabulated chemistry approach with correction for flame surface density due to subfilter-scale flame wrinkling. This is particularly true for very lean flames, where differential diffusion effects are major and undermine modeling based on flame surface density.
These results are extremely promising. They demonstrate that it is possible to build an ML-based model of the burning rates of turbulent lean premixed
 $ {\mathrm{H}}_2 $
-air flames—an extremely challenging task—that can generalize outside the scope for which it has been trained. Generalization is very important if we are really going to consider implementing this type of model in engineering simulation software. This work paves the way for a new modeling approach to turbulent
$ {\mathrm{H}}_2 $
-air flames—an extremely challenging task—that can generalize outside the scope for which it has been trained. Generalization is very important if we are really going to consider implementing this type of model in engineering simulation software. This work paves the way for a new modeling approach to turbulent
 $ {\mathrm{H}}_2 $
combustion, which we want to pursue with the scientific community in the very near future.
$ {\mathrm{H}}_2 $
combustion, which we want to pursue with the scientific community in the very near future.
We can then draw up a roadmap for integration into an LES code. First, the modeling of the subfilter-scale fluxes in Eq. (1.2) remains to be addressed. It could be done through gradient transport models with a turbulent viscosity hypothesis (Boger et al., Reference Boger, Veynante, Boughanem and Trouvé1998). If this closure fails to retrieve correct flame propagation speeds, we could consider training the CNN to approximate the fluxes using several output channels. Second, the evolution of the entire chemical system must be described. This can be done by training the CNN on the source term of a progress variable, transported instead of the individual species that make up the reactive mixture. This is done, for example, in Lapenna et al. (Reference Lapenna, Berger, Attili, Lamioni, Fogla, Pitsch and Creta2021, Reference Lapenna, Remiddi, Molinaro, Indelicato and Creta2024) with a tabulation method for the closure of the transport equation of the progress variable. However, the transport of the mixture fraction must be modeled to account for equivalence ratio fluctuations. We could also train the model again on a database generated with a single global chemical reaction (Millán-Merino and Boivin, Reference Millán-Merino and Boivin2024; Schiavone et al., Reference Schiavone, Detomaso, Torresi and Laera2024). This has the advantage of being able to transport physical species instead of a progress variable, accounting for preferential diffusion through the multi-species Navier–Stokes equations directly.
Second, there are a number of practical integration challenges to be tackled. In a massively parallel HPC code, the fluid domain is decomposed in many partitions distributed over the MPI tasks (typically one MPI per GPU). When inference is performed on each MPI, artefacts may appear at the boundaries of the partitions (Serhani et al., Reference Serhani, Xing, Dupuy, Lapeyre and Staffelbach2024). To avoid this, the inference must be given its neighboring context to produce overlapping predictions. However, this incurs additional MPI communication costs that must be evaluated on a case-by-case basis. Another major challenge is related to the voxel grid requirement for the CNN. If the CFD code uses an irregular grid that does not match the voxel/pixel structure, two grids have to be used: one for the fluid solver, and one for the CNN inference. This requires the development of efficient methods for interpolating on the fly and transferring data between the two grids. The PhyDLLFootnote 1 (Serhani et al., Reference Serhani, Xing, Dupuy, Lapeyre and Staffelbach2024) open-source library is one effort that could help to address these issues. These questions will be the focus of a future project, now that we have shown that CNN-based modeling of the burning rates is possible with this work.
Supplementary material
The supplementary material for this article can be found at http://doi.org/10.1017/dce.2025.1.
Data availability statement
Code for training and inference is available via GitLab at https://gitlab.com/male.quentin/cnn_h2flame. A set of solutions from DNS is distributed via Kaggle as part of BLASTNetFootnote 2 (https://www.kaggle.com/organizations/blastnet) with the following identifiers:
-
• blastnet/premixed-flame-slot-burner-dns-h2air-phi035
-
• blastnet/premixed-flame-slot-burner-dns-h2air-phi04
-
• blastnet/premixed-flame-slot-burner-dns-h2air-phi05
-
• blastnet/premixed-flame-slot-burner-dns-h2air-phi06
-
• blastnet/premixed-flame-slot-burner-dns-h2air-phi07
Acknowledgments
The authors gratefully acknowledge CERFACS for providing the LES solver AVBP and the Antares and ARCANE libraries.
Author contribution
Q.M.: conceived the research project, performed the DNS, generated the database, trained the CNN, post-processed the results, performed the analysis, discussed the results, and wrote the article. C.J.L.: discussed the results, and reviewed and edited the article. N.N.: discussed the results, and reviewed and edited the article.
Funding statement
This research was funded in part by the Swiss National Science Foundation (SNSF) under grant agreement No. 219938. This work was supported by a grant from the Swiss National Supercomputing Centre (CSCS) under project ID s1262.
Competing interest
The authors declare none.
Ethical standard
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.



























































 Open access
Open access
Comments
No Comments have been published for this article.