



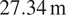
Impact Statement
Engineering structures, such as bridges, tunnels, power plants, or buildings, are vital to the functioning of society. So far, they have been designed, built, and maintained primarily with the aid of computational finite element models that rely on numerous empirical assumptions and codified safety factors. The predictions of such models often bear little resemblance to the behavior of the actual structure. Lately, advances in infrastructure monitoring using sensor networks are providing an unprecedented amount of data from structures in operation. The recently proposed statistical finite element method (statFEM) boosts the predictive accuracy of models by synthesizing their output with sensor data. In this work, the statFEM is used in developing a digital twin of an operational railway bridge. The obtained digital twin enables the autonomous continuous monitoring and condition assessment of the bridge.
1. Introduction
Designers, engineers, and maintenance managers commonly rely on finite element (FE) models to help better understand the current and future behavior of infrastructure assets. FE models are used both to facilitate the design of new structures and to help assess structures that have already been in operation for many years. The level of sophistication of the FE models depends on their intended purpose, the structure modeled, and the resources available (i.e., technical skill, time, computational power, etc.). As with any other model, FE models rely on assumptions and parameters, which are inevitably subject to uncertainties, both epistemic and aleatoric, and require sufficient degree of experience to verify and interpret the predicted results (Oden et al., Reference Oden, Moser and Ghattas2010; Lau et al., Reference Lau, Adams, Girolami, Butler and Elshafie2018).
More recently, a trend toward monitoring of infrastructure assets using sensor networks has led to the development of new data-driven approaches to assess the performance of structures, see the reviews Abdulkarem et al. (Reference Abdulkarem, Samsudin, Rokhani and Rasid2020); Lynch (Reference Lynch2007); Brownjohn (Reference Brownjohn2007). Sensing data can, for instance, provide performance information to help decide when to inspect, repair, or decommission a structure and to accelerate or improve prototyping of new construction techniques and materials (Frangopol and Soliman, Reference Frangopol and Soliman2016). There has been a wide array of field studies that have implemented sensing in bridges, tunnel linings, high-rise buildings, and dams. For instance, De Battista et al. (Reference De Battista, Cheal, Harvey and Kechavarzi2017) instrumented several columns and walls on every floor in a 50-storey residential tower in central London. Using distributed fiber optic sensors (DFOS), they measured the axial shortening of the various columns and walls as the building was being erected. Recently, Di et al. (Reference Di, Ruan, Zhou, Wang and Peng2021) reported a study in which electrical-based strain gauges were installed on a
 $ 450\hskip1.5pt \mathrm{m} $
steel tied-arch bridge with an orthotropic steel deck. These types of bridge structures are particularly susceptible to fatigue damage and, using the data captured via the sensors, they were able to identify several fatigue-vulnerable locations along the structure. Another unique application of structural health monitoring of a
$ 450\hskip1.5pt \mathrm{m} $
steel tied-arch bridge with an orthotropic steel deck. These types of bridge structures are particularly susceptible to fatigue damage and, using the data captured via the sensors, they were able to identify several fatigue-vulnerable locations along the structure. Another unique application of structural health monitoring of a
 $ 100\hskip1.5pt \mathrm{m} $
segment of tunnel lining at the CERN (European Council for Nuclear Research) was conducted by Di Murro et al. (Reference Di Murro, Pelecanos, Soga, Kechavarzim and Morton2016). Localized tension and compression cracks were observed in the tunnel and prompted instrumentation and monitoring using DFOS. In light of data captured over 10 months, they reported strain levels in the tunnel, which ultimately proved to be insignificant.
$ 100\hskip1.5pt \mathrm{m} $
segment of tunnel lining at the CERN (European Council for Nuclear Research) was conducted by Di Murro et al. (Reference Di Murro, Pelecanos, Soga, Kechavarzim and Morton2016). Localized tension and compression cracks were observed in the tunnel and prompted instrumentation and monitoring using DFOS. In light of data captured over 10 months, they reported strain levels in the tunnel, which ultimately proved to be insignificant.
With the increase in structural health monitoring campaigns, the infrastructure engineering sector has been inundated with large quantities of data whose value is still being realized. In particular, this emerging sensing paradigm has resulted in the development of new data-driven strategies to model infrastructure performance, see the insightful reviews Huang et al. (Reference Huang, Shao, Wu, Beck and Li2019); Wu and Jahanshahi (Reference Wu and Jahanshahi2020). Unlike FE modeling, data-driven approaches utilizing monitoring data provide information about the actual operational performance of a particular infrastructure asset. The modeling effort associated with data-driven techniques is lower than in FE modeling. However, even the most advanced data-driven models, which are often based on artificial neural networks, Gaussian process regression, or Bayesian model updating, require a copious amount of real-world training data to make predictions. This challenge has prompted research in the areas of model updating and system identification which have attempted to use both FE and data-driven models to provide better predictions of structural behavior, see, for example, Malekzadeh et al. (Reference Malekzadeh, Atia and Catbas2015); Pasquier and Smith (Reference Pasquier and Smith2016); Tsialiamanis et al. (Reference Tsialiamanis, Wagg, Dervilis and Worden2021). However, the current modeling approaches seem to be unable to synthesize measurement data with uncertainties and predictions from inherently misspecified FE models in a manner that allows for the generation of continuous predictions as new measurement data become available. This ability is, however, critical to the realization of digital twins (Rasheed et al., Reference Rasheed, San and Kvamsdal2020; Worden et al., Reference Worden, Cross, Barthorpe, Wagg and Gardner2020). In its broadest sense, as defined in a UK governmental report, a digital twin is a realistic digital representation of assets, processes, or systems in the built or natural environment (Bolton et al., Reference Bolton, Enzer and Schooling2018).
The statistical construction of the FE method, dubbed statistical finite element method (statFEM), recently introduced in Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021) allows predictions to be made about the true system behavior in light of limited sensor data and a misspecified FE model. As in all Bayesian approaches, any lack of knowledge, or uncertainty, associated with the errors in the collected data, choice of the FE model, and its parameters are represented as random variables. See Beck (Reference Beck2010) or Huang et al. (Reference Huang, Shao, Wu, Beck and Li2019) for an overview on Bayesian approaches in structural health monitoring. Typically, the as-built dimensions, support conditions, and loadings of a structure are only partially known and can be treated as random. Starting from some assumed (subjective) prior probability densities for the random variables, Bayes rule provides a coherent formalism to infer, or learn, the respective posterior densities using the likelihood of the observations (Gelman et al., Reference Gelman, Carlin, Stern, Dunson, Vehtari and Rubin2013; Stuart, Reference Stuart2010; Kaipio and Somersalo, Reference Kaipio and Somersalo2006).
In statFEM, following Kennedy and O’Hagan (Reference Kennedy and O’Hagan2001), the observed data
 $ \mathbf{y} $
is equated to three random components: a FE component
$ \mathbf{y} $
is equated to three random components: a FE component
 $ \mathbf{u} $
, a model misspecification component
$ \mathbf{u} $
, a model misspecification component
 $ \mathbf{d} $
, and measurement noise
$ \mathbf{d} $
, and measurement noise
 $ \mathbf{e} $
. The prior densities of each of the three random components may depend on additional random hyperparameters to be learned from the sensor data. In this paper, only the model misspecification component has hyperparameters. It is straightforward to introduce other hyperparameters pertaining to aspects of the FE model and the measurement noise, see Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021). The choice of additional hyperparameters leads to an increase in computational cost and requires particular care to circumvent non-identifiability issues (Arendt et al., Reference Arendt, Apley and Chen2012; Nagel and Sudret, Reference Nagel and Sudret2016). The posterior density of the FE component, the true system response, and the hyperparameters are inferred via the Bayes rule. The overall approach is akin to the empirical Bayes or evidence approximation techniques prevalent in machine learning (MacKay, Reference MacKay1992, Reference MacKay1999; Murphy, Reference Murphy2012). The prior probability density of the FE component is obtained by solving a traditional probabilistic forward problem with random parameters (Sudret and Der Kiureghian, Reference Sudret and Der Kiureghian2000; Ghanem and Spanos, Reference Ghanem and Spanos1991).
$ \mathbf{e} $
. The prior densities of each of the three random components may depend on additional random hyperparameters to be learned from the sensor data. In this paper, only the model misspecification component has hyperparameters. It is straightforward to introduce other hyperparameters pertaining to aspects of the FE model and the measurement noise, see Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021). The choice of additional hyperparameters leads to an increase in computational cost and requires particular care to circumvent non-identifiability issues (Arendt et al., Reference Arendt, Apley and Chen2012; Nagel and Sudret, Reference Nagel and Sudret2016). The posterior density of the FE component, the true system response, and the hyperparameters are inferred via the Bayes rule. The overall approach is akin to the empirical Bayes or evidence approximation techniques prevalent in machine learning (MacKay, Reference MacKay1992, Reference MacKay1999; Murphy, Reference Murphy2012). The prior probability density of the FE component is obtained by solving a traditional probabilistic forward problem with random parameters (Sudret and Der Kiureghian, Reference Sudret and Der Kiureghian2000; Ghanem and Spanos, Reference Ghanem and Spanos1991).
This paper evaluates the application of statFEM to the development of a statistical digital twin of the superstructure of an operational railway bridge, see Figure 1. The newly constructed skewed half-through bridge has previously been instrumented with fiber optic-based sensors (FOSs). The instrumentation of the bridge using FBG strain sensors is described in Butler et al. (Reference Butler, Lin, Xu, Gibbons, Elshafie and Middleton2018). The sensor measurements have since been compared with a deterministic FE model of the bridge in Lin et al. (Reference Lin, Butler, Elshafie and Middleton2019). The contributions of the present work are threefold: (1) the first-time application of a new modeling paradigm for use in structural health monitoring; (2) evaluating the trade-off between the number of sensor measurements and the accuracy of statFEM prediction; and (3) introducing the concept of a statistical digital twin by demonstrating the application of statFEM to continuous strain sensing.

Figure 1. Railway intersection bridge, a representative finite element discretization and the statistical model underlying statFEM. The unobserved “true” bridge response
 $ \mathbf{\mathsf{z}} $
, the strain
$ \mathbf{\mathsf{z}} $
, the strain
 $ \mathbf{\mathsf{y}} $
measured using fiber Bragg grating (FBG) sensors, and the finite element response
$ \mathbf{\mathsf{y}} $
measured using fiber Bragg grating (FBG) sensors, and the finite element response
 $ \mathbf{\mathsf{u}} $
are all random.
$ \mathbf{\mathsf{u}} $
are all random.
The outline of this paper is as follows. In Section 2, the structural system of the railway bridge and its instrumentation with FBG sensors are introduced. The proposed statistical digital twin of the superstructure is discussed in Section 3. To this end, first the statFEM is reviewed in Section 3.1, and the FE model of the structure is then presented in Section 3.2. In Section 4, the obtained digital twin is used to infer the true strain distribution over the entire structure during the passage of a train. In particular, it is shown that the inference results are largely insensitive to the number of sensors and sampling frequency confirming the utility of a statFEM model as an integral part of a digital twin. Section 5 concludes the paper and discusses several promising directions for future research.
2. Self-sensing Railway Bridge
This section provides a summary of the structural system of the railway bridge and its sensor instrumentation with a FOS network. Both were previously introduced in Butler et al. (Reference Butler, Lin, Xu, Gibbons, Elshafie and Middleton2018) and Lin et al. (Reference Lin, Butler, Elshafie and Middleton2019).
2.1. Structural system
Completed in 2016, Intersection Bridge 20A is a
 $ 27.34\ \mathrm{m} $
steel skewed half-through railway bridge located along the West Coast Mainline in Staffordshire in UK (Figure 1). The bridge carries two lines of passenger trains (with speeds up to
$ 27.34\ \mathrm{m} $
steel skewed half-through railway bridge located along the West Coast Mainline in Staffordshire in UK (Figure 1). The bridge carries two lines of passenger trains (with speeds up to
 $ 160\ \mathrm{k}\mathrm{m}/\mathrm{h} $
) over another heavily trafficked rail corridor along the West Coast Main Line. The superstructure consists of a pair of steel main I-beams and 21 transverse I-beams spanning the
$ 160\ \mathrm{k}\mathrm{m}/\mathrm{h} $
) over another heavily trafficked rail corridor along the West Coast Main Line. The superstructure consists of a pair of steel main I-beams and 21 transverse I-beams spanning the
 $ 7.3\ \mathrm{m} $
width of the structure, see Figure 2. The two main I-beams (referred to as east and west) are
$ 7.3\ \mathrm{m} $
width of the structure, see Figure 2. The two main I-beams (referred to as east and west) are
 $ 26.84\ \mathrm{m} $
long and
$ 26.84\ \mathrm{m} $
long and
 $ 2.2\ \mathrm{m} $
deep (including doubler plates). Web stiffeners welded along the outside web of the main I-beams are used to improve stability and to prevent local buckling of the web and top flanges. Four rocker-type bearings, which sit atop reinforced concrete abutments, support the bridge superstructure.
$ 2.2\ \mathrm{m} $
deep (including doubler plates). Web stiffeners welded along the outside web of the main I-beams are used to improve stability and to prevent local buckling of the web and top flanges. Four rocker-type bearings, which sit atop reinforced concrete abutments, support the bridge superstructure.

Figure 2. Dimensions of the bridge superstructure (all in mm).
The transverse I-beams are
 $ 368\ \mathrm{m}\mathrm{m} $
deep and the attached shear stud connectors provide for composite action with the reinforced concrete deck slab. The transverse beams are spaced at every
$ 368\ \mathrm{m}\mathrm{m} $
deep and the attached shear stud connectors provide for composite action with the reinforced concrete deck slab. The transverse beams are spaced at every
 $ 1.5\ \mathrm{m} $
in the middle of the bridge and are fanned closer toward the two ends. Two types of connection are used between the transverse and main I-beams. The transverse beams are consecutively either pinned with a 6-bolt end plate or moment connected with a 10-bolt stiffened end plate. A
$ 1.5\ \mathrm{m} $
in the middle of the bridge and are fanned closer toward the two ends. Two types of connection are used between the transverse and main I-beams. The transverse beams are consecutively either pinned with a 6-bolt end plate or moment connected with a 10-bolt stiffened end plate. A
 $ 250\ \mathrm{m}\mathrm{m} $
thick reinforced concrete deck slab spans between transverse beams and supports the ballasted track bed system. The ballast has the minimum depth of
$ 250\ \mathrm{m}\mathrm{m} $
thick reinforced concrete deck slab spans between transverse beams and supports the ballasted track bed system. The ballast has the minimum depth of
 $ 300\ \mathrm{m}\mathrm{m} $
and supports the prestressed concrete sleepers to which the rails are fastened.
$ 300\ \mathrm{m}\mathrm{m} $
and supports the prestressed concrete sleepers to which the rails are fastened.
2.2. Sensor instrumentation
This recently constructed bridge was instrumented with an innovative FOS network which was designed to provide reliable long-term measurements of the bridge’s operational performance (Butler et al., Reference Butler, Lin, Xu, Gibbons, Elshafie and Middleton2018). The FBG sensors used were based on draw tower grating technology in which the gratings are inscribed at the time of glass drawing and prior to application of the core cladding. Compared with traditionally manufactured FBGs in which the core cladding must be stripped prior to FBG inscription, draw tower gratings are inherently more robust and, in the case of the sensors used in this project, enable the inscription of up to 20 FBGs along a single sensor cable. As depicted in Figure 3, FBG sensors were installed on the main structural elements. The sensor arrays used had up to 108 strain FBGs. Along the east main I-beam, 20 FBGs were placed at 1m spacing along both the top and bottom flanges. Similarly, the same sensor arrangement is installed along the west main I-beam (i.e., 40 FBGs per I-beam). The other 28 FBGs are located along the top and bottom flanges of two adjacent transverse I-beams close to the midspan of the main I-beams.

Figure 3. Position and numbering of the FBG strain sensors installed on the bridge. The same numbering is used for the sensors at both top and bottom flanges. Not to scale.
The sensors installed were based on FBG technology which can measure strain and temperature at discrete points along an optical fiber. Consisting of glass fibers, FOS is lightweight, requires minimal number of wiring cables, and provides stable long-term measurements. When laser light is shone down a fiber optic cable, the gratings act like dielectric mirrors reflecting only those wavelengths, which match the Bragg wavelength. When the fiber optic cable is elongated (or shortened), the wavelength of the reflected light shifts in proportion to this change in strain. Once a fiber optic cable is attached to a structure, the cable can be used to measure changes in strain of the structure itself. The mechanical strain can be calculated by removing temperature effects associated with the thermal expansion of glass, the effect of temperature on the index of refraction, and the thermal expansion of the substrate material (i.e., steel) using
 $$ \Delta {\varepsilon}_m=\frac{1}{k_{\varepsilon }}\left({\left(\frac{\Delta \lambda }{\lambda_0}\right)}_S-{k}_T\frac{{\left(\frac{\Delta \lambda }{\lambda_0}\right)}_T}{k_{T_T}}\right)-{\alpha}_{\mathrm{sub}}\frac{{\left(\frac{\Delta \lambda }{\lambda_0}\right)}_T}{k_{T_T}}, $$
$$ \Delta {\varepsilon}_m=\frac{1}{k_{\varepsilon }}\left({\left(\frac{\Delta \lambda }{\lambda_0}\right)}_S-{k}_T\frac{{\left(\frac{\Delta \lambda }{\lambda_0}\right)}_T}{k_{T_T}}\right)-{\alpha}_{\mathrm{sub}}\frac{{\left(\frac{\Delta \lambda }{\lambda_0}\right)}_T}{k_{T_T}}, $$
where
 $ \Delta {\varepsilon}_m $
is the change in mechanical strain;
$ \Delta {\varepsilon}_m $
is the change in mechanical strain;
 $ {\left(\Delta \lambda /{\lambda}_0\right)}_S $
is the change in relative wavelength of the strain sensor;
$ {\left(\Delta \lambda /{\lambda}_0\right)}_S $
is the change in relative wavelength of the strain sensor;
 $ {\left(\Delta \lambda /{\lambda}_0\right)}_T $
is the change in relative wavelength of the temperature-compensating sensor;
$ {\left(\Delta \lambda /{\lambda}_0\right)}_T $
is the change in relative wavelength of the temperature-compensating sensor;
 $ {k}_{\varepsilon } $
is the gauge factor provided by the strain FBG manufacturer (typically 0.78);
$ {k}_{\varepsilon } $
is the gauge factor provided by the strain FBG manufacturer (typically 0.78);
 $ {k}_T $
is the change of the refractive index of glass;
$ {k}_T $
is the change of the refractive index of glass;
 $ {k}_{T_T} $
is the experimentally derived constant for the FBG temperature-compensating sensor; and
$ {k}_{T_T} $
is the experimentally derived constant for the FBG temperature-compensating sensor; and
 $ {\alpha}_{\mathrm{sub}} $
is the linear coefficient of thermal expansion of the substrate material (concrete:
$ {\alpha}_{\mathrm{sub}} $
is the linear coefficient of thermal expansion of the substrate material (concrete:
 $ 10\times {10}^{-6}/{}^{\circ}\mathrm{C} $
; steel:
$ 10\times {10}^{-6}/{}^{\circ}\mathrm{C} $
; steel:
 $ 12\times {10}^{-6}/{}^{\circ}\mathrm{C} $
). Each FBG is capable of recording strain with an accuracy of approximately
$ 12\times {10}^{-6}/{}^{\circ}\mathrm{C} $
). Each FBG is capable of recording strain with an accuracy of approximately
 $ \pm 5\cdot {10}^{-6} $
at a data acquisition rate of up to
$ \pm 5\cdot {10}^{-6} $
at a data acquisition rate of up to
 $ 250\ \mathrm{H}\mathrm{z} $
.
$ 250\ \mathrm{H}\mathrm{z} $
.
Monitoring data were captured by the sensor network beginning from the time the bridge was being constructed (Butler et al., Reference Butler, Lin, Xu, Gibbons, Elshafie and Middleton2018). Following the construction, the bridge was monitored sporadically for 2 years (Lin et al., Reference Lin, Butler, Elshafie and Middleton2019). During this period, FBG data were captured during the passage of more than 130 individual trains. This dataset contains strain data for the passage of two passenger train types: the London Midland Class 350 Desiro (type T1) and the Cross Country Class 221 Super Voyager (type T2). Both train types included 4 or 5 car configurations. Their axle weightings and spacing were provided by Network Rail, the UK’s national rail authority.
3. Statistical Digital Twin
This section provides a brief review of statFEM and presents the FE model of the bridge superstructure. For further details on statFEM and its application to diffusion problems refer to Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021). In the FE model, the main sources of uncertainty are the partially known train weight, the resulting structural loads, and the particulars of the FE model. The material properties and geometry parameters are assumed to be deterministic. Moreover, the inertia effects are not taken into account due to the relatively short span of the bridge (Lin et al., Reference Lin, Butler, Elshafie and Middleton2019).
3.1. Review of the statFEM
3.1.1. Probabilistic forward FE formulation
The bridge superstructure is modeled using isogeometrically discretized Kirchhoff–Love shell FEs (Cirak et al., Reference Cirak, Ortiz and Schröder2000, Reference Cirak, Scott, Antonsson, Ortiz and Schröder2002; Cirak and Long, Reference Cirak and Long2011). The shell model takes into account the in-plane membrane and out-of-plane bending response of the structural members. The FE model of the superstructure, consisting of the main girders, cross I-beams, and the reinforced concrete deck, is obtained by rigidly connecting horizontally and vertically aligned plates, that is, initially planar shells, along joints. The joints are able to transfer both forces and moments.
The weak form of the shell equilibrium equation, or the principle of virtual work, for a Kirchhoff–Love shell with the midsurface
 $ \Omega $
and the position vector
$ \Omega $
and the position vector
 $ \boldsymbol{x} $
reads
$ \boldsymbol{x} $
reads
 $$ {\int}_{\hskip-4pt \Omega}(\boldsymbol{n}(\boldsymbol{x}):\delta \boldsymbol{\alpha} (\boldsymbol{x})+\boldsymbol{m}(\boldsymbol{x}):\delta \boldsymbol{\beta} (\boldsymbol{x}))\mathrm{d}\Omega =\sum \limits_j\hskip2.5pt {\boldsymbol{f}}^{(j)}\cdot \delta {\boldsymbol{u}}^{(j)}+{\int}_{\hskip-4pt \Omega}\boldsymbol{r}(\boldsymbol{x})\cdot \delta \boldsymbol{u}(\boldsymbol{x})\mathrm{d}\Omega . $$
$$ {\int}_{\hskip-4pt \Omega}(\boldsymbol{n}(\boldsymbol{x}):\delta \boldsymbol{\alpha} (\boldsymbol{x})+\boldsymbol{m}(\boldsymbol{x}):\delta \boldsymbol{\beta} (\boldsymbol{x}))\mathrm{d}\Omega =\sum \limits_j\hskip2.5pt {\boldsymbol{f}}^{(j)}\cdot \delta {\boldsymbol{u}}^{(j)}+{\int}_{\hskip-4pt \Omega}\boldsymbol{r}(\boldsymbol{x})\cdot \delta \boldsymbol{u}(\boldsymbol{x})\mathrm{d}\Omega . $$
Here, the penalty term enforcing the conformity of the displacements and rotations of all plates attached to the same joint has been omitted for the sake of brevity. The internal virtual work on the left-hand side depends on the membrane force resultant
 $ \boldsymbol{n}\left(\boldsymbol{x}\right) $
, the bending moment resultant
$ \boldsymbol{n}\left(\boldsymbol{x}\right) $
, the bending moment resultant
 $ \boldsymbol{m}\left(\boldsymbol{x}\right) $
, the virtual membrane strain
$ \boldsymbol{m}\left(\boldsymbol{x}\right) $
, the virtual membrane strain
 $ \delta \boldsymbol{\alpha} \left(\boldsymbol{x}\right) $
, and the virtual bending strain
$ \delta \boldsymbol{\alpha} \left(\boldsymbol{x}\right) $
, and the virtual bending strain
 $ \delta \boldsymbol{\beta} \left(\boldsymbol{x}\right) $
. Evidently, these fields depend in turn either on the displacements
$ \delta \boldsymbol{\beta} \left(\boldsymbol{x}\right) $
. Evidently, these fields depend in turn either on the displacements
 $ \boldsymbol{u}\left(\boldsymbol{x}\right) $
or the virtual displacements
$ \boldsymbol{u}\left(\boldsymbol{x}\right) $
or the virtual displacements
 $ \delta \boldsymbol{u}\left(\boldsymbol{x}\right) $
. Furthermore, the material is assumed to be linear elastic and isotropic so that the two resultants
$ \delta \boldsymbol{u}\left(\boldsymbol{x}\right) $
. Furthermore, the material is assumed to be linear elastic and isotropic so that the two resultants
 $ \boldsymbol{n}\left(\boldsymbol{x}\right) $
and
$ \boldsymbol{n}\left(\boldsymbol{x}\right) $
and
 $ \boldsymbol{m}\left(\boldsymbol{x}\right) $
depend on the respective strains
$ \boldsymbol{m}\left(\boldsymbol{x}\right) $
depend on the respective strains
 $ \boldsymbol{\alpha} \left(\boldsymbol{x}\right) $
and
$ \boldsymbol{\alpha} \left(\boldsymbol{x}\right) $
and
 $ \boldsymbol{\beta} \left(\boldsymbol{x}\right) $
via the Young’s modulus
$ \boldsymbol{\beta} \left(\boldsymbol{x}\right) $
via the Young’s modulus
 $ E $
, Poisson’s ratio
$ E $
, Poisson’s ratio
 $ \nu $
, and the shell thickness
$ \nu $
, and the shell thickness
 $ h $
. The right-hand side of (2) represents the external virtual work and depends on the deterministic concentrated forces
$ h $
. The right-hand side of (2) represents the external virtual work and depends on the deterministic concentrated forces
 $ {\boldsymbol{f}}^{(j)} $
applied at the respective positions
$ {\boldsymbol{f}}^{(j)} $
applied at the respective positions
 $ {\boldsymbol{x}}^{(j)} $
and the random distributed loading
$ {\boldsymbol{x}}^{(j)} $
and the random distributed loading
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
. The random distributed loading takes into account the uncertainty in train weight and other uncertainties pertaining to the choice of the FE model. As will be detailed later, it is assumed that the loading applied by the train axles is composed only of vertical components so that both
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
. The random distributed loading takes into account the uncertainty in train weight and other uncertainties pertaining to the choice of the FE model. As will be detailed later, it is assumed that the loading applied by the train axles is composed only of vertical components so that both
 $ {\boldsymbol{f}}^{(j)} $
and
$ {\boldsymbol{f}}^{(j)} $
and
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
have only a nonzero vertical component. The random distributed train loading
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
have only a nonzero vertical component. The random distributed train loading
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
is a Gaussian process with a zero mean and prescribed covariance, that is,
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
is a Gaussian process with a zero mean and prescribed covariance, that is,
 $$ \boldsymbol{r}\left(\boldsymbol{x}\right)=\left(\begin{array}{c}0\\ {}0\\ {}\mathcal{GP}\left(0,{c}_r\left(\boldsymbol{x},,,\hskip-5pt ,{\boldsymbol{x}}^{\prime}\right)\right)\end{array}\right). $$
$$ \boldsymbol{r}\left(\boldsymbol{x}\right)=\left(\begin{array}{c}0\\ {}0\\ {}\mathcal{GP}\left(0,{c}_r\left(\boldsymbol{x},,,\hskip-5pt ,{\boldsymbol{x}}^{\prime}\right)\right)\end{array}\right). $$
Without loss of generality, the squared-exponential kernel is chosen as the covariance function
 $$ {c}_r\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime}\right)={\sigma}_r^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_r^2}\right), $$
$$ {c}_r\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime}\right)={\sigma}_r^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_r^2}\right), $$
where
 $ {\sigma}_r $
is a scaling factor and
$ {\sigma}_r $
is a scaling factor and
 $ {\mathrm{\ell}}_r $
is a length scale parameter. Although the Euclidean squared-distance
$ {\mathrm{\ell}}_r $
is a length scale parameter. Although the Euclidean squared-distance
 $ \parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2 $
has been used, in structural mechanics it may be more appropriate to use the squared geodesic distance (Scarth et al., Reference Scarth, Adhikari, Cabral, Silva and do Prado2019).
$ \parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2 $
has been used, in structural mechanics it may be more appropriate to use the squared geodesic distance (Scarth et al., Reference Scarth, Adhikari, Cabral, Silva and do Prado2019).
The position and displacement vectors
 $ \boldsymbol{x} $
and
$ \boldsymbol{x} $
and
 $ \boldsymbol{u}\left(\boldsymbol{x}\right) $
in the weak form (2) are discretized using basis functions obtained from Catmull–Clark subdivision surfaces (Cirak et al., Reference Cirak, Ortiz and Schröder2000; Zhang et al., Reference Zhang, Sabin and Cirak2018). The weak form (2) depends on the curvature so that the FE basis functions must be smooth or, in other words, must have square-integrable second derivatives. Subdivision surfaces are the generalization of B-splines from computer-aided geometric design to unstructured meshes and provide smooth basis functions for discretizing the position and displacement vectors
$ \boldsymbol{u}\left(\boldsymbol{x}\right) $
in the weak form (2) are discretized using basis functions obtained from Catmull–Clark subdivision surfaces (Cirak et al., Reference Cirak, Ortiz and Schröder2000; Zhang et al., Reference Zhang, Sabin and Cirak2018). The weak form (2) depends on the curvature so that the FE basis functions must be smooth or, in other words, must have square-integrable second derivatives. Subdivision surfaces are the generalization of B-splines from computer-aided geometric design to unstructured meshes and provide smooth basis functions for discretizing the position and displacement vectors
 $ \boldsymbol{x} $
and
$ \boldsymbol{x} $
and
 $ \boldsymbol{u}\left(\boldsymbol{x}\right) $
. The resulting FE approach is referred to as isogeometric analysis (Hughes et al., Reference Hughes, Cottrell and Bazilevs2005) and allows one to use the same representation for geometric design and analysis. Without going into further detail, the subdivision basis functions
$ \boldsymbol{u}\left(\boldsymbol{x}\right) $
. The resulting FE approach is referred to as isogeometric analysis (Hughes et al., Reference Hughes, Cottrell and Bazilevs2005) and allows one to use the same representation for geometric design and analysis. Without going into further detail, the subdivision basis functions
 $ {\phi}_i\left({\theta}^1,{\theta}^2\right) $
furnish the two approximants
$ {\phi}_i\left({\theta}^1,{\theta}^2\right) $
furnish the two approximants
 $$ \boldsymbol{x}\left({\theta}^1,{\theta}^2\right)=\sum \limits_i\;{\phi}_i\left({\theta}^1,{\theta}^2\right){\boldsymbol{x}}_i,\hskip2em \boldsymbol{u}\left({\theta}^1,{\theta}^2\right)=\sum \limits_i{\phi}_i\left({\theta}^1,{\theta}^2\right){\boldsymbol{u}}_i, $$
$$ \boldsymbol{x}\left({\theta}^1,{\theta}^2\right)=\sum \limits_i\;{\phi}_i\left({\theta}^1,{\theta}^2\right){\boldsymbol{x}}_i,\hskip2em \boldsymbol{u}\left({\theta}^1,{\theta}^2\right)=\sum \limits_i{\phi}_i\left({\theta}^1,{\theta}^2\right){\boldsymbol{u}}_i, $$
where
 $ {\boldsymbol{x}}_i $
is the coordinate and
$ {\boldsymbol{x}}_i $
is the coordinate and
 $ {\boldsymbol{u}}_i $
is the displacement of the FE node with the index
$ {\boldsymbol{u}}_i $
is the displacement of the FE node with the index
 $ i $
and
$ i $
and
 $ \left({\theta}^1,{\theta}^2\right) $
are the parametric coordinates. The sums in (5) are over all the nodes in the FE mesh. After introducing (5) into the weak form (2) and numerically evaluating the integrals the linear system of equations
$ \left({\theta}^1,{\theta}^2\right) $
are the parametric coordinates. The sums in (5) are over all the nodes in the FE mesh. After introducing (5) into the weak form (2) and numerically evaluating the integrals the linear system of equations
 $$ \mathbf{\mathsf{A}}\mathbf{\mathsf{u}}=\mathbf{\mathsf{f}} $$
$$ \mathbf{\mathsf{A}}\mathbf{\mathsf{u}}=\mathbf{\mathsf{f}} $$
is obtained. Herein,
 $ \mathbf{A} $
is the stiffness matrix,
$ \mathbf{A} $
is the stiffness matrix,
 $ \mathbf{u} $
is the nodal displacement vector, and the force vector
$ \mathbf{u} $
is the nodal displacement vector, and the force vector
 $ \mathbf{f} $
has the multivariate Gaussian density
$ \mathbf{f} $
has the multivariate Gaussian density
 $$ \mathbf{\mathsf{f}}\sim p(\mathbf{\mathsf{f}})=\mathcal{N}(\overline{\mathbf{\mathsf{f}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}}), $$
$$ \mathbf{\mathsf{f}}\sim p(\mathbf{\mathsf{f}})=\mathcal{N}(\overline{\mathbf{\mathsf{f}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}}), $$
where
 $ \overline{\mathbf{\mathsf{f}}} $
is the mean vector and
$ \overline{\mathbf{\mathsf{f}}} $
is the mean vector and
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}} $
is the covariance matrix. See Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021) for the computation of
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}} $
is the covariance matrix. See Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021) for the computation of
 $ \overline{\mathbf{\mathsf{f}}} $
and
$ \overline{\mathbf{\mathsf{f}}} $
and
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}} $
. Because the stiffness matrix
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}} $
. Because the stiffness matrix
 $ \mathbf{\mathsf{A}} $
is deterministic, it is easy to show that the resulting random displacement vector has the probability density
$ \mathbf{\mathsf{A}} $
is deterministic, it is easy to show that the resulting random displacement vector has the probability density
 $$ \mathbf{\mathsf{u}}\sim p(\mathbf{\mathsf{u}})=\mathcal{N}({\mathbf{\mathsf{A}}}^{-1}\overline{\mathbf{\mathsf{f}}},\hskip1.5pt {\mathbf{\mathsf{A}}}^{-1}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}}{\mathbf{\mathsf{A}}}^{-\mathsf{T}})=\mathcal{N}(\overline{\mathbf{\mathsf{u}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}) $$
$$ \mathbf{\mathsf{u}}\sim p(\mathbf{\mathsf{u}})=\mathcal{N}({\mathbf{\mathsf{A}}}^{-1}\overline{\mathbf{\mathsf{f}}},\hskip1.5pt {\mathbf{\mathsf{A}}}^{-1}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{f}}}{\mathbf{\mathsf{A}}}^{-\mathsf{T}})=\mathcal{N}(\overline{\mathbf{\mathsf{u}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}) $$
Although not considered in the present study, it is possible to consider uncertainties in the internal work in (2), such as random material parameters or geometry, leading to a random stiffness matrix
 $ \mathbf{\mathsf{A}} $
.
$ \mathbf{\mathsf{A}} $
.
3.1.2. Statistical model and Bayesian inference
In the posited statistical model, the observed strain
 $ \mathbf{\mathsf{y}} $
at the
$ \mathbf{\mathsf{y}} $
at the
 $ {n}_y $
sensor locations is assumed to be composed of three random components, that is,
$ {n}_y $
sensor locations is assumed to be composed of three random components, that is,
 $$ \mathbf{\mathsf{y}}=\mathbf{\mathsf{z}}+\mathbf{\mathsf{e}}=\rho \mathbf{\mathsf{P}}\mathbf{\mathsf{u}}+\mathbf{\mathsf{d}}+\mathbf{\mathsf{e}}. $$
$$ \mathbf{\mathsf{y}}=\mathbf{\mathsf{z}}+\mathbf{\mathsf{e}}=\rho \mathbf{\mathsf{P}}\mathbf{\mathsf{u}}+\mathbf{\mathsf{d}}+\mathbf{\mathsf{e}}. $$
The observed strain
 $ \mathbf{\mathsf{y}} $
is equal to the sum of the unknown (i.e., unobserved) “true” strain
$ \mathbf{\mathsf{y}} $
is equal to the sum of the unknown (i.e., unobserved) “true” strain
 $ \mathbf{\mathsf{z}} $
and the Gaussian measurement error
$ \mathbf{\mathsf{z}} $
and the Gaussian measurement error
 $$ \mathbf{\mathsf{e}}\sim p(\mathbf{\mathsf{e}})=\mathcal{N}(\mathbf{\mathsf{0}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}) $$
$$ \mathbf{\mathsf{e}}\sim p(\mathbf{\mathsf{e}})=\mathcal{N}(\mathbf{\mathsf{0}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}) $$
with a diagonal covariance matrix
 $ \hskip0.1em {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}={\sigma}_e^2\mathbf{\mathsf{I}} $
and a standard deviation
$ \hskip0.1em {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}={\sigma}_e^2\mathbf{\mathsf{I}} $
and a standard deviation
 $ {\sigma}_e $
. In turn, the true system response
$ {\sigma}_e $
. In turn, the true system response
 $ \mathbf{\mathsf{z}} $
is the linear combination of the FE strain
$ \mathbf{\mathsf{z}} $
is the linear combination of the FE strain
 $ \mathbf{\mathsf{Pu}} $
, depending on the nodal displacements
$ \mathbf{\mathsf{Pu}} $
, depending on the nodal displacements
 $ \mathbf{\mathsf{u}} $
, and the mismatch, or model inadequacy, error
$ \mathbf{\mathsf{u}} $
, and the mismatch, or model inadequacy, error
 $ \mathbf{\mathsf{d}} $
. In the FE component,
$ \mathbf{\mathsf{d}} $
. In the FE component,
 $ \rho $
is an unknown scaling parameter and
$ \rho $
is an unknown scaling parameter and
 $ \mathbf{\mathsf{P}} $
is a matrix for obtaining the strain at the
$ \mathbf{\mathsf{P}} $
is a matrix for obtaining the strain at the
 $ {n}_y $
sensor locations from the nodal displacement vector
$ {n}_y $
sensor locations from the nodal displacement vector
 $ \mathbf{\mathsf{u}} $
. The three random components
$ \mathbf{\mathsf{u}} $
. The three random components
 $ \mathbf{\mathsf{u}} $
,
$ \mathbf{\mathsf{u}} $
,
 $ \mathbf{\mathsf{d}} $
, and
$ \mathbf{\mathsf{d}} $
, and
 $ \mathbf{\mathsf{e}} $
are assumed to be statistically independent.
$ \mathbf{\mathsf{e}} $
are assumed to be statistically independent.
The random parameter
 $ \rho $
and the random mismatch error
$ \rho $
and the random mismatch error
 $ \mathbf{\mathsf{d}} $
are the unknowns of the statistical model (9) and will be characterized using the measured strain data
$ \mathbf{\mathsf{d}} $
are the unknowns of the statistical model (9) and will be characterized using the measured strain data
 $ \mathbf{\mathsf{y}} $
and the random FE solution
$ \mathbf{\mathsf{y}} $
and the random FE solution
 $ \mathbf{\mathsf{u}} $
in (8). The probability density of the mismatch error is assumed to be a multivariate Gaussian
$ \mathbf{\mathsf{u}} $
in (8). The probability density of the mismatch error is assumed to be a multivariate Gaussian
 $$ \mathbf{\mathsf{d}}\sim p(\mathbf{\mathsf{d}})=\mathcal{N}(\mathbf{\mathsf{0}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}), $$
$$ \mathbf{\mathsf{d}}\sim p(\mathbf{\mathsf{d}})=\mathcal{N}(\mathbf{\mathsf{0}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}), $$
and the covariance matrix
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}} $
is obtained from the squared-exponential kernel
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}} $
is obtained from the squared-exponential kernel
 $$ {c}_d\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime}\right)={\sigma}_d^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_d^2}\right)\hskip0.1em $$
$$ {c}_d\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime}\right)={\sigma}_d^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_d^2}\right)\hskip0.1em $$
with the hyperparameters
 $ {\sigma}_d $
and
$ {\sigma}_d $
and
 $ {\mathrm{\ell}}_d $
. In the following, the three hyperparameters of the statistical model are collected in the vector
$ {\mathrm{\ell}}_d $
. In the following, the three hyperparameters of the statistical model are collected in the vector
 $$ \mathbf{\mathsf{w}}:={(\rho \hskip3pt {\ell}_d\hskip3pt {\sigma}_d)}^{\mathsf{T}}. $$
$$ \mathbf{\mathsf{w}}:={(\rho \hskip3pt {\ell}_d\hskip3pt {\sigma}_d)}^{\mathsf{T}}. $$
Next, the Bayesian inference of the random FE solution
 $ \mathbf{\mathsf{u}} $
and the hyperparameters
$ \mathbf{\mathsf{u}} $
and the hyperparameters
 $ \mathbf{\mathsf{w}} $
in light of the observed data
$ \mathbf{\mathsf{w}} $
in light of the observed data
 $ \mathbf{\mathsf{y}} $
and the statistical model (9) are considered. Since all the variables in the statistical model are Gaussians, one can write by inspection for the likelihood, see, for example, Murphy (Reference Murphy2012),
$ \mathbf{\mathsf{y}} $
and the statistical model (9) are considered. Since all the variables in the statistical model are Gaussians, one can write by inspection for the likelihood, see, for example, Murphy (Reference Murphy2012),
 $$ p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}\mathbf{\mathsf{u}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}). $$
$$ p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}\mathbf{\mathsf{u}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}). $$
According to the Bayes rule, the posterior density of the FE solution is given by
 $$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}},\mathbf{\mathsf{w}})=\frac{p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})p(\mathbf{\mathsf{u}})}{p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})}\hskip1.5pt . $$
$$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}},\mathbf{\mathsf{w}})=\frac{p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})p(\mathbf{\mathsf{u}})}{p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})}\hskip1.5pt . $$
Note that in the present study, the prior
 $ p(\mathbf{\mathsf{u}}) $
does not have any hyperparameters, that is,
$ p(\mathbf{\mathsf{u}}) $
does not have any hyperparameters, that is,
 $ p(\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})=p(\mathbf{\mathsf{u}}) $
.
$ p(\mathbf{\mathsf{u}},\mathbf{\mathsf{w}})=p(\mathbf{\mathsf{u}}) $
.
In statFEM, one is interested in the posterior FE density
 $$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})=\int p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{w}},\mathbf{\mathsf{y}})p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}})\mathrm{d}\mathbf{\mathsf{w}}. $$
$$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})=\int p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{w}},\mathbf{\mathsf{y}})p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}})\mathrm{d}\mathbf{\mathsf{w}}. $$
Following an empirical Bayes or evidence approximation approach, see, for example, MacKay (Reference MacKay1999), this integral can be approximated by
 $$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})\hskip0.24em \approx \hskip0.24em p(\mathbf{\mathsf{u}}|{\mathbf{\mathsf{w}}}^{\ast },\mathbf{\mathsf{y}}). $$
$$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})\hskip0.24em \approx \hskip0.24em p(\mathbf{\mathsf{u}}|{\mathbf{\mathsf{w}}}^{\ast },\mathbf{\mathsf{y}}). $$
As a point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
either the maximum
$ {\mathbf{\mathsf{w}}}^{\ast } $
either the maximum
 $$ {\mathbf{\mathsf{w}}}^{\ast }=\underset{\mathbf{\mathsf{w}}}{\mathrm{arg}\max}\hskip1.5pt p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}}) $$
$$ {\mathbf{\mathsf{w}}}^{\ast }=\underset{\mathbf{\mathsf{w}}}{\mathrm{arg}\max}\hskip1.5pt p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}}) $$
or the mean
is suitable. When the hyperparameters are endowed with a prior
 $ p(\mathbf{\mathsf{w}}) $
, the posterior
$ p(\mathbf{\mathsf{w}}) $
, the posterior
 $ p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}})\hskip0.35em \propto \hskip0.35em p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})p(\mathbf{\mathsf{w}}) $
can be considered for obtaining the point estimate. In this paper,
$ p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}})\hskip0.35em \propto \hskip0.35em p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})p(\mathbf{\mathsf{w}}) $
can be considered for obtaining the point estimate. In this paper,
 $ p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}}) $
is sampled with the Markov-chain Monte Carlo (MCMC) method and the empirical mean of the samples is taken as
$ p(\mathbf{\mathsf{w}}|\mathbf{\mathsf{y}}) $
is sampled with the Markov-chain Monte Carlo (MCMC) method and the empirical mean of the samples is taken as
 $ {\mathbf{\mathsf{w}}}^{\ast } $
. According to the statistical model (9) and noting that the linear combination of Gaussian vectors is a Gaussian vector, the marginal likelihood is given by
$ {\mathbf{\mathsf{w}}}^{\ast } $
. According to the statistical model (9) and noting that the linear combination of Gaussian vectors is a Gaussian vector, the marginal likelihood is given by
 $$ p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{e}}+{\rho}^2{\mathbf{\mathsf{P}}\mathbf{\mathsf{C}}}_{\ \mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}). $$
$$ p(\mathbf{\mathsf{y}}|\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{e}}+{\rho}^2{\mathbf{\mathsf{P}}\mathbf{\mathsf{C}}}_{\ \mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}). $$
Finally, introducing the obtained point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
in (15) yields the sought posterior density
$ {\mathbf{\mathsf{w}}}^{\ast } $
in (15) yields the sought posterior density
 $ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
. To this end, note that the densities on the right-hand side of (15) are Gaussians so that the posterior is a Gaussian as well. As shown in Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021), the posterior density reads
$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
. To this end, note that the densities on the right-hand side of (15) are Gaussians so that the posterior is a Gaussian as well. As shown in Girolami et al. (Reference Girolami, Febrianto, Yin and Cirak2021), the posterior density reads
 $$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})=\mathcal{N}({\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}\mid \mathbf{\mathsf{y}}}) $$
$$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})=\mathcal{N}({\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}\mid \mathbf{\mathsf{y}}}) $$
with the covariance matrix
 $$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}={\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}-{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}{\left(\frac{1}{\rho^2}({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})+\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}\right)}^{-1}\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}} $$
$$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}={\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}-{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}{\left(\frac{1}{\rho^2}({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})+\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}\right)}^{-1}\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}} $$
and the mean
 $$ {\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}}={\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}(\rho {\mathbf{\mathsf{P}}}^{\mathsf{T}}{({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})}^{-1}\mathbf{\mathsf{y}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}^{-1}\overline{\mathbf{\mathsf{u}}}) $$
$$ {\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}}={\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}(\rho {\mathbf{\mathsf{P}}}^{\mathsf{T}}{({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})}^{-1}\mathbf{\mathsf{y}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}^{-1}\overline{\mathbf{\mathsf{u}}}) $$
The mean can also be expressed as
 $$ {\overline{\mathbf{\mathsf{u}}}}_{\mid \mathbf{\mathsf{y}}}=\overline{\mathbf{\mathsf{u}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}{\left(\frac{1}{\rho^2}({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})+{\mathbf{\mathsf{P}}\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}\right)}^{-1}\left(\frac{\mathbf{\mathsf{y}}}{\rho }-\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}}\right). $$
$$ {\overline{\mathbf{\mathsf{u}}}}_{\mid \mathbf{\mathsf{y}}}=\overline{\mathbf{\mathsf{u}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}{\left(\frac{1}{\rho^2}({\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}})+{\mathbf{\mathsf{P}}\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}\right)}^{-1}\left(\frac{\mathbf{\mathsf{y}}}{\rho }-\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}}\right). $$
That is, the posterior mean is obtained by updating the prior mean
 $ \overline{\mathbf{\mathsf{u}}} $
with the difference between the observed and prior mean strain
$ \overline{\mathbf{\mathsf{u}}} $
with the difference between the observed and prior mean strain
 $ \mathbf{\mathsf{y}}/\rho -\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
. The respective weight depends on the scaling parameter
$ \mathbf{\mathsf{y}}/\rho -\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
. The respective weight depends on the scaling parameter
 $ \rho $
and the relative magnitude of the covariance matrices
$ \rho $
and the relative magnitude of the covariance matrices
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}} $
,
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}} $
,
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}} $
and
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}} $
and
 $ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}} $
.
$ {\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}} $
.
With the determined posterior FE density, the posterior true strain density is given by
 $$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}{\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},\hskip1.5pt {\rho}^2\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\ \mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}). $$
$$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}{\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},\hskip1.5pt {\rho}^2\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\ \mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{d}}}). $$
3.1.3. Mismatch modeling and multiple observations
The previous section considered only one single observation vector
 $ \mathbf{y} $
recorded at a fixed time instant
$ \mathbf{y} $
recorded at a fixed time instant
 $ {t}_k $
. However, the passage of a single train yields several hundreds of such observation vectors. These vectors are collected in the observation matrix
$ {t}_k $
. However, the passage of a single train yields several hundreds of such observation vectors. These vectors are collected in the observation matrix
 $$ \mathbf{\mathsf{Y}}=({\mathbf{\mathsf{y}}}_0\hskip0.5em {\mathbf{\mathsf{y}}}_1\hskip0.5em \dots \hskip0.5em {\mathbf{\mathsf{y}}}_{n_o}). $$
$$ \mathbf{\mathsf{Y}}=({\mathbf{\mathsf{y}}}_0\hskip0.5em {\mathbf{\mathsf{y}}}_1\hskip0.5em \dots \hskip0.5em {\mathbf{\mathsf{y}}}_{n_o}). $$
In principle, it is possible to consider each time instant
 $ {t}_k $
independently and to obtain for each a point estimate
$ {t}_k $
independently and to obtain for each a point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
according to (18a) or (18b). This can be very costly given that each time instant requires MCMC sampling. More critically, the information content available in one single observation vector
$ {\mathbf{\mathsf{w}}}^{\ast } $
according to (18a) or (18b). This can be very costly given that each time instant requires MCMC sampling. More critically, the information content available in one single observation vector
 $ \mathbf{\mathsf{y}} $
often gives only a very poor estimate for
$ \mathbf{\mathsf{y}} $
often gives only a very poor estimate for
 $ {\mathbf{\mathsf{w}}}^{\ast } $
. Consequently, it is advantageous to consider all observation vectors simultaneously and to obtain one single
$ {\mathbf{\mathsf{w}}}^{\ast } $
. Consequently, it is advantageous to consider all observation vectors simultaneously and to obtain one single
 $ {\mathbf{\mathsf{w}}}^{\ast } $
. To this end, the mismatch error covariance kernel (12) is replaced with the scaled squared-exponential kernel
$ {\mathbf{\mathsf{w}}}^{\ast } $
. To this end, the mismatch error covariance kernel (12) is replaced with the scaled squared-exponential kernel
 $$ {c}_d\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime },k\right)={\left({\gamma}_k{\sigma}_d\right)}^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_d^2}\right) $$
$$ {c}_d\left(\boldsymbol{x},{\boldsymbol{x}}^{\prime },k\right)={\left({\gamma}_k{\sigma}_d\right)}^2\exp \left(-\frac{\parallel \boldsymbol{x}-{\boldsymbol{x}}^{\prime }{\parallel}^2}{2{\mathrm{\ell}}_d^2}\right) $$
with
 $$ {\gamma}_k=\frac{ \parallel {\mathbf{\mathsf{f}}}_k\parallel }{\max_k\parallel {\mathbf{\mathsf{f}}}_k\parallel }, $$
$$ {\gamma}_k=\frac{ \parallel {\mathbf{\mathsf{f}}}_k\parallel }{\max_k\parallel {\mathbf{\mathsf{f}}}_k\parallel }, $$
where the index
 $ k $
corresponds to the time instant
$ k $
corresponds to the time instant
 $ {t}_k $
and
$ {t}_k $
and
 $ \parallel \cdot \parallel $
denotes
$ \parallel \cdot \parallel $
denotes
 $ {L}_2 $
norm. The scale factor
$ {L}_2 $
norm. The scale factor
 $ {\gamma}_k $
is necessary because the number of axles on the bridge, hence the loading
$ {\gamma}_k $
is necessary because the number of axles on the bridge, hence the loading
 $ {\mathbf{\mathsf{f}}}_k $
at each
$ {\mathbf{\mathsf{f}}}_k $
at each
 $ {t}_k $
is different. As implied by the statistical model (9), it is necessary to scale each random vector
$ {t}_k $
is different. As implied by the statistical model (9), it is necessary to scale each random vector
 $ {\mathbf{\mathsf{d}}}_k $
in dependence of the magnitude of the observed strain
$ {\mathbf{\mathsf{d}}}_k $
in dependence of the magnitude of the observed strain
 $ {\mathbf{\mathsf{y}}}_k $
, which is approximately proportional to the actual loading
$ {\mathbf{\mathsf{y}}}_k $
, which is approximately proportional to the actual loading
 $ {\mathbf{\mathsf{f}}}_k $
. Assuming statistical independence between the observations, the marginal likelihood for determining
$ {\mathbf{\mathsf{f}}}_k $
. Assuming statistical independence between the observations, the marginal likelihood for determining
 $ {\mathbf{\mathsf{w}}}^{\ast } $
reads
$ {\mathbf{\mathsf{w}}}^{\ast } $
reads
 $$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}})=\prod \limits_{k=1}^{n_o}p({\mathbf{\mathsf{y}}}_k|\mathbf{\mathsf{w}}) $$
$$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}})=\prod \limits_{k=1}^{n_o}p({\mathbf{\mathsf{y}}}_k|\mathbf{\mathsf{w}}) $$
with
 $$ p({\mathbf{\mathsf{y}}}_k|\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}{\overline{\mathbf{\mathsf{u}}}}_k,{\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{d}}}_k}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}+{\rho}^2\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\ {\mathbf{\mathsf{u}}}_k}{\mathbf{\mathsf{P}}}^{\mathsf{T}}). $$
$$ p({\mathbf{\mathsf{y}}}_k|\mathbf{\mathsf{w}})=\mathcal{N}(\rho \mathbf{\mathsf{P}}{\overline{\mathbf{\mathsf{u}}}}_k,{\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{d}}}_k}+{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{e}}}+{\rho}^2\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\ {\mathbf{\mathsf{u}}}_k}{\mathbf{\mathsf{P}}}^{\mathsf{T}}). $$
The prior mean
 $ {\overline{\mathbf{\mathsf{u}}}}_k $
and covariance
$ {\overline{\mathbf{\mathsf{u}}}}_k $
and covariance
 $ {\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{u}}}_k} $
are given by (8) and correspond to the loading
$ {\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{u}}}_k} $
are given by (8) and correspond to the loading
 $ {\mathbf{\mathsf{f}}}_k $
at the time
$ {\mathbf{\mathsf{f}}}_k $
at the time
 $ {t}_k $
.
$ {t}_k $
.
In summary, starting with the FE prior densities
 $ p({\mathbf{\mathsf{u}}}_k)=\mathcal{N}({\overline{\mathbf{\mathsf{u}}}}_k,{\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{u}}}_k}) $
and the observation matrix
$ p({\mathbf{\mathsf{u}}}_k)=\mathcal{N}({\overline{\mathbf{\mathsf{u}}}}_k,{\mathbf{\mathsf{C}}}_{{\mathbf{\mathsf{u}}}_k}) $
and the observation matrix
 $ \mathbf{\mathsf{Y}} $
the posterior FE and true strain densities are determined in three steps.
$ \mathbf{\mathsf{Y}} $
the posterior FE and true strain densities are determined in three steps.
-
1. Sample the marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
given by (25a) using MCMC.
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
given by (25a) using MCMC. -
2. Determine from the MCMC samples the point estimate
$ {\mathbf{\mathsf{w}}}^{\ast } $
. -
3. Compute the posterior FE and true strain densities
$ p({\mathbf{\mathsf{u}}}_k|{\ \mathbf{\mathsf{y}}}_k) $
and
$ p({\mathbf{\mathsf{z}}}_k|{\mathbf{\mathsf{y}}}_k) $
by introducing the determined
$ {\mathbf{\mathsf{w}}}^{\ast } $
into (20a) and (22).





3.2. FE model of the bridge superstructure
As detailed in Section 2.1, the bridge superstructure is comprised of 2 identical main I-beams (east and west), 21 transverse I-beams, and a reinforced concrete deck. The transverse I-beams are modeled as rigidly connected to the reinforced concrete deck owing to the double row of shear connectors atop the transverse I-beams. In the actual structure, the transverse beams are alternatingly pinned and moment connected to the main I-beams. For simplicity in the considered model, following the numerical studies in Lin et al. (Reference Lin, Butler, Elshafie and Middleton2019), all transverse beams are modeled as moment connected. Consequently, all components of the superstructure are modeled using shell FEs and along joints moment connected to each other, see Figure 4. Each moment connected joint is able to transfer both forces and moments. As noted in Figure 2, in the FE model the two main I-beams are
 $ 26.84\ \mathrm{m} $
long,
$ 26.84\ \mathrm{m} $
long,
 $ 0.7\ \mathrm{m} $
wide, and
$ 0.7\ \mathrm{m} $
wide, and
 $ 2.04\ \mathrm{m} $
deep. The two main I-beams are
$ 2.04\ \mathrm{m} $
deep. The two main I-beams are
 $ 7.3\ \mathrm{m} $
apart. Instead of doubler plates as in the actual structure, the flanges consist of a single plate with equivalent second moment of area. The 21 transverse I-beams are categorized either as orthogonal or fanned. The orthogonal beams are located in the center of the superstructure and are placed at every
$ 7.3\ \mathrm{m} $
apart. Instead of doubler plates as in the actual structure, the flanges consist of a single plate with equivalent second moment of area. The 21 transverse I-beams are categorized either as orthogonal or fanned. The orthogonal beams are located in the center of the superstructure and are placed at every
 $ 1.5\ \mathrm{m} $
, and the fanned beams are situated near the two ends of the bridge. The transverse beams are
$ 1.5\ \mathrm{m} $
, and the fanned beams are situated near the two ends of the bridge. The transverse beams are
 $ 0.4\ \mathrm{m} $
wide and
$ 0.4\ \mathrm{m} $
wide and
 $ 0.4\ \mathrm{m} $
deep. The dimensions of all the I-beams are listed in Table 1.
$ 0.4\ \mathrm{m} $
deep. The dimensions of all the I-beams are listed in Table 1.

Figure 4. Finite element model of the bridge superstructure. The two main I-beams and the 21 transverse I-beams are moment connected at the mesh nodes in blue. The reinforced concrete deck is moment connected to the transverse I-beams at the mesh nodes in red.
Table 1. Web and flange dimensions of the main and transverse I-beams (all in
 $ mm $
).
$ mm $
).

The Young’s modulus and Poisson’s ratio of the steel I-beams are assumed to be
 $ {E}_s=210\ \mathrm{G}\mathrm{P}\mathrm{a} $
and
$ {E}_s=210\ \mathrm{G}\mathrm{P}\mathrm{a} $
and
 $ {\nu}_s=0.3 $
, respectively. The deck of the bridge is modeled without the ancillary structures such as the ballast and prestressed concrete sleepers. The thickness of the deck in the FE model is
$ {\nu}_s=0.3 $
, respectively. The deck of the bridge is modeled without the ancillary structures such as the ballast and prestressed concrete sleepers. The thickness of the deck in the FE model is
 $ 0.25\ \mathrm{m} $
. Assuming a uniform distribution of the steel reinforcement across the cross-section of the concrete deck, the equivalent reinforced concrete elasticity modulus according to the rule of mixtures is given by
$ 0.25\ \mathrm{m} $
. Assuming a uniform distribution of the steel reinforcement across the cross-section of the concrete deck, the equivalent reinforced concrete elasticity modulus according to the rule of mixtures is given by
 $$ {E}_{rc}={qE}_s+\left(1-q\right){E}_c. $$
$$ {E}_{rc}={qE}_s+\left(1-q\right){E}_c. $$
A steel reinforcement ratio of
 $ q=0.03 $
and a concrete elasticity modulus of
$ q=0.03 $
and a concrete elasticity modulus of
 $ {E}_c=35\ \mathrm{G}\mathrm{P}\mathrm{a} $
are assumed yielding
$ {E}_c=35\ \mathrm{G}\mathrm{P}\mathrm{a} $
are assumed yielding
 $ {E}_{rc}=40.5\ \mathrm{G}\mathrm{P}\mathrm{a} $
. The Poisson’s ratio of the reinforced concrete is
$ {E}_{rc}=40.5\ \mathrm{G}\mathrm{P}\mathrm{a} $
. The Poisson’s ratio of the reinforced concrete is
 $ {\nu}_{rc}=0.2 $
. The equivalent elasticity modulus (26) does not take into account that the rebar is usually placed away from the center of the cross-section.
$ {\nu}_{rc}=0.2 $
. The equivalent elasticity modulus (26) does not take into account that the rebar is usually placed away from the center of the cross-section.
Two different FE meshes for discretizing the bridge superstructure are considered. Mesh M1 is a relatively coarse mesh consisting of 4635 nodes and 4600 quadrilateral elements and the finer mesh M2 consisting of 7191 nodes and 7144 quadrilateral elements, see Figures 1 and 5. To model the rocker type bridge supports, pinned and roller supports at the relevant FE nodes are applied.

Figure 5. The fine FE mesh M2.
Although there are data for two different types of train crossing the bridge, this paper focuses on type T1 train (London Midland Class 350 Desiro) with four carriages and a total length of
 $ 81.47\ \mathrm{m} $
(Lin et al., Reference Lin, Butler, Elshafie and Middleton2019). The average normal axle load is
$ 81.47\ \mathrm{m} $
(Lin et al., Reference Lin, Butler, Elshafie and Middleton2019). The average normal axle load is
 $ 104\ \mathrm{k}\mathrm{N} $
(
$ 104\ \mathrm{k}\mathrm{N} $
(
 $ 52\ \mathrm{k}\mathrm{N} $
per wheel), see Figure 6. The speed of the train is approximately
$ 52\ \mathrm{k}\mathrm{N} $
per wheel), see Figure 6. The speed of the train is approximately
 $ 131\ \mathrm{k}\mathrm{m}/\mathrm{h} $
so that the train crosses the bridge in less than 3 s. The moving loads generated by the train wheels are directly applied to the concrete slab neglecting any load distribution effects by the sleepers and the track ballast. Moreover, the rail tracks are assumed to have no vertical cant so that any centrifugal forces are neglected. Clearly, a more faithful modeling of the train loading and its transfer to the bridge superstructure requires a significantly more advanced FE model. Due to the relatively short span of the bridge, inertia effects are not taken into account in the FE analysis. That is, for a given set of wheel forces and positions a single static analysis is performed.
$ 131\ \mathrm{k}\mathrm{m}/\mathrm{h} $
so that the train crosses the bridge in less than 3 s. The moving loads generated by the train wheels are directly applied to the concrete slab neglecting any load distribution effects by the sleepers and the track ballast. Moreover, the rail tracks are assumed to have no vertical cant so that any centrifugal forces are neglected. Clearly, a more faithful modeling of the train loading and its transfer to the bridge superstructure requires a significantly more advanced FE model. Due to the relatively short span of the bridge, inertia effects are not taken into account in the FE analysis. That is, for a given set of wheel forces and positions a single static analysis is performed.

Figure 6. Location and magnitude of the forces applied to the superstructure. Forces are directly applied to the deck. The axle weight of 104 kN is split into two forces representing the two attached wheels.
The weight of the train and its approximation as static point loads in the FE model is obviously subject to a number of assumptions and uncertainties. In the proposed Bayesian statFEM framework, these uncertainties are taken into account by considering the FE solution
 $ \mathbf{\mathsf{u}} $
as a random variable. It bears emphasis that this randomness is epistemic, that is, it is due to lack of knowledge and not due to inherent variability of the FE solution. To obtain the respective FE prior density
$ \mathbf{\mathsf{u}} $
as a random variable. It bears emphasis that this randomness is epistemic, that is, it is due to lack of knowledge and not due to inherent variability of the FE solution. To obtain the respective FE prior density
 $ p(\mathbf{\mathsf{u}}) $
in (8), a random loading
$ p(\mathbf{\mathsf{u}}) $
in (8), a random loading
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
as described by the Gaussian process (3) is applied. The respective covariance scaling and length scale parameters are chosen as
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
as described by the Gaussian process (3) is applied. The respective covariance scaling and length scale parameters are chosen as
 $ {\sigma}_r=1000\ \mathrm{P}\mathrm{a} $
and
$ {\sigma}_r=1000\ \mathrm{P}\mathrm{a} $
and
 $ {\ell}_r=1\ \mathrm{m} $
. The scaling factor
$ {\ell}_r=1\ \mathrm{m} $
. The scaling factor
 $ {\sigma}_r $
represents 20% of the maximum train load distributed over the planform of the bridge, see Figure 7a. The length scale parameter
$ {\sigma}_r $
represents 20% of the maximum train load distributed over the planform of the bridge, see Figure 7a. The length scale parameter
 $ {\mathrm{\ell}}_r $
is chosen to be in the order of the distance between the transverse beams and is about three times the ballast depth. The random loading
$ {\mathrm{\ell}}_r $
is chosen to be in the order of the distance between the transverse beams and is about three times the ballast depth. The random loading
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
is applied in addition to the deterministic point forces of
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
is applied in addition to the deterministic point forces of
 $ 52\ \mathrm{k}\mathrm{N} $
per wheel. The choice of the two parameters
$ 52\ \mathrm{k}\mathrm{N} $
per wheel. The choice of the two parameters
 $ {\sigma}_r $
and
$ {\sigma}_r $
and
 $ {\mathrm{\ell}}_r $
requires input from domain experts, that is, bridge engineers, and may be formalized with prior elicitation techniques from statistics, see the recent review Mikkola et al. (Reference Mikkola, Martin, Chandramouli, Hartmann, Pla, Thomas, Pesonen, Corander, Vehtari, Kaski, Bürkner and Klami2021). Alternatively,
$ {\mathrm{\ell}}_r $
requires input from domain experts, that is, bridge engineers, and may be formalized with prior elicitation techniques from statistics, see the recent review Mikkola et al. (Reference Mikkola, Martin, Chandramouli, Hartmann, Pla, Thomas, Pesonen, Corander, Vehtari, Kaski, Bürkner and Klami2021). Alternatively,
 $ {\sigma}_r $
and
$ {\sigma}_r $
and
 $ {\mathrm{\ell}}_r $
can be interpreted as hyperparameters and inferred from the observed data (Kennedy and O’Hagan, Reference Kennedy and O’Hagan2001; Nagel and Sudret, Reference Nagel and Sudret2016).
$ {\mathrm{\ell}}_r $
can be interpreted as hyperparameters and inferred from the observed data (Kennedy and O’Hagan, Reference Kennedy and O’Hagan2001; Nagel and Sudret, Reference Nagel and Sudret2016).

Figure 7. Total train loading applied to the superstructure and its deflection at five distinct time instances.
4. Results and Discussion
Throughout this section, a train of type T1 with four carriages heading from north to south on the east track is considered. Specifically, the analysis and discussion focus on the axial strains along the top and bottom flanges of the east main I-beam. In the FE model, the axial strains are obtained by multiplying the nodal displacement vector
 $ \mathbf{\mathsf{u}} $
with the projection matrix
$ \mathbf{\mathsf{u}} $
with the projection matrix
 $ \mathbf{\mathsf{P}} $
which discretizes the symmetric gradient operator. The total loading depends on the number of train wheels on the bridge and is depicted in Figure 7a. The deflected superstructure at five distinct time instances is shown in Figure 7.
$ \mathbf{\mathsf{P}} $
which discretizes the symmetric gradient operator. The total loading depends on the number of train wheels on the bridge and is depicted in Figure 7a. The deflected superstructure at five distinct time instances is shown in Figure 7.
4.1. Mesh convergence and probabilistic FE analysis
The axial FE strains at the midspan of the east I-beam obtained using meshes M1 and M2 are compared in Figure 8a. The results for both meshes are in close agreement; therefore, the coarser mesh M1 is chosen for subsequent computations. The large-scale oscillations in the strains result from the changing number of train wheels on the bridge. The small-scale oscillations in the lower flange are due to the relative position of the wheel with respect to the relatively stiff transverse I-beams and the less stiff reinforced concrete deck.

Figure 8. Normal strains along the top and bottom flanges of the east main I-beam at the midspan.
The measured and computed FE strains at the midspan of the main I-beams are compared in Figure 8b. Each measured strain is depicted with a “+”. Evidently, there is a significant scatter in the measured strains between neighboring measurement points. Furthermore, the offset between the measured and FE strains in time indicates a mismatch between the actual and the assumed train speed. The actual train speed and position corresponding to the measured strains are unknown. The time coordinate for the FE strains is chosen so that the offset between the two sets of strains is minimized. Although the FE strains are smaller than the measured strains, their overall oscillation pattern is in close agreement. In comparison to the measured strains, the bottom flange FE strains have multiple small dips which is again related to the modeling of the connection between the main and transverse I-beams and the concrete deck.
The random loading
 $ \boldsymbol{r}\left(\boldsymbol{x}\right) $
representing the uncertainties in the train loading and its application to the superstructure yields according to (8) the prior FE strain density
$ \boldsymbol{r}\left(\boldsymbol{x}\right) $
representing the uncertainties in the train loading and its application to the superstructure yields according to (8) the prior FE strain density
 $ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}})=\mathcal{N}(\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}},\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}) $
. The mean and the 95% confidence region of the strains computed at 20 sensor locations along the top and bottom flanges of the east main I-beam (i.e., 40 sensor locations in total) are shown in Figure 10. The plotted curves are nonsmooth because the strains are linearly interpolated between the sensor locations. The actual FE strains are smooth and quadratic within each element (Zhang et al., Reference Zhang, Sabin and Cirak2018).
$ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}})=\mathcal{N}(\mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}},\mathbf{\mathsf{P}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}}{\mathbf{\mathsf{P}}}^{\mathsf{T}}) $
. The mean and the 95% confidence region of the strains computed at 20 sensor locations along the top and bottom flanges of the east main I-beam (i.e., 40 sensor locations in total) are shown in Figure 10. The plotted curves are nonsmooth because the strains are linearly interpolated between the sensor locations. The actual FE strains are smooth and quadratic within each element (Zhang et al., Reference Zhang, Sabin and Cirak2018).
4.2. Statistical FE analysis
4.2.1. Inference of true strain response using all sensors
The measured strains are used to predict the “true” axial strains along the east main I-beam. The posterior FE strain density
 $ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
and the true strain density
$ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
and the true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on the measured strains
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on the measured strains
 $ \mathbf{\mathsf{y}} $
are determined by evaluating (20a) and (22) using the parameters in Table 2. Evidently, the true strain response
$ \mathbf{\mathsf{y}} $
are determined by evaluating (20a) and (22) using the parameters in Table 2. Evidently, the true strain response
 $ \mathbf{\mathsf{z}} $
is unknown and only the measured strain response including some measurement error, that is,
$ \mathbf{\mathsf{z}} $
is unknown and only the measured strain response including some measurement error, that is,
 $ \mathbf{\mathsf{y}}=\mathbf{\mathsf{z}}+\mathbf{\mathsf{e}} $
, at the
$ \mathbf{\mathsf{y}}=\mathbf{\mathsf{z}}+\mathbf{\mathsf{e}} $
, at the
 $ {n}_y $
locations is known. At each time instant
$ {n}_y $
locations is known. At each time instant
 $ {t}_k $
, the posterior FE strain density
$ {t}_k $
, the posterior FE strain density
 $ p({\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}}_k|{\mathbf{\mathsf{y}}}_k) $
and the true strain density
$ p({\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}}_k|{\mathbf{\mathsf{y}}}_k) $
and the true strain density
 $ p({\mathbf{\mathsf{z}}}_k|{\mathbf{\mathsf{y}}}_k) $
are computed from the measured strains
$ p({\mathbf{\mathsf{z}}}_k|{\mathbf{\mathsf{y}}}_k) $
are computed from the measured strains
 $ {\mathbf{\mathsf{y}}}_k $
. For simplicity, the subscript
$ {\mathbf{\mathsf{y}}}_k $
. For simplicity, the subscript
 $ k $
is omitted here and in the following.
$ k $
is omitted here and in the following.
Table 2. Covariance and algorithmic parameters used in Section 4.2

Before computing the posterior densities, the marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
given by (25a) is sampled to obtain the point estimate
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
given by (25a) is sampled to obtain the point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
. Recall that the hyperparameter vector
$ {\mathbf{\mathsf{w}}}^{\ast } $
. Recall that the hyperparameter vector
 $ \mathbf{\mathsf{w}} $
consists of the scaling parameter
$ \mathbf{\mathsf{w}} $
consists of the scaling parameter
 $ \rho $
and the covariance kernel parameters
$ \rho $
and the covariance kernel parameters
 $ {\sigma}_d $
and
$ {\sigma}_d $
and
 $ {\mathrm{\ell}}_d $
of the mismatch error
$ {\mathrm{\ell}}_d $
of the mismatch error
 $ \mathbf{\mathsf{d}} $
. The strain recordings from all
$ \mathbf{\mathsf{d}} $
. The strain recordings from all
 $ {n}_y=40 $
FBG sensors of the east main I-beam are included in the observation (measurement) matrix
$ {n}_y=40 $
FBG sensors of the east main I-beam are included in the observation (measurement) matrix
 $ \mathbf{\mathsf{Y}}\in {\unicode{x211D}}^{n_y\times {n}_o} $
. The sensor locations are as specified in Figure 3. Only data recorded when a train is present on the bridge (i.e.,
$ \mathbf{\mathsf{Y}}\in {\unicode{x211D}}^{n_y\times {n}_o} $
. The sensor locations are as specified in Figure 3. Only data recorded when a train is present on the bridge (i.e.,
 $ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
yielding
$ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
yielding
 $ {n}_o=501 $
readings for each sensor) are included. The standard deviation
$ {n}_o=501 $
readings for each sensor) are included. The standard deviation
 $ {\sigma}_e=1\mathrm{microstrain} $
of the measurement error
$ {\sigma}_e=1\mathrm{microstrain} $
of the measurement error
 $ \mathbf{e} $
is estimated from the strain recordings within
$ \mathbf{e} $
is estimated from the strain recordings within
 $ 0\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 0.5\hskip1.5pt \mathrm{s} $
prior to the arrival of the train (see Figure 8b). The marginal likelihood
$ 0\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 0.5\hskip1.5pt \mathrm{s} $
prior to the arrival of the train (see Figure 8b). The marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
is sampled with a standard MCMC algorithm. In Figure 9, the normalized histograms for
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
is sampled with a standard MCMC algorithm. In Figure 9, the normalized histograms for
 $ p(\mathbf{\mathsf{Y}}|\rho ) $
,
$ p(\mathbf{\mathsf{Y}}|\rho ) $
,
 $ p(\mathbf{\mathsf{Y}}|{\sigma}_d) $
, and
$ p(\mathbf{\mathsf{Y}}|{\sigma}_d) $
, and
 $ p(\mathbf{\mathsf{Y}}|{\ell}_d) $
obtained with 20,000 iterations and an acceptance ratio of 0.283 are depicted. Convergence is ensured by checking the trace plot of the samples and monitoring the empirical mean and standard deviation of the samples. As mentioned before, the empirical mean of the MCMC samples is used as a point estimate
$ p(\mathbf{\mathsf{Y}}|{\ell}_d) $
obtained with 20,000 iterations and an acceptance ratio of 0.283 are depicted. Convergence is ensured by checking the trace plot of the samples and monitoring the empirical mean and standard deviation of the samples. As mentioned before, the empirical mean of the MCMC samples is used as a point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
, see Table 3. The unimodal nature of the histograms in Figure 9 and the relatively small standard deviations indicate that the available data are sufficient to identify the hyperparameters with a high certainty. Lack of sufficient data usually leads to multimodal histograms and large standard deviations.
$ {\mathbf{\mathsf{w}}}^{\ast } $
, see Table 3. The unimodal nature of the histograms in Figure 9 and the relatively small standard deviations indicate that the available data are sufficient to identify the hyperparameters with a high certainty. Lack of sufficient data usually leads to multimodal histograms and large standard deviations.

Figure 9. Normalized histogram of the marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
for
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
for
 $ {n}_y=40 $
and
$ {n}_y=40 $
and
 $ {n}_o=501 $
sampled with MCMC. The red dashed lines indicate the empirical mean
$ {n}_o=501 $
sampled with MCMC. The red dashed lines indicate the empirical mean
 $ {\mathbf{\mathsf{w}}}^{\ast } $
of the samples.
$ {\mathbf{\mathsf{w}}}^{\ast } $
of the samples.
Table 3. Empirical mean and standard deviation of the hyperparameters.

In Figure 10, the prior and posterior densities of the axial FE strains and the measured strains at
 $ t=1\hskip1.5pt \mathrm{s} $
,
$ t=1\hskip1.5pt \mathrm{s} $
,
 $ t=2\hskip1.5pt \mathrm{s} $
, and
$ t=2\hskip1.5pt \mathrm{s} $
, and
 $ t=3\hskip1.5pt \mathrm{s} $
are plotted. For the FE strains, in addition to the mean, the corresponding 95% confidence regions are plotted. Observe how the mean of the posterior FE strain lies much closer than the prior FE strain to the measured strains. It is also evident that the uncertainty in the prior FE strains is significantly reduced by conditioning them on the sensor measurements. In the corresponding Figure 11, the posterior densities of the true system response at
$ t=3\hskip1.5pt \mathrm{s} $
are plotted. For the FE strains, in addition to the mean, the corresponding 95% confidence regions are plotted. Observe how the mean of the posterior FE strain lies much closer than the prior FE strain to the measured strains. It is also evident that the uncertainty in the prior FE strains is significantly reduced by conditioning them on the sensor measurements. In the corresponding Figure 11, the posterior densities of the true system response at
 $ t=1\,\mathrm{s} $
,
$ t=1\,\mathrm{s} $
,
 $ t=2\hskip1.5pt \mathrm{s} $
, and
$ t=2\hskip1.5pt \mathrm{s} $
, and
 $ t=3\,\mathrm{s} $
are shown. The respective confidence regions encompass all the strain measurements and their mean is always visually very close to the mean of the data. These results clearly demonstrate that the FE strains conditioned on the measured strains (i.e., black curves in Figure 10) provide an improvement of strain prediction over the unconditioned FE strain results. Moreover, the 95% confidence regions provide a quantifiable method for identifying anomalous sensor readings. As a further note, observe that the confidence interval of
$ t=3\,\mathrm{s} $
are shown. The respective confidence regions encompass all the strain measurements and their mean is always visually very close to the mean of the data. These results clearly demonstrate that the FE strains conditioned on the measured strains (i.e., black curves in Figure 10) provide an improvement of strain prediction over the unconditioned FE strain results. Moreover, the 95% confidence regions provide a quantifiable method for identifying anomalous sensor readings. As a further note, observe that the confidence interval of
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
in Figure 11 is wider than the confidence interval of
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
in Figure 11 is wider than the confidence interval of
 $ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
in Figure 10 due to the contribution of the inferred mismatch term.
$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
in Figure 10 due to the contribution of the inferred mismatch term.

Figure 10. Posterior FE strains
 $ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
conditioned on the measured strains (+) along the east main I-beam. The blue and red lines represent the mean
$ p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
conditioned on the measured strains (+) along the east main I-beam. The blue and red lines represent the mean
 $ \mathbf{P}\overline{\mathbf{u}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
$ \mathbf{P}\overline{\mathbf{u}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
 $ \rho \mathbf{P}{\overline{\mathbf{u}}}_{\mid \mathbf{y}} $
. The shaded areas denote the corresponding
$ \rho \mathbf{P}{\overline{\mathbf{u}}}_{\mid \mathbf{y}} $
. The shaded areas denote the corresponding
 $ 95\% $
confidence regions. The unit of the vertical axis is microstrain.
$ 95\% $
confidence regions. The unit of the vertical axis is microstrain.

Figure 11. Inferred true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam. The blue and red lines represent the mean
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam. The blue and red lines represent the mean
 $ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
$ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
 $ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
$ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
 $ 95\% $
confidence regions. The unit of the vertical axis is microstrain.
$ 95\% $
confidence regions. The unit of the vertical axis is microstrain.
4.2.2. Inference of true strain response using a reduced number of sensors
Given the considerable efforts and costs associated with instrumenting operational structures, methods for optimizing both number and location of sensing points are critical. The statFEM approach allows for both data and physics-informed prediction even in situations where very limited measurement data are available. In the following, a reduced number of measurements are considered to obtain the posterior FE strain density
 $ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
and the true strain density
$ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}) $
and the true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
. A reduced number of sensors
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
. A reduced number of sensors
 $ {n}_y $
and readings per sensor
$ {n}_y $
and readings per sensor
 $ {n}_o $
are considered. The purpose of this study is to confirm empirically the convergence of the two posteriors with increasing number of data and to determine the minimum number of data required for an acceptable estimate. The use of fewer data has advantages in terms of reduced instrumentation, increased numerical efficiency, and the corresponding reduction in effort spent on data analysis and interpretation.
$ {n}_o $
are considered. The purpose of this study is to confirm empirically the convergence of the two posteriors with increasing number of data and to determine the minimum number of data required for an acceptable estimate. The use of fewer data has advantages in terms of reduced instrumentation, increased numerical efficiency, and the corresponding reduction in effort spent on data analysis and interpretation.
Three numbers of sensing points
 $ {n}_y\in \left\{40,20,10\right\} $
along the east main I-beam are considered. In each case, half of the sensing points are along the top and the other half along the bottom flange. Recall that the total number of sensors installed along the top and bottom flanges of each main I-beam is 40 (20 top and 20 bottom). For each
$ {n}_y\in \left\{40,20,10\right\} $
along the east main I-beam are considered. In each case, half of the sensing points are along the top and the other half along the bottom flange. Recall that the total number of sensors installed along the top and bottom flanges of each main I-beam is 40 (20 top and 20 bottom). For each
 $ {n}_y $
, a subset of FBG sensors with the IDs given in Table 4 is selected. Furthermore, the number of strain measurements
$ {n}_y $
, a subset of FBG sensors with the IDs given in Table 4 is selected. Furthermore, the number of strain measurements
 $ {n}_o $
is altered by selecting four different time intervals
$ {n}_o $
is altered by selecting four different time intervals
 $ \Delta t=\{1/250\hskip1.5pt \mathrm{s},\,1/50\hskip1.5pt \mathrm{s},\,1/25\hskip1.5pt \mathrm{s},\,1\hskip1.5pt \mathrm{s}\} $
between the measurements within the observation window
$ \Delta t=\{1/250\hskip1.5pt \mathrm{s},\,1/50\hskip1.5pt \mathrm{s},\,1/25\hskip1.5pt \mathrm{s},\,1\hskip1.5pt \mathrm{s}\} $
between the measurements within the observation window
 $ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
. The respective number of measurements is
$ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
. The respective number of measurements is
 $ {n}_o=\left\{501,101,51,3\right\} $
. As in the preceding section, the marginal likelihood
$ {n}_o=\left\{501,101,51,3\right\} $
. As in the preceding section, the marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
is sampled using MCMC. For each combination of
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
is sampled using MCMC. For each combination of
 $ {n}_y $
and
$ {n}_y $
and
 $ {n}_o $
, a total of 20,000 MCMC samples are generated with an average acceptance ratio of 0.326.
$ {n}_o $
, a total of 20,000 MCMC samples are generated with an average acceptance ratio of 0.326.
Table 4. Strain gauge ID for computations with
 $ {n}_y=\left\{\mathrm{40,20,10}\right\} $
sensors on the east main I-beam.
$ {n}_y=\left\{\mathrm{40,20,10}\right\} $
sensors on the east main I-beam.

The normalized histograms for
 $ p(\mathbf{\mathsf{Y}}|\rho ) $
,
$ p(\mathbf{\mathsf{Y}}|\rho ) $
,
 $ p(\mathbf{\mathsf{Y}}|{\sigma}_d) $
, and
$ p(\mathbf{\mathsf{Y}}|{\sigma}_d) $
, and
 $ p(\mathbf{\mathsf{Y}}|{\ell}_d) $
for
$ p(\mathbf{\mathsf{Y}}|{\ell}_d) $
for
 $ {n}_y=20 $
are shown in Figure 12. It is apparent that the standard deviations become significantly smaller with increasing number of readings
$ {n}_y=20 $
are shown in Figure 12. It is apparent that the standard deviations become significantly smaller with increasing number of readings
 $ {n}_o $
. The empirical mean and standard deviation for all combinations of
$ {n}_o $
. The empirical mean and standard deviation for all combinations of
 $ {n}_y $
and
$ {n}_y $
and
 $ {n}_o $
are given in Tables 5, 6 and 7. In almost all cases, the standard deviation of the samples becomes smaller with increasing number of readings. Moreover, the standard deviation becomes smaller when data from more sensors are considered (larger
$ {n}_o $
are given in Tables 5, 6 and 7. In almost all cases, the standard deviation of the samples becomes smaller with increasing number of readings. Moreover, the standard deviation becomes smaller when data from more sensors are considered (larger
 $ {n}_y $
). For the scaling parameter
$ {n}_y $
). For the scaling parameter
 $ \rho $
, the difference between the means obtained with
$ \rho $
, the difference between the means obtained with
 $ {n}_o=501 $
and
$ {n}_o=501 $
and
 $ {n}_o=3 $
is around
$ {n}_o=3 $
is around
 $ 5\% $
and decreases as additional readings are incorporated. For the mismatch parameter
$ 5\% $
and decreases as additional readings are incorporated. For the mismatch parameter
 $ {\sigma}_d $
, the difference can be as high as
$ {\sigma}_d $
, the difference can be as high as
 $ 25\% $
, and then decreases to
$ 25\% $
, and then decreases to
 $ 2\hbox{--} 8\% $
depending on the number of sensors
$ 2\hbox{--} 8\% $
depending on the number of sensors
 $ {n}_y $
. It is remarkable that with 50 times fewer readings, the difference of the estimated
$ {n}_y $
. It is remarkable that with 50 times fewer readings, the difference of the estimated
 $ \rho $
and
$ \rho $
and
 $ {\sigma}_d $
is still acceptable. The length scale parameter
$ {\sigma}_d $
is still acceptable. The length scale parameter
 $ {\mathrm{\ell}}_d $
, however, shows a larger difference between the two smaller number of sensing points
$ {\mathrm{\ell}}_d $
, however, shows a larger difference between the two smaller number of sensing points
 $ {n}_o=\left\{3,11\right\} $
and the larger number of sensing points
$ {n}_o=\left\{3,11\right\} $
and the larger number of sensing points
 $ {n}_o=501 $
. This result, however, does not significantly affect the inferred posterior true strains.
$ {n}_o=501 $
. This result, however, does not significantly affect the inferred posterior true strains.

Figure 12. Normalized histogram of the marginal likelihood
 $ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
for
$ p(\mathbf{\mathsf{Y}}|\mathbf{\mathsf{w}}) $
for
 $ {n}_y=20 $
and
$ {n}_y=20 $
and
 $ {n}_o\in \left\{3,11,101,501\right\} $
sampled with MCMC.
$ {n}_o\in \left\{3,11,101,501\right\} $
sampled with MCMC.
Table 5. Empirical mean and standard deviation of the hyperparameter
 $ \rho $
.
$ \rho $
.

Table 6. Empirical mean and standard deviation of the hyperparameter
 $ {\sigma}_d $
.
$ {\sigma}_d $
.

Table 7. Empirical mean and standard deviation of the hyperparameter
 $ {\mathrm{\ell}}_d $
.
$ {\mathrm{\ell}}_d $
.

Next, the posterior true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
is evaluated for different numbers of sensing points
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
is evaluated for different numbers of sensing points
 $ {n}_y $
and a fixed number of readings
$ {n}_y $
and a fixed number of readings
 $ {n}_o=11 $
, see Figure 13. In contrast, Figure 14 shows the posterior true strains for different
$ {n}_o=11 $
, see Figure 13. In contrast, Figure 14 shows the posterior true strains for different
 $ {n}_o $
and a fixed
$ {n}_o $
and a fixed
 $ {n}_y=10 $
. It can be observed that the means
$ {n}_y=10 $
. It can be observed that the means
 $ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
obtained using fewer observation data show close agreement with those obtained using more data. Similarly, the 95% confidence intervals of the different posteriors
$ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
obtained using fewer observation data show close agreement with those obtained using more data. Similarly, the 95% confidence intervals of the different posteriors
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
look visually very similar for all combinations of
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
look visually very similar for all combinations of
 $ {n}_o $
and
$ {n}_o $
and
 $ {n}_y $
. These results confirm that it is possible to use data from fewer sensors
$ {n}_y $
. These results confirm that it is possible to use data from fewer sensors
 $ {n}_y $
and fewer readings
$ {n}_y $
and fewer readings
 $ {n}_o $
to obtain a sufficiently reliable estimate for the true strain response.
$ {n}_o $
to obtain a sufficiently reliable estimate for the true strain response.

Figure 13. Inferred true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam for
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam for
 $ {n}_o=11 $
readings. The blue and red lines represent the mean
$ {n}_o=11 $
readings. The blue and red lines represent the mean
 $ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
$ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
 $ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
$ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
 $ 95\% $
confidence regions. In each row, the number of sensors
$ 95\% $
confidence regions. In each row, the number of sensors
 $ {n}_y $
is fixed. In each column, the observation time
$ {n}_y $
is fixed. In each column, the observation time
 $ t $
is fixed. The unit of the vertical axis is microstrain.
$ t $
is fixed. The unit of the vertical axis is microstrain.

Figure 14. Inferred true strain density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam for
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
conditioned on strains (+) measured along the east main I-beam for
![]() sensors. The blue and red lines represent the mean
sensors. The blue and red lines represent the mean
 $ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
$ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
of the prior along the top and bottom flanges, respectively, and the black lines the conditioned mean
 $ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
$ {\overline{\mathbf{\mathsf{z}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
 $ 95\% $
confidence regions. In each row, the number of readings
$ 95\% $
confidence regions. In each row, the number of readings
 $ {n}_o $
and in each column the observation time
$ {n}_o $
and in each column the observation time
 $ t $
is fixed. The unit of the vertical axis is microstrain.
$ t $
is fixed. The unit of the vertical axis is microstrain.
4.2.3. Predictive strains at nonsensor locations
Another advantage of statFEM is the possibility of generating strain predictions at locations where no sensing data are available. Limited sensing points may arise due to cost and labor considerations, but it is also common in structural monitoring for sensor systems to malfunction and for entire sections of a sensor network to stop recording. The sensor strains along the west main I-beam are estimated by using only the readings from sensors installed along the east main I-beam. Although strain data along the west I-beam are available, they are not included in the observation matrix
 $ \mathbf{\mathsf{Y}} $
. This test is an extreme case of missing measurement data due either to sensor malfunction or temporary system error.
$ \mathbf{\mathsf{Y}} $
. This test is an extreme case of missing measurement data due either to sensor malfunction or temporary system error.
Consider the vector of unobserved strains
 $ \hat{\mathbf{\mathsf{y}}} $
at the locations with the coordinates
$ \hat{\mathbf{\mathsf{y}}} $
at the locations with the coordinates
 $ \hat{\mathbf{\mathsf{X}}} $
. The matrix
$ \hat{\mathbf{\mathsf{X}}} $
. The matrix
 $ \hat{\mathbf{\mathsf{X}}} $
contains the coordinates of the FBG sensors along the west I-beam, see Figure 3. The predictive density of sensors strains
$ \hat{\mathbf{\mathsf{X}}} $
contains the coordinates of the FBG sensors along the west I-beam, see Figure 3. The predictive density of sensors strains
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
conditioned on the observations
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
conditioned on the observations
 $ \mathbf{\mathsf{y}} $
is given by
$ \mathbf{\mathsf{y}} $
is given by
 $$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}})=\int p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{u}})p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})\mathrm{d}\mathbf{\mathsf{u}}. $$
$$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}})=\int p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{u}})p(\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}})\mathrm{d}\mathbf{\mathsf{u}}. $$
With the likelihood (14) and the FE posterior (20) this becomes
 $$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}})=\mathcal{N}(\rho \hat{\mathbf{\mathsf{P}}}{\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},{\rho}^2\hat{\mathbf{\mathsf{P}}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}{\hat{\mathbf{\mathsf{P}}}}^{\mathsf{T}}+{\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{d}}}+{\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{e}}}) $$
$$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}})=\mathcal{N}(\rho \hat{\mathbf{\mathsf{P}}}{\overline{\mathbf{\mathsf{u}}}}_{|\mathbf{\mathsf{y}}},{\rho}^2\hat{\mathbf{\mathsf{P}}}{\mathbf{\mathsf{C}}}_{\mathbf{\mathsf{u}}|\mathbf{\mathsf{y}}}{\hat{\mathbf{\mathsf{P}}}}^{\mathsf{T}}+{\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{d}}}+{\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{e}}}) $$
where the matrices
 $ \hat{\mathbf{\mathsf{P}}} $
,
$ \hat{\mathbf{\mathsf{P}}} $
,
 $ {\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{d}}} $
, and
$ {\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{d}}} $
, and
 $ {\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{e}}} $
are obtained by introducing the coordinates collected in
$ {\hat{\mathbf{\mathsf{C}}}}_{\mathbf{\mathsf{e}}} $
are obtained by introducing the coordinates collected in
 $ \hat{\mathbf{\mathsf{X}}} $
in the respective operator and covariance kernels. Note that this expression is very similar to the true system density
$ \hat{\mathbf{\mathsf{X}}} $
in the respective operator and covariance kernels. Note that this expression is very similar to the true system density
 $ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
given in (22) up to the additional covariance term due to the measurement errors.
$ p(\mathbf{\mathsf{z}}|\mathbf{\mathsf{y}}) $
given in (22) up to the additional covariance term due to the measurement errors.
To evaluate the predictive strain density
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
, the hyperparameters of the statistical model
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
, the hyperparameters of the statistical model
 $ \mathbf{\mathsf{w}} $
are learned first as before. To this end, included in the observation matrix
$ \mathbf{\mathsf{w}} $
are learned first as before. To this end, included in the observation matrix
 $ \mathbf{\mathsf{Y}} $
are the strains of the
$ \mathbf{\mathsf{Y}} $
are the strains of the
 $ {n}_y=40 $
sensors along the east I-beam and for each sensor the
$ {n}_y=40 $
sensors along the east I-beam and for each sensor the
 $ {n}_o=101 $
readings between the time
$ {n}_o=101 $
readings between the time
 $ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
. Subsequently,
$ 1\hskip1.5pt \mathrm{s}\hskip0.24em \le \hskip0.24em t\hskip0.24em \le \hskip0.24em 3\hskip1.5pt \mathrm{s} $
. Subsequently,
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
is computed by introducing the point estimate
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
is computed by introducing the point estimate
 $ {\mathbf{\mathsf{w}}}^{\ast } $
obtained by MCMC sampling into (28). The point estimate obtained in this example is
$ {\mathbf{\mathsf{w}}}^{\ast } $
obtained by MCMC sampling into (28). The point estimate obtained in this example is
 $ {\mathbf{\mathsf{w}}}^{\ast }={(0.87723\hskip2pt 3.996\hskip2.5pt \mathrm{m}\mathrm{icrostrain}\hskip2.5pt 0.43\,\mathrm{m})}^{\mathsf{T}} $
. The prediction
$ {\mathbf{\mathsf{w}}}^{\ast }={(0.87723\hskip2pt 3.996\hskip2.5pt \mathrm{m}\mathrm{icrostrain}\hskip2.5pt 0.43\,\mathrm{m})}^{\mathsf{T}} $
. The prediction
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
is computed at all the 40 sensor positions along the west I-beam.
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
is computed at all the 40 sensor positions along the west I-beam.
As shown in Figure 15, with only measurement data from the east I-beam taken into account, the predictive strain distribution
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
differs from the prior FE computed strains
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
differs from the prior FE computed strains
 $ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}) $
and the measured strains. Its mean
$ p(\mathbf{\mathsf{P}}\mathbf{\mathsf{u}}) $
and the measured strains. Its mean
 $ {\overline{\hat{\mathbf{\mathsf{y}}}}}_{|\mathbf{\mathsf{y}}} $
lies mostly in between the mean of the prior
$ {\overline{\hat{\mathbf{\mathsf{y}}}}}_{|\mathbf{\mathsf{y}}} $
lies mostly in between the mean of the prior
 $ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
and the measured strains. The 95% confidence regions of the predictive strain distribution and the prior have almost the same width. Hence, even at locations where there are no measurement data available, statFEM is able to improve the FE prior by utilizing measurement data from other parts of the bridge.
$ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
and the measured strains. The 95% confidence regions of the predictive strain distribution and the prior have almost the same width. Hence, even at locations where there are no measurement data available, statFEM is able to improve the FE prior by utilizing measurement data from other parts of the bridge.

Figure 15. Predictive strain distribution
 $ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
along the west I-beam conditioned on strains (+) measured along the east main I-beam. The blue and red lines represent the prior mean
$ p(\hat{\mathbf{\mathsf{y}}}|\mathbf{\mathsf{y}}) $
along the west I-beam conditioned on strains (+) measured along the east main I-beam. The blue and red lines represent the prior mean
 $ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
along the top and bottom flanges, respectively, and the black lines the predictive mean
$ \mathbf{\mathsf{P}}\overline{\mathbf{\mathsf{u}}} $
along the top and bottom flanges, respectively, and the black lines the predictive mean
 $ \rho \mathbf{\mathsf{P}}{\overline{\hat{\mathbf{\mathsf{u}}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
$ \rho \mathbf{\mathsf{P}}{\overline{\hat{\mathbf{\mathsf{u}}}}}_{\mid \mathbf{\mathsf{y}}} $
. The shaded areas denote the corresponding
 $ 95\% $
confidence regions. The unit of the vertical axis is microstrain.
$ 95\% $
confidence regions. The unit of the vertical axis is microstrain.
5. Conclusions
In this study, a statistical digital twin of an operational bridge superstructure has been developed to synthesize FBG strain measurements with FE model predictions for obtaining improved strain predictions. To this end, the application of statFEM as a new modeling paradigm in creating digital twins was proposed. In light of the presented results, several conclusions can be drawn.
-
1. By considering strain data captured along the top and bottom flanges of the east and west main I-beams, statFEM analysis showed an improvement of the mean strain estimates after being conditioned on the recorded sensor data. The 95% confidence bounds provided a quantifiable means of identifying anomalous sensor readings, which represents a significant step change in how structural monitoring data may be more reliably interpreted.
-
2. To evaluate the effect of the number of sensing points on statFEM predictions, several sensor subsets (40, 20, and 10 sensors) for each main I-beam were considered. The resulting predictive strain distributions and associated 95% confidence bounds between the three sensor subsets were negligible. This demonstrated that statFEM may be used to optimize sensor network design leading to significant reductions in instrumentation costs.
-
3. In addition to evaluating the effect of a reduced number of sensing points, several reduced sampling rates for each individual FBG sensor (originally capturing data at
$ 250\hskip2pt \mathrm{H}\mathrm{z} $
) were considered. Once again, statFEM provided robust mean estimates of the predictive strains regardless of sampling rate. -
4. Using only strain data captured along the east main I-beam, the predictive strain distribution along the west main I-beam was estimated. It was shown that the predictive mean along the west I-beam incorporates the effects from both the FE prior and the measured data at the opposite east main I-beam. Therefore, in cases where missing or damaged parts of a sensor network exist, statFEM can still be used to generate meaningful interpretations of the data.

In summary, this study has highlighted the suitability of statFEM for structural health monitoring and condition assessment of instrumented civil infrastructure assets. The presented results demonstrated that a relatively coarse FE model and a modest amount of data are sufficient to obtain reliable predictions. Combined with advanced computing technologies, this paves the way for future continuous, real-time monitoring, and condition assessment of infrastructure assets. Furthermore, the choice of a suitable coarse FE model can be rationalized with the Bayesian model selection paradigm (Beck, Reference Beck2010; Girolami et al., Reference Girolami, Febrianto, Yin and Cirak2021). Indeed, Bayesian model selection can provide a means to discover sudden changes in the state of the infrastructure by comparing the plausibility of different predefined “what-if” scenarios, including simulated damage and failure mechanisms.
Acknowledgments
We are grateful to the Cambridge Centre of Smart Infrastructure and Construction (CSIC) for providing access to the bridge monitoring data used in this study.
Data Availability Statement
The data set used for this study is available via the University of Cambridge data repository. The link to the repository can be found in Butler et al. (Reference Butler, Lin, Xu, Gibbons, Elshafie and Middleton2018).
Author Contributions
Conseptualization: E.F., L.B., M.G., and F.C.; methodology: E.F., F.C.; data curation: L.B.; analysis, validation, visualization: E.F., F.C.; writing original draft: E.F., L.B., F.C.; all authors approved the final submitted draft.
Funding Statement
This work was supported by Wave 1 of The UKRI Strategic Priorities Fund under the EPSRC Grant EP/T001569/1, particularly the “Digital twins for complex engineering systems” theme within that grant, and The Alan Turing Institute.
Competing Interests
The authors declare no competing interests exist.































































 Open access
Open access
Comments
No Comments have been published for this article.