



1. Introduction
Artificial intelligence (AI) and machine learning often address challenges that are relatively monolithic: determine the safest action for an autonomous car; translate a document from English to French and analyse a medical image to detect a cancer; answer a question about a difficult topic. These kinds of challenge are important and worthwhile targets for AI research. However, an alternative set of challenges exist that are collective in nature:
-
• help to minimise a pandemic’s impact by coordinating mitigating interventions;
-
• help to manage an extreme weather event using real-time physical and social data streams;
-
• help to avoid a stock market crash by managing interactions between trading agents;
-
• help to guide city developers towards more sustainable coordinated city planning decisions;
-
• help people with diabetes to collaboratively manage their condition while preserving privacy.
The capability of naturally occurring collective systems to solve problems of coordination, collaboration and communication has been a long-standing inspiration for engineering (Bonabeau et al., Reference Bonabeau, Dorigo and Theraulaz1999). However, developing AI systems for these types of problem presents unique challenges: extracting reliable and informative patterns from multiple overlapping and interacting real-time data streams; identifying and controlling for evolving community structure within the collective; determining local interventions that allow smart agents to influence collective systems in a positive way; developing privacy-preserving machine learning; advancing ethical best practice and governance; embedding novel machine learning and AI in portals, devices and tools that can be used transparently and productively by different types of user. Tackling them demands moving beyond typical AI/machine learning approaches to achieve an understanding of relevant group dynamics, collective decision-making and the emergent properties of multi-agent systems, topics more commonly studied within the growing research area of collective intelligence. Consequently, addressing these challenges requires a productive combination of collective intelligence research and AI research (Berditchevskaia & Baeck, Reference Berditchevskaia and Baeck2020; Berditchevskaia et al., Reference Berditchevskaia, Maliaraki and Stathoulopoulos2022).
In this paper we introduce and detail a research strategy for approaching this challenge that is being taken by a new national artificial intelligence research hub for the United Kingdom: AI for Collective Intelligence (AI4CI).Footnote 1 The AI4CI Hub is a multi-institution collaboration involving seven partner universities from across the UK’s four constituent nations and over forty initial stakeholder partners from academia, government, charities and industry. It pursues applied research at the interface between the fields of AI and collective intelligence and works to build capacity, capability and community in this area of research across the UK and beyond. This paper presents the AI4CI research strategy, details how it can be pursued across multiple different research themes and summarises some of the key unifying research challenges that it must address.
2. Research context
Between 2022 and 2024, the UK government initiated several significant investments in national-scale AI research amounting to approximately
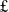 $\unicode{x00A3}$
1Bn of support. Foremost amongst these investments were: the establishment of the UK’s first national supercomputing facility for AI research (Isambard-AI;
$\unicode{x00A3}$
1Bn of support. Foremost amongst these investments were: the establishment of the UK’s first national supercomputing facility for AI research (Isambard-AI;
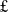 $\unicode{x00A3}$
225m),Footnote 2 plus an additional
$\unicode{x00A3}$
225m),Footnote 2 plus an additional
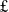 $\unicode{x00A3}$
500m of AI compute hardware investment across UK universities,Footnote 3 the inception of twelve new Centres for Doctoral Training in AI (AI CDTs;
$\unicode{x00A3}$
500m of AI compute hardware investment across UK universities,Footnote 3 the inception of twelve new Centres for Doctoral Training in AI (AI CDTs;
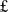 $\unicode{x00A3}$
117m),Footnote 4 funding for a raft of AI research projects including AI for net zero (
$\unicode{x00A3}$
117m),Footnote 4 funding for a raft of AI research projects including AI for net zero (
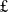 $\unicode{x00A3}$
13m)Footnote 5 and AI for healthcare (
$\unicode{x00A3}$
13m)Footnote 5 and AI for healthcare (
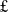 $\unicode{x00A3}$
13m),Footnote 6 the creation of UK Responsible AI, a national network to conduct and fund research into responsible AI (UKRAI,
$\unicode{x00A3}$
13m),Footnote 6 the creation of UK Responsible AI, a national network to conduct and fund research into responsible AI (UKRAI,
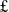 $\unicode{x00A3}$
31m),Footnote 7 and the launch of nine new national Research Hubs for AI, three focusing on the mathematical foundations of AI and six focusing on applied AI research (
$\unicode{x00A3}$
31m),Footnote 7 and the launch of nine new national Research Hubs for AI, three focusing on the mathematical foundations of AI and six focusing on applied AI research (
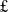 $\unicode{x00A3}$
100m).Footnote 8
$\unicode{x00A3}$
100m).Footnote 8
These significant investments were driven by growing recognition that modern AI has the potential to achieve a positive and revolutionary impact on society. Here, we focus on a research strategy proposed in response to the findings of a recent Nesta reportFootnote 9 which recommended that policymakers ‘put collective intelligence at the core of all AI policy in the United Kingdom’ (Berditchevskaia & Baeck, Reference Berditchevskaia and Baeck2020, p. 57), arguing that ‘the first major funder to put
 $\unicode{x00A3}$
10 million into this field will make a lasting impact on the future trajectory for AI and create new opportunities for stimulating economic growth as well as more responsible and democratic AI development’ (ibid, p. 58).
$\unicode{x00A3}$
10 million into this field will make a lasting impact on the future trajectory for AI and create new opportunities for stimulating economic growth as well as more responsible and democratic AI development’ (ibid, p. 58).
3. Vision and structure
Our ability to address the most pressing current societal challenges (e.g., healthcare, sustainability, climate change, financial stability) increasingly depends upon the extent to which we can reliably and successfully engineer important kinds of collective intelligence, which we define as:
-
Connected communities of people, devices, data and software collaboratively sensing and interacting in real time to achieve positive outcomes at multiple scales.
Whether we are aiming to minimise the impact of a global pandemic through effectively managing successive waves of vaccination (Brooks-Pollock et al., Reference Brooks-Pollock, Danon, Jombart and Pellis2021), to prevent financial ‘flash crashes’ through effective regulation of autonomous trading agents (Cartlidge et al., Reference Cartlidge, Szostek, Luca, Cliff, Filipe and Fred2012; Johnson et al., Reference Johnson, Zhao, Hunsader, Qi, Johnson, Meng and Tivnan2013), to make our cities sustainable and liveable through using real-time analytics to inform short-, medium- and long-term planning (Spooner et al., Reference Spooner, Abrams, Morrissey, Shaddick, Batty, Milton, Dennett, Lomax, Malleson, Nelissen, Coleman, Nur, Jin, Greig, Shenton and Birkin2021; Batty, Reference Batty2024), to combat social polarisation and climate disinformation on social media (Treen et al., Reference Treen2020), or to achieve the UK NHS 2019 Long-Term Plan (NHS, 2019) by enabling effective healthcare ecosystems that integrate clinical care, technology, education and social support for patients with chronic health conditions (Duckworth et al., Reference Duckworth, Guy, Kumaran, O’Kane, Ayobi, Chapman, Marshall and Boniface2024), invariably what is required is an ability to engineer smart collectives.Footnote 10
This will necessarily involve addressing both halves of what we characterise as the ‘AI4CI Loop’ (Fig. 1 left)—(1) Gathering Intelligence: collecting and making sense of distributed information; (2) Informing Behaviour: acting on that intelligence to effectively support decision making at multiple levels. New AI methods are unlocking progress on both halves. The first is being revolutionised by a combination of mobile devices, instrumented environments, data science, machine learning analytics and real-time visualisation, while the second is being transformed by decentralised, distributed smart agent technologies that interact directly with users. However, successfully linking both halves of the AI4CI Loop requires new human-centred design principles, new governance practices and new infrastructure appropriate for systems that deploy AI for collective intelligence at national scale.
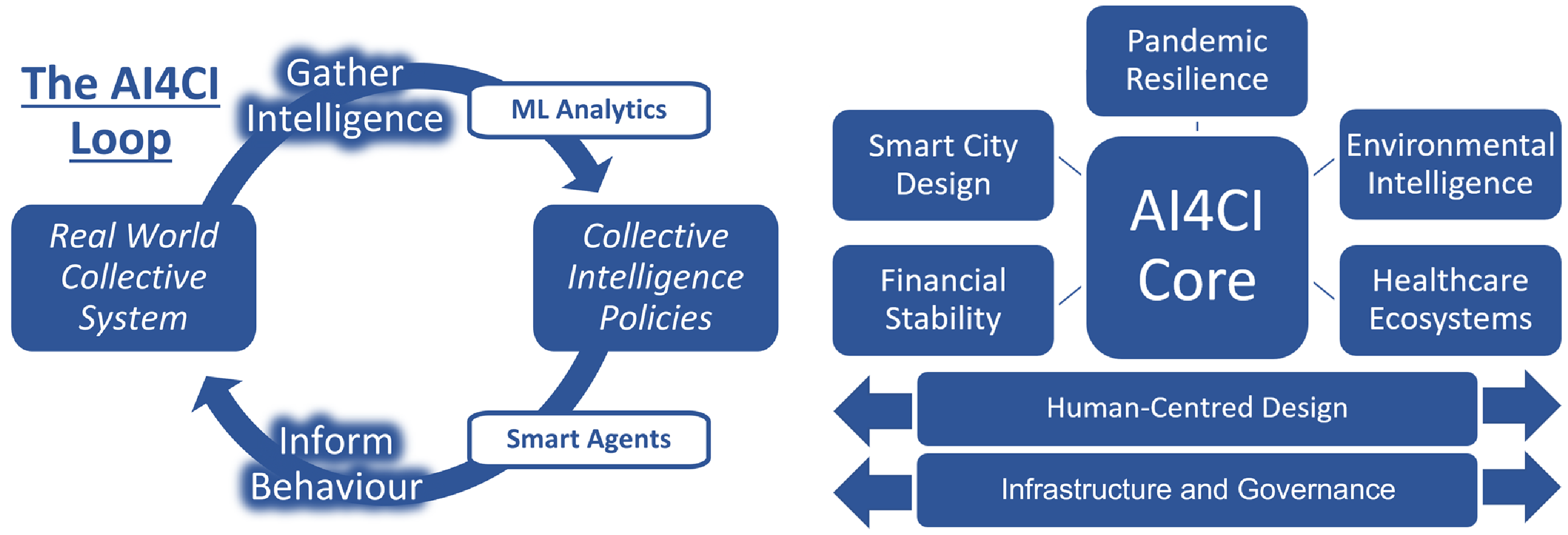
Figure 1. Left—The AI4CI Loop: Machine learning and AI enable distributed real-time data streams to inform effective collective action via smart agents. Right—The AI4CI Hub: Five applied research themes and two cross-cutting research themes are supported by the hub’s central core.
4. Research themes
The AI for Collective Intelligence Hub (Figure 1 right) addresses and connects both halves of the AI4CI Loop across a set of five important application domains (healthcare, finance, the environment, pandemics and cities) and two cross-cutting themes (human-centred design and infrastructure and governance). In each domain, the challenge is to leverage and make sense of real time, dynamic data streams generated across hybrid systems of interacting people, machines and software distributed over space and across networks, in order to achieve systemic insights and drive effective interventions via the automated behaviour of smart AI agents. Pursuing research across multiple domains in concert enables each to benefit from the others’ insights and maximises the chance of uncovering principles and that have domain-general application (Smaldino & O’Connor, Reference Smaldino and O’Connor2022).
4.1. Smart city design
Plan-making systems for UK cities are not currently fit for purpose.Footnote 11 Local plans, the major instrument of the statutory planning system, must be modernised to exploit collective data and machine intelligence (Batty, Reference Batty2024). Meeting the challenges associated with smart planning for smart citiesFootnote 12 in a way that delivers practical tools and applications requires integrating and exploiting multiple streams of city data provided by local and national government, urban analytics and infrastructure firms, national agencies, survey data and human mobility patterns derived from digital traces or social media.Footnote 13
These data can drive new AI for two purposes: (i) automating real-time intelligence for the smart city (Malleson et al., Reference Malleson, Birkin, Birks, Ge, Heppenstall, Manley, McCulloch and Ternes2022; An et al., Reference An, Grimm, Bai, Sullivan and Turner2023); (ii) informing longer-term smart city planning to meet the challenges of climate, ageing, housing affordability and health (Batty, Reference Batty2024). Achieving smarter cities that optimise behaviours in the short and long term requires AI that extends and improves on existing models of urban structure, dealing with highly fluid situations dominated by rapid change (Batty, Reference Batty2024). This is a major challenge not only for the way that we design cities but also for how AI must deal with many/most human problem-solving contexts. Supervised and unsupervised learning methods can be used to reveal new patterns in large messy mobility datasets such as mobile phone traces, cross-validated with rich survey data to produce spatially, temporally and attribute rich insights into the seismic shift in post-COVID mobility patterns (Batty et al., Reference Batty, Clifton, Tyler and Wan2020). Predictive tools for the design of new patterns of transport and land development at different scales can be founded on models that take multiple land suitability and mobility indices as inputs (see, e.g., Figure 2; Zhang et al., Reference Zhang, Chapple, Cao, Dennett and Smith2020). Deriving meaningful interpretations of these models and enabling decision-makers to explore how optimal plans play out over time and space in the context of synthetic AI agent models (Batty et al., Reference Batty, Crooks, See, Heppenstall, Heppenstall, Crooks, See and Batty2012) delivers the explanatory accounts that are essential for public accountability in the use of these methods for city decision making.
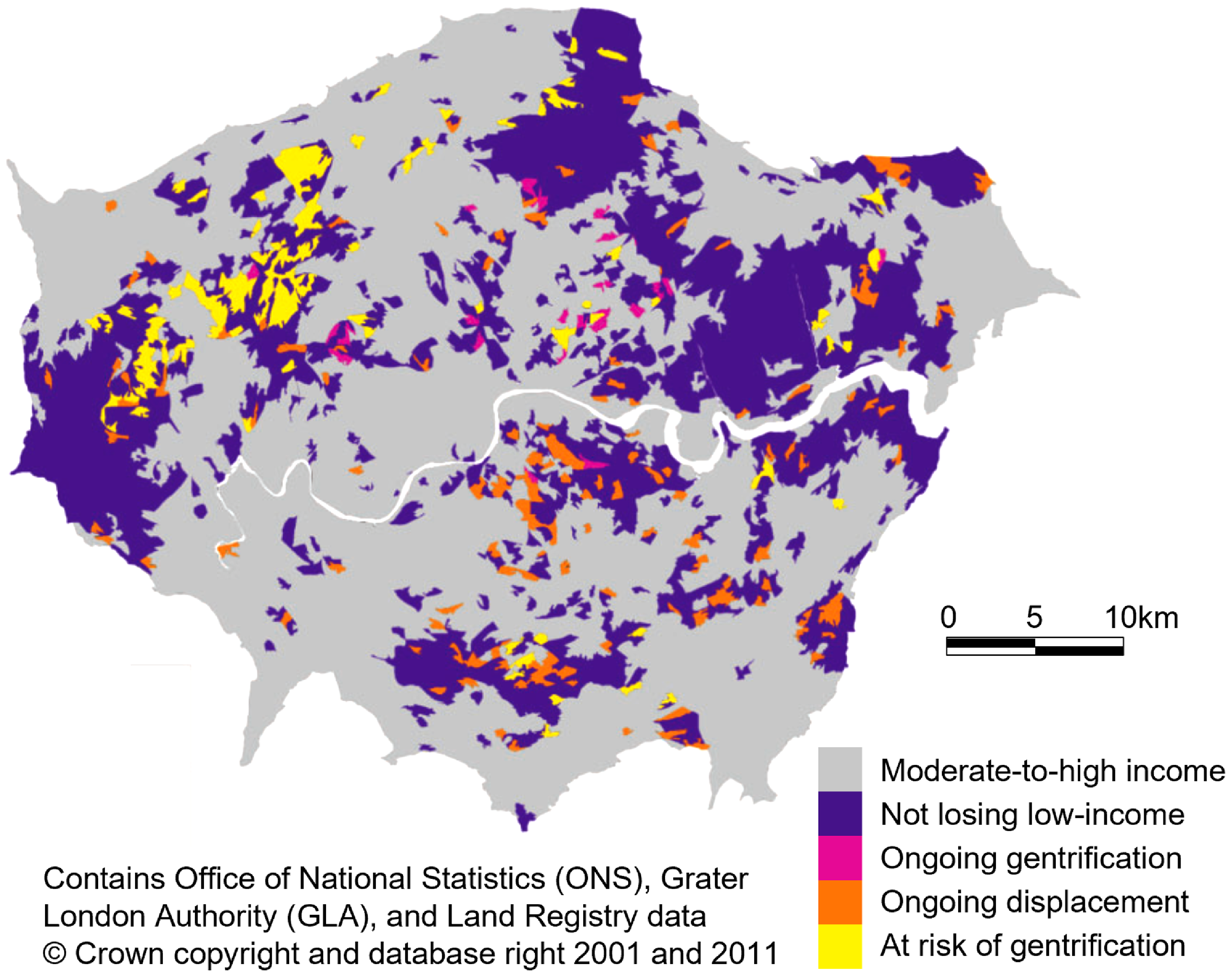
Figure 2. An indicative snapshot of smart city datasets informing AI for collective intelligence research. Gentrification and displacement typologies for Greater London in 2011 at neighbourhood level with cartogram distortion based on London’s residential population in 2011. Adapted from Zhang et al. (Reference Zhang, Chapple, Cao, Dennett and Smith2020).
4.2. Pandemic resilience
COVID-19 exposed weaknesses in the UK’s pandemic resilience. A combination of collective intelligence and AI can help us do better next time. Data crucial for managing novel pandemics are inherently fragmented, arising from communities of medics, public health professionals and analysts to describe the spread of the disease, characterise its phenotype, and, with appropriate modelling, inform appropriate policies nationally and locally (Brooks-Pollock et al., Reference Brooks-Pollock, Danon, Jombart and Pellis2021). National spatio-temporal datasets describing SARS-CoV-2 hospital testing and community testing, and the extent and effects of the mitigations put in place against it, can be exploited in order to build new AI/machine learning tools for future pandemics—and potentially for mitigating seasonal outbreaks of endemic disease.
Two strands of research can be identified. First, a suite of machine learning models fuelled by national SARS-CoV-2 pandemic data can be used to explore and demonstrate how the integration of multiple population-level indicators could have improved decision making during the pandemic. Due to the urgency of the need for response during the pandemic, developing and validating this kind of analytical infrastructure was not possible. With it in place, however, challenges associated with imperfect data can be addressed. For example, data from unreliable laboratories distorted local and national COVID-19 reproduction number (
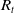 $R_t$
) estimates in 2022Footnote 14 leading to under-informed policy decisions. Automatic detection and correction for such errors will alert policy makers and decision makers more quickly.
$R_t$
) estimates in 2022Footnote 14 leading to under-informed policy decisions. Automatic detection and correction for such errors will alert policy makers and decision makers more quickly.
Second, detailed local data can be used to understand localised interventions and spontaneous behavioural responses. Here, relevant AI challenges include: establishing the relative value of diverse data streams at different stages of the pandemic and their consistency across spatial scales; the use of anomaly and change point detection to identify meaningful discontinuities; robust data imputation, pattern completion, bias detection and correction; evaluating the impact of both vaccination and behavioural change resulting from, for example, non-pharmaceutical interventions (and their interactions); and coping with delay and bias in data capture and clinical outcome results during the exponential growth phase of a new variant. One particular focus is the impact of contact tracing apps on the behaviour of individuals and the public-health messaging around their use (see Figure 3).
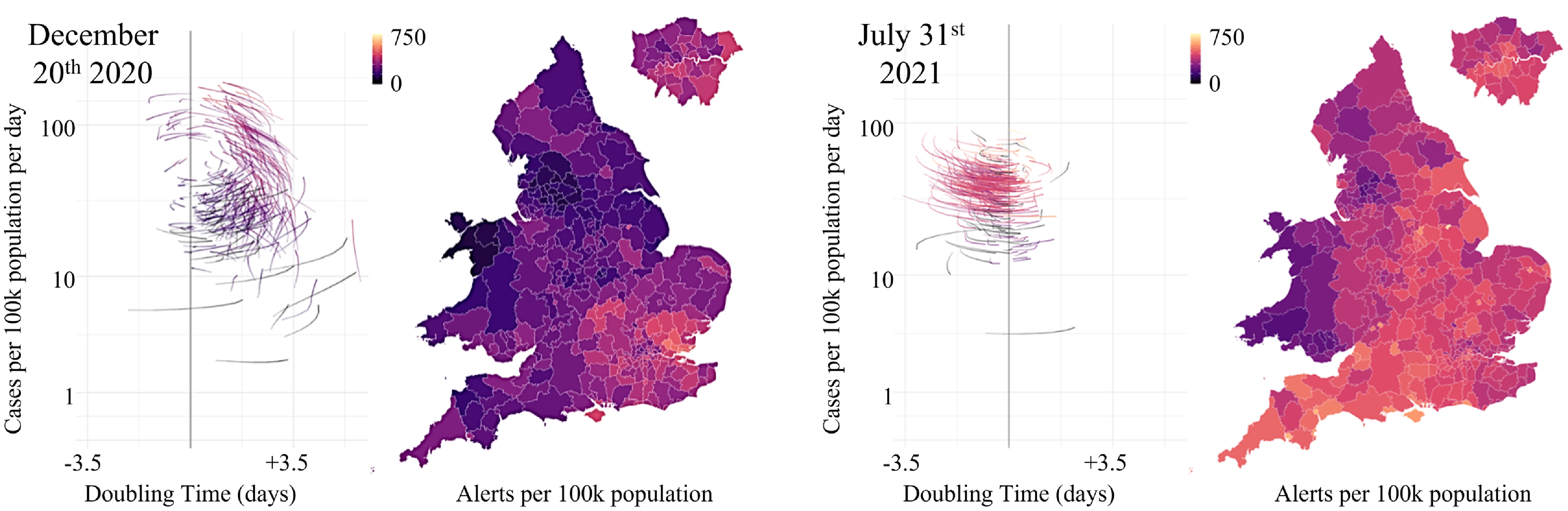
Figure 3. A snapshot of pandemic datasets informing AI for collective intelligence research. Regionally disaggregated datasets relate the level and growth rate of COVID-19 cases (phase plots) with the rate of digital contact tracing alerts delivered to citizens by the NHS mobile phone app (maps) at two points in time during the COVID-19 pandemic. Left—December 20
 $^{\mathrm{th}}$
2020: the alpha variant is spreading in the south-east despite a ‘circuit-breaker’ lockdown. Right—July 31
$^{\mathrm{th}}$
2020: the alpha variant is spreading in the south-east despite a ‘circuit-breaker’ lockdown. Right—July 31
 $^{\mathrm{st}}$
2021: Digital contact tracing alerts are triggered by high COVID-19 case burden.
$^{\mathrm{st}}$
2021: Digital contact tracing alerts are triggered by high COVID-19 case burden.
Two major challenges cut across both strands: quality assurance within a privacy protecting framework (Challen et al., Reference Challen, Denny, Pitt, Gompels, Edwards and Tsaneva-Atanasova2019) and managing the regional heterogeneity of pandemic impact and associated behavioural change (Challen et al., Reference Challen, Tsaneva-Atanasova, Pitt, Edwards, Gompels, Lacasa, Brooks-Pollock and Danon2021).
If these can be overcome, there is the potential to deliver a suite of tools (sensitive to local population properties: income, mobility, demographics) that inform policy on where and when to increase or decrease testing capacity, implement contact tracing and/or isolation measures, distribute limited hospital capacity, etc. By working in collaboration with key stakeholders in government, a set of interactive portals can be developed that effectively inform policy decisions (by reporting well understood metrics: the reproduction number,
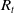 $R_t$
, hospitalisations, excess deaths) and/or individual behaviour (e.g., by presenting bespoke risk scenarios to increase adherence to government-imposed restrictions).
$R_t$
, hospitalisations, excess deaths) and/or individual behaviour (e.g., by presenting bespoke risk scenarios to increase adherence to government-imposed restrictions).
4.3. Environmental intelligence
In order to meet the challenge of mitigating climate change, there is a need to improve access to, and comprehension of, different kinds of complex, time-varying environmental data, for example: (1) outputs from climate, weather and ocean model ensembles and empirical observations, (2) high-volume geospatial, ecological, satellite and remote sensing data; (3) socioeconomic data on resource flows, supply chains, energy consumption and carbon emissions and (4) online media including news media and cross-platform social media content. Many decision-makers (including citizens and policy-makers) would benefit from better environmental information. A huge volume of this data is now available, but it often requires a high level of expertise to obtain it and interpret the associated uncertainties. Large language models are increasingly suggested as a potential solution to part of this problem (Vaghefi et al., Reference Vaghefi, Stammbach, Muccione, Bingler, Ni, Kraus, Allen, Colesanti-Senni, Wekhof and Schimanski2023; Koldunov & Jung, Reference Koldunov and Jung2024). Meanwhile, public debate is weakened by the profusion of poor quality or deliberately false information, especially concerning the contested issue of climate change (Treen et al., Reference Treen2020; Acar, Reference Acar2023). A combination of AI and collective intelligence approaches can deliver tools that overcome these challenges by democratising access to good quality information about environmental change.
Novel ‘climate avatar’ agents can act as simple interfaces between complex environmental data and the people who need it in order to improve their decision-making. They ingest weather and climate data from existing large datasets,Footnote 15 peer-reviewed climate science literature and other trusted sources (e.g., IPCC reportsFootnote 16) and expose this data via natural-language interfaces that allow users to access information and gain understanding in a conversational style. By summarising scientific literature and generating on-the-fly visualisations from raw data, climate avatars enable lay users to make sense of complex climate data and uncertainties, tailored to their specific context (e.g., where they live or the sector in which they work). Similar smart agents engage with other environmental data sources, such as geospatial data, satellite imagery and ecological data. Once created, validated and trusted, these avatars can be deployed to interact with human users in different contexts, for example: allowing expert and non-expert academics to interrogate complex federated models of natural and human capital; enabling chatbots to explain extreme weather events and provide warnings/guidance; providing timely responses to policy formulation queries; or defusing toxic discourse on social media (Treen et al., Reference Treen2020). Data ethics, governance and usability challenges must be addressed in order to ensure that agents are explainable, trustworthy and able to effectively influence public understanding in order to achieve positive social outcomes.
4.4. Financial stability
Modern financial technology (FinTech) presents major challenges for both regulation (cf. the UK Government’s 2021 Kalifa ReviewFootnote 17) and consumer protection/trust (cf. the UK Financial Conduct Authority’s 2022 Consumer DutyFootnote 18). These challenges can be addressed through collaboration with relevant SMEs, non-profits, consultancies, national research organisations, data providers, platform providers and national FinTech hubs, to co-create personalised AI for early warning indicators, informing financial decision making and reducing vulnerability to manipulation.
The development of personalised, adaptive AI driven by collective intelligence derived from financial systems to enable individuals, businesses and government to make better-informed decisions can be considered in two contexts: (i) financial markets (Shi & Cartlidge, Reference Shi and Cartlidge2022; Buckle et al., Reference Buckle, Chen, Guo and Li2023; Liu et al., Reference Liu, Jahanshahloo, Chen and Eshraghi2023; Zhang et al., Reference Zhang, Yang, Liang, Pitts, Prakah-Asante, Curry, Duerstock, Wachs and Yu2023; Shi & Cartlidge, Reference Shi and Cartlidge2024; You et al., Reference You, Zhang, Zheng and Cartlidge2024) and (ii) personal finances (Bazarbash, Reference Bazarbash2019; van Thiel & Elliott, Reference van Thiel and Elliott2024). Progress on either requires that systems take advantage of a range of rich and often non-traditional financial datasets: for example, high frequency financial trading data, equity investment data for retail traders, personal finance, lending records and psychometric credit ratings, demographic household data, NLP-enhanced social media and news and FCA-approved synthetic datasets used for testing all aspects of financial technology for the UK’s Financial Conduct Authority regulatory sandbox.
Models that leverage social media, news media and traditional data (prices, volumes, etc.) can provide regulators with early warning signals of bubbles/crashes and protect non-professional investors from pathological investment behaviour (e.g., the viral herding that led to the recent GameStop short squeeze; Klein Reference Klein2022; Dambanemuya et al., Reference Dambanemuya, Wachs, Ágnes Horvát, Bernstein, Savage and Bozzon2023) with model validation taking place within the Financial Conduct Authority sandbox.Footnote 19 AI assistants that enable collective ethical investment and protect vulnerable households from exploitative personal finance providers can be co-created with relevant charities, for example, working with data-driven psychometric credit rating tools that personalise the immediate and longer-term implications of personal and SME borrowing decisions. Overall, work in this area can make use of rich forms of non-traditional financial data to develop new AI tools that can de-risk the rapid “democratisation of finance” that is being provoked by the ongoing FinTech revolution (Arner et al., 2015).
4.5. Healthcare ecosystems
The ability of the UK’s NHS to deliver its Long-Term Plan depends critically on its capacity to automate bespoke monitoring and support for a range of long-term health conditions at population scale (Topol, Reference Topol2019). This cannot be achieved without a step change in the use of longitudinal data analysis and smart software assistants. Doing so will require working in close collaboration with clinical partners and technology firms on healthcare analytics and the design of user experience for healthcare AI.
Anonymised patient records that track, for example, mental health consultations or diabetes progression are complex, partial and noisy reflections of longitudinal patient trajectories with potential to improve clinical decision making and empower patients (Rajkomar et al., Reference Rajkomar, Dean and Kohane2019). The UK’s NHS trusts and healthcare technology firms have extensive expertise in leveraging data to manage and treat these conditions, including cohorts of diabetes patients engaged in the co-design of AI systems for collective intelligence that are trustworthy and effective (Duckworth et al., Reference Duckworth, Guy, Kumaran, O’Kane, Ayobi, Chapman, Marshall and Boniface2024).
Here, two interacting strands of research can be identified: (i) machine learning analytics for collective healthcare data and (ii) co-design of smart healthcare agents for patient collectives. Strand (i) develops methods for unsupervised extraction and quantification of patterns from patient data pooled across heterogeneous sources from clinical systems to networked personal devices in order to discover clusters in symptom trajectories, detect adverse events and recommend treatment and self-care strategies. This work leverages cutting-edge privacy preserving and federated machine learning methodologies to enable machine learning on data across all the sources interactively and in real-time while guaranteeing that the identity of the individual patients and the data they provide will not be leaked through for example training-data leakage attacks (Chen & Campbell, Reference Chen and Campbell2022). Strand (ii) works with hard-to-reach patients (those suffering from secondary health conditions, mental health conditions, or living circumstances that prevent them from accessing health care unaided and limit their use of technology), plus their carers and clinicians, to address issues of trust, usability and efficacy in ethical AI for informing healthcare decision making across patient populations (Stawarz et al., Reference Stawarz, Katz, Ayobi, Marshall, Yamagata, Santos-Rodriguez, Flach and O’Kane2023). The over-arching challenge for both strands is to leverage population-wide data collection for informing robust individualised decision-making without compromising anonymity and under realistic data and user assumptions. A key challenge is using AI to mediate between patients and care systems rather than burdening already overloaded clinicians with another software tool (Emanuel & Wachter, Reference Emanuel and Wachter2019).
5. Cross-cutting themes
The application domains described above are by no means the only areas in which AI for collective intelligence has strong potential. Additional problems for which productive work could have significant transformative effects include preventing violent extremism (Smith et al., Reference Smith, Blackwood and Thomas2020; Bullock & Sayama, Reference Bullock, Sayama, Iizuka, Suzuki, Uno, Damiano, Spychalav, Aguilera, Izquierdo, Suzuki and Baltieri2023), addressing the climate crisis (Góis et al., Reference Góis, Santos, Pacheco and Santos2019), collaborating with autonomous systems (Pitonakova et al., Reference Pitonakova, Crowder and Bullock2018; Hart et al., Reference Hart, Banks, Bullock, Noyes, Ahram and Taiar2022) and reducing energy consumption (Bourazeri & Pitt, Reference Bourazeri and Pitt2018). However, in addition to confronting issues specific to each of these individual use cases, achieving AI for collective intelligence also faces challenges that cut across these application areas.
5.1. Human-centred design
One issue vital to developing AI for collective intelligence within any use domain is achieving successful interaction with human users. Methods from social and cognitive psychology and human factors must be integrated with the various kinds of research activity outlined above in order to derive human-centred design principles for effective, trustworthy AI agents that inform behavioural change at scale within socio-technical human-AI collectives.
Three parallel strands can be identified: (i) bringing human-centred design considerations to the work within various domain-specific AI for collective intelligence research themes; (ii) developing usable smart agents that assist users in accessing, understanding and acting on guidance derived from collective intelligence data and (iii) pursuing fundamental questions related to understanding and managing ‘tipping points’ in collective intelligence systems. For (i), participatory design methods (Bratteteig et al., Reference Bratteteig, Bødker, Dittrich, Mogensen, Simonsen, Simonsen and Robertson2012) involving academics and stakeholders can be employed to prototype human-machine interfaces (HMIs) for the AI systems being developed. For (ii), data from human experiments can inform a series of design iterations, focussing on accessibility, usability, explainability, adaptability and trust (Choung et al., Reference Choung, David and Ross2023), drawing upon long-standing approaches to defining and measuring trust in automation (e.g., Lee & See, Reference Lee and See2004), with all being key factors for the acceptance, adoption and continued use of new technologies. Comparative analyses of these data reveal transfer effects between different theme settings, guiding development of demonstrators within each domain. For (iii), testable predictions of how to identify, characterise and influence tipping point thresholds for behaviour change can be derived from data on explainability, confidence, persistent adoption, praise and blame, for example, based on the perceived capability of the system (Zhang et al., Reference Zhang, Wallbridge, Jones and Morgan2024).
Rigorous empirical methods (including controlled experiments and human simulations) must be informed by relevant psychological theory (e.g., Gibsonian affordances; see, e.g., Greeno, Reference Greeno1994), human factors approaches (e.g., hierarchical task analysis; see, e.g., Stanton, Reference Stanton2006), tools (e.g., vigilance protocols, Al-Shargie et al., Reference Al-Shargie, Tariq, Mir, Alawar, Babiloni and Al-Nashash2019) and measures (e.g., of situational awareness and cognitive load; Haapalainen et al., Reference Haapalainen, Kim, Forlizzi and Dey2010; Zhang et al., Reference Zhang, Yang, Liang, Pitts, Prakah-Asante, Curry, Duerstock, Wachs and Yu2023) and tipping point analytics (e.g., autocorrelation and critical slowing down measures, Scheffer et al., 2009). Frameworks for technology acceptance and adoption (e.g., ‘designing for appropriate resilience and responsivity’, Chiou & Lee, Reference Chiou and Lee2023) can be employed to measure trust in new technology. Of equal importance is being able to optimally measure loss of trust (which can and will happen, e.g., due a negative experience) and crucially how to restore it—all of which will likely involve ensuring that human-centred design from prototype to deployment considers factors including system accessibility, functionality, usability and adaptability.
Combining the three strands ensures that research in each domain translates into usable, trustworthy demonstrator systems supported by insights into smart agent adoption, trust and trust restoration and that methods for anticipating and influencing collective change inform interaction design principles for practitioners developing and employing AI systems for collective intelligence across multiple socio-technical domains.
5.2. Infrastructure and governance
A second cross-cutting issue vital to deploying AI for collective intelligence at scale in any use domain is ensuring that such systems have robust infrastructure and governance (I&G) guided by appropriate regulations and principles, delivering trustworthy AI systems and solutions that are human-centred, fair, transparent and interpretable for the diverse range of end users.
New I&G tools and guidelines for national scale collective AI systems that ensure privacy, quality and integrity of data and control access to data and systems across relevant AI infrastructures (Aarestrup et al., Reference Aarestrup, Albeyatti, Armitage, Auffray, Augello, Balling, Benhabiles, Bertolini, Bjaalie, Black, Blomberg, Bogaert, Bubak, Claerhout, Clarke, De Meulder, D’Errico, Di Meglio, Forgo, Gans-Combe, Gray, Gut, Gyllenberg, Hemmrich-Stanisak, Hjorth, Ioannidis, Jarmalaite, Kel, Kherif, Korbel, Larue, László, Maas, Magalhaes, Manneh-Vangramberen, Morley-Fletcher, Ohmann, Oksvold, Oxtoby, Perseil, Pezoulas, Riess, Riper, Roca, Rosenstiel, Sabatier, Sanz, Tayeb, Thomassen, Van Bussel, Van Den Bulcke and Van Oyen2020; Shi et al., Reference Shi, Nikolic, Fischaber, Black, Rankin, Epelde, Beristain, Alvarez, Arrue, Pita Costa, Grobelnik, Stopar, Pajula, Umer, Poliwoda, Wallace, Carlin, Pääkkönen and De Moor2022; Cao et al., Reference Cao, Wachowicz, Richard and Hsu2023) should be informed by experiences with previous large-scale AI platforms, such as that developed within the EU-wide MIDAS project (Black et al., Reference Black, Wallace, Rankin, Carlin, Bond, Mulvenna, Cleland, Fischaber, Epelde, Nikolic, Pajula and Connolly2019). One key context in which to pursue this challenge is work developing effective applied AI for national-scale healthcare systems (e.g., cancer, dementia, arthritis; Tedesco et al., Reference Tedesco, Andrulli, Larsson, Kelly, Timmons, Alamäki, Barton, Condell, O’Flynn and Nordström2021; Behera et al., Reference Behera, Condell, Dora, Gibson and Leavey2021; Henderson et al., Reference Henderson, Condell, Connolly, Kelly and Curran2021). The data sensitivity and outcome criticality of these challenges for AI makes this an ideal domain in which to develop effective I&G tools and thinking. However, considering these issues across multiple diverse applications domains also enables the unique and novel aspects of those settings to inform new thinking on I&G questions.
Such research must address ethical, legal and social aspects (ELSA) of I&G (Van Veenstra et al., Reference Van Veenstra, van Zoonen and Helberger2021), embedding ELSA accountability in robust governance frameworks and data infrastructure plans. For instance, studies should embed ELSA, FAIR PrinciplesFootnote 20 and the Assessment List for Trustworthy Artificial Intelligence (ALTAI)Footnote 21 into their Data Management Plans (DMPs) and infrastructure governance and should be informed by outputs of the Artificial Intelligence Safety Institute (AISI)Footnote 22 and other relevant guidelines, for example, the EU’s Ethics Guidelines for Trustworthy AI,Footnote 23 and relevant regulation frameworks such as the EU AI Act.Footnote 24
Finally, the prospect of truly national-scale AI systems of the kinds being considered here foregrounds the pressing need for truly trans-national governance structures and mechanisms. These are particularly relevant in collective intelligence settings, since the people, diseases, finance, etc., at the heart of such systems and the data pertaining to them, all transcend national boundaries. As the Final Report of the United Nation’s AI Advisory Body puts it ‘the technology is borderless’, necessitating the establishment of ‘a new social contract for AI that ensures global buy-in for a governance regime that protects and empowers us all’ (UN AI Advisory Body, 2024).
6. Research strategy
To make significant progress across the research strands outlined above, an effective AI for collective intelligence research strategy must also consider the set of meta-level research challenges that must be overcome if academic research findings are to translate into effective and impactful real-world outcomes. There include addressing underpinning issues around stakeholder engagement; equality, diversity and inclusion (EDI); environmental sustainability; and responsible research and innovation (RRI).
6.1. Stakeholder engagement
We distinguish here between three categories of research stakeholder relevant to AI for collective intelligence research: data partners, skills partners and academic partners. These categories are not disjoint since a single organisation may play more than one of these roles, but they do serve to distinguish between different kinds of research interaction that may be necessary in order to achieve successful applied research in the AI for collective intelligence space at national or trans-national scale.
Data Partners are ‘problem owning’ organisations willing to provide controlled access to data, expertise, tools, personnel and strategic guidance relevant to a societal challenge or user need that can be addressed by AI for collective intelligence research. For national-scale efforts, these will tend to be national or trans-national agencies (e.g. the UK’s National Health Service or the UK Health Security Agency) and departments within national government (e.g., the UK’s Department for Health and Social Care), but may also include commercial outfits such as pharmaceutical firms involved in vaccine development, etc. Crucial issues for research collaboration here include those surrounding intellectual property, privacy, regulatory frameworks (e.g., GDPR in the EU), secure data hosting, etc. There are also challenges around the emerging role of synthetic data as a substitute for data that is too sensitive to share or is too hard to anonymise. Such synthetic data can be useful where a mature understanding of the underlying real-world system and the data generating process is in place, but can be problematic in the absence of such an understanding since it can be difficult to provide assurances that the synthetic data captures all of the necessary structural relationships that are present in the original (poorly understood) dataset (Whitney & Norman, Reference Whitney and Norman2024). More generally, issues around incomplete or noisy data or data that is not sufficiently representative of the underlying population are familiar problems that have significance here.
Skills Partners are ‘problem solving’ organisations that are already involved in pioneering the AI and collective intelligence skills, tools and technologies that are driving the next generation of AI for collective intelligence applications, for example, multi-agent systems, collective systems data science, advanced modelling and machine learning, AI governance and ethics, etc. These may include blue-chip outfits and national facilities (e.g., the UK’s Office of National Statistics) but will also include many of the small and medium-sized enterprises (SMEs) emerging in this space (e.g., Flowminder,Footnote 25 who leverage decentralised mobility data to support humanitarian interventions in real-time). Research opportunities here include connecting innovating skills partners to the data partners that require their expertise while navigating the intellectual property and commercial sensitivity issues that surround an emerging (and therefore somewhat contested) part of the growing AI consultancy sector.
Academic Partners are individuals, research groups or larger academic research activities that are operating in the AI for collective intelligence space. This is a growing area of activity and a key challenge here is connecting and consolidating the emerging community and linking it effectively with the two categories of non-academic stakeholder described above. One key challenge for academic research in this space is balancing the need for rigorous well-understood and mature theory and methods in order to provide quality assurances and guarantee robustness of AI system behaviour against the need to explore and develop new and improved theory and methods that take us beyond the current limited capabilities of extant tools and systems.
6.2. Equality, diversity and inclusion
The AI workforce lacks diversity (e.g., Young et al., Reference Young, Wajcman and Sprejer2021). Moreover, AI technology can tend to impose and perpetuate societal biases (e.g., Kotek et al., Reference Kotek, Dockum, Sun, Bernstein, Savage and Bozzon2023). Consequently, it is important that AI for collective intelligence research operations be a beacon for best practice in equality, diversity and inclusion (EDI). Moreover, an effective AI for collective intelligence research strategy should itself also be driven by equality, diversity and inclusion research considerations. The emerging ‘AI Divide’ separating those that have access to, and command of, powerful new AI technologies from those that do not threatens to further marginalise under-represented, vulnerable and oppressed individuals and communities (Wang et al., Reference Wang, Boerman, Kroon, Möller and de Vreese2024). Collective intelligence methods sometimes focus on achieving consensus and collective agreement (which can tend to prioritise majority views and experiences). However, in addition to aggregating signals at a population level in order to inform the high-level policies and operations of national agencies (which will themselves benefit from being sensitive to population heterogeneity), the AI for collective intelligence research described here is equally interested in deriving bespoke guidance for individuals (or groups) that respects their specific circumstances and needs. This aspect of the research strategy explicitly foregrounds the challenge of reaching and supporting diverse users and those that are intersectionally disadvantaged, for example, diabetes patients that also have mental health conditions (Benton et al., Reference Benton, Cleal, Prina, Baykoca, Willaing, Price and Ismail2023).
6.3. Environmental sustainability
The carbon footprint of most academic research is dominated by travel (Achten et al., Reference Achten, Almeida and Muys2013). Consequently, research in this area, like any other, should seek to minimise the use of flights and consider virtual or hybrid meetings wherever possible. Other steps that can be taken to reduce the environmental impact of research practice and move towards ‘net zero’ and ‘nature positive’ ways of working include making sustainable choices for procurement (e.g., accredited sustainable options) and catering (e.g., plant-based food choices).
Moreover, the environment can itself be the focus of AI for collective intelligence research (see ‘Environmental Intelligence’, above) or a key driving factor (see ‘Smart City Design’, above). Many associated research themes are consistent with a sustainability agenda in their motivation to achieve effective interventions at scale without consuming vast resources. Intended outcomes and technologies aim to transition society to more sustainable practices (e.g., by using healthcare resource more efficiently, by encouraging sustainable cities, etc.).
However, in common with AI research more generally, AI for collective intelligence makes use of energy-intensive technologies. Computational research is energy-intensive: machine learning incurs high CPU/GPU energy cost for training (Patterson et al., Reference Patterson, Gonzalez, Le, Liang, Munguia, Rothchild, So, Texier and Dean2021), while storage/transfer/duplication of large datasets consumes energy in data centres. Hardware components use rare metals linked to environmental damage and inequalities. Consequently, the environmental impacts of AI for collective intelligence research should always be considered and reduced using, inter alia, computational resources powered by renewable energy, energy efficient algorithms and coding practices and minimal data duplication. The technologies developed through this kind of research should be evaluated using full Life Cycle Assessment (LCA) techniques that measure their direct impacts (e.g., production, use and disposal costs), indirect impacts (e.g., rebound effects that increase carbon emissions elsewhere in the economy) and identify possible mitigations (e.g., substitution and optimisation effects) (Preist et al., Reference Preist, Schien and Shabajee2019).
6.4. Responsible research and innovation
Researchers can never know with certainty what future their work will produce, but they can agree on what kind of future they are aiming to bring about and work inclusively towards making that happen (Owen et al., Reference Owen, Stilgoe, Macnaghten, Gorman, Fisher, Guston and Bessant2013; Stilgoe et al., Reference Stilgoe, Owen and Macnaghten2020). For AI for collective intelligence research, this means working with diverse end users and stakeholders to produce a future in which national-scale AI for collective intelligence systems are tools for societal good (Leonard & Levin, Reference Leonard and Levin2022).
There are several reasons for taking responsible research and innovation (RRI) concerns especially seriously in the context of AI research projects. First, since AI is one of the 17 sensitive research areas named in the UK’s National Security and Investment Act,Footnote 26 particular care must be taken by UK universities when establishing and pursuing AI research collaborations. Stakeholder partners must be vetted and input from the UK Government’s Research Collaboration Advisory Team (RCAT)Footnote 27 must be sought where there are concerns regarding, for instance, the exploitation of intellectual property arising from the research activity. Moreover, applied AI research is often fuelled by data that is sensitive, meaning that huge care must be taken to safeguard this data and ensure privacy through the use of, for example, secure research data repositories that feature robust controlled data access protocols. More generally, since AI innovations have the potential to radically reshape the future in ways that are very hard to predict, articulating a clear shared vision of the future that is being aimed for is particularly important. Finally, AI researchers have a responsibility to engage with the public discourse around AI which is currently driving considerable anxiety and confusion.Footnote 28
7. Unifying research challenges
The research strategy outlined here sets out to develop, build and evaluate systems that exploit machine learning and AI to achieve improved collective intelligence at multiple scales: driving improved policy and operations at the level of national agencies and offering bespoke guidance and decision support to individual citizens.
Why are systems of this kind not already in routine operation? Many of the component technologies are established and some are becoming reasonably well understood: recommender systems (Resnick & Varian, Reference Resnick and Varian1997), machine learning at scale (Lwakatare et al., Reference Lwakatare, Raj, Crnkovic, Bosch and Olsson2020), networked infrastructure and Internet devices (Radanliev et al., Reference Radanliev, De Roure, Walton, Van Kleek, Montalvo, Santos, Maddox and Cannady2020; Rashid et al., Reference Rashid, Wei and Wang2023), conversational AI (Kulkarni et al., Reference Kulkarni, Mahabaleshwarkar, Kulkarni, Sirsikar and Gadgil2019), network science analyses (Börner et al., Reference Börner, Sanyal and Vespignani2007), etc. However, several important and interacting challenges obstruct the realisation of AI for collective intelligence and these must be targets for this research effort. Here, we distinguish three categories: human challenges, technical challenges and scale challenges. Each application domain manifests a combination of challenges in a distinctive way (see Table 1), but since these challenges are inter-related they should be approached holistically.Footnote 29
Table 1. Examples of how three different categories of unifying research challenge apply within five different AI for collective intelligence application domains

7.1. Human challenges
In order to be successful, the systems developed at the boundary between AI and collective intelligence must actually be engaged with and used by individual people as well as by institutions and agencies. For this to be the case, these systems must be trusted. Individual people must trust the systems with their data and must trust the guidance that they are offered.Footnote 30 Institutions and agencies must trust the reliability of the aggregated findings delivered by the systems and must trust that the systems will operate in a way that does not expose them to reputational risk by disadvantaging users or putting them at risk. The European Commission’s High-Level Expert Group on Artificial Intelligence suggests that trust in AI should arise from seven properties: empowering human agency, security, privacy, transparency, fairness, value alignment and accountability.Footnote 31
What are the hallmarks of these properties that users of AI for collective intelligence systems intuitively and readily recognise? What kinds of guarantees for these properties could be credibly offered to regulators or law makers? More generally, how can users of all kinds become confident that these properties are present in a particular system and remain confident as they continue to interact with it?
Moreover, since the systems envisioned here purport to offer bespoke decision support tailored to the needs of individual users, one acute aspect of this challenge relates to supporting the needs of all kinds of user including those from marginalised or under-represented groups. It is typically the case that machine learning extracts patterns that generalise over the diversity in a data set in order to capture central tendencies, robust trends, etc. This can fail to capture, respect or represent the features of dataset outliers. Within society, these outliers are often individuals particularly in need of support, and this support may not be useful unless it is sensitive to the specific features of these individuals’ circumstances. Meeting this challenge, and the more general challenge of deserving, achieving and maintaining trust, will require an interdisciplinary combination of both social and technical insights (Gilbert & Bullock, Reference Gilbert and Bullock2014).
7.2. Technical challenges
Amongst the many technical challenges that must be overcome to enable AI for collective intelligence to be effective, we will mention three: nonstationarity in collective systems, privacy and robustness of multi-level machine learning and the ethics of multi-agent collective decision support.
All machine learning makes a gamble that the future will resemble the past, yet we know that the data from collective systems can be nonstationary, that is, these systems can make transitions between regimes that may differ radically from one another (Scheffer et al., 2009). How can we anticipate and detect these sudden shifts, phase transitions, regime changes and tipping points at the level of entire collectives, sub-groups and even individuals? These questions have been considered within collective intelligence research (Mann, Reference Mann2022; Tilman et al., Reference Tilman, Vasconcelos, Akçay and Plotkin2023), and the large scale of systems under study here offers potential to trial methods that have been applied to physical and biological systems, for example, early warning signals from dynamical systems theory (Scheffer et al., 2009), but can these be effective for complex fast-moving socio-technical systems?
Amongst the many other machine learning challenges relevant here, we will highlight two that arise as a consequence of the fundamentally multi-level nature of collective intelligence. The AI4CI Loop (Figure 1) depicts the way in which the approach to AI for collective intelligence being pursued here involves machine learning models that deliver findings at different levels of description, from findings that characterise the entire collective through intermediate results related to sub-groups within the collective to bespoke results relevant to individual members of the collective. Delivering this requires (likely unsupervised) methods to cluster and/or unbundle heterogeneous data stream trajectories derived from groups and individuals. Moreover, achieving this whilst maintaining the privacy of individual members of the collective requires robust privacy-preserving machine learning methods. Employing foundation models to capture and compress the patterns in the collective system is one possible approach, but understanding the vulnerabilities of these models remains an open research challenge (Chen et al., Reference Chen, Namboodiri and Padget2023; Messeri & Crockett, Reference Messeri and Crockett2024).
Within collectives, one member’s actions can affect other members. In this context, systems that support decision making do not only impact their direct user (Ajmeri et al., Reference Ajmeri, Guo, Murukannaiah and Singh2018; Vinitsky et al., Reference Vinitsky, Köster, Agapiou, Duéñez-Guzmán, Vezhnevets and Leibo2023). While there is potential to leverage this collective decision making to achieve efficient coordinated outcomes (Jacyno et al., Reference Jacyno, Bullock, Luck, Payne, Sierra, Castelfranchi, Decker and Sichman2009), it remains the case that a typical AI agent tends to cater to the interests of their primary user even if they are intended to reflect the preferences of multiple stakeholders (Murukannaiah et al., Reference Murukannaiah, Ajmeri, Jonker and Singh2020). This may reinforce existing privileges and could worsen the challenges faced by vulnerable individuals and marginalised groups. Thus, it is imperative that AI agents consider and communicate the broader collective implications of the decision support that they offer. In this way, we can encourage these agents to respect societal norms and their stakeholders’ needs and value preferences and inform decisions that promote fairness, inclusivity, sustainability and equitability (Murukannaiah et al., Reference Murukannaiah, Ajmeri, Jonker and Singh2020; Woodgate & Ajmeri, Reference Woodgate and Ajmeri2022, Reference Woodgate and Ajmeri2024).
7.3. Scale challenges
This paper has articulated a set of research challenges in terms of ‘producing national-scale AI for collective intelligence’. For some domains, for example, pandemic response, this scale might appear to be a natural level of description because relevant policy, operations, data and governance are all ultimately defined at the level of national government. However, most if not all collective intelligence challenges engage with multiple spatial, social and governmental scales. Decision making at national, regional, local, household and personal scales are simultaneously in play, and in some cases trans-national scales are also significant as when pandemics, environmental disasters or financial contagion cross national borders. Consequently, the adjective “national-scale” should not be taken here to imply a single scale of operation and a single locus of decision making. Rather, the most effective AI for collective intelligence systems will be able to operate in a hierarchical, cross-scale fashion as anticipated in the work of, for example, Ostrom (Reference Ostrom2010) and others.
Operating at national or trans-national scale can help to address some of the human and technical challenges discussed in the previous sections: national agencies, such as the UK’s NHS or Met Office, are often trusted agencies; engaging with large populations of users can enable better support for marginalised groups of users that are typically under-represented; operating at scale can increase sensitivity to nonstationarity in an underlying collective system. However, scale also brings its own challenges in terms of establishing and managing appropriate infrastructure in a way that is secure, well-governed and sustainable.
Such infrastructure must support data collection at massive volume. Services must be delivered at point of use, in real time, without failure. Sensitive personal data must be handled securely and systems must respect the privacy of individuals while also providing solutions that rely on data aggregation and sharing. Since the security of national digital infrastructure is increasingly important in a global context where cyberattacks and information operations are becoming more common, infrastructure and service delivery must be robust to external threats as well as internal perturbations and flaws. The infrastructure and associated services and processes must be subject to appropriate and effective governance. Finally, environmental sustainability must be a core aim. How can the national scale systems and services envisioned here operate in a way that has low environmental impact?
8. Conclusion
There is considerable potential for productive research at the intersection between the fields of AI and collective intelligence. This paper has presented one research strategy for operating at this intersection, articulated in terms of the AI4CI Hub’s research vision and research themes, its approach to prosecuting interdisciplinary, collaborative research, and its set of unifying research challenges. The Hub’s first steps include pursuing case study research projects within each of the AI4CI themes in collaboration with relevant stakeholders,Footnote 32 hosting workshops and symposia to cross-fertilise and disseminate new tools, methods and thinking at the AI/collective intelligence interface,Footnote 33 and launching a funding opportunity to support new collaborative research activities in this space across the UK.Footnote 34 No doubt there are many viable alternative research strategies at this same interface, and we echo Nesta’s conclusion that “the field can only evolve through more organisations experimenting with different models of AI and CI and the opportunity to deliver novel solutions to real-world challenges”.Footnote 35
Acknowledgements
This work was supported by UKRI EPSRC Grant No. EP/Y028392/1: AI for Collective Intelligence (AI4CI).
Competing interests
The authors declare none.







 Open access
Open access