



No CrossRef data available.
Article contents
On Bayesian credibility mean for finite mixture distributions
Published online by Cambridge University Press: 29 March 2023
Abstract
Consider the problem of determining the Bayesian credibility mean 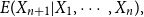 $E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims
$E(X_{n+1}|X_1,\cdots, X_n),$ whenever the random claims 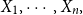 $X_1,\cdots, X_n,$ given parameter vector
$X_1,\cdots, X_n,$ given parameter vector 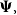 $\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information
$\boldsymbol{\Psi},$ are sampled from the K-component mixture family of distributions, whose members are the union of different families of distributions. This article begins by deriving a recursive formula for such a Bayesian credibility mean. Moreover, under the assumption that using additional information 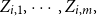 $Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim
$Z_{i,1},\cdots,Z_{i,m},$ one may probabilistically determine a random claim 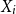 $X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about
$X_i$ belongs to a given population (or a distribution), the above recursive formula simplifies to an exact Bayesian credibility mean whenever all components of the mixture distribution belong to the exponential families of distributions. For a situation where a 2-component mixture family of distributions is an appropriate choice for data modelling, using the logistic regression model, it shows that: how one may employ such additional information to derive the Bayesian credibility model, say Logistic Regression Credibility model, for a finite mixture of distributions. A comparison between the Logistic Regression Credibility (LRC) model and its competitor, the Regression Tree Credibility (RTC) model, has been given. More precisely, it shows that under the squared error loss function, it shows the LRC’s risk function dominates the RTC’s risk function at least in an interval which about 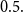 $0.5.$ Several examples have been given to illustrate the practical application of our findings.
$0.5.$ Several examples have been given to illustrate the practical application of our findings.
Keywords
MSC classification
- Type
- Original Research Paper
- Information
- Copyright
- © The Author(s), 2023. Published by Cambridge University Press on behalf of Institute and Faculty of Actuaries
References
Atienza, N., Garcia-Heras, J. & Munoz-Pichardo, J.M. (2006). A new condition for identifiability of finite mixture distributions. Metrika, 63(2), 215–221.CrossRefGoogle Scholar
Bailey, A. (1950). A generalized theory of credibility. Proceedings of the Casualty Actuarial Society, 13, 13–20.Google Scholar
Blostein, M. & Miljkovic, T. (2019). On modeling left-truncated loss data using mixtures of distributions. Insurance: Mathematics and Economics, 85, 35–46.Google Scholar
Bühlmann, H. (1967). Experience rating and credibility. Astin Bulletin, 4(3), 199–207.CrossRefGoogle Scholar
Bühlmann, H. & Gisler, A. (2005). A Course in Credibility Theory and its Applications. Springer, Netherlands.Google Scholar
Bülmann, H. & Straub, E. (1970). Glaubwüdigkeit für Schadens
 ${\ddot{z}}$
e. Bulletin of the Swiss Association of Actuaries, 70, 111–133.Google Scholar
${\ddot{z}}$
e. Bulletin of the Swiss Association of Actuaries, 70, 111–133.Google Scholar
 ${\ddot{z}}$
e. Bulletin of the Swiss Association of Actuaries, 70, 111–133.Google Scholar
${\ddot{z}}$
e. Bulletin of the Swiss Association of Actuaries, 70, 111–133.Google ScholarCarvajal, R., Orellana, R., Katselis, D., Escárate, P. & Agüero, J.C. (2018). A data augmentation approach for a class of statistical inference problems. PloS One, 13(12), 1–24.CrossRefGoogle ScholarPubMed
Cai, X., Wen, L., Wu, X. & Zhou, X. (2015). Credibility estimation of distribution functions with applications to experience rating in general insurance. North American Actuarial Journal, 19(4), 311–335.CrossRefGoogle Scholar
de Alencar, F.H., Galarza, C.E., Matos, L.A. & Lachos, V. H. (2022). Finite mixture modeling of censored and missing data using the multivariate skew-normal distribution. Advances in Data Analysis and Classification, 16(3), 521–557.CrossRefGoogle Scholar
Dempster, A.P., Laird, N.M. & Rubin, D.B. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society: Series B (Methodological), 39(1), 1–22.Google Scholar
Diao, L. & Weng, C. (2019). Regression tree credibility model. North American Actuarial Journal, 23(2), 169–196.CrossRefGoogle Scholar
Diebolt, J. & Robert, C.P. (1994). Estimation of finite mixture distributions through Bayesian sampling. Journal of the Royal Statistical Society: Series B (Methodological), 56(2), 363–375
Google Scholar
Fellingham, G.W., Kottas, A. & Hartman, B.M. (2015). Bayesian nonparametric predictive modeling of group health claims. Insurance: Mathematics and Economics, 60, 1–10.Google Scholar
Frühwirth-Schnatter, S., Celeux, G. & Robert, C.P. (Eds.) (2019). Handbook of Mixture Analysis. CRC Press, New York.CrossRefGoogle Scholar
Hong, L. & Martin, R. (2017). A flexible Bayesian nonparametric model for predicting future insurance claims. North American Actuarial Journal, 21(2), 228–241.CrossRefGoogle Scholar
Hong, L. & Martin, R. (2018). Dirichlet process mixture models for insurance loss data. Scandinavian Actuarial Journal, 2018(6), 545–554.CrossRefGoogle Scholar
Hong, L. & Martin, R. (2020). Model misspecification, Bayesian versus credibility estimation, and Gibbs posteriors. Scandinavian Actuarial Journal, 2020(7), 634–649.CrossRefGoogle Scholar
Hong, L. & Martin, R. (2022). Imprecise credibility theory. Annals of Actuarial Science, 16(1), 136–150.CrossRefGoogle Scholar
Jewell, W.S. (1974). Credible means are exact Bayesian for exponential families. ASTIN Bulletin: The Journal of the IAA, 8(1), 77–90.CrossRefGoogle Scholar
Keatinge, C.L. (1999). Modeling losses with the mixed exponential distribution. In Proceedings of the Casualty Actuarial Society, 86, 654–698.Google Scholar
Lau, J.W., Siu, T.K. & Yang, H. (2006). On Bayesian mixture credibility. ASTIN Bulletin: The Journal of the IAA, 36(2), 573–588.CrossRefGoogle Scholar
Lee, K., Marin, J.M., Mengersen, K. & Robert, C. (2009). Bayesian inference on finite mixtures of distributions. In Perspectives in Mathematical Sciences I: Probability and Statistics (pp. 165–202).Google Scholar
Li, H., Lu, Y. & Zhu, W. (2021). Dynamic Bayesian ratemaking: a Markov chain approximation approach. North American Actuarial Journal, 25(2), 186–205.CrossRefGoogle Scholar
Lo, A.Y. (1984). On a class of Bayesian nonparametric estimates: I. Density estimates. The Annals of Statistics, 12(1), 351–357.CrossRefGoogle Scholar
Marin, J.M., Mengersen, K. & Robert, C.P. (2005). Bayesian modelling and inference on mixtures of distributions. Handbook of Statistics, 25, 459–507.CrossRefGoogle Scholar
Maroufy, V. & Marriott, P. (2017). Mixture models: building a parameter space. Statistics and Computing, 27(3), 591–597.CrossRefGoogle Scholar
Miljkovic, T. & Grün, B. (2016). Modeling loss data using mixtures of distributions. Insurance: Mathematics and Economics, 70, 387–396.Google Scholar
Mowbray, A. (1914). How extensive a payroll is necessary to give dependable pure premium? Proceedings of the Casualty Actuarial Society, 1, 24–30.Google Scholar
Payandeh Najafabadi, A.T. (2010). A new approach to the credibility formula. Insurance: Mathematics and Economics, 46(2), 334–338.Google Scholar
Payandeh Najafabadi, A.T. & Sakizadeh, M. (2019). Designing an optimal bonus-malus system using the number of reported claims, steady-state distribution, and mixture claim size distribution. International Journal of Industrial and Systems Engineering, 32(3), 304–331.CrossRefGoogle Scholar
Payandeh Najafabadi, A.T. & Sakizadeh, M. (2023). Bayesian Estimation for ij-Inflated Mixture Power Series Distributions using an EM Algorithm. Accepted for publication by Thailand Statistician Journal.
Google Scholar
Rufo, M.J., Pérez, C.J. & Martín, J. (2006). Bayesian analysis of finite mixture models of distributions from exponential families. Computational Statistics, 21(3), 621–637.CrossRefGoogle Scholar
Rufo, M.J., Pérez, C.J. & Martín, J. (2007). Bayesian analysis of finite mixtures of multinomial and negative-multinomial distributions. Computational Statistics & Data Analysis, 51(11), 5452–5466.CrossRefGoogle Scholar
Teicher, H. (1960). On the mixture of distributions. The Annals of Mathematical Statistics, 31(1), 55–73.CrossRefGoogle Scholar
Teicher, H. (1963). Identifiability of finite mixtures. The Annals of Mathematical Statistics, 34(4) 1265–1269.CrossRefGoogle Scholar
Whitney, A. (1918). The theory of experience rating. Proceedings of the Casualty Actuarial Society, 4, 274–292.Google Scholar
Zhang, B., Zhang, C. & Yi, X. (2004). Competitive EM algorithm for finite mixture models. Pattern Recognition, 37(1), 131–144.CrossRefGoogle Scholar
Zhang, J., Qiu, C. & Wu, X. (2018). Bayesian ratemaking with common effects modeled by mixture of Polya tree processes. Insurance: Mathematics and Economics, 82, 87–94.Google Scholar